
Integration of Classical Mathematical Modeling with an Artificial Neural Network for the Problems with Limited Dataset


Abstract
:1. Introduction
2. Literature Review
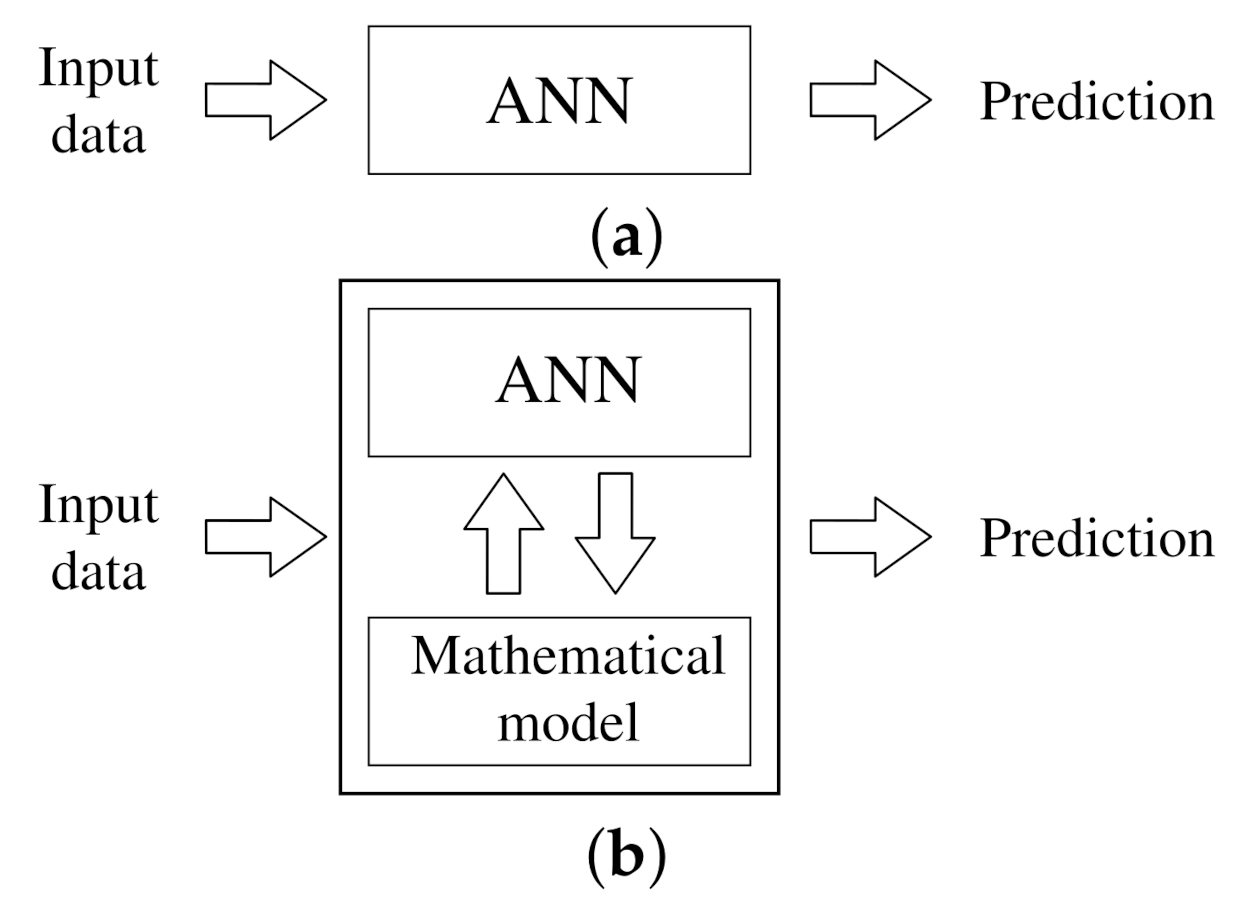
3. Methodology
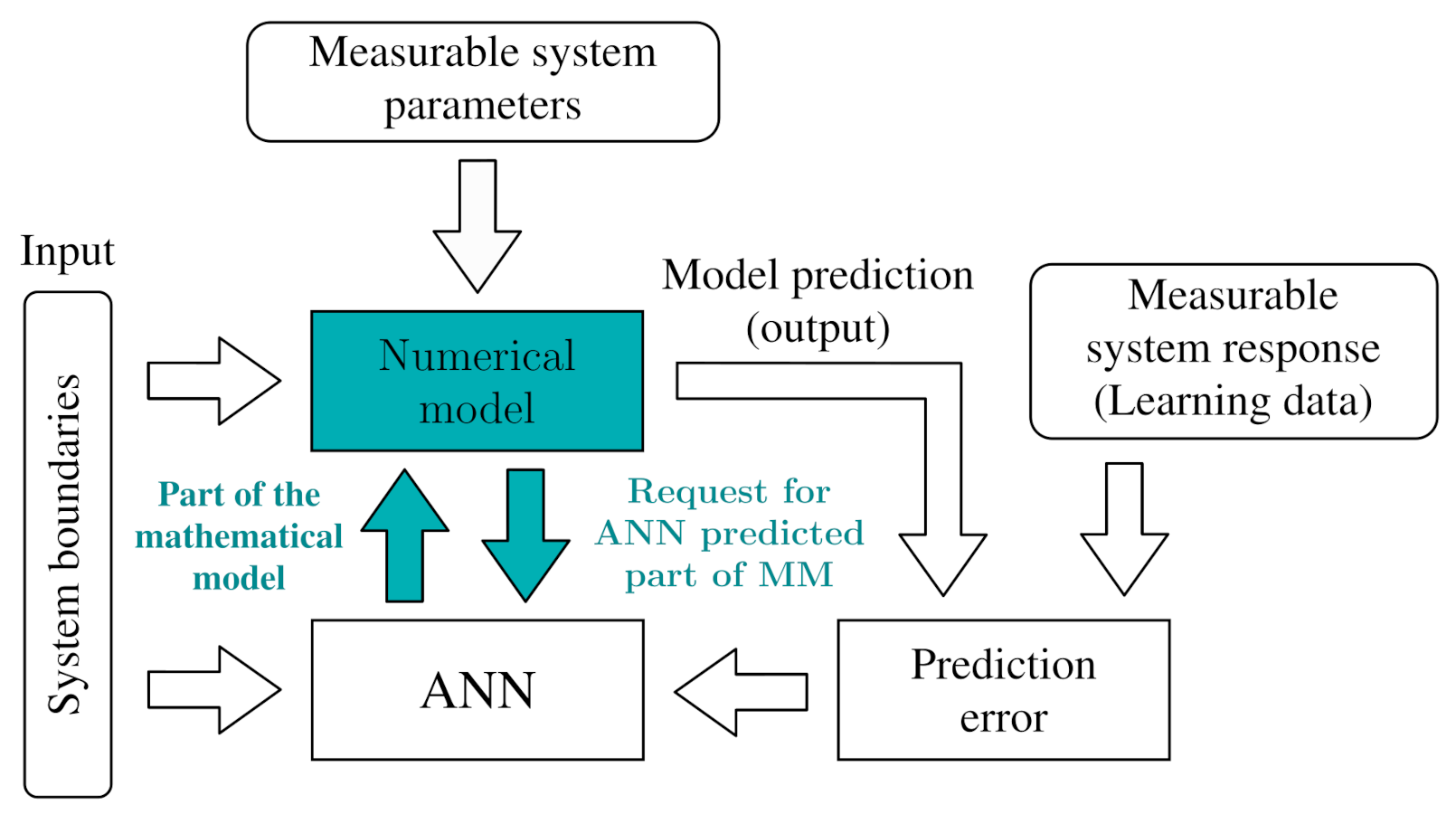
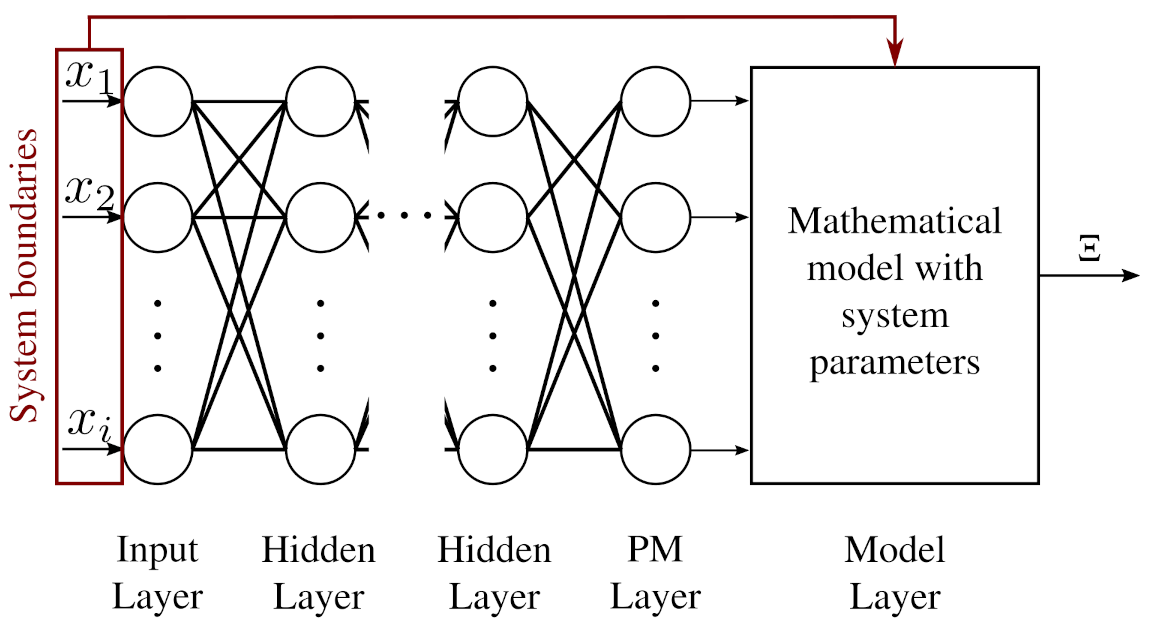
3.1. Implementation
3.2. Learning Process
3.3. Learning Algorithm
- 1.
- Having an empirical dataset D of a N system’s input () and output () paired vectors, define a function which divides the dataset D into training and test data sets— and .
- 2.
- Having a numerical model M and neural network , define a function IMANN(M,) that combines the M and into IMANN.
- 3.
- For a given CMA-ES, optimization parameters initialize the CMA-ES optimization algorithm.
- 4.
- Perform one optimization step for optimization of the weights and biases vector based on a fitness function dependent on the and .
- 5.
- For every solution check squared error made on () and (), save the lowest, throughout whole optimization, value of and the corresponding solution .
- 6.
