1. Introduction
The emerging grid is defined as the future power system with a clean, affordable, sustainable energy generation and delivery system. The emerging grid is also characterized by high efficiency and reliability achievable through the accompanying components such as renewable energy sources distributed generators (RES-DG) units. There has been a concerted effort to enhance the emerging grid to accommodate high penetration levels of RES-DG units as the power grid moves to a carbon-less grid. To deliver a reliable, resilient, and secure grid, the power grid requires intelligence to sense, assess, and predict the security state of the grid [
1]. The rapid transition towards a more active and intelligent grid will help to achieve high RES-DG penetration, improved security, and reliability. As the emerging grid evolves to accommodate the increasing integration of RES-DG units and energy storage systems (ESS), it is essential to ensure its security through security analysis and prediction.
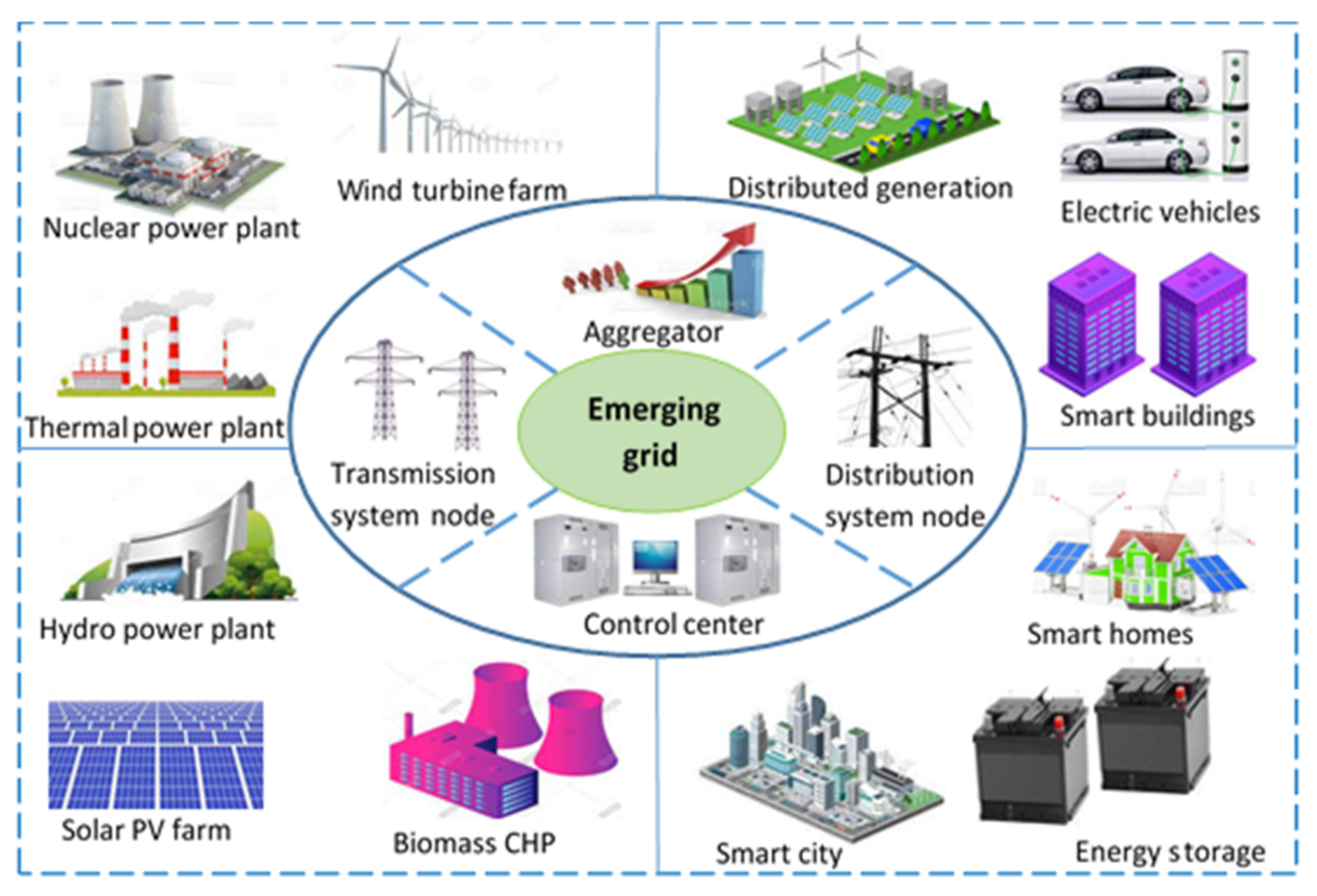
Figure 1 shows the emerging power grid with several components related to the generation, control, and utilization of energy. These components may be categorized into smart generation, smart transmission, smart distribution, and smart communication systems [
2]. The smart generation is strongly linked to decarbonization and digitalization since the grid will contain a mix of large and small RES-based generation units. The smart generation also includes the microgrid model where active customer (prosumers) generates power through the distributed generation together with storage systems and transfers the surplus power generated to the grid [
3]. The smart distribution system is based on the adoption of advanced distribution management technologies that will help optimize distribution network operations and increase network resiliency. The use of smart meters is also critical for energy usage monitoring and management. Smart distribution is the most recent notion, and it entails putting in place managerial measures. Smart distribution’s most recent concept is the use of managerial strategies to develop resources on the demand side by influencing load demand. The goal of smart communication systems is to eliminate information asymmetry and hence improve supply reliability. Power line communication technology, which allows bi-directional communication over existing power lines, is a key technology to achieve this goal [
4].
System security has been defined by system regulators and operators for decades as the ability of a grid to withstand sudden changes in load and disturbances such as short circuits or unexpected network elements losses due to natural causes. Under this definition, the grid’s security can be evaluated under static security through voltage and thermal limits and under dynamic/transient security through voltage, angular, frequency stability studies [
5]. The assessment of grids’ security under the impact of disturbances and unexpected network elements losses using these limits and stability studies may be regarded as a conventional security assessment. However, in modern grids with several Internet of Things (IoT) devices and wide area network controls, the focus of security assessments has been expanded to include cybersecurity assessment of the cyber-physical grid. The assessment of the cyber-physical grid security includes estimating the impacts of feasible cyber-physical attacks, evaluating the grid’s dependency on its cyber infrastructure, and assessing the ability of the grid to tolerate potential failures due to the cyberinfrastructure [
6]. Comprehensive security assessment for the modern grid will be performed under the conventional security and cybersecurity assessments. However, the security state of the grid due to the impact of either the traditional disturbances or cyberattacks remains classifiable into the secure, insecure, and asecure states as given by Dy Liacco [
7].
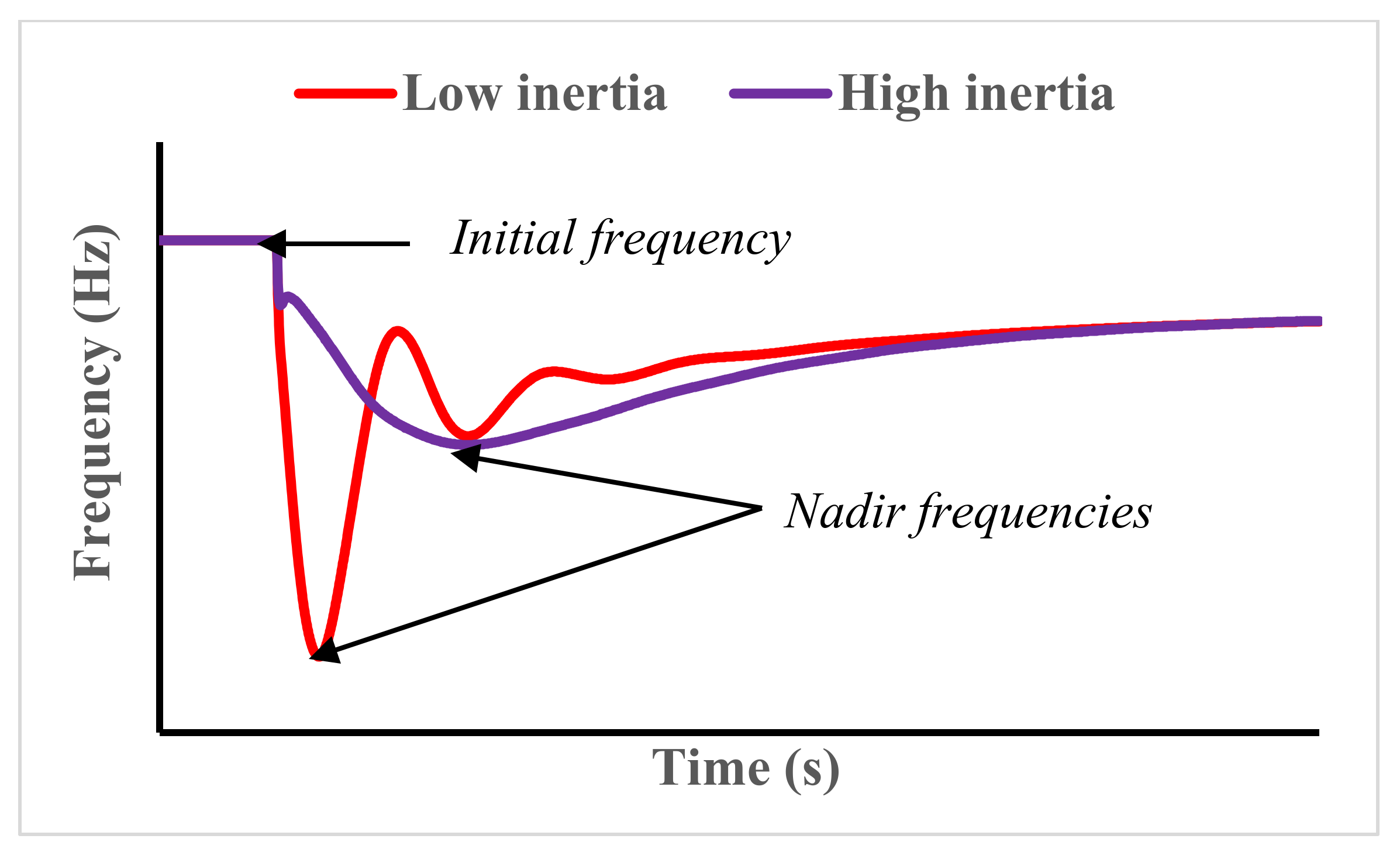
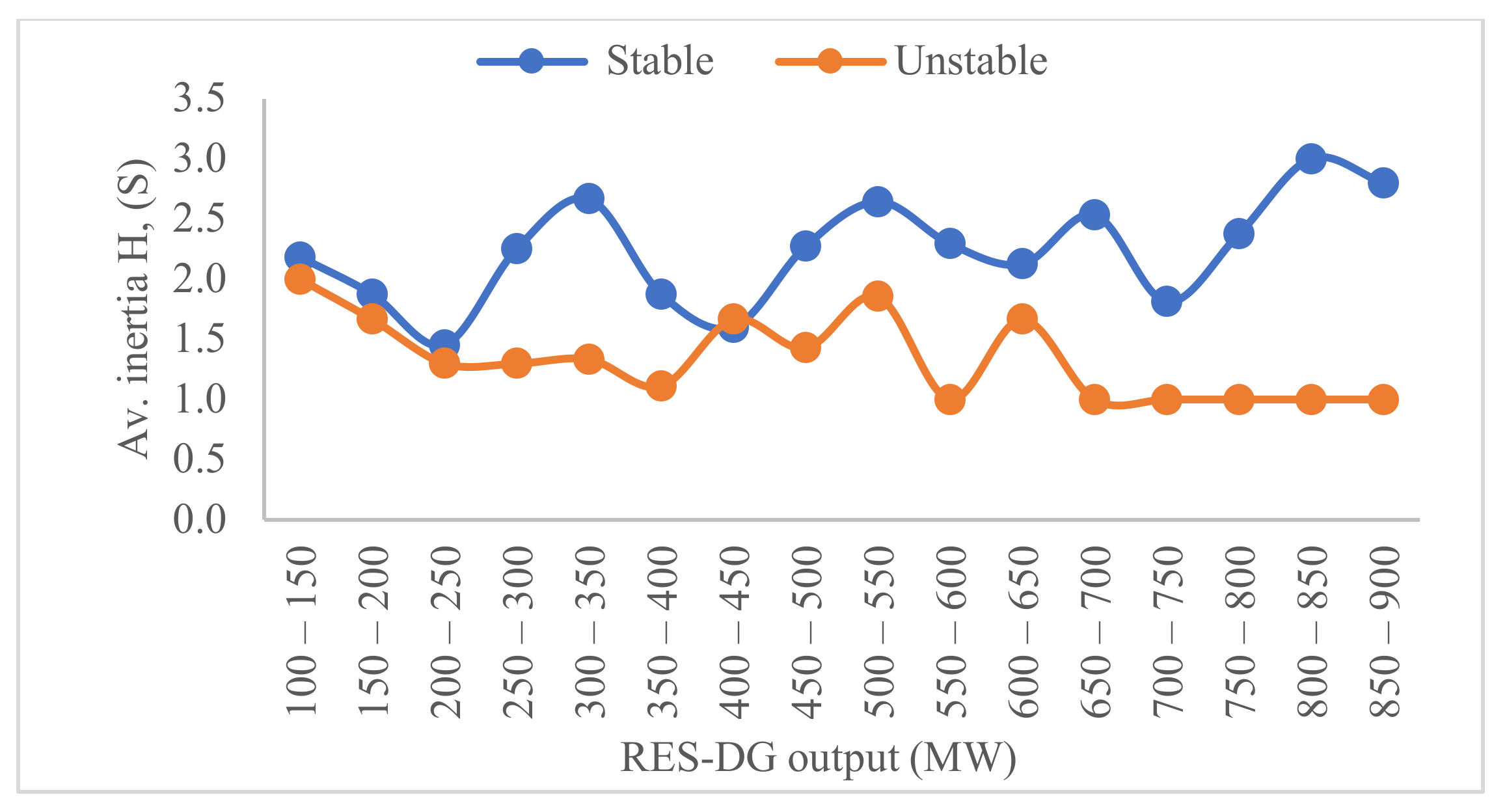
As more renewable energy sources distributed generation (RES-DG) units are added to the grid, the existing synchronous generators are disconnected and decommissioned. Since the RES-DG units do not provide any significant mechanical inertia to the grid, the grid’s resultant inertia constant is therefore notably reduced under high penetration of RES-DG units [
8]. At reduced inertia, the steady-state operation of the grid may be secure since the disturbance is usually small and gradual. However, during fault conditions and large changes in load, the security of the grid may not be guaranteed. The insecure state is consequential to the grid not having sufficient inertial energy to withstand the perturbation during the period of the fault or large change in load. In addition to the inertia constant challenge, the reliability of the grid at high penetration levels of RES-DG units may be compromised due to the variability and intermittency of the power generation from the RES-DG units [
9].
