High-Resolution PV Forecasting from Imperfect Data: A Graph-Based Solution

 , ,
, , 
Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
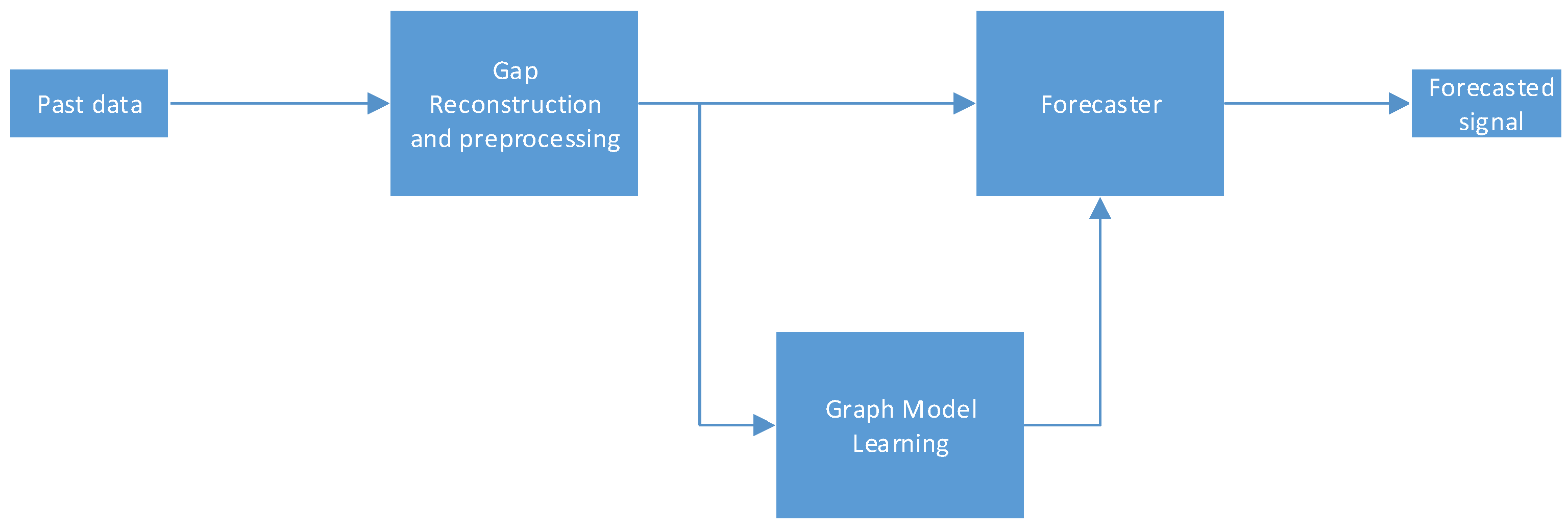
2. Methods
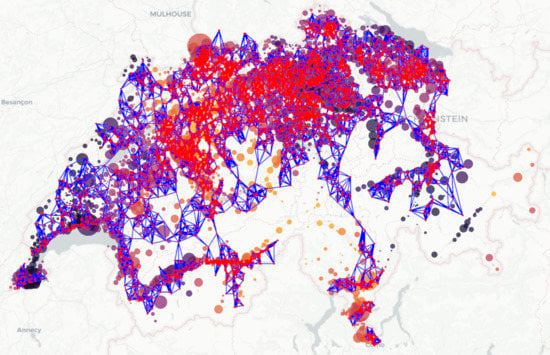
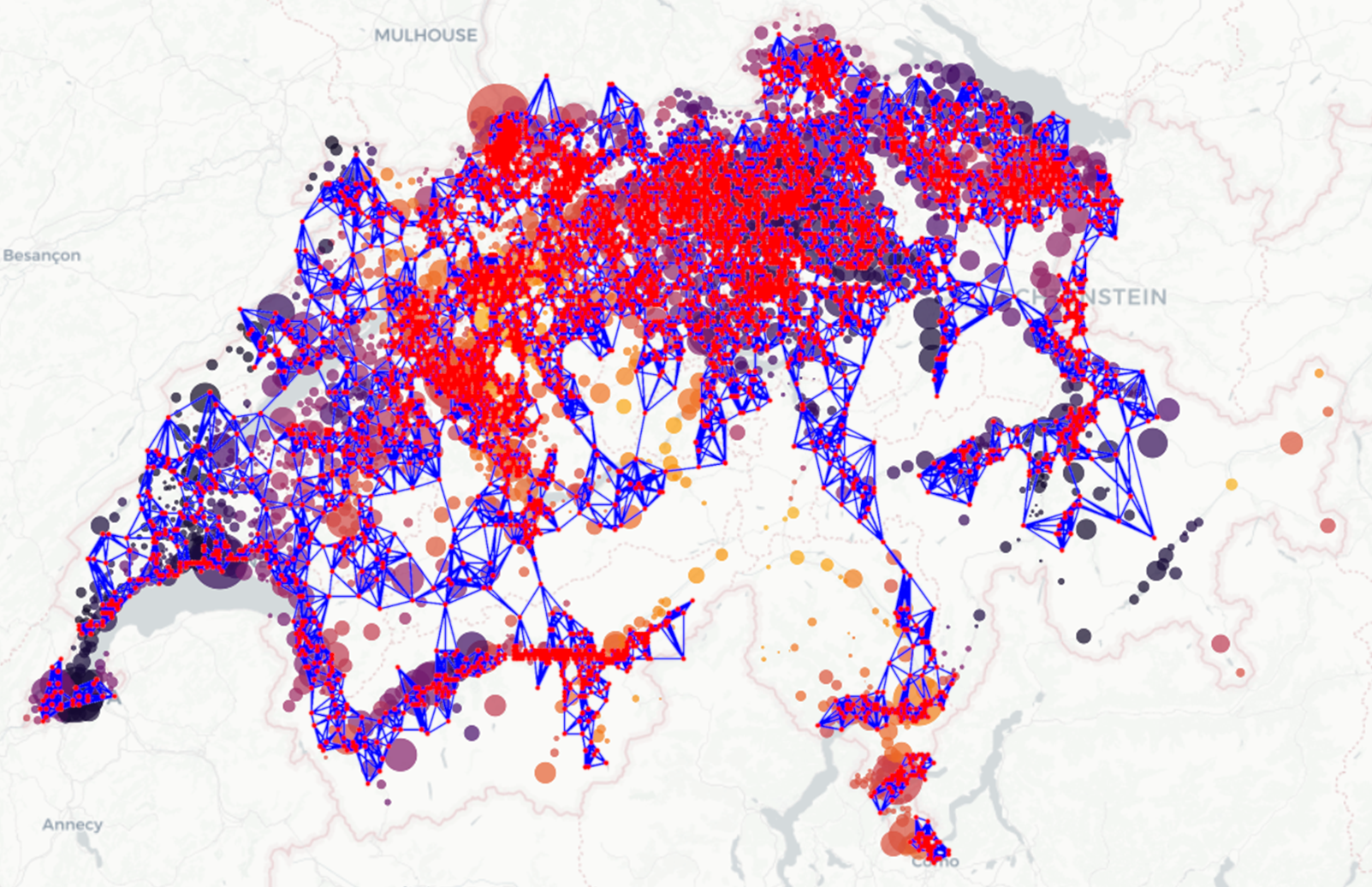
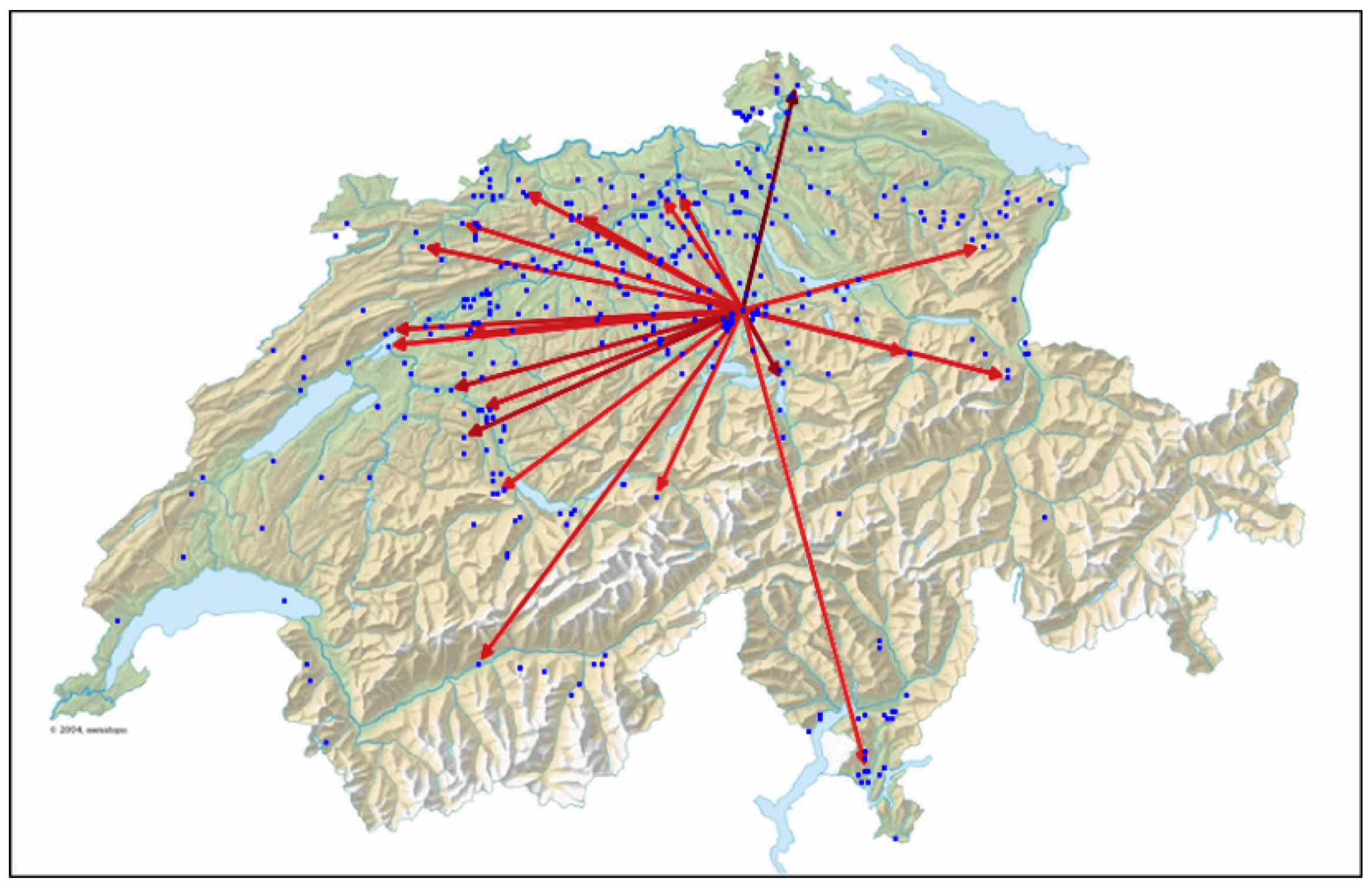
2.1. Graph-Based Data Reconstruction: Filling the Gaps
2.2. Spatio-Temporal Forecast Method
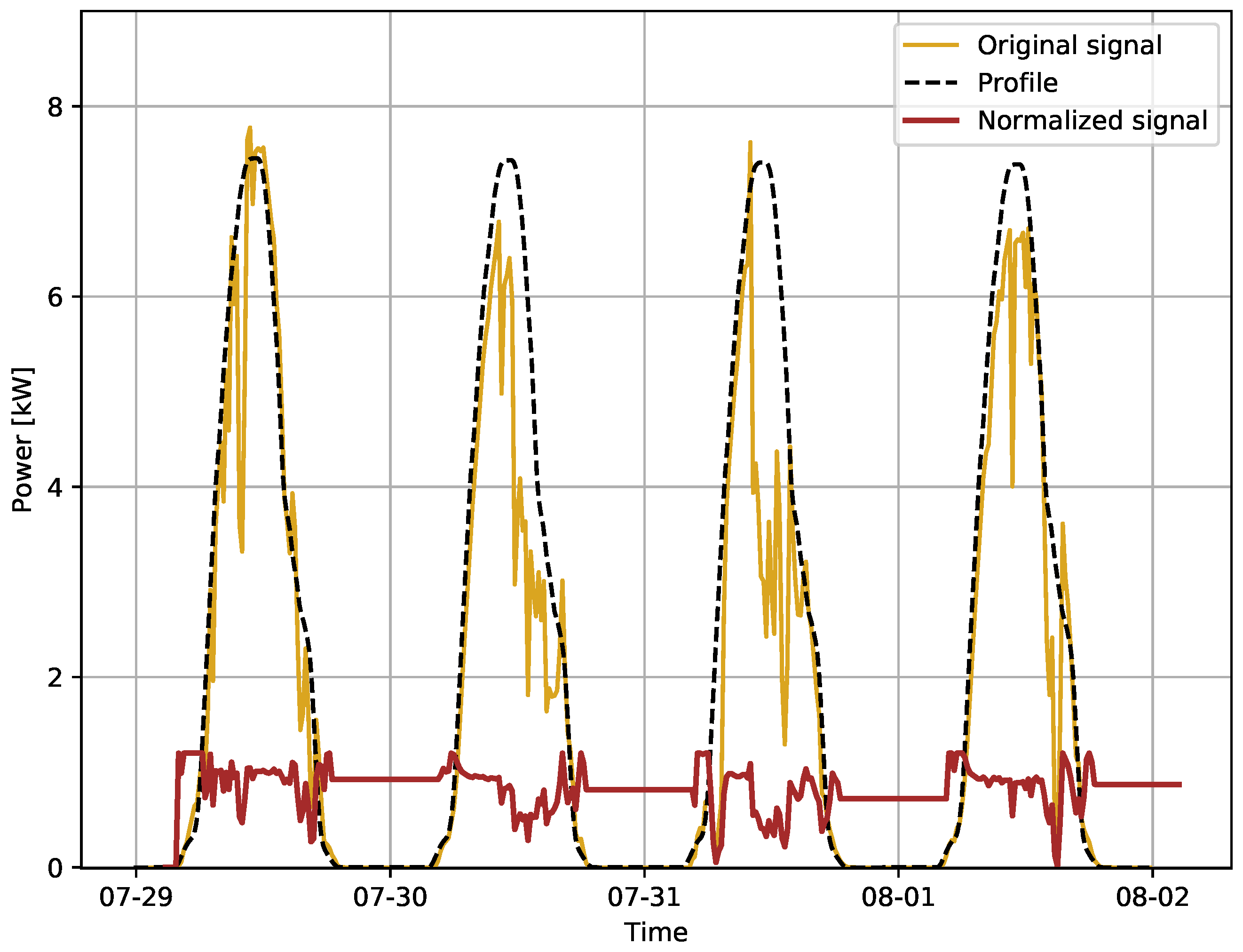
2.2.1. Normalization and De-Trending
2.2.2. Spatio-Temporal Auto-Regressive Forecast Model
2.2.3. Prediction for Short-Term Horizon
3. Results
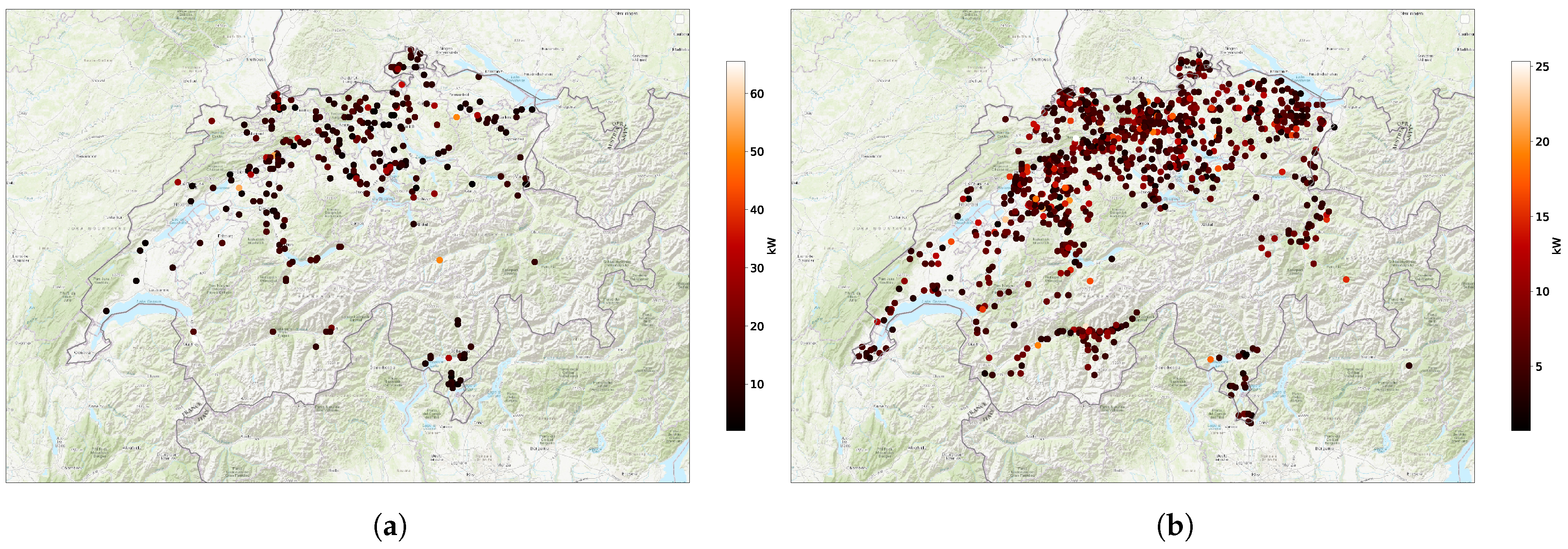
3.1. Evaluation Data and Metrics
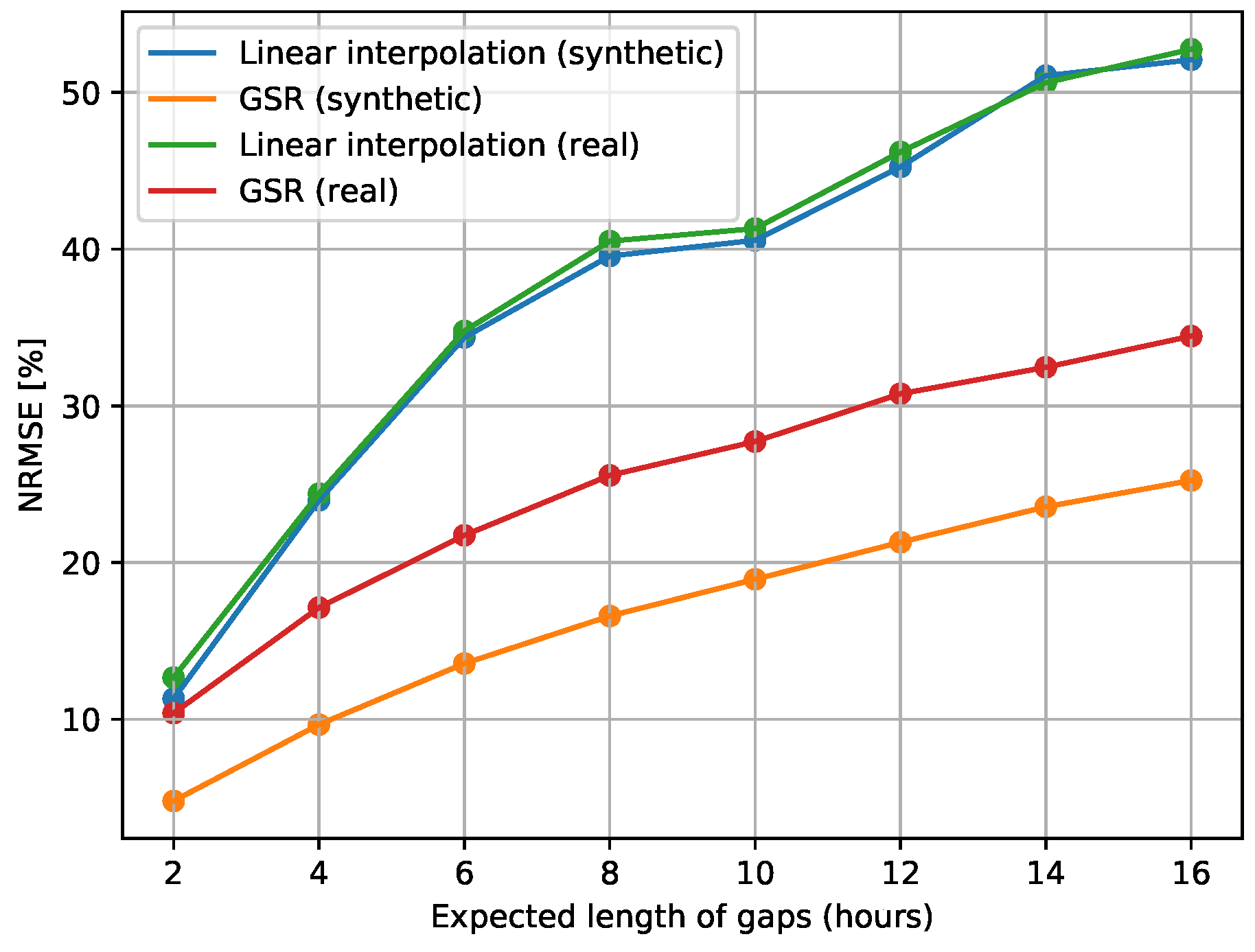
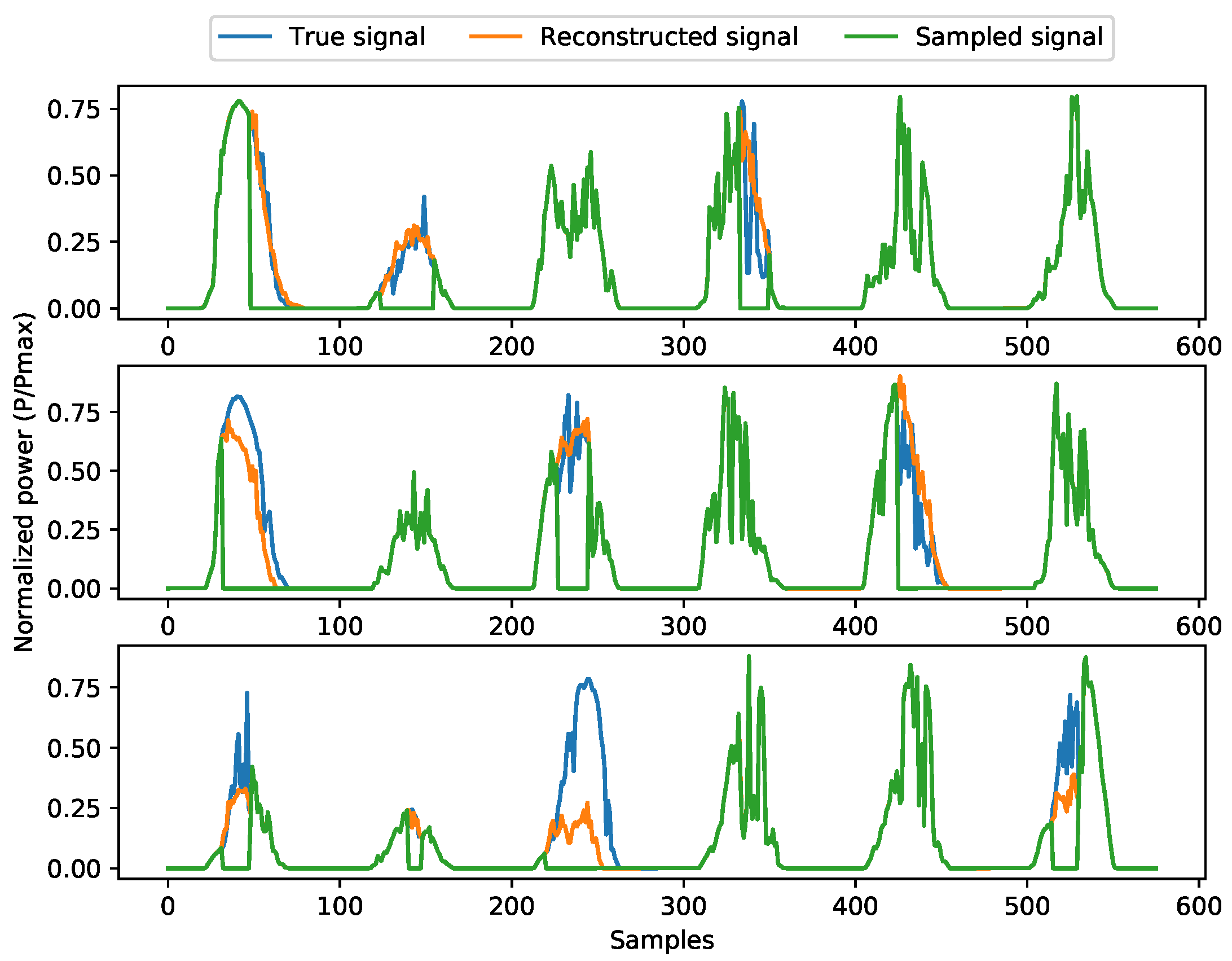
3.2. Results of the Graph-Based Algorithm for Data Reconstruction
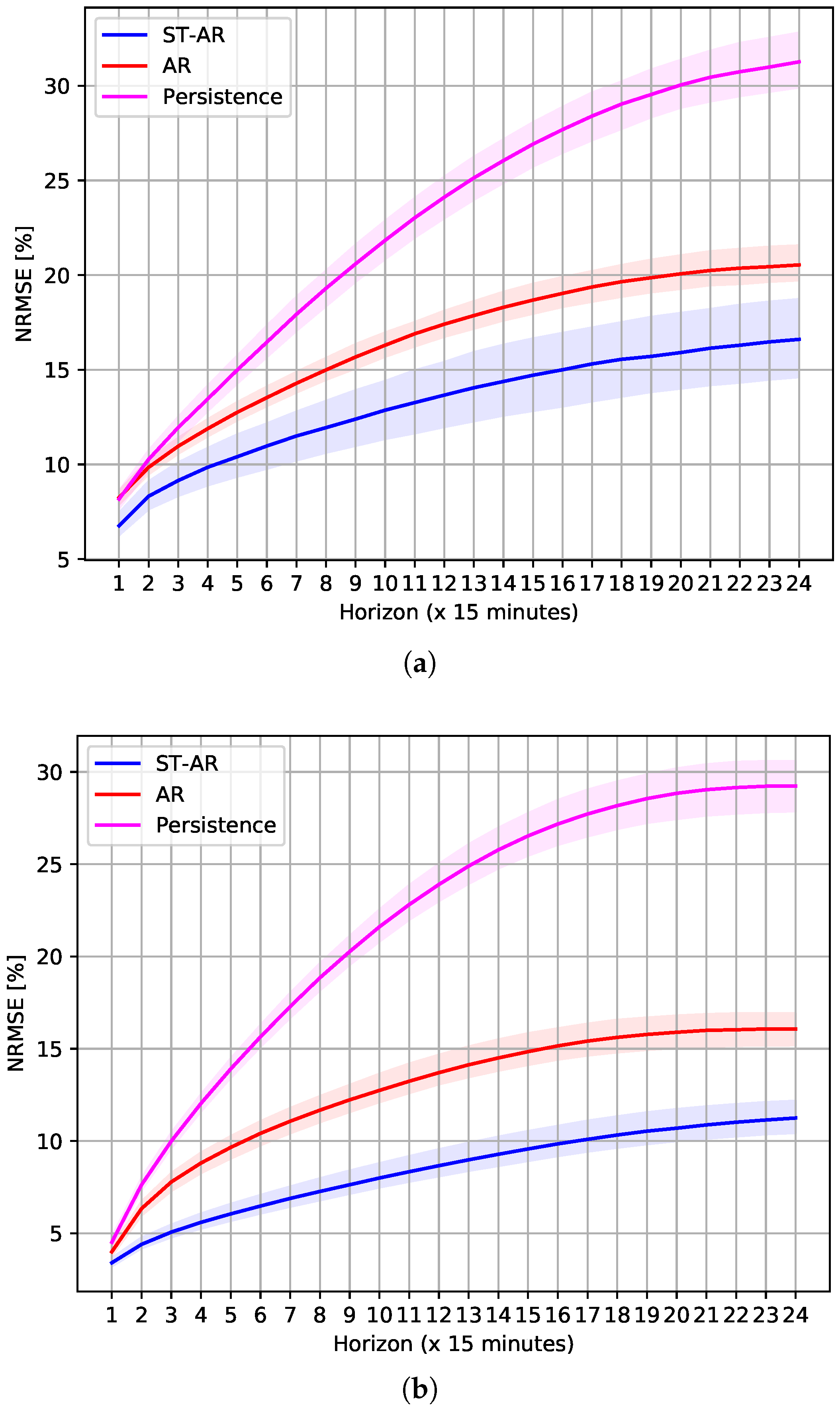
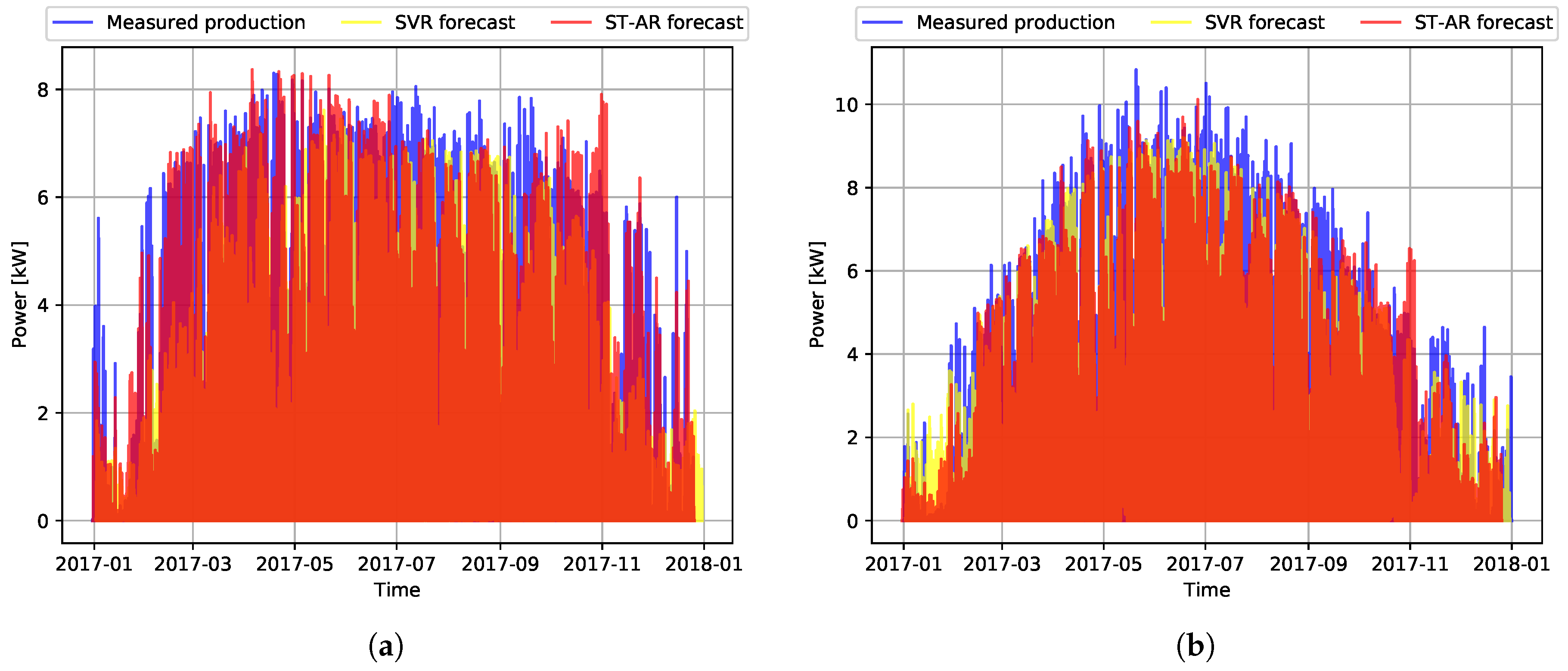
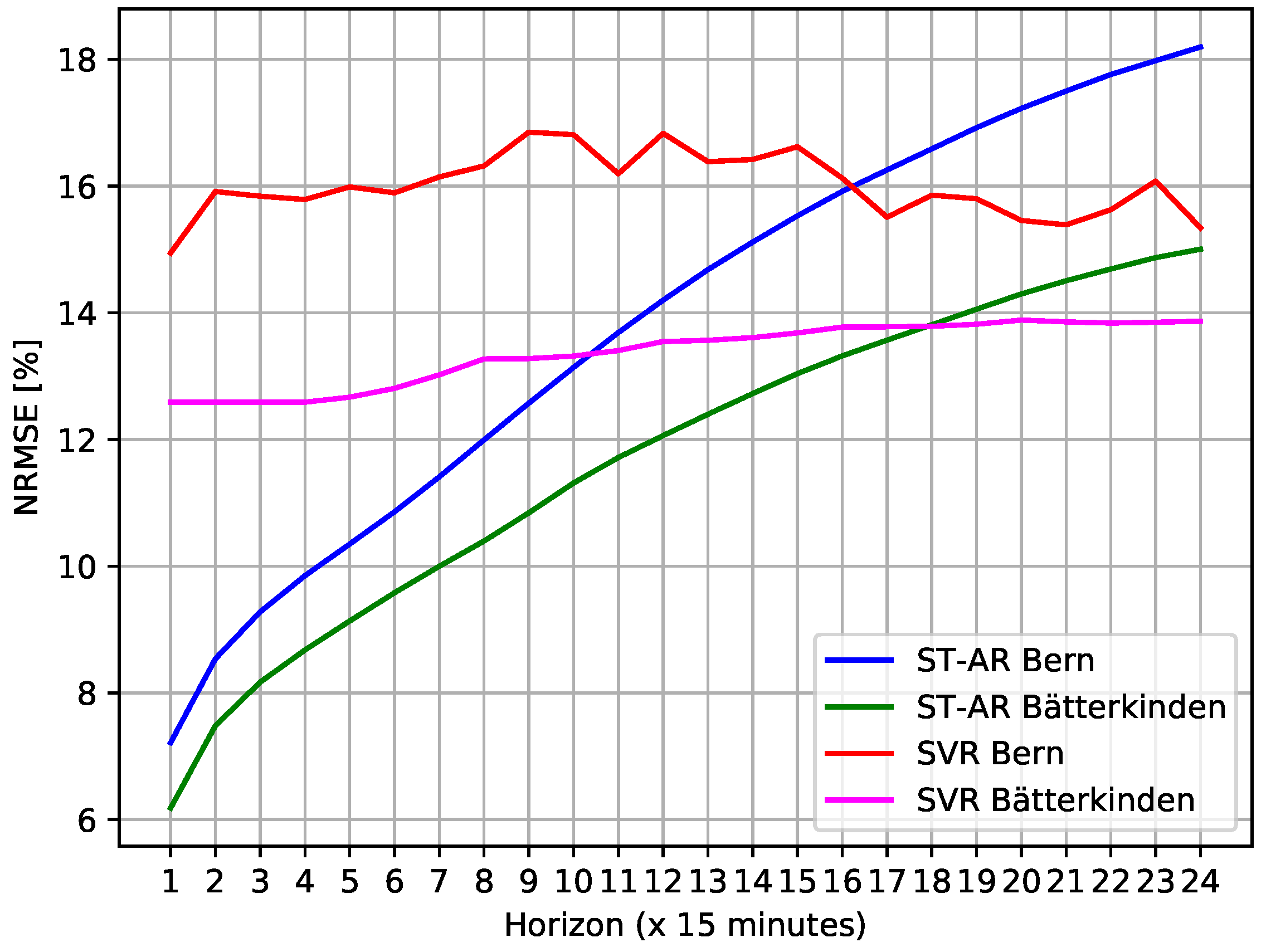
3.3. Forecasting Results Using Uninterrupted Data
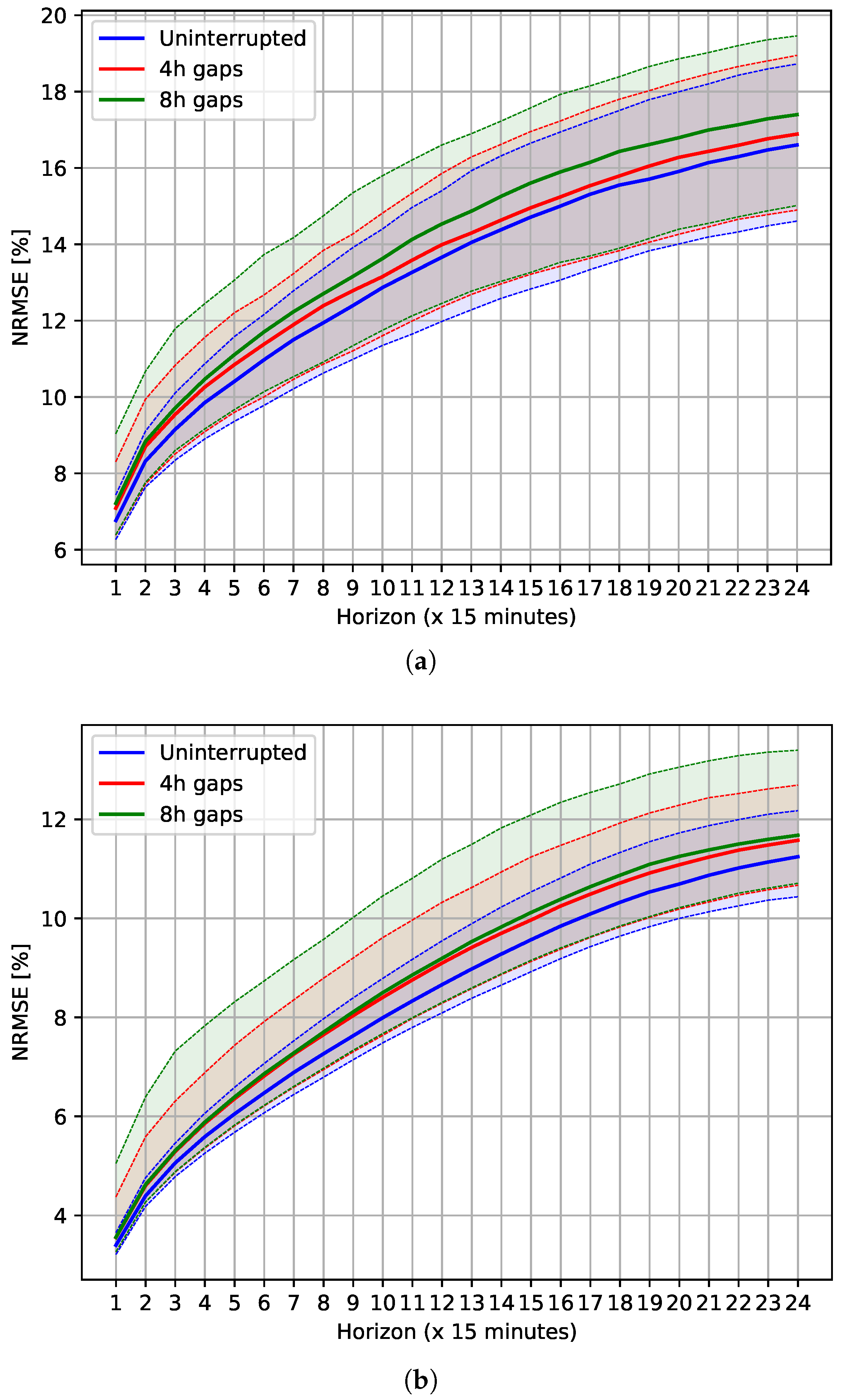
3.4. Forecasting Results Using Incomplete Data
