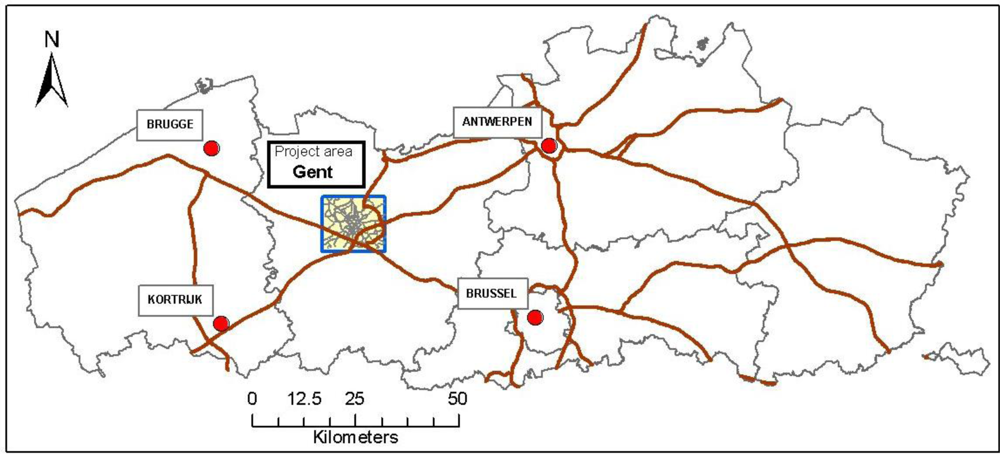
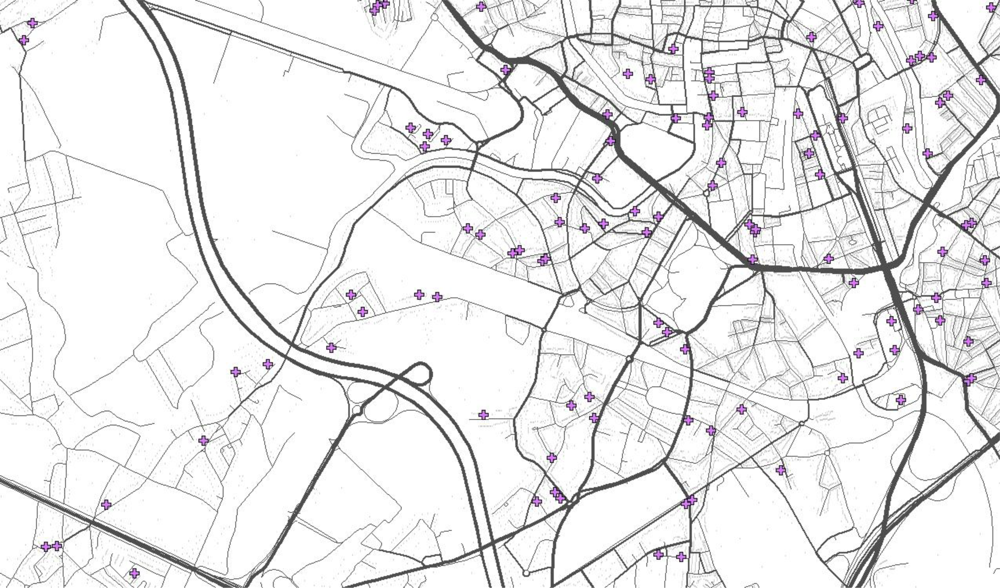
3.1. Analyses of the Survey Data
It is interesting to investigate first the response to the open question Q1.2 since it justifies the choice of variables included in the further analyses and modeling of exposure. In
Figure 3 the words—or synonyms—that are frequently used by the survey respondents when mentioning reasons to recommend to friends and acquaintances to either come to (a) live in this neighborhood or (b) not, are shown. On the positive side the availability of green spaces and nature dominates, followed by a group of factors relating to tranquility and absence of traffic. Many respondents nevertheless also mention accessibility to city center and facilities as being important. The importance of green spaces and nature was previously investigated in detail by Gidlof-Gunnarsson
et al. [
21]. On the negative side too much traffic pops up together with several traffic-associated burdens such as traffic safety, unsafe traffic for children, too high traffic speed, traffic noise. In addition, noise in general and industry and other sources of annoyance are mentioned frequently as well as a lack of tranquility. Traffic and traffic noise thus seem of sufficient importance to merit a specific investigation, both in the positive as in the negative sense. This finding corresponds to the work by Leslie
et al. [
22] that identified traffic and traffic noise as one of the five principle component in a 17 item investigation of neighborhood satisfaction and showed a significant relationship with mental health. O.Campo
et al. [
23] based on concept mapping session also discussed traffic and noise, but with a much less prominent role. The latter study was done in Toronto, which is a completely different context which might explain these differences. It should however also be mentioned for completeness that the survey used in the underlying work was conducted by the regional government which might have urged participants to focus more on issues that are related to this level of governance and not on local urban issues.
