Prediction of Sorption Processes Using the Deep Learning Methods (Long Short-Term Memory)

 ,
,  ,
,  , ,
, ,  , ,
, , 
Abstract
:
1. Introduction
2. Problem Formulation and Solving
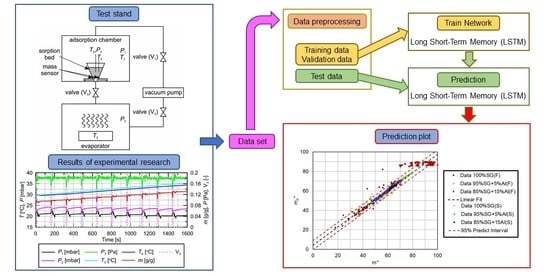
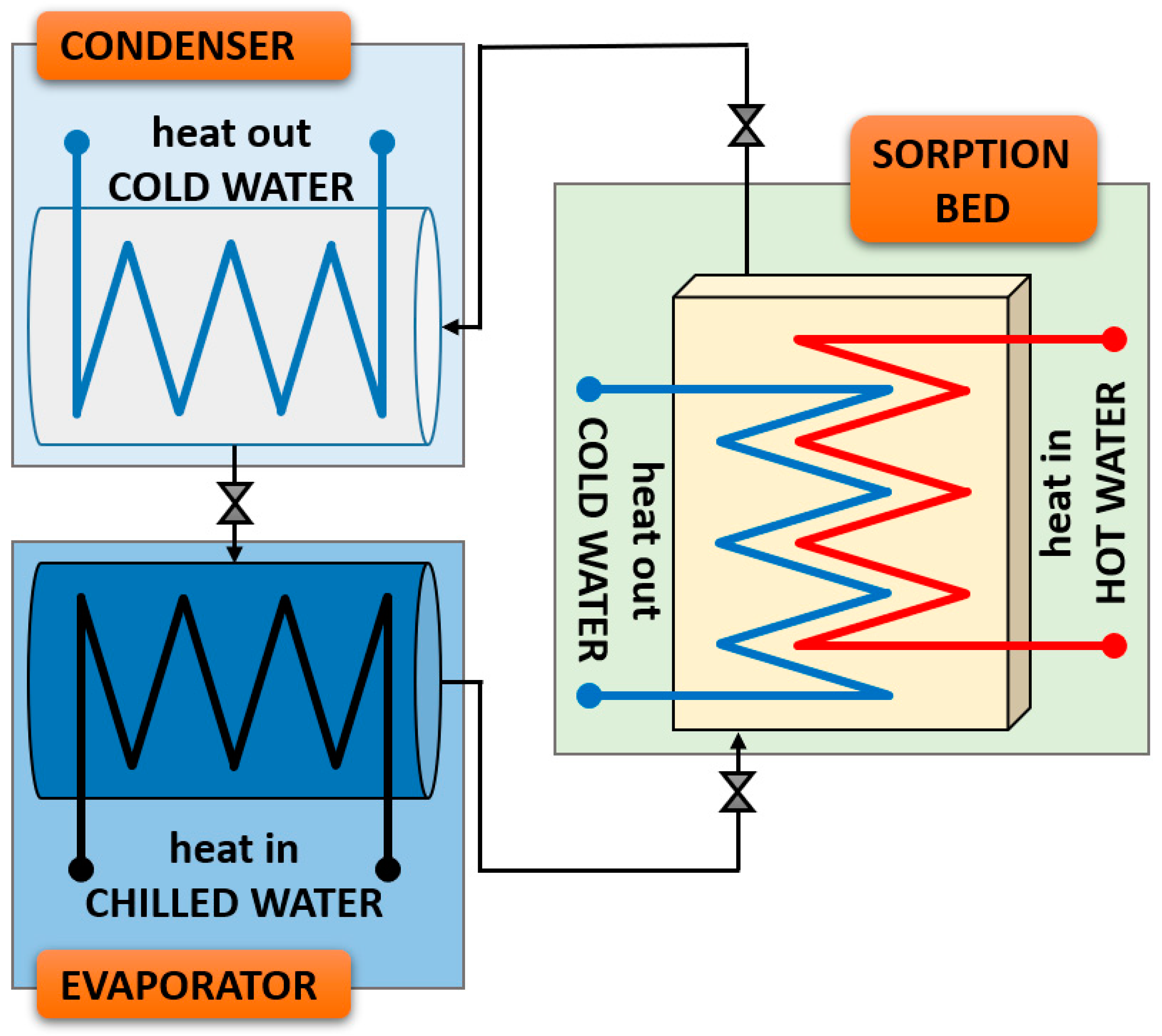
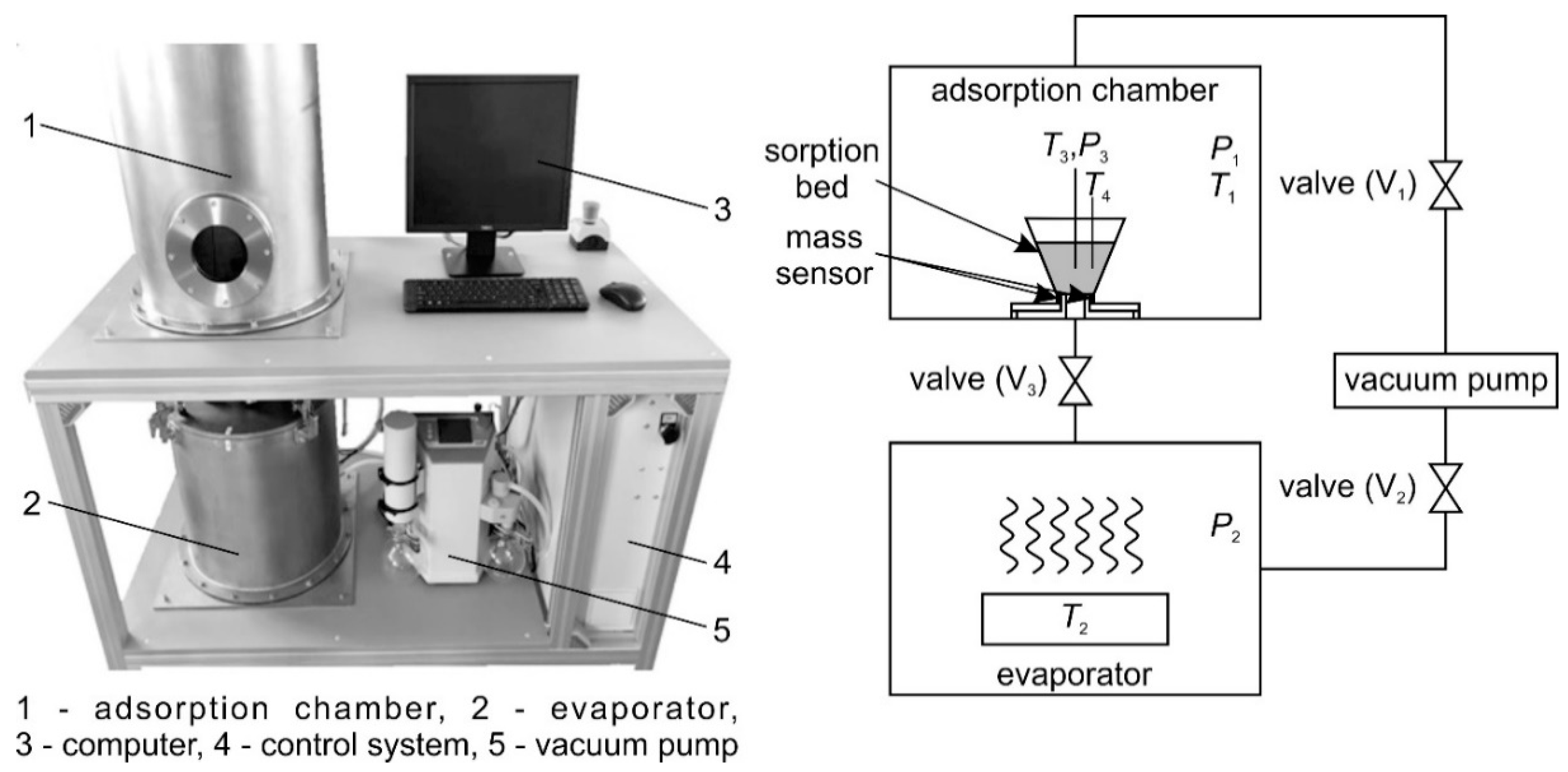
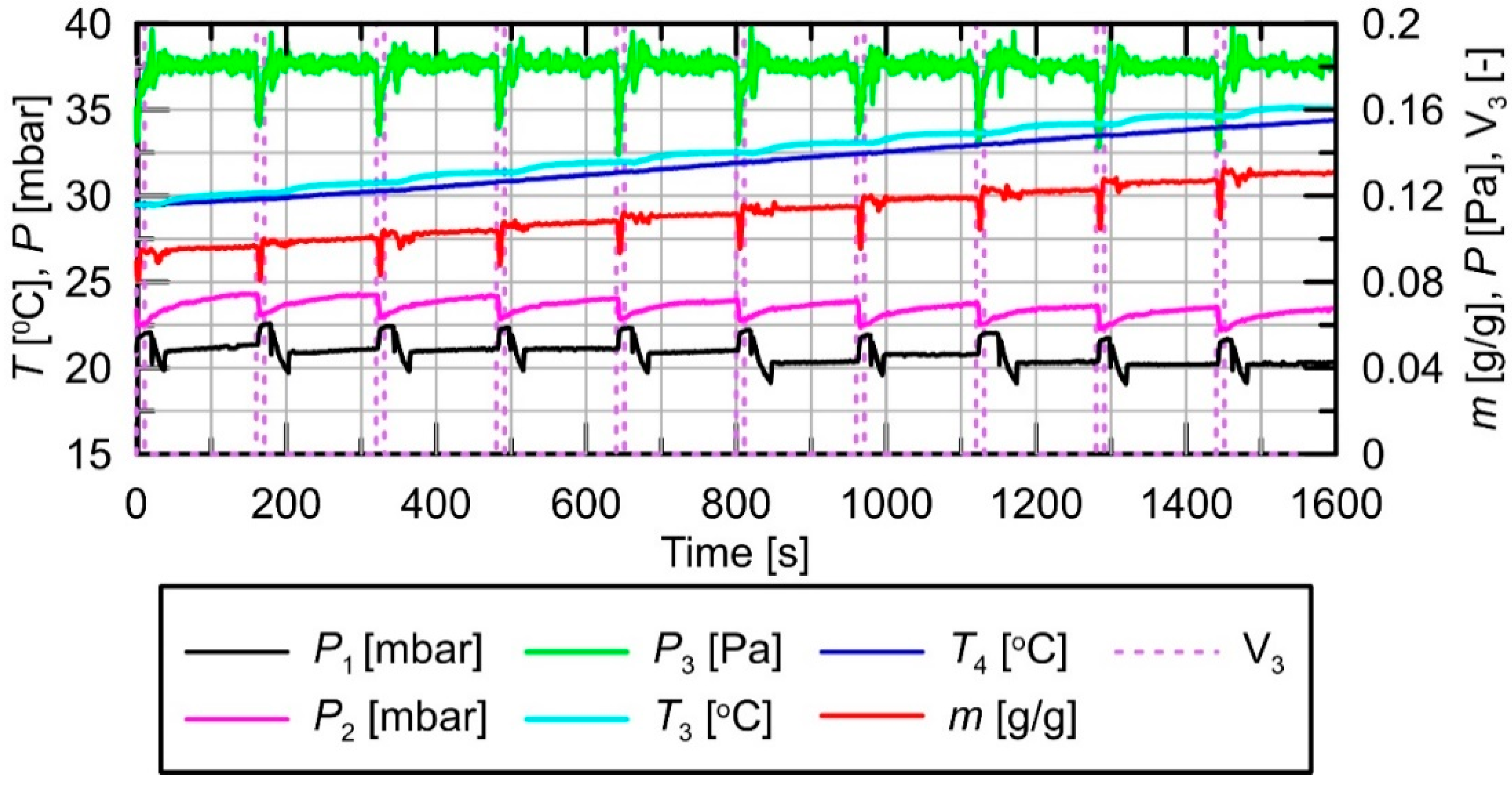
2.1. Experimental Test
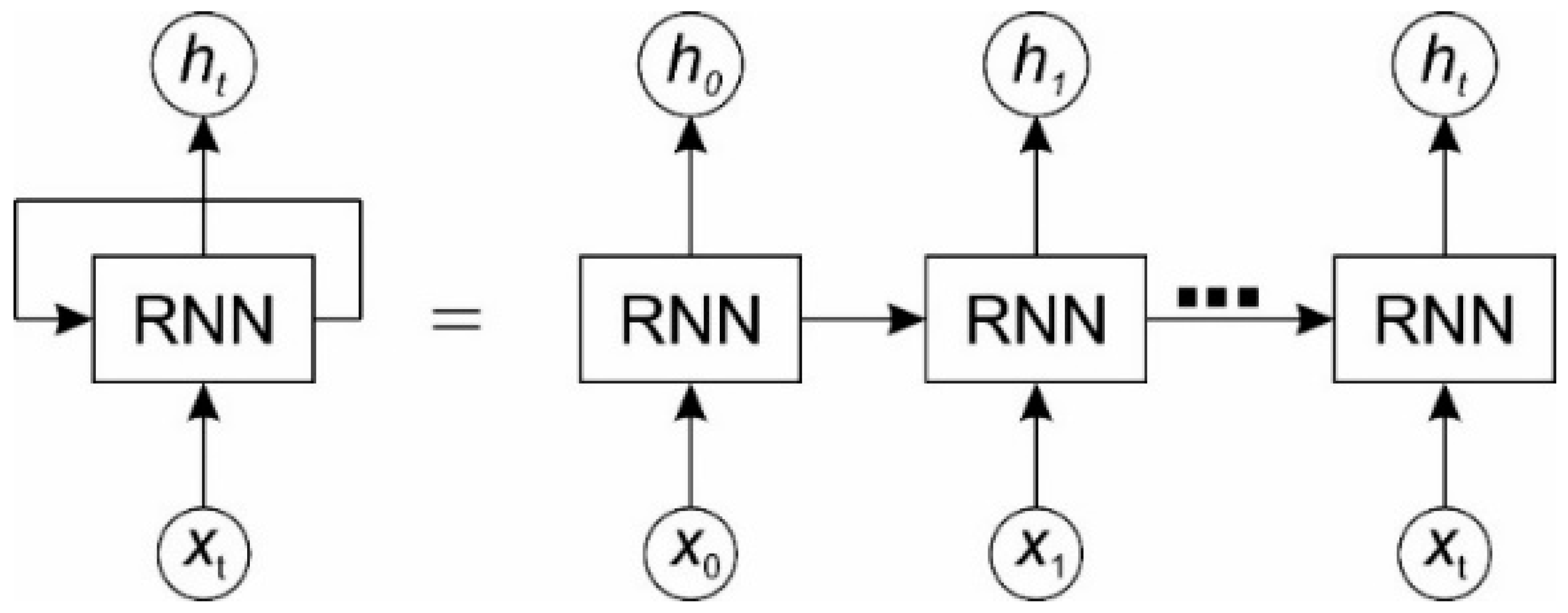
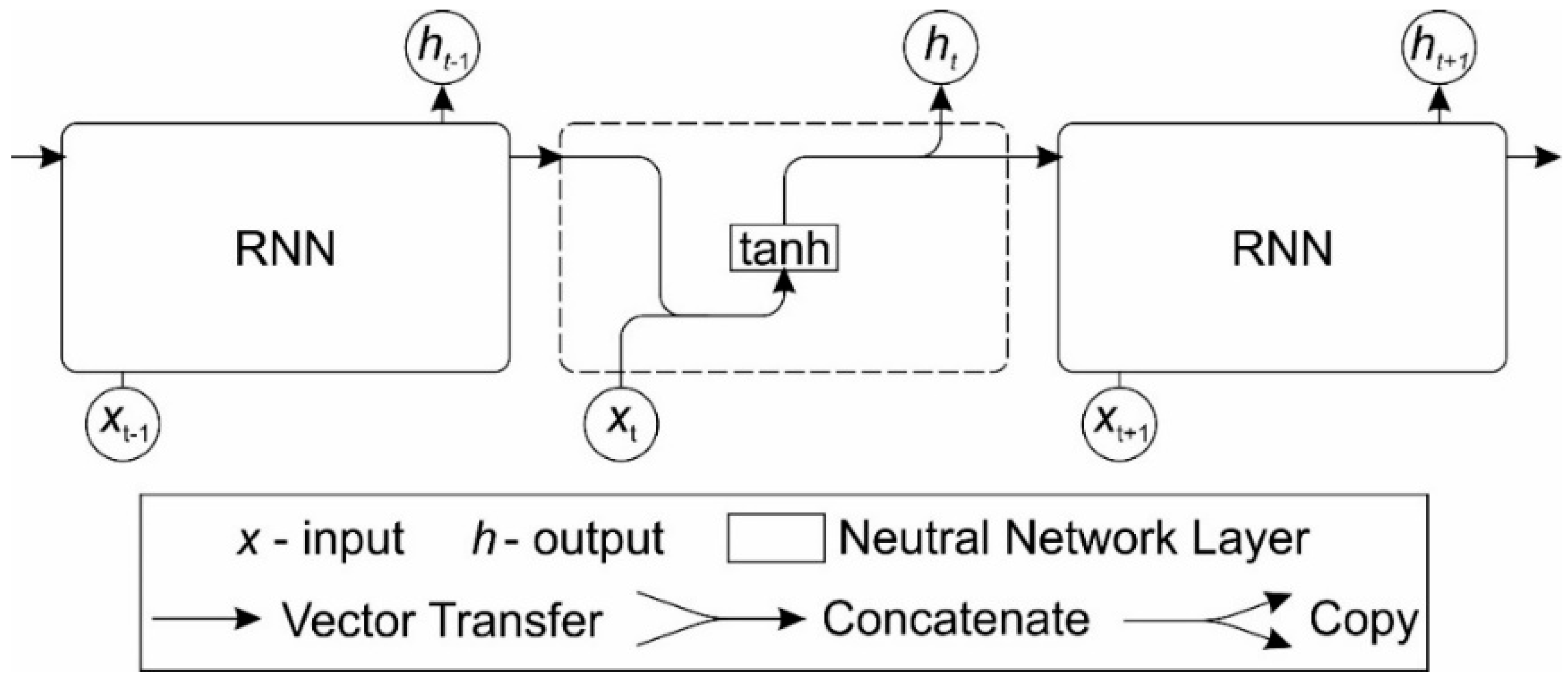
