In this paper, by considering the shortcomings of HMM and the advantages of high-order modeling, an improved high-order hidden semi-Markov model (HOHSMM) is proposed based on HSMM.
3.1. The Model Order Reduction Based on Permutation Mapping
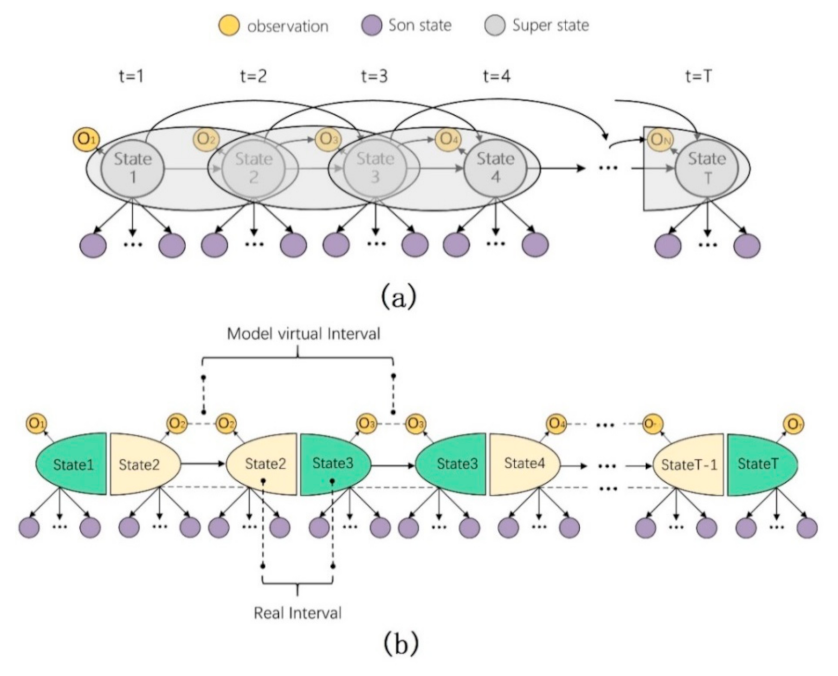
Similarly, taking the second-order HOHSMM as an example, due to the structural changes of the second-order model, the model parameters and related algorithms can be changed accordingly. The respective algorithms for solving the three problems of the low-order model are not applicable to the high-order model. Thus, this paper proposes a model reduction method based on combinatorial mapping, and it is essential to merge the hidden state nodes corresponding to two adjacent time points in the second-order model into one node; then, the merged nodes can be modeled by the Markov process, as shown in
Figure 2.
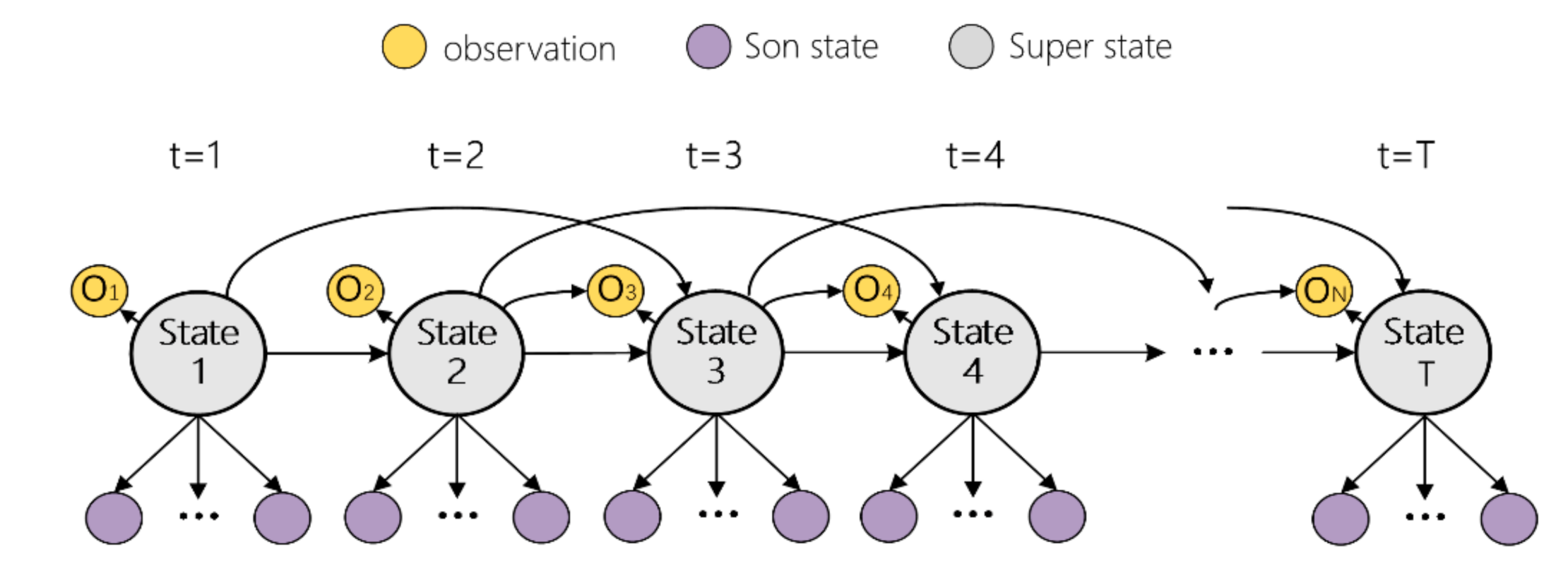
In this paper, a health state in HSMM generates a segment of observations, as opposed to a single observation in the HMM. Thus, the states in a segment semi-Markov model are called super states. Each super state consists of several single states, which are called son states, which can be seen in
Figure 2.
Figure 2a is a division of the model on the second-order HOHSMM, and the adjacent state nodes can be combined into a new, larger node. The relationship between the two health states in the new node has no impact on the Markov property of the whole model. The Markov property of the new model after order reduction can be described as Equation (1).
The description of time in the new model also changes
to
. If the first element of the time combination
is the unique index of the time of the new model, the time can also be expressed as
.
is different from
in the mathematical sense, but in the physical sense,
. When the implicit state node of the new model combination time
is expressed as
