The Schaake Shuffle Technique to Combine Solar and Wind Power Probabilistic Forecasting


Abstract
:1. Introduction
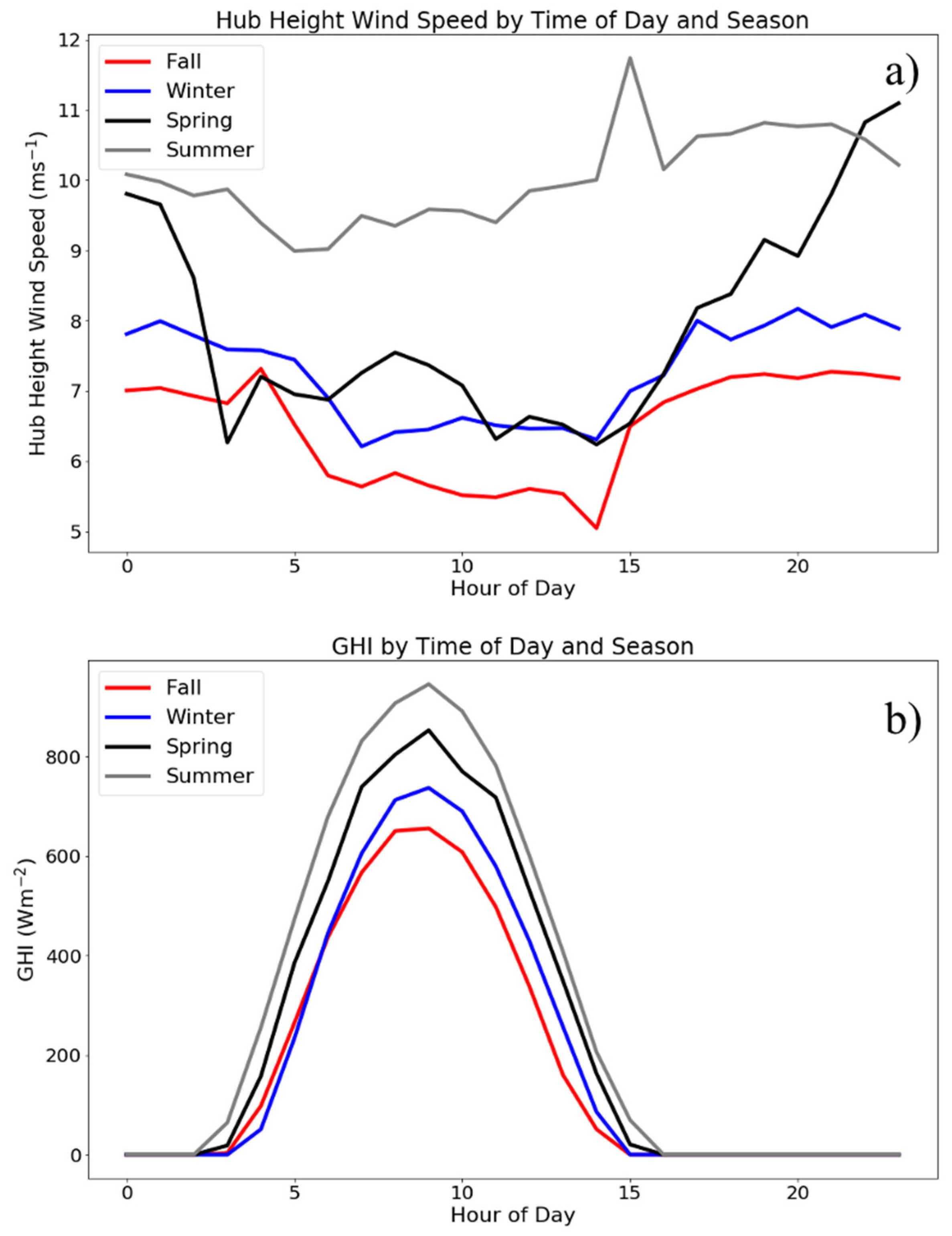
2. Shagaya Renewable Energy Park
3. The Probabilistic Solar and Wind Power Forecasting System at Shagaya
3.1. The Dynamic Integrated Forecast System (DICast)
