Adaptive Surrogate Estimation with Spatial Features Using a Deep Convolutional Autoencoder for CO2 Geological Sequestration



Abstract
:1. Introduction
2. Methodology
2.1. 3D Heterogeneous Aquifer Models and CO2 Sequestration
2.2. Design of the Deep Convolutional Autoencoder
2.3. Adaptive Surrogate Estimation with Spatial Feature and Data Integration
- Generate 3D geo-models stochastically and split them into the training, validation, and test datasets
- Carry out flow simulations to obtain the dynamic responses from CO2 sequestration such as the trapped volume and CO2 amount injected
- Normalize the inputs and the outputs
- Build and train the DCAE for encoding/decoding the spatial data (permeability and porosity)
- Develop the adaptive surrogate model to give estimates for the trapped CO2 volume and the injection amount without the need for time-consuming numerical simulations
3. Results and Discussion
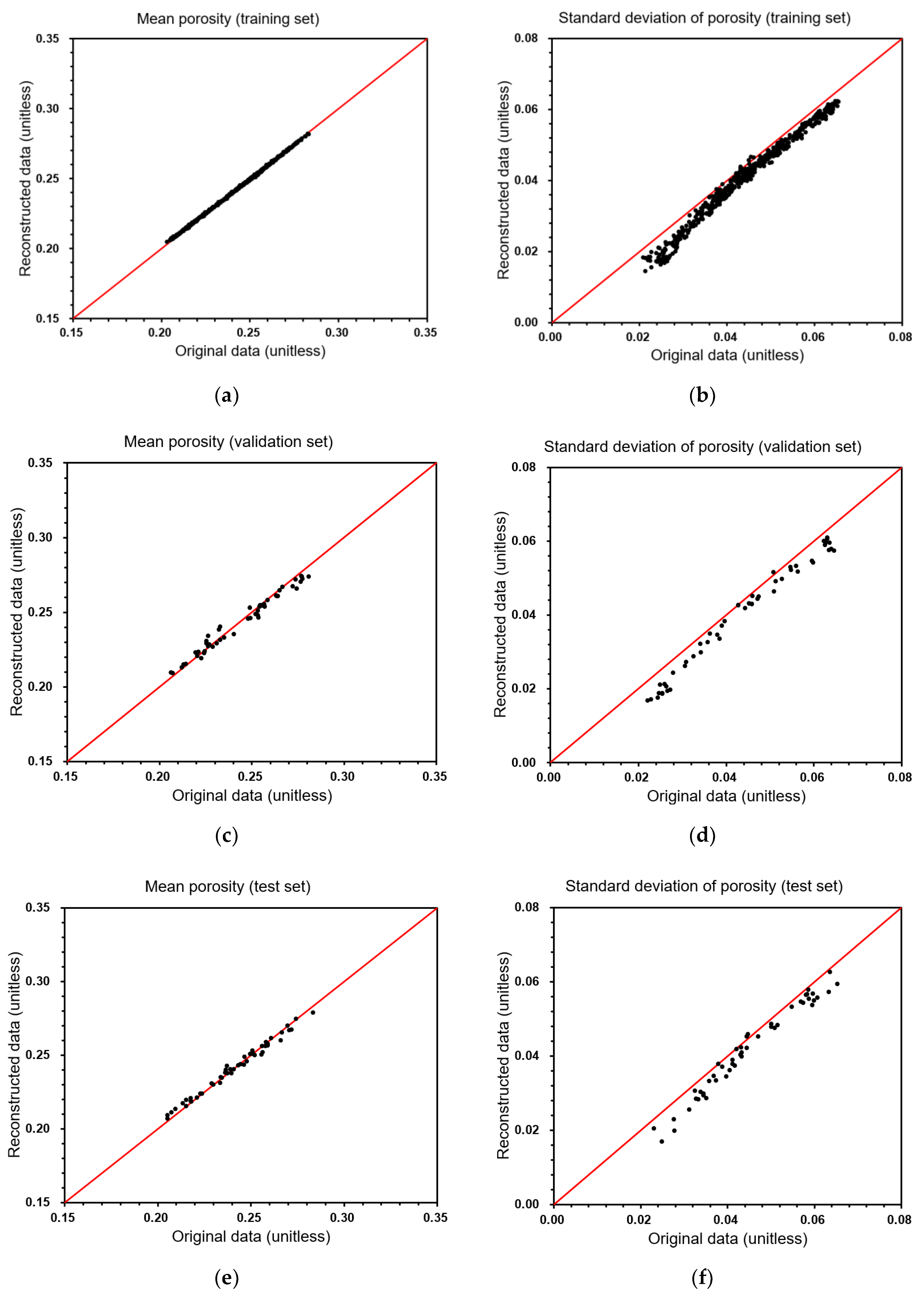
3.1. Reconstruction Performances of Rock Properties
3.2. Surrogate Estimation for CO2 Geological Sequestration
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schuetter, J.; Mishra, S.; Zhong, M.; LaFollette, R. A Data-Analytics Tutorial: Building Predictive Models for Oil Production in an Unconventional Shale Reservoir. SPE J. 2018, 23, 1075–1089. [Google Scholar] [CrossRef]
- Ertekin, T.; Sun, Q. Artificial Intelligence Applications in Reservoir Engineering: A Status Check. Energies 2019, 12, 2897. [Google Scholar] [CrossRef] [Green Version]
- Alakeely, A.; Horne, R.N. Simulating the Behavior of Reservoirs with Convolutional and Recurrent Neural Networks. SPE Reserv. Eval. Eng. 2020, 23, 992–1005. [Google Scholar] [CrossRef]
- Ki, S.; Jang, I.; Cha, B.; Seo, J.; Kwon, O. Restoration of Missing Pressures in a Gas Well Using Recurrent Neural Networks with Long Short-Term Memory Cells. Energies 2020, 13, 4696. [Google Scholar] [CrossRef]
- Seong, Y.; Park, C.; Choi, J.; Jang, I. Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe. Energies 2020, 13, 968. [Google Scholar] [CrossRef] [Green Version]
