1. Introduction
Necessity to construct a short-term load forecasting (STLF) model that has flexible applications at the system’s level and end user’s level grows rapidly by the common implementation of a future ahead bidding system, such as day-ahead demand response programs. System level refers to the electricity utilities, such as medium-voltage level customers, the distribution system, or aggregated residential users in one region. End-user’s level refers to the single residential load, apartment user, or a small-scale distribution user. End-user’s load characteristic has more variety than system’s level because it is strongly related to the user’s behavior, which is hard to model.
Both system and end-user data sets are necessary to have an accurate load prediction model to support further process, such as energy utilization [
1], microgrid scheduling [
2], and system demand analysis [
3]. Habib et al. [
1] applied the load prediction result to improve the energy and batteries utilization in hybrid power system, while Jin et al. [
2] designed a load prediction which is fed to determine the optimal scheduling of distributed energy resources and microgrid of a smart building. Meanwhile, He et al. [
3] used the load prediction accuracy derived from decoupling relation between electricity consumption and economic growth.
To have an accurate STLF method, several approaches estimate the load patterns and non-stationary part of load signal by modeling the user behavior and use signal decomposition to extract the non-stationary part of load signal. The user behavior model is built to estimate the exact load signals by considering various inputs, such as user daily schedules, as investigated by Stephen et al. [
4] and Sajjad et al. [
5], while Perfumo et al. [
6] used specific temperature formulation. Another way to investigate user behavior is by using non-intrusive load monitoring to know status of each set of appliances as proposed by Welikala et al. [
7]. However, information to build user behavior is scarcer in the wide area data set and driven by the seasonal effect of the time series, a fact that makes this approach less attractive, as applied in the work of Kong et al. [
8], Xie et al. [
9], and Erdinc et al. [
10]. In contrast to modeling user behavior, the decomposition method is built after the load inputs are determined. Signal decomposition is used to smoothen the load variations, by using discrete wavelet transform (DWT), so that the input load pattern can be decomposed into low- and high-frequency parts of sub-signals for the input variables formulated.
To construct a closely fitting model of the load, a ubiquitous implementation of DWT is strongly related to proper selection of both the decomposition level and type of wavelet. Among the types of wavelet, Daubechies is well known due to its practicality in multiresolution signal application in which there is flexibility in analyzing the content of the signal. Li et al. [
11], Chen et al. [
12], and Reis and Alves da Silva [
13] use the fourth order Daubechies (Db4) to predict the electric load with different decomposition levels of 3 to 5. Meanwhile, Guan et al. [
14] and Li et al. [
15] use the Daubechies types varying between Db1 to Db3 and the decomposition level of level-2. Bashir and El-Hawary [
16] use Db2 with level-2 to reflect the uncertain factors on daily load characteristics. A particle swarm optimization (PSO) algorithm is then employed to adjust the weights of the artificial neural network (ANN) in the training process.
In addition to selection of the DWT’s decomposition level and type of wavelet, arrangement of the correct related exogenous inputs is necessary. Arrangement of input variables is mainly based on various weather information, lagged historical data, or an ensemble of sub-signals after wavelet decomposition. Pandey et al. [
17] use conditional mutual information-based feature selection to extract information of the built wavelet models before assembling those models into a final prediction model. The prediction model designed by Chen et al. [
12] is built based on Db4 and uses a similar day’s load as the input. A forecasting method proposed by Guan et al. [
14] uses 12 dedicated models with two levels of decomposition and boundary of Daubechies type varying from Db1 to Db3. The problem of selecting input variables becomes more difficult when every related exogenous factor is added to the prediction model. Thus, this paper takes the idea of using correlation analysis and statistical
t-test on the common related weather information to carefully select them.
ANNs can be used to predict load by several input variables, such as month, hour, day, the demand for same hour in the previous week, the demand of first- and second-forecasting hours, weighted temperature, humidity, and power demand pattern, as applied by Kong et al. [
8]. Within a day of prediction horizon, some of the methods need to build separate ANN model for each hour as shown by Chen et al. [
12] and Guan et al. [
14] or using decomposed signal as proposed by Rocha Reis and Alves da Silva [
13]. Guan et al. [
14] proposed a prediction interval in which the decomposition needs to filter out the high-frequency part of the signal to smoothen the load variation. Li et al. [
15] indicate the usage of the predetermined wavelet component and decomposition level cannot always improve the performance of prediction model. In addition, manual tuning of a hidden layer in an ANN cannot guarantee a general performance in a prediction model either, when it is used in another data set. Thus, to accommodate the problems with how to automatically select proper parameters for an accurate model, an optimal tuning algorithm is necessary.
To generalize the application of the load forecasting method, the prediction model must have accuracy in both system and end-user data sets. Sun et al. [
18] use wavelet neural network (WNN) and load distribution factor to find suitable wavelet type varying from Db2 to Db20 for irregular and regular nodes of load flow in distribution system, respectively. The method uses two decomposition levels and trains each decomposed signal in separate networks. However, the method fails to keep its prediction accuracy for the smart meter load due to the unpredicted behavior of an end-user affecting the load variation.
From the related works, the prediction model of STLF strongly depends on two key variables, which are the predictors and structure of the prediction algorithm. The predictors are designed to capture the load characteristics, while the structure of prediction algorithm determines the close-fitting process between targeted output and the prediction result. Integrating the evolutionary algorithm becomes the prominent way to address the issue to find optimal structure of prediction algorithm. He et al. [
3] show that an improved particle swarm optimization-extreme learning machine (IPSO-ELM) can optimize the weight in an ELM, which improves the overall load prediction result. Bashir and El-Hawary [
16] used PSO to the ANN model combined with wavelet decomposition to successfully extract redundant information from the load and achieve high precision.
For the design of highly correlated predictors to closely-fit the actual load, it is proved by Stephen et al. [
4] that the ensemble forecast from Autoregressive Integrated Moving Average (ARIMA), ANN, persistent forecast, and Gaussian load profile can improve the mean absolute percentage error (MAPE) from 18.56% to 11.13% for the residential load. In Kong et al. [
8], long short-term memory is used in the residential load forecasting to improve the performance by 21.99% of MAPE. Pandey et al. [
17] apply the WNN to Canadian utility load data, in which the predictors are grouped into seasons, to achieve 1.033% of MAPE on average. Thus, the proposed method adheres to the related works and investigates how to design the optimal predictors and prediction structure through several preconditioning schemes and discrete wavelet decomposition.
This paper proposes a one-day ahead hourly prediction model that integrates multiple linear regression (MLR) and discrete wavelet transform (DWT) optimized by using the whale optimization algorithm (WOA). The WOA is proposed by Mirjalili and Lewis [
19] as a novel meta-heuristic optimization algorithm which mimics the social behavior of humpback whales to find a global optimum solution. Compared to the other optimization algorithms, WOA converges fast and tunes only a few parameters to approach an optimal solution. The proposed model provides a more accurate prediction method that closely fits system-side loads and aggregated loads at downstream level (end-user). Instead of using ANN, the proposed method is suitable for real time application because it uses MLR that requires less time while dealing with multiple inputs. Multiple weather attributes and load data conditions are employed as the input of MLR. Based on Daubechies type wavelet, DWT is used to decompose a non-stationary signal into several components. The signal is independently decomposed to the set of Daubechies levels and types by handling the selected decomposition coefficients, while the remaining coefficients are replaced with zero. Based on this scheme, the signal can be extracted with its unique characteristics reflected by individual approximation and detail components. Then, WOA is used to optimize the combination of signals for constructing a prediction model.
The proposed method is validated in both system-side and end-user data sets, respectively, associated with actual weather information. The state-of-the-art features of the proposed method include:
Accurate and consistent implementation of STLF is achieved in both system-side and aggregated end-user data sets by integrating WOA-based DWT in the MLR model.
Due to the superior optimization ability of WOA, the best of DWT is implemented for more accurate prediction with more sensible load pattern reconstruction and more flexibility to interpret unique load characteristics of each data set.
The simple design is targeted yet does not lose accuracy of prediction via best reconstructing signals of DWT and determining the historical input from common related weather information.
The rest of the paper is organized as follows. In
Section 2, the modeling approach of historical data used in the proposed method is clearly described.
Section 3 describes the proposed WOA-DWT-MLR prediction method.
Section 4 provides the testing results for ISO-NE and aggregated load data. Comparisons with other well-established methods are also provided in this section.
Section 5 provides the discussion. Finally, conclusions are given in
Section 6.