To quantify these first observations and to identify potential pathways before proceeding with relating the survey to exposure indicators, relationships between answers on the survey questions are investigated. Since no exposure calculation is needed for this, the full statistical power of the region wide survey can be used.
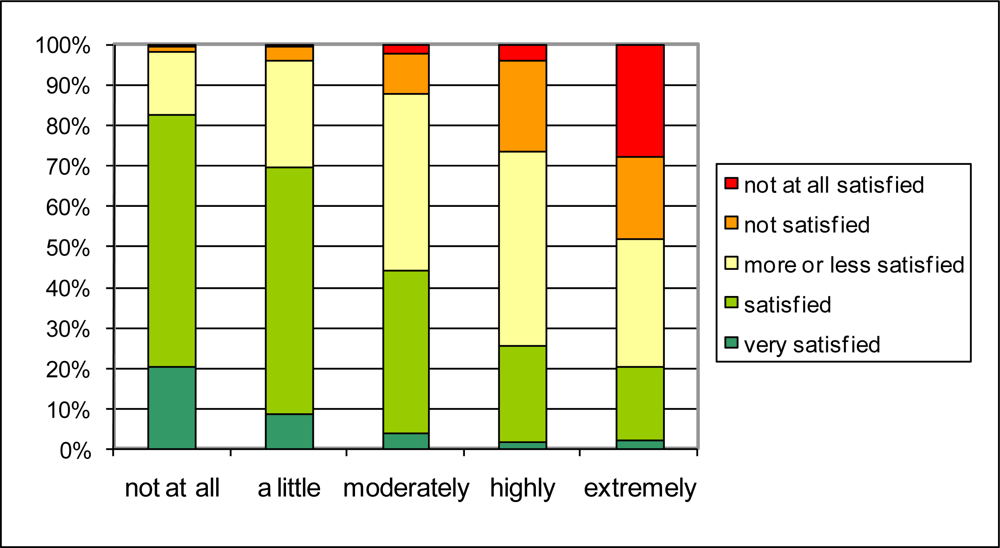
The importance of traffic noise for the quality of life in the neighborhood that boiled up in the open question, is confirmed by plotting the answer to the question on quality of life in the neighborhood (Q1.1) against the answer to the question on noise annoyance at home caused by street traffic (Q2.1a) in
Figure 4 and that caused by air traffic (Q2.1c) in
Figure 5. People reporting to be highly or extremely annoyed by street traffic noise, are more likely to be not (or not at all) satisfied about the over-all living quality (resp. up to 30% and 50% of the people reporting highly or extremely annoyance). Only 20 to 25% of the people reporting high to extreme annoyance by street traffic noise, are still satisfied about their living quality. Reporting no annoyance by street traffic noise at all, seems to be sufficient for the large majority of people to report being satisfied to very satisfied with the overall quality of life in the neighborhood. Although the prevalence of being highly to extremely annoyed by air traffic noise is much lower (2.6%) than the prevalence of being highly to extremely annoyed by road traffic noise (11.5%), the effect on reported overall quality of the living environment is rather similar. In the categories of highly and extremely annoyed people, resp. over 20% and over 30% are not or not at all satisfied about the living quality. On the other hand, about 30% of these respondents are nevertheless satisfied or very satisfied about the living quality. It was also observed that this general trend is conserved when the population under study is limited to those living in a city or those living in smaller villages (not shown in the graphs). Both the insensitivity to the cause of noise annoyance and the insensitivity to living in a city or in a village on the countryside suggest that there is indeed a strong relationship between reported noise annoyance and reported quality of life in the neighborhood. The spread in the answers do not exclude—even suggest—the existence of other hidden spatially determined variables steering both noise annoyance and quality of life. Personal factors influencing sensitivity to the environment or reporting style can however not be ruled out at this point.
