


Monopolar Grounding Fault Location Method of DC Distribution Network Based on Improved ReliefF and Weighted Random Forest


Abstract
:1. Introduction
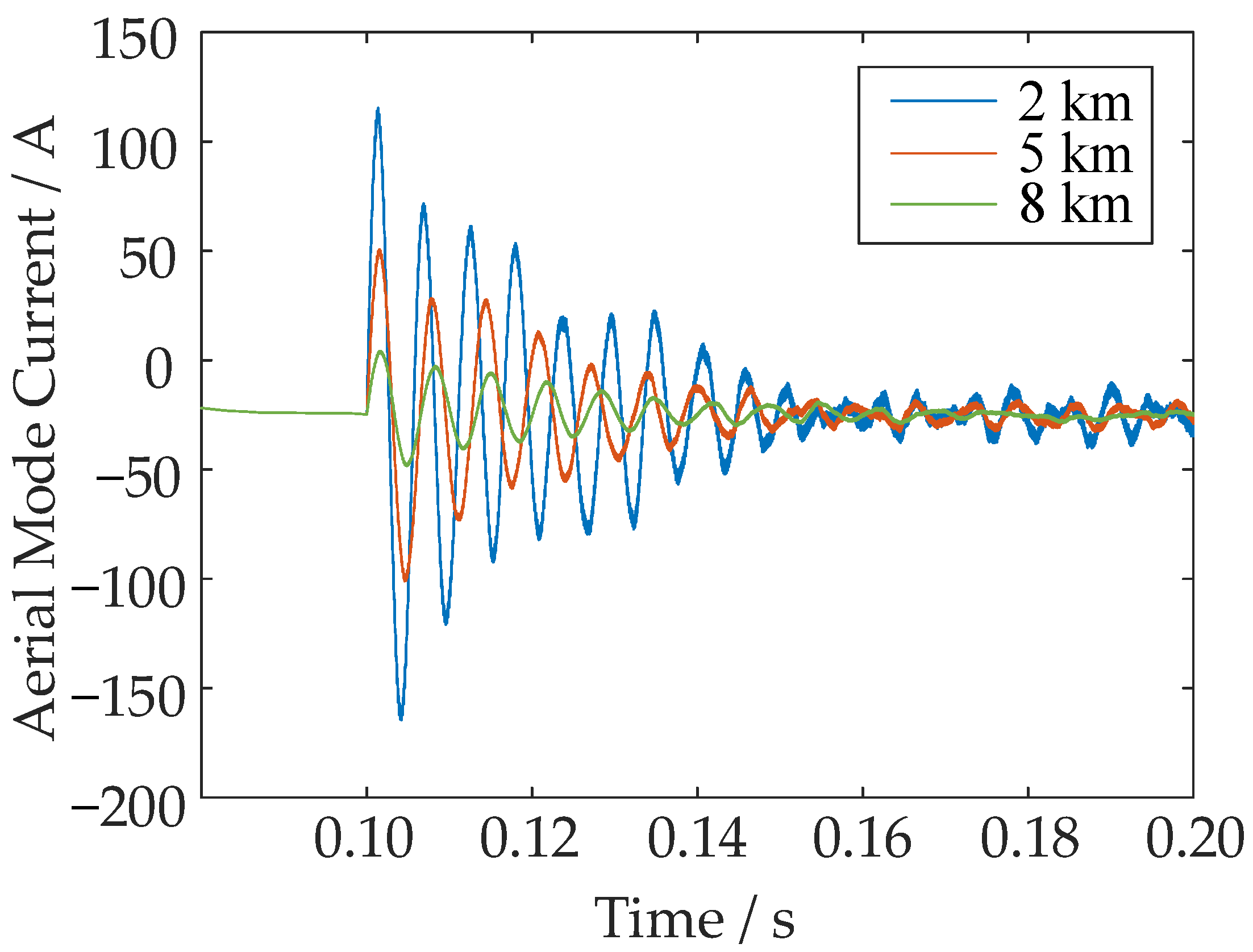
- When a monopolar grounding short-circuit occurs in DC distribution lines, we construct 24 time and frequency-domain fault characteristics using the aerial mode current at the single terminal of the line.
- In this paper, the limited coefficient q is introduced to solve the shortcomings of the ReliefF algorithm in application and combined with the Pearson correlation coefficient method to automatically screen the optimal feature subset. The optimal subset and feature weight are calculated by the improved ReliefF algorithm, and the average value of the weights is taken as the final weight value. The optimal feature subset containing the weight coefficient can be obtained. The weight coefficient can continue to be used to improve the performance and fault location accuracy of the WRF algorithm in subsequent steps.
- The weighted random forest algorithm proposed in this paper mainly improves the traditional random forest algorithm in two aspects. On the one hand, considering that the improved ReliefF can obtain the specific values of the feature weight, it can be combined with the RF algorithm to form a weighted random forest algorithm, which can improve the accuracy of the model in a targeted manner. On the other hand, using the loop statement to find the values of mtry and ntree with the best model fit makes the fault location scheme more accurate. Combining the improved ReliefF with the RF, the features are no longer selected randomly, but the optimal feature subset is selected for the dataset in advance. This improvement reduces the dimensionality of the features in its input RF and eliminates redundant features, thereby greatly reducing the computation time and improving the accuracy.