- Schuetter, J.; Mishra, K.S.; Ganesh, P.R.; Mooney, D. Building Statistical Proxy Models for CO2 Geologic Sequestration. Energy Procedia 2014, 63, 3702–3714. [Google Scholar] [CrossRef] [Green Version]
- Shahkarami, A.; Mohaghegh, S.; Gholami, V.; Haghighat, A.; Moreno, D. Modeling pressure and saturation distribution in a CO2 storage project using a Surrogate Reservoir Model (SRM). Greenh. Gases Sci. Technol. 2014, 4, 289–315. [Google Scholar] [CrossRef]
- Golzari, A.; Sefat, M.H.; Jamshidi, S. Development of an adaptive surrogate model for production optimization. J. Pet. Sci. Eng. 2015, 133, 677–688. [Google Scholar] [CrossRef]
- Tang, M.; Liu, Y.; Durlofsky, L.J. A deep-learning-based surrogate model for data assimilation in dynamic subsurface flow problems. J. Comput. Phys. 2020, 413, 109456. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Sun, W.; Durlofsky, L.J. A Deep-Learning-Based Geological Parameterization for History Matching Complex Models. Math. Geol. 2019, 51, 725–766. [Google Scholar] [CrossRef] [Green Version]
- Chu, M.-G.; Min, B.; Kwon, S.; Park, G.; Kim, S.; Huy, N.X. Determination of an infill well placement using a data-driven multi-modal convolutional neural network. J. Pet. Sci. Eng. 2020, 195, 106805. [Google Scholar] [CrossRef]
- Deng, X.; Tian, X.; Chen, S.; Harris, C.J. Deep learning based nonlinear principal component analysis for industrial process fault detection. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; Institute of Electrical and Electronics Engineers (IEEE): Anchorage, AK, USA, 2017; pp. 1237–1243. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv 2016, arXiv:1611.03530. Available online: https://arxiv.org/abs/1611.03530 (accessed on 10 January 2021).
- Canchumuni, S.W.A.; Emerick, A.A.; Pacheco, M.A.C. Towards a robust parameterization for conditioning facies models using deep variational autoencoders and ensemble smoother. Comput. Geosci. 2019, 128, 87–102. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 9780262035613. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. Available online: https://arxiv.org/abs/1511.08458 (accessed on 10 January 2021).
