2. Literature Review
According to the efficient market hypothesis (EMH), investors and traders in stock markets are not able to make abnormal positive returns by using publicly available information (
Hu et al. 2021). However, abnormal phenomena in the financial markets have brought about an impact on classical financial theory. Such assumptions about abnormal positive returns are unrealistic, because people acting to maximize their personal utility in their public capacities as well as their private lives is the most fundamental principle.
Ziobrowski et al. (
2004) conducted an empirical analysis to test whether U.S. Senators have an informational advantage over other investors in terms of common stock investments by testing for abnormal returns during the period of 1993–1998, proving that stocks purchased by U.S. Senators earn statistically significant positive abnormal returns and outperform the market by 85 basis points per month on a trade-weighted basis. This result proves that U.S. Senators have an informational advantage compared to other investors.
Zamanian et al. (
2013) used the cumulative abnormal return (CAR) method to test long-run returns from 1 February 2006 to 29 February 2011 on the initial public offerings (IPO) of 18 public and 15 private companies in the Tehran Stock Exchange (TSE), and proved that corporate ownership has no significant impact on the returns of IPOs in the short run or long run.
Lamba and Tripathi (
2015) used the concepts of average abnormal return (AAR) and cumulative average abnormal return (CAAR) to detect whether Indian firms are able to create value for shareholders after cross-border mergers and acquisitions. Their results proved that acquisitions do not create value to Indian acquiring companies in the long run, and abnormal returns and cumulative abnormal returns have significantly deteriorated since the period of 1998–2009; this value destruction could be attributed to the financial crisis.
Bharandev and Rao (
2021) examined the stock market and trading volume reaction with respect to the information content of 34 selected companies’ stock splitting announcements between 1 January to 31 July 2016; the average abnormal return (AAR) and cumulative average abnormal return (CAAR) were used to test whether an opportunity was available to make abnormal returns, and their study proved that no one can obtain abnormal returns from the Indian stock market, but stock splitting announcements have a negative impact on stock returns.
The difference between CAR and BHAR is that CAR ignores compounding, but BHAR includes the effect of compounding.
Barber and Lyon (
1997) proved that the empirical analysis of CAR may result in more bias than BHAR. In fact, there are two disadvantages for buy-and-hold abnormal returns (BHAR), even though they proved that the empirical results of BHAR are much better than CAR. When the variables
are the returns between the time periods of
, the expression of
represents the compounding return of the stock during the time period
. When we consider the conditional compounding effect, the conditional expected value is
, then the buy-and-hold abnormal returns will be
. However, if
, there is
, which cannot protect us by obtaining a consistent forecasting result with a zero abnormal return at the end of the time period. Another disadvantage of BHAR is that, theoretically, the expectation of
is a geometric average return, but not a compound average return. This is not consistent with the main assumption of the compounding effect suggested by the BHAR model.
To overcome these weaknesses of the traditional cumulative abnormal returns (CAR) and buy-and-hold abnormal returns (BHAR) models, we define a new cumulative return gap (CRG) model. The principal of our cumulative return gap (CRG) model is similar to the concept of buy-and-hold abnormal returns (BHAR).
Assume the time variable is
, where
is the biggest width of the time window; variable
represents the stock price,
; the return index
is defined as
,
; the new defined cumulative return index is defined as
,
; the average compound return of the cumulative return
is defined as
,
; and the average cumulative compound return index of the cumulative return index
is defined as
. Based on these assumed variables, the cumulative return gap (CRG) is defined as
When comparing our new concept of the cumulative return gap (CRG) with the concept of buy-and-hold abnormal returns (BHAR), CRG will provide us with a consistent forecasting result with a zero abnormal return at the end of the time period.
Furthermore, the average compound return is a constant during the time period , which is also a compound return.
Traditionally, the cumulative abnormal return (CAR) and BHAR models are used to study the long-term behavior of stock returns during a particular period, such as several days, several months, or several years. However, there are fewer studies using the cumulative abnormal return model to forecast stock returns. Our research will fill the research gap by using the cumulative return gap (CRG) model as an improvement of the cumulative abnormal return model to forecast stock returns.
The aim of prediction is to look for future information on the basis of previous information. Based on historical events, prediction is aimed towards forecasting the events which may happen in the future.
Shen et al. (
2012) believe that a single stock price can be directly predicted by its autocorrelation, because the performance of a stock market prediction heavily depends on the correlation between the data used. If the trend of a stock price is always an extension of yesterday, or if a time series of the stock market price has a high autocorrelation, the accuracy of prediction should be fairly high. The results of
Shen et al. (
2012) prove that autocorrelation is a very useful tool for predicting a single stock price; however, their analysis does not mention the disturbance of the regression model’s residual noise, which may influence the accuracy of the prediction values.
A very important part of forecasting is analyzing the time series and building a proper forecasting model, especially when the initial stochastic time series of the return is nonstationary in nature and can be analyzed based on the selection of any method (
Rabbani et al. 2021). When autoregressive-related models are used to analyze time series, such as in the ES, AR, MA, ARMA, ARIMA and SARMA models, many researchers prefer to assume that the residual item is zero with the absolute lowest error.
Usually,
, also known as the Box–Jenkins method, is used to remove the trend of the series by differencing so that a stationary series is obtained by transforming a non-stationary series (
Dimri et al. 2020). Here, the parameter
represents the order of the autoregressive process, such as a model of
; the parameter