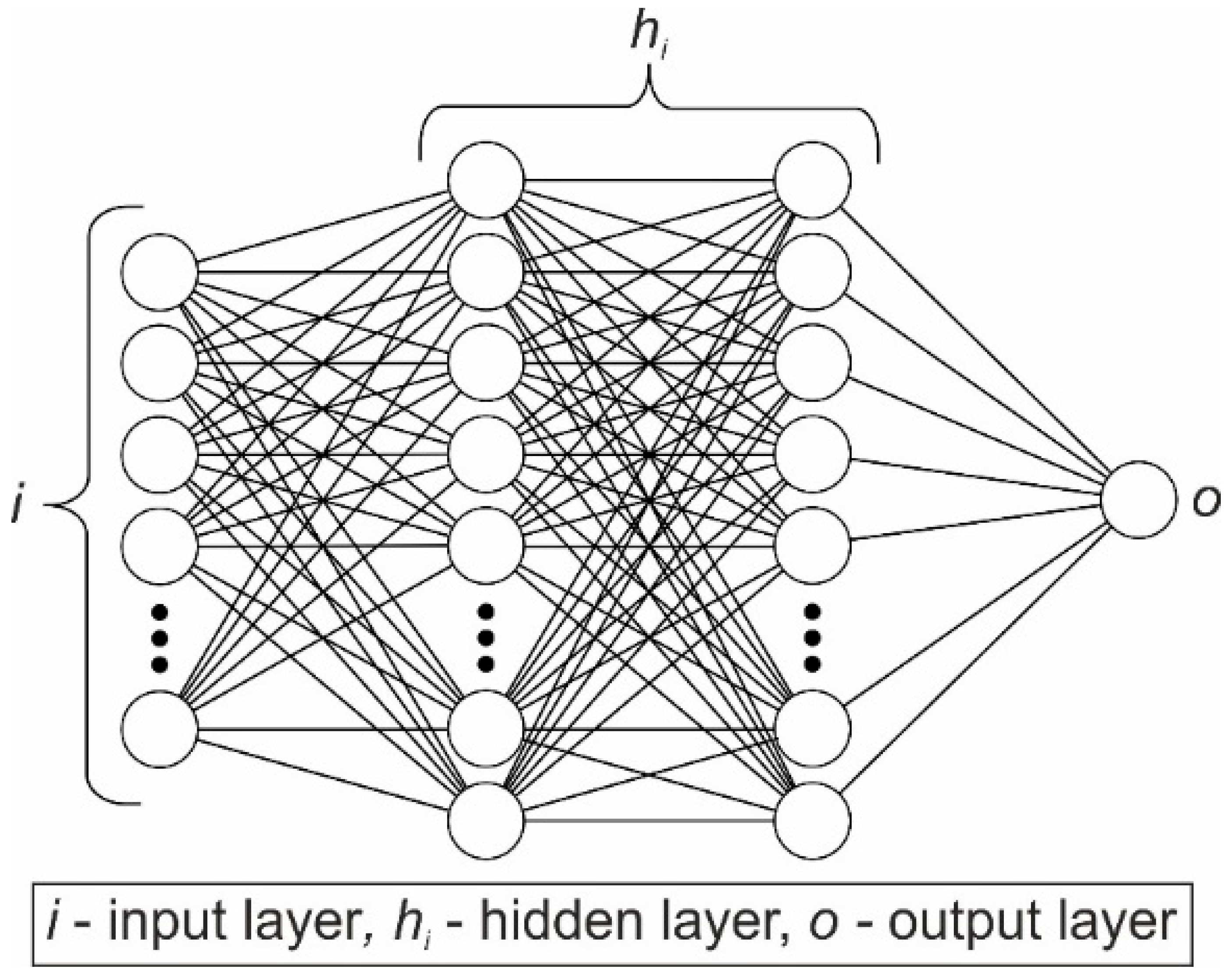
2.2. Recurrent Neural Network (RNN)
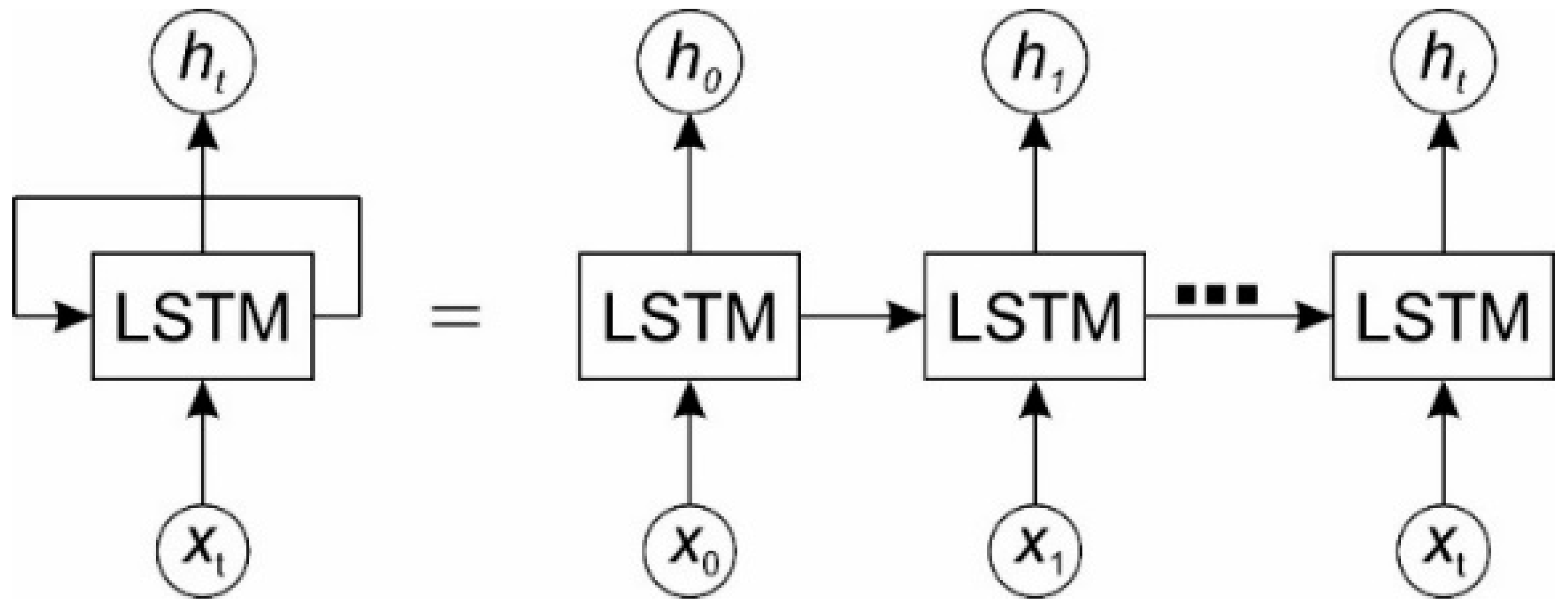
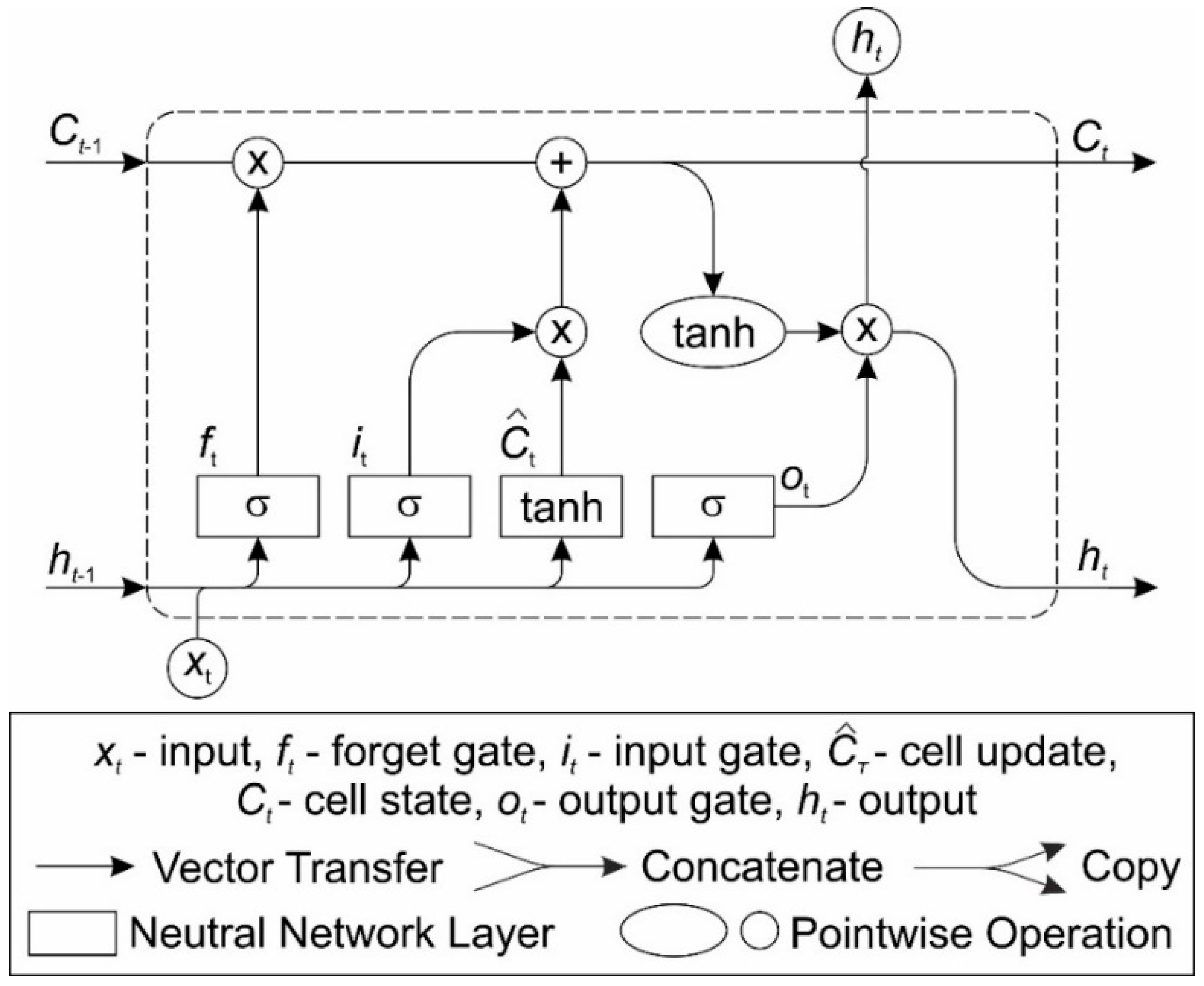
2.3. Long Short-Term Memory (LSTM)
- forget gate ft –filters information from the input and previous output and decides which information to remember or forget and discard,
- input gate it –controls the flow of activation to enter the cell,
- output gate ot –controls the output flow of cell activation.
