Ensemble Learning or Deep Learning? Application to Default Risk Analysis



Abstract
:1. Introduction
2. Data and Experimental Design
2.1. Machine-Learning Techniques
- Bagging.
- Random forest.
- Boosting.
- Neural network (activation function is Tanh).
- Neural network (activation function is ReLU).
- Neural network (activation function is Tanh with Dropout).
- Neural network (activation function is ReLU with Dropout).
- Deep neural network (activation function is Tanh).
- Deep neural network (activation function is ReLU).
- Deep neural network (activation function is Tanh with Dropout).
- Deep neural network (activation function is ReLU with Dropout).
2.2. Data
- X1: Amount of given credit (NT dollar).
- X2: Gender (1 = male; 2 = female).
- X3: Education (1 = graduate school; 2 = university; 3 = high school; 4 = others).
- X4: Marital status (1 = married; 2 = single; 3 = others).
- X5: Age (year).
- X6–X11: History of past payment tracked via past monthly payment records (−1 = payment on time; 1 = payment delay for one month; 2 = payment delay for two months; …; 8 = payment delay for eight months; 9 = payment delay for nine months and above).
- X6: Repayment status in September 2005.
- X7: Repayment status in August 2005.
- X8: Repayment status in July 2005.
- X9: Repayment status in June 2005.
- X10: Repayment status in May 2005.
- X11: Repayment status in April 2005.
- X12: Amount on bill statement in September 2005 (NT dollar).
- X13: Amount on bill statement in August 2005 (NT dollar).
- X14: Amount on bill statement in July 2005 (NT dollar).
- X15: Amount on bill statement in June 2005 (NT dollar).
- X16: Amount on bill statement in May 2005 (NT dollar).
- X17: Amount on bill statement in April 2005 (NT dollar).
- X18: Amount of previous payment in September 2005 (NT dollar).
- X19: Amount of previous payment in August 2005 (NT dollar).
- X20: Amount of previous payment in July 2005 (NT dollar).
- X21: Amount of previous payment in June 2005 (NT dollar).
- X22: Amount of previous payment in May 2005 (NT dollar).
- X23: Amount of previous payment in April 2005 (NT dollar).
2.3. Performance Evaluation
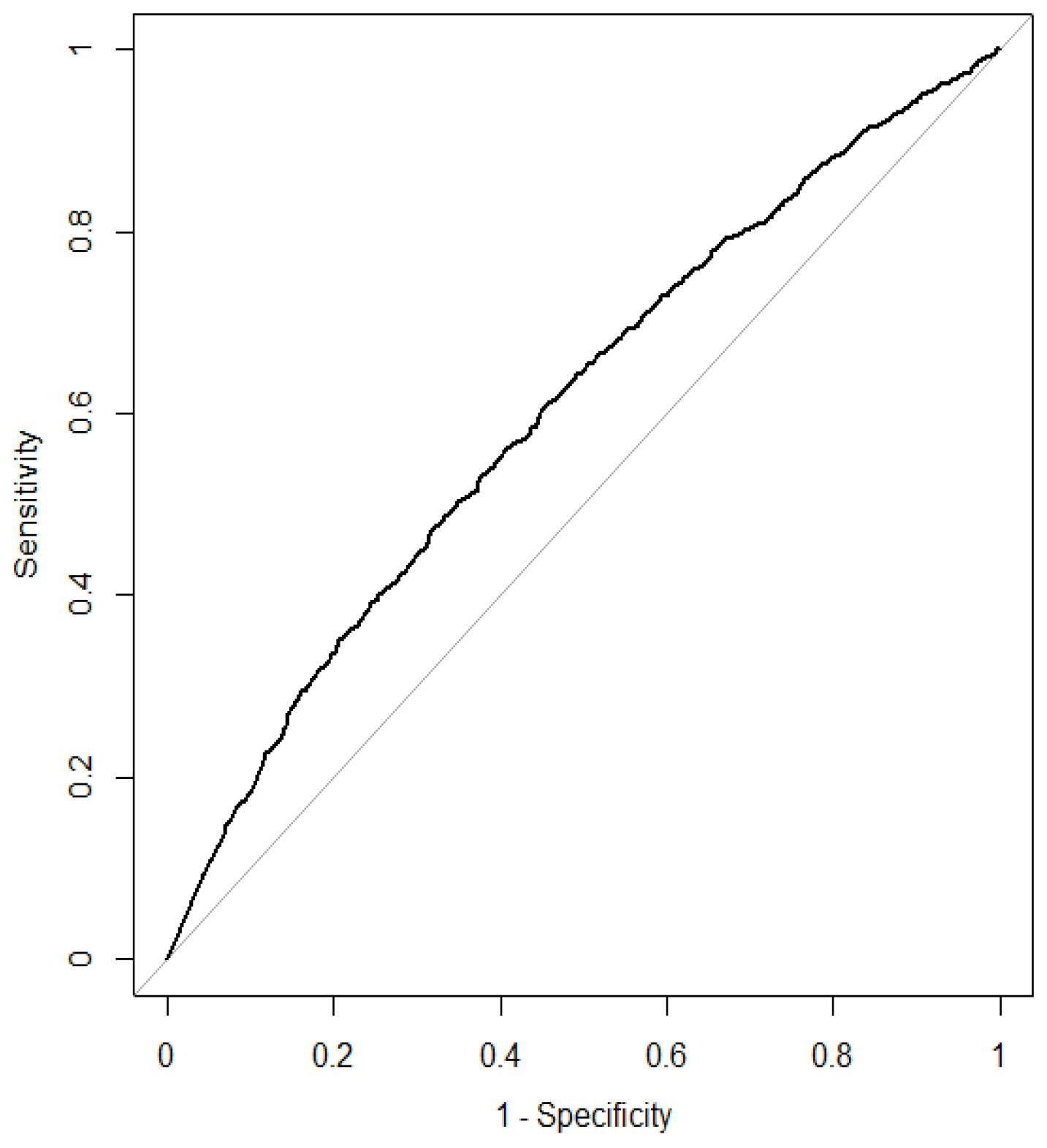
3. Results
4. Conclusions
- (1)
- The classification ability of boosting is superior to other machine-learning methods.
- (2)
- The prediction accuracy rate, AUC value, and F-score of NN are better than those of DNN when Tanh is used as an activation function. However, this result is not apparent when ReLU is used as an activation function.
- (3)
- NN (DNN) outperforms NN (DNN) with dropout when Tanh is used as an activation function in terms of AUC value and F-score. However, NN (DNN) with dropout outperforms NN (DNN) when ReLU is used as an activation function in terms of AUC value and F-score.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Results of Bayesian Optimization

