2.1. Time-Varying Volatility
One important measure in the financial management area is the risk metric, which is usually gauged by volatility or standard deviation of return series of investment assets over a certain period of time. Estimation or prediction of investment assets’ volatility then becomes necessary and vital during portfolio optimization and risk management. Two of the most classic models of volatilities are the so-called ARCH (autoregressive conditional heteroskedastic) introduced by (
Engle 1982) and GARCH (generalized autoregressive conditional heteroskedastic) models from (
Engle and Bollerslev 1986) and (
Taylor 1987). Let us first review some basic concepts.
Denote
as the month end price for an investment asset or economics indicator. Thus, the log return
can be expressed as the log-percentage change below:
is final time series with mean
and volatility
with the assumption that volatility varies over time. The return series of assets observed across different financial markets all share some common factors known as “stylized empirical facts.” These facts include the following properties:
Heavy Tails: the distribution of returns usually shows a power-law or Pareto-like tail index with a value between two to five for most financial data.
Gain or Loss Asymmetry: large drawdowns in stock prices or index do not necessarily reflect equally large upward movements.
Volatility Clustering: different measures of volatility tend to have positive correlation over multiple trading periods, which reveals the fact that high-volatility events tend to cluster over time.
In order to capture the time-varying and clustering effects of the volatility, we first introduce ARCH model assuming return of investment assets or economics indicator is given by:
An ARCH (
) process is given by
where
is a sequence of white noise with mean 0 and variance 1, and
,
. In this article, we assume
follows a skewed generalized error distribution (SGED), which was introduced by (
Theodossiou 2015) to accommodate skewness and leptokurtosis to the generalized error distribution (GED). The probability density function (PDF) for SGED is as follows:
where
,
is the mode of the random variable
,
is a scaling constant related to the standard deviation of
,
is a skewness parameter,
is a kurtosis parameter,
is the sign function of −1 for
and 1 for
and
is gamma function.
For simplicity’s sake, given
, we have ARCH(1) process and error term
with conditional mean and conditional variance as follows:
and unconditional variance of
is
since
is a stationary process and
E
.
As the extension to include flexible lag terms for ARCH model, GARCH (
) model considers the same stochastic process defined under Equation (3) and introduces an additional lagged
-period conditional variance term within the formulation of conditional variance:
where
. The simplest and most widely used version for GARCH (
) model is GARCH(1,1):
It can be shown that the above has a stationary solution with a finite expected value if and only if
and its long run variance is
. Thus GARCH(1,1) can be rewritten as
2.2. Dependence Modeling and Pair Copula
There is a large body of research articles that indicate that conditional volatility of economic time series varies over time. Researchers then proposed the copula technique, which allows us to model a dependence structure independent of multivariate distribution. (
Sklar 1959) first proposed copula to measure nonlinear interdependence between variables. Then, (
Jondeau and Rockinger 2006) proposed the copula-GARCH model and applied it to extract the dependence structure between financial assets. Copula plays a vital role in financial management and econometrics and is widely used on Wall Street to model and price various structured products, including Collateralized Debt Obligations (CDOs). The key contribution of copula is to separate the marginal distribution from the dependence structure and improve the correlation definition from linear to also considering nonlinear relationships.
In a review article from (
Patton 2012), he defined a n-dimensional copula assuming
as random vector with cumulative distribution function
and for
, letting
denote the marginal distribution of
, thus there exists a copula
such that for all
In the application of multivariate time series, Patton used a version of Sklar’s theorem and decomposed the conditional joint distribution given some previous information set into conditional marginal distribution and conditional copula. For
, let
and
then
From the above section of the GARCH model, we now incorporate Equations (2) and (11) to the multivariate copula, and the white noise term
can be derived from copula structure
where
can be estimated from
.
As the marginal distributions
are usually not known or hard to obtain from a parametric approach, here we propose a nonparametric method to estimate them using the empirical distribution function (EDF) introduced by (
Patton 2012). For a nonparametric estimate of
, we use the following function with uniform marginal distribution:
where
is the indicator function of 1 when
.
There are two well-known classes of parametric copula functions, i.e., elliptical family and the Archimedean copula. Gaussian and -copulas are the two types from the elliptical family where their density functions come from elliptical distribution.
Assume random variable
where
is the correlation matrix of
. Gaussian copula is defined as:
where
is standard normal cumulative distribution function (CDF) and
is the joint CDF for multivariate normal variable
. This copula above is the same for random variable
if
has the same correlation matrix
as
.
Similar to the Gaussian copula above, if
follows multivariate
-distribution with
degree of freedom and can be written as
where
and
independent of
. the
-copula is defined as:
where
is the correlation matrix of
,
is the joint CDF of
and
is the standard
-distribution with degree of freedom
.