2. Historical Data Modeling Approach
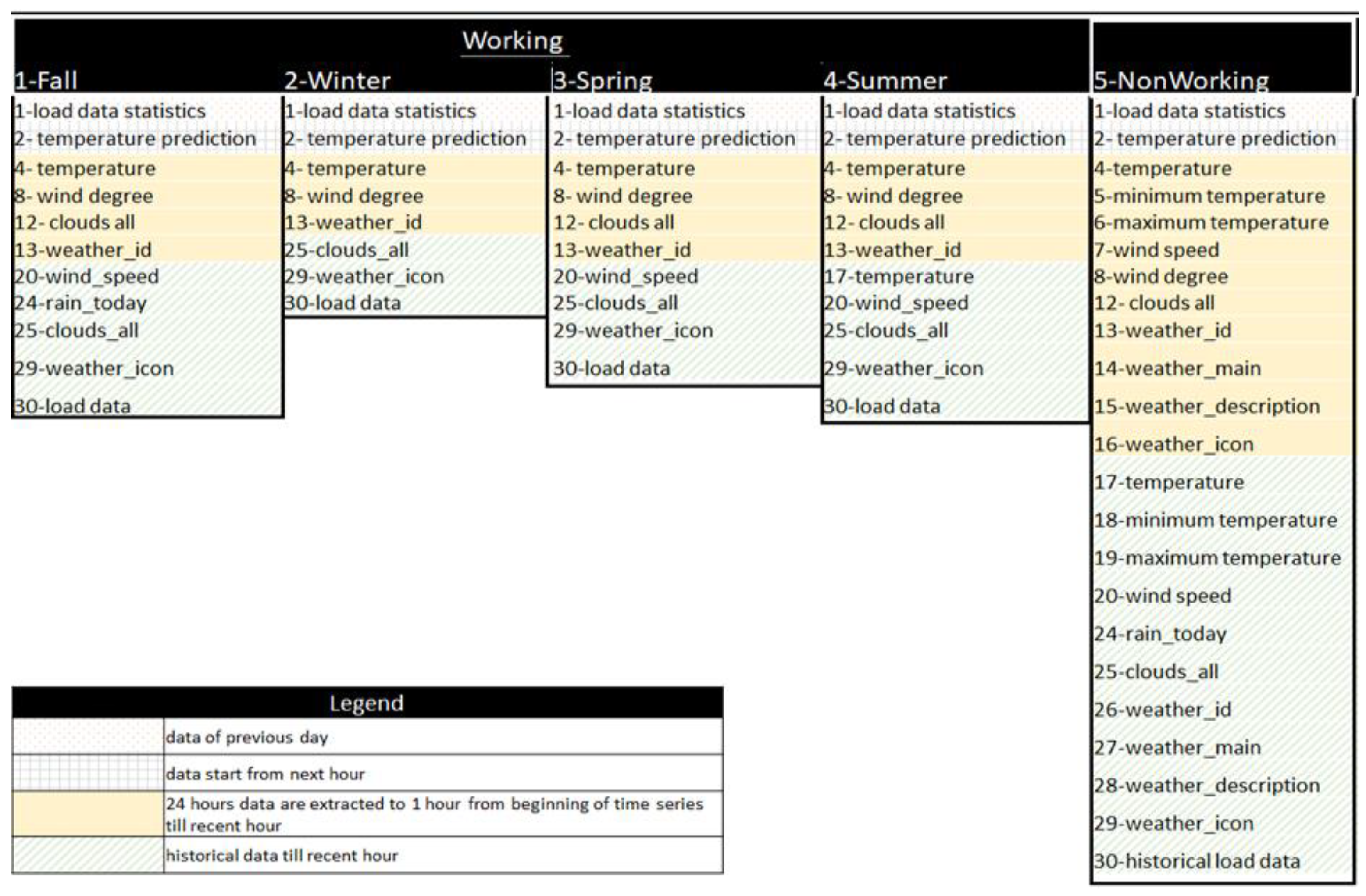
Appropriate selection of input variables based on historical load and weather variables that affect load pattern is essential for STLF. Xin et al. [
20] use correlation analysis to choose the decomposed signal. In this paper, the correlation analysis is utilized to select proper input variables from several preconditioned data. As shown in
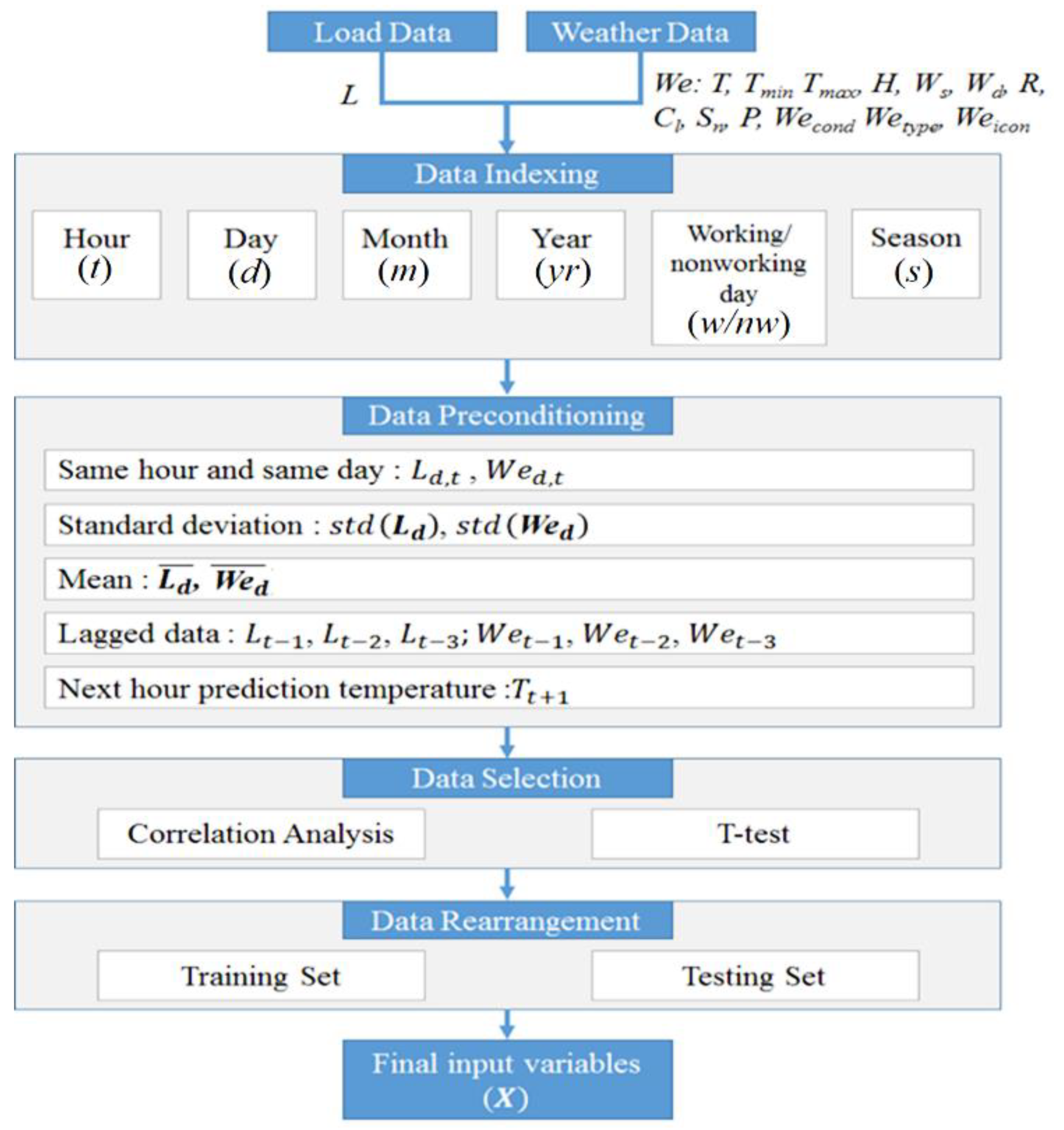
Figure 1, for selection of the input variables, historical data is modeled through the following steps, which are the data indexing, data preconditioning, data selection, and data rearrangement.
As the initial step, load data and weather information are prepared based on [
21,
22], respectively. The data are arranged as a column-vector sorted in the row sequence. The input data for both system- and end-user load are hourly data. The historical load (
L) data are in metric of kW. The historical weather data (
We) consist of temperature (T), maximum temperature (
Tmax), minimum temperature (
Tmin), humidity (
H), wind speed (
Ws), wind direction (
Wd), rain (
R), cloud (
Cl), snow (
Sn), pressure (
P), weather condition (
Wecond), weather type (
Wetype), and weather icon (
Weicon).
Wecond,
Wetype, and
Weicon above are the weather information summary within the observed hour.
Wecond describes the general weather conditions, varying from clouds, rain, smoke, thunderstorm, drizzle, haze, and mist.
