
Data-Driven Signal–Noise Classification for Microseismic Data Using Machine Learning


Abstract
:
1. Introduction
2. Methodology
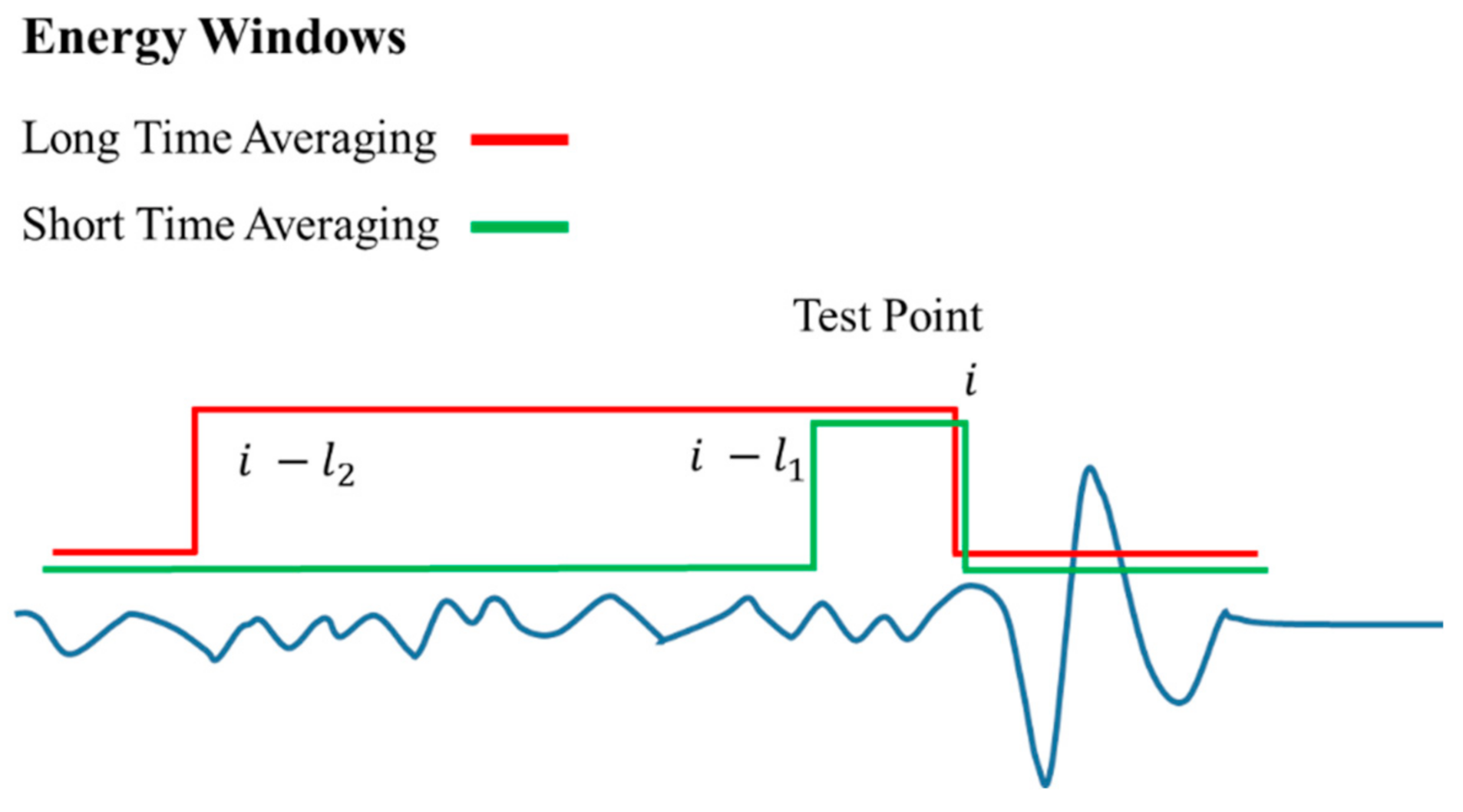
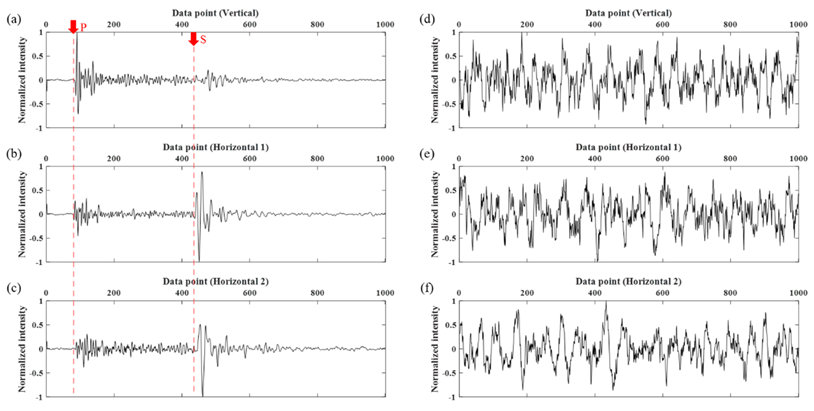
2.1. Acquisition and Preprocessing of Microseismic Data
2.2. Supervised Learning: Random Forest and Convolutional Neural Network
2.3. Unsupervised Learning: K-Medoids Clustering
- Given training data samples are presented in the dimension of data features and randomly select k data points as the representatives (medoids) among the entire n data points (Figure 9a).
