
A Fault-Line Selection Method for Small-Current Grounded System Based on Deep Transfer Learning


Abstract
:1. Introduction
- An FLS model architecture based on deep transfer learning is proposed. Fine-tuning is used to transfer the fault features extracted from other substation instances to the target instances that lack samples. This will reduce the number of samples required to train the model in the target instance and improve the FLS accuracy.
- The historical averaging technique is proposed for introduction into the transfer learning of the FLS model. It can limit the model parameters to vary widely during the training process. The model can retain the general fault features learned from other substation instances and learn the specific fault features in the target substation instance during transfer training, which improves the transfer effectiveness of the FLS model.
2. Materials and Methods
2.1. Dataset
2.2. Improved Method Based on Deep Transfer Learning
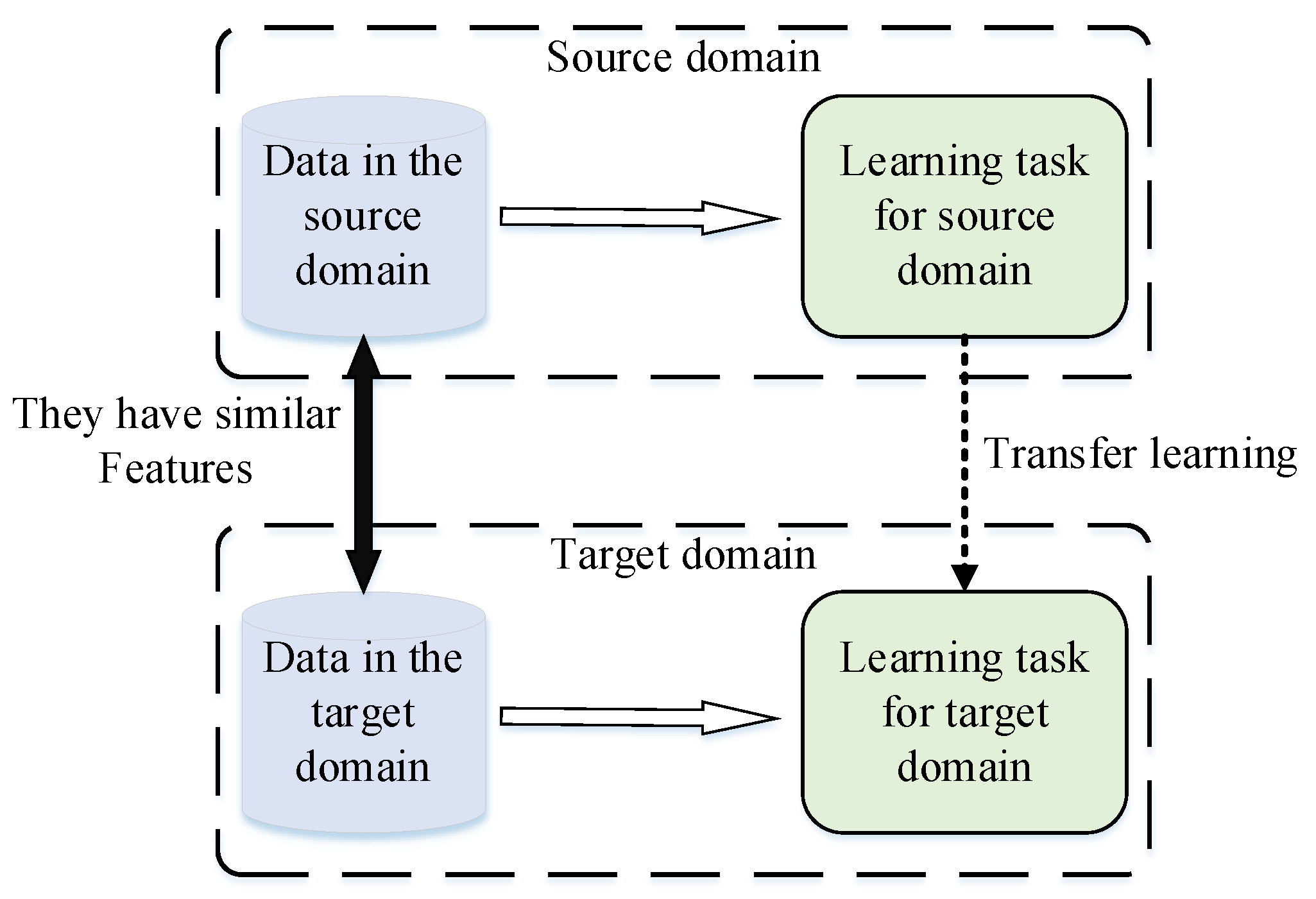
2.2.1. Introduction to Deep Transfer Learning
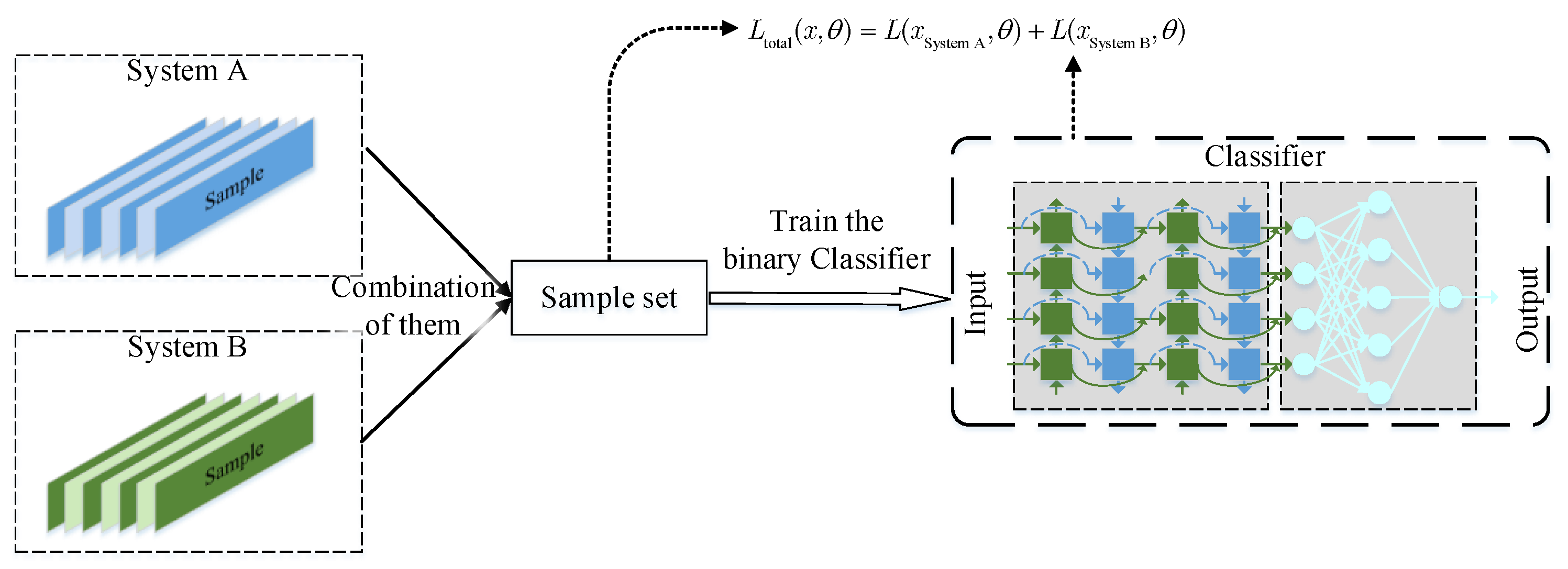
2.2.2. Network-Based Deep Transfer Learning Model
