COVID-19: Detecting Government Pandemic Measures and Public Concerns from Twitter Arabic Data Using Distributed Machine Learning



Abstract
:1. Introduction
1.1. Description of the Proposed Work
1.2. Findings
2. Literature Review
2.1. Use of Social Media in Research (Pre-COVID-19)
2.2. COVID-19 and Social Media (General)
2.3. COVID-19 and Topic Modeling
2.4. COVID-19 and Twitter (Arabic Language)
2.5. Research Gap, Novelty, and Contributions
3. The System Methodology and Design
3.1. The System Overview
| Algorithm 1: Master |
| Input: search_query; geo_coordinate; location_d Output: The discovered concerns and their space and time information
|
3.2. Data Collection and Storage Component (DCSC)
| Algorithm 2: Data Collection and Storage |
| Input: search_query; geo_coordinate Output: The collected tweets
|
3.3. Data Pre-Processing Component (DPC)
3.4. Measures and Concerns Detector Component (MCDC)
| Algorithm 3: Measures and Concerns Detector |
| Input: tweets_p; [K]; [R]; threshold Output: concerns[][], tweets_g_DF
|
3.5. Spatio-Temporal Information Component (STIC)
3.6. Validation and Visualization Component (VVC)
4. Results and Analysis
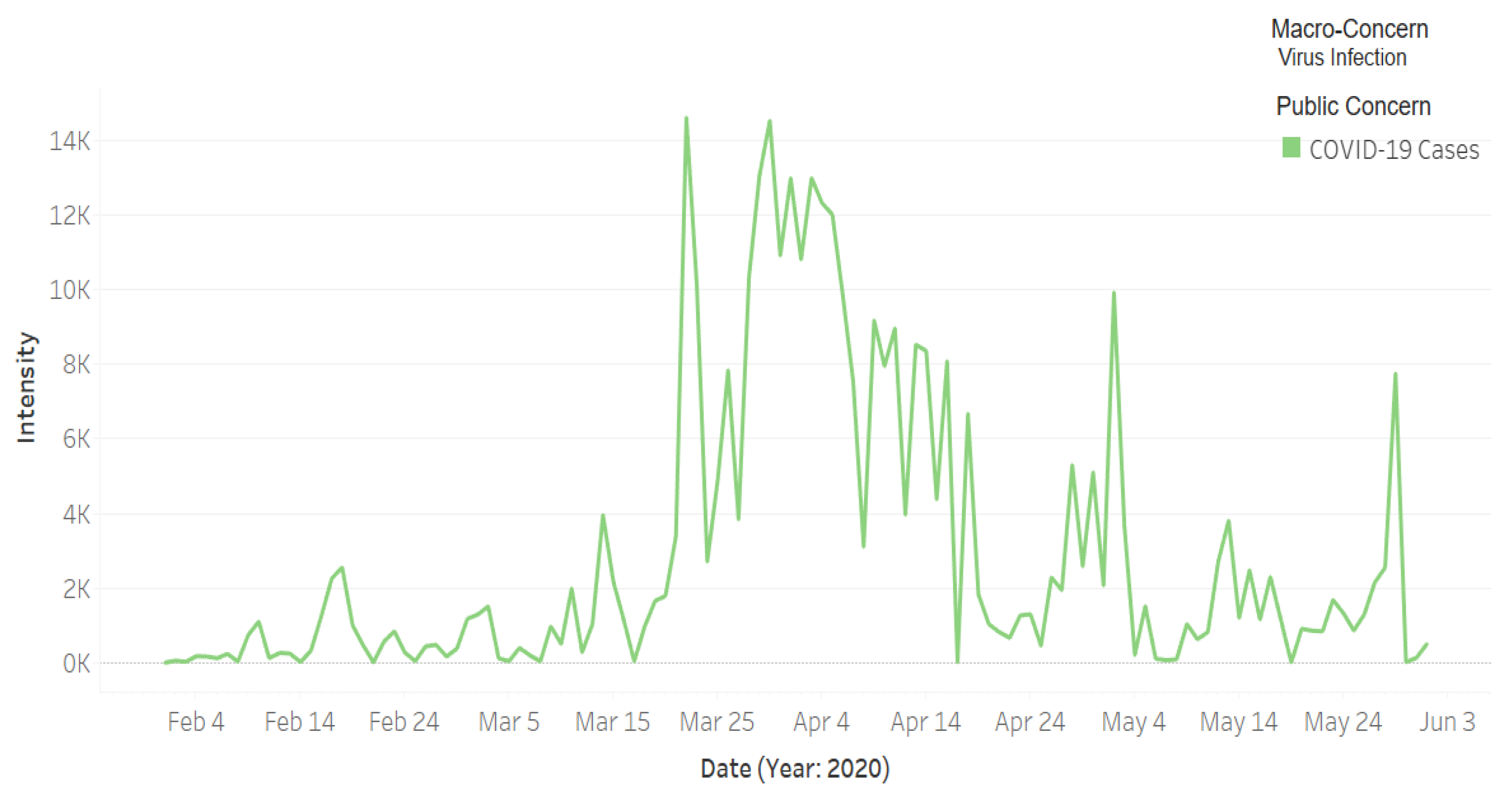
4.1. COVID-19: Pandemic Measures, Public Concerns, and Macro-Concerns
الصحة تعلن عن تسجيل (382) حاله إصابه جديدة بفايروس #كورونا الجديد (كوفيد 19) وتسجل (35) حاله تعافي و (5) حالة وفاه رحمهم الله
The Ministry of Health announces the registration of (382) new cases of infection with the new Coronavirus (COVID 19) and records (35) cases of recovery and (5) cases of death, may God have mercy on them.
