2.2. Classifying the Biofuel Energetic-Environmental Efficiency
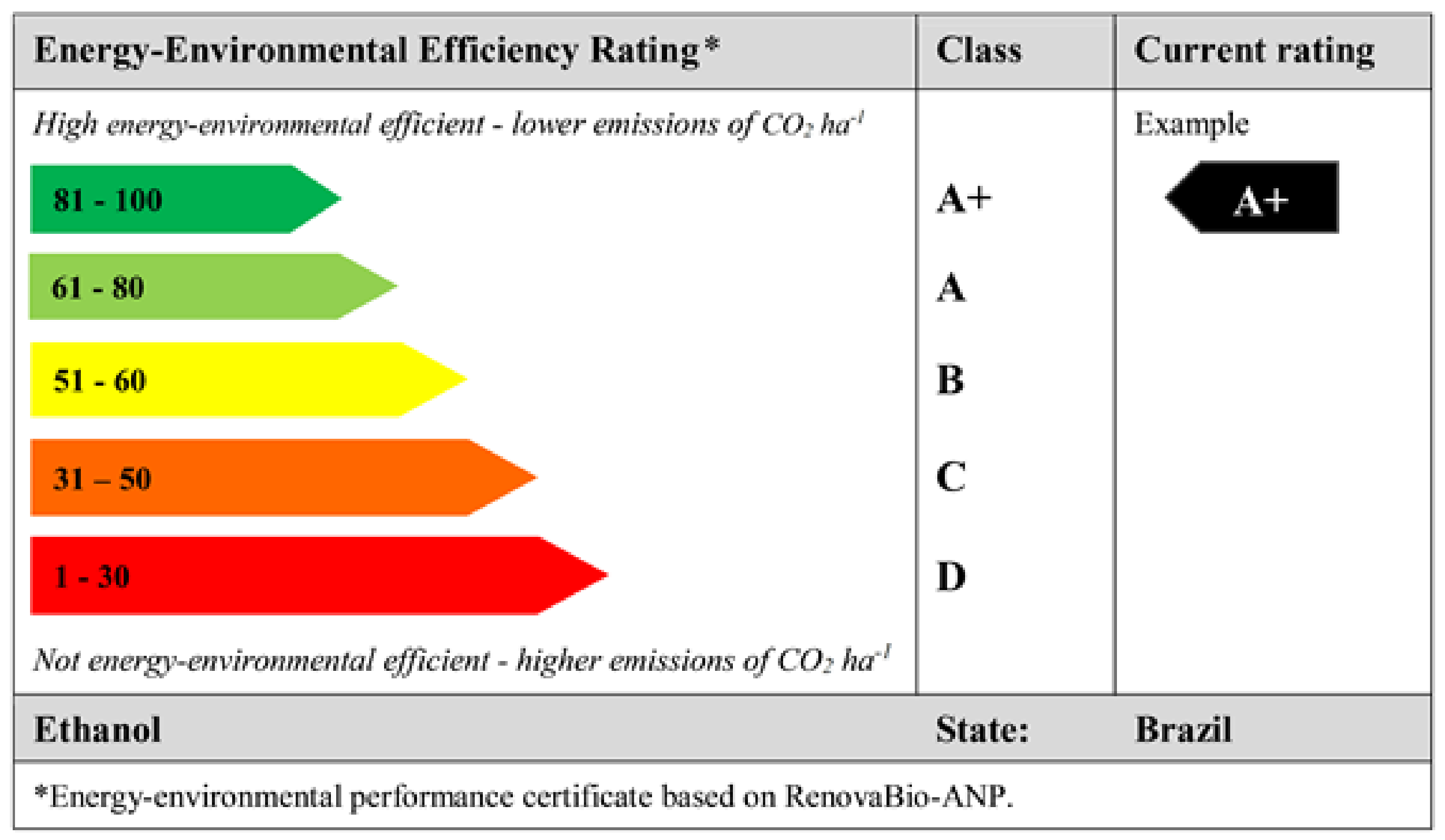
The classification levels of the biofuel environmental efficiency were performed based on the Energy-Environmental Efficiency Rating. Such a rating is the result of the certificates of the production or efficient import of biofuels informed through the calculation (RenovaCalc), linked to the volume of biofuel produced and commercialized, generating Decarbonization Credits (CBio) in the RenovaBio’s program.
