1. Introduction
The participation of active end users in the creation of advanced services and new business models is one of the main goals in the smartification of the energy sector. Through the setting-up of innovative energy-balancing services or dynamic tariffs, such as the ones that are usually developed within the demand response (DR) schemes [
1], active end users and prosumers can become aware and conscious managers of their own energy resources. The integration and coordination of such resources in an urban context is also a key point in the development of smart distribution grids [
2] and smart cities [
3].
This paper refers to an EMS architecture developed for controlling low voltage energy resources of a small residential or tertiary prosuming unit, and enabling DR. This architecture was developed within the R&D project named “Energy Router” (ER) [
4,
5,
6], carried out in collaboration with several Italian industrial companies. The project aimed at the design, test, prototyping and possible later industrialization, of a controller that manages in real time all available DERs with applications in both residential and tertiary sectors. The ER architecture is typically organized following a hierarchical structure with a local controller responsible for the actual real-time dispatch of resources (generation, storage, controllable loads) and a higher-level global controller built on a cloud platform. The presence of a cloud platform allows the externalizing of all metering, data analysis, and forecast functions. Since the presence of at least one storage unit is assumed, the higher control tier is based on predictive control that permits to optimize charge and discharge time trajectories in a specific time window [
7,
8], or to adopt rolling horizon techniques [
9,
10]. The use of predictive control requires the availability of generation and load forecasts with an acceptable level of accuracy. This paper shows the microforecast algorithm proposed for the ER architecture and provides test results based on actual real-time data acquired on two pilot systems implemented in public buildings.
The main issue of a forecasting method in a micro or smart grid is to predict the demand of the loads in the network or the power generated by renewable energy connected to the network for the near future. This is necessary for determining how much power is used from the controllable resources and devices [
11]. Therefore, for micro and smart grid applications, the generation and load forecasts required are usually considered short-term forecasting (e.g., a forecast performed in the order of hours or a few days in advance) [
12,
13]. The scientific literature on the elaboration of forecast models of demand loads highlights a lack of studies conducted on real data, especially for data that are collected in a disaggregated manner (e.g., at the individual user level or residential/commercial or industrial building). Often the used sample consists of an extremely reduced number of users, and data collected (where they have not been artificially generated) have a limited temporal extension.
The studies present in the literature can be mainly grouped into two macro-categories: (i) those which refer to the forecast of domestic consumption [
14,
15], and (ii) those concerning the forecast of commercial or industrial consumption [
13,
16,
17]. The opportunity to distinguish between these two groups mainly concerns the needs that characterize the two energy profiles and the purposes for which these forecasts are generated. In the first case, in fact, greater variability in the behavior can be observed in the users, who—within a smart grid—can express preferences in optimizing their consumption, which often translate into soft constraints [
18,
19]. On the other hand, commercial or industrial users can tend to have a repetitive load profiles, and will have some operative constraints of the plants turning in the definition of hard constraints in the planning or optimization of the overall smart grid [
18,
19].
The approach adopted in this work to obtain the predictions of the generation or consumption of energy is based on the study of the so-called time series. A historical series or a time series is a realization of a stochastic process observed sequentially over time. Therefore, after collecting a historical series of data, it is possible to identify a mathematical model to describe this stochastic process. The study of the theoretical properties of the model thus defined makes it possible to carry out a statistical analysis of the historical series and to predict the future values of the series itself. In recent years there has been a great deal of research to develop automatic prediction algorithms for time series [
20], as it represents a crucial need in many different real-world problems [
21,
22].
This paper is an extended version of the conference paper [
23] and is organized as follows.
Section 2 introduces the building blocks of the considered Energy Router architecture. The successive
Section 3 details the Mircoforecasting module. Next, the experimental campaign is illustrated in
Section 4, while results are presented and discussed in the successive
Section 5. Finally, some conclusions are drawn in the closing
Section 6.
2. The Energy Router Architecture
The monitoring and control architecture developed in the ER Project was designed to enable EMS functions for small residential or tertiary end users. The main assumption is that in the near future, any customer at low voltage level could be considered as an active end user, or a prosumer, having at their own disposal a set of grid-connected dispatchable resources such as renewable microsources (most likely rooftop photo-voltaic (PV) generators), storage systems, and controllable loads (interruptible or curtailable loads). Theoretically, the load shifting functions provided by a battery energy storage system (BESS) could be also obtained with an electric vehicle (EV) connected to the grid in vehicle-to-grid (V2G) framework. It is also assumed that the Distribution System Operator (DSO), or even an energy aggregator, will provide time variant price signals on a daily base, according to dynamic energy pricing or DR schemes.
The ER architecture is aimed to provide automation tools and overcome the intrinsic inelasticity characterizing energy customers at low voltage level, and especially in residential or public sectors. Optimal control strategies are used to control distributed resources, exploiting real-time data and price signals received from the grid. Due to the presence of storage systems, the use of predictive control techniques is preferred to pursue optimality in a larger time horizon [
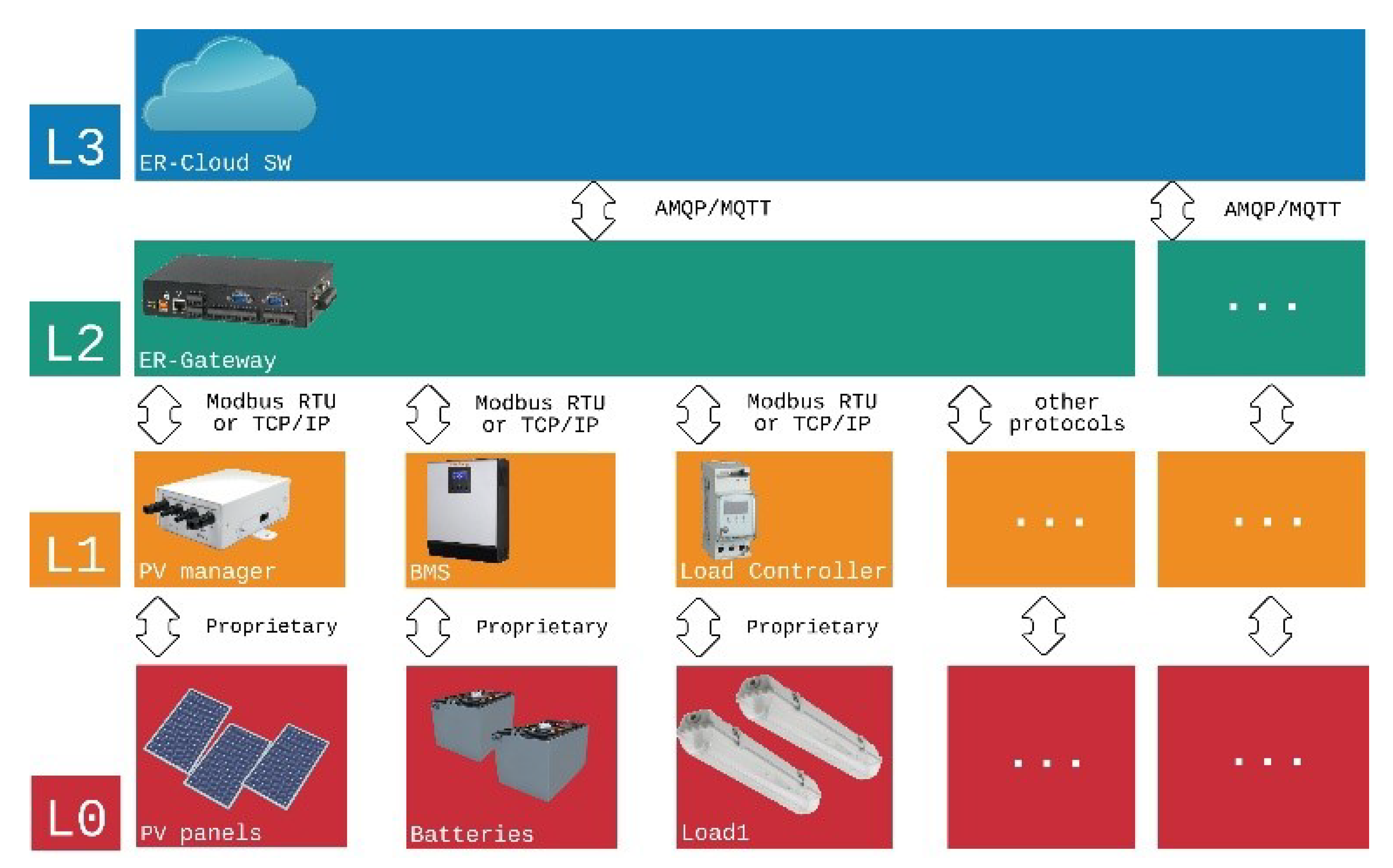
9]. In the ER architecture the optimal exploitation of DERs is obtained through the numerical solution of an optimal control problem which pursues the minimization of an objective function representing the energy cost, while assuring that all devices are within their security and technical operating conditions. This problem, which provides time-varying references for all DERs to be followed along a specific time window, is solved within the first tier (L3) of a hierarchical control scheme whose architecture is schematically depicted in the diagram reported in
Figure 1.
The overall optimal control strategy is implemented at cloud-level (L3) where a predictive optimal control problem is solved exploiting both real-time system state information and external price signals, and generation and load forecasts as well. Load forecasts are elaborated by the microforecasting application presented in this paper. The layer L2 is the one responsible for collecting measurements from the field and actuating real-time control of distributed microsources. In the ER architecture, this layer is managed by a hardware component (the ER Gateway) whose physical prototype was designed and tested during the project. The ER Gateway is built adopting a multiprotocol approach and can dialogue with the lower layer using most of industrial and home automation protocols (Modbus, Profibus, CAN-BUS, KNX, Zigbee, Z-Wave), and multiple physical media. It collects measurements which are sent to the upper layer and stored on the cloud servers, to build historical data series. The ER Gateway is also responsible for real-time control and therefore it interprets the time-varying optimal set-points given by the upper layer, and sends commands to the controllers of the microsources (layer L1) based on real-time measurements. Controllers at this layer (L1) manage field components (Layer L0) through proprietary protocols. The ER monitoring structure permits to collect wide pieces of information to be stored in the cloud database. Power demand data can be collected with high time resolution that can go up to the physical constraints of the measuring components (usually about one measure per second for a typical industrial automation metering unit). However, due to the randomness of real-time load fluctuation, data used in energy demand forecasts are averaged in larger time intervals (usually 15 min or more) so that they do not lose significance.