عاجل ابتداءً من يوم الاحد 8 شوال 1441هـ حتى نهاية يوم السبت 28 شوال 1441هـ السماح باداء الجمعه في جميع مساجد المملكة ماعدا #مكه
Urgent starting from Sunday 8 Shawwal 1441 AH until the end of Saturday 28 Shawwal 1441 AH prayers are permitted to be performed in all mosques of the Kingdom, except for #Makkah
# امانه_الرياض تواصل جولاتها في تعقيم وتنظيف طرق # الرياض خلال فترة #منع_التجول بهدف توفير بيئة صحية امنه للسكان #واس_عام
#Riyadh_municipality continues its tours to sterilize and clean the roads of Riyadh during the period of #curfew to provide a safe and healthy environment for the residents # WAS_general
عاجل صاحب الملف ----- بحاجه #تبرع #دم الفصيلة : يقبل جميع الفصائل مستشفى الملك فيصل #جدة
Urgent owner of the file ----- needs #Blood #Donation type: accepts all blood types King Faisal Hospital #Jeddah
خادم الحرمين الشريفين يصدر أمره بمنع التجول للحد من إنتشار # فيروس_كورونا الجديد ابتداءً من الساعة 7 مساءً
The Custodian of the Two Holy Mosques issues a curfew order to limit the spread of the new #Corona_virus starting at 7 p.m.
من أجل سلامتكم ننصح بتأجيل المواعيد والإجراءات الطبية غير الملحة #الوقاية_من_كورونا
For your safety, we recommend postponing non-urgent medical appointments and procedures. #Coronavirus_prevention
أنصح الجميع بإستخدام الكمامة القماشية عند الحاجة للخروج من المنزل #الوقاية_من_كورونا
I advise everyone to use a cloth mask when going out of the house #Coronavirus_prevention
وزير الصحة يعلن عن أمر خادم الحرمين الشريفين يحفظه الله بالعلاج المجاني لجميع المصابين بفيروس #كورونا الجديد من المواطنين والمقيمين ومخالفي نظام الإقامة.
The Minister of Health announces the order of the Custodian of the Two Holy Mosques, may God preserve him for free treatment to all citizens and residents infected and violators of the residency system with the new #Coronavirus.
السحب الليلة موثق بالفيديو.. هدية ايفون 11 ريتويت و تابع
Withdrawal tonight is documented in the video … the gift is iPhone 11 retweet and follow
طرق جده تشهد انخفاضا في مستوى الحركة المرورية ، ممايعكس الالتزام بالاجراءات الوقائيه و الاحترازية شكراً لكم و نتمنى للجميع السلامة
Jeddah roads are witnessing a decrease in the level of traffic, which reflects the commitment to preventive and precautionary procedures [.] Thank you and we wish everyone safety.
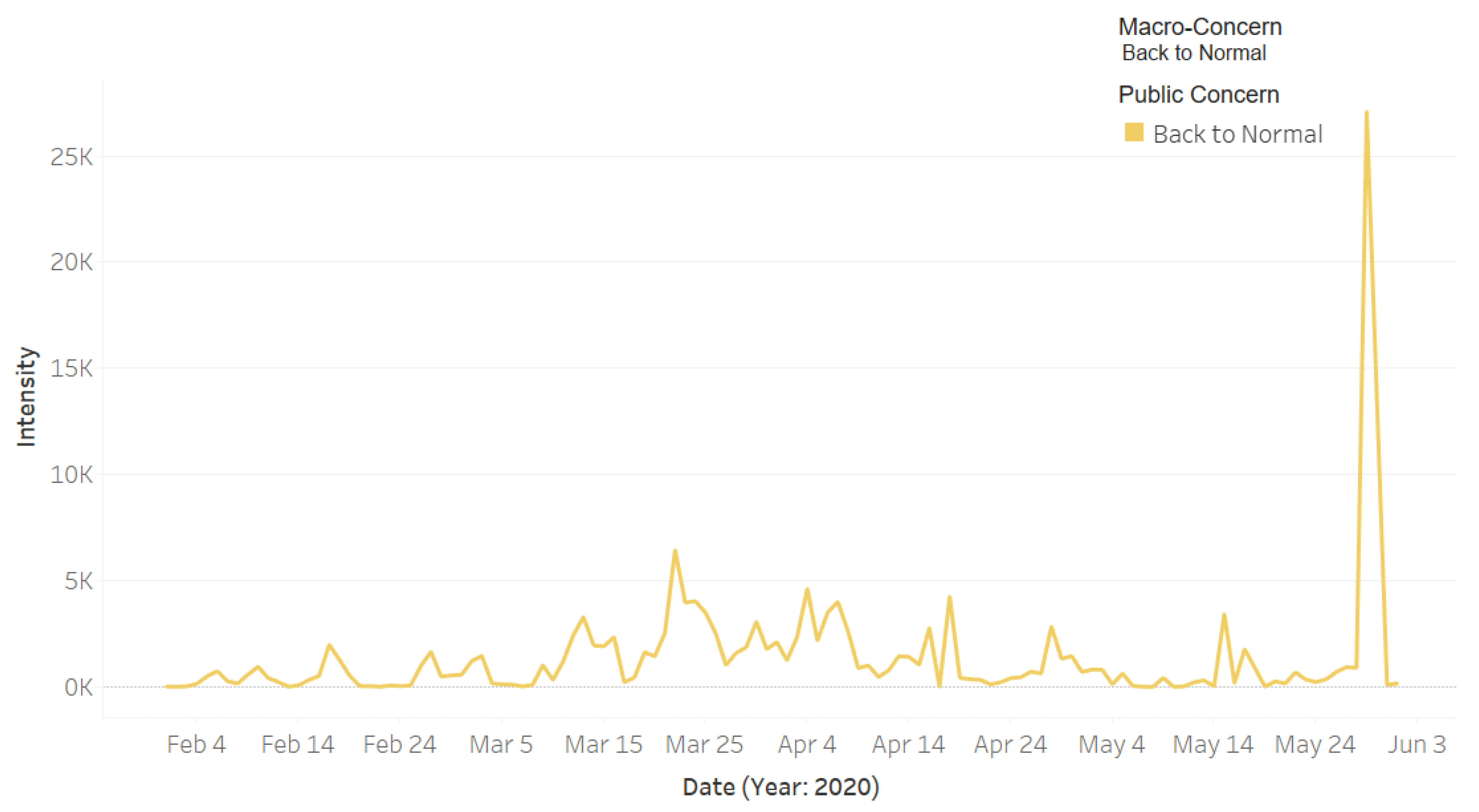
4.2. Temporal Analysis
