
Prediction Method of Beijing Electric-Energy Substitution Potential Based on a Grid-Search Support Vector Machine

Abstract
:1. Introduction
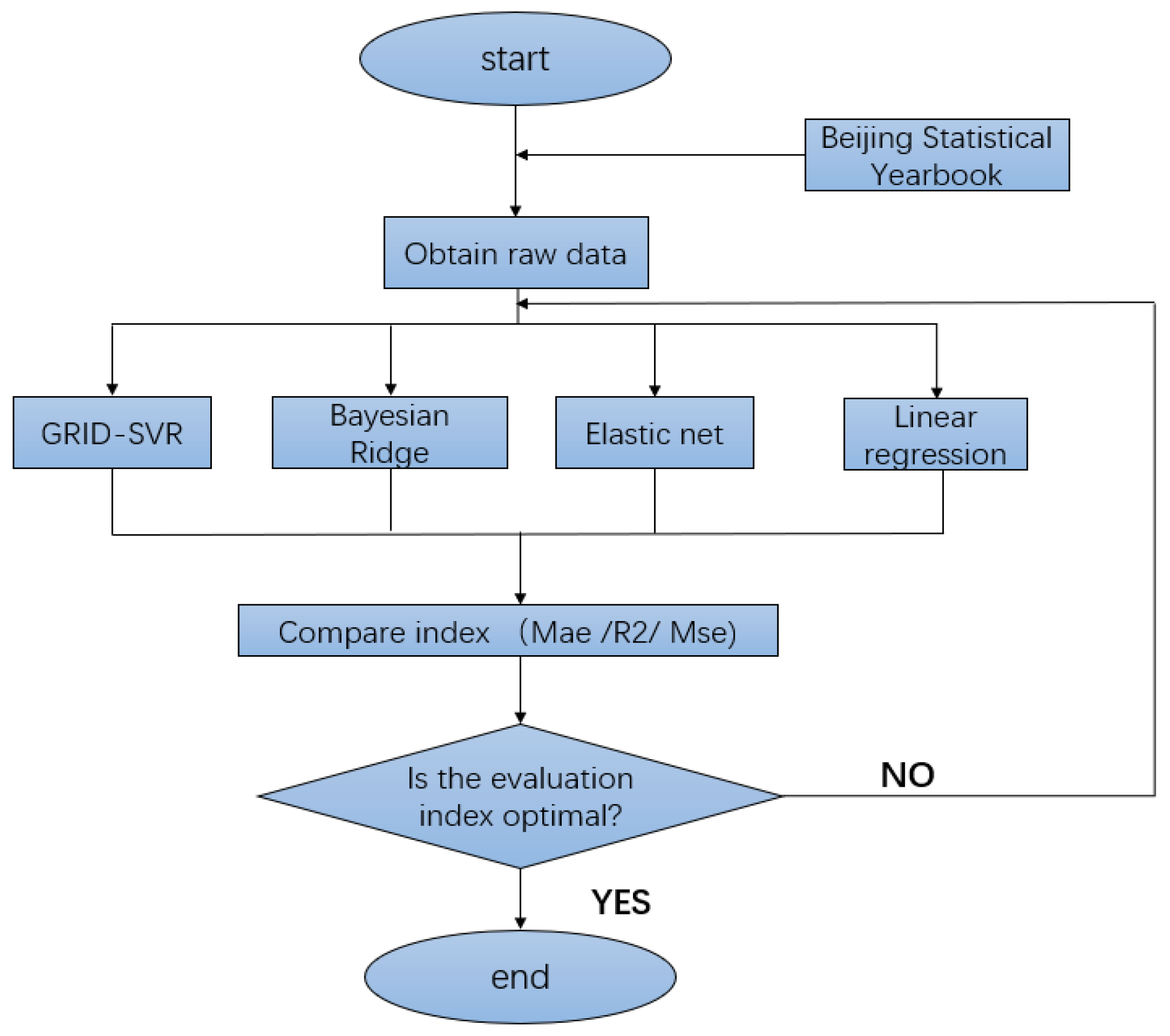
2. Methodology
2.1. Gaussian Kernel Support Vector Machine Model Based on Grid Search
2.1.1. The Basic Principle of Grey Correlation Degree Analysis
2.1.2. Cross-Validation of Grid Search
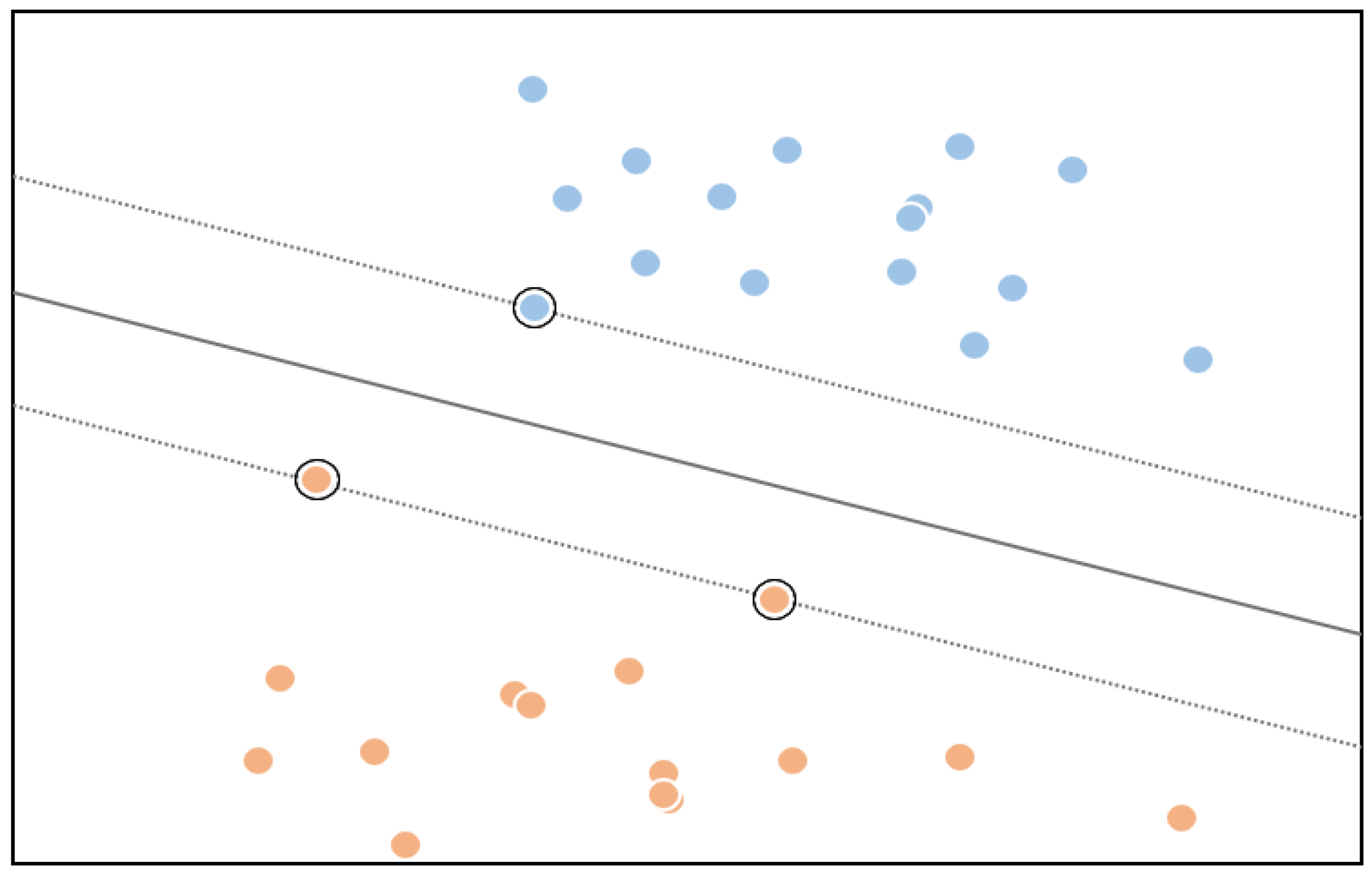
2.1.3. Gaussian Kernel Support Vector Machine
2.2. Model Accuracy Analysis
3. Results
3.1. Data Description and Model Parameters
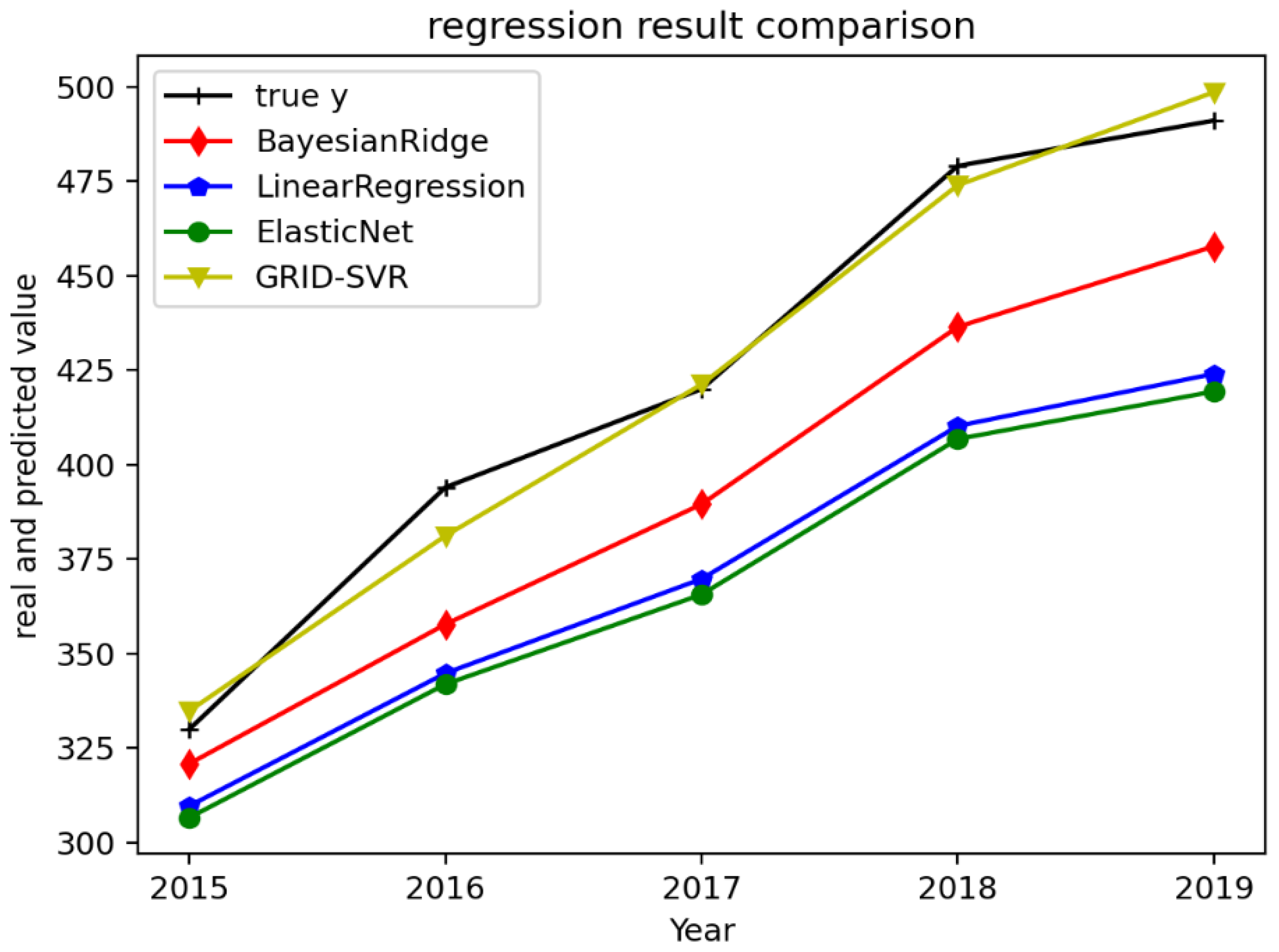
3.2. Forecasting Results of the Prediction Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Z. Electric energy substitution is an important way to achieve carbon peak carbon neutrality. Report. Obs. 2021, 13, 25–27. [Google Scholar]
- National Development and Reform Commission; National Energy Administration; Ministry of Finance. Guiding Opinions on Promoting Electric Energy Substitution; Development and Reform Energy [2016] No. 1054; National Development and Reform Commission: Beijing, China, 2016. [Google Scholar]
- Yan, T.; Cheng, H.; Zeng, P. Architecture and key technologies of energy Internet. Power Grid Technol. 2016, 40, 105–113. [Google Scholar]
- Tang, J.; Liu, J.; Yang, K.; Liu, Y. Short-term load combination forecasting by grey model and least square support vector machine. Power Syst. Technol. 2009, 33, 63–68. [Google Scholar]
- Song, H.; Hou, Y.; Wang, L. Apparent potential of energy saving and emission reduction analysis based on DEA model. Environ. Pollut. Prev. 2015, 37, 100–105. [Google Scholar]