The other important class of copula is the Archimedean copula (
Cherubini et al. 2004), which can be created using a function
, continuous, decreasing, convex, and
. Such function is called generator, and pseudo-inverse is defined from the generator function as follows:
This pseudo-inverse will generate the same result as the normal inverse function as long as it is within the domain and range
:
for every
. Given the generator and pseudo-inverse, Archimedean copula
can be generated from the following form:
There are two important subclasses of Archimedean copulas that have only one parameter in the generator—Gumbel and Clayton copulas, as given in
Table 1.
In practice, the complexity of estimating parameters from multivariate copula increases rapidly when the dimension of time series data expands. Therefore, (
Harry 1996), (
Bedford and Cooke 2001), (
Aas et al. 2009), and (
Min and Czado 2010) independently proposed a multivariate probability structure via a simple building block—pair copula construction (PCC) framework. The model decomposes multivariate joint distribution into a series pair copula on different conditional probability distributions with an iterative process. The copula definition from Equation (12) can be rewritten using uniformly distributed marginals
, as follows:
where
is the inverse distribution function of the marginal. We can then derive the joint probability density function (PDF)
as follows:
for some (uniquely identified)
-variate copula density
with a conditional density function given as,
where for a
-dimensional vector
,
represents an element from
and
is the vector without element
.
Therefore, the multivariate joint density function can be written as a product of pair copula on different conditional distributions. For example, under the bivariate case, the marginal density distribution of
can be written using the formula above as,
For high-dimension data, there are a large number of combinations for the pair copulas. Therefore, (
Bedford and Cooke 2001,
1999) proposed using a graphic approach known as “