- The rest of the data points are assigned to each of the k center points when data have the closest distance from the medoids (Figure 9b).
- The locations of the medoids are changed, and the sum of within-cluster distances for before and after (Figure 9c) situations is computed.
- Medoids option showing the lower sum of within-cluster distances is selected (Figure 9c).
- Steps 2 to 4 are repeated until there is no change in the locations of the medoids.
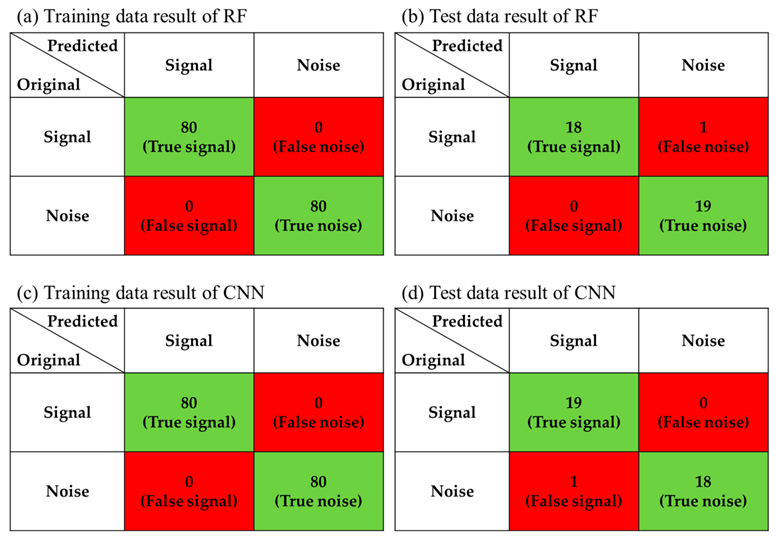
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


References
- Leake, M.R.; Conrad, W.J.; Westman, E.C.; Afrouz, S.G.; Molka, R.J. Microseismic Monitoring and Analysis of Induced Seismicity Source Mechanisms in a Retreating Room and Pillar Coal Mine in the Easter Unites States. Undergr. Space 2017, 2, 115–124. [Google Scholar] [CrossRef]
- Maxwell, S. Microseismic Imaging of Hydraulic Fracturing: Improved Engineering of Unconventional Shale Reservoirs. Soc. Explor. Geophys. 2014. [Google Scholar] [CrossRef]
- Provost, F.; Hibert, C.; Malet, J.P. Automatic Classification of Endogenous Landslide Seismicity Using the Random Forest Supervised Classifier. Geophys. Res. Lett. 2017, 44, 113–120. [Google Scholar] [CrossRef]
- Contrucci, I.; Balland, C.; Kinscher, J.; Bennani, M.; Bigarre, P.; Bernard, P. Aseismic Mining Subsidence in an Abandoned Mine: Influence Factors and Consequences for Post-Mining Risk Management. Pure Appl. Geophys. 2019, 176, 801–825. [Google Scholar] [CrossRef]
- Hong, J.S.; Lee, H.S.; Lee, D.H.; Kim, H.Y.; Choe, Y.T.; Park, Y.J. Microseismic Event Monitoring of Highly Stressed Rock Mass Around Underground Oil Storage Caverns. Tunn. Undergr. Space Technol. 2006, 21, 292. Available online: http://worldcat.org/issn/08867798 (accessed on 8 March 2021). [CrossRef]
- Lin, B.; Wei, X.; Junjie, Z. Automatic Recognition and Classification of Multi-Channel Microseismic Waveform Based on DCNN and SVM. Comput. Geosci. 2019, 123, 111–120. [Google Scholar] [CrossRef]
- Peng, P.; He, Z.; Wang, L. Automatic Classification of Microseismic Signals Based on MFCC and GMM-HMM in Underground mines. Shock Vib. 2019. [Google Scholar] [CrossRef]
- Kim, K.; Min, K.; Kim, K.; Choi, J.; Yoon, K.; Yoon, W.; Yoon, W.; Yoon, B.; Lee, T.; Song, Y. Protocol for Induced Microseismicity in the First Enhanced Geothermal Systems Project in Pohang, Korea. Renew. Sustain. Energy Rev. 2018, 91, 1182–1191. [Google Scholar] [CrossRef]
- The Definition of Micro-Earthquake. Available online: https://en.wikipedia.org/wiki/Microearthquake (accessed on 25 February 2021).