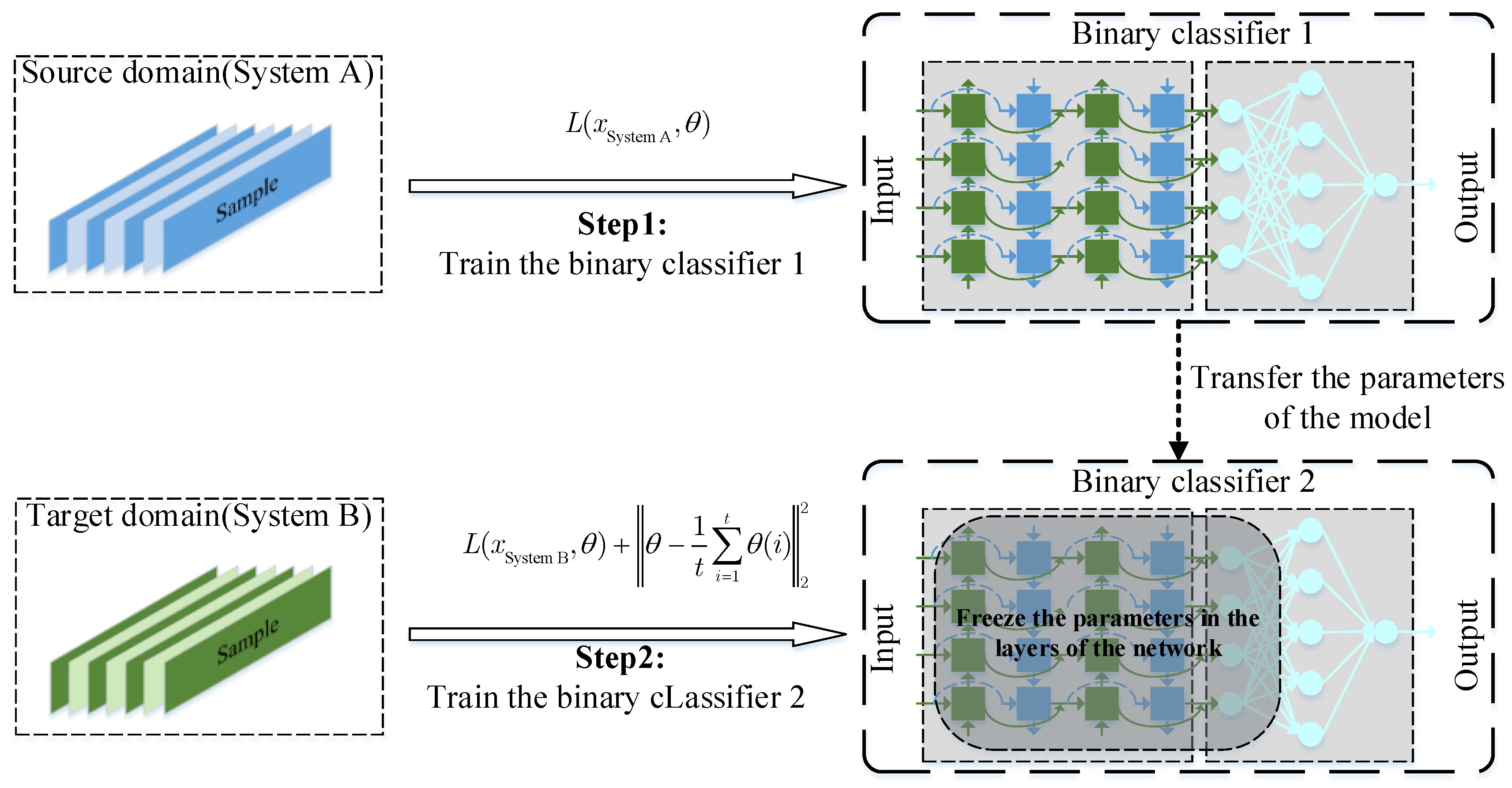
2.2.3. Improved Model Using Historical Averaging Technique
2.3. FLS Model Based on Deep Transfer Learning
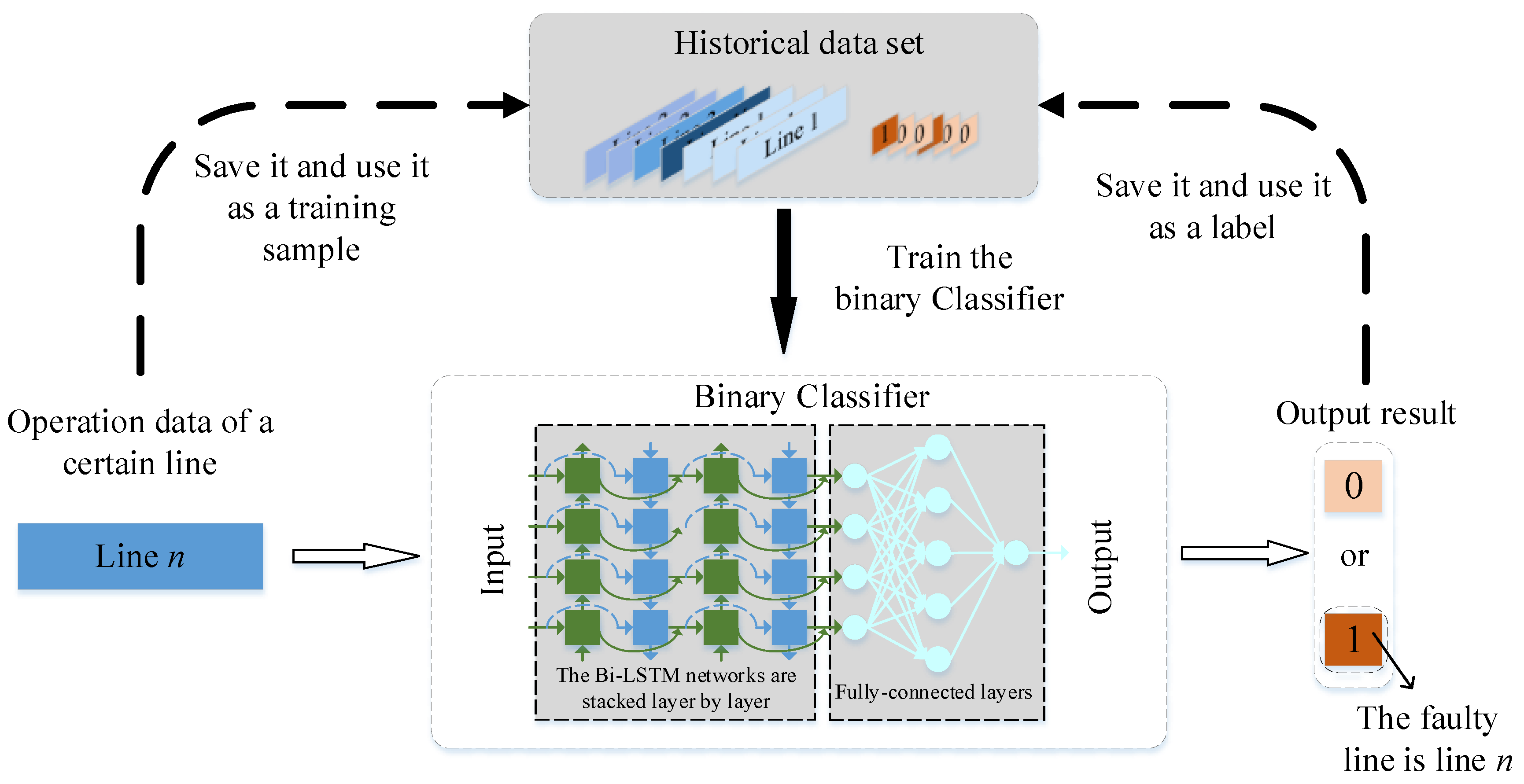
2.3.1. Data Processing of FLS Model
2.3.2. FLS Model Architecture Based on Deep Transfer Learning