Optimal control is performed adopting a rolling horizon strategy as in typical model predictive control applications. This means that the optimal set-points evaluated at L3 are applied by L2 only in a time window shorter than the one used to solve the optimal control problem, because subsequent set-points are recalculated using updated information about the system. This strategy allows for compensation errors due to time resolution or forecasts, and takes into account unexpected events (for example sudden unavailability, weather change, DR events, etc.) [
4]. Clearly the availability of a suitable microforecasting tool that can update forecasts using real-time measurements obtained in the control phase may increase the performance of the overall control system.
3. The Microforecasting Module for Energy Management
Although the control strategy adopted in the ER Project proved robustness regarding the possible variability with respect to generation/load forecasts [
4], the assumption of deterministic prosumer’s data may not hold in real contexts, or at least it can be misleading [
19]. For this reason, the accurate forecasting of the generation/load and the related uncertainties can be considered as a main crucial step for the framework under study. In general, the objective to optimize the final customer’s service in a single building unit is an issue with a great impact on the methodologies needed to perform this microforecasting task; i.e., to provide a specific forecast for every single unit [
24]—assuming that each unit has an active role in energy consumption. In fact, aggregation across units and/or across buildings may be inadequate or misleading in these cases [
21]. The optimization and control strategies must be based on the single-unit generation/load forecast which is usually based on short-term forecasts, ranging from a few hours to one day. Moreover, it possibly takes into account controllable or non-controllable exogenous variables to represent, for example, prices, occupancy, promotional and calendar events, or weather conditions. Such a distributed and recurrent forecasting activity, involving many units and/or buildings, requires the use of some modular and automatable procedure to be included in a cloud-based system architecture.
The main requirements for a microforecasting implementation are two-fold: (i) a measurement and information system able to assure that short-term (daily/hourly) data are available for each considered unit; (ii) effectiveness and suitable speed of both the forecasting and optimization/control modules included in the system.
Presently, several EMSs already have access to the required information with the possibility to implement and use forecasting modules. Nevertheless, the users or the decision makers should not be exposed to the complexity of these systems [
21,
25]. Therefore, a modular and adaptive forecasting system would provide relevant support by automatically selecting the best performing model with respect to the current instance. The process is repeated for each individual unit (if needed) in the considered context and for each forecast session adopting a rolling scheme [
25] using a fixed-length (e.g., 4–6 h) window to update forecasts and (possibly) re-configure the models. In this way the model’s choice is obtained by setting a small number of parameters keeping the number of samples constant, to preserve results accuracy.
Microforecasting Module Architecture
The forecasting tool was developed in the MATLAB [
26] environment, whereas the core of the forecasting module was developed in
R [
27], an open source statistical computing environment, specifically using the forecast package, developed by Hyndman et al. [
28].
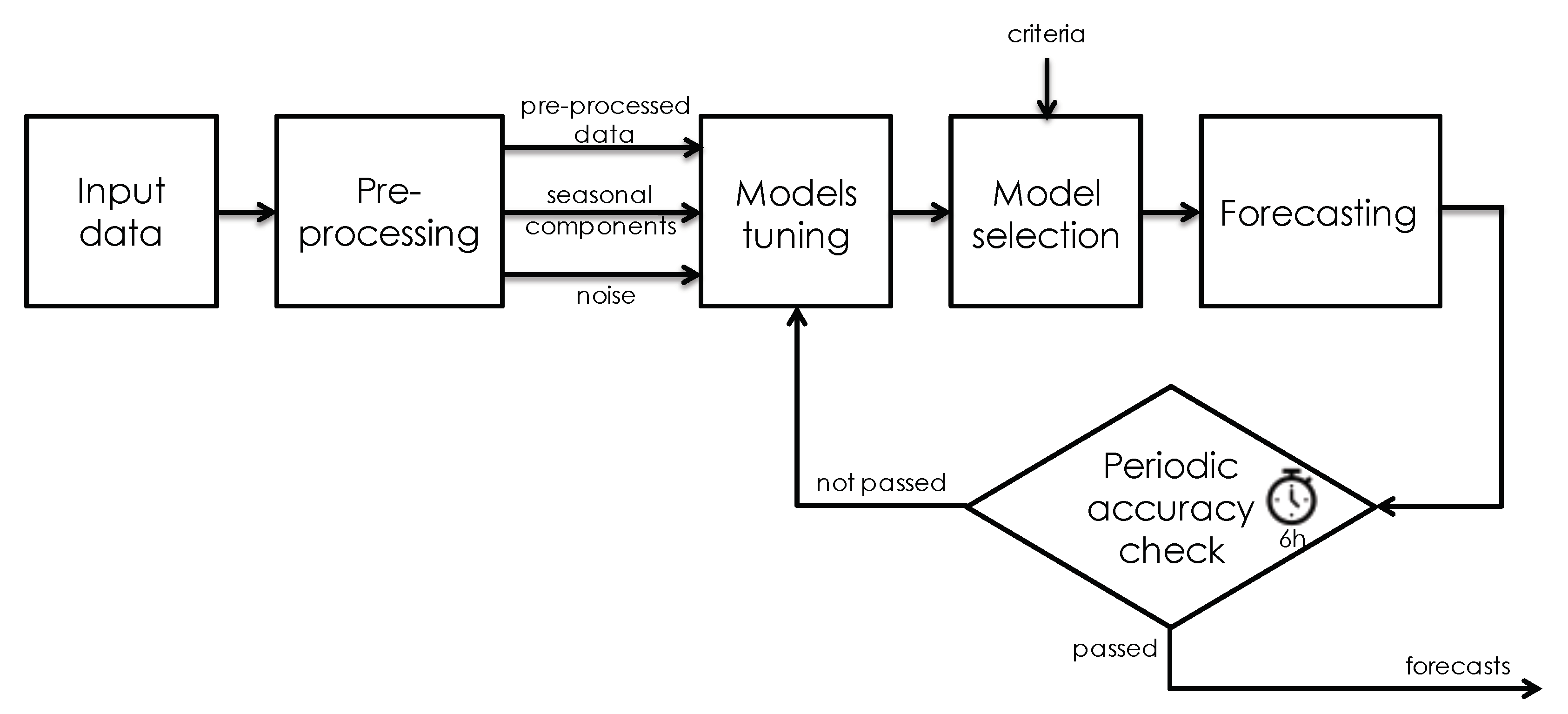
Figure 2 depicts the architecture of the forecasting tool, which requires the following input data: (i) historical data of power consumption, including the corresponding date, time, and possible exogenous variables such as the outdoor temperature; (ii) length of the forecasting horizon; (iii) sample size of both training and test sets; (iv) number of samples per hour for both historical data and forecasts; the frequency of the periodic accuracy check (e.g., by default this parameter is set in order to perform the check every 6 h).
The considered time series contain samples of data from the measures, and the acquisition campaign was started after the installation of a set of energy meters and the implementation of a commercial web server. The monitoring system, together with all other installed components, went through an acceptance testing after the completion of works. Moreover, simple coherence tests can be made to generate alarms on suspected bad data. These tests can be made checking the value of voltages and frequency that must stay within the ordinary operative ranges. Furthermore, the monitoring system was designed to be redundant since it measures not only the energy exchanged at the point of common coupling (PCC), but also the one flowing from/to loads, PV generation, and battery. A simple test on energy balance is used to check the coherence of each sampled dataset.
Regarding the proposed forecasting tool, input data, as shown in
Figure 2, go through a pre-processing stage. The latter has been implemented to remove duplicate records from time series of historical data and to insert any missing data with interpolated values. The noise is identified and eventually removed, in the event that it significantly affects the quality of the underlying data [
25,
29]. Then, the short-term seasonality of the time series of power is analyzed.
Pre-processed data and information on noise and seasonality is provided as input to the forecasting core module, which includes multiple alternative forecasting techniques. Namely, (i) an exponential smoothing model using a seasonal-trend decomposition procedure based on loss (STL) [
30]; (ii) an autoregressive integrated moving average model (ARIMA) [
20]; and (iii) a neural networks (NN) model [
28].
Exponential smoothing is an approach that constructs a forecast from a mean, exponentially weighted (hence the name of the method), of past observations; this means that the prediction is obtained starting from the previous observations by attributing a greater weight to the more recent observations and gradually smaller weights to the remotest observations over time.
One of the best-known classes of mathematical models for predicting time series is represented by the ARIMA models. These models are widely used in statistics, econometrics and engineering for several reasons: they are considered one of the best performing models in terms of forecasting; they are used as a benchmark for more sophisticated models; they are easy to implement and have a high degree of flexibility thanks to their mathematical structure.
NN are often used to approximate continuous functions through more general and flexible functional forms compared to classical predictive techniques, particularly in cases where the real system is characterized by a complex relationship between input and output. The most commonly used architecture is the so-called Multilayer Perceptron (MLP) which uses a supervised learning technique called back propagation. The neural network consists of nodes arranged on several levels: the input level, one or more hidden levels, and an output level. The nodes present in each level are not interconnected, but can share one or more inputs. The network will have an output node to process a single forecast (for example for the next hour or the next day); instead, it will have more output nodes to predict a sequence of data (such as the hourly charge of the day after).
A classical persistence model based on a Pseudo Steady State (PSS) method has also been included in the forecasting framework, which assumes that the forecasted power consumption is the same as the corresponding observed value in the day before. A PSS model is very often used as a benchmark for new forecasting models [
31,
32].