- Repeat steps 4 and 5 until one of the optimization’s stopping criteria is satisfied.
| Algorithm 1 IMANN training process |
| Require: Empirical dataset , CMA-ES optimization parameters , numerical model M |
| 1: |
| 2: // Divide data to training and test sets |
| 3: CMAoptimizer = InitializeCMA // Initialize optimizer |
| 4: do |
| 5: NextGeneration(CMAoptimizer) |
| 6: // Get current population |
| 7: for do |
| 8: // Initialize network from candidate’s weights vector |
| 9: // Initialize IMANN as an integration of the numerical model and the ANN |
| 10: |
| 11: setCandidateFitness(, ) |
| 12: |
| 13: |
| 14: if then |
| 15: |
| 16: save() |
| 17: end if |
| 18: end for |
| 19: while !stopCondition(CMAoptimizer) |
3.4. This Study
4. Benchmarking Functions
Functions
5. Results
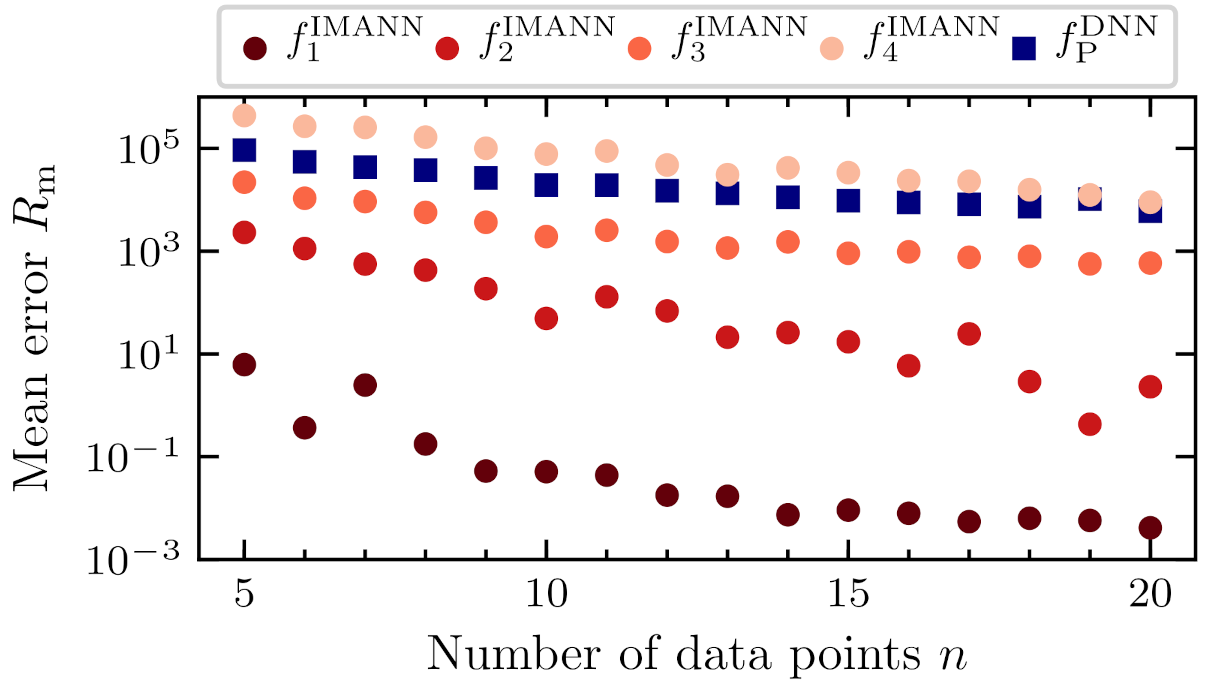
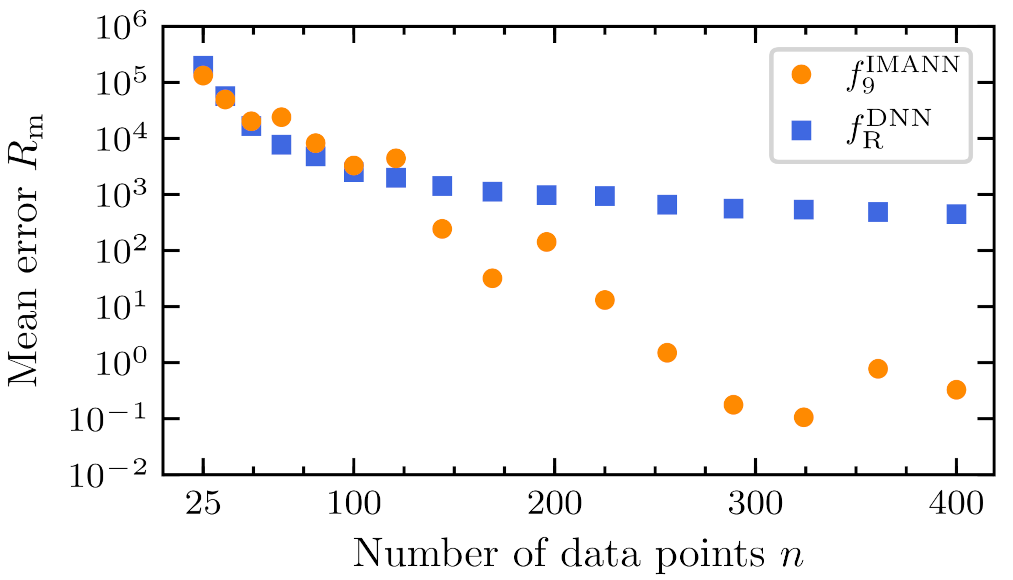
5.1. Architecture
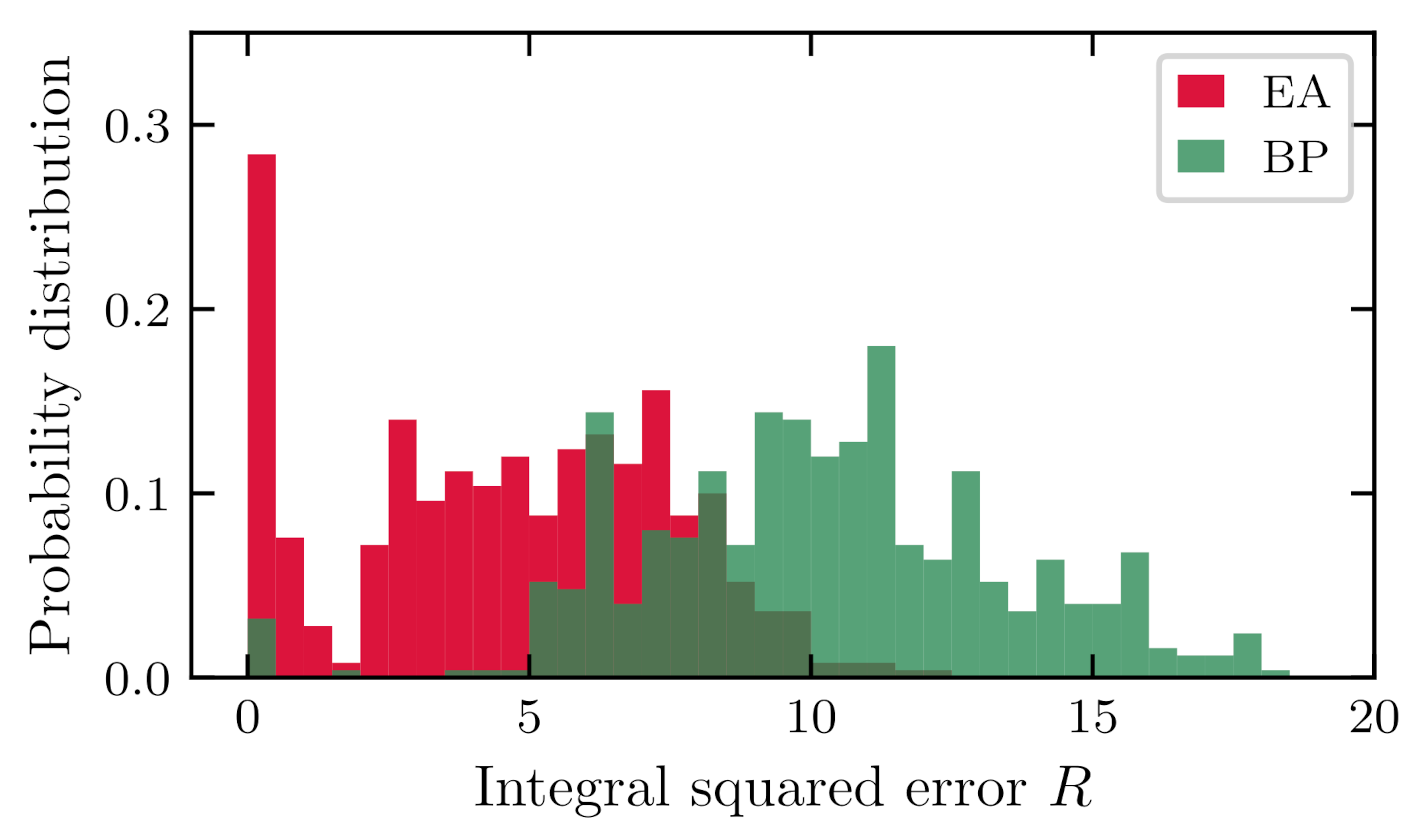
5.2. Statistical Testing
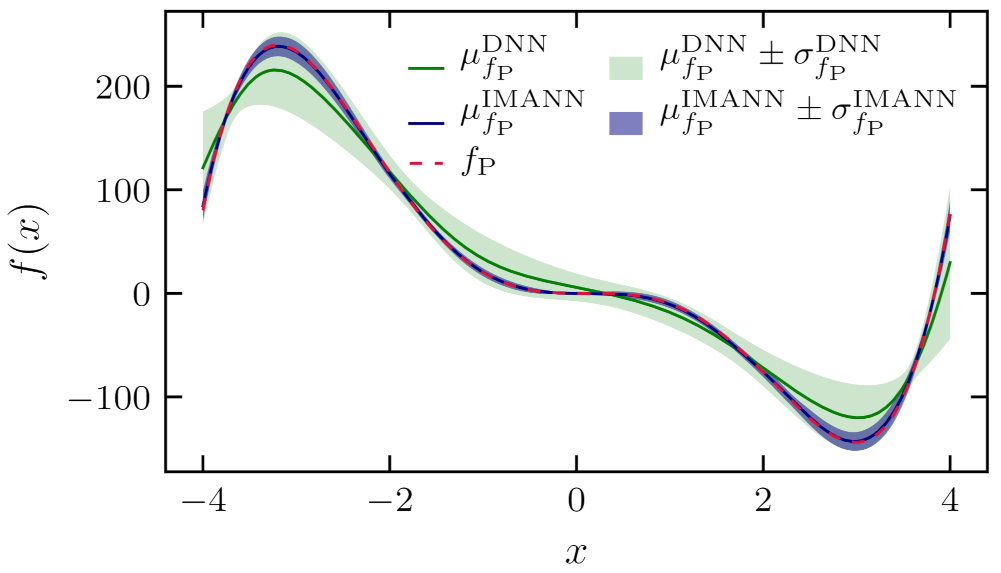
5.3. Examples of Prediction
6. Discussion
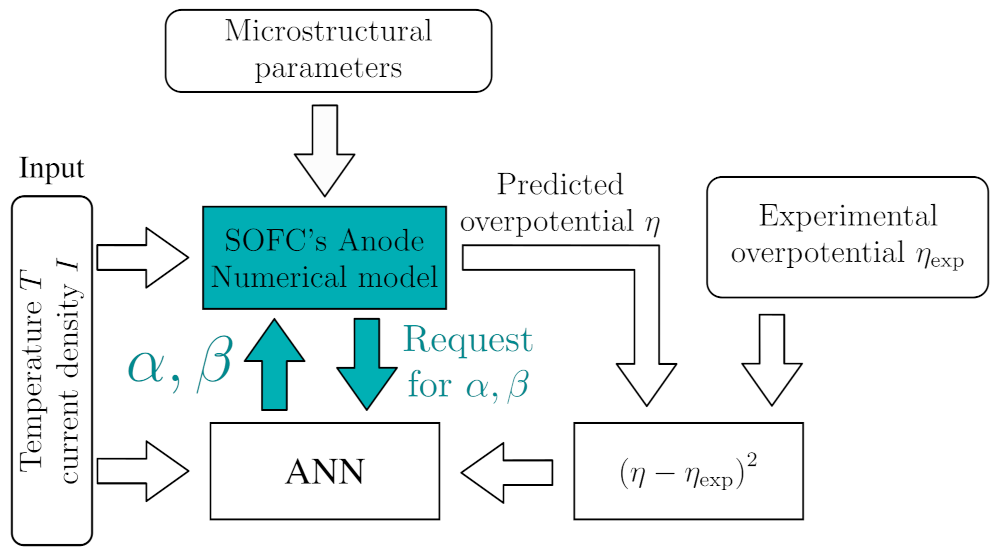
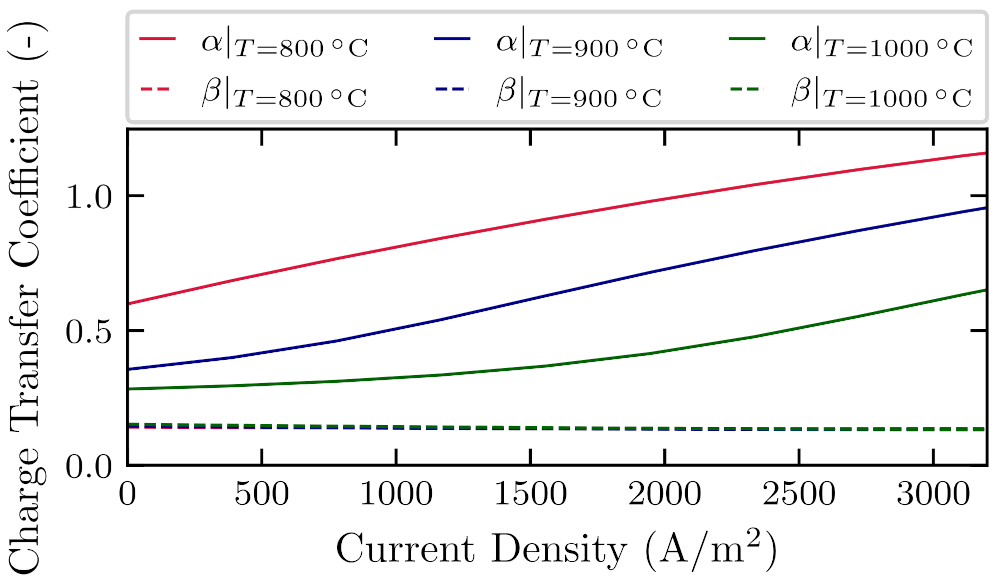
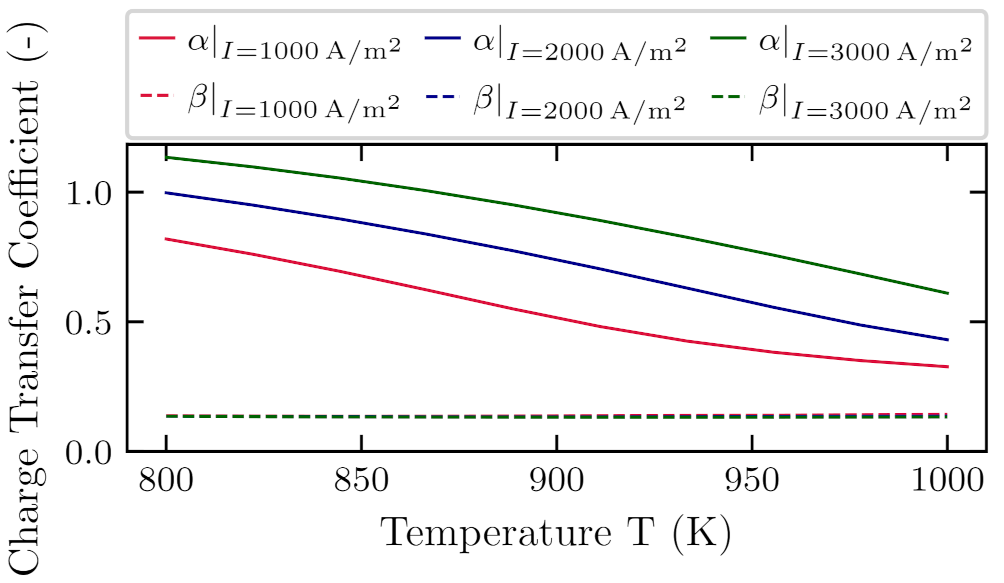
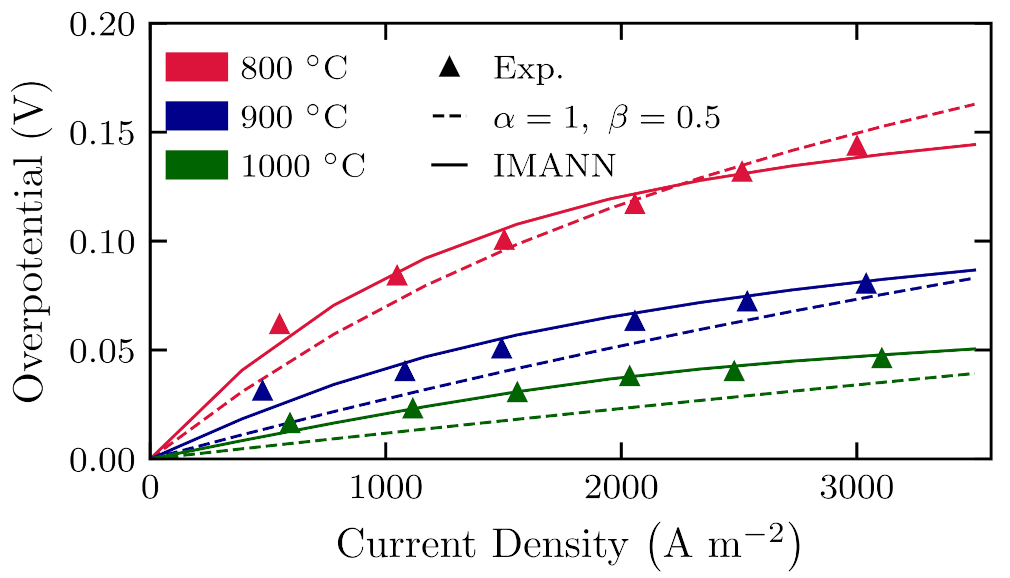
7. Practical Application in Solid Oxide Fuel Cells Modeling
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nikzad, M.; Movagharnejad, K.; Talebnia, F. Comparative Study between Neural Network Model and Mathematical Models for Prediction of Glucose Concentration during Enzymatic Hydrolysis. Int. J. Comput. Appl. Technol. 2012, 56, 43–48. [Google Scholar] [CrossRef]
- Tan, W.C.; Iwai, H.; Kishimoto, M.; Brus, G.; Szmyd, J.S.; Yoshida, H. Numerical analysis on effect of aspect ratio of planar solid oxide fuel cell fueled with decomposed ammonia. J. Power Sources 2018, 384, 367–378. [Google Scholar] [CrossRef]
- Brus, G.; Raczkowski, P.F.; Kishimoto, M.; Iwai, H.; Szmyd, J. A microstructure-oriented mathematical model of a direct internal reforming solid oxide fuel cell. Energy Convers. Manag. 2020, 213, 112826. [Google Scholar] [CrossRef]
- Brus, G.; Iwai, H.; Otani, Y.; Saito, M.; Yoshida, H.; Szmyd, J.S. Local Evolution of Triple Phase Boundary in Solid Oxide Fuel Cell Stack After Long-term Operation. Fuel Cells 2015, 15, 545–548. [Google Scholar] [CrossRef]
- Chalusiak, M.; Nawrot, W.; Buchaniec, S.; Brus, G. Swarm Intelligence-Based Methodology for Scanning Electron Microscope Image Segmentation of Solid Oxide Fuel Cell Anode. Energies 2021, 14, 3055. [Google Scholar] [CrossRef]
