
Multivariate SCADA Data Analysis Methods for Real-World Wind Turbine Power Curve Monitoring




Abstract
:1. Introduction
- the methodology for the input variables selection;
- the exploitation of the information contained in the SCADA data sets.
- the minimum, maximum and standard deviation of the most meaningful environmental and operation variables are abundantly selected by the features selection algorithm;
- the selection of the input variables heavily depends on the wind turbine model and it is therefore supported that data-driven power curve models should be customized on the wind turbines of interest;
- by employing the selected input variables and the selected regression type, it is possible to achieve error metrics which are in general lower than the state of the art in the literature and are shown to be lower than those given by an appropriate benchmark model. This is the qualifying point for this kind of approaches because the lower the error metrics and the higher the capability of recognizing performance deviations with respect to the normal: in this regard, the data-driven methods prove to be superior to the design curves of the wind turbines.
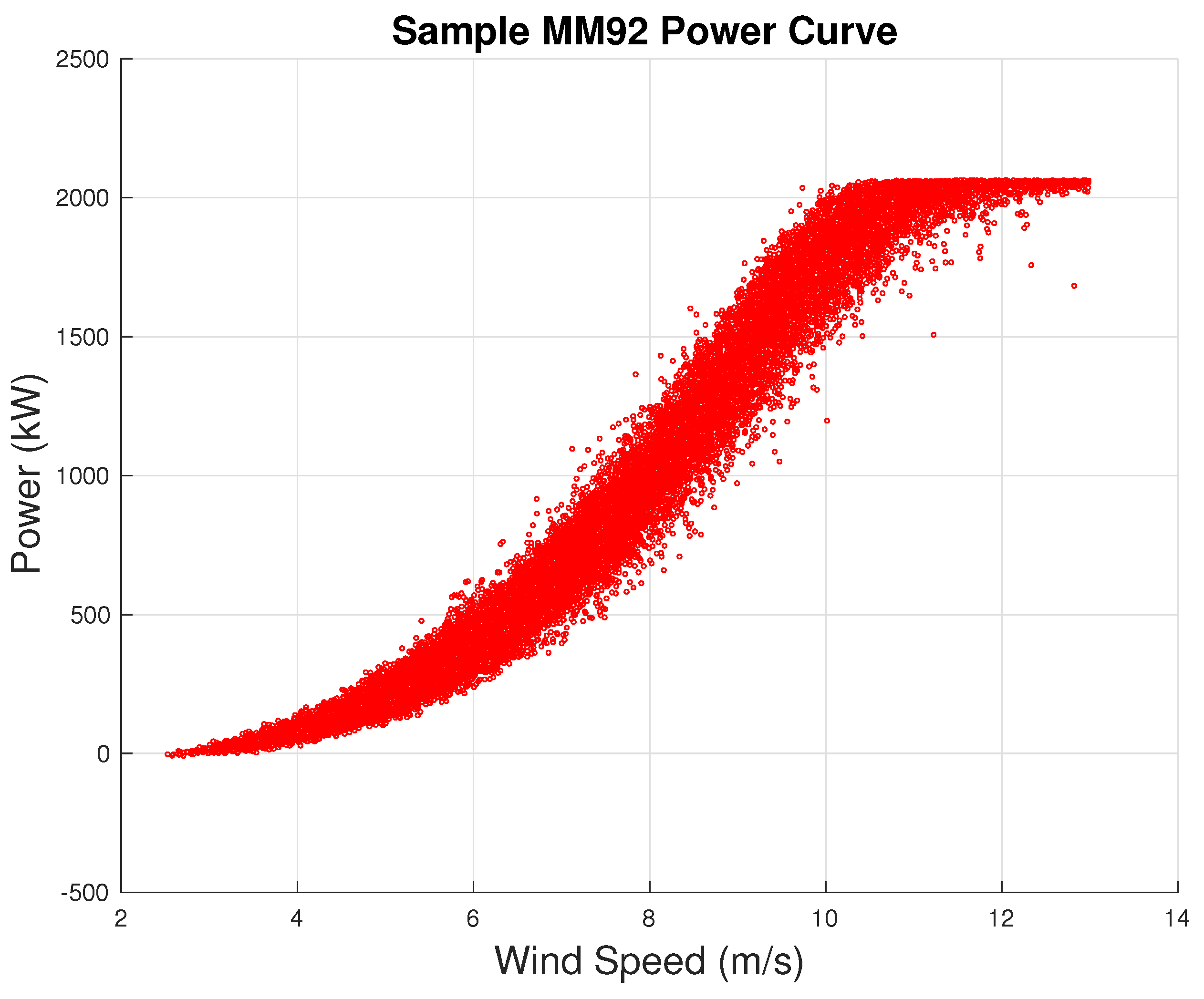
2. Test Cases and Data Sets
- a Senvion MM92;
- a Vestas V90;
- a Vestas V117.
- Wind speed v (m/s) (average, minimum, maximum, standard deviation);
- Power P (kW) (average);
- Blade pitch () (average, minimum, maximum, standard deviation);
- Generator speed (rpm) (average, minimum, maximum, standard deviation);
- Rotor speed (rpm) (average, minimum, maximum, standard deviation);
- Ambient temperature T () (average);
- Run time counter R (s).
- filter using the run time counter, requesting production for 600 s out 600;
- filter below rated power (approximately );
- since grid curtailments are operated by forcing the wind turbine to pitch anomalously, these are filtered out by removing outliers with respect to the average wind speed—blade pitch curve ( of tolerance).
3. Methods
- is the vector of measured output (power production P);
- is the matrix of covariates, which can be selected between
- Renormalized wind speed (average);
- Renormalized windspeed (mimimum);
- Renormalized wind speed (maximum);
- Renormalized wind speed (standard deviation);
- Blade pitch (average);
- Blade pitch (mimimum);
- Blade pitch (maximum);
- Blade pitch (standard deviation);
- Generator speed (average);
- Generator speed (minimum);
- Generator speed (maximum);
- Generator speed (standard deviation);
- Rotor speed (average);
- Rotor speed (minimum);
- Rotor speed (maximum);
- Rotor speed (standard deviation).
- is the vector of simulated output, for given input variables .
- the precision of the regression, which means that the absolute difference between the model estimate and the measurement should be lower than a threshold (Equation (5));
- the flatness of the model, which means that the norm of the coefficients should be minimum. In one dimension, it means that regression line should be as close as possible to the x-axis.
