A Comprehensive Health Indicator Integrated by the Dynamic Risk Profile from Condition Monitoring Data and the Function of Financial Losses


Abstract
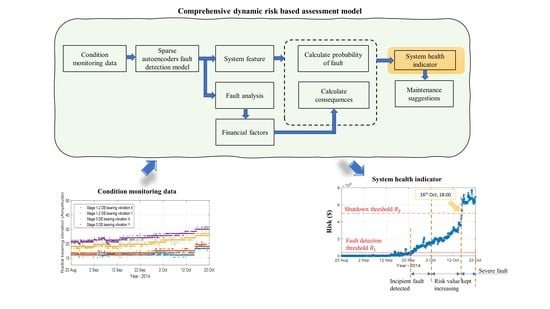
:
1. Introduction
- On one hand, dynamic risk-based maintenance research [13,14,15,16,19,20,21,22] focuses on lowering the entire risk of the system, without putting much attention on the early detection of the fault. In the dynamic risk model, the fault/failure probability is heavily related to fault detection. Therefore, there is a requirement to improve the fault/failure probability calculation model with the application of advanced fault detection methods. Meanwhile, the loss function is suggested to be integrated into the risk model, as it can help estimate process economic risk and assist in effective operational decision-making.
- On the other hand, fault detection research [23,24,25,26] mainly focused on the development of an advanced model to detect an incipient fault, without considering the optimum time for maintenance. Most of the models [23,24,25] were tested on simulated or experimental data only, lacking the evaluation on real industrial data.
2. Methodology
2.1. Offline Phase—Model Development and Threshold Calculation
2.1.1. Fault Detection Model Training
2.1.1.1. Calculation of a System-Wide Feature
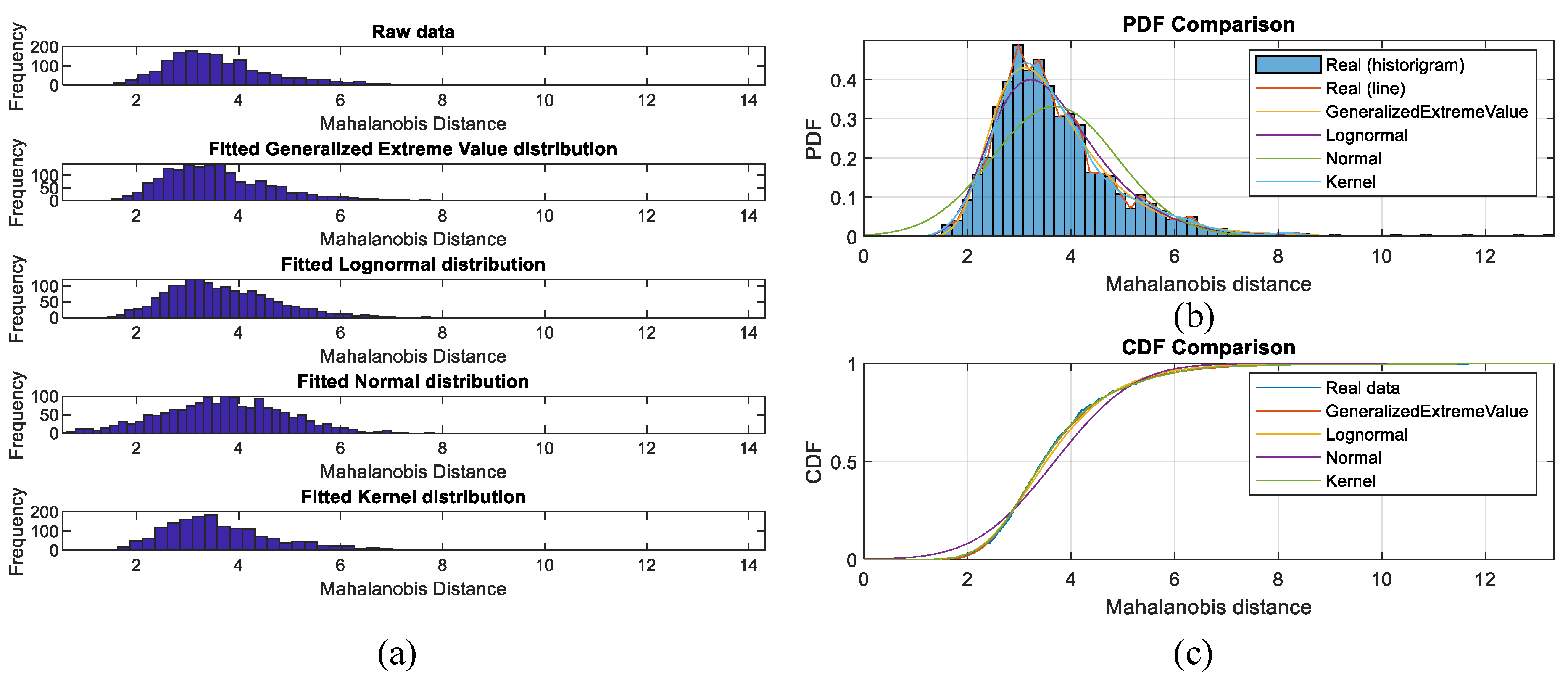
2.1.1.2. Estimation of Probability Density Function (PDF)
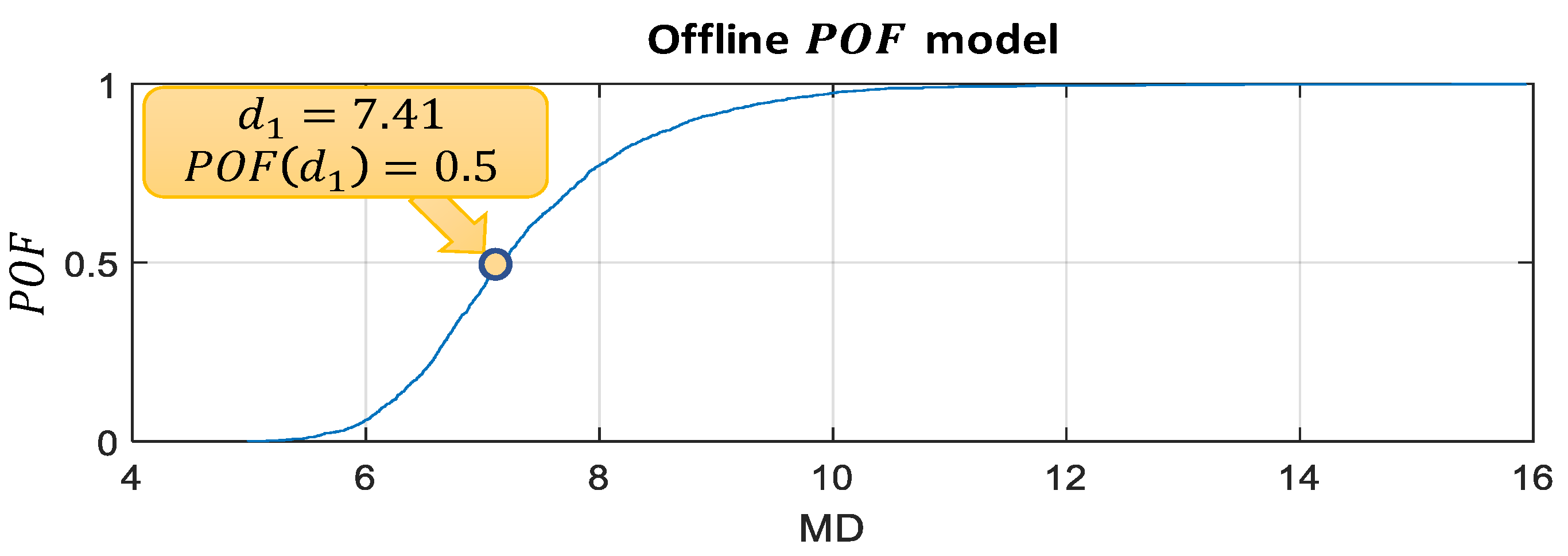
2.1.1.3. Calculation of Thresholds
2.1.2. Build Probability of Fault () Model
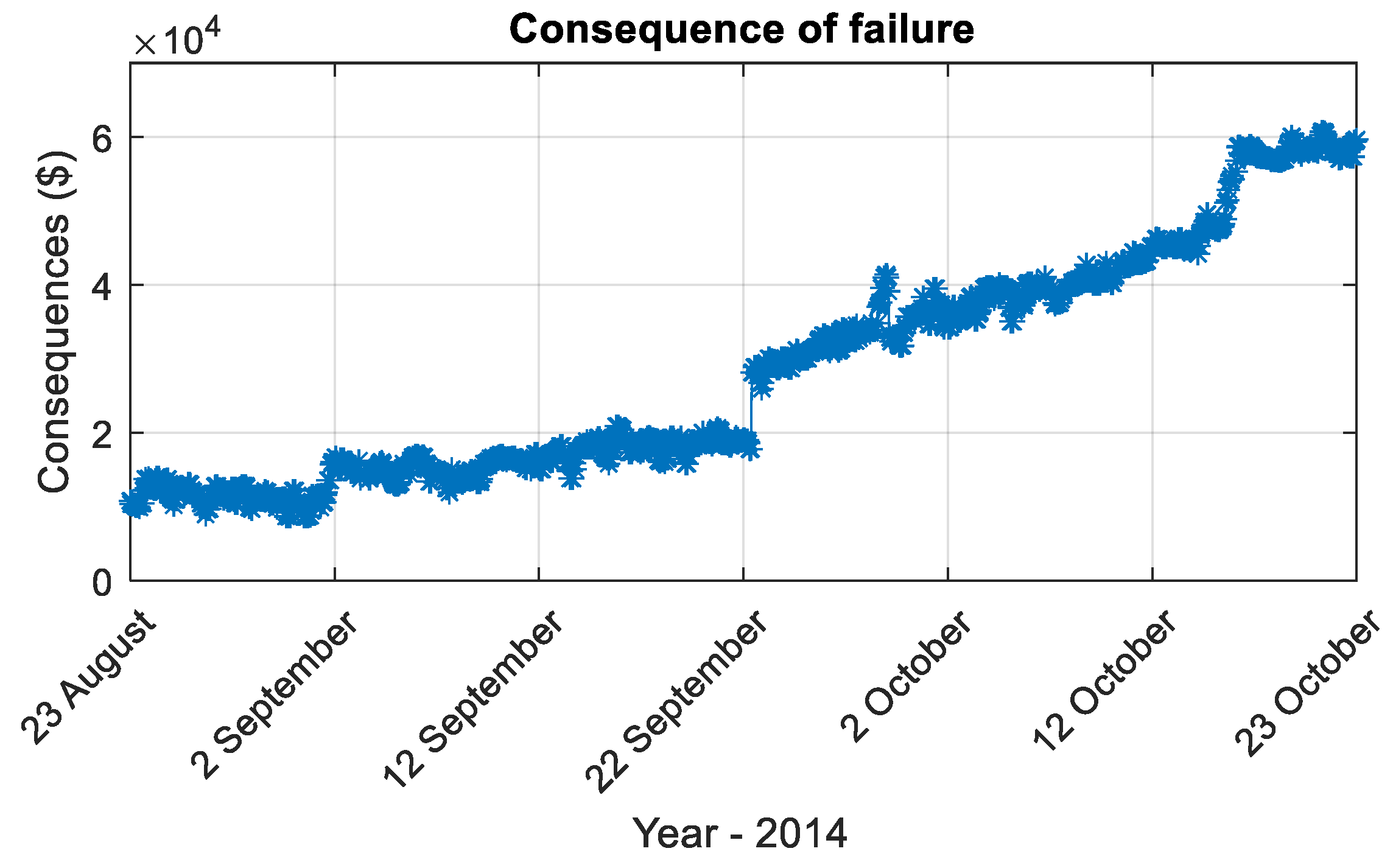
2.1.3. Build Consequence of Fault () Model Using Loss Function
2.1.4. Calculate Health Indicator and Threshold
2.2. Online Phase—Fault Detection and Decision Making
2.2.1. Calculate Probability of Fault ()
2.2.2. Calculate Consequence of Fault ()
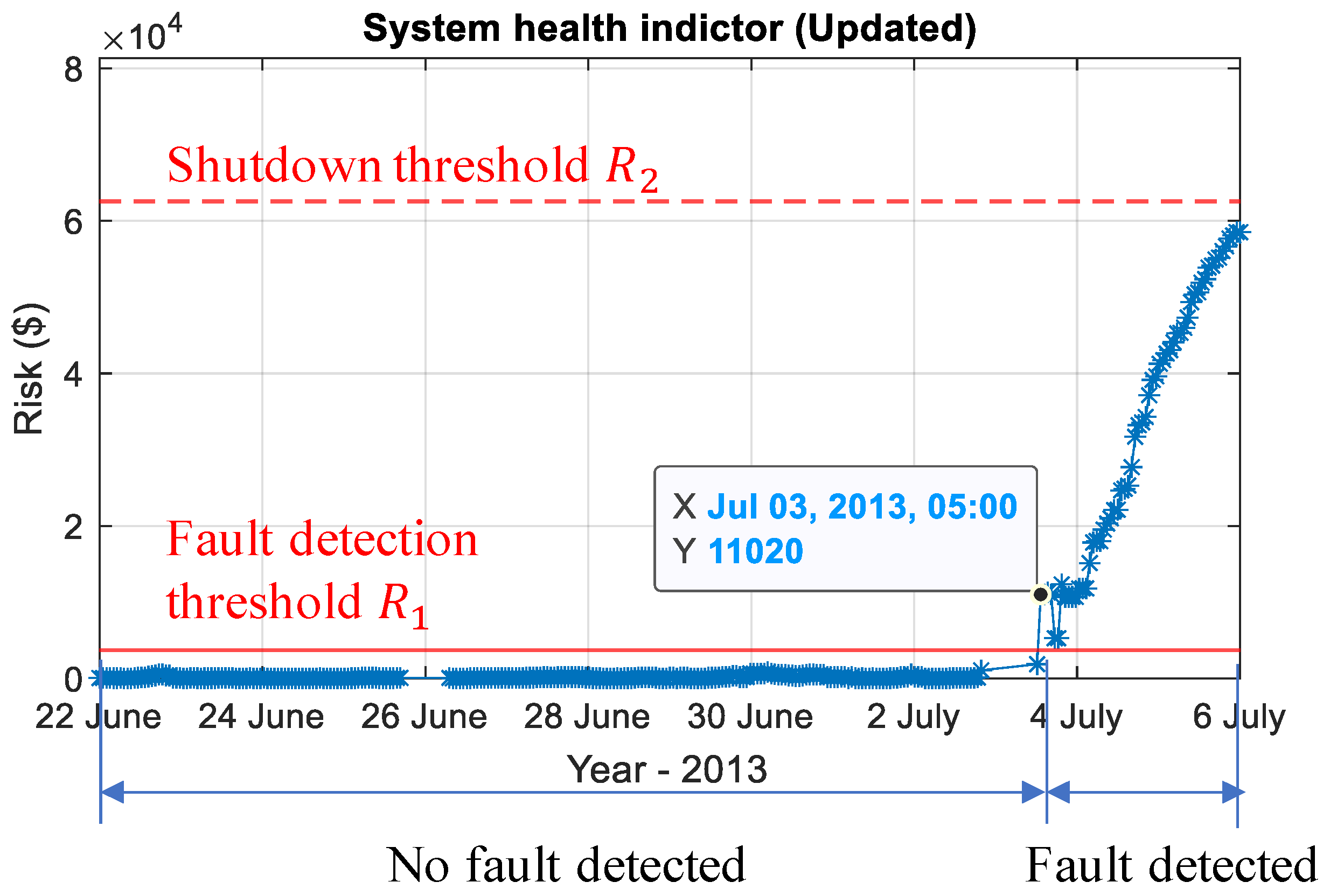
2.2.3. Calculate System Health Indicator and Shutdown Threshold
3. Case One: Health Indicator Applied on a Pump Data Set