- The simulation validation shows that the improved WRF algorithm has high accuracy under various conditions when applied to fault location in a DC distribution network. It has strong anti-fault resistance and anti-noise capability within a certain time window and has strong adaptability. The principle of the method is simple; only local measurement is required, no need to send and synchronize information at both ends, which greatly reduces the management and investment costs of sampling equipment and has strong engineering practicability.
2. Multiple Fault Characteristics and Optimal Feature Selection Algorithm
2.1. Monopolar Grounding Fault in a DC Distribution Network
2.2. Multiple Fault Characteristics
- Time-domain: T1: average value; T2: standard deviation; T3: square root amplitude; T4: root mean square; T5: peak value; T6: skewness; T7: kurtosis; T8: crest factor; T9: clearance indicator; T10: shape indicator; T11: impulse indicator.
- Frequency-domain: T12: central frequency; T13: variance frequency; T14: skewness frequency; T15: peak value frequency; T16: gravity frequency; T17: standard deviation frequency; T18: root mean square frequency; T19: mean square frequency; T20: waveform stability factor; T21: coefficient of variation; T22: skewness frequency; T23: kurtosis frequency; T24: square root ratio.
2.3. Optimal Feature Subset Selection
2.3.1. ReliefF Algorithm
- Randomly select a sample Ri from the feature ensemble training set.
- Find the K nearest neighbor samples Hj and Mj (j = 1, 2, …, K) from the set of samples of both the same and different classes as sample Ri, respectively.
- Use the K-nearest neighbors (KNN) idea to iterate repeatedly on each feature dimension and update the weight W(Tp) of each feature Tp (p = 1, 2, …,24) according to Formula (3).
- 4.
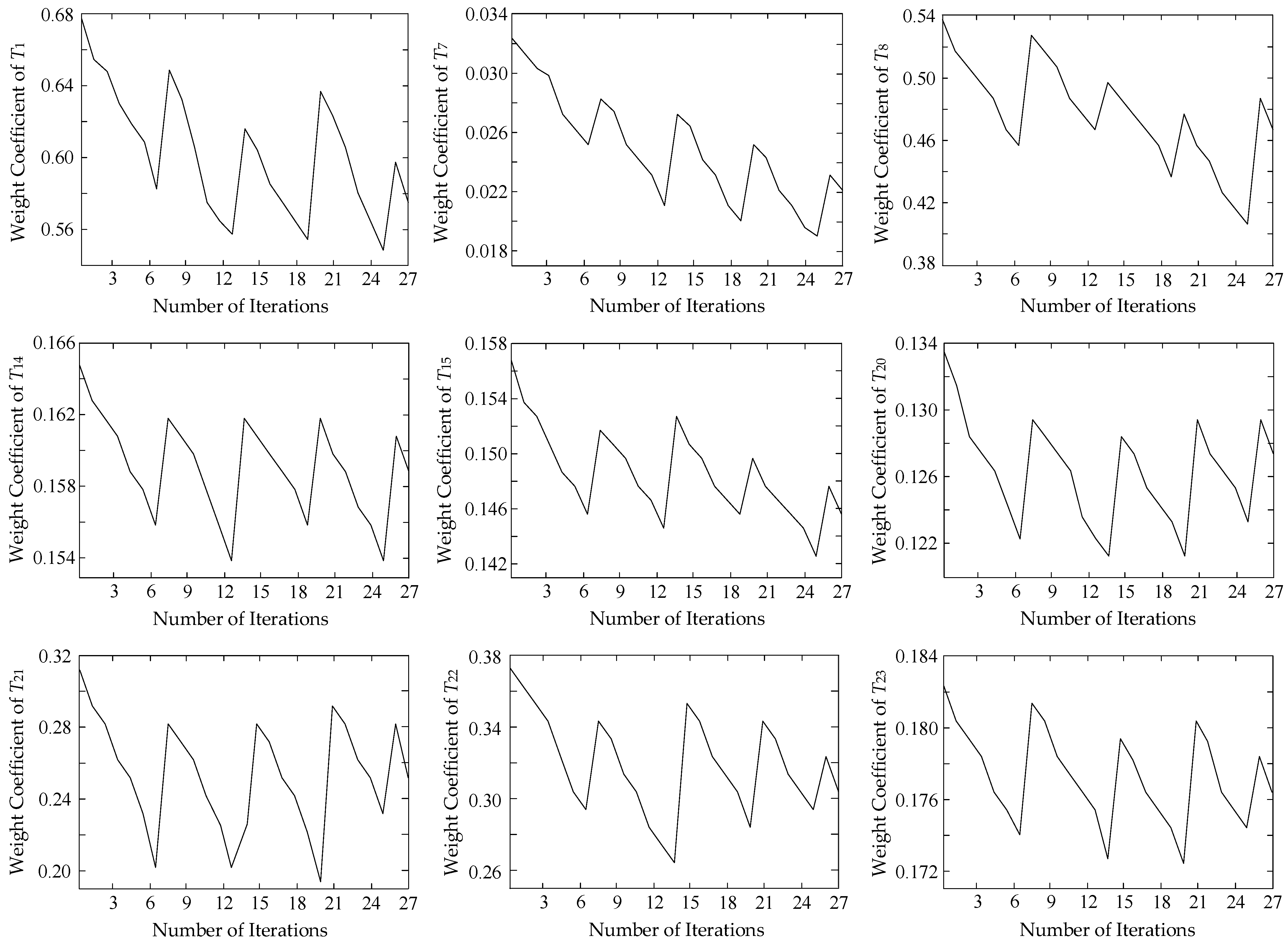
- Repeat the above process m times, and calculate the average weight as the final assignment result of the feature.