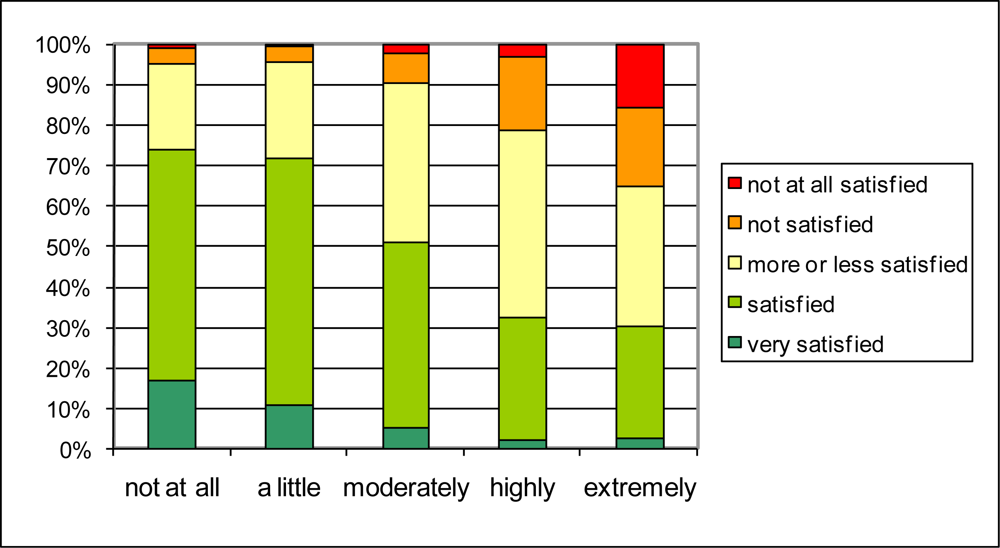
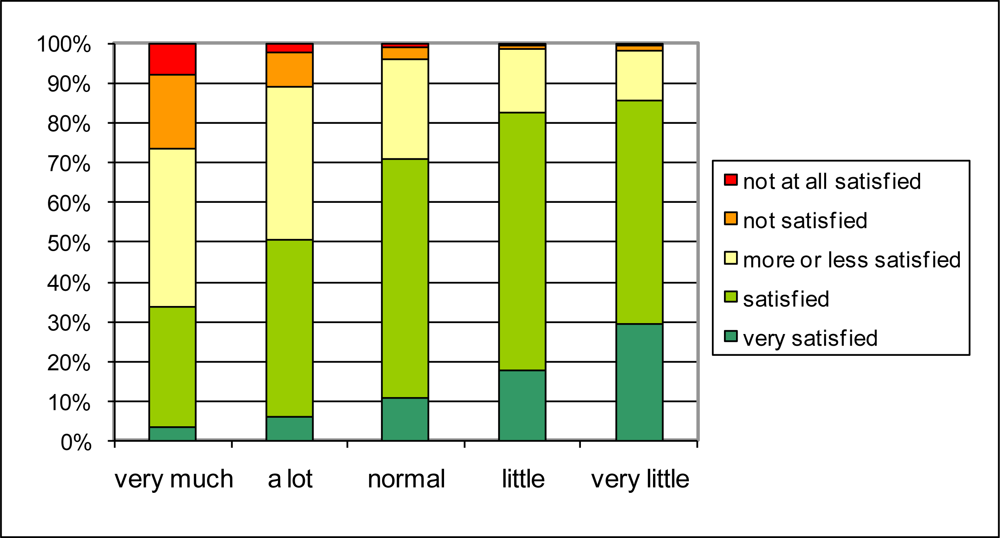
The reported traffic intensity in the neighborhood (Q1.8) is related to satisfaction with the general quality of life in the neighborhood in a similar way as noise annoyance (
Figure 6), but in general the relationship is less strong. From the people who judge that there is ‘very much traffic’ in their neighborhood, less than 30% is not or not all satisfied about the general living quality. In the category reporting ‘a lot of traffic’ in their neighborhood, about 10% is not (or not all) satisfied about the living quality. Reporting “very little traffic” results in 30% of the people reporting also being very satisfied with the quality of the living environment. At this end of the scale, reported traffic intensity is thus a somewhat stronger predictor for quality of life in the neighborhood than the absence of traffic noise annoyance.