3.1. Data Description
3.2. Offline Phase—Model Development and Threshold Calculation
3.2.1. Fault Detection Model Training
3.2.2. POF Model
3.2.3. COF Model Using Loss Function
3.2.4. Calculate Default Health Indicator Thresholds
3.3. Online Phase—Fault Detection and Decision Making
3.3.1. Calculating
3.3.2. Calculating
3.3.3. Calculating the System Health Indicator
4. Case Two: Health Indicator Applied on a Compressor Data Set
4.1. Data Description
4.2. Offline Phase—Model Generation and Threshold Calculation
4.3. Online Phase—Fault Detection and Decision Making
5. Conclusions
- (1)
- A system-wide health indicator has been developed using condition-based dynamic risk assessment. The proposed health indictor presented the system’s risk in dollars, making it easier for operators to make maintenance decisions. In addition, the health indicator can demonstrate the health condition of the system to the operator in real time, and assist the operators as to when an incipient fault is detected, how the system is degraded, what type of fault the machine suffers from, and when the deadline is for maintenance.
- (2)
- The probability of a fault is calculated based on the application of a state-of-the-art fault detection models, SAE and MD. To the authors’ knowledge, this is the first time a study has obtained fault probability from a single system-wide feature calculated in MD value, instead of using multiple measurements of a system. Compared with other statistical measurements, such as Hotelling’s and Euclidean distance, the MD is a better way to calculate probability of fault. The value of Hotelling’s is much higher than MD (nearly squared). When using Hotelling’s , the value can increase rapidly to a very high value after a fault appears. This makes a fault more obvious in a fault detection process; however, it is hard to transfer such rapidly changing and highly statistical value to a fault probability. In contrast, the value of Euclidean distance is much more moderate. However, it is not as sensitive as MD for early fault detection in our cases.