- 5.
- After the iterations are completed, the weights W(Tp) of the features are ranked from largest to smallest, and the top-ranked features are extracted according to the set weight threshold α to form the feature subset.
2.3.2. Deficiency and Improvement Strategy
- The random selection of samples may lead to the selection of edge samples or interference samples with wild values, which may cause errors when updating the feature weights. At the same time, random selection does not guarantee every small category sample is selected, and the number of samples selected is uneven. These factors will affect the stability and accuracy of feature selection.
- The algorithm is sensitive to the number of iterations m and the number of nearest neighbor samples K. Different combinations of parameters may lead to different assignment results. It is necessary to consider the actual classification situation and assign values determined by m and K.
- Only the contribution of different features to the classification can be calculated, and the subset of features formed does not exclude the possible redundant features.
2.3.3. Process of Improved ReliefF Algorithm
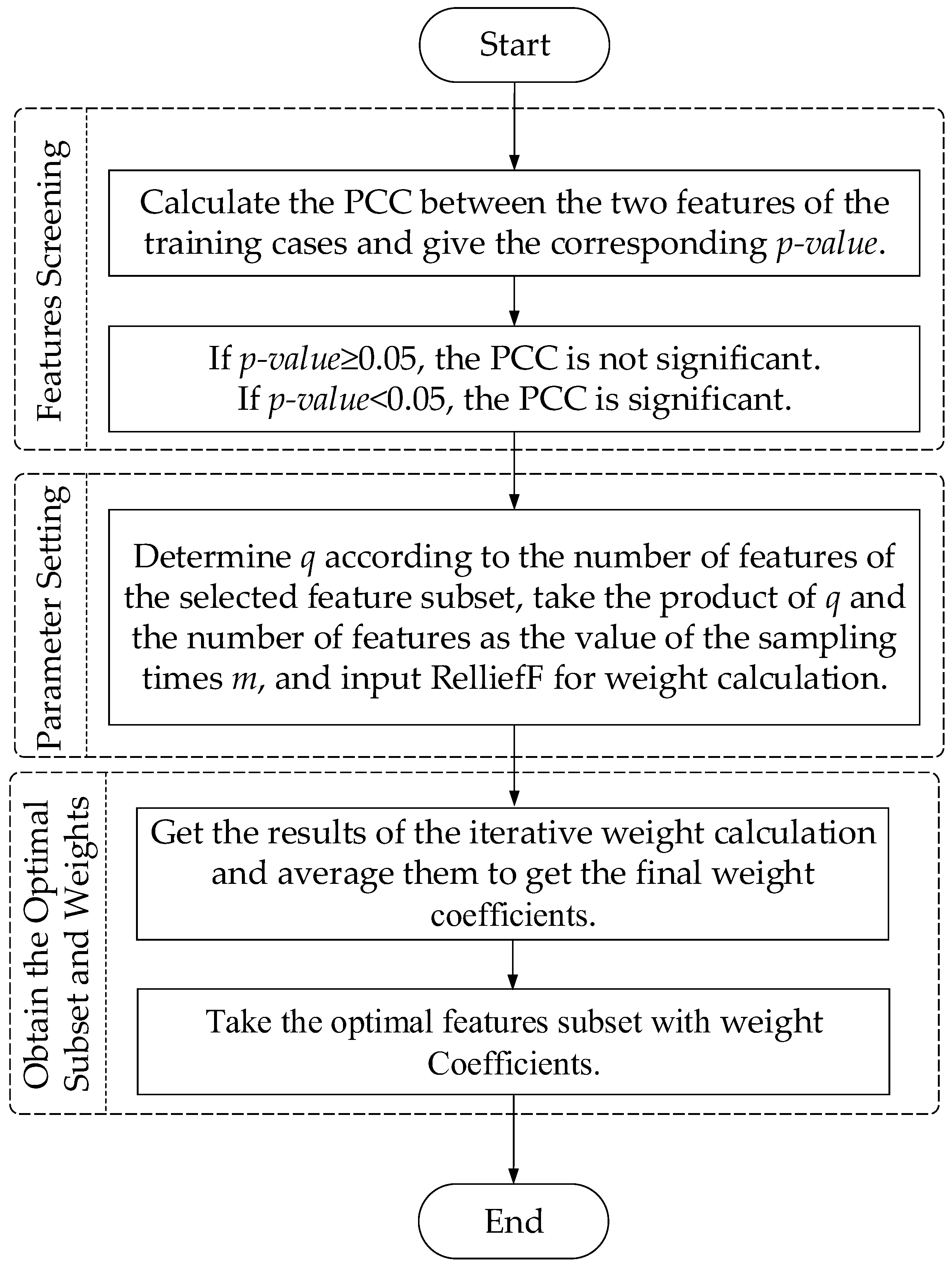
- The process of feature subset selection mainly includes the following three steps: Calculate the PCC between each feature in the training set and select features based on whether the p-value is greater than 0.05. If the p-value ≥ 0.05, it means that there is no significant correlation between them, even if the PCC is close to 0, the two features cannot be selected together. Otherwise, if the p-value < 0.05, the calculated correlation coefficient result is significant.
