Since the inception of modern portfolio theory (MPT) and mean-variance optimization (MVO), introduced by
Markowitz (
1952) academic literature has expanded with insights into improvements to this fundamental basis of portfolio allocation. Choosing the best portfolio of assets and their individual weights,
x, out of all possible portfolios being considered is the essence of portfolio optimization. Each asset has an expected return,
, and a standard deviation of returns,
, computed from historical data. The relationship between the assets is governed by the variance–covariance (VCV) matrix of asset returns
, which indicates the correlations between assets that a solver uses to minimize the portfolio variance,
. MVO portfolios seek the lowest amount or risk for a given level of return and is represented in Model (
1). This model uses both performance aspects and risk aspects to achieve the optimal asset allocations by considering the trade-off between risk and return that is governed by the asset correlations.
When achieving the minimum variance (MV) for a target return the optimization does not consider the individual risk of assets, only the total risk of the portfolio. Due to this feature of the MVO, portfolios can be allocated into a few assets as the framework concentrates into assets with low volatility or vice versa for maximum return (
Markowitz 1952). This is the leading criticism of mean-variance portfolios. The uncertainty of the estimated parameters can lead to undiversified portfolios in terms of asset weights and risk. MVO portfolios are typically high in estimation error and are sensitive to inputs due to the estimated expected returns as shown by
Best and Grauer (
1991) and
Chopra and Ziemba (
1993). This leads to unstable portfolios depending on the quality of the estimated parameters and it is shown that small changes in the input estimated returns can lead to significant changes to asset allocations (
Merton (
1980);
Black and Litterman (
1992)).
1.1.1. Shift to Risk Based Ideology
The confounding effects of the uncertainty in MVO has led to the study of techniques that try to eliminate the need for estimated parameters, mainly expected returns and covariances. As shown by
Chopra and Ziemba (
1993), the estimated VCV matrix causes less instability then the estimated expected returns and it is suggested by Chopra and
Frahm and Wiechers (
2011) that simply removing the need for estimated expected returns from the optimization is possible and leads to primarily risk-based optimizations that are more stable. In MVO, this equates to the minimum-variance portfolio which itself concentrates into the assets with the lowest volatility. However, this still produces undiversified portfolios with even lower returns.
The available methods of asset allocation have evolved primarily from extensions and changes to the original mean-variance framework and efforts have been made to correct for the MVO’s tendency to produce over-concentrated portfolios. This has led to the development of equal-risk contribution (ERC) portfolios as measured by the standard deviation (
Maillard et al. (
2010);
Roncalli (
2014)) without the need to incorporate expected returns and results in diversification.
The risk contribution of an asset is defined by the product of its weight in the portfolio and its marginal risk contribution (MRC). As discussed in
Bai et al. (
2016) and confirmed by
Roncalli and Weisang (
2016), Euler’s Decomposition can be used to decompose the total portfolio risk measure, standard deviation
, into individual asset risk contributions
, where
n is the number of assets in the portfolio. The assets marginal risk contributions will define how individual assets are approached in the optimization beyond just using the total portfolio risk which is asset agnostic in an MVO.
By enforcing a risk bound on each asset as explored by
Haugh et al. (
2015) and
Cesarone and Tardella (
2017) or in this case, equal risk budgets, every available asset is present in some magnitude, ensuring diversity. The differences between risk contributions are minimized with a strategy commonly known as risk parity optimization, which leads to this desired diversification trait. Risk parity optimization protects against over-concentration into individual assets; it is the forced construction of diversified portfolios in which resources are allocated based on the measure of risk where all assets contribute equal risk
(
2), rather then equal weight. Risk-based portfolios do not require an explicit estimation of asset expected returns and the sum of the asset absolute risk contributions (ARC) equates to the total portfolio risk (
3).
Various methods exist for producing risk parity portfolios as explored by
Maillard et al. (
2010);
Feng and Palomar (
2015) and
Bai et al. (
2016), including the least squares approach and the log barrier methods. Risk parity overcomes the drawbacks of Markowitz portfolios by attempting to reduce the reliance on noisy estimated parameters which may mislead the optimization to rely on unreliable estimated asset returns. Risk parity optimization eliminates the expected returns from the model entirely. Traditionally, the risk parity formulation is a least squares fourth-order objective problem as composed in model (
4). The risk contribution of each asset is represented by
and is compared to another assets risk contribution denoted by
. The model will compare risk contribution of each asset with every other asset and reach an objective value of 0 indicating all risk contributions are the same.
This polynomial objective is non-linear and non-convex and concerns over its numerical complexity are raised when considering additional constraints in the model. To alleviate these concerns,
Lobo et al. (
1998) discuss the applications of a second-order cone programming (SOCP) model and a clear implementation to risk parity is shown by
Mausser and Romanko (
2014) who use an equivalent SOCP formulation as it appears in Model (0). Model (4) is reformulated by transformation of the constraints into cone constraints and a transformation of the objective into linear form. This SOCP formulation is an epigraph of the least squares method, but it is readily and efficiently solvable by quadratic solvers due to its convex nature (
Ben-Tal and Nemirovski (
1998);
Alizadeh and Goldfarb (
2003)) and is more friendly and flexible to additional constraints to deal with the expected return information. The SOCP model is suitable since the model is using the standard deviation of returns as the risk measure which maps to the second order constraints (7) and (8). Alternative risk measures are not compatible with this model.