regular vine” to systematically define the pair copula relationship in the tree structure. Each edge in the vine tree corresponds to a pair copula density. The density of a regular vine distribution is defined by the multiplication of pair copula densities over
edges in a regular vine tree structure and the multiplication of the marginal densities. (
Aas et al. 2009) and (
Kurowicka and Cooke 2007) further introduced
canonical vine and
D-vine as two special cases of regular vine to decompose the density. Canonical vine distribution is a regular vine distribution but with unique nodes connected to the remaining
nodes under each tree. In the D-vine structure, no node in any tree can be connected to more than two nodes. The
n-dimensional density of canonical vine can be written as follows:
where
denotes the trees and
spans the edge of each tree. The
n-dimensional density of D-vine is given as,
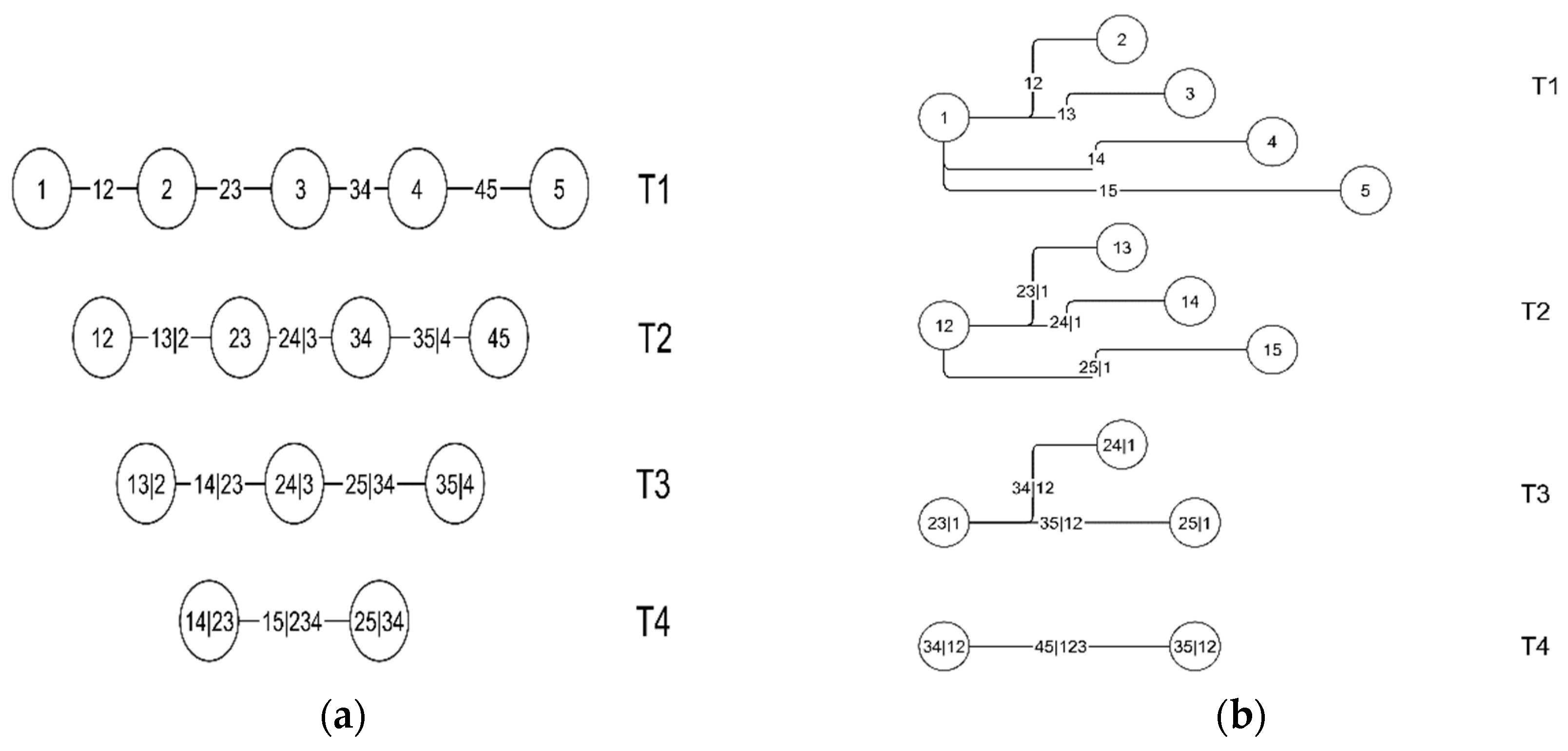
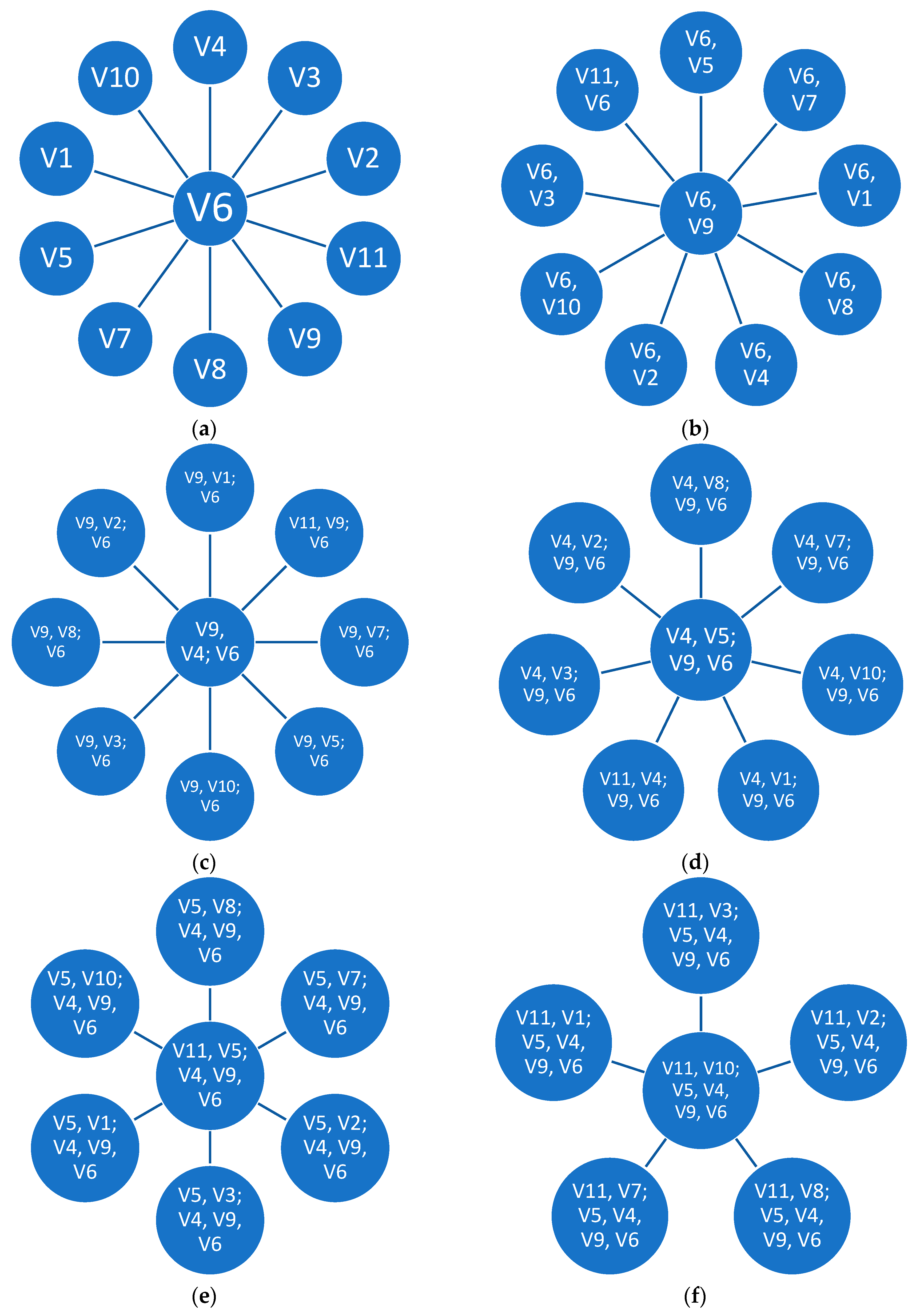
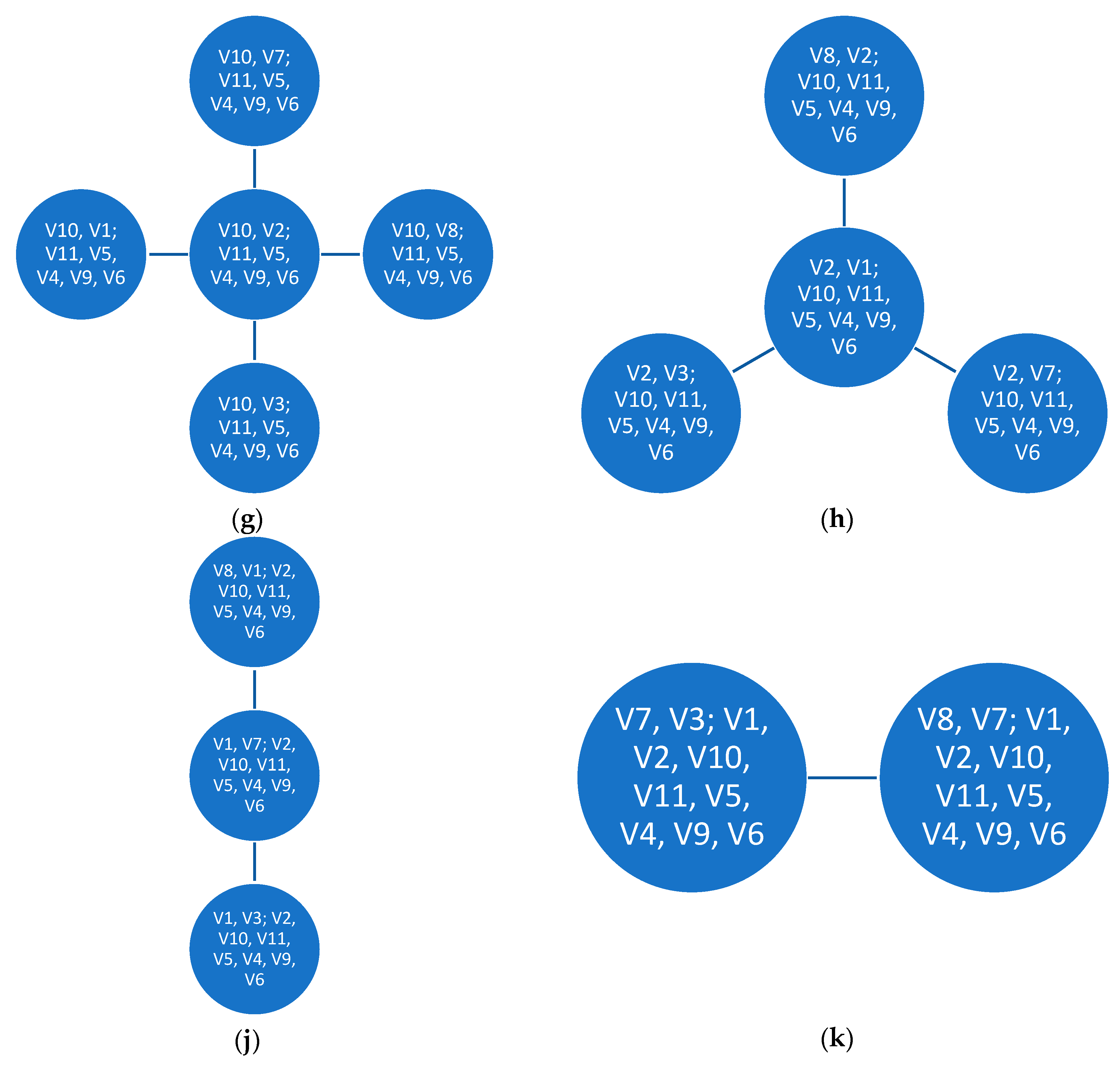
The chart in
Figure 1 shows an example of five variable vine copulas constructed from canonical vine and D-vine structures, respectively.