The energy-environmental efficiency level parameters were standardized according to
Table 1. The dataset was categorized according to the Energy-Environmental Efficiency Rating (RenovaBio) [
12], the rating scale varying between lower efficiency and high efficiency + (highest efficiency), and an example of the label’s design of the energy-environmental efficiency for the performance of a certificate is given (
Figure 1).
The calculation and indication of the environmental energy efficiency score (E-EER) of the certification for efficient production of biofuel, made available by the ANP, was discretized into categories of levels (classes) (pre-processing of the dataset) for the classification (data mining) and to create one of the labels of the energy-environmental performance (post-processing) of Brazilian ethanol. This labeling system allowed it to be classified into five classes (A+, A, B, C, and D) to provide consumers with a differentiation of the ethanol consumed from different producers, regions, or states.
The RenovaBio Program allows producers and importers to be able to declare the energy-environmental efficiency of their product, which is economically attractive for decarbonization and the competitiveness of biofuels in the oil market, with a complex and solid structure (
Figure 2) [
2,
12,
18,
33,
34]. The label may be shown at fuel pumps to consumers with a validity of one to three years, a validity that is applied to the Certification of Efficient Production of Biofuels when approved by the ANP. It can also endorse the information and increase transparency in the biofuel market at the consumer level, helping to make a purchase decision. The objective of energy-environmental labeling is to encourage Brazilian sugar and alcohol industries to develop innovations and improvements beyond the minimum levels of efficiency. However, it is expected that more ethanol producers will be able to adhere to the ANP certifications of RenovaBio [
2,
12,
19,
33,
34], and consequently, the labeling system can be improved with the inclusion of more data on the platform.
2.3. Classification of Model Prediction
Data mining applies to this study, through techniques (algorithms), for the classification of the levels (classes) of energy-environmental efficiency in the search of strategic information that allows the extraction of implicit information existing in the databases, contributing to the process of identifying and classifying new patterns [
35,
36,
37]. The steps of the data mining method were selection, pre-processing, data mining, and post-processing (knowledge filtering, interpretation and explanation, evaluation, and knowledge integration) for knowledge discovery from the classifiers [
36,
37]. The results obtained could be used in information management, information processing, decision making, and process control.
The data contained in the databases could be used to learn a specific target concept [
35,
36,
37,
38]. The tasks performed by data mining techniques and machine learning, the classification, build models that can be applied to unclassified data to categorize them into classes, to relate the meta attribute (whose value will be predicted) and a set of forecasting attributes [
35,
36,
37,
38].
The data were assessed in the ANP database for the registration of certificates of the production or efficient import of biofuels approved and included in the RenovaBio program in 2019 [
12,
33,
34]. We considered only anhydrous ethanol and hydrated ethanol products, generating two products for the same biofuel producer and importer. The data pre-processing was performed in Excel spreadsheets for further processing in the data mining software Weka © (Waikato Environment for Knowledge Analysis) Version 3.8.4 [
39,
40,
41,
42]. The attributes used to build the predictive model were: “biofuel-type”, “state”, “eligible-volume (%)”, “emission factor”, “Energy-Environmental Efficiency Rating”, and “LER” (Level of Efficiency Rating).