Wetype gives a detailed description of each
Wecond, such as scattered clouds, few clouds, broken clouds, proximity shower rain, thunderstorm with light rain, light-intensity shower rain, light rain, light-intensity drizzle, and mist.
Weicon is the visualization code of
Wetype and
Wecond. Detailed information about the weather can be found in [
22].
In the next step, the following inputs are indexed into six different labels according to the hour (t), day (d), month (m), year (yr), working/non-working day (w/nw), and season (s). This process is done to ease the later process in the data preconditioning. Using this index, we can easily rearrange the data into several preconditions that may have strong relations to the predicted signal. Weather information and calendar events are also mapped to a load pattern to explain feature correlation.
Then, the load and weather data are manipulated into several conditions in the data preconditioning step. The same hour and same day, daily mean and standard deviation, lagged data, and next-hour prediction temperature are chosen. The lagged data, up to the previous three hours, are used to avoid misinterpretation of non-stationary load patterns. The lagged version of the load data allows the prediction model to include the recent history of a load sequence. For example, load in hour-24 is highly correlated with the load variation between hour-21 and hour-23. By using the lagged data, the sequential load variation pattern can thus be captured.
After the data preconditioning is done, the data selection and data rearrangement are processed. From the following series, the correlation analysis and t-test are used to achieve the input-output relation and relationship strength between each input to the output. Based on the result of t-test, the input vectors that have p-value lower than 0.05 are classified as significant and used as input variables. Then, the selected vectors are classified into the tuning set and testing set with ratios of 70% and 30%, respectively, to the length of total historical data. The final input variables are then constructed.
3. Proposed Prediction Method
In general, a load pattern is the result of aggregated user behaviors from a downstream level to a high-voltage level, in which the pattern repetition is affected in accordance to the level of aggregation. The wider the system region, the lower non-stationary part of the load pattern is than the narrow system region because the associated weather or user-behavior changes are canceled out by each other. The difficulties in the STLF lie on the precision of modeling different load characteristics, especially from system-side to aggregate end-user load data. DWT has been used to model various load characteristics with different wavelet types and decomposition levels, as previously investigated in [
11,
12,
13,
14,
15,
16]. However, the best reconstruction of DWT remained unsolved.
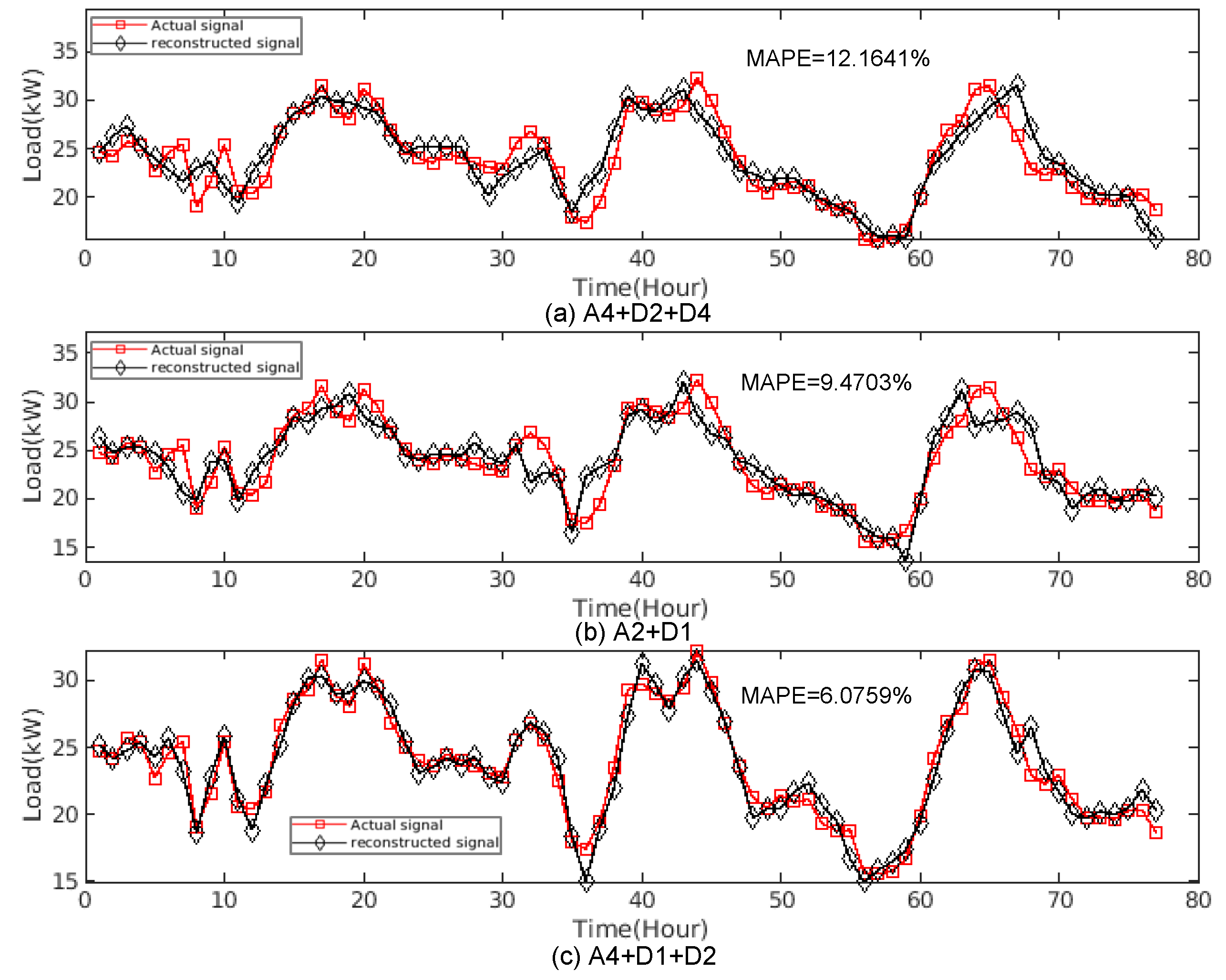
Figure 2 shows the forecasting results of different reconstructions of DWT using Db2. The figure shows that the forecasting accuracy varies by different combinations of approximation and detail components (A
m + D
m). In
Figure 2a, the signal is reconstructed from approximation level-4 and detail components level-2 and level-4, which are shortened as A4, D2, and D4, respectively. Similarly, the combination of A2 and D1 and combination of A4, D1, and D2 are used for
Figure 2b,c, respectively. As seen from
Figure 2a,c, though they use same level of decomposition with different combination of detail components, the MAPE changes drastically. Besides, in
Figure 2b, by only using approximation and detail component in decomposition level-2, it may achieve 9.4703% of MAPE, which is lower than the MAPE in
Figure 2a that uses decomposition level-4. It reflects that, unique to each signal, the chosen set of approximation and detail components affects the decomposed signals and accuracy of prediction. The reconstruction by using decomposed signals may either fit to the original load pattern or distort the original signal. Therefore, the best reconstruction by using decomposed signals is an important task in modeling historical data and prediction.
3.1. The Proposed WOA-DWT-MLR Method
In this paper, the term of “open-ended” defines the general functionality of the prediction method which is flexible in the application of system and end-user sides. An open-ended prediction method is expected to have the capability to accommodate different load characteristics of aggregated system load and individual end-user load, which have majorly different load characteristics observed from their signal waveform and load capacity. The characteristic of system load is steadier in variation than end-user load because the changes of aggregated load from various feeders are canceled out by each other and result in less fluctuation.
Differing from the system load, the end-user load fluctuates much more according to the local weather, user behavior, calendar, and usage of appliances. Those factors complicate the variation and randomness of the load pattern from hour to hours and day to days. An open-ended prediction method is expected to always have the best performance without any site-specific constraint, a fact which is possible to be achieved by setting the optimal prediction model from the chosen inputs.
The open-ended prediction method is formulated based on WOA-DWT-MLR model. WOA is used to find the optimal level of decomposition, type of wavelet, and composition of details and approximations before those sub-signals are modeled into several MLR models. The DWT decomposes the non-stationary part of inputs into several high- and low- frequency components and reconstructs them in the original time domain signal. DWT uses the Daubechies type of wavelet which has scale and translation parameters for transforming the signal into low- and high-frequency coefficients. The low-frequency sub-signal is called as approximation component, while the high frequency part is called as detail component. Search space of the Daubechies can be formulated as:
where
r is DWT’s level of resolution, and
m is scale parameter relating to time step
n. DWT is tuned to find appropriate values in the wavelet type and decomposition level. The trend of the signal is coarsened by the approximation component. The high frequency of the signal is captured by the detail component. When the decomposition level is increased, the density of signal variation decreases or sparser. For further details, refer to Mallat [
23].