نحن في بداية أولى مراحل #العودة_بحذر ، لذا اعتمد على التزامكم. إن العودة لزيادة الإحترازات تعتمد على الله ثم على امتثال الجميع. نرجو اتباعكم الإجراءات الوقائية
We are cautiously beginning the first stages of #returning_with_Caution, so we depend on your commitment. We hope that you follow the precautions.
بنوك الدم تشكو قلة المتبرعين بعد جائحة #كورونا.
مديرة بنك الدم في التخصصي “د.الحميدان” تؤكد شدة الحاجة وتحث على التبرع بالدم والصفائح خصوصاً لمرضى #الأورام و #زراعة_الأعضاء
Blood banks complain about the lack of donors after the Corona pandemic. The director of the blood bank in Specialist Hospital, Dr. Al-Humaidan, emphasizes the need and urges to donate blood and platelets, especially for the patients of #oncology and #organ_transplants.
4.3. Spatio-Temporal Analysis
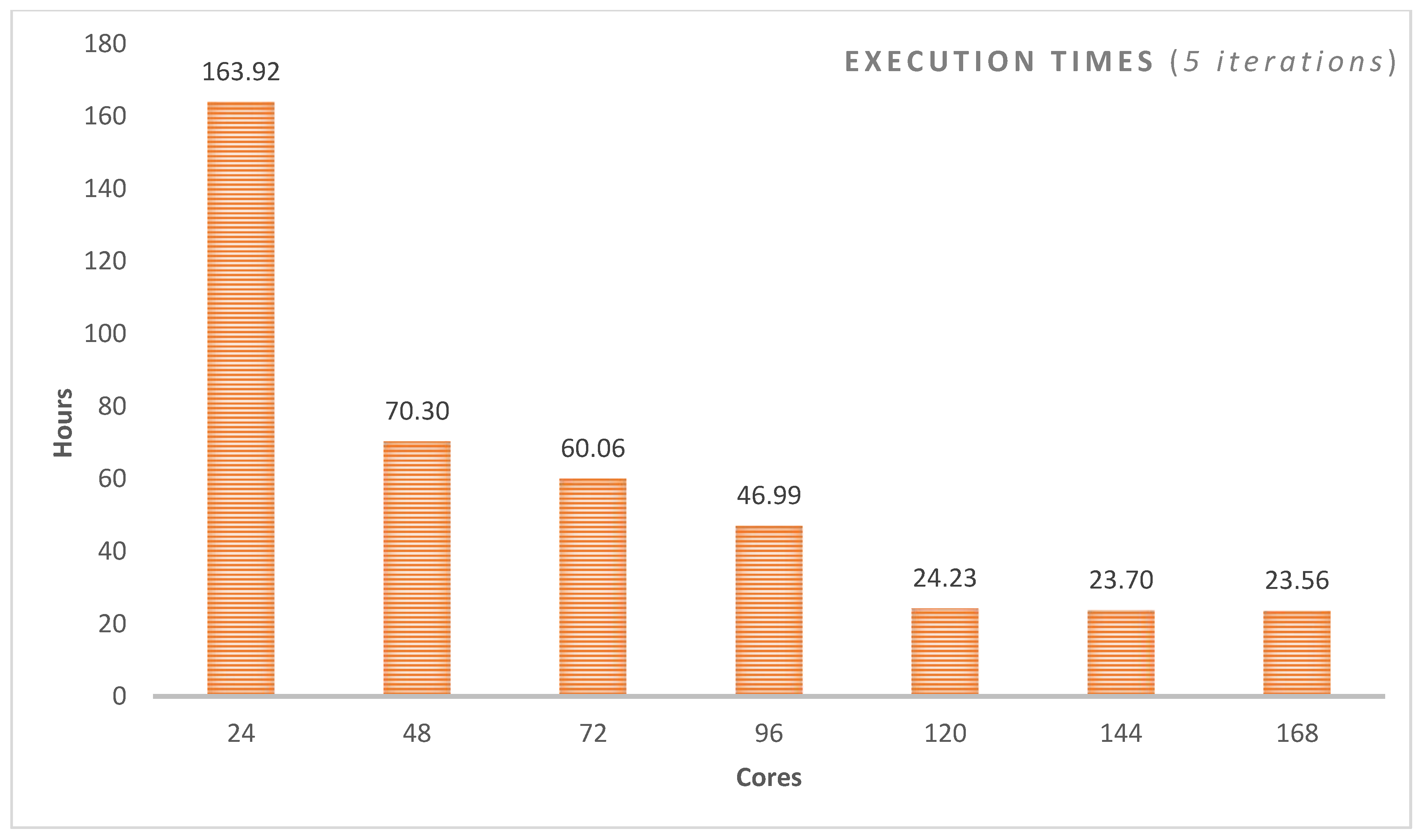
4.4. Execution Time Analysis
4.5. Pandemic Measures, and Public Concerns, and Their Interrelationship
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Johns Hopkins University. Coronavirus COVID-19 Global Cases by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU); Johns Hopkins University: Baltimore, MD, USA, 2020. [Google Scholar]
- Agarwal, S.; Mittal, N.; Sureka, A. Potholes and Bad Road Conditions- Mining Twitter to Extract Information on Killer Roads. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Dona Paula, India, 11–13 January 2018. [Google Scholar]
- Klaithin, S.; Haruechaiyasak, C. Traffic Information Extraction and Classification from Thai Twitter. In Proceedings of the 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- D’Andrea, E.; Ducange, P.; Lazzerini, B.; Marcelloni, F. Real-Time Detection of Traffic from Twitter Stream Analysis. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2269–2283. [Google Scholar] [CrossRef]
- Kurniawan, D.A.; Wibirama, S.; Setiawan, N.A. Real-time Traffic Classification with Twitter Data Mining. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 5–6 October 2016. [Google Scholar] [CrossRef]
- Alomari, E.; Katib, I.; Mehmood, R. Iktishaf: A Big Data Road-Traffic Event Detection Tool Using Twitter and Spark Machine Learning. Mob. Netw. Appl. 2020. [Google Scholar] [CrossRef]
- Alomari, E.; Mehmood, R.; Katib, I. Sentiment Analysis of Arabic Tweets for Road Traffic Congestion and Event Detection. In Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; Springer International Publishing: Cham, Switzerland, 2020; pp. 37–54. [Google Scholar]
