1. Introduction
Since Markowitz formulated portfolio selection as an optimization problem trading off risk and return over sixty years ago, mean-variance optimization has occupied a central role in constructing portfolios in both academic literature, and industry (
Markowitz 1952). The reasons for its success are diverse. The model was the first to quantify the benefits of diversification towards reducing portfolio risk. Further, it simplified the portfolio selection problem by introducing the concept of an efficient frontier. On this delimitating line or frontier, we can find the portfolio with the highest return for a given level of risk. Despite its vast success, the model has its drawbacks. To arrive at a mean-variance portfolio, an optimization problem is solved for one fixed period: hours, days, months, and years. However, an investor’s end goal is broader than what could be achieved by a single mean-variance portfolio. The investor cares about maximizing their wealth over their entire investment period, which could last until a significant event or purchase, their lifetime or many generations (sovereign wealth funds). Superimposing one static set of returns and risk completely ignores the time-varying properties of asset prices over a long period of time. To address this drawback, we propose a reactive multi-period portfolio optimization framework that allows the direct incorporation of investor views and quantitatively generated degrees of confidence in each view on behalf of the investor.
Multi-period optimization (MPO) is a promising research area that allows us to optimize portfolio holdings for the immediately adjacent time period simultaneously and multiple periods beyond it. Considering only one period at a time, single-period mean-variance optimization is a sub-optimal nearsighted strategy. The objective for the current period, unlike the real world, is oblivious to unavoidable future constraints and, at a minimum, unaware of reasonable expectations for further future periods. Suppose our long-term return forecast encourages us to build a large position in one asset; however, our short term return forecast is negative. In this case, an optimal solution might be to buy over periods of negative returns to prepare for the long term expectation, a solution not easily incorporated in a single period setting.
Similarly, we can incorporate known macroeconomic events such as the US election directly into upcoming future periods. Suppose a reduction in portfolio holdings is desirable to prepare for the event. In that case, it can be expressed in MPO as a forecasted increase or a hard constraint of the underlying securities’ risk in a future period. Reducing the portfolio size over multiple periods would likely achieve this with lower market impact as opposed to one period. Using MPO, the investor also gains the ability to incorporate time-varying return predictions into one model, e.g., mean reversion or alpha decay (
Boyd et al. 2017). This subset of examples serves to showcase the vast potential that MPO has to improve on the existing single period models.
Starting with
Samuelson (
1969) and
Merton (
1969)’s work, the literature on multi-period optimization (MPO) has focused on dynamic programming, which appropriately incorporates updated information for each period in the sequence of trades (
Gârleanu and Pedersen 2013). Unfortunately, applying dynamic programming to the problem of trade selection is impractical for non-trivial cases due to the ‘curse of dimensionality’ (
Powell 2007). Most studies focusing on dynamic programming only include simple objectives and constraints and a minimal number of assets. Various approximations to the dynamic programming problem are employed to achieve tractability, such as approximate dynamic programming or simpler formulations that generalize SPO into MPO (
Boyd et al. 2014).
The method we will be leveraging in this article was recently introduced by
Boyd et al. (
2017) and consists of a relaxation from dynamic programming’s consideration of the entire time horizon. Successfully used in many industrial applications, model predictive control (MPC) incorporates new information into the optimization problem. At each time step, a multi-period optimization problem using information known at time
T is solved for
H periods ahead. Despite obtaining optimal actions for multiple time periods, only the first period’s actions are implemented, and the optimization problem is solved anew with updated information gained at time
. We apply this receding horizon procedure to the MPO setting and simplify the full horizon dynamic programming problem while maintaining fast reaction times to changing financial markets. Applications to finance include portfolio optimization (see
Herzog et al. 2007;
Nystrup et al. 2019), optimal trade execution (
Anis and Kwon 2020) and index tracking (
Primbs and Sung 2008). Using the same MPO framework as (
Boyd et al. 2017),
Nystrup et al. (
2019) leverage multi-period forecasts in order to minimize the chances of the portfolio falling below a certain level relative to its previous peak, i.e., achieve a lower maximum drawdown.
Boyd et al. (
2017) demonstrate that this MPO method remains computationally tractable since it leverages convex programming throughout, can incorporate many costs and constraints and improves the risk-return frontier over SPO for daily equity trading in an ex-post example. From an optimality perspective, it is possible to produce a bound on the optimal performance for the dynamic trading of a portfolio of assets over a finite time horizon (
Boyd et al. 2014). This performance bound can be used to judge the performance of any sub-optimal policy. While there is no theoretical guarantee of the performance of the method we are using, Boyd et al. show through Monte Carlo simulations that its results are typically close to the optimal performance bound. Although this optimization method is designed to look into the future, there is no set optimal horizon
H to use. This article analyzes the results of portfolio allocation performance across one, two and five-period horizons.
We leverage the Black-Litterman (BL) model to generate more stable risk and return estimates for the optimization problem while avoiding common pitfalls found in direct and risk factor model-based estimation. Even in MPO, the mean-variance portfolio remains the core of portfolio optimization. However, when attempting to use the original Markowitz mean-variance optimization model for portfolio allocation decisions, the resulting portfolios are often uninvestable.
Green and Hollifield (
1992) documents the tendency of mean-variance portfolios to be skewed by having large positions in only a small subset of assets, thus going against the very concept behind their inception, diversification. Similarly, the model would almost always result in large short positions in many assets when allowing short positions. These troublesome results stem from two well-documented problems. First, portfolio managers tend to be extremely knowledgeable only on a specific set of assets, while a standard optimization model requires them to produce both return and risk estimates across all assets. We know that estimation errors can cause mean-variance optimized portfolios to perform poorly (see
Michaud 1989;
DeMiguel et al. 2009). Second, as a compounding effect, mean-variance portfolios are extremely sensitive to the return assumptions used. When any constraints are introduced to the optimization problem, a surprisingly small change to the return estimate of even one asset shifts half the portfolio’s allocation of assets while leaving the portfolio’s return and variance unchanged (
Best and Grauer 1991).
Since estimation error is a leading cause of unexpected results from mean-variance optimization, significantly reducing the parameters to estimate also improves the mean-variance results. As mitigation,
Fama and French (
1992) introduced size and book-to-market equity factors that, when combined, capture the cross-sectional variation in stock returns. Leveraging explainable factors as drivers of returns enables financial practitioners to reduce the need to estimate
parameters for a full risk covariance matrix to only
, where
n is the number of assets and
m is the number of explanatory factors. Although extremely popular in academia and industry, implementing factor models in practice is not trivial. The presence of correlated factors can cause unit factor portfolios that are unintuitive to even experienced practitioners. Further, using trailing averages of factor returns implies a follower momentum strategy at the factor level without strong empirical justifications (
Carvalho 2016).
Different mathematical techniques can also be employed in order to reframe the problem of portfolio selection. Credibility theory has been used to expand from traditional MVO to a fuzzy multiobjective model that also includes liquidity constraints beyond risk and return measures (
Garcia et al. 2020). Similarly, uncertainty theory can be used to introduce new sources of background risk (income shortages, health-related expenses) that affect individual investors’ risk preferences into the portfolio selection problem (
Huang and Yang 2020). Models using different choices of risk measures (semi-variance) and objectives (entropy, price-to-earnings ratio, satisfaction functions and environmental, social and governance (ESG) scores) have also been shown to be good alternatives to traditional MVO (see
Chen and Xu 2019;
Garcia et al. 2019;
Mansour et al. 2019;
Garcia et al. 2019).
As a widely-known approach to solving the Markowitz model’s problems,
Black and Litterman (
1992) developed their namesake model that combined the mean-variance optimization framework with Sharpe’s capital asset pricing model (CAPM) and applied it to global assets. The model starts with a baseline of global equilibrium returns defined as the asset returns that would stabilize the global supply-demand of risk assets. In practice, these returns are equivalent to portfolio holdings that are market capitalization-weighted, proportionally more allocated to better-capitalized countries (
Sharpe 1964). Layered on top of the baseline equilibrium returns, the model allows an investor to incorporate their own return views for the areas where they have expertise while leaving the remaining assets to be allocated according to equilibrium returns. This approach addresses both inadequacies that exist in the standard mean-variance optimization. Managers are empowered to focus only on their subset of views while the layered approach anchors the final result to the well-diversified market capitalization-weighted portfolio. The enrichment of baseline returns with dynamic investor views is the reasoning behind using the BL model at our framework’s core.
Although conceptually simple, the Black Litterman (BL) model is imperfect. BL is static and effectively single-period. Once the target weights are obtained, portfolio managers are expected to actively track the results of their view and reoptimize upon any changes in their view or confidence levels. Using data-driven methods to infer dynamic confidence levels in an investment view eliminates the need to choose an entry/exit point and enables its expansion to multiple periods without further investor input. Further, BL is relatively complex to understand even for a quantitative researcher, as evidenced by the number of papers dedicated to presenting it in more straightforward ways (see
He and Litterman 2002;
Idzorek 2004;
Walters 2007). We introduce a regime-switching component that makes the model reactive to market regime changes and, in turn, reduces the work needed to interact with the model.
A growing set of literature shows that we can exploit shorter-term trends in both returns and volatility, similar to what we propose in this article. Hidden Markov models (HMM) have been successfully used in speech recognition (
Jelinek 1997), natural language modelling (
Manning and Schutze 1999) and the analysis of biological sequences such as proteins and DNA (
Krogh et al. 1994).