, it generates two groups of observations,
and
, where,
completely depends on
and
completely depends on
. Moreover, at time
, the observations connected by dotted lines are the same observation in
Figure 2b, and the sub-state set connected by dotted lines is also the same sub-state set. Thus, each group of observations can be obtained from the unique combined hidden state node, while the unique determined observations corresponding to the combined hidden state can be only retained (except the initial time) in its topology.
In the reduced order model, taking the combination of hidden states as the modeling object, different states are essentially an arrangement problem. Based on the above partial definitions of HMM parameters, if a second-order HOHSMM has
N different super states, and considering the power system has performance degradation and the state is irreversible, then there are
states appearing in the original model. In this paper, a simple mapping between the arrangement scheme and natural numbers is introduced, as shown in Equation (2), where
are states, respectively.
In the parameters of the second-order HOHSMM original model, the transition probability matrix becomes the transition probability cube of and the observation probability matrix becomes the observation probability cube of . The initial probability distribution remains unchanged and the initial transition probability matrix and the initial observation probability matrix are the same as the first-order model. The new model parameters after order reduction are composed of a transition probability matrix , observation probability matrix , initial probability distribution, initial transition probability matrix, and initial observation probability matrix. Letting the reduced-order transition probability matrix be with the element , the reduced-order observation probability matrix is , and the element is . For , the element of is , the element of is , and the element of is .
