
Catalyzing Knowledge-Driven Discovery in Environmental Health Sciences through a Community-Driven Harmonized Language

 , ,
, ,  ,
,
Abstract
:1. Introduction
2. Discussion
2.1. Representative Challenge Areas
2.2. Recent Efforts
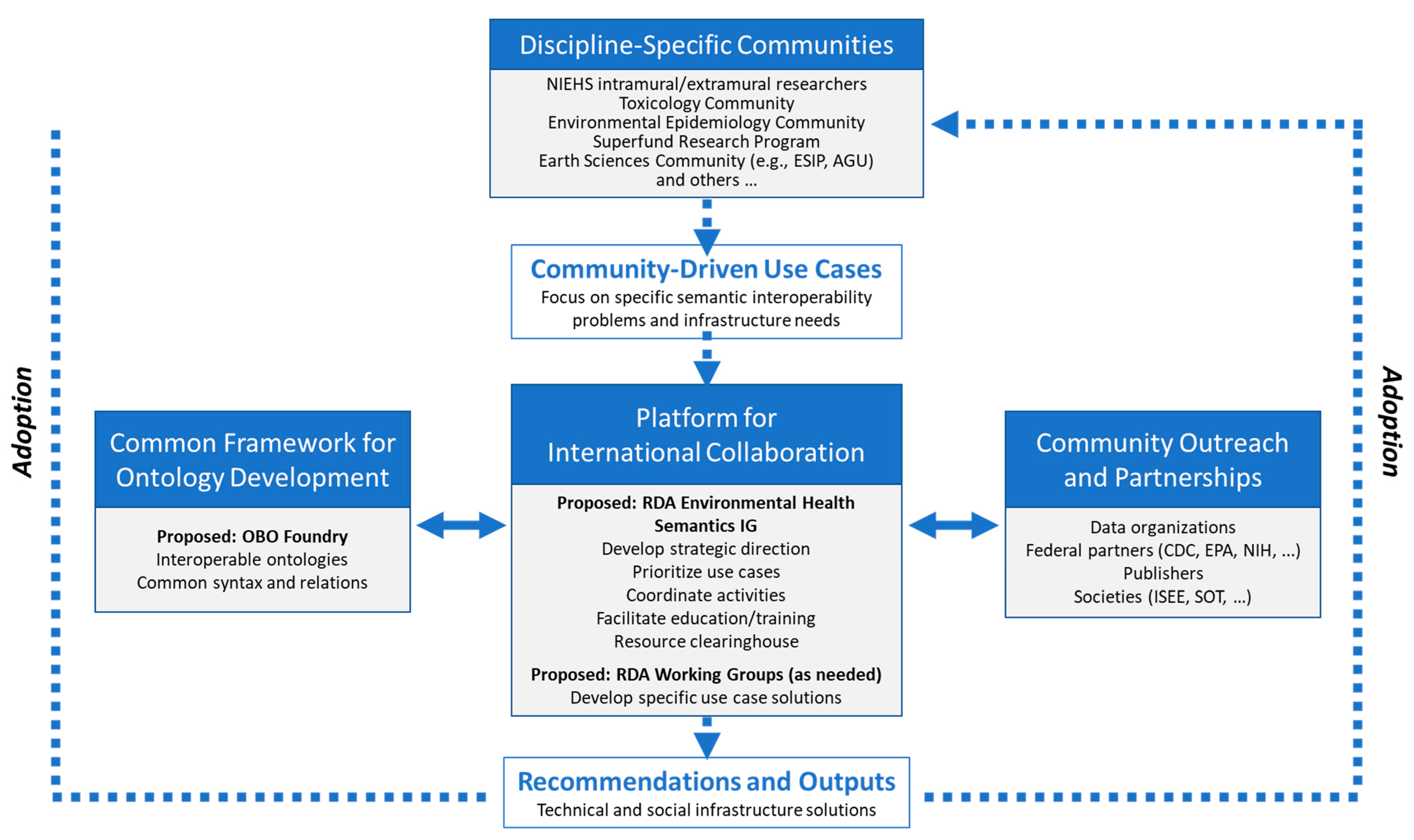