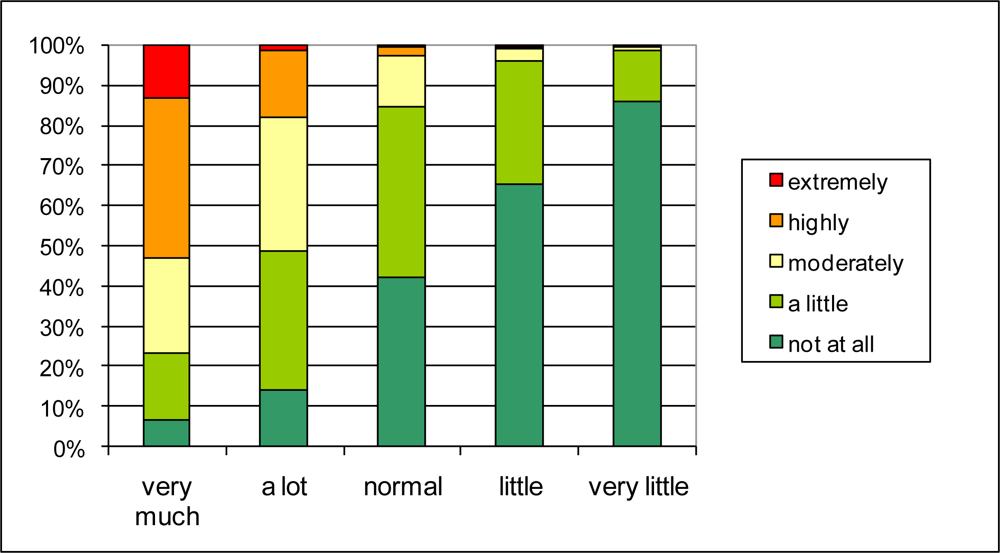
The connection between traffic intensity and quality of life in the neighborhood could exist through street traffic noise annoyance or through other negative or positive aspects of traffic such as safety, exhaust smell, or even accessibility. The distribution of answers on the street traffic noise annoyance question (Q2.1a) for different reported traffic intensities (Q1.8) in
Figure 7 reveals a rather strong relationship. Over 50% of the people that report “very much traffic” also report high to extreme street traffic noise annoyance. Of those reporting little or very little traffic, no one reports high to extreme noise annoyance. The relationship between reported traffic intensity and quality of life in the neighborhood through street traffic noise annoyance seems possible. To investigate its probability further, the percentages in
Figure 4 and
Figure 7 are interpreted as conditional probabilities P(S
i|A
j) and P(A
j|T
k) respectively. S
i refers to the i
th degree of satisfaction with quality of life in the neighborhood; A
j refers to the j
th level of street traffic noise annoyance; and T
k to the k
th level of reported traffic intensity. P(S
i|T
k) can now be calculated in a probabilistic way as P(S
i|T
k) = ∑
j P(S
i|A
j) P(A
j|T
k). The result is shown in
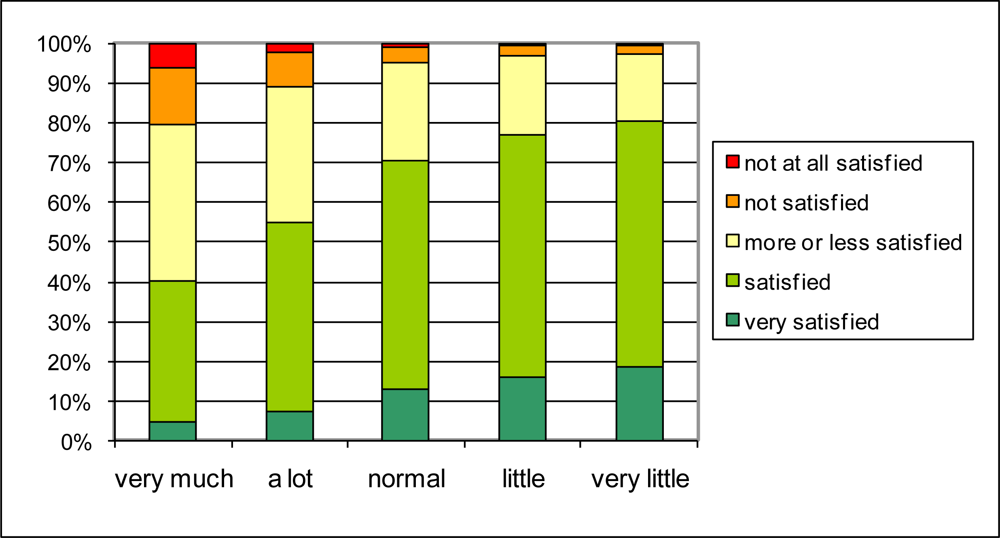
Figure 8. By comparing these results to
Figure 6, it can be observed that the probabilistic approach slightly underestimates the percentage “not satisfied” to “not at all satisfied” in case of very much traffic and underestimates the percentage “very satisfied” in case of very little traffic, but that overall the agreement is strong. Thus the pathway through noise annoyance—that was the basic assumption for the probabilistic calculation—seems to be quite valid. The above mentioned deviations could be explained by other effects of traffic that impact the overall quality of life in both in positive (little or calm traffic in itself or child friendliness) and negative sense (traffic safety).
