The identification of risk factors is important and can be done by using various methods (
He et al. 2019). This study has only predicted the duration, the number of infections and deaths, and the virus’s impact on the economy because the data on COVID-19 are limited. However, these three risk points are highly important. They not only provide useful public health and safety information but also useful insights to economics and policy making. This study used publicly available data from 20 January 2019 to 31 January 2020 to compare COVID-19 with severe acute respiratory syndrome (SARS) and make predictions. The predictions are mainly divided into the following three sections: duration, infections and deaths, and the impact on China’s economy.
2.1. Duration
The predicted duration was mainly based on the curve comparison. Firstly, this study drew the curves of the number of infected, dead, and cured people based on SARS data; then, it found the inflection point (IP) and Key Point (EP) based on the curve and data; finally, it computed the IP and EP of the COVID-19. A schematic diagram of the entire process is shown in
Figure 4.
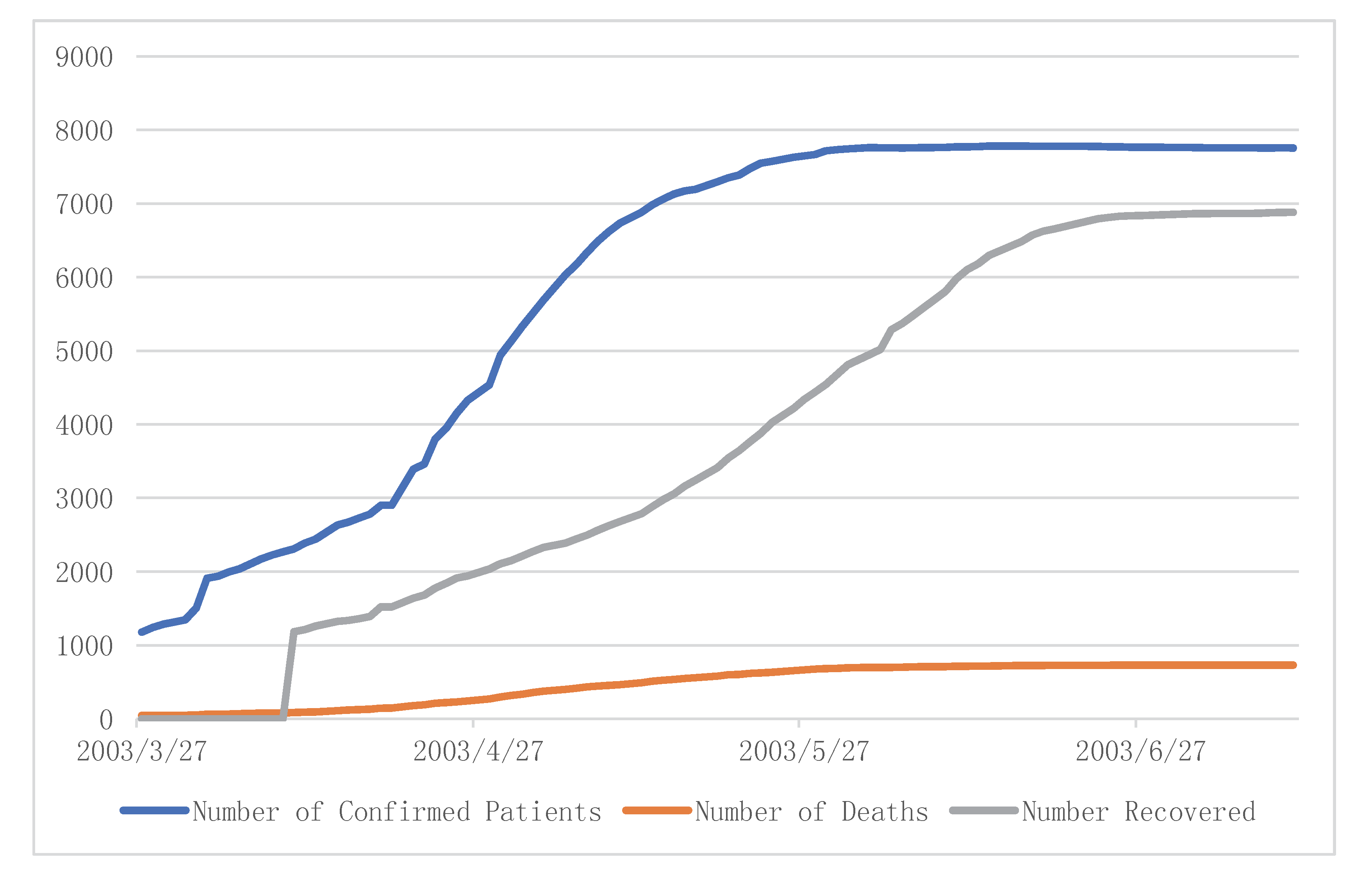
In the first step, this study compared the COVID-19 with SARS data to analyze and predict the time when the virus could continue to infect people. World Health Organization (WHO) data regarding the number of confirmed cases of SARS (2003), deaths, and recoveries are presented in
Table 4, with the data on China’s SARS infection from 27 March 2003 to 11 July 2003 shown in
Figure 5.
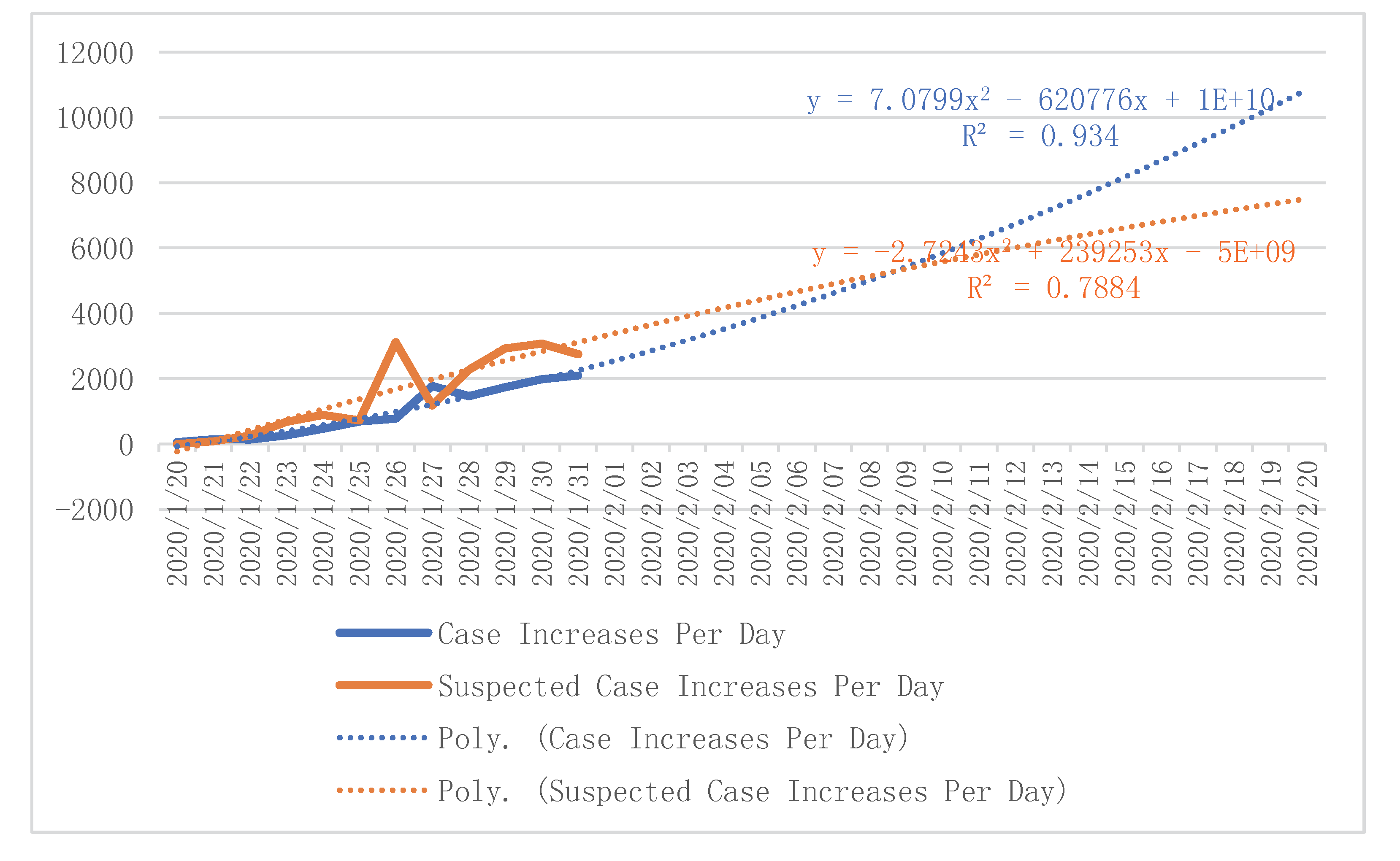
By following the SARS data, we determined two key time points, one being the Inflection Point (IP). The IP is the time at which the infected person does not worsen significantly. This study argues that when the number of suspected cases increasing per day equals to the number of cases increasing daily, the condition stabilizes and reaches the IP. As per
Table 5 and
Figure 6, we predicted that the IP would appear on 8 February 2020, based on the Polynomial Method. According to the judgment of Professor Liubo Zhang, Director of the Center for Disinfection and Testing of the Chinese Center for Disease Control and Prevention, combined with media reports, we set the IP of SARS to 14 May 2003 (
CCTV 2003;
CNTV 2012;
Zhejiang News 2017) and its KP (Key Point) to 11 July 2003. We then calculated that the KP of the COVID-19 was 19 February 2020.