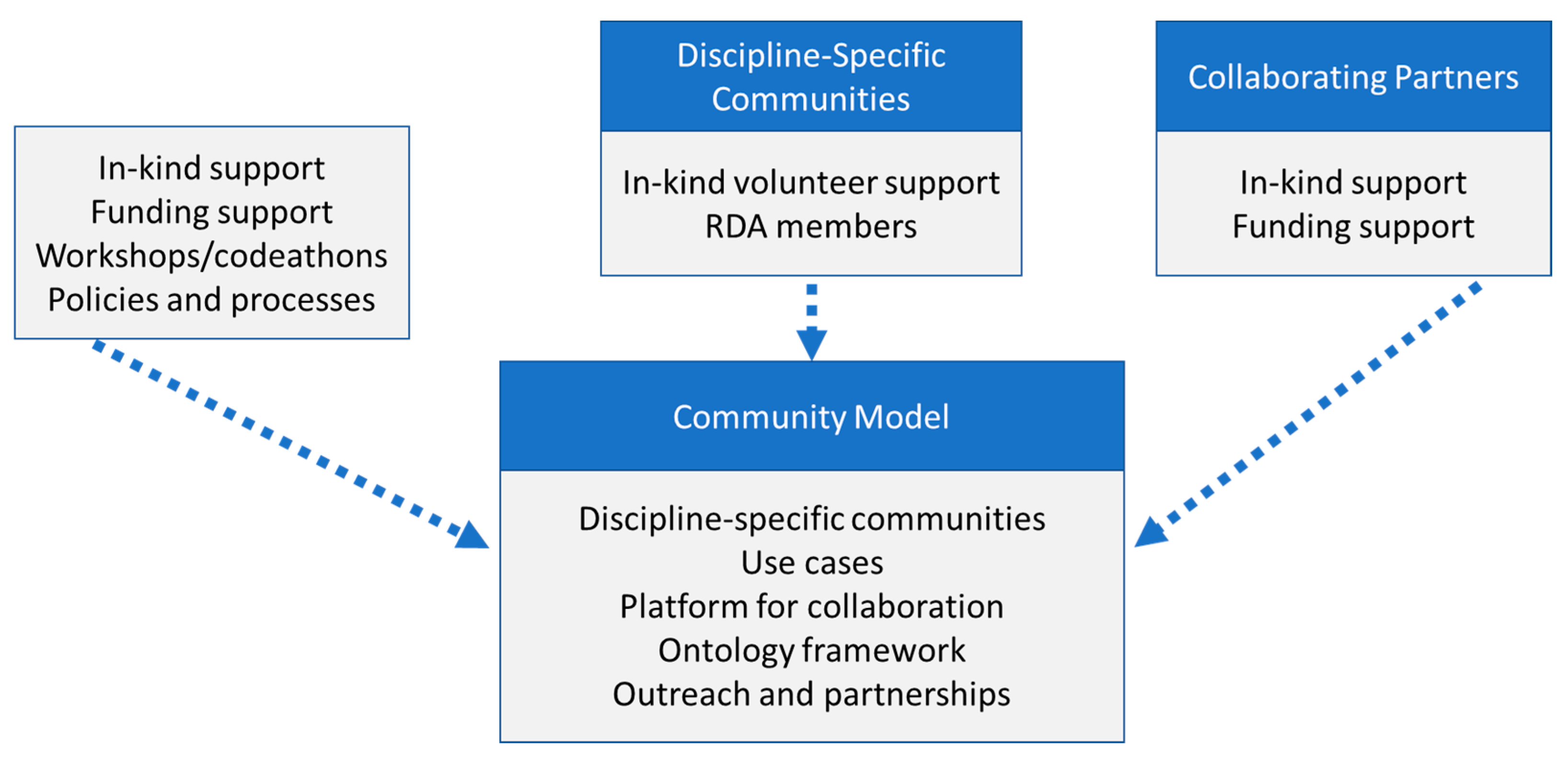
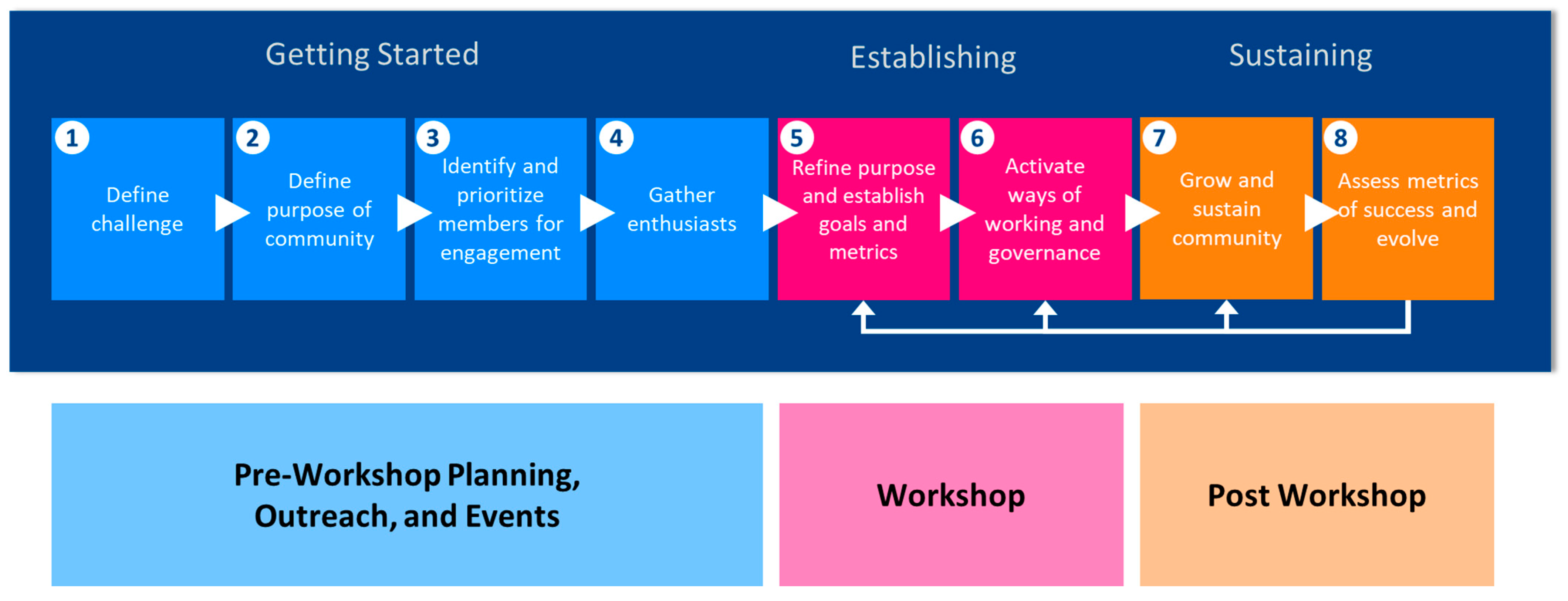
3. Proposed EHS Community Model
- A minimum reporting standard for exposure science and toxicology.
- Curated mappings across chemical authorities.
- A semantic model for exposure data.
- Ontological coverage.
