1. Introduction
The identification of geothermal sites has historically depended on field evidence of hot fluids circulating at depth, including the presence of geysers, fumaroles, mud pots, and diagnostic mineral deposits [
1]. However, surface manifestations such as these are absent for blind geothermal systems, which require more advanced methods for discovery. With the support of the United States Department of Energy, researchers recently pivoted to play fairway analysis (PFA) as a method adopted from the oil and gas industry for regional exploration opportunity identification and risk assessments [
2]. Conceptually, PFA decomposes risk into the constituent elements of a successful play, e.g., reservoir, source, seal, and trap geometry for hydrocarbons [
3]. Maps are generated for each risk element based on available data, including published research, field observations, and modeling results. Taking the collective evidence as input, subject matter experts define a chance of success for each element and then use statistical approaches to combine multiple risk element maps into a single view of play favorability [
4]. Geothermal PFA studies typically divide the geothermal system into enthalpy (heat), permeability, and fluids risk elements, which are then combined by weighted average based on data confidence or expert opinion [
5,
6,
7]. The resulting maps reveal geothermal fairways inclusive of both surface-visible and blind geothermal systems.
Following the ongoing trend of digital transformation in the earth sciences [
8], both unsupervised and supervised machine learning techniques are now being incorporated into geothermal exploration workflows. Unsupervised methods learn directly from the structure of geologic, geochemical, geophysical, and other relevant data sets. One such approach applies dimensionality-reduction techniques such as principal component analysis or non-negative matrix factorization to consolidate meaningful signals within the input data sets (or “features”), producing a smaller number of derived features useful for identifying data clusters [
9,
10,
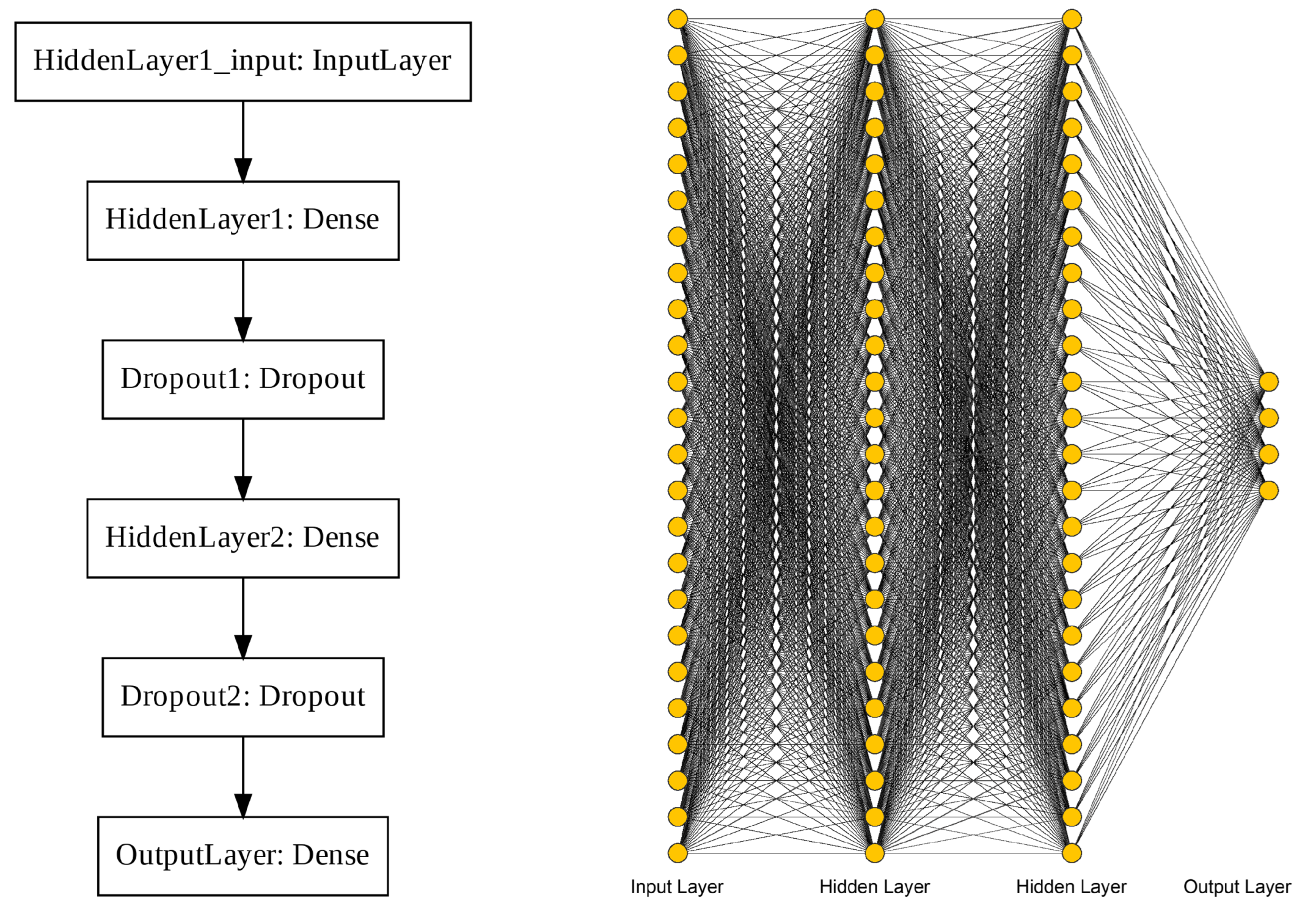
11]. However, the physical significance of these clusters is not unequivocally clear. Alternatively, supervised algorithms require labeled example data for training before providing predictive values. When applied to field data, advanced supervised methods such as artificial neural networks (ANN) have shown promise in predicting geothermal favorability [
12]. Still, selecting which supervised algorithm to use for prediction either relies on an a priori decision or competitive ranking of several algorithms by some metric of predictive success [
13,
14]. This study considers how the combined insights from more than one model can define both robust trends and areas of disagreement, thereby revealing a relative measure of uncertainty in the prediction system.
Uncertainty derives from many sources in subsurface resource exploration, be it for water, hydrocarbons, minerals, or enthalpy [
15]. To build an integrated understanding of the spatial variation in earth properties, data spanning multiple scales and sensitivities must be combined, including detailed point samples, well log records, and coarser potential field measurements [
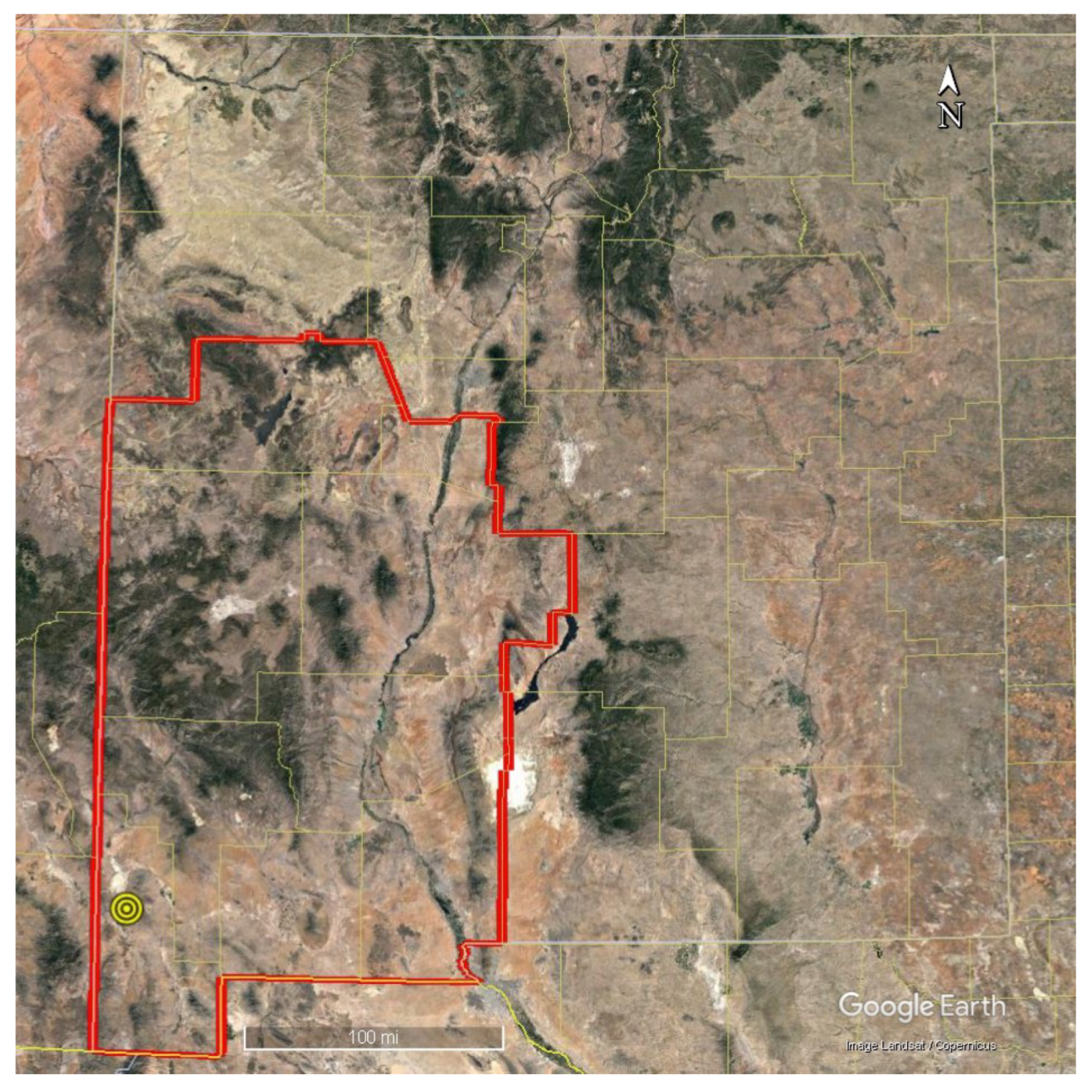
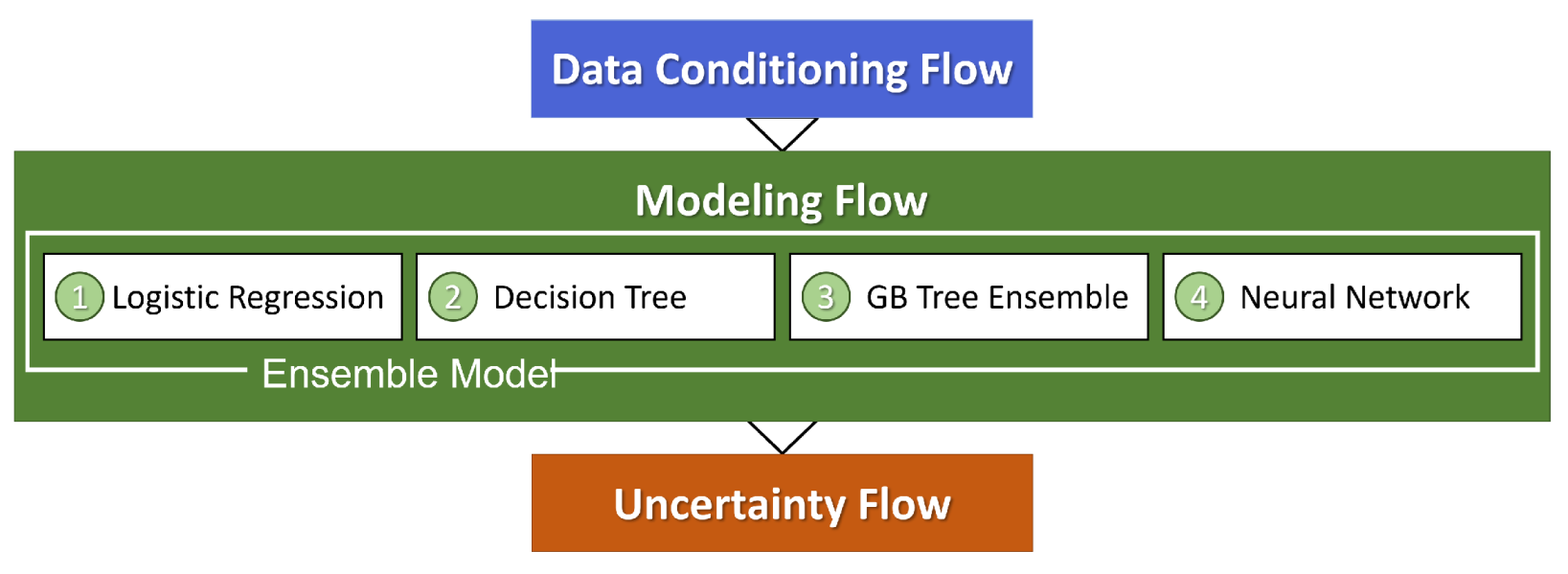
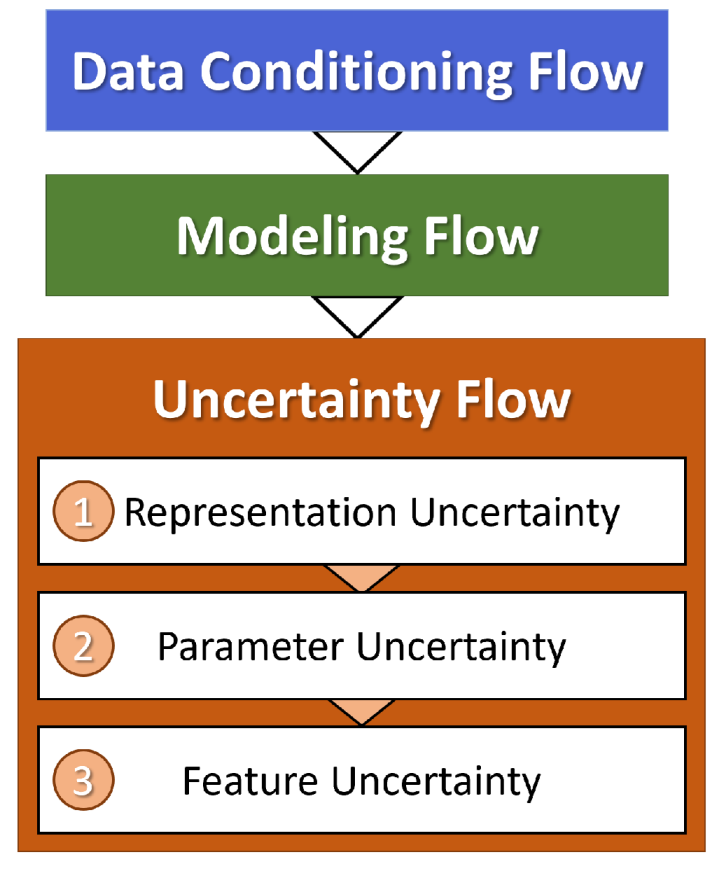
13]. The decisions made as these data are incorporated into models become important sources of uncertainty that have downstream impacts on prospect selection, appraisal, and development choices made by a firm. The following sections introduce a novel methodology that extends the use of ML for PFA predictions to also incorporate uncertainty estimation with normalized Shannon entropy as the uncertainty metric. Specifically, this study characterizes three varieties of uncertainty: those associated with the choice of machine learning model architecture; those in the learned parameters within a single model; and those in the input feature data and their preparation. This approach is applied to a region of New Mexico with known geothermal resource areas (KGRAs) to illustrate how the methodology provides comprehensive predictions of resource presence, unique insights on prediction confidence, and the opportunity for data-driven early-stage resource allocations and decision making in geothermal projects.