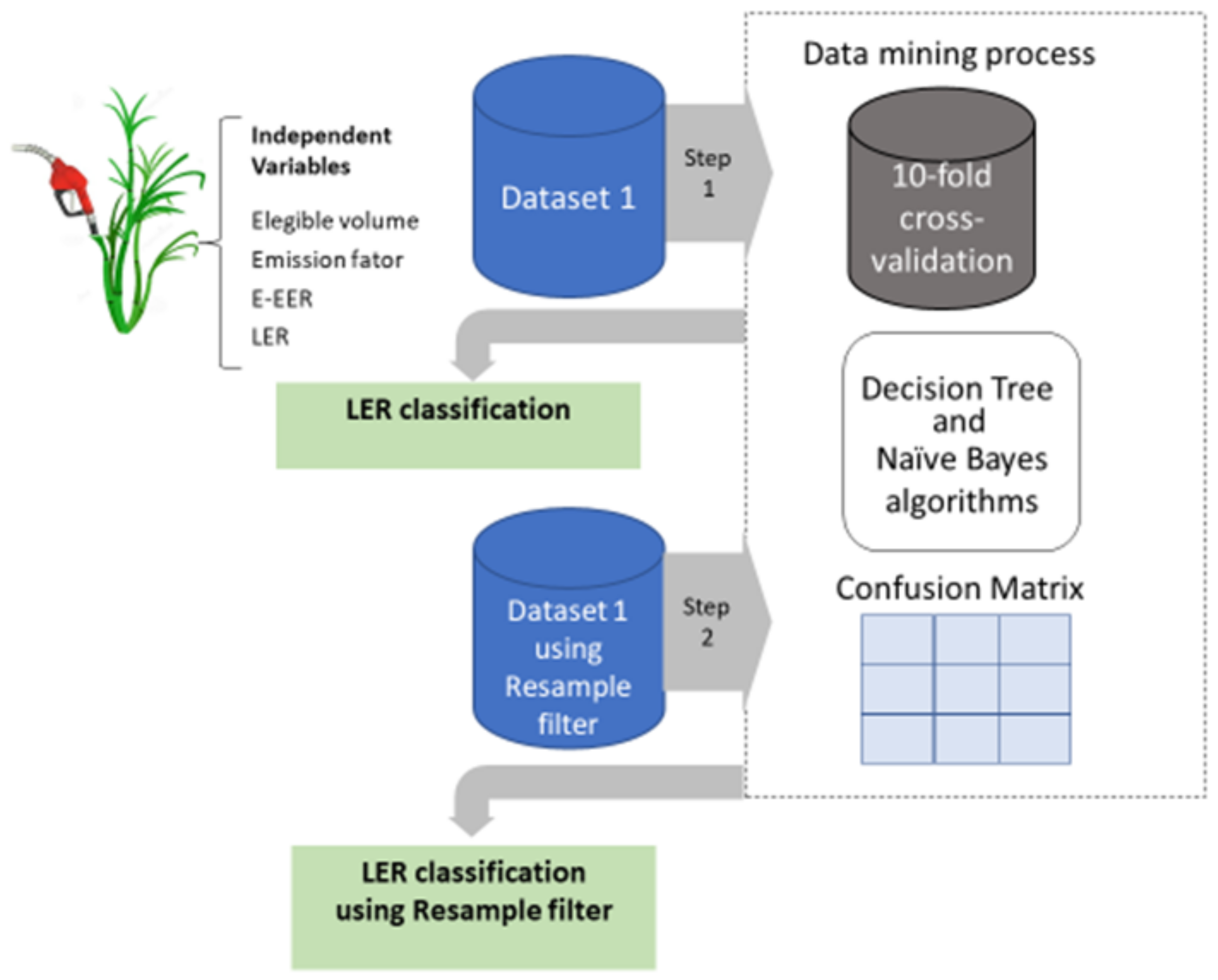
Figure 3 presents the modeling process used to classify the Energy-Environmental Efficiency Rating.
A classifier is a mapping from unlabeled instances to (discrete) classes. Classifiers have a form (classification tree) plus an interpretation procedure (including how to handle unknown values). Most classifiers also can provide probability estimates (or other likelihood scores), which can be thresholded to yield a discrete class decision, thereby taking into account a cost/benefit or utility function [
43,
44].