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Data | Ratio of Training and Test Data (%) | Input Layer | Middle Layer | Output Layer |
|---|---|---|---|---|---|
| Tanh | Original | 75:25 | 23 | 7 | 2 |
| Tanh | Original | 90:10 | 23 | 5 | 2 |
| Tanh with Dropout | Original | 75:25 | 23 | 14 | 2 |
| Tanh with Dropout | Original | 90:10 | 23 | 12 | 2 |
| ReLU | Original | 75:25 | 23 | 3 | 2 |
| ReLU | Original | 90:10 | 23 | 7 | 2 |
| ReLU with Dropout | Original | 75:25 | 23 | 14 | 2 |
| ReLU with Dropout | Original | 90:10 | 23 | 19 | 2 |
| Tanh | Normalized | 75:25 | 23 | 5 | 2 |
| Tanh | Normalized | 90:10 | 23 | 5 | 2 |
| Tanh with Dropout | Normalized | 75:25 | 23 | 5 | 2 |
| Tanh with Dropout | Normalized | 90:10 | 23 | 10 | 2 |
| ReLU | Normalized | 75:25 | 23 | 11 | 2 |
| ReLU | Normalized | 90:10 | 23 | 4 | 2 |
| ReLU with Dropout | Normalized | 75:25 | 23 | 16 | 2 |
| ReLU with Dropout | Normalized | 90:10 | 23 | 12 | 2 |
| Method | Data | Ratio of Training and Test Data (%) | Input Layer | Middle Layer 1 | Middle Layer 2 | Output Layer |
|---|---|---|---|---|---|---|
| Tanh | Original | 75:25 | 23 | 5 | 17 | 2 |
| Tanh | Original | 90:10 | 23 | 2 | 9 | 2 |
| Tanh with Dropout | Original | 75:25 | 23 | 9 | 7 | 2 |
| Tanh with Dropout | Original | 90:10 | 23 | 3 | 11 | 2 |
| ReLU | Original | 75:25 | 23 | 4 | 6 | 2 |
| ReLU | Original | 90:10 | 23 | 4 | 9 | 2 |
| ReLU with Dropout | Original | 75:25 | 23 | 13 | 9 | 2 |
| ReLU with Dropout | Original | 90:10 | 23 | 5 | 20 | 2 |
| Tanh | Normalized | 75:25 | 23 | 6 | 17 | 2 |
| Tanh | Normalized | 90:10 | 23 | 4 | 3 | 2 |
| Tanh with Dropout | Normalized | 75:25 | 23 | 9 | 4 | 2 |
| Tanh with Dropout | Normalized | 90:10 | 23 | 3 | 18 | 2 |
| ReLU | Normalized | 75:25 | 23 | 4 | 6 | 2 |
| ReLU | Normalized | 90:10 | 23 | 10 | 7 | 2 |
| ReLU with Dropout | Normalized | 75:25 | 23 | 16 | 9 | 2 |
| ReLU with Dropout | Normalized | 90:10 | 23 | 5 | 21 | 2 |
References
- Aksoy, Selim, and Robert M. Haralick. 2001. Feature normalization and likelihood-based similarity measures for image retrieval. Pattern Recognition. Letters 22: 563–82. [Google Scholar] [CrossRef]
- Angelini, Eliana, Giacomo di Tollo, and Andrea Roli. 2008. A neural network approach for credit risk evaluation. Quarterly Review of Economics and Finance 48: 733–55. [Google Scholar] [CrossRef]
- Boguslauskas, Vytautas, and Ricardas Mileris. 2009. Estimation of credit risks by artificial neural networks models. Izinerine Ekonomika-Engerrring Economics 4: 7–14. [Google Scholar]
- Breiman, Leo. 1996. Bagging predictors. Machine Learning 24: 123–40. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Freund, Yoav, and Robert E. Schapire. 1996. Experiments with a new boosting algorithm. Paper presented at the Thirteenth International Conference on Machine Learning, Bari, Italy, July 3–6; pp. 148–56. [Google Scholar]