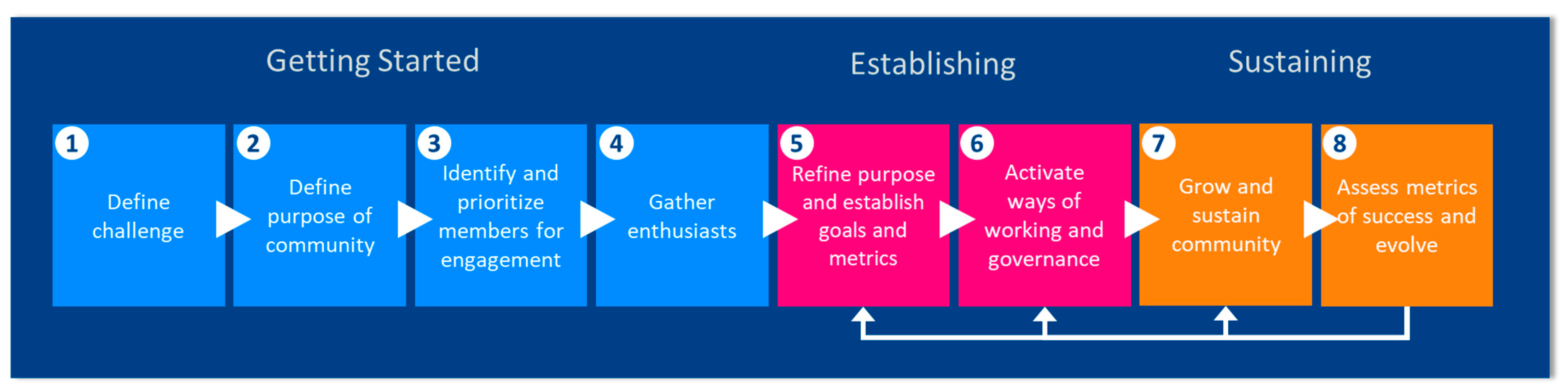
- Form the community around a defined/shared purpose. The community needs to identify its purpose and have a clear understanding of its goals.
- Start with a small circle of champions who can communicate the value of the community.
- Have committed/dedicated financial, technical, and labor resources. Successful communities have an infrastructure to support administrative operations.
- Create a sense of “I found my people” among the members.
- Target a specific action to undertake and grow from there.
- Identify the incentives that are needed to get people actively engaged. While the most likely incentive is that the community activities align with the person’s work-related tasks, some members are simply motivated to make a difference.
- Activate ways of working that meet the community’s culture (e.g., formal versus informal governance, preferred channels of communication).
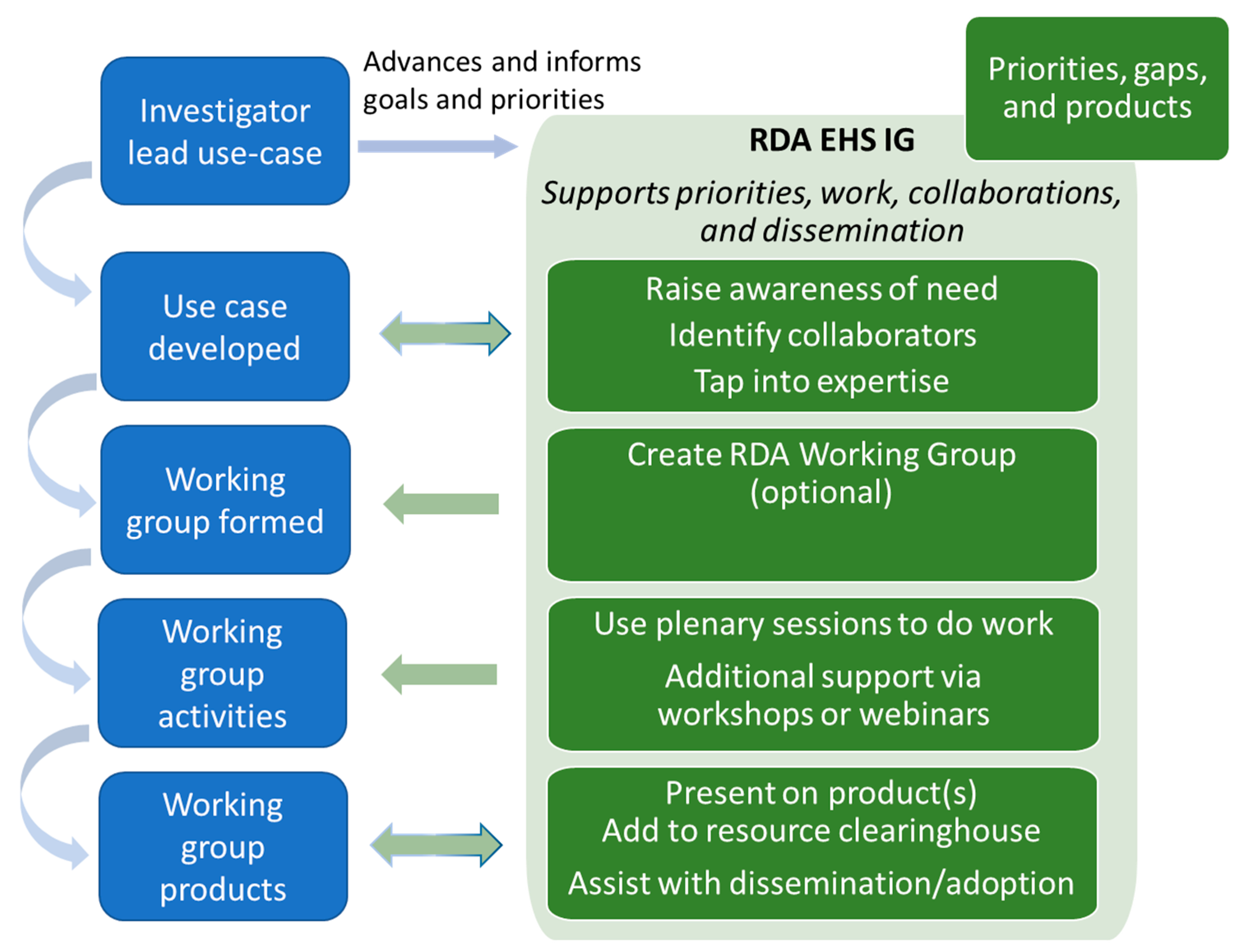
3.1. Proposed Community Organization
- Define use cases for applying knowledge organization systems in research.