IP (COVID-19) = 39 days (31/12/2019–08/02/2020)
IP (SARS) = 194 days (01/11/2002–14/05/2003)
KP (SARS) = 252 days (01/11/2002–11/07/2003)
39/(194/252) = 50.65 days≈50 days (Data lags, fetches one day forward)
KP (COVID-19) = 50 days (2019/12/31–2020/02/19), the Key Point date is 19 February 2020.
Duration (COVID-19) = 50 + 24 = 74 days (31/12/2019–14/03/2020)
Therefore, our predicted duration was seventy-four days (up to 14 March 2020).
2.2. Infections and Deaths
Previous researchers (e.g.,
Myers et al. 2000;
Ong et al. 2010;
Tizzoni et al. 2012) have conducted work to forecast epidemic trends. Two concerns are usually investigated: one relating to geographic development and the other to time series. For the former, if the focus is on accuracy and generalization, the global epidemic and mobility model is popular for urban mobility tracking and forecasting with the prerequisite that transmission tracks of infectors should be timely and fully traced and kept. For example, when SARS occurred in 2003, according to the WHO summary, travel records of super-spreaders, including where they lived, which public transportations they had taken, and who had possibly had contact with them. However, the overwhelmed transportation system and huge population movement during the Chinese New Year holiday increased infectors or carriers of COVID-19 exponentially. That increased the difficulty for us to track all the infectors and carriers’ activities as compared to SARS in 2003. Therefore, we focused on the time series development of the new virus. Time series sequence development contains three components: trend, season, and cycle. The three factors should be considered equivalently. The Autoregressive Moving Average model (ARMA) and Autoregressive Integrated Moving Average model (ARIMA) are widely used to conduct time series analysis and prediction (forecasts) in finance, business, real estate and epidemics. ARIMA is based on ARMA by including integration. If the dataset rejects the stationary hypothesis, this proves that the dataset is stationary and that ARMA is the better choice to perform the prediction. Conversely, if it cannot reject the hypothesis, the dataset is not stationary, and therefore ARIMA should be adopted. The difference should be conducted multiple times on training data in ARIMA to ensure a stationary series for the next step (
Li and Chau 2016;
Mollison 1977;
Riley 2007;
Valipour et al. 2013;
Nieto et al. 2018). The flowchart is shown in
Figure 7.
Taking the number of patients as an instance, the P-value is 0.8. It indicates that we can reject the stationary hypothesis. For the analysis, we set
where
are parameters,
is a constant, and the random variable
is the white noise.
stands for a time series. N stands for the length of
.
In this case, we treated the growth of patients, deaths, or suspected cases as a series changing with time. Auto-covariance of the temporal series can be represented by:
To exempt the effect of scale of different samples, we introduced correlation based on covariance, where correlation is a scale-free measure compared with covariance.
Since we here compared elements of different time slots from the same time series, and used autocorrelation to measure the effect of previous performance on current data:
It is defined as describing the relationship between two elements on different time slots based on time intervals to find the pattern with time passing. However, ACF here is the correlation between the t element with the one of k lag. Actually, it is not just about and . Because is also affected by elements between them, e.g. . And these elements also have relevance with and . So we here introduced partial autocorrelation (PACF). It eliminates the influence of elements between and .
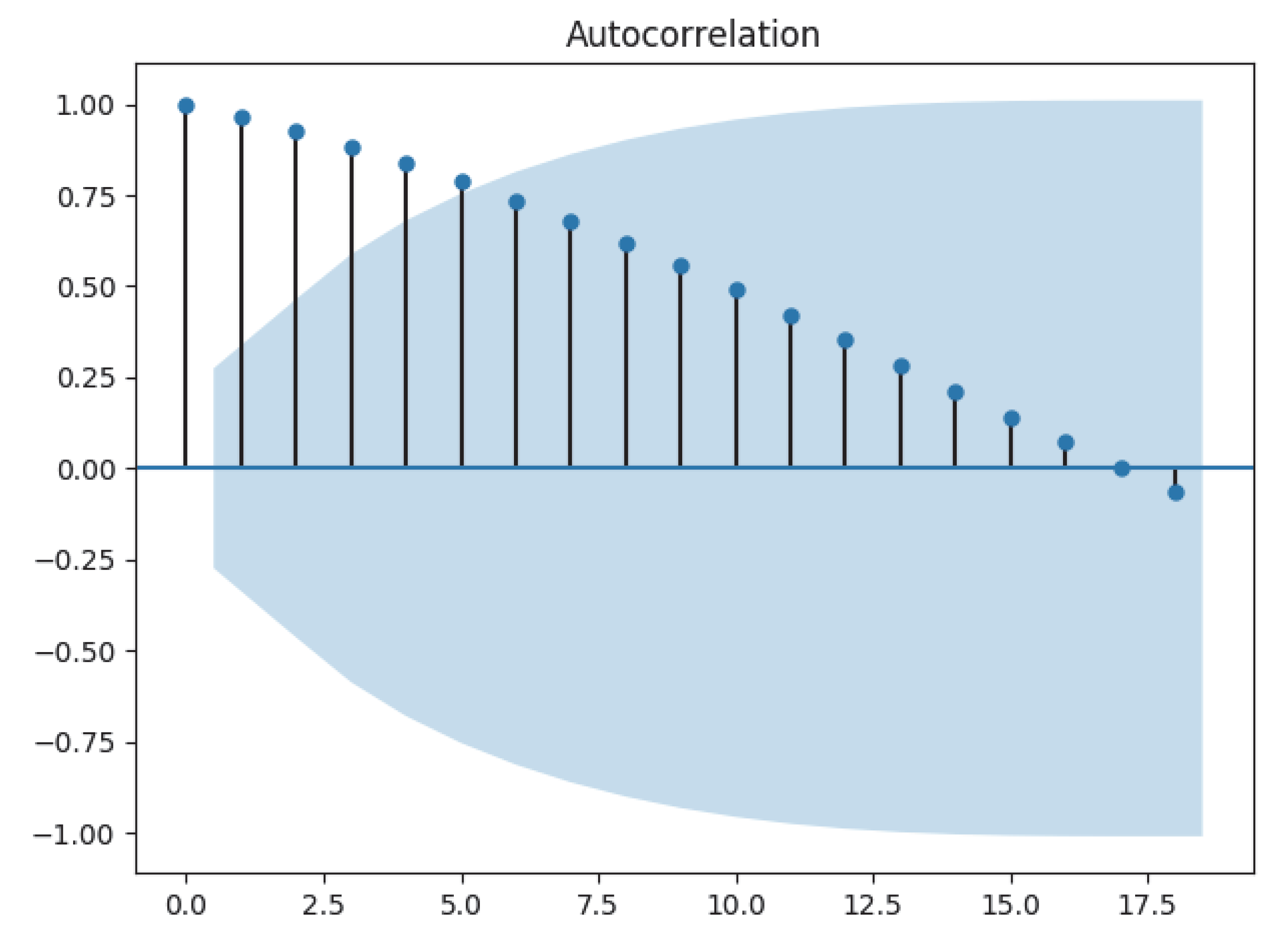
We then draw two plots on autocorrelation and partial autocorrelation.
