Convolutional neural network is a feedforward network. Compared with the results of traditional fully connected layer networks, convolution calculations are more suitable for feature extraction of two-dimensional image data. In a deep convolutional neural network, the edge, texture, color, and abstract semantic features of the image are extracted layer by layer using the convolutional network, and then the fully connected layer is used as a classifier to classify the class space.
The convolutional network feature update calculation formula is shown below
where
Mj is the set of elements that this layer needs to map;
Fj l is the eigenvalue of the position
j of the
l th layer;
kij l is the weight of the convolution kernel at the
l th position
ij; ∗ is convolution calculation, and it can be analogized to the weighted summation of the eigenvalues in the range of the mapping set.
bj l is the extra bias added by position
j at level
l th layer.
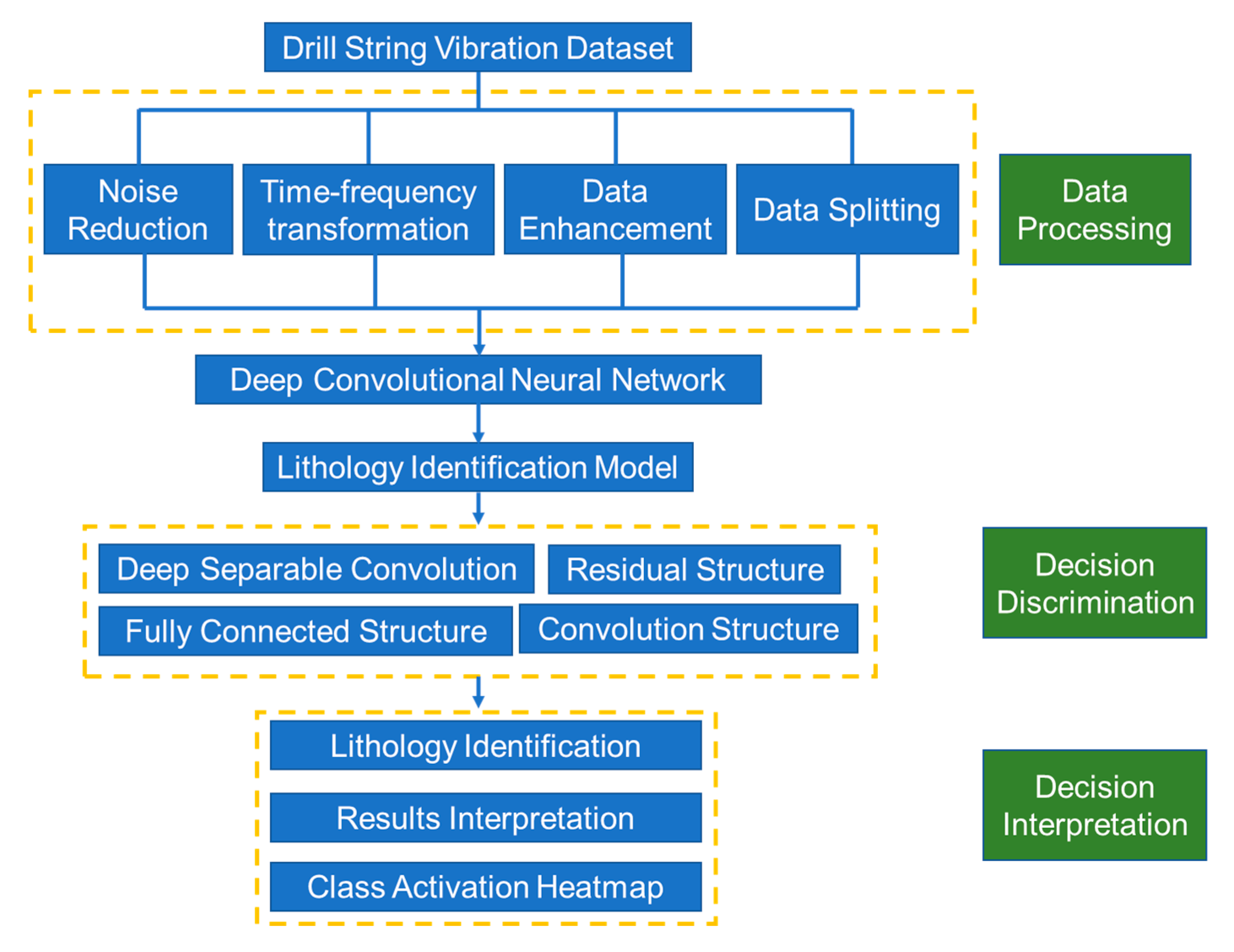
3.2. Model Architectures and Calculation Process
In view of training efficiency and model complexity, two structural units, MobileNet and ResNet, are generally used to ensure the calculation efficiency and prediction accuracy of the lithology identification model.