As the linear objective of the SOCP formulation approaches zero, the risk contribution between each asset becomes equal. Each asset’s absolute risk contribution (ARC), denoted , is compared to the average risk of the portfolio, . The average risk of the portfolio in (7) is an upper bound on the risk contribution of any individual asset and dictates that any one asset’s risk contribution should be equal to or less than the average risk. The average risk of the portfolio equates to an equal risk magnitude, so the objective is effectively enforcing the risk parity allocations. To facilitate this, the lower bound of an individual asset’s risk contribution is , enforcing that ≥ . The total risk contribution of each asset is computed using the asset’s MRC and asset weight through constraints (6) and (8), respectively. When = , it is obvious that it is a risk parity portfolio and the model becomes a minimization of the difference between these two risk values. The SOCP effectively minimizes the difference between each asset’s risk contribution and the average risk of the portfolio instead of comparing each asset to another, reducing the computational complexity along the way. Lastly, constraint (9) defines the common portfolio budget requirements.
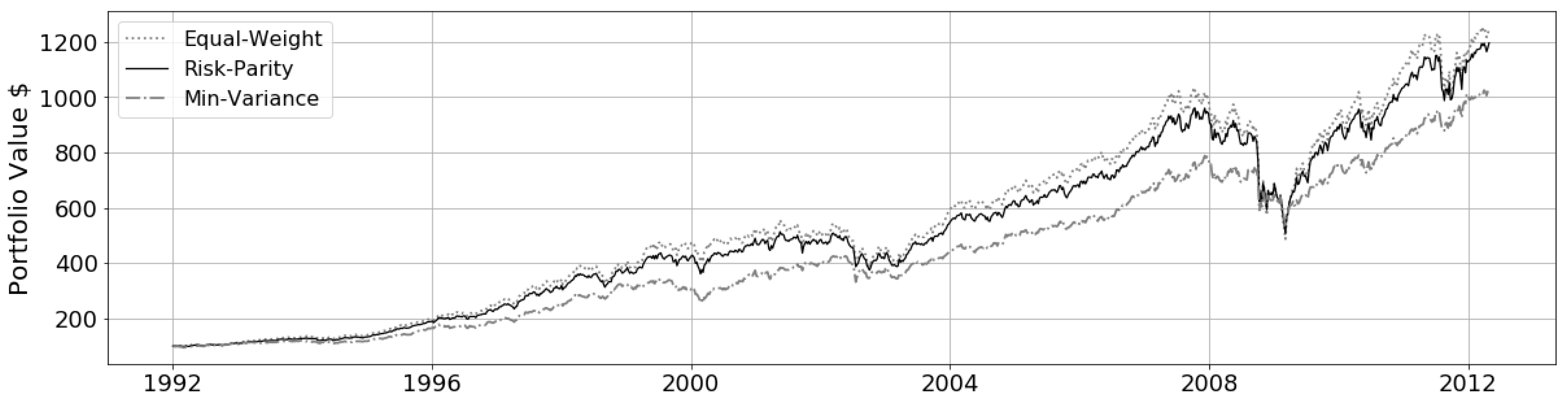
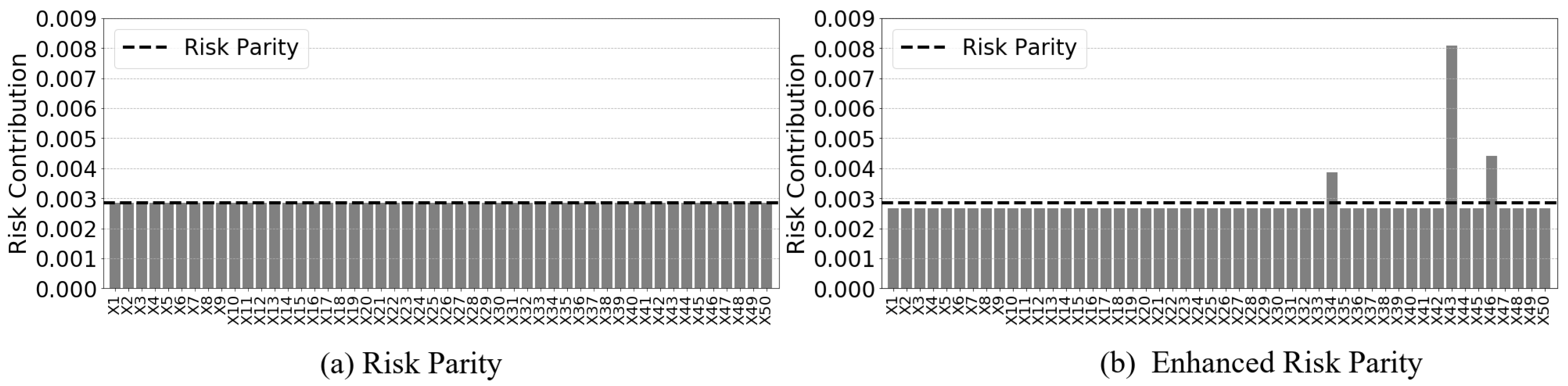
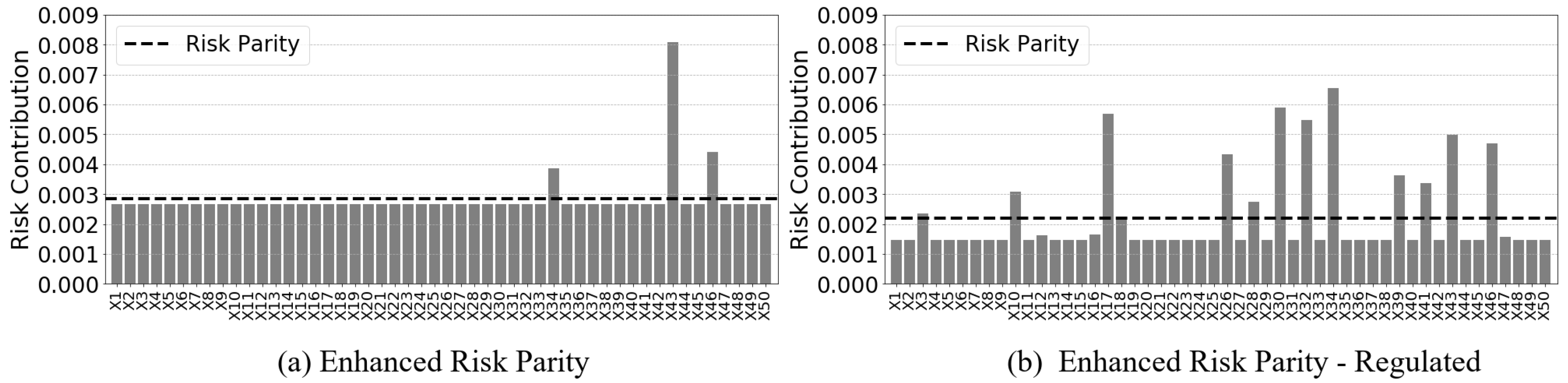
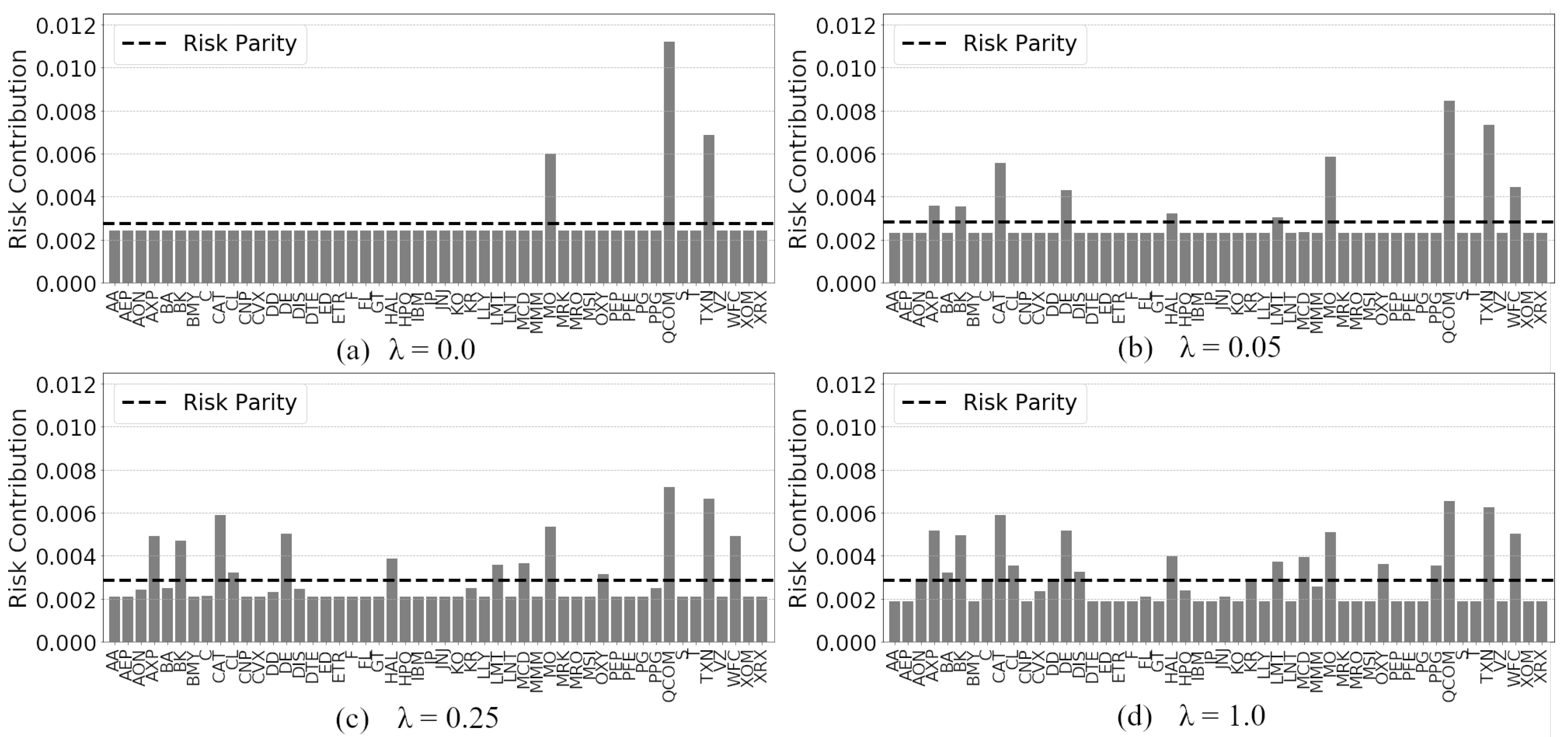
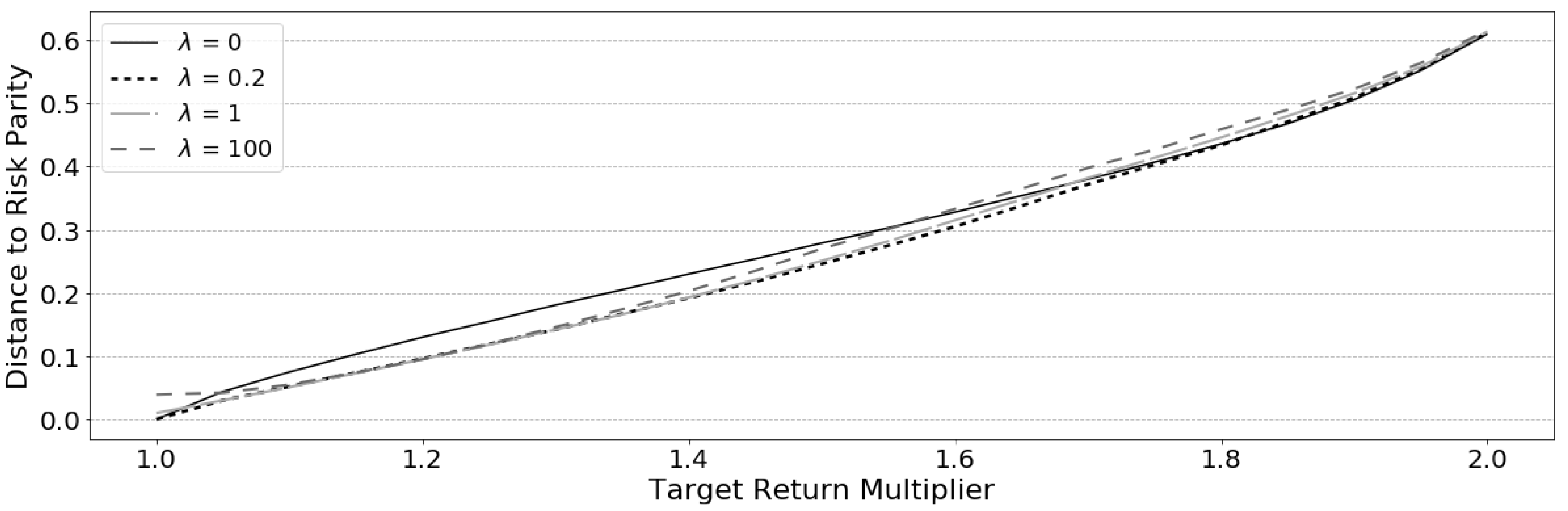
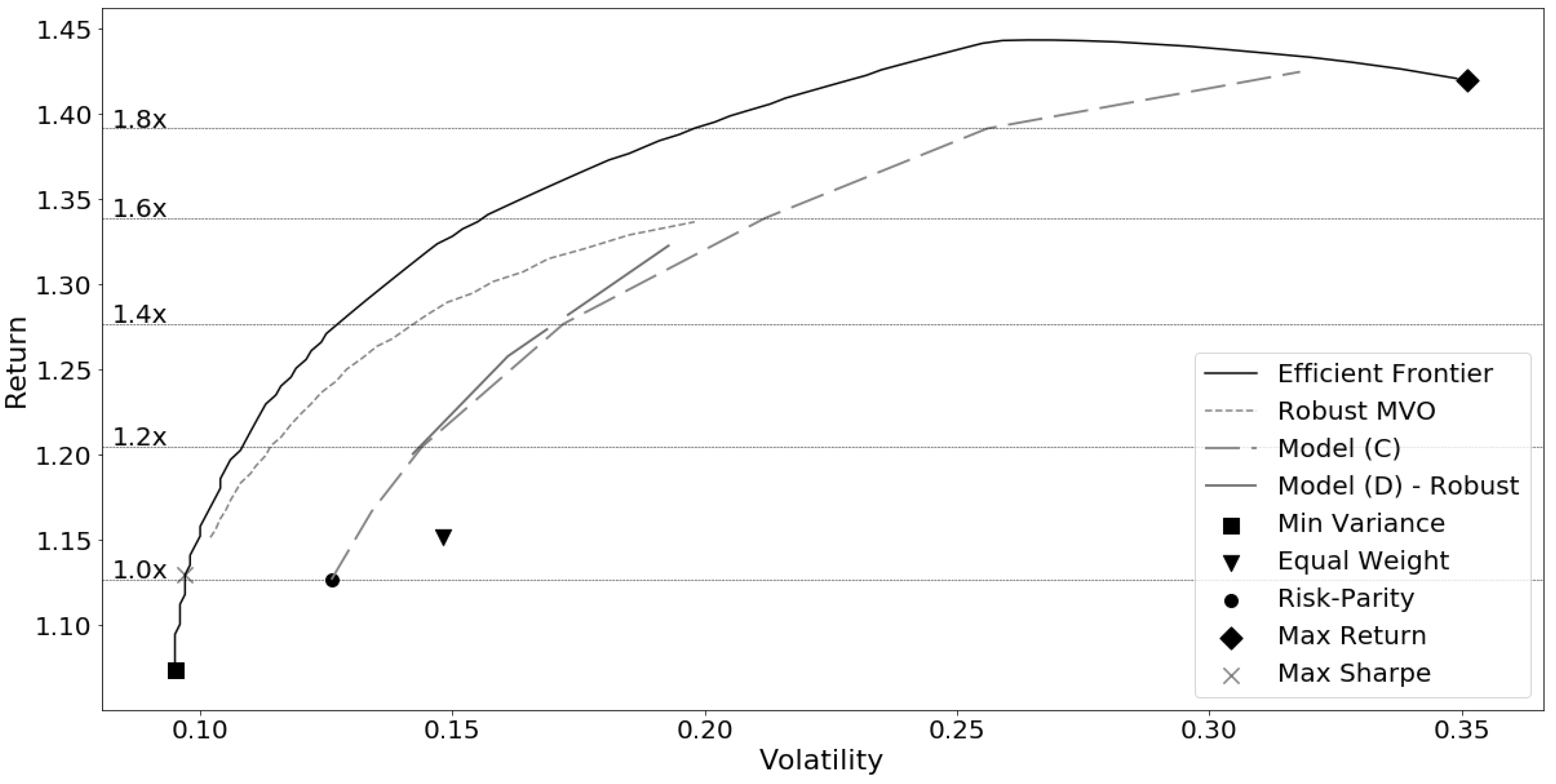
Due to the ability to enforce diversity, risk parity achieves neither minimum risk nor maximum returns and it is shown by
Maillard et al. (
2010) that the performance lies between the minimum-variance and the equal weight portfolio. An in-sample analysis was conducted over a 20 year period on a 50-asset set and plotted in