Autocorrelation is shown as per
Figure 8:
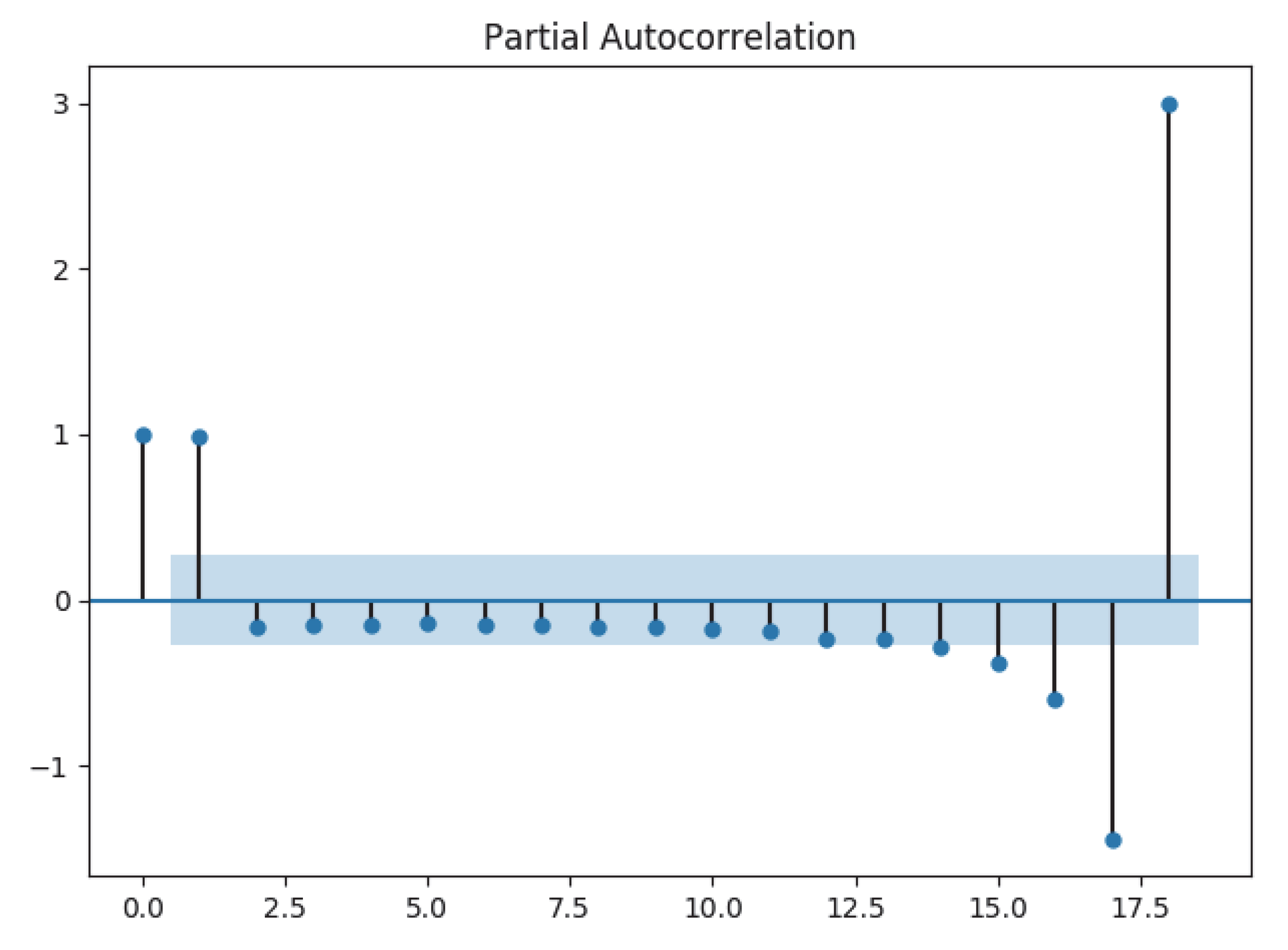
Partial autocorrelation is shown in
Figure 9:
According to these two plots, we know that
and
, and the Akaike information criterion estimator is used to generate
and
again for verification, which are equal. Alternatively, we may use automatic parameter modification Python library to generate models (Pyramid_Arima), which is shown in
Figure 10. Here p stands for the number of lag observations included in the model, also called the lag order, d is the number of times that the raw observations are differenced, also called the degree of differencing. And q is the size of the moving average window.