These conclusions form the basis for the analysis in the next paragraph, where several models are compared to explain and predict the perceived quality of life in a neighborhood. In this further analysis exposure indicators will form the main topic of interest.
3.2. Logistic Regression Model for Gent Data
The main outcome variable in this study is the reported general satisfaction with the quality of life in the neighborhood (Q1.1). This question is answered using a five point bipolar scale: very satisfied, satisfied, more or less satisfied, not satisfied, not at all satisfied. This coarse granulation can hardly be approximated as a continuous answer variable. In addition, it was shown that reasons mentioned in the open question differ significantly depending on whether they relate to positive or negative evaluation. For these reasons, the outcome is quantified either as ‘satisfied and very satisfied’ at the one hand and as ‘not satisfied and not at all satisfied’ at the other hand. A logistic regression model (without interaction terms) is used to quantify the importance of indicators studied: 1/(1 + exp[–z]), with z = β0 + β1 × 1 + β2 × 2 …
Since all indicators for exposure to noise during a trip (
Table 1) are expected to be correlated (correlation coefficient reaches 0.7 in some cases), it is useful to first determine which ones are more appropriate to add to an overall logistic regression model. Therefore we first consider traffic noise annoyance in and around the house (Q2.1a). Answer categories are grouped to {moderately, highly, extremely} represented as 1 and {not at all, slightly} represented as 0 to balance the number of responses in each class. In
Table 2 the p value in a chi square for each of the indicators for exposure during a trip is given when this indicator is added as an additional factor in a model based on the maximum façade exposure during the day, L
day,façade. The latter indicator is always included in the model since it is most often used for exposure at home. L
day,facade has very high significance in the model with a p value of 1.7 × 10
−7. The table shows that exposure within 300 m from the house taking an equivalent level over the length of each trip has the most significant effect. The method for averaging over different trips does not significantly affect this result. It should come as no surprise that an exposure level calculation over the first 300 m of a trip has exactly the same significance since most trips are over 300 m long. When trips are restricted to biking and walking, where exposure to external noise is expected to be more important, the influence of the parameter is largely reduced. This is mainly due to the introduction of uncertainty about the biking and walking habits of the surveyed persons. .
It comes as no surprise that the first 300 m of a trip are important for noise annoyance since the noise annoyance question explicitly refers to “in and around your house”. Therefore the same exercise is repeated for the question on general satisfaction with the quality of life in the neighborhood (Q1.1).
Table 3 shows the p value for adding different indicators in a logistic model to the primary indicator L
day,façade for predicting the answers “satisfied” and “very satisfied” while
Table 4 shows the same results for predicting the answers “not satisfied” to “not at all satisfied”. Grouping positive and negative evaluation respectively assures again a balanced number of responses in each class. Before interpreting these results it should be noted that the p value for façade exposure itself is much lower than in the case of the question on annoyance (0.013 and 0.0052 respectively). For the response category “not satisfied” to “not at all satisfied”, an equivalent level outperforms other methods for aggregating over different trips. The equivalent level is the aggregator that puts most weight in the most exposed trips. Just as for traffic noise annoyance an equivalent level over the first 300 m of a trip has a significant predictive effect. However, in the case of predicting “satisfaction” or “high satisfaction” with the quality of life of a neighborhood, also the exposure level during whole trips on foot or by bike pop up as highly significant.