Ang and Timmermann (
2012) explored their predictive power on financial variables and discovered that they could be used across various financial markets and macro variables. HMMs can describe the financial market’s tendency to abruptly change its behaviour and the propensity for financial variables to maintain their behaviour over more extended periods. Within the field of finance, their application is referred to as regime-switching. Incorporating their predictions within mean-variance optimization has been found to improve portfolio performance in multiple ways.
Nystrup et al. (
2017) found that regime based asset allocation improves portfolio return and risk metrics over rebalancing using static weights.
Costa and Kwon (
2019) used regime-switching to build factor models to assist with the difficult problem of estimating covariances and demonstrated higher ex-post return for the same level of risk compared to a nominal factor model.
Despite numerous examples of using regime-switching in finance, there is a dearth of literature on the benefits of tactically improving the BL returns and risk through regime-switching predictions. The only directly connected article uses a two-state regime-switching model as the return estimates provided to the Black-Litterman model. It finds that regime-switching returns outperform directly estimated returns (
Fischer and Seidl 2013). Our approach is different; the BL equilibrium returns are kept intact as a base while our goal is to improve the investor views. This article extracts predicted returns from the most straightforward HMM consisting of only two states and uses them to compute dynamic confidence values in investment views. The reason for choosing a two-state model as opposed to more is two-fold. First,
Nystrup et al. (
2019) find no benefit from increasing the number of states above two out of sample when using long-term daily data. Second, a simpler model is less likely to overfit the training data and is more likely to be embraced in practice due to its increased interpretability. The lack of interpretability is a significant barrier to model adoption by investors. By leveraging regime-switching, we propose that it is possible to compute a practical dynamic confidence level by comparing the investor view to the regime-switching predicted view return. This dynamic comparison serves to remove the BL model’s dependency from correctly chosen confidence levels or entry and exit points.
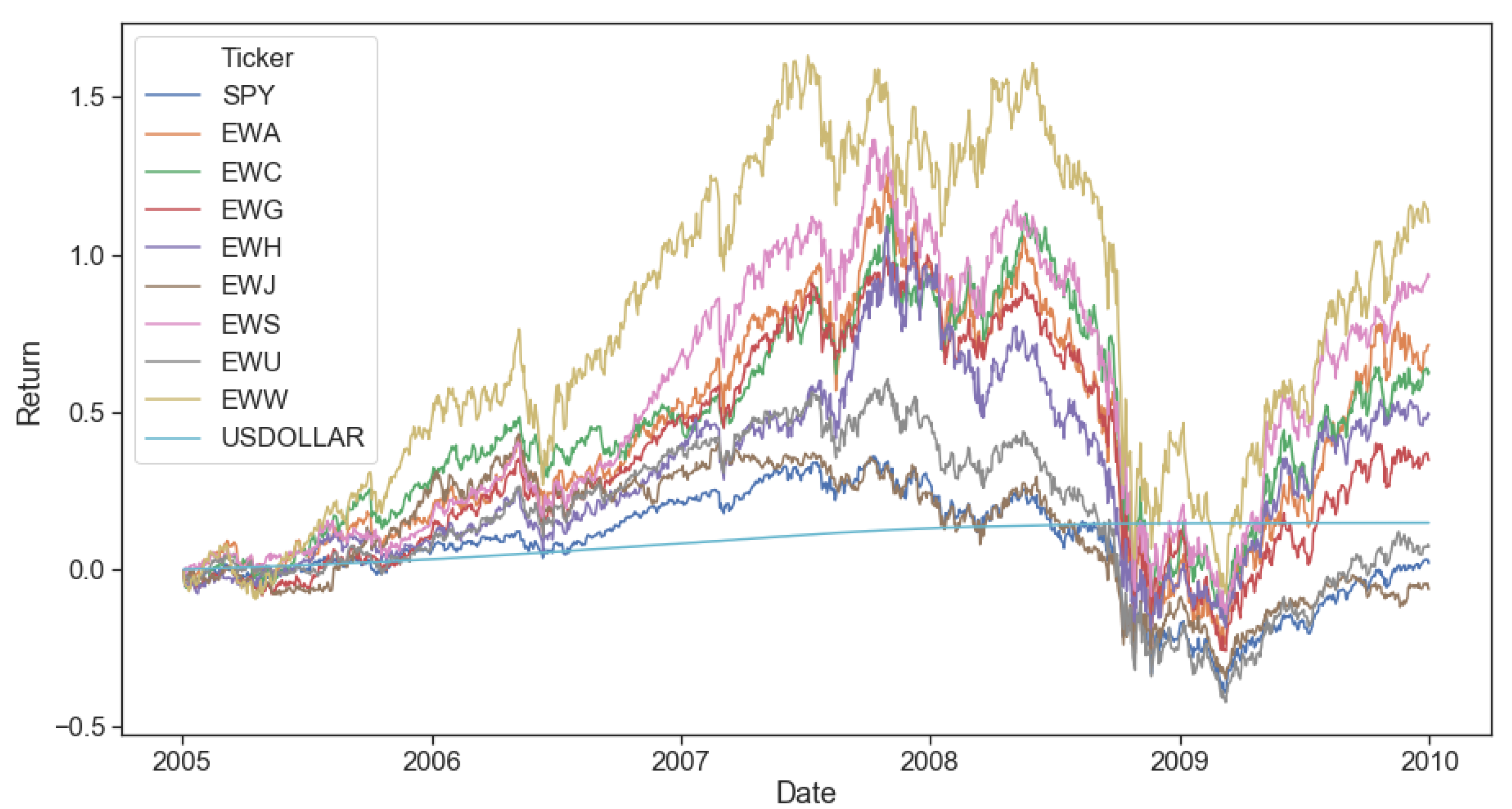
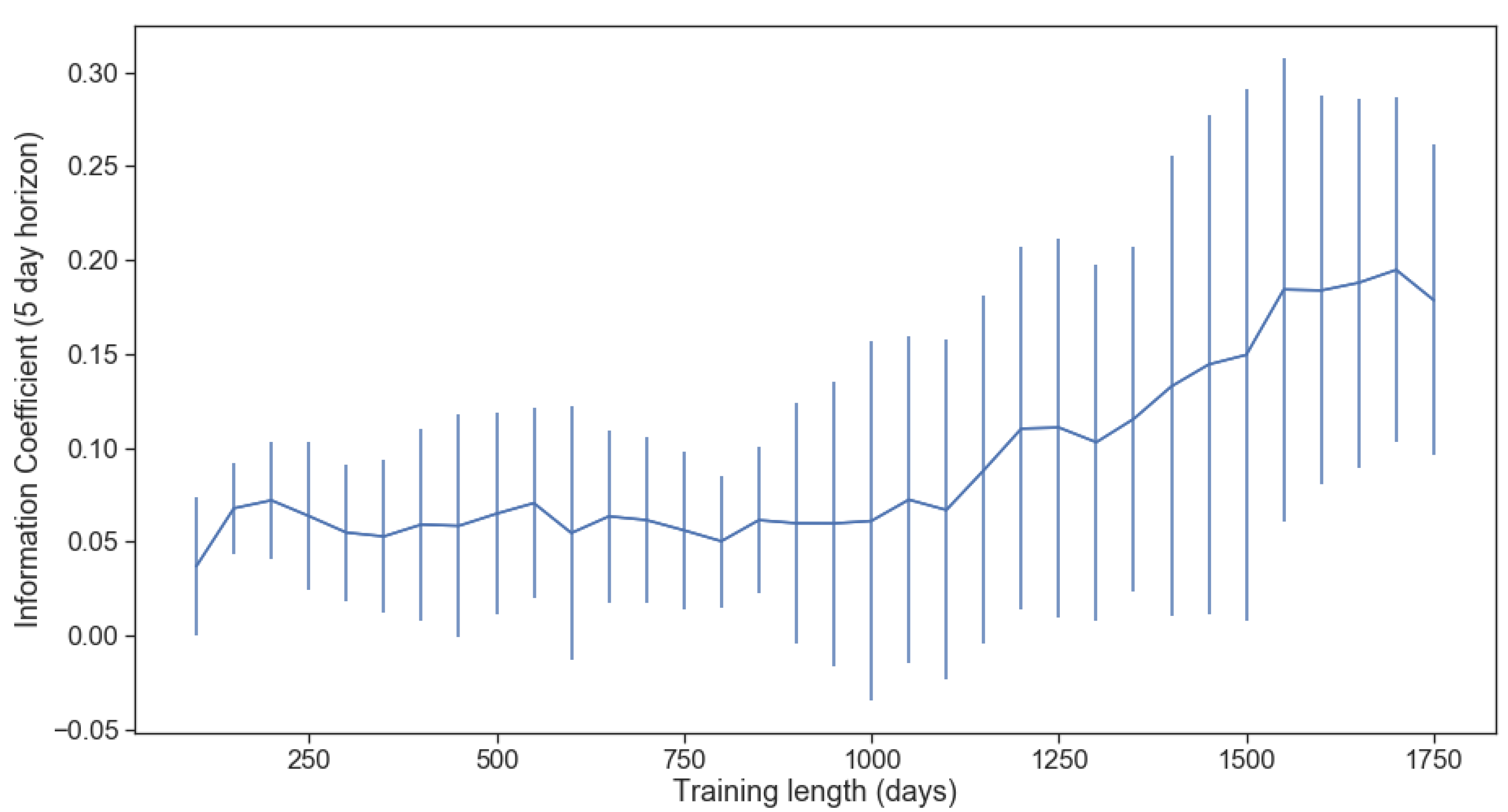
Our essential assumptions regarding the trading frequency should be noted, given our use of both market equilibrium returns and regime-switching models based on daily return data. Market equilibrium returns are based on supply and demand reaching a stable balance. At higher frequencies (tick, second, minute), we expect this stable balance to be more fleeting, making market microstructure and short term effects much more critical. Conversely, it is more likely to observe stable supply-demand equilibria to base trading decisions on at a lower frequency. Further, our regime-switching training was performed over multiple years, with only two states (bull and bear), making the predictive power at a higher frequency (intraday or daily) lower. That said, reacting to a regime change faster is better than reacting to a regime change slower. Therefore, the interval we chose to strike a balance between these two factors was a weekly trading frequency and was applied in most simulations performed.