4. Discussion
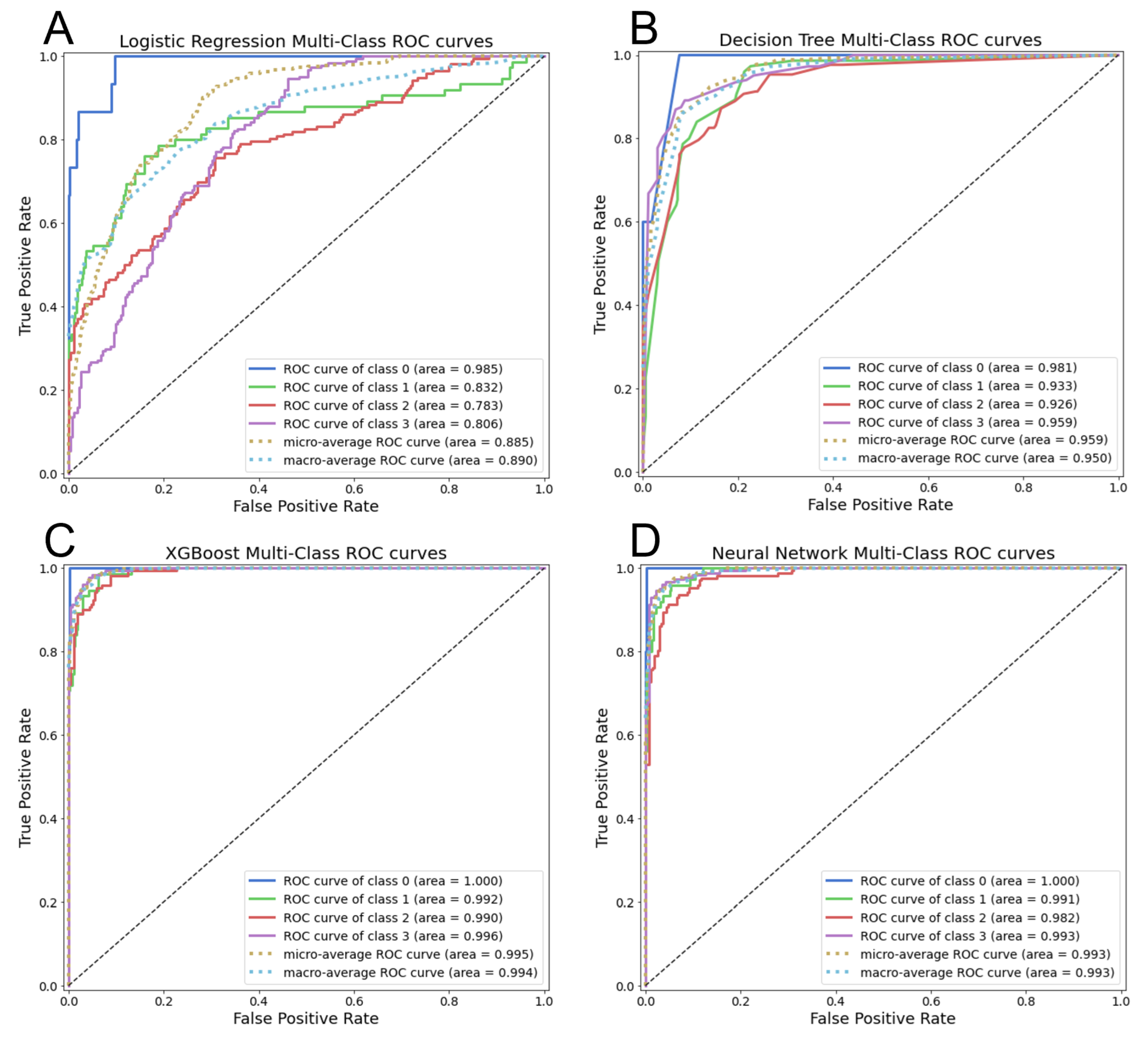
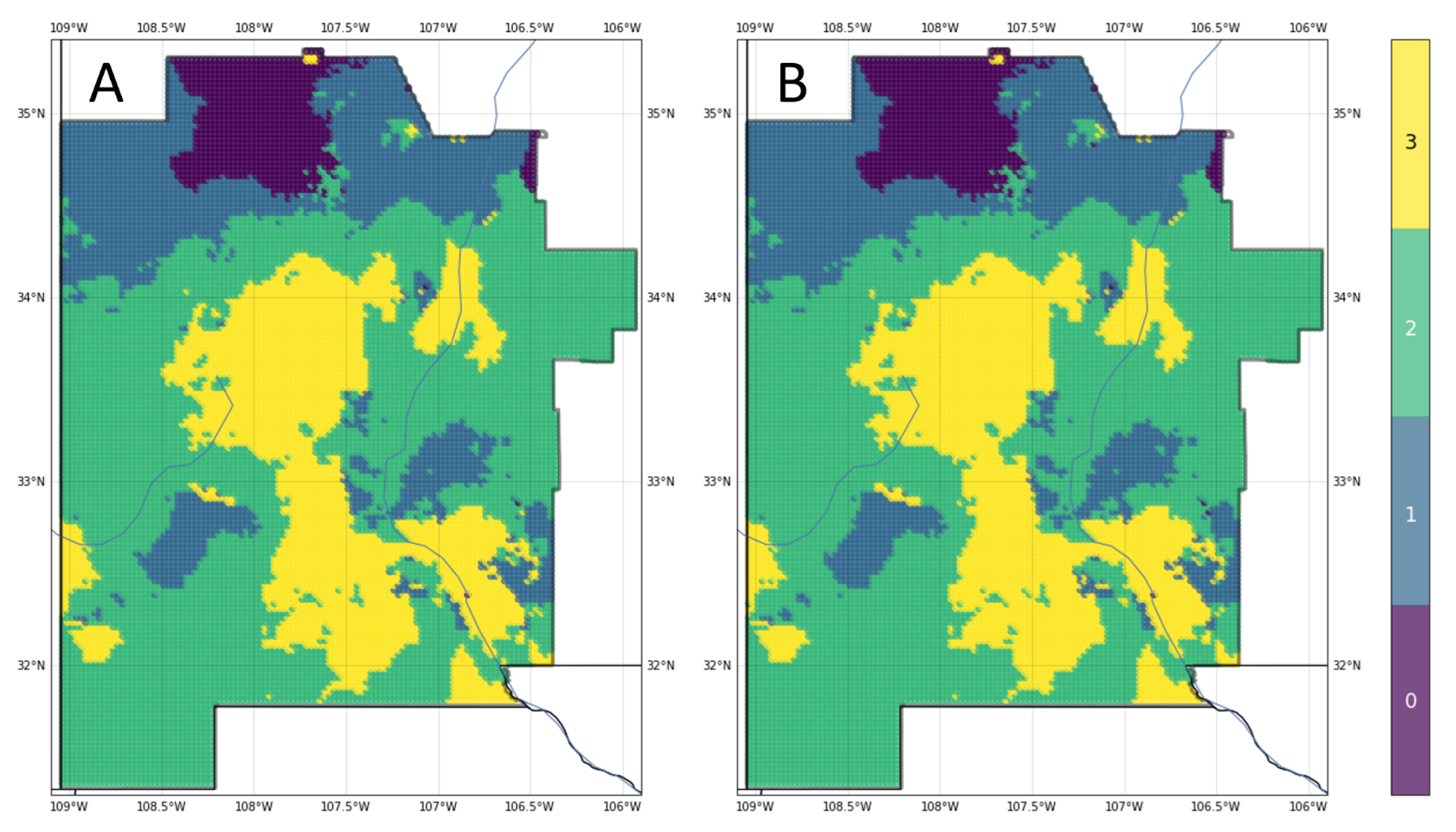
Although similar in regional trends, each of the four supervised ML methods presented in
Section 3.1 show differences in local predictions and overall performance as geothermal gradient classifiers. The weighted-average ensemble model demonstrates better performance than the individual models alone, supporting an argument for ensemble approaches to the ML-enhanced PFA methodology.
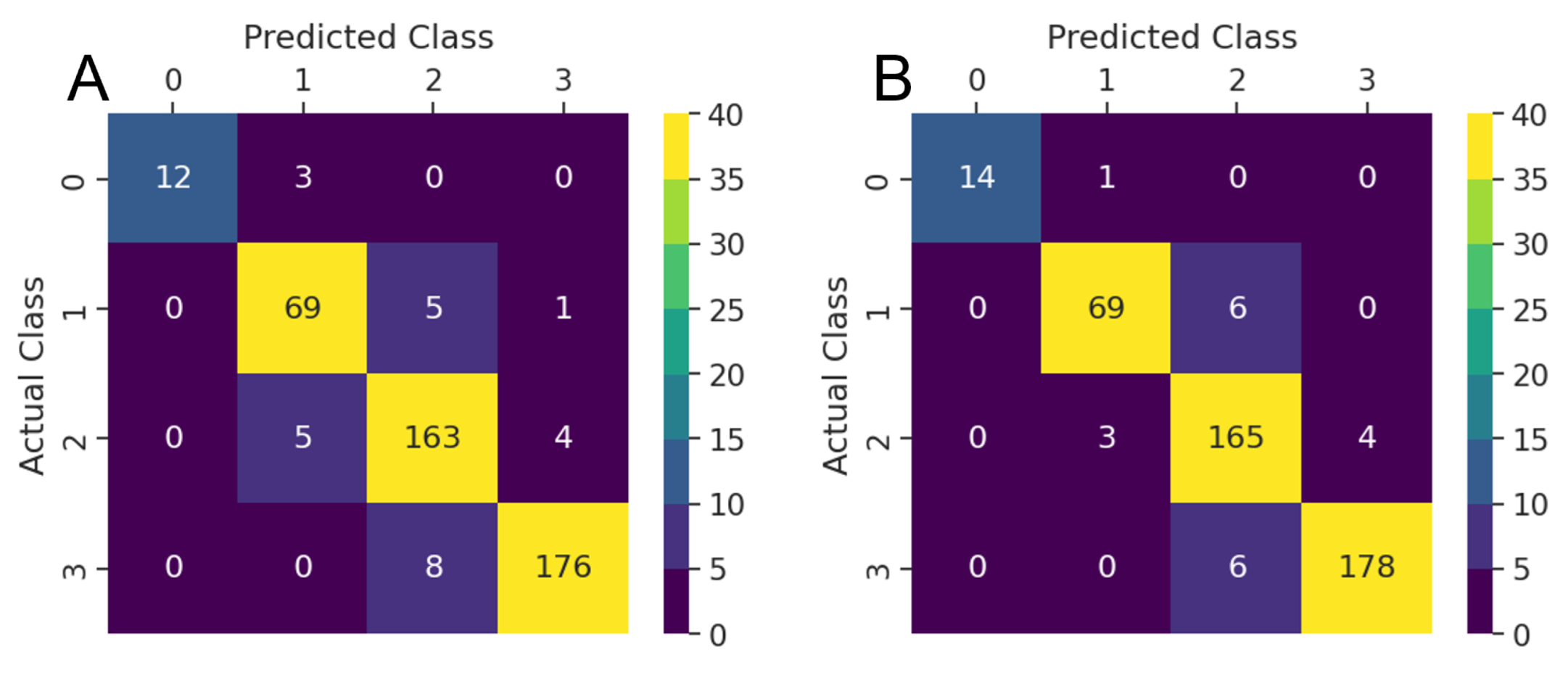
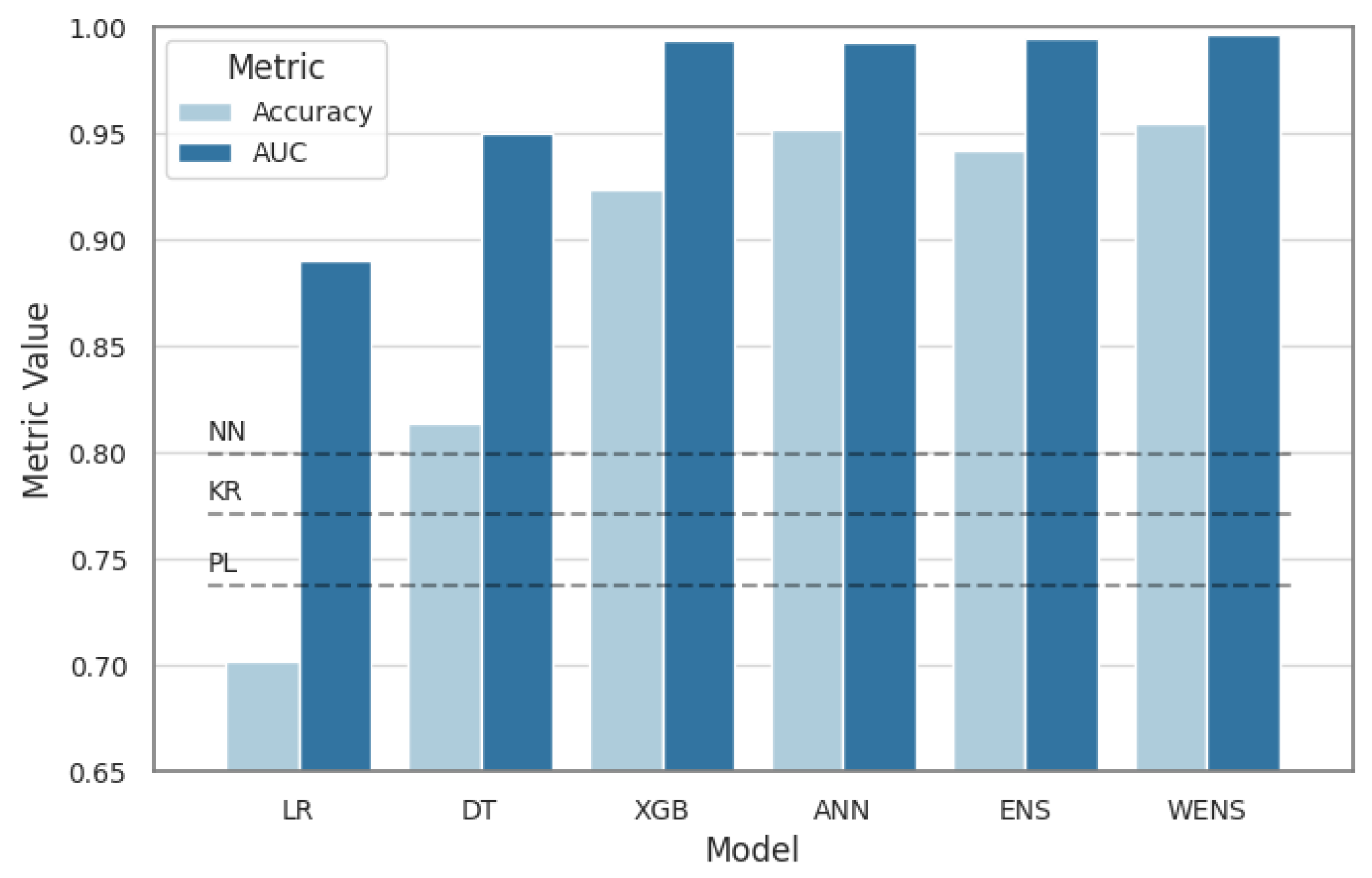
Figure 16 summarizes the comparison between the ML models based on test set accuracy and AUC.