The deployment of data acquisition devices within the grid enables the generation of enormous data related to the state of the grid. Recent research focused on the application of machine learning techniques to identify patterns within the generated data to predict the security of the grid. Machine learning techniques are basically of two types, batch, and incremental learning techniques. In a real life application environment, machine learning is implemented as a repetitive process. A trained model is obtained using an appropriate algorithm on a preprocessed training dataset. If model performance is satisfactory, predictions of the class of new instances from the test dataset can then be obtained using the trained model [
10]. The old (training) and the new (testing) datasets may then be combined to generate a new and larger dataset. Under the batch machine learning process, the predictive model needs to be retrained using the new and larger dataset. The performance of the latest model does not depend on the former model [
11].
With the rapid deployment of data acquisition devices, the modern power grid will continue to generate a large amount of data in short time intervals. The models developed from the batch training modes are often discarded when a new model is obtained. There are several challenges associated with developing a batch machine learning model from a large dataset considering the continual increase in the dataset volume. To begin with, the time required in retraining a model from the combination of the old and new datasets is increased. The training time is proportional to the volume of the data. Consequently, the time lost between model retraining and deployment impacts the model user experience. In addition, the challenge of large memory requirements for the storage of the data for future applications will also be considered. The incremental learning process provides a solution to these challenges [
12]. With batch training algorithms, the obtained classification model is seamlessly updated with new instances. The capability to effortlessly update the incremental machine learning models makes them more suitable for real life and online applications [
13].
Many security prediction and control strategies have been proposed for the grid with and without considerations of the penetration of RES-DG units. One of the recent strategies is the application of a suitable machine learning algorithm to the existing dataset containing the historical security information of the grid. These machine learning-based prediction techniques were implemented in [
14,
15,
16,
17]. These techniques have shown their effectiveness to predict the security of the grid in case of transient security [
14], frequency deviation [
17], and distance to insecurity [
18], without considering the penetration of any type of distributed generation into the grid. The techniques were based on only one system variable (voltage [
14,
15,
16,
18], frequency [
17]). Considering the grid with high penetration of RES-DG, the proposed techniques may not be applicable under changing inertia and system loading. Batch machine learning-based techniques were proposed in [
19,
20]. Batch models may not be effective for real-time security prediction considering the time required to retrain the model when new data is available. For real-time security prediction capability, an incremental model that requires less amount of data for initial training is more effective.
Many existing models and techniques for security control in recent literature are based on restorative actions aimed to restore the system from the unstable to the normal state. Cases of implementation of primary and secondary frequency controls have been are presented in [
21,
22,
23,
24]. Models based on virtual power plant (VPP) application were proposed in [
25,
26]; synthetic inertia techniques were developed in [
27,
28]; and fast frequency response (FFR) control methods using backup generators were proposed in [
29,
30]. The VPP and FFR controls require complex algorithms, which are made more difficult by the significant penetration of RES-DG in the grid.
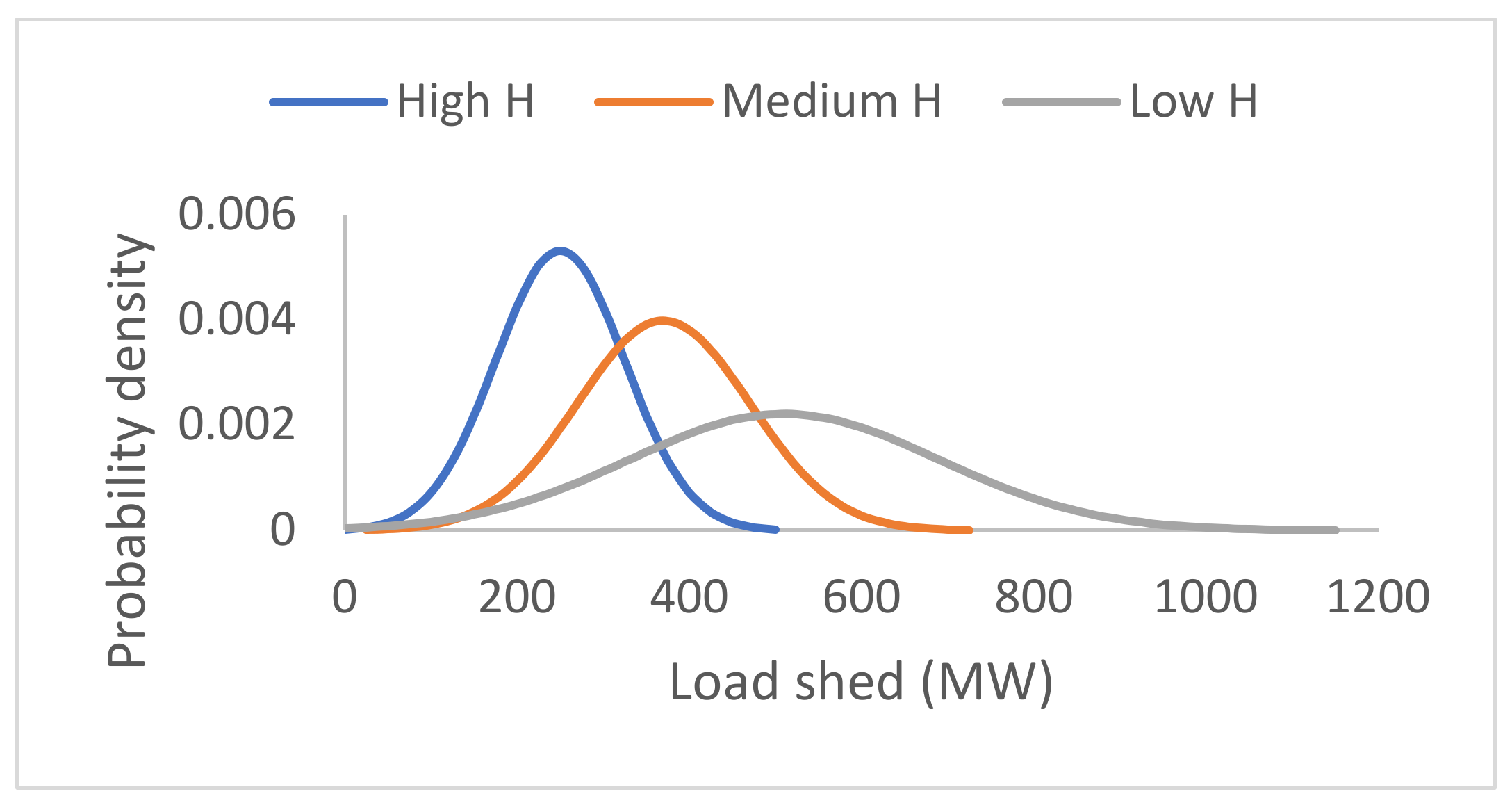
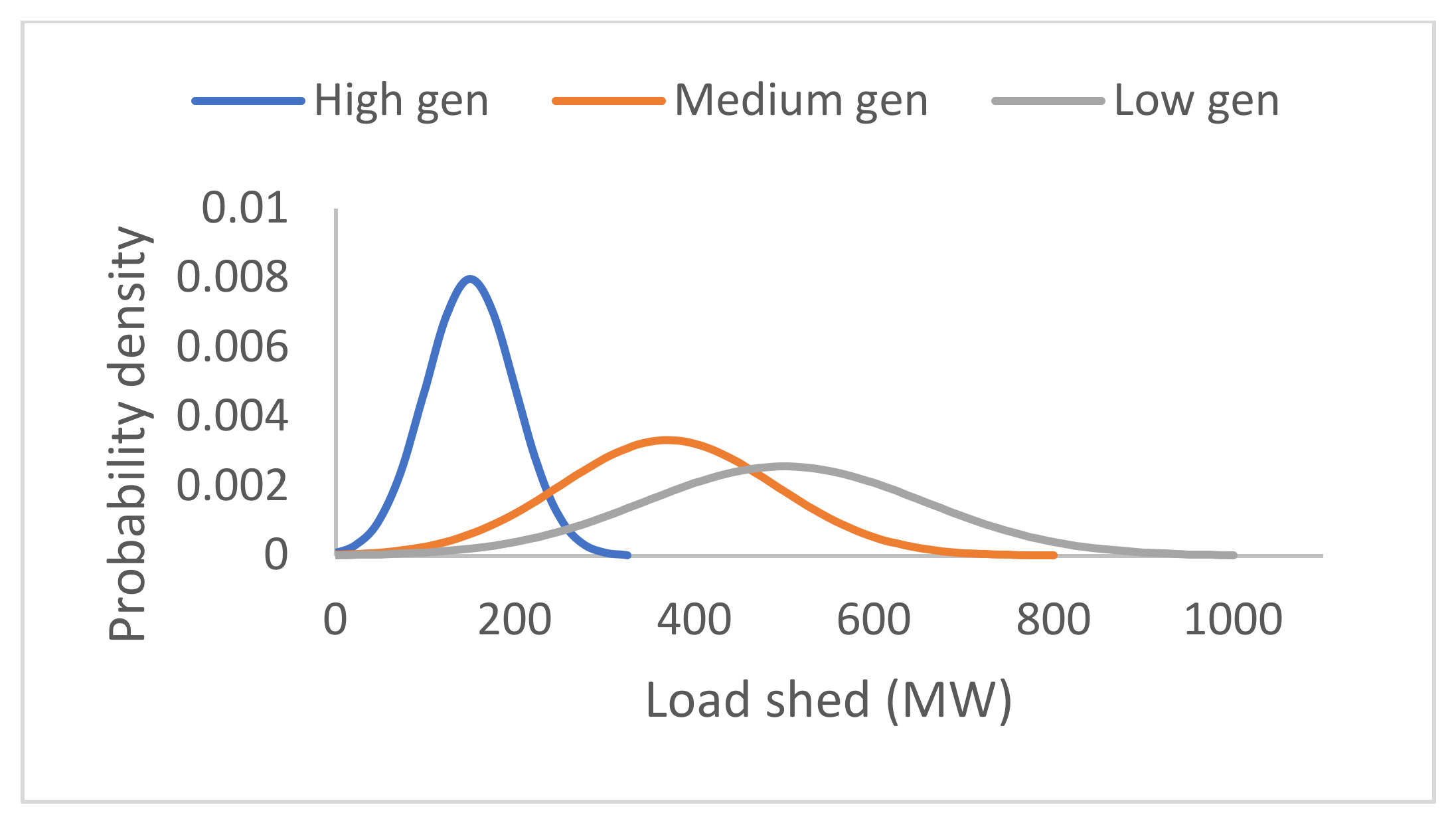
Considering the existing methods for under-frequency control due to the substantial variance in generation and load, demand-side contribution with load shedding has been effective to ensure quick system recovery grids frequency [
31,
32]. To estimate the load shedding required for frequency recovery, conventional analytical and optimization techniques [
33,
34,
35], adaptive techniques [
36,
37], and meta-heuristic techniques [
38,
39] have been proposed. Although the existing methods can estimate and predict, to a reasonable degree of accuracy, the amount of load shed required to ensure the security of the grid through frequency control, the determination of the optimal load shedding nodes was not discussed. Also, most of the existing techniques are developed based on the relation of the grid’s power imbalance, the rate of change of frequency (ROCOF), and the frequency nadir. Therefore, the applicability of the techniques to a grid under varying attributes is highly doubtful. Furthermore, as synthetic inertia techniques for supporting conventional inertia in low inertia grids become more popular [
40], it is necessary to anticipate the security of the grid for a specific level of inertia.
Table 1 shows a summary of existing techniques in recent literature for the security assessment and prediction of a power grid.