represents the order of the moving average process, such as a model of
; and the parameter
represents the order of differencing of the time series.
Samrad et al. (
2021) suggest that the ARIMA modelling approach, according to various measures, is the most effective and best model for predicting trend stock prices by keeping the residuals at zero.
Zaham and Kenett (
2013) also use ARIMA models such as
and
to forecast the stock prices by letting residuals be zero.
Ye and Wei (
2015) think that since the ARIMA model is a typical linear time series model, it is not easy to represent the nonlinear dynamic system of stock markets; if the ARIMA model is used to predict complex time series such as stock prices, the forecasting result will be not ideal.
Skare et al. (
2021) preferred to use the autoregressive model (AR) and the vector autoregressive model (VAR) to perform the purpose of forecasting. The autoregressive model is a good model when the dependent variable is a univariate; however, when the number of dependent variables is more than one, then the vector autoregressive model has an advantage over the former.
The residual item generally includes a lot of private information and some public information such as economic shocks, and it is easy to reduce the accuracy of forecasting when the residual is assumed to be zero, as
Dimri et al. (
2020) have done. Because the auto-regressive-related models such as SE, AR, MA, ARMA, and ARIMA are based on linear models, most of the nonlinear information is composited into the residual items. If the residual items are simply assumed to be zero, most of the nonlinear information will be removed, and the accuracy of forecasting will be disturbed. Even though the moving average (MA) model considers the influence of residual lagged items, it is based on linear models and not on nonlinear models. If the residual items are mostly not considered, the auto-regressive-related models will not be able to significantly improve the accuracy of forecasting within the models. The key of improving the forecasting accuracy by using auto-regressive-related models is to forecast the trend of residual items. For this reason, we will try to improve the forecasting accuracy by forecasting the residual items. The probability method and finite difference (FD) method will be used to deal with the residual items.
Thus, for this study, we chose the autoregressive distributed lag (ARDL) model as the regression model to predict the underlying stock returns. The ARDL model was first defined by
Pesaran and Shin (
1999). The purpose of the ARDL model is to represent the long-term relationships between variables in econometric analysis.
The general
ARDL(
p,
q) model can be defined as
The ARDL model represents the long-term relationship between the variable and , where is the dimensional order 1 difference stationary variable ( for short, meaning it has an order 1 unit root) or an order 0 difference stationary variable ( for short, meaning the level variable is stationary). If the variable is the order 1 difference stationary variable, even though it has an order 1 unit root, the vector autoregressive process in is stable.
Wang et al. (
2021) have approved that the ARDL model is good for dealing with the time series econometric variables; additionally, the ARDL model has the advantage of predicting consistent estimates of the long-run coefficients and cointegrating relationships between variables that are asymptotically normal but irrespective of whether the underlying stock prices’ regressions are
I(1) or
I(0).
Li et al. (
2020) preferred to use the autoregressive distributed lag (ARDL) model proposed by
Shin et al. (
2014) for prediction, because the ARDL model has three important stages that include changes in the policy rate: first, it can be applied regardless of what levels of stationary or what orders of unit root the underlying variables; second, ARDL is suitable for both big and small samples; and third, the appropriate order modification of ARDL is sufficient for simultaneously correcting the residual serial correlation and the problem of endogenous variables. In this paper, the prediction model for the cumulative return index
will be defined by the following ARDL-CRG model
For carrying out a comparison, the AR model is also usually used to build the prediction model
For both the ARDL and AR models, because the residual item
is very important for building prediction models, we will borrow the finite difference method to deal with the residual item
. For dealing with the residual variable
, we will focus on dealing with the probability variable
. The relationship between
and
is
There are seldom studies that use the finite difference method to deal with the residual items of . We will apply different orders of the finite difference to the probability variable .
4. Empirical Results
4.1. Return Index
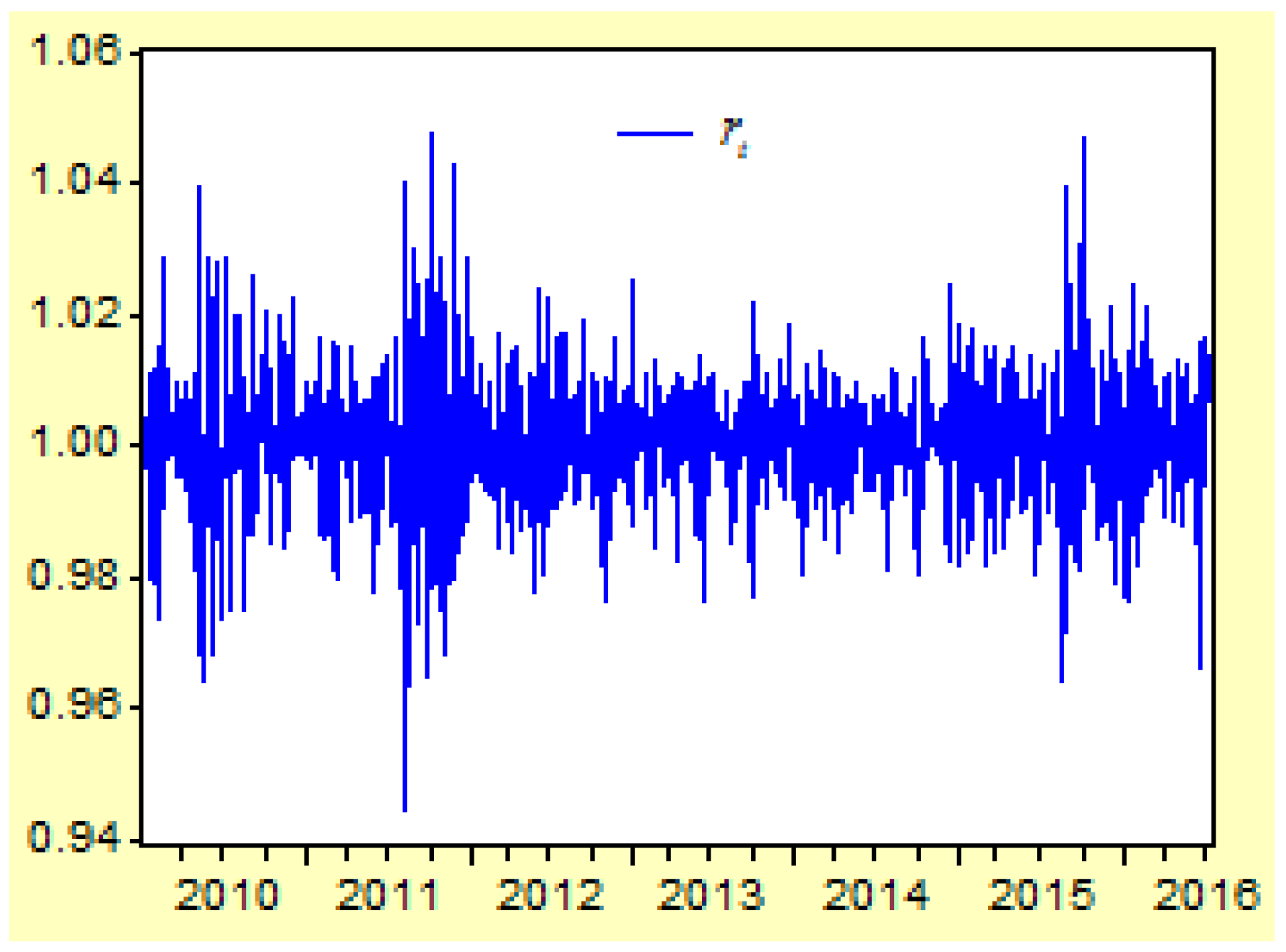
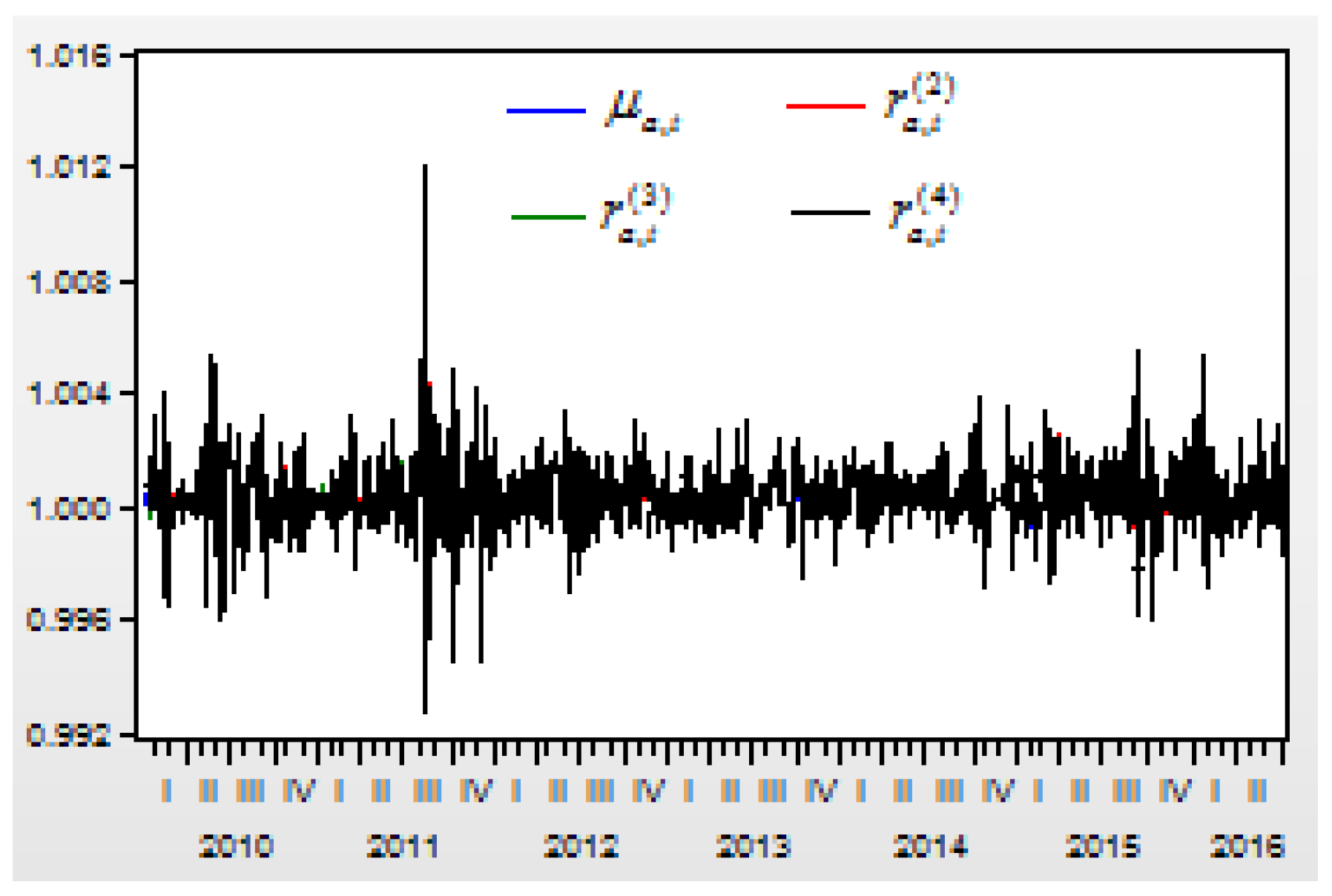
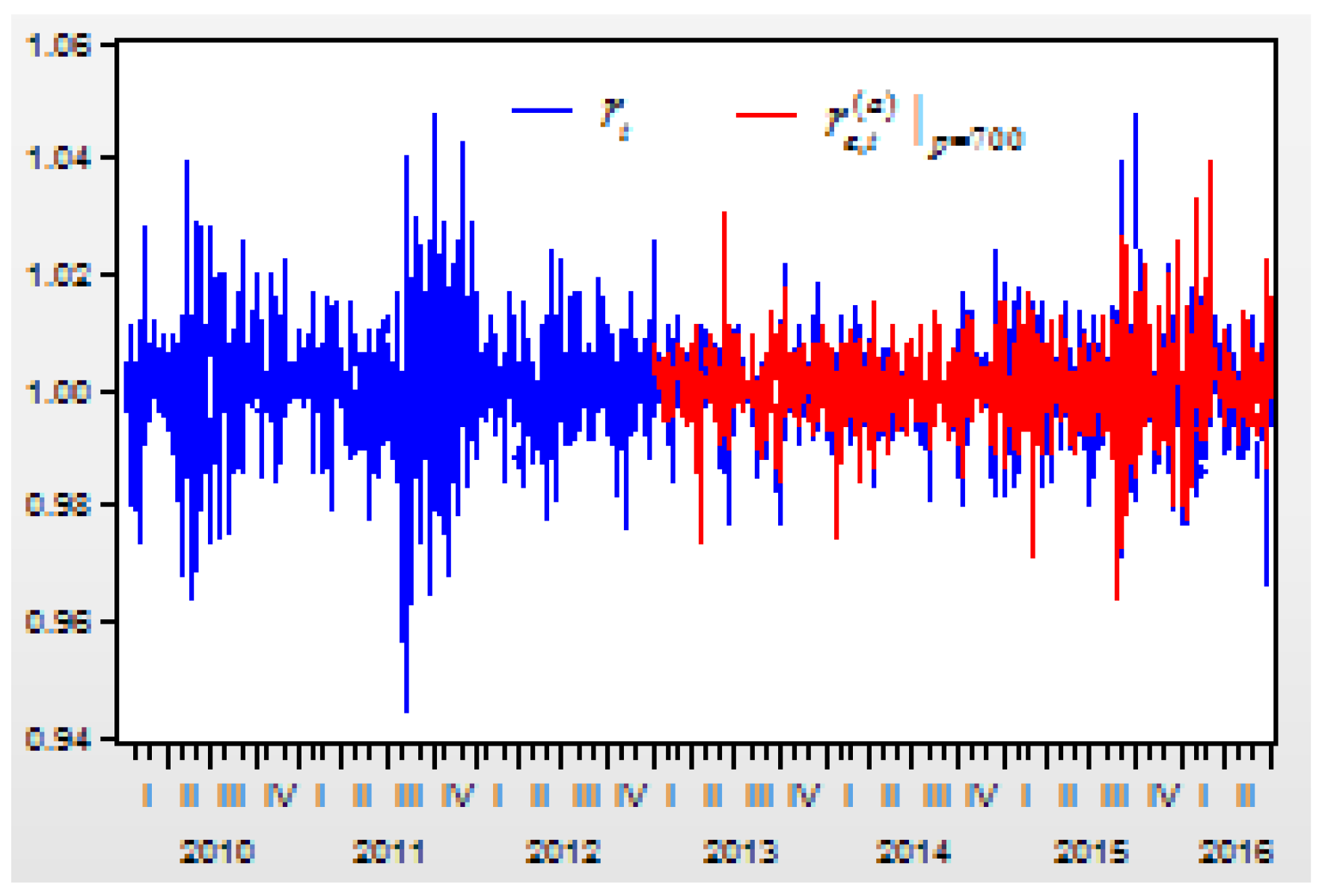
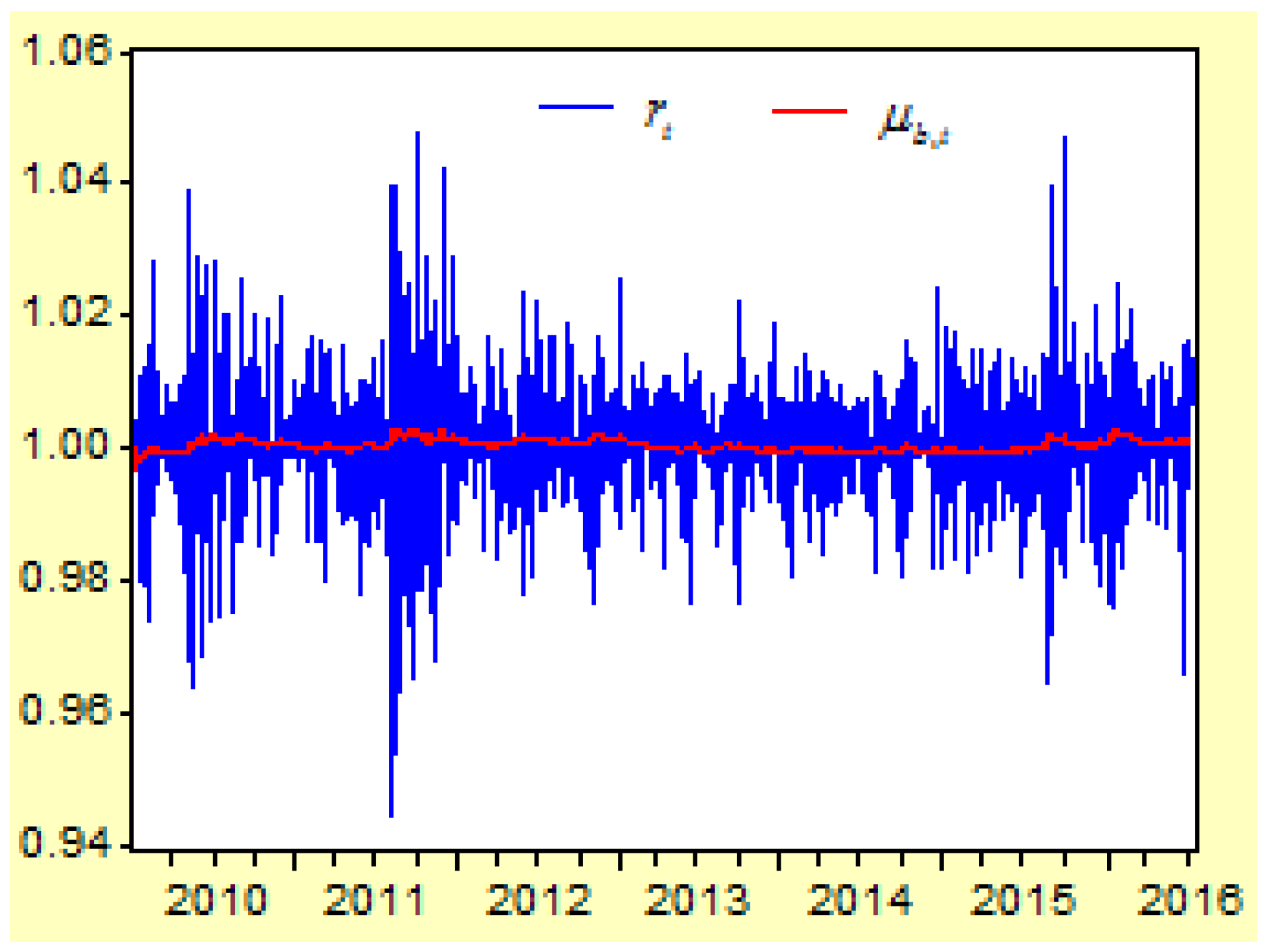
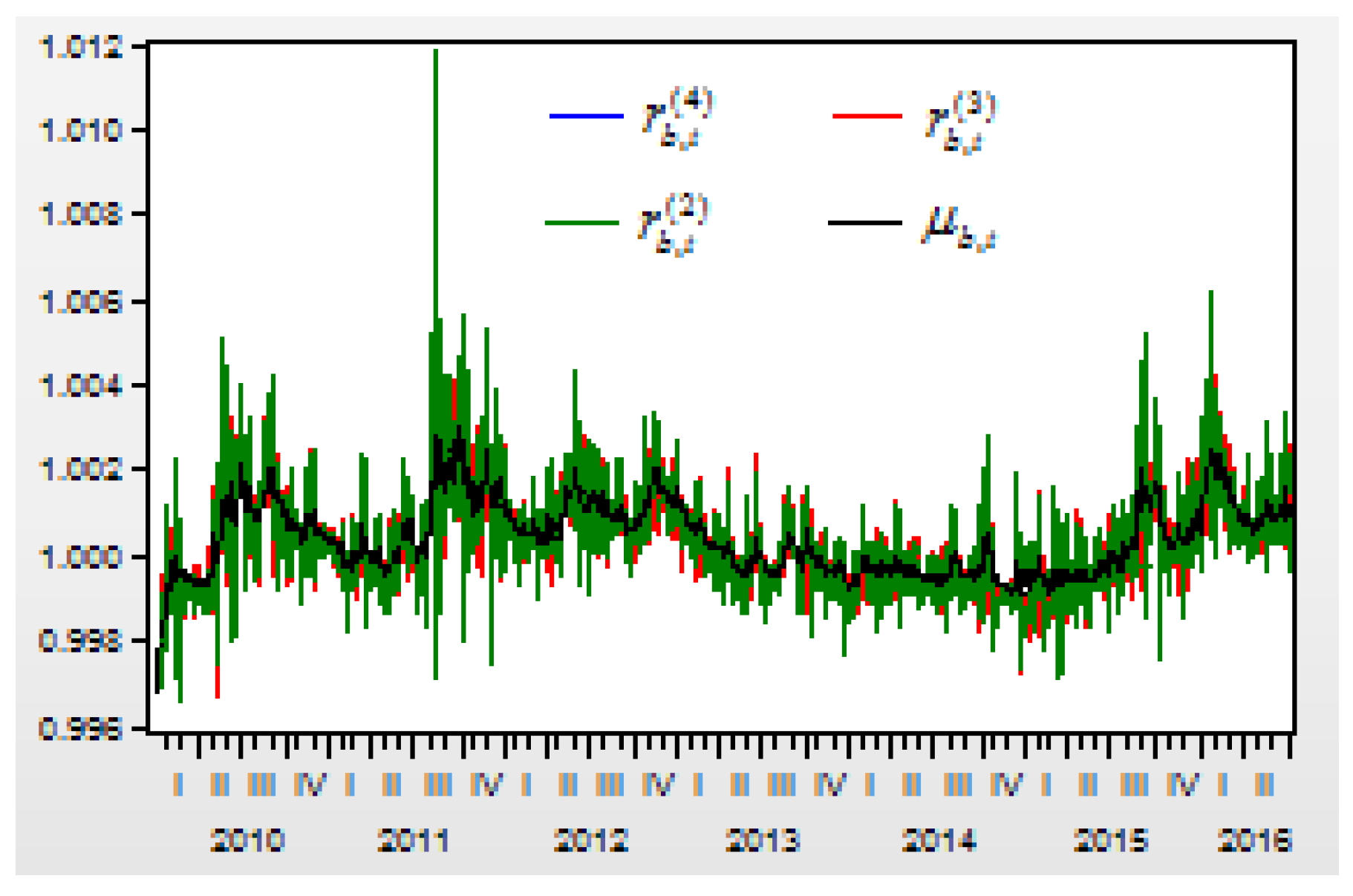
Figure 2 shows the moving curves of the return index
of the US Dow Jones Industry Index between 1 April 2010 and 8 July 2016. The sample size is 1531, and the time interval is
,
. There are three cluster vibrations during 2010, 2011, and 2015. These cluster vibrations can be expressed by a GARCH model.
Here we can see that the term of the return index shows the moving trend of a stock price during a short period . When the return index is defined as , it shows that the trend of a stock price is down when or up when . The purpose of forecasting is to predict the moving trend of a stock price in the next time when the information set is already known.
4.2. Autocorrelation Test for the Return Index
Table 2 lists the test results of the autocorrelations,
Ljung and Box (
1978) statistics and related probabilities for the return index
. It shows a significant autocorrelation between
and
at the probability degree levels of 5% and 1%.
These autocorrelations are better expressed in an model as . Generally, when defined as , the model will be . If the information set is already known, then , , . Here, the expectations and variances are conditional expectations and conditional variances.
For building a stable autoregressive model, it is necessary to test if there are any unit roots for the time series of the return index. By using an ADF unit root test,
Table 3 has listed the t-statistic values and probabilities under the three criteria of AIC, SIC and HQC. We can see that there are not any unit roots at the three levels’ time series of level variables, first-order difference variables, and second-order difference variables. Because the return index
is an autocorrelation time series, and it does not have any unit roots, we will build an autoregressive model to carry out forecasting tasks.