- Determine the limit coefficient q according to the number of feature elements of the remaining feature subsets, and then use the product of q and the number of features as the sampling times. Then input it into the ReliefF model for feature weight calculation
- The average of the feature weights are taken as the final weight value, and the feature values in the feature subset are multiplied by the corresponding final weights to obtain the optimal feature subset containing the weight coefficients. The weight coefficient can continue to be used to improve the performance and fault location accuracy of the subsequent RF algorithm [21].
3. Weighted Random Forest
3.1. Random Forest Algorithm
- Use bootstrap resampling to extract an equal number of samples with replacement from the training set and use them as the training set for a single decision tree.
- The decision tree starts to split from the top to the bottom of the node. When splitting, a portion of the features m (m is a positive integer less than M) from the M explanatory variables in the sample is extracted as a sub-feature. Then, select an optimal feature from the sub-feature m for node splitting.
- Each decision tree is repeatedly split according to step 2 until the node cannot be split.
- A total of N decision trees are generated through steps 2 and 3. Each decision tree is fitted with a weak learner, and the optimal fitting result is finally selected by voting and output as the result.
3.2. Weighted Random Forest
- Use the improved ReliefF algorithm to filter out the optimal subset of features in the original training set and generate the corresponding weights for the features.
- Build the WRF fault location model, then find and set the optimal mtry and ntree values by using a loop statement.
- Multiply the calculated weights with the feature values and input them into the WRF model for fitting. Calculate the error rate of out of bag (OOB) data and evaluate the goodness of fit of the model.
4. Monopolar Grounding Fault Location Method Based on Improved ReliefF and WRF
- Start to record the current and voltage data at the observation point for 100 ms when the relay protection device detects the monopolar grounding in the DC distribution line. The Karenbauer transform was performed on the recorded data to calculate the aerial mode currents.
- According to the aerial mode current, 11 time-domain features and 13 frequency-domain features are calculated to form the original multi-feature parameter table.
- The PPC is used to eliminate the redundant features in the original multi-feature parameter table.
- The de-redundant features are input into the improved ReliefF model for weight iterative calculation. We take the average value of the weight as the weight of the feature. ReliefF automatically selects the feature with the highest weight to form the optimal feature subset.
- Calculate the product of the weights and the value of the feature as the weight for the input WRF. Establish the fault location model based on WRF, where the optimal parameters of the algorithm are determined by loop statements.
- Use the WRF algorithm to solve for the location of monopolar grounding on a DC distribution line and output the fault location results. The WRF algorithm is used to solve the monopolar grounding fault location of the DC distribution network and output the fault location result.
5. Simulation and Discussions
5.1. Model Construction and Simulation Analysis
5.2. Effect of Fault Resistances
5.3. Effect of Noise