- Alomari, E.; Mehmood, R. Analysis of tweets in Arabic language for detection of road traffic conditions. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2018; Volume 224, pp. 98–110. [Google Scholar] [CrossRef]
- Alomari, E.; Mehmood, R.; Katib, I. Road Traffic Event Detection Using Twitter Data, Machine Learning, and Apache Spark. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; pp. 1888–1895. [Google Scholar] [CrossRef]
- Alotaibi, S.; Mehmood, R.; Katib, I.; Rana, O.; Albeshri, A. Sehaa: A Big Data Analytics Tool for Healthcare Symptoms and Diseases Detection Using Twitter, Apache Spark, and Machine Learning. Appl. Sci. 2020, 10, 1398. [Google Scholar] [CrossRef] [Green Version]
- Suma, S.; Mehmood, R.; Albeshri, A. Automatic Detection and Validation of Smart City Events Using HPC and Apache Spark Platforms. In Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; Springer: Cham, Switzerland, 2020; pp. 55–78. [Google Scholar]
- Suma, S.; Mehmood, R.; Albugami, N.; Katib, I.; Albeshri, A. Enabling Next Generation Logistics and Planning for Smarter Societies. Procedia Comput. Sci. 2017, 109, 1122–1127. [Google Scholar] [CrossRef]
- Alsulami, M.; Mehmood, R. Sentiment Analysis Model for Arabic Tweets to Detect Users’ Opinions about Government Services in Saudi Arabia: Ministry of Education as a case study. In Proceedings of the Al Yamamah Information and Communication Technology Forum, Riyadh, Saudi Arabia, 4 March 2018. [Google Scholar]
- The Best Global Responses to COVID-19 Pandemic|Time. Available online: https://time.com/5851633/best-global-responses-covid-19/ (accessed on 26 July 2020).
- Jeremy, S.; Monschauer, Y. Changes in Transport Behaviour during the Covid-19 Crisis. IEA. Available online: https://www.iea.org/articles/changes-in-transport-behaviour-during-the-covid-19-crisis (accessed on 1 January 2021).
- Marks, P. Coronavirus (COVID-19) Update: Blood Donations FDA. 2020. Available online: https://www.fda.gov/news-events/press-announcements/coronavirus-covid-19-update-blood-donations (accessed on 1 January 2021).
- Covid-19 Coronavirus: Finance Minister Says Government Has More Fiscal Firepower to Fight Virus—NZ Herald. Available online: https://www.nzherald.co.nz/nz/news/article.cfm?c_id=1&objectid=12319300 (accessed on 26 July 2020).