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alet, P.J.; Efthymiou, V.; Graditi, G.; Henze, N.; Juel, M.; Moser, D.; Nemac, F.; Pierro, M.; Rikos, E.; Tselepis, S.; et al. Forecasting and Observability: Critical Technologies for System Operations with High PV Penetration. In Proceedings of the 32nd European Photovoltaic Solar Energy Conference and Exhibition (EUPVSEC), Munich, Germany, 20–24 June 2016. [Google Scholar]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de Pison, F.J.; Antonanzas-Torres, F. Review of photovoltaic power forecasting. Sol. Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Visser, L.; AlSkaif, T.; Sark, W.V. Benchmark analysis of day-ahead solar power forecasting techniques using weather predictions. In Proceedings of the 2019 IEEE 46th Photovoltaic Specialists Conference (PVSC); IEEE: Chicago, IL, USA, 2019; pp. 2111–2116. [Google Scholar] [CrossRef]
- Pierro, M.; De Felice, M.; Maggioni, E.; Moser, D.; Perotto, A.; Spada, F.; Cornaro, C. A New Approach for Regional Photovoltaic Power Estimation and Forecast. In Proceedings of the 33rd European Photovoltaic Solar Energy Conference and Exhibition (EUPVSEC), Amsterdam, Netherlands, 25–29 September 2017. [Google Scholar]