MobileNet is mainly composed of deeply separable convolutions. Under the limitations of computation efficiency and computing resources of mobile or embedded devices, it guarantees efficient computing, and at the same time compresses the number of parameters to ensure computing storage efficiency.
ResNet is mainly composed of residual structure, which can effectively control model parameters and maintain the expressiveness of feature transfer. This is helpful to ensure the effectiveness of gradient direction propagation and can build deep networks with rich semantic space.
In addition, we need to use the softmax activation function to normalize and scale the final prediction probability.
MobileNet is a lightweight grid that can effectively reduce the storage and calculation overhead of model networks and provides an effective solution for convolution calculations and parameter storage overhead. The core is to split the traditional convolution process into Depthwise and Pointwise processes, also known as deep separable convolutions.
Comparing traditional convolution (a) and depth separable convolution (b) in Formula (4), the difference between the two calculations is mainly focused on the channel processing of the input data by the convolution check [
37].
where
m is the number of input layer channels,
n is the number of output layer channels,
K is the convolution kernel,
F is the feature layer, and
G is the output feature layer.
ResNet helps suppress performance degradation caused by neural network stacking.
Increasing the depth of the neural network can improve the expression ability of the neural network, but it also increases the risk of gradient disappearance, which leads to the degradation of the performance of the neural network. Therefore, the residual structure helps to solve the model degradation problem of the deep network. The residual unit has the following unit mapping relationship [
38].
where
Yl is the output of the
l th residual unit,
Xl is the input of the
l th residual unit,
F is the residual structure map,
Wl is the
l th residual structure weight.
The implementation structure of the residual unit is mentioned in He’s study [
38]., the residual unit has the identity map
x of the upper layer as information to supplement the output unit
F(
x) of the lower layer, so the training center of gravity of the next stacked residual unit can be transferred to the residual
F(
x) between
y and
x.
3.4. Lithology Identification Model Training
The data set is split into a training set, a test set, and a validation set. The training set is used to update the iteration parameters for the training process of the lithology classification model. The test set is used to check whether the model has the generalization ability. The validation set is used to monitor the training process. Whether the model accuracy and loss meet the requirements.
The rock recognition model uses the back-propagation algorithm to achieve the training purpose. The parameters are mainly updated by obtaining the partial derivatives of the loss function for each weight parameter. The training process needs to set the hyper-parameters, such as the learning rate, learning decay rate, sample batch processing capacity, and sample iteration rounds. The setting of hyperparameters is related to the model’s convergence rate and final effect. It can add monitoring to the model training process, record weights, gradient changes, and track and observe the model training process to lay the foundation for model tuning.
In addition, in order to further improve the generalization ability of the model, necessary data enhancement measures can be taken on the data, that is, a slight disturbance is applied under the condition that the original data semantics and labels are unchanged. The disturbance can include random cropping, center cropping, image flipping, saturation degree disturbance, and brightness disturbance.
Therefore, the training process of the lithology recognition model needs to consider the data quantity and quality, tuning of hyperparameter settings, network structure design, and training strategies.