A vital additional comparison must address whether or not ML provides meaningful uplift over conventional methods used in PFA workflows. For the southwest New Mexico study area, the prior PFA predicted an integrated favorability assessment for hydrothermal resources, not enthalpy alone [
16]. Nevertheless, PFA data uploaded to the open-access Geothermal Data Repository include an interpolated map of geothermal gradient based on well data similar to those included in this study [
17]. Using the PFA as a baseline, we consider interpolation as the the primary alternative to predicting temperature gradient with ML techniques. More precisely, a comparison can be made between the ML results and those for interpolation functions constructed using the WDS training subset and evaluated against the remaining WDS data points. This assessment was performed using three algorithms: piecewise-linear interpolation and nearest-neighbor interpolation from the scipy Python library [
64], and ordinary kriging with a spherical variogram model available in ArcGIS. These methods provide deterministic estimates of gradient for the combined WDS validation and test subsets, which were then converted to the classification scheme in
Table 2 for comparison with the ML models. AUC cannot be calculated, but interpolant accuracy scores fall short of those achieved by all but one individual ML model (
Figure 16), and they are well below the ensemble model accuracies.
It is important to note a fundamental difference between the two estimation methodologies: interpolation algorithms predict geothermal gradient from the spatial relationships embedded in the training data, while the ML models learn from signals within the features listed in
Table 1, which notably do not include geospatial coordinates. Not only does the ML workflow result in better predictions, those predictions are data-driven at each map location rather than spatially derived. This narrow focus in detection may be particularly advantageous for identifying blind geothermal systems whose presence and bounds can be highly local in nature.
However, presenting the individual and ensemble results to explorationists interested in prospect identification and maturation would invariably elicit two important questions: (1) how much confidence should be assigned to the class labels agreed by only a plurality of models, and (2) what would be the best next steps to take based on these models. At the heart of the first question is the need to pair the use of ML methods with uncertainty characterization, specifically uncertainty due to different model representations and where those models fail to agree in classifications. Incorporating several high-performance models into an ensemble estimate with an uncertainty metric such as entropy can give a geothermal exploration team confidence in which areas should receive more attention and resources, either in data purchases, new data acquisition campaigns, or hours of traditional play fairway and prospect interpretation activities.
