1. Introduction
On 24 January 2020, the first three cases of COVID-19 in continental Europe were anounced in France [
1]. Two months later on 17 March 2020, Montenegro was the last country in Europe to report at least one case of COVID-19. In the early phase of the pandemic, transmission rates in Europe were comparably low [
2]. Nevertheless, by the end of the year 2020, more than 22 million confirmed cases and more than 500,000 COVID-19 related deaths were counted by the European health authorities. However, infection rates with SARS-CoV-2 and the related mortality of COVID-19 have not been equal among European countries. Significant differences both in infections and COVID related death rates have been observed on a local, regional and national level [
3,
4,
5].
An uncontrolled spread of SARS-CoV-2 infections would have disastrous consequences for individuals and health care systems worldwide. However, the severe global economic and social impact of lockdown measures needs to be taken into consideration. Gaining a better understanding of dynamic patterns exhibited by the pandemic in Europe is paramount as political inequalities between countries followed by at times opposing strategies to fight the pandemic has made Europe a challenging place to contain the virus.
Observing variables in fixed time intervals, like the daily numbers of COVID-19 incidences and related deaths in each country, naturally produces time series. In the ongoing research focussing on these time series, one can distinguish three main directions: First, the temporal dynamics of COVID-19 incidences and related deaths at the onset of the pandemic in a specific country [
6,
7,
8,
9]; second, the correlation between COVID-19 incidences and another factor of interest, ranging from air pollution [
10] through social capital [
11] to stroke admissions [
12]; third, the effect of political measures—from social distancing to complete lockdown of public life—on COVID-19 incidence and related death numbers [
13,
14,
15].
In the present study, we sought to model the temporal relation between COVID-19 incidences and related deaths for 35 European countries with at least 1 million inhabitants, extending our analysis over a period of nine months, including both spring and fall waves of 2020 and the relatively quiet summer months of 2020 observed in most European countries.
We hypothesized that incidence rates and death rates are coupled at certain times, whereas an uncoupling of incidence rates and death rates can be observed when incidences stay below a certain infection threshold. The goal of our study was to describe the dependency of death rates from COVID-19 incidences, taking into account the time delay between infection and death, the changes in mortality over time, and the differences from country to country. Additionally, we aimed to estimate the threshold value of coupled death and incidence rates for each country. The geographical structure of the clusters can provide insights about the dynamic of the spread of the SARS-CoV-2 virus across Europe.
4. Results
Table 1 contains the results of our statistical analysis for the 35 European countries that were included in our study. Following the country name, the next seven columns contain the parameter estimates of our model (see Equation (
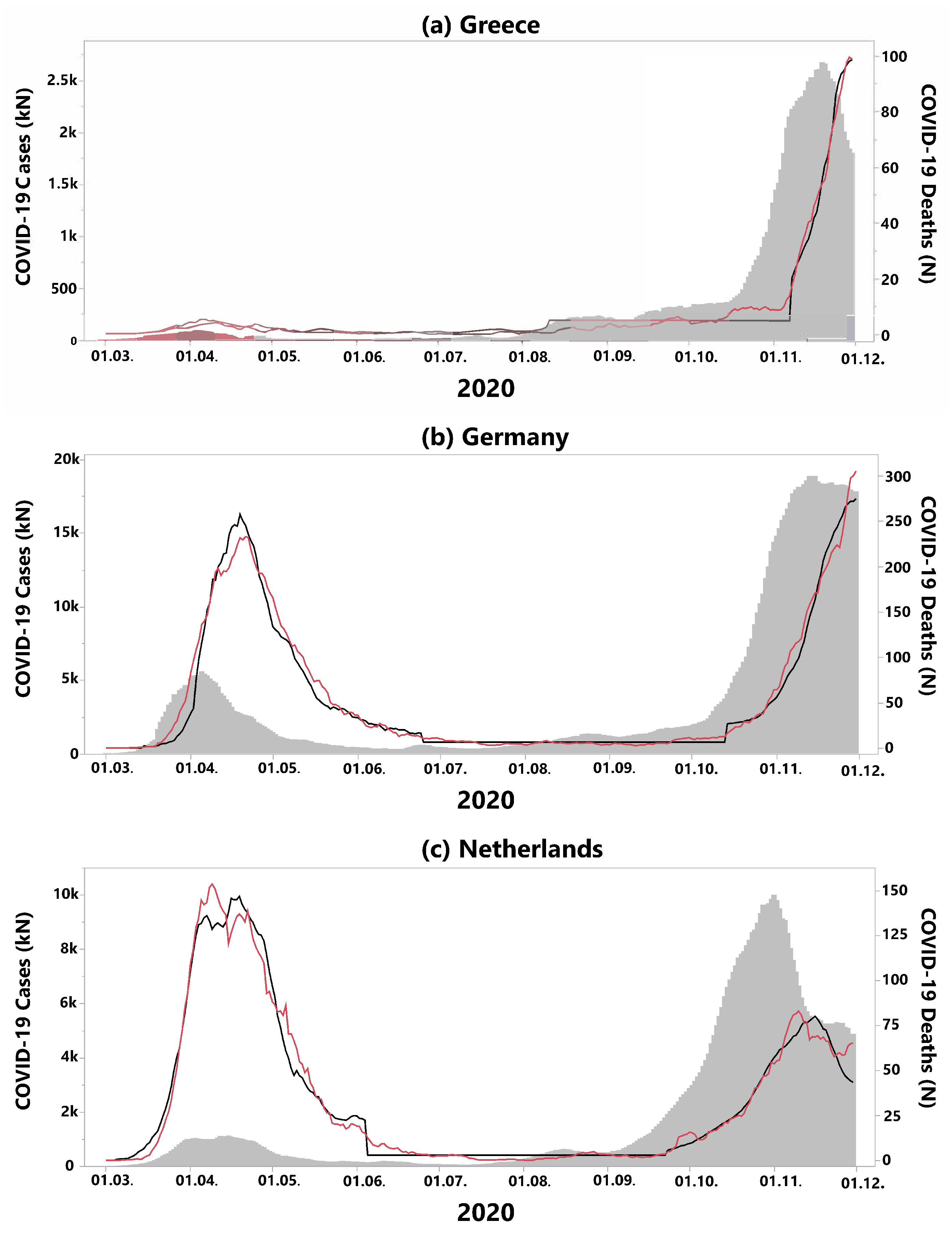
1)). Based on these parameter estimates, countries were assigned to groups with similar outcomes (clusters). A typical representative of the time series model for each cluster is displayed in
Figure 1: Greece, representing cluster 1, Germany, representing cluster 2, and the Netherlands, representing cluster 3. The table is organized by cluster, and alphabetically by country name within each of the three clusters.
Cluster 1 consists of countries that were mildly affected by the first wave, but suffered from high cCFRs in the second wave (
Figure 2a red cluster,
Figure 2b rank parallel plot). In addition, these countries exhibit high relative death rates