The complete mathematical description of each adopted predictive method was omitted for the sake of brevity, and to focus on the specific contribution of the paper. Anyway, these mathematical models are based on well accepted formulations which are available in the cited literature.
The operations of the forecasting module mainly consist of three steps [
20]:
Forecasts can be regularly updated under a rolling horizon scheme, to counteract possible worsening in predictions. It is worth observing that other different techniques may also be integrated in the framework, to provide both load and generation forecasts, using exogenous variables [
25,
29,
31]. In fact, a drawback of classical forecasting models can be the lack of information about the impact of exogenous variables on the time series, and in many cases it may be more profitable to take into account the impact of relevant external phenomena.
5. Results
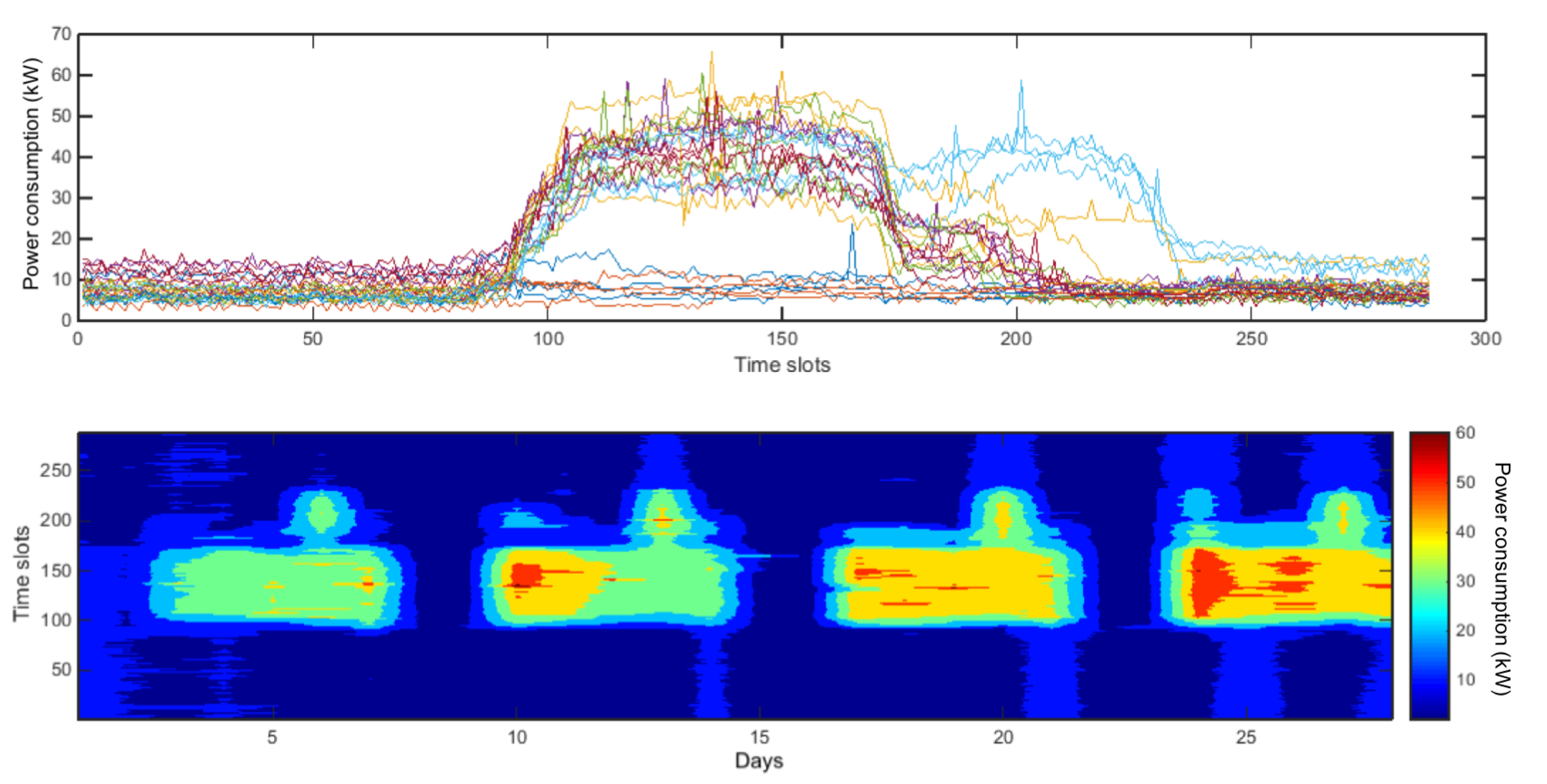
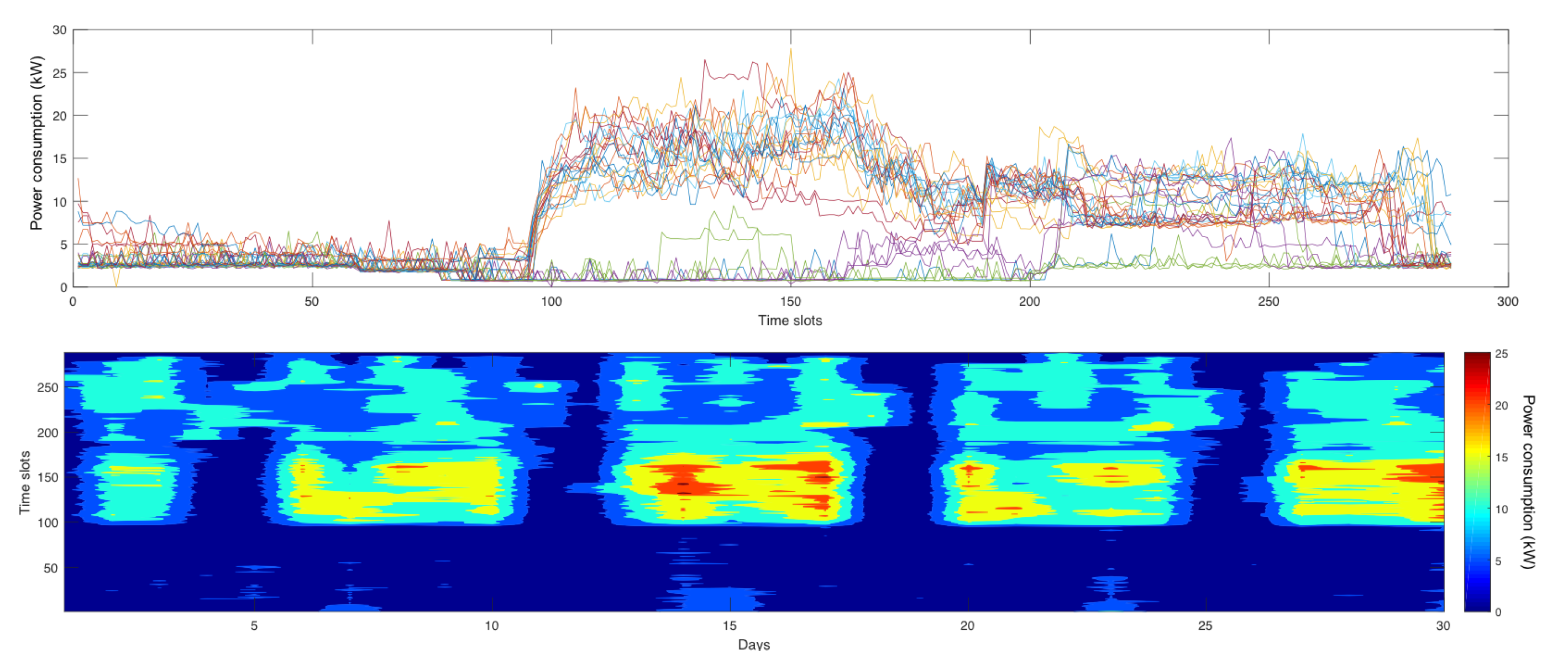
The analysis of the power time series derived for both pilot systems showed a daily and a weekly seasonality. In both cases there was a marked reduction in energy consumption during the night and at weekends. As for the pilot case related to the municipal office, this is evident from
Figure 4, which shows the daily energy consumption and the corresponding contour plot (where a color scale describes the intensity of power demand) for the duration of a month. The latter clearly shows a regular daily trend, with an increase in energy consumption at around 8:00, remaining essentially stable until 15:00 and subsequently decreasing.
On Thursday, however, after a first reduction around the lunch break, the energy consumption increases again for a time window of three hours of width. This change in behavior is associated with the afternoon work shift, which occurs once a week. The weekends, on the other hand, are characterized by a low general consumption profile, in the same order of magnitude as night-time consumption, as foreseeable by the fact that the municipal office in these days remains closed.