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time-Series. In The Handbook of Brain Theory and Neural Networks; Arbib, M.A., Ed.; MIT Press: Cambridge, MA, USA, 1995; Volume 3361. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Razak, S.M.; Jafarpour, B. Convolutional neural networks (CNN) for feature-based model calibration under uncertain geologic scenarios. Comput. Geosci. 2020, 24, 1625–1649. [Google Scholar] [CrossRef]
- Ahn, S.; Park, C.; Kim, J.; Kang, J.M. Data-driven inverse modeling with a pre-trained neural network at heterogeneous channel reservoirs. J. Pet. Sci. Eng. 2018, 170, 785–796. [Google Scholar] [CrossRef]
- Kim, J.; Park, C.; Lee, K.; Ahn, S.; Jang, I. Deep neural network coupled with distance-based model selection for efficient history matching. J. Pet. Sci. Eng. 2020, 185, 106658. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Lecture Notes in Computer Science, Proceedings of the Lecture Notes in Computer Science, Espoo, Finland, 14–17 June 2011; Springer Science and Business Media LLC: New York, NY, USA, 2011; pp. 52–59. [Google Scholar]
- Cheung, C.M.; Goyal, P.; Prasanna, V.K.; Tehrani, A.S. OReONet: Deep convolutional network for oil reservoir optimization. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; Institute of Electrical and Electronics Engineers (IEEE): Washington, DC, USA, 2017; pp. 1277–1282. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Maggipinto, M.; Masiero, C.; Beghi, A.; Susto, G.A. A Convolutional Autoencoder Approach for Feature Extraction in Virtual Metrology. Procedia Manuf. 2018, 17, 126–133. [Google Scholar] [CrossRef]
- Zhu, Y.; Zabaras, N. Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification. J. Comput. Phys. 2018, 366, 415–447. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Grana, D. Petrophysical characterization of deep saline aquifers for CO2 storage using ensemble smoother and deep convolutional autoencoder. Adv. Water Resour. 2020, 142, 103634. [Google Scholar] [CrossRef]
- Yellig, W.F.; Metcalfe, R.S. Determination and Prediction of CO2 Minimum Miscibility Pressures (includes associated paper 8876). J. Pet. Technol. 1980, 32, 160–168. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2014, arXiv:1312.4400v3. Available online: https://arxiv.org/pdf/1312.4400.pdf (accessed on 10 January 2021).
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: New York, NY, USA, 2016; pp. 2921–2929. [Google Scholar]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Lecture Notes in Computer Science; Springer Science and Business Media LLC: New York, NY, USA, 2010; pp. 92–101. [Google Scholar]
- Glantz, S.A.; Slinker, B.K.; Neilands, T.B. Primer of Applied Regression & Analysis of Variance, 3rd ed.; McGraw-Hill: New York, NY, USA, 2016; ISBN 9780071824118. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean Absolute Percentage Error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.A.; Vincent, P.; Bengio, S. Why does unsupervised pre-training help deep learning? J. Mach. Learn. Res. 2010, 11, 625–660. Available online: https://dl.acm.org/doi/10.5555/1756006 (accessed on 10 January 2021).
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1026–1034. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; Kudlur, M. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI’16), Savannah, GA, USA, 2–4 November 2016; Available online: https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf (accessed on 10 January 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Value Range |