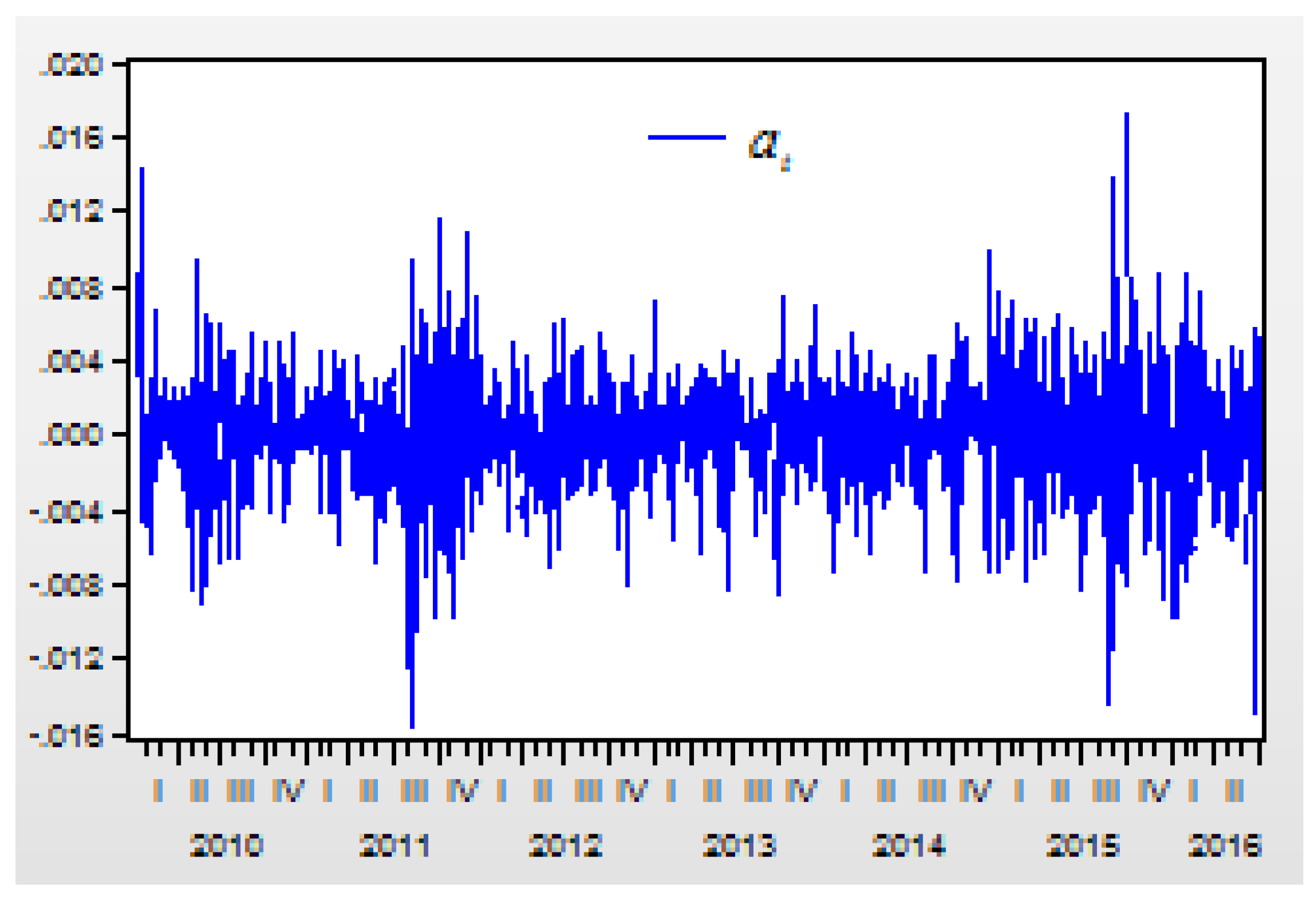
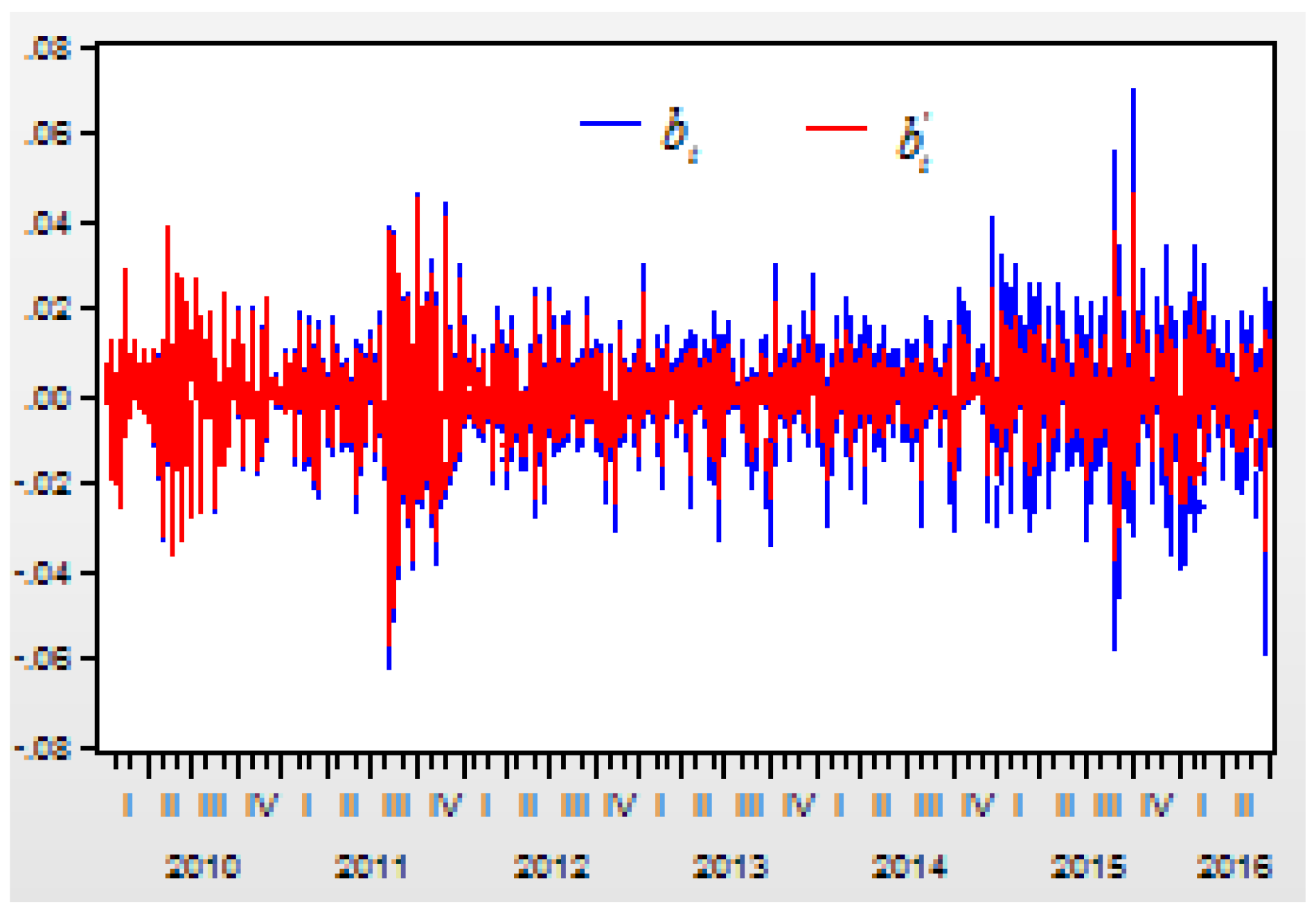
Figure 3 shows the residual item
from AR model of
.
4.3. AR(p) Prediction Model for Return Index
Because the return index is an autocorrelation time series, and it does not have any unit roots, we will build an autoregressive model to carry out forecasting tasks.
After assessing many autoregressive models, next
model is selected
This
model has a very small determined coefficient as
. When define
, the residual item
may include too much information about the return index
.
Figure 3 shows the residual item
form AR model of
. The correlation between the return index
and its residual item
of
model is 0.9908. The correlation is as high as
. For this reason, it is very important to estimate the values of residual items.
4.4. Direct Prediction of the Return Index Based on the Finite Difference Method and the AR-FD Model
For improving the prediction accuracy of the AR model, we will introduce the finite difference (FD) method to the AR model and build a new AR-FD model.
Because the residual item
has a strong impact on the prediction value of the return index
, it is important to predict the trend of the residual item
. When we define
Then, the variable can be seen as a probability of . Assume the first-order difference is , the second-order difference is , the third-order difference is , and the difference is , and if the level variable is not the autocorrelation time series, the difference may be the autocorrelation time series, then the higher degree difference can be expressed by a regression model as .
The
-order difference
can also be expressed by a regression model as
Here, the variable
is the residual item of the regression model. Then, according to the definition of the difference method, the probability
can be predicted by
It is important to determine a proper order number, which depends on both the degree of autocorrelation and the probability degree of the residual.
Table 3 has listed the autocorrelation (AC) values and
Ljung and Box (
1978) statistics and probabilities of the time series differences. When the difference orders of the probability time series
are increased, the autocorrelation degrees of the related time series will be increased. The autocorrelation of the level time series
is
, which is quite low and the level time series
cannot be called an autocorrelation time series. The autocorrelation of the first-order time series
is
, which is much more than the autocorrelation of the level time series
. The autocorrelations of the second-order, third-order, and fourth-order difference time series
,
,
are
,
, and
, respectively. Obviously, the second-order, third-order, and fourth-order difference time series have a higher degree of autocorrelation.
The probability prediction models from the second-order difference are
The probability prediction models from the third-order difference are
The probability prediction models from the fourth-order difference are
After obtaining the prediction value of
, the prediction value of the return index
will be estimated by
By applying the equation, it is easy to obtain the prediction value of the return index .
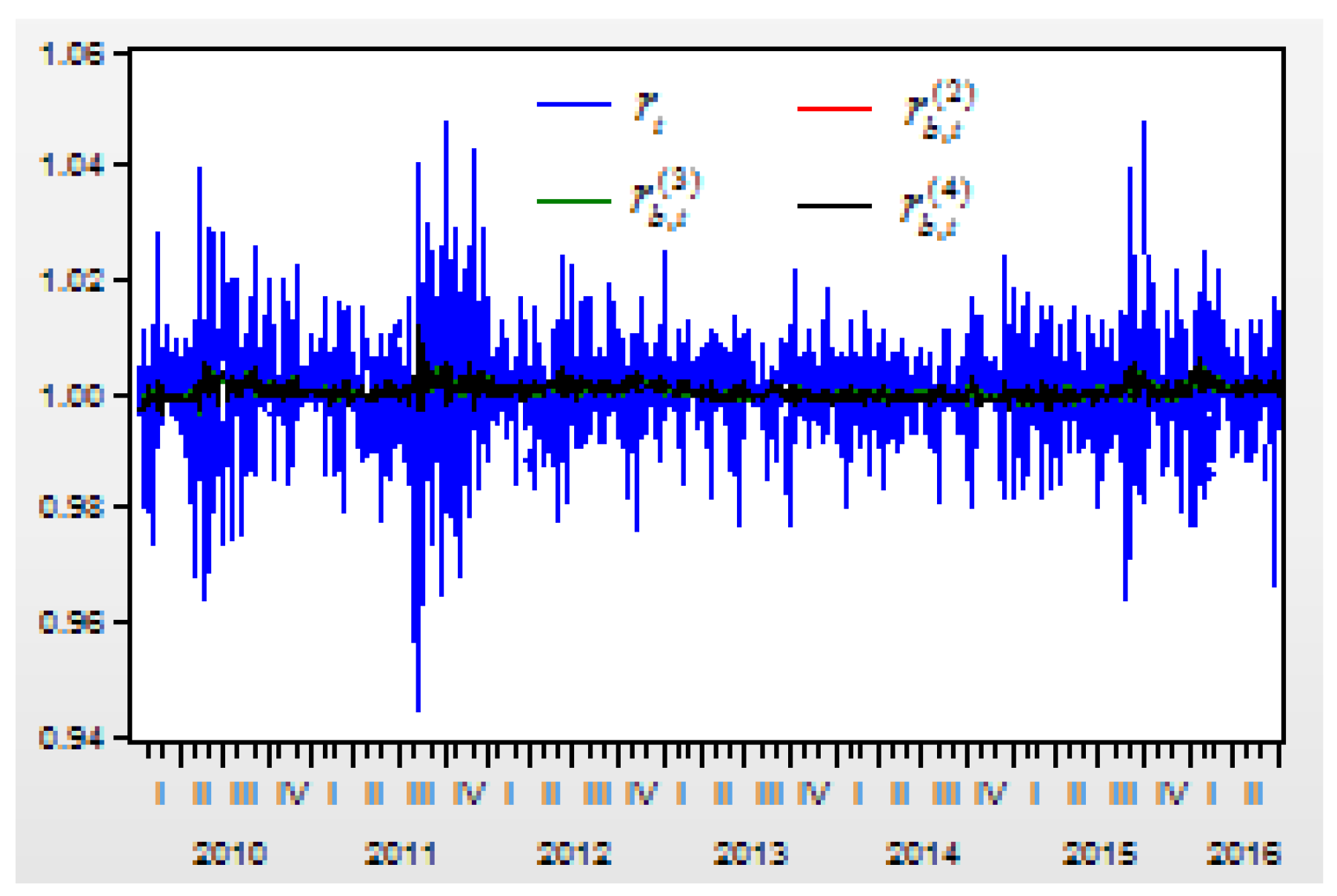
Assume variable is the conditional mean from the autoregressive model when or . When , assume variable represents the prediction index of the return index from the second-order difference variable ; variable represents the prediction index of the return index from the third-order difference variable ; and variable represents the prediction index of the return index from the fourth-order difference variable .