- (3)
- The proposed health indicator is evaluated by using a pump and a compressor using multivariate industrial data. This methodology can also be applied to other types of machines’ health assessments, such as turbines and motors. In addition, our experience of processing the industrial data set can benefit relevant readers.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quatitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Liao, G.-L. Optimal economic production quantity policy for randomly failing process with minimal repair, backorder and preventive maintenance. Int. J. Syst. Sci. 2012, 44, 1602–1612. [Google Scholar] [CrossRef]
- Arunraj, N.S.; Maiti, J. Risk-based maintenance—Techniques and applications. J. Hazard. Mater. 2007, 142, 653–661. [Google Scholar] [CrossRef]
- Holland, M.L. Cost savings achievable through application of risk based inspection philosophies. In Risk, Economy and Safety, Failure Minimisation and Analysis Failures ’96, Proceedings of the Second International Symposium, Pilanesberg, South Africa, 22–26 July 1998; Penny, R.K., Ed.; CRC Press: Roca Raton, FL, USA, 1998; p. 8. [Google Scholar]
- Kalantarnia, M.; Khan, F.; Hawboldt, K. Dynamic risk assessment using failure assessment and Bayesian theory. J. Loss Prev. Process. Ind. 2009, 22, 600–606. [Google Scholar] [CrossRef]
- Meel, A.; Seider, W.D. Plant-specific dynamic failure assessment using Bayesian theory. Chem. Eng. Sci. 2006, 61, 7036–7056. [Google Scholar] [CrossRef]
- Kaplan, S.; Garrick, B.J. On the quantitative definition of risk. Risk Anal. 1981, 1, 11–27. [Google Scholar] [CrossRef]
- Yang, M.; Khan, F.I.; Lye, L. Precursor-based hierarchical Bayesian approach for rare event frequency estimation: A case of oil spill accidents. Process Saf. Environ. Prot. 2013, 91, 333–342. [Google Scholar] [CrossRef]
- Khakzad, N.; Khan, F.; Amyotte, P. Dynamic risk analysis using bow-tie approach. Reliab. Eng. Syst. Saf. 2012, 104, 36–44. [Google Scholar] [CrossRef]