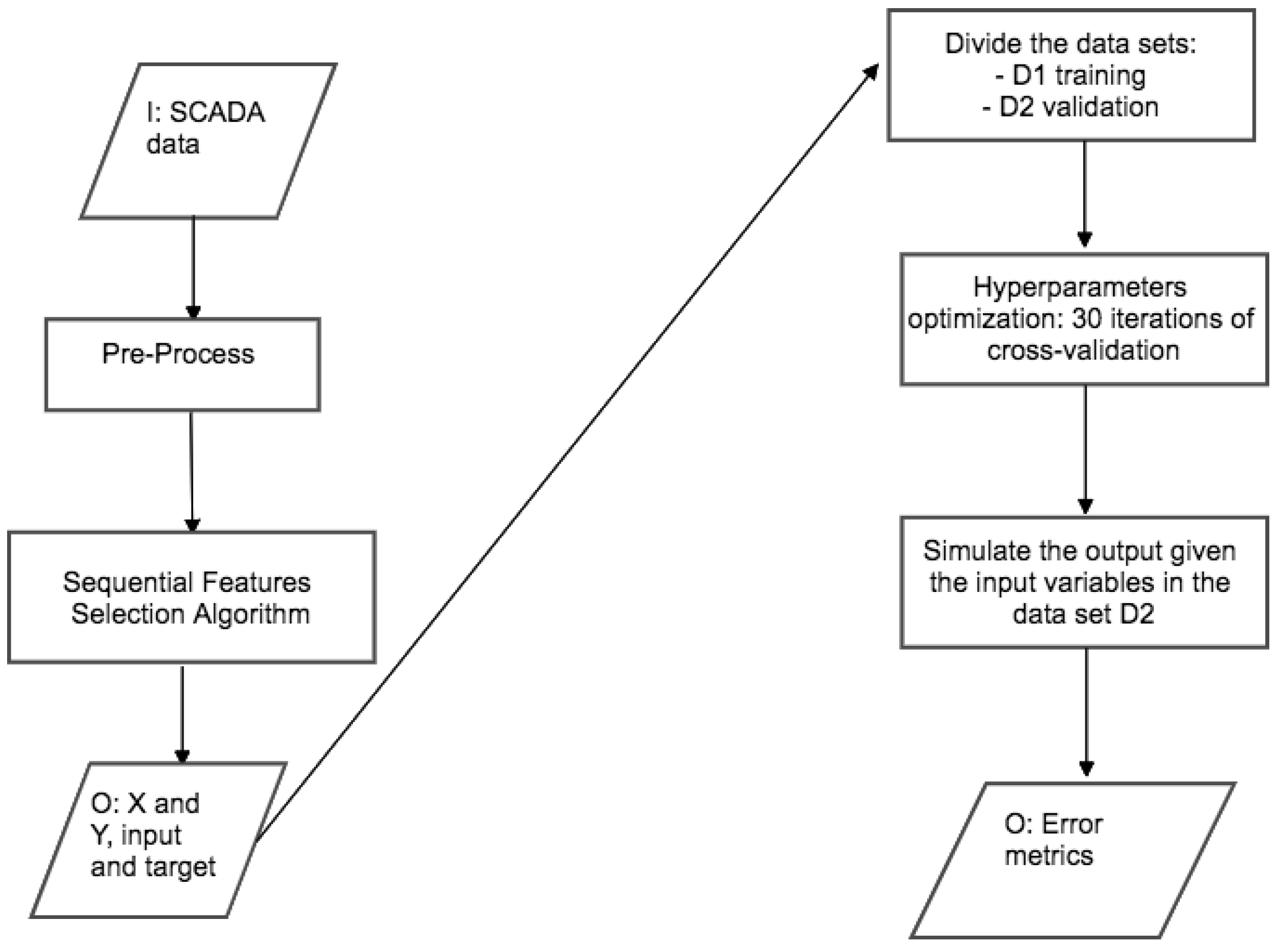
- the matrix , containing the sixteen possible regressors listed above, and the vector of power output are passed to a sequence of Support Vector Regressions;
- starting from an empty matrix, the algorithm adds once at a time each possible input variable (i.e., each column), performs a 10-fold cross-validation of the regression and estimates the loss function;
- the regressor associated to the lowest value of the loss function is selected as input of the model;
- sequentially, each other possible regressor is added once at a time, the cross-validation is performed, the loss function is estimated;
- if, by adding a regressor, there is no more improvement in the loss function, the algorithm stops and returns the input variables selected up to this step;
- else, the algorithm adds to the input variables selection the regressor which diminishes most the loss function and the sequence proceeds.
- a random 50% selection is used for training the model and is noted as D1;
- the remainder 50% (hence named D2) is used for evaluating the goodness of the regression, by evaluating the out-of-sample error metrics.
4. Results