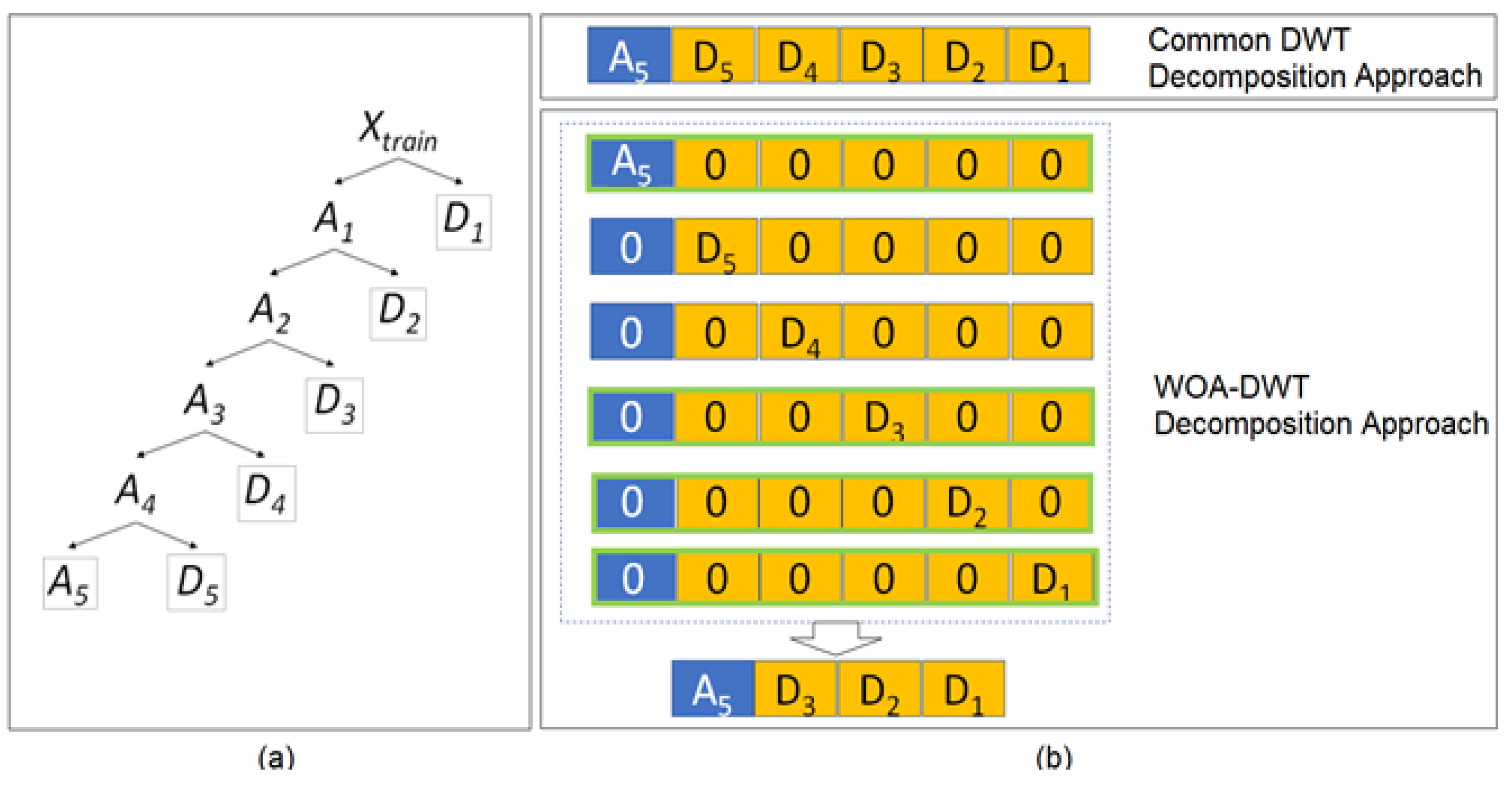
Figure 3 shows the DWT modeling process in the proposed WOA-DWT-MLR.
Figure 3a shows the decomposition tree of the proposed WOA-DWT-MLR, setting level-5 as the maximal level for the WOA-DWT. In the proposed decomposition approach, the signal is independently decomposed to the set of Daubechies levels and types by handling the selected decomposition coefficients while the remaining coefficients are replaced with zero. Based on this scheme, the signal can be extracted to its unique characteristics reflected by individual approximation and detail components. Instead of taking the common decomposition structure as [
Ar,
Dr, …,
D1], WOA is utilized to find the optimal combination of the decomposed parts. This approach is taken to sort out the less necessary DWT components to achieve accurate reconstruction of the actual signal. Only the selected parts of decomposition are reconstructed.
Figure 3b shows the illustration with the proposed method having [
A5,
D3,
D2,
D1] as the final combination, due to less Least Square Error (LSE), as in Equation (12), than the common structure of [
A5,
D5,
D4,
D3,
D2,
D1].
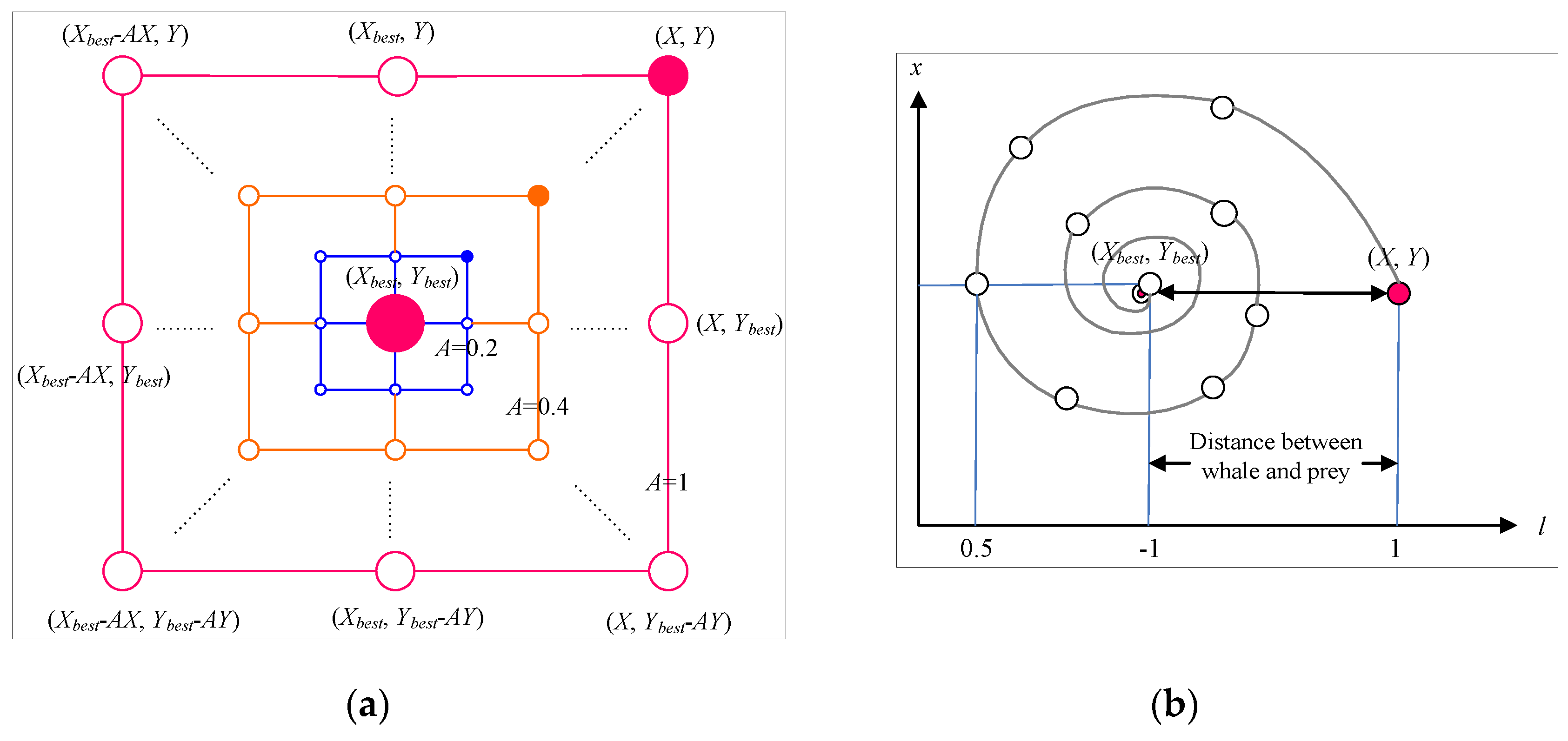
According to Mirjalili and Lewis [
19], a humpback whale attacks prey by adopting the bubble-net feeding strategy.