Security predictors in existing frameworks and techniques have largely been determined by changes in system load and generation. These determinants are effective for conventional grids with insignificant penetration of non-synchronous generators. However, to achieve effective security prediction for the modern and emerging grid, there is a need to extend the predictor determinants to include varying parameters critical to the grids with high penetration of non-synchronous generators. Consequently, it is important to develop a method to achieve fast security prediction and control that takes into consideration changes in inertia, generation levels from renewable energy systems, and network contingencies. Hence, the contributions of this paper include:
demonstrating the feasibility of security prediction using a time-varying system’s deterministic and probabilistic attributes,
developing a model using an incremental Naïve-Bayes algorithm for online security prediction for the emerging grid,
proposing a gaussian process regression load shed estimation method to ensure the security of the predicted insecure network operation instances and,
proposing a voltage security index ranking technique for optimal load shed node(s) selection.
This paper is focused on the emerging grid with variable penetration levels of RES-DG units that will result in varying inertia constants of the grid. The proposed model is based on an incremental Naïve Bayes classification algorithm for security prediction based on the rotor angle response obtained from the transient stability assessment of the network to a three-phase short circuit fault. The attributes considered for the classification are inertia constants, the system loadings, the RES-DG power generation, and the fault location within the grid. An additive Gaussian process regression (GPR) model using the Pearson Universal kernel (PUK) is developed to estimate the amount of load shed required to ensure the security of the insecure predicted network instances. In conclusion, the suitable node (s) for the load shedding is determined using a ranking algorithm based on the node loads and voltage security margins.
The rest of this paper is organized as follows.
Section 2 discusses the impact of high penetration of RES-DG units on the power grid as well as the security modeling and assessment of the integrated transmission and distribution network considering time-changing inertia. Online machine learning with the proposed incremental classification algorithm and intelligent security control are presented in
Section 3.
Section 4 contains the results and discussions obtained from testing the proposed techniques on the IEEE 39 bus network, while the conclusions are presented in
Section 5.
3. Online Security Prediction
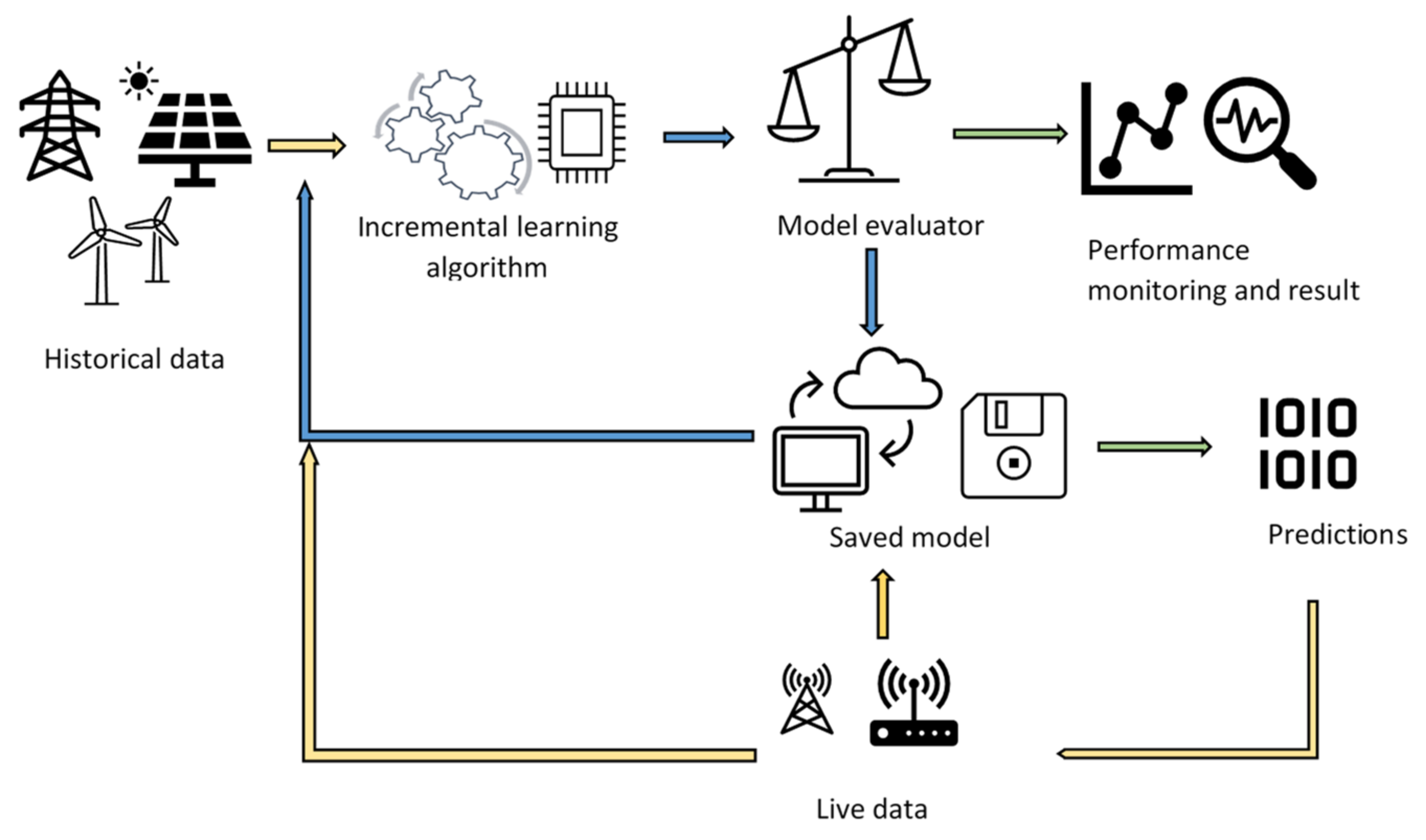
This section describes the steps involved in the development and deployment of an online machine learning model. As shown in
Figure 4, historical training data is obtained through recorded real-life operations and responses to significant events such as three-phase short circuit fault. Historical training data can also be represented by the responses of the network to several transient stability simulation scenarios using an appropriate simulation tool. The training dataset is then preprocessed to determine attribute suitability and impact on security (class of dataset) through filtering and/or correlation. A suitable machine learning algorithm is selected and then applied to the training dataset. The suitability of an algorithm for a classification model depends on several factors that include the data types, storage availability, and type of training (batch or incremental). The step-by-step operation of an online prediction model is shown in
Figure 4. Since the model in the paper is intended for online security prediction, this paper focuses on the incremental Naïve Bayes classification algorithm.
The performance of the incremental model is evaluated at each training step. In a classification problem, a model with high accuracy (
) and low misclassification rate (
) is desirable. If
is the total correctly classified instances in the stream of the dataset,
is the total instances in the stream of the dataset,
is the number of misclassification in the
and
is the total number of instances in the
class [
45], then the accuracy and misclassification of a model can be evaluated using Equations (10) and (11).
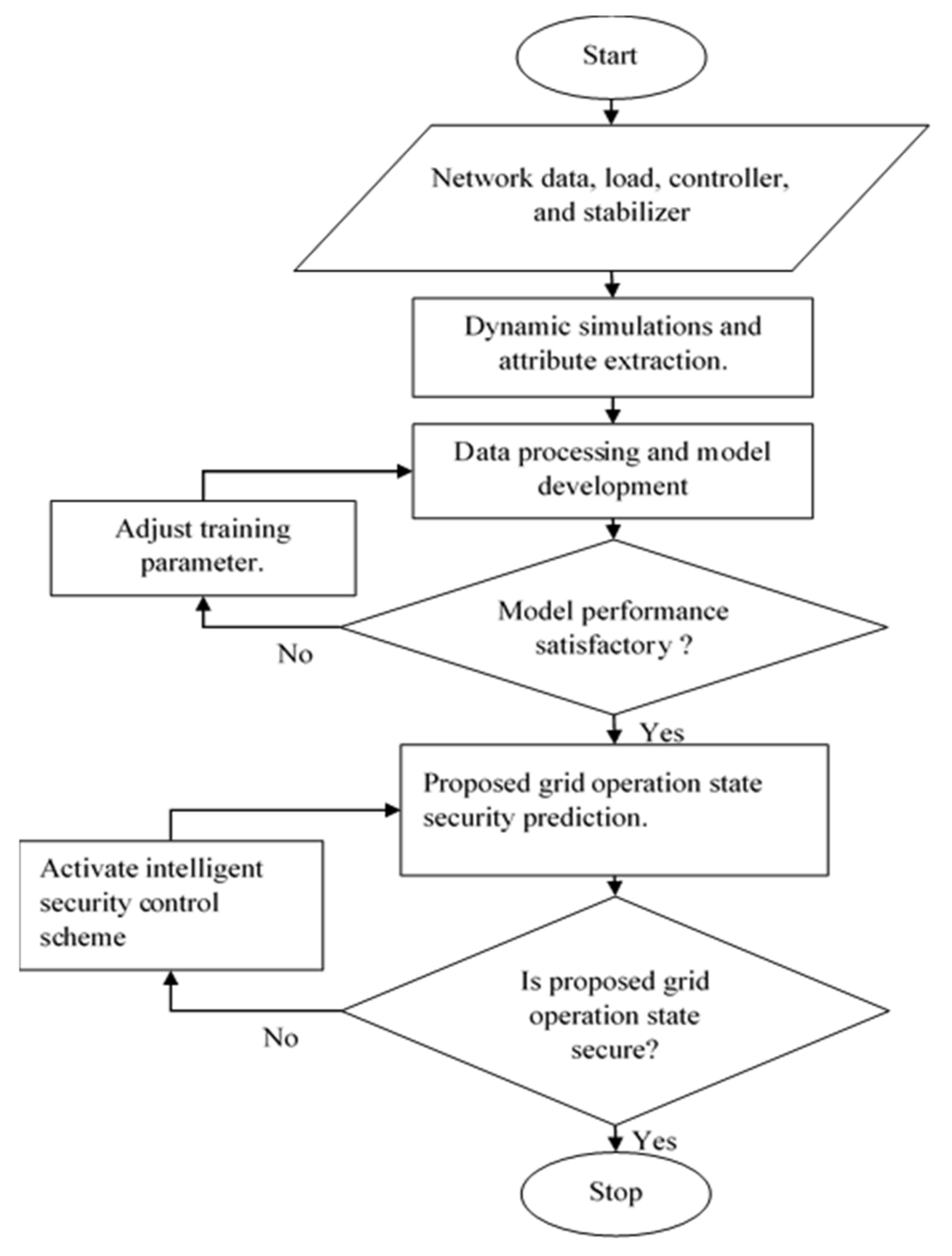
The approach proposed in this paper involves transient security assessment under varying system parameters and grid operation points. The methodology proposed in the section above is focused on the prediction of the security of the grid for a given grid operating point. The knowledge of the security state of the grid using past and present data is required to determine techniques to ensure the security of the grid. The steps for the online security prediction and control technique proposed in this paper are described in the flowchart in
Figure 5. The integrated transmission and distribution network is modelled with a suitable automatic voltage regulator, power system stabilizer, and governor control for transient stability assessment with the necessary controllers for the RES-DG units. Transient stability assessment is performed on the grid to determine its response to three-phase bolted fault. The transient security assessment is performed several times using varying network parameters and grid operation points to obtain instances for the training dataset. The variable network parameters and grid operation points are regarded as the attributes of the training dataset and include the equivalent inertia constant, the load level, the aggregated RES-DG units output, and the fault distance. To optimize the model’s accuracy and performance, the incremental Naïve-Bayes based-model training is carried out using the continual learning approach. With continual learning, the model can autonomously relearn from a stream of data and adapt automatically as new data is available to improve accuracy and performance.
The continually trained model is saved after the best obtainable accuracy is obtained. The obtained Naïve Bayes security prediction model is ready for deployment at any stage of the training between each data streams. If the security state prediction of the model to a proposed system operating state (live data) is correct, the predicted security state with the system operating state is afterward considered as historical data and used to improve the performance of the model. For the predicted insecure states, a regression-based model is proposed to estimate the amount of load shed required to ensure the security of the grid. Also, an algorithm to determine the optimal node for load shedding is proposed.
3.1. Online Machine Learning Model Development
Online security prediction is the response to system operation state given the knowledge of the true security state of previous operation states and, possibly, the availability of additional information. Online prediction models imitate the ability of humans to give responses and make rational decisions in an intelligent and programmed manner using basic everyday attributes. An online prediction model is used to predict the outcome of successive instances. In this paper, a binary classification model to predict whether the grid is secured or not using specific grid attributes is proposed. After the proposed grid event (instance), the true security response is received as feedback from the grid. Using this feedback, the difference in the precision of the prediction and the true security state can be measured. Based on the precision difference, the model is updated to improve predictive performance for future predictions. If
is the classification model and
is the number of training rounds for the model, then the steps for the development of an online binary classification model can be summarized as below [
50]:
Initialize the prediction function, ,
Receive new instance: ; where ,
Predict class for ,
Obtain true class label: ,
Measure the loss suffered: ,
Update model from to .
The number of classification mistakes made by online learning algorithm can be measured using Equation (12). The performance of an online algorithm is measured by the cumulative loss it suffers during the run of the
sequences. The objective of the online learning task is to minimize the regret function of the model’s predictions against the best-saved model before the present prediction task as defined in Equation (13). Assuming that the true responses are generated by an unknown but fixed hypothetical factor
such that
for all
the cumulative loss of
over an entire sequence is zero and is independent of
. The loss function in this paper is formulated as an online convex optimization (OCO) problem with respect to
and is defined as Equation (14)
where
w is the classification model, and
is the loss suffered by the optimal model. It is important to note that
can only be known after the examination of all the instances and their class labels.