- Chow, C.W.; Urquhart, B.; Lave, M.; Dominguez, A.; Kleissl, J.; Shields, J.; Washom, B. Intra-hour forecasting with a total sky imager at the UC San Diego solar energy testbed. Sol. Energy 2011, 85, 2881–2893. [Google Scholar] [CrossRef] [Green Version]
- Marquez, R.; Coimbra, C.F.M. Intra-hour DNI forecasting based on cloud tracking image analysis. Sol. Energy 2013, 91, 327–336. [Google Scholar] [CrossRef]
- Jang, H.S.; Bae, K.Y.; Park, H.S.; Sung, D.K. Solar Power Prediction Based on Satellite Images and Support Vector Machine. IEEE Trans. Sustain. Energy 2016, 7, 1255–1263. [Google Scholar] [CrossRef]
- Perez, R.; Kivalov, S.; Schlemmer, J.; Hemker, K.; Renné, D.; Hoff, T.E. Validation of short and medium term operational solar radiation forecasts in the US. Sol. Energy 2010, 84, 2161–2172. [Google Scholar] [CrossRef]
- Sharma, N.; Sharma, P.; Irwin, D.; Shenoy, P. Predicting solar generation from weather forecasts using machine learning. In Proceedings of the 2011 IEEE International Conference on Smart Grid Communications (SmartGridComm), Brussels, Belgium, 17–20 October 2011; pp. 528–533. [Google Scholar]