- The covariates which are selected for all the test cases are the average wind speed and the standard deviation of the wind speed . This indicates that it is fundamental to incorporate in the model information regarding the turbulence intensity on site and this results support the idea of this study to include minimum, maximum and standard deviation of the main possible input variables.
- A large number of covariates is selected for each test case (8 or 9) and the minimum, maximum and standard deviation of the variables are the most selected: the maximum number of average values which are selected is 3. This strongly supports the intuition of this work.
- There is a remarkable difference in the variables selection between the Senvion MM92 and the two Vestas test cases: for the Senvion MM92, 5 rotational speed variables and 1 blade pitch variable are selected, while for the Vestas wind turbines, 1 rotational speed variable and 4 blade pitch variables are selected. This is likely due to the different type of control of the wind turbine: Senvion MM92 has electric pitch control, while the Vestas wind turbines have hydraulic pitch control. This result supports that the multivariate regression for the power curve should be custom, depending on the wind turbine model, despite in general it is definitely reasonable that blade pitch and rotational speed are very important working parameters.
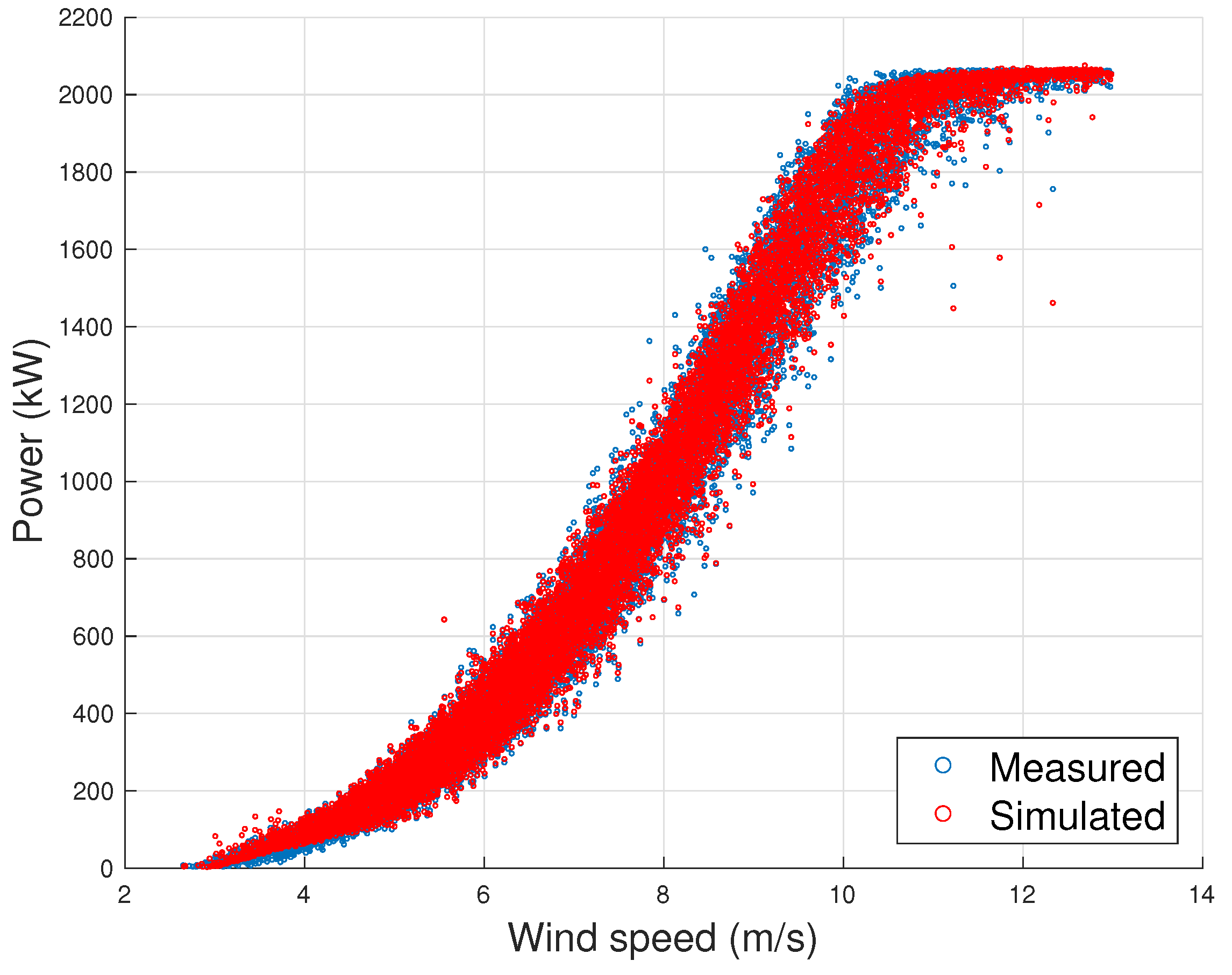
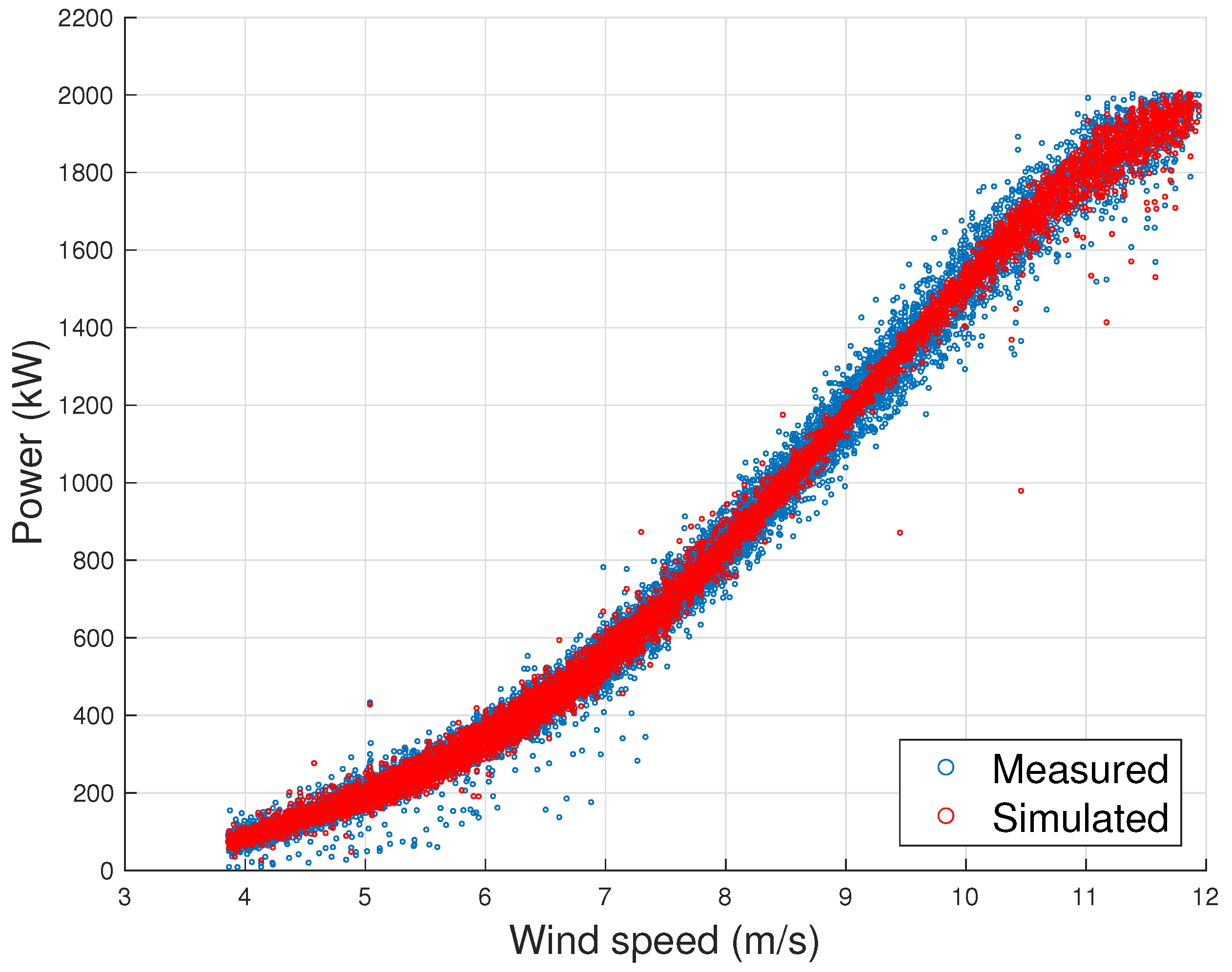
4.1. Senvion MM92
4.2. Vestas V90
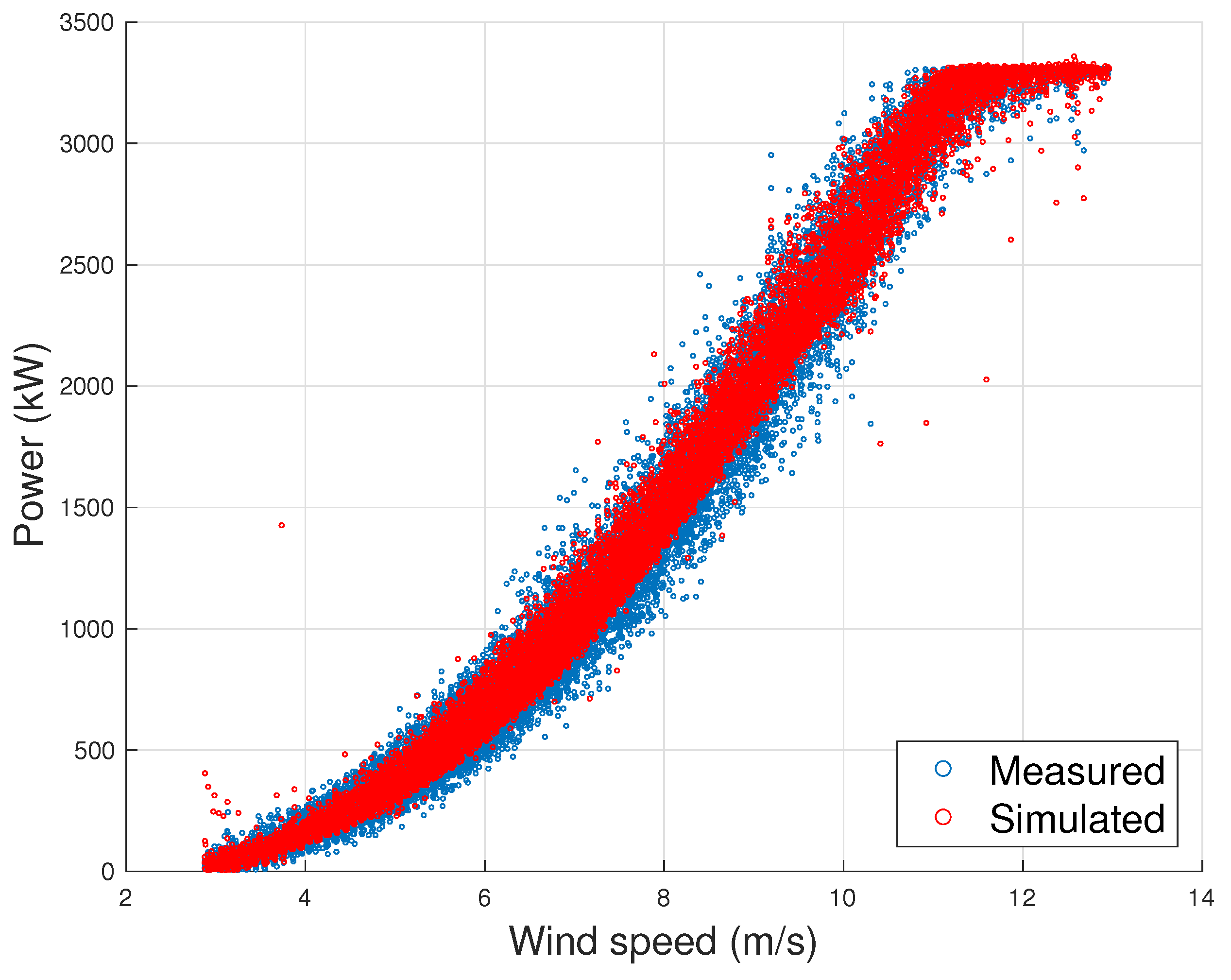
4.3. Vestas V117
4.4. Discussion
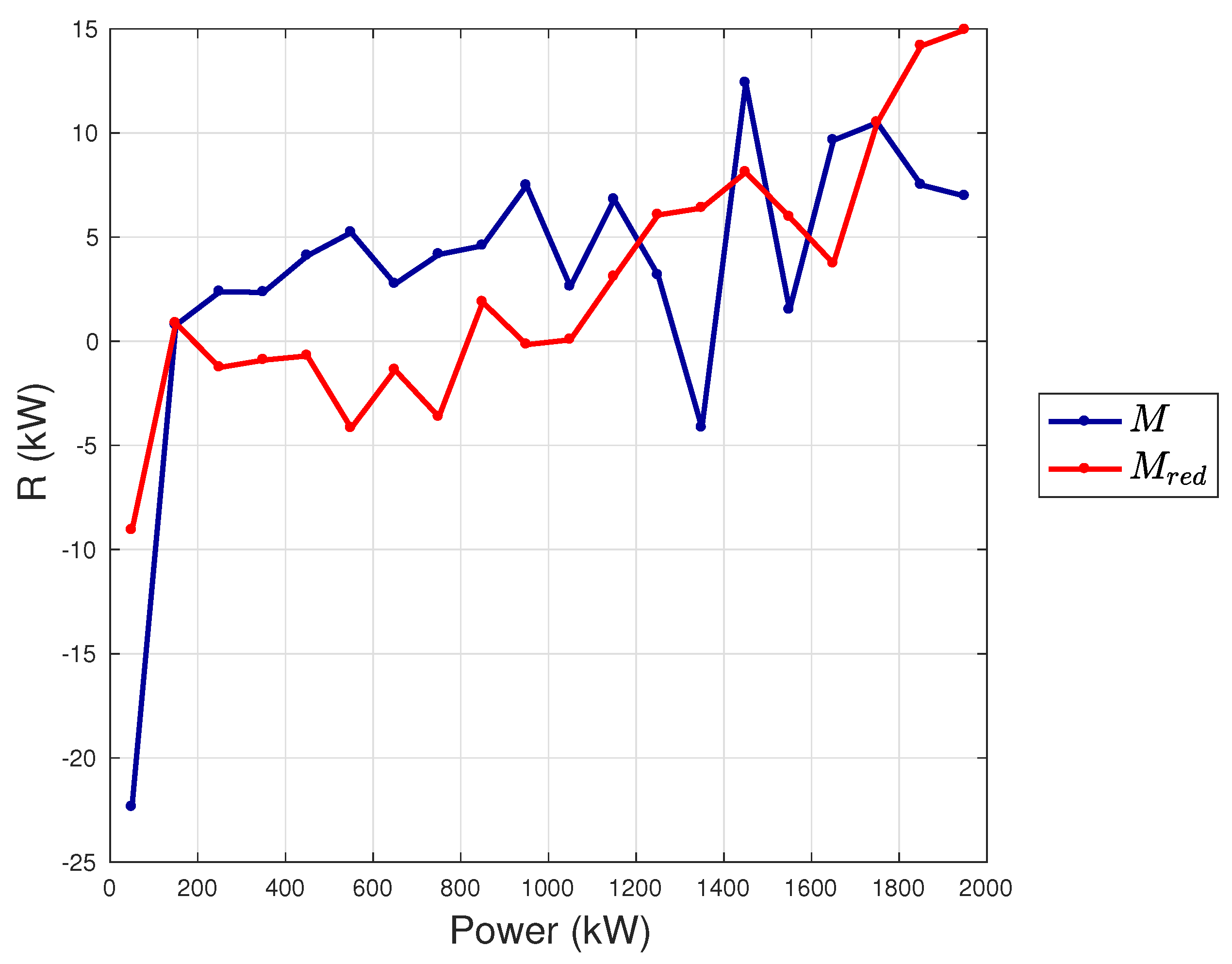
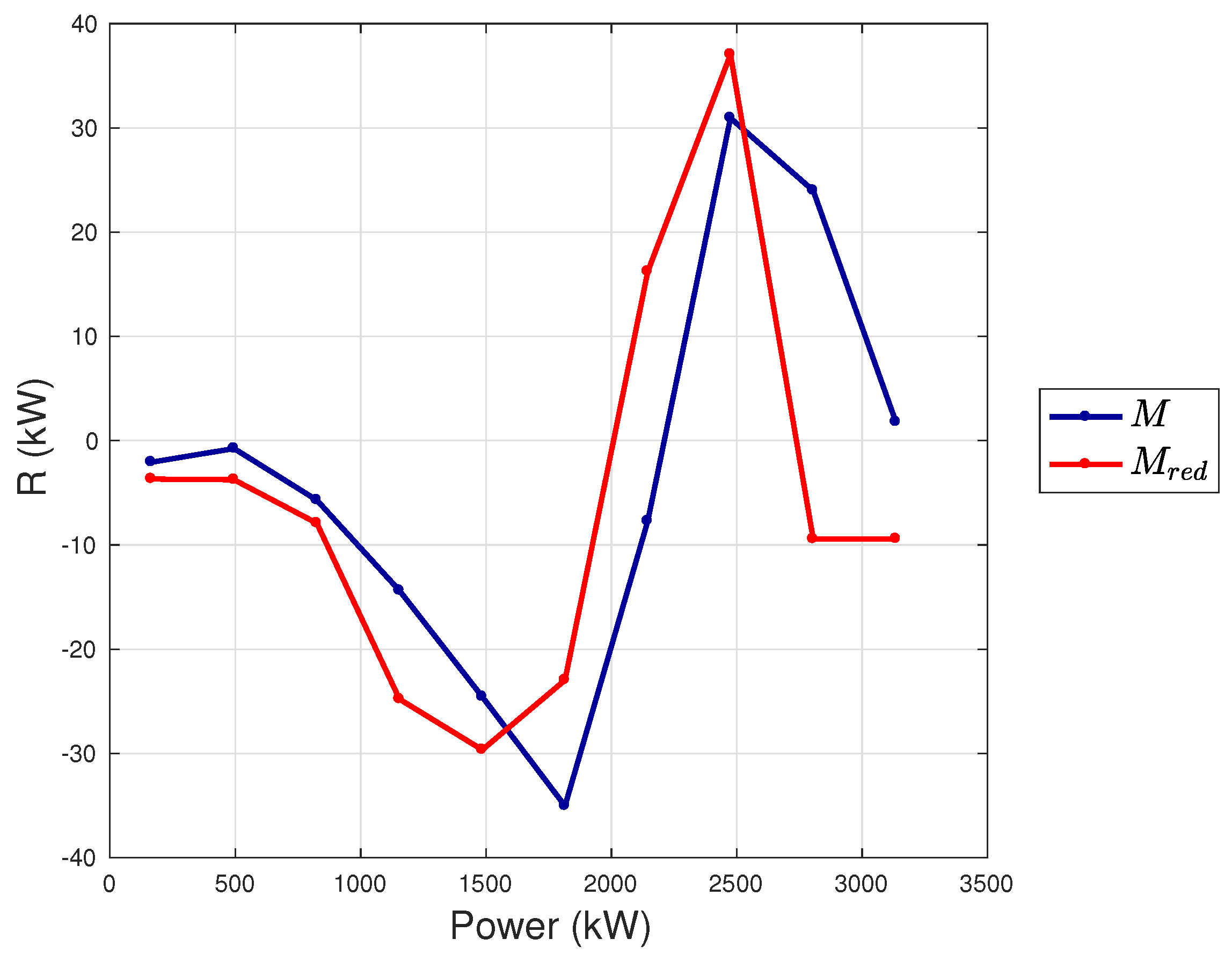
- The first observation arising from Section 4.1, Section 4.2 and Section 4.3 is that the models proposed in this work, whose input variables selections are reported in Table 2, provide lower error metrics with respect to the selected benchmark model. The error metrics decrease from to M is approximately in the order of 20–30%.
- The error metrics which have been achieved are slightly different, depending on the test case: for the Senvion MM92, the is 0.87% of the rated power, for the Vestas V90 it is 1.28% of the rated power and for the Vestas V117 it is 1.41% of the rated power.
- The above results are competitive and in general lower with respect to the state of the art in the literature. In [39], the obtained is in the order of 1.5% of the rated power, in [37] a in the order of 1.1% of the rated power is obtained, in [35] (dealing with the Vestas V90 as in the present work) the is approximately 1.45% of the rated power.