Based on the order reduction method in
Section 3.1, the transition probability matrix
(
) after dimension reduction can be obtained. The transition probability matrix
is sparse, and the actual amount of effective data in the matrix that is not 0 is
where
is the second state in the state arrangement
. Taking the second-order HOHSMM with
n = 4 as an example, the effective data of the reduced probability transfer matrix of order reduction are 20. In
Table 1, the positions represented by 1 and 1* are the effective data, the composite state represented by the column header at the position of 1* is the main state, and the composite state represented by the column header at the position of 1 is defined as the transition state, while the location represented by 0 is invalid data.
3.2. The Model Reasoning
In view of the idea of a forward–backward algorithm, a linger time (LT) mechanism is introduced, and an auxiliary variable
is established, as is described in Equation (4).
The probability that the observation sequence is generated at the cut-off time and has stayed in the current state for d time under a given model parameter group can be obtained by Equation (4).
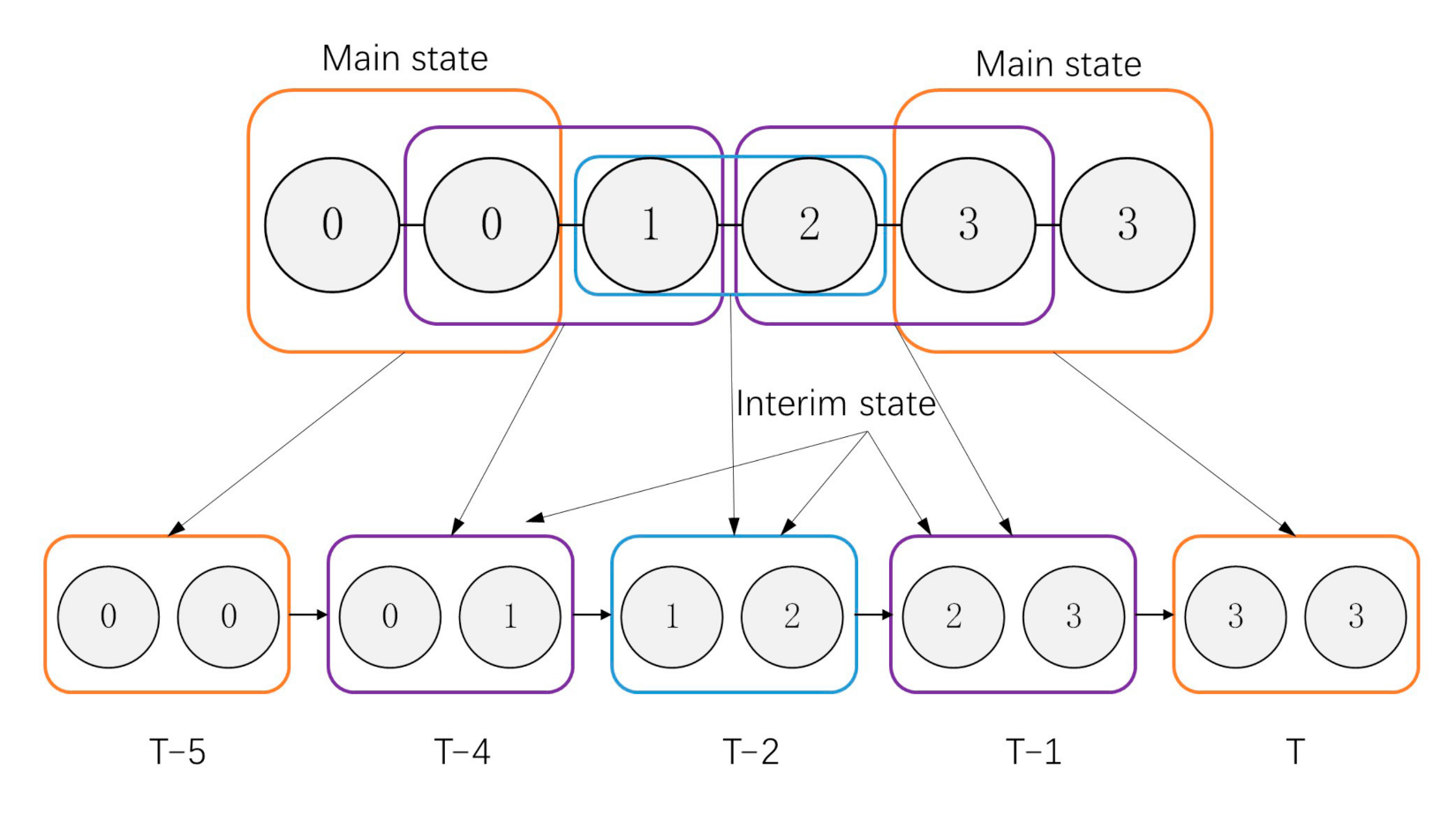
In this section, the sparse representation of the transition probability matrix of the general second-order HOHSMM is given, and the significance of the main state and the transition state can be described, respectively. The transition among the different main health states of the conventional second-order model is a gradual process.