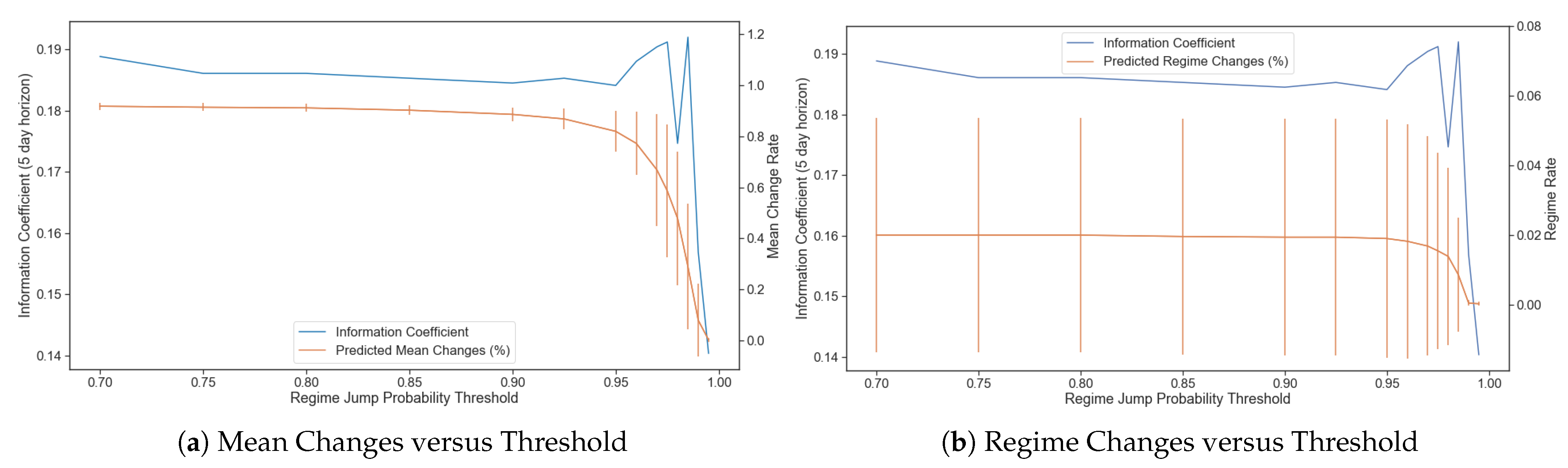
Introducing a more dynamic allocation as proposed (based on direct market data) can lead to potential problems that we mitigate against, namely, return instability and overtrading. Since regime-switching models using higher frequency data are faster to update their confidence in each regime, this can lead to fleeting regimes and unnecessarily high portfolio reallocation. To prevent this, similar to
Nystrup et al. (
2015), we incorporate a minimum probability threshold to overcome before allowing the regime to change. The threshold reduces regime jitter at the expense of a slightly slower reaction to regime changes. We know that transaction costs can be high when trades are made frequently (
Kolm et al. 2014) and that SPO can be augmented to efficiently include many types of costs and constraints in the portfolio selection (
Lobo et al. 2007). Therefore, we incorporate transaction costs into the portfolio optimization. These two changes, regime-switching thresholds and transaction cost optimization, serve to mitigate the potential adverse effects we mentioned above. Market microstructure issues such as liquidating large positions or information leakage to other participants are only partially addressed by using a temporary impact cost component. The first to introduce the concept of optimal intraday execution of portfolio transactions,
Almgren and Chriss (
2001) developed a simple linear temporary impact cost model and introduced efficient frontiers trading off the minimum expected cost versus a given level of uncertainty. However, since its introduction, the field of optimal execution has advanced significantly through the introduction of permanent impact costs, dynamically adaptive strategies and stochastic volatility, among others (see
Lorenz and Almgren 2011;
Almgren 2012). Given our lower frequency of trading (daily or longer) and liquid developed country based ETFs, we do not focus further on this topic but note that it would be an exciting area of future research.
Overall, the proposed model improves traditional single-period mean-variance portfolios by incorporating multi-period trading and interpretable investment views into one easy-to-use framework. We leverage a multi-period portfolio optimization model introduced by
Boyd et al. (
2017) that approximates the entire trading range optimization by repeatedly optimizing smaller, more tractable consecutive sub-ranges. Although trading decisions are made for multiple periods in advance, only the next period trading decisions are executed. The model requires accurate risk and return estimates for the portfolio optimization, which we obtain from the BL model as the combination of the market portfolio and investment views. To mitigate against BL’s static nature and provide dynamism to the estimates, we propose a novel method of using regime-switching to determine each investment view’s confidence. We do not address the actual generation of investment views; instead, we focus on trading them effectively once provided.
1.1. Outline
The article is structured as follows:
Section 2 introduces the multi-period optimization model based on receding horizon MPC.
Section 3 presents the computation of risk and returns estimates needed to instantiate the portfolio optimization model. It starts by showing how the Black Litterman model is used to incorporate investor views in
Section 3.1, then introduces the dynamic investor view confidence levels obtained through regime-switching in
Section 3.3. It concludes with pseudo-code that details all the parts needed for the complete algorithm and simulation.
Section 4 showcases our empirical results using this framework. Finally,
Section 5 concludes.
1.2. Contribution
The main contributions to the existing literature are two-fold. First, we are the first to develop a multi-period optimization model to solve a portfolio allocation problem based on return and risk estimates from the Black Litterman (BL) model. As opposed to traditional dynamic programming, this method enables the optimization to be dynamic across time and, as such, allows new information to be incorporated as soon as it’s realized. This multi-period relaxation method aptly named receding horizon, is borrowed from model predictive control and was first introduced by
Boyd et al. (
2017). Given the increase in trading frequency over static models, convex transaction costs are also considered in the optimization objective. Second, we introduce a novel data-driven method to infer dynamically updated confidence levels for investment views. The confidence is obtained by computing the view’s regime expected return (based on each underlying asset’s current regime) and comparing it to the investor inputted expected return. The more the two forecasts are in agreement, the higher the confidence obtained and vice versa. Overall, the result is a framework that is reactive, numerically tractable and easy to use by a portfolio manager looking to trade researched investment views optimally. We have also developed an open-source software library that implements all of the methods in the paper and can be used to replicate our results easily:
https://github.com/roprisor/alphamodel.
2. Multi-Period Optimization
Multi-period optimization (MPO) has shown great promise as a flexible solution for constructing optimal portfolios over multiple separate but connected time periods. The traditional mean-variance is designed for only one time period and, therefore, more fit for stationary risk and return assumptions. In practice, financial asset prices exhibit non-stationary behaviour, which is better incorporated in a multi-period optimization model. Academic literature has focused on dynamic programming, a method that has proven impractical for non-trivial cases due to the ‘curse of dimensionality’ (
Powell 2007). Recently,
Boyd et al. (
2017) developed a model that generalizes from single-period optimization (SPO) to MPO. Its advantages include tractability and flexibility while still achieving near-optimal results. Through convex optimization for all objectives and constraints, the model can remain tractable despite introducing multiple periods and many constraints for each period. While there is no theoretical guarantee of the performance of the method we are using,
Boyd et al. (
2014) show through Monte Carlo simulations that its results are typically close to the optimal performance bound. This model, presented below, will be leveraged as a base for the framework presented in this paper.
At each time period
T, a multi-period optimization problem using information (risk, return, and transaction cost estimates) known at time
T is solved for H periods ahead, where
. Despite obtaining optimal actions for multiple future time periods, only the first period’s actions are implemented, and the optimization problem is solved anew with updated information gained at time
(see
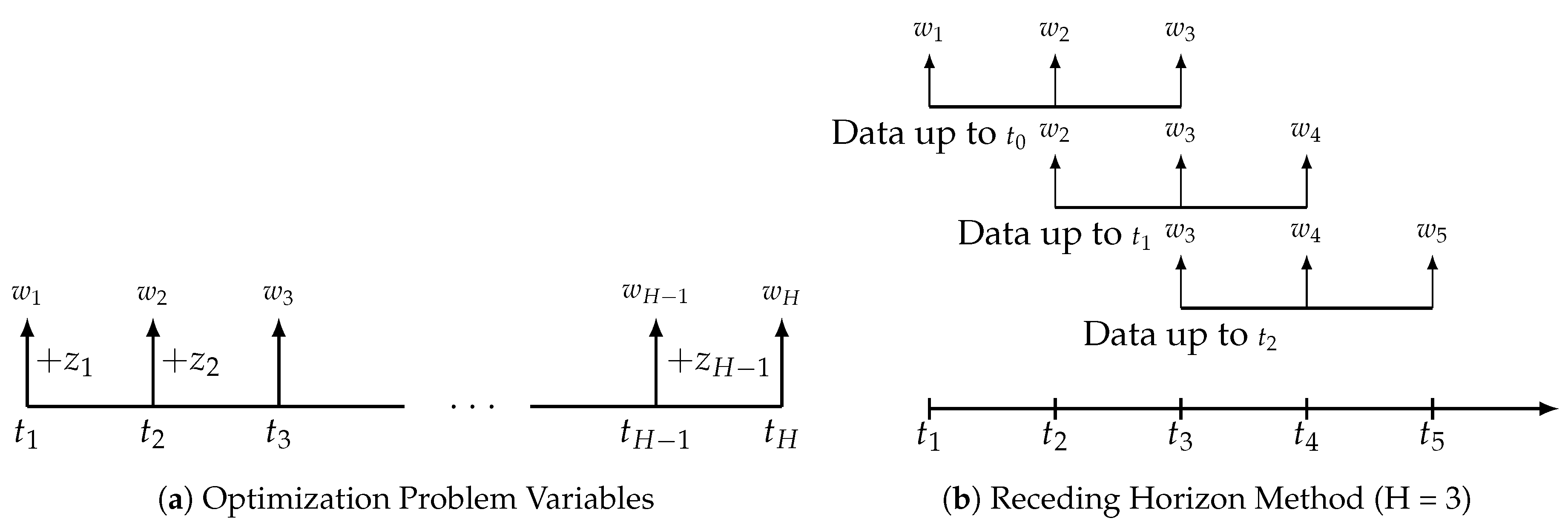
Figure 1a,b). This receding horizon procedure simplifies the full horizon dynamic programming problem while maintaining fast reaction times to changing financial markets.