Figure 1. This plot demonstrates how risk parity takes advantage of riskier assets much like an equal weight portfolio and produces returns above minimum variance. This trend is reversed in market crashes seen immediately following the 2008 market crash where equal weight and risk parity portfolio losses converge below the minimum variance portfolio due to added weight in the higher risk assets.
Risk parity is both a meaningful and effective approach to portfolio construction. It has removed expected returns to alleviate the concerns of instability and balance return with diversification of risk, thereby avoiding concentration into risky assets.
1.1.2. Motivation and the Utilization of Return Estimates
Few studies exist on the introduction of performance aspects into risk parity.
Roncalli (
2014) shows how to build risk parity portfolios that depend on the expected returns by using a risk measure that incorporates expected returns rather than just the standard deviation of realized returns. Roncalli demonstrates this risk-budgeting technique where each asset has a performance and volatility aspect and the risk budget limits define the weight allocations based on that trade-off. Much like the risk parity optimization, when a risk budget is greater than zero, it must hold the asset in some weight, enforcing diversity. His model serves to benefit from the additional information that the expected returns provide to find more accurate risk parity portfolios. He finds that some merit exists in the balance of risk-based allocation and performance-based allocation, which this paper seeks to exploit.
Lee (
2011) had a similar sentiment prior, rejecting that risk parity improves efficiency and arguing that it is the starting point in the absence of stronger investment views which Roncalli supplements with expected returns; the model presented in this paper is driven from this inclusion.