- Brus, G.; Iwai, H.; Szmyd, J.S. An Anisotropic Microstructure Evolution in a Solid Oxide Fuel Cell Anode. Nanoscale Res. Lett. 2020, 15, 427. [Google Scholar] [CrossRef] [PubMed]
- Chalusiak, M.; Wrobel, M.; Mozdzierz, M.; Berent, K.; Szmyd, J.S.; Brus, G. A numerical analysis of unsteady transport phenomena in a Direct Internal Reforming Solid Oxide Fuel Cell. Int. J. Heat Mass Transf. 2019, 131, 1032–1051. [Google Scholar] [CrossRef]
- Mozdzierz, M.; Berent, K.; Kimijima, S.; Szmyd, J.S.; Brus, G. A Multiscale Approach to the Numerical Simulation of the Solid Oxide Fuel Cell. Catalysts 2019, 9, 253. [Google Scholar] [CrossRef] [Green Version]
- Andonie, R. Extreme Data Mining: Inference from Small Datasets. Int. J. Comput. Commun. Control 2010, 5, 280–291. [Google Scholar] [CrossRef] [Green Version]
- Cataron, A.; Andonie, R. How to infer the informational energy from small datasets. In Proceedings of the 2012 13th International Conference on Optimization of Electrical and Electronic Equipment (OPTIM 2012), Brasov, Romania, 24–26 May 2012; pp. 1065–1070. [Google Scholar] [CrossRef]
- Shaikhina, T.; Khovanova, N.A. Handling limited datasets with neural networks in medical applications: A small-data approach. Artif. Intell. Med. 2017, 75, 51–63. [Google Scholar] [CrossRef]
- Micieli, D.; Minniti, T.; Evans, L.M.; Gorini, G. Accelerating Neutron Tomography experiments through Artificial Neural Network based reconstruction. Sci. Rep. 2019, 9, 2450. [Google Scholar] [CrossRef] [PubMed]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, UK, 6 August 2003; pp. 958–963. [Google Scholar] [CrossRef]
- Baird, H.S.; Bunke, H.; Yamamoto, K. (Eds.) Document Image Defect Models. In Structured Document Image Analysis; Springer: Berlin/Heidelberg, Germany, 1992; pp. 546–556. [Google Scholar] [CrossRef]
- Simard, P.; Victorri, B.; LeCun, Y.; Denker, J. Tangent Prop—A formalism for specifying selected invariances in an adaptive network. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 2–5 December 1991; pp. 895–903. [Google Scholar]
- Rozsa, A.; Rudd, E.M.; Boult, T.E. Adversarial Diversity and Hard Positive Generation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 410–417. [Google Scholar] [CrossRef] [Green Version]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart Augmentation Learning an Optimal Data Augmentation Strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Letscher, D.; Zomorodian, A. Topological persistence and simplification. In Proceedings of the 41st Annual Symposium on Foundations of Computer Science, Redondo Beach, CA, USA, 12–14 November 2000; pp. 454–463. [Google Scholar] [CrossRef]