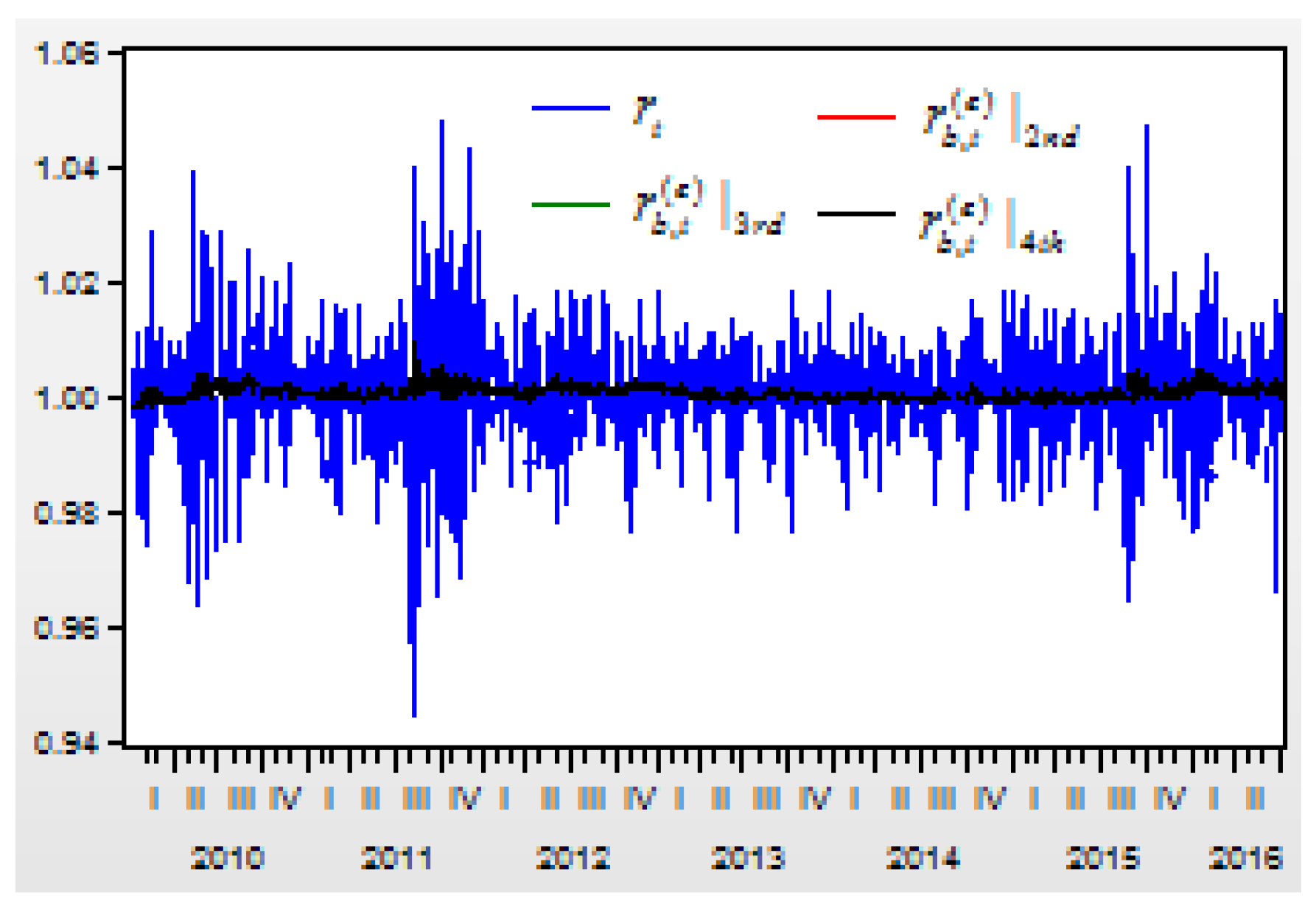
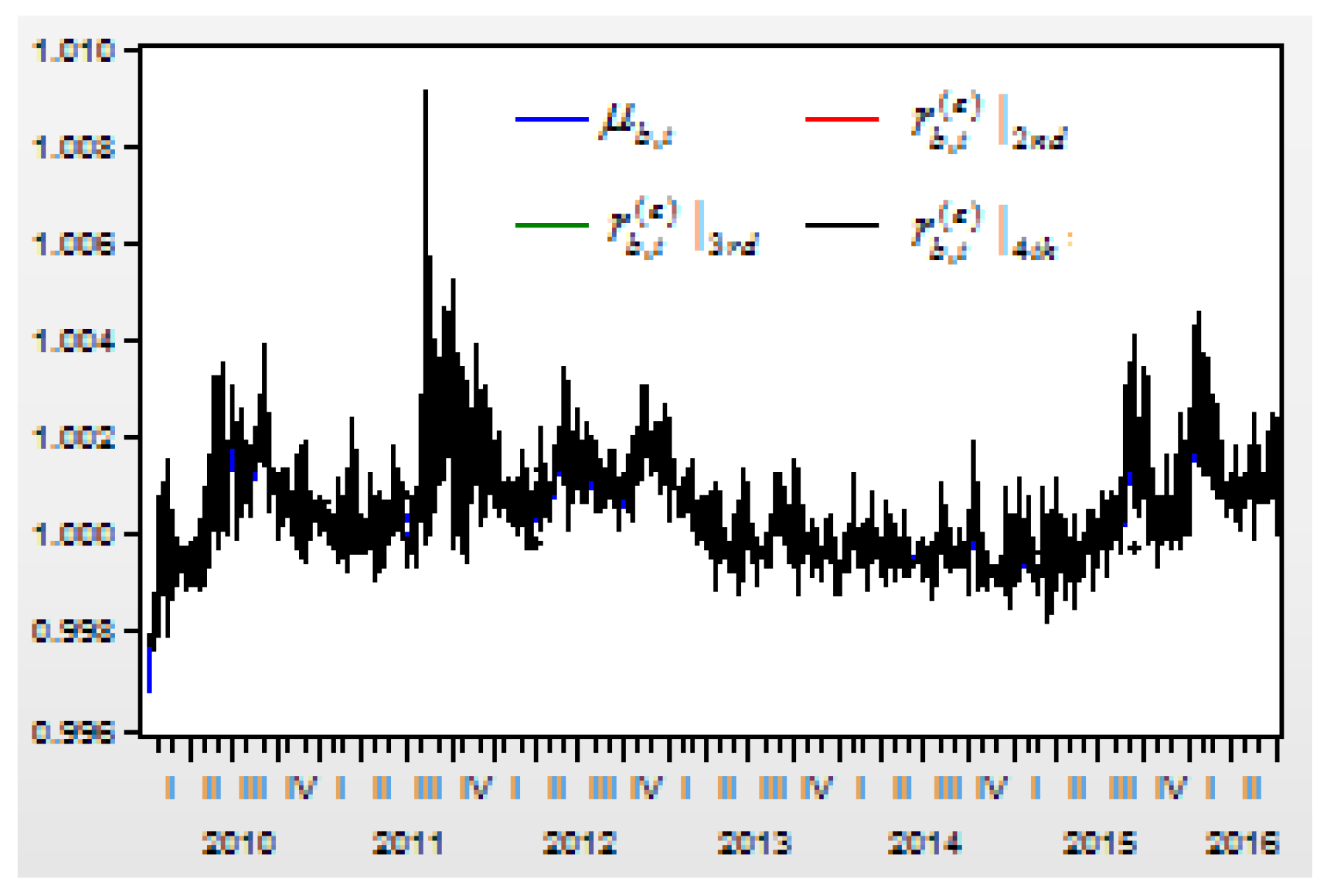
Figure 4 shows the return index
and its prediction values of
,
, and
from the second-, third-, and fourth-order differences.
Figure 5 shows the prediction values of
,
, and
under the second-, third-, and fourth-order differences, and the conditional mean
of
.
The correlation between the return index and its conditional mean , and its prediction values of , , and are 0.136470, 0.136472, 0.136519, 0.13652, respectively.
For improving the correlations between the return index and its prediction values, we will try to improve the lag order of the finite order differences’ variables.
After improving the lag order of the finite order differences’ variables, when , assume variable represents the prediction index of the return index from the second-order difference variable ; variable represents the prediction index of the return index from the third-order difference variable ; and variable represents the prediction index of the return index from the fourth-order difference variable . Then, there is a correlation between the return index and its conditional mean , and its prediction values of , , are 0.136470, 0.156046, 0.158559, 0.163743, respectively. Obviously, improving the lag order of the finite order differences’ variables can improve the correlations between the return index and its prediction value a lot.
4.5. Return Index Prediction Based on the Second-Order Difference and the AR-FD Model
From the above empirical analysis, we find that if we increasingly improve the order of the finite order differences’ variables, the correlations between the return index and its prediction value cannot increase more and more. We will focus on conducting an analysis on the second-order finite difference regression model and test if higher lags of the probability variable can lead to a higher correlation between the real return index and its prediction value.
The second-order finite difference
can be expressed as
When the lag order of the probability variable is defined as , we can obtain ten different prediction models of . According to the equation of , , we will obtain the return index prediction values of .
Table 4 lists the first three parameters of the second-order difference regression models for the residual of the return index prediction model.
When the lag order , the regression model of the second-order difference includes the intercept , and the coefficient for item , the coefficient for item , and the coefficient for item .
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
Similarly, when the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
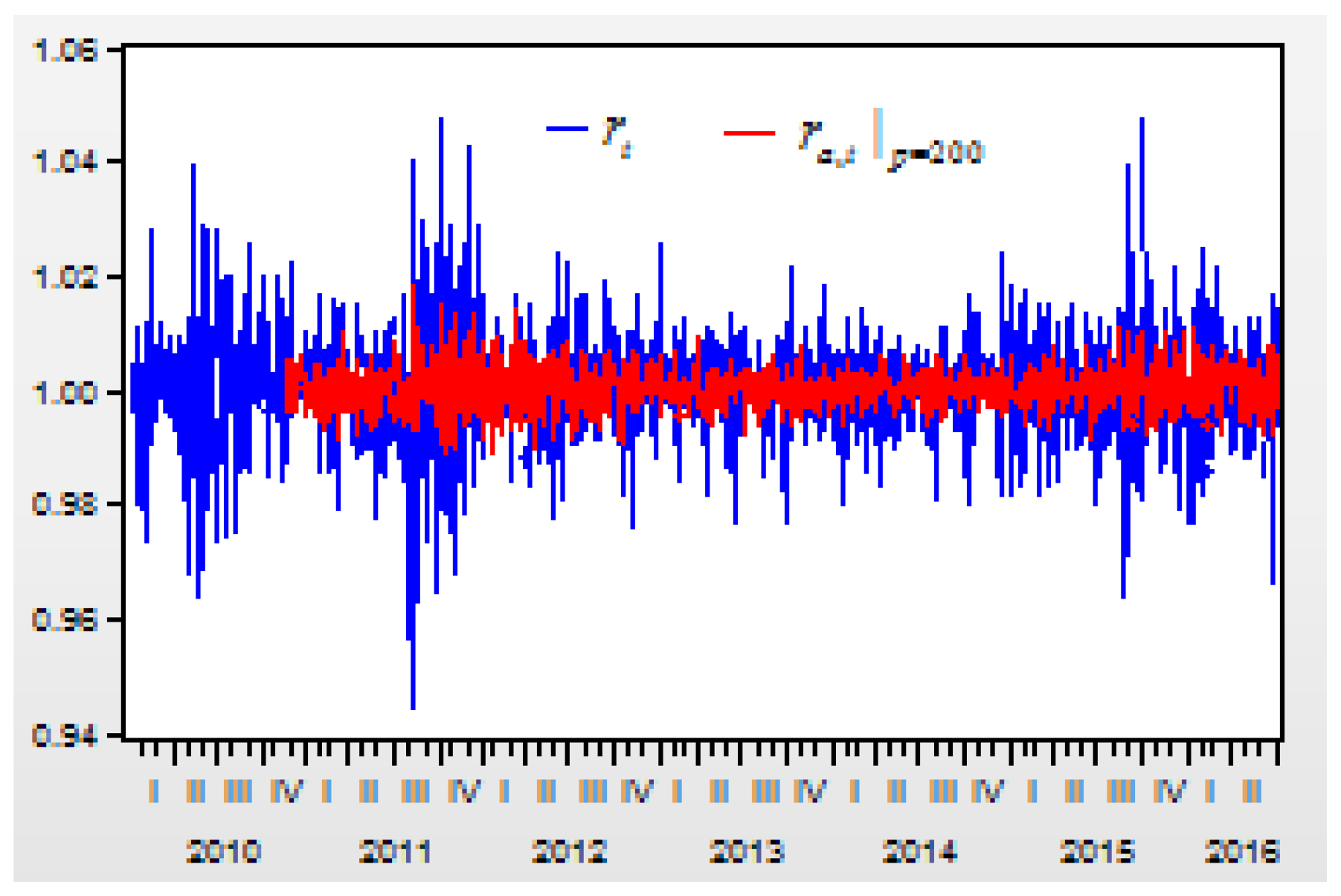
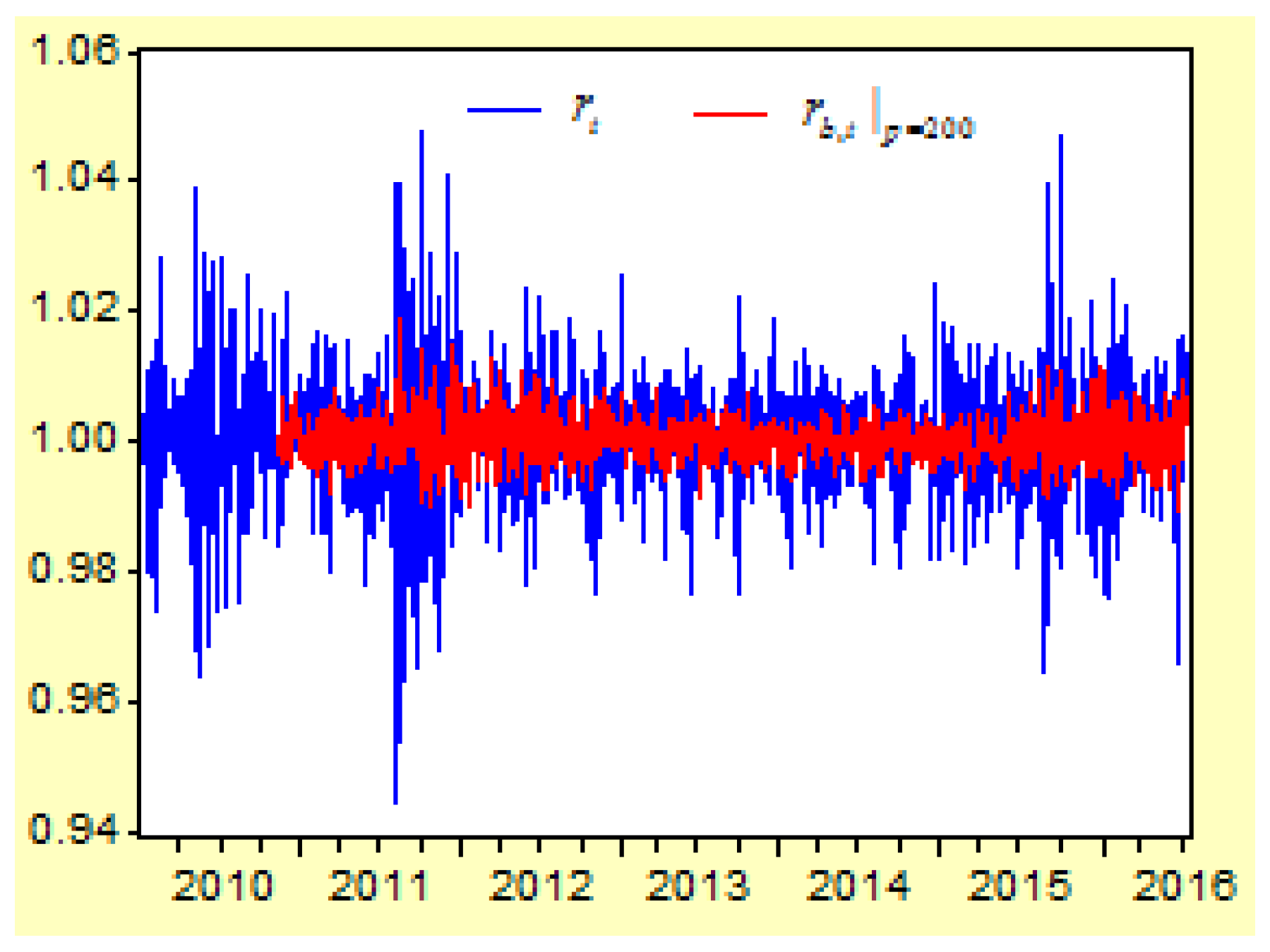
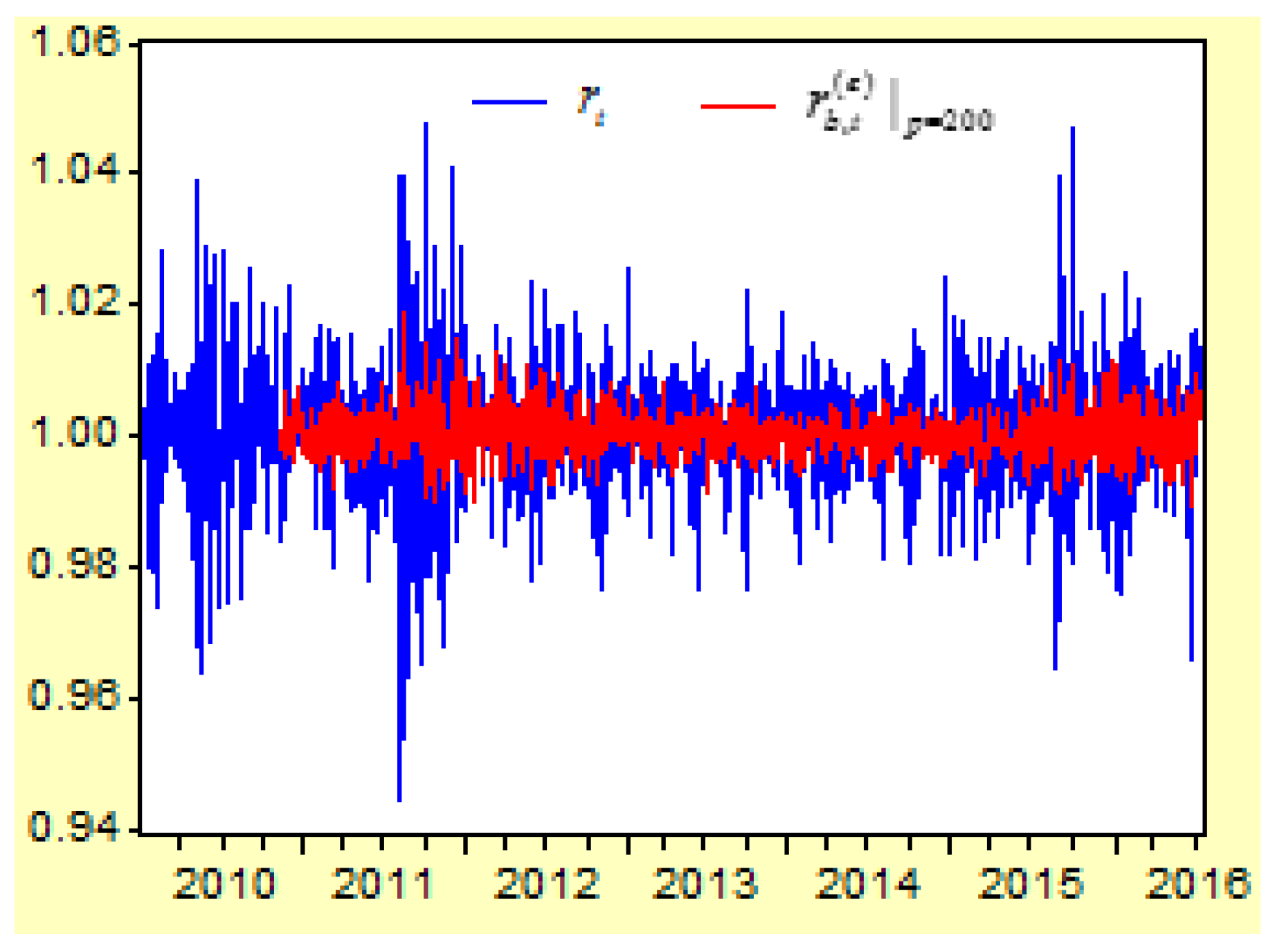
Figure 6 depicts the curves of the return index
and its prediction values of
from the second-order difference regression model.