In this paper, we focus on the canonical vine copula structure. To review the simulation techniques from canonical vine, here are the main steps proposed by (
Aas et al. 2009) as shown in Algorithm 1:
| Algorithm 1. Simulation algorithm for canonical vine copula. |
| Generate one samplefrom canonical vine |
| Sample independently from |
| |
| for |
| |
| for |
| |
| end for |
| |
| if then |
| stop |
| end if |
| for |
| |
| end for |
| end for |
where function
is defined as the marginal conditional distribution function derived from the conditional density defined in Equation (22). Thus, when
and
are uniform, i.e.,
,
has the following form:
where
denotes the set of parameters for the copula of the joint distribution function of
and
, further defining
as the inverse of the conditional distribution and as the inverse function of
with respect to
To estimate the parameters of the pair copula, (
Aas et al. 2009) proposed using the pseudo-maximum likelihood to estimate parameters sequentially along the multiple layers of pair copula trees. The log-likelihood is given as,
where
is the density of bivariate copula with parameter
.
With the goodness-of-fit test using the
Akaike Information Criterion (AIC) metric defined by (
Akaike 1998), we can find the copula family that minimizes this metric as the best copula family for each tree.
where
is the number of parameters in the model. It is used to penalize the log-likelihood by its complexity. The model selection process involves finding the copula family that minimizes the AIC score.
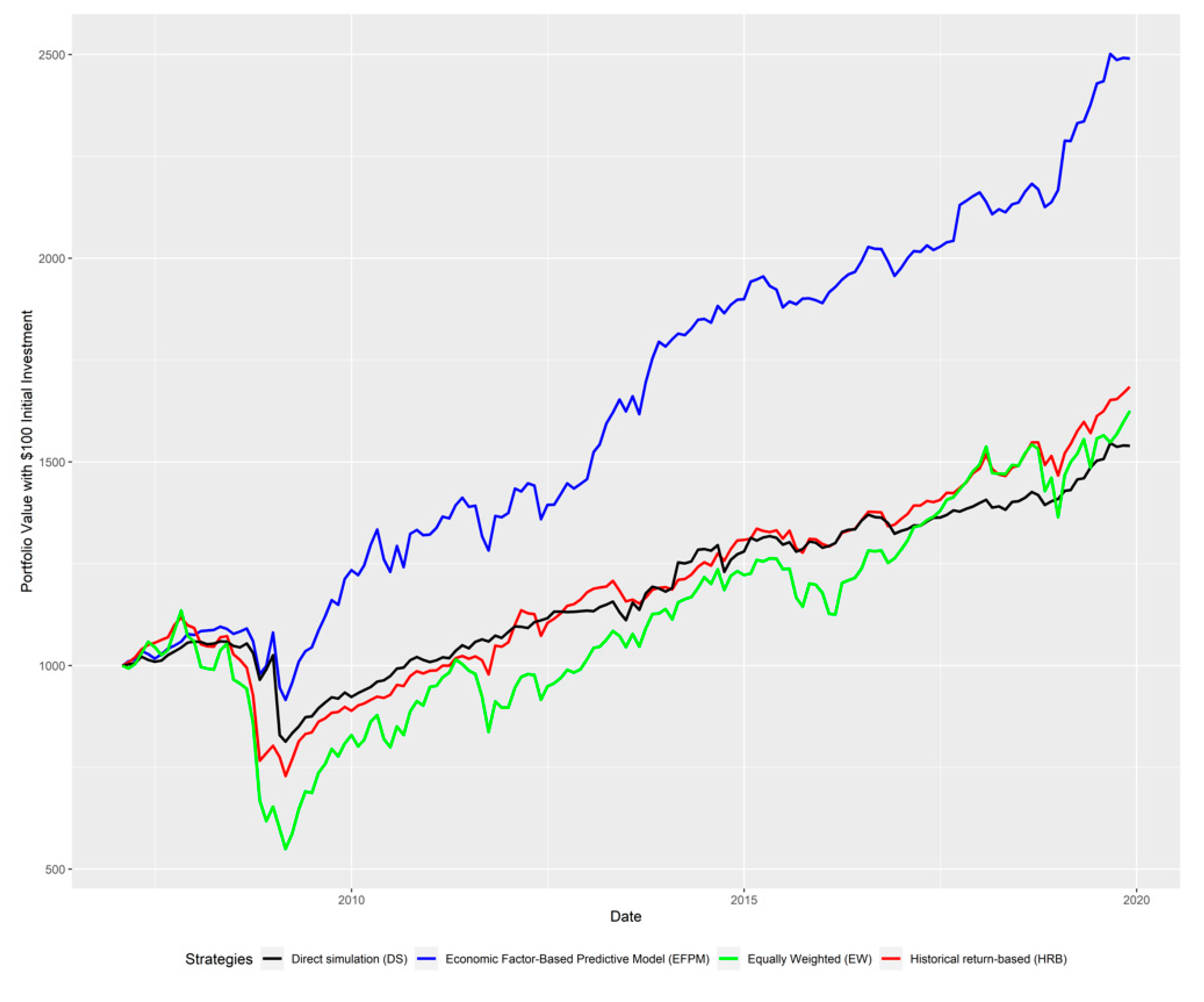
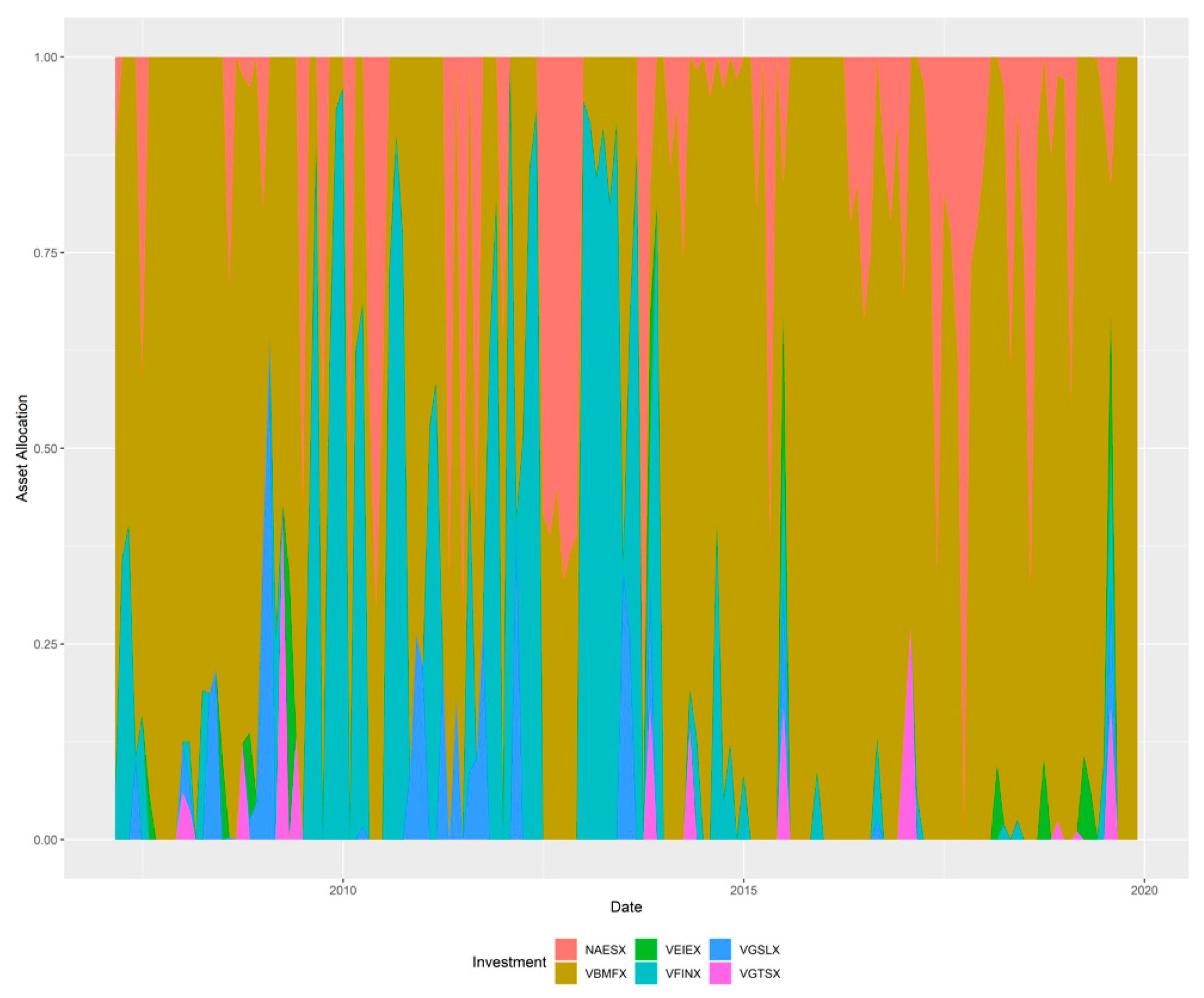
2.3. Portfolio Optimization Using Mean-CVaR
In this section, we first review the traditional mean-variance portfolio optimization framework proposed by (
Markowitz 1952). Then we review another classical risk metric, value-at-risk (VaR), as an alternative to variance. (
Rockafellar and Uryasev 2002) and (
Rockafellar and Uryasev 2000) extended VaR metrics, which focused on the percentile loss to conditional VaR (CVaR) or expected shortfall as average of the tail loss. We will then focus on portfolio optimization using the mean-CVaR framework.