Figure 4 shows this strategy with its shrinking encircling mechanism and spiral updating process as used in the WOA [
19]. The bubble-net feeding strategy is the hunting method of whales by creating some bubbles along a spiral to corner the prey close to the surface before eating them. In the mathematical model as illustrated in
Figure 4a, the bubble tags are modeled as position from (
X, Y) towards (
Xbest, Ybest), following a vector coefficient of 0 ≤ A ≤ 1, to replicate the shrinking spiral of a whale to corner the prey. As shown in
Figure 4b, the spiral position updating process is used to update the distance between the whale located at (
X, Y) and the prey located at (
Xbest, Ybest). The whale corners the prey within the shrinking circle and spiral shape, simultaneously, through random update of position (
X, Y) toward (
Xbest, Ybest). In the optimization algorithm, WOA optimizes the solutions following the number of search agents to tune the best performance. Basically, WOA calculates the location of bubbles as the solutions and encircles them in the
n-dimension search space. In this research, WOA finds the set of approximation and detail components that has the minimum LSE as the objective function in the tuning stage. Search agents then move in a hyper-cubed way around the current best solution. The position of a search agent can be updated according to the position of the current best record X
best. Different places around the best agent can be achieved with respect to the current position by adjusting the value of coefficient vectors
and
.
The updating process of current position is written as follows:
where
iter indicates the current iteration,
and
are the latest position vector of the best solution obtained and position vector, respectively, and
describes the shrinking bubble-net strategy to the surface by linearly decreased from 2 to 0 over the course of iterations, while
is a random vector in [0, 1]. The humpback whales swim around the prey within a shrinking circle and along a spiral-shaped path simultaneously. There are two approaches to search for prey in WOA, which are exploitation and exploration. The exploitation phase uses the bubble-net attacking method, following the shrinking encircling mechanism and spiral updating position, which assumes 50% probability as follows:
Shrinking encircling mechanism: this behavior is modeled by decreasing the value of in Equation (4) and further use in Equation (6) with p < 0.5. is a random value in the interval of [−a, a], where a is decreased from 2 to 0 over the iterations.
Spiral updating position: this approach initially calculates the distance between the whale location X and prey location and then constructs a spiral equation between the X and and to mimic the helix-shaped movement of humpback whales as Equation (6) with p ≥ 0.5, where indicates the distance of the ith whale to the current best solution. In this approach, b is a constant describing the shape of the logarithmic spiral, while l is a random number in [−1, 1].
The exploration of the humpback whales is defined by a random search with coefficient vector
that allows WOA to perform a global search. Instead of using the current best agent, the humpback whales choose the search agent randomly based on the position of each other. This mechanism can be modeled as follows:
where
is a random position vector (a random whale) chosen from the current population.
In the proposed method, the search vectors of WOA are the wavelet type
, decomposition level
, and reconstruction of details and approximation being used
. These search vectors are accommodated in
, which is then extended to the size of agent numbers and search vectors as row and column, respectively. After several iterations, the set of solutions is fed to DWT to get the optimal approximation-component
and detail-components
varying from
k = 1, 2, 3, …,
that achieve minimum prediction error. Then, the final decomposition sub-signals of WOA-DWT are used in prediction model, following the multiple linear regression model as in Equation (9):
The final prediction output is the summation of best combination MLR model that has the minimum LSE as in Equation (10). The prediction output of each Daubechies wavelet component
yi is calculated from the input variables
X, regression coefficients
β, intercept α, and observed model error
e. The intercept α and regression coefficient β are obtained using the least-square estimator that minimizes the sum of square errors (residuals).
where
is residual error between actual
and prediction value
at observed hour
t.
The proposed prediction model is evaluated by LSE and Mean Absolute Percentage Error (MAPE). LSE evaluates the WOA optimization, while MAPE evaluates absolute error between the prediction result and actual load data. Calculation of MAPE and LSE based on number of hours Nh is shown in Equations (12) and (13) as follows:
3.2. Prediction Models of Tuning and Testing Stages
Tuning, validation, and testing stages are run to build the prediction models.
Figure 5a,b shows the tuning and testing stages, respectively, of the proposed WOA-DWT-MLR to find the best prediction model. In the proposed method, the DWT is subjected to each data set to handle the unique periodicity of those seasons. DWT with the initial parameter tuned by WOA calculates the decomposition layer of a set of input and output data. The initial parameter is taken randomly between 2 to 5 for Daubechies level r and 1 to 5 for Daubechies type m. The validation stage is performed as the preliminary testing after prediction model is built in the tuning stage. Each of these reconstructed signals is utilized in several individual MLR models. The output of each MLR is summed and the LSE is calculated. The best prediction model with the minimum LSE is chosen as the final prediction model after several iterations. In the tuning process, validation will be conducted using last 24-h time series data in each season. In the testing stage, the tuned prediction model is tested with the testing data set. The tuning stage takes 70% of the data to get more insight of the daily pattern. Both validation and testing stages use the remaining 15% of data.
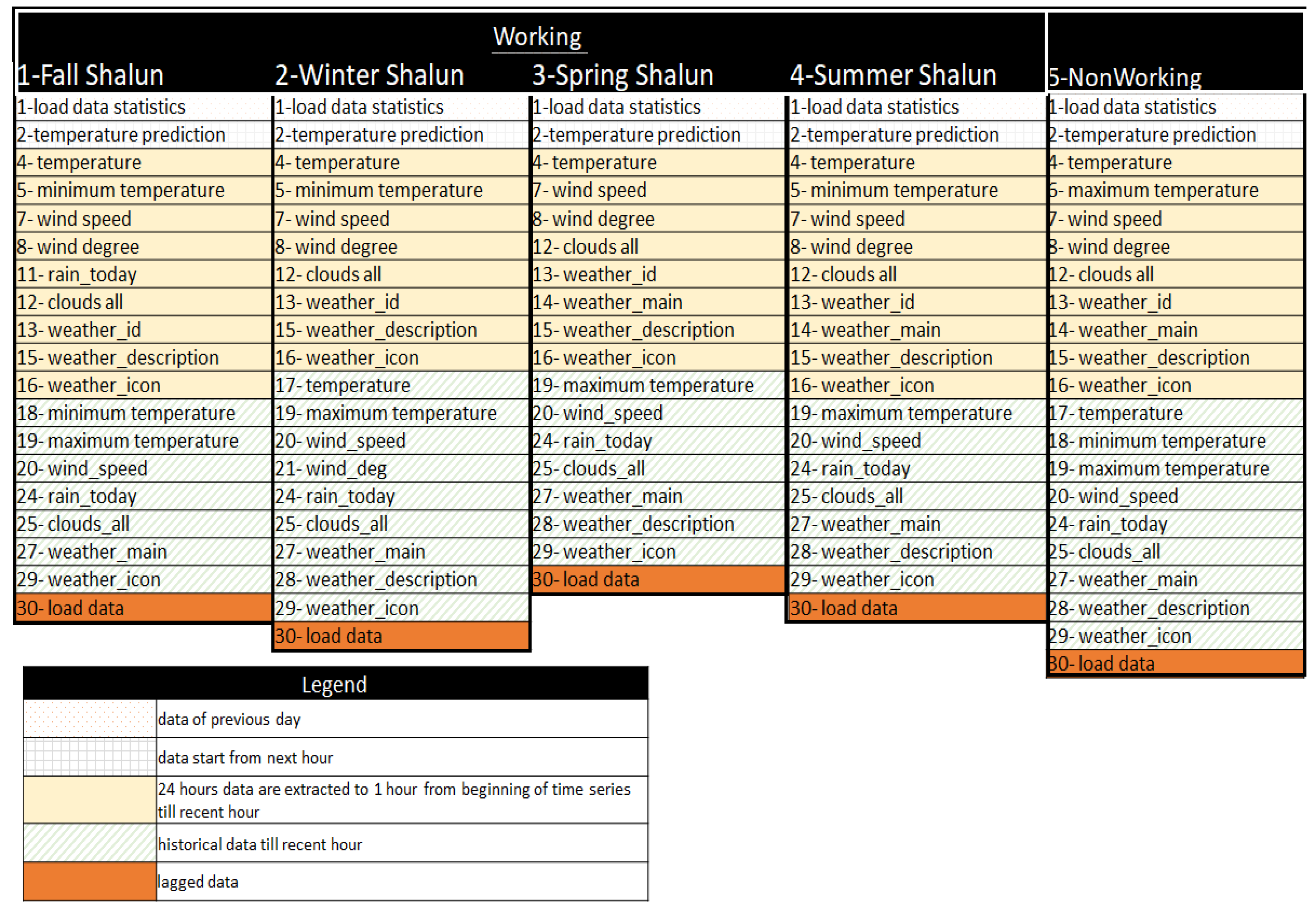
To show the effectiveness of the proposed prediction model, the inputs for both system and end-user data sets are differentiated into working day and non-working day models. In the working day model, historical data from Monday to Friday is contained, including deferred holidays to compensate for holidays that fall on weekends. The data set excludes holiday happening within these days. The non-working day model covers Saturday to Sunday, including national holidays happening on weekdays.