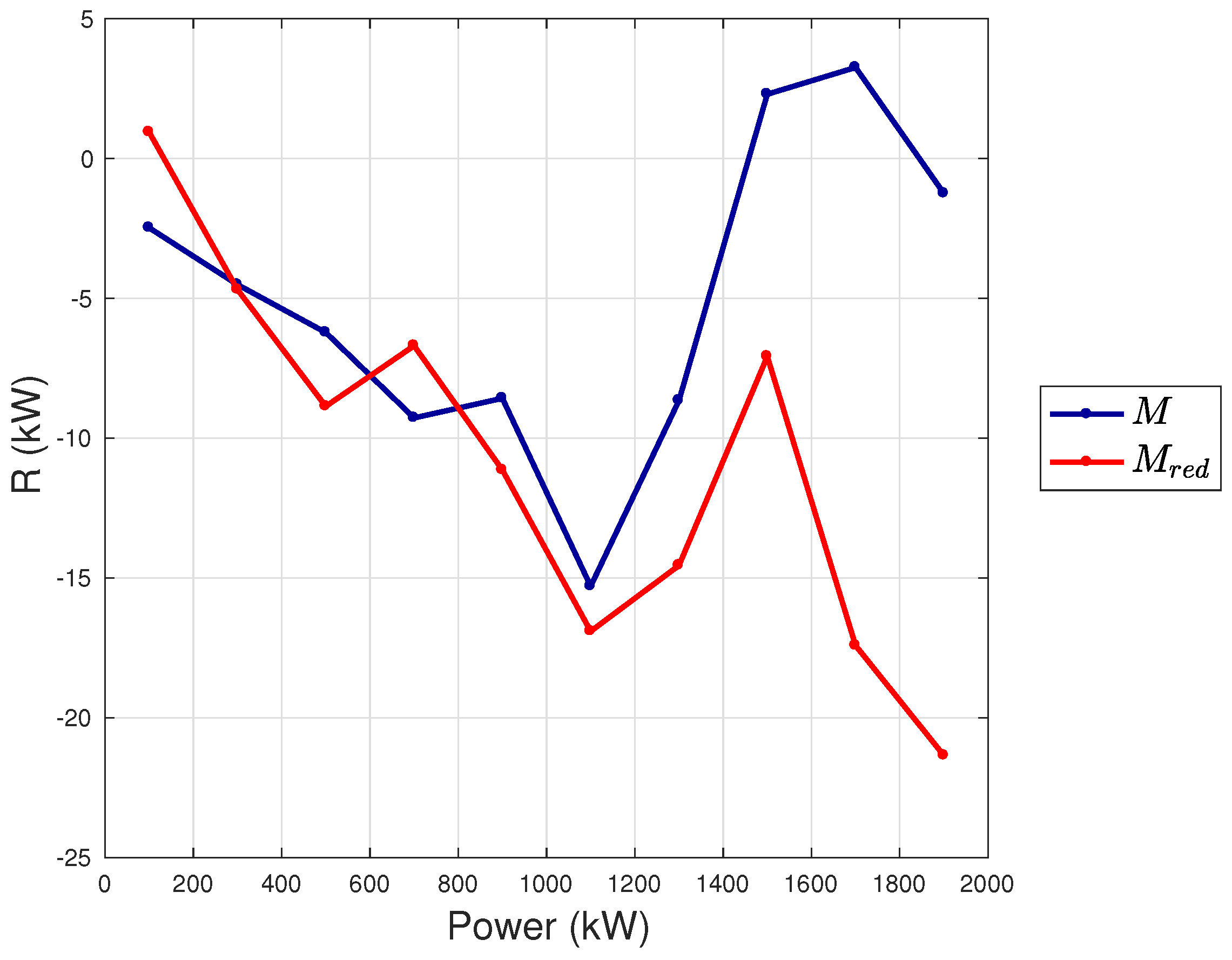
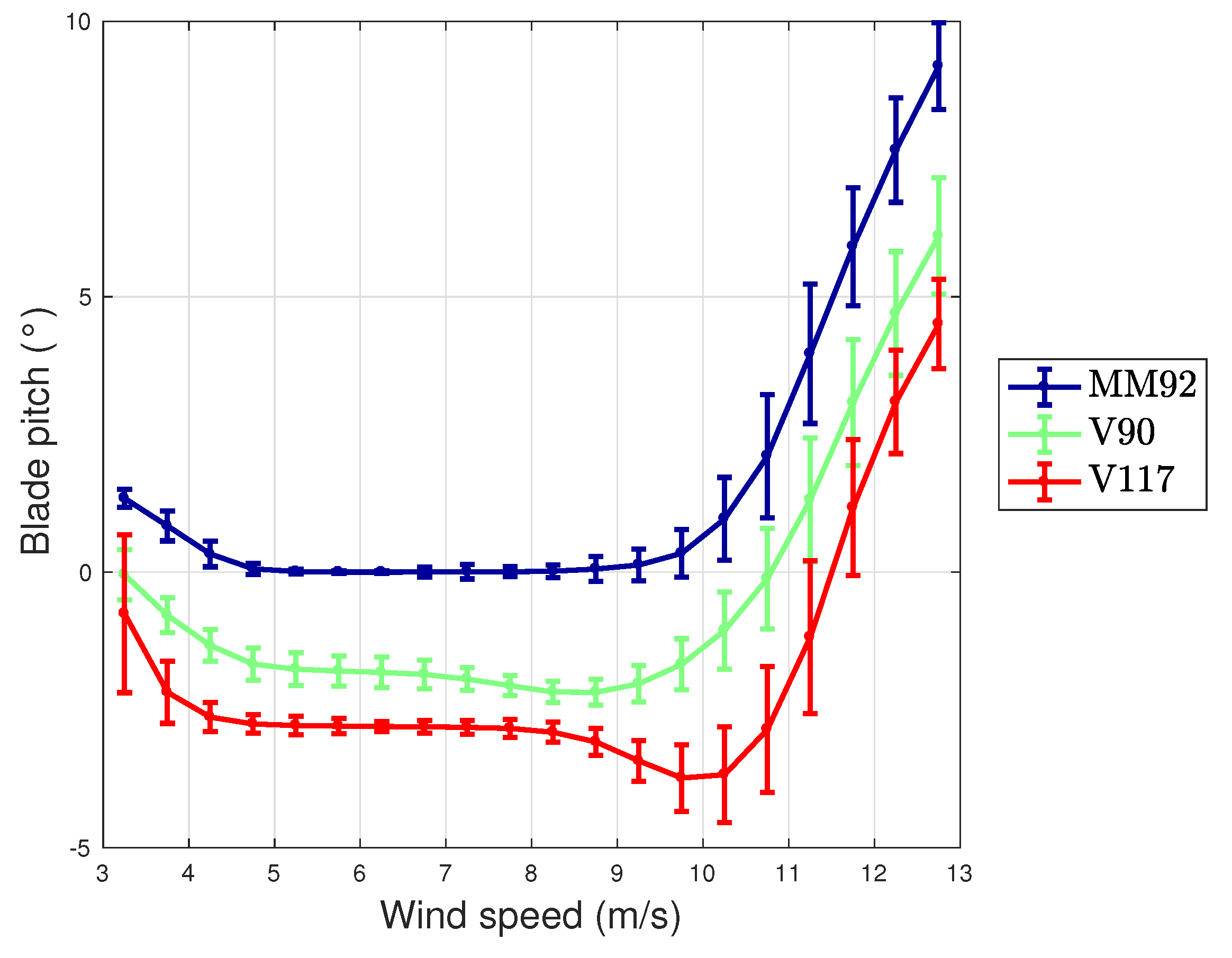
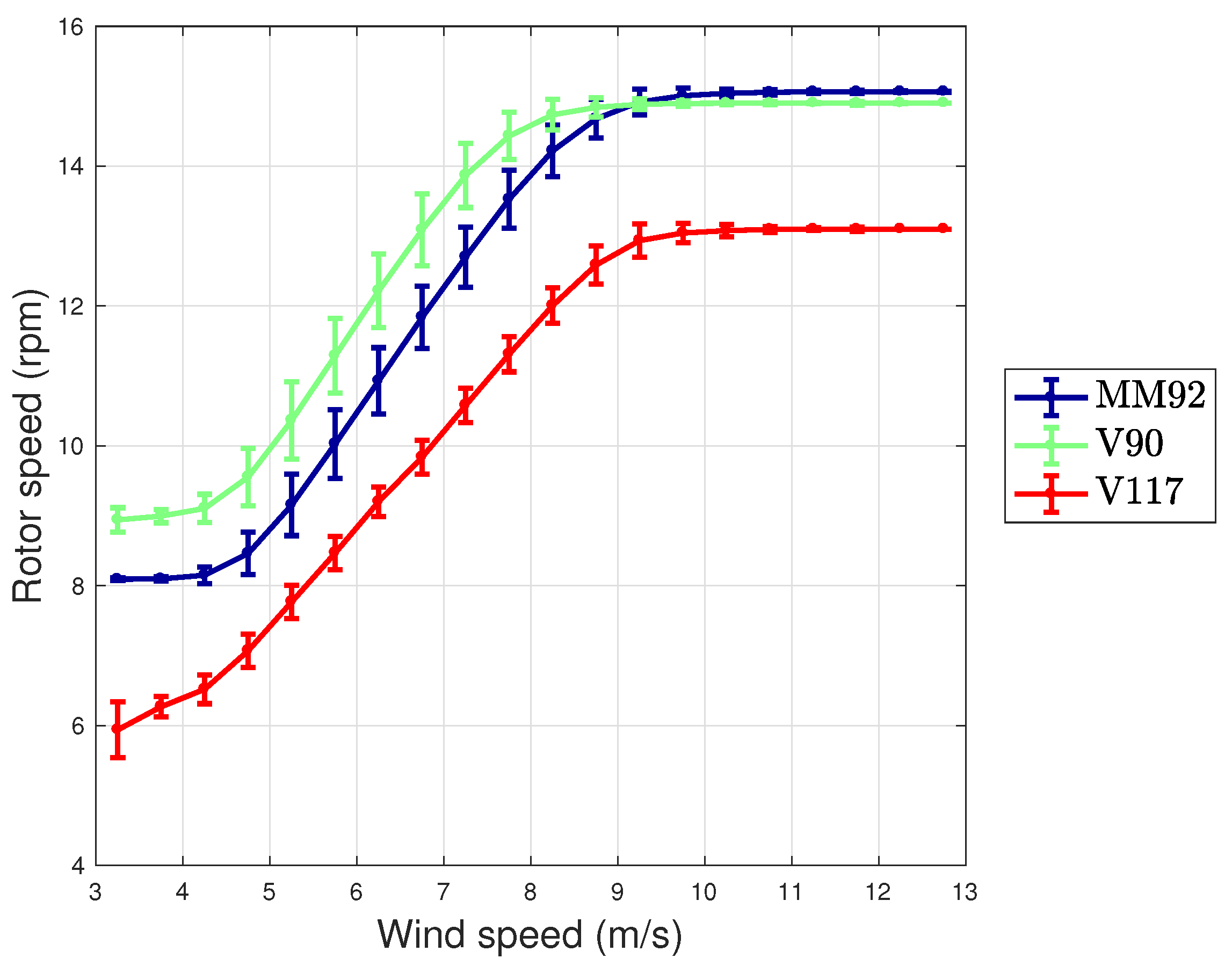
- The case of Vestas V117 deserves a further discussion, because it is the test case with largest rotor diameter and highest rated power available in the literature, to the best of the authors’ knowledge. The error metrics for this test case resulted to be slightly highest with respect to the other test cases of this work, which have 2 MW of rated power. In order to understand the possible critical points, in Figure 10 and Figure 11, the average wind speed—blade pitch and wind speed—rotor speed curves [42] are reported for each test case. It arises that the behavior of the blade pitch for the Vestas V117 is more critical because there is higher variability near the cut-in and approaching rated power. From Figure 10, it also arises that the wind turbine displaying a more regular pitch behavior is the Senvion MMM92 and this likely explains why for this test case the regression (Table 2) employs only one input variable related to the blade pitch. Recall that, as reported in Table 1, the Senvion MM92 has electric pitch control, while the Vestas wind turbines have hydraulic pitch control [50]. Furthermore, from Figure 11, it arises that the the Vestas V117 wind turbine has a lower variability in the behavior of the rotor speed and this likely contributes to explain why the rotational speed variables are less important for this wind turbine.
- Potentially, there are no drawbacks regarding the extension of the proposed methodology to other models of wind turbines. It should be noticed that, in general, the older the wind turbines and the less rich are the SCADA data sets. As a rule of thumb, it can be stated that the benefits of the proposed approach can be appreciated when applied to wind turbines of the generation of Vestas V52 [51] up to the latest models in the market. For wind turbines like the Vestas V52, the model could in particular be useful for a long term analysis of the performance trend in the context of the assessment of performance decline with age. In relation to the application of the method to the latest models in the market, of increasing rotor size, it should be noticed that the exploitation of all the available wind intensity sensors could be decisive for further diminishing the error metrics.