There is no obvious low correlation after k lag either in PACF nor in ACF, so we used ARMA to do the prediction. To clarify, if there was clear correlation performance after k lag in ACF only, we used Moving Average (MA); if only in PACF we used Autoregression (AR). If neither shows correlation, we use ARMA. Under the ARMA condition, if the performance with time passing is stable, we used ARMA; if not stable, we used ARIMA to deal with random unstableness.
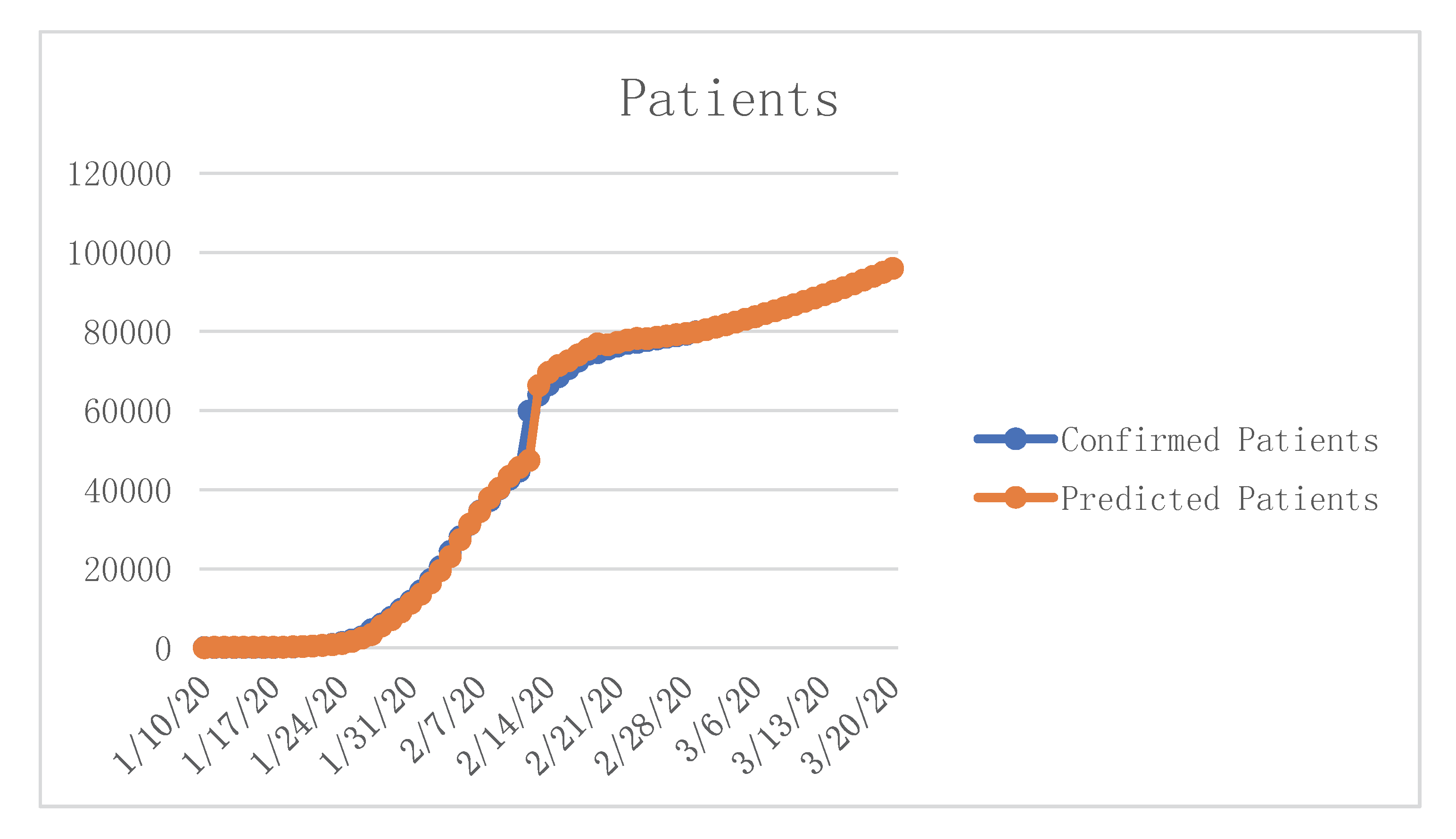
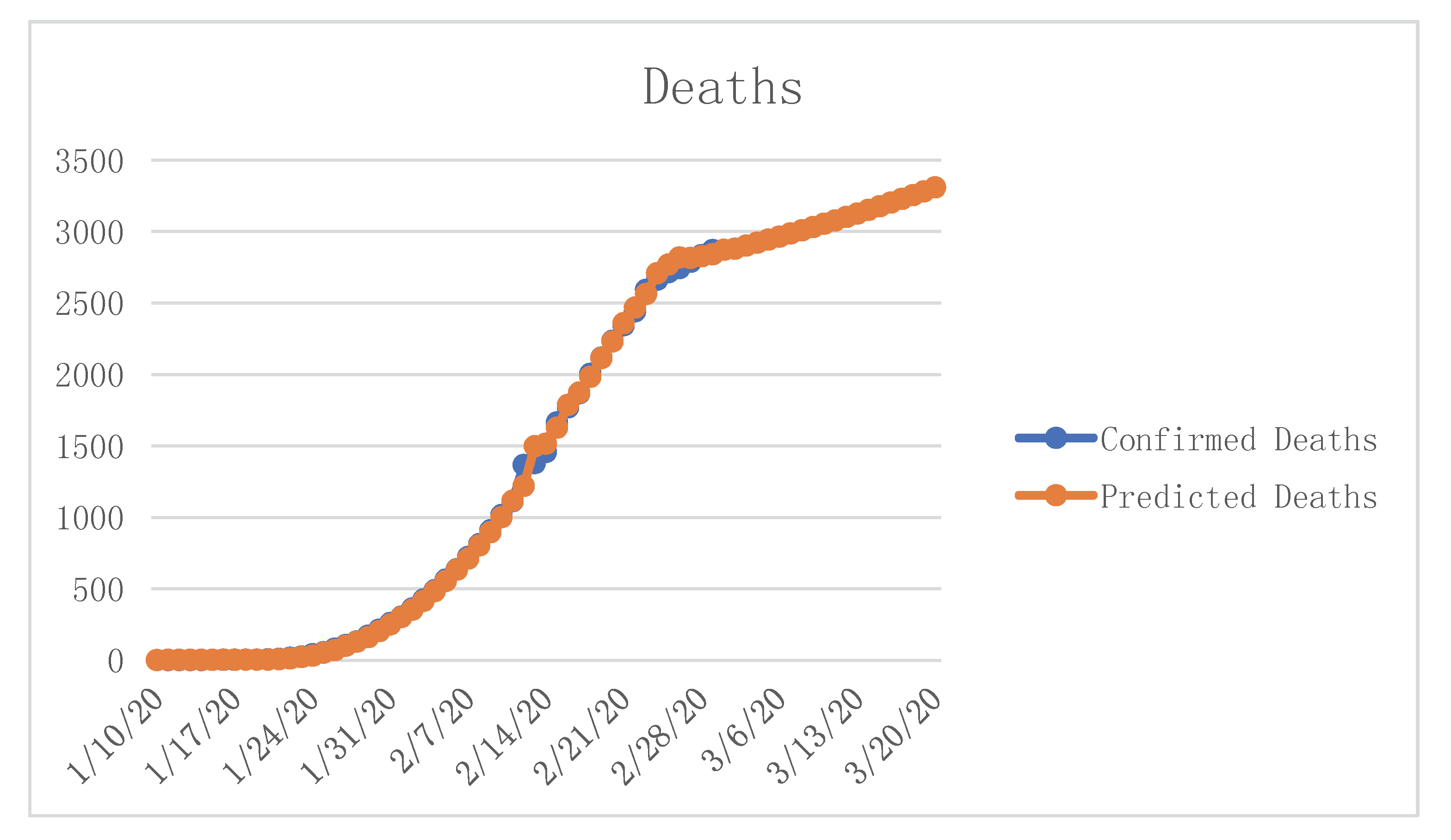
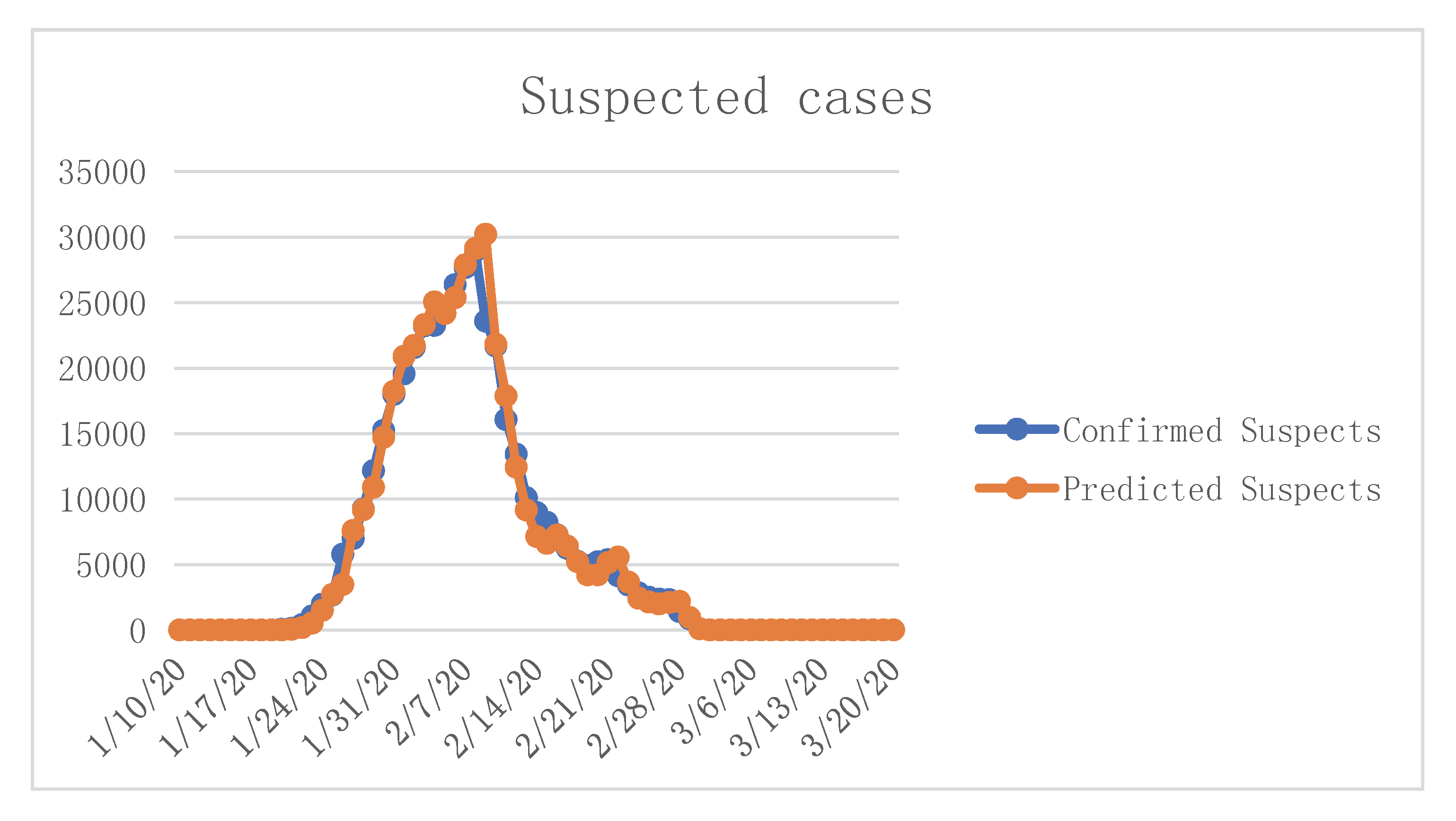
Through our calculations, we attained the forecast results for 20 March 2020; simultaneously, we assumed that after March 20, the condition would become stable, and the number would not have major changes. The results are shown in
Table 6,
Figure 11,
Figure 12 and
Figure 13.