3.2. The Analog Ensemble Technique (AnEn)
3.3. The Schaake Shuffle Technique (SS)
4. Verification
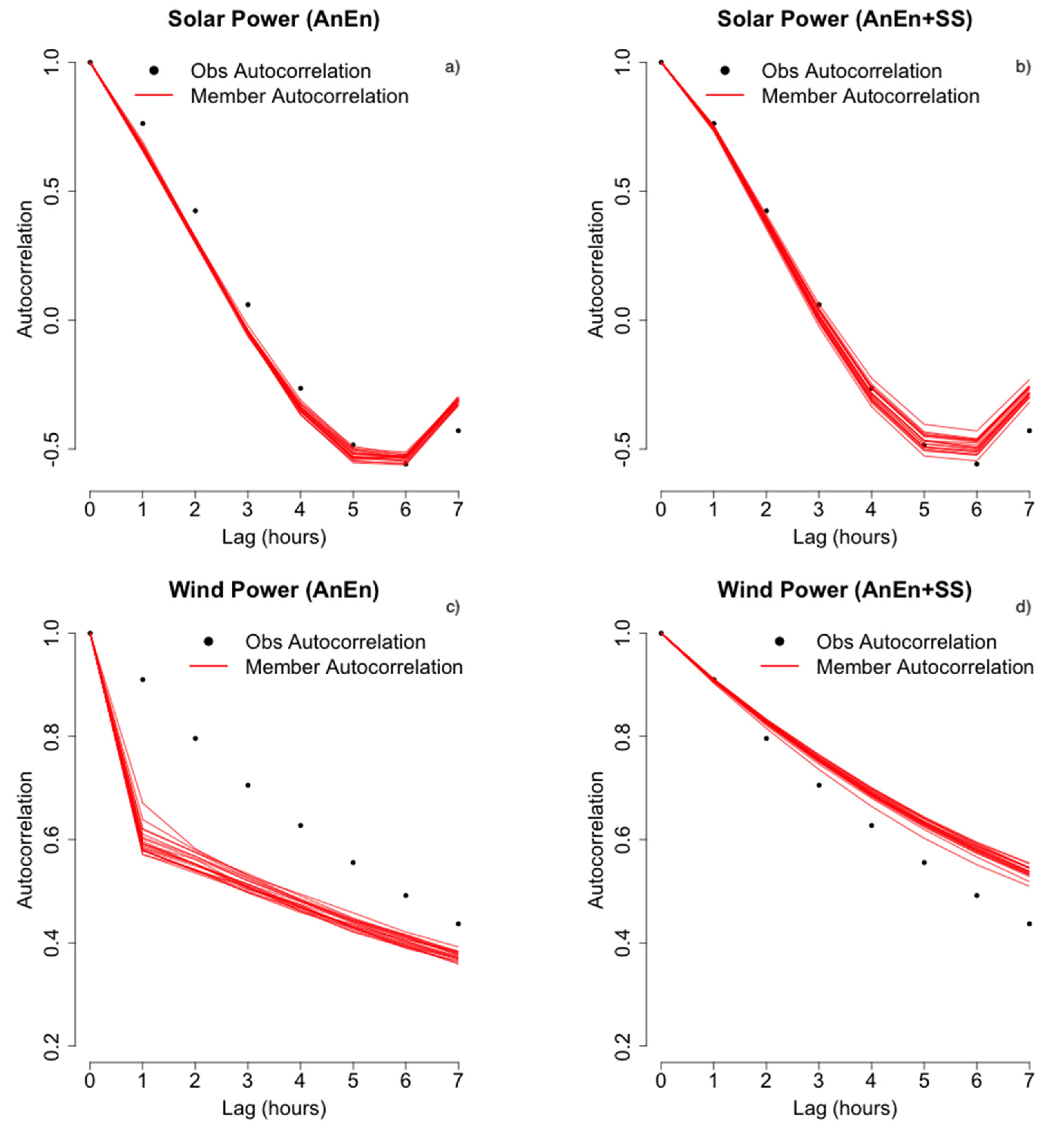
4.1. Temporal Auto Correlation of the Power Ensemble Members
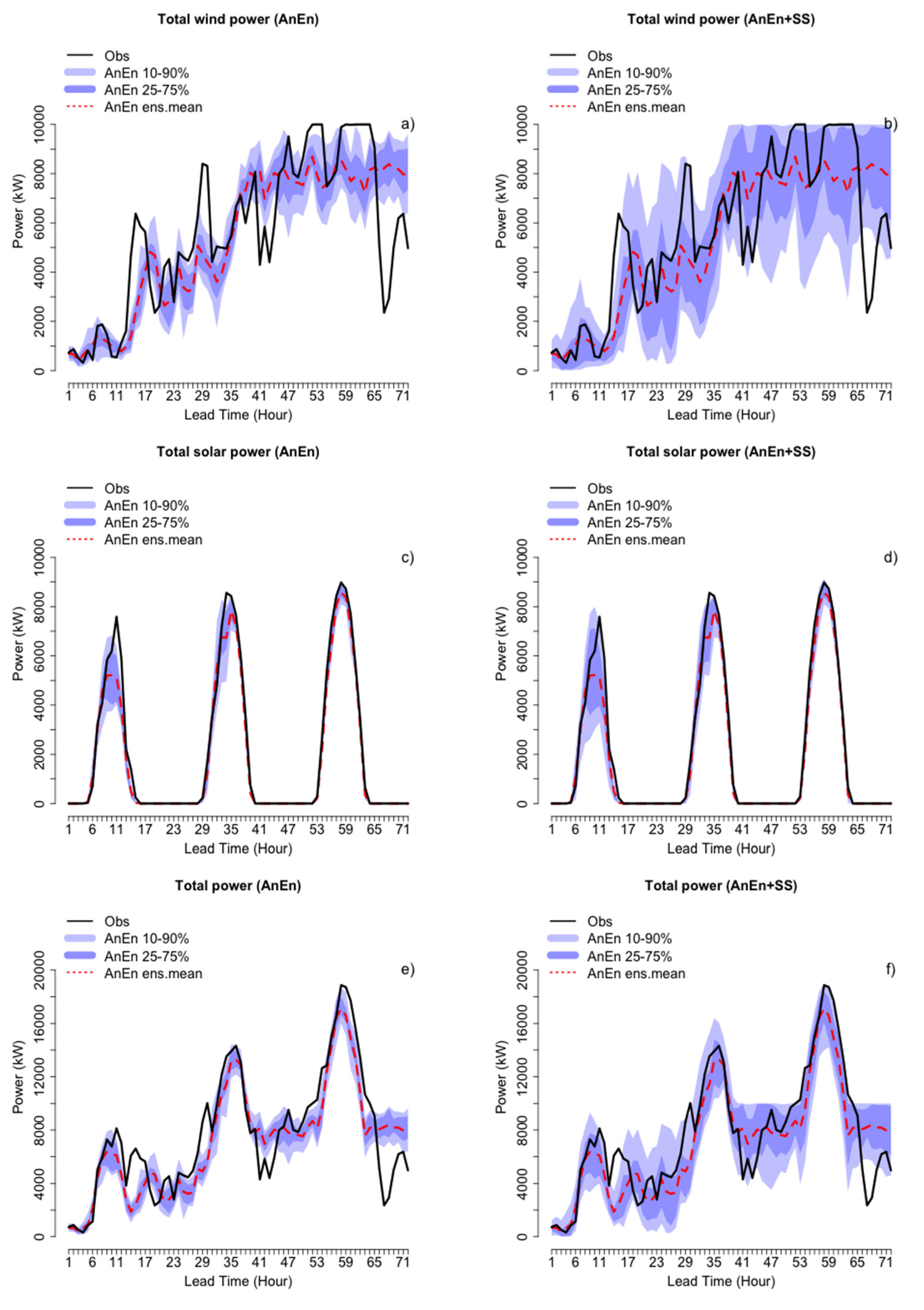
4.2. Ensemble of Total Generated Power
4.2.1. Spread-Skill Consistency
4.2.2. Continuous Ranked Probability Score
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
References
- WWEA Wind Power Istalled Capacity. Available online: https://wwindea.org/information-2/information/ (accessed on 28 August 2019).
- IEA Solar Installed Capacity. Available online: https://www.iea.org/topics/renewables/solar/ (accessed on 28 August 2019).
