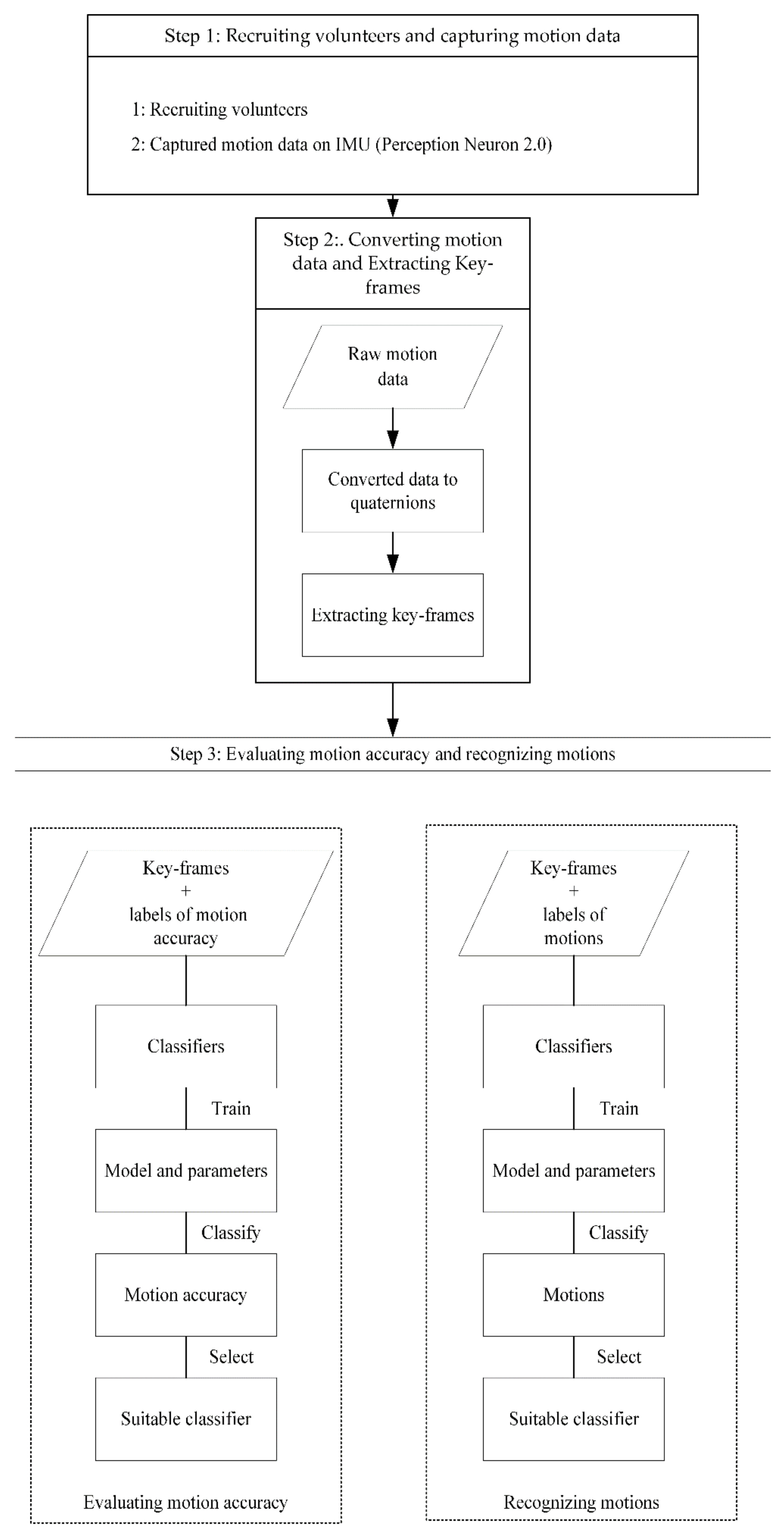
2.2. Motion Data Conversion and Keyframes Extraction
Fifty-six participants were recruited and divided into two groups. The first group comprised 20 students and a martial arts teacher. The teacher has bachelor and master’s degrees in traditional Chinese sports (martial arts) and more than 10 years of experience teaching Baduanjin. The IMU was used to capture the motions of these participants three times. The second group comprised 35 students, and IMU was used to measure the motions of these participants. Students were undergraduates without disabilities and no clinical or mental illnesses. Therefore, for each motion of Baduanjin, 98 “motion data” were captured. The entire dataset of motions included 98 × 8 = 784 motion data (760 motions of students and 24 motions of a teacher).
The BVH file output from Perception Neuron 2.0 used the rotation data on skeleton points represented by Euler angles. The data on Euler angles were converted to quaternions to avoid universal joint locking and singularity in the rotation data represented by Euler angles [
22]. The quaternion is a four-dimensional super-complex number representing the three-dimensional vector space on the real number [
23]. The symbol used to represent a quaternion is as follows:
In Equation (1), w is the scalar component, and x, y, z are the vectors. Set the rotation order of Euler angles as z, y, x, and set the rotation angles around the x, y, and z axes as α, β, γ, then the Euler angles can be converted to quaternions, as follows:
The motion data obtained from MoCap for a single motion is several thousand frames.
Table 1 shows the mean duration and the mean number of frames of Baduanjin captured in the study.
Due to the limited storage space and bandwidth capacity available to users in actual applications, the large amount of collected motion data may limit its application [
24]. The keyframe extraction technique, to extract a small number of representative keyframes from long motion sequences, has been widely used in motion analysis. Therefore, this technique was applied to extract keyframes to reduce the amount of motion data, to improve data storage and subsequent data analysis [
24,
25]. In order to extract the keyframes on the desired compression rate, a method that extracts the keyframes by a preset compression rate on k-means clustering was used in the study [
26]. In this algorithm, Step 1 is to preset the value of k, which is the value of the preset keyframes. In this study, the value of k is determined by the preset compression rate of the extracted keyframes, as follows [
27]:
In Equation (3), k is the value of the preset keyframes, C_rate is the compression rate of the keyframes to be extracted, and N is the number of original frames. On the preset value of k, Step 2 uses k-means to extract k cluster centroids from the dataset of 3D coordinates ([x, y, z]) of the skeleton points of the original frame. In k-means, the distance is the applied Euclidean distance in this study. The skeleton model has 17 skeleton points. Therefore, a cluster centroid is composed of 51 (17 × 3) vectors. Based on these extracted cluster centroids, the keyframes were extracted by calculating the Euclidean distance of skeleton points between the cluster centroids and the original frames. The algorithm to extract the keyframe is shown in
Figure 3.
The reconstruction error between the reconstructed frames and the original frames was calculated to evaluate the effects on extracting keyframes in this study [
28]. Motion reconstruction is based on reconstructing non-keyframes by interpolating adjacent keyframes, thereby rebuilding the same number of frames as the original frames. The interpolation method is: p
1 and p
2 are the positions of the skeleton points of adjacent keyframes at time t
1 and t
2, calculation of p
t (representing the position of the non-key frame point at time t) as follows [
29]:
After reconstructing the motion by interpolation, the reconstruction error is calculated as follows:
In Equation (5), n represents the number of skeleton points, in the study m = 17; is the coordinate of j skeleton point for i frame in original frames, and is the coordinate of the j skeleton point for the coordinate frames in reconstructed frames. represents the calculated distance of the human posture in the i frame between the original frames and reconstructed frames. m1 is the original frames, m2 is the reconstruction frames. N represents the number of frames for reconstructed frames or original frames. Error (m1, m2) is the reconstructed errors calculated by the distance of human posture.