- Bae, K.Y.; Jang, H.S.; Sung, D.K. Hourly Solar Irradiance Prediction Based on Support Vector Machine and Its Error Analysis. IEEE Trans. Power Syst. 2017, 32, 935–945. [Google Scholar] [CrossRef]
- Yang, C.; Thatte, A.A.; Xie, L. Multitime-Scale Data-Driven Spatio-Temporal Forecast of Photovoltaic Generation. IEEE Trans. Sustain. Energy 2015, 6, 104–112. [Google Scholar] [CrossRef]
- Agoua, X.G.; Girard, R.; Kariniotakis, G. Short-Term Spatio-Temporal Forecasting of Photovoltaic Power Production. IEEE Trans. Sustain. Energy 2018, 9, 538–546. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Yoo, S.; Heiser, J.; Kalb, P. Sensor network based solar forecasting using a local vector autoregressive ridge framework. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, SAC ’16, Association for Computing Machinery, Pisa, Italy, 4–8 April 2016; pp. 2113–2118. [Google Scholar]
- Kashyap, Y.; Bansal, A.; Sao, A.K. Spatial Approach of Artificial Neural Network for Solar Radiation Forecasting: Modeling Issues. J. Sol. Energy 2015, 2015, 410684. [Google Scholar] [CrossRef] [Green Version]