During the pre-processing of the data, the dataset was extracted from the RenovaBio Program (ANP) platform, selecting only the data on the ethanol product and organized in a spreadsheet. The implementation of the supervised filter Resample was applied to maintain the distribution of classes in the subsample and to reach a uniform distribution for comparing the data not submitted to the filter (noResample). The filter Resample produces a random subsample of a dataset using either sampling with replacement or without replacement. The filter was made to maintain the class distribution in the subsample or to bias the class distribution toward a uniform distribution.
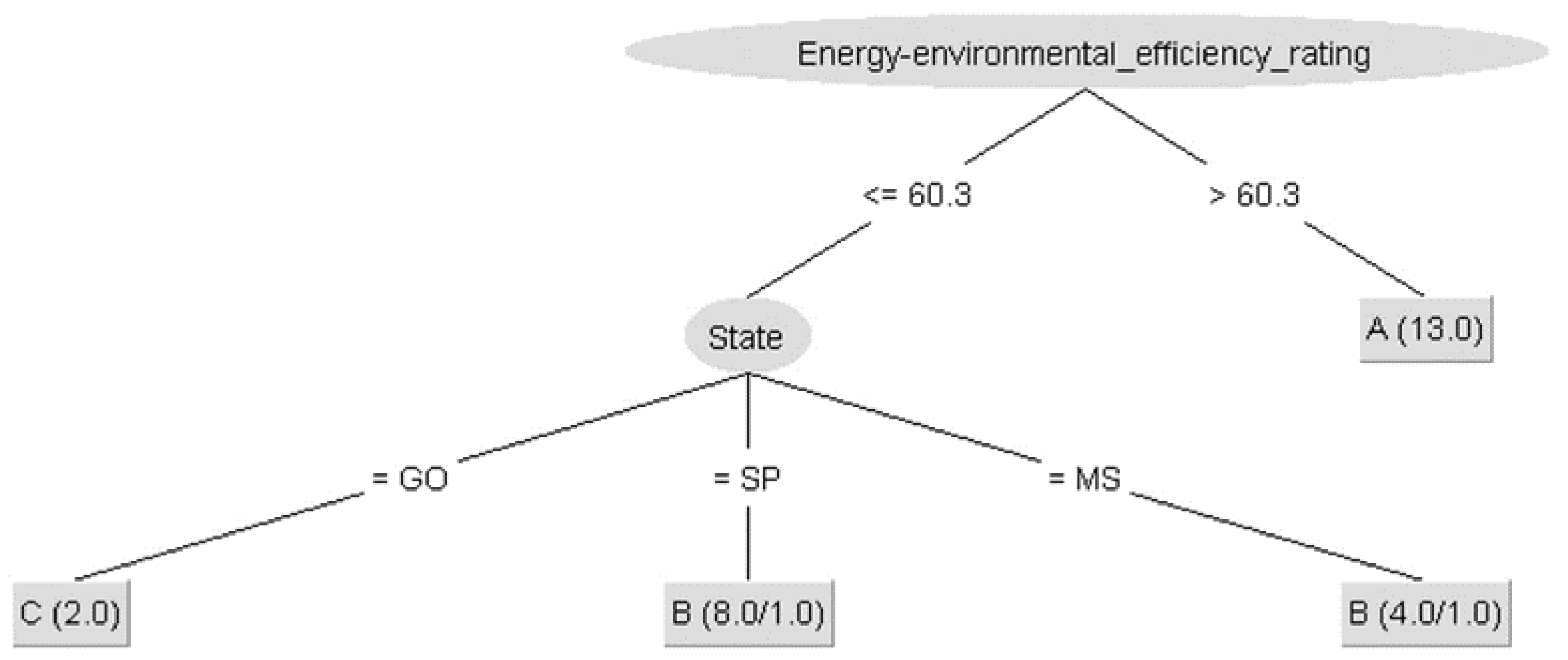
The J48 decision tree classification algorithms (“” without the filter and in relation to “” using the resample filter) and the naive Bayes algorithm (“” without the filter and in relation to “” using the resample filter) were used. The model validation was done using cross-validation (10 folds) applied to the dataset of 27 instances and six attributes (“biofuel-type”, “state”, “eligible-volume (%)”, “emission-factor”, “energy-environmental-efficiency-rating”, and “LER” (Level of Efficiency Rating)). For each sample, the known class label was compared with the prediction of the learned class model.