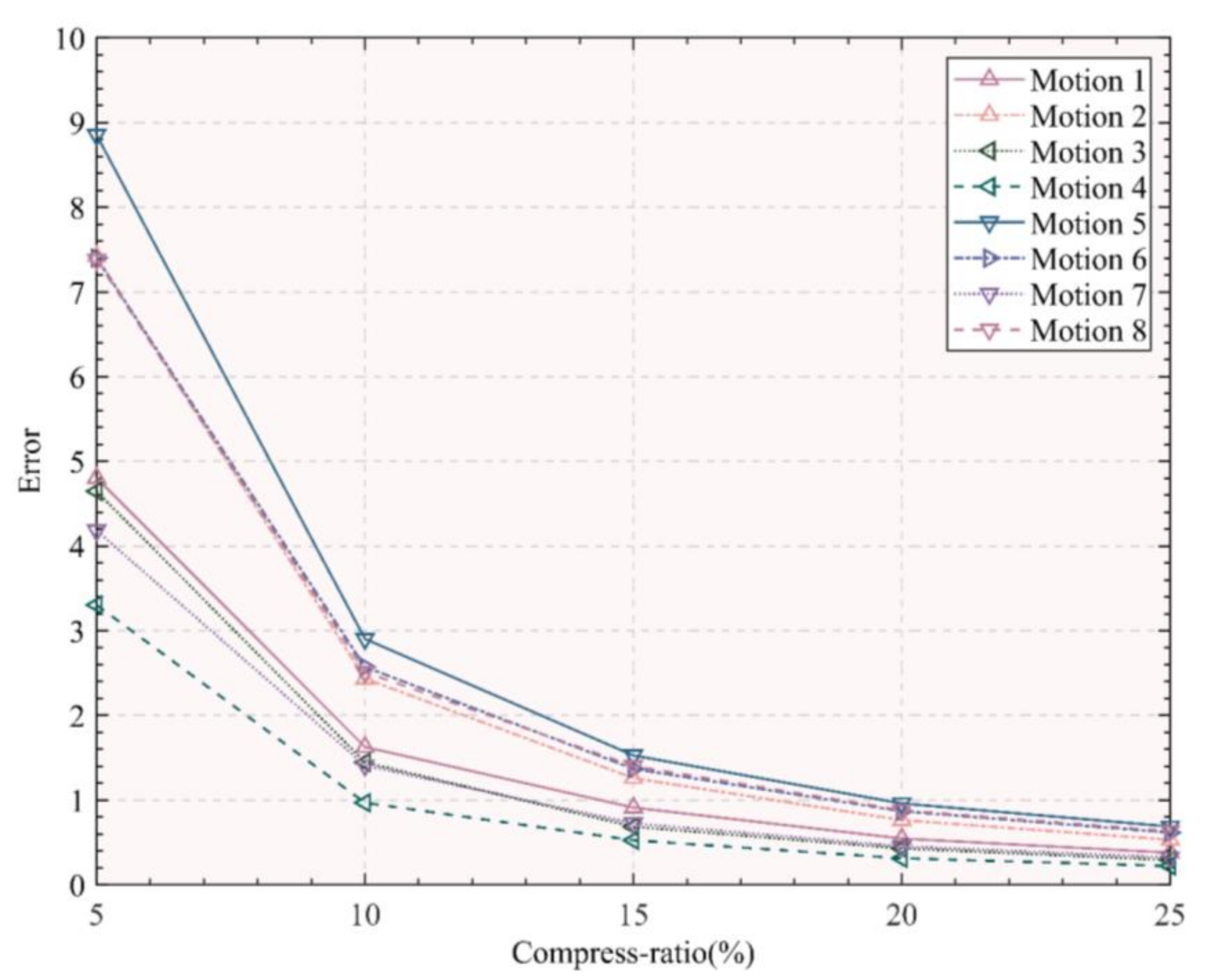
Five different compression ratios (5%, 10%, 15%, 20%, 25%) are chosen to extract keyframes and calculate the reconstruction errors of the corresponding keyframes under the different compression ratios (
Figure 4). This figure shows the average reconstruction error between the extracted keyframes on the corresponding compression rate and the original frames. The Y-axis represents the reconstruction error, and the X-axis represents the five compression ratios (5%, 10%, 15%, 20%, 25%) to the extracted keyframes. The reconstruction errors corresponding to the eight motions of Baduanjin under different compression ratios are represented by different symbols and line segments (as shown in the legend in the figure).
It can be seen from
Figure 4 that as the compression rate decreases, the error of motion reconstruction increases. When the compression ratio increases from 15% to 25%, the reconstruction error does not change much. However, the reconstruction error increases significantly when the compression ratio is between 5% and 15%. Therefore, keyframes on the compression ratio (15%) are extracted to ensure that the compression ratio and reconstruction error are reasonable.
2.3. Traditional Manual Assessment of Baduanjin
Motion recognition can be regarded as a classification issue of time-varying data, where the test motion is matched with a pre-calibrated motion representing typical motion [
30]. Therefore, assessing motion accuracy is similar to an issue for classifying motions. In this study, two martial arts teachers who have more than 10 years of experience teaching Baduanjin from a university in Southwest China were invited to assess the motion accuracy for each student’s motions. According to the grading scale of Baduanjin, the two teachers assess the motion accuracy of the students’ motions into three grades: fail, pass, and good. The Kendall correlation coefficient test is used to calculate the correlation between the scores results from two teachers to ensure the consistency of the evaluation.
Table 2 shows that the captured motions of students have three different grades (fail, pass, and good) except for Motion-8, with only two grades (good and pass). The two teachers explained that Motion-8 is a simple motion in Baduanjin, which the students easily pass (
Figure 5). The Kendall coefficient values between the scores of the two teachers are higher than 0.7, indicating that the two teachers have a high degree of consistency in assessing motion accuracy in Baduanjin. Based on the motion data and the scores of the two teachers, the three sequence-based methods were applied to assess motion accuracy: dynamic time warping (DTW) combined with classifiers, hidden Markov model (HMM) and recurrent neural network (RNN).
2.3.1. Dynamic Time Warping (DTW) Combined with Classifiers
In previous studies [
12,
31], one method assessed the motion accuracy on the differences between the motions of the students and the teacher. The duration of the captured motions was different. DTW, the method used for calculating differences for different time series was applied [
32]. Although the difference between motions calculated by DTW can be used to recognise motions, it is difficult to classify the motions based on the difference to assess the motion accuracy without classifiers. Therefore, classifiers were used to classify the motions after calculating the difference between the students’ motions and the teacher’s motions through DTW. The specific steps are as follows:
Step 1: to calculate the minimum cumulative distance between corresponding skeleton points between two motions of students and teacher with DTW [
13,
32]. In order to prevent DTW from mismatching by excessive time warping, the global warping window was limited in this study, which was set to 10% of the entire window range:
. n and m are, respectively, the frame length of the two motions. Since the warping path of each corresponding skeleton point of the two motions may be different, the average value of the cumulative distance of the warping path was used to indicate the differences between the points:
In Equation (6), stu represents the students’ motions; tea represents the teacher’s motions; qi is the vectors of the quaternion of the i skeleton point in the two motions, and the total number of points is n. length(pathi) is the length of the warping path on the i skeleton point.
Step 2: because the human posture is composed of multiple skeleton points, the overall difference between the two motions from students and the teacher was calculated as distance:
Step 3: after calculating the difference between the teacher’s motion and the student’s motion, the classifier is trained with the scores of the two teachers to classify motion-for-motion accuracy. A variety of classifiers were selected in the study, namely
k-nearest neighbour (
k-NN) [
33], support vector machine (SVM) [
34], naive Bayes (NB) [
35], logistic regression [
36], decision tree (DT) [
37], and artificial neural network (ANN). Due to the diversity of ANNs, two commonly used ANNs: back propagation neural network (BPNN) and radial basis function neural network (RBFNN) [
38], were chosen as classifiers (
Figure 6).
BPNN is a multi-layer feedforward network trained according to the error backpropagation algorithm. In this study, BPNN was constructed with three layers. The first layer was the input layer. The number of neurons was equivalent to the dimension of the feature vectors; the second layer was the hidden layer, the tangent sigmoid equation was applied as the activation equation:
The third layer is the output layer.