The workflow described in
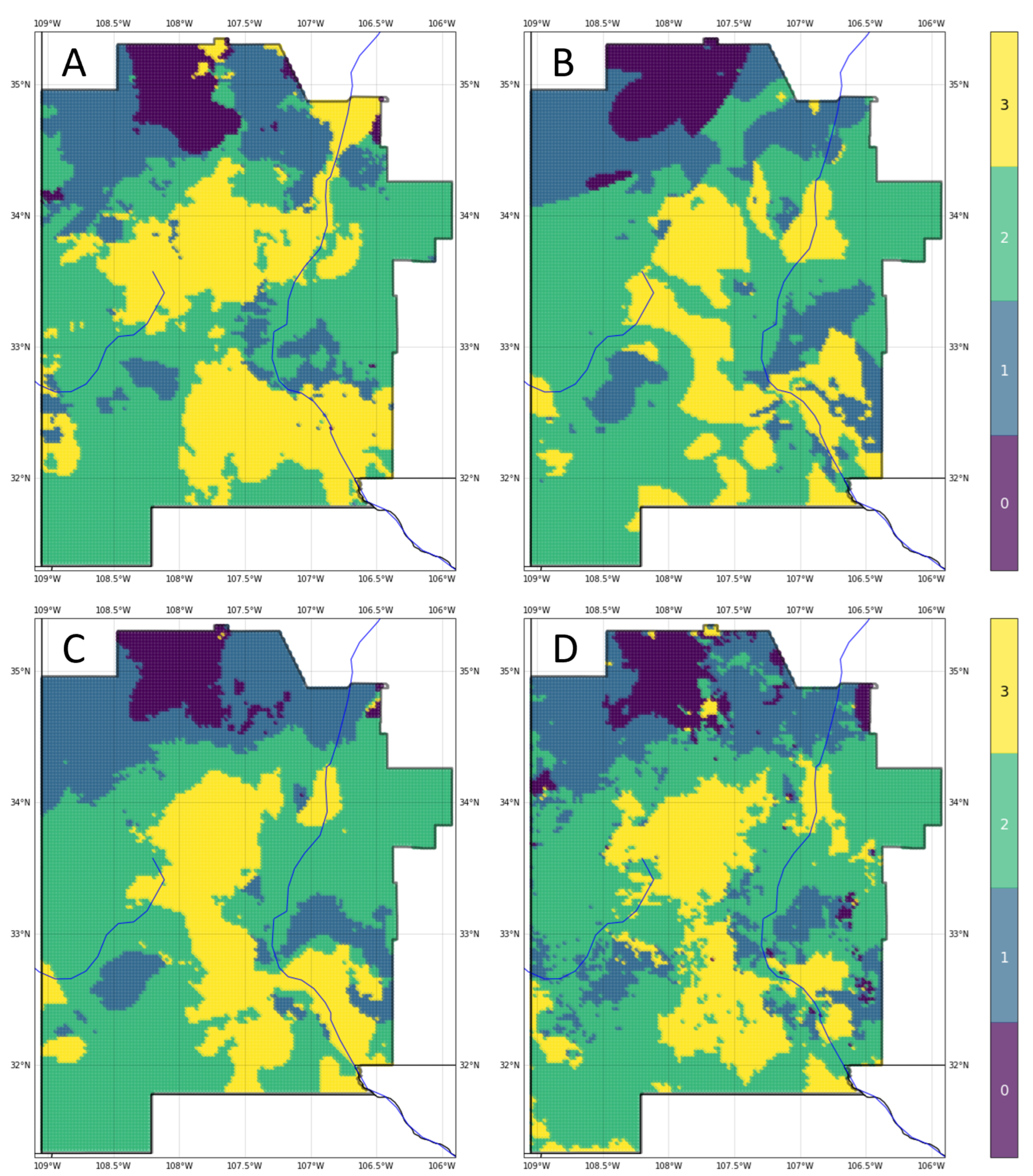
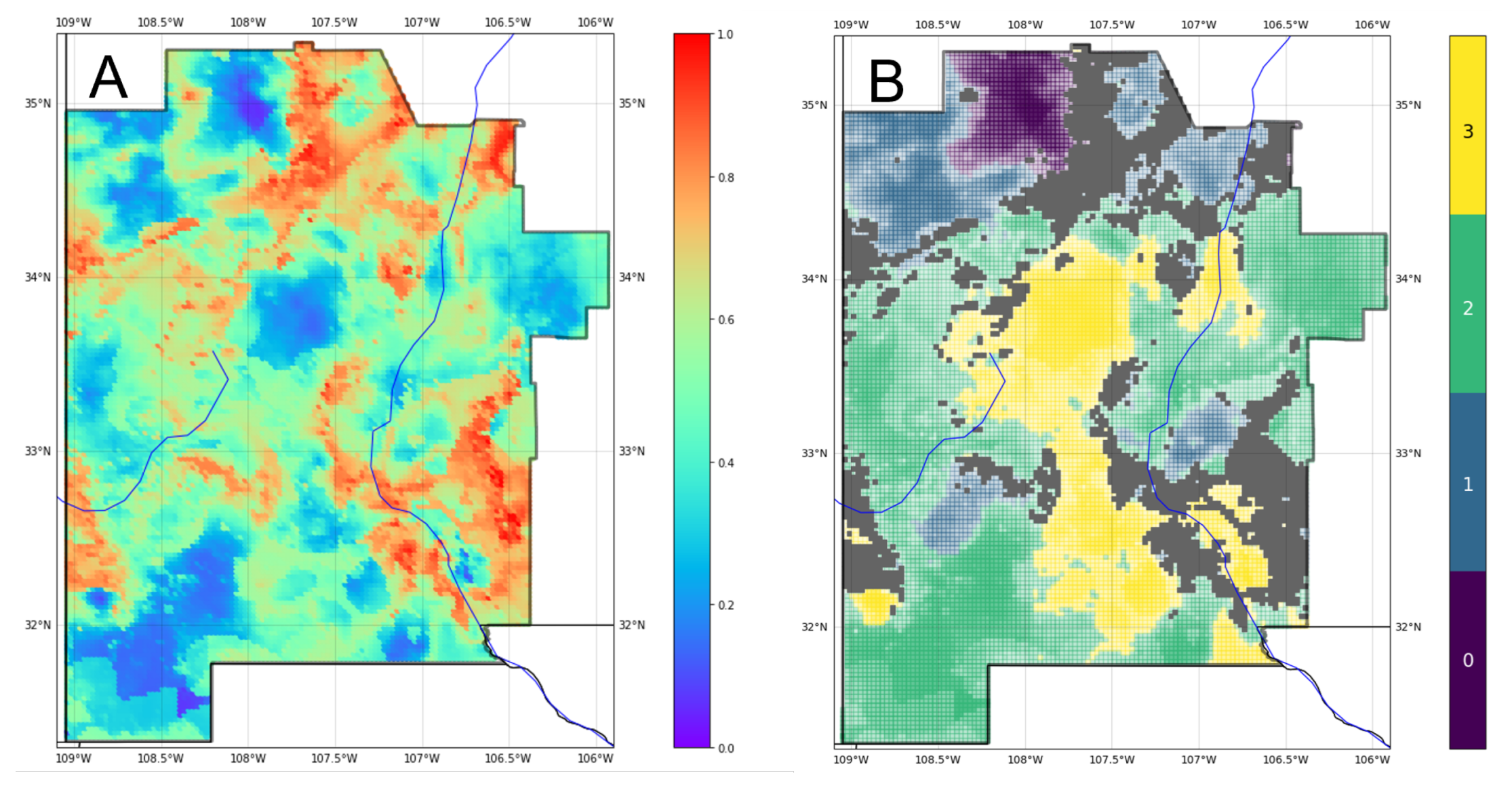
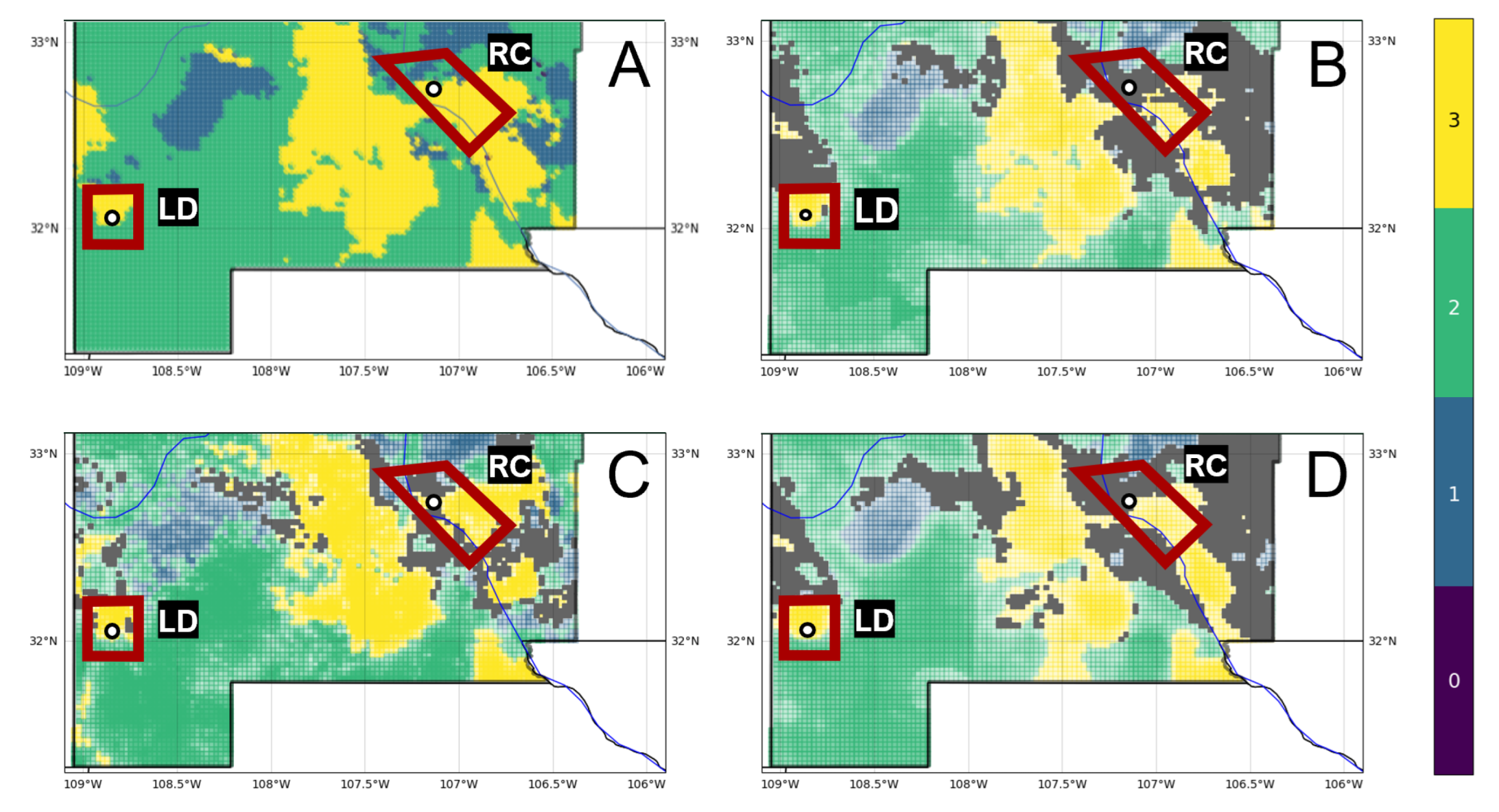
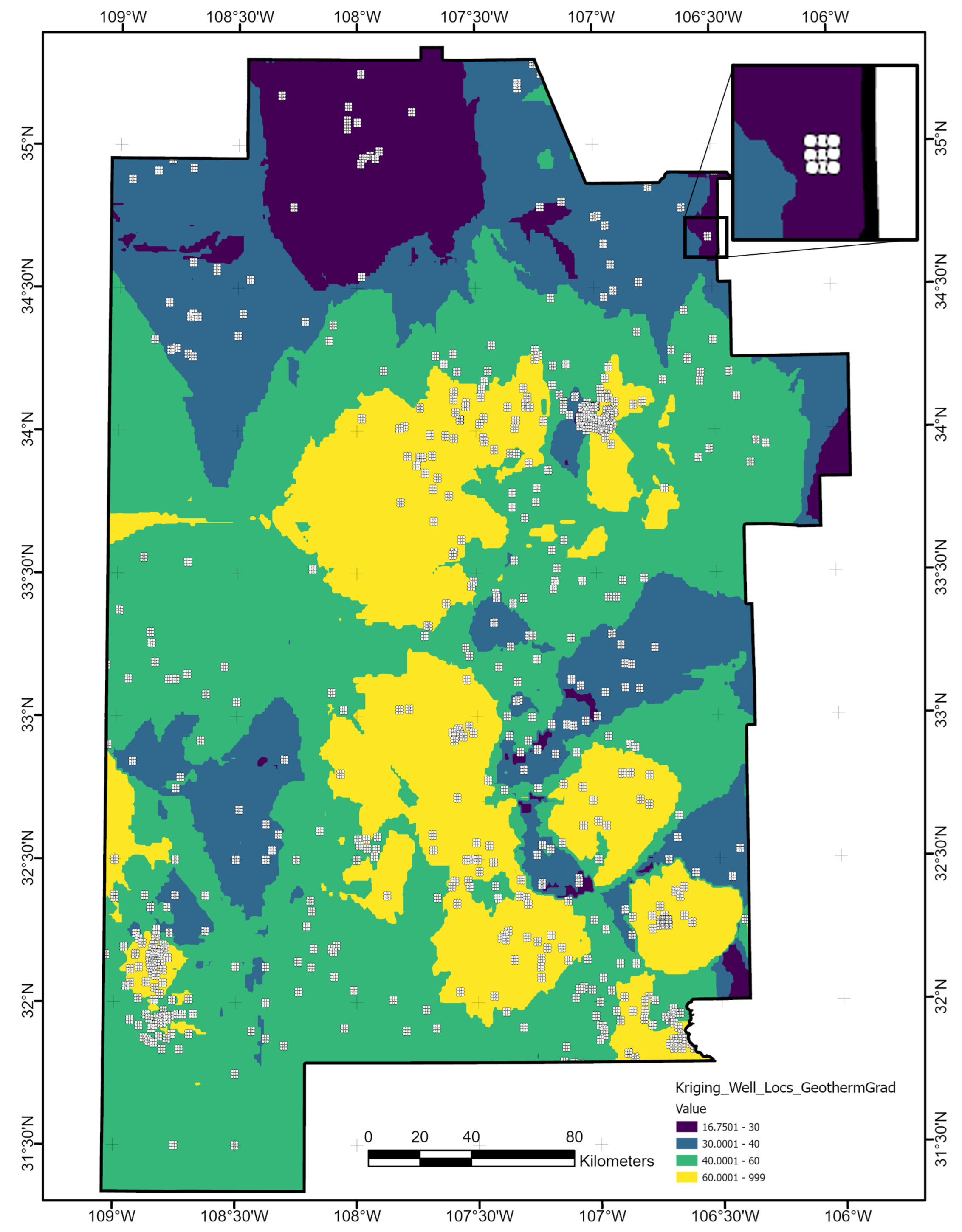
Figure 6 notes multiple sources of uncertainty, each with the potential for providing meaningful information in translating predictions into exploration decisions. To illustrate this point, we consider the scenario where the hypothetical prospect outlines identify two areas of interest, Lightning Dock (LD) and Rincon (RC), for an EGS installation within the southern half of the study area (
Figure 17). The ensemble classifier predicts high-grade enthalpy resources, approximated by geothermal gradient, within either quadrangle (
Figure 17A). Note that the primary risk element for EGS is enthalpy, since permeability and fluids solutions could be engineered. White markers indicated reference points as proposed drill locations, which are presumably influenced by additional factors such as access to transmission lines, infrastructure, or permitting constraints. With no additional information, LD and RD would rank equally high in prospect favorability.
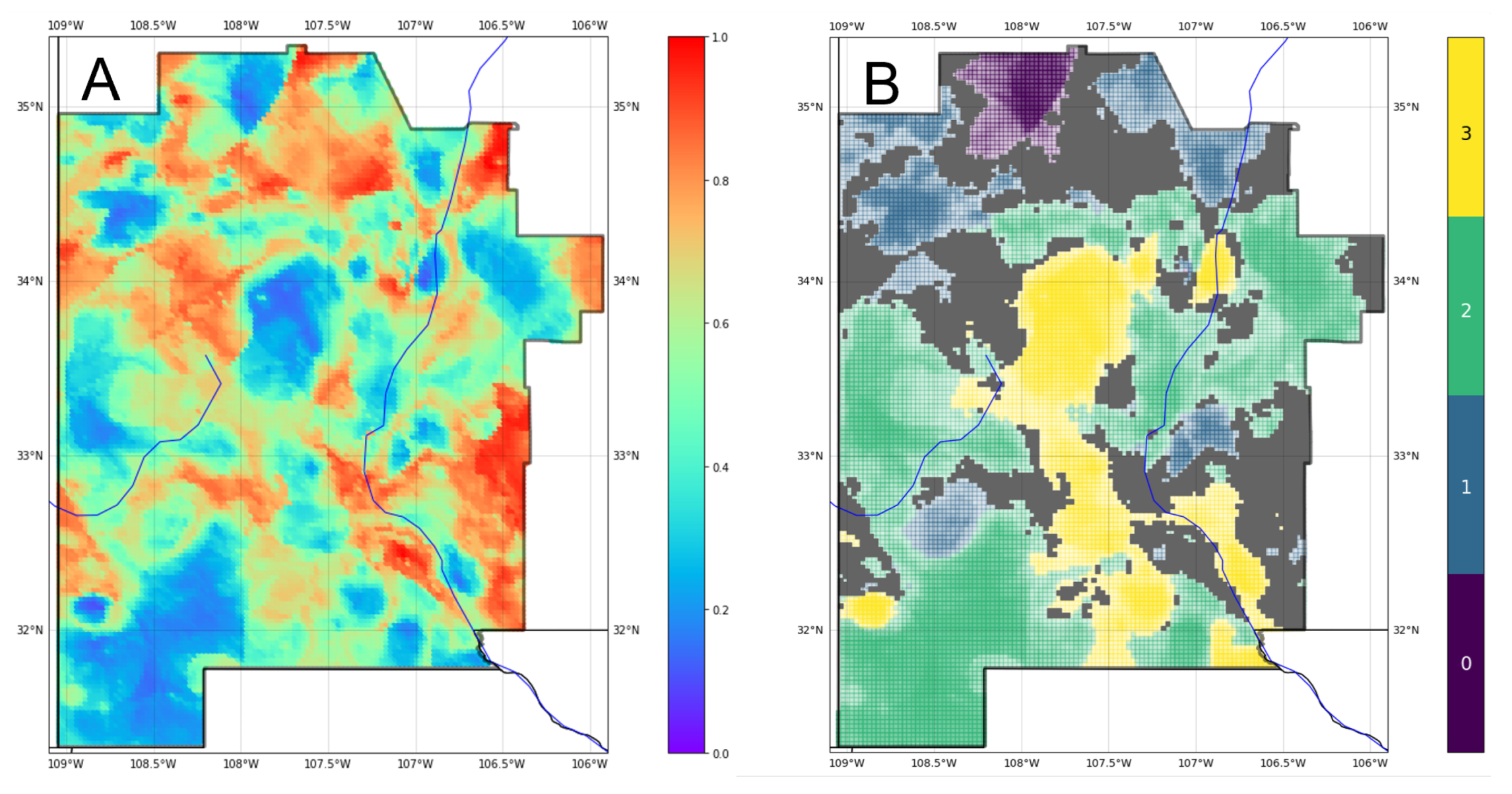
Model representation uncertainty reveals a greater level of confidence in the gradient prediction at LD compared to RC (
Figure 17B). Masked values at the RC reference point indicate high entropy, suggesting that the project team should explore options to obtain more information and rerun the ML PFA workflow with any additional data. If no additional information is available, the team could either adjust their risk tolerance on RC, focus further subsurface characterization efforts on this region, or choose to abandon RC as a prospect altogether, since the ML models cannot clearly differentiate among gradient classes with the available feature data.
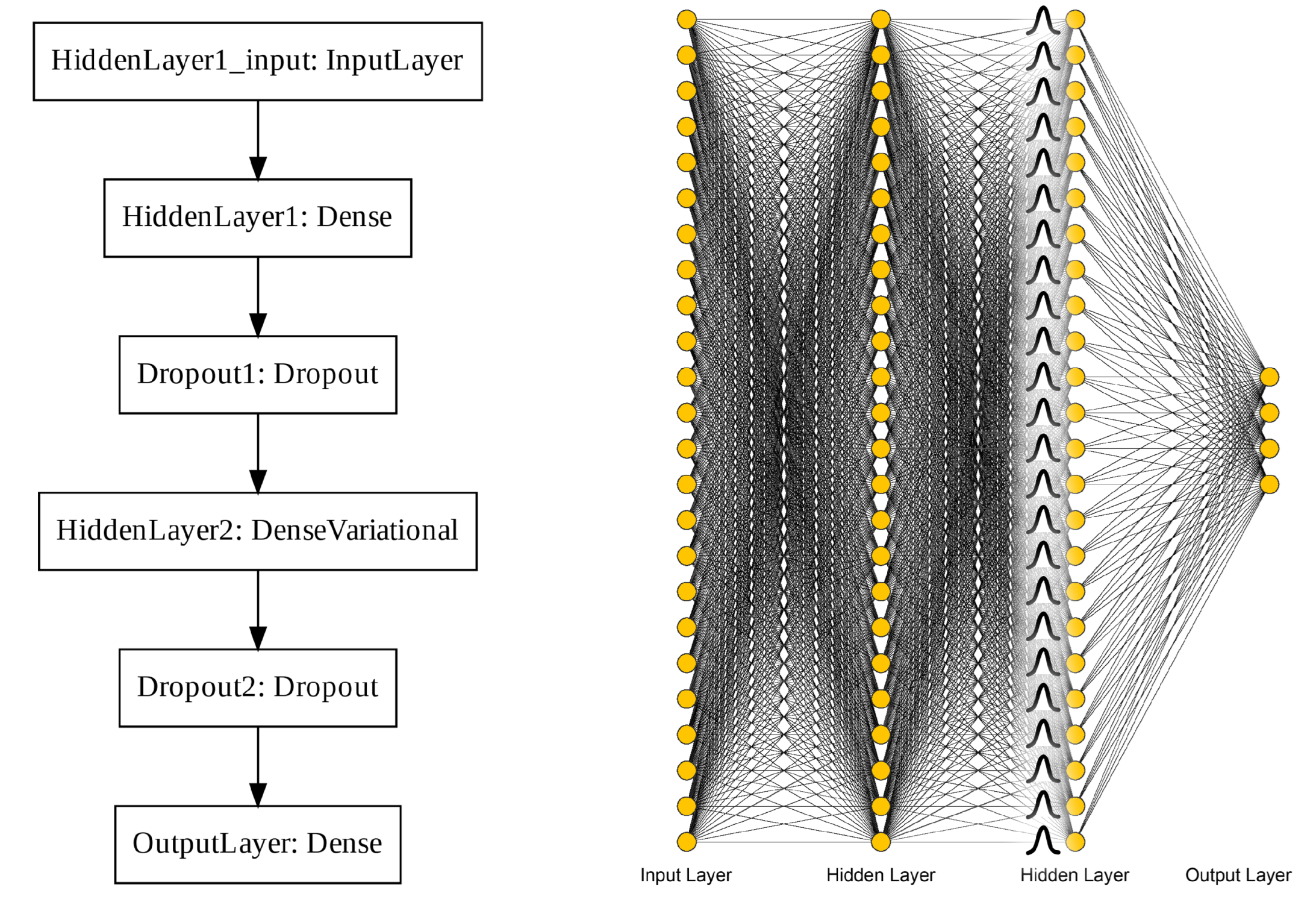
Shifting focus to the ANN classifier as one of the top-performing models, an analysis of parameterization uncertainty shows low entropy across most of both the LD and RC quadrangles (
Figure 17C). However, the reference point for RC lies along a narrow northwest–southeast trend of high entropy. The project team could choose to adjust this proposed well location slightly east or west to avoid this trend while staying within a Class 3-labeled region. Alternatively, an ML model with fewer trainable parameters may be a more appropriate choice for RC predictions, in addition to traditional subsurface interpretation and modeling efforts, to help mitigate the risk of this prospect.