In supervised learning, each data input object is preassigned a class label. The main task of supervised algorithms (J48 and naive Bayes) is to learn a model that produces the same labeling for the provided data [
43,
44,
45]. The decision tree algorithm is a widely used algorithm for classification, which uses attribute values to partition the decision space into smaller subspaces in an iterative manner, and the decision processes can be represented graphically as a tree. Each possible decision is covered and represented as a branch, and a complete decision process is essentially a path or branch from the root node to a leaf [
43,
44]. Naive Bayes is a classification algorithm widely used in problems due to its simplicity, effectiveness, and robustness, being a probabilistic approach based on assumptions that resources are independent of each other and that their weights are equally important [
46]. They can better represent the complex relationships between input variables found in real problems [
46]. Probabilistic inference can be studied as an approach based on the assumption that decision variables follow probable distributions. The essence of a Bayesian classifier is to estimate the probabilities of all alternative models or hypotheses, given data as evidence, and then to find the most probable classification to be assigned to each new input [
44,
46].
In the step of the post-processing for filtering, interpretation and explanation, evaluation, and knowledge integration generated by the algorithms for knowledge discovery from the classifiers, the metrics of the performance of the algorithms were used. Post-processing procedures usually include various pruning routines, rule quality processing, rule filtering, rule combination, model combination, or even knowledge integration [
47].
The last step is to evaluate the prediction, and such an analysis was made based on the performance values obtained through the test of the prediction model [
48]. The performance evaluation measures of the prediction models used were the confusion matrix, accuracy, precision, and recall and the correlation coefficient between classes (Matthews Correlation Coefficient (MCC)) for testing with the resample filter. The Kappa statistic measured the learning capacity of the algorithm.
The confusion matrix presented a matrix with results obtained during the test phase of the model, and it was used in models that used classification algorithms. Considering a confusion matrix of a hypothesis, it offered an adequate measure of the classification model, by showing the number of correct classifications versus the predicted rankings for each class, over a set of instances. The number of correct answers, for each class, was located on the main diagonal of the matrix, and the other elements represented errors in the classification.
The precision represents what has been classified correctly. The values obtained in correctly classified instances and incorrectly classified instances are determinant for predicted accuracy, since they display the values of correct classification and incorrect classification obtained by the algorithm (Equation (
1)).
where TP = True Positive; FP = False Positive. The sensitivity (recall) signifies the proportion of wrong classifications or the occurrence of defects. In addition to accuracy and precision, its value varies from 0 to 1, with values closer to 1 being indicators of a good performance prediction model obtained by Equation (
2).
where TP = True Positive; FN = False Negative.
The Kappa statistic is a metric that compares an observed precision with an expected precision (random chance). It is a measure used to deal with multi-class and unbalanced class problems. The Kappa statistic can be defined as a measure of the degree of agreement between two categorized datasets. The Kappa result varies between 0 and 1. The higher the Kappa value, the stronger the bond [
49] (Equation (
3)).
where
= proportion of observed agreements;
= proportion of agreements expected by chance.
The Matthews Correlation Coefficient (MCC) is a correlation coefficient between the dependent classes and represents a measure of quality. Unlike accuracy, precision, and sensitivity, its value ranges from −1 to 1, where values closer to −1 are indicators of a poor prediction model, values equal to 0 indicate that the prediction model is entirely random, and values closer to 1 are indicators of a prediction model with good performance (Equation (
4)).
where TP = True Positive; TN = True Negative; P = False Positive; FN = False Negative.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}