- Adams, H.; Emerson, T.; Kirby, M.; Neville, R.; Peterson, C.; Shipman, P.; Chepushtanova, S.; Hanson, E.; Motta, F.; Ziegelmeier, L. Persistence Images: A Stable Vector Representation of Persistent Homology. J. Mach. Learn. Res. 2017, 18, 1–35. [Google Scholar]
- Adcock, A.; Carlsson, E.; Carlsson, G. The ring of algebraic functions on persistence bar codes. Homol. Homotopy Appl. 2016, 18, 381–402. [Google Scholar] [CrossRef] [Green Version]
- Towell, G.G.; Shavlik, J.W. Knowledge-based artificial neural networks. Artif. Intell. 1994, 70, 119–165. [Google Scholar] [CrossRef]
- Su, H.T.; Bhat, N.; Minderman, P.; McAvoy, T. Integrating Neural Networks with First Principles Models for Dynamic Modeling. IFAC Proc. Vol. 1992, 25, 327–332. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, Q.j. Knowledge-based neural models for microwave design. IEEE Trans. Microw. Theory Tech. 1997, 45, 2333–2343. [Google Scholar] [CrossRef]
- Bandler, J.W.; Ismail, M.A.; Rayas-Sanchez, J.E.; Zhang, Q.-J. Neuromodeling of microwave circuits exploiting space-mapping technology. IEEE Trans. Microw. Theory Tech. 1999, 47, 2417–2427. [Google Scholar] [CrossRef]
- Na, W.; Feng, F.; Zhang, C.; Zhang, Q. A Unified Automated Parametric Modeling Algorithm Using Knowledge-Based Neural Network and l1 Optimization. IEEE Trans. Microw. Theory Tech. 2017, 65, 729–745. [Google Scholar] [CrossRef]
- Psichogios, D.C.; Ungar, L.H. A Hybrid Neural Network-First Principles Approach to Process Modeling. AIChE J. 1992, 38, 1499–1511. [Google Scholar] [CrossRef]
- Hagge, T.; Stinis, P.; Yeung, E.; Tartakovsky, A.M. Solving differential equations with unknown constitutive relations as recurrent neural networks. arXiv 2017, arXiv:1710.02242. [Google Scholar]
- De Veaux, R.D.; Bain, R.; Ungar, L.H. Hybrid neural network models for environmental process control: (The 1998 Hunter Lecture). Environmetrics 1999, 10, 225–236. [Google Scholar] [CrossRef]
- Acuña, G.; Cubillos, F.; Thibaule, J.; Latrille, E. Comparison of methods for training grey-box neural network models. Comput. Chem. Eng. 1999, 23, S561–S564. [Google Scholar] [CrossRef]
- Oliveira, R. Combining first principles modelling and artificial neural networks: A general framework. Comput. Chem. Eng. 2004, 28, 755–766. [Google Scholar] [CrossRef]