5. Conclusions
- The SCADA data at disposal have been exploited more in depth with respect to the state of the art in the literature, because minimum, maximum and standard deviation in the sampling time of the main environmental and working variables have been included as possible covariates of the model for the power. In the literature, the typical choice is employing only the average values.
- A sequential features selection algorithm has been employed in order to identify the most appropriate covariates for the regression. The algorithm starts from an empty set and adds each covariate one at a time, selecting iteratively the one which leads to a lower error metric, and stopping when there is no improvement in adding further inputs.
- The inclusion of minimum, maximum and standard deviation of the main variables as possible regressors is meaningful: from Table 2, where the features selection for three test cases is reported, it arises that the average values are only around 20% of the selected input variables.
- There are some regular characteristics in the features selection of Table 2: the average wind speed is the most important input, the standard deviation of the wind speed is the second most important, at least a variable related to rotational speed and to blade pitch is selected. The number of selected features is quite high (8, 9) with respect to most models in the literature, which typically employ average wind speed, blade pitch, rotor speed and possibly the yaw error.
- There are differences between the features selected for the various test cases: for the Senvion MM92 technology, the information related to rotational speed results being more meaningful, while for the Vestas technology all the measurements regarding the blade pitch are included in the models. This could probably be interpreted in light of the control of the wind turbines (Figure 10).