- FACTBOX-Global Economic Policy Response to the Coronavirus Crisis—Reuters. Available online: https://www.reuters.com/article/health-coronavirus-economy/factbox-global-economic-policy-response-to-the-coronavirus-crisis-idUSL3N2C11C3 (accessed on 26 July 2020).
- How is WHO responding to COVID-19? Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/who-response-in-countries (accessed on 26 July 2020).
- 4 ‘SAMA’ Initiatives to Mitigate Corona’s Economic Impacts. Available online: https://ajel.sa/9JRdyv/ (accessed on 1 January 2021).
- By Order of the King … the State Bears 60% of the Salaries of Saudis in the ‘Private Sector’. Available online: https://www.okaz.com.sa/news/local/2018078 (accessed on 1 January 2021).
- Mehmood, R.; See, S.; Katib, I.; Chlamtac, I. (Eds.) Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; EAI/Springer Innovations in Communication and Computing, Springer International Publishing: Cham, Switzerland, 2020; p. 692. [Google Scholar]
- Mehmood, R.; Bhaduri, B.; Katib, I.; Chlamtac, I. (Eds.) Smart Societies, Infrastructure, Technologies and Applications; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering (LNICST); Springer: Cham, Switzerland, 2018; Volume 224, p. 367. [Google Scholar]
- Janbi, N.; Katib, I.; Albeshri, A.; Mehmood, R. Distributed Artificial Intelligence-as-a-Service (DAIaaS) for Smarter IoE and 6G Environments. Sensors 2020, 20, 5796. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Butler, L.; Windle, E.; Desouza, K.C.; Mehmood, R.; Corchado, J.M. Can Building ‘Artificially Intelligent Cities’ Safeguard Humanity from Natural Disasters, Pandemics, and Other Catastrophes? An Urban Scholar’s Perspective. Sensors 2020, 20, 2988. [Google Scholar] [CrossRef]
- Mohammed, T.; Albeshri, A.; Katib, I.; Mehmood, R. UbiPriSEQ—Deep reinforcement learning to manage privacy, security, energy, and QoS in 5G IoT hetnets. Appl. Sci. 2020, 10, 7120. [Google Scholar] [CrossRef]
- Kemp, S. Digital Trends 2019: Every Single Stat you Need to Know about the Internet, thenextweb.com. 2019. Available online: https://thenextweb.com/contributors/2019/01/30/digital-trends-2019-every-single-stat-you-need-to-know-about-the-internet/ (accessed on 10 January 2020).
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Yigitcanlar, T.; Kankanamge, N.; Vella, K. How Are Smart City Concepts and Technologies Perceived and Utilized? A Systematic Geo-Twitter Analysis of Smart Cities in Australia. J. Urban Technol. 2020. [Google Scholar] [CrossRef]
- Amaxilatis, D.; Mylonas, G.; Theodoridis, E.; Diez, L.; Deligiannidou, K. Learningcity: Knowledge generation for smart cities. In EAI/Springer Innovations in Communication and Computing; Springer Science and Business Media Deutschland GmbH: Berlin, Germany, 2020; pp. 17–41. [Google Scholar]
- Yigitcanlar, T.; Kankanamge, N.; Regona, M.; Maldonado, A.; Rowan, B.; Ryu, A.; Desouza, K.C.; Corchado, J.M.; Mehmood, R.; Li, R.Y.M. Artificial Intelligence Technologies and Related Urban Planning and Development Concepts: How Are They Perceived and Utilized in Australia? J. Open Innov. Technol. Mark. Complex. 2020, 6, 187. [Google Scholar] [CrossRef]
- Bello, J.P.; Silva, C.; Nov, O.; DuBois, R.L.; Arora, A.; Salamon, J.; Mydlarz, C.; Doraiswamy, H. SONYC: A System for Monitoring, Analyzing, and Mitigating Urban Noise Pollution. Commun. ACM 2019, 62, 68–77. [Google Scholar] [CrossRef]
- Pandhare, K.R.; Shah, M.A. Real Time Road Traffic Event Detection Using Twitter and Spark. Available online: https://ieeexplore.ieee.org/document/7975237 (accessed on 1 January 2021).