- Jurasz, J.; Canales, F.A.; Kies, A.; Guezgouz, M.; Beluco, A. A review on the complementarity of renewable energy sources: Concept, metrics, application and future research directions. Sol. Energy 2020, 195, 703–724. [Google Scholar] [CrossRef]
- Widén, J.; Carpman, N.; Castellucci, V.; Lingfors, D.; Olauson, J.; Remouit, F.; Bergkvist, M.; Grabbe, M.; Waters, R. Variability assessment and forecasting of renewables: A review for solar, wind, wave and tidal resources. Renew. Sustain. Energy Rev. 2015, 44, 356–375. [Google Scholar] [CrossRef]
- Santos-Alamillos, F.J.; Pozo-Vázquez, D.; Ruiz-Arias, J.A.; Von Bremen, L.; Tovar-Pescador, J. Combining wind farms with concentrating solar plants to provide stable renewable power. Renew. Energy 2015, 76, 539–550. [Google Scholar] [CrossRef]
- Kariniotakis, G.; Martí, I.; Casas, D.; Pinson, P.; Nielsen, T.S.; Madsen, H.; Giebel, G.; Usaola, J.; Sanchez, I. What performance can be expected by short-term wind power prediction models depending on site characteristics? In Proceedings of the EWC 2004 Conference, Taipei, Taiwan, 4–8 December 2004; pp. 22–25. [Google Scholar]
- Mahoney, W.P.; Parks, K.; Wiener, G.; Liu, Y.; Myers, W.L.; Sun, J.; Delle Monache, L.; Hopson, T.; Johnson, D.; Haupt, S.E. A wind power forecasting system to optimize grid integration. IEEE Trans. Sustain. Energy 2012, 3, 670–682. [Google Scholar] [CrossRef]
- Zugno, M.; Conejo, A.J. A robust optimization approach to energy and reserve dispatch in electricity markets. Eur. J. Oper. Res. 2015, 247, 659–671. [Google Scholar] [CrossRef] [Green Version]
- Davò, F.; Alessandrini, S.; Sperati, S.; Delle Monache, L.; Airoldi, D.; Vespucci, M.T. Post-processing techniques and principal component analysis for regional wind power and solar irradiance forecasting. Sol. Energy 2016, 134, 327–338. [Google Scholar] [CrossRef] [Green Version]
- Alessandrini, S.; Davò, F.; Sperati, S.; Benini, M.; Delle Monache, L. Comparison of the economic impact of different wind power forecast systems for producers. Adv. Sci. Res. 2014, 11, 49–53. [Google Scholar] [CrossRef] [Green Version]
- Roulston, M.S.; Kaplan, D.T.; Hardenberg, J.; Smith, L.A. Using medium-range weather forcasts to improve the value of wind energy production. Renew. Energy 2003, 28, 285–602. [Google Scholar] [CrossRef]
- Zugno, M.; Jõnsson, T.; Pinson, P. Trading wind energy on the basis of probabilistic forecasts both of wind generation and of market quantities. Wind Energy 2013, 16, 909–926. [Google Scholar] [CrossRef] [Green Version]
- Giebel, G.; Brownsword, R.; Kariniotakis, G.; Denhard, M.; Draxl, C. The State-of-ohe-Art in Short-Term Prediction of Wind Power a Literature Overview, 2nd ed.; ANEMOS.plus; Available online: https://doi.org/10.11581/DTU:00000017 (accessed on 28 August 2019).
- Pinson, P. Very-short-term probabilistic forecasting of wind power with generalized logit-normal distributions. J. R. Stat. Soc. Ser. C Appl. Stat. 2012, 61, 555–576. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Nissen, J.N. A novel application of an analog ensemble for short-term wind power forecasting. Renew. Energy 2015, 76, 768–781. [Google Scholar] [CrossRef]
- Sperati, S.; Alessandrini, S.; Pinson, P.; Kariniotakis, G. The “Weather intelligence for renewable energies” benchmarking exercise on short-term forecasting of wind and solar power generation. Energies 2015, 8, 9594–9619. [Google Scholar] [CrossRef] [Green Version]
- Cassola, F.; Burlando, M. Wind speed and wind energy forecast through Kalman filtering of Numerical Weather Prediction model output. Appl. Energy 2012, 99, 154–166. [Google Scholar] [CrossRef]