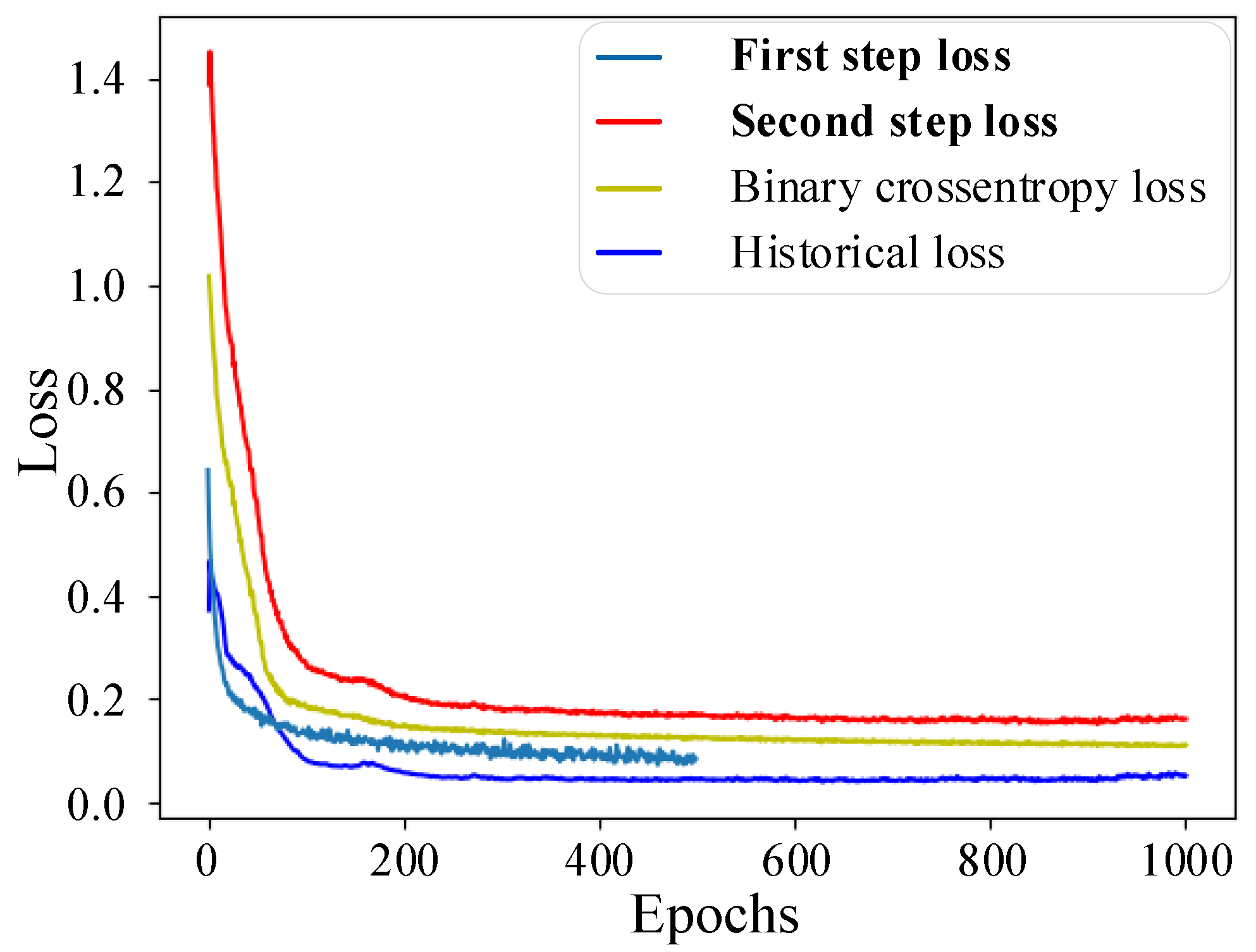
2.4. Training Strategy for FLS Model
2.4.1. One-Step Training Strategy
2.4.2. Two-Step Training Strategy
3. Results and Discussion
3.1. The Transfer Learning Process of FLS Model
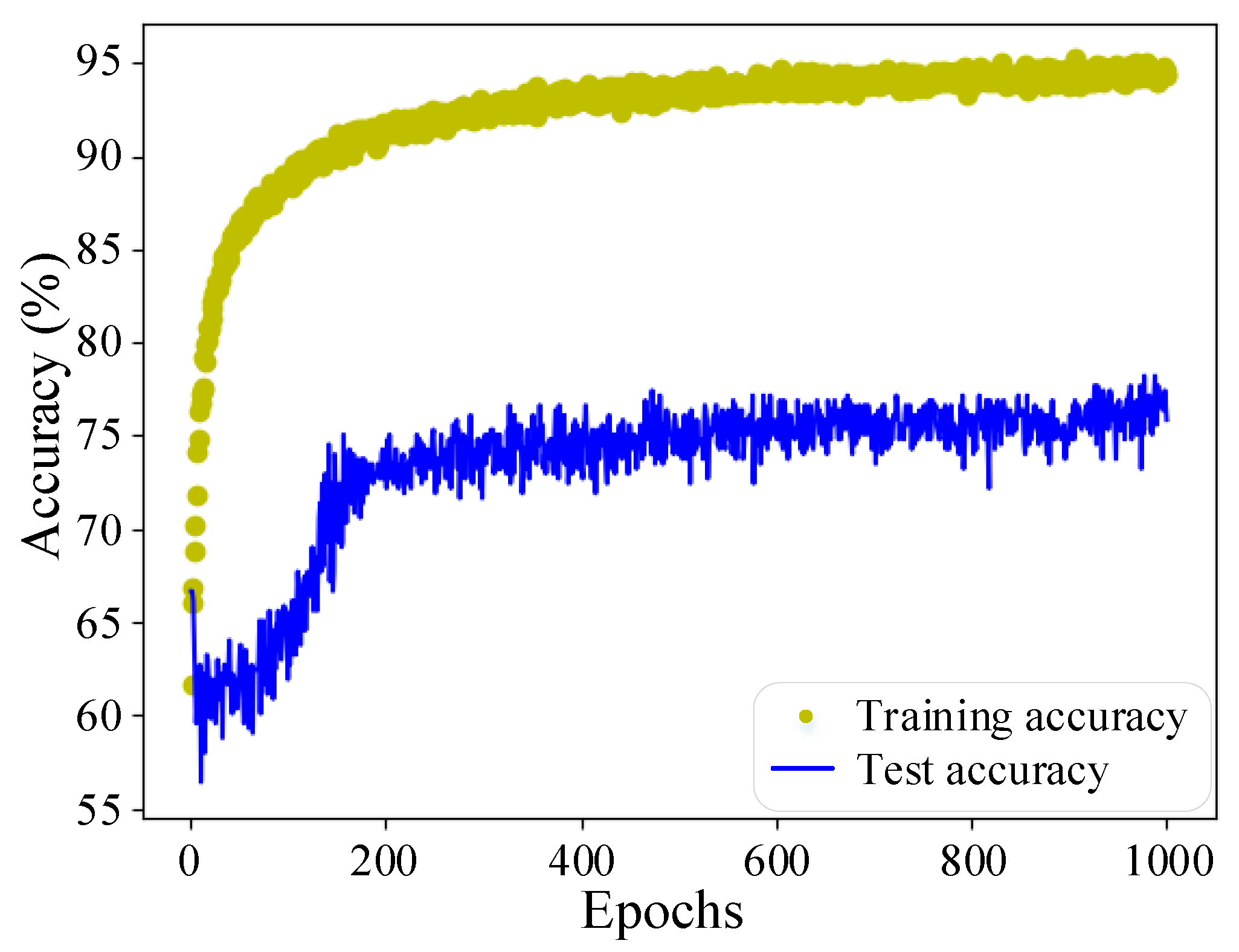