A natural question that arises when considering the horizon for each multi-period optimization problem is how exactly we decide how many periods ahead the optimization should consider, i.e., what should H be? Let us consider the limiting values for H. As a minimum value, when , we are performing sequential single-period optimization. As a theoretical maximum, when , we are effectively considering the entire trading range all at once. Although possible, optimization across the entire trading range is impractical unless we have accurate return and risk forecasts that far into the future. Therefore, a practical value for H will depend heavily on the forecast horizon of our return and risk estimates. We will compare multiple values for H to validate its impact in the empirical results section.
2.1. Multi-Period Optimization Model
Consider a portfolio of n assets, plus a cash account, over a finite time horizon split into discrete time periods labeled . The time period in the model can be of arbitrary length however we will consider each period to be a trading day throughout this paper. Let denote the portfolio (or vector of holdings) at the beginning of time period t, where is the dollar value of asset i. implies a short position in asset i. As a corollary, when for , we call the portfolio long-only. Since asset represents the cash account, implies that at time t the portfolio is fully invested, i.e., we hold zero cash, all holdings are invested in non-cash assets. The total value of the portfolio, in dollars, at time t is expressed by .
Another way to describe the portfolio is through fractions of the entire dollar value or weights. Given a portfolio with holdings , the weights (or weight vector) are defined as . The portfolio weights always sum to one, by definition, , and are unitless (dollar holdings divided by portfolio total dollar value). Equivalent to the holdings scenario, the last weight is the fraction of the total portfolio value being held in cash.
Let be the dollar value of our trades in period t. We will assume that all trading happens at the beginning of each time period. implies that we bought dollars of asset i and implies the opposite, for . Normalizing the dollar value trades relative to the total portfolio value we obtain the normalized trades .
SPO only considers the most recent trade decision
while ignoring any future periods in the current optimization. Effectively, SPO is the specific case of MPO where the forward horizon only includes one period. In MPO, we obtain the current trade vector
by solving an optimization problem over a planning horizon that extends
H periods into the future as illustrated in
Figure 1a for times:
We develop the multi-period optimization problem from the core mean-variance objective: maximizing returns while minimizing risk and transaction costs. Let
denote our sequence of planned trades over the horizon. Given estimated returns
, risk
and transaction cost
, a natural multi-period objective is to maximize the sum of risk-adjusted return over the horizon:
where
and
are variables,
and
are positive parameters used to scale the respective costs and the
denotes an estimate rather than a known or realized quantity. These parameters are sometimes called hyper-parameters, analogous to the identically named parameters we obtain when fitting statistical models to data. The hyper-parameters can significantly affect the performance of the MPO method and should be chosen carefully through backtesting.
As noted earlier, although only the trades for period t are executed for each optimization looking H periods into the future, the model has both the ability to incorporate newly discovered information and to consider the optimal allocation of trading across all the H periods into the future. When , we are solving an SPO problem.
2.2. Degrees of Freedom
The optimization model purposefully leaves open multiple degrees of freedom required for it to be instantiated (
Boyd et al. 2017). The performance analysis associated with the originally proposed model is done ex-post (using realized future data that could not be known when optimizing) with no future projections provided. To build a complete trading model, we fill in the missing components as follows:
return and risk estimates: returns and risk are replaced by and generated from the Black Litterman model
transaction cost estimates: remains the 3/2 transaction cost model
Since returns are represented as a vector , replacing the vector with Black Litterman estimates is straighforward.
2.2.1. Risk
Assuming the returns
are randomly distributed, with covariance matrix
, the variance of the portfolio return
is given by
We obtain the traditional quadratic risk measure from the Black Litterman model covariance for period
t,
We note that is an estimate of the return covariance based on sample data and model assumptions. The exact distribution of the process generating real asset price returns can never be known.
2.2.2. Transaction Cost
Trading in financial markets generally incurs a transaction cost, denoted as , where is the (dollar) transaction cost function. The model assumes that the transaction cost function is separable, i.e., the transaction cost breaks down into a sum of transaction costs for each individual asset. This assumption ignores the cointegration effect of asset prices at the high-frequency level which is a reasonable assumption given the period considered in our paper is one day. , a function from into , is the transaction cost function for asset i, period t.
Similar to
Boyd et al. (
2017), the model chosen for the transaction cost function
is
where
a,
b,
,
V, and
c are numbers and
x is a dollar trade amount (
Grinold and Kahn 2000).
a represents the asset’s half-spread (half the bid-ask spread) at the beginning of the time period when trading occurs. This term is represented relative to the asset price and is therefore unitless. If desired,
a can be increased by an amount representing broker fees expressed as a function of the dollar value traded. The second term represents the
temporary impact cost of our trading.
b is a positive constant of unit
.
V represents the total dollar value of the asset traded in the market in the current time period. The number
reflects the asset price’s standard deviation over the most recent periods, expressed in dollar units. As mentioned by
Boyd et al. (
2017), a common rule of thumb is that trading one day’s volume is expected to move the price roughly by one day’s volatility. This would lead to a value of
b around one. Given that
c is linear in dollars traded
x, we can use the third term to express differences between buying and selling an asset. If the
term is ignored (
), the cost is the same regardless of the trade direction. However, when
, selling is more expensive than buying, which could reflect a market with difficulty borrowing stock to short sell or otherwise increased selling pressure (more sellers than buyers).
5. Conclusions
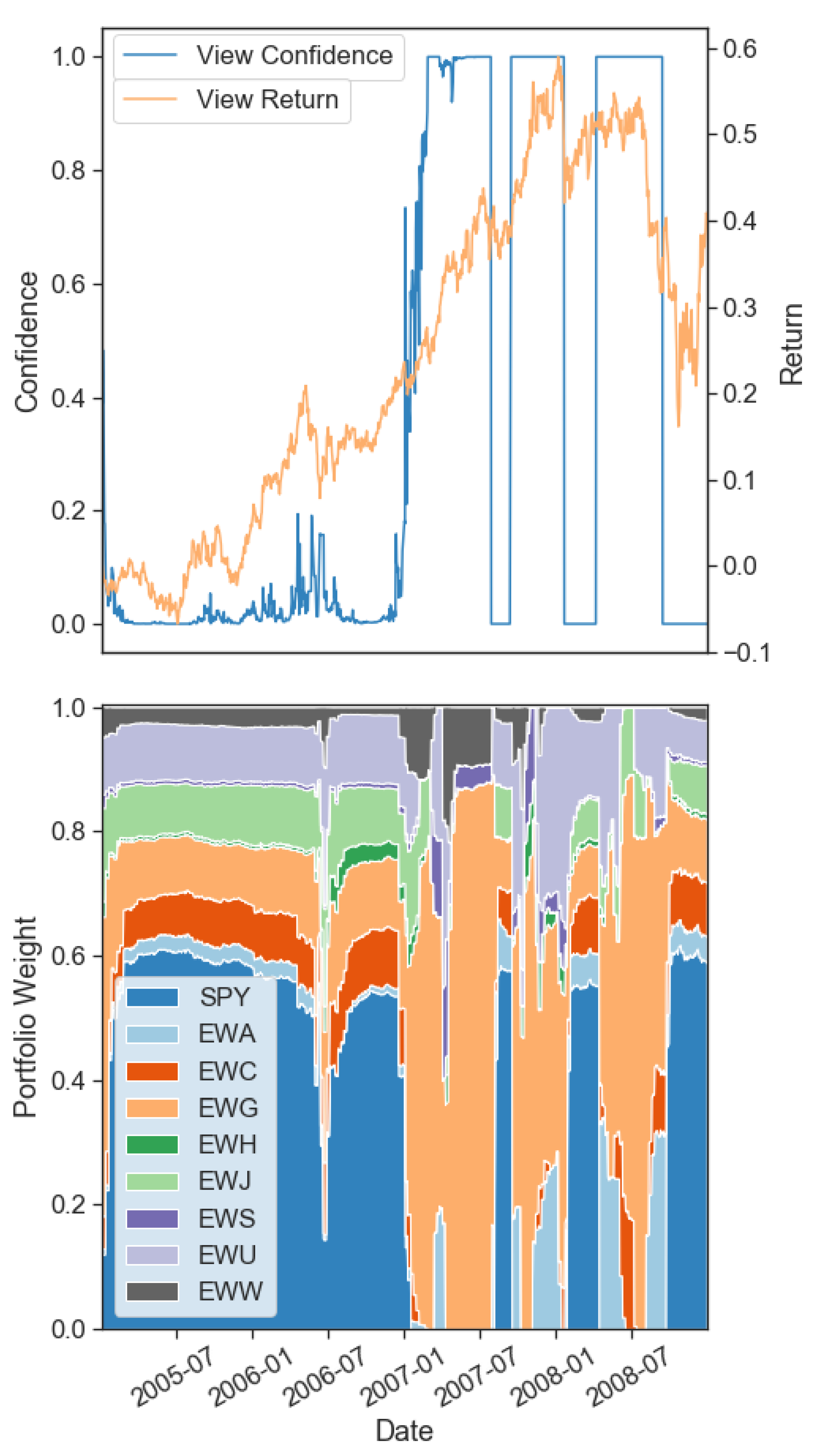
This paper developed a novel multi-period trading model that allows portfolio managers to perform optimal dynamic asset allocation while easily incorporating their investment views in the market portfolio. This framework’s significant advantage is its intuitive design that provides a new quantitative tool for portfolio managers. It incorporates the latest asset return regimes obtained from Hidden Markov Models (HMMs) to quantitatively solve the question: how certain should one be that a given investment view is being realized in the current market?