- Salas, A.; Georgakis, P.; Nwagboso, C.; Ammari, A.; Petalas, I. Traffic event detection framework using social media. In Proceedings of the 2017 IEEE International Conference on Smart Grid and Smart Cities (ICSGSC), Singapore, 23–26 July 2017; pp. 303–307. [Google Scholar] [CrossRef] [Green Version]
- Lau, R.Y.K. Toward a social sensor based framework for intelligent transportation. In Proceedings of the 2017 IEEE 18th International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macau, 12–15 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Parker, J.; Yates, A.; Goharian, N.; Frieder, O. Health-related hypothesis generation using social media data. Soc. Netw. Anal. Min. 2015, 5, 1–15. [Google Scholar] [CrossRef]
- Bian, J.; Topaloglu, U.; Yu, F. Towards large-scale twitter mining for drug-related adverse events. In Proceedings of the 2012 International Workshop on Smart Health and Wellbeing—SHB ’12, Maui, HI, USA, 29 October 2012; p. 25. [Google Scholar] [CrossRef] [Green Version]
- Lamb, A.; Paul, M.J.; Dredze, M. Separating fact from fear: Tracking flu infections on Twitter. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 789–795. [Google Scholar]
- Aramaki, E. Twitter Catches The Flu: Detecting Influenza Epidemics using Twitter. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Wakamiya, S.; Kawai, Y.; Aramaki, E. Twitter-based influenza detection after flu peak via tweets with indirect information: Text mining study. J. Med. Internet Res. 2018, 20. [Google Scholar] [CrossRef] [PubMed]
- Wakamiya, S.; Morita, M.; Kano, Y.; Ohkuma, T.; Aramaki, E. Tweet Classification Toward Twitter-Based Disease Surveillance: New Data, Methods, and Evaluations. J. Med. Internet Res. 2019, 21, e12783. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, L.; Bansal, S.; Bode, L.; Budak, C.; Chi, G.; Kawintiranon, K.; Padden, C.; Vanarsdall, R.; Vraga, E.; Wang, Y. A first look at COVID-19 information and misinformation sharing on Twitter. arXiv 2020, arXiv:2003.13907. [Google Scholar]
- Gencoglu, O. Large-scale, Language-agnostic Discourse Classification of Tweets During COVID-19. Learn. Knowl. Extr. 2020, 2, 603–616. [Google Scholar] [CrossRef]
- Li, X.; Zhou, M.; Wu, J.; Yuan, A.; Wu, F.; Li, J. Analyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions. arXiv 2020, arXiv:2005.14464. [Google Scholar]
- Sri, A.; Venigalla, M.; Vagavolu, D.; Chimalakonda, S. Mood of India During Covid-19—An Interactive Web Portal Based on Emotion Analysis of Twitter Data. arXiv 2020, arXiv:2005.02955. [Google Scholar]
- Ziems, C.; He, B.; Soni, S.; Kumar, S. Racism is a Virus: Anti-Asian Hate and Counterhate in Social Media during the COVID-19 Crisis. arXiv 2020, arXiv:2005.12423. [Google Scholar]
- Marli, F.; de Andrade, R.; Lu, Y. Twitter in Brazil: Discourses on China in Times of Coronavirus. Available online: https://ssrn.com/abstract=3608566 (accessed on 1 January 2021).
- Medford, R.J.; Saleh, S.N.; Sumarsono, A.; Perl, T.M.; Lehmann, C.U. An ‘ Infodemic ’: Leveraging High -Volume Twitter Data to Understand Public Sentiment for the COVID-19 Outbreak. Available online: https://www.medrxiv.org/content/10.1101/2020.04.03.20052936v1 (accessed on 1 January 2021).
- Kouzy, R.; Abi Jaoude, J.; Kraitem, A.; El Alam, M.B.; Karam, B.; Adib, E.; Zarka, J.; Traboulsi, C.; Akl, E.W.; Baddour, K. Coronavirus Goes Viral: Quantifying the COVID-19 Misinformation Epidemic on Twitter Data collection. Cureus 2020, 12. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Torres-lugo, C.; Menczer, F. Prevalence of Low-Credibility Information on Twitter During the COVID-19 Outbreak. arXiv 2020, arXiv:2004.14484. [Google Scholar]
- Memon, S.A.; Carley, K.M. Characterizing COVID-19 Misinformation Communities Using a Novel Twitter Dataset. 2020. Available online: https://arxiv.org/abs/2008.00791 (accessed on 1 January 2021).
- Ferrara, E. What Types of COVID-19 Conspiracies are Populated by Twitter Bots? 2020. Available online: https://arxiv.org/abs/2004.09531 (accessed on 1 January 2021).
- Gencoglu, O.; Gruber, M. Causal Modeling of Twitter Activity During COVID-19. arXiv 2020, arXiv:2005.07952. [Google Scholar]
- Budhwani, H.; Sun, R. Creating COVID-19 Stigma by Referencing the Novel Coronavirus as the ‘ Chinese virus ’ on Twitter: Quantitative Analysis of Social Media Data Corresponding Author. J. Med. Internet Res. 2020, 22, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Zheng, Z.; Zheng, J.; Chen, Q.; Liu, G. Health Communication Through News Media During the Early Stage of the COVID-19 Outbreak in China: Digital Topic Modeling Approach Corresponding Author. J. Med. Internet Res. 2020, 22, 1–12. [Google Scholar] [CrossRef]