- Ghaderi, A.; Sanandaji, B.M.; Ghaderi, F. Deep Forecast: Deep Learning-based Spatio-Temporal Forecasting. arXiv 2017, arXiv:1707.08110. [Google Scholar]
- Lee, J.I.; Lee, I.W.; Kim, S.H. Multi-site photovoltaic power generation forecasts based on deep-learning algorithm. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 18–20 October 2017; pp. 1118–1120. [Google Scholar]
- Zhu, Q.; Chen, J.; Zhu, L.; Duan, X.; Liu, Y. Wind Speed Prediction with Spatio–Temporal Correlation: A Deep Learning Approach. Energies 2018, 11, 705. [Google Scholar] [CrossRef] [Green Version]
- Jeong, J.; Kim, H. Multi-Site Photovoltaic Forecasting Exploiting Space-Time Convolutional Neural Network. Energies 2019, 12, 4490. [Google Scholar] [CrossRef] [Green Version]
- Khodayar, M.; Mohammadi, S.; Khodayar, M.E.; Wang, J.; Liu, G. Convolutional Graph Autoencoder: A Generative Deep Neural Network for Probabilistic Spatio-Temporal Solar Irradiance Forecasting. IEEE Trans. Sustain. Energy 2020, 11, 571–583. [Google Scholar] [CrossRef]