- Foster community-based development of harmonized vocabularies, terminologies, and ontologies.
- Promote and develop methods and tools for applying harmonized language in research.
- Cultivate a vocabulary-aware environmental health community through training and education.
- Apply language standards and best practices for accurate environmental health data and knowledge representation
3.2. Community Events
3.3. Use Cases
- What studies measuring endocrine systems perturbation are available?
- What chemicals are chemically similar to compound X and are there any 2-year cancer bioassay data available for these chemicals?
- What animal data exist that provides conclusions on endpoint X given different terms used to describe endpoint X?
- What other data are available for chemical X when it is found in a formulation?
- What assays were “active” for this chemical (where “active” may have different meanings across assays)?
- Combine individual-level data from multiple independent studies (heterogeneous study designs and data collection protocols) to understand (with increased statistical power) how exposures X and Y impact health outcome Z.
- How can we describe model organism toxicological assays/data in a way that is interoperable and reusable to better understand the phenotypic/epigenomic/transcriptomic impact of exposures X and Y across species A and B?
- Integrate and compare data across labs to support more robust corroboration in the confidence of results from toxicological assessments.
- Given conclusive changes in endpoints to one or more exposures, what other data sources exist on the same exposures and endpoints that can confirm or contradict the findings, including across similar endpoints across different species?
- Given natural text mentions of concepts from scientific studies, what ontology(ies) do these mentions map to in order to normalize terminologies across 100–1000s of studies?
- Given conclusive changes in endpoints to one or more exposures, what are biological processes that might lead to the observed changes?
- How can we use a knowledge graph to fill in the adverse outcome or adverse exposure pathways based on the start or end of the pathway?
- What other modes of action/adverse outcome pathways does this assay hit?
- What assays target this mode of action or key event?
- Given an association between exposure and outcome found in an epidemiological study, find the in vivo and in vitro studies that lend support to the association and that suggest involved bioprocesses, including associations that are dependent on developmental windows.
- Given the signatures of biological responses to exposures from multiple modalities (e.g., gene expression, pathology), can we link these signatures to known biological phenotypes and processes to characterize response signatures and to identify gaps in characterizations?
- Can we link a set of available assays (e.g., in PubChem) to known biological processes and phenotypes in order to better characterize chemical exposures?
- What biomarkers can be used to examine exposure to a given chemical?
- Can we identify biomarkers for different classes of exposures (e.g., exposures to metals/metalloids in soil via dust inhalation, exposure to common pesticides via well water) that are contextualized by delivery route?
- Given conclusive changes in endpoints in response to one or more exposures, what other data sources exist on the same exposures and endpoints that can confirm or contradict the findings, including across similar endpoints across different species?
- What is my biggest exposure risk based on my geographical location?
- What am I exposed to in my particular line of work? How might this impact my health?
- For what components of X industrial emission do we need more information on health outcomes?
- What levels of exposure to X will decrease the risk of health outcomes?
- What are the health and economic benefits from regulations or policies that reduce exposure to X?
- What are my biggest exposure risks based on work-life conditions, especially where I live and work (work, geography, hobbies)? What is the route of exposure that is most relevant to my specific conditions?
- How does the response to exposure change based on susceptibility (e.g., genetic, disease, SES backgrounds, differences between signatures of exposures, and differences of risk)?
3.4. Anticipated Outcomes
4. Contribute to the Community
- Review the materials from previous workshop events at https://www.niehs.nih.gov/research/programs/ehlc/resources/index.cfm (accessed on 23 August 2021).
- Provide input on the proposed community initiative and use cases at https://www.niehs.nih.gov/research/programs/ehlc/ (accessed on 23 August 2021)
- Sign up for our email distribution list to be informed of future events and join the community of researchers, systems developers, ontologists, and others interested in working together on language standards in the environmental health sciences.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Prüss-Üstün, A.; Corvalán, C. Preventing Disease through Healthy Environments. Towards an Estimate of the Environmental Burden of Disease; WHO: Geneva, Switzerland, 2006; Available online: https://apps.who.int/iris/bitstream/handle/10665/43457/9241593822_eng.pdf?sequence=1&isAllowed=y (accessed on 23 August 2021).