- Kwiatek, G.; Saarno, T.; Ader, T.; Bluemle, F.; Bohnhoff, M.; Chendorain, M.; Dresen, G.H.; Kukkonen, I.; Leary, P.; Leonhardt, M. Controlling Fluid-Induced Seismicity During a 6.1-km-Deep Geothermal Stimulation in Finland. Sci. Adv. 2019, 5, 7224. [Google Scholar] [CrossRef] [Green Version]
- Wilks, M.; Wuestefeld, A.; Oye, V.; Thomas, P.; Kolltveit, E. Tailoring Distributed Acoustic Sensing Techniques for the Microseismic Monitoring of Future CCS Sites: Results from the Field. In SEG Technical Program Expanded Abstracts, Proceedings of the SEG International Exhibition and 87th Annual Meeting, Houston, TX, USA, 23 October 2017; Society of Exploration Geophysicists: Houston, TX, USA, 2017; pp. 2762–2766. [Google Scholar] [CrossRef]
- Wang, H.; Li, M.; Shang, X. Current Developments on Micro-Seismic Data Processing. J. Nat. Gas. Sci. Eng. 2016, 32, 521–537. [Google Scholar] [CrossRef]
- Pan, S.; Qin, Z.; Lan, H.; Badal, J. Automatic First-Arrival Picking Method Based on an Image Connectivity Algorithm and Multiple Time Windows. Comput. Geosci. 2019, 123, 95–102. [Google Scholar] [CrossRef] [Green Version]
- Chamberlain, C.J.; Hopp, C.J.; Boese, C.M.; Warren-Smith, E.; Chambers, D.; Chu, S.X.; Michailos, K.; Townend, J. EQcorrscan: Repeating and Near-Repeating Earthquake Detection and Analysis in Python. Seismol. Res. Lett. 2018, 89, 173–181. [Google Scholar] [CrossRef]
- Lin, B.; Wei, X.; Junjie, Z.; Hui, Z. Automatic Classification of Multi-Channel Microseismic Waveform Based on DCNN-SPP. J. Appl. Geophys. 2018, 159, 446–452. [Google Scholar] [CrossRef]
- Miao, F.; Carpenter, N.S.; Wang, Z.; Holcomb, A.S.; Woolery, E.W. High-Accuracy Discrimination of Blasts and Earthquakes Using Neural Networks with Multiwindow Spectral Data. Seismol. Res. Lett. 2020, 91, 1646–1659. [Google Scholar] [CrossRef]
- Sertcelik, F.; Yavuz, E.; Birdem, M.; Merter, G. Discrimination of the Natural and Artificial Quakes in the Eastern Marmara region, Turkey. Acta Geod. Geophys. 2020, 55, 645–665. [Google Scholar] [CrossRef]
- KIGAM. Characteristic Analysis and Library Buildup for Microseismic Signals Originated by Mining Activities; Report GP2018-001-2019; Inha University: Daejeon, Korea, 2019; p. 51. [Google Scholar]
- Kislov, K.V.; Gravirov, V.V. Use of Artificial Neural Networks for Classification of Noisy Seismic Signals. Seism. Instrum. 2017, 53, 87–101. [Google Scholar] [CrossRef]
- Ross, Z.E.; Meier, M.A.; Hauksson, E.; Heaton, T.H. Generalized Seismic Phase Detection with Deep Learning. Bull. Seismol. Soc. Am. 2018, 108, 2894–2901. [Google Scholar] [CrossRef] [Green Version]
- Ross, Z.E.; Meier, M.A.; Hauksson, E. P Wave Arrival Picking and First-Motion Polarity Determination with Deep Learning. J. Geophys. Res. Solid Earth 2018, 123, 5120–5129. [Google Scholar] [CrossRef]
- Bergen, K.J.; Johnson, P.A.; Maarten, V.; Beroza, G.C. Machine Learning for Data-Driven Discovery. Solid Earth Geosci. Sci. 2019, 363, 323. [Google Scholar] [CrossRef]