during the “quiet” phase 2. Cluster 1 can be described as countries in which the CFRs increased slowly over the course of two waves, but, unfortunately, the situation declined constantly and ultimately led to the highest cCFRs in all of Europe. Countries in cluster 1 are all geographically located in the South-East of Europe. A typical representative of cluster 1 is Greece (see
Figure 1a), switching from a relatively low
to a relatively high
, which was the highest value of all considered countries in the second wave.
Cluster 2 includes Central European countries such as Germany, Poland, and the Czech Republic (
Figure 2a). These countries started with the lowest cCFRs across Europe in the first wave. Cluster 2 also showed a slow progression of CFRs during the pandemic; however, compared to cluster 1, the CFRs in cluster 2 never reached the same increase in CFR during the second wave. In Germany, for example (
Figure 1b), during the first wave,
was similar to
of Greece. However, Germany‘s CFR during the second wave (phase 3) remained much lower than the CFR of Greece during the same time period (
). Furthermore, in Germany, the incidences during the summer months (phase 2) declined substantially when compared to the first wave (phase 1) which marks a difference between the countries in cluster 1 where the incidences failed to drop during phase 2.
The third cluster, located in Western Europe (blue countries in
Figure 2), showed an opposite course to cluster 1. As demonstrated in the rank parallel plot (
Figure 2b), countries in cluster 3 started out with the highest cCFRs across Europe in the first wave, and switched to relatively low CFRs in the second wave. France, for example, had the highest cCFR of all 35 countries in the first wave (
), while in the second wave, despite a high number of incidences, the cCFR was low (
). In the Netherlands (cluster 3,
Figure 1c), the first wave led to a very high
, followed by an absolute and relative decrease to
.
The 5-point summary statistics for the five model parameters (
,
,
,
,
) are summarized in
Table 2.
In general, cCFRs in Europe were lower in the fall (phase 3, second wave) than in the spring (phase 1, first wave) of 2020. While the median of the cCFRs during the first wave was , it dropped to in the second wave. The shift parameters increased from nine days in the first wave to 12 days in the second wave. Both results indicate a less vulnerable population and improved treatment of COVID-19 patients during the second wave.
The fact that the constant model for the death rate was the best fit for the data in most countries during the summer months has another important consequence. In many European countries, the COVID-19 incidences were slightly increasing over the summer, whereas death rates remained low. This result undermines our findings that incidences and death rates are not necessarily connected, as long as the incidences stay below a certain threshold, which can be described as an “uncoupling” of incidences and deaths. Once an individual threshold of infections in a country is reached, the death rates will begin to increase following the incidence rates, which can be described as the “re-coupling” of incidences and deaths. This “threshold” effect is shown in
Figure 1 for representative countries of all three clusters.
Table 3 shows examples of uncoupling for Austria, France, Germany, and Denmark during the quiet summer months of the pandemic, where incidences were slowly increasing as the pandemic approached the second wave. In all four countries, the number of cases increased between 2- and 4-fold. In contrast to the first (phase 1) and second wave (phase 3), the absolute number of COVID-19 related deaths stayed constantly low.
Column 9 in
Table 1 contains difference in
-ranks (see Equation (
3)), followed by the threshold value
(see Equation (
4)). Based on the relative increase of the distance metric in the hierarchical clustering, three clusters were used with 7, 10, and 15 members, respectively. The mean values of the four parameters (
,
,
,
) that were used for the cluster algorithm are displayed in
Table 4.