- Diagne, M.; David, M.; Lauret, P.; Boland, J.; Schmutz, N. Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renew. Sustain. Energy Rev. 2013, 21, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Heinemann, D.; Lorenz, E.; Girodo, M. Forecasting of solar radiation. In Solar Energy Resource Management for Electricity Generation from Local Level to Global Scale; Nova Science Publishers: New York, NY, USA, 2006; pp. 83–94. ISBN 1594549192. [Google Scholar]
- Yang, D.; Kleissl, J.; Gueymard, C.A.; Pedro, H.T.C.; Coimbra, C.F.M. History and trends in solar irradiance and PV power forecasting: A preliminary assessment and review using text mining. Sol. Energy 2018, 168, 60–101. [Google Scholar] [CrossRef]
- Inman, R.H.; Pedro, H.T.C.; Coimbra, C.F.M. Solar forecasting methods for renewable energy integration. Prog. Energy Combust. Sci. 2013, 39, 535–576. [Google Scholar] [CrossRef]
- Pedro, H.T.C.; Coimbra, C.F.M. Assessment of forecasting techniques for solar power production with no exogenous inputs. Sol. Energy 2012, 86, 2017–2028. [Google Scholar] [CrossRef]
- Molteni, F.; Buizza, R.; Palmer, T.N.; Petroliagis, T. The ECMWF ensemble prediction system: Methodology and validation. Q. J. R. Meteorol. Soc. 1996, 122, 73–119. [Google Scholar] [CrossRef]
- Alessandrini, S.; Sperati, S.; Pinson, P. A comparison between the ECMWF and COSMO Ensemble Prediction Systems applied to short-term wind power forecasting on real data. Appl. Energy 2013, 107, 271–280. [Google Scholar] [CrossRef]
- Hamill, T.M.; Whitaker, J.S. Probabilistic quantitative precipitation forecasts based on reforecast analogs: Theory and application. Mon. Weather Rev. 2006, 134, 3209–3229. [Google Scholar] [CrossRef]
- Monache, L.D.; Anthony Eckel, F.; Rife, D.L.; Nagarajan, B.; Searight, K. Probabilistic weather prediction with an analog ensemble. Mon. Weather Rev. 2013, 141, 3498–3516. [Google Scholar] [CrossRef] [Green Version]
- Alessandrini, S.; Sperati, S.; Delle Monache, L. Improving the analog ensemble wind speed forecasts for rare events. Mon. Weather Rev. 2019, 147, 2677–3692. [Google Scholar] [CrossRef]
- Bremnes, J.B. Probabilistic wind power forecasts using local quantile regression. Wind Energy 2004, 7, 47–54. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar power forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef] [Green Version]
- Junk, C.; Monache, L.D.; Alessandrini, S. Analog-based ensemble model output statistics. Mon. Weather Rev. 2015, 143, 2909–2917. [Google Scholar] [CrossRef]
- Cervone, G.; Clemente-Harding, L.; Alessandrini, S.; Delle Monache, L. Short-term photovoltaic power forecasting using Artificial Neural Networks and an Analog Ensemble. Renew. Energy 2017, 108, 274–286. [Google Scholar] [CrossRef] [Green Version]
- Sperati, S.; Alessandrini, S.; Delle Monache, L. An application of the ECMWF Ensemble Prediction System for short-term solar power forecasting. Sol. Energy 2016, 133, 437–450. [Google Scholar] [CrossRef] [Green Version]
- Schefzik, R.; Thorarinsdottir, T.L.; Gneiting, T. Uncertainty quantification in complex simulation models using ensemble copula coupling. Stat. Sci. 2013, 28, 616–640. [Google Scholar] [CrossRef]
- Clark, M.; Gangopadhyay, S.; Hay, L.; Rajagopalan, B.; Wilby, R. The Schaake shuffle: A method for reconstructing space-time variability in forecasted precipitation and temperature fields. J. Hydrometeorol. 2004, 5, 243–262. [Google Scholar] [CrossRef] [Green Version]
- KISR 2019 Kuwait Energy Outlook: Sustaining Prosperity Through Strategic Energy Management. Kuwait Institute for Scientific Research: Shuwaikh, Kuwait. Available online: https://www.arabstates.undp.org/content/dam/rbas/doc/EnergyandEnvironment/KEO_report_English.pdf (accessed on 8 October 2019).