- Camci, F.; Medjaher, K.; Atamuradov, V.; Berdinyazov, A. Integrated maintenance and mission planning using remaining useful life information. Eng. Optim. 2018, 51, 1794–1809. [Google Scholar] [CrossRef]
- Hu, C.; Youn, B.D.; Wang, P.; Yoon, J.T. Ensemble of data-driven prognostic algorithms for robust prediction of remaining useful life. Reliab. Eng. Syst. Saf. 2012, 103, 120–135. [Google Scholar] [CrossRef] [Green Version]
- Zio, E. The future of risk assessment. Reliab. Eng. Syst. Saf. 2018, 177, 176–190. [Google Scholar] [CrossRef] [Green Version]
- Zadakbar, O.; Imtiaz, S.; Khan, F. Dynamic risk assessment and fault detection using a multivariate technique. Process Saf. Prog. 2013, 32, 365–375. [Google Scholar] [CrossRef]
- Bao, H.; Khan, F.; Iqbal, T.; Chang, Y. Risk-based fault diagnosis and safety management for process systems. Process Saf. Prog. 2010, 30, 6–17. [Google Scholar] [CrossRef] [Green Version]
- Zadakbar, O.; Imtiaz, S.; Khan, F. Dynamic risk assessment and fault detection using principal component analysis. Ind. Eng. Chem. Res. 2013, 52, 809–816. [Google Scholar] [CrossRef]
- Zadakbar, O.; Khan, F.; Imtiaz, S. Dynamic risk assessment of a nonlinear non-gaussian system using a particle filter and detailed consequence analysis. Can. J. Chem. Eng. 2015, 93, 1201–1211. [Google Scholar] [CrossRef]
- Zeng, Z.; Zio, E. Dynamic risk assessment based on statistical failure data and condition-monitoring degradation data. IEEE Trans. Reliab. 2018, 67, 609–622. [Google Scholar] [CrossRef]
- American Petroleum Institute. A.P.I. 581, Risk-Based Inspection Methodology, 3rd ed.; API: Washington, DC, USA, 2016. [Google Scholar]
- Khan, F.; Wang, H.; Yang, M. Application of loss functions in process economic risk assessment. Chem. Eng. Res. Des. 2016, 111, 371–386. [Google Scholar] [CrossRef]
- Hashemi, S.J.; Ahmed, S.; Khan, F. Risk-based operational performance analysis using loss functions. Chem. Eng. Sci. 2014, 116, 99–108. [Google Scholar] [CrossRef]