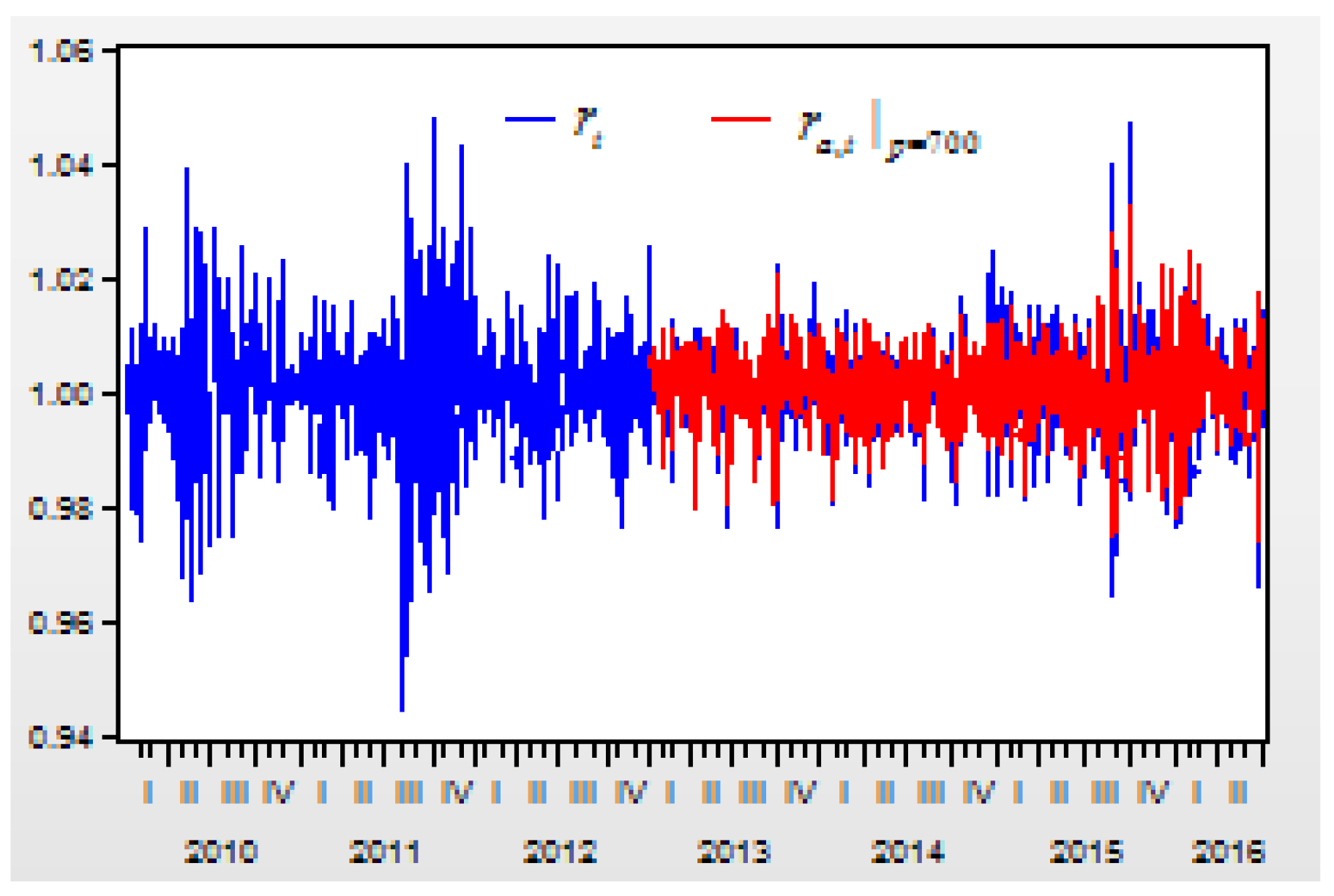
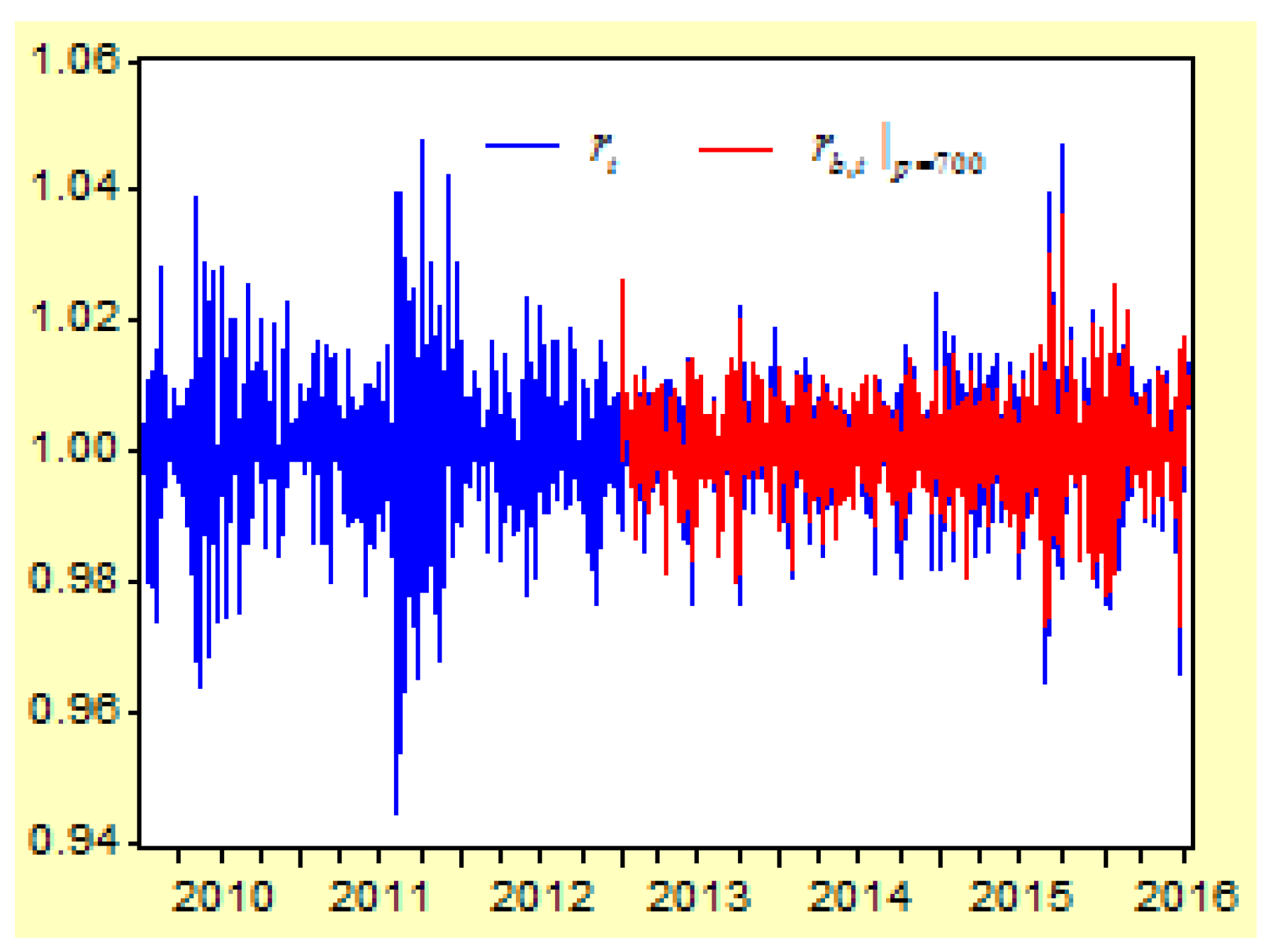
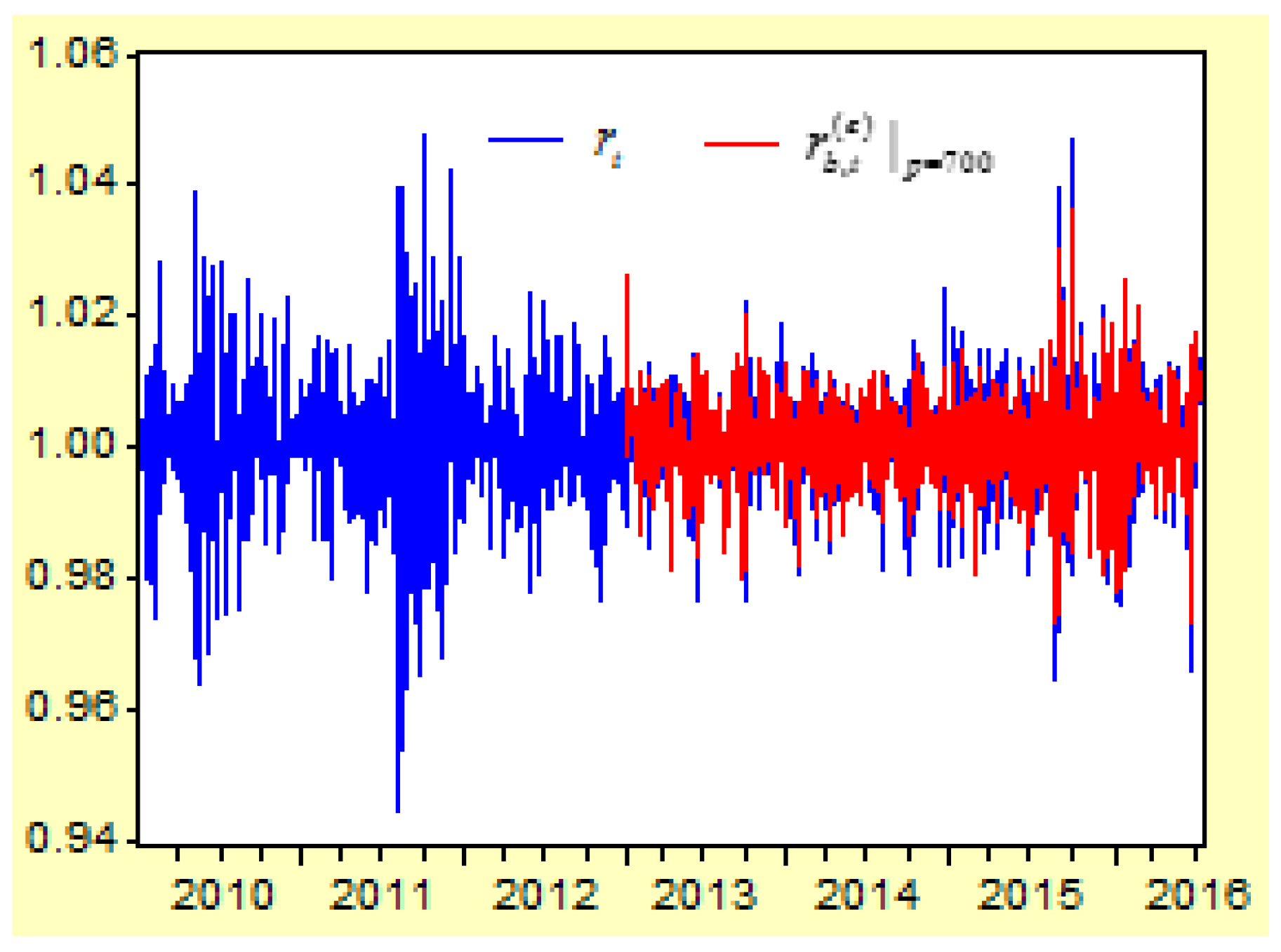
Figure 7 depicts the curves of the return index
and its prediction values of
from the second-order difference regression model.
From these regression models for the second-order difference variable , there are three results:
First, when the lag order of the probability variable increases, the determinate coefficient for the regression model will increase. When the lag order is increased from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the R-squared value of the regression model is increased from 0.833302 to 0.839955, 0.844830, 0.851597, 0.856684, 0.872071, 0.888580, 0.899775, 0.924362, and 0.957954.
Second, when the lag order increases, the correlations between the real return index and its prediction values will increase. When the lag order is increased from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the correlation between and its prediction value of , , , , , , , , , is increased from 0.136766 to 0.238128, 0.294749, 0.341969, 0.389903, 0.486086, 0.578318, 0.651674, 0.745966, and 0. 0.867847, respectively.
Third, when comparing both figures, we can see that the prediction values of are more approximated to the real return index than the prediction values of . This means that higher lags of the AR-FD prediction model can create a higher approximated result between the real return index and its prediction value.