5.4. Effect of Time Window Length
5.5. Comparison with Other Estimators and Intelligent Fault Location Methods
5.6. Application to Fault Line Identification
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x(actual)/km | Rf = 10 Ω | Rf = 100 Ω | ||
| x(measure)/km | Perror/% | x(measure)/km | Perror/% | |
| 0.3 | 0.2870 | 0.130 | 0.2672 | 0.328 |
| 0.8 | 0.7997 | 0.003 | 0.7894 | 0.106 |
| 1.0 | 1.0320 | 0.320 | 1.0425 | 0.425 |
| 1.5 | 1.5009 | 0.009 | 1.5107 | 0.107 |
| 2.0 | 1.9963 | 0.037 | 1.9866 | 0.134 |
| 2.7 | 2.7222 | 0.222 | 2.7528 | 0.528 |
| 3.0 | 3.0323 | 0.323 | 3.0423 | 0.423 |
| 3.1 | 3.1043 | 0.043 | 3.1140 | 0.140 |
| 4.0 | 4.0072 | 0.072 | 4.0179 | 0.179 |
| 4.4 | 4.4024 | 0.024 | 4.4121 | 0.121 |
| 5.0 | 5.0097 | 0.097 | 5.0192 | 0.192 |
| 5.6 | 5.6299 | 0.299 | 5.6390 | 0.390 |
| 6.0 | 6.0390 | 0.390 | 6.0491 | 0.491 |
| 7.0 | 7.0014 | 0.014 | 7.0417 | 0.417 |
| 7.3 | 7.3001 | 0.001 | 7.3105 | 0.105 |
| 8.0 | 8.0029 | 0.029 | 8.0126 | 0.126 |
| 8.8 | 8.8189 | 0.189 | 8.8284 | 0.284 |
| 9.0 | 8.9877 | 0.123 | 8.9778 | 0.222 |
| 9.8 | 9.8318 | 0.318 | 9.8319 | 0.319 |
| x(actual)/km | SNR = 60 dB | SNR = 40 dB | SNR = 20 dB | |||
| x(measure)/km | Perror/% | x(measure)/km | Perror/% | x(measure)/km | Perror/% | |
| 0.3 | 0.2670 | 0.330 | 0.2660 | 0.340 | 0.2654 | 0.346 |
| 0.8 | 0.7790 | 0.210 | 0.7784 | 0.216 | 0.7777 | 0.223 |
| 1.0 | 1.0354 | 0.354 | 1.0427 | 0.427 | 1.0508 | 0.508 |
| 1.5 | 1.5093 | 0.093 | 1.5170 | 0.170 | 1.5245 | 0.245 |
| 2.0 | 1.9878 | 0.122 | 1.9875 | 0.125 | 1.9876 | 0.124 |
| 2.7 | 2.7273 | 0.273 | 2.7317 | 0.317 | 2.7363 | 0.363 |
| 3.0 | 3.0256 | 0.256 | 3.0251 | 0.251 | 3.0241 | 0.241 |
| 3.1 | 3.1220 | 0.220 | 3.1250 | 0.250 | 3.1282 | 0.282 |
| 4.0 | 4.0041 | 0.041 | 4.0042 | 0.042 | 4.0034 | 0.034 |
| 4.4 | 4.4089 | 0.089 | 4.4171 | 0.171 | 4.4253 | 0.253 |
| 5.0 | 5.0096 | 0.096 | 5.0143 | 0.143 | 5.0195 | 0.195 |
| 5.6 | 5.6202 | 0.202 | 5.6307 | 0.307 | 5.6414 | 0.414 |
| 6.0 | 6.0291 | 0.291 | 6.0338 | 0.338 | 6.0386 | 0.386 |
| 7.0 | 7.0163 | 0.163 | 7.0174 | 0.174 | 7.0187 | 0.187 |
| 7.3 | 7.3121 | 0.121 | 7.3262 | 0.262 | 7.3400 | 0.400 |
| 8.0 | 8.0059 | 0.059 | 8.0151 | 0.151 | 8.0243 | 0.243 |
| 8.8 | 8.8148 | 0.148 | 8.8283 | 0.283 | 8.8411 | 0.411 |
| 9.0 | 8.9876 | 0.124 | 8.9727 | 0.273 | 8.9572 | 0.428 |
| 9.8 | 9.8302 | 0.302 | 9.8471 | 0.471 | 9.8638 | 0.638 |
| x(actual)/km | 80 ms Data Window Length | 50 ms Data Window Length | ||
| x(measure)/km | Perror/% | x(measure)/km | Perror/% | |
| 0.3 | 0.2741 | 0.259 | 0.2619 | 0.381 |
| 0.8 | 0.8673 | 0.673 | 0.8565 | 0.565 |
| 1.0 | 1.0455 | 0.455 | 1.0651 | 0.651 |
| 1.5 | 1.5789 | 0.789 | 1.5885 | 0.885 |
| 2.0 | 2.0407 | 0.407 | 2.0512 | 0.512 |
| 2.7 | 2.6699 | 0.301 | 2.6582 | 0.418 |
| 3.0 | 3.0409 | 0.409 | 3.0518 | 0.518 |
| 3.1 | 3.1014 | 0.014 | 3.1118 | 0.118 |
| 4.0 | 4.0103 | 0.103 | 4.0211 | 0.211 |
| 4.4 | 4.4116 | 0.116 | 4.4270 | 0.270 |
| 5.0 | 5.0476 | 0.476 | 5.0567 | 0.567 |
| 5.6 | 5.5516 | 0.484 | 5.6416 | 0.416 |
| 6.0 | 6.0141 | 0.141 | 6.0214 | 0.214 |
| 7.0 | 7.0761 | 0.761 | 7.0828 | 0.828 |
| 7.3 | 7.3052 | 0.052 | 7.3158 | 0.158 |
| 8.0 | 8.0052 | 0.052 | 8.0195 | 0.195 |
| 8.8 | 8.8271 | 0.271 | 8.8399 | 0.399 |
| 9.0 | 9.0712 | 0.712 | 9.0801 | 0.845 |
| 9.8 | 9.8473 | 0.473 | 9.8586 | 0.457 |
References