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; McMorran, R.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. The Comparative Toxicogenomics Database: Update 2019. Nucleic. Acids. Res. 2019, 47, D948–D954. [Google Scholar] [CrossRef]
- Mungall, C.J.; McMurry, J.A.; Köhler, S.; Balhoff, J.P.; Borromeo, C.; Brush, M.; Carbon, S.; Conlin, T.; Dunn, N.; Engelstad, M.; et al. The Monarch Initiative: An integrative data and analytic platform connecting phenotypes to genotypes across species. Nucleic. Acids. Res. 2017, 45, D712–D722. [Google Scholar] [CrossRef] [Green Version]
- Patlewicz, G.; Cronin, M.T.D.; Helman, G.; Lambert, J.C.; Lizarraga, L.E.; Shah, I. Navigating through the minefield of read-across frameworks: A commentary perspective. Comput. Toxicol. 2018, 6, 39–54. [Google Scholar] [CrossRef]
- Mi, H.; Muruganujan, A.; Ebert, D.; Huang, X.; Thomas, P.D. PANTHER version 14: More genomes, a new PANTHER GO-slim and improvements in enrichment analysis tools. Nucleic. Acids. Res. 2019, 47, D419–D426. [Google Scholar] [CrossRef] [PubMed]
- Landauer, T.K.; Dumais, S.T. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psych. Rev. 1997, 104, 211–240. [Google Scholar] [CrossRef]
- Chen, Q.; Lee, K.; Yan, S.; Kim, S.; Wei, C.H.; Lu, Z. BioConceptVec: Creating and evaluating literature-based biomedical concept embeddings on a large scale. PLoS Comput. Biol. 2020, 16, e1007617. [Google Scholar] [CrossRef] [PubMed]
- Cappuzzo, R.; Papotti, P.; Thirumuruganathan, S. Creating Embeddings of Heterogeneous Relational Datasets for Data Integration Tasks. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1335–1349. [Google Scholar]
- Hudson, I.L. Data integration using advances in machine learning in drug discovery and molecular biology. In Artificial Neural Networks. Methods in Molecular Biology; Cartwright, H., Ed.; Humana Press: New York, NY, USA, 2021; pp. 167–184. [Google Scholar]
- Jiang, S.; Wu, W.; Tomita, N.; Ganoe, C.; Hassanpour, S. Multi-Ontology Refined Embeddings (MORE): A hybrid multi-ontology and corpus-based semantic representation model for biomedical concepts. J. Biomed. Inform. 2020, 111, 103581. [Google Scholar] [CrossRef]
- Alshahrani, M.; Khan, M.A.; Maddouri, O.; Kinjo, A.R.; Queralt-Rosinach, N.; Hoehndorf, R. Neuro-symbolic representation learning on biological knowledge graphs. Bioinformatics 2017, 33, 2723–2730. [Google Scholar] [CrossRef]
- Arguello Casteleiro, M.; Demetriou, G.; Read, W.; Fernandez Prieto, M.J.; Maroto, N.; Maseda Fernandez, D.; Nenadic, G.; Klein, J.; Keane, J.; Stevens, R. Deep learning meets ontologies: Experiments to anchor the cardiovascular disease ontology in the biomedical literature. J. Biomed. Semantics 2018, 9, 13. [Google Scholar] [CrossRef] [Green Version]
- Smaili, F.Z.; Gao, X.; Hoehndorf, R. Onto2Vec: Joint vector-based representation of biological entities and their ontology-based annotations. Bioinformatics 2018, 34, i52–i60. [Google Scholar] [CrossRef] [PubMed]
- Alshahrani, M.; Hoehndorf, R. Semantic Disease Gene Embeddings (SmuDGE): Phenotype-based disease gene prioritization without phenotypes. Bioinformatics 2018, 34, i901–i907. [Google Scholar] [CrossRef] [Green Version]
- Kulmanov, M.; Khan, M.A.; Hoehndorf, R.; Wren, J. DeepGO: Predicting protein functions from sequence and interactions using a deep ontology-aware classifier. Bioinformatics 2018, 34, 660–668. [Google Scholar] [CrossRef] [Green Version]
- Treloar, A. The Research Data Alliance: Globally co-ordinated action against barriers to data publishing and sharing. Learn. Pub. 2014, 27, 9–13. [Google Scholar] [CrossRef] [Green Version]
- Richarz, A.-N. Chapter 1: Big data in predictive toxicology: Challenges, opportunities and perspectives. In Big Data in Predictive Toxicology; Royal Society of Chemistry: London, UK, 2019; pp. 1–37. [Google Scholar]
- Aaseth, J.; Wallace, D.R.; Vejrup, K.; Alexander, J. Methylmercury and developmental neurotoxicity: A global concern. Curr. Opin. Toxicol. 2020, 19, 80–87. [Google Scholar] [CrossRef]
- Lee, W.V.; Steemers, K. Exposure duration in overheating assessments: A retrofit modelling study. Build. Res. Inf. 2017, 45, 60–82. [Google Scholar] [CrossRef] [Green Version]
- Spear, L.P. Timing Eclipses Amount: The Critical Importance of Intermittency in Alcohol Exposure Effects. Alcohol Clin. Exp. Res. 2020, 44, 806–813. [Google Scholar] [CrossRef] [PubMed]
- Gwinn, M.R.; DeVoney, D.; Jarabek, A.M.; Sonawane, B.; Wheeler, J.; Weissman, D.N.; Masten, S.; Thompson, C. Meeting report: Mode(s) of action of asbestos and related mineral fibers. Environ. Health Perspect. 2011, 119, 1806–1810. [Google Scholar] [CrossRef] [Green Version]
- Custer, K.W.; Hammerschmidt, C.R.; Burton, G.A., Jr. Nickel toxicity to benthic organisms: The role of dissolved organic carbon, suspended solids, and route of exposure. Environ. Pollut. 2016, 208, 309–317. [Google Scholar] [CrossRef]
- U.S. EPA (U.S. Environmental Protection Agency). Guidelines for Human Exposure Assessment; (EPA/100/B-19/001); Risk Assessment Forum, U.S. EPA: Washington, DC, USA, 2019. Available online: https://www.epa.gov/sites/default/files/2020-01/documents/guidelines_for_human_exposure_assessment_final2019.pdf (accessed on 23 August 2021).