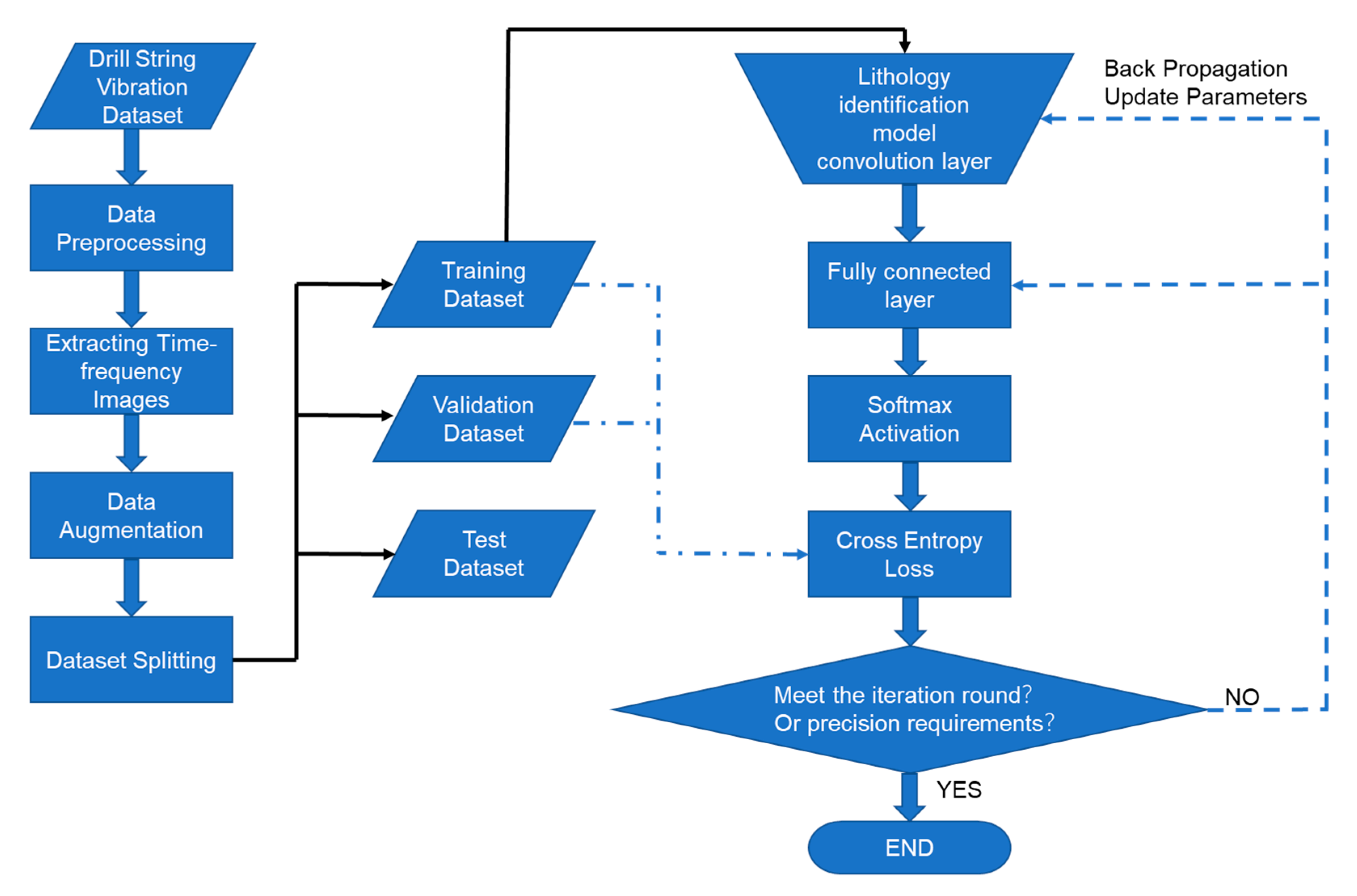
When training the lithology recognition model, there are two ways of data and weight flow. One is forward propagation. The data is extracted from the network topic and the prediction results are given. The other is back propagation. The partial derivatives further update the parameter weights, and the training is stopped when the model’s convergence loss function reaches the accuracy requirement or iterative rounds are reached. The complete training process is shown in
Figure 10.
The training model needs to complete basic tasks, such as data preprocessing, time–frequency image integration, data enhancement, and data set splitting, to ensure reliable data quality and accurate classification labels. The training set and the validation set are used to test the loss cost function of the model and provide parameter gradients. When the model does not meet the end condition, a second iteration occurs, and the parameters are updated according to the back-propagation algorithm.
The back-propagation algorithm needs to calculate the gradient based on the target cost function. Because lithology recognition tasks can be classified as multi-class target tasks, cross-entropy loss is usually chosen as the target cost function for multi-class problems. The formula is as follows:
where
M is the target category;
yc is the indicator variable, when the predicted category and label are the same,
yc is equal to 1, otherwise it is 0.
pc is the prediction sample, the probability of
c.
The back-propagation algorithm mainly uses the partial derivative of the loss function on the network weight parameters as the gradient and updates the parameters in the reverse direction of the gradient to reduce the loss parameters. [
40] The algorithm is as follows:
where
wij is model weight,
oi is neuron input,
y is actual value,
netj is neuron output value of this value,
φ is activation function,
J is loss function,
E is error of loss function calculation,
∂E/∂wi is the gradient of error versus weight, which can be obtained by the chain derivation rule,
α is learning rate, and Δ
wij is the weight update amount.