- Cubillos, F.A.; Alvarez, P.I.; Pinto, J.C.; Lima, E.L. Hybrid-neural modeling for particulate solid drying processes. Powder Technol. 1996, 87, 153–160. [Google Scholar] [CrossRef]
- Piron, E.; Latrille, E.; René, F. Application of artificial neural networks for crossflow microfiltration modelling: “Black-box” and semi-physical approaches. Comput. Chem. Eng. 1997, 21, 1021–1030. [Google Scholar] [CrossRef]
- Vieira, J.A.; Mota, A.M. Combining first principles with grey-box approaches for modelling a water gas heater system. In Proceedings of the 20th IEEE International Symposium on Intelligent 652 Control, ISIC’05 and the 13th Mediterranean Conference on Control and Automation, MED’05, Limassol, Cyprus, 27–29 June 2005; pp. 1137–1142. [Google Scholar] [CrossRef]
- Romijn, R.; Özkan, L.; Weiland, S.; Ludlage, J.; Marquardt, W. A grey-box modeling approach for the reduction of nonlinear systems. J. Process Control 2008, 18, 906–914. [Google Scholar] [CrossRef]
- Chaffart, D.; Ricardez-Sandoval, L.A. Optimization and control of a thin film growth process: A hybrid first principles/artificial neural network based multiscale modelling approach. Comput. Chem. Eng. 2018, 119, 465–479. [Google Scholar] [CrossRef]
- Cen, Z.; Wei, J.; Jiang, R. A grey-box neural network based identification model for nonlinear dynamic systems. In Proceedings of the 4th International Workshop on Advanced Computational Intelligence (IWACI 2011), Wuhan, China, 19–21 October 2011; pp. 300–307. [Google Scholar] [CrossRef]
- Lagaris, I.E.; Likas, A.; Fotiadis, D.I.F. Artificial Neural Networks for Solving Ordinary and Partial Differential Equations. IEEE Trans. Neural Netw. 1998, 9, 987–1000. [Google Scholar] [CrossRef] [Green Version]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Parish, E.J.; Duraisamy, K. A paradigm for data-driven predictive modeling using field inversion and machine learning. J. Comput. Phys. 2016, 305, 758–774. [Google Scholar] [CrossRef] [Green Version]
- Shukla, K.; Jagtap, A.D.; Karniadakis, G.E. Parallel Physics-Informed Neural Networks via Domain Decomposition. arXiv 2021, arXiv:2104.10013. [Google Scholar]
- Jagtap, A.D.; Em Karniadakis, G. Extended Physics-Informed Neural Networks (XPINNs): A Generalized Space-Time Domain Decomposition Based Deep Learning Framework for Nonlinear Partial Differential Equations. Commun. Comput. Phys. 2020, 28, 2002–2041. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Kharazmi, E.; Karniadakis, G.E. Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems. Comput. Methods Appl. Mech. Eng. 2020, 365, 113028. [Google Scholar] [CrossRef]