- input xt,
- previous output ht−1
- cell state Ct−1
- the forget gate ft (sigmoid layer):
- the input gate it (sigmoid layer):
- the cell state Ct:
- the output gate ot (sigmoid layer):where: —the cell update; Wf, Wi, Wc, Wo—matrices of weights; bf, bi, bc, bo—bias vector.
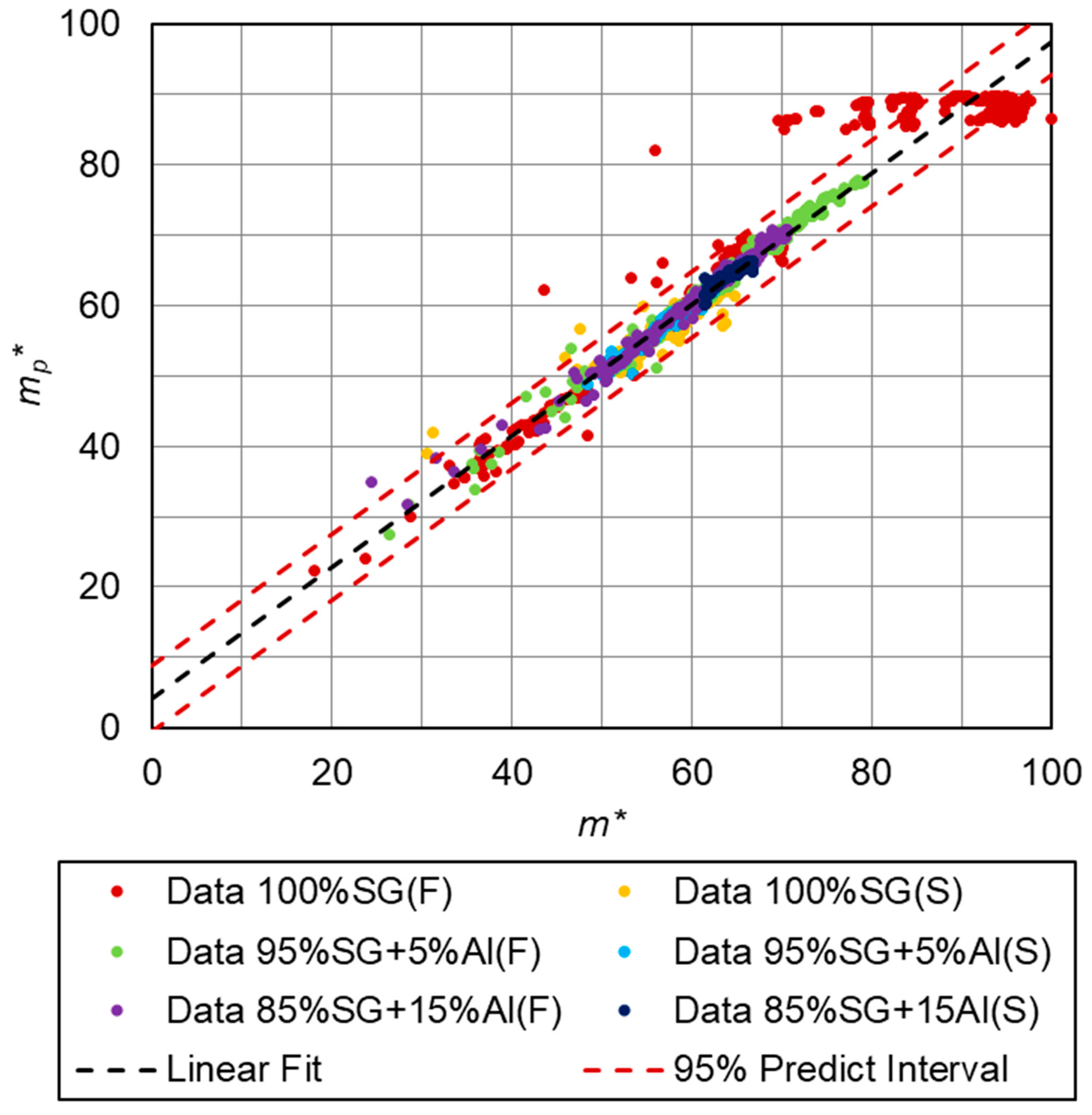
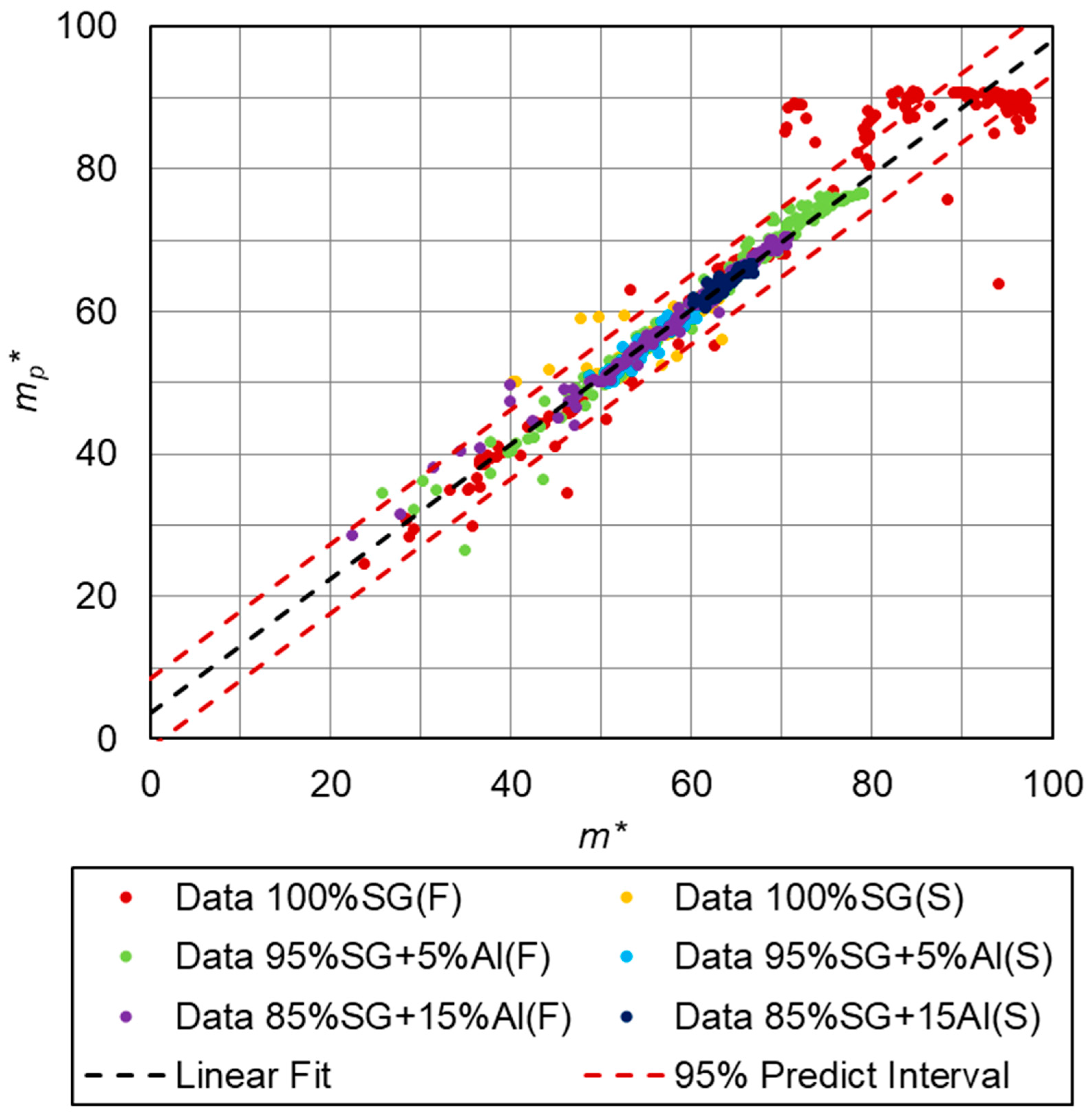
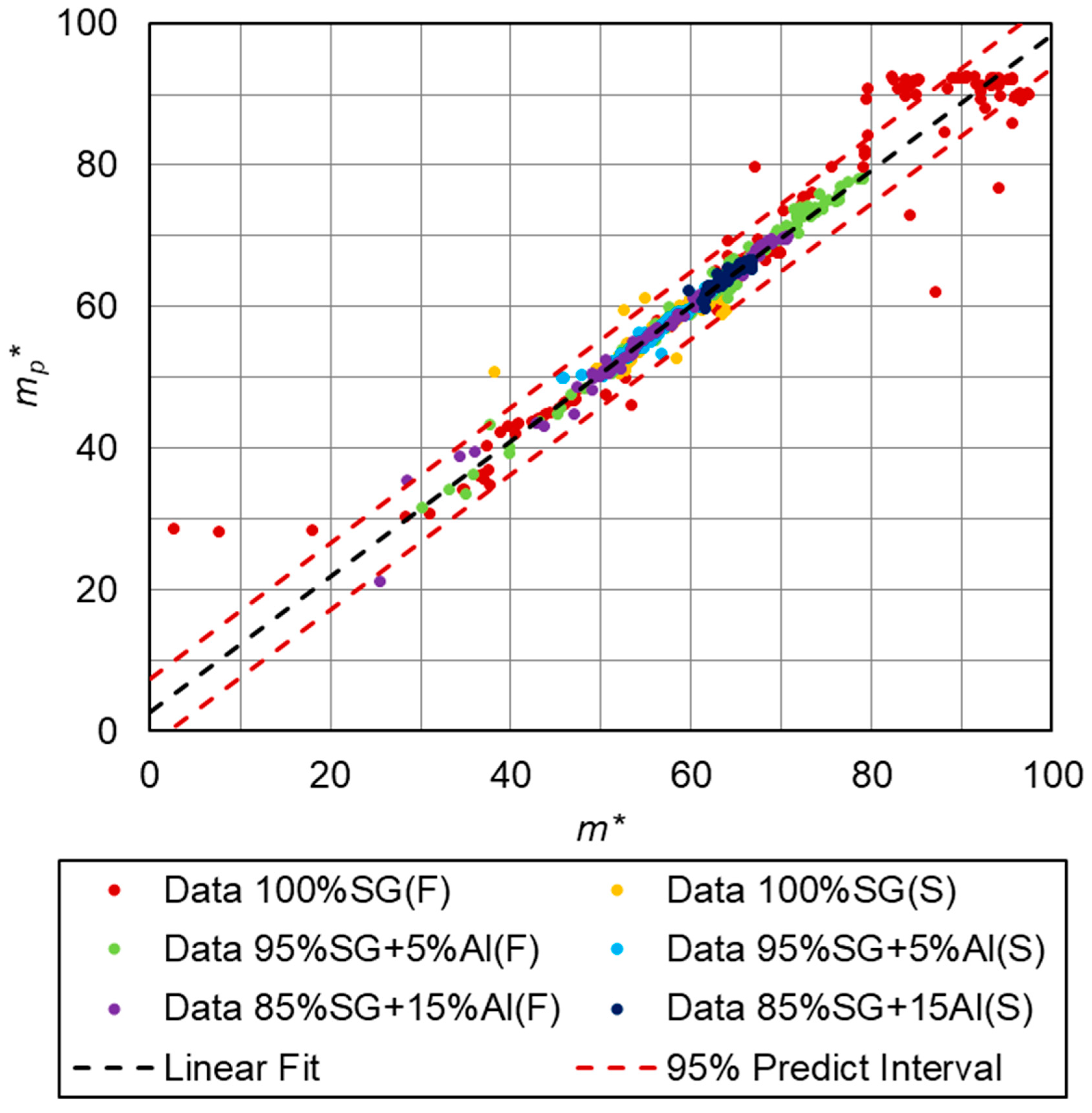
3. Results of Numerical Calculations
- (a)
- First numerical research (60-20-20):
- training data—60% of all data,
- validation data—20% of all data,
- test data—20% of all data,
- (b)
- Second numerical research (70-15-15):
- training data—70% of all data,
- validation data—15% of all data,
- test data—15% of all data,
- (c)
- Third numerical research (80-10-10):
- training data—80% of all data,
- validation data—10% of all data,
- test data—10% of all data.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Al | aluminum |
| F | fluidized state corresponding to fluidized bed conditions |
| LSTM | Long Short-Term Memory |
| m* | normalized sorbent mass (experimental value), – |
| mp* | normalized sorbent mass predicted by the LSTM, – |
| NN | neural network |
| n% | the percentage of the additive in the mixture, % |
| RNN | Recurrent Neural Network |
| S | stationary state corresponding to the fixed bed conditions |
| SG | silica gel |
References
- Sosnowski, M. Evaluation of Heat Transfer performance of a Multi-Disc Sorption Bed Dedicated for Adsorption Cooling Technology. Energies 2019, 12, 4660. [Google Scholar] [CrossRef] [Green Version]
- Saha, B.B.; Koyama, S.; Lee, J.B.; Kuwahara, K.; Alam, K.C.A.; Hamamoto, Y.; Akisawa, A.; Kashiwagi, T. Performance evaluation of a low-temperature waste heat driven multi-bed adsorption chiller. Int. J. Multiph. Flow 2003, 29, 1249–1263. [Google Scholar] [CrossRef]
- Scapino, L.; Zondag, H.A.; Diriken, J.; Rindt, C.C.M.; Van Bael, J.; Sciacovelli, A. Modeling the performance of a sorption thermal energy storage reactor using artificial neural networks. Appl. Energy 2019, 253, 113525. [Google Scholar] [CrossRef]
- Argyropoulos, D.; Paraforos, D.S.; Alex, R.; Griepentrog, H.W.; Müller, J. NARX Neural Network Modelling of Mushroom Dynamic Vapour Sorption Kinetics. IFAC-PapersOnLine 2016, 49, 305–310. [Google Scholar] [CrossRef]
- Hua, J.; Faghri, A. Applications of artificial neural networks to intelligent vehicle-highway systems. Transp. Res. Rec. 1994, 1453, 83. [Google Scholar]
- Ashraf, W.M.; Uddin, G.M.; Arafat, S.M.; Afghan, S.; Kamal, A.H.; Asim, M.; Khan, M.H.; Rafique, M.W.; Naumann, U.; Niazi, S.G. Optimization of a 660 MWe Supercritical Power Plant Performance—A Case of Industry 4.0 in the Data-Driven Operational Management Part 1. Thermal Efficiency. Energies 2020, 13, 5592. [Google Scholar] [CrossRef]
- Ashraf, W.M.; Uddin, G.M.; Kamal, A.H.; Khan, M.H.; Khan, A.A.; Ahmad, H.A.; Ahmed, F.; Hafeez, N.; Sami, R.M.Z.; Arafat, S.M. Optimization of a 660 MWe Supercritical Power Plant Performance—A Case of Industry 4.0 in the Data-Driven Operational Management. Part 2. Power Generation. Energies 2020, 13, 5619. [Google Scholar] [CrossRef]
- Krzywanski, J.; Grabowska, K.; Herman, F.; Pyrka, P.; Sosnowski, M.; Prauzner, T.; Nowak, W. Optimization of a three-bed adsorption chiller by genetic algorithms and neural networks. Energy Convers. Manag. 2017, 153, 313–322. [Google Scholar] [CrossRef]
- Krzywanski, J. A General Approach in Optimization of Heat Exchangers by Bio-Inspired Artificial Intelligence Methods. Energies 2019, 12, 4441. [Google Scholar] [CrossRef] [Green Version]