From the above analyses it is concluded that
is the first candidate as an indicator for exposure to noise during trips. A second candidate, especially when satisfaction with the general quality of the living environment is at stake, could be
. Strictly speaking, a linear average over dB values for different trips has a slightly more significant effect, but for the sake of simplicity, it was decided to stick to the same aggregation procedure for both trip-related indicators.
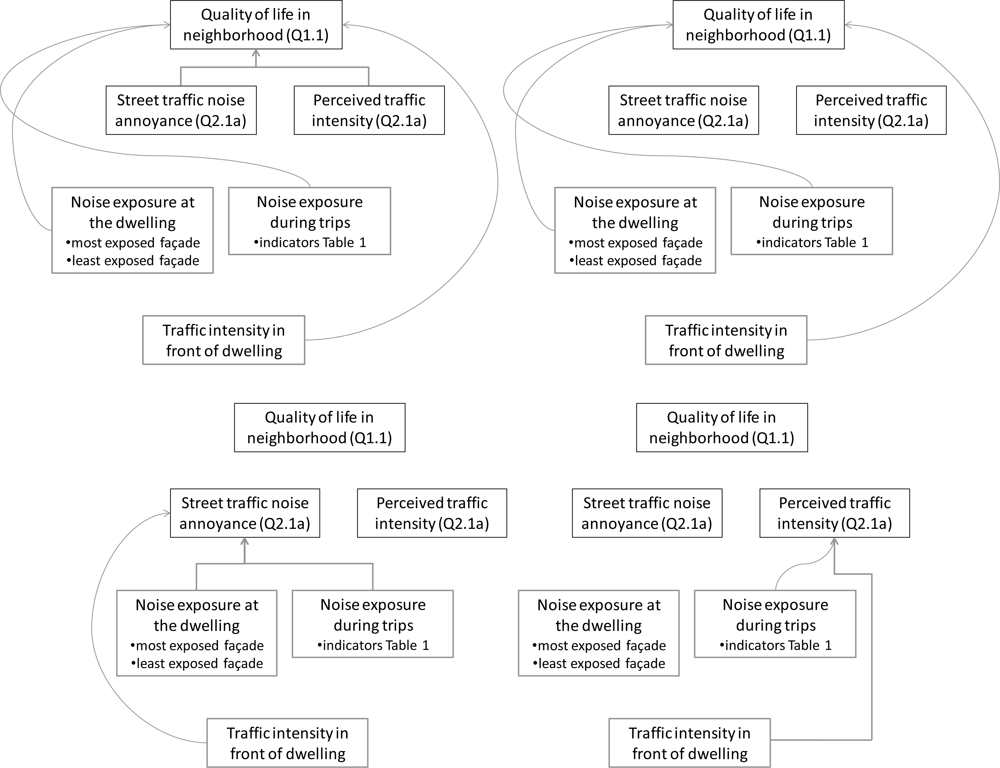
With the knowledge on suitable indicators for noise exposure during a trip in mind, a multiple logistic regression model for the influence of traffic noise on satisfaction with the quality of life in the neighborhood (
Figure 9) is now constructed.
When constructing multiple regression models with parameters that are not orthogonal, one could either look for principle components first or account for the order in which parameters are entered. Exposure indicators used in this study are mutually dependent but have physical relevance clearly linked to neighborhood situations and some are commonly used in environmental noise assessment. Therefore it is preferred not to combine them in a principle component. Moreover this approach will allow finding the best indicators to add to common practice. This choice implies that all parameters will need to be entered in the models in different orders. The first model contains variables taken from the survey (Q2.1a on traffic noise annoyance and Q1.8 on traffic load of the neighborhood) but also the noise exposure variables (
Lday,façade,
Lday,quiet, the traffic noise level at the quiet side of the house,
,
) selected above and the traffic intensity on the road in front of the house (
Nstreet). In the full model, the variables are added in different orders, in order to evaluate the (added) significance of each specific variable set. The variables taken from the survey have the highest significance even when added to the model last (
Table 5). Survey results are indeed expected to be the best estimate of subjective evaluation of noise exposure since they account for personal factors that might influence the way the sonic environment is perceived or the way a person reports about it [
24]. In addition, using reported annoyance and traffic intensity avoids potential errors in the noise exposure model or the model accounting for the behavior of the respondents. It is interesting to investigate whether exposure to traffic noise—as measured by the proposed indicators—has an influence on reported satisfaction with the quality of life in the neighborhood that is not captured by the question on noise annoyance at home and the question on perceived traffic intensity in the neighborhood. Therefore the performance of a model including only these questionnaire variables is compared to the full model. The ANOVA test results in
Table 6 show that there is a moderately significant improvement by adding exposure indicators for predicting satisfaction with the quality of life in the neighborhood but not for predicting “not satisfied” to “not at all satisfied”. The availability of a quiet side, measured by
Lday,quiet, and quiet walking and biking routes near the house, measured by
, could be a proxy for the availability of tranquility and availability of green and nature, that were mentioned in the open question as a positive factor, but less prominent as negative factors.