The last column in
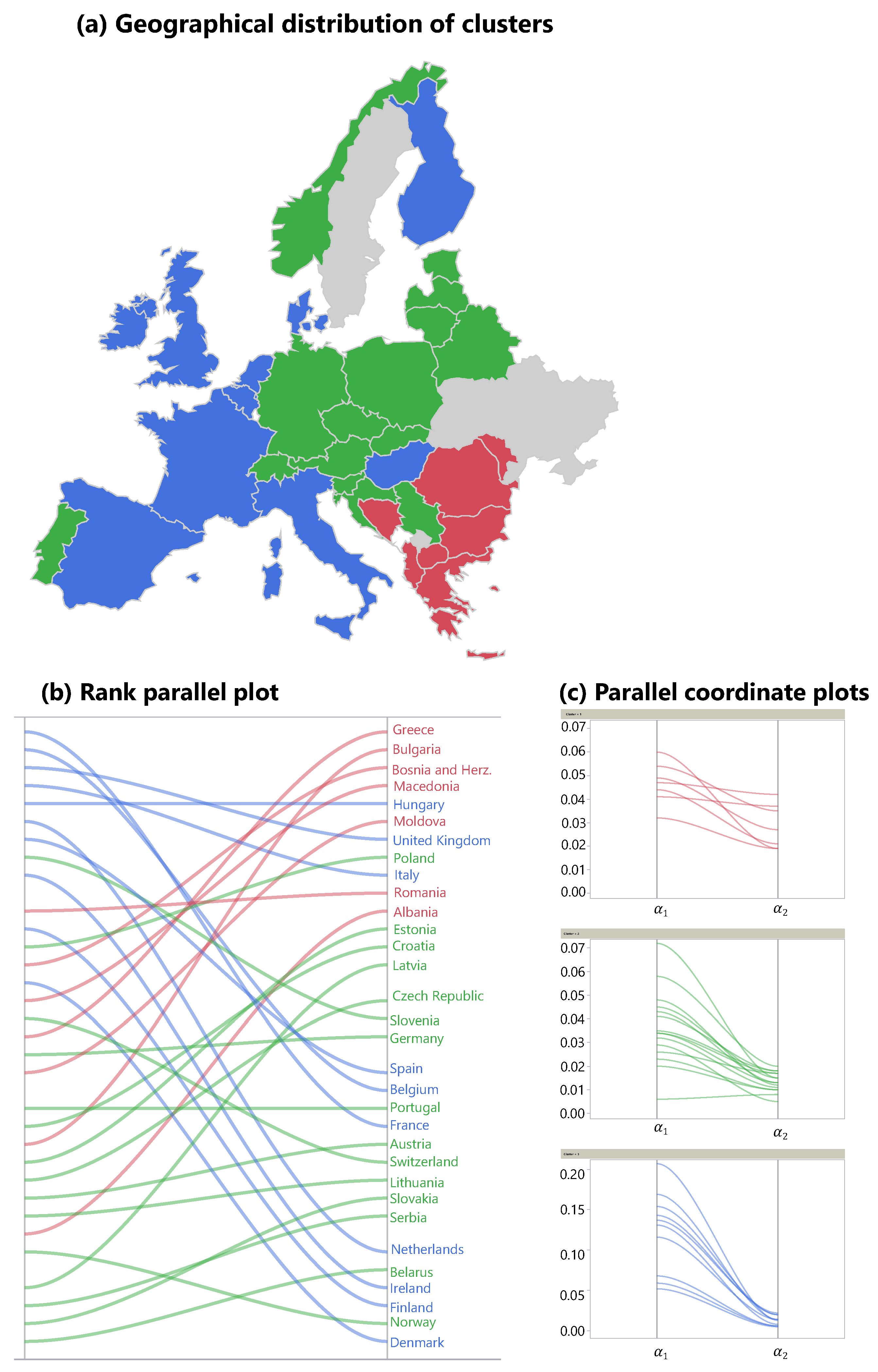
Table 1 displays the cluster the corresponding country has been assigned to. A geographical representation of the clusters is shown in
Figure 2a. The parallel coordinate plots in
Figure 2c show the absolute values of the parameters (
,
) for each country in the three clusters. The last parameter
is represented in
Figure 2b. Each line in this graph connects the rank of
on the left side with the corresponding rank of
on the right side for the given country. The rank difference
between both sides represents the relative improvement or deterioration, and was used as a fourth parameter in the clustering process.
The linear regression model (see Equation (
5)) is given by Equation
The variance inflation factors of all involved factors were below 2, so that there is no indication of multicollinearity in the data.