- Krzywanski, J.; Grabowska, K.; Sosnowski, M.; Zylka, A.; Sztekler, K.; Kalawa, W.; Wojcik, T.; Nowak, W. An adaptive neuro-fuzzy model of a re-heat two-stage adsorption chiller. Therm. Sci. 2019, 23, 1053–1063. [Google Scholar] [CrossRef] [Green Version]
- Park, D.; Rilett, L.R. Forecasting freeway link travel times with a multilayer feed-forward neural network. Comput. Aided Civ. Infrastruct. Eng. 1999, 14, 357–367. [Google Scholar] [CrossRef]
- Yin, H.; Wong, S.; Xu, J.; Wong, C. Urban traffic flow prediction using a fuzzy-neural approach. Transp. Res. Part C Emerg. Technol. 2002, 10, 85–98. [Google Scholar] [CrossRef]
- Van Lint, J.; Hoogendoorn, S.; Van Zuylen, H. Freeway travel time prediction with state-space neural networks: Modeling state-space dynamics with recurrent neural networks. Transp. Res. Rec. J. Transp. Res. Board 2002, 1811, 30–39. [Google Scholar] [CrossRef]
- Yu, R.; Li, Y.; Shahabi, C.; Demiryurek, U.; Liu, Y. Deep learning: A generic approach for extreme condition traffic forecasting. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 777–785. [Google Scholar]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), Lille, France, 6–11 July 2015; pp. 2342–2350. [Google Scholar]
- Liu, H.; Chen, C. Data processing strategies in wind energy forecasting models and applications: A comprehensive review. Appl. Energy 2019, 249, 392–408. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Eck, D.; Schmidhuber, J. A first look at music composition using lstm recurrent neural networks. Istituto Dalle Molle Di Studi Sull Intelligenza Artificiale 2002, 103, 48. [Google Scholar]
- Shahid, F.; Zameer, A.; Muneeb, M. Prediction for COVID-19 with deep learning models of LSTM, GRU, and Bi-LSTM. Choas Solitions Fractals 2020, 140, 110212. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar] [CrossRef] [Green Version]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 961–971. [Google Scholar]
- Martinez-Garcia, M.; Zhang, Y.; Suzuki, K.; Zhand, Y.-D. Deep Recurrent Entropy Adaptive Model for System Reliability Monitoring. IEEE Trans. Ind. Inform. 2020, 17, 839–848. [Google Scholar] [CrossRef]
- Martinez-Garcia, M.; Zhang, Y.; Gordon, T. Memory pattern identification for feedback tracking control in human-machine system. Hum. Factors 2019. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.-Y.; Lv, Y.; Li, Z.; Wang, F.-Y. Long short-term memory model for traffic congestion prediction with online open data. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 132–137. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H. Short-term traffic flow forecasting with spatial temporal correlation in a hybrid deep learning framework. arXiv 2016, arXiv:1612.01022. [Google Scholar]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Duan, Y.; Lv, Y.; Wang, F.-Y. Travel time prediction with lstm neural network. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1053–1058. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using lstm and gru neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. Lstm network: A deep learning approach for short-term traffic forecast. IET Intell Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Jaitly, N.; Mohamed, A.-R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Kirbas, I.; Sozen, A.; Tuncer, A.D.; Kazancioglu, F.S. Comparative analysis and forecasting of Covid-19 cases in various European countries with ARIMA, NARN and LSM approaches. Chaos Solitons Fractals 2020, 138. [Google Scholar] [CrossRef]