The main contributions to the existing literature are two-fold. First, we are the first to develop an optimization model based on return and risk estimates from the Black Litterman (BL) model in order to solve a portfolio allocation problem across a multi-period horizon. The BL model combines simple investment views with the market portfolio to arrive at its risk and return estimates (
Black and Litterman 1992). As a result, placing the BL return and risk estimates in a multi-period framework allows for the introduction of dynamicity to the problem of optimally trading already provided investment views. The chosen multi-period horizon does not encompass the entire trading range, instead spanning a shorter period. This enables the optimization to remain tractable and dynamic across time since new information about the investment views is incorporated as soon as it’s realized. The multi-period relaxation method employed, aptly named receding horizon, is borrowed from model predictive control and was first introduced by
Boyd et al. (
2017). Given the increase in trading frequency over static models, convex transaction costs are also considered in the optimization objective.
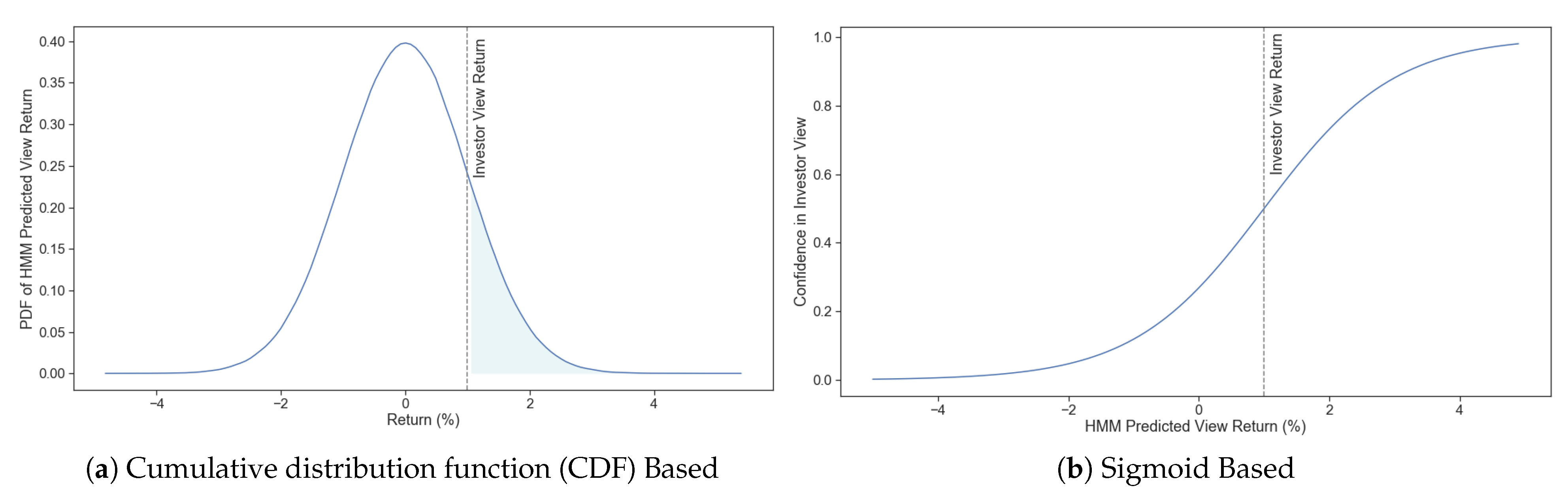
Second, we introduce a novel data-driven method to infer dynamically updated confidence levels for an investor’s views through the use of regime-switching. Using a sigmoid activation function to obtain the confidence levels from the underlying regimes was shown to perform better in a numerical example. This method replaces portfolio managers’ need to provide estimated confidence levels for their views, instead replacing them with a dynamic quantitative approach generated directly from the latest available asset returns. The confidence in each view is obtained by computing the view’s expected regime return (based on each underlying asset’s current regime) and comparing it to the investor inputted expected return. The more the two forecasts are in agreement, the higher the confidence obtained and vice versa. The confidence effect size can be configured since the model has toggles that can increase or decrease the confidence’s reaction to the regime predicted returns (activate faster or slower). It is worth noting that we do not address the actual generation of investment views since the optimization problem is focused on trading provided views effectively.