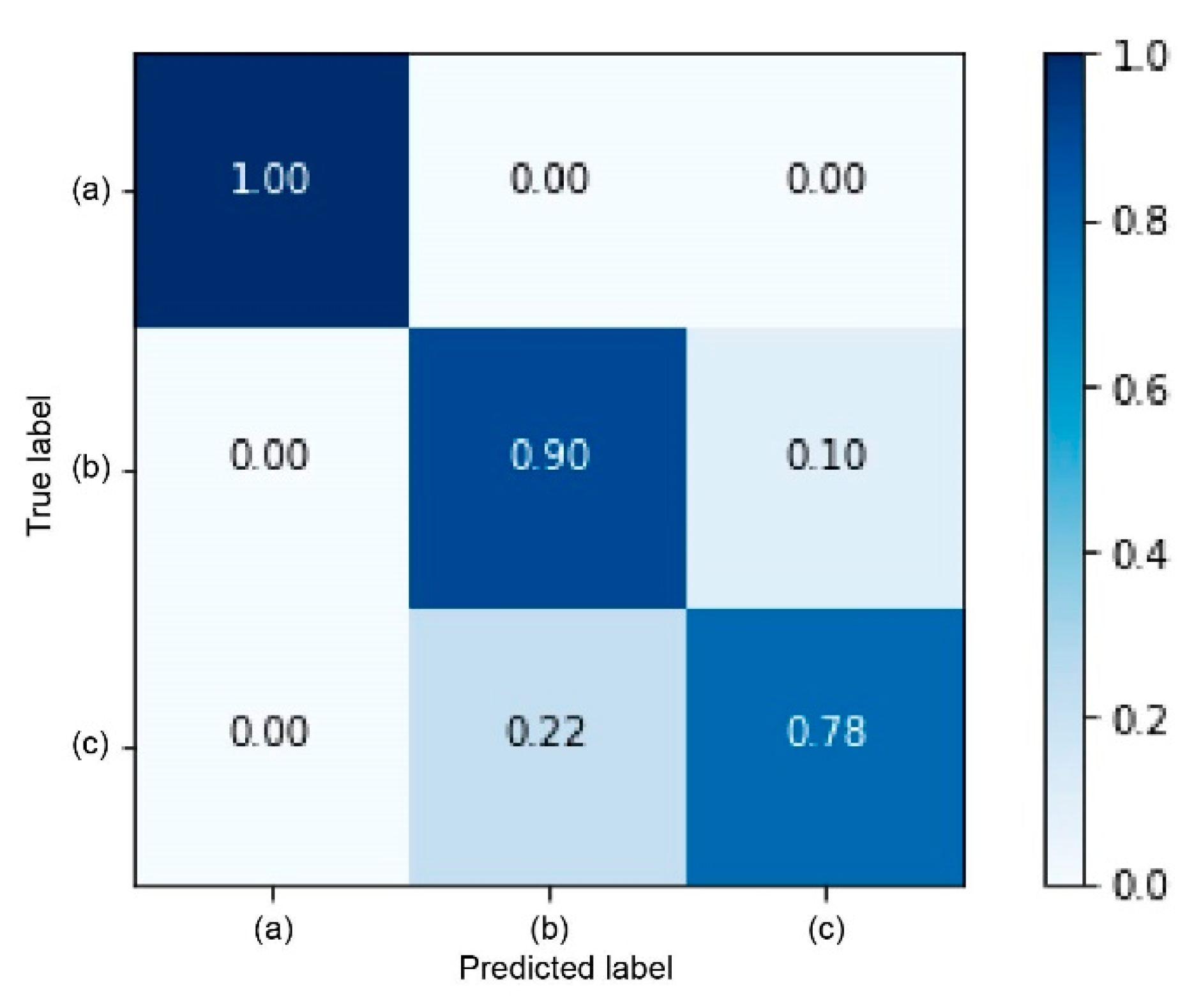
In order to reasonably train, monitor, and evaluate the lithology recognition model, the data set is split into a training set, a validation set, and a test set, with a data volume ratio of 7:2:1. The classification target of the lithology identification model is to distinguish three types of lithology. Therefore, there are three types of lithology samples in the collected raw data. It is not appropriate to use random sampling to determine the three types of data sets during data set splitting. The results after stratified sampling are shown in
Table 2Effective data augmentation can increase the number of training samples, increase sample diversity, avoid overfitting, and improve the generalization performance of the model. Common enhancement measures include horizontal image flipping, random interception, size conversion, random rotation, and color dithering.