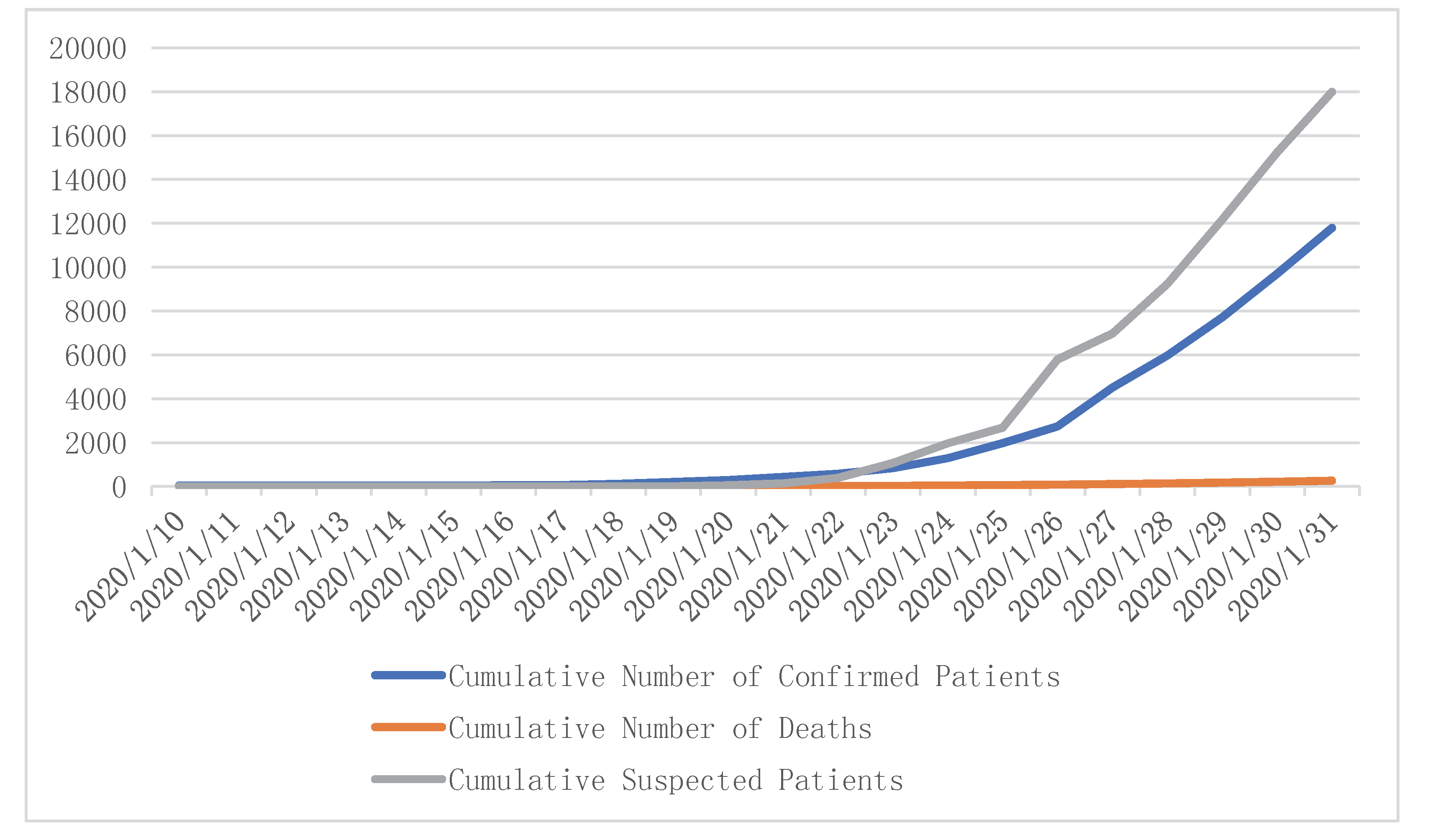
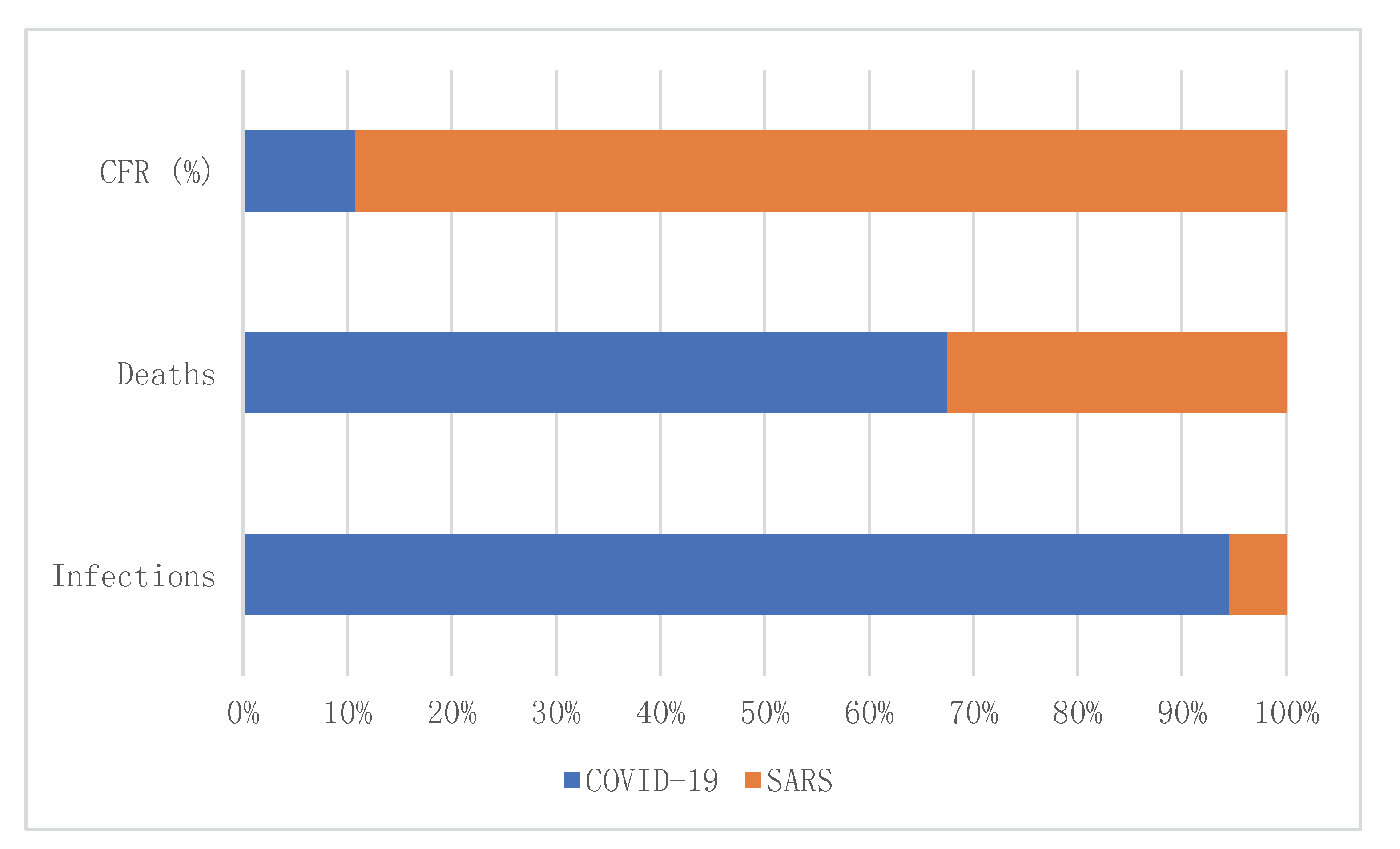
Our prediction results show that COVID-19 would be effectively controlled by 19 February 2020, the number of infected patients was expected to be 133,548, the number of deaths was expected to be 1517, and the case fatality rate (CFR) was 1.14 percent. After that, the number of infections and deaths would stabilize at these two values. The condition would gradually stabilize, more and more people would recover, and social production activities should begin to return to normal after 14 March 2020.