4.6. GARCH Model
For the residual variable
, the conditional volatility in the GARCH (1,1) model is regressed as:
where the static variance is
, the coefficient of the ARCH item is
, the coefficient of the GARCH item is
, the intercept is
, and the three parameters satisfy the relation of
,
.
The mean and variance of the random variable are −0.008643 and 1.000669, respectively. When the new standardized random variable is defined by , the mean and variance of the random variable are 3.86E-17 and 1.000328, respectively. Obviously, the random variable is more approximate to the standardized normal distribution than the random variable .
4.7. Return Index Prediction Based on the Second-Order Finite Difference AR-GARCH-FD Model
When
,
, the residual item can be defined as
, then the autoregressive prediction model of the return index
is
Generally, when
, then
. For simplicity, we will use
to replace
. When the variable
represents the probability of the quantile of
, let
. Assuming that the probability
is the same as the probability of the random variable, the autoregressive prediction model of the return index
can be defined by
We will test if a higher lag order of the probability variable regression model can lead to a higher correlation between the real return index and its prediction value. For this purpose, we will focus on conducting an analysis of the second-order finite difference regression model.
The second-order finite difference
can be expressed by a regression model as
When the lag order is , we can obtain ten different prediction regression models for the second-order finite difference .
According to the second-order finite difference equation , the return index prediction regression model , we will be able to obtain the return index prediction values of .
Table 5 lists the first three parameters of the second-order finite difference regression models for different lags of the probability from the residual of the return index prediction model.
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
Similarly, When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
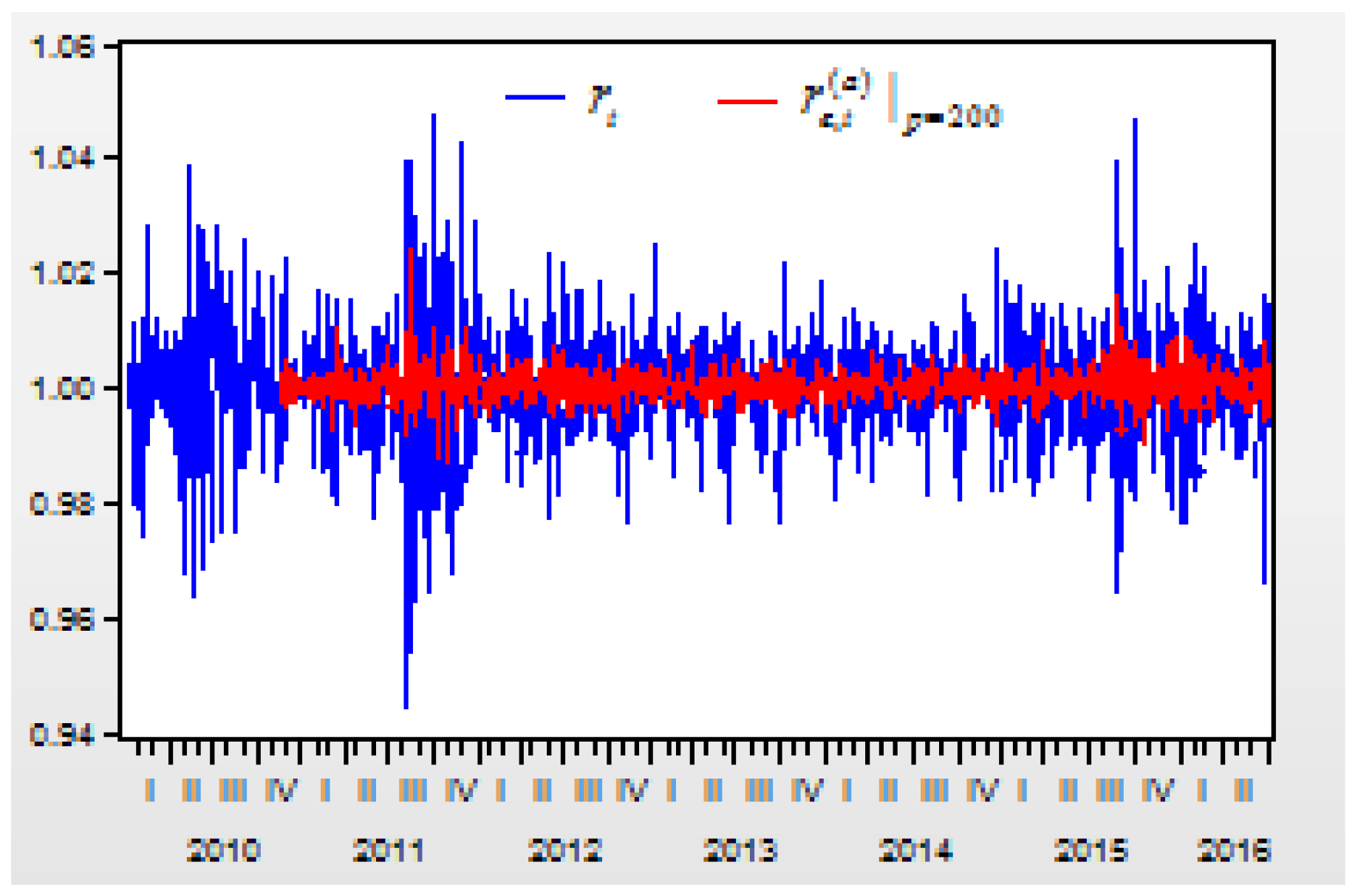
Figure 8 depicts the curves of the return index
and its prediction values of
from the second-order difference regression model.
Figure 9 depicts the curves of the return index
and its prediction values of
from the second-order difference regression model.
From these regression models for the second-order difference variable , there are three results:
First, when the lag order increases, the determinate coefficient for the regression model will increase. When the lag order is increased from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the R-squared value of the regression model is increased from 0.833870 to 0.837518, 0.843600, 0.849075, 0.853597, 0.869262, 0.887668, 0.905421, 0.930127, and 0.962585.
Secondly, when the lag order increases, the correlations between the real return index and its prediction values will increase. When the lag order is increased from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the correlation between and its prediction values of , , , , , , , , , increases from 0.119018 to 0.209055, 0.268237, 0.315291, 0.367438, 0.472224, 0.552860, 0.640771, 0.701112, and 0.847974, respectively.
Thirdly, when comparing both figures, we can see that the prediction values of are more approximated to the real return index than the prediction values of . This means that higher lags of the AR-GARCH-FD prediction model can create a higher approximated result between the real return index and its prediction value.
5. Empirical Analysis Based on the Cumulative Return Index
5.1. The Cumulative Return Index
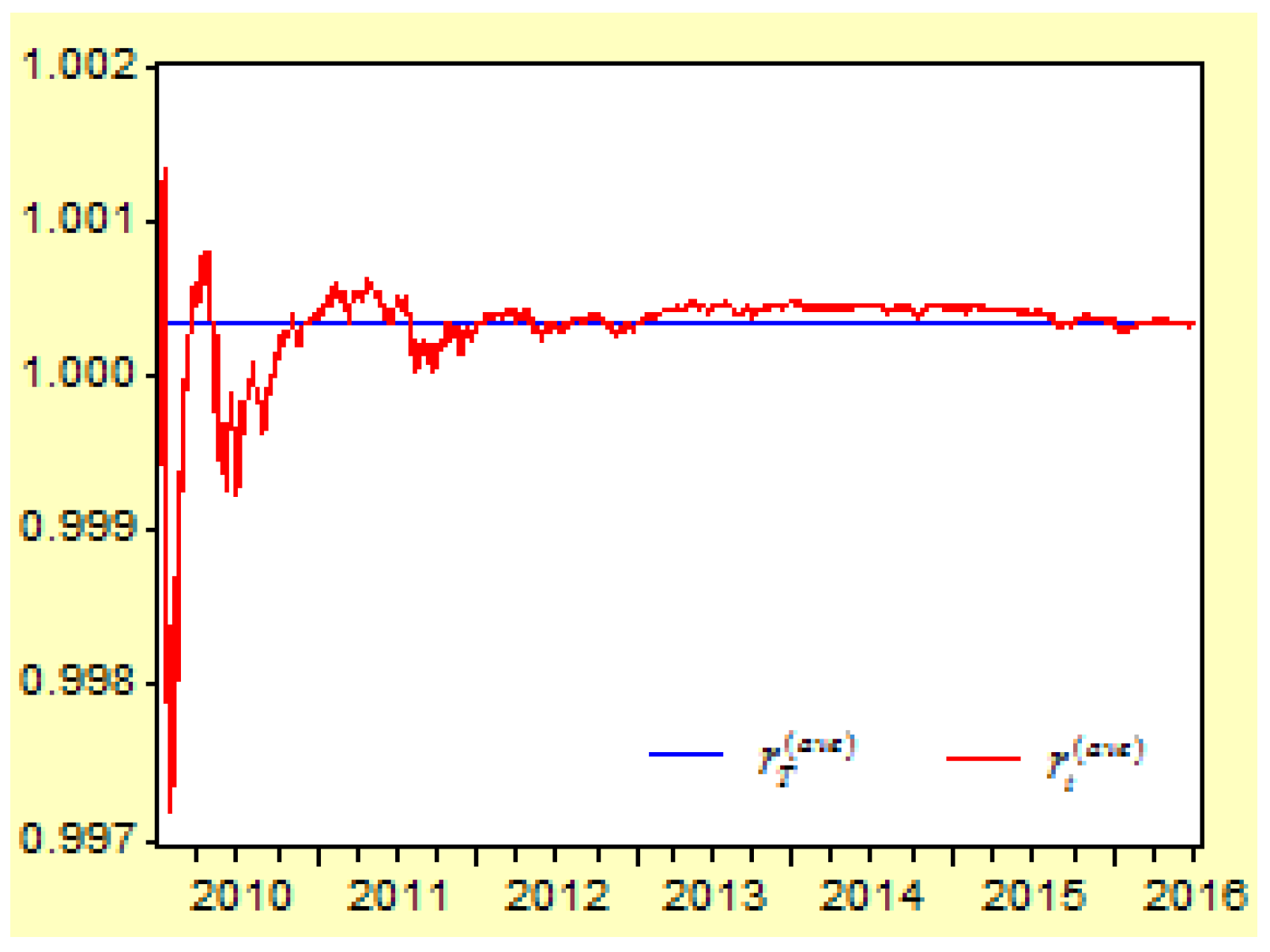
Figure 10 shows the moving curves of the average compound return index
between the time period
and the average compound return index
when
between 4 January 2010 and 8 July 2016.
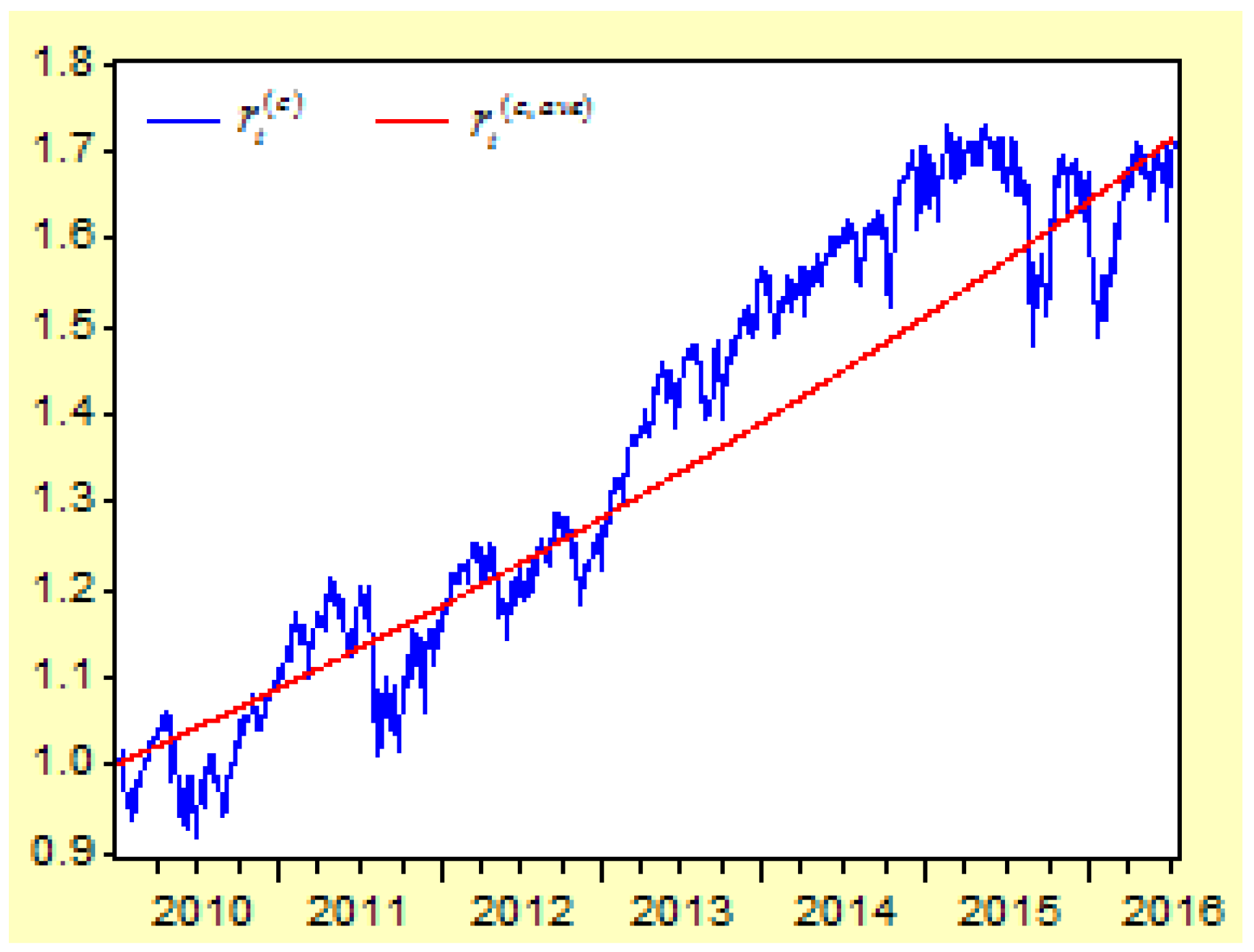
Figure 11 shows the cumulative return index
and the cumulative average compound return index
between 4 January 2010 and 8 July 2016.
According to statistics, the average arithmetic return index , and the average compound return index . The average arithmetic return index is not equal to the average compound return index. The average compound return index reveals the characteristics of the risk assets’ return indices.
It is clear that the cumulative return index represents the long-term moving trend of the return index , and the cumulative average compound return index represents the long-term moving trend of the average compound return index .
When comparing the trends between the short-term return index and the long-term cumulative return index , it is obvious that the long-term cumulative return index has a clearer moving trend than the short-term return index. For this reason, we will focus on conducting an analysis of the long-term cumulative return index.