- Zheng, J. Analysis of Rural Electric Energy Substitution Potential and Environmental Benefits. Ph.D. Thesis, North China Electric Power University, Beijing, China, 2015. [Google Scholar]
- Wang, A. Grey Forecasting Model and Application of Medium and Long Term Power Load Forecasting. Ph.D. Thesis, Huazhong University of Science and Technology, Wuhan, China, 2013. [Google Scholar]
- Liu, T.; Chen, K. Research on diffusion model of new energy vehicles in china based on bass model. Enterp. Econ. 2016, 11, 115–118. [Google Scholar]
- Lv, T.; Zhang, M.; Lei, Q. Scenario analysis and forecast of India’s energy and coal demand based on system dynamics. Resour. Sci. 2015, 6, 1199–1206. [Google Scholar]
- Liu, L.; Huang, T.; Fu, Y. Neural network prediction method of critical section considering meteorological factors. Power Grid Technol. 2016, 40, 3399–3405. [Google Scholar]
- Luo, N.; Zhu, Y.; Du, C. Application of Support Vector Machine in Power Load Forecasting. Power Grid Technol. 2007, 31, 215–218. [Google Scholar]
- Huang, R.; Wang, Z. Influencing factors of carbon emissions from energy consumptions in Chongqing. Acta Sci. Circumstantiae 2013, 33, 602–608. [Google Scholar]
- Jiao, W.; Chen, X. Environmental impact analysis of Gansu province based on the STIRPAT model. Resour. Environ. Yangtze Basin 2012, 21, 105–110. [Google Scholar]
- Lu, N.; Qu, F.; Feng, S.; Shao, X. Trends and determining factors of energy consumption carbon footprint—an analysis for Suzhou-Wuxi-Changzhou region based on STIRPAT model. J. Nat. Resour. 2011, 26, 814–824. [Google Scholar]