2.3. Impact on China’s Economy
Due to the complexity of China’s economic system, this study focused on COVID-19′s impact on workers’ income and the impact on China’s GDP. Individual’s income represents China’s microeconomy while GDP represents its macroeconomy. The impact on work is in the next section, which forecasts GDP.
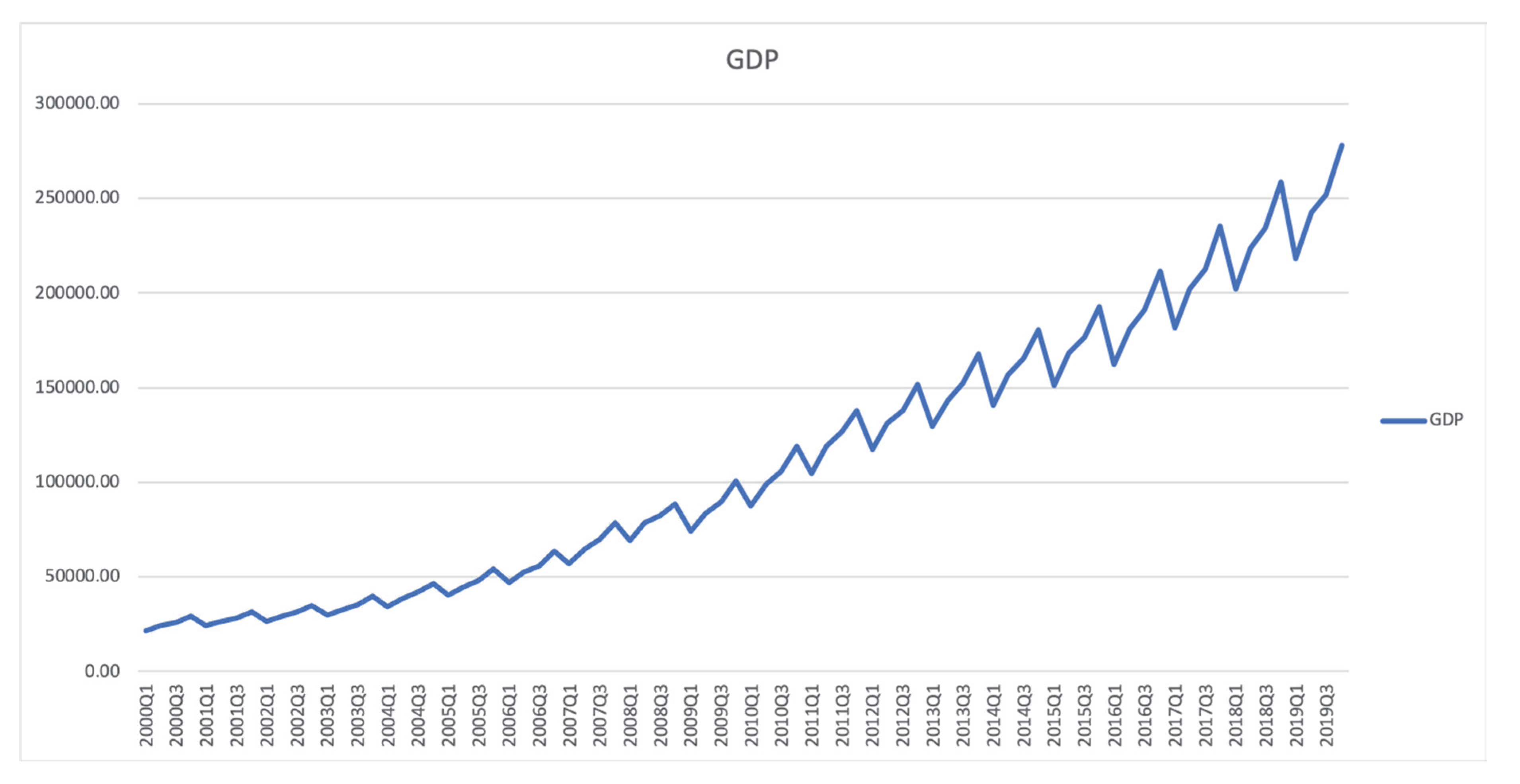
Based on data from the National Bureau of Statistics of China, we have a rising trend of GDP for the past 2 decades (
Figure 14). The question is that whether the trend keeps pace with the lag in the trade war and COVID-19.
Figure 14 indicates that GDP kept rising as the trade war problem worsened in the second quarter of 2019. The increase in GDP reduced, possibly indicating worsening data pointing to the risk of a sharper decline, but soon recovered due to the People’s Bank of China’s (PBOC) efforts to help domestic companies, such as an increase in liquidity. However, in other areas of the world, for example the US, where the Federal Reserve has slashed broad borrowing costs since July, the PBOC has been trying to maintain gradual approaches. This is an effective means of constraining re-inflating debt bubbles.
In December 2019, the novel coronavirus epidemic broke out in the center part of China. This caused a fear of cascading spillovers of supply and demand, regardless of whether they would be peripheral or domestic. Katrina Ell, economist at Moody’s Analytics, has already expressed her gloomy view on China’s GDP with a forecast of 5.4 percent for 2020 (
Bloomberg 2020).
Because the SARS outbreak had side effects on China’s economy, we labelled both 2003 and 2020 with the same features for data training (
Table 8). Considering SARS affected four quarters (2002Q4, 2003Q1, 2003Q2, and 2003Q3), we forecast COVID-19 to be under control by 14 March, people will still need at least one or two months to restore confidence, so we calculated the figures according to a three quarters model (2019Q4, 2020Q1, and 2020Q2).
After exploring the stationary level, we concluded the statistical parameters shown in
Table 9.
GDP prediction is a complicated process as that is affected by many economic variables. Here we do not go deeply into the discussion on how these factors are accounted for when calculating GDP. We will explore the temporal relationships within the data.
Figure 14 shows that there is no clear trend. Normally in the economy or business industries, a cyclic performance is considered. Since we can see that there is a fixed season (seasonal = 4), and the cyclic is used to define an unfixed pattern, we confirm the performance of GDP distribution with no trend and seasonal = 4.