- Kong, Q.; Trugman, D.T.; Ross, Z.E.; Bianco, M.J.; Meade, B.J.; Gerstoft, P. Machine Learning in Seismology: Turning data into insights. Seismol. Res. Lett. 2019, 90, 3–14. [Google Scholar] [CrossRef] [Green Version]
- Linville, L.; Pankow, K.; Draelos, T. Deep Learning Models Augment Analyst Decisions for Event Discrimination. Geophys. Res. Lett. 2019, 46, 3643–3651. [Google Scholar] [CrossRef]
- Nakano, M.; Sugiyama, D.; Hori, T.; Kuwatani, T.; Tsuboi, S. Discrimination of Seismic Signals from Earthquakes and Tectonic Tremor by Applying Convolutional Neural Network to Running Spectral Images. Seismol. Res. Lett. 2019, 90, 530–538. [Google Scholar] [CrossRef]
- Rojas, O.O.; Alvarado, L.; Mus, S.; Tous, R.T. Artificial Neural Networks as Emerging Tools for Earthquake Detection. Comput. Sist. 2019, 23, 335–350. [Google Scholar] [CrossRef]
- Foody, G.M.; Pal, M.; Rocchini, D.; Garzon-Lopez, C.X.; Bastin, L. The Sensitivity of Mapping Methods to Reference Data Quality: Training Supervised Image Classifications with Imperfect Reference Data. Int. J. Geo-Inf. 2016, 5, 199. [Google Scholar] [CrossRef] [Green Version]
- Korean Government Commission. Final Report of the Korean Government Commission on Relations between the 2017 Pohang Earthquake and EGS Project; Technical Report; The Geological Society of Korea: Seoul, Korea, 2019. [Google Scholar]
- Woo, J.U.; Kim, M.; Sheen, D.H.; Kang, T.S.; Rhie, J.; Grigoli, F.; Ellsworth, W.L.; Giardini, D. An in-depth Seismological Analysis Revealing a Causal Link Between the 2017 MW 5.5 Pohang Earthquake and EGS Project. J. Geophys. Res. Solid Earth 2019, 124, 13060–13078. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Kim, K.I.; Xie, L.; Yoo, H.; Min, K.B.; Kim, M.; Yoon, B.; Kim, K.Y.; Zimmermann, G.; Guinot, F.; et al. Observations and Analyses of the First Two Hydraulic Stimulations in the Pohang Geothermal Development Site, South Korea. Geothermics 2020, 88. [Google Scholar] [CrossRef]
- Song, Y.; Lee, T.; Jeon, J.; Yoon, W. Background and Progress of the Korea EGS Pilot Project. In Proceedings of the WGC (World Geothermal Congress), Melbourne, Australia, 19–25 April 2015. [Google Scholar]
- Sohn, Y.K.; Rhee, C.W.; Shon, H. Revised Stratigraphy and Reinterpretation of the Miocene Pohang Basinfill, SE Korea: Sequence Development in Response to Tectonism and Eustasy in a Back-Arc Basin Margin. Sediment. Geol. 2001, 143, 265–285. [Google Scholar] [CrossRef]
- Trnkoczy, A.; Bormann, P.; Hanka, W.; Holcomb, L.G.; Nigbor, R.L. Site Selection, Preparation and Installation of Seismic Stations. In New Manual of Seismological Observatory Practice (NMSOP); Deutsches GeoForschungsZentrum GFZ: Potsdam, Germany, 2009; pp. 1–108. [Google Scholar]
- Lee, T.; Song, Y.; Park, D.; Jeon, J.; Yoon, W. Three-Dimensional Geological Model of Pohang EGS Pilot Site, Korea. In Proceedings of the WGC (World Geothermal Congress), Melbourne, Australia, 19–25 April 2015. [Google Scholar]
- InStie Software. Available online: https://www.itascainternational.com/software/InSite-Geo (accessed on 17 February 2021).