- Prabhakar Kaila, D.; Prasad, D.A. Informational Flow on Twitter—Corona Virus Outbreak—Topic. Int. J. Adv. Res. Eng. Technol. 2020, 11, 128–134. [Google Scholar]
- Abd-alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study Corresponding Author. J. Med. Internet Res. 2020, 22, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Med, J.G.I. Public Priorities and Concerns Regarding COVID-19 in an Online Discussion Forum: Longitudinal Topic Modeling. J. Gen. Intern. Med. 2020. [Google Scholar] [CrossRef]
- Ordun, C.; Hamilton, B.A.; Raff, E.; Hamilton, B.A. Exploratory Analysis of Covid-19 Tweets using Topic Modeling, UMAP, and DiGraphs. arXiv 2020, arXiv:2005.03082. [Google Scholar]
- Mackey, T.; Purushothaman, V.; Li, J.; Shah, N.; Nali, M.; Bardier, C.; Liang, B.; Cai, M.; Cuomo, R. Machine Learning to Detect Self-Reporting of Symptoms, Testing Access, and Recovery Associated With COVID-19 on Twitter: Retrospective Big Data Infoveillance Study. JMIR Public Health Surveill. 2020, 6, e19509. [Google Scholar] [CrossRef]
- Li, D.; Chaudhary, H.; Zhang, Z. Modeling spatiotemporal pattern of depressive symptoms caused by COVID-19 using social media data mining. Int. J. Environ. Res. Public Health 2020, 17, 4988. [Google Scholar] [CrossRef]
- Alam, F.; Shaar, S.; Nikolov, A.; Mubarak, H.; Martino, G.D.S.; Abdelali, A.; Dalvi, F.; Durrani, N.; Sajjad, H.; Darwish, K. Fighting the COVID-19 Infodemic: Modeling the Perspective of Journalists, Fact-Checkers, Social Media Platforms, Policy Makers, and the Society. arXiv 2020, arXiv:2005.00033. [Google Scholar]
- Alshaabi, T.; Minot, J.R.; Arnold, M.V.; Adams, J.L.; Dewhurst, D.R.; Reagan, A.J.; Muhamad, R.; Danforth, C.M.; Dodds, P.S. How the world’s collective attention is being paid to a pandemic: COVID-19 related 1-gram time series for 24 languages on Twitter. arXiv 2020, arXiv:2003.12614. [Google Scholar]
- Alsudias, L.; Rayson, P. COVID-19 and Arabic Twitter: How can Arab World Governments and Public Health Organizations Learn from Social Media? In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Seattle, WA, USA, 9–10 July 2020. [Google Scholar]
- Diab, M.; Ghoneim, M.; Habash, N. Arabic Diacritization in the Context of Statistical Machine Translation. In Proceedings of the Eleventh Machine Translation Summit (MT-Summit XI), Copenhagen, Denmark, 10–14 September 2007. [Google Scholar]
- Blei, D.M.; Edu, B.B.; Ng, A.Y.; Edu, A.S.; Jordan, M.I.; Edu, J.B. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Tweet Objects. Available online: https://developer.twitter.com/en/docs/tweets/data-dictionary/overview/intro-to-tweet-json (accessed on 1 January 2021).
- 24-Hour Curfew in Mecca and Medina. Available online: https://www.skynewsarabia.com/middle-east/1333463-منع-التجول-مكة-والمدينة-مدار-24-ساعة (accessed on 1 January 2021).
- Althumairi, A. ‘Governmental Communication’ Launches the Visual Identity of the ‘We are All Responsible’ Initiative to Confront ‘Covid 19’. Available online: https://www.aleqt.com/2020/03/21/article_1785661.html (accessed on 1 January 2021).
- WAS, S.P.A. General/Custodian of the Two Holy Mosques Issues a Curfew Order to Limit the Spread of the New Corona Virus Starting from 7 pm until Six in the Morning for 21 days from the Evening of Monday 28 Rajab 23 March. Available online: https://www.spa.gov.sa/2050399 (accessed on 1 January 2021).
- The Minister of Health: The Custodian of the Two Holy Mosques Orders the Treatment of all (Corona) Patients Free of Charge. Ministry of Health. Available online: https://www.moh.gov.sa/Ministry/MediaCenter/News/Pages/News-2020-03-30-005.aspx (accessed on 1 January 2021).
- Allow Prayer to be Held in Mosques. «Interior»: The Return of Normal Life in all Regions Except Mecca. Available online: https://www.okaz.com.sa/news/local/2025741 (accessed on 1 January 2021).
- Corona … This is How the Streets of Saudi Arabia Appeared in the First Days of the Curfew. Available online: https://www.aljazeera.net/news/politics/2020/3/24/السعودية-حظر-التجول-كورونا-الحرس (accessed on 1 January 2021).
- Alnajar, S. Umloj Blood Bank: Corona Reduced the Number of Donors. Available online: https://www.okaz.com.sa/news/local/2018263 (accessed on 1 January 2021).
- Alqarni, A. ‘Iradat Riyadh’ Donates Blood to ‘Specialist’ Patients. Available online: https://www.okaz.com.sa/news/local/2018828 (accessed on 1 January 2021).
- Alsaeid, A. ‘Health’: 119 New Cases of ‘Corona Case’ ... and the Total is 511. 2020. Available online: https://www.okaz.com.sa/news/local/2016269 (accessed on 1 January 2021).
- COVID-19 Cases on 30 March 2020. Available online: https://twitter.com/SaudiMOH/status/1244609485563461633 (accessed on 1 January 2021).