- Shukla, K.; Di Leoni, P.C.; Blackshire, J.; Sparkman, D.; Karniadakis, G.E. Physics-Informed Neural Network for Ultrasound Nondestructive Quantification of Surface Breaking Cracks. J. Nondestruct. Eval. 2020, 39, 61. [Google Scholar] [CrossRef]
- Shukla, K.; Jagtap, A.D.; Blackshire, J.L.; Sparkman, D.; Karniadakis, G.E. A physics-informed neural network for quantifying the microstructure properties of polycrystalline Nickel using ultrasound data. arXiv 2021, arXiv:2103.14104. [Google Scholar]
- Ling, J.; Kurzawski, A.; Templeton, J. Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. J. Fluid Mech. 2016, 807, 155–166. [Google Scholar] [CrossRef]
- Wu, J.L.; Xiao, H.; Paterson, E. Physics-informed machine learning approach for augmenting turbulence models: A comprehensive framework. Phys. Rev. Fluids 2018, 7, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Chan, S.; Elsheikh, A.H. A machine learning approach for efficient uncertainty quantification using multiscale methods. J. Comput. Phys. 2018, 354, 493–511. [Google Scholar] [CrossRef] [Green Version]
- Tripathy, R.K.; Bilionis, I. Deep UQ: Learning deep neural network surrogate models for high dimensional uncertainty quantification. J. Comput. Phys. 2018, 375, 565–588. [Google Scholar] [CrossRef] [Green Version]
- Hansen, N.; Ostermeier, A. Adapting arbitrary normal mutation distributions in evolution strategies: The covariance matrix adaptation. In Proceedings of the IEEE International Conference on Evolutionary Computation, Nagoya, Japan, 20–22 May 1996; pp. 312–317. [Google Scholar] [CrossRef]
- Hansen, N.; Akimoto, Y.; Baudis, P. CMA-ES/Pycma on Github. 2019. Available online: https://github.com/CMA-ES/Pycma (accessed on 30 September 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org (accessed on 30 September 2020).
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Li, X. Principles of Fuel Cells, 1st ed.; Taylor & Francis: New York, NY, USA, 2006. [Google Scholar]
- Buchaniec, S.; Sciazko, A.; Mozdzierz, M.; Brus, G. A Novel Approach to the Optimization of a Solid Oxide Fuel Cell Anode Using Evolutionary Algorithms. IEEE Access 2019, 7, 34361–34372. [Google Scholar] [CrossRef]
- de Boer, B. SOFC Anode. Hydrogen Oxidation at Porous Nickel and Nickel/Zirconia Electrodes. Ph.D. Thesis, University of Twente, Enschede, The Netherlands, 1998. [Google Scholar]