- Hashemi, S.J.; Ahmed, S.; Khan, F. Loss functions and their applications in process safety assessment. Process Saf. Prog. 2014, 33, 285–291. [Google Scholar] [CrossRef]
- Yu, H.; Khan, F.; Garaniya, V.; Gareaniya, V. Risk-based process system monitoring using self-organizing map integrated with loss functions. Can. J. Chem. Eng. 2016, 94, 1295–1307. [Google Scholar] [CrossRef]
- Zouari, R.; Sieg-Zieba, S.; Sidahmed, M. Fault detection system for centrifugal pumps using neural networks and neuro-fuzzy techniques. Surveillance 2004, 5, 11–13. [Google Scholar]
- Rajakarunakaran, S.; Venkumar, P.; Devaraj, D.; Rao, K.S.P. Artificial neural network approach for fault detection in rotary system. Appl. Soft Comput. 2008, 8, 740–748. [Google Scholar] [CrossRef]
- Eom, Y.H.; Yoo, J.W.; Bin Hong, S.; Kim, M.S. Refrigerant charge fault detection method of air source heat pump system using convolutional neural network for energy saving. Energy 2019, 187, 115877. [Google Scholar] [CrossRef]
- Gugulothu, N.; Malhotra, P.; Vig, L.; Shroff, G. Sparse neural networks for anomaly detection in high-dimensional time series. In Proceedings of the AI4IOT—Workshop on AI for Internet of Things, Stockholm, Sweden, 13–15 July 2018. [Google Scholar]
- Bokrantz, J.; Tjernberg, L.B. An artificial neural network approach for early fault detection of gearbox bearings. IEEE Trans. Smart Grid 2015, 6, 980–987. [Google Scholar] [CrossRef]
- Bangalore, P.; Letzgus, S.; Karlsson, D.; Patriksson, M. An artificial neural network-based condition monitoring method for wind turbines, with application to the monitoring of the gearbox. Wind Energy 2017, 20, 1421–1438. [Google Scholar] [CrossRef]
- Jiang, G.; Xie, P.; He, H.; Yan, J. Wind turbine fault detection using a denoising autoencoder with temporal information. IEEE/ASME Trans. Mechatron. 2018, 23, 89–100. [Google Scholar] [CrossRef]