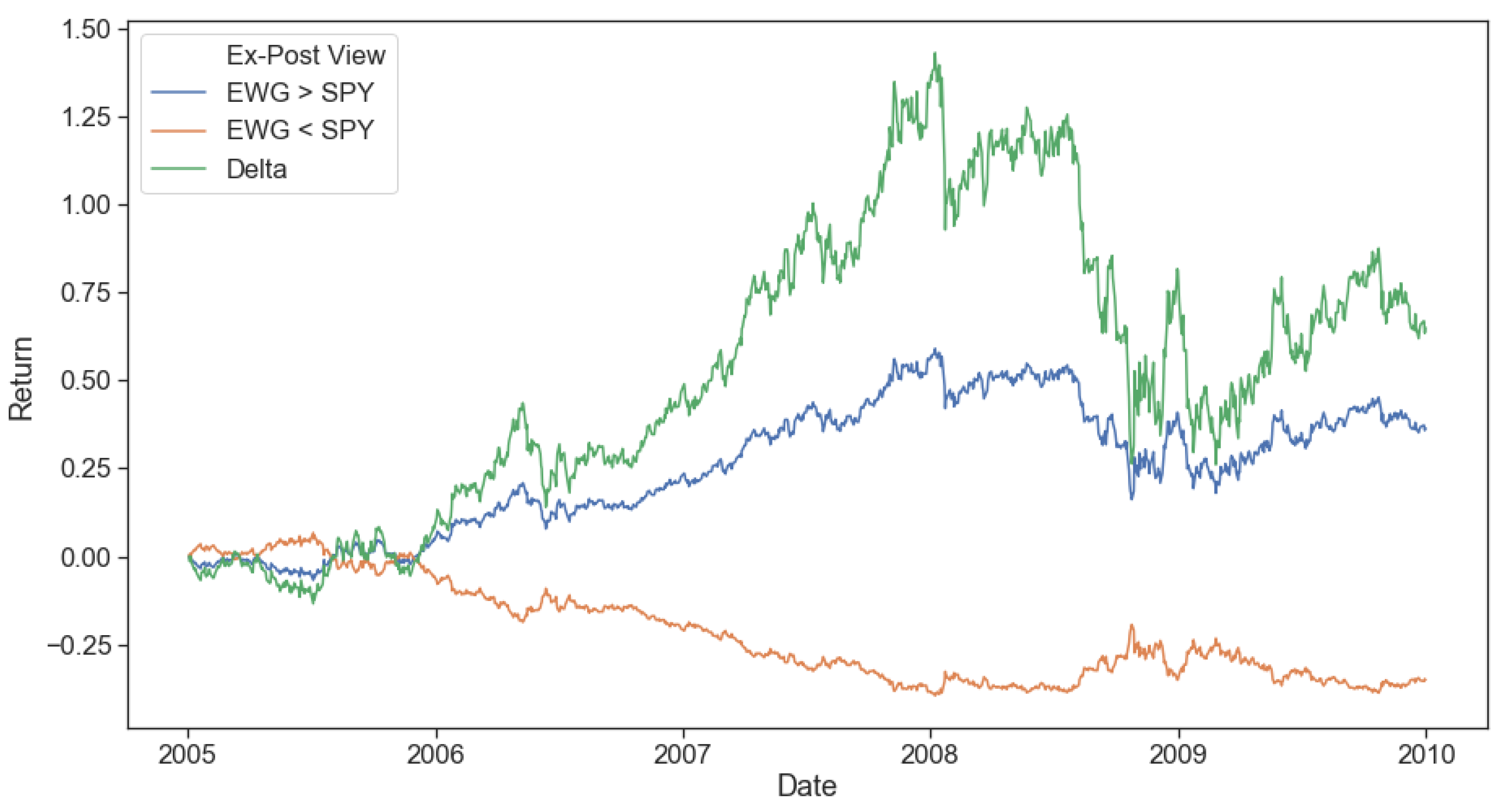
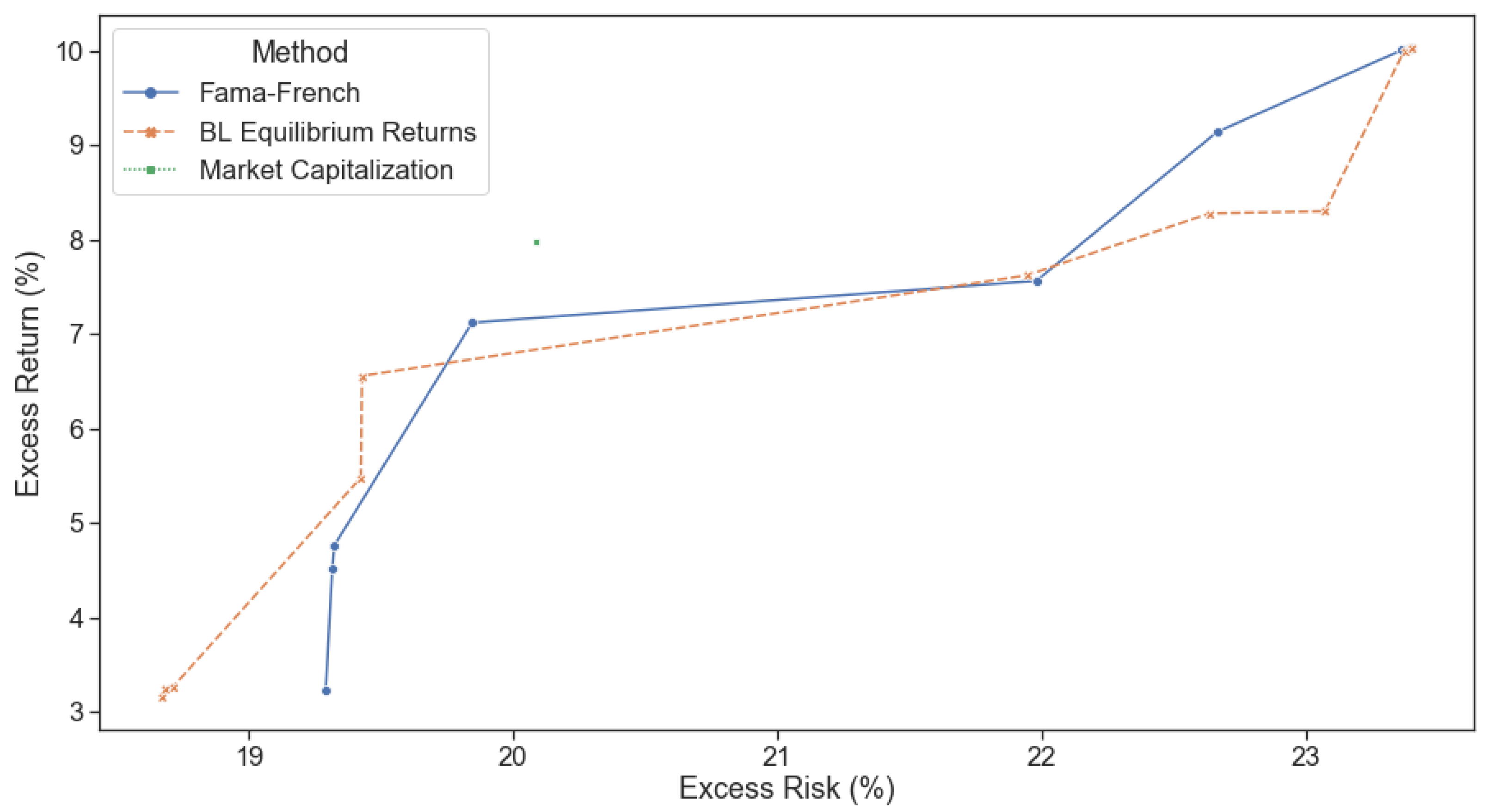
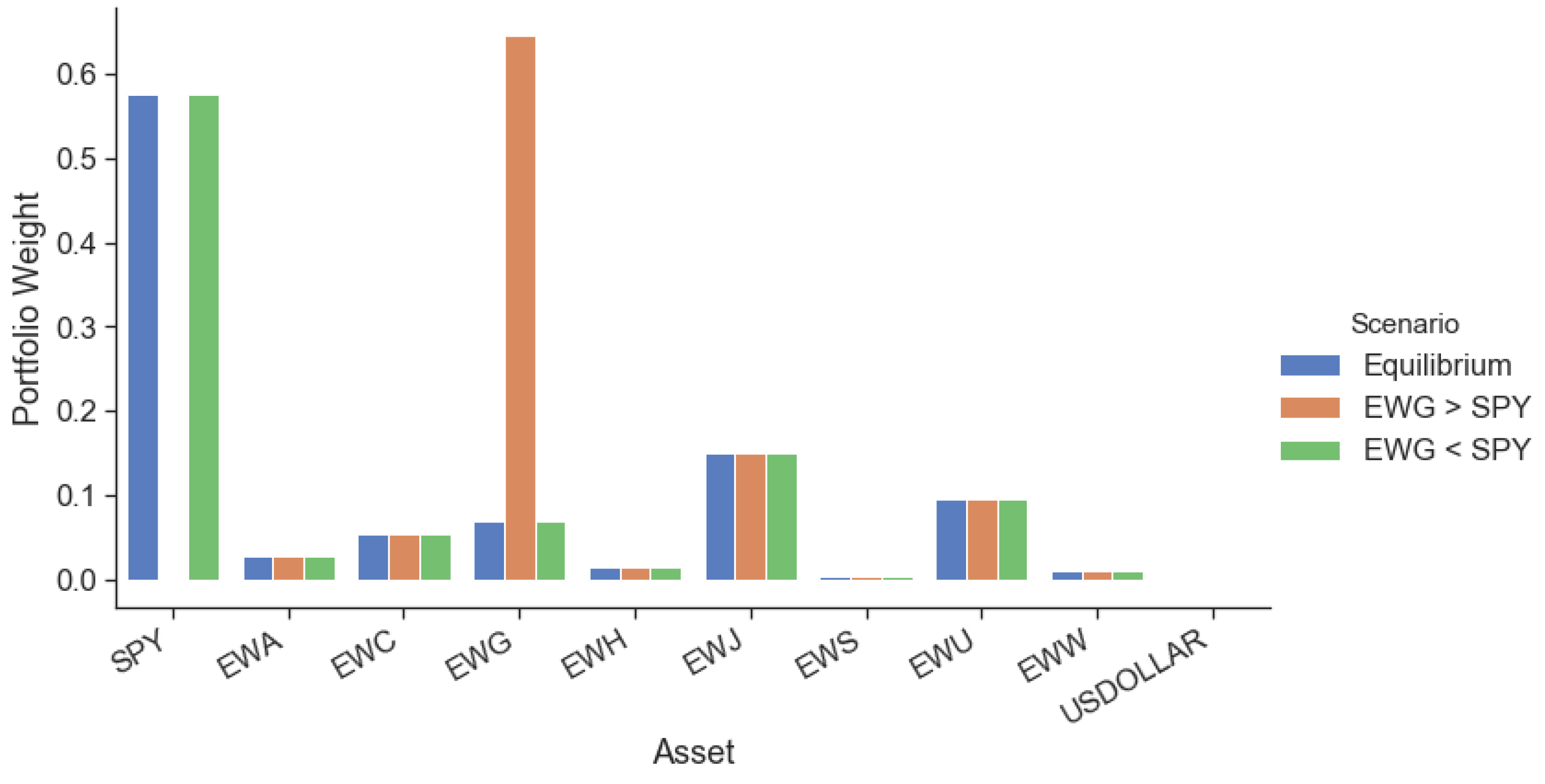
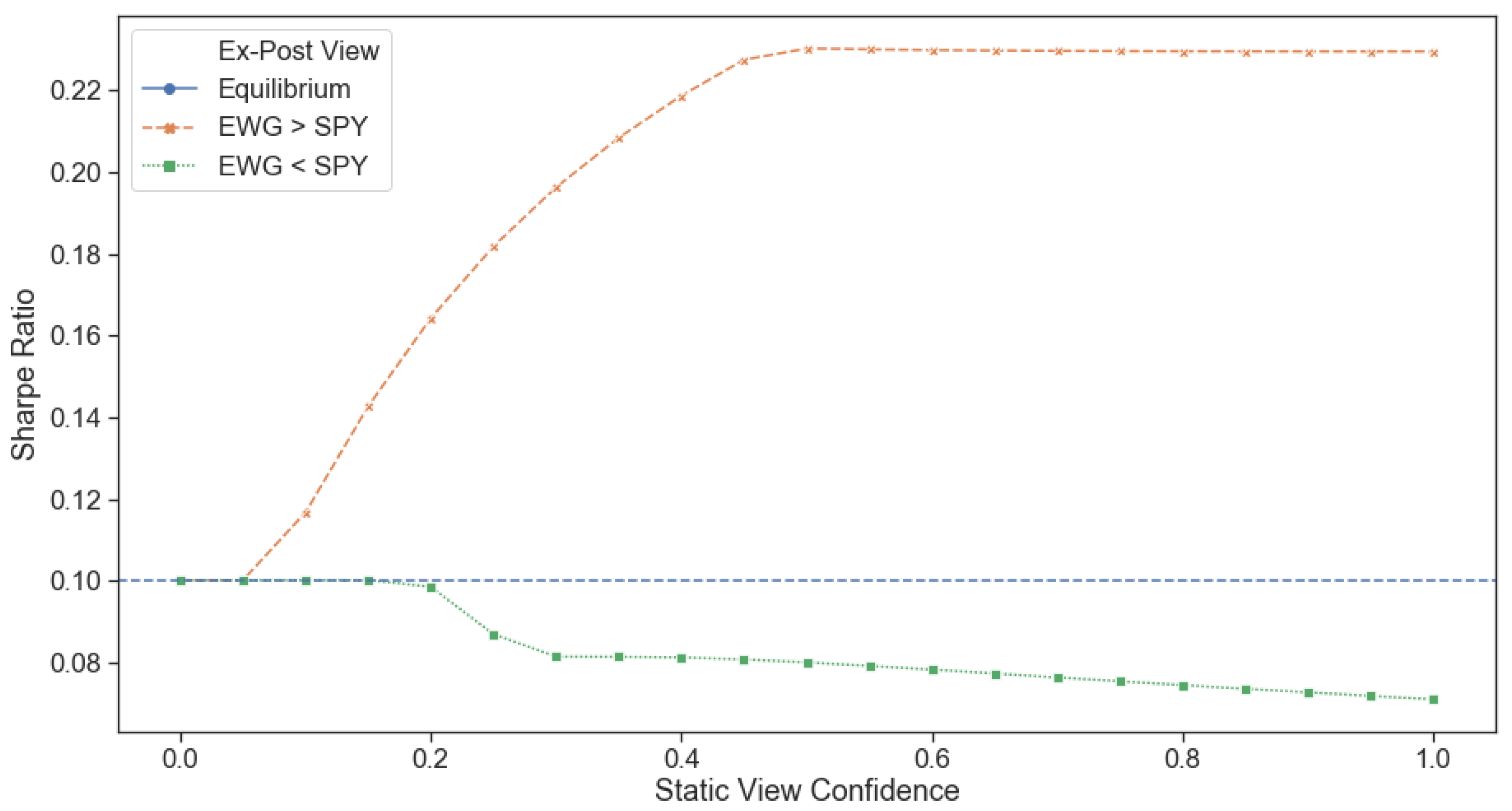
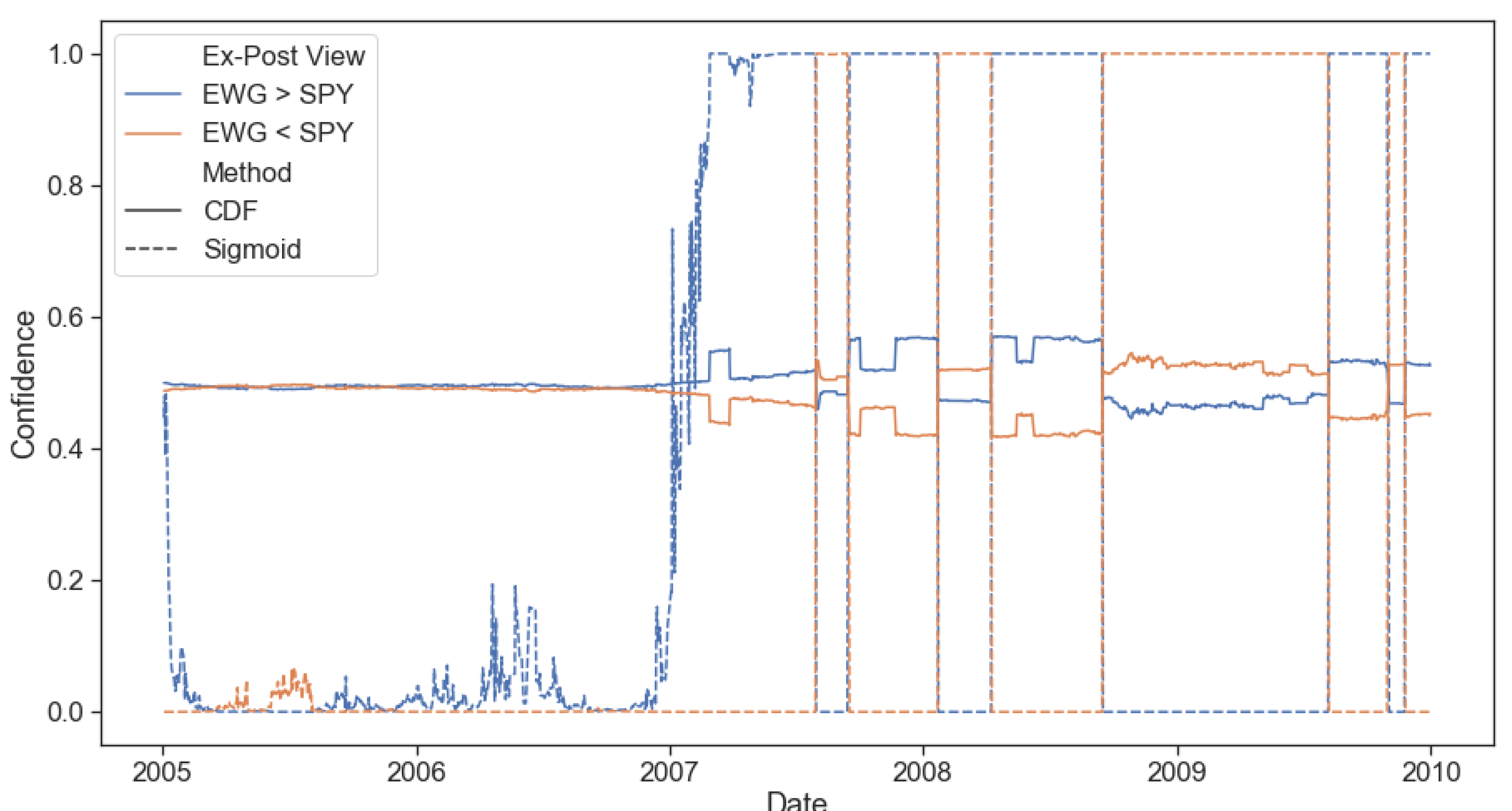
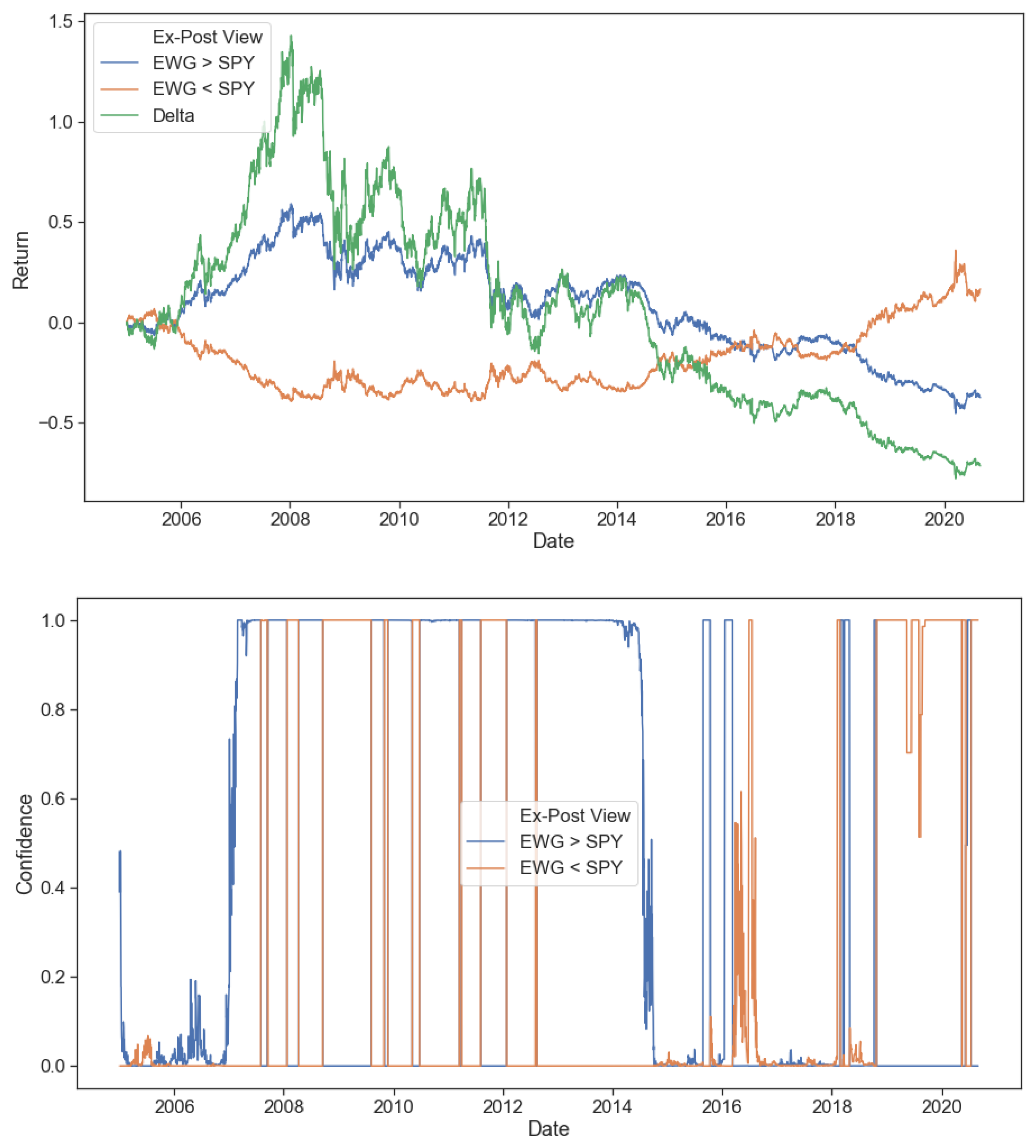
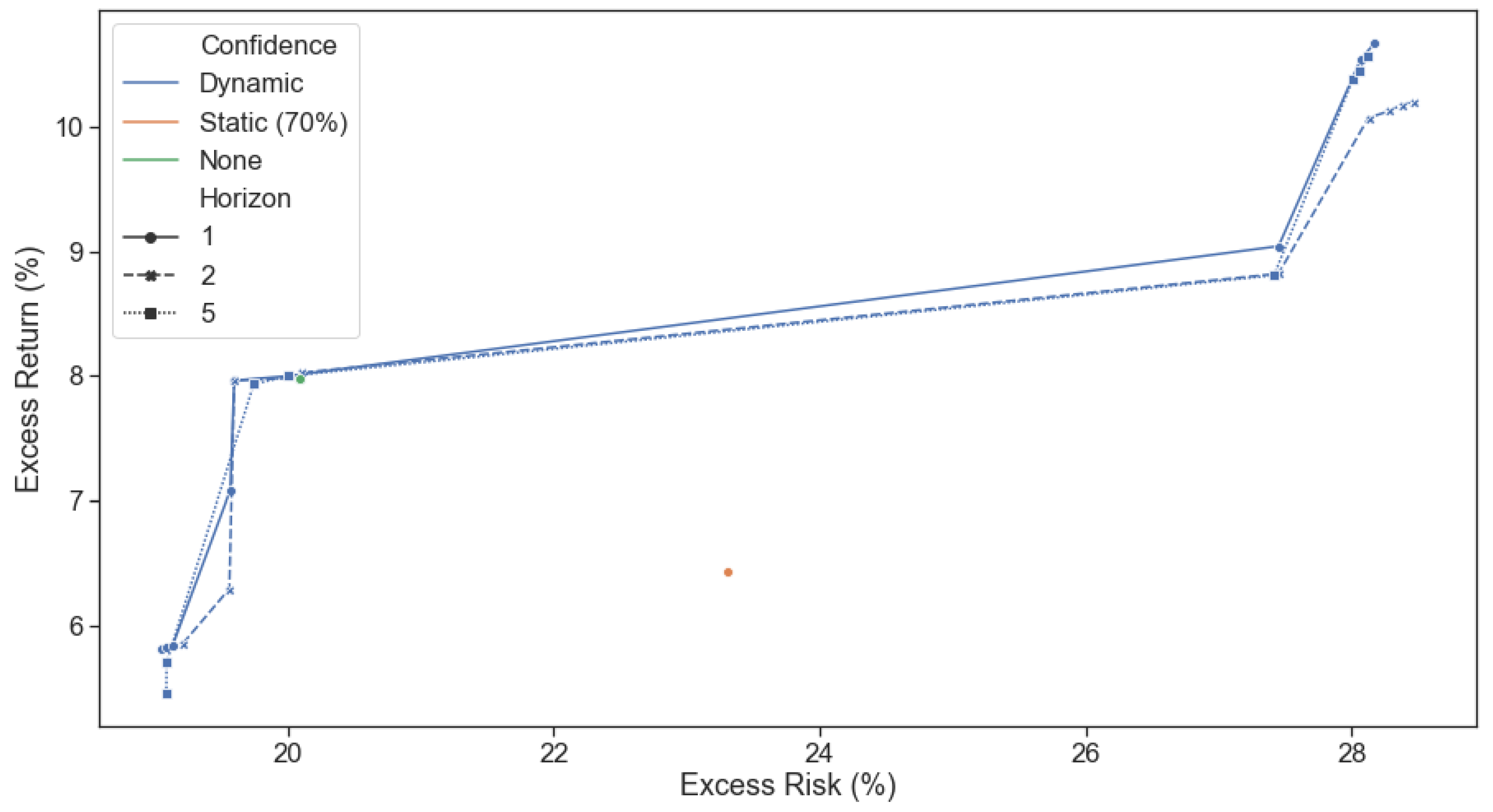
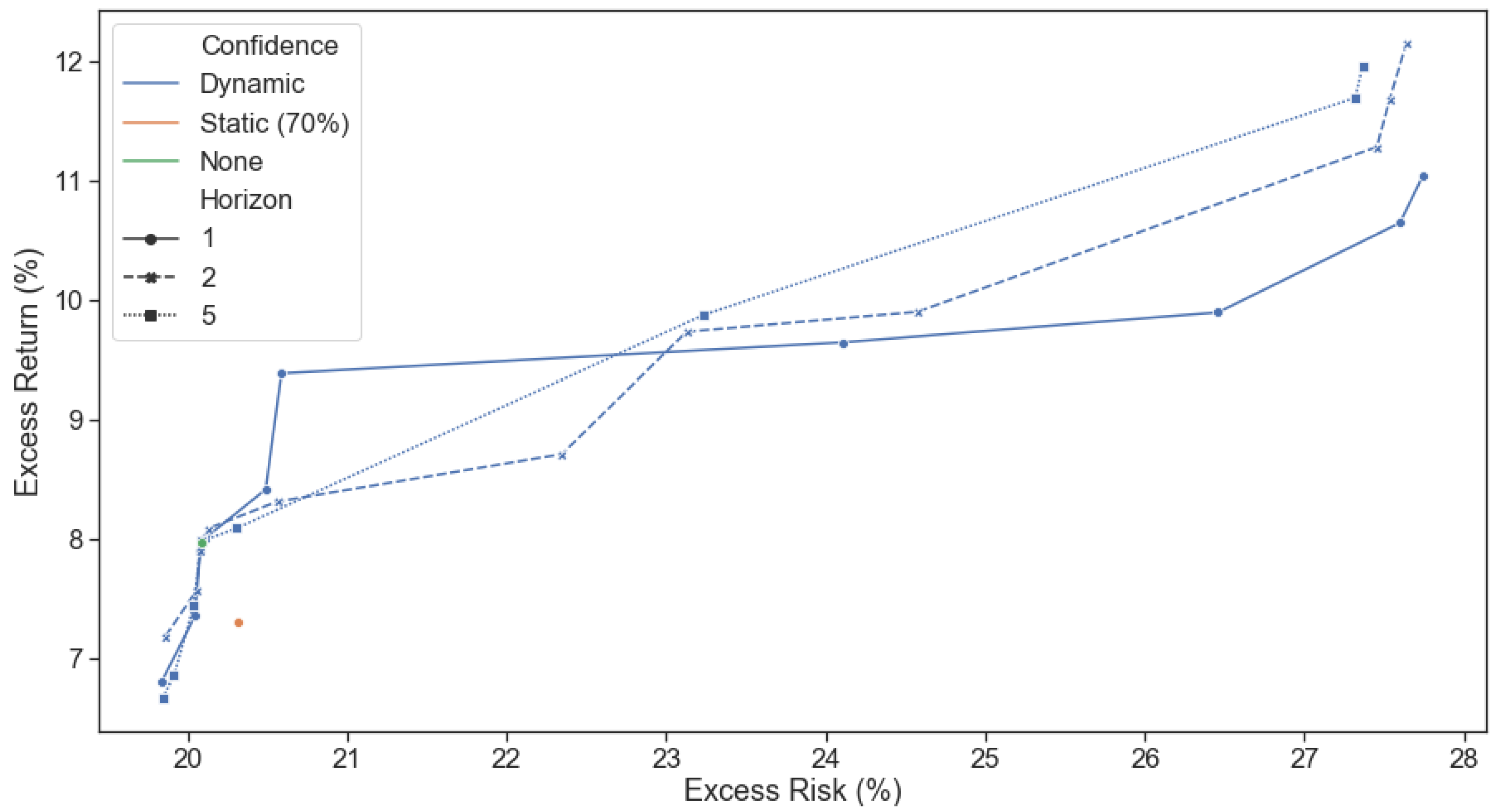
To empirically test the dynamic advantage of our framework, we isolated two tricky exactly opposite views, the results of which we obtained through the benefit of hindsight. The model needs to identify when views are being realized (and allocate capital to them) and, more importantly, when views are not being realized in the market (and divest capital from them) to prove useful. We showed that its confidence in the ‘correct’ view increased as the view was realized, and its confidence in the ‘incorrect’ view decreased when the returns expected failed to materialize. Our proposed dynamic confidence level-based asset allocation model, despite its increased trading costs, outperformed realistic BL scenarios with static confidence levels from a trading perspective. Our framework produced higher expected returns for the same portfolio risk level in the tested tricky numerical examples. Further, optimizing for multiple periods ahead (two or five) showed increased performance over a single period model when returns are emphasized more than risk.
In conclusion, we have shown our framework to be intuitive, tractable and improve performance (risk-adjusted return) over static Black-Litterman allocations through its ability to adjust to market conditions and asset regimes dynamically. This dynamicity allows it to allocate a risk budget away from underperforming investment views and into outperforming ones shortly after the latest price information is realized. Further investigation into the implications of trying to satisfy multiple investment views simultaneously, using higher frequency data for regime predictions, sensitivity analysis to trading frequency, incorporating multiple return forecasts and optimal execution sequences into the portfolio optimization problem is left for further research. The framework has been made available as an open-source library to facilitate future investigations and its use as an investment tool.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}