- Lauret, P.; Voyant, C.; Soubdhan, T.; David, M.; Poggi, P. A benchmarking of machine learning techniques for solar radiation forecasting in an insular context. Sol. Energy 2015, 112, 446–457. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.; Kim, K.; Park, J.; Kim, J.; Kim, Y. Forecasting Solar Power Using Long-Short Term Memor and Convolutional Neural Networks. IEEE Access 2018, 6, 73068–73080. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR ’18, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Killinger, S.; Engerer, N.; Müller, B. QCPV: A quality control algorithm for distributed photovoltaic array power output. Sol. Energy 2017, 143, 120–131. [Google Scholar] [CrossRef]
- González Ordiano, J.; Waczowicz, S.; Reischl, M.; Mikut, R.; Hagenmeyer, V. Photovoltaic power forecasting using simple data-driven models without weather data. Comput. Sci. Res. Dev. 2017, 32, 237–246. [Google Scholar] [CrossRef]
- Heidari Kapourchali, M.; Sepehry, M.; Aravinthan, V. Multivariate spatio-temporal solar generation forecasting: A unified Approach to deal with communication failure and invisible sites. IEEE Syst. J. 2019, 13, 1804–1812. [Google Scholar] [CrossRef]
- Qiu, K.; Mao, X.; Shen, X.; Wang, X.; Li, T.; Gu, Y. Time-Varying Graph Signal Reconstruction. IEEE J. Sel. Top. Signal Process. 2017, 11, 870–883. [Google Scholar] [CrossRef]
- Shuman, D.; Narang, S.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef] [Green Version]
- Combettes, P.L.; Pesquet, J.C. Proximal Splitting Methods in Signal Processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Bauschke, H.H., Burachik, R.S., Combettes, P.L., Elser, V., Luke, D.R., Wolkowicz, H., Eds.; Springer: New York, NY, USA, 2011; pp. 185–212. [Google Scholar]
- Stein, J.S.; Holmgren, W.F.; Forbess, J.; Hansen, C.W. PVLIB: Open source photovoltaic performance modeling functions for Matlab and Python. In Proceedings of the 2016 IEEE 43rd Photovoltaic Specialists Conference (PVSC), Portland, OR, USA, 5–10 June 2016; pp. 3425–3430. [Google Scholar]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Dong, X.; Thanou, D.; Rabbat, M.; Frossard, P. Learning graphs from data: A signal representation perspective. IEEE Signal Process. Mag. 2019, 36, 44–63. [Google Scholar] [CrossRef] [Green Version]