Therefore, we have two possible models:
- -
Seasonal Autoregressive Integrated Moving-Average with Exogenous Regressors (SARIMAX)
- -
Holt Winter’s Exponential Smoothing (HWES)
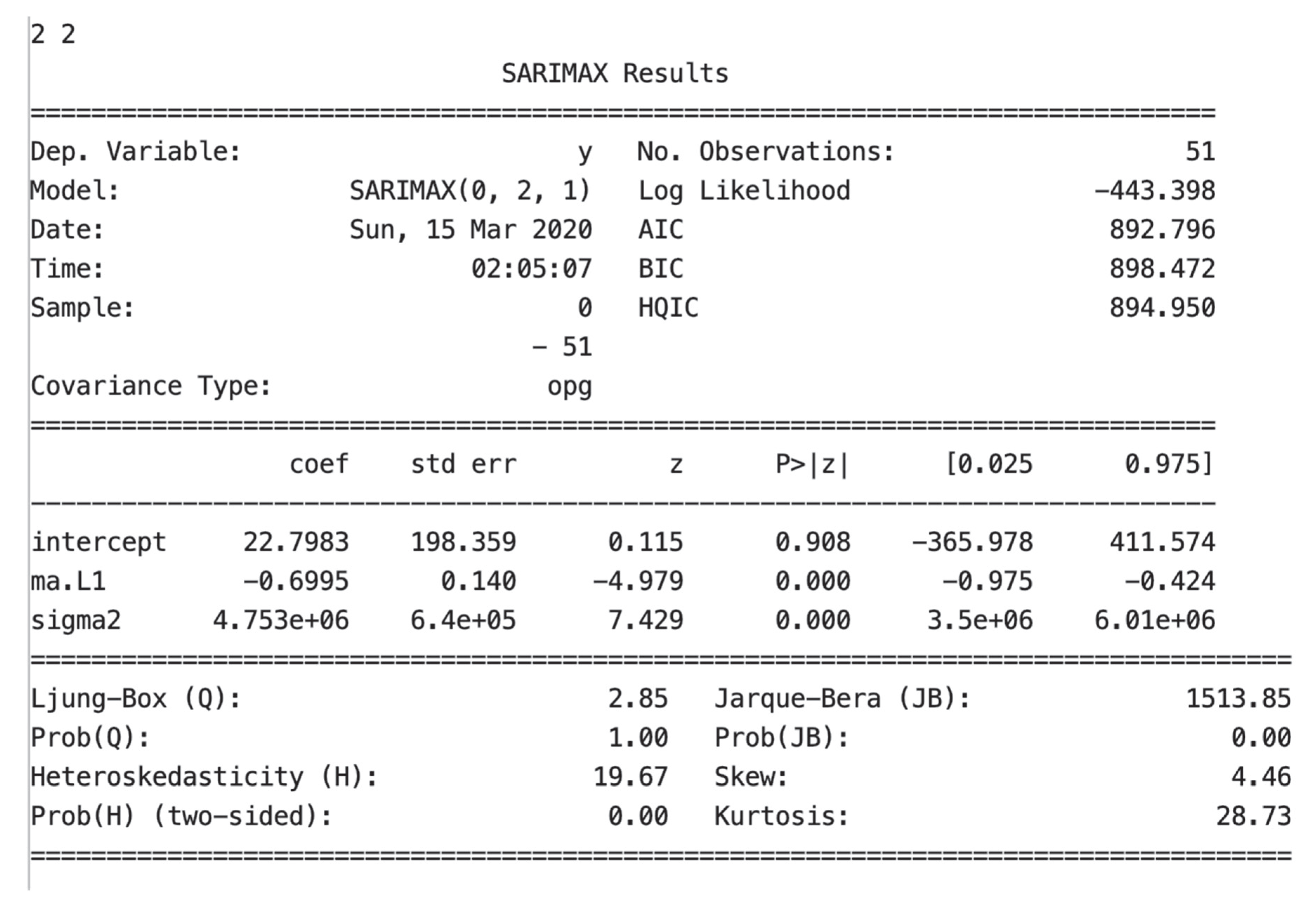
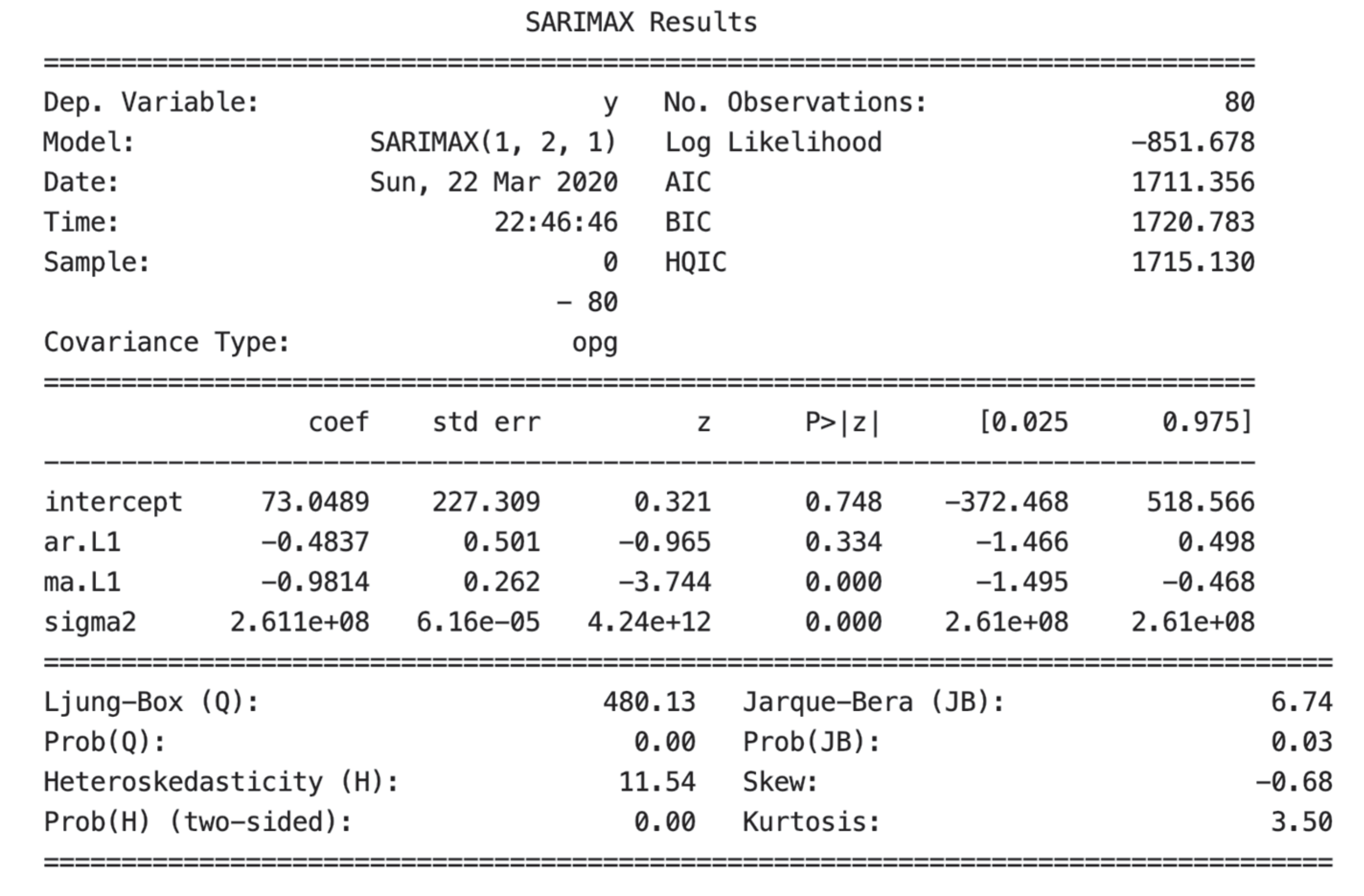
SARIMAX is an extension of SARIMA that includes the modeling of exogenous variables. In an economy, there are always exogenous variables that have no relationship within the data but are imported by peripheral effects. Here we treat epidemic and time as considerations of exogenous variables for regression. A summary of the SARIMAX model is shown in
Figure 15:
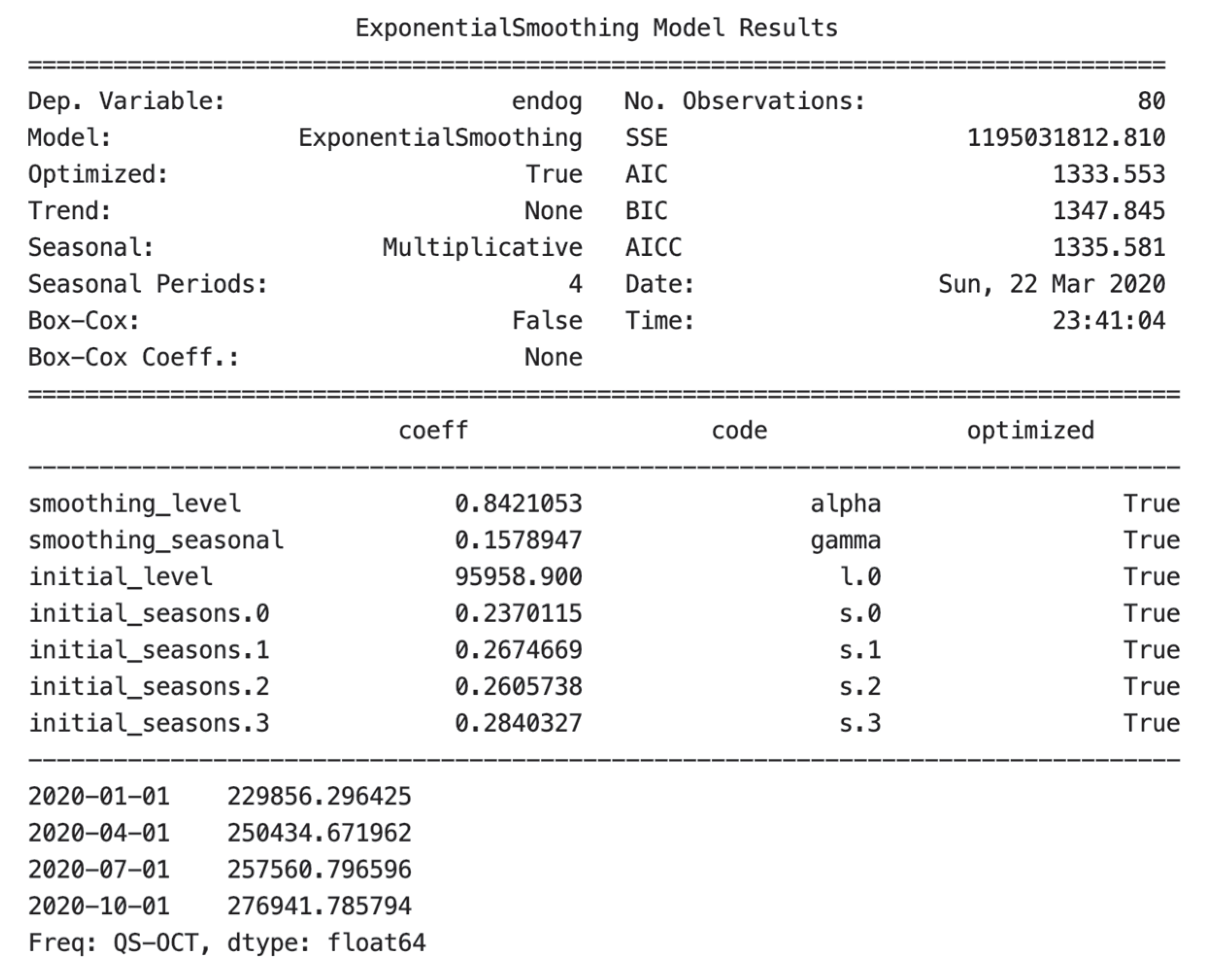