Feng and Palomar (
2015) explore different risk parity formulations and apply different performance objectives and risk measures, such as volatility, VaR and CVaR, to a successive convex optimization to solve for long and long/short portfolios. They show the non-convexity of the various risk parity formulations that lead to the necessity of a numerical algorithm to solve to find the most optimal solutions. This gives rise to the use of a second order epigraph of the least-squares risk parity by
Mausser and Romanko (
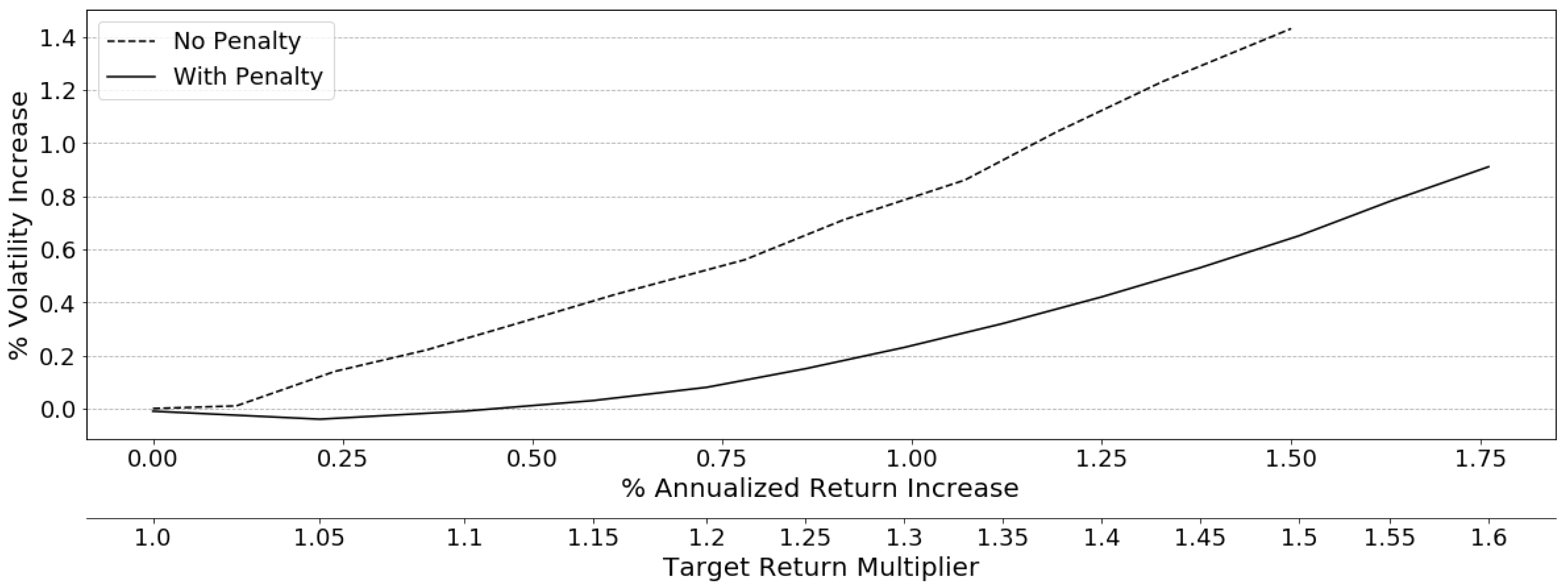
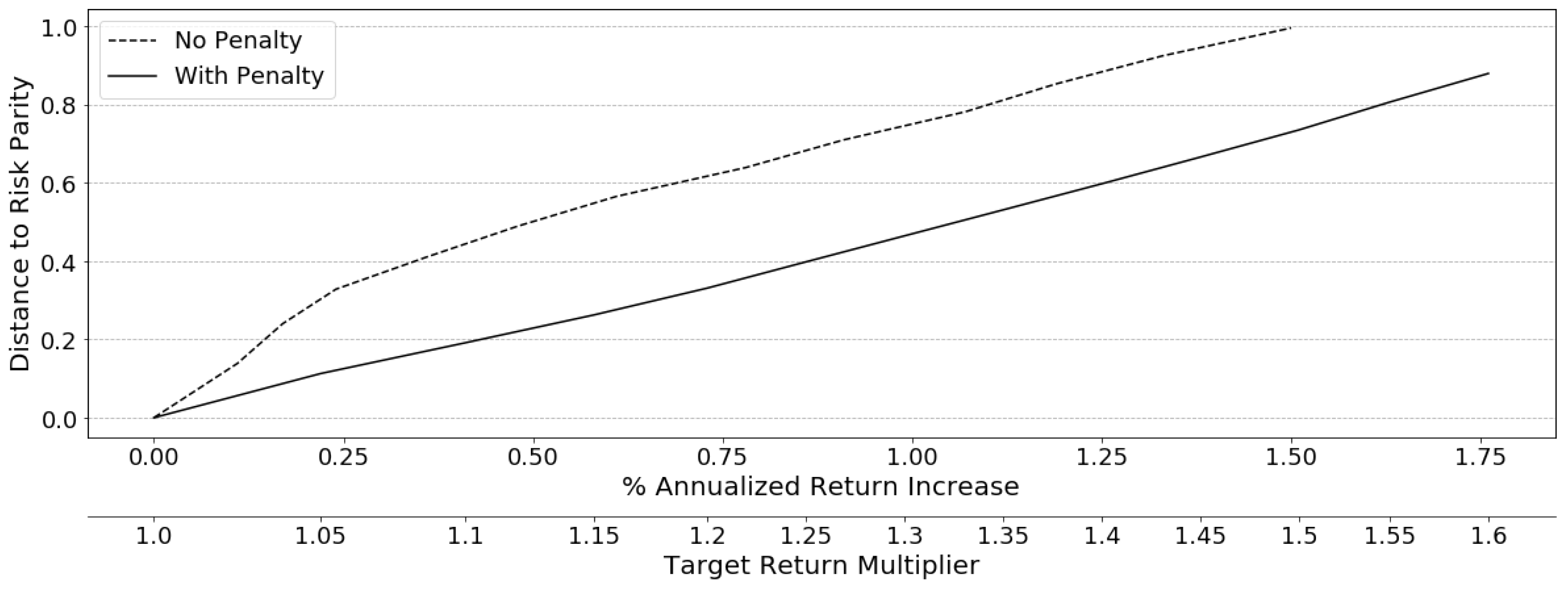
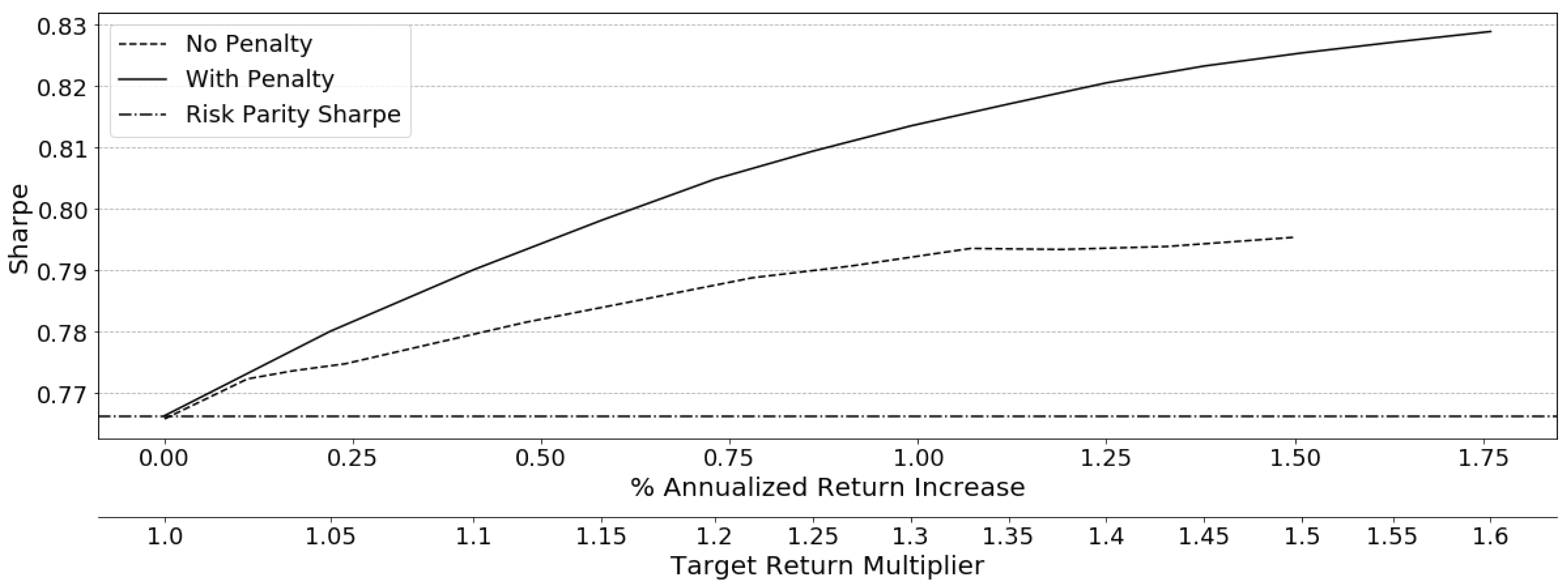
2014) as the basis for our model. This second-order cone program (SOCP) model permits the addition of further open-faced constraints, such as the target return used to force a violation, and is solvable via modern quadratic solvers in the long-only domain, alleviating some of the numerical difficulties for practical implementation.
Ardia et al. (
2018) develops a metric to optimize the balance between performance and risk aspects. The metric measures concentration of weight and how much it diverges from the risk contributions, measuring the mismatch between performance and risk contributions. They use the framework to optimize other strategies to match the underlying performance of risk parity in terms of volatility and return and not to specifically enhance returns as is the aim of this study. Along with Ardia, this paper infuses the performance and risk aspects to achieve this. Rather than finding an optimal mean-variance trade-off the notion of targeting near risk parity, portfolios are introduced to capture the useful traits of risk parity to the highest degree possible or passing control to the practitioner. To alleviate the mean-variance aspect,