- Boegli, M.; Pierro, M.; Moser, D.; Alet, P.J. Machine learning techniques for forecasting single-site PV production. In Proceedings of the 34th European Photovoltaic Solar Energy Conference and Exhibition (EUPVSEC), Brussels, Belgium, 24–27 September 2018. [Google Scholar]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carrillo, R.E.; Leblanc, M.; Schubnel, B.; Langou, R.; Topfel, C.; Alet, P.-J. High-Resolution PV Forecasting from Imperfect Data: A Graph-Based Solution. Energies 2020, 13, 5763. https://doi.org/10.3390/en13215763
Carrillo RE, Leblanc M, Schubnel B, Langou R, Topfel C, Alet P-J. High-Resolution PV Forecasting from Imperfect Data: A Graph-Based Solution. Energies. 2020; 13(21):5763. https://doi.org/10.3390/en13215763
Chicago/Turabian StyleCarrillo, Rafael E., Martin Leblanc, Baptiste Schubnel, Renaud Langou, Cyril Topfel, and Pierre-Jean Alet. 2020. "High-Resolution PV Forecasting from Imperfect Data: A Graph-Based Solution" Energies 13, no. 21: 5763. https://doi.org/10.3390/en13215763
APA StyleCarrillo, R. E., Leblanc, M., Schubnel, B., Langou, R., Topfel, C., & Alet, P. -J. (2020). High-Resolution PV Forecasting from Imperfect Data: A Graph-Based Solution. Energies, 13(21), 5763. https://doi.org/10.3390/en13215763