HWES contains three exponentially weighted linear functions of observations. One works at a prior time step of exponential smoothing. If the dataset contains neither trends nor seasonal trends, single exponential smoothing is used; if it contains trends, then double smoothing is considered; if seasonal with trends are observed, the triple exponential smoothing is used. The model summary is shown in
Figure 16:
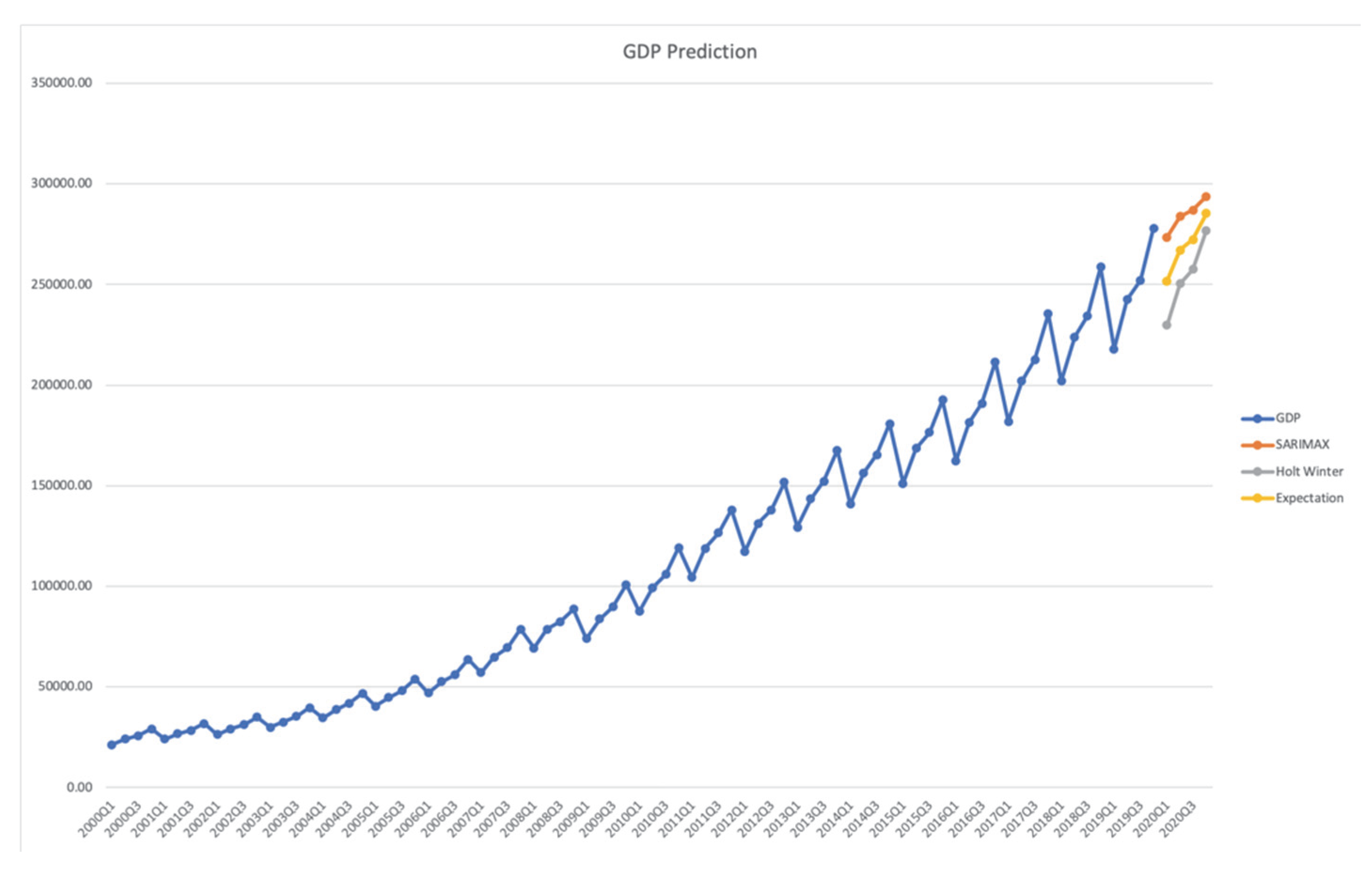
This study used Python library stats models to explore both of the methods and the prediction of the GDP dataset as listed below, in
Table 10 and
Figure 17:
In addition, the graph of distribution is below in
Figure 17:

 ,
, 

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}