Main state → (Transition state sequence) → Next main state
This transformation process needs at most
time points to be fully described. Taking the transition from the health state (0,0) to (3,3) as an example, the transition process needs five time points to be described, as shown in
Figure 3.
In order to facilitate model reasoning, a transition variable is defined, representing the process intermediate value from the main state ) to the time main state ) of t time. The main states, by being transferred out, can be defined as acceptance states, and the main states being transferred in can be defined as return states. is defined as the time point when the acceptance states appear.
- (1)
For i = 0 and d = t, can be described as
The recursive initial value is
The inner transfer recursion is
- (2)
For i = 1, can be described as
The acceptance state can only be (0,0) and the transition state can only be (0,1). Then, the acceptance value is
,
. Thus, the recursive median is described as
=
, and the recursive equation of internal transfer is
- (3)
For I = 2, the acceptance states can be (0,0) and (1,1) and can be described as
The inner transfer recursion is
Sit1: When the acceptance state is (0,0), it needs four time points to describe from (0,0) to (2,2) and the acceptance value is
The corresponding
can be described as
The corresponding return value is given by Equation (14).
Sit2: When the acceptance state is (1,1), it needs three time points to describe from (1,1) to (2,2) and the corresponding
acceptance value is
- (4)
For I = 3, the acceptance states can be (0,0), (1,1), and (2,2) and can be described as
Inner transfer recursion is
Sit1: When the acceptance state is (0,0), it needs five time points to describe from (0,0) to (3,3), and the corresponding acceptance value is
can be described as
The return value is the product of the corresponding acceptance value and the intermediate value.
Sit2: When the acceptance state is (1,1), it needs four time points to describe from (1,1) to (3,3), and the corresponding acceptance value is
The corresponding intermediate value
is
Sit3: When the acceptance state is (2,2), it needs three time points to describe from (2,2) to (3,3), and the corresponding acceptance value is
The corresponding intermediate value
is
The general recursive equation of
can be expressed by Equation (27):
where
,
is the length of
.
Based on the above classification and derivation of recursion, the auxiliary variables
in the higher state are decomposed into the expression of lower auxiliary variables. In the recursive process, all the transition process state paths meeting the main state transition can be generated, and
can calculated by traversing all possible transition state paths. The transition state paths included by each main state are given in
Table 2, where
x is not included in the path length.
By the given model parameters, the probability of generating observations
O is
Auxiliary variable
is the probability of being in
at time
t under the premise of the given model parameters and observations.
Where
can be obtained by calculating
, and the
recursive equation can be shown as follows.
For the corresponding low-order model, the probability in a single state
at time t can be described by the high-order model.
I is the index set corresponding to the second sub state
i under different composite states, and the index correspondence is given in
Table 3.