- For each test case, the error metrics obtained with the regression method proposed in this work are lower with respect to the state of the art in the literature and are considerably lower with respect to those obtained through a benchmark model employing average wind speed, blade pitch and rotor speed.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DA | Data Access |
| IEC | International Electrotechnical Commission |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| OPC | Open Platform Communication |
| RMSE | Root Mean Square Error |
| SCADA | Supervisory Control And Data Acquisition |
| SVR | Support Vector Regression |
References
- Zhang, Y.; Pan, G.; Chen, B.; Han, J.; Zhao, Y.; Zhang, C. Short-term wind speed prediction model based on GA-ANN improved by VMD. Renew. Energy 2020, 156, 1373–1388. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Kong, C.; Chen, B. A new prediction method based on VMD-PRBF-ARMA-E model considering wind speed characteristic. Energy Convers. Manag. 2020, 203, 112254. [Google Scholar] [CrossRef]
- Wagner, R.; Antoniou, I.; Pedersen, S.M.; Courtney, M.S.; Jørgensen, H.E. The influence of the wind speed profile on wind turbine performance measurements. Wind. Energy Int. J. Prog. Appl. Wind. Power Convers. Technol. 2009, 12, 348–362. [Google Scholar] [CrossRef]
- Han, X.; Liu, D.; Xu, C.; Shen, W.Z. Atmospheric stability and topography effects on wind turbine performance and wake properties in complex terrain. Renew. Energy 2018, 126, 640–651. [Google Scholar] [CrossRef]
- Astolfi, D.; Castellani, F.; Natili, F. Wind turbine yaw control optimization and its impact on performance. Machines 2019, 7, 41. [Google Scholar] [CrossRef] [Green Version]
- Sequeira, C.; Pacheco, A.; Galego, P.; Gorbeña, E. Analysis of the efficiency of wind turbine gearboxes using the temperature variable. Renew. Energy 2019, 135, 465–472. [Google Scholar] [CrossRef]
- Dai, J.; Yang, W.; Cao, J.; Liu, D.; Long, X. Ageing assessment of a wind turbine over time by interpreting wind farm SCADA data. Renew. Energy 2018, 116, 199–208. [Google Scholar] [CrossRef] [Green Version]
- Byrne, R.; Astolfi, D.; Castellani, F.; Hewitt, N.J. A Study of Wind Turbine Performance Decline with Age through Operation Data Analysis. Energies 2020, 13, 2086. [Google Scholar] [CrossRef] [Green Version]
- Astolfi, D.; Byrne, R.; Castellani, F. Analysis of Wind Turbine Aging through Operation Curves. Energies 2020, 13, 5623. [Google Scholar] [CrossRef]
- Martin, C.M.S.; Lundquist, J.K.; Clifton, A.; Poulos, G.S.; Schreck, S.J. Atmospheric turbulence affects wind turbine nacelle transfer functions. Wind. Energy Sci. 2017, 2, 295–306. [Google Scholar] [CrossRef] [Green Version]
- Honrubia, A.; Vigueras-Rodríguez, A.; Gómez-Lázaro, E. The influence of turbulence and vertical wind profile in wind turbine power curve. In Progress in Turbulence and Wind Energy IV; Springer: Berlin/Heidelberg, Germany, 2012; pp. 251–254. [Google Scholar]
- Larios, D.F.; Personal, E.; Parejo, A.; García, S.; García, A.; Leon, C. Operational Simulation Environment for SCADA Integration of Renewable Resources. Energies 2020, 13, 1333. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.H.; Huh, J.H. Optimal Location Recommendation System for Offshore Floating Wind Power Plant Using Big Data Analysis. In Advances in Computer Science and Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 583–590. [Google Scholar]
- Abdallah, I.; Dertimanis, V.; Mylonas, H.; Tatsis, K.; Chatzi, E.; Dervilis, N.; Worden, K.; Maguire, E. Fault diagnosis of wind turbine structures using decision tree learning algorithms with big data. In Proceedings of the European Safety and Reliability Conference, Trondheim, Norway, 17–21 June 2018; pp. 3053–3061. [Google Scholar]
- Castellani, F.; Garinei, A.; Terzi, L.; Astolfi, D.; Moretti, M.; Lombardi, A. A new data mining approach for power performance verification of an on-shore wind farm. Diagnostyka 2013, 14, 35–42. [Google Scholar]
- Astolfi, D.; Castellani, F.; Terzi, L. Mathematical methods for SCADA data mining of onshore wind farms: Performance evaluation and wake analysis. Wind. Eng. 2016, 40, 69–85. [Google Scholar] [CrossRef] [Green Version]
- Castellani, F.; Garinei, A.; Terzi, L.; Astolfi, D.; Gaudiosi, M. Improving windfarm operation practice through numerical modelling and supervisory control and data acquisition data analysis. IET Renew. Power Gener. 2014, 8, 367–379. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F.; Achiche, S. Wind turbine condition monitoring based on SCADA data using normal behavior models. Part 1: System description. Appl. Soft Comput. 2013, 13, 259–270. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F. Wind turbine condition monitoring based on SCADA data using normal behavior models. Part 2: Application examples. Appl. Soft Comput. 2014, 14, 447–460. [Google Scholar] [CrossRef]
- Pandit, R.K.; Infield, D.; Kolios, A. Comparison of advanced non-parametric models for wind turbine power curves. IET Renew. Power Gener. 2019, 13, 1503–1510. [Google Scholar] [CrossRef] [Green Version]
- Saint-Drenan, Y.M.; Besseau, R.; Jansen, M.; Staffell, I.; Troccoli, A.; Dubus, L.; Schmidt, J.; Gruber, K.; Simões, S.G.; Heier, S. A parametric model for wind turbine power curves incorporating environmental conditions. Renew. Energy 2020, 157, 754–768. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Zou, R.; Foley, A.M.; Al Kez, D.; Song, D.; Hu, Q.; Srinivasan, D. Sparse Heteroscedastic Multiple Spline Regression Models for Wind Turbine Power Curve Modeling. IEEE Trans. Sustain. Energy 2020, 12, 191–201. [Google Scholar] [CrossRef]
- Mehrjoo, M.; Jozani, M.J.; Pawlak, M. Wind turbine power curve modeling for reliable power prediction using monotonic regression. Renew. Energy 2020, 147, 214–222. [Google Scholar] [CrossRef]
- Helbing, G.; Ritter, M. Improving wind turbine power curve monitoring with standardisation. Renew. Energy 2020, 145, 1040–1048. [Google Scholar] [CrossRef]
- Rogers, T.; Gardner, P.; Dervilis, N.; Worden, K.; Maguire, A.; Papatheou, E.; Cross, E. Probabilistic modelling of wind turbine power curves with application of heteroscedastic Gaussian Process regression. Renew. Energy 2020, 148, 1124–1136. [Google Scholar] [CrossRef]
- Yun, E.; Hur, J. Probabilistic estimation model of power curve to enhance power output forecasting of wind generating resources. Energy 2021, 223, 120000. [Google Scholar] [CrossRef]
- Pandit, R.; Kolios, A. SCADA Data-Based Support Vector Machine Wind Turbine Power Curve Uncertainty Estimation and Its Comparative Studies. Appl. Sci. 2020, 10, 8685. [Google Scholar] [CrossRef]
- International Electrotechnical Commission (IEC). Power Performance Measurements of Electricity Producing Wind Turbines; Technical Report 61400–12; International Electrotechnical Commission: Geneva, Switzerland, 2005. [Google Scholar]
- Wang, Y.; Hu, Q.; Li, L.; Foley, A.M.; Srinivasan, D. Approaches to wind power curve modeling: A review and discussion. Renew. Sustain. Energy Rev. 2019, 116, 109422. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F.; Achiche, S. Using data-mining approaches for wind turbine power curve monitoring: A comparative study. IEEE Trans. Sustain. Energy 2013, 4, 671–679. [Google Scholar] [CrossRef]
- Lee, G.; Ding, Y.; Genton, M.G.; Xie, L. Power curve estimation with multivariate environmental factors for inland and offshore wind farms. J. Am. Stat. Assoc. 2015, 110, 56–67. [Google Scholar] [CrossRef] [Green Version]
- Janssens, O.; Noppe, N.; Devriendt, C.; Van de Walle, R.; Van Hoecke, S. Data-driven multivariate power curve modeling of offshore wind turbines. Eng. Appl. Artif. Intell. 2016, 55, 331–338. [Google Scholar] [CrossRef]
- Burton, T.; Jenkins, N.; Sharpe, D.; Bossanyi, E. Wind Energy Handbook; John Wiley & Sons: Chicester, UK, 2011. [Google Scholar]
- Pelletier, F.; Masson, C.; Tahan, A. Wind turbine power curve modelling using artificial neural network. Renew. Energy 2016, 89, 207–214. [Google Scholar] [CrossRef]