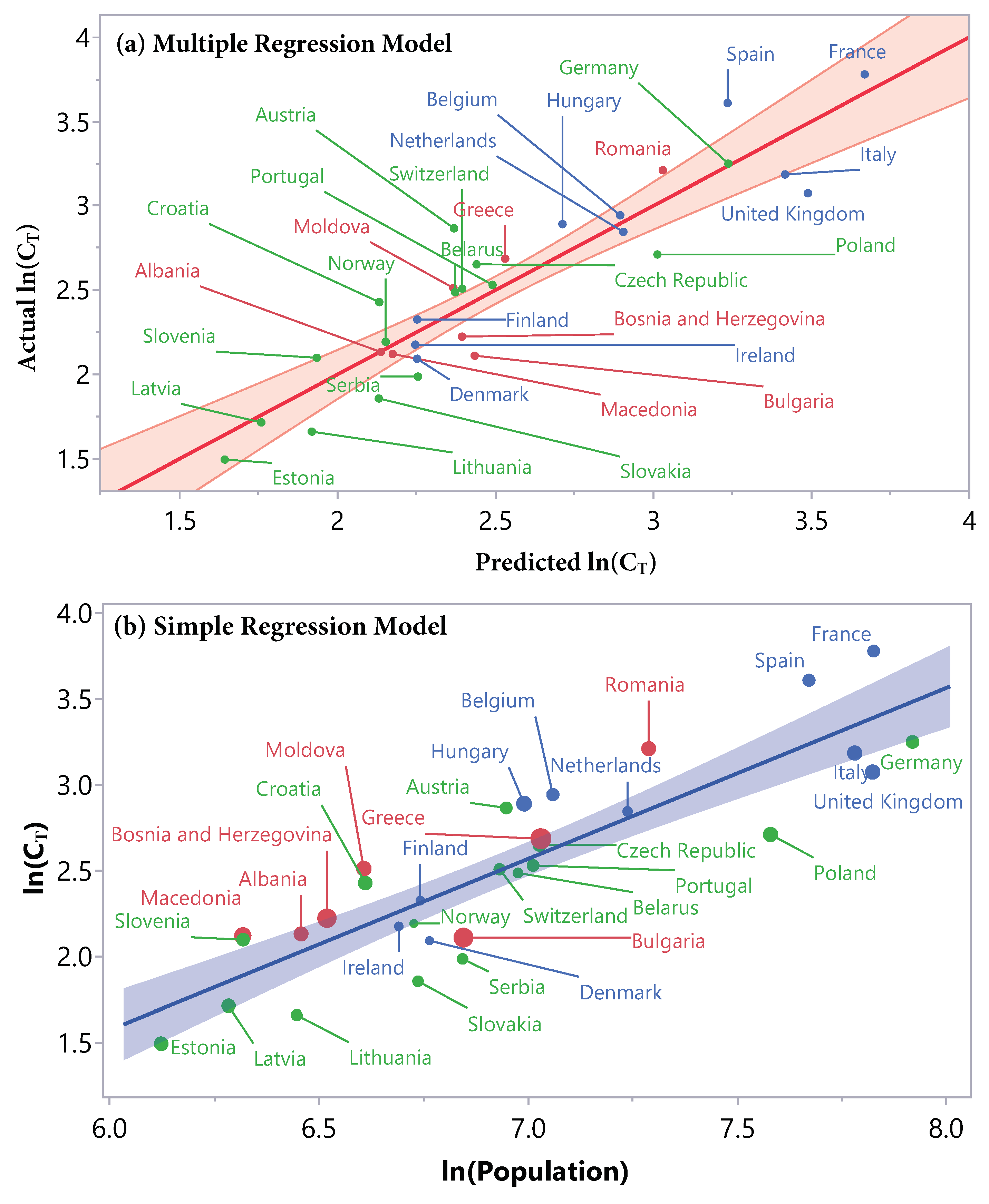
A graphical representation of the model is shown in
Figure 3a. The predicted response value is displayed versus the actual response value. The better the points follow the diagonal line, the better the model fits the data. The results of the
t-tests for every parameter in the model are displayed in
Table 5.
For comparison, we also fitted a simple linear regression, with the logarithm of population size as only factor. This resulted in the following model:
with
dropping to
, and root mean squared error (RMSE)
. The corresponding graph with the factor
on the
x-axis and the response
on the
y-axis is shown in
Figure 3b. The color of the points corresponds to the respective cluster, the size of the points is proportional to the cCFR
during the second wave.