The proposed method is tested by the system data set and end-user data set. In the system data set, there are four different season models, starting from Fall, Winter, Spring, and Summer. It is assumed that Fall runs from September to November, and so on for the remaining season models in different months. For the end-user data set, there are only two different season models which are sets of Fall-Winter and Spring-Summer, respectively. The Fall-Winter model is assumed to begin at September and last till February. The end-user data set consists of only two different unique models because of data lacking issues.
3.3. Benchmark Algorithms
To validate performance of the proposed method, five well-known algorithms are used as benchmark. These methods have been applied to the same day-ahead load forecasting to show individual prominent results. The comparison methods are traditional MLR, ANN, Autoregressive moving average with exogenous input (ARMAX), support vector regression (SVR), and PSO-DWT-MLR. Brief descriptions about the algorithms are as follows:
MLR (Mohammad et al. [
24])
: the MLR prediction model calculates the targeted output based on a set of predictors in which the coefficients of each predictor are calculated by least sum of squares as in Equation (9). For the validation of the proposed method, MLR uses the same input variables as the proposed method.
ANN (Hernández et al. [
25]): the ANN consists of the input layer, hidden layers, and output layer interconnected via weights between nodes or neurons. To get the best weights from regression models that describe the relationship between input variables and next-day hourly prediction, the number of ANN’s hidden neurons needs to be fine-tuned.
ARMAX (Hong-Tzer et al. [
26])
: ARMAX is used to model the relationship between load demand and exogenous input variables. The ARMAX model can be written as follows:
where
y(
t) is the load demand,
u(
t) is the exogenous input related to load demand,
e(
t) is white noise, and
q−1 is a back-shift operator.