Given a list of
investment assets, the mean-variance optimization is to find the optimal weights vector
of those assets so that the portfolio variance is minimized given a specific level of portfolio expected returns. This problem can be written as follows,
where
is the return vector for each of the
investment asset classes,
is the covariance matrix of the
asset return series, and
is the minimum expected return of the portfolio.
In this framework, Markowitz combined return with covariance matrix as the risk metric. However, other risk metrics have been introduced to focus on the tail events where losses occur. Value at Risk (VaR) is one of these measures, proposed by (
Morgan 1996) for the extreme potential change in value of a portfolio under a given probability over a certain predefined time horizon. In this paper, we focus on an extension of VaR – Conditioned VaR (CVaR), which is defined as the mean loss that exceeds the VaR at some confidence level. Mathematically, VaR and CVaR can be written as follows:
where
represents returns with density
and
is the confidence level.
Here we define the loss function as
and the corresponding probability of the loss that would not exceed a certain level
can be expressed as
. Thus,
is the VaR and
is the expected loss of the portfolio at the
confidence level. It is clear that
. (
Rockafellar and Uryasev 2002) and (
Rockafellar and Uryasev 2000) show that CVaR can be derived from the following optimization problem without first calculating VaR:
where
and
is a function of
and convex as well as continuously differentiable. Furthermore, the integral part under
can be simplified by discretizing based on the density function
to a
-dimension sample,
Minimizing CVaR as the risk metric is thus equivalent to minimizing
from the above formula. To construct the portfolio optimization using CVaR as the risk metric, we can formulate the following problem similar to the Mean-Variance problem above,
where
is an auxiliary term to approximate
so that the problem becomes a linear programming problem that can be solved easily and does not depend on any distribution assumption for the return series
.



{kind=link}
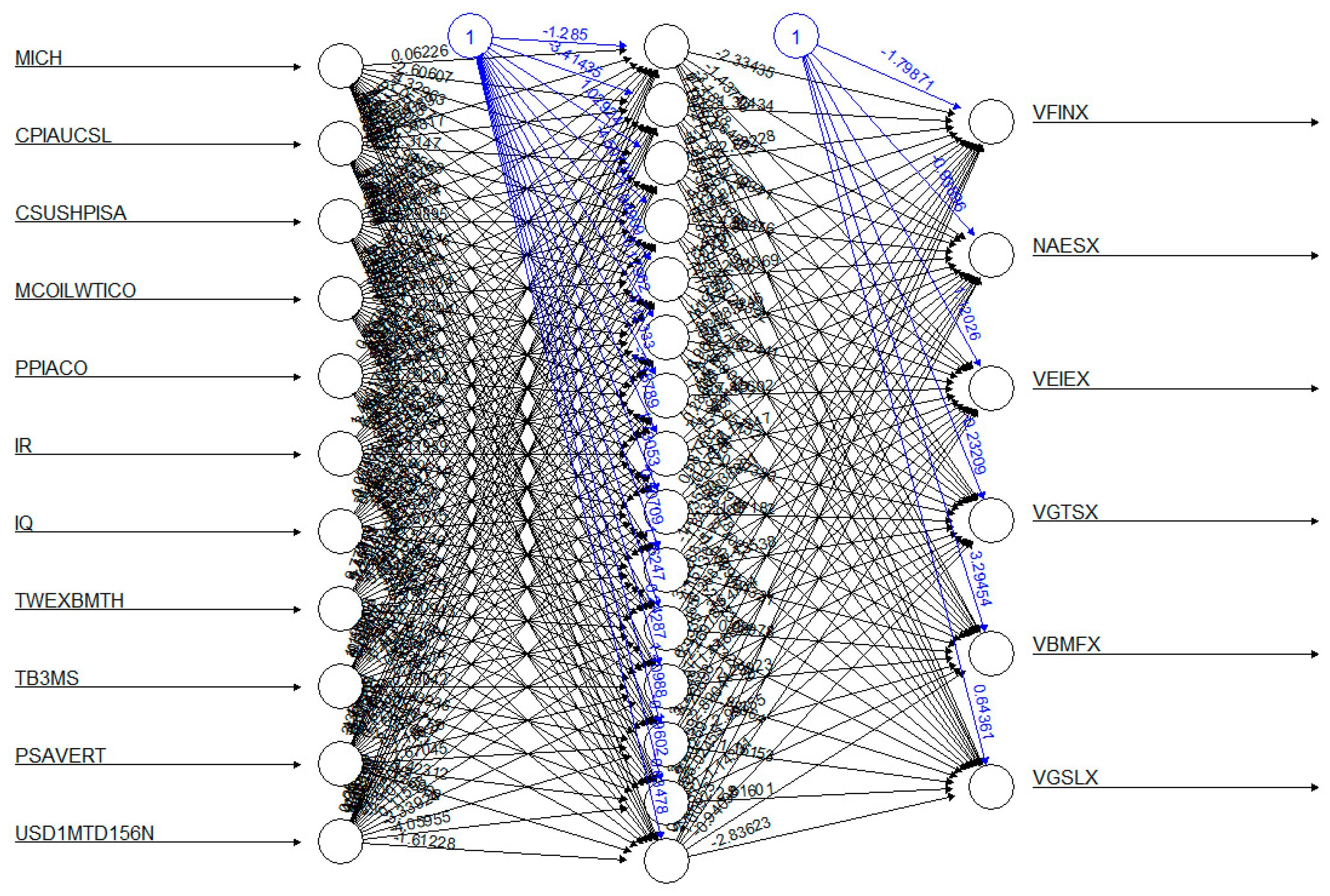{kind=link}
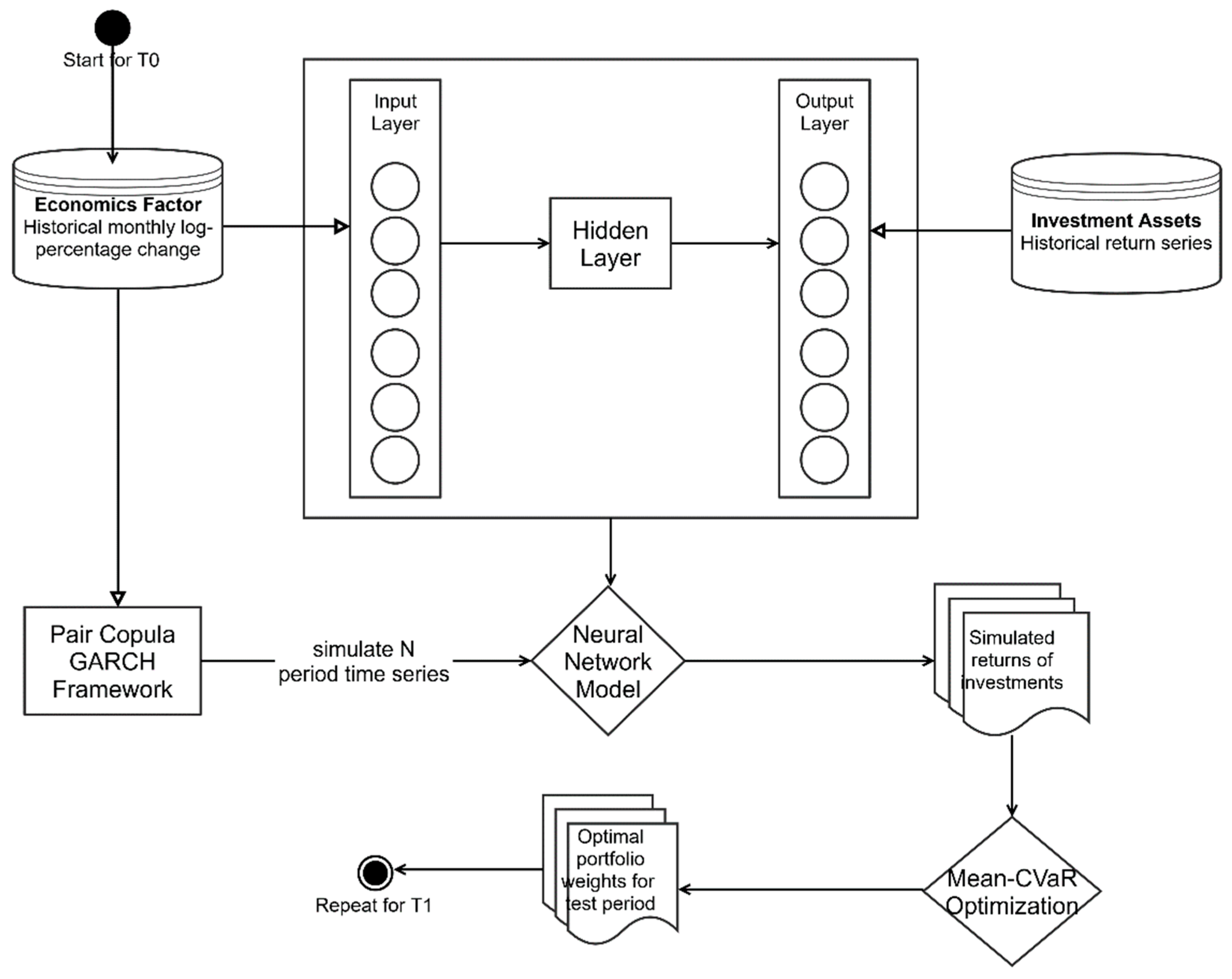{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