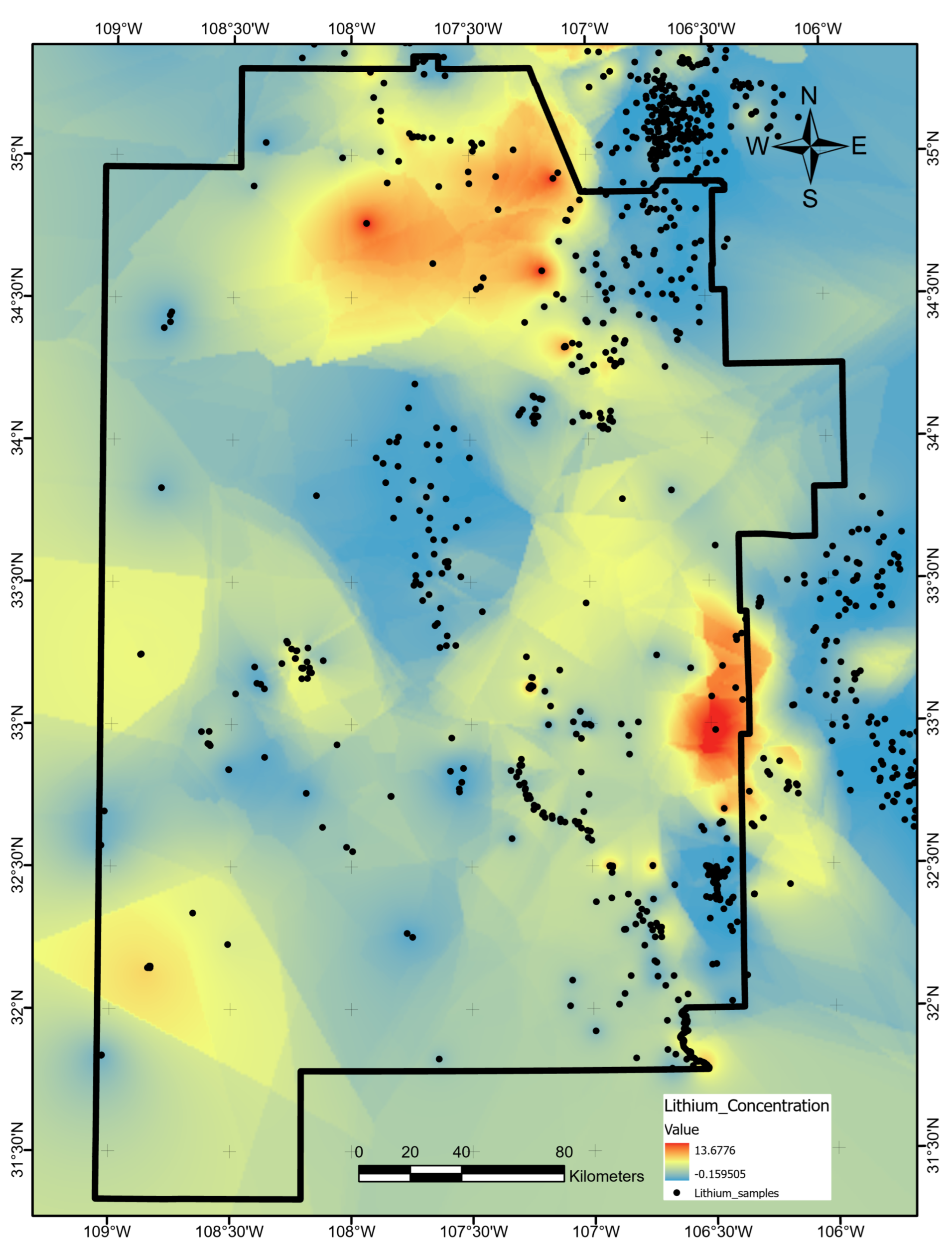
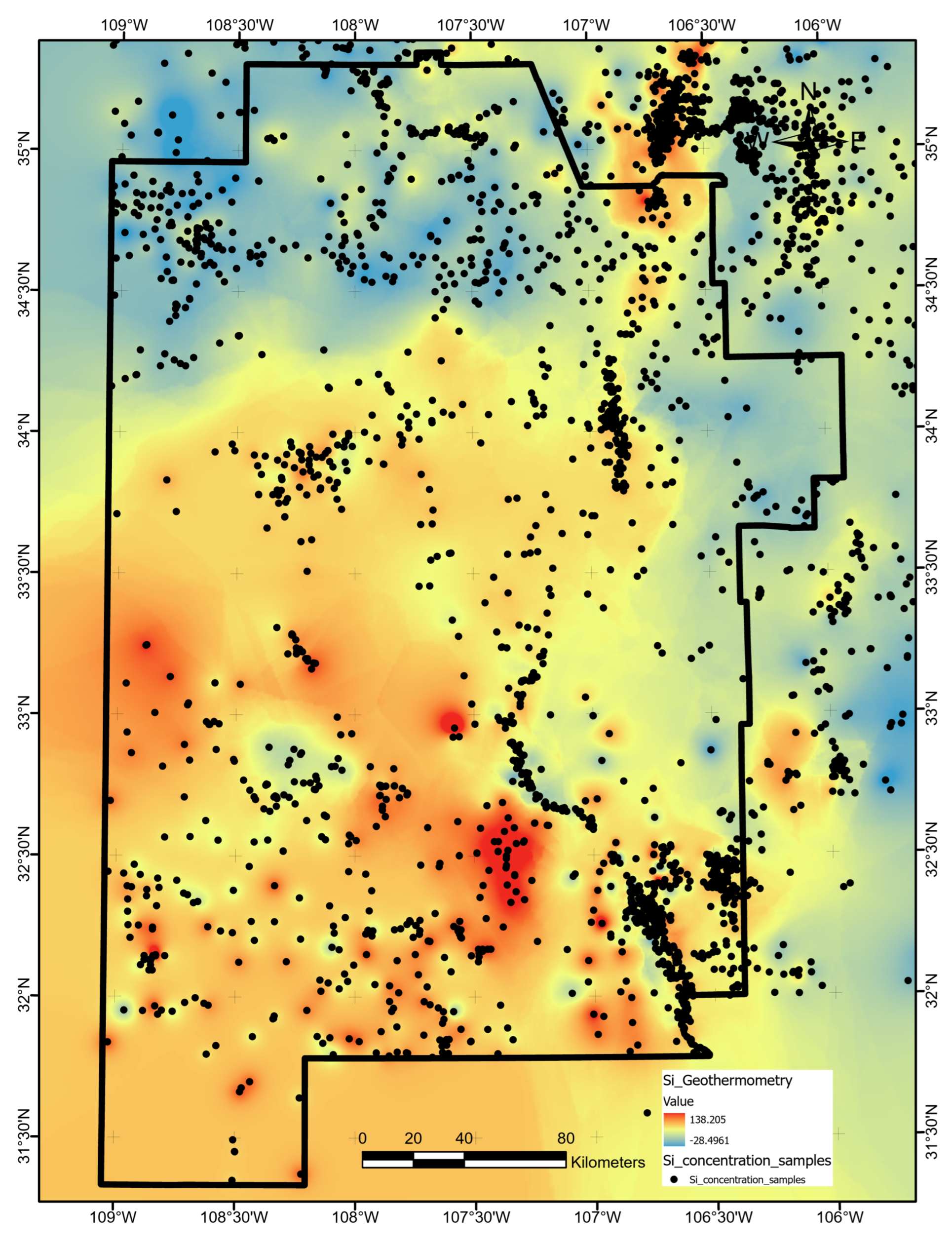
Uncertainties tied to the feature of highest importance, SiGT, also offer useful insights into this hypothetical prospect evaluation. Entropy levels appear quite low at LD and marginally high at the RC reference point (
Figure 17D). High entropy throughout the northern section of the RC quadrangle could be mitigated with additional silica concentration sampling in the field. A closer review of SiGT data in the RC area might prove beneficial as well. Anomalous values in the original data, if they are erroneous, will increase standard errors, impacting both the EBK interpolation routine and overall predictive value of the feature. On the other hand, anomalous values that are trustworthy must be accepted as indicators of strong lateral heterogeneity. Thus, uncertainties here can contribute to an important feedback loop for appropriate data conditioning, which is the key first step in the ML-enhanced PFA workflow.
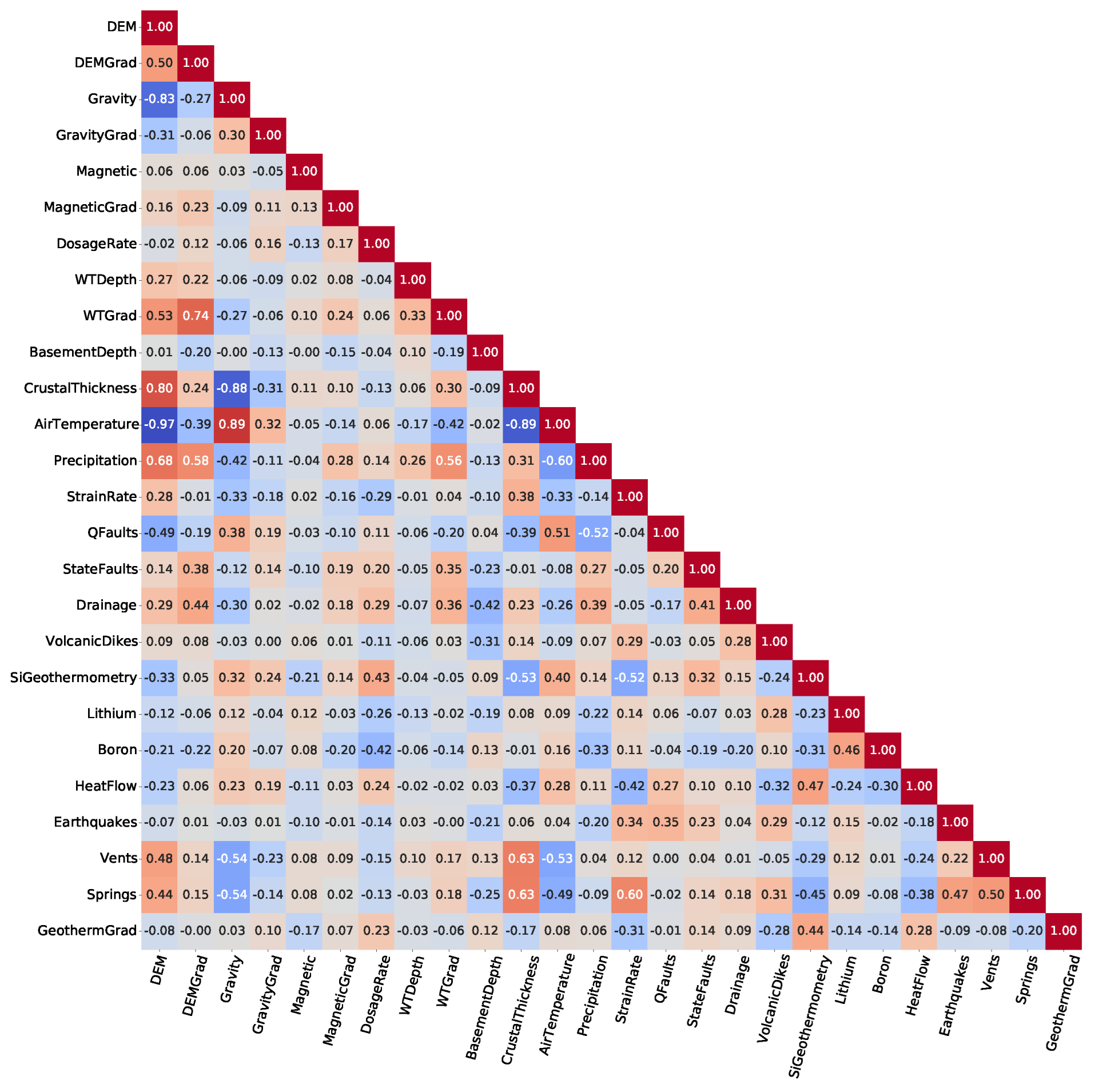
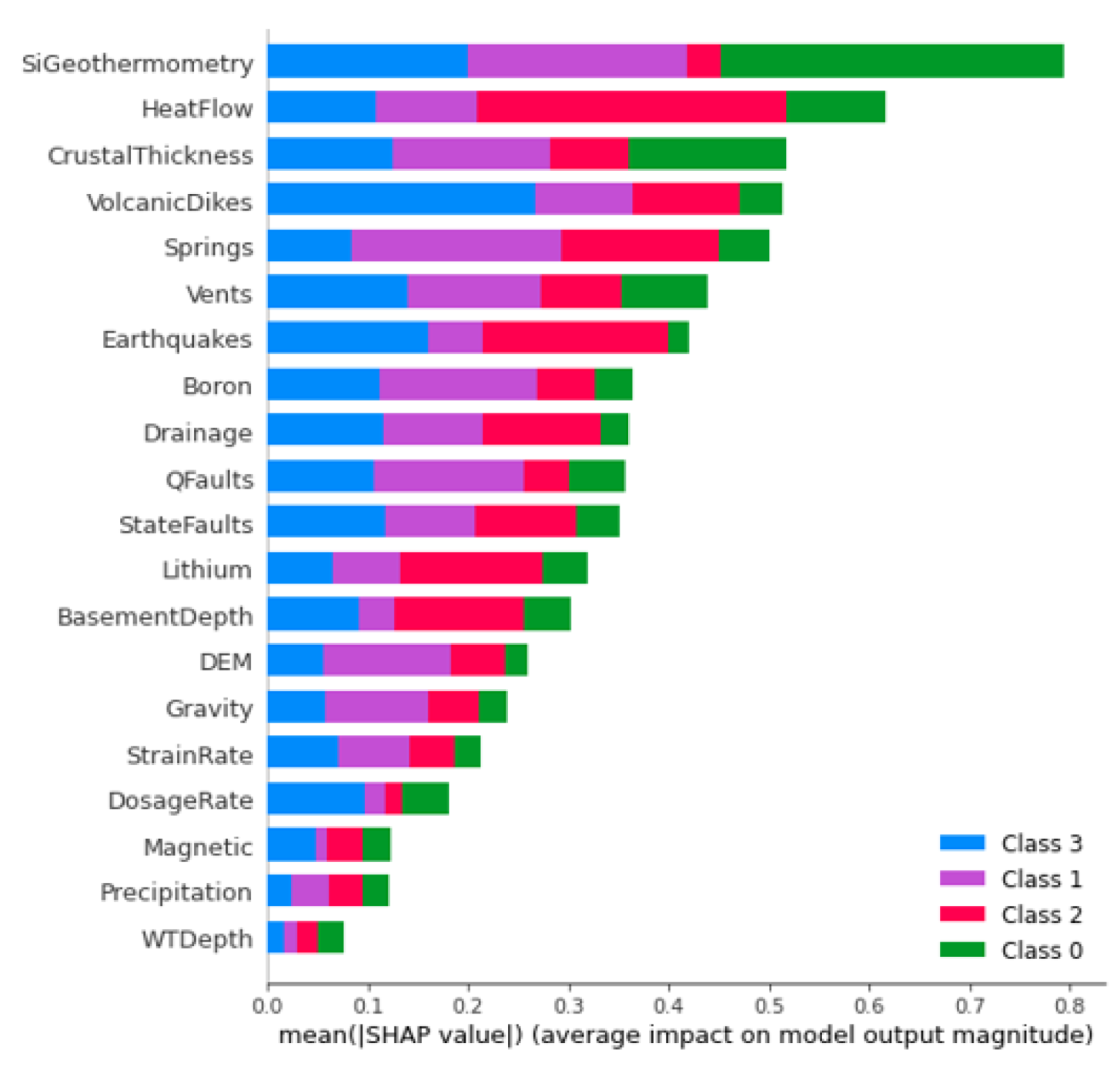
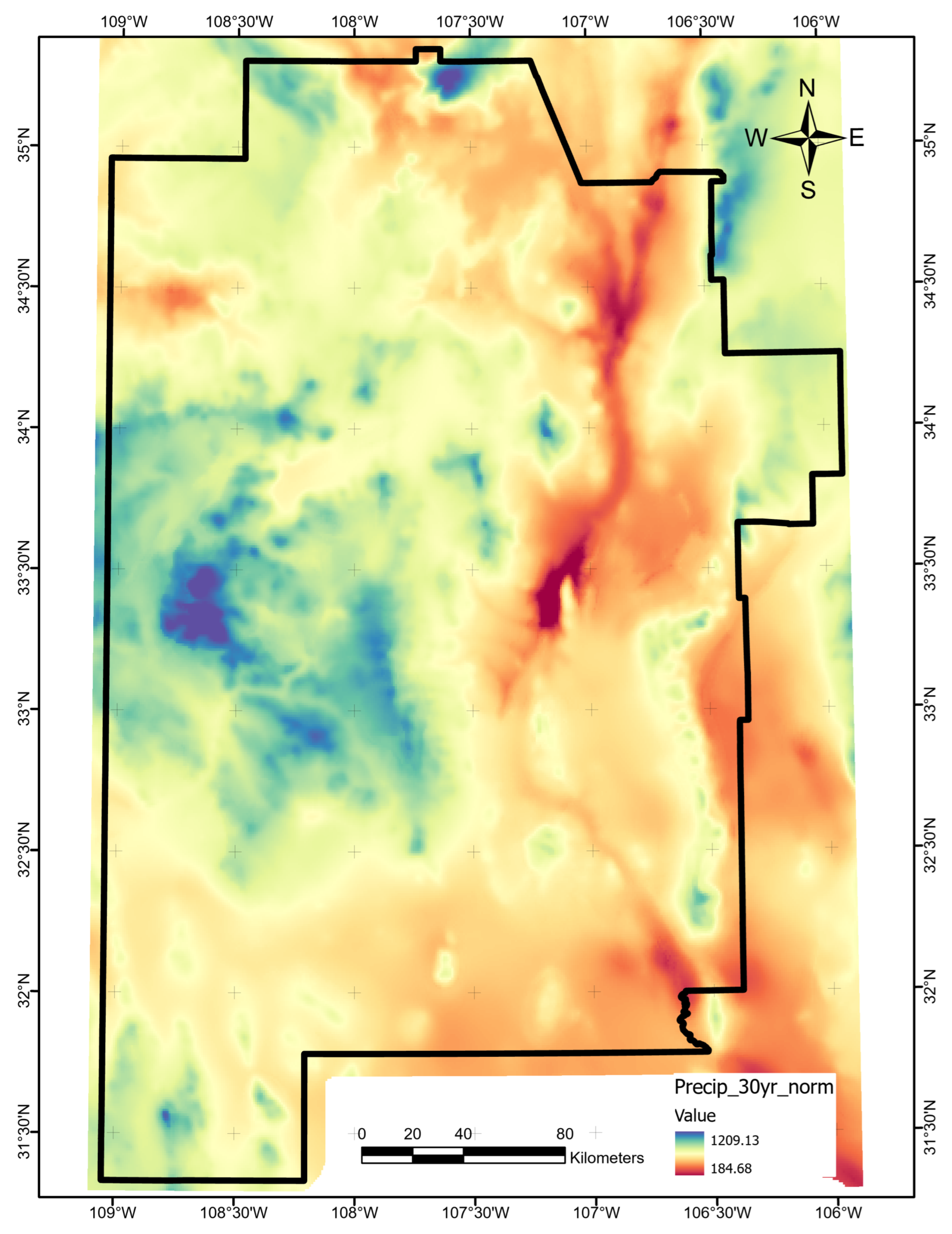
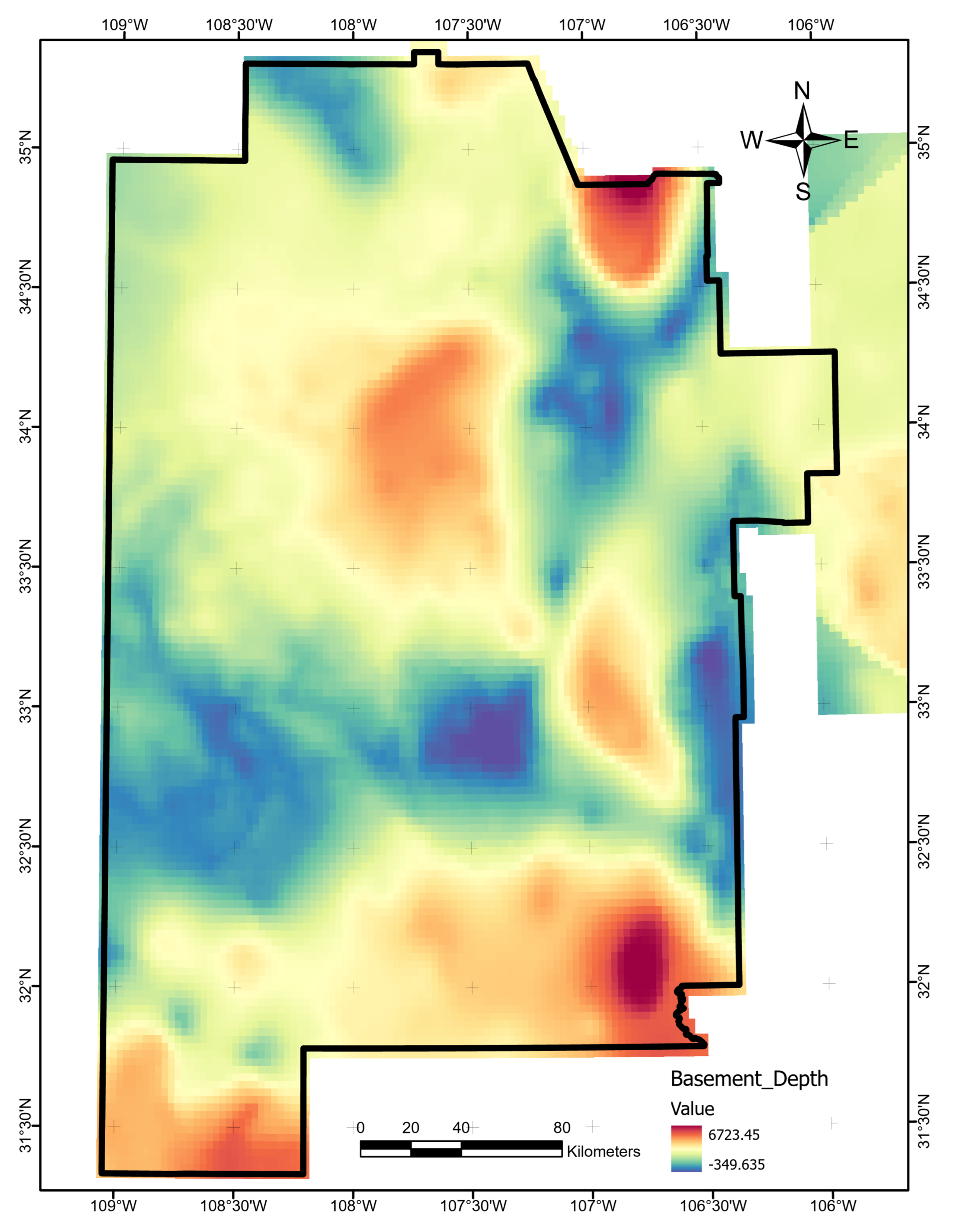
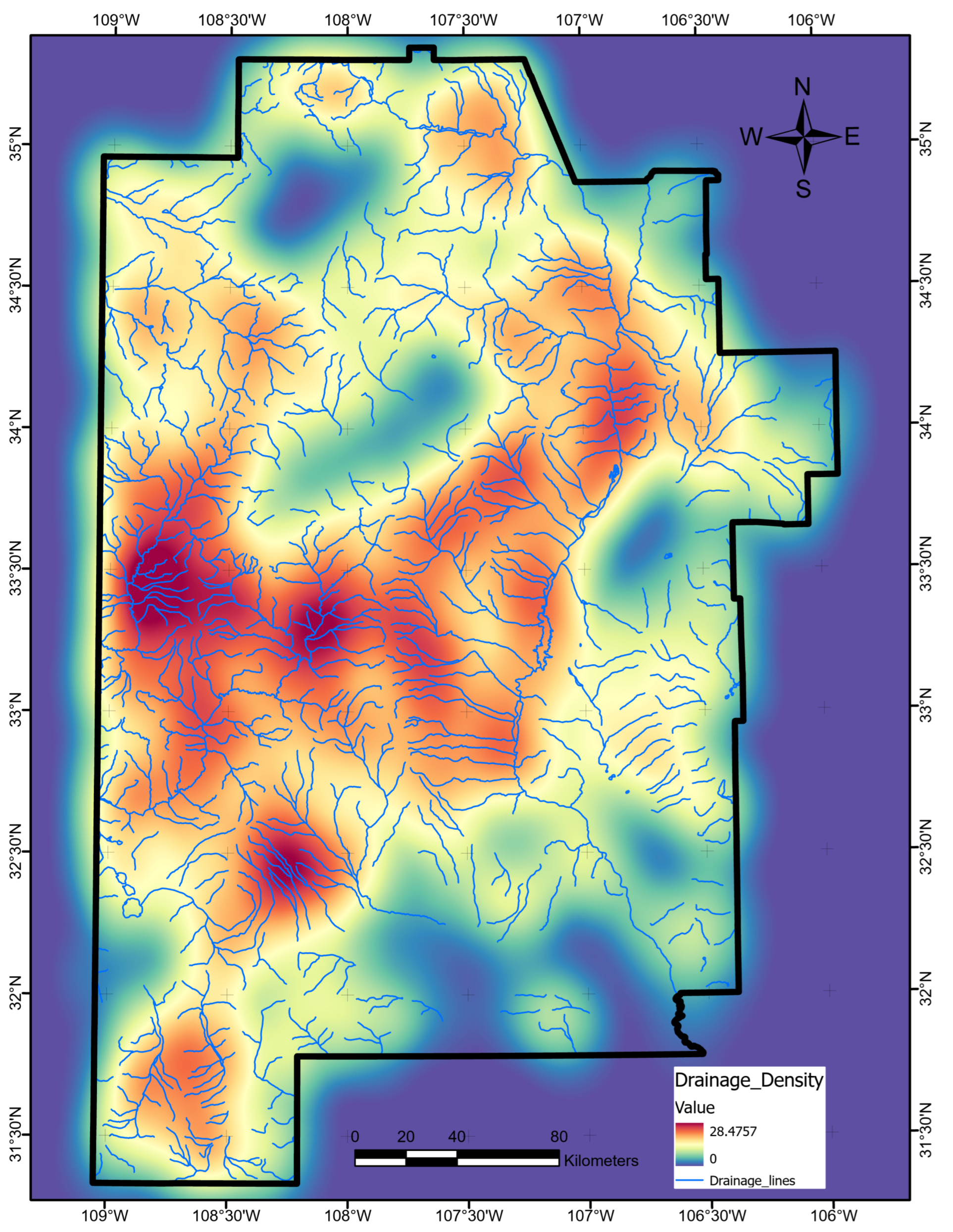
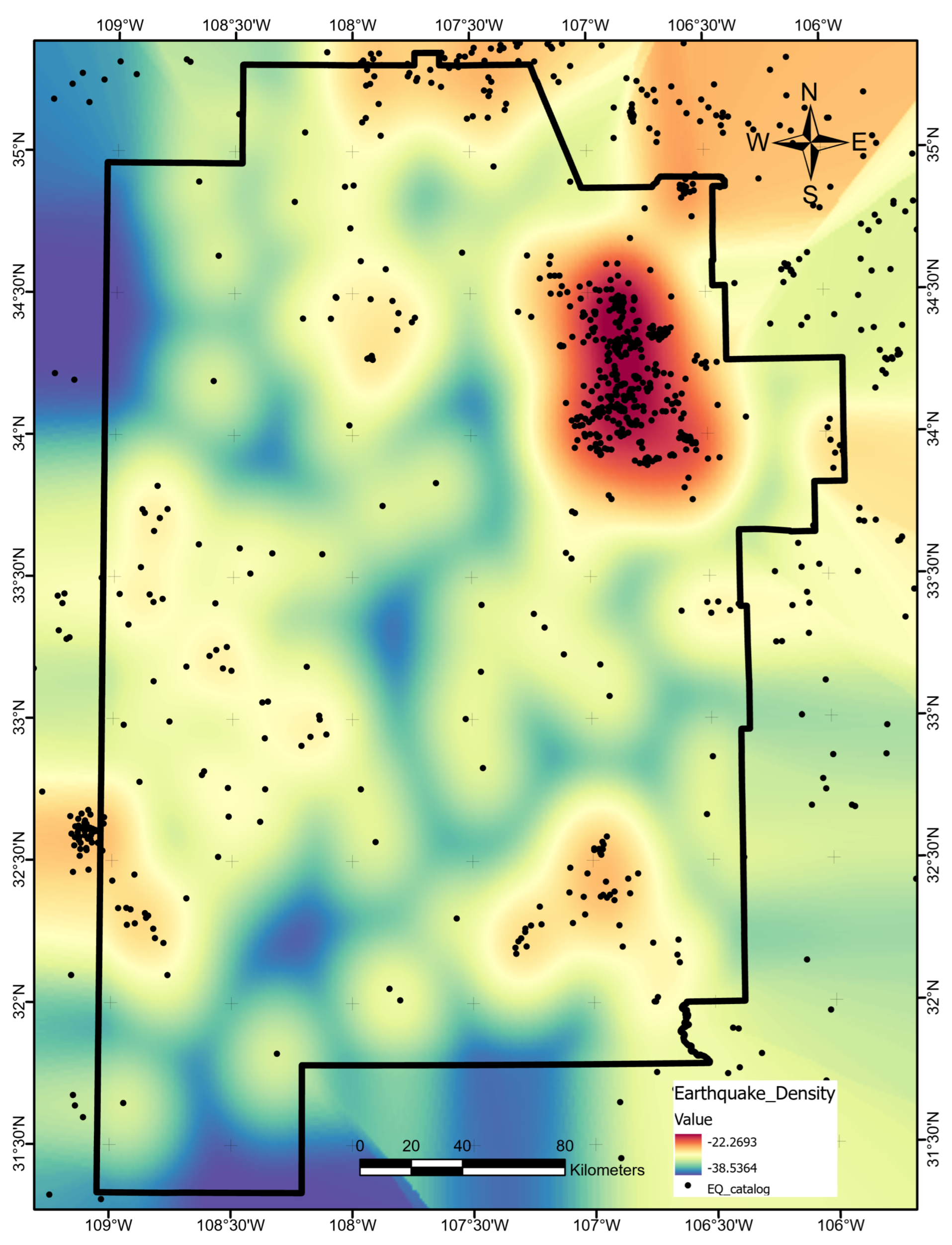
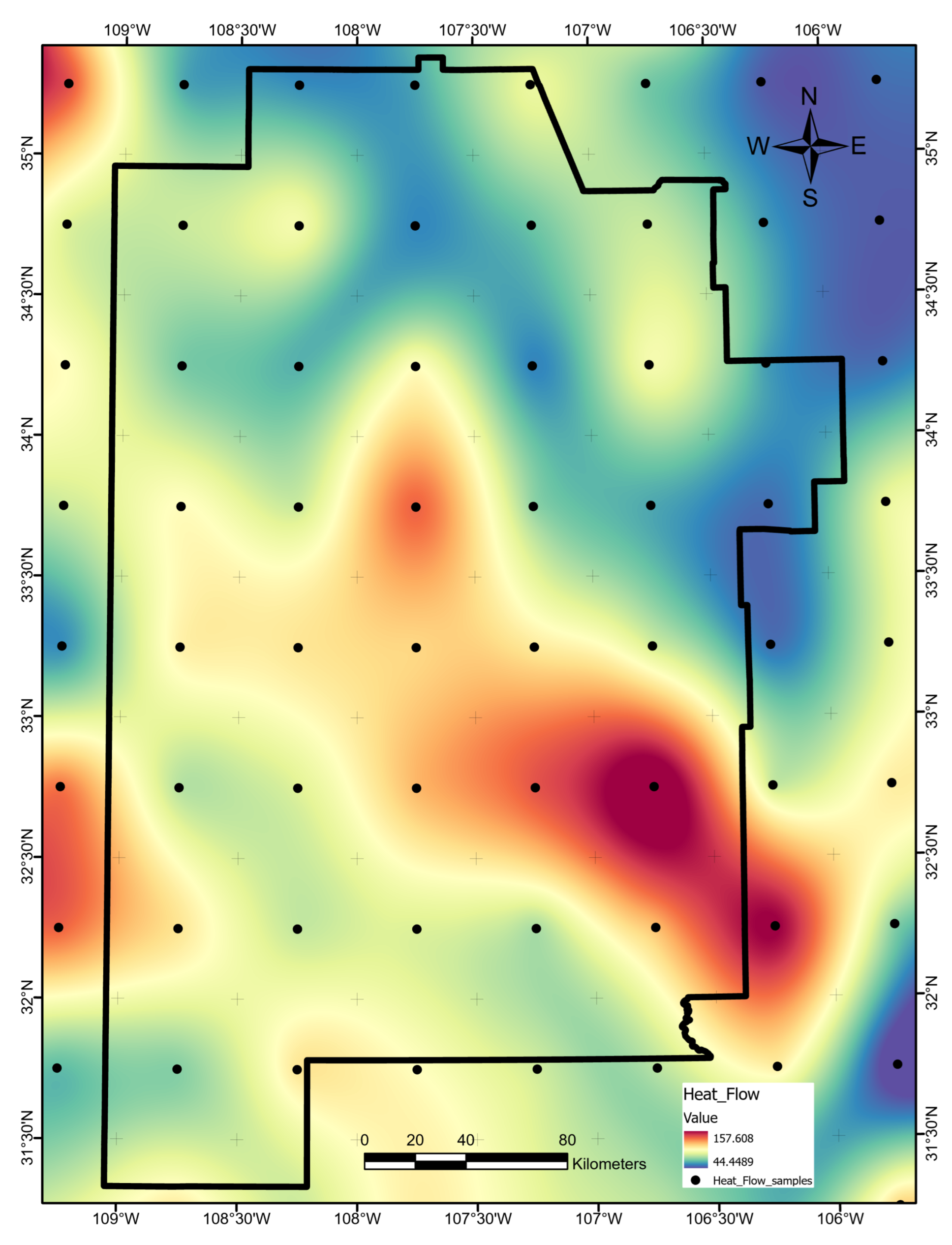
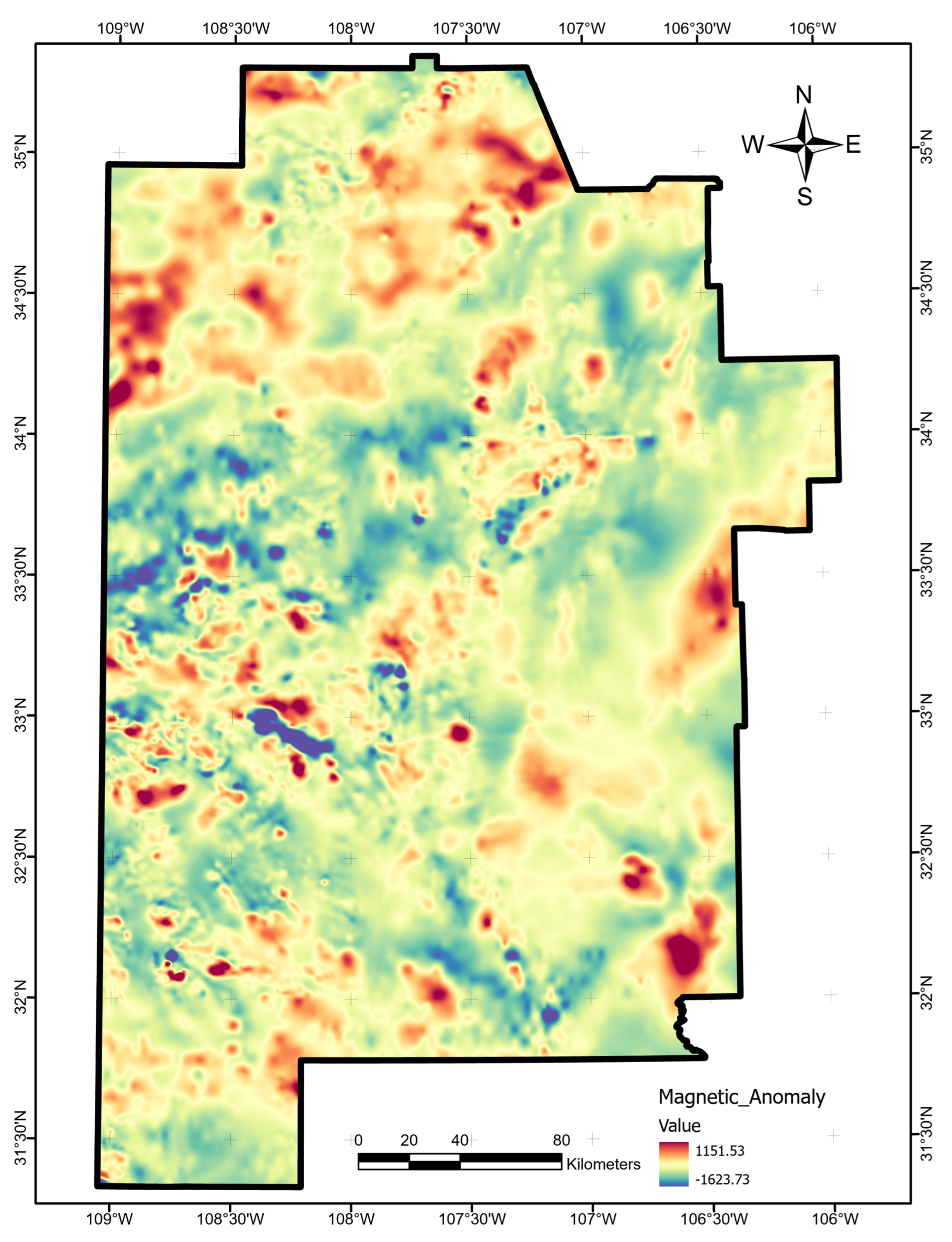
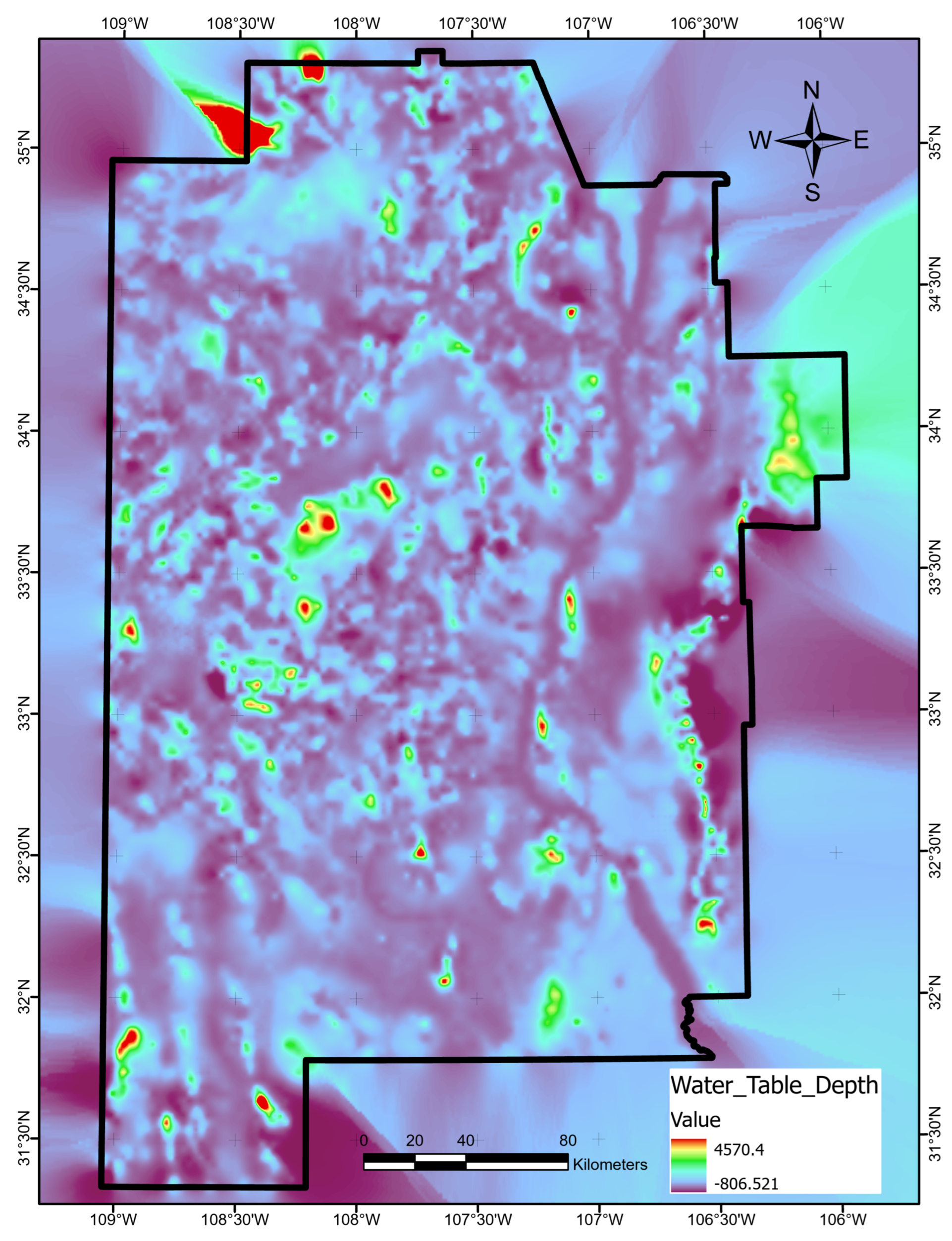
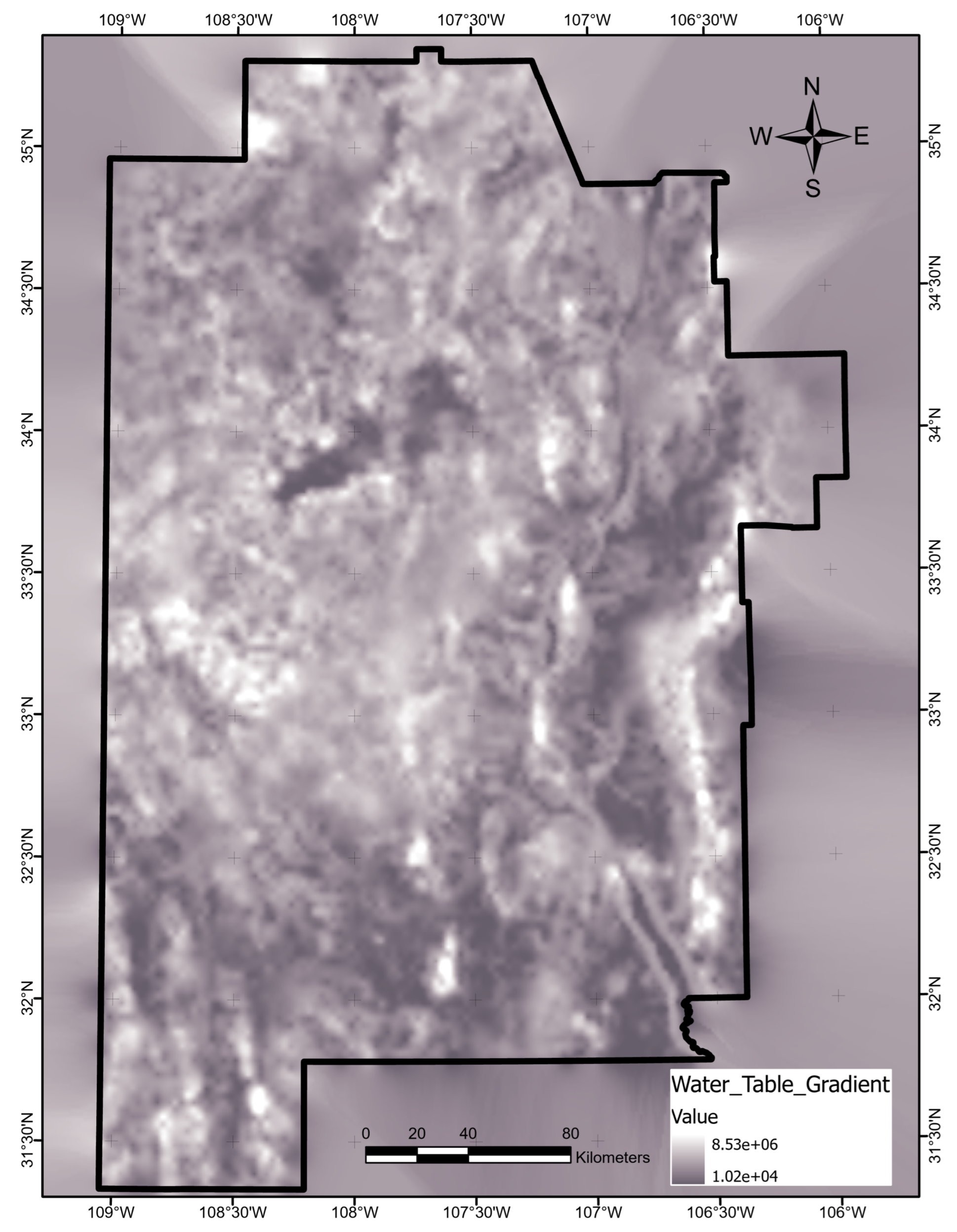