Perchet et al. (
2015) recognizes that driving the optimization on the VCV matrix converges an MVO towards minimum-variance and confirms that using the diagonal of the VCV matrix converges towards equal risk allocations instead, due to a less aggressive driving matrix. Methods are implemented in this study that utilize these findings to incorporate the estimated expected returns to tilt the standard risk parity portfolio away from its current conservative allocation and seek greater returns.
1.1.3. Parameter Uncertainty and Robust Optimization
Rejecting the statistical uncertainty in models using estimation is impossible; however, significant works have been produced to depart from the simpler agnostic data-driven descriptive statistics which need to be mentioned here. Both the sample mean return and sample covariance matrix are estimated using traditional first and second order methods over the historical returns of each asset. The introduction of estimated expected returns into the risk parity model raises concerns over its estimation error as well. Estimated parameters from raw data have a degree of uncertainty, which can render the optimal solutions a poor fit to the model. There have been multiple approaches introduced to deal with estimation error (
Black and Litterman (
1992);
Roncalli (
2014);
Jorion (
1986);
DeMiguel and Nogales (
2006); bauwens2006multivariate), the most popular approaches being autoregressive conditional heteroscedastic models, shrinkage methods and robust optimization, as discussed by
Goldfarb and Iyengar (
2003) and
Tütüncü and Koenig (
2004).