3.1.1. Incremental Naïve Bayes model
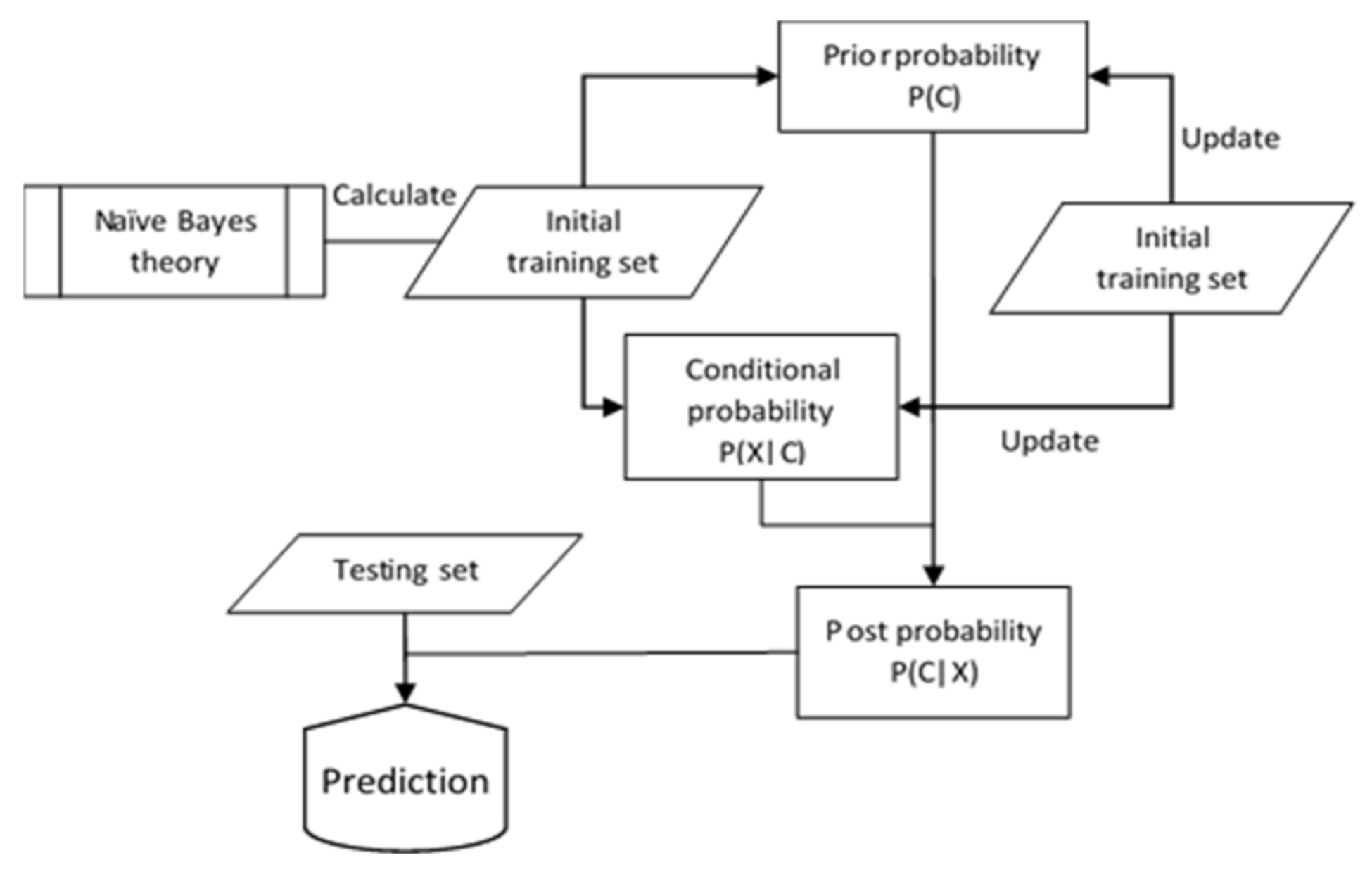
The incremental Naïve Bayes algorithm is used to realize the online classification model in this paper. The basic idea of the incremental Naive Bayes algorithm is to calculate a posterior probability based on the prior probability and new data [
51]. The ability of the incremental Naive Bayes classification algorithm to support online learning is due to its leverage on and exploitation of prior information of the datasets. The structure for the incremental Naïve Bayes algorithm is shown in
Figure 6. The posterior probability is estimated from the prior probability and existing data. The predicted posterior probability will then become the new prior probability for the next learning batch [
52,
53]. Subsequently, the incremental learning algorithm saves the updated prior probability as knowledge. To achieve unification of knowledge when new data is received, incremental learning algorithms estimate a new knowledge for the new data based on the old knowledge. The classification accuracy and precision are improved by adjusting the prior probability.
The post probability
is the probability of an instance belonging to class
. The conditional probability
is the likelihood of a specific class occurring, based on the occurrence of a previous instance. The class prior probability
is the estimate of the probability that a randomly sampled instance from a dataset will yield a given class notwithstanding the attributes of the instance. If
is a sample dataset with
attributes, then the post probability from the traditional Naïve Bayes principle can be evaluated using Equation (15).
If
denotes the
different possible classes, then for each dataset
, the post probability
is evaluated using the prior probability
and conditional probability
as given in Equation (16).
where
.
From
Figure 6, it is shown that the process of updating the incremental learning of the Naïve Bayes classifier is a recursive Bayesian estimation of parameters. Its advantage is that information in initial training data is preserved in the form of parameters. During the incremental learning process, the initial training data can be discarded to conserve memory since the information contained in the initial training set has been stored in the form of two key statistic parameters: the class prior probability and the conditional probability. Suppose
is the new testing dataset and
are the new instances for updating the prior and conditional probabilities, then the model for updating the class prior probability is given in Equation (17).
where
is the class label,
is the class prior probability of class label
,
,
is the number of instances in the initial training set
and
is the number of instances in the new training dataset
.
The performance of incremental Naïve Bayes models is assessed using specified metrics, similar to the traditional Naïve Bayes models. Generality, accuracy, learning rate, classification costs, and storage requirements are some of the common metrics. This paper, however, focuses on the accuracy evaluation metrics that can be expressed using the precision (
), recall (
), and F measure (
) as shown in Equations (18)–(20). The precision of the model is the proportion of the predicted security state from the dataset that is correct, the recall is the proportion of the dataset that is correctly classified. Occasionally, the precision or recall may not truly represent the properties of a model. Consequently, the F-Measure is employed to combine the recall and precision into a single metric that effectively captures the performance of the model as given in Equation (21) [
54].
where
TP (true positive) is the number of correct predictions that an instance is relevant,
TN is the number of correct predictions that an instance is irrelevant,
FP (false positive) is the number of incorrect predictions that an instance is relevant, and
FN (false negative) is the number of incorrect predictions that an instance is irrelevant.
3.1.2. Implementation for Real-Time Security Prediction
The dimensionality and types of attributes of the dataset determine the feasibility of real-time applicability. Using the incremental learning technique, highly dimensional large training datasets are reduced into small dataset batches. In this case for power system real network application, security predictions are made for a single instance as obtained from field devices such as PMU, therefore, the prediction time is diminutive. The situation that may be regarded as a challenge is the speed at which the saved incremental classifier can be retrieved from the different storage means.
There are several artificial intelligence application development tools for implementing incremental learning approaches. However, only a few tools support online applications. Weka software is one of the few tools that provides an online machine learning application development environment [
51]. In particularly demanding real-world applications like security state prediction for the grid operators, the Weka environment can be used to produce real-time predictions. On Weka, many classifiers can be trained and implemented using the incremental mode. However, training classifiers on large datasets can be challenging even after reduction into smaller batches, particularly using the Weka explorer interface.
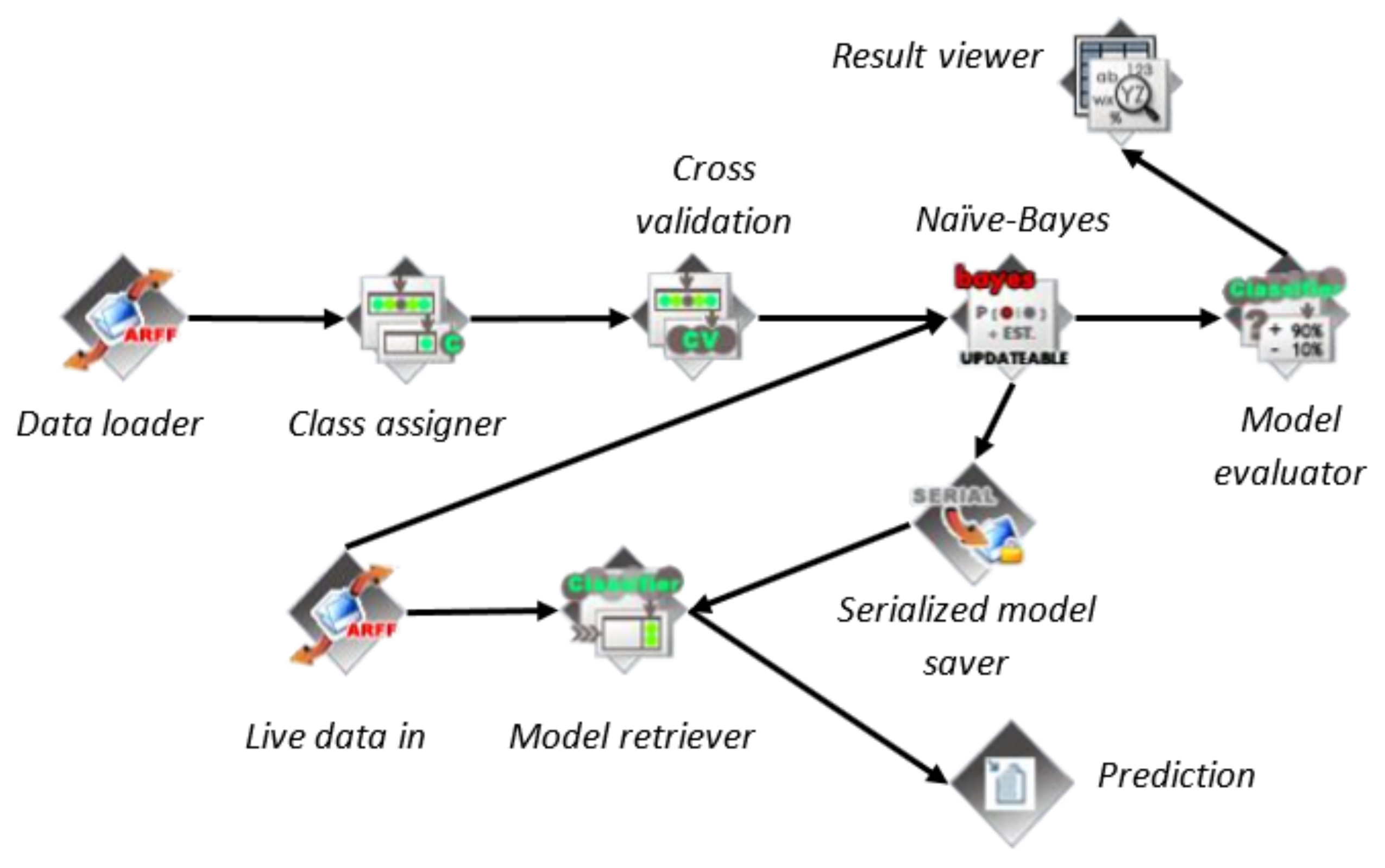
In the Weka explorer interface, due to the visualization and other functionalities, the computer’s memory may be overloaded, which may significantly impact the training and prediction times. An alternative to the graphical user interface is the Knowledge Flow interface. The knowledge flow layout showing the important steps and elements for the proposed set-up is shown in
Figure 7. The knowledge flow interface makes it possible to process large datasets that would have significantly impacted the computer’s processing speed. By loading and processing each instance in a dataset separately, updateable classifiers may be trained incrementally. After each successful training, the serialized model saver saves the most recent model, which is then retrieved by the model retriever to make future security state predictions using live data.