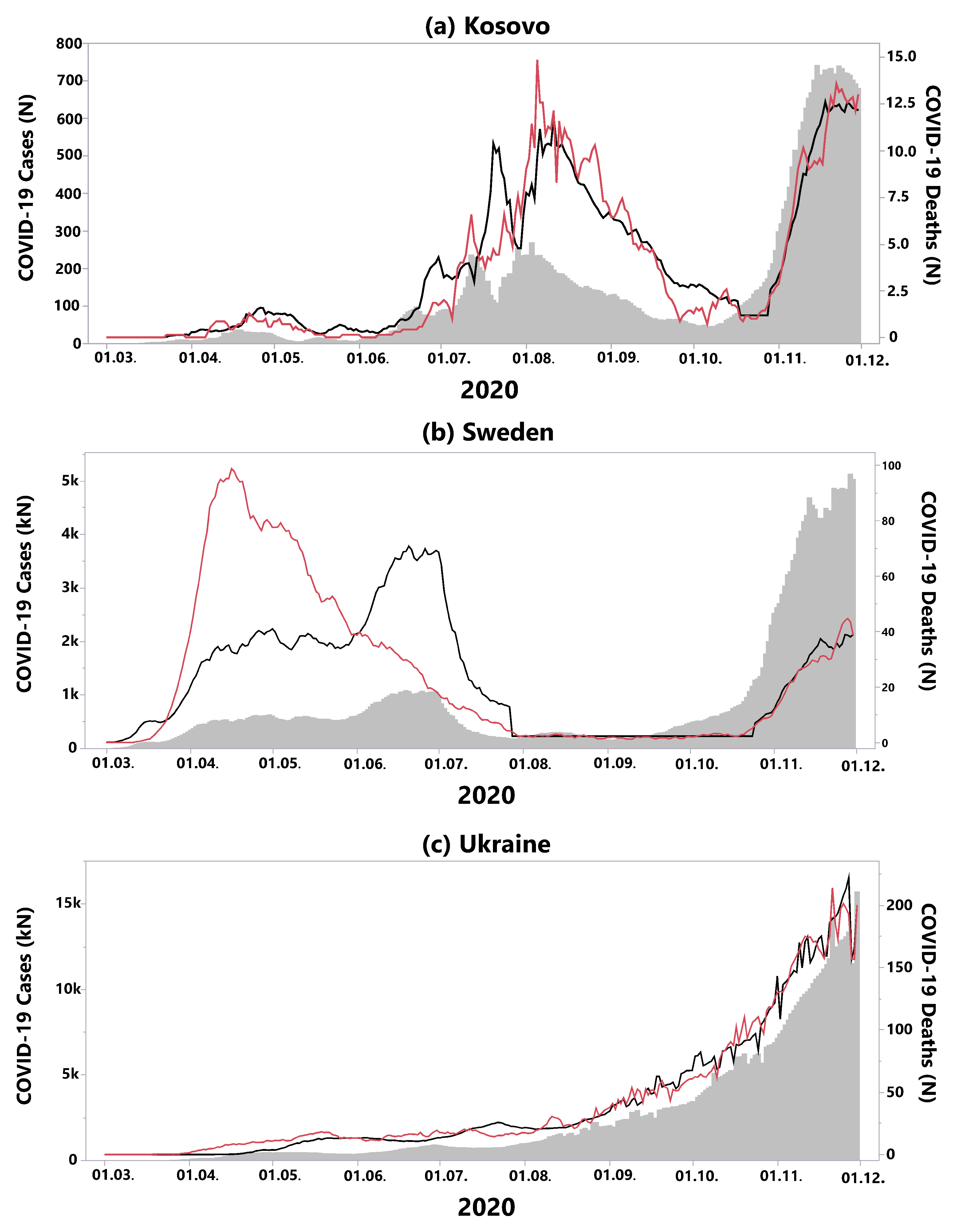
Three European countries displayed exceptional courses of the pandemic; hence, our three-phase-model was not suited to describe the course of the pandemic (
Figure 4):
In Kosovo, the second phase with generally low death rates and defined by an uncoupling of incidences and death rates is missing (
Figure 4a). Instead, the country suffered from a second wave during summer, directly followed by a third wave.
It is well known that Sweden chose a different way to respond to the pandemic compared to neighbouring states in terms of restrictive measures [
21]. In particular, during the first wave, the recorded death rate was much higher than predicted by the incidences, probably due to a relatively low level of political protective measures (
Figure 4b). In the meantime, Sweden changed its policies with strict protective measures for the population [
22]. Consequently, in the second wave, our model fits the data well, with a cCFR of
.
In Ukraine, no waves could be observed to date, instead COVID-19 incidences and related deaths increased constantly over the course of the year 2020 (
Figure 4c).
The phenomenon of clustering due to similar epidemiological patterns raises the question of whether it is favourable for a country to belong to a certain cluster. Therefore, current data from the WHO were used to calculate the cumulative incidence of COVID-19 associated deaths and the cumulative CFR for each of the countries examined herein.