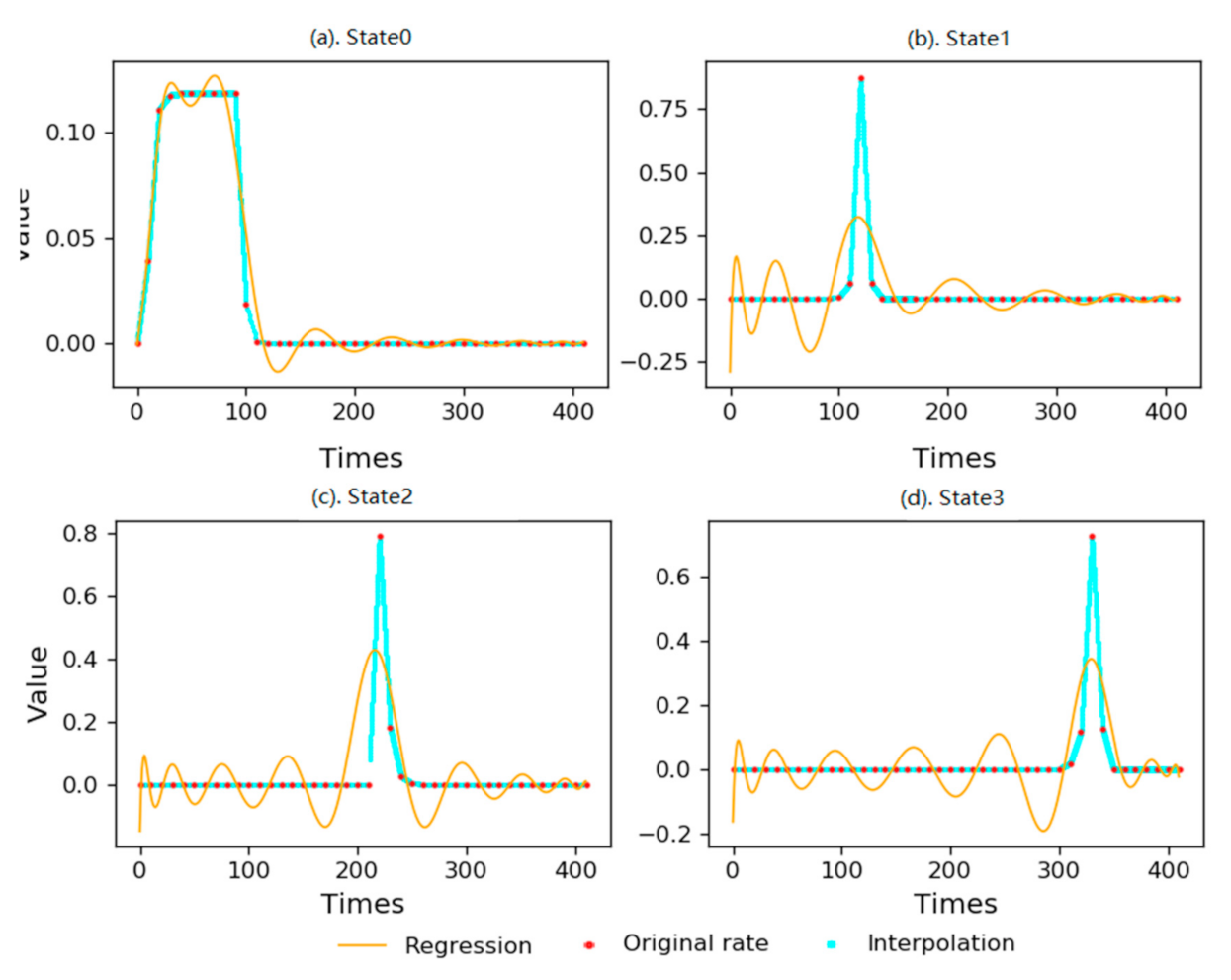
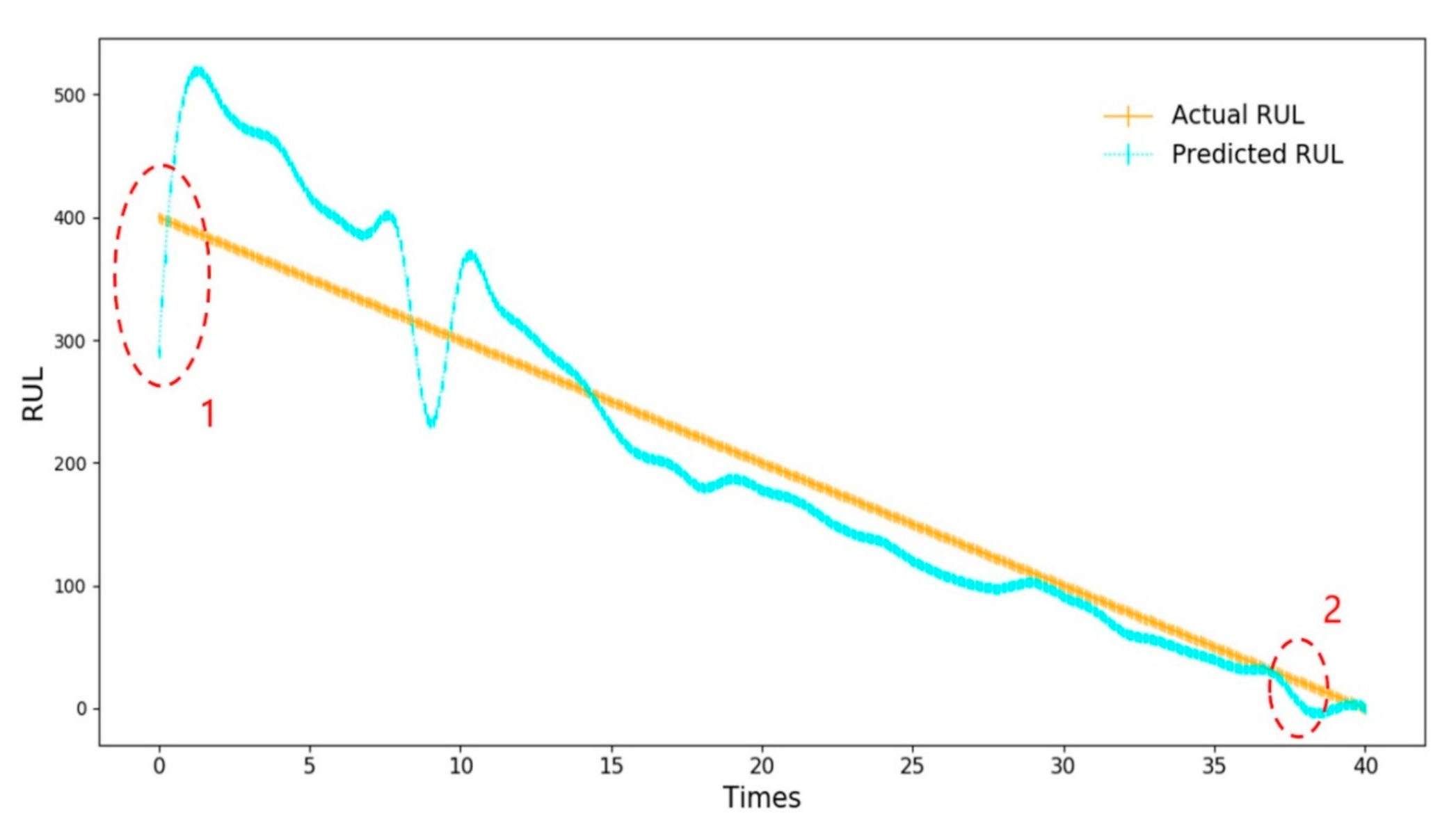
For the parameter estimation problem, this paper selects the intelligent simulation algorithm group to replace the Baum–Welch algorithm and carries out a two-stage estimation. First, a one-stage likelihood function