Conditional heteroscedastic models relax the assumption of constancy of the covariance matrix and instead follow a flexible dynamic structure (
Engle 2002). Using many assets requires a multi-variate generalized autoregressive conditional heteroscedasticity (M-GARCH) model that forecasts changes to the volatility of financial time series in the short term (
Bauwens et al. 2006). The proposed model will utilize a longer term rolling procedure that estimates the covariance over a 3-year period. Holding a portfolio over the 6–12-month period before re-balancing may not add significant value to the model and the proposed model avoids the added complexity. Alternatively, shrinkage methods (
Ledoit and Wolf (
2003);
Kwan (
2011)) improves the conditioning of the covariance matrix. Sample covariance matrices are subject to estimation error of the kind most likely to perturb a mean-variance optimizer. Instead it uses a weighted average of the sample and target covariance matrices to generate a near-true covariance matrix by pulling the most extreme coefficients towards a more central value and systematically reducing estimation error (
Ledoit and Wolf 2004). Two aspects arise here—this is usually required when there are insufficient observations of the underlying variables to the number of assets
Daniels and Kass (
2001). This is not the case in the proposed model analysis where there are 15x the number of observations of assets. Secondly, the risk parity-like behavior of the proposed model naturally limits the extremes in variance allocation which counteracts the underlying purposes of using shrinkage methods. The strongest argument against using either method is the naturally risk limiting behavior of the risk parity like model that avoids concentration into high return assets and sub-sequentially the uncertainty that comes with them.
Robust optimization seeks to optimize a portfolio to the worst-case realization of the estimated parameters. Strong discussions on the traction of robust portfolios are authored by
Ceria and Stubbs (
2006),
Fabozzi et al. (
2007),
Kim et al. (
2014b) and
Kim et al. (
2014a).
Santos (
2010) confirms that the methods by Ceria et al. and
Tütüncü and Koenig (
2004) produce better portfolios in terms of the Sharpe ratio and turnover when compared to mean-variance portfolios. This indicates that robust optimization is an effective way to alleviate problems with estimation errors in returns.
Much like minimum variance and equal weight portfolios, risk parity portfolios are assumed to be robust due to the diversification of risk.
Poddig and Unger (
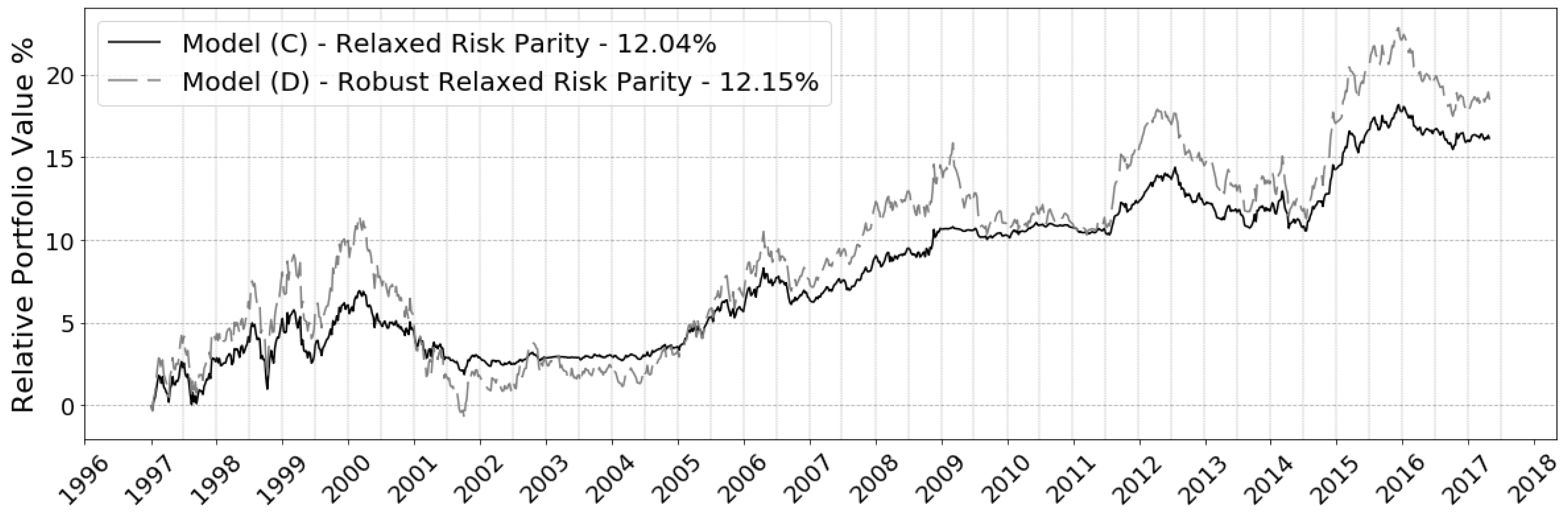
2012) show that the outcome of risk parity portfolios are far less influenced by estimation errors than MVO portfolios. This paper demonstrates that robust optimization adds a layer of complexity to the optimization, which sees little benefit (
Section 5.6). By using risk parity as the underlying optimization for the enhanced model, it is argued that it retains some inherent robustness to estimated expected returns and, to some degree, nullifies the effects of uncertainty. Further details can be found in
Bertsimas et al. (
2011), including a comprehensive list of literature on robust optimization.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}