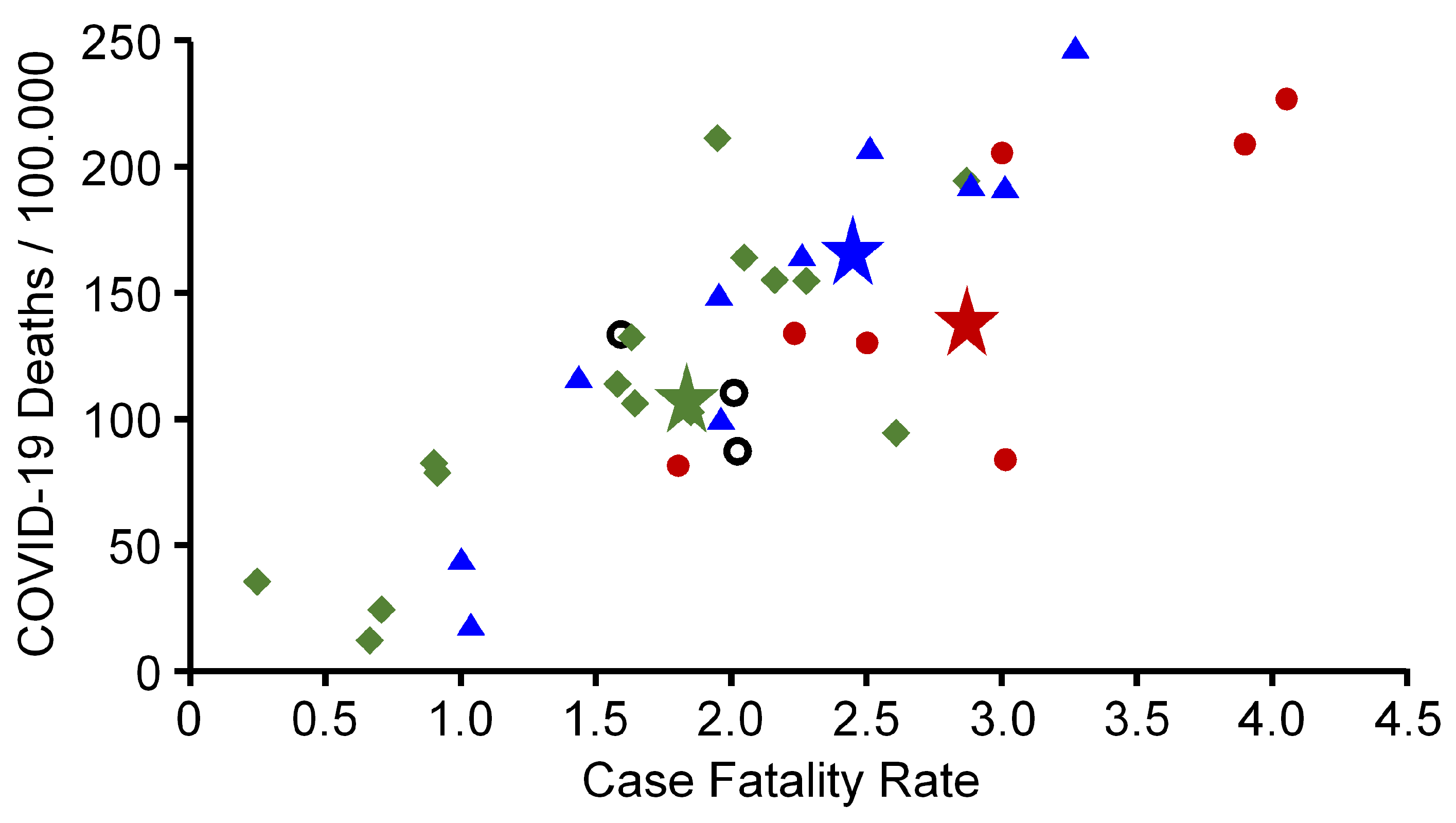
Figure 5 shows that countries belonging to cluster 1 and 3 had similar COVID-19 associated death incidences and CFRs, although there was a high variance especially of countries belonging to cluster 3. When calculating both values for the total population of all countries belonging to a cluster, cumulative incidence of COVID-19 associated deaths were
,
, and
for cluster 1, 2, and 3, respectively. The CFR of cluster 1, 2, and 3 was
,
, and
, respectively (stars in
Figure 5). This finding suggests that, in summary, it was probably favourable for a country to have been affected by a moderate first wave (cluster 2) while it was unfavourable to miss out on the first wave (cluster 1), or to be struck by a disastrous first wave (cluster 3)—although Finland and Denmark, both belonging to cluster 3, exhibited a cumulative low COVID-19 burden. In Denmark, 42.08 of 100,000 individuals died from COVID-19 (CFR
) and in Finland 15.84 of 100,000 inhabitants (CFR
). The highest death incidence was noticed in Hungary (245.37/100,000 inhabitants) (CFR
) and in Bosnia and Herzegovina (226.81/100,000 inhabitants) (CFR
) belonging to cluster 3 and cluster 1, respectively.
5. Discussion
Our data show that COVID-19 has spread inhomogeneously across Europe during the first and second waves. We conducted a time series analysis, which showed that our three-phase-model (first wave–in-between waves–second wave) describes the course of the pandemic very well in 32 out of 35 European countries.
The coupling of COVID-19 incidences and death rates could be shown in two distinct phases, namely the first and second waves in the spring and fall of 2020, whereas an uncoupling could be found in the phase in between waves. Once a certain individual threshold of infection rates was reached, death rates and incidences started to re-couple and deaths started to increase. This finding is important as health care systems across Europe vary greatly and display fundamental differences in ICU capacities and medical resources. If the individual coupling threshold in certain countries could be predicted, preparations for distribution of medical resources and staff could be undertaken early and an overcrowding of hospitals as well as overflowing ICUs might be limited. We have previously shown that individual coupling thresholds can be successfully applied to smaller geographical regions within a country to further maximize preparation efforts as well as political measures for closures of schools and businesses [
3]. These individual thresholds for countries as well as defined geographical regions could define the way countries and communities handle lockdown measures and guide school opening strategies as well as economy stabilizing business opening concepts.