- Beyreuther, M.; Barsch, R.; Krischer, L.; Megies, T.; Behr, Y.; Wassermann, J. ObsPy: A Python toolbox for seismology. Seismol. Res. Lett. 2010, 81, 530–533. [Google Scholar] [CrossRef] [Green Version]
- Baer, M.; Kradolfer, U. An Automatic Phase Picker for Local and Teleseismic Events. Bull. Seismol. Soc. Am. 1987, 77, 1437–1445. [Google Scholar]
- Withers, M.; Aster, R.; Young, C.; Beiriger, J.; Harris, M.; Moore, S.; Trujillo, J. A Comparison of Select Trigger Algorithms for Automated Global Seismic Phase and Event Detection. Bull. Seismol. Soc. Am. 1998, 88, 95–106. [Google Scholar]
- Akazawa, T. A Technique for Automatic Detection of Onset Time of P-and S-Phases in Strong Motion Records. In Proceedings of the 13th World Conference on Earthquake Engineering, Vancouver, BC, Canada, 1–6 August 2004. [Google Scholar]
- Havskov, J.; Ottemoller, L. Routine Data Processing in Earthquake Seismology: With Sample Data, Exercises, and Software; Springer: Dordrecht, The Netherlands, 2010. [Google Scholar] [CrossRef]
- Han, L.; Wong, J.; Bancroft, J.C. Time Picking and Random Noise Reduction on Microseismic Data. CREWES Res. Rep. 2009, 21, 1–13. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Lee, K.; Lee, M.; Ahn, T.; Lee, J. Data-Driven Three-Phase Saturations Identification from X-ray CT Images with Critical gas Hydrate Saturation. Energies 2020, 13, 5844. [Google Scholar] [CrossRef]
- Dong, L.; Li, X.; Xie, G. Nonlinear Methodologies for Identifying Seismic Event and Nuclear Explosion Using Random Forest, Support Vector Machine, and Naive Bayes Classification. Abstr. Appl. Anal. 2014, 459137. [Google Scholar] [CrossRef] [Green Version]
- Hibert, C.; Provost, F.; Malet, J.P.; Maggi, A.; Stumpf, A.; Ferrazzini, V. Automatic Identification of Rockfalls and Volcano-tectonic Earthquakes at the Piton de la Fournaise Volcano Using a Random Forest Algorithm. J. Volcanol. Geotherm. 2017, 340, 130–142. [Google Scholar] [CrossRef]
- Kim, S.; Lee, K.; Lee, M.; Ahn, T.; Lee, J.; Suk, H.; Ning, F. Saturation Modeling of Gas Hydrate Using Machine Learning with X-ray CT Images. Energies 2020, 13, 5032. [Google Scholar] [CrossRef]
- Kim, T.; Kim, S.; Lim, J. Modeling and Prediction of Slug Characteristics Utilizing Data-Driven Machine-Learning Methodology. J. Petrol. Sci. Eng. 2020, 195, 107712. [Google Scholar] [CrossRef]
- Huang, L.; Li, J.; Hao, H.; Li, X. Micro-Seismic Event Detection and Location in Underground Mines by Using Convolutional Neural Networks (CNN) and Deep Learning. Tunn. Undergr. Space Technol. 2018, 81, 265–276. [Google Scholar] [CrossRef]
- Such, F.P.; Peri, D.; Brockler, F.; Hutkowski, P.; Ptucha, R.; Alaris, K. Fully Convolutional Networks for Handwriting Recognition. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 86–91. [Google Scholar] [CrossRef] [Green Version]
- Chu, M.; Min, B.; Kwon, S.; Park, G.; Kim, S.; Huy, N.X. Determination of an Infill Well Placement Using a Data-Driven Multi-modal Convolutional Neural Network. J. Petrol. Sci. Eng. 2020, 195, 106805. [Google Scholar] [CrossRef]
- Cunha, A.; Pochet, A.; Lopes, H.; Gattass, M. Seismic Fault Detection in Real Data Using Transfer Learning from a Convolutional Neural Network Pre-trained with Synthetic Seismic Data. Comput. Geosci. 2020, 135, 104344. [Google Scholar] [CrossRef]
- Kim, S.; Lee, K.; Lim, J.; Jeong, H.; Min, B. Development of Ensemble Smoother-Neural Network and its Application to History Matching of Channelized Reservoir. J. Petrol. Sci. Eng. 2020, 191, 107159. [Google Scholar] [CrossRef]