3.2. Intelligent Security Control System
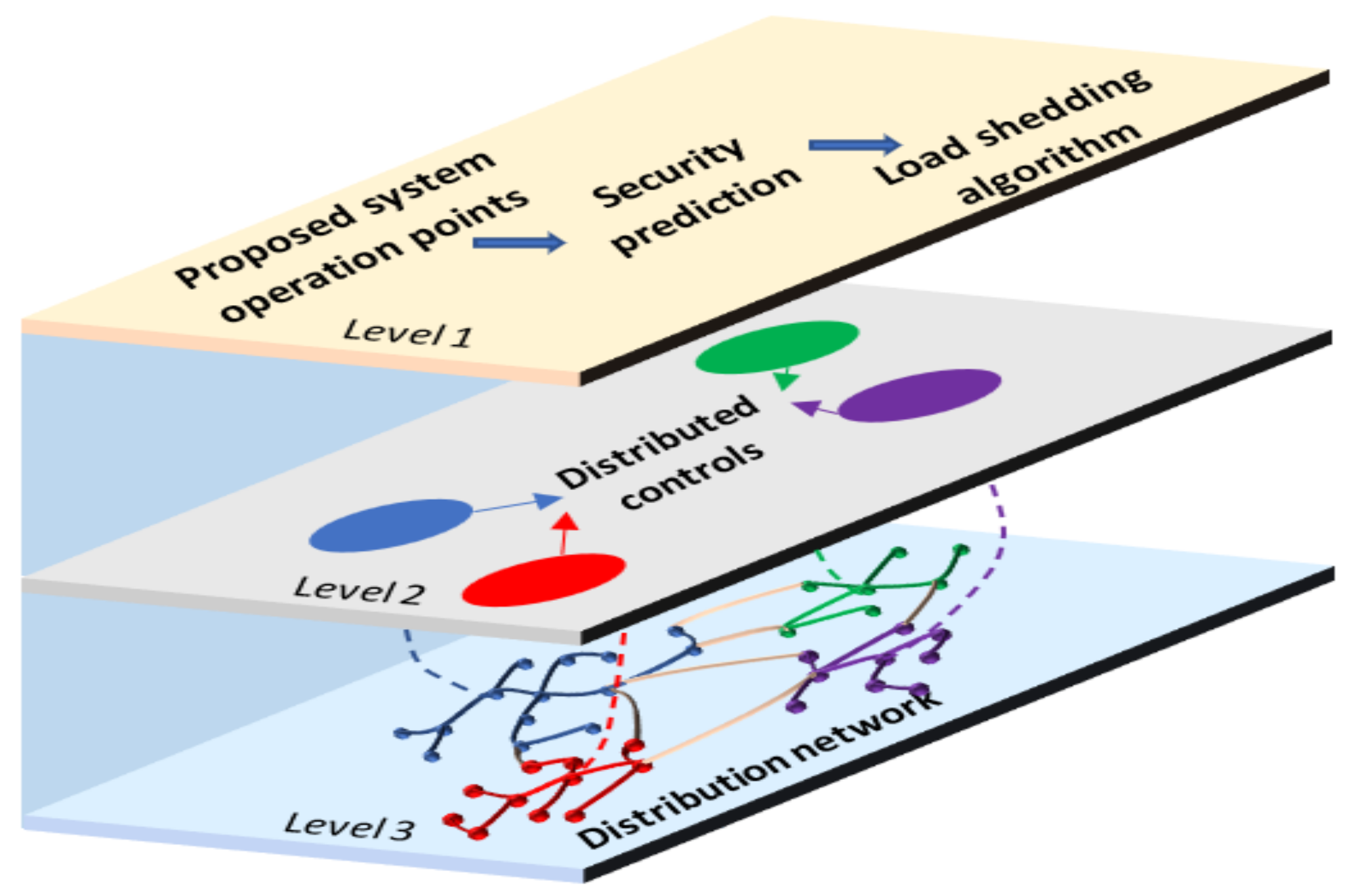
An intelligent security control (ISC) system based on load shedding is proposed to ensure the security of the grid for predicted insecure states. The ISC system determines the secured load level for an insecure state, estimates the required load shed value, and determines the best node within the network for load shedding action. The ISC system model is developed from a dataset of proposed grid operating points with a new load and simulated response from the offline transient security studies. A load shed value for an insecure proposed grid operation point is estimated to ensure grid security by constantly monitoring the output of the security prediction model. The proposed ISC system is implemented on the physical distribution network through the distributed controls enabled by communication devices as shown in the modern grid structure in
Figure 8. The proposed security prediction and ISC model exists on the first layer of the integrated grid structure. Layer 2 comprises distributed control systems for different zones of the distribution network. Commands from the ISC are implemented to activate the necessary switches in sections of the distribution network on layer 3 of the integrated transmission and distribution network structure.
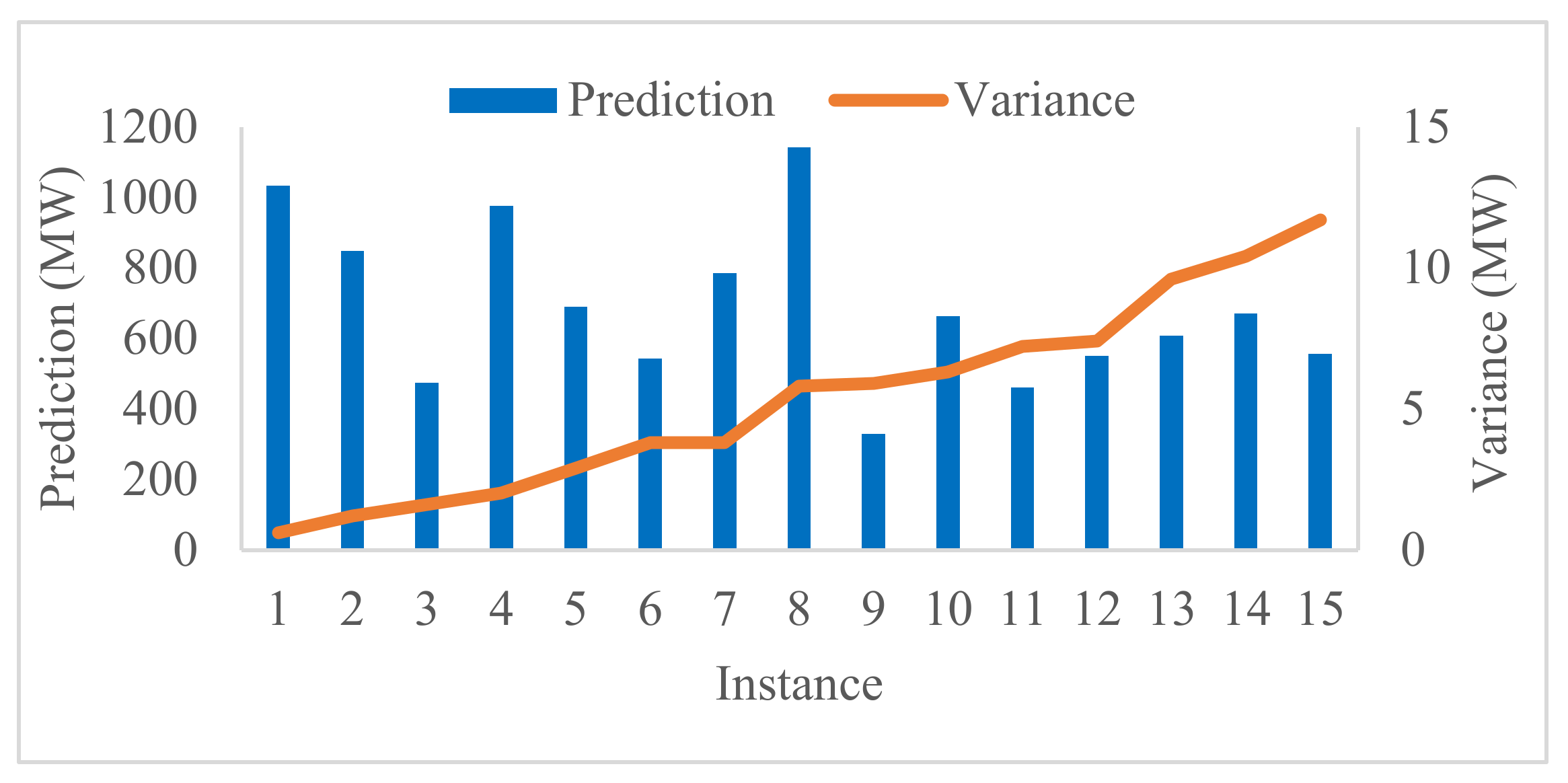
The development of the model for the ISC is achieved in two stages. In the first stage, the estimation of the amount of load shed to ensure the security for the predicted insecure state of the network is carried out. To estimate the load shed amount, an additive Gaussian process regression algorithm is applied to train the developed dataset. In the second stage, the optimal node for load shedding action is determined using a ranking algorithm based on the network node’s security margin.
3.2.1. Gaussian Process-Based Load Shed Value Estimation
This section describes the proposed algorithm to estimate the amount of load shed required to ensure the security of the grid for all predicted insecure states. A new dataset containing the new loads’ values for every insecure instance from the initial dataset is developed. An additive Gaussian process regression (GPR) prediction algorithm is proposed to predict the secured load level for insecure predictions from
Section 3.1. GPR is a nonparametric Bayesian approach with several benefits. A few of the benefits include the capability to work well on small datasets and the ability to provide uncertainty measurements on the predictions. A GPR is a generalization of the Gaussian probability distribution. It is a stochastic process in which a multivariate normal distribution exists for every finite collection of random variables. In other words, a normal distribution is assumed for any finite combination of variables.
Since the proposed load shedding model is described by more than one attribute
with high correlation to each other, the distribution of the attribute can be represented by a multivariate Gaussian distribution model defined in Equation (22).
where
is the dimension of the dataset,
is the variable,
is the mean vector, and
is the
covariance matrix. Since it is possible to have a probability distribution function for all possible predictions in GPR, the means of the predictions, as well as the prediction variances, can be calculated. The multivariate regression prediction can be modelled as given in Equation (23).
where
is the vector of attributes denoted by
,
,
and
,
represents the mean function, and
represents a positive kernel function. A kernel function is commonly used in GPR to represent the behavior of the dataset. The Pearson Universal Kernel (PUK) function expressed in Equation (24) is chosen due to its ability to adapt to various other functions [
55]. The conditional densities and posterior for prediction are given by Equations (25) and (26), respectively. The GPR performance indices
and
are given in Equations (27) and (28).
where
,
is the center of the peak of the kernel function,
represents an independent variable,
is used to control the Pearson width,
is the tailing factor of the function peak,
is the vector of the target values, and
and
are the lowest and highest values of the inverted covariance matrix, respectively. To optimize the performance of the GPR model, the model is implemented using the additive function. An additive GPR is a function that decomposes into a sum of low-dimensional functions, each depending on only a subset of the input attributes. If the attribute-class pair is
R
d × R, where
then the additive non-parametric GPR is defined as Equations (29) and (30) [
56]
where
is the sample dimension,
is the dimensions of
,
is the sum of the
regression function, and
is the parameter that prevents
from sample overfitting.
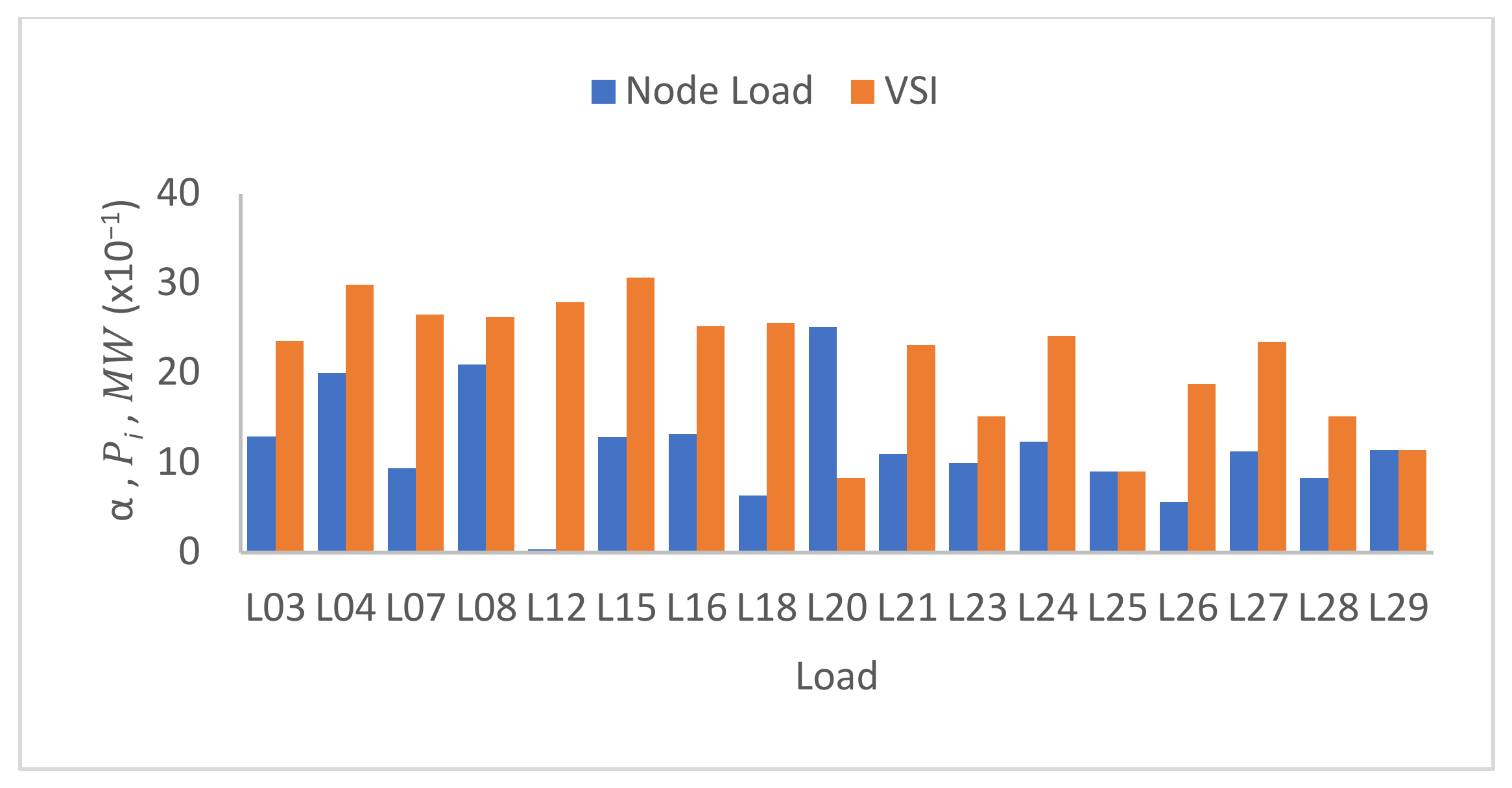
3.2.2. Optimal Node Selection
After estimating the load shed value required to ensure the security of the grid, the next step is to determine the appropriate node within the grid to apply the intelligent load shedding scheme. The proposed optimal node selection algorithm is based on the security margin of individual nodes within the network. Security margin is defined as the closeness of a node to insecurity, and is obtained from the critical voltage () and the initial voltage (). The is the voltage at the point of collapse obtained from the voltage stability assessment for each node while is the initial voltage at the node. If is the total nodes in the network, the proposed algorithm for load shedding node identification is given below.