- Manobel, B.; Sehnke, F.; Lazzús, J.A.; Salfate, I.; Felder, M.; Montecinos, S. Wind turbine power curve modeling based on Gaussian processes and artificial neural networks. Renew. Energy 2018, 125, 1015–1020. [Google Scholar] [CrossRef]
- Pandit, R.K.; Infield, D.; Carroll, J. Incorporating air density into a Gaussian process wind turbine power curve model for improving fitting accuracy. Wind Energy 2019, 22, 302–315. [Google Scholar] [CrossRef] [Green Version]
- Pandit, R.K.; Infield, D.; Kolios, A. Gaussian process power curve models incorporating wind turbine operational variables. Energy Rep. 2020, 6, 1658–1669. [Google Scholar] [CrossRef]
- Shetty, R.P.; Sathyabhama, A.; Pai, P.S. Comparison of modeling methods for wind power prediction: A critical study. Front. Energy 2020, 14, 347–358. [Google Scholar] [CrossRef]
- Karamichailidou, D.; Kaloutsa, V.; Alexandridis, A. Wind turbine power curve modeling using radial basis function neural networks and tabu search. Renew. Energy 2020, 163, 2137–2152. [Google Scholar] [CrossRef]
- Astolfi, D.; Castellani, F.; Natili, F. Wind Turbine Multivariate Power Modeling Techniques for Control and Monitoring Purposes. J. Dyn. Syst. Meas. Control 2021, 143, 034501. [Google Scholar] [CrossRef]
- Astolfi, D. Wind Turbine Operation Curves Modelling Techniques. Electronics 2021, 10, 269. [Google Scholar] [CrossRef]
- Pandit, R.K.; Infield, D. Comparative assessments of binned and support vector regression-based blade pitch curve of a wind turbine for the purpose of condition monitoring. Int. J. Energy Environ. Eng. 2019, 10, 181–188. [Google Scholar] [CrossRef] [Green Version]
- Pandit, R.; Infield, D. Gaussian process operational curves for wind turbine condition monitoring. Energies 2018, 11, 1631. [Google Scholar] [CrossRef] [Green Version]
- Aha, D.W.; Bankert, R.L.; Aha, D.W.; Bankert, R.L. A comparative evaluation of sequential feature selection algorithms. In Learning from Data; Springer: Berlin/Heidelberg, Germany, 1996; pp. 199–206. [Google Scholar]
- Cascianelli, S.; Astolfi, D.; Costante, G.; Castellani, F.; Fravolini, M.L. Experimental Prediction Intervals for Monitoring Wind Turbines: An Ensemble Approach. In Proceedings of the 2019 International Conference on Control, Automation and Diagnosis (ICCAD), Grenoble, France, 2–4 July 2019; pp. 1–6. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Astolfi, D.; Castellani, F.; Becchetti, M.; Lombardi, A.; Terzi, L. Wind Turbine Systematic Yaw Error: Operation Data Analysis Techniques for Detecting It and Assessing Its Performance Impact. Energies 2020, 13, 2351. [Google Scholar] [CrossRef]
- Tang, M.; Chen, W.; Zhao, Q.; Wu, H.; Long, W.; Huang, B.; Liao, L.; Zhang, K. Development of an SVR Model for the Fault Diagnosis of Large-Scale Doubly-Fed Wind Turbines Using SCADA Data. Energies 2019, 12, 3396. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Kocsis, G.; Xydis, G. Repair process analysis for wind turbines equipped with hydraulic pitch mechanism on the US market in focus of cost optimization. Appl. Sci. 2019, 9, 3230. [Google Scholar] [CrossRef] [Green Version]
- Astolfi, D.; Byrne, R.; Castellani, F. Estimation of the Performance Aging of the Vestas V52 Wind Turbine through Comparative Test Case Analysis. Energies 2021, 14, 915. [Google Scholar] [CrossRef]
- Wagner, R.; Cañadillas, B.; Clifton, A.; Feeney, S.; Nygaard, N.; Poodt, M.; St Martin, C.; Tüxen, E.; Wagenaar, J. Rotor equivalent wind speed for power curve measurement–comparative exercise for IEA Wind Annex 32. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2014; Volume 524, p. 012108. [Google Scholar]
- Van Sark, W.G.; Van der Velde, H.C.; Coelingh, J.P.; Bierbooms, W.A. Do we really need rotor equivalent wind speed? Wind Energy 2019, 22, 745–763. [Google Scholar] [CrossRef] [Green Version]
- Enevoldsen, P.; Xydis, G. Examining the trends of 35 years growth of key wind turbine components. Energy Sustain. Dev. 2019, 50, 18–26. [Google Scholar] [CrossRef]
- Astolfi, D.; Castellani, F.; Fravolini, M.L.; Cascianelli, S.; Terzi, L. Precision computation of wind turbine power upgrades: An aerodynamic and control optimization test case. J. Energy Resour. Technol. 2019, 141, 051205. [Google Scholar] [CrossRef]
- Astolfi, D.; Castellani, F.; Terzi, L. Wind Turbine Power Curve Upgrades. Energies 2018, 11, 1300. [Google Scholar] [CrossRef] [Green Version]
- Glowacz, A. Fault diagnosis of electric impact drills using thermal imaging. Measurement 2021, 171, 108815. [Google Scholar] [CrossRef]
- Marti-Puig, P.; Serra-Serra, M.; Solé-Casals, J. Wind Turbine Prognosis Models Based on SCADA Data and Extreme Learning Machines. Appl. Sci. 2021, 11, 590. [Google Scholar] [CrossRef]
- Delgado, I.; Fahim, M. Wind Turbine Data Analysis and LSTM-Based Prediction in SCADA System. Energies 2021, 14, 125. [Google Scholar] [CrossRef]
- Maldonado-Correa, J.; Martín-Martínez, S.; Artigao, E.; Gómez-Lázaro, E. Using SCADA Data for Wind Turbine Condition Monitoring: A Systematic Literature Review. Energies 2020, 13, 3132. [Google Scholar] [CrossRef]
- Vidal, Y.; Pozo, F.; Tutivén, C. Wind turbine multi-fault detection and classification based on SCADA data. Energies 2018, 11, 3018. [Google Scholar] [CrossRef] [Green Version]
- Astolfi, D.; Scappaticci, L.; Terzi, L. Fault diagnosis of wind turbine gearboxes through temperature and vibration data. Int. J. Renew. Energy Res. (IJRER) 2017, 7, 965–976. [Google Scholar]
- Xiao, C.; Liu, Z.; Zhang, T.; Zhang, X. Deep Learning Method for Fault Detection of Wind Turbine Converter. Appl. Sci. 2021, 11, 1280. [Google Scholar] [CrossRef]
- McKinnon, C.; Carroll, J.; McDonald, A.; Koukoura, S.; Infield, D.; Soraghan, C. Comparison of new anomaly detection technique for wind turbine condition monitoring using gearbox SCADA data. Energies 2020, 13, 5152. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Case | Rotor Diameter (m.) | Rated Power (MW) | Pitch Control | Data |
|---|---|---|---|---|
| Senvion MM92 | 92 | 2 | Electric | 2017–2018 |
| Vestas V90 | 90 | 2 | Hydraulic | 2019–2020 |
| Vestas V117 | 117 | 3.45 | Hydraulic | 2019–2020 |
| Test Case | Input Variables for the M Model |
|---|---|
| Senvion MM92 | (average) (mimimum) (standard deviation) (average) (minimum) (average) (minimum) (maximum) (standard deviation) |
| Vestas V90 | (average) (maximum) (standard deviation) (maximum) (average) (minimum) (maximum) (standard deviation) |
| Vestas V117 | (average) (maximum) (standard deviation) (standard deviation) (standard deviation) (average) (minimum) (maximum) (standard deviation) |
| Metric | M Model | Model |
|---|---|---|
| MAE (kW) | 17.4 | 23.9 |
| MAPE (%) | 4.7 | 4.9 |
| RMSE (kW) | 28.2 | 40.4 |
| Metric | M Model | Model |
|---|---|---|
| MAE (kW) | 25.5 | 31.2 |
| MAPE (%) | 4.7 | 6.0 |
| RMSE (kW) | 38.6 | 44.3 |
| Metric | M Model | Model |
|---|---|---|
| MAE (kW) | 48.8 | 61.6 |
| MAPE (%) | 10.1 | 12.9 |
| RMSE (kW) | 76.4 | 91.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Astolfi, D.; Castellani, F.; Lombardi, A.; Terzi, L. Multivariate SCADA Data Analysis Methods for Real-World Wind Turbine Power Curve Monitoring. Energies 2021, 14, 1105. https://doi.org/10.3390/en14041105
Astolfi D, Castellani F, Lombardi A, Terzi L. Multivariate SCADA Data Analysis Methods for Real-World Wind Turbine Power Curve Monitoring. Energies. 2021; 14(4):1105. https://doi.org/10.3390/en14041105
Chicago/Turabian StyleAstolfi, Davide, Francesco Castellani, Andrea Lombardi, and Ludovico Terzi. 2021. "Multivariate SCADA Data Analysis Methods for Real-World Wind Turbine Power Curve Monitoring" Energies 14, no. 4: 1105. https://doi.org/10.3390/en14041105
APA StyleAstolfi, D., Castellani, F., Lombardi, A., & Terzi, L. (2021). Multivariate SCADA Data Analysis Methods for Real-World Wind Turbine Power Curve Monitoring. Energies, 14(4), 1105. https://doi.org/10.3390/en14041105