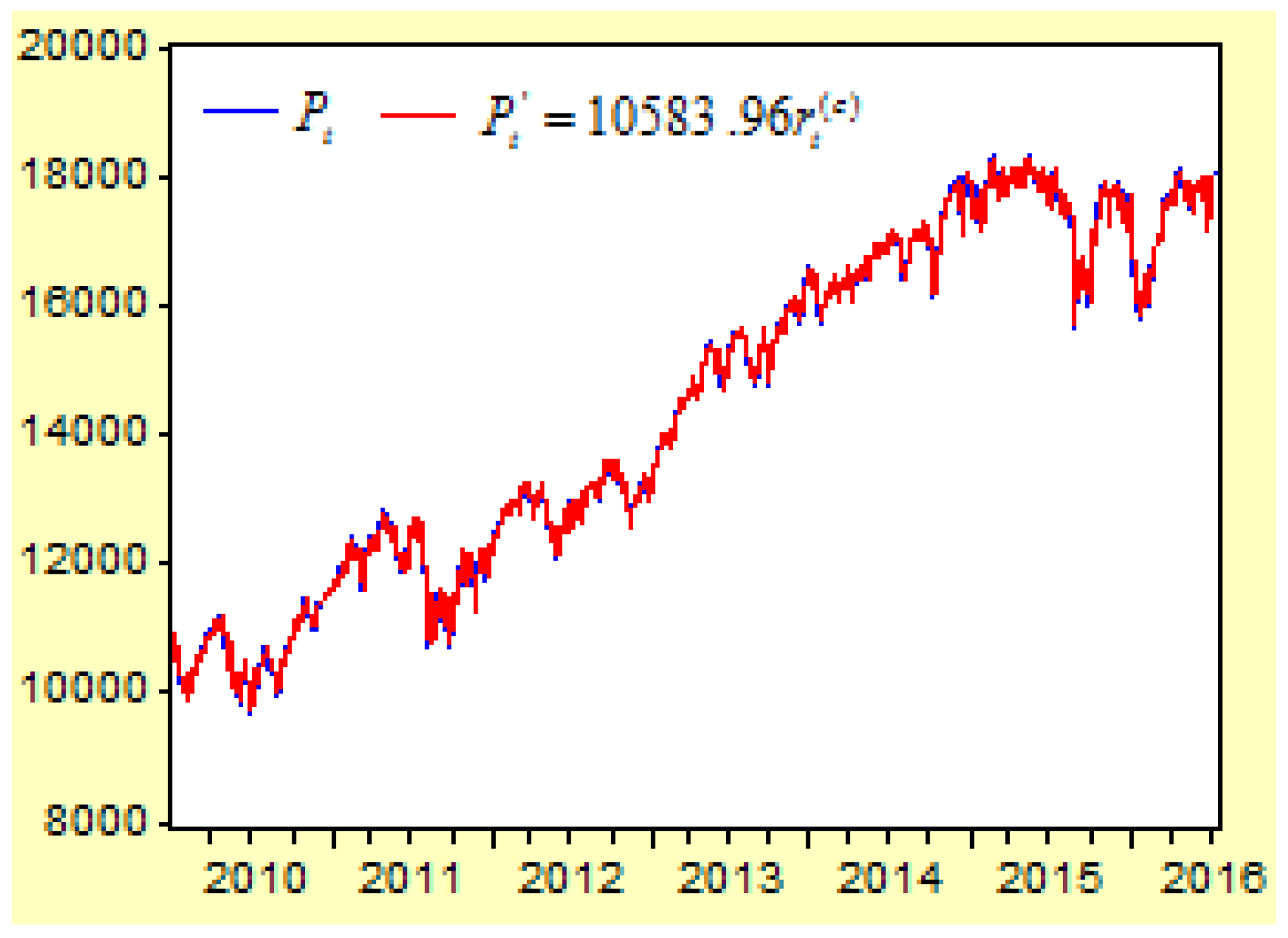
If we have already learned the prediction value of the cumulative return index , we will obtain the prediction value of the stock price . Because the stock price on the first day (4 January 2010) is , if we can predict the value of the cumulative return index , the prediction value of the price at any time will be .
Figure 12 has listed the stock price
and its prediction value from the formula
. Because the cumulative return index
is from the real value of the return index
, the curves of both
and
are almost the same.
It is clear from comparing the curves of the cumulative return index and the real return index that the forecasting procedure of the cumulative return index may be much easier than the forecasting procedure of the real return index .
5.2. The Cumulative Return Gap Index
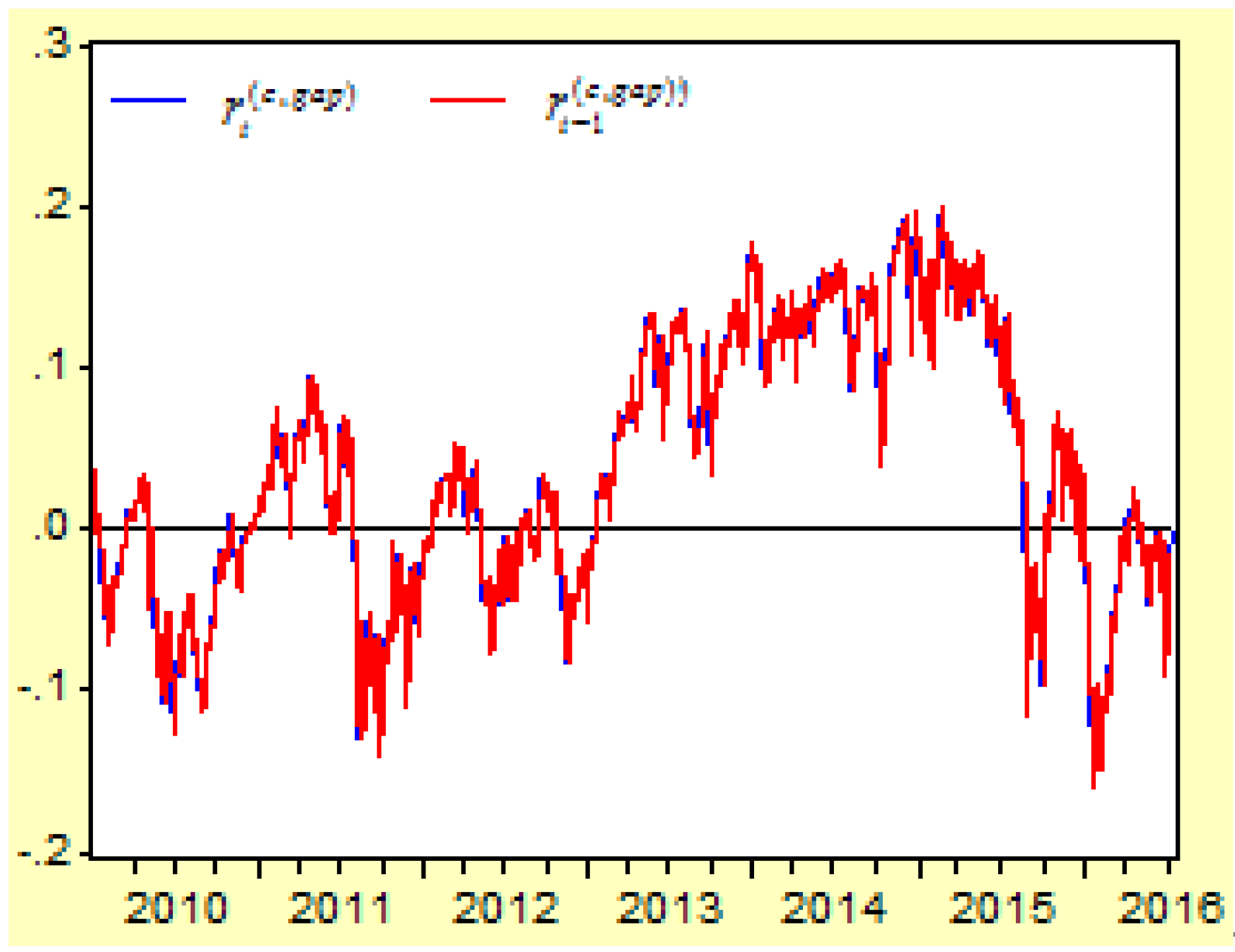
Figure 13 shows the moving curves of the cumulative return gap (CRG) index
and its lag 1 item
between 4 January 2010 and 8 July 2016.
The cumulative return gap index represents a long-term cumulative excess return, which has an average arithmetic mean of 0.0375. We can see that it is difficult to differentiate both curves of and its lag 1 item ; this is because the time series of the cumulative return gap index has a very high autocorrelation.
The cumulative return gap () reveals a cumulative risk premium during the time period of . When the general risk premium () reveals a difference between the return of a risk asset and the return of a risk-free asset, the cumulative return gap reveals the difference between the cumulative compound return and the cumulative average compound return of a risk asset.
Table 6 lists the autocorrelations and the probabilities of
Ljung and Box (
1978) statistics for the time series variable
. The autocorrelation between both time series
and
is 0.988, which is much higher than the value of the autocorrelation of −0.052 between the time series
and
.
Because the correlation between the cumulative return gap index and its lag 1 item is as high as 0.988, or , the term of can be applied into the prediction model to replace the value of . We have already learned that the cumulative return index can be depicted as ; if , then . For this reason, the expression of will include these two items of and .
5.3. ARDL-CRG Prediction Model for the Cumulative Return Index
According to the definition, the cumulative return index
is related to four components: the cumulative average compound return index
, the time function
, the cumulative return gap index
, and the residual variable
. Because the cumulative return gap item
is introduced to the ARDL model, the new model can be called the ARDL-CRG model with the following equation
The ARDL-CRG model shows that the dependent variable can be represented by the independent variable , , and very well. The determined coefficient is as high as .
The coefficient of is 0.998355. The coefficient of is 0.985347. Both of the coefficients are very close to one. Because the coefficient of is 0.000818, this means that the long-term trend of the stock market increases when the time variable is moving forward.
When the residual value of
is ignored, it is easy to obtain the predicted value
from this ARDL-CRG model. From the ARDL_CRM model, we can predict the return index by following the equations
Figure 14 shows the return index
and its prediction value of
. The prediction value of
is the conditional mean of
, which is similar to the equation of
when
. The correlation between
and
is 0.0984. Although the correlation is low, it is good for representing the relationship between the return index
and the conditional mean
.
Figure 15 shows the residual
from the prediction model of
and the residual
from the prediction model of
. The correlation between
and
is 0.9803. The correlation is quite high. It means that the prediction model of the cumulative return index is consistent with the prediction model of the real return index, although the most historic information is included in the residual items.
5.4. Indirect Prediction of the Return Index Based on the Finite Difference Method ARDL-CRG-FD Model
When the finite difference method is introduced into the ARDL-CRG model, the model will become the ARDL-CRG-FD model.
Because the residual item
has a strong impact on the prediction value of the cumulative return index
, it is important to predict the trend of the residual item
. When defining
then the variable
can be seen as a probability of
. If we assume the first-order difference is
, the second-order difference is
, the third-order difference is
, and the
difference is
. If the level variable
is not the autocorrelation time series, the
difference
may be the autocorrelation time series. If the
difference
can be expressed as
the
-order difference
can also be expressed as
Then, according to the definition of the difference method, the probability
can be predicted by
The variable is the residual item of the regression model. It is important to determine a proper order number; for example, we will consider the first-, second- and fourth-order differences. For simplicity, we will not consider the residual again and assume .
After obtaining the prediction value of the probability
, it is easy to obtain the prediction value of the cumulative return index
by
By applying the equation of , it is easy to obtain the prediction value of the return index .
The probability prediction models from the second-order difference are
The probability prediction models from the third-order difference are
The probability prediction models from the fourth-order difference are
Assume variable represents the prediction value of the return index from the second-order difference probability prediction value of ; variable represents the prediction value of the return index from the third-order difference probability prediction value of ; and variable represents the prediction value of the return index from the fourth-order difference probability prediction value of .
Figure 16 shows the curves of the return index
and its prediction values of
,
, and
from the second, third and fourth difference probability prediction values during 2010–2016.
Figure 17 shows the curves of the conditional mean
of the return index
and the prediction values
,
, and
of the return index
from the second, third, and fourth difference probability prediction values during 2010–2016.
The correlations between and , , , are 0.1018, 0.1614, 0.1435, 0.1614, respectively. It is obvious that the residual item has made the correlations between the return index and its prediction values, , , increase much more than the correlation between the return index and its prediction values of the conditional mean . This means that applying the second-, third-, and fourth-order finite differences to the residual item can improve the correlations between the real return index and its prediction values.
5.5. Return Index Prediction Based on the Second-Order Difference ARDL-CRG-FD Model
Because applying the second, third, and fourth-order finite difference methods to the residual item can improve the correlations between the real return index and its prediction values, we will test if higher lags of the probability regression model can lead to a higher correlation between the real return index and its prediction value. For this purpose, we will focus on conducting an analysis of the second-order finite difference regression model.
The second-order difference
can be expressed by a regression model as
When the lag-order is , we can obtain ten different prediction regression models for the second-order difference .
By applying the equations of , , and , we will be able to obtain the return index prediction values of .
Table 7 has listed the first three parameters of the second-order difference regression models for the residual of the cumulative return index prediction model.
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
Similarly, When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
Figure 18 depicts the curves of the return index
and its prediction values of
from the second-order difference regression model.
Figure 19 depicts the curves of the return index
and its prediction values of
from the second-order difference regression model.
From these regression models for the second-order difference variable , there are three results:
First, when the lag order increases, the determinate coefficient for the regression model will increase. When the lag order increases from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the R-squared value of the regression model increases from 0.842668 to 0.847195, 0.852919, 0.860050, 0.863607, 0.877231, 0.891028, 0.906935, 0.930281, and 0.961514, respectively.
Second, when the lag order increases, the correlations between the real return index and its prediction values will increase. When the lag order increases from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the correlation between and its prediction value of , , , , , , , , , increases from 0.161486 to 0.242633, 0.296988, 0.344799, 0.382242, 0.478909, 0.584397, 0.656670, 0.752572, and 0.873537, respectively.
Third, when comparing both figures, we can see that the prediction values of are more approximated to the real return index than the prediction values of . This means that a higher lag order prediction model can create a higher approximated result between the real return index and its prediction value.
5.6. ARDL-CRG-GARCH-FD Model and Return Index Prediction Based on the Finite Difference Method
For the residual variable
, the conditional volatility in the GARCH (1,1) model is regressed as
where the static variance is
, the coefficient of the ARCH item is
, the coefficient of the GARCH item is
, the intercept is
, and the three parameters satisfy the relation of
,
.
Because the regressive residual is unavoidable, the mean and variance of the random variable are 0.000692 and 1.005242, respectively. When the new standardized random variable is defined by , the mean and variance of the random variable are 1.74E-18 and 1.000327, respectively. Obviously, the random variable is more approximate to the standardized normal distribution than the random variable .
Then, the prediction value of the cumulative return index
will be
When the variable
represents the probability of the quantile of
, let
. Assume that the probability
is the same as the probability of the random variable with the standard normal distribution, then for simplicity, the prediction model of the cumulative return index
can be defined as
Then, the prediction model of the return index
can be defined as
The probability prediction models from the second-order difference are
The probability prediction models from the third-order difference are
The probability prediction models from the fourth-order difference are
Assume variable represents the prediction value of the return index from the second-order difference probability prediction value of ; variable represents the prediction value of the return index from the third-order difference probability prediction value of ; and variable represents the prediction value of the return index from the fourth-order difference probability prediction value of .
Figure 20 shows the curves of the return index
and its prediction values of
,
, and
from the second, third, and fourth difference probability prediction values during 2010–2016.