- Al-Rasheedi, M.A.; Gueymard, C.A.; Al-Khayat, M.H.; Ismail, A.H.; Lee, J.A.; Al-Duaj, H. Performance evaluation of a utility-scale dual-technology photovoltaic power plant at the Shagaya Renewable Energy Park in Kuwait. Renew. Sustain. Energy Rev. 2020. Submitted. [Google Scholar]
- Naegele, S.M.; McCandless, T.C.; Greybush, S.J.; Young, G.S.; Haupt, S.E.; Al-Rasheedi, M. Climatology of wind variability for the Kuwait region. Renew. Sustain. Energy Rev. 2020. Accepted. [Google Scholar]
- Jiménez, P.A.; Alessandrini, S.; Haupt, S.E.; Deng, A.; Kosovic, B.; Lee, J.A.; Monache, L.D. The role of unresolved clouds on short-range global horizontal irradiance predictability. Mon. Weather Rev. 2016, 144, 3099–3107. [Google Scholar] [CrossRef]
- Jimenez, P.A.; Hacker, J.P.; Dudhia, J.; Haupt, S.E.; Ruiz-Arias, J.A.; Gueymard, C.A.; Thompson, G.; Eidhammer, T.; Deng, A. WRF-SOLAR: Description and clear-sky assessment of an augmented NWP model for solar power prediction. Bull. Am. Meteorol. Soc. 2016, 97, 1249–1264. [Google Scholar] [CrossRef]
- Junk, C.; Monache, L.D.; Alessandrini, S.; Cervone, G.; Von Bremen, L. Predictor-weighting strategies for probabilistic wind power forecasting with an analog ensemble. Meteorol. Z. 2015, 24, 361–379. [Google Scholar] [CrossRef]
- Sperati, S.; Alessandrini, S.; Delle Monache, L. Gridded probabilistic weather forecasts with an analog ensemble. Q. J. R. Meteorol. Soc. 2017, 143, 2874–2885. [Google Scholar] [CrossRef]
- Schefzik, R. A similarity-based implementation of the Schaake shuffle. Mon. Weather Rev. 2016, 144, 1909–1921. [Google Scholar] [CrossRef] [Green Version]
- Fortin, V.; Abaza, M.; Anctil, F.; Turcotte, R. Corrigendum to Why should ensemble spread match the RMSE of the ensemble mean? J. Hydrometeor. 2014, 15, 1708–1713. [Google Scholar] [CrossRef]
- Hopson, T.M. Assessing the ensemble spread-error relationship. Mon. Weather Rev. 2014, 142, 1125–1142. [Google Scholar] [CrossRef]
- Hersbach, H. Decomposition of the continuous ranked probability score for ensemble prediction systems. Weather Forecast. 2000, 15, 559–570. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E.; Westveld, A.H.; Goldman, T. Calibrated probabilistic forecasting using ensemble model output statistics and minimum CRPS estimation. Mon. Weather Rev. 2005, 133, 1098–1118. [Google Scholar] [CrossRef]
- Brown, T.A. Admissible Scoring Systems for Continuous Distributions; Rand Corp.: Santa Monica, CA, USA, 1974. [Google Scholar]
- NCAR-Research Applications Laboratory (2015). Verification: Weather Forecast Verification Utilities. R package version 1.42. Available online: https://CRAN.R-project.org/package=verification (accessed on 1 December 2019).
- Brier, G.W. Verification of forecasts expressed in terms of probability. Mon. Weather Rev. 1950, 78, 1–3. [Google Scholar] [CrossRef]
- Hamill, T.M. Interpretation of rank histograms for verifying ensemble forecasts. Mon. Weather Rev. 2001, 129, 550–560. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Production Unit | GHI | 2-MT | WS | WD | Cloud Cover |
|---|---|---|---|---|---|
| Turbine 1 | NT | 0.1 | 0.8 | 0.1 | NT |
| Turbine 2 | NT | 0. | 0.9 | 0.1 | NT |
| Turbine 3 | NT | 0.1 | 0.8 | 0.1 | NT |
| Turbine 4 | NT | 0.1 | 0.8 | 0.1 | NT |
| Turbine 5 | NT | 0.1 | 0.8 | 0.1 | NT |
| PV farm 1 | 0.5 | 0.1 | NT | NT | 0.4 |
| PV farm 2 | 0.5 | 0.2 | NT | NT | 0.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alessandrini, S.; McCandless, T. The Schaake Shuffle Technique to Combine Solar and Wind Power Probabilistic Forecasting. Energies 2020, 13, 2503. https://doi.org/10.3390/en13102503
Alessandrini S, McCandless T. The Schaake Shuffle Technique to Combine Solar and Wind Power Probabilistic Forecasting. Energies. 2020; 13(10):2503. https://doi.org/10.3390/en13102503
Chicago/Turabian StyleAlessandrini, Stefano, and Tyler McCandless. 2020. "The Schaake Shuffle Technique to Combine Solar and Wind Power Probabilistic Forecasting" Energies 13, no. 10: 2503. https://doi.org/10.3390/en13102503
APA StyleAlessandrini, S., & McCandless, T. (2020). The Schaake Shuffle Technique to Combine Solar and Wind Power Probabilistic Forecasting. Energies, 13(10), 2503. https://doi.org/10.3390/en13102503