- Mandelli, S.; Lipari, V.; Bestagini, P.; Tubaro, S. Interpolation and Denoising of Seismic Data Using Convolutional Neural Network. arXiv 2019, arXiv:1901.07927. [Google Scholar]
- Jin, H.; Song, Q.; Hu, X. Auto-Keras: An Efficient Neural Architecture Search System. In Proceedings of the KDD’19: 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining Anchorage, Anchorage, AK, USA, 4–8 August 2019; pp. 1946–1956. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 2, pp. 180–184. [Google Scholar]
- Park, H.S.; Jun, C.H. A Simple and Fast Algorithm for K-Medoids Clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Arora, P.; Deepali, D.; Varshney, S. Analysis of K-Means and K-Medoids Algorithm for Big Data. Procedia Comput. Sci. 2016, 78, 507–512. [Google Scholar] [CrossRef] [Green Version]
- Budiaji, W.; Leisch, F. Simple K-Medoids Partitioning Algorithm for Mixed Variable Data. Algorithms 2019, 12, 177. [Google Scholar] [CrossRef] [Green Version]
- Shearer, P.M. Introduction to Seismology; Cambridge University Press: Cambridge, UK, 2009; ISBN 0-521-88210-1. [Google Scholar]
- Chopra, A.K. The Importance of the Vertical Component of Earthquake Motions. Bull. Seismol. Soc. Am. 1966, 56, 1163–1175. [Google Scholar]
- Kang, B.; Kim, S.; Jung, H.; Choe, J.; Lee, K. Efficient Aassessment of Reservoir Uncertainty Using Distance-Based Clustering: A review. Energies 2019, 12, 1859. [Google Scholar] [CrossRef] [Green Version]
- Kumar, C.V.; Vardhan, H.; Murthy, C.S.N.; Karmakar, N.C. Estimating Rock Properties Using Sound Dominant Frequencies During Diamond Core Drilling Operations. J. Rock Mech. Geotech. Eng. 2019, 11, 850–859. [Google Scholar] [CrossRef]
- Liang, Z.; Xue, R.; Xu, N.; Li, W. Characterizing Rockbursts and Analysis on Frequency-Spectrum Evolutionary Law of Rockburst Precursor Based on Microseismic Monitoring. Tunn. Undergr. Space Technol. 2020, 105, 103564. [Google Scholar] [CrossRef]
- Li, B.; Wang, E.; Li, Z.; Niu, Y.; Li, N.; Li, X. Discrimination of Different Blasting and Mine Microseismic Waveforms Using FFT, SPWVD and Multifractal Method. Environ. Earth Sci. 2021, 80. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Conditions | |
|---|---|---|
| Entire data | 198 (Signal 99 + Noise 99) | |
| Training data | 160 (Signal 1–80 + Noise 1–80) | |
| Test data | 38 (Signal 81–99 + Noise 81–99) | |
| Size of one sample | 3003 (1001 points for each of the three axes) | |
| RF | Maximum depth | 10 |
| Number of trees | 200 | |
| Number of properties | 55 | |
| CNN | Optimization | Automated deep learning by Auto-Keras |
| Maximum epochs | 300 | |
| Validation split | 20% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Yoon, B.; Lim, J.-T.; Kim, M. Data-Driven Signal–Noise Classification for Microseismic Data Using Machine Learning. Energies 2021, 14, 1499. https://doi.org/10.3390/en14051499
Kim S, Yoon B, Lim J-T, Kim M. Data-Driven Signal–Noise Classification for Microseismic Data Using Machine Learning. Energies. 2021; 14(5):1499. https://doi.org/10.3390/en14051499
Chicago/Turabian StyleKim, Sungil, Byungjoon Yoon, Jung-Tek Lim, and Myungsun Kim. 2021. "Data-Driven Signal–Noise Classification for Microseismic Data Using Machine Learning" Energies 14, no. 5: 1499. https://doi.org/10.3390/en14051499
APA StyleKim, S., Yoon, B., Lim, J. -T., & Kim, M. (2021). Data-Driven Signal–Noise Classification for Microseismic Data Using Machine Learning. Energies, 14(5), 1499. https://doi.org/10.3390/en14051499