- Han, B.; Li, Y. Simulation Test of a DC Fault Current Limiter for Fault Ride-Through Problem of Low-Voltage DC Distribution. Energies 2020, 13, 1753. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Yuan, X.; Xiong, W.; Zheng, H.; Xu, Y.; Cai, Y.; Zhong, J. Flexible Interconnected Distribution Network with Embedded DC System and Its Dynamic Reconfiguration. Energies 2022, 15, 5589. [Google Scholar] [CrossRef]
- Jia, K.; Xuan, Z.; Feng, T.; Wang, C.; Bi, T.; Thomas, D.W.P. Transient High-Frequency Impedance Comparison-Based Protection for Flexible DC Distribution Systems. IEEE Trans. Smart Grid 2020, 11, 323–333. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, J.; Jin, W.; Fu, Y.; Yang, H. Fault Location Method for DC Distribution Systems Based on Parameter Identification. Energies 2018, 11, 1983. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Jia, K.; Bi, T.; Yang, Q. Sixth harmonic-based fault location for VSC-DC distribution systems. IET Gener. Transm. Distrib. 2017, 11, 3485–3490. [Google Scholar] [CrossRef]
- Wang, S.; Fan, C.; Jiang, S. Fault protection scheme for DC distribution network based on ratio of transient voltage principle. Electr. Power Autom. Equip. 2020, 40, 196–205. [Google Scholar]
- Wang, X.; Gao, J.; Wu, L.; Song, G.; Wei, Y. A high impedance fault detection method for flexible DC distribution network. Trans. China Electrotech. Soc. 2019, 34, 2806–2819. [Google Scholar]
- Wang, C.; Jia, K.; Bi, T.; Xuan, Z.; Zhu, R. Transient current curvature based protection for multi-terminal flexible DC distribution systems. IET Gener. Transm. Distrib. 2019, 13, 3484–3492. [Google Scholar] [CrossRef]
- Wu, Y.; Ye, Y.; Ma, X.; Li, Z.; Wu, T.; Xu, H. Single pole-to-ground fault locating method with ability against synchronization error and high fault resistance for DC distribution network. Electr. Power Autom. Equip. 2022, 42, 1–8. [Google Scholar]
- Masaoki, A.; Schweitzer, E.; Baker, R. Development and field-data evaluation of single-end fault locator for two-terminal HVDC transmission lines-II:algorithm and evaluation. IEEE Trans. Power Appar. Syst. 1985, 104, 3531–3537. [Google Scholar]
- Cheng, J.; Guan, M.; Tang, L.; Huang, H.; Chen, X.; Xie, J. Paralleled multi-terminal DC transmission line fault locating method based on travelling wave. IET Gener. Transm. Distrib. 2014, 8, 2092–2101. [Google Scholar] [CrossRef]
- He, Z.; Liao, K.; Li, X.; Lin, S.; Yang, J.; Mai, R. Natural frequency-based Line fault location in HVDC Lines. IEEE Trans. Power Deliv. 2014, 29, 851–859. [Google Scholar] [CrossRef]
- Zhang, S.; Zou, G.; Huang, Q.; Gao, H. A traveling-wave-based fault location scheme for MMC-based multi-terminal DC grids. Energies 2018, 11, 401. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Liu, J.; Zhang, S. Fault Location Method Based on Genetic Algorithm for DC Distribution Network. Acta Energ. Sol. Sin. 2020, 41, 1–8. [Google Scholar]
- Ma, C.; Li, B.; He, J.; Li, Y.; Mao, Q.; Wang, S.; Li, G.; Hu, Z. The improved fault location method for flexible direct current grid based on clustering and iterating algorithm. IET Renew. Power Gener. 2021, 15, 3577–3587. [Google Scholar] [CrossRef]
- Yang, H.; Xu, Y.; Qin, B.; Wang, Q. Fault Location Method for DC Distribution Network Based on Particle Swarm Optimization. In Proceedings of the2019 IEEE 2nd International Conference on Electronics Technology (ICET), Chengdu, China, 10–13 May 2019. [Google Scholar]
- Mohammad, F. Locating Short-circuit Faults in HVDC Systems Using Automatically Selected Frequency-domain Features. Int. Trans. Trans. Electr. Energy Syst. 2019, 29, e2765. [Google Scholar]