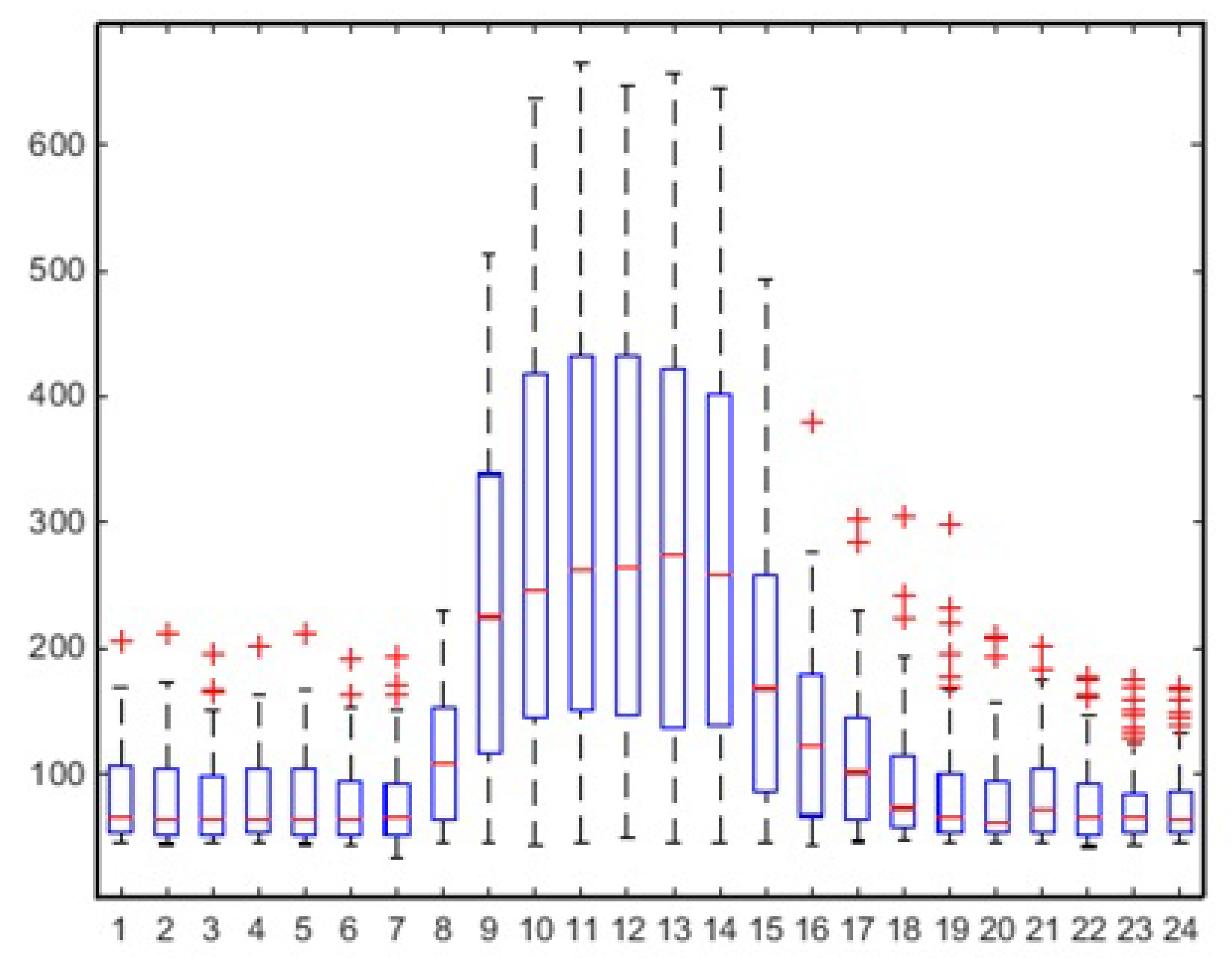
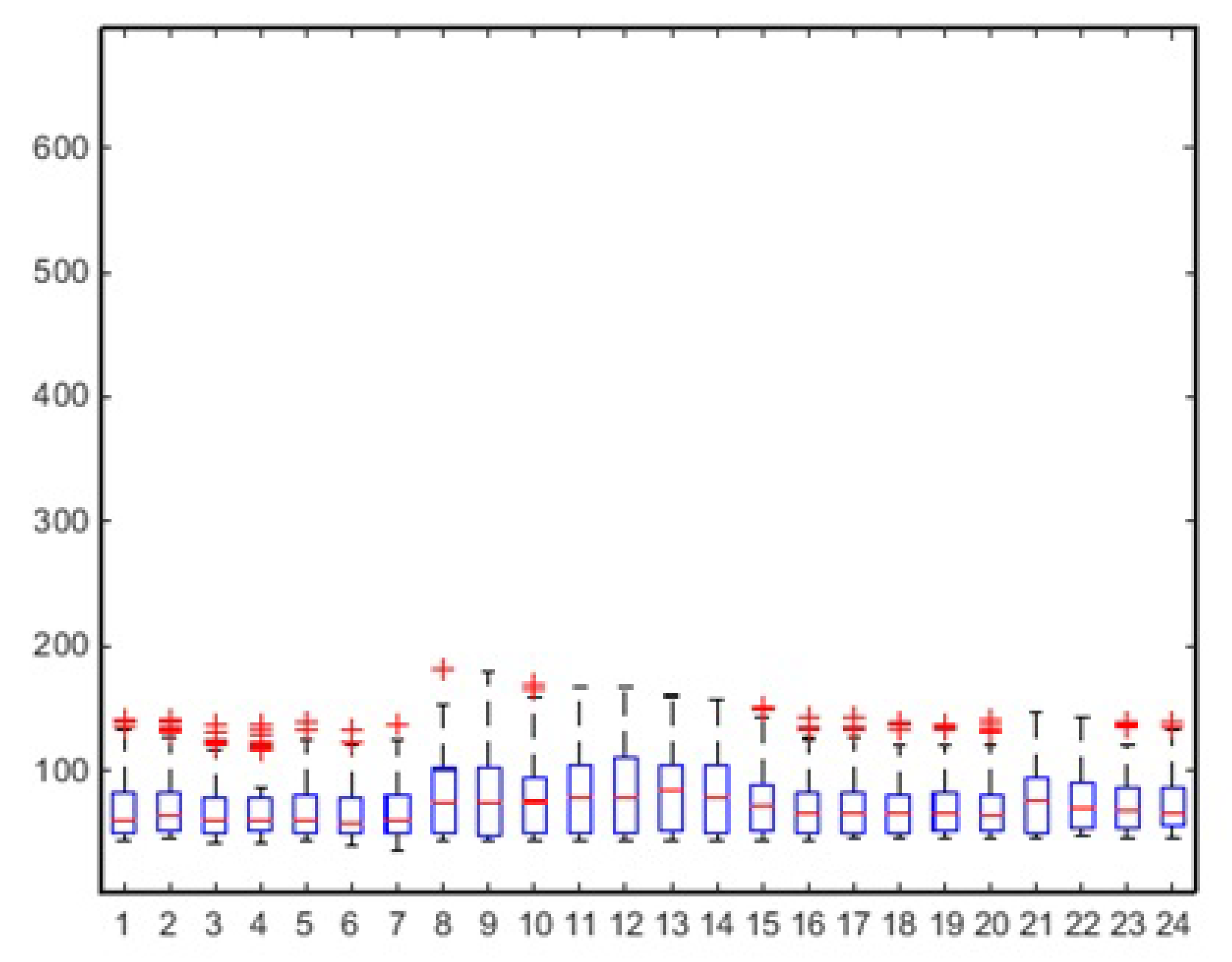
As part of the analysis of seasonality, we report the box plots—calculated for the days of surveys—of aggregate consumption on an hourly basis, distinguishing between midweek (i.e., working days) behavior (
Figure 5) and behavior at the weekend (
Figure 6). In this case, the consumption trends associated with Thursday are not explicitly reported, but they have been excluded from the data representation in
Figure 5. This exclusion makes the representation of the data more “clean”, reducing the number of outliers; in fact, if the Thursday had been included like the other working days, the box plots associated with the time slots 15–18 would have recorded a greater number of outliers.
A similar behavior is observed in the school consumption profile:
Figure 7 clearly shows a regular weekly pattern, with lower consumption at night (from 11 p.m. to 8 a.m.) and on the weekends. Power consumption decreases from 1 p.m. to 3 p.m. In the afternoon, consumption remains generally lower than in the morning but higher than at night; this could be related to some afternoon/evening activity taking place during the week.