The RBFNN is a kind of feedforward network trained using a supervised training algorithm, but the calculation and processing time is lower than that of BPNN. The main advantage of the RBFNN is that it has only one hidden layer and uses the radial basis equation as the activation equation [
38]. Unlike BPNN, the Gaussian equation is used as the basic equation in RBFNN, as follows:
2.3.2. Hidden Markov Model (HMM)
HMM is a sequence-based method that has been successfully applied in recognising human motion [
39,
40]. HMM is a double random process consisting of a hidden Markov chain and a set of explicit discrete probabilities or probability density functions [
40]. HMM can be expressed as follows:
In Equation (8), N presents the set of states in the HMM model, which is the set of possible states of the event. M is the set of possible observation events corresponding to each state, which is the observation set. π is the a priori probability of state occupancy. A is the state transition probability matrix. B is associated with the observations from the various states, which describes the probability of each observation event in each state. HMM can solve three kinds of problems: evaluation, decoding, and learning. In this study, recognising or classifying motions is an evaluation problem [
41]. The method supposes the output probability in one observation sequence: O = o
1, o
2, ..., o
r of a given HMM(λ) is:
. The state with the highest probability in
, the result of recognition or classification.
can be calculated by the forward algorithm, a dynamic programming algorithm that uses a table to store intermediate values when establishing the probability of an observation sequence. α
t(j) in the forward trellis represents the forward probability of the given HMM(λ), which the observed sequence o
1, o
2, ..., o
r at time t and the state is j:
α
t(j) is calculated by superimposing all possible paths:
In Equations (10) and (11), N represents the number of paths from t − 1 to t when the state at time t is j. Then:
Corresponding to the forward algorithm is the backward algorithm, which is used to train the model. β
t(i) represents the backward probability of the given HMM(λ), which the observed sequence o
t+1, o
t+2, ..., o
T at time t and the state is i:
2.3.3. Recurrent Neural Network (RNN)
Motion data of humans is a type of sequence data on time. A RNN is a recursive neural network that takes sequence data as input, recurses in the evolution direction of the sequence, and all nodes (recurrent units) are connected in a chain network [
42]. Trained by the end-to-end training method, RNN can solve sequence labelling problems with unknown input–output alignment [
43]. However, traditional RNNs have the problem of vanishing gradients or exploding gradients. Vanishing gradients cause the parameters to be affected by short-term information, and the earlier information decays with the increase of the time steps. Exploding gradients cause long-term dependence, which refers to the state of the current system that may be affected by the previous state of the system that can lead to information overload [
42]. Long short-term memory (LSTM), a type of RNN, is a neural network especially designed to reduce the problem of vanishing or exploding gradients by using gates to obtain relevant information and forget irrelevant information [
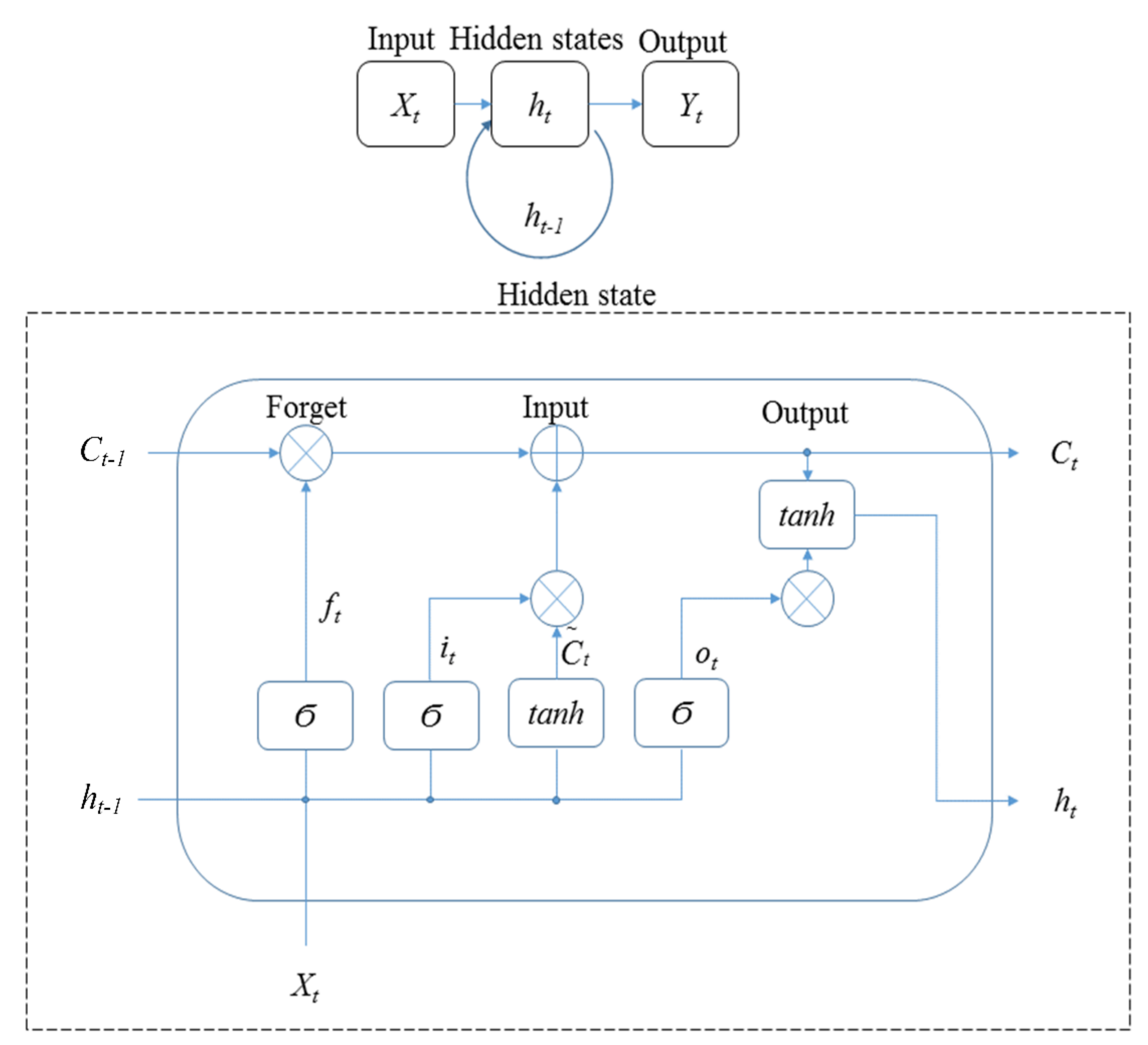
44]. Therefore, LSTM was used as a method of RNN to assess the motion accuracy in this study.