In addition, we defined so-called “shift parameters” that represent the number of days between reported infections and reported COVID-19 associated deaths. The shift factors show a wide range in the two waves (phase 1 and phase 3) across Europe. The wide range of values emphasises that it is crucial to account for these shifts in order to obtain reliable cCFRs for individual countries. The shift parameters increased from nine days in the first wave to 12 days in the second wave across Europe. The increase in time between infection and death could possibly be explained by a certain immunity that had occurred by the second wave resulting in a less vulnerable population and a lower overall CFR in the second wave. The cCFRs in the second wave ranged from in Denmark to in Greece. Overall, these values are significantly lower than in the first wave. Possible explanations include increased test rates, protection of the most vulnerable individuals within a population and other political measures. In addition, medical knowledge of the virus and its resulting disease had improved from wave one to wave two, adding more specific pharmacological treatments as well as progress in hospital organization and resource management.
We postulate that there are two additional effects that lead to lower cCFRs in the second wave. First, the most vulnerable individuals within a population had already been affected during the first wave, and outcomes were detrimental. Second, there is a large body of evidence showing a high number of unreported, often asymptomatic cases of SARS-CoV-2 infections [
23,
24] that might have contributed to a certain level of immunity across European countries with limited means for widespread testing. A recent meta-analysis of seroprevalence estimates a global factor between confirmed and actual infections of 11.9 on national levels [
25], pointing towards a high level of undetected infections. Hence, the exposure to the virus had been much higher during the first wave than reported by the registered positive tests, which might have led to a partial immunity of the exposed population. Partial immunity of the population would also explain the observation that, after one year of the pandemic, countries belonging to cluster 2 in general had lower cumulative CFRs and lower cumulative COVID-19 associated death incidences than countries belonging to cluster 1 (
Figure 5).
Adding both effects might have lowered the overall vulnerability of the population in the second wave and hence might have contributed to the lower cCFRs reported in our data. If these statements were true, we should also have observed the opposite: countries that were mildly affected in the first wave would have suffered from higher cCFRs in the second wave. These switches from “high to low” and from “low to high” respectively are called a “flip effect”.
Indeed, we could show that the geographical spread of SARS-CoV-2 in Europe followed a distinct pattern with similarities and discrepancies in death rates over time. Based on those similarities, we were able to define geographical clusters of countries showing a similar dynamic as the pandemic evolved during the first and second waves in 2020.
In summary, the western part of Europe (cluster 3) went from high cCFRs to low cCFRs, while the countries in the southeastern parts of Europe (cluster 1) exhibited the opposite starting off with low CFRs in the first wave and flipping to extremely high CFRs in the second wave, adding evidence to the “flip effect.” A particularly clear view of this flip effect is offered by the rank parallel plot in
Figure 2b. While the red lines (cluster 1) are all trending upwards, the blue lines (cluster 3) are trending downwards. Without the presence of the flip effect, the lines in this diagram would be mostly horizontal. The situation in cluster 2 is similar to cluster 1 but less pronounced, with an average rank loss of
, compared to
in cluster 1. In cluster 1, the average duration of the first wave was 138.4 days, compared to 112.5 days in cluster 3, a difference of 26 days. The countries in cluster 3 were much more affected by the first wave, potentially leading to more drastic restriction measures and hence a faster decline of incidences than in less severely affected countries.
It is an interesting result by itself that, although the clustering algorithm did not use any geographical information, the clusters are clearly assignable to different regions of Europe (see
Figure 2a). The first cluster is entirely located in the southeastern part of Europe, with Greece, Romania and Bulgaria being its three largest representatives. As mentioned, the southeastern part of Europe was less affected by the first wave, but heavily affected by the second wave. Cluster 3, showing the opposite behaviour, covers the whole western part of Europe, from Denmark to Italy, with France, UK, and Italy being its three largest representatives. It is worth noting two exceptions: on one hand, Portugal was warned by the terrible course of the pandemic in its only neighbouring state Spain, and therefore imposed lockdown measures at a very early stage [
26], keeping the incidences and the death rate relatively low during the first wave (
). On the other hand, Hungary had low incidence numbers, but an unusually high cCFR of
. At least partially, this might be explained by a low test rate in Hungary during these months [
27].
The questions arises as to why certain geographical regions in Europe follow certain similar patterns of viral spread and CFRs. Recent data point towards a link between national gross domestic product (GDP), tourism and COVID-19 cases during the initial phase of the pandemic. Countries with a high GDP as well as high tourist activity had more COVID-19 cases during the initial first wave than countries with a lower GDP and lower tourist activity [
28]. These findings support our data and are in keeping with our three geographical clusters. Clusters 2 and 3 representing the Central and Western parts of Europe, with higher GDPs on average as well as high levels of tourism as well as business travel facilitating the initial spread. Cluster 1 representing the southeastern parts of Europe with a relatively low average GDP suffered tremendously from the second wave after it had been spared from the first wave due to low tourist and business travel activity. Countries with higher GDP such as clusters 1 and 2 were less affected by the second wave as health care systems were able to adapt, and medical innovations could be widely applied and resources distributed.