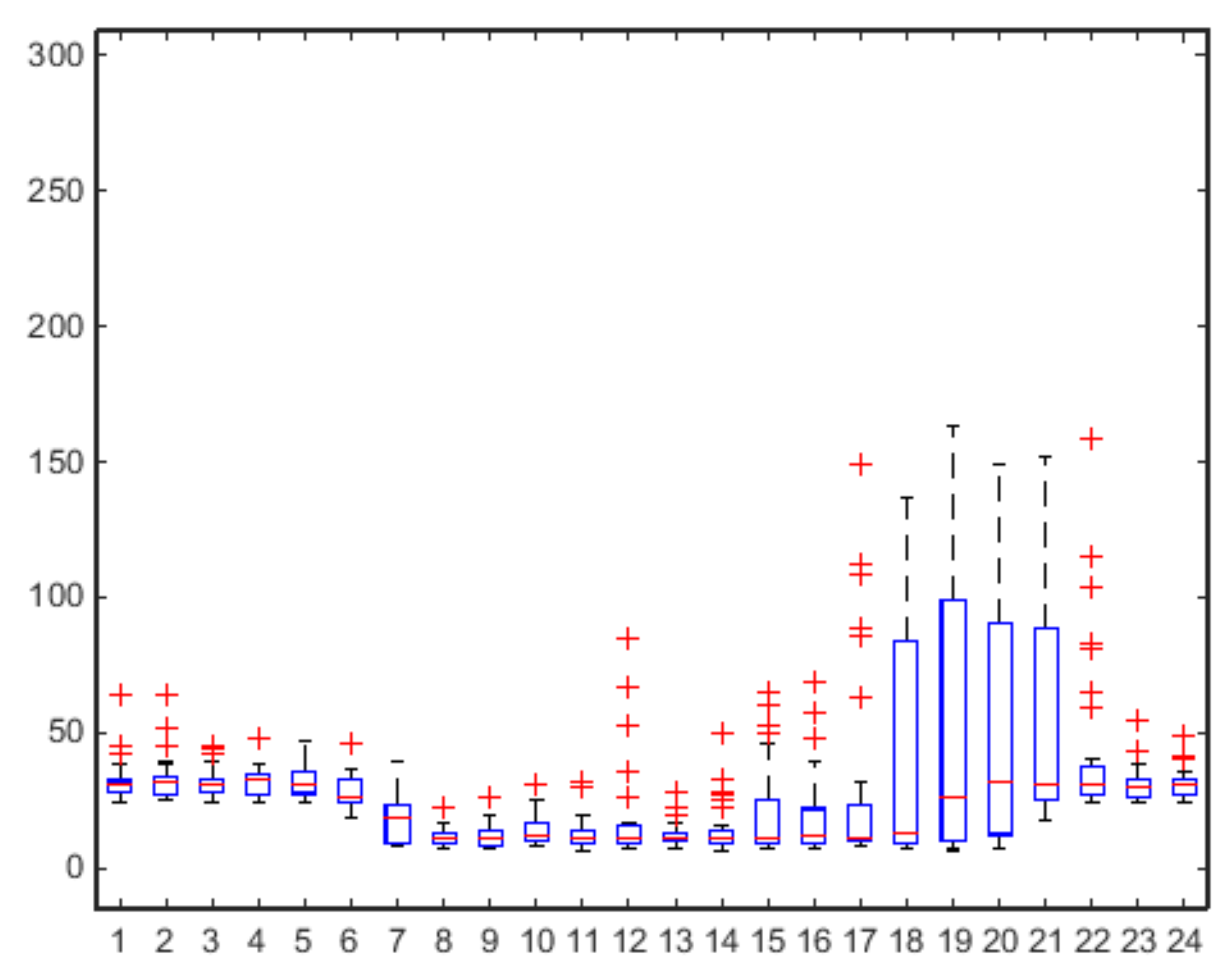
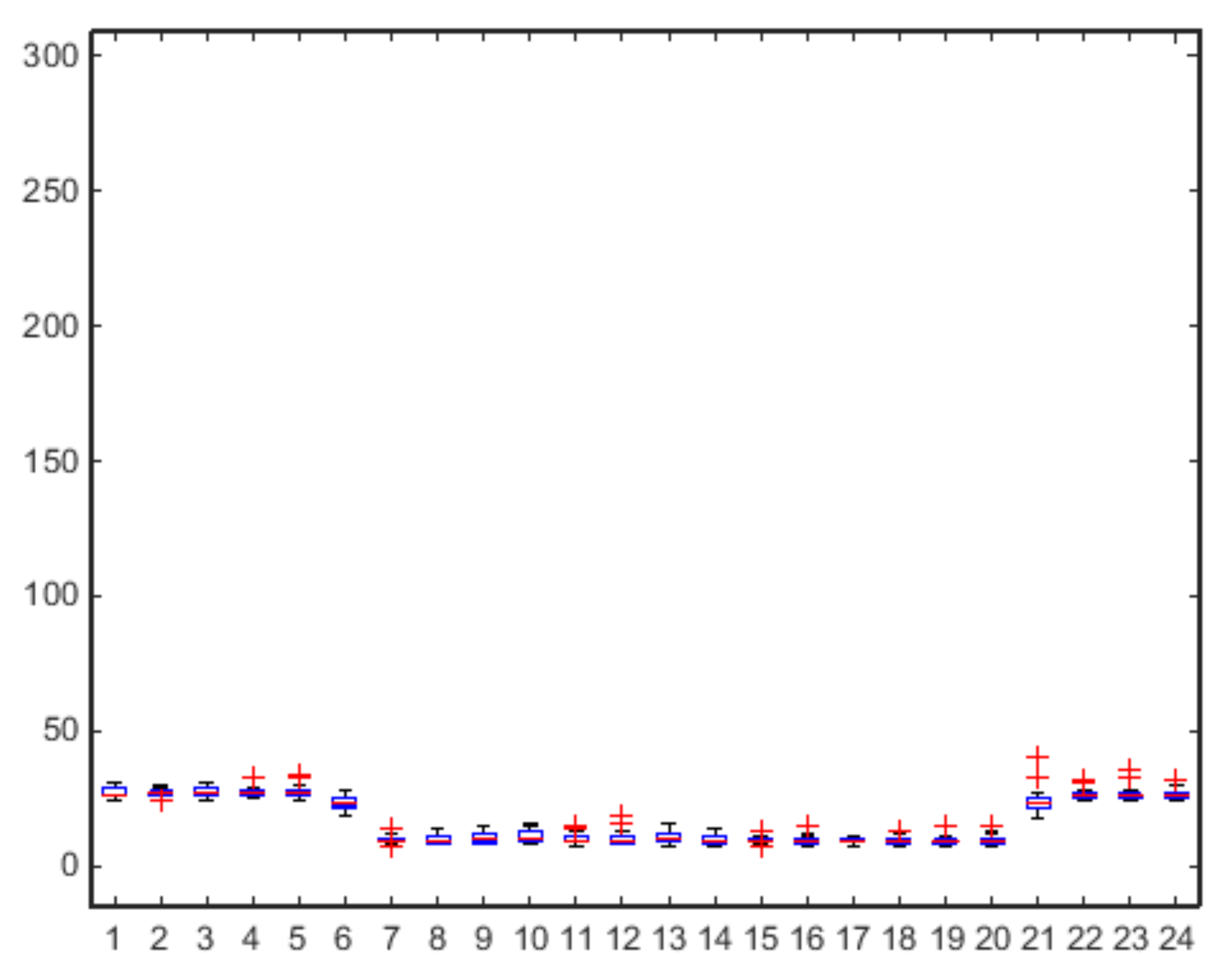
As for the previous case study, also for the school building in Palo del Colle we report the box plots of aggregate consumption on an hourly basis for both working days (
Figure 8) and the weekend (
Figure 9). In general, compared to the municipal office, where all activities are strictly regulated by working time and contractual obligations with employees, school activities (and consequently also electricity consumption) seem to be more unpredictable, especially as regards afternoon/evening extra-curricular activities. This peculiarity clearly influences the efficiency of the proposed approach which in fact has generally shown lower accuracy in the prediction of the electric load in the pilot system of the school building.