Figure 7 shows the architecture of LSTM applied in the study. In the figure, X
t is input; h
t is hidden states; Y
t is output; U
t is the cell state, and Ϭ is the activation function. There are three gates in the hidden state of LSTM: forget, input, and output. The equations in
Figure 7 are:
LSTM remembers and forgets the long sequence input data using the gates. However, LSTM also has problems: whether the gates included in the architecture of LSTM already provide good predictions and whether additional data training is needed to further improve the predictions [
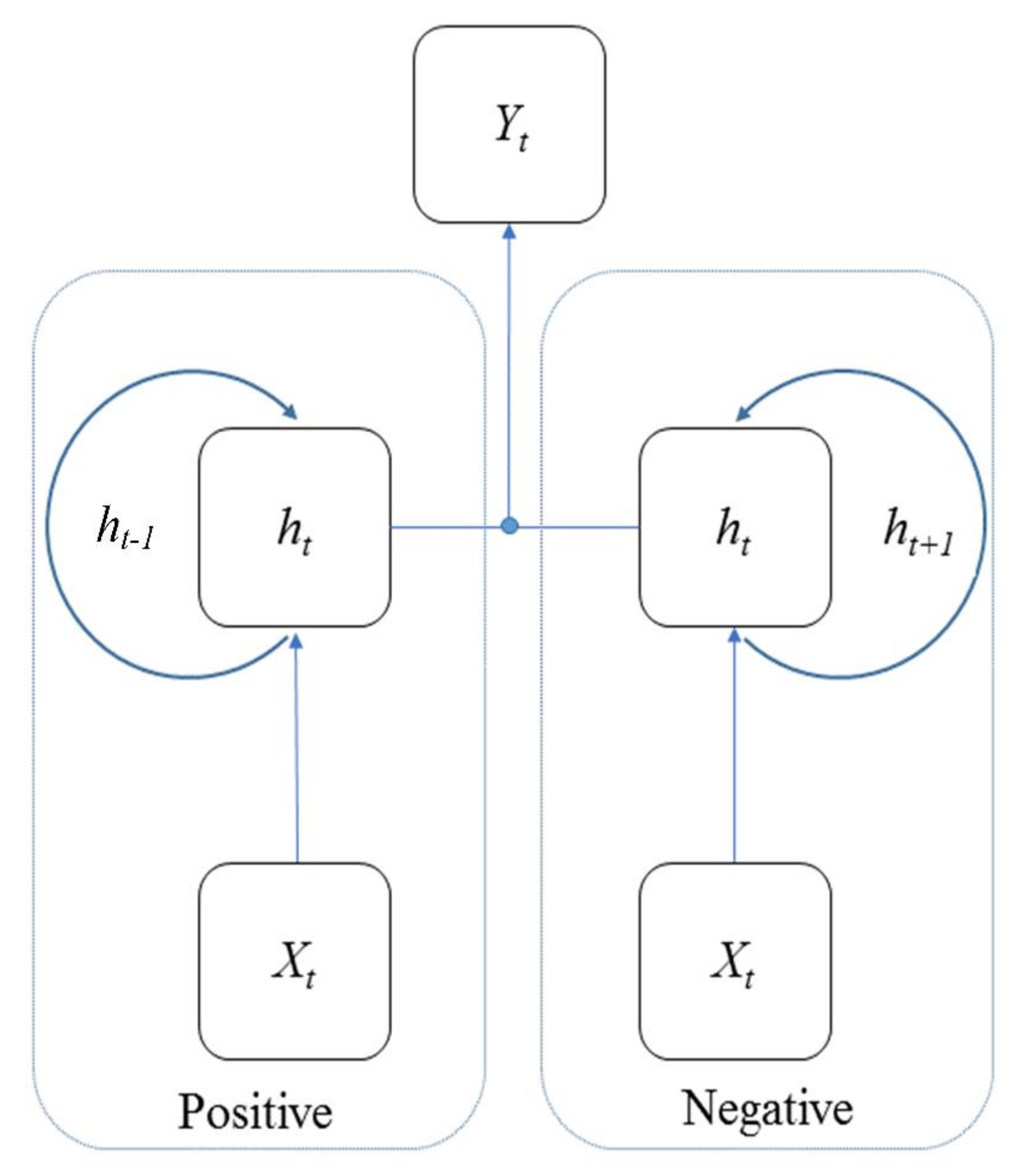
45]. Bidirectional LSTM (BiLSTM) is an improvement to this problem of LSTM, which enables additional training by training the input data twice. Based on the traditional LSTM for positive training on a time series from front to back, BiLSTM adds negative training on a time series from back to front [
45]. The architecture of BiLSTM is shown in
Figure 8.
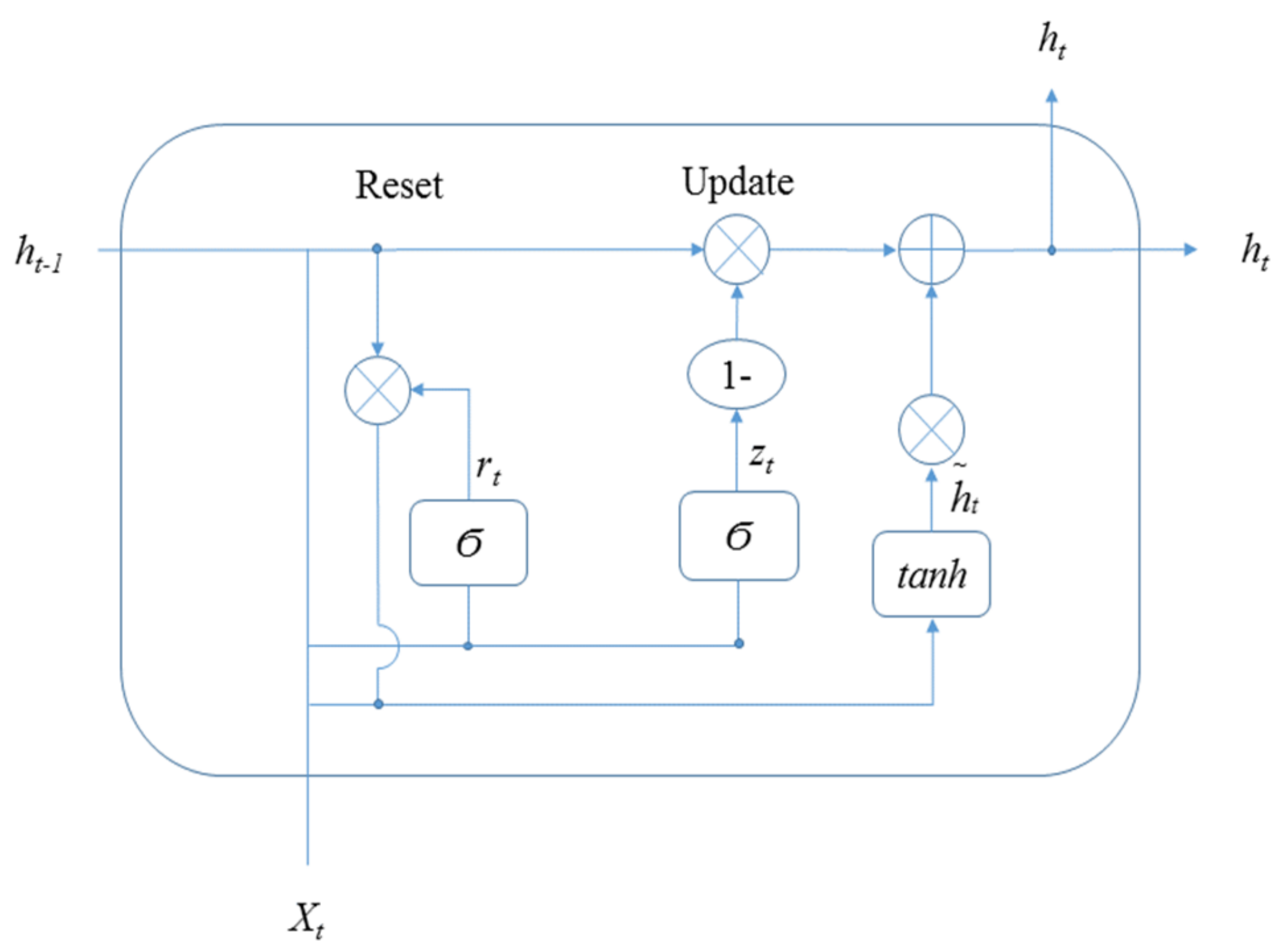
Cho et al., in 2014, proposed a model similar to LSTM but with simpler calculations and implementations, namely the gated recurrent unit (GRU) [
46]. Similar to LSTM, GRU is a positive training model based on time series [
47]. However, the architecture of the hidden state in GRU is different from that of LSTM. The architecture of the hidden state in GRU applied in this study is shown in
Figure 9.