are parameters of the Autoregressive (AR) part,
na is the AR order;
are parameters of the exogenous input (X) part,
nb is the input order;
are parameters of the Moving Average (MA) part, and
nc is the MA order. To get the best tune of ARMAX parameters, PSO is used for each data set.
SVR (Cortez and Vapnik [
27], Chen et al. [
28])
: SVR is a non-parametric technique using sequential minimal optimization to solve a decomposed equation for the input variables. For each iteration, a working set of two points is chosen to find a function
f(x) that deviates from
yn by the value not greater than the error in each previous training point of
x. The result of iteration process can be recalled as the mapping of the training data
x into high dimensional feature space to represent nonlinear relationship between input variables and targeted output.
PSO-DWT-MLR: the prediction method uses PSO (Zhan et al. [
29]) as the optimization algorithm to find the best combination of reconstructed signals. PSO is used to optimize the DWT type, level, and combination of wavelet component, as WOA did in the proposed method.
5. Discussion
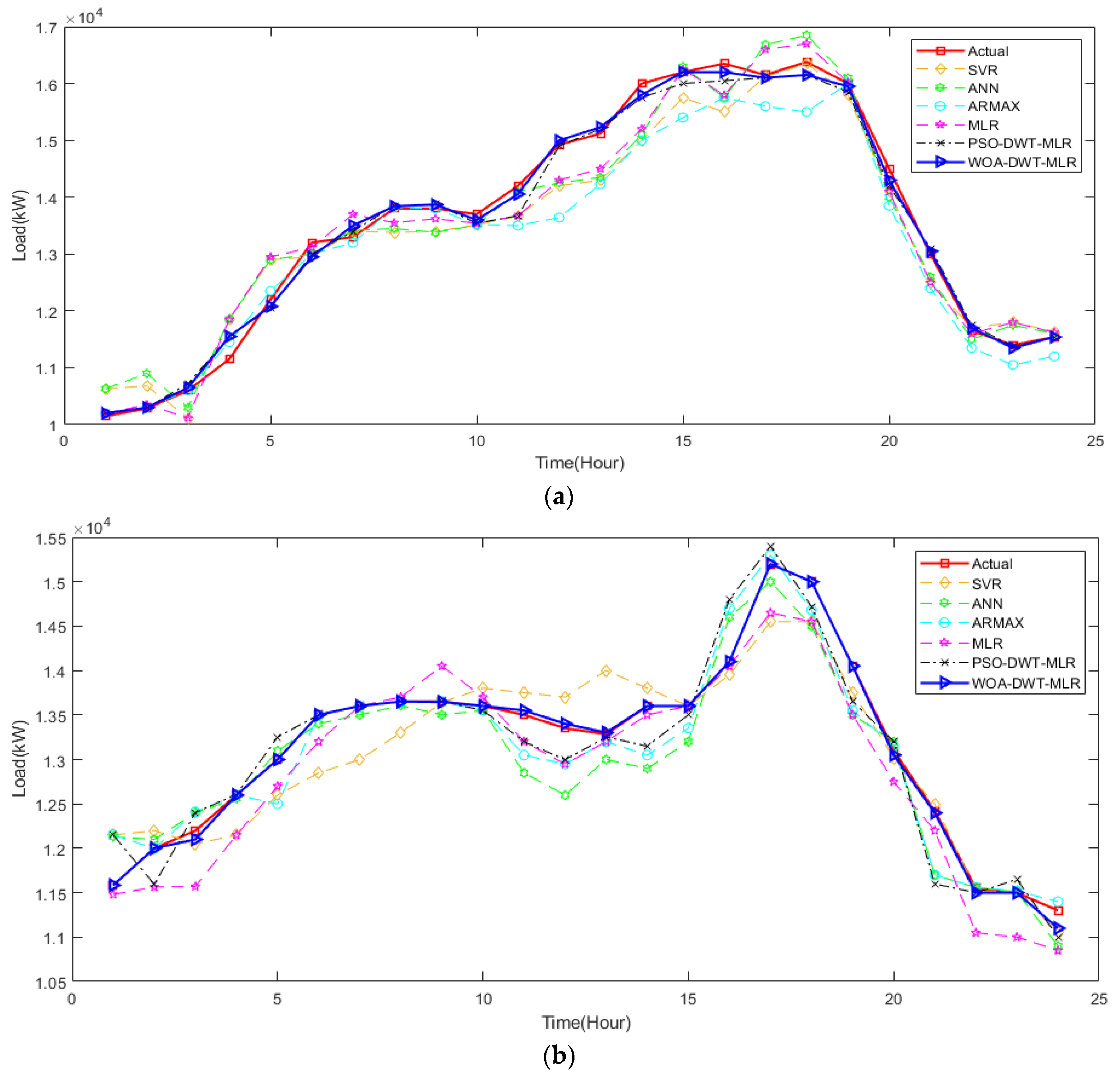
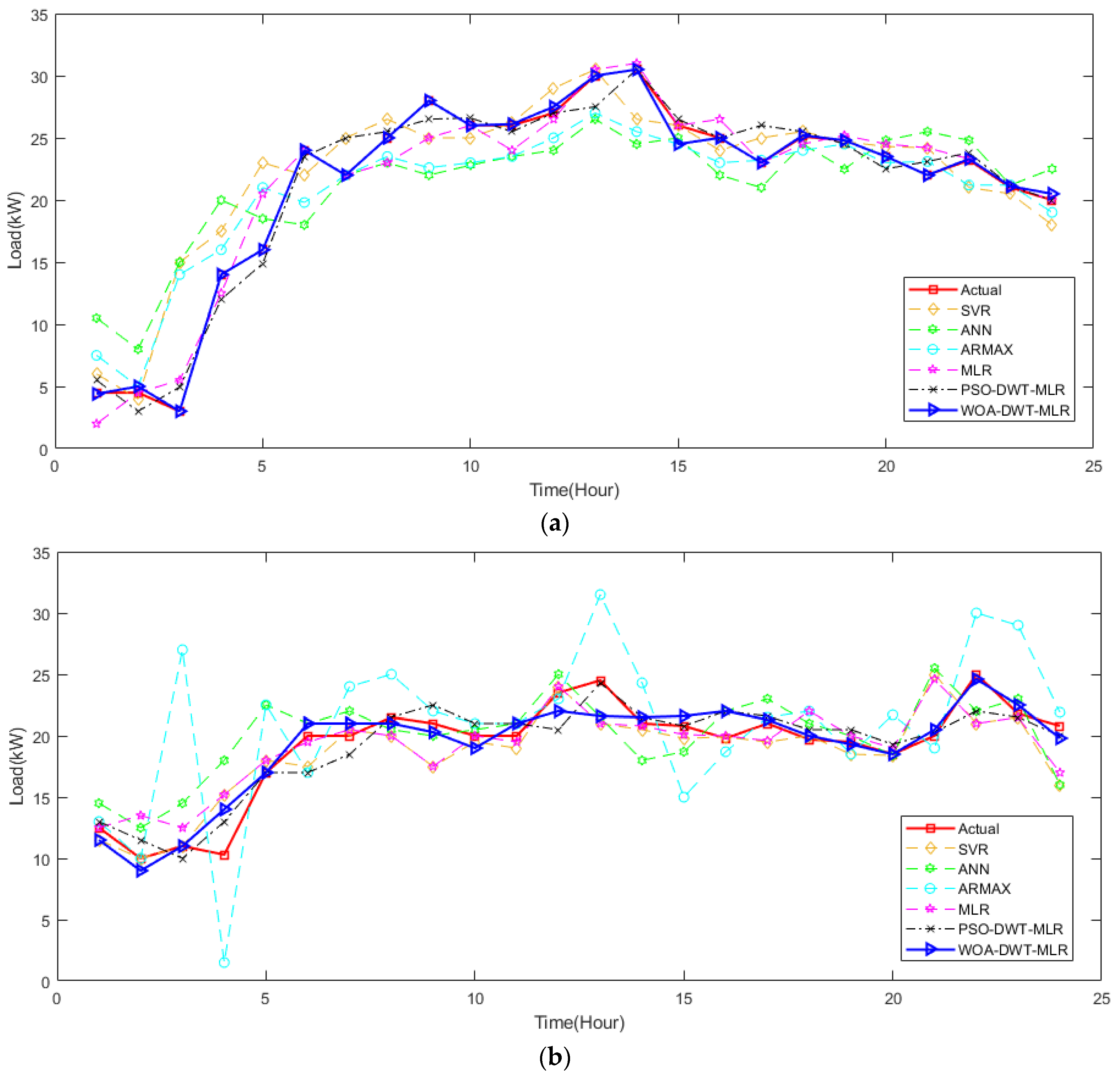
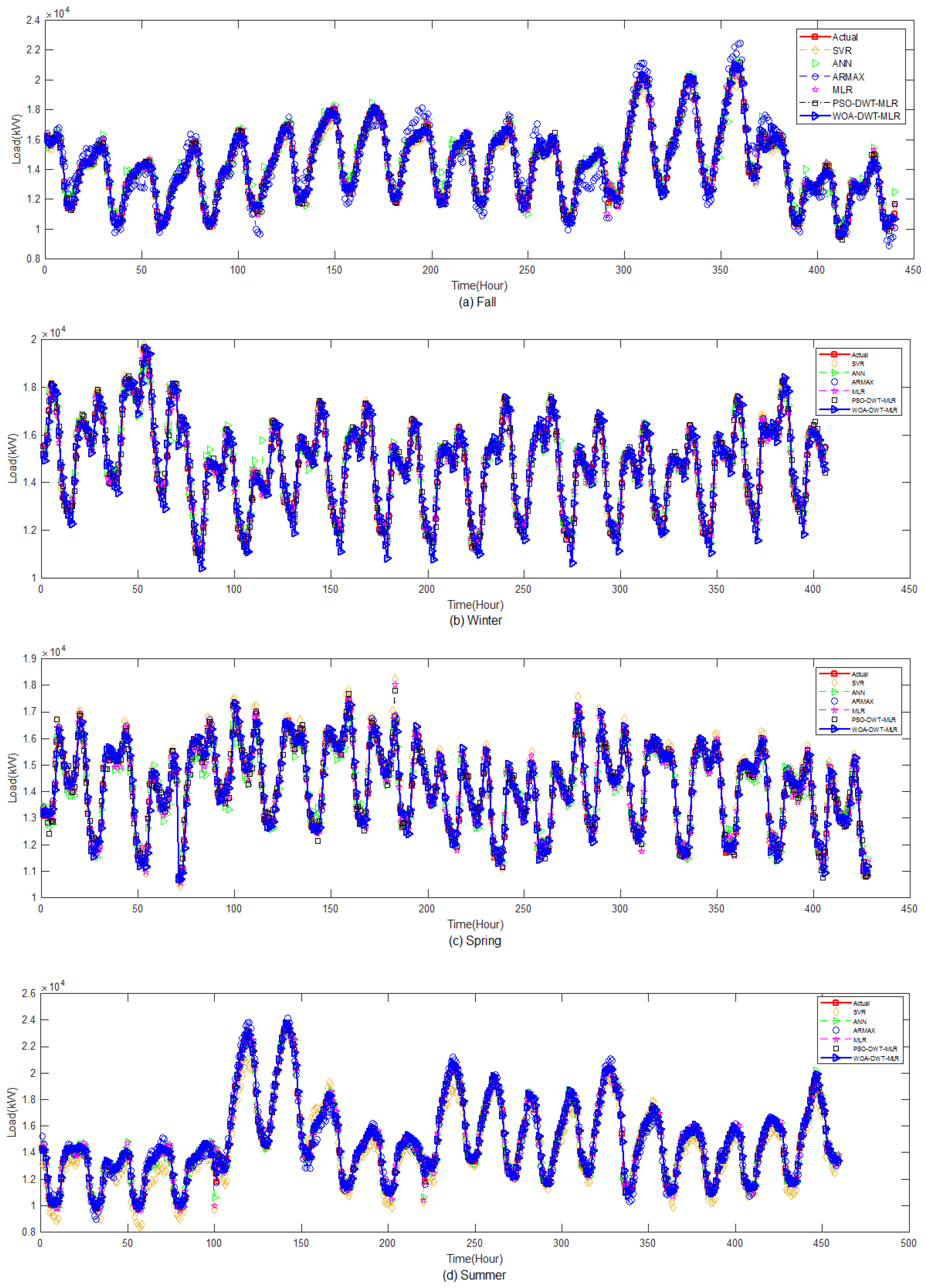
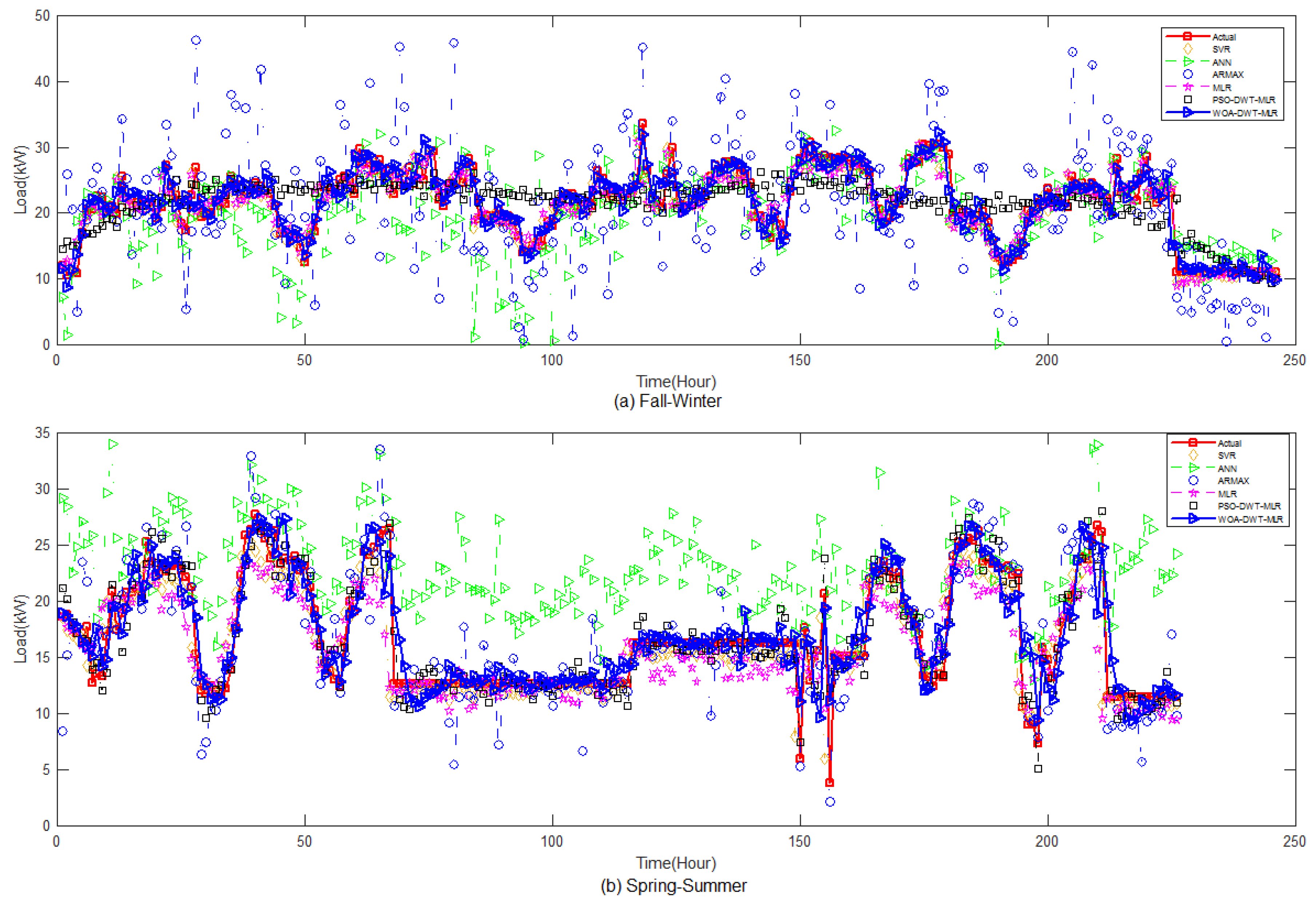
To get deeper observation of the prediction results of the proposed method, we extended the prediction period into several days for each season in the ISO-NE and Shalun data set, as depicted in
Figure 11 and
Figure 12, respectively. It is noted that, due to some missing data, the pattern of some hours of a day is neglected to avoid greater error in prediction evaluation. From these figures, we can infer that both the system and end-user data set are non-stationary with weekly seasonality and seasonal trends, even though we have treated the data based on its season. Especially in the Shalun data set, as seen in
Figure 12, the seasonal trend is distinct because of the combination of seasons in Fall-Winter and Spring Summer groups, due to lack of data.