- Gante, Dionicio D., Bobby D. Gerardo, and Bartolome T. Tanguilig. 2015. Neural network model using back propagation algorithm for credit risk evaluation. Paper presented at the 3rd International Conference on Artificial Intelligence and Computer Science (AICS2015), Batu Ferringhi, Penang, Malaysia, October 12–13; pp. 12–13. [Google Scholar]
- Jayalakshmi, T., and A. Santhakumaran. 2011. Statistical Normalization and Back Propagation for Classification. International Journal of Computer Theory and Engineering 3: 83–93. [Google Scholar]
- Khashman, Adnan. 2010. Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes. Expert Systems with Applications 37: 6233–39. [Google Scholar] [CrossRef]
- Khemakhem, Sihem, and Younes Boujelbene. 2015. Credit risk prediction: A comparative study between discriminant analysis and the neural network approach. Accounting and Management Information Systems 14: 60–78. [Google Scholar]
- Khshman, Adnan. 2009. A neural network model for credit risk evaluation. International Journal of Neural Systems 19: 285–94. [Google Scholar] [CrossRef] [PubMed]
- Lantz, Brett. 2015. Machine Learning with R, 2nd ed. Birmingham: Packt Publishing Ltd. [Google Scholar]
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. Nature 521: 436–44. [Google Scholar] [CrossRef] [PubMed]
- Oreski, Stjepan, Dijana Oreski, and Goran Oreski. 2012. Hybrid system with genetic algorithm and artificial neural networks and its application to retail credit risk assessment. Expert Systems with Applications 39: 12605–17. [Google Scholar] [CrossRef]
- Schapire, Robert E. 1999. A brief introduction to boosting. Paper presented at the Sixteenth International Joint Conference on Artificial Intelligence, Stockholm, Sweden, July 31–August 6; pp. 1–6. [Google Scholar]
- Shapire, Robert E., and Yoav Freund. 2012. Boosting: Foundations and Algorithms. Cambridge: The MIT Press. [Google Scholar]
- Sola, J., and Joaquin Sevilla. 1997. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Transactions on Nuclear Science 44: 1464–68. [Google Scholar] [CrossRef]
- Srivastava, Nitish, Georey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research 15: 1929–58. [Google Scholar]
- Yeh, I-Cheng, and Che-hui Lien. 2009. The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Systems with Applications 36: 2473–80. [Google Scholar] [CrossRef]
| 1 | The German credit dataset is publicly available at UCI Machine Learning data repository, https://archive.ics.uci.edu/ml/datasets/statlog+(german+credit+data). |
| 2 | |
| 3 | See LeCun et al. (2015). |