- Diezt, T.; Rosa, E.A. Rethinking the environmental impacts of population, affluence and technology. Hum. Ecol. Rev. 1994, 1, 277–300. [Google Scholar]
- Wang, Y.; Wang, X.; Sun, C.; Lu, X. Research on the application of IPAT and its extended model. Chin. J. Appl. Ecol. 2015, 26, 949–957. [Google Scholar]
- Shan, B.; Zhao, J.; Jia, D. Electric power substitution potential analysis method based on STIRPAT-ridge regression. Distrib. Util. 2018, 35, 68–73. [Google Scholar]
- Sun, Y.; Shan, B.; Cao, Y. Analysis method of electric energy substitution potential based on particle swarm optimization support vector machine. Power Grid Technol. 2017, 41, 1767–1771. [Google Scholar]
- Fan, D.; Wang, S.; Zhang, W. Research on China’s power demand forecast under the goal of low-carbon economy. Power Grid Technol. 2012, 36, 19–25. [Google Scholar]
- Lin, B. Structural change, efficiency improvement and energy demand forecast-taking China’s electric power industry as an example. Econ. Res. 2003, 19, 57–65. [Google Scholar]
- Li, Y.; Fang, T.; Yu, E. Study of support vector machines for short-term load forecasting. Proc. CSEE 2003, 23, 55–59. (In Chinese) [Google Scholar]
- Yuan, X.; Wang, C.; Zhang, Y.; Yuan, Y. A survey on application of particle swarm optimization to electric power systems. Power Syst. Technol. 2004, 28, 14–19. [Google Scholar]
- Gao, H.; Gao, L.; Zhou, C.; Yu, D. Particle swarm optimization based algorithm for neural network learning. Acta Electron. Sin. 2004, 32, 1572–1574. [Google Scholar]