- Chitra, M.; Sutha, S.; Pappa, N. Application of deep neural techniques in predictive modelling for the estimation of Escherichia coli growth rate. J. Appl. Microbiol. 2020. [Google Scholar] [CrossRef]
- Thapa, S.; Zhao, Z.; Li, B.; Lu, L.; Fu, D.; Shi, X.; Tang, B.; Qi, H. Snowmelt-Driven Streamflow Prediction Using Machine Learning Techniques (LSTM, NARX, GPR, and SVR). Water 2020, 12, 1734. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Krzywanski, J.; Grabowska, K.; Sosnowski, M.; Zylka, A.; Kulakowska, A.; Czakiert, T.; Sztekler, K.; Wesolowska, M.; Nowak, W. Heat transfer in fluidized and fixed beds of adsorption chillers. E3S Web Conf. 2019, 128, 01003. [Google Scholar] [CrossRef]
- Krzywanski, J.; Grabowska, K.; Sosnowski, M.; Zylka, A.; Kulakowska, A.; Czakiert, T.; Wesolowska, M.; Nowak, W. Heat transfer in adsorption chillers with fluidized beds of silica gel, zeolite, and carbon nanotubes. Heat Transf. Eng. 2019, 128, 01003. [Google Scholar]
- Stanek, W.; Gazda, W.; Kostowski, W. Thermo-ecological assessment of CCHP (combined cold-heat-and-power) plant supported with renewable energy. Energy 2015, 92, 279–289. [Google Scholar] [CrossRef]
- Stanek, W.; Gazda, W. Exergo-ecological evaluation of adsorption chiller system. Energy 2014, 76, 42–48. [Google Scholar] [CrossRef]
- Aristov, Y.I. Review of adsorptive heat conversion/storage in cold climate countries. Appl. Therm. Eng. 2020, 180, 115848. [Google Scholar] [CrossRef]
- Krzywanski, J.; Żyłka, A.; Czakiert, T.; Kulicki, K.; Jankowska, S.; Nowak, W. A 1.5D model of a complex geometry laboratory scale fuidized bed clc equipment. Powder Technol. 2017, 316, 592–598. [Google Scholar] [CrossRef]
- Muskała, W.; Krzywański, J.; Czakiert, T.; Nowak, W. The research of CFB boiler operation for oxygen-enhanced dried lignite combustion. Rynek Energii 2011, 1, 172–176. [Google Scholar]
- Krzywanski, J.; Fan, H.; Feng, Y.; Shaikh, A.R.; Fang, M.; Wang, Q. Genetic algorithms and neural networks in optimization of sorbent enhanced H2 production in FB and CFB gasifiers. Energy Convers. Manag. 2018, 171, 1651–1661. [Google Scholar] [CrossRef]
- Chorowski, M.; Pyrka, P. Modelling and experimental investigation of an adsorption chiller using low-temperature heat from cogeneration. Energy 2015, 92, 221–229. [Google Scholar] [CrossRef]
- Rogala, Z.; Kolasiński, P.; Gnutek, Z. Modelling and experimental analyzes on air-fluidised silica gel-water adsorption and desorption. Appl. Therm. Eng. 2017, 127, 950–962. [Google Scholar] [CrossRef]
- Aristov, Y.I.; Glaznev, I.S.; Girnik, I.S. Optimization of adsorption dynamics in adsorptive chillers: Loose grains configuration. Energy 2012, 46, 484–492. [Google Scholar] [CrossRef]
- Girnik, I.S.; Grekova, A.D.; Gordeeva, L.G.; Aristov, Y.I. Dynamic optimization of adsorptive chillers: Compact layer vs. bed of loose grains. Appl. Therm. Eng. 2017, 125, 823–829. [Google Scholar] [CrossRef]
- Grabowska, K.; Krzywanski, J.; Nowak, W.; Wesolowska, M. Construction of an innovative adsorbent bed configuration in the adsorption chiller - Selection criteria for effective sorbent-glue pair. Energy 2018, 151, 317–323. [Google Scholar] [CrossRef]
- Grabowska, K.; Sztekler, K.; Krzywanski, J.; Sosnowski, M.; Stefanski, S.; Nowak, W. Construction of an innovative adsorbent bed configuration in the adsorption chiller part 2. experimental research of coated bed samples. Energy 2021, 215, 119123. [Google Scholar] [CrossRef]