is established, and it is described as
For the situation of the current
, if the probability of the first two observations is generated, then the optimal
in one stage is
The two-stage likelihood function is
In the situation of the current
, the probability from the third to the final observation is generated, and the corresponding optimal parameters
in the second stage are
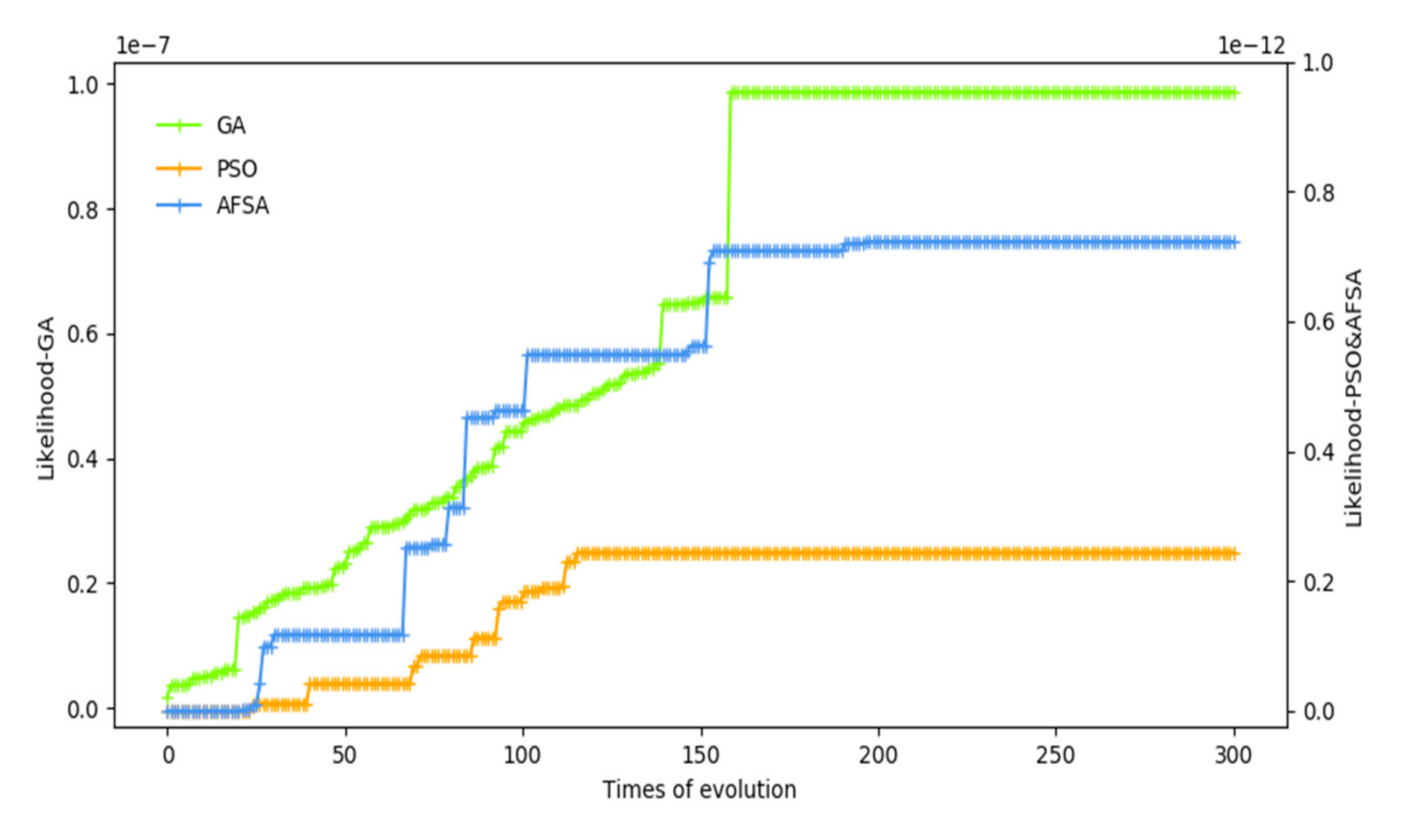
Different intelligent simulation algorithms are used to optimize and compare the two-stage likelihood function, and finally to select the best result.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}