- Vineis, P.; Russo, F.E. Epigenetics and the exposome: Environmental exposure in disease etiology. In Oxford Research Encyclopedia of Environmental Science; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Rogers, M.F.; Ben-Hur, A. The use of gene ontology evidence codes in preventing classifier assessment bias. Bioinformatics 2009, 25, 1173–1177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kluxen, F.M. "New statistics" in regulatory toxicology? Regul. Toxicol. Pharmacol. 2020, 117, 104763. [Google Scholar] [CrossRef]
- Boyles, R.R.; Thessen, A.E.; Waldrop, A.; Haendel, M.A. Ontology-based data integration for advancing toxicological knowledge. Curr. Opin. Toxicol. 2019, 16, 67–74. [Google Scholar] [CrossRef]
- Hankin, S.; Blower, J.D.; Carval, T.; Casey, K.S.; Donlon, C.; Lauret, O.; Loubrieu, T.; Srinivasan, A.; Trinanes, J.; Godøy, Ø.; et al. NetCDF-CF-OPeNDAP: Standards for Ocean Data Interoperability and Object Lessons for Community Data Standards Processes. In Proceedings of the Oceanobs 2009, Venezia, Italy, 21–25 September 2009. [Google Scholar]
- Knudsen, T.B. Roadmap for animal-free reproductive toxicity testing: Predictive toxicology and computational embryology. Presented at Scientific Roadmap for the Future of Animal-free Systemic Toxicity Testing Workshop, College Park, MD, USA, 30–31 May 2013. [Google Scholar]
- Alghamdi, S.M.; Sundberg, B.A.; Sundberg, J.P.; Schofield, P.N.; Hoehndorf, R. Quantitative evaluation of ontology design patterns for combining pathology and anatomy ontologies. Sci. Rep. 2019, 9, 4025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aulbach, A.; Vitsky, A.; Arndt, T.; Ramaiah, L.; Logan, M.; Siska, W.; Cregar, L.; Tripathi, N.; Adedeji, A.; Provencher, A.; et al. Overview and considerations for the reporting of clinical pathology interpretations in nonclinical toxicology studies. Vet. Clin. Pathol. 2019, 48, 389–399. [Google Scholar] [CrossRef]
- Viant, M.R.; Ebbels, T.M.D.; Beger, R.D.; Ekman, D.R.; Epps, D.J.T.; Kamp, H.; Leonards, P.E.G.; Loizou, G.D.; MacRae, J.I.; van Ravenzwaay, B.; et al. Use cases, best practice and reporting standards for metabolomics in regulatory toxicology. Nat. Commun. 2019, 10, 3041. [Google Scholar] [CrossRef] [Green Version]
- Escher, B.I.; Hackermuller, J.; Polte, T.; Scholz, S.; Aigner, A.; Altenburger, R.; Bohme, A.; Bopp, S.K.; Brack, W.; Busch, W.; et al. From the exposome to mechanistic understanding of chemical-induced adverse effects. Environ. Int. 2017, 99, 97–106. [Google Scholar] [CrossRef]
- Vermeulen, R.; Schymanski, E.L.; Barabasi, A.L.; Miller, G.W. The exposome and health: Where chemistry meets biology. Science 2020, 367, 392–396. [Google Scholar] [CrossRef]
- Vineis, P. A self-fulfilling prophecy: Are we underestimating the role of the environment in gene-environment interaction research? Int. J. Epidemiol. 2004, 33, 945–946. [Google Scholar] [CrossRef]
- Wesseling, C.; Glaser, J.; Rodriguez-Guzman, J.; Weiss, I.; Lucas, R.; Peraza, S.; da Silva, A.S.; Hansson, E.; Johnson, R.J.; Hogstedt, C.; et al. Chronic kidney disease of non-traditional origin in Mesoamerica: A disease primarily driven by occupational heat stress. Rev. Panam. Salud Publica 2020, 44, e15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smedley, D.; Jacobsen, J.O.; Jager, M.; Kohler, S.; Holtgrewe, M.; Schubach, M.; Siragusa, E.; Zemojtel, T.; Buske, O.J.; Washington, N.L.; et al. Next-generation diagnostics and disease-gene discovery with the Exomiser. Nat. Protoc. 2015, 10, 2004–2015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bakal, G.; Talari, P.; Kakani, E.V.; Kavuluru, R. Exploiting semantic patterns over biomedical knowledge graphs for predicting treatment and causative relations. J. Biomed. Inform. 2018, 82, 189–199. [Google Scholar] [CrossRef] [PubMed]
- Nicholson, D.N.; Greene, C.S. Constructing knowledge graphs and their biomedical applications. Comput. Struct. Biotechnol. J. 2020, 18, 1414–1428. [Google Scholar] [CrossRef] [PubMed]
- Hasan, S.M.S.; Rivera, D.; Wu, X.C.; Durbin, E.B.; Christian, J.B.; Tourassi, G. Knowledge Graph-Enabled Cancer Data Analytics. IEEE J. Biomed. Health Inform. 2020, 24, 1952–1967. [Google Scholar] [CrossRef]
- Reese, J.T.; Unni, D.; Callahan, T.J.; Cappelletti, L.; Ravanmehr, V.; Carbon, S.; Shefchek, K.A.; Good, B.M.; Balhoff, J.P.; Fontana, T.; et al. KG-COVID-19: A Framework to Produce Customized Knowledge Graphs for COVID-19 Response. Patterns 2021, 2, 100155. [Google Scholar] [CrossRef]
- Zemojtel, T.; Kohler, S.; Mackenroth, L.; Jager, M.; Hecht, J.; Krawitz, P.; Graul-Neumann, L.; Doelken, S.; Ehmke, N.; Spielmann, M.; et al. Effective diagnosis of genetic disease by computational phenotype analysis of the disease-associated genome. Sci. Transl. Med. 2014, 6, 252ra123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, A.P.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. Public data sources to support systems toxicology applications. Curr. Opin. Toxicol. 2019, 16, 17–24. [Google Scholar] [CrossRef] [PubMed]