In
Figure 9, X
t is input; h
t is hidden states; Y
t is output, and δ is activation function. There are two gates in the hidden state of LSTM. The equations in
Figure 9 are:
From
Figure 7 to
Figure 9, the hidden state of LSTM and GRU is similar, in that the output at time t is calculated using the hidden state at time t − 1 and the value of input at time t. In addition, the equation of the forget gate for LSTM is similar to the equation of the reset gate for GRU. The difference is that LSTM has three gates, whereas GRU has two gates. There is no output gate in GRU as in LSTM, which means GRU directly transmitted the memory to the next cell, but LSTM selects whether to transmit memory by the output gate.
2.3.4. Evaluating the Effectiveness of Methods
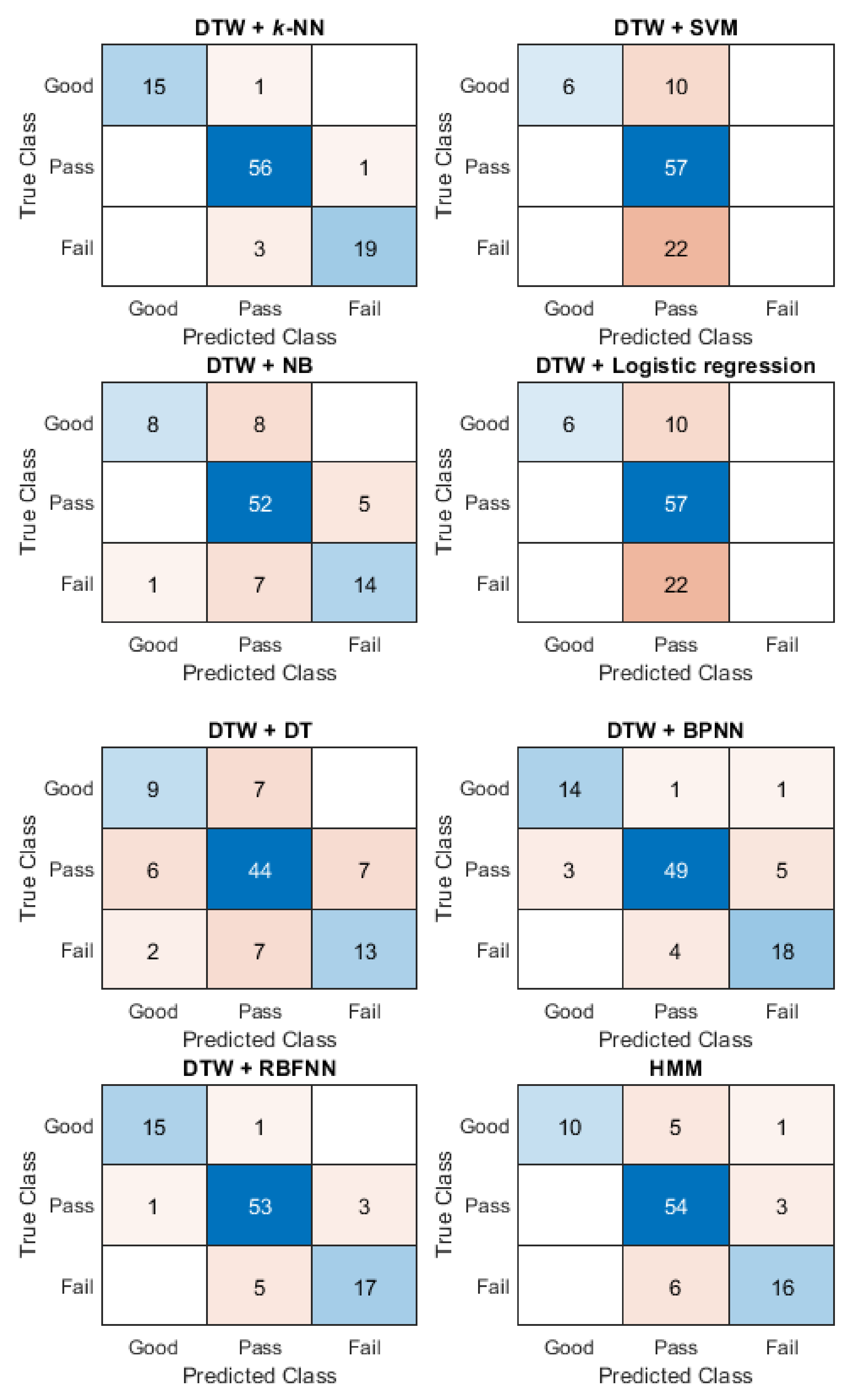
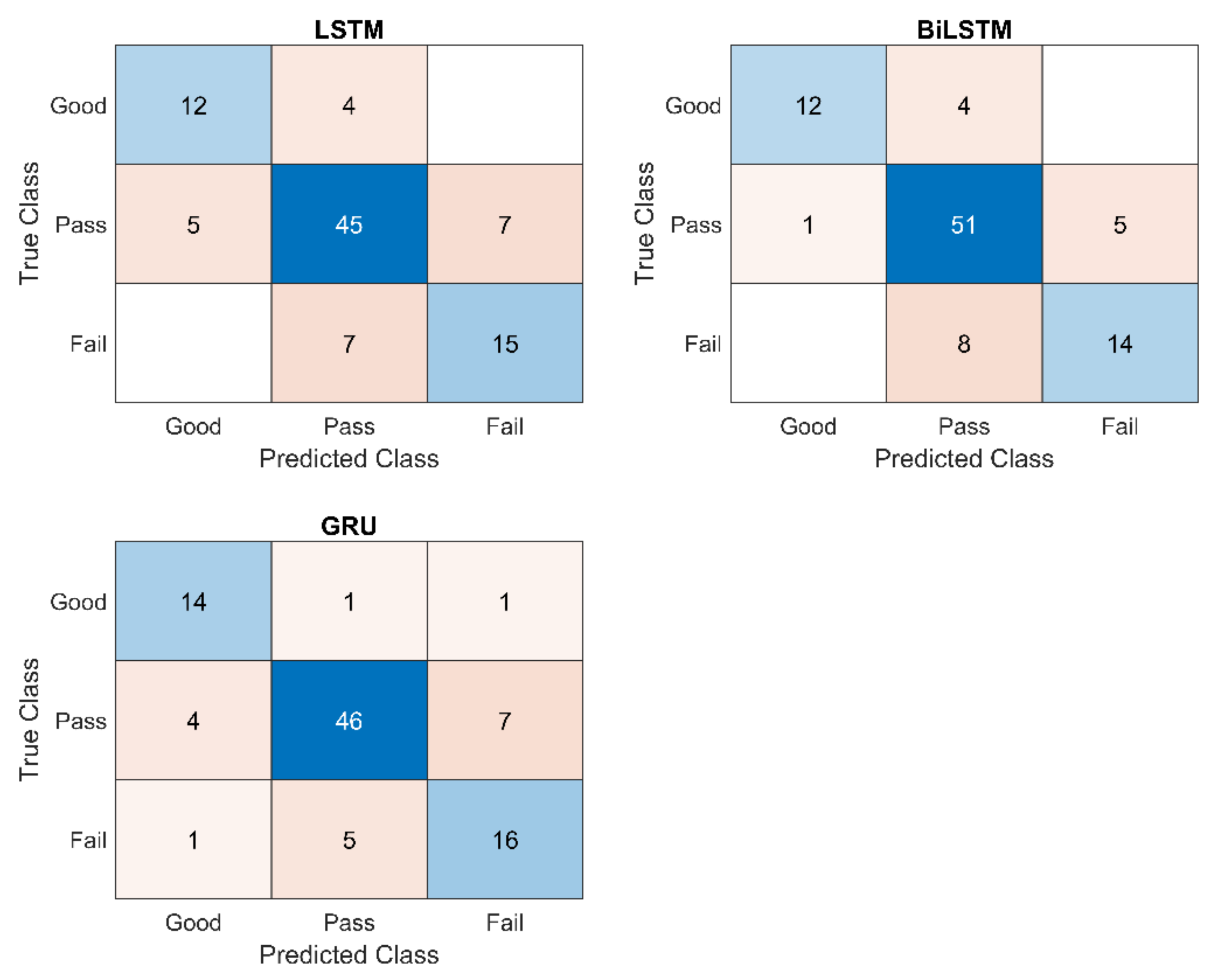
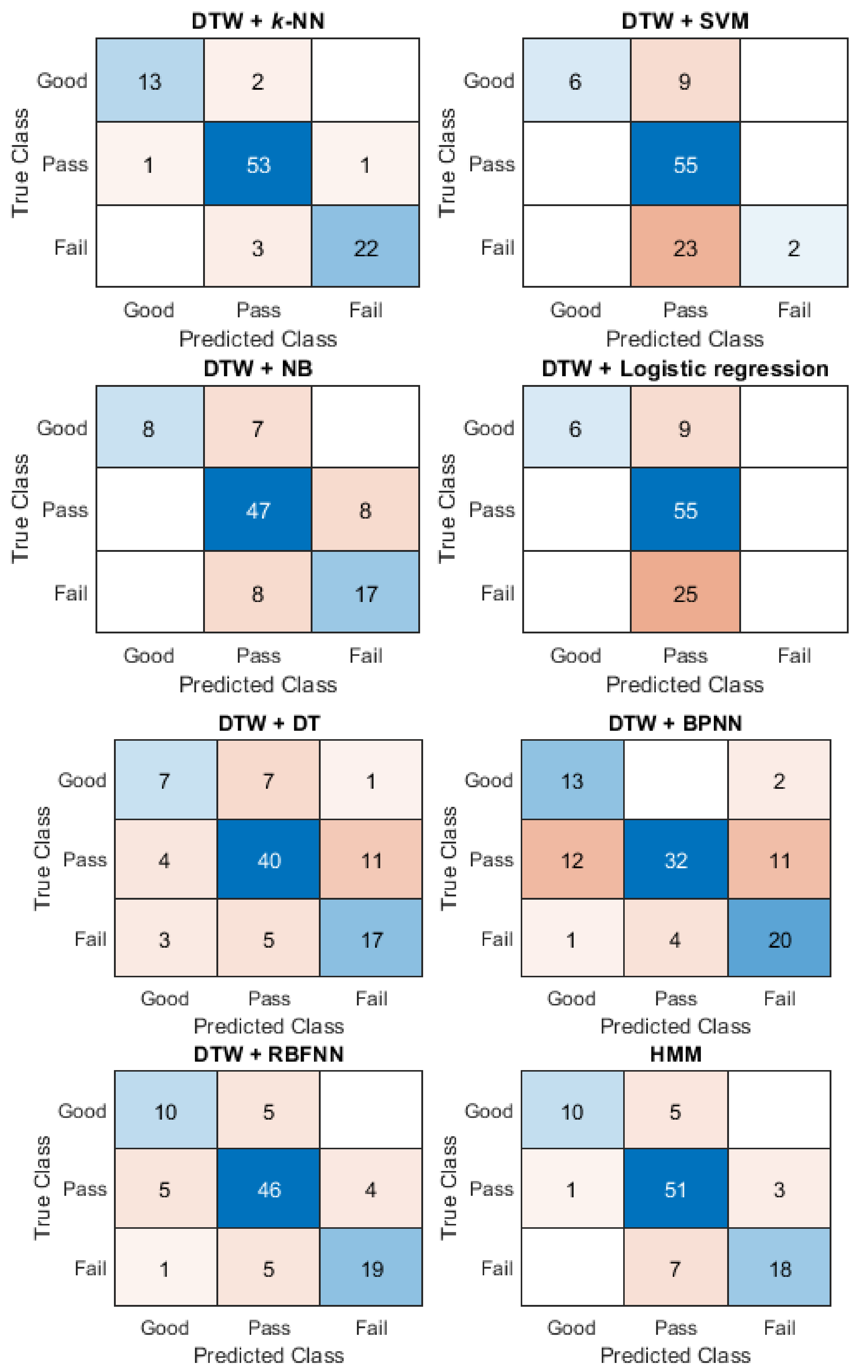
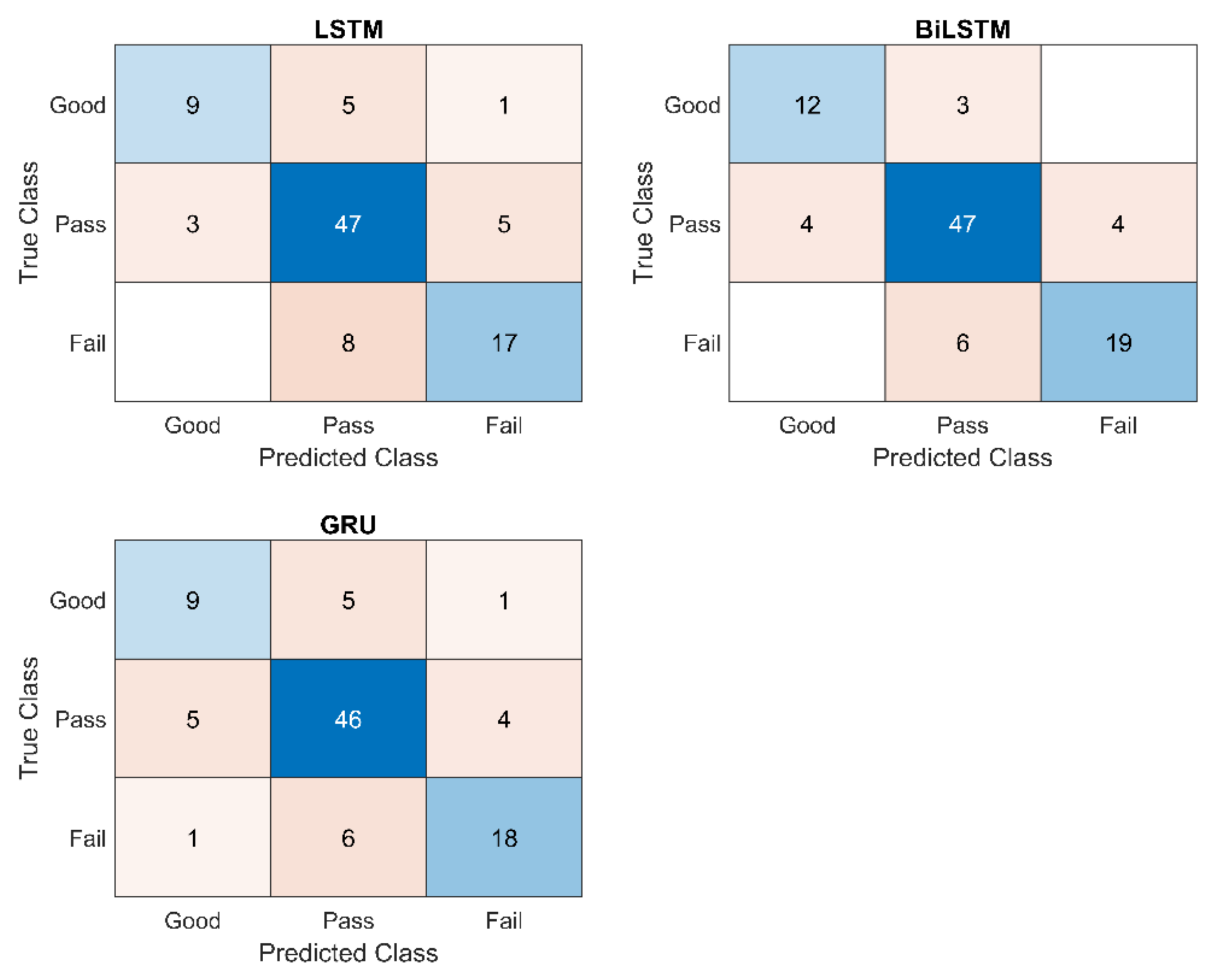