Model 1: Load shedding node(s) selection
System initialization .
Read the node load and required load shed value .
Evaluate the node’s security margin
,
Sort (largest smallest).
Initialize .
if then.
is a load shedding node.
else .
until .
end
return node(s), .
5. Conclusions
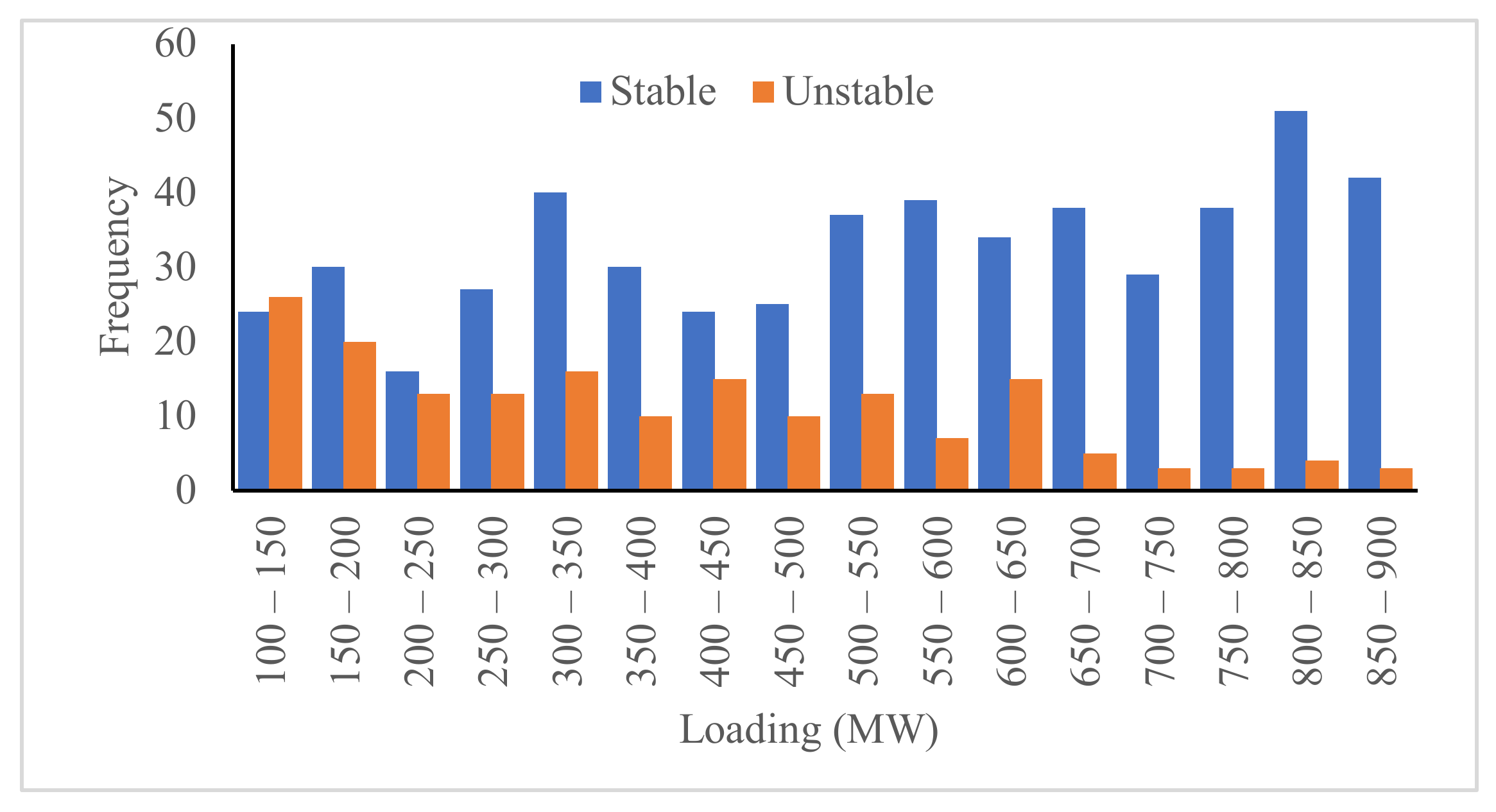
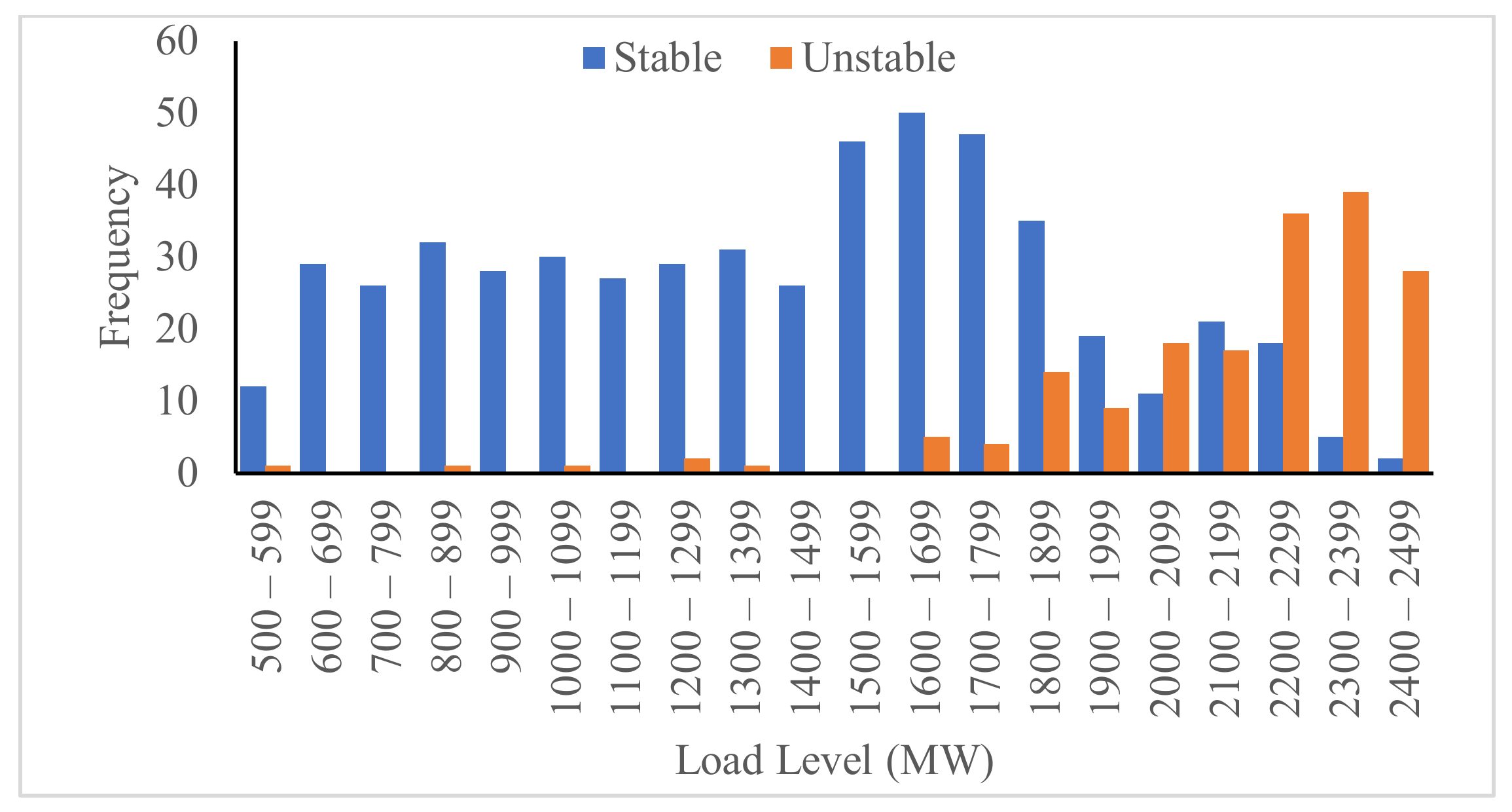
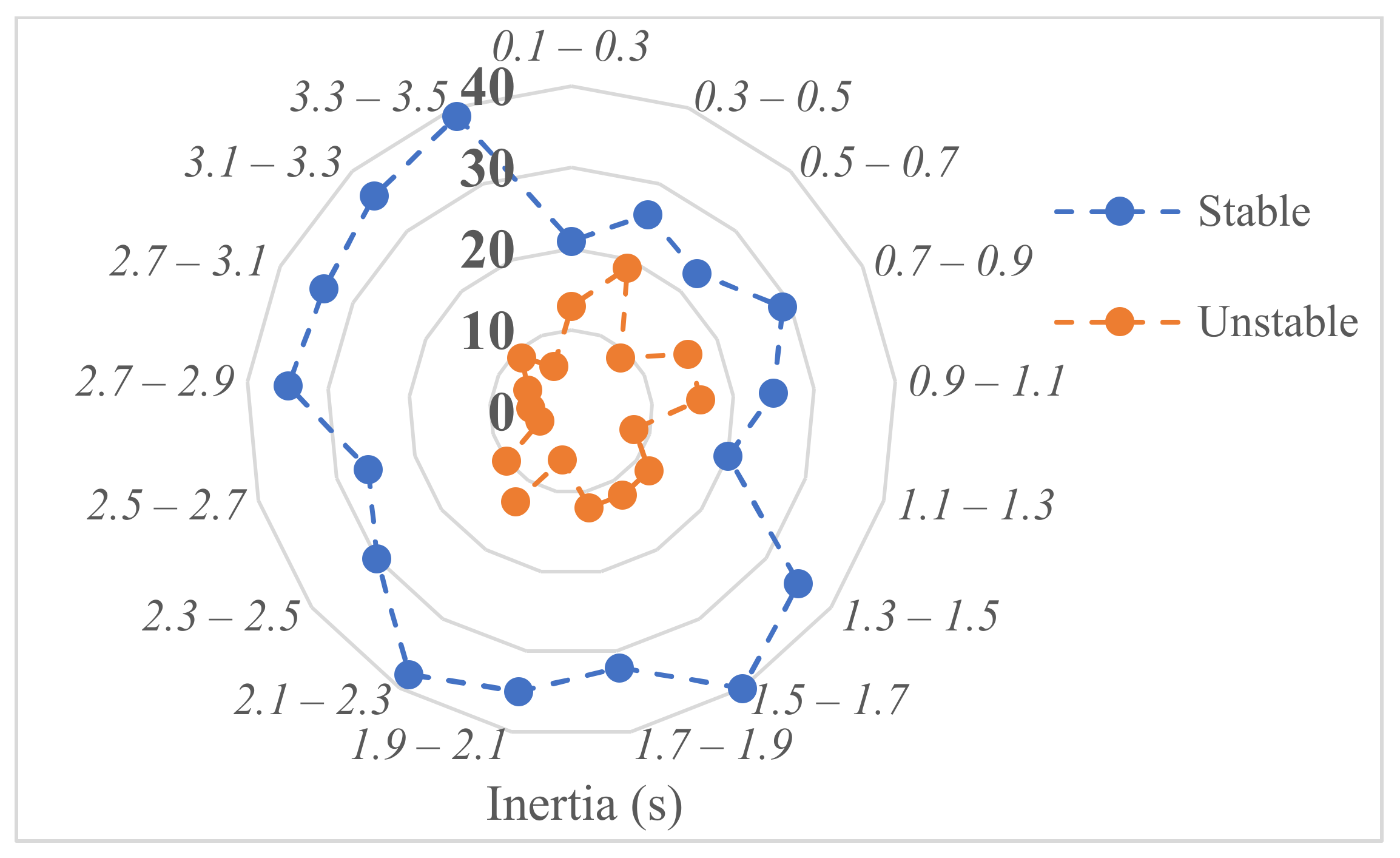
The replacement of synchronous generators with renewable energy sources distributed generation (RES-DG) reduces the resultant inertia constant of the grid, thereby undermining the ability of the grid to remain secure after the occurrence of disturbances. The proliferation of RES-DG units into the grid results in a time-varying inertia constant which necessitates the prediction of the security state for every proposed grid operation. This paper proposed a suitable model for real-time security prediction and control using machine learning algorithms. The proposed model includes an incremental Naïve-Bayes algorithm for dataset classification and future security state prediction. The dataset comprised of 700 instances of inertia constant, load level, generation from the renewable energy sources, fault distance, and security label as the attributes. The proposed intelligent security control technique involves an additive Gaussian process regression to estimate the load shed required to ensure the security of predicted insecure outcomes, and a node ranking model to determine the optimal node for load shedding. The optimal node selection model is based on the cumulative sum of the node loads ranked by the voltage security index.