- Liang, X.; Duan, F.; Bennett, I.; Mba, D. A sparse autoencoder-based unsupervised scheme for pump fault detection and isolation. Appl. Sci. 2020, 10, 6789. [Google Scholar] [CrossRef]
- Ng, A. Sparse autoencoder. In CS294A Lecture Notes; 2011; Volume 72, pp. 1–19. Available online: http://ailab.chonbuk.ac.kr/seminar_board/pds1_files/sparseAutoencoder.pdf (accessed on 28 November 2020).
- Leys, C.; Klein, O.; Dominicy, Y. Detecting multivariate outliers: Use a robust variant of the Mahalanobis distance. J. Exp. Soc. Psychol. 2018, 74, 150–156. [Google Scholar] [CrossRef]
- Hua, C.; Zhang, Q.; Xu, G.; Zhang, Y.; Xu, T. Performance reliability estimation method based on adaptive failure threshold. Mech. Syst. Signal. Process. 2013, 36, 505–519. [Google Scholar] [CrossRef]
- Feldman, R.M.; Valdez-Flores, C. Applied Probability and Stochastic Processes; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Wang, H.; Khan, F.; Ahmed, S.; Imtiaz, S. Dynamic quantitative operational risk assessment of chemical processes. Chem. Eng. Sci. 2016, 142, 62–78. [Google Scholar] [CrossRef]
- Deketelaere, B.; Hubert, M.; Schmitt, E. Overview of PCA-based statistical process-monitoring methods for time-dependent, high-dimensional data. J. Qual. Technol. 2015, 47, 318–335. [Google Scholar] [CrossRef]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control. 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Mastrangelo, C. Statistical monitoring of complex multivariate processes with applications in industrial process control. J. Qual. Technol. 2013, 45, 118–119. [Google Scholar] [CrossRef]
- Brown, S.; Tauler, R.; Walczak, B. Comprehensive Chemometrics: Chemical and Biochemical Data Analysis, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Zhu, X.; Braatz, R.D. Two-dimensional contribution map for fault identification [Focus on Education]. IEEE Control. Syst. 2014, 34, 72–77. [Google Scholar] [CrossRef]