Interestingly, the weather seems to have an impact on viral spread and COVID-19 [
29,
30]. Data from Spain, which is part of our “Western” cluster 3, show that UV-radiation during the winter months of 2019–2020 seemed to be inversely correlated with the number in infections in the spring of 2020. It remains unclear whether this effect is caused by direct effects of UV-radiation on virus replication or whether it is an effect of increased immunity by higher Vitamin-D levels [
31]. The weather-hypothesis has been studied elsewhere. Incidences were much higher in the North of Italy for example than in southern Italian regions. Again, UV-radiation from North to South correlated inversely with COVID-19 [
32]. Our cluster 3 is mainly composed of “southwestern” European countries defined by high UV-radiation and a dry southern climate which might partly explain the relatively mild second wave with low CFRs.
We already elucidated how the fit of our three-phase-model implies the existence of a threshold value for each country individually at the beginning of the second wave. As long as the incidences stayed below this threshold value during the summer months, changes in COVID-19 incidences did not affect the number of related deaths in the same way as during the first and second wave.
The aim of the multiple regression model was to find out if it is possible to predict the threshold value, where the COVID-19 incidences and the death rates re-couple leading to increasing death rates and marking the beginning of a new wave. The multiple regression model has an
value of
, which means that the model can explain
of the variation in the data (see
Figure 3a). The comparison with the one-dimensional model (see
Figure 3b) that exhibited an
value of
proves two statements: first, the logarithm of the population (
) is the dominant factor for the prediction of the threshold. Second, adding the factors
and
improves the model. This is also reflected by the significant effect tests (see
Table 4). The fact that the parameter estimates for
are close to 1 (0.99 in the simple regression, 0.86 in the multiple regression) is highly plausible and implies the following interpretation: a 10-fold increase in population size leads to a
-fold increase in the threshold value. The two other factors in the multiple regression model,
and
, can be interpreted as measurements of the severity of the pandemic before the second wave. A positive sign of these factors indicates the degree of preparedness: a more extended first wave, and a summer with slightly higher incidences, always staying under the predicted coupling threshold, might have produced higher rates of immunity within communities, potentially decreasing the severity of the following second wave and delaying the re-coupling of incidences and rising death rates.
We can draw another conclusion from
Figure 3b by looking at the size and color of the points. The color represents the cluster, the size corresponds to the cCFR
. There is no structure visible with respect to the color or size of the points. This means that the linear connection expressed by the regression model for the prediction of the threshold is independent of the other factors. It holds through all clusters and for any severity of the second wave, expressed by
.
Our study has limitations. Our analyses are based on observational data for 35 European countries provided by the ECDC. The definition of a COVID-19 related death might vary from country to country, as might the reliability of the reporting itself. In addition, it is important to keep in mind that we analyse case fatality rates and not the mortality of the novel coronavirus. Due to the high number of unreported cases, the cCFR are an overestimation of mortality. The analysis of excess mortality might provide additional information about the threat that COVID-19 poses for the population [
5,
33,
34]. The testing strategies vary a lot from country to country, and changed within each country over the course of the pandemic. This introduces a source of variation to the incidence data that we did not control for.
In addition, our predicted thresholds are estimated ex-post. Further investigation is needed to assess the predictive power for future data. Another interesting aspect could be the analysis of possible interactions between, for instance, countries in the same cluster. Two other approaches could be used to study COVID-19 time series on a European level in further studies: entropy ratios [
35] and a detrended cross-correlation analysis [
36]. Finally, results of time series analysis might facilitate predicting the peak of the epidemic in terms of new cases or new deaths in each country [
37].
Recently, mutations of the corona virus have been detected in many European countries. At this point, we cannot predict if our three-phase model could be adjusted to the seemingly more aggressive spread of newer virus mutations which seem to elucidate an entirely new dynamic in terms of infectiousness as well as aggressiveness of the resulting COVID-19.
6. Conclusions
Our results show that, in 32 out of 35 European countries, the COVID-19 pandemic can be accurately depicted by a three-phase-model. In the first and third phase, the corrected case fatality rates were coupled to the incidences. However, in the second phase, we see a random unconnected behaviour of incidences and deaths indicating an uncoupling of COVID-19 related deaths with incidences as long as the incidences stay below a specific threshold.
Three distinct clusters were obtained when clustering the parameters of the three-phase-model: The first cluster in the south east of Europe, with relatively low cCFRs in the first wave and high cCFRs in the second wave. A second cluster in the centre of Europe, with low cCFRs in the first wave, and slightly higher cCFRs in the second wave, and a third cluster in the western part of Europe, with very high cCFR during the first wave, and low cCFRs in the second wave.
Finally, a strong linear relationship was found for the prediction of the threshold value at the beginning of the second wave, where the incidences and the COVID-19 related death rates reconnected. Using the size of the population, the corrected case fatality rate from the first wave, and the relative death rate during the second phase, the model predicts a 7.24-fold increase of the threshold for a 10-fold increase of the population. Below this country-specific threshold, an increase in COVID-19 incidences did not lead to a significant rise of COVID-19 related deaths.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}