The optimal allocation strategy for geothermal-project resources should also take the full feature importance analysis results into account. Average ShAP magnitudes for water table depth, average precipitation, and magnetic anomalies rank lowest among the features in this study (
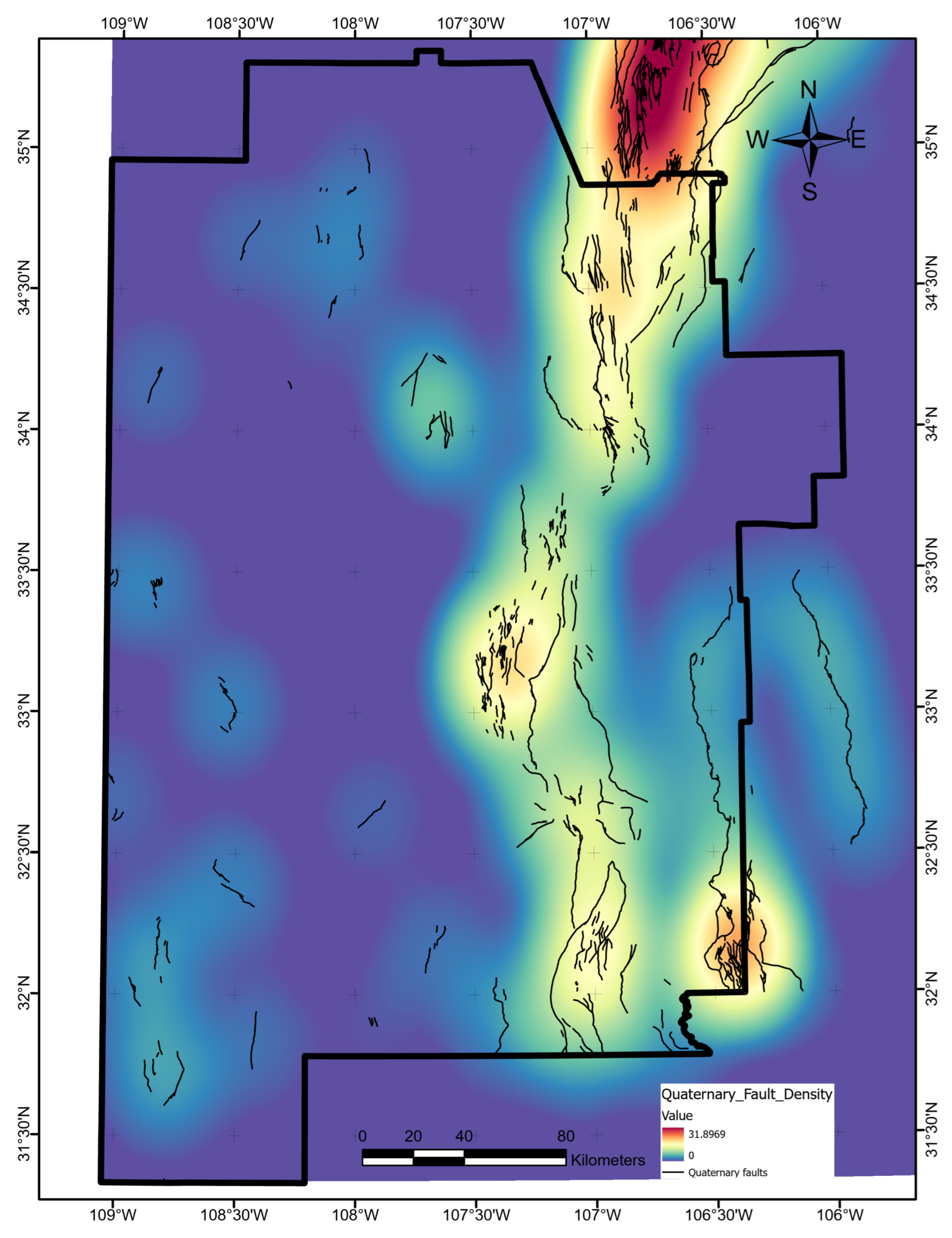
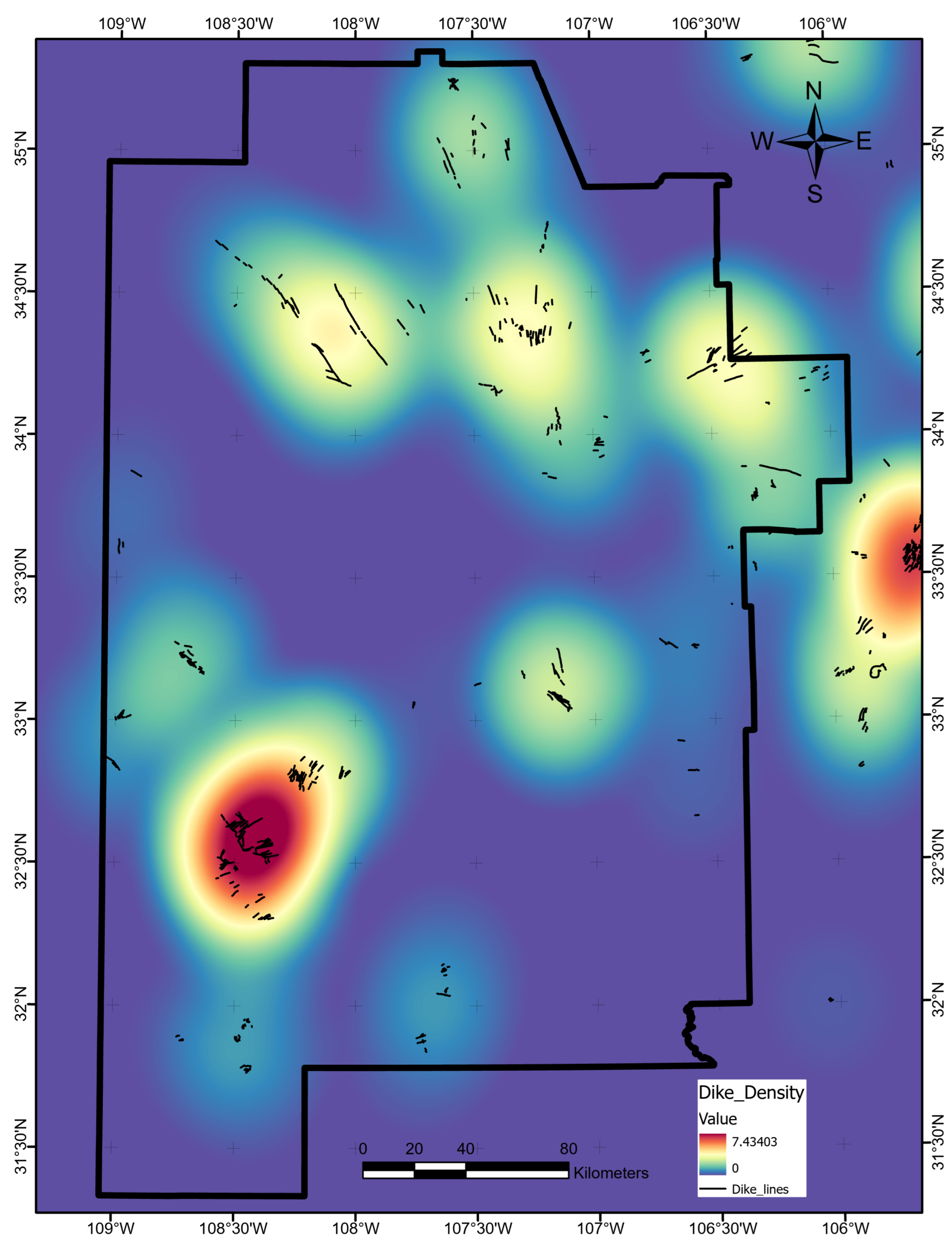
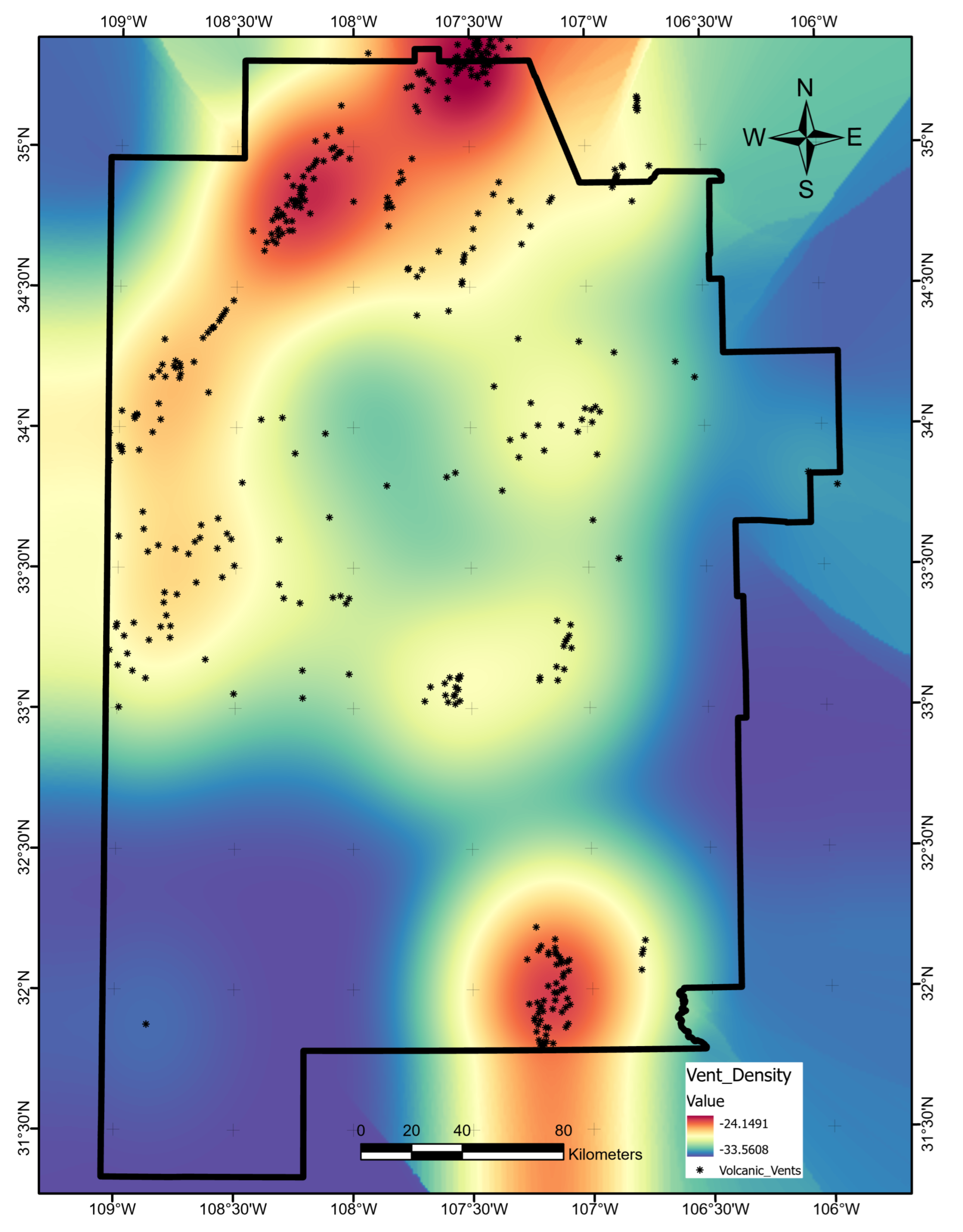
Figure 14). The poor predictive value of these data sets would not justify additional project time or budget appropriations targeting their collection or analysis. Similarly, water-table gradient, topographic gradient, gravity-anomaly gradient, and magnetic-anomaly gradient do not even appear in the ShAP value sensitivity report and could reasonably be set aside as low priority data sets. Instead, spending should focus on high-value data, including fault and drainage maps; the earthquake catalog and heat-flow estimates; mapped vents, springs, and volcanic dikes; crustal thickness estimates; and boron and silica concentrations. Note that feature importance rankings will likely vary from locality to locality if the local geophysical configurations are just sufficiently different, or even in the same project area if features are replaced with newly acquired or reprocessed data. Insights from ShAP analysis apply to models trained on a particular feature set and would necessarily require a refresh should that feature set or the geophysical configuration change.
5. Conclusions