- Usman, S.; Mehmood, R.; Katib, I.; Albeshri, A.; Altowaijri, S.M. ZAKI: A Smart Method and Tool for Automatic Performance Optimization of Parallel SpMV Computations on Distributed Memory Machines. Mob. Netw. Appl. 2019. [Google Scholar] [CrossRef]
- Usman, S.; Mehmood, R.; Katib, I.; Albeshri, A. ZAKI+: A Machine Learning Based Process Mapping Tool for SpMV Computations on Distributed Memory Architectures. IEEE Access 2019, 7, 81279–81296. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Macro-Concern | Rank | % | Public Concern | Keywords |
|---|---|---|---|---|
| Virus Infection | 1 | 10.46% | COVID-19 Cases | حاله, اصابه, جديده, حالات, بفيروس, وتسجيل, تسجيل, صحه, جديد, تعلن Case, Infection, New, Cases, Virus, Register, Health, New, Announce |
| Daily Matters | 2 | 8.86% | Supplications | امين, عظيم, بلد, عافيه, مسلم, سبحان, رمضان, وباء, رحمه, اجعل Ameen, Great, Country, Health, Muslim, Glory to, Ramadan, Epidemic, Mercy, Make |
| 4 | 7.87% | Five Daily Prayers (Salah) | احد, حياه, شوال, سلام, نهايه, جمعه, صلاه, جماعه, مساجد, سبت Sunday, Life, Shawwal, Peace, End, Friday, Prayer, Group, Mosque, Saturday | |
| 11 | 5.81% | Mobility | جده, رياض, طريق, عبر, مرور, طرق, وقت, محلى, ارض, حسب Jeddah, Riyad, Road, Through, Traffic, Roads, Time, Local, Land, According to | |
| Contain the Virus | 3 | 8.38% | Quarantine | ناس, شيء, حجر, شخص, طيب, حمدلل, يعنى, ممكن, راح, صح People, Things, Quarantine, Person, Fine, Praise be to God, Means, Possible, Go, True |
| 5 | 6.53% | Stay Home | مسؤول, فايروس, منزل, كورونا, لمواجه, بقاء, اقوى, سلاحنا, دوره, صحه Responsible, Virus, Home, Corona, Facing, Stay, Strong, Weapon, Circle, Health | |
| 9 | 6.13% | Prevention (COVID-19) | حرمين, شريف, خادم, ملك, انتشار, مساء, فيروس, كورونا, ساعه, للحد Haramain, Holy, Custodian, King, Spread, Evening, Virus, Corona, Hour, Reduce | |
| 7 | 6.46% | Cleaning Services | رياض, شركه, تنظيف, مكه, وسلم, مدينه, نقل, امانه, تواصل, امطار Riyadh, Company, Clean, Makkah, Peace, Medinah, Move, Municipality, Continue, Rains | |
| 13 | 5.70% | Curfew | منع, مكه, تجول, مكرمه, مدينه, داخل, قرار, جبيل, فيديو, منوره Prevent, Makkah, Wandering, Mukaramah, Medinah, Inside, Order, Jubail, Video, Munawarah | |
| Social Sustainability | 8 | 6.39% | Hospital Treatment | خير, مستشفى, بحاجه, ملف, صباح, فصيله, دم, تبرع, رقم, صاحب Good, Hospital, Need, File, Morning, Type, Blood, Donation, Number, Owner |
| Economic Sustainability | 6 | 6.48% | Loan | رياض, صباح, حمد, قروض, سداد, يوم, نور, قادمه, امن, اهلى Riyadh, Morning, Thank, Loans, Pay, Day, Light, Coming, Security, My family |
| 10 | 5.92% | Prize Draw | كورونا, فيديو, رتويت, هديه, فيروس, سحب, مواطن, يوم, شروط, موثق Corona, Video, Retweet, Gift, Virus, Withdraw, Citizen, Day, Terms, Documented | |
| 12 | 5.80% | Salary | خاص, تم, قطاع, سعودي, رواتب, حكومه, ازمه, اجتماع, نظام, مجلس Private, Done, Sector, Saudi, Salary, Government, Crisis, Meeting, System, Council | |
| 14 | 4.74% | Offers | خصم, كود, عكاظ, تكون, اولا, كورونا, وتسجل, نون, كوبون, حقوق Discount, Code, Okaz, Be, First, Corona, Register, Noon, Coupon, Rights | |
| Back to Normal | 15 | 4.48% | Back to Normal | عوده, بدايه, اولى, رساله, دفاع, مراحل, احترازه, كورونا, امتثال, تعتمد Back, Beginning, First, Message, Defense, Phase, Precaution, Corona, Compliance, Depend |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alomari, E.; Katib, I.; Albeshri, A.; Mehmood, R. COVID-19: Detecting Government Pandemic Measures and Public Concerns from Twitter Arabic Data Using Distributed Machine Learning. Int. J. Environ. Res. Public Health 2021, 18, 282. https://doi.org/10.3390/ijerph18010282
Alomari E, Katib I, Albeshri A, Mehmood R. COVID-19: Detecting Government Pandemic Measures and Public Concerns from Twitter Arabic Data Using Distributed Machine Learning. International Journal of Environmental Research and Public Health. 2021; 18(1):282. https://doi.org/10.3390/ijerph18010282
Chicago/Turabian StyleAlomari, Ebtesam, Iyad Katib, Aiiad Albeshri, and Rashid Mehmood. 2021. "COVID-19: Detecting Government Pandemic Measures and Public Concerns from Twitter Arabic Data Using Distributed Machine Learning" International Journal of Environmental Research and Public Health 18, no. 1: 282. https://doi.org/10.3390/ijerph18010282
APA StyleAlomari, E., Katib, I., Albeshri, A., & Mehmood, R. (2021). COVID-19: Detecting Government Pandemic Measures and Public Concerns from Twitter Arabic Data Using Distributed Machine Learning. International Journal of Environmental Research and Public Health, 18(1), 282. https://doi.org/10.3390/ijerph18010282