- Kulakowska, A.; Pajdak, A.; Krzywanski, J.; Grabowska, K.; Zylka, A.; Sosnowski, M.; Wesolowska, M.; Sztekler, K.; Nowak, W. Effect of Metal and Carbon Nanotube Additives on the Thermal Diffusivity of a Silica Gel-Based Adsorption Bed. Energies 2020, 13, 1391. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Kanasugi, H.; Shibasaki, R. Deep transport: Prediction and simulation of human mobility and transportation mode at a citywide level. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2618–2624. [Google Scholar]
- Yu, H.; Wu, Z.; Wang, S.; Wang, Y.; Ma, X. Spatiotemporal Recurrent Convolutional Networks for Traffic Prediction in Transportation Networks. arXiv 2017, arXiv:1705.02699, 1501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Glorot, X.; Youshua, B. Understanding the difficult of training deep feedforward neural networks. In Proceedings of the Thirteen International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Type of Material | Additive to the Mixture | t0 [s] 1 | tz [s] 2 | P1 [bar] 3 | P2 [bar] 4 | State | Mass of Sorbent in the Bed [g] |
|---|---|---|---|---|---|---|---|---|
| 1 | 100%SG 5 | - | 10 | 150 | 13 | 23 | F 7 | 55 |
| 2 | 100%SG 5 | - | 10 | 150 | 21 | 23 | S 8 | 55 |
| 3 | 95%SG 5 | +5%Al 6 | 10 | 150 | 13 | 23 | F 7 | 55 |
| 4 | 95%SG 5 | +5%Al 6 | 10 | 150 | 21 | 23 | S 8 | 55 |
| 5 | 85%SG 5 | +15%Al 6 | 10 | 150 | 13 | 23 | F 7 | 55 |
| 6 | 85%SG 5 | +15%Al 6 | 10 | 150 | 21 | 23 | S 8 | 55 |
| Hyperparameter | Value |
|---|---|
| Number of epochs | 200 |
| Learning rate | 0.005 |
| Number of LSTM layers | 2 |
| Number of cells in layer 1 | 210 |
| Number of cells in layer 2 | 190 |
| Drop out layer | 0.05 |
| R2 | ||||||
|---|---|---|---|---|---|---|
| All Data | 100%SG (F) | 100%SG (S) | 95%SG +5%Al (F) | 95%SG +5%Al (S) | 85%SG +15%Al (F) | 85%SG +15%Al (S) |
| 0.9515 | 0.8934 | 0.9218 | 0.9891 | 0.9732 | 0.9848 | 0.9505 |
| R2 | ||||||
|---|---|---|---|---|---|---|
| All Data | 100%SG (F) | 100%SG (S) | 95%SG +5%Al (F) | 95%SG +5%Al (S) | 85%SG +15%Al (F) | 85%SG +15%Al (S) |
| 0.9507 | 0.8404 | 0.9250 | 0.9788 | 0.9738 | 0.9800 | 0.9363 |
| R2 | ||||||
|---|---|---|---|---|---|---|
| All Data | 100%SG (F) | 100%SG (S) | 95%SG +5%Al (F) | 95%SG +5%Al (S) | 85%SG +15%Al (F) | 85%SG +15%Al (S) |
| 0.9554 | 0.8670 | 0.9343 | 0.9915 | 0.9611 | 0.9874 | 0.9244 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skrobek, D.; Krzywanski, J.; Sosnowski, M.; Kulakowska, A.; Zylka, A.; Grabowska, K.; Ciesielska, K.; Nowak, W. Prediction of Sorption Processes Using the Deep Learning Methods (Long Short-Term Memory). Energies 2020, 13, 6601. https://doi.org/10.3390/en13246601
Skrobek D, Krzywanski J, Sosnowski M, Kulakowska A, Zylka A, Grabowska K, Ciesielska K, Nowak W. Prediction of Sorption Processes Using the Deep Learning Methods (Long Short-Term Memory). Energies. 2020; 13(24):6601. https://doi.org/10.3390/en13246601
Chicago/Turabian StyleSkrobek, Dorian, Jaroslaw Krzywanski, Marcin Sosnowski, Anna Kulakowska, Anna Zylka, Karolina Grabowska, Katarzyna Ciesielska, and Wojciech Nowak. 2020. "Prediction of Sorption Processes Using the Deep Learning Methods (Long Short-Term Memory)" Energies 13, no. 24: 6601. https://doi.org/10.3390/en13246601
APA StyleSkrobek, D., Krzywanski, J., Sosnowski, M., Kulakowska, A., Zylka, A., Grabowska, K., Ciesielska, K., & Nowak, W. (2020). Prediction of Sorption Processes Using the Deep Learning Methods (Long Short-Term Memory). Energies, 13(24), 6601. https://doi.org/10.3390/en13246601