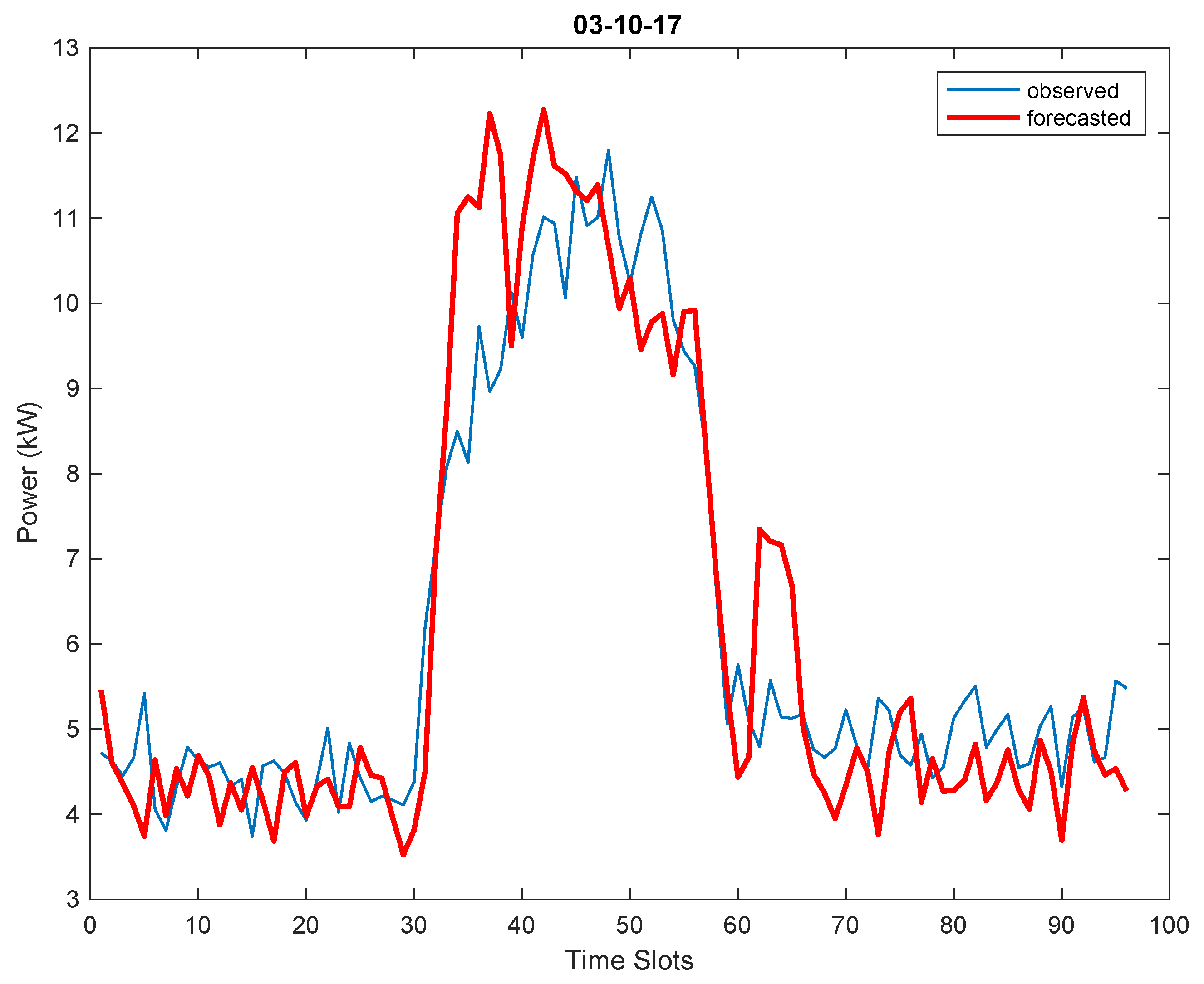
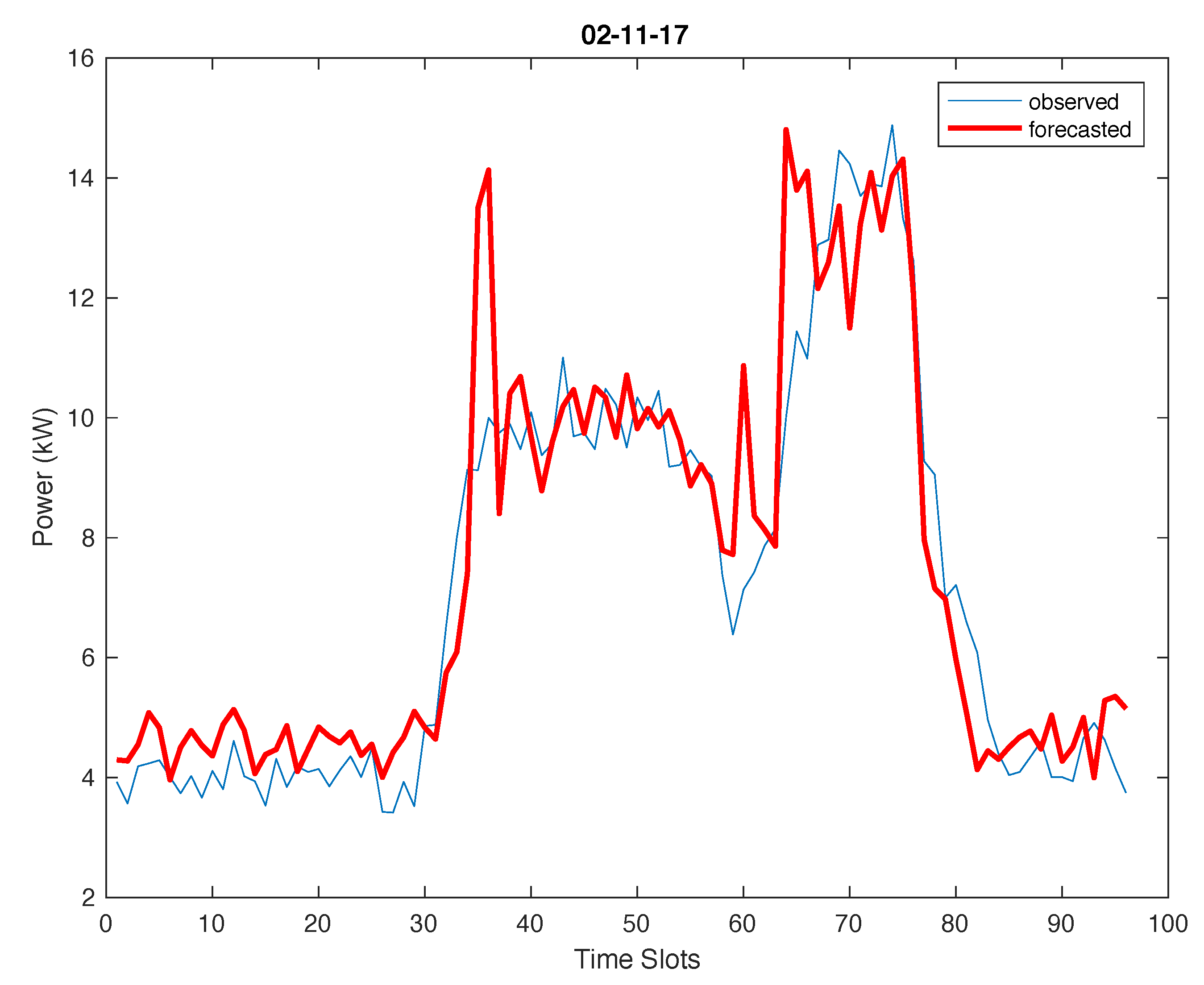
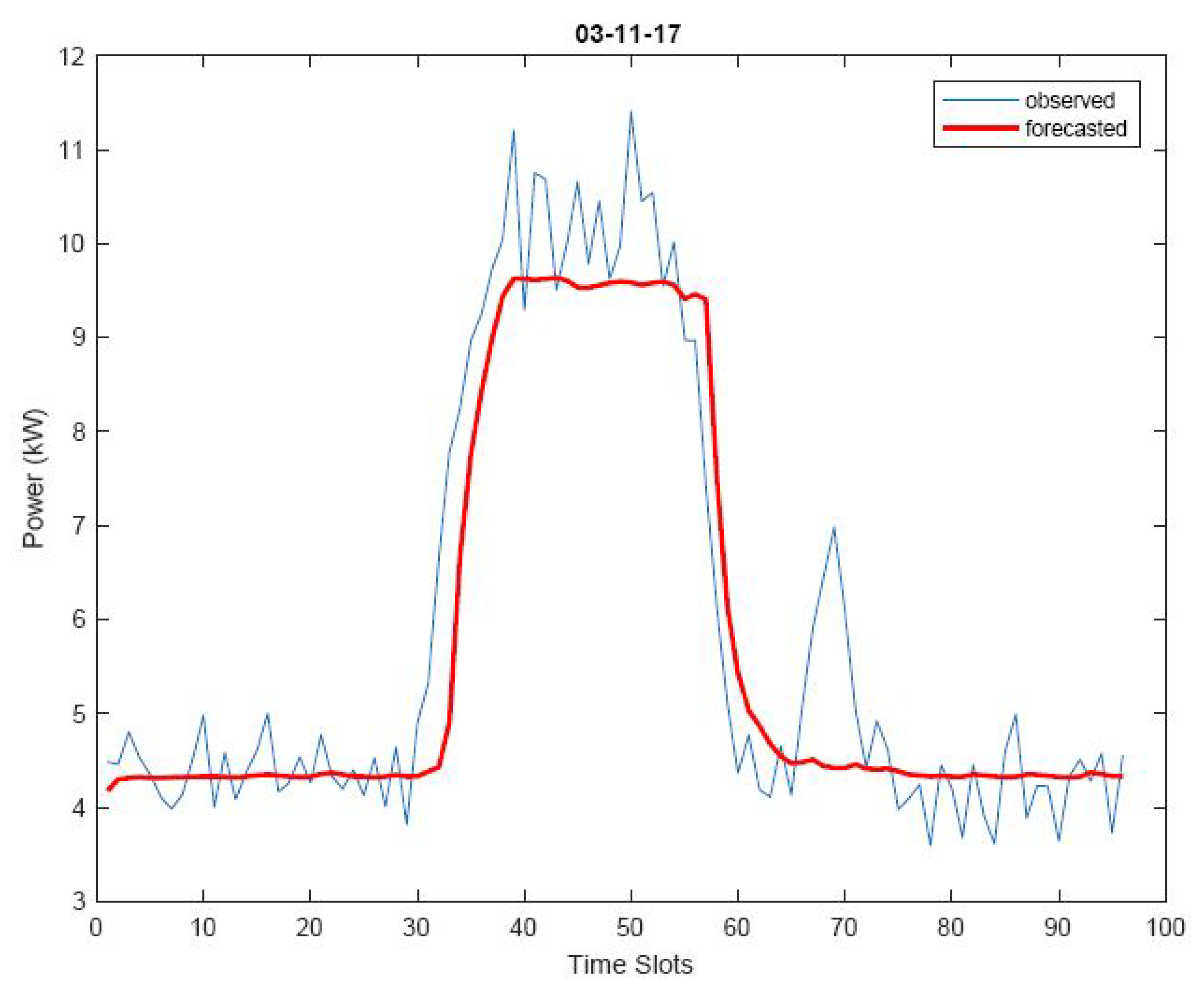
However, satisfactory or promising results were obtained for both pilot systems even without model updates (i.e., adopting UpdFreq = 24 h), with mean absolute deviations of about 1 kW for the municipal office and 2–3 kW for the school (for which higher power consumptions are registered); MAPE remains around 10–15% for the municipal office, while it gets a bit higher for the school, with values ranging from about 20 to 40%. Examples referring to three different prediction days are shown in
Figure 10,
Figure 11 and
Figure 12 for the municipal office, while a summary of the results and the corresponding statistical indicators are reported in
Table 3.