- Li, C.; Niu, D.; Zhang, X.; Miao, B. Prediction model of Zhejiang electric energy substitution potential based on improved particle swarm optimization BP neural network. Sci. Technol. Eng. 2020, 20, 5173–5179. [Google Scholar]
- Yin, H. Research on Evaluation Method of Electric Energy Replacing Other Energy Sources in Energy-Saving and Emission-Reducing Environment. Ph.D. Thesis, North China Electric Power University, Beijing, China, 2013. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Degree of Correlation | Factors | Degree of Correlation |
|---|---|---|---|
| Total energy consumption | 0.97 | Coal and oil consumption | 0.72 |
| Per capita GDP | 0.95 | Investment in power infrastructure | 0.84 |
| Renewable energy generation | 0.83 | Urbanization rate | 0.93 |
| Sales of electricity | 0.87 | CO2 emissions | 0.92 |
| Year | Urbanization Rate (%) | Electric Energy Consumption (Ten Thousand Tons of Standard Coal) | Per Capita GDP (Yuan) | CO2 Emissions (Million Tons) | Cumulative Electric Energy Substitution (Ten Thousand Tons of Standard Coal) |
|---|---|---|---|---|---|
| 2019 | 0.87 | 1434 | 164,220 | 71 | 491 |
| 2018 | 0.87 | 1404 | 153,095 | 71 | 479 |
| 2017 | 0.87 | 1311 | 137,596 | 70 | 420 |
| 2016 | 0.87 | 1254 | 124,516 | 75 | 394 |
| 2015 | 0.87 | 1171 | 114,662 | 83 | 330 |
| 2014 | 0.86 | 1152 | 107,472 | 89 | 306 |
| 2013 | 0.86 | 1122 | 101,023 | 87 | 295 |
| 2012 | 0.86 | 1075 | 93,078 | 96 | 273 |
| 2011 | 0.86 | 1010 | 86,365 | 95 | 235 |
| 2010 | 0.86 | 995 | 78,307 | 97 | 226 |