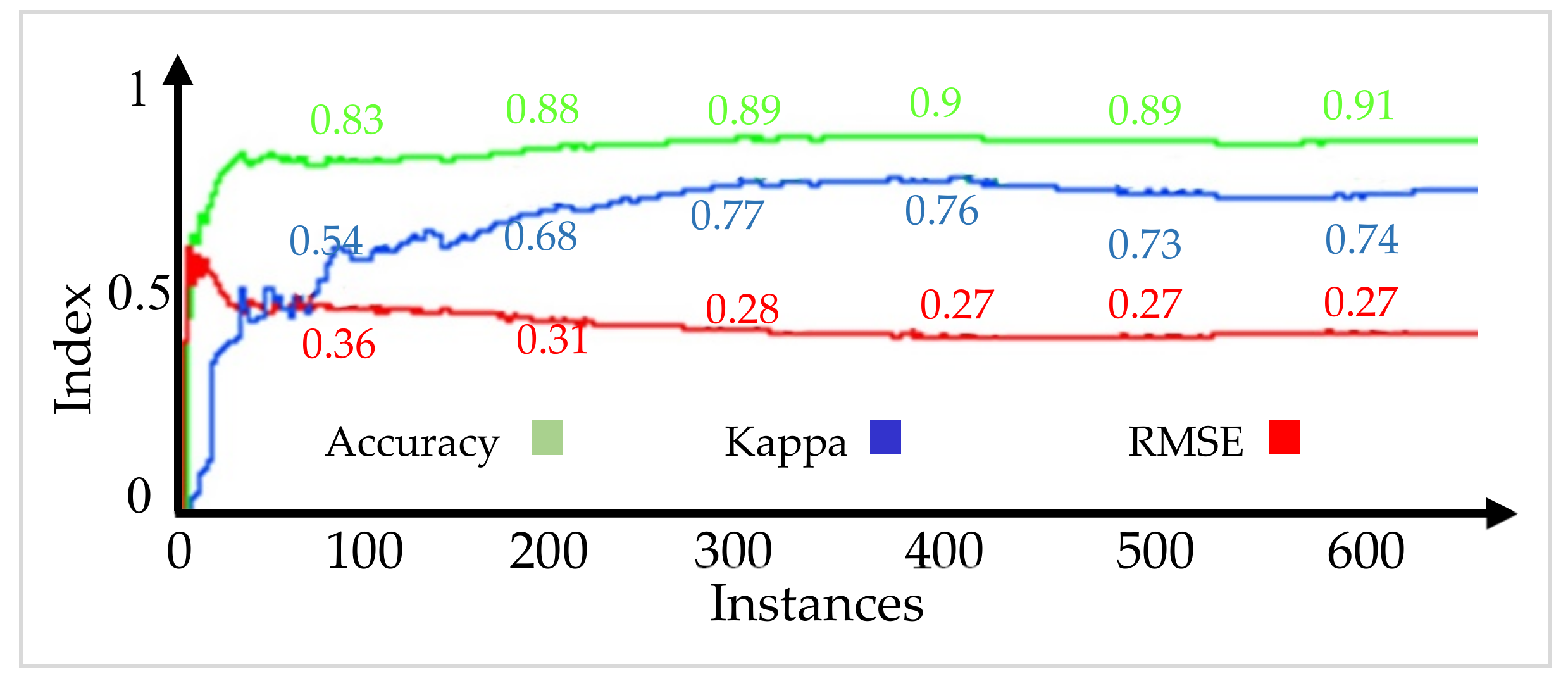
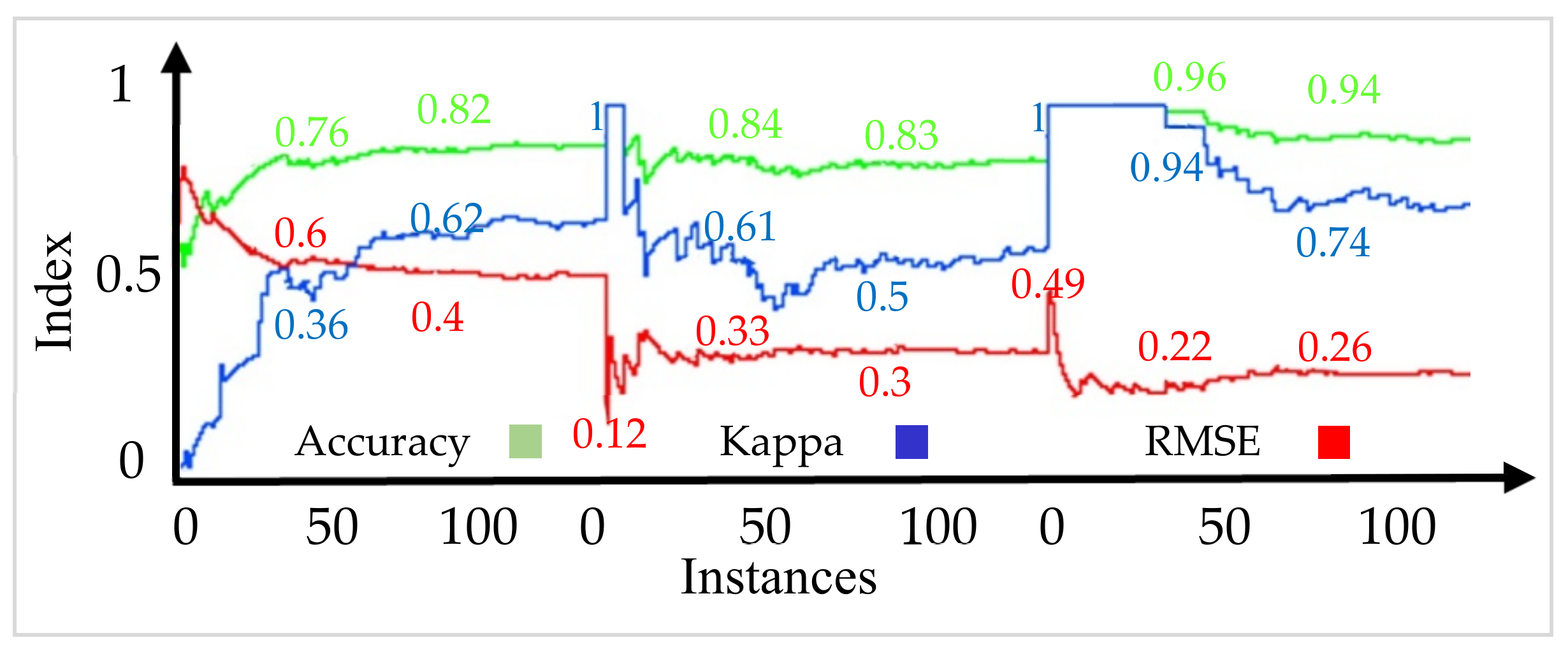
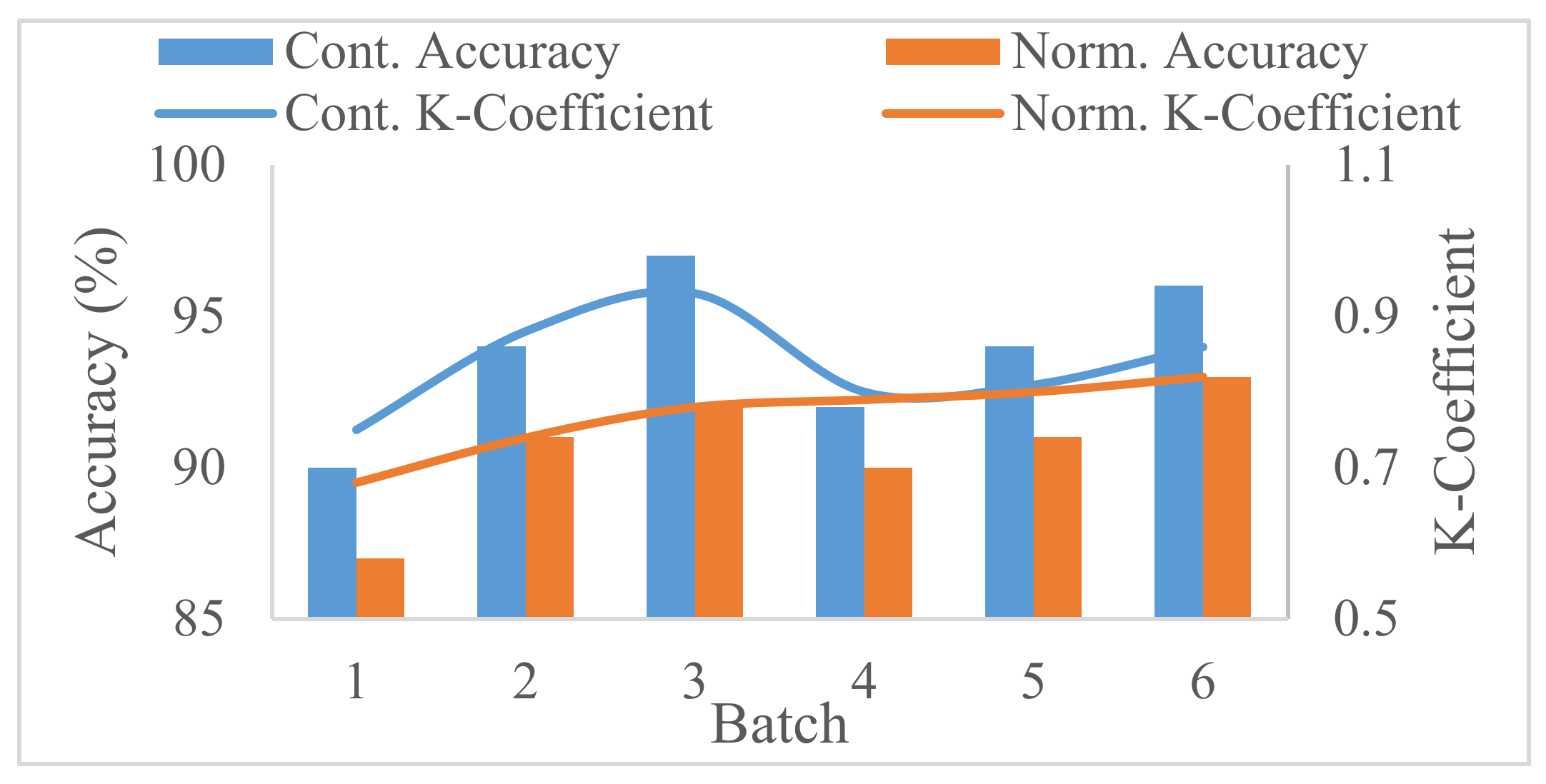
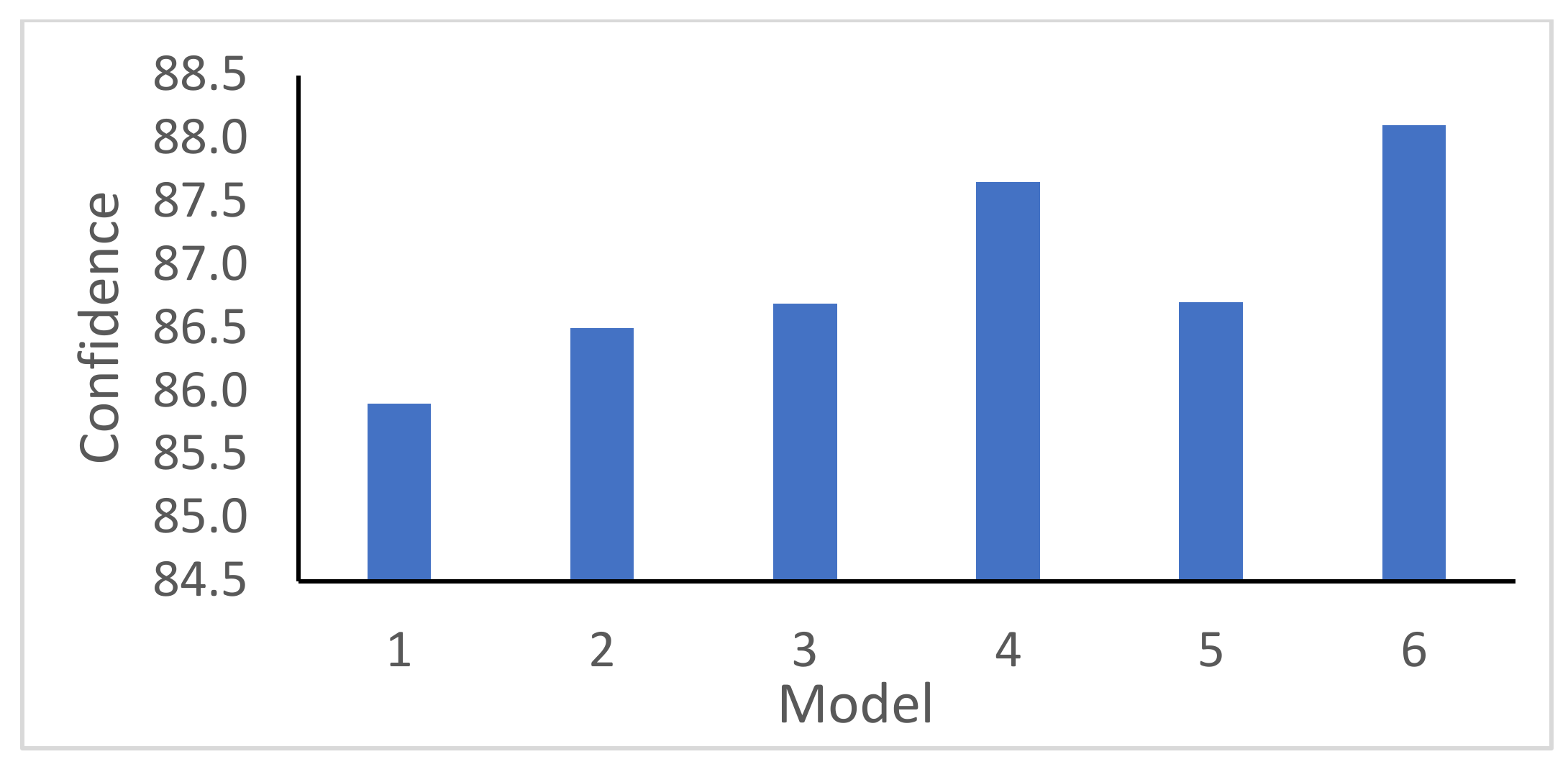
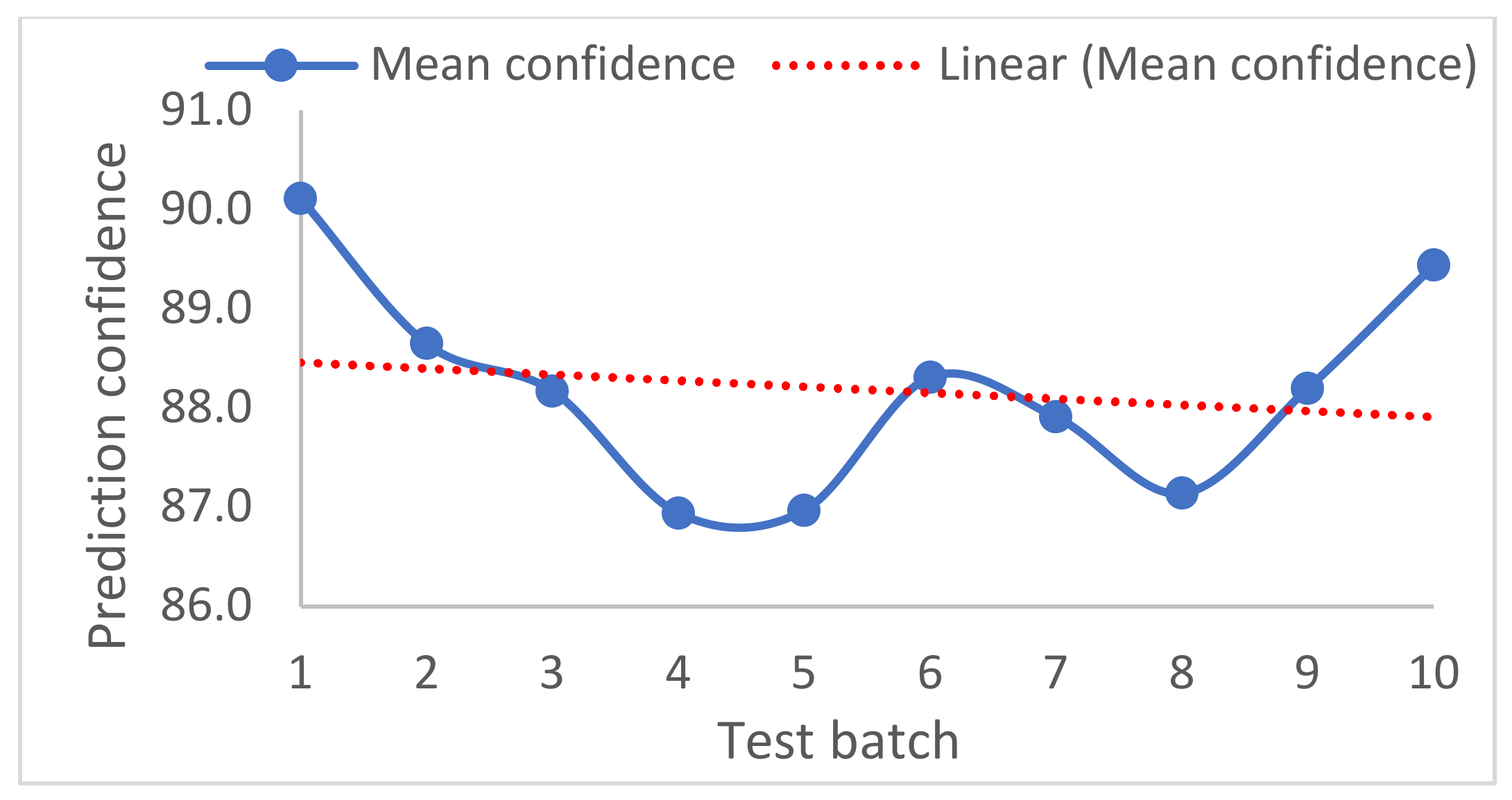
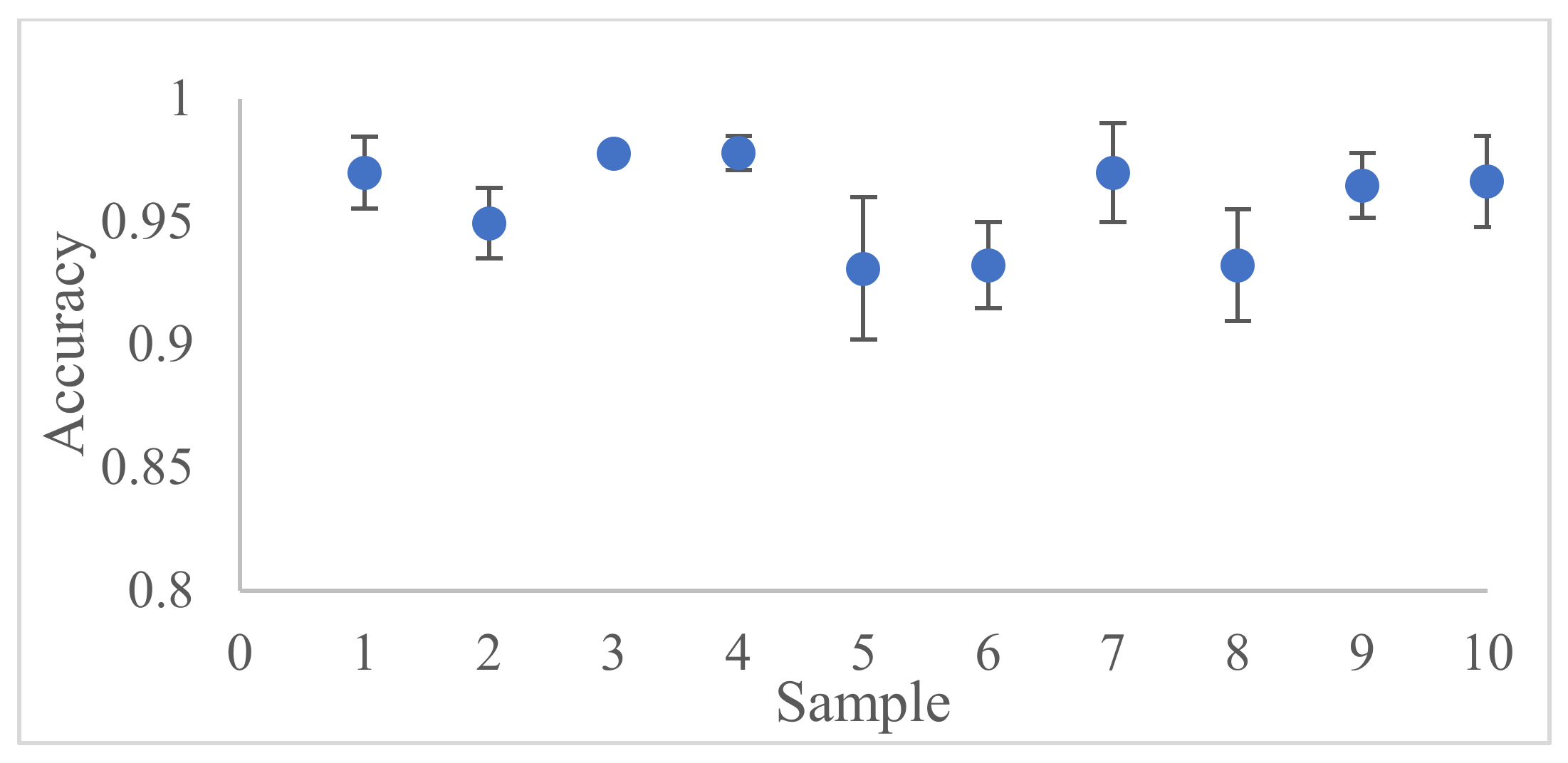
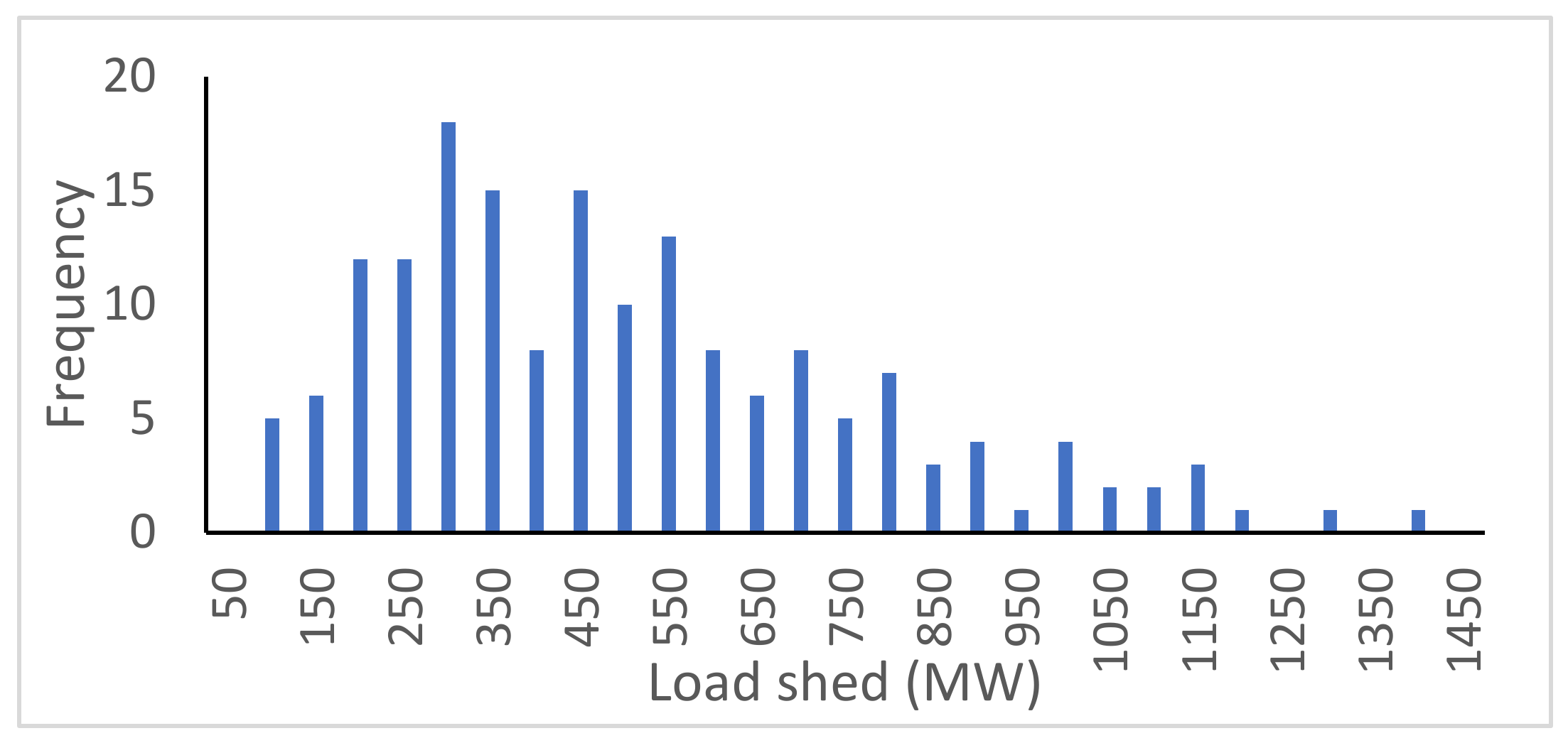
The security prediction models are obtained at the end of each batch training. The mean accuracy and standard deviation of 0.94 and 0.025, respectively, were obtained from six dataset batches of 100 instances per batch. A 90% accurate prediction of the security state of a testing dataset with 10 instances was obtained when compared to the true security state. The obtained AGRP model for security control was able to predict the load shed values within 50 MW variance for 30 test instances. A 100% secure state was achieved using the proposed optimal load shedding node identification. In conclusion, the proposed models can predict and control the security state of the emerging power grid under the described varying grid attributes.
Future research of this paper will focus on considering parallel computation techniques to improve the efficiency of the proposed online security prediction model, especially for very large power systems. It is also important to see how the Gaussian regression process model can be optimized to avoid unnecessary interruption of supply through appropriate hyperparameter selection. Although this paper has presented and discussed the possibility of implementing the proposed technique in a real power system, the deployment of the proposed model as an executable software for system operator utilization after being evaluated for robustness and scalability is a good consideration for future research. Lastly, considering that synthetic inertia is a tradable but costly commodity, the estimation of the optimal amount of synthetic inertia needed to ensure the stability of every unstable grid operation instance is also a significant and relevant future research area.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}