|---|---|
| 1 Permeability (millidarcy) | 100~1000 (sandstone), 1~10 (shale) |
| Porosity (unitless) | 0.2~0.3 (sandstone), 0.1~0.15 (shale) |
| Shale volume ratio (%) | 1~20 |
| Temperature (Celsius) | 40~50 |
| 2 Salinity (ppm) | 100,000~250,000 |
| Description | Output Shape | The Number of Parameters | |
|---|---|---|---|
| Encoder | Network input | (44,460) | - |
| Hidden layer 1 | (14,820) | 658,912,020 | |
| Hidden layer 2 | (4940) | 73,215,740 | |
| Hidden layer 3 | (1920) | 9,486,720 | |
| Encoder total | - | 741,614,480 | |
| Decoder | Hidden layer 4 | (4940) | 9,489,740 |
| Hidden layer 5 | (14,820) | 73,225,620 | |
| Network output | (44,460) | 658,941,660 | |
| Decoder total | - | 741,657,020 | |
| Network total | - | 1,483,271,500 | |
| Layer Description | Kernels | Output Shape | The Number of Parameters | Remark |
|---|---|---|---|---|
| Network input | (38, 45, 13, 2) | - | - | |
| 1 Conv 1 | 16, (3 × 3 × 3) | (38, 45, 13, 16) | 880 | - |
| 2 BN 1 | - | (38, 45, 13, 16) | 64 | |
| Convn 2 | 16, (3 × 3 × 3) | (38, 45, 13, 16) | 880 | Dilated kernel |
| BN 2 | - | (38, 45, 13, 16) | 64 | |
| Concatenate | - | (38, 45, 13, 32) | - | - |
| Conv 3 | 32, (3 × 3 × 3) | (38, 45, 13, 32) | 27,680 | - |
| BN 3 | - | (38, 45, 13, 32) | 128 | |
| Conv 4 | 64, (2 × 2 × 2) | (19, 23, 7, 64) | 16,448 | Strided convolution |
| BN 4 | - | (19, 23, 7, 64) | 256 | |
| Conv 5 | 64, (3 × 3 × 3) | (19, 23, 7, 64) | 110,656 | - |
| BN 5 | - | (19, 23, 7, 64) | 256 | |
| Conv 6 | 64, (3 × 3 × 3) | (19, 23, 7, 64) | 110,656 | - |
| BN 6 | - | (19, 23, 7, 64) | 256 | |
| Conv 7 | 128, (2 × 2 × 2) | (10, 12, 4, 128) | 65,664 | Strided convolution |
| BN 7 | - | (10, 12, 4, 128) | 512 | |
| Conv 8 | 64, (1 × 1 × 1) | (10, 12, 4, 64) | 8256 | Cross-channel pooling |
| BN 8 | - | (10, 12, 4, 64) | 256 | |
| Conv 9 | 128, (3 × 3 × 3) | (10, 12, 4, 128) | 221,312 | - |
| BN 9 | - | (10, 12, 4, 128) | 512 | |
| Conv 10 | 64, (1 × 1 × 1) | (10, 12, 4, 64) | 8256 | Cross-channel pooling |
| BN 10 | - | (10, 12, 4, 64) | 256 | |
| Conv 11 | 128, (3 × 3 × 3) | (10, 12, 4, 128) | 221,312 | - |
| BN 11 | - | (10, 12, 4, 128) | 512 | |
| Conv 12 | 64, (1 × 1 × 1) | (10, 12, 4, 64) | 8256 | Cross-channel pooling |
| BN 12 | - | (10, 12, 4, 64) | 256 | |
| Conv 13 | 256, (2 × 2 × 2) | (5, 6, 2, 256) | 131,328 | Strided convolution |
| BN 13 | - | (5, 6, 2, 256) | 1024 | |
| Conv 14 | 64, (1 × 1 × 1) | (5, 6, 2, 64) | 16,448 | Cross-channel pooling |
| BN 14 | - | (10, 12, 4, 64) | 256 | |
| Conv 15 | 256, (3 × 3 × 3) | (5, 6, 2, 256) | 442,624 | - |
| BN 15 | - | (5, 6, 2, 256) | 1024 | |
| Conv 16 | 64, (1 × 1 × 1) | (5, 6, 2, 64) | 16,448 | Cross-channel pooling |
| BN 16 | - | (10, 12, 4, 64) | 256 | |
| Conv 17 | 256, (3 × 3 × 3) | (5, 6, 2, 256) | 442,624 | - |
| BN 17 | - | (5, 6, 2, 256) | 1024 | |
| Conv 18 | 32, (1 × 1 × 1) | (5, 6, 2, 32) | 16,448 | Cross-channel pooling |
| BN 18 | - | (5, 6, 2, 32) | 256 | |
| Encoder total | 1,864,992 | |||
| Layer Description | Kernels | Output Shape | The Number of Parameters | Remark |
|---|---|---|---|---|
| Decoder input | (5, 6, 2, 32) | - | - | |
| 1 Conv 19 | 128, (3 × 3 × 3) | (5, 6, 2, 128) | 110,720 | - |
| 2 BN 19 | - | (5, 6, 2, 128) | 512 | |
| Conv 20 | 64, (1 × 1 × 1) | (5, 6, 2, 64) | 8256 | Cross-channel pooling |
| BN 20 | - | (5, 6, 2, 64) | 256 | |
| Conv 21 | 128, (3 × 3 × 3) | (5, 6, 2, 128) | 221,312 | - |