The objective of this paper was to revisit the play fairway analysis (PFA) methodology and apply machine learning (ML) models for risk element prediction, uncertainty estimation, and decision guidance for a geothermal project team in the exploration phase of field development. Fundamentally, this process successfully resulted in classification maps of geothermal gradient, a proxy for subsurface enthalpy resource presence, covering the study area in southwest New Mexico. Maps were generated from four separate machine learning methods and from a weighted ensemble model that demonstrated better overall predictive performance. The ensemble also outperformed common interpolation routines that only rely on spatial patterns for prediction. Variance in the individual ML classifier results within the ensemble is rooted in different underlying distributions of the class probabilities based on the chosen model representations. We applied distribution summation on the class probabilities and calculated entropy to quantitatively measure spatial locations where ensemble predictions had high confidence or where ensemble results could not be trusted due to this representation uncertainty. Incorporating probabilistic components into ML models allows parameterization uncertainty to be measured in a similar way. This measure helped us identify areas in the case study where the neural network may be under-constrained due to lack of sufficient training data or iterations. Standard errors in the input features define a third source of uncertainty that is easily measurable using a solution ensemble and entropy approach. When applied to features that rank highly in an importance analysis, such as silica geothermometer temperature in southwest New Mexico, feature uncertainty can provide clear guidance on locations where information gain from data-gathering activities would be of the highest value.
We believe applying these steps in a comprehensive ML-enhanced PFA strategy for mapping enthalpy favorability can influence conventional hydrothermal, enhanced geothermal systems, and even advanced closed loop geothermal exploration projects. Further enthalpy resource characterization would also need to take other parameters, such as thermal conductivity, into account. Furthermore, practitioners should extend the workflow for pre-screening other risk elements such as permeability and fluids for a complete PFA depending on the targeted type of geothermal system. One further caveat must also be addressed: ML-enhanced PFA methods cannot replace subject matter experts in geothermal exploration. Rather, the methods proposed here give practitioners valuable decision support for more efficient project execution. The associated data-driven insights enable highly targeted technical efforts and rapid identification of prospects, both of which are requirements to support future growth of the geothermal industry.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