- Kishimoto, M.; Iwai, H.; Saito, M.; Yoshida, H. Quantitative evaluation of solid oxide fuel cell porous anode microstructure based on focused ion beam and scanning electron microscope technique and prediction of anode overpotentials. J. Power Sources 2011, 196, 4555–4563. [Google Scholar] [CrossRef]
- Marina, O.A.; Pederson, L.R.; Williams, M.C.; Coffey, G.W.; Meinhardt, K.D.; Nguyen, C.D.; Thomsen, E.C. Electrode Performance in Reversible Solid Oxide Fuel Cells. J. Electrochem. Soc. 2007, 154, B452. [Google Scholar] [CrossRef]
- Kawada, T.; Sakai, N.; Yokokawa, H.; Dokiya, M.; Mori, M.; Iwata, T. Characteristics of Slurry-Coated Nickel Zirconia Cermet Anodes for Solid Oxide Fuel Cells. J. Electrochem. Soc. 1990, 137, 3042–3047. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 5 | |||||||||
| 6 | |||||||||
| 7 | |||||||||
| 8 | |||||||||
| 9 | |||||||||
| 10 | |||||||||
| 11 | |||||||||
| 12 | |||||||||
| 13 | |||||||||
| 14 | |||||||||
| 15 | |||||||||
| 16 | |||||||||
| 17 | |||||||||
| 18 | |||||||||
| 19 | |||||||||
| 20 |
| Algorithm | Ranking |
|---|---|
| 9.000 | |
| 7.331 | |
| 5.581 | |
| 1.000 | |
| 7.669 | |
| 5.294 | |
| 4.125 | |
| 3.000 | |
| 2.000 |
| Algorithms | z | p | Adjusted p |
|---|---|---|---|
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. | |||
| vs. |
| Dataset | ||
|---|---|---|
| 25 | ||
| 36 | ||
| 49 | ||
| 64 | ||
| 81 | ||
| 100 | ||
| 121 | ||
| 144 | ||
| 169 | ||
| 196 | ||
| 225 | ||
| 256 | ||
| 289 | ||
| 324 | ||
| 361 | ||
| 400 |
| Algorithm | Ranking |
|---|---|
| 57 | |
| 79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buchaniec, S.; Gnatowski, M.; Brus, G. Integration of Classical Mathematical Modeling with an Artificial Neural Network for the Problems with Limited Dataset. Energies 2021, 14, 5127. https://doi.org/10.3390/en14165127
Buchaniec S, Gnatowski M, Brus G. Integration of Classical Mathematical Modeling with an Artificial Neural Network for the Problems with Limited Dataset. Energies. 2021; 14(16):5127. https://doi.org/10.3390/en14165127
Chicago/Turabian StyleBuchaniec, Szymon, Marek Gnatowski, and Grzegorz Brus. 2021. "Integration of Classical Mathematical Modeling with an Artificial Neural Network for the Problems with Limited Dataset" Energies 14, no. 16: 5127. https://doi.org/10.3390/en14165127
APA StyleBuchaniec, S., Gnatowski, M., & Brus, G. (2021). Integration of Classical Mathematical Modeling with an Artificial Neural Network for the Problems with Limited Dataset. Energies, 14(16), 5127. https://doi.org/10.3390/en14165127