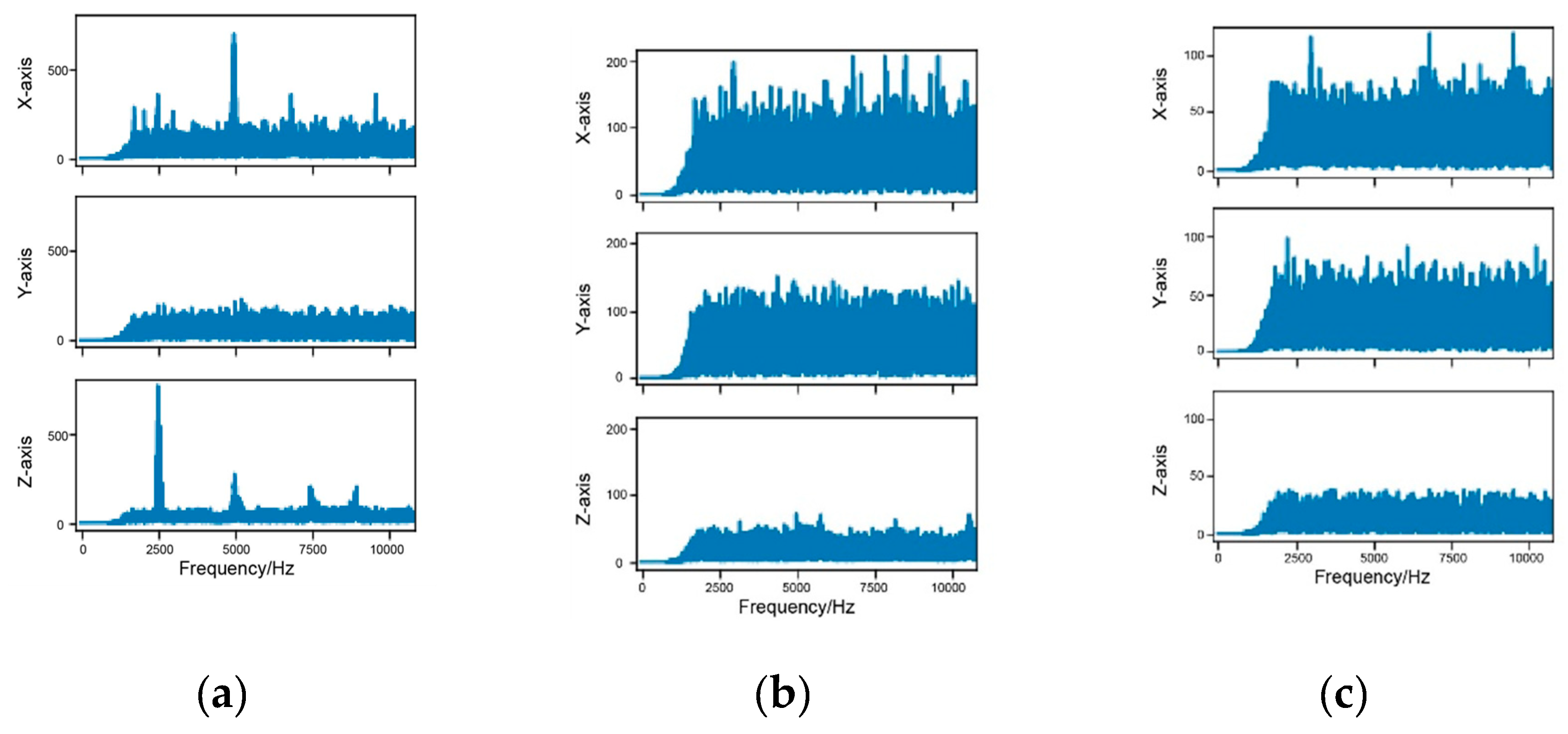
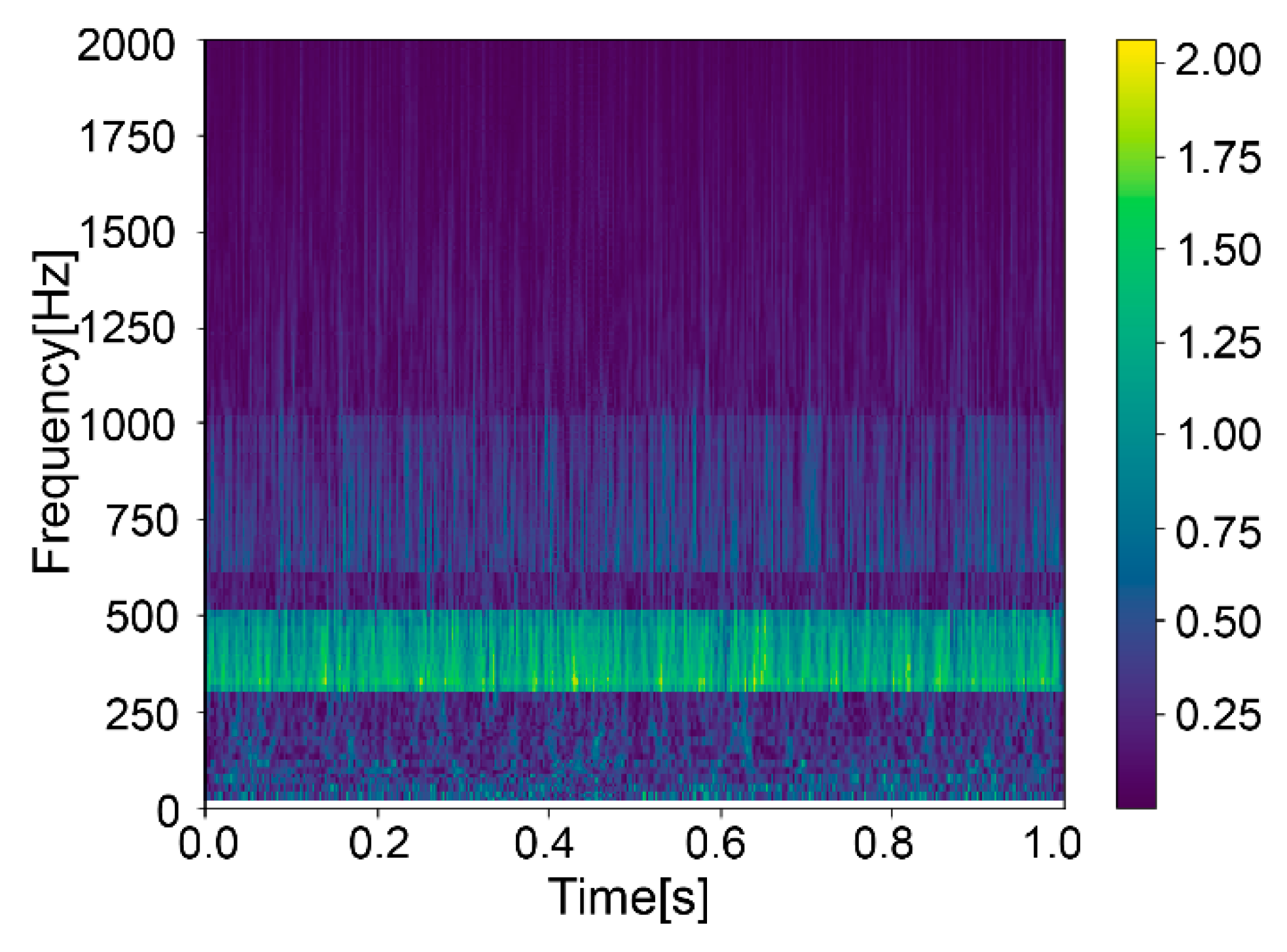
The lithology identification model data source is a time–frequency image converted from vibration data, which has time and frequency dimension information. It is not suitable to use horizontal flip or random flip. Color dithering can be used to simulate noise disturbances, and random cropping of analog signal acquisition is not complete. The fine sandstone time–frequency image is taken as an example to show the data enhancement effect.
The essence of training a neural network is the process of constantly updating the network weights so that they eventually converge on the training target. Before training, you need to build a network and prepare data. Initially, you need to initialize the network weights. During training, you need to update the weights according to the set sample batches, sample iterations, learning rate, and learning rate decay rate. The hyperparameters are set by referring to the previous hyperparameter setting values, combining the data of lithology classification and task characteristics.
Table 3 is the configuration of hyperparameters. The best hyperparameters are finally determined after parameter optimization in
Table 4.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}