| 4 | There are two typical ways to implement machine learning. One is to use training data, validation data, and test data, and the other is to use training data and test data. In the first approach, the result of the test is randomly determined and we cannot obtain robust results. Also, it is not advisable to divide the small sample into three pieces. Thus, we use the second approach in this study. We repeat the test results over 100 times to obtain robust results. |
| 5 | We used set. seed(50) to remove the difference caused by random numbers in drawing the ROC curve and calculating the AUC. |
| 6 | The number of units in the middle layers of NN and DNN is determined based on the Bayesian optimization method. (See Appendix A for details.) |











| Actual Class | |||
|---|---|---|---|
| Event | No-Event | ||
| Predicted Class | Event | TP (True Positive) | FP (False Positive) |
| No-Event | FN (False Negative) | TN (True Negative) | |
| (a) Original data: the ratio of training and test data is 75% to 25% | ||||||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Average (%) | Standard Deviation | Average (%) | Standard Deviation | |||
| Bagging | 80.13 | 0.003 | 55.98 | 0.008 | ||
| Boosting | 71.66 | 0.003 | 71.06 | 0.008 | ||
| Random Forest | 69.59 | 0.544 | 58.50 | 0.844 | ||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Model | Activation Function | Middle Layer | Average (%) | Standard Deviation | Average (%) | Standard Deviation |
| DNN | Tanh | 2 | 70.66 | 0.721 | 68.93 | 0.972 |
| NN | Tanh | 1 | 71.01 | 0.569 | 69.59 | 0.778 |
| DNN | Tanh with Dropout | 2 | 58.47 | 3.566 | 58.46 | 3.404 |
| NN | Tanh with Dropout | 1 | 67.27 | 1.237 | 67.14 | 1.341 |
| DNN | ReLU | 2 | 69.57 | 0.707 | 68.61 | 0.863 |
| NN | ReLU | 1 | 68.81 | 0.708 | 68.30 | 1.008 |
| DNN | ReLU with Dropout | 2 | 69.97 | 0.903 | 69.01 | 0.956 |
| NN | ReLU with Dropout | 1 | 70.12 | 0.637 | 69.48 | 0.881 |
| (b) Original Data: the Ratio of Training and Test Data is 90% to 10% | ||||||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Average (%) | Standard Deviation | Average (%) | Standard Deviation | |||
| Bagging | 79.58 | 0.003 | 56.23 | 0.015 | ||
| Boosting | 71.57 | 0.003 | 70.88 | 0.011 | ||
| Random Forest | 68.55 | 0.453 | 58.77 | 1.331 | ||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Model | Activation Function | Middle Layer | Average (%) | Standard Deviation | Average (%) | Standard Deviation |
| DNN | Tanh | 2 | 69.64 | 0.683 | 69.31 | 1.325 |
| NN | Tanh | 1 | 70.49 | 0.550 | 69.61 | 1.312 |
| DNN | Tanh with Dropout | 2 | 57.29 | 3.681 | 57.27 | 4.117 |
| NN | Tanh with Dropout | 1 | 66.37 | 1.619 | 66.25 | 1.951 |
| DNN | ReLU | 2 | 69.49 | 0.695 | 68.76 | 1.408 |
| NN | ReLU | 1 | 69.16 | 0.728 | 68.54 | 1.261 |
| DNN | ReLU with Dropout | 2 | 69.74 | 0.796 | 68.84 | 1.438 |
| NN | ReLU with Dropout | 1 | 70.26 | 0.573 | 69.55 | 1.210 |
| (a) Normalized data: the ratio of training and test data is 75% to 25% | ||||||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Average (%) | Standard Deviation | Average (%) | Standard Deviation | |||