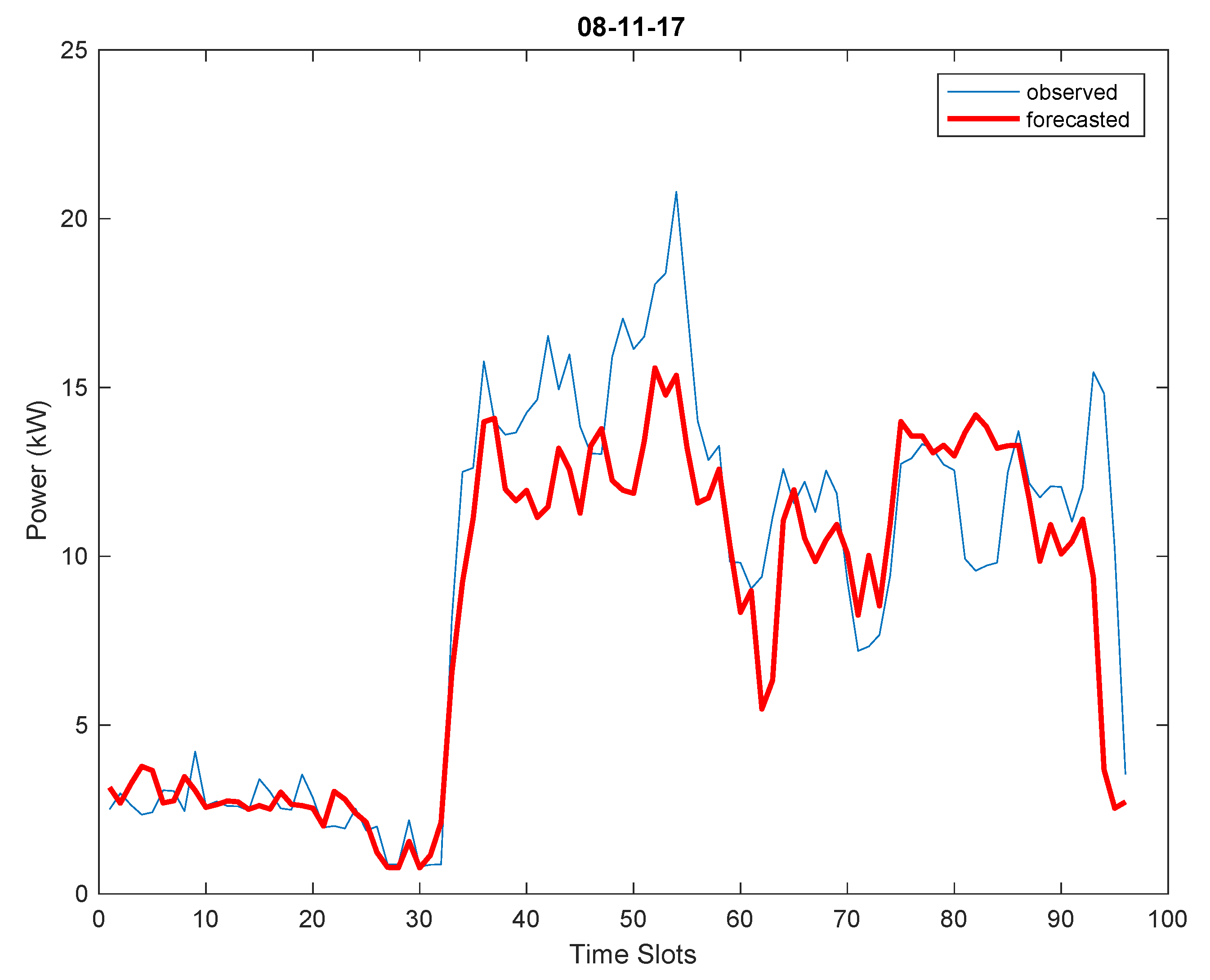
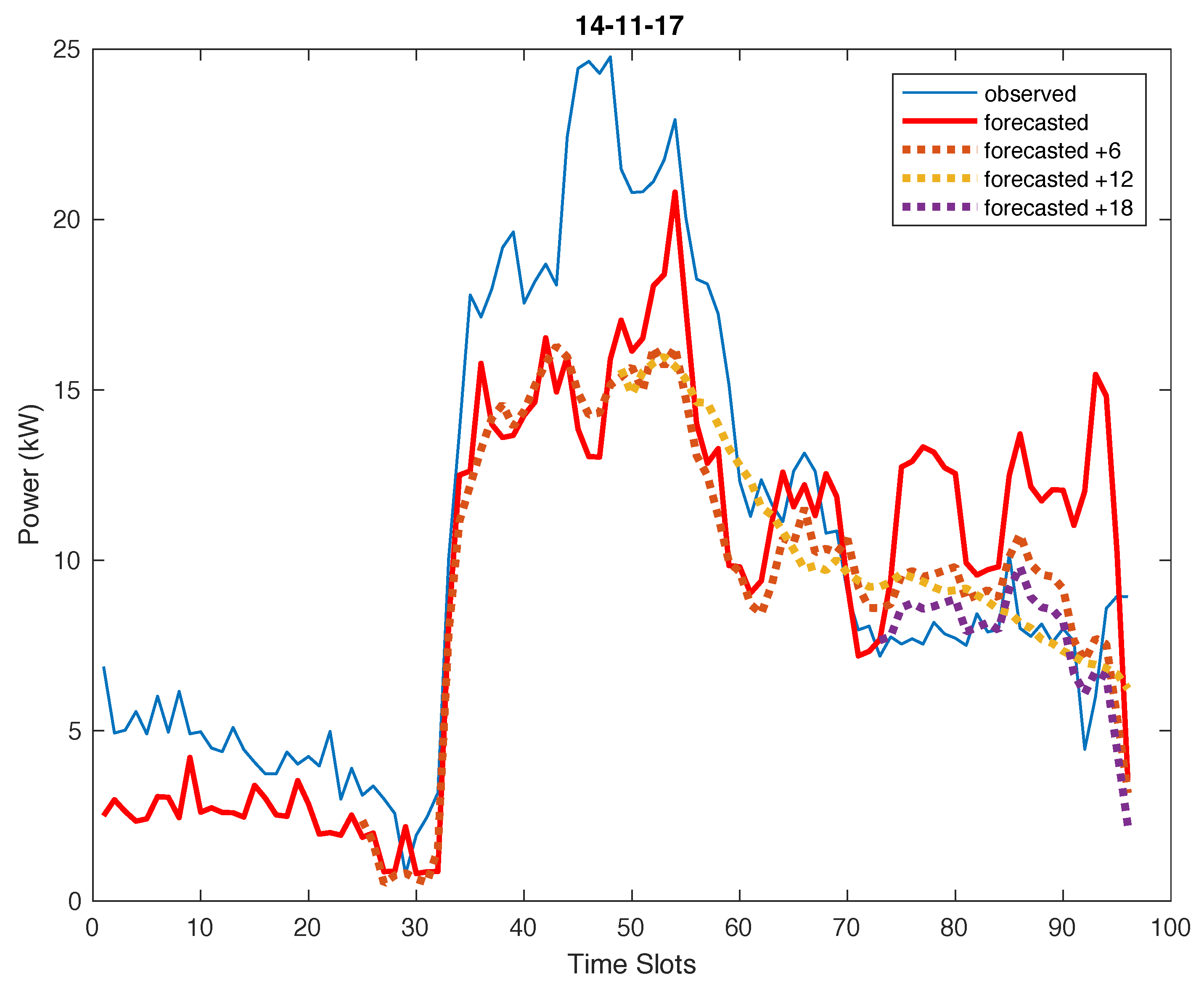
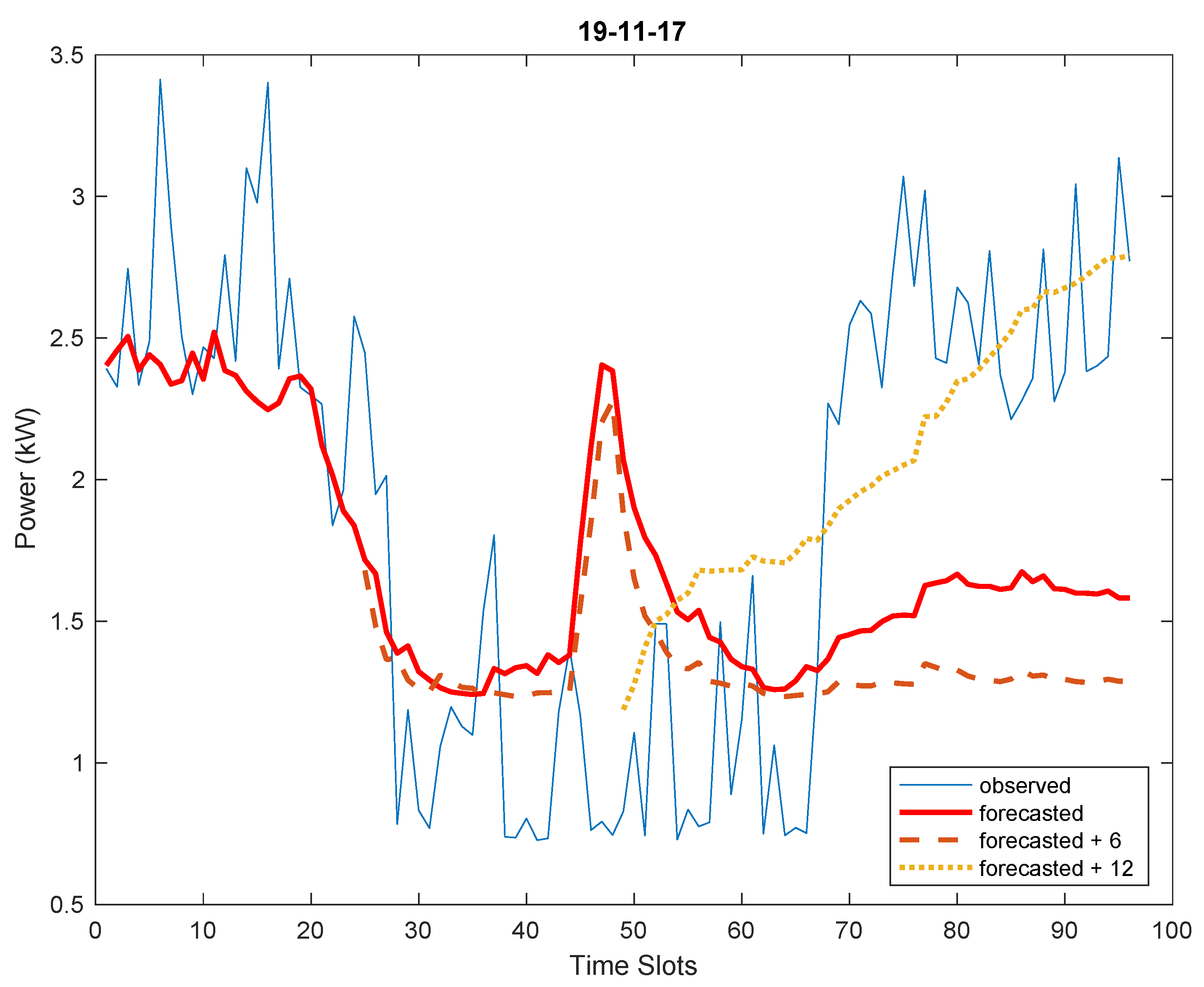
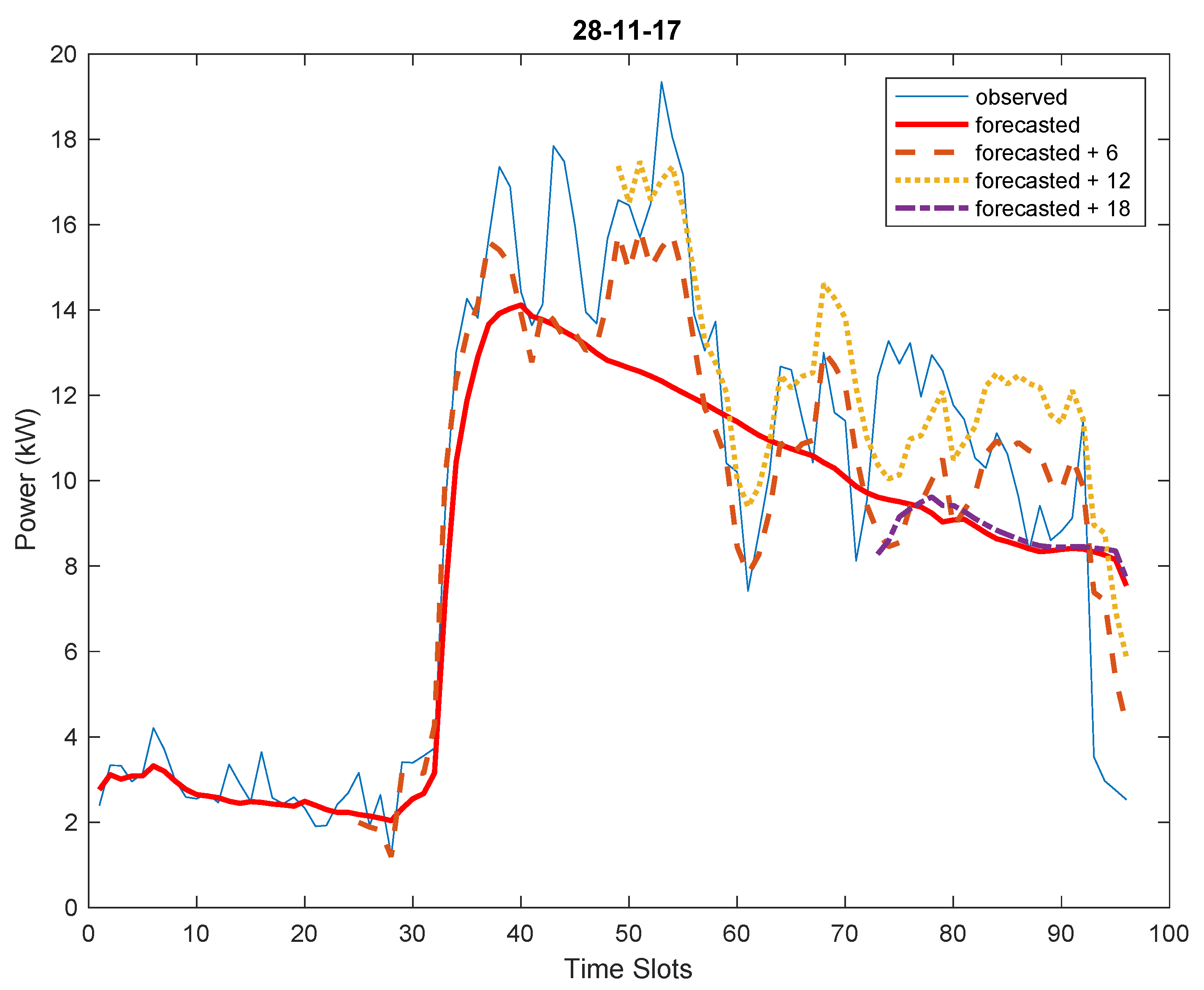
As already noted above, the load profile in the pilot system concerning the school building is less predictable than that concerning the municipal office and the load forecast has proved to be affected by higher errors. Some examples are shown in
Table 4 which reports the results related to days 8th, 14th, 19th, 28th November 2017 when PSS and NN models have been selected two times each. The daily forecasts are graphically compared to the observed power consumption for the day 8th November in
Figure 13.
Results for day November 19th shown a clear example of how, due to the randomness of electric demand, the forecasts can deviate significantly from actual measurements, especially if consumption is low. In this specific case the error in terms of MAPE is high, but it should be considered that this day is a holiday (Sunday) when the school is closed, and electric demand is very low. Therefore, error figures are higher in relative value (MAPE) but still very small in absolute value (MAE and MaxAE). In fact, in this case, MAE is about 0.6 kW. This is also coherent with the choice of having chosen MAE as the criterion for the final choice in the non-domination analysis in the tuning phase of the models.
In view of these results, some tests were carried out considering the possibility of updating the forecasting model during the day based on new data coming from measurements and the (re)evaluation of the behavior of the current model. This type of update can effectively improve the overall accuracy of the microforecasting module and can also be exploited in the implementation of a model predictive control architecture. In fact, it is possible to evaluate different daily corrections whenever new updated forecasts are available, both for generation and for electric load.
In the case of the Municipal Office, for the considered sample days, the accuracy check never requires model updates, whereas in 3 over 4 sample days they are needed for the school.
Table 5 and
Figure 14,
Figure 15 and
Figure 16 show forecast results obtained for the school power consumption for four different sample days (namely, November 8th, 14th, 19th and 28th) with forecast updates computed every six hours during the day according to the indications obtained from the accuracy check. The latter compares the predictions and the realized values of the last period (i.e., six hours) adopting the MAPE as relevant criterion, and a threshold of 15% above which is required to update the model. Otherwise the system continues to use the current model. It is worth noting that even in the event of an update request, it may happen that the best model is still the current one. Thus, when the update does not occur, in
Table 5 symbols “–” are reported.
In the adopted setting, a prediction accuracy check is performed every 6 h and, if necessary, the process is restarted repeating the model selection phase. For the first sample day (i.e., 8th, November) no updates occur and only the initial PSS model is used.
Table 5 reports on the errors evaluated with respect to the period which starts when the method has been adopted, and ends at 12:00 p.m. of the same prediction day (i.e., they are not the results of the accuracy check which refer to a previous period).
Figure 14,
Figure 15 and
Figure 16 reports a graphical representation of the results and effects of the model updating. For the day November 14th this led to the generation of the following models: PSS for forecasts from 00:00; STL for the updated forecasts from 6:00 a.m.; NN for updated forecasts from 12:00; STL again for the updated forecasts from 18:00. In the case of day November 19th only three models (i.e., always a NN model has been selected) were calculated as the last update was not necessary. For the case of day November 28th four models are used starting with NN and continuing with two successive STL models, whereas the last update led to the adoption of another NN model. In general, comparing forecasts and observed values shows that updated forecasts improve the results, as they get closer to the observed power consumption. In fact, the statistical indicators tend to improve during the day, as summarized in
Table 5. We note that in the graphs shown in
Figure 14,
Figure 15 and
Figure 16, the red solid line represents the result of the prediction of the first selected model if no updates are used, allowing a comparison with the behavior shown in
Figure 13 for the day 8th November for which no update occurs.
Forecasting results make evident that there is no ‘one-size-fits-all’ technique which is always more accurate than others; rather, the model adopted strongly depends on the historical data used for forecasting. In fact, results show that the forecasting module may return power forecasts based on different forecasting techniques in different days, as one model turned out to be better than the others for a given day. This is evident in
Table 3, where two different techniques have been adopted for forecasting the load of the same system in three different days (namely, October 3rd and November 2nd and 3rd). Also,