| BN 21 | - | (5, 6, 2, 128) | 512 | |
| Conv 22 | 64, (2 × 2 × 2) | (10, 12, 4, 64) | 65,600 | Transposed convolution |
| BN 22 | - | (10, 12, 4, 64) | 256 | |
| Conv 23 | 32, (2 × 2 × 2) | (20, 24, 8, 32) | 16,416 | Transposed convolution |
| BN 23 | - | (20, 24, 8, 32) | 128 | |
| Conv 24 | 32, (2 × 2 × 2) | (19, 23, 7, 32) | 8224 | Convolution without zero-padding |
| BN 24 | - | (19, 23, 7, 32) | 128 | |
| Conv 25 | 16, (2 × 2 × 2) | (38, 46, 14, 16) | 4112 | Transposed convolution |
| BN 25 | - | (38, 46, 14, 16) | 64 | |
| Conv 26 | 16, (1×2×2) | (38, 45, 13, 16) | 1040 | Convolution without zero-padding |
| BN 26 | - | (38, 45, 13, 16) | 64 | |
| Conv 27 | 2, (3 × 3 × 3) | (38, 45, 13, 2) | 866 | - |
| BN 27 | - | (38, 45, 13, 2) | 8 | |
| Decoder Total | 438,474 | |||
| Data Set | Permeability | Porosity | |||
|---|---|---|---|---|---|
| Mean | Standard Deviation | Mean | Standard Deviation | ||
| R2 (R-squared) | Training set | 0.999 | 0.992 | 0.999 | 0.985 |
| Validation set | 0.997 | 0.983 | 0.979 | 0.985 | |
| Test set | 0.996 | 0.980 | 0.989 | 0.972 | |
| 1RMSE | Training set | 0.872 | 11.56 | 0.0007 | 0.0037 |
| Validation set | 9.48 | 14.36 | 0.005 | 0.0042 | |
| Test set | 9.93 | 14.61 | 0.003 | 0.0038 | |
| 2MAPE (%) | Training set | 0.18 | 4.85 | 0.25 | 8.64 |
| Validation set | 1.90 | 5.92 | 1.21 | 10.40 | |
| Test set | 1.79 | 5.85 | 0.85 | 8.25 | |
| Layer Description | Kernels | Output Shape | The Number of Parameters | Remark |
|---|---|---|---|---|
| Network input | (5, 6, 2, 36) | - | - | |
| 1 Conv 1 | 64, (3 × 3 × 2) | (5, 6, 2, 64) | 41,536 | |
| 2 BN 1 | - | (5, 6, 2, 64) | 256 | |
| Conv 2 | 64, (3 × 3 × 2) | (5, 6, 2, 64) | 73,792 | |
| BN 2 | - | (5, 6, 2, 64) | 256 | |
| Conv 3 | 128, (2 × 2 × 2) | (3, 3, 1, 128) | 65,664 | Strided convolution |
| BN 3 | - | (3, 3, 1, 128) | 512 | |
| Conv 4 | 128, (2 × 2 × 1) | (3, 3, 1, 128) | 65,664 | |
| BN 4 | - | (3, 3, 1, 128) | 512 | |
| Conv 5 | 128, (2 × 2 × 1) | (3, 3, 1, 128) | 65,664 | |
| BN 5 | - | (3, 3, 1, 128) | 512 | |
| Conv 6 | 64, (2 × 2 × 1) | (3, 3, 1, 64) | 32,832 | |
| BN 6 | - | (3, 3, 1, 64) | 256 | |
| Conv 7 | 3, (2 × 2 × 1) | (3, 3, 1, 3) | 771 | |
| BN 7 | - | (3, 3, 1, 3) | 12 | |
| Global average pooling | (3) | - | ||
| Network Total | 348,239 |
| Structural Trap | Dissolved Trap | Total CO2 Volume Injected | |
|---|---|---|---|
| R2 (R-squared) | 0.892 | 0.989 | 0.951 |
| 1RMSE (MMm3) | 56.53 | 11.14 | 115.38 |
| 2MAPE (%) | 2.88 | 3.02 | 2.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, S.; Park, C.; Ryu, D.-W.; Ahn, S. Adaptive Surrogate Estimation with Spatial Features Using a Deep Convolutional Autoencoder for CO2 Geological Sequestration. Energies 2021, 14, 413. https://doi.org/10.3390/en14020413
Jo S, Park C, Ryu D-W, Ahn S. Adaptive Surrogate Estimation with Spatial Features Using a Deep Convolutional Autoencoder for CO2 Geological Sequestration. Energies. 2021; 14(2):413. https://doi.org/10.3390/en14020413
Chicago/Turabian StyleJo, Suryeom, Changhyup Park, Dong-Woo Ryu, and Seongin Ahn. 2021. "Adaptive Surrogate Estimation with Spatial Features Using a Deep Convolutional Autoencoder for CO2 Geological Sequestration" Energies 14, no. 2: 413. https://doi.org/10.3390/en14020413
APA StyleJo, S., Park, C., Ryu, D.-W., & Ahn, S. (2021). Adaptive Surrogate Estimation with Spatial Features Using a Deep Convolutional Autoencoder for CO2 Geological Sequestration. Energies, 14(2), 413. https://doi.org/10.3390/en14020413