| Bagging | 80.12 | 0.003 | 56.15 | 0.008 | ||
| Boosting | 71.66 | 0.004 | 70.95 | 0.007 | ||
| Random Forest | 69.67 | 0.565 | 58.39 | 0.880 | ||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Model | Activation Function | Middle Layer | Average (%) | Standard Deviation | Average (%) | Standard Deviation |
| DNN | Tanh | 2 | 71.14 | 0.732 | 68.75 | 0.912 |
| NN | Tanh | 1 | 70.64 | 0.652 | 69.42 | 0.763 |
| DNN | Tanh with Dropout | 2 | 57.00 | 4.324 | 56.69 | 4.485 |
| NN | Tanh with Dropout | 1 | 68.09 | 0.641 | 68.01 | 0.904 |
| DNN | ReLU | 2 | 70.37 | 0.627 | 69.35 | 0.856 |
| NN | ReLU | 1 | 70.92 | 0.615 | 69.37 | 0.943 |
| DNN | ReLU with Dropout | 2 | 70.00 | 0.811 | 68.96 | 0.946 |
| NN | ReLU with Dropout | 1 | 70.25 | 0.692 | 69.56 | 0.813 |
| (b) Normalized data: the ratio of training and test data is 90% to 10% | ||||||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Average (%) | Standard Deviation | Average (%) | Standard Deviation | |||
| Bagging | 79.54 | 0.003 | 56.28 | 0.013 | ||
| Boosting | 71.50 | 0.003 | 70.80 | 0.012 | ||
| Random Forest | 68.66 | 0.475 | 58.83 | 1.368 | ||
| Method | Accuracy Ratio of Training Data | Accuracy Ratio of Test Data | ||||
| Model | Activation Function | Middle Layer | Average (%) | Standard Deviation | Average (%) | Standard Deviation |
| DNN | Tanh | 2 | 70.18 | 0.698 | 69.35 | 1.382 |
| NN | Tanh | 1 | 70.52 | 0.594 | 69.51 | 1.309 |
| DNN | Tanh with Dropout | 2 | 58.04 | 5.134 | 58.14 | 5.016 |
| NN | Tanh with Dropout | 1 | 67.33 | 1.285 | 67.13 | 1.787 |
| DNN | ReLU | 2 | 71.41 | 0.710 | 69.17 | 1.334 |
| NN | ReLU | 1 | 69.55 | 0.772 | 68.97 | 1.426 |
| DNN | ReLU with Dropout | 2 | 69.76 | 0.785 | 69.13 | 1.426 |
| NN | ReLU with Dropout | 1 | 69.88 | 0.701 | 69.25 | 1.279 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamori, S.; Kawai, M.; Kume, T.; Murakami, Y.; Watanabe, C. Ensemble Learning or Deep Learning? Application to Default Risk Analysis. J. Risk Financial Manag. 2018, 11, 12. https://doi.org/10.3390/jrfm11010012
Hamori S, Kawai M, Kume T, Murakami Y, Watanabe C. Ensemble Learning or Deep Learning? Application to Default Risk Analysis. Journal of Risk and Financial Management. 2018; 11(1):12. https://doi.org/10.3390/jrfm11010012
Chicago/Turabian StyleHamori, Shigeyuki, Minami Kawai, Takahiro Kume, Yuji Murakami, and Chikara Watanabe. 2018. "Ensemble Learning or Deep Learning? Application to Default Risk Analysis" Journal of Risk and Financial Management 11, no. 1: 12. https://doi.org/10.3390/jrfm11010012
APA StyleHamori, S., Kawai, M., Kume, T., Murakami, Y., & Watanabe, C. (2018). Ensemble Learning or Deep Learning? Application to Default Risk Analysis. Journal of Risk and Financial Management, 11(1), 12. https://doi.org/10.3390/jrfm11010012