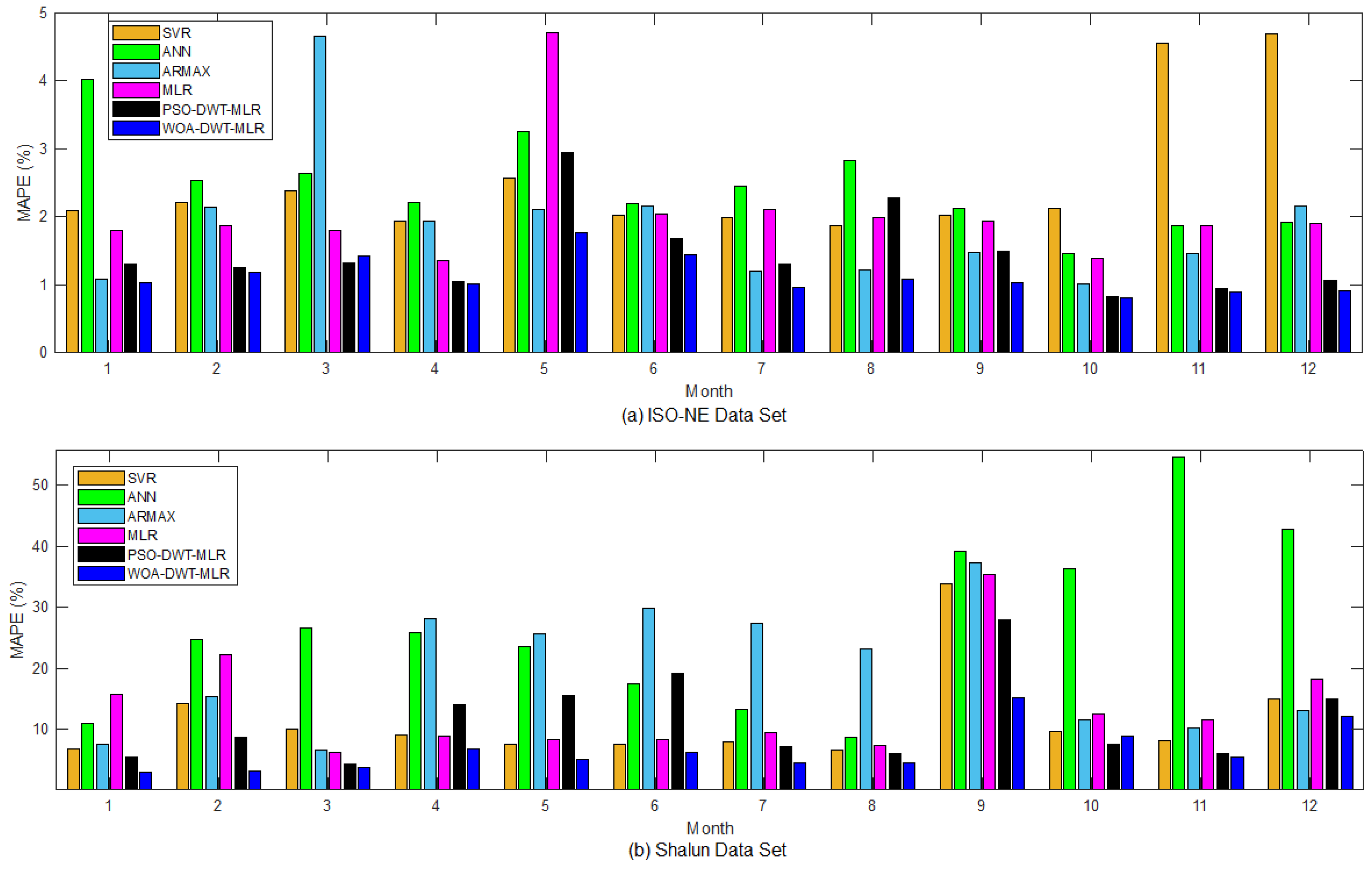
To avoid subjective judgement based on visual observation of the prediction pattern results, the annual averages of MAPE for both the ISO-NE and Shalun data sets are plotted monthly in
Figure 13a,b, respectively. Axis-
y represents the average MAPE of the month, while axis-
x represents month with month-1, month-2, …, and month-12 being January, February, …, and December. For the ISO-NE data set, as shown in
Figure 13a, we can observe that prediction techniques without discrete wavelet transform do not have better accuracy due to its inability to extract nonstationary part of the load pattern. Besides, though ARMAX can produce a mostly better performance in January, July, August, September, and October, the prediction performance is gets worse in the other months, showing an unsteady prediction performance of ARMAX.
Different from the former prediction techniques, the prediction result of PSO-DWT-MLR and WOA-DWT-MLR are more stable in magnitude of 1% to 3% MAPE and 1% to 2% of MAPE, respectively. For the PSO-DWT-MLR, the MAPE in May and August is worse than traditional MLR because of the PSO trapped at the local minima. Thus, though DWT is already used, the combination of approximation and detailed component cannot effectively produce accurate prediction. For the proposed WOA-DWT-MLR, the MAPE is higher in May for about 1.77% but quite stable at 0.98% of MAPE for the remaining months. As shown in
Figure 13b for the Shalun data set, the performance of WOA-DWT-MLR is better than other comparison methods. Though, in September, the MAPE is higher, up to 15.21%, in comparison, the comparison method has 33.82%, 39.29%, 37.27%, 35.45%, and 28.01% for SVR, ANN, ARMAX, MLR, and PSO-DWT-MLR, respectively. The main cause of the higher errors in September comes from the data scarcity due to too many bad data.
For the end-user data set, the prediction accuracy of all the methods for comparison is worse than the ISO-NE data set because of its irregular power consumptions. Though relevant weather information has been selected, the other exogenous factors, like user behavior, still highly affect the randomness in the load consumption pattern. Further disturbing the load pattern for the tuning stage, the irregularity is also worsened by the outlier data due to out of order of the communication system for collecting the load data. Therefore, in further research, a more reliable data preconditioning scheme is needed to support the prediction modeling.
Related to the length of available data, the proposed method has strong consistency in accuracy, as proved by the MAPE. The accuracy is not bounced away when facing a lack of data, such as that happening in the Summer and Fall model, when the other methods lose their accuracy. It reveals that the proposed method can handle the highly nonlinear end-user data set, while the other methods fail to maintain their accuracy.
For the computation time, the proposed method constructs the final prediction model by storing the best information of MLR coefficients, type of DWT, and level of wavelet decomposition in each iteration. Without the WOA-DWT, MLR needs less than 1 min to build a load forecasting model, while ANN and ARMAX require more computation time. After the WOA-DWT strategy applied in MLR by the proposed method, the computation time increases to several minutes and up to ten minutes. Once the testing stage begins, the algorithm needs to manage the process of wavelet decomposition and requires more time than the other methods to produce prediction but fits the application requirement.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}