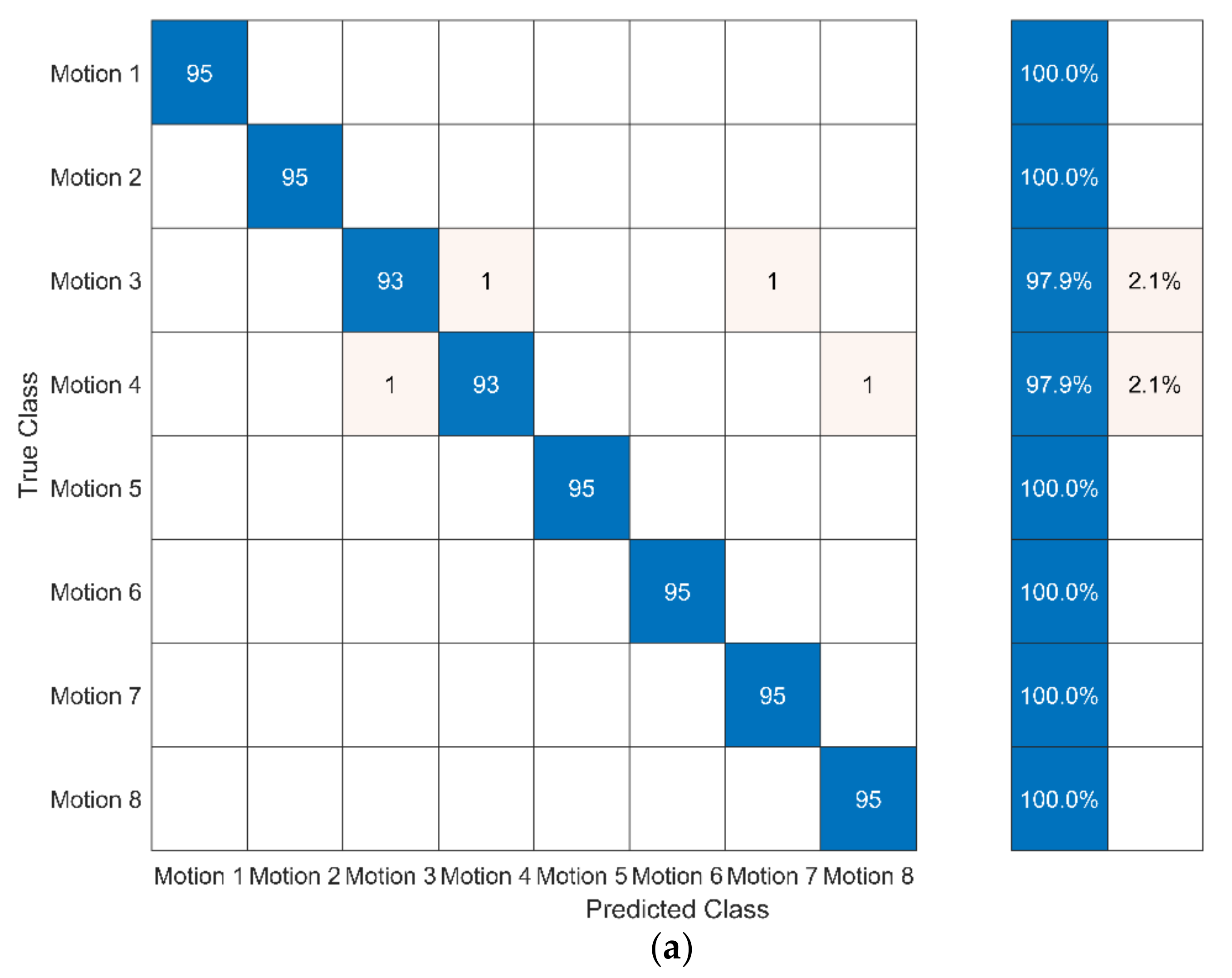
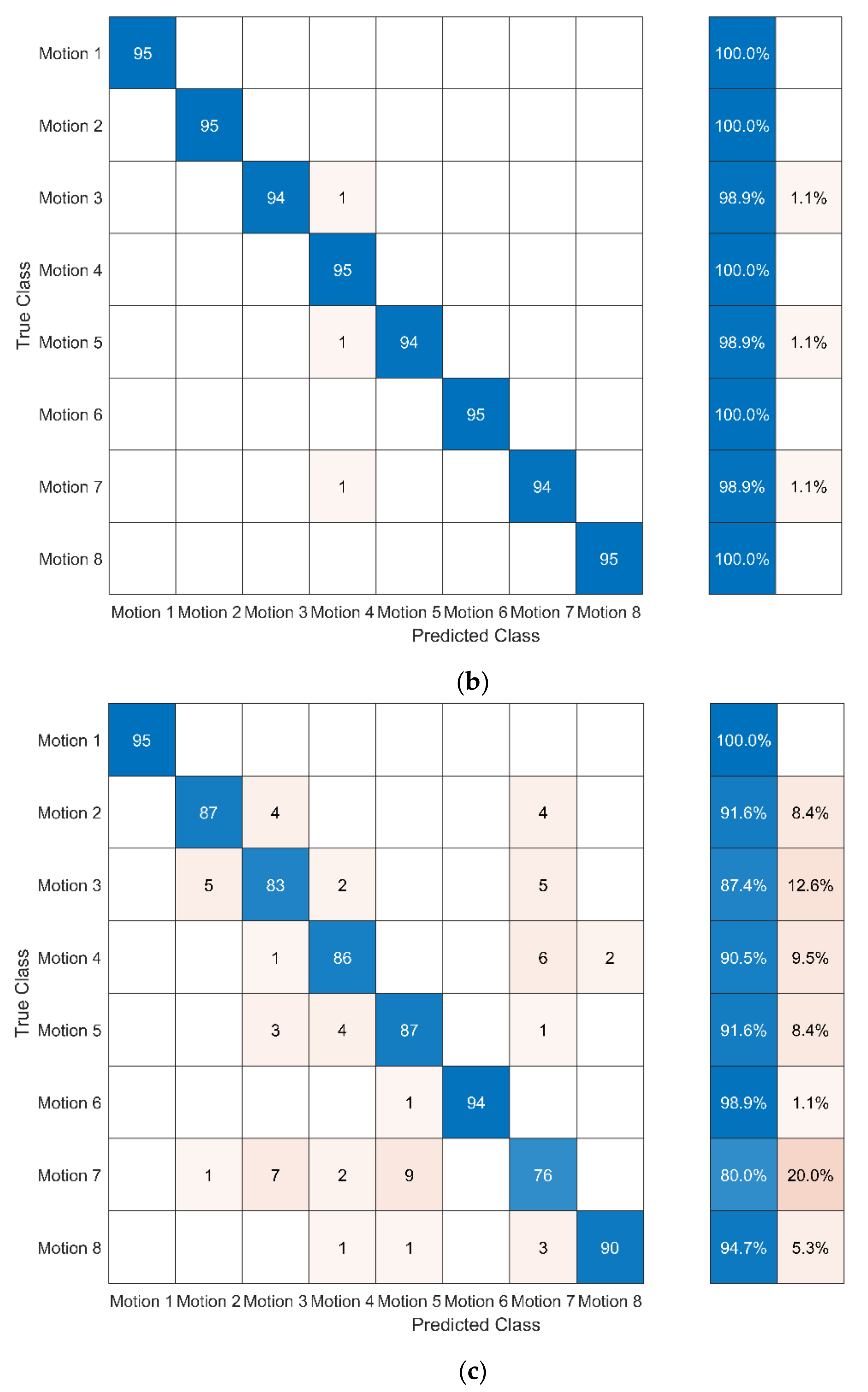
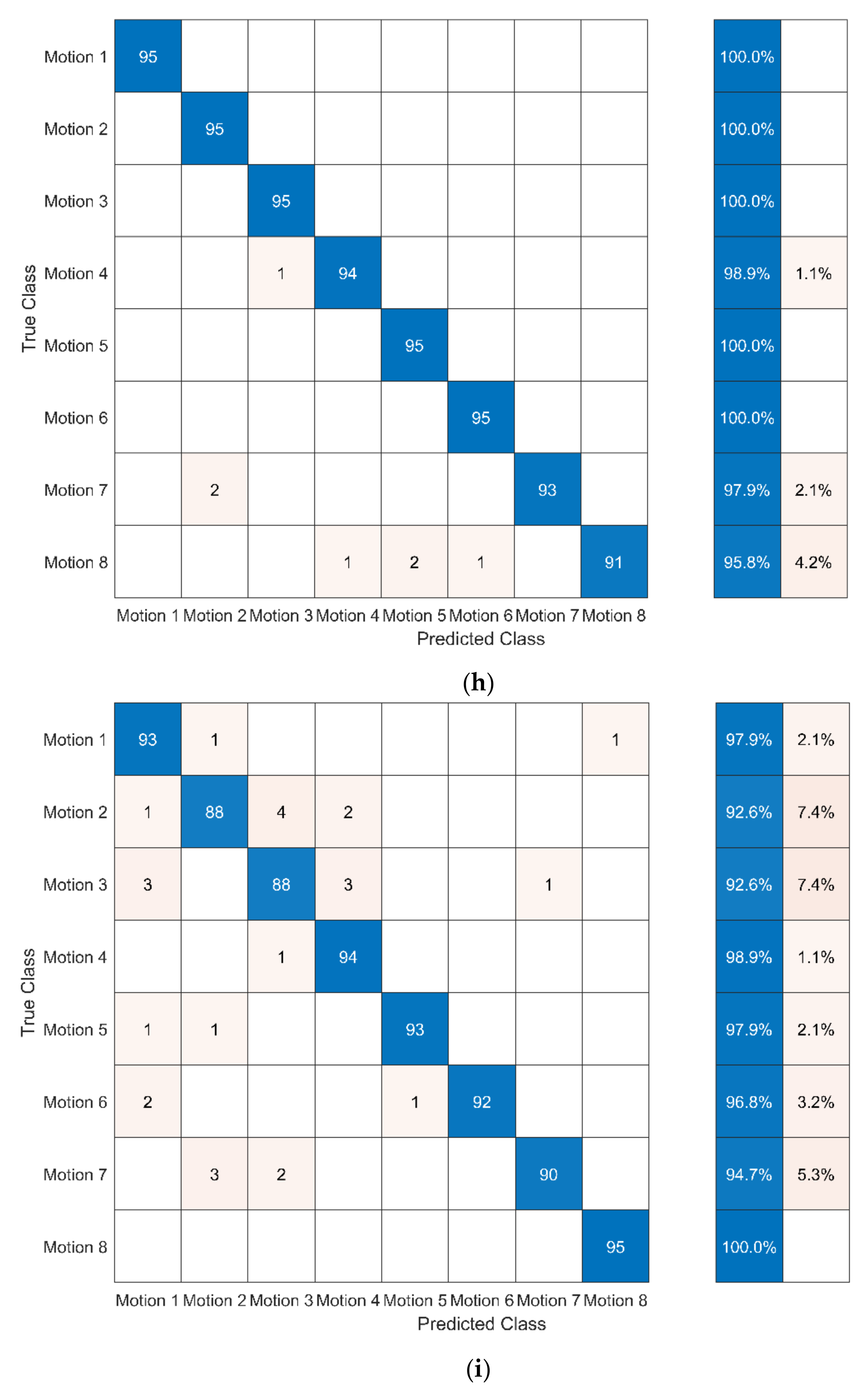
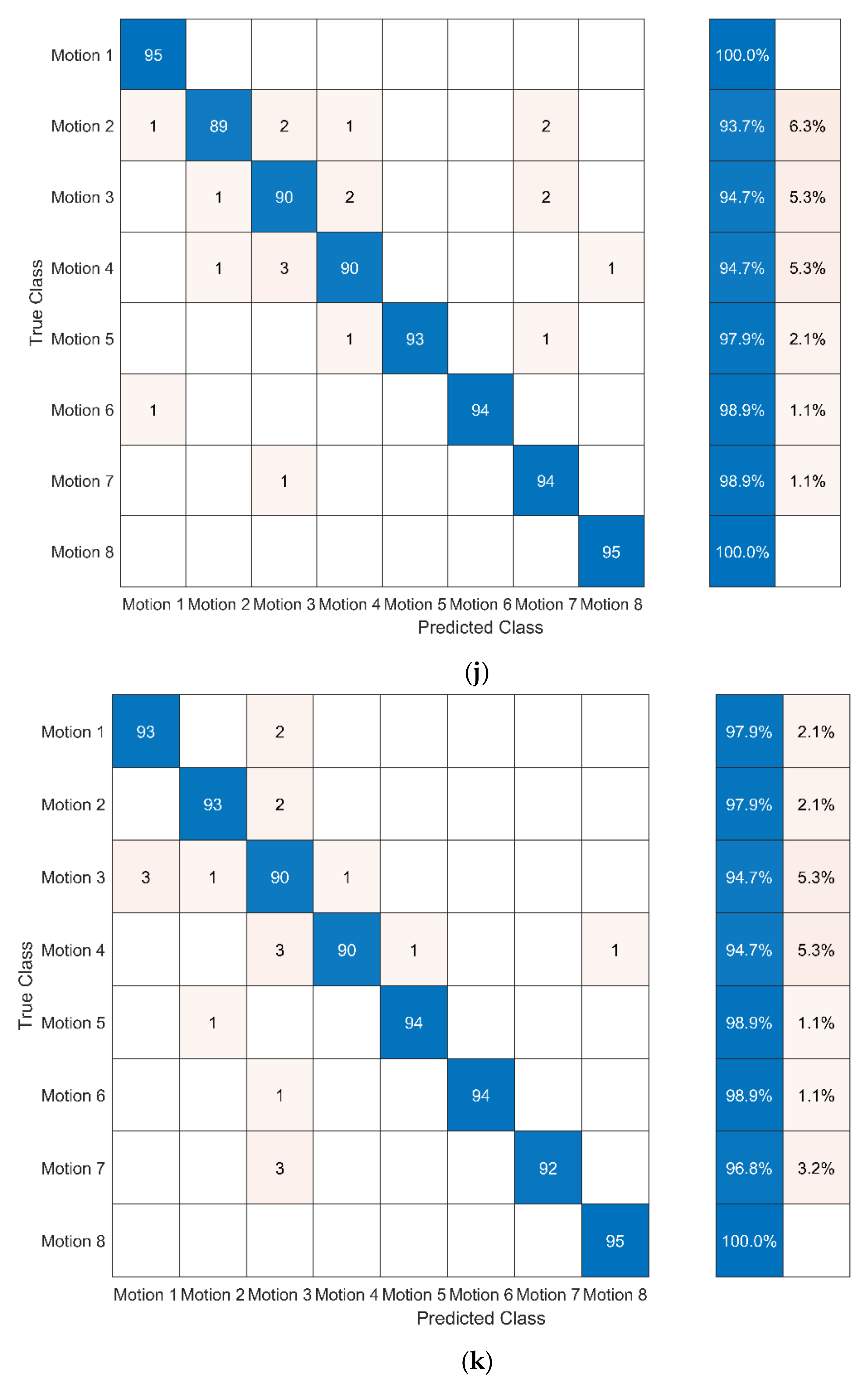
In this study, cross-validation is applied to evaluate the effectiveness of different sequence-based methods for assessing motion accuracy. In cross-validation, the dataset is divided into a training set and a test set: (1) the training set is used to train the model and (2) the test set is used to test the trained model. The 10-fold cross-validation was used in the study. The confusion matrix and the assessment accuracy rate were used to express the effectiveness of different sequence-based methods. The confusion matrix shows the degree of confusion in the classification between different motions. The assessment accuracy is calculated as:























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}