- Su, W.; Yang, J.; Jia, Y.; Xiao, X.; Liu, R.; Si, X. Single-terminal traveling wave line selection in DC distribution system. In Proceedings of the 16th IET International Conference on AC and DC Power Transmission (ACDC 2020), Online Conference, 2–3 July 2020. [Google Scholar]
- Saber, A.; Zeineldin, H.H.; El-Fouly, T.H.M.; Al-Durra, A. Time-Domain Fault Location Algorithm for Double-Circuit Transmission Lines Connected to Large Scale Wind Farms. IEEE Access 2021, 9, 11393–11404. [Google Scholar] [CrossRef]
- Yang, J.; Wang, X.; Wang, D. An Unsupervised Feature Selection Method Based on Improved ReliefF and Bisecting K-means. In Proceedings of the International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018. [Google Scholar]
- Peker, M.; Arslan, A.; Şen, B.; Çelebi, F.V.; But, A. A novel hybrid method for determining the depth of anesthesia level: Combining ReliefF feature selection and random forest algorithm (ReliefF+RF). In Proceedings of the International Symposium on Innovations in Intelligent SysTems and Applications (INISTA), Madrid, Spain, 2–4 September 2015. [Google Scholar]
- Tzelepis, D.; Dyśko, A.; Fusiek, G.; Niewczas, P.; Mirsaeidi, S.; Booth, C.; Dong, X. Advanced fault location in MTDC networks utilising optically-multiplexed current measurements and machine learning approach. Int. J. Electr. Power Energy Syst. 2018, 97, 319–333. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Le, B.S.; Aggarwal, R.; Wang, Y.; Li, J. New ANN method for multi-terminal HVDC protection relaying. Electr. Power Syst. Res. 2017, 148 (Suppl. C), 192–201. [Google Scholar] [CrossRef] [Green Version]
- Hao, Y.; Wang, Q.; Li, Y.; Song, W. An intelligent algorithm for fault location on VSC-HVDC system. Int. J. Electr. Power Energy Syst. 2018, 94 (Suppl. C), 116–123. [Google Scholar] [CrossRef]












| No. | Formula | No. | Formula | No. | Formula | No. | Formula |
|---|---|---|---|---|---|---|---|
| 1 | 7 | 13 | 19 | ||||
| 2 | 8 | 14 | 20 | ||||
| 3 | 9 | 15 | 21 | ||||
| 4 | 10 | 16 | 22 | ||||
| 5 | 11 | 17 | 23 | ||||
| 6 | 12 | 18 | 24 |
| Parameters | Value |
|---|---|
| DC bus voltage/V | 500 |
| DC capacitance/mF | 20 |
| Line resistance value per unit length/Ω·km−1 | 0.0139 |
| Line inductance value per unit length/mH·km−1 | 0.159 |
| Length/km | 10 |
| Sampling frequency/kHz | 100 |
| Rated wind speed/m·s−1 | 12 |
| Wind power rated speed/r·min−1 | 75 |
| VSC rated power/kW | 20 |
| Battery rated power/kW | 20 |
| Load unit rated power/kW | 20 |
| Optimal Features Tp | Weight Coefficient W(Tp) | Optimal Features Tp | Weight Coefficient W(Tp) |
|---|---|---|---|
| T1 | 0.621978 | T20 | 0.126173 |
| T7 | 0.029730 | T21 | 0.258922 |
| T8 | 0.592293 | T22 | 0.321860 |
| T14 | 0.147733 | T23 | 0.177813 |
| T15 | 0.131527 | - | - |
| x(actual)/km | Random Forest | Weighted Random Forest | ||
|---|---|---|---|---|
| x(measure)/km | Perror/% | x(measure)/km | Perror/% | |
| 0.3 | 0.2301 | 0.699 | 0.2957 | 0.043 |
| 0.8 | 0.8036 | 0.036 | 0.8027 | 0.027 |
| 1.0 | 1.0077 | 0.077 | 1.0055 | 0.055 |
| 1.5 | 1.5224 | 0.224 | 1.5030 | 0.030 |
| 2.0 | 2.0139 | 0.139 | 2.0017 | 0.017 |
| 2.7 | 2.7427 | 0.427 | 2.7029 | 0.029 |
| 3.0 | 3.0350 | 0.350 | 3.0084 | 0.084 |
| 3.1 | 3.1227 | 0.227 | 3.1027 | 0.027 |
| 4.0 | 4.0383 | 0.383 | 4.0073 | 0.073 |
| 4.4 | 4.4523 | 0.523 | 4.4083 | 0.083 |
| 5.0 | 5.0339 | 0.339 | 5.0009 | 0.009 |
| 5.6 | 5.5220 | 0.780 | 5.6014 | 0.014 |
| 6.0 | 6.0921 | 0.921 | 6.0113 | 0.113 |
| 7.0 | 7.0801 | 0.801 | 7.0101 | 0.101 |
| 7.3 | 7.3007 | 0.007 | 7.3007 | 0.007 |
| 8.0 | 8.0088 | 0.088 | 8.0068 | 0.068 |