Table 5 shows the results obtained using sample updates from the field and repeating the model selection phase possibly choosing a different approach.
Computation time always remains in the order of a few minutes for a 24-h-ahead forecasting horizon with a granularity of 15 min; it gets faster if no re-tuning is needed for the forecasting model. The computational time is compatible with the operations of the overall monitoring and control architecture whose time resolution has been set to 15 min, in accordance to the expected performance of the second-generation smart meters that will be soon deployed in Italy. Another source of computation time reduction can be exploited using the parallel computing capabilities of the cloud platform.
6. Conclusions
The research project “Energy Router” had as main objective to design an EMS device dedicated to the optimization and control of energy resources distributed in the context of smart grids. The work presented in this article focuses more specifically on the design and development of the microforecasting module that provides day-by-day estimates of energy consumption for EMS applications. This module has been designed to be flexible enough to include different alternative forecasting techniques, in the knowledge that there is no predictive approach that can dominate others for all operating situations and time series considered in this study. The current version of the module includes exponential smoothing, ARIMA and NN. However, other approaches can also be easily integrated into the system, including the possibility to take into account relevant exogenous variables such as temperature and weather conditions, as well as the use and occupation of the building.
The proposed microforecasting module has been tested and validated on two different public sector pilot systems. The results demonstrated the usefulness of the proposed microforecasting module, as the most appropriate and accurate approach is automatically selected for each instance, in accordance with the criteria specified by the user.
The results obtained show that the proposed approach is valid and promising both in terms of quality and in terms of calculation time needed. The results obtained show small prediction errors that can be easily handled by the subsequent control procedure performed in the ER. These results further support the usefulness of adopting rigorous forecasting methods, rather than relying only on rules based on experience, which could leave specific hidden trends or behaviors unobserved. Further advantages are linked to the subsequent stages dedicated to planning and control, since more accurate predictions can generally reduce systems complexity and variability and consequently facilitate their design and tend to mitigate the total required computational efforts.
Electric demand of a single user is characterized by an inherent volatility that restraints the reliability of microforecasting algorithms with respect to the case of forecasting routines applied to larger aggregations of loads. Even though this is a clear drawback of the proposed approach, to assess the impacts of such limitation, the role of micro-forecasts in the proposed energy management systems (EMS) architecture should be considered. In this specific case, forecasts are employed in EMS to optimize the use of generation, storage, and demand resources of a small-sized prosuming unit. The use of model predictive control (MPC) in a hierarchical control structure has been proved to limit the impacts of forecast errors [
4], since it takes into account state updates and adjusts dynamically control actions along the operational window. Moreover, in the proposed EMS, whenever microforecast should significantly fail, and MPC provide results too far from optimality, back-up local control strategies that are not based on predictive control but on simple rules, such as for example self-consumption maximization, can always be applied. In any case, significant forecast errors will only draw the solution far from optimality, but the functionality or the security of the system is ensured by the local controller.
The current work is devoted to providing a better assessment of the impact of forecast errors in the use of distributed resources and in the sizing of storage systems. Future research directions include the improvement of the forecasting method considering: (a) the possibility of taking into account exogenous variables; (b) improving the pre-processing phase; (c) studying the impact of the model updating in a new or more articulated forecasting scheme. These possibilities need to adapt the overall framework to provide data (and forecasts) of adequate accuracy for the considered external variables, and the necessary computation methods for the extension of the forecasting models. Further research work can be devoted to performing long-run experimental campaigns (e.g., over one year) for evaluating the overall performance of the proposed framework also collecting and analyzing the feedback from the field.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}