- American Petroleum Institute. API Recommended Practice 581—Risk-Based Inspection Technology, 2nd ed.; API: Washington, DC, USA, 2008. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Life Distribution | Probability Density Function | Parameters |
|---|---|---|
| Generalized extreme value distribution | , | is the shape parameter. is the scale parameter. is the location parameter. |
| Lognormal distribution | is the mean of logarithmic values. is the standard deviation of logarithmic values. | |
| Normal distribution | is the mean value. is the standard deviation. | |
| Kernel distribution | is the bandwidth. is the sample size. |
| ID | Variable Name | ID | Variable Name | ID | Variable Name |
|---|---|---|---|---|---|
| 1 | Speed | 2 | Suction pressure | 3 | Discharge pressure |
| 4 | Discharge temperature | 5 | Actual flow | 6 | Radial vibration overall X1 |
| 7 | Radial vibration overall Y1 | 8 | Radial bearing temperature 1 | 9 | Radial vibration overall X2 |
| 10 | Radial vibration overall Y2 | 11 | Radial bearing temperature 2 | 12 | Thrust position axial probe1 |
| 13 | Thrust position axial probe 2 | 14 | Active thrust bearing temperature 1 | 15 | Inactive thrust bearing temperature 1 |
| Distribution | p | |
|---|---|---|
| Generalized Extreme Value | 0 | 0.6802 |
| Lognormal | 0 | 0.0576 |
| Normal | 0 | 0.0757 |
| Kernel | 0 | 0.9944 |
| Financial Factors | Values ($) |
|---|---|
| Downtime Cost () | 83,000 |
| Material Cost () | 4000 |
| Labor Cost () | 1080 |
| Technical Support Cost () | 4000 |
| 33,048 |
| ID | Variable Name | ID | Variable Name | ID | Variable Name |
|---|---|---|---|---|---|
| 1 | Stage1 Suction Pressure | 2 | Stage1 Discharge Pressure | 3 | Stage1 Suction Temperature |
| 4 | Stage1 Discharge Temperature | 5 | Stage2 Suction Pressure | 6 | Stage2 Discharge Pressure |
| 7 | Stage2 Suction Temperature | 8 | Stage2 Discharge Temperature | 9 | Stage3 Suction Pressure |
| 10 | Stage3 Discharge Pressure | 11 | Stage3 Suction Temperature | 12 | Stage3 Discharge Temperature |
| 13 | Stage1 Standard flow | 14 | Stage2 Standard flow | 15 | Stage3 Standard flow |