Figure 21 shows the curves of the conditional mean
of the return index
and the prediction values
,
, and
of the return index
from the second, third, and fourth order difference probability prediction values during 2010–2016.
The correlations between and , , , and are 0.1006, 0.1467, 0.1467, 0.1467, respectively. It is obvious that the residual item has made the correlations between the return index and its prediction values , , and increase much more than the correlation between the return index and its prediction values of the conditional mean .
5.7. Return Index Prediction Based on the Second-Order Difference ARDL-CRG-GARCH-FD Model
Because applying the second-, third-, and fourth-order finite difference methods to the residual item can improve the correlations between the real return index and its prediction values, we will test if higher lags of the probability prediction value of the regression model can lead to a higher correlation between the real return index and its prediction value. For this purpose, we will focus on conducting an analysis of the second-order finite difference regression model.
The second-order difference
can be expressed by a regression model as
When the lag order is , we can obtain ten different prediction regression models for the second-order difference .
According to the second-order difference equation , the return index prediction regression model , and the return index prediction model , we will be able to obtain the return index prediction values of .
Table 8 has listed the first three parameters of the second-order finite difference regression models for the residual of the cumulative return index prediction model.
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
When the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
Similarly, when the lag order , the regression model of the second-order difference includes the intercept and the coefficient for item , the coefficient for item , and the coefficient for item .
Figure 22 depicts the curves of the return index
and its prediction values of
from the second-order finite difference regression model.
Figure 23 depicts the curves of the return index
and its prediction values of
from the second-order finite difference regression model.
From these regression models for the second-order difference variable , there are three results:
First, when the lag order increases, the determinate coefficient for the regression model will increase. When the lag order increases from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the R-squared value of the regression model increases from 0.842384 to 0.845745, 0.852091, 0.857610, 0.861082, 0.875154, 0.892694, 0.910258, 0.933839, and 0.965393, respectively.
Second, when the lag order increases, the correlations between the real return index and its prediction values will increase. When the lag order increases from 3 to 50, 100, 150, 200, 300, 400, 500, 600, and 700, the correlation between and its prediction values of , , , , , , , , , increases from 0.146718 to 0.220724, 0.284660, 0.329443, 0.368404, 0.472701, 0.566134, 0.646393, 0.732672, and 0.840273, respectively.
Third, when we compare both figures, we can see that the prediction values of are more approximated to the real return index than the prediction values of . This means that a higher lag order of the probability prediction model can create a higher approximated result between the real return index and its prediction value.
6. Tests of the Prediction Accuracy for the Four Kinds of Models
6.1. Comparison of the Correlations between the Real and Predicted Returns from the Four Different Models
From the probability prediction models, we have already learned that the correlations between the real return index and its prediction values from the higher order differences are higher than the correlations between the real return index and its prediction values from the lower order differences.
When we fixed the finite difference order of the probability variable that transferred from the residual variable at the second order, the higher lags of the probability variable will make higher correlations between the real return index and its prediction values for each of the four different prediction models.
It is clear that the higher correlations mean that the prediction accuracy is high. For the four different models, we will compare the empirical results based on the perspectives of the correlations.
From the previous study, we built an AR(5) model when the lag order is and the lag items are from the real return index . We also built an ARDL-CRG model when the cumulative gap lag order is 1 as item . Based on the two models’ residual items, by using a second-order finite difference method, we have already built four different models.
Table 9 has listed the correlations between the real return index
and its prediction values of
,
,
, and
from the four different kinds of prediction models.
First, the perspective of AR-FD models is considered. The prediction values of are from the traditional autoregressive (AR) model . When the probability is defined as , the residual item can be predicted by predicting the probability . Because the second-order difference of the probability is an autoregressive time series, the probability can be predicted by predicting its second-order difference . When we choose different lag orders for the second-order difference as , , …, and , we will obtain the prediction values of , , …, and . When the lag order increases, the correlation between the real return index and the prediction values of will increase.
Second, from the perspective of ARDL-CRG-FD models, the prediction values of are from the traditional autoregressive distribution lag (ARDL) model . Because , it is easy to predict the values of the return index if we know the prediction values of the cumulative return index. When the probability is defined as , then the residual item can be predicted by predicting the probability . Because the second-order difference of the probability is an autoregressive time series, the probability can be predicted by predicting its second-order difference . When we choose different lag orders for the second-order difference as , , …, and , we will get the prediction values of , , …, and . When the lag order increases, the correlation between the real return index and the prediction values of will increase.
Third, from the perspective of AR-GARCH-FD models, the prediction values of are from the traditional autoregressive (AR) model and the generalized autoregressive conditional heteroscedasticity (GARCH) model , , , . When the probability is defined as , by predicting the probability , the residual item can be predicted. Because the second-order difference of the probability is an autoregressive time series, the probability can be predicted by predicting its second-order difference . When we choose different lag orders for the second-order difference as , , …, and , we will get the prediction values of , , …, and . When the lag order increases, the correlation between the real return index and the prediction values of will increase.
Fourth, from the perspective of ARDL-CRG-GARCH-FD models, the prediction values of are from the traditional autoregressive distribution lag (ARDL) model and the generalized autoregressive conditional heteroscedasticity (GARCH) model , , , . When the probability is defined as , by predicting the probability , the residual item can be predicted. Because the second-order difference of the probability is an autoregressive time series, the probability can be predicted by predicting its second-order difference . When we choose different lag orders for the second-order difference as , , …, and , we will get the prediction values of , , …, and . When the lag order increases, the correlation between the real return index and the prediction values of will increase.
Table 10 lists the comparison values of the correlations between the return index and the prediction values from the AR, ARDL, AR-GARCH, and ARDL-GARCH models.
From the comparative results, we can get the following four results:
Firstly, the comparison between the correlations of and shows that the correlations of are mostly greater than the correlations of . It means that the correlations between the return index and the prediction values . from the ARDL-CRG-FD models for the cumulative return index are greater than the correlations between the return index and the prediction values from the AR-FD models for the return index. It reveals that the CRG model can improve the prediction accuracy.
Secondly, the comparison between the correlations of and shows that the correlations of are mostly greater than the correlations of . It means that the correlations between the return index and the prediction values from the ARDL-CRG-GARCH-FD models for the cumulative return index are greater than the correlations between the return index and the prediction values from the AR-GARCH-FD models for the return index. It reveals that the CRG model can improve the prediction accuracy.
Thirdly, the comparison between the correlations of and shows that the correlations of are greater than the correlations of . It means that the correlations between the return index and the prediction values from the AR-FD models for the return index are greater than the correlations between the return index and the prediction values from the AR-GARCH-FD models for the return index. It means that the GARCH model has little impact on prediction values.
Fourthly, the comparison between the correlations of and shows that the correlations of are greater than the correlations of . It means that the correlations between the return index and the prediction values from the ARDL-CRG-FD models for the cumulative return index are greater than the correlations between the return index and the prediction values from the ARDL-CRG-GARCH-FD models for the cumulative return index. It means that the GARCH model has little impact on prediction values.
6.2. Hit Ratio Tests
Hit ratio analysis includes four cases: both the return index and the prediction value are upward, both the return index and the prediction value are downward, the return index is up but the prediction value is down, and the return index is down but the prediction value is up.
The ideal prediction values are that the higher hit ratios are better under the two cases when both the return index and the prediction values move upward or downward together, or the lower hit ratios are better in the two cases in both the return index and the prediction values are moving in the inverse directions.
First, the hit ratios from the AR-FD models were analyzed.
Table 11 lists the hit ratios between the real return index
and its prediction values of
from the direct AR-FD model for the return index at ten levels of different lag orders.
Under the ideal prediction criteria, it is clear that a higher level of lag order leads to a higher hit ratio than a lower level of lag order when both the return index and the prediction values move upward or downward together.
Secondly, the hit ratios from the ARDL-CRG-FD models were analyzed.
Table 12 lists the hit ratios between the real return index
and its prediction values of
from the indirect ARDL-CRG-FD model for the return index at ten levels of different lag orders.
Under the ideal prediction criteria, it is clear that a higher level of lag order has led to a higher hit ratio than a lower level of lag order when both the return index and the prediction values move upward or downward together.
Third, we carried out a comparison between the hit ratios from the ARDL-CRG-FD models and from the AR-FD models.
Table 13 has listed the comparative results of hit ratios between the results from the direct AR-FD model and the results from the indirect ARDL-CRG-FD model.
Under the ideal prediction criteria, the comparison shows that the prediction values from the indirect prediction model ARDL-CRG-FD for the cumulative return index are mostly better than the prediction values from the direct prediction model AR-FD for the return index, especially when the lag order is higher and greater than 400. For example, under the two cases when both the return index and the prediction values move upward together and expressed as or downward together and expressed as , the hit ratios of , , , , , , and are greater than the hit ratios of , , , , , , and .
Inversely, in the case when the return index is downward but the prediction values are upward and expressed as , the hit ratios of , , , , , , and are less than the hit ratios of , , , , , , and . It means that the ARDL-CRG-FD model is better for improving the hit ratios than the AR-FD models, especially when the difference orders or lags are higher.
Fourth, the hit ratios from the AR-GARCH-FD models were analyzed.
Table 14 lists the hit ratios between the real return index
and its prediction values of
from the direct AR-GARCH-FD model for the return index at ten levels of different lag orders.
Under the ideal prediction criteria, it is clear that the higher level of lag order has led to a higher hit ratio than the lower level of lag order.
Fifth, the hit ratios from the ARDL-CRG-GARCH-FD models were analyzed.
Table 15 lists the hit ratios between the real return index
and its prediction values of
from the indirect ARDL-CRG-GARCH-FD model for the cumulative return index at ten levels of different lag orders.
Under the ideal prediction criteria, it is clear that the higher level of lag order has led to a higher hit ratio than the lower level of lag order.
Sixth, a comparison between the hit ratios from the AR-GARCH-FD and the ARDL-CRG-GARCH-FD models was carried out.
Table 16 lists the comparative results of hit ratios between the results from the direct AR-GARCH-FD model and the results from the indirect ARDL-CRG-GARCH-FD model.
The comparison shows that the hit ratios from the indirect prediction values of the ARDL-CRG-GARCH-FD model for the cumulative return index are similar to the direct prediction values of the AR-GARCH-FD model for the return index. It means that in terms of the hit ratios, the ARDL-CRG-GARCH-FD model is similar to the AR-GARCH-FD model.
Seventh, a comparison between the hit ratios from the AR-FD and the AR-GARCH-FD models was carried out.
Table 17 lists the comparative results of the hit ratios between the results from the direct AR-FD models and the results from the indirect AR-GARCH-FD models.
The comparison shows that the hit ratios from the direct prediction values of the AR-GARCH-FD models for the return index are better than the hit ratios from the direct prediction values of the AR-FD model for the return index. It means that when it comes to the hit ratios, the AR-GARCH-FD models are better than the AR-FD models.
Eighth, a comparison between the hit ratios from the ARDL-CRG-FD and ARDL-CRG-GARCH-FD models was carried out.
Table 18 has listed the comparative results of the hit ratios between the results from the indirect ARDL-CRG-FD model and the results from the indirect ARDL-CRG-GARCH-FD model.
The comparison shows that the hit ratios from the indirect prediction values of the ARDL-CRG-GARCH-FD models for the cumulative return index are better than the hit ratios from the indirect prediction values of the ARDL-CRG-FD models for the cumulative return index. It means that when it comes to the hit ratios, the ARDL-CRG-GARCH-FD models are better than ARDL-CRG-FD models.
6.3. RMSE Tests
We will analyze the average values of the root mean square error (RMSE) for the four kinds of models.
Table 19 has listed the values of the RMSE including the prediction values from the direct prediction AR-FD and AR-GARCH-FD models for the return index and the indirect prediction ARDL-CRG-FD and ARDL-CRG-GARCH-FD models for the cumulative return index.
The RMSE is focused on summarizing the average values of the root mean square error (RMSE). The ideal criterion is that the smaller value is the better value.
In considering the ideal criterion of the RMSE, it is clear that the higher level lags of the second-order probability variable led to a smaller RMSE value than the lower level lags of the second-order probability variable for all of the four kinds of models including AR-FD, AR-GARCH-FD, ARDL-CRG-FD and ARDL-CRG-GARCH-FD.
Table 20 lists the comparison results between the RMSE values resulting from the AR-FD, AR-GARCH-FD, ARDL-CRM-FD, and ARDL-CRM-GARCH-FD models.
When we compare the results of the RMSE prediction values between the four kinds of models, there are four results.
First, we make a comparison between both the AR-FD and AR-GARCH-FD models. The RMSE of the AR-FD model is defined as . The RMSE of the AR-GARCH-FD model is defined as . The comparison between the RMSE values of and shows that the RMSE values of are less than the RMSE values of . It means that the RMSE values between the return index and the prediction values from the AR-FD model for the return index are less than the RMSE values between the return index and the prediction values from the AR-GARCH-FD model for the return index. It means that the GARCH model has little impact on the decrease in the RMSE value, or it means that when the finite difference method is used, the GARCH model cannot improve the prediction accuracy by a lot.
Second, we made a comparison between both the ARDL-CRG-FD and ARDL-CRG -GARCH-FD models. The RMSE of the ARDL-CRG-FD model is defined as . The RMSE of the ARDL-CRG -GARCH-FD model is defined as . The comparison between the RMSE values of and shows that the RMSE values of are less than the RMSE values of . It means that the RMSE values between the return index and the prediction values from the ARDL-CRG-FD model for the cumulative return index are less than the RMSE values between the return index and the prediction values from the ARDL-CRG -GARCH-FD model for the cumulative return index. It means that the GARCH model has little impact on the decrease in the RMS value, or it means that when the finite difference method is used, the GARCH model cannot improve the prediction accuracy by a lot.
Third, we made a comparison between both the AR-FD and ARDL-CRM-FD models. The RMSE of the AR-FD model is defined as . The RMSE of the ARDL-CRM-FD model is defined as . The comparison between the RMSE values of both the AR-FD and ARDL-CRM-FD models shows that mostly the values of are less than the values of . It means that mostly the RMSE values between the return index and the prediction values from the ARDL-CRG-FD model for the cumulative return index are less than the RMSE values between the return index and the prediction values from the AR-FD model for the return index. It means that the ARDL-CRG-FD model has a higher impact on the decrease in the RMSE value than the AR-FD model, or it means that the ARDL-CRG-FD model can improve the prediction accuracy more than the AR-FD model.
Fourth, we made a comparison between both the AR-GARCH-FD and ARDL-CRG-GARCH-FD models. The RMSE of the AR-GARCH-FD model is defined as . The RMSE of the ARDL-CRG-GARCH-FD model is defined as . The comparison between the RMSE values of both the AR-GARCH-FD and ARDL-CRG-GARCH-FD models shows that mostly the RMSE values of are less than the RMSE values of . It means that, for the most part, the RMSE values between the return index and the prediction values from the ARDL-CRG-GARCH-FD model for the cumulative return index are less than the RMSE values between the return index and the prediction values from the AR-GARCH-FD model for the return index. It means that the ARDL-CRG-GARCH-FD model has a higher impact on the decrease in the RMS value than the AR-GARCH-FD model, or that the CRG model can improve the prediction accuracy by a lot.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}