| 2009 | 0.85 | 908 | 71,059 | 96 | 192 |
| 2008 | 0.85 | 848 | 68,541 | 92 | 164 |
| 2007 | 0.85 | 820 | 63,629 | 80 | 142 |
| 2006 | 0.84 | 752 | 53,438 | 81 | 122 |
| 2005 | 0.84 | 701 | 47,182 | 95 | 120 |
| 2004 | 0.8 | 627 | 42,402 | 77 | 35 |
| 2003 | 0.79 | 567 | 36,583 | 69 | 35 |
| 2002 | 0.79 | 541 | 32,231 | 64 | 34 |
| 2001 | 0.78 | 492 | 28,097 | 62 | 9 |
| Model Error Analysis | |||
|---|---|---|---|
| MODEL | R2 | MAE | MSE |
| Bayesian Ridge | 0.7 | 30.3 | 1048 |
| Linear Regression | 0.16 | 51.1 | 2912 |
| Elastic Net | 0.04 | 54.7 | 3311 |
| Grid-SVR | 0.98 | 6.3 | 54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chi, Y.; Zhang, Y.; Li, G.; Yuan, Y. Prediction Method of Beijing Electric-Energy Substitution Potential Based on a Grid-Search Support Vector Machine. Energies 2022, 15, 3897. https://doi.org/10.3390/en15113897
Chi Y, Zhang Y, Li G, Yuan Y. Prediction Method of Beijing Electric-Energy Substitution Potential Based on a Grid-Search Support Vector Machine. Energies. 2022; 15(11):3897. https://doi.org/10.3390/en15113897
Chicago/Turabian StyleChi, Yuanying, Yangyi Zhang, Guozheng Li, and Yongke Yuan. 2022. "Prediction Method of Beijing Electric-Energy Substitution Potential Based on a Grid-Search Support Vector Machine" Energies 15, no. 11: 3897. https://doi.org/10.3390/en15113897
APA StyleChi, Y., Zhang, Y., Li, G., & Yuan, Y. (2022). Prediction Method of Beijing Electric-Energy Substitution Potential Based on a Grid-Search Support Vector Machine. Energies, 15(11), 3897. https://doi.org/10.3390/en15113897