For many practical applications, a model for quality of the living environment should not depend on questions in a survey. Hence, the response to question Q1.8 on traffic intensity and Q2.1a on road traffic noise annoyance, were removed from the model. The significance of the different factors remains the same as can be seen from
Table 5. However, when
is entered in the model first (model 2b), it becomes the most significant factor, performing even better than
Lday,façade in model 2a. Adding L
day,façade no longer improves the model, as can be seen from the chi squared test on the comparison between models in
Table 6. Adding an additional indicator for exposure during trips that is specifically targeting trips made on foot or by bike,
, has a significant influence in the model for predicting satisfaction with the quality of life in the neighborhood, but not for predicting dissatisfaction. A similar conclusion hold for adding the quiet side indicator,
Lday,quiet, but adding both factors does not add any new value to the model. The fact that only satisfaction is predicted more accurately shows that a quiet side and quiet (and green) biking or walking routes are not missed when absent and their absence is not a negative aspect for the neighborhood, but that their presence is perceived as an asset for the living quality. This is again confirmed by the open question results shown in
Figure 3.
Still, the model based on exposure only, performs significantly worse than the model including noise annoyance and traffic intensity questions from the survey (
Table 6). Thus it is useful to investigate whether traffic noise annoyance and reported (subjective) traffic intensity can accurately be modeled based on exposure indicators (the lower models in
Figure 9). In
Table 7 the significance of several exposure indicators in a logistic model for predicting street traffic noise annoyance and reported traffic intensities are shown. The indicators that come out significant in the noise annoyance model differ depending on the level of annoyance. For high to extreme annoyance, the noise level at the most exposed façade is the only significant indicator while for moderate to extreme annoyance and for “no annoyance at all”, the exposure during trips should be added as an indicator. Previous work showed the importance of the noise level at the quiet side for perceived noise annoyance [
20] but this effect could not be found here, probably because the noise level at the least exposed façade was not determined accurately enough.
Table 8 shows that a model for moderate to extreme annoyance and a model for the absence of annoyance improve statistically significantly by adding the indicator for exposure during the first 300 m of trips:
. Adding additional factors to the model gives no significant improvement. In contrast to the model for satisfaction with the quality of life in the neighborhood,
Lday,façade remains an important indicator. The geographical area referred to in the noise annoyance question: in and around your house, focuses attention more on the façade than the quality of life question that refers to the neighborhood, which could explain this difference. It was nevertheless shown in previous work by Klaboe
et al. [
25] that the soundscape in the wider area also matters for rating noise annoyance at home, which seems to be confirmed here, at least if moderate to extreme annoyance is considered.
In the multiple logistic models for reported traffic intensity (
Table 7), the number of vehicles in the street in front of the house, N
street, comes out rather insignificant when noise exposure indicators are added first. When N
street is added first, it becomes strongly significant for predicting heavy and very heavy traffic but not for predicting little traffic. In both cases noise exposure during trips is very significant. The model comparison in
Table 9 confirms that adding noise exposure during the first part of trips helps very significantly in predicting both reported intensities of traffic. Thus,
—although initially designed for predicting the quality of life in a neighborhood—also mimics very well how persons sample traffic intensity in their neighborhood. The most obvious explanation is that
Nstreet only incorporates the traffic in the own street, while the noise indicator adds up the traffic in a larger area around the house. Another explanation might include the way people perceive traffic intensity which might include the noise level.
To conclude and summarize, the β coefficients in the multiple linear regression models that include the minimal number of factors are given in
Table 10.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}