- Mattingly, C.J.; McKone, T.E.; Callahan, M.A.; Blake, J.A.; Hubal, E.A. Providing the missing link: The exposure science ontology ExO. Environ. Sci. Technol. 2012, 46, 3046–3053. [Google Scholar] [CrossRef] [PubMed]
- Buttigieg, P.L.; Morrison, N.; Smith, B.; Mungall, C.J.; Lewis, S.E.; Consortium, E. The environment ontology: Contextualising biological and biomedical entities. J. Biomed. Semant. 2013, 4, 43. [Google Scholar] [CrossRef] [Green Version]
- Biomedical Data Translator, C. Toward A Universal Biomedical Data Translator. Clin. Transl. Sci. 2019, 12, 86–90. [Google Scholar] [CrossRef] [PubMed]
- Shefchek, K.A.; Harris, N.L.; Gargano, M.; Matentzoglu, N.; Unni, D.; Brush, M.; Keith, D.; Conlin, T.; Vasilevsky, N.; Zhang, X.A.; et al. The Monarch Initiative in 2019: An integrative data and analytic platform connecting phenotypes to genotypes across species. Nucleic. Acids. Res. 2020, 48, D704–D715. [Google Scholar] [CrossRef] [Green Version]
- Callahan, T.J.; Tripodi, I.J.; Hunter, L.E.; Baumgartner, W.A. A framework for automated construction of heterogeneous large-scale biomedical knowledge graphs. bioRxiv 2020. [Google Scholar] [CrossRef]
- Ives, C.; Campia, I.; Wang, R.L.; Wittwehr, C.; Edwards, S. Creating a Structured AOP Knowledgebase via Ontology-Based Annotations. Appl. In Vitro Toxicol. 2017, 3, 298–311. [Google Scholar] [CrossRef]
- Fantke, P.; von Goetz, N.; Schluter, U.; Bessems, J.; Connolly, A.; Dudzina, T.; Ahrens, A.; Bridges, J.; Coggins, M.A.; Conrad, A.; et al. Building a European exposure science strategy. J. Expo. Sci. Environ. Epidemiol. 2020, 30, 917–924. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wittwehr, C.; Aladjov, H.; Ankley, G.; Byrne, H.J.; de Knecht, J.; Heinzle, E.; Klambauer, G.; Landesmann, B.; Luijten, M.; MacKay, C.; et al. How Adverse Outcome Pathways Can Aid the Development and Use of Computational Prediction Models for Regulatory Toxicology. Toxicol. Sci. 2017, 155, 326–336. [Google Scholar] [CrossRef] [Green Version]
- Balshaw, D.M.; Collman, G.W.; Gray, K.A.; Thompson, C.L. The Children’s Health Exposure Analysis Resource: Enabling research into the environmental influences on children’s health outcomes. Curr. Opin. Pediatr. 2017, 29, 385–389. [Google Scholar] [CrossRef] [PubMed]
- FAIRsharing.org. CHEAR; Children’s Health Exposure Analysis Resource. Available online: https://www.niehs.nih.gov/news/events/pastmtg/2016/chear/index.cfm (accessed on 23 August 2021).
- McCusker, J.P.; Rashid, S.M.; Liang, Z.; Liu, Y.; Chastain, K.; Pinheiro, P.; Stingone, J.A.; McGuinness, D.L. Broad, Interdisciplinary Science In Tela: An Exposure and Child Health Ontology; Association for Computing Machinery: Troy, NY, USA, 2017; pp. 349–357. [Google Scholar]
- Heacock, M.L.; Amolegbe, S.M.; Skalla, L.A.; Trottier, B.A.; Carlin, D.J.; Henry, H.F.; Lopez, A.R.; Duncan, C.G.; Lawler, C.P.; Balshaw, D.M.; et al. Sharing SRP data to reduce environmentally associated disease and promote transdisciplinary research. Rev. Environ. Health 2020, 35, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, C.M.; Strader, L.C.; Pratt, J.G.; Maiese, D.; Hendershot, T.; Kwok, R.K.; Hammond, J.A.; Huggins, W.; Jackman, D.; Pan, H.; et al. The PhenX Toolkit: Get the most from your measures. Am. J. Epidemiol. 2011, 174, 253–260. [Google Scholar] [CrossRef]
- Miller, A.; Yeskey, K.; Garantziotis, S.; Arnesen, S.; Bennett, A.; O’Fallon, L.; Thompson, C.; Reinlib, L.; Masten, S.; Remington, J.; et al. Integrating Health Research into Disaster Response: The New NIH Disaster Research Response Program. Int. J. Environ. Res. Public Health 2016, 13, 676. [Google Scholar] [CrossRef] [Green Version]
- Mattingly, C.J.; Boyles, R.; Lawler, C.P.; Haugen, A.C.; Dearry, A.; Haendel, M. Laying a Community-Based Foundation for Data-Driven Semantic Standards in Environmental Health Sciences. Environ. Health. Perspect. 2016, 124, 1136–1140. [Google Scholar] [CrossRef] [Green Version]
- Thessen, A.E.; Grondin, C.J.; Kulkarni, R.D.; Brander, S.; Truong, L.; Vasilevsky, N.A.; Callahan, T.J.; Chan, L.E.; Westra, B.; Willis, M.; et al. Community Approaches for Integrating Environmental Exposures into Human Models of Disease. Environ. Health. Perspect. 2020, 128, 125002. [Google Scholar] [CrossRef]
- Hardy, B.; Apic, G.; Carthew, P.; Clark, D.; Cook, D.; Dix, I.; Escher, S.; Hastings, J.; Heard, D.J.; Jeliazkova, N.; et al. A toxicology ontology roadmap. ALTEX 2012, 29, 129–137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Costigan, S.L.; Werner, J.; Ouellet, J.D.; Hill, L.G.; Law, R.D. Expression profiling and gene ontology analysis in fathead minnow (Pimephales promelas) liver following exposure to pulp and paper mill effluents. Aquat. Toxicol. 2012, 122–123, 44–55. [Google Scholar] [CrossRef] [PubMed]