| 16 | Stage 1–2 DE Radial Vibration Overall X | 17 | Stage 1–2 DE Radial Vibration Overall Y | 18 | Stage 1–2 NDE Radial Vibration Overall X |
| 19 | Stage 1–2 NDE Radial Vibration Overall Y | 20 | Stage 1–2 Thrust Position Axial Probe 1 | 21 | Stage 1–2 Thrust Position Axial Probe 2 |
| 22 | Stage3 DE Radial Vibration Overall X | 23 | Stage3 DE Radial Vibration Overall Y | 24 | Stage3 NDE Radial Vibration Overall X |
| 25 | Stage3 NDE Radial Vibration Overall Y | 26 | Stage3 Thrust Position Axial Probe 1 | 27 | Stage3 Thrust Position Axial Probe 2 |
| 28 | Speed 1 |
| Distribution | H | p |
|---|---|---|
| Generalized Extreme Value | 0 | 0.1261 |
| Lognormal | 1 | 8.2503 × 10−7 |
| Normal | 1 | 3.3784 × 10−33 |
| Kernel | 0 | 0.9890 |
| Financial Factors | Values ($) |
|---|---|
| Downtime Cost () | 62,500 |
| Material Cost () | 1000 |
| Labor Cost () | 720 |
| Technical Support Cost() | 3000 |
| 33,048 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.; Duan, F.; Bennett, I.; Mba, D. A Comprehensive Health Indicator Integrated by the Dynamic Risk Profile from Condition Monitoring Data and the Function of Financial Losses. Energies 2021, 14, 28. https://doi.org/10.3390/en14010028
Liang X, Duan F, Bennett I, Mba D. A Comprehensive Health Indicator Integrated by the Dynamic Risk Profile from Condition Monitoring Data and the Function of Financial Losses. Energies. 2021; 14(1):28. https://doi.org/10.3390/en14010028
Chicago/Turabian StyleLiang, Xiaoxia, Fang Duan, Ian Bennett, and David Mba. 2021. "A Comprehensive Health Indicator Integrated by the Dynamic Risk Profile from Condition Monitoring Data and the Function of Financial Losses" Energies 14, no. 1: 28. https://doi.org/10.3390/en14010028
APA StyleLiang, X., Duan, F., Bennett, I., & Mba, D. (2021). A Comprehensive Health Indicator Integrated by the Dynamic Risk Profile from Condition Monitoring Data and the Function of Financial Losses. Energies, 14(1), 28. https://doi.org/10.3390/en14010028