| 8.8 | 8.8311 | 0.311 | 8.8086 | 0.086 |
| 9.0 | 9.0628 | 0.628 | 9.0091 | 0.091 |
| 9.8 | 9.8825 | 0.825 | 9.8095 | 0.095 |
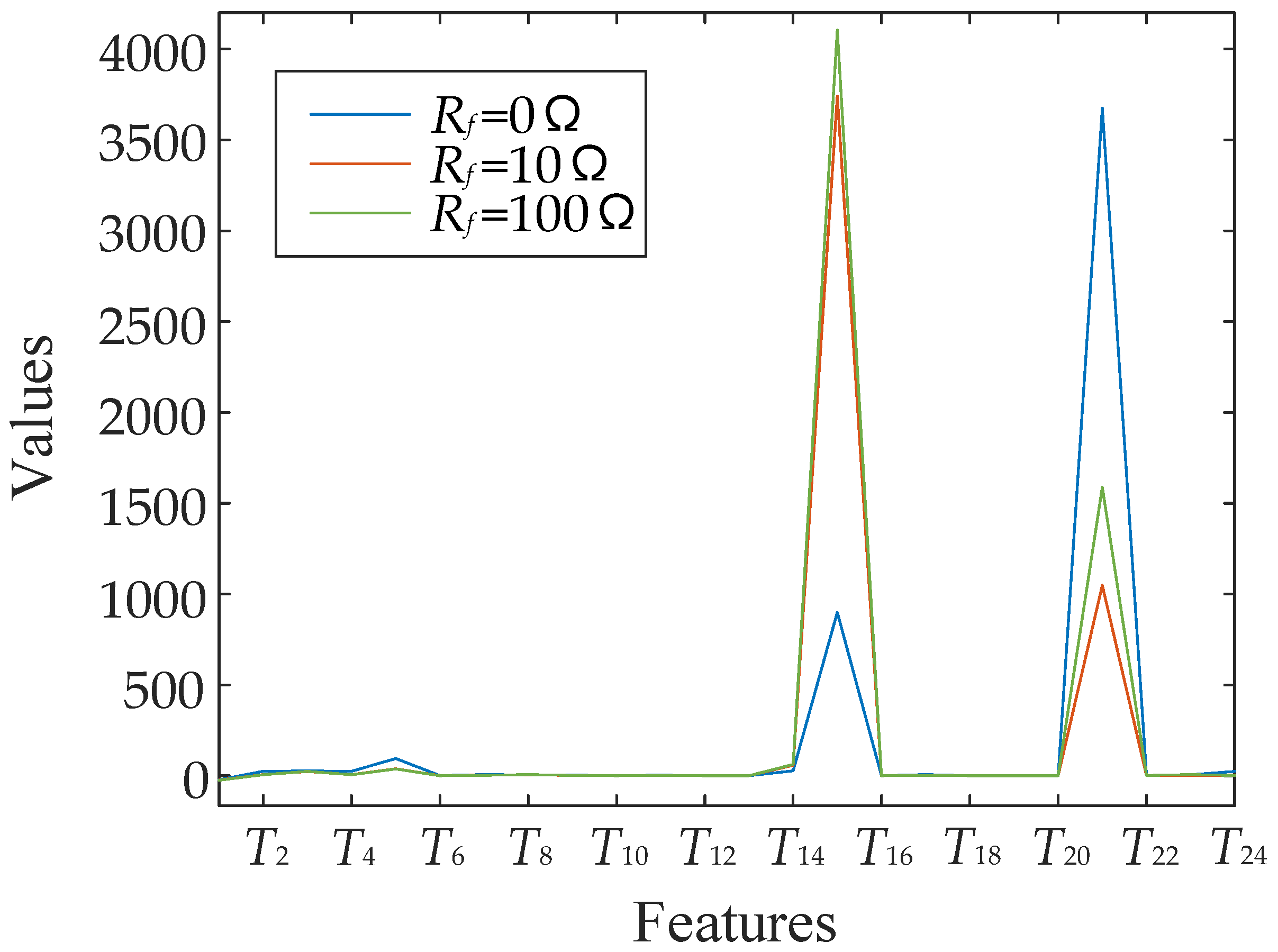
| Fault Resistances | Fault Features and Values | |||||||
|---|---|---|---|---|---|---|---|---|
| Rf = 0 Ω | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 |
| −22.4555345 | 24.5180054 | 26.4290631 | 24.5192314 | 95.1385402 | 1.11573634 | 6.26347973 | 3.88015997 | |
| T9 | T10 | T11 | T12 | T13 | T14 | T15 | T16 | |
| 3.59976969 | 0.84705480 | 3.28670813 | 0.03603943 | 0.34007241 | 27.6020470 | 899.678554 | 0.00167930 | |
| T17 | T18 | T19 | T20 | T21 | T22 | T23 | T24 | |
| 6.17048228 | 0.03906557 | 0.03603943 | 0.00261003 | 3674.42539 | 2.13959375 | 5.89237887 | 24.1578590 | |
| Rf = 10 Ω | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 |
| −23.7409934 | 6.69391958 | 23.1461072 | 6.69425430 | 38.1291214 | 0.71045427 | 3.42611937 | 5.69579817 | |
| T9 | T10 | T11 | T12 | T13 | T14 | T15 | T16 | |
| 1.64732329 | 0.28197027 | 1.60604574 | 0.01798488 | 0.13035299 | 57.9065772 | 3739.96752 | 0.00208018 | |
| T17 | T18 | T19 | T20 | T21 | T22 | T23 | T24 | |
| 2.18045779 | 0.01394780 | 0.01798488 | 0.00584912 | 1048.20842 | 0.90658752 | 1.21975124 | 3.91253691 | |
| Rf = 100 Ω | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 |
| −24.4414665 | 5.61344182 | 24.0988859 | 5.61372252 | 37.5885683 | 0.12268724 | 2.56588102 | 6.69583653 | |
| T9 | T10 | T11 | T12 | T13 | T14 | T15 | T16 | |
| 1.55976373 | 0.22968027 | 1.53790151 | 0.01211139 | 0.13196106 | 61.8340625 | 4103.87198 | 0.00093823 | |
| T17 | T18 | T19 | T20 | T21 | T22 | T23 | T24 | |
| 1.49022602 | 0.00947254 | 0.01211139 | 0.00256927 | 1588.33645 | 1.98663941 | 6.17647147 | 2.00997774 | |
| Estimators | Positive Pole-to-Ground | Negative Pole-to-Ground |
|---|---|---|
| Perror/% | Perror/% | |
| MLPNN | 0.2093 | 0.2188 |
| Ε-SVR | 0.8280 | 0.0791 |
| RF | 0.4097 | 0.4311 |
| WRF | 0.0554 | 0.0592 |
| Fault Location Method | Required Current Data | Sampling Frequency | Perror/% |
|---|---|---|---|
| continuous wavelet transform and Pearson correlation coefficient based on pattern matching [22] | current data for multiple points across the line | 5 kHz | 0.2079 |
| current frequency spectra based on MLPNN method [23] | two-terminal current data of the line | 10 kHz | 0.5370 |
| Hilbert–Huang transform and bat algorithm based on SVR method [24] | one-terminal current data of the line | 1000 kHz | 0.3104 |
| Improved ReliefF and WRF fault location method in this paper | one-terminal current data of the line | 100 kHz | 0.0554 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Hu, Z.; Ma, T. Monopolar Grounding Fault Location Method of DC Distribution Network Based on Improved ReliefF and Weighted Random Forest. Energies 2022, 15, 7261. https://doi.org/10.3390/en15197261
Xu Y, Hu Z, Ma T. Monopolar Grounding Fault Location Method of DC Distribution Network Based on Improved ReliefF and Weighted Random Forest. Energies. 2022; 15(19):7261. https://doi.org/10.3390/en15197261
Chicago/Turabian StyleXu, Yan, Ziqi Hu, and Tianxiang Ma. 2022. "Monopolar Grounding Fault Location Method of DC Distribution Network Based on Improved ReliefF and Weighted Random Forest" Energies 15, no. 19: 7261. https://doi.org/10.3390/en15197261
APA StyleXu, Y., Hu, Z., & Ma, T. (2022). Monopolar Grounding Fault Location Method of DC Distribution Network Based on Improved ReliefF and Weighted Random Forest. Energies, 15(19), 7261. https://doi.org/10.3390/en15197261