- Currie, R.A.; Bombail, V.; Oliver, J.D.; Moore, D.J.; Lim, F.L.; Gwilliam, V.; Kimber, I.; Chipman, K.; Moggs, J.G.; Orphanides, G. Gene ontology mapping as an unbiased method for identifying molecular pathways and processes affected by toxicant exposure: Application to acute effects caused by the rodent non-genotoxic carcinogen diethylhexylphthalate. Toxicol. Sci. 2005, 86, 453–469. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Egeghy, P.P.; Sheldon, L.S.; Isaacs, K.K.; Ozkaynak, H.; Goldsmith, M.R.; Wambaugh, J.F.; Judson, R.S.; Buckley, T.J. Computational Exposure Science: An Emerging Discipline to Support 21st-Century Risk Assessment. Environ. Health Perspect. 2016, 124, 697–702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jarabek, A.M.; Hines, D.E. Mechanistic integration of exposure and effects: Advances to apply systems toxicology in support of regulatory decision-making. Curr. Opin. Toxicol. 2019, 16, 83–92. [Google Scholar] [CrossRef]
- Meyer, D.E.; Bailin, S.C.; Vallero, D.; Egeghy, P.P.; Liu, S.V.; Cohen Hubal, E.A. Enhancing life cycle chemical exposure assessment through ontology modeling. Sci. Total Environ. 2020, 712, 136263. [Google Scholar] [CrossRef]
- Kavlock, R.J.; Ankley, G.; Blancato, J.; Breen, M.; Conolly, R.; Dix, D.; Houck, K.; Hubal, E.; Judson, R.; Rabinowitz, J.; et al. Computational toxicology--a state of the science mini review. Toxicol. Sci. 2008, 103, 14–27. [Google Scholar] [CrossRef] [PubMed]
- International Organization for Standardization (ISO). Collaborative Business Relationship Management Systems—Requirements and Framework; ISO Standard NO 44001:2017; ISO: Geneva, Switzerland, 2017. [Google Scholar]
- Janke, K.K.; Seaba, H.H.; Welage, L.S.; Scott, S.A.; Rabi, S.M.; Kelley, K.A.; Mason, H.L. Building a multi-institutional community of practice to foster assessment. Am. J. Pharm. Educ. 2012, 76, 58. [Google Scholar] [CrossRef] [Green Version]
- Pyrko, I.; Dorfler, V.; Eden, C. Thinking together: What makes Communities of Practice work? Hum. Relat. 2017, 70, 389–409. [Google Scholar] [CrossRef] [Green Version]
- Valdes-Dapena, C. Lessons from Mars: How One Global Company Cracked the Code on High Performance Collaboration and Teamwork; John Hunt Publishing: Hampshire, UK, 2018. [Google Scholar]
- Arnaud, E.; Laporte, M.A.; Kim, S.; Aubert, C.; Leonelli, S.; Miro, B.; Cooper, L.; Jaiswal, P.; Kruseman, G.; Shrestha, R.; et al. The Ontologies Community of Practice: A CGIAR Initiative for Big Data in Agrifood Systems. Patterns 2020, 1, 100105. [Google Scholar] [CrossRef]
- Stevens, S.L.R.; Kuzak, M.; Martinez, C.; Moser, A.; Bleeker, P.; Galland, M. Building a local community of practice in scientific programming for life scientists. PLoS Biol. 2018, 16, e2005561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berman, F.; Wilkinson, R.; Wood, J. Guest editorial: Building global infrastructure for data sharing and exchange through the Research Data Alliance. D-Lib. Mag. 2014, 20, 1–4. [Google Scholar] [CrossRef]
- Berman, F. The Research Data Alliance—The First Five Years. 2019. Available online: https://www.rd-alliance.org/research-data-alliance-%E2%80%93-first-five-years (accessed on 23 August 2021).
- Office of The Director National Institutes of Health. Final NIH Policy for Data Management and Sharing. 2020. Available online: https://grants.nih.gov/grants/guide/notice-files/NOT-OD-21-013.html (accessed on 6 July 2021).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event | Date |
|---|---|
| The Value of Creating Language and Community in Catalyzing Knowledge-Driven Discovery in Environmental Health Research (virtual) | 24 June 2021 |
| A Primer on Using Terminologies, Vocabularies, and Ontologies for Knowledge Organization (virtual) | 20 July 2021 |
| Catalyzing Knowledge-Driven Discovery in Environmental Health Sciences through a Harmonized Language (virtual) | 9–10 September 2021 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holmgren, S.D.; Boyles, R.R.; Cronk, R.D.; Duncan, C.G.; Kwok, R.K.; Lunn, R.M.; Osborn, K.C.; Thessen, A.E.; Schmitt, C.P. Catalyzing Knowledge-Driven Discovery in Environmental Health Sciences through a Community-Driven Harmonized Language. Int. J. Environ. Res. Public Health 2021, 18, 8985. https://doi.org/10.3390/ijerph18178985
Holmgren SD, Boyles RR, Cronk RD, Duncan CG, Kwok RK, Lunn RM, Osborn KC, Thessen AE, Schmitt CP. Catalyzing Knowledge-Driven Discovery in Environmental Health Sciences through a Community-Driven Harmonized Language. International Journal of Environmental Research and Public Health. 2021; 18(17):8985. https://doi.org/10.3390/ijerph18178985
Chicago/Turabian StyleHolmgren, Stephanie D., Rebecca R. Boyles, Ryan D. Cronk, Christopher G. Duncan, Richard K. Kwok, Ruth M. Lunn, Kimberly C. Osborn, Anne E. Thessen, and Charles P. Schmitt. 2021. "Catalyzing Knowledge-Driven Discovery in Environmental Health Sciences through a Community-Driven Harmonized Language" International Journal of Environmental Research and Public Health 18, no. 17: 8985. https://doi.org/10.3390/ijerph18178985
APA StyleHolmgren, S. D., Boyles, R. R., Cronk, R. D., Duncan, C. G., Kwok, R. K., Lunn, R. M., Osborn, K. C., Thessen, A. E., & Schmitt, C. P. (2021). Catalyzing Knowledge-Driven Discovery in Environmental Health Sciences through a Community-Driven Harmonized Language. International Journal of Environmental Research and Public Health, 18(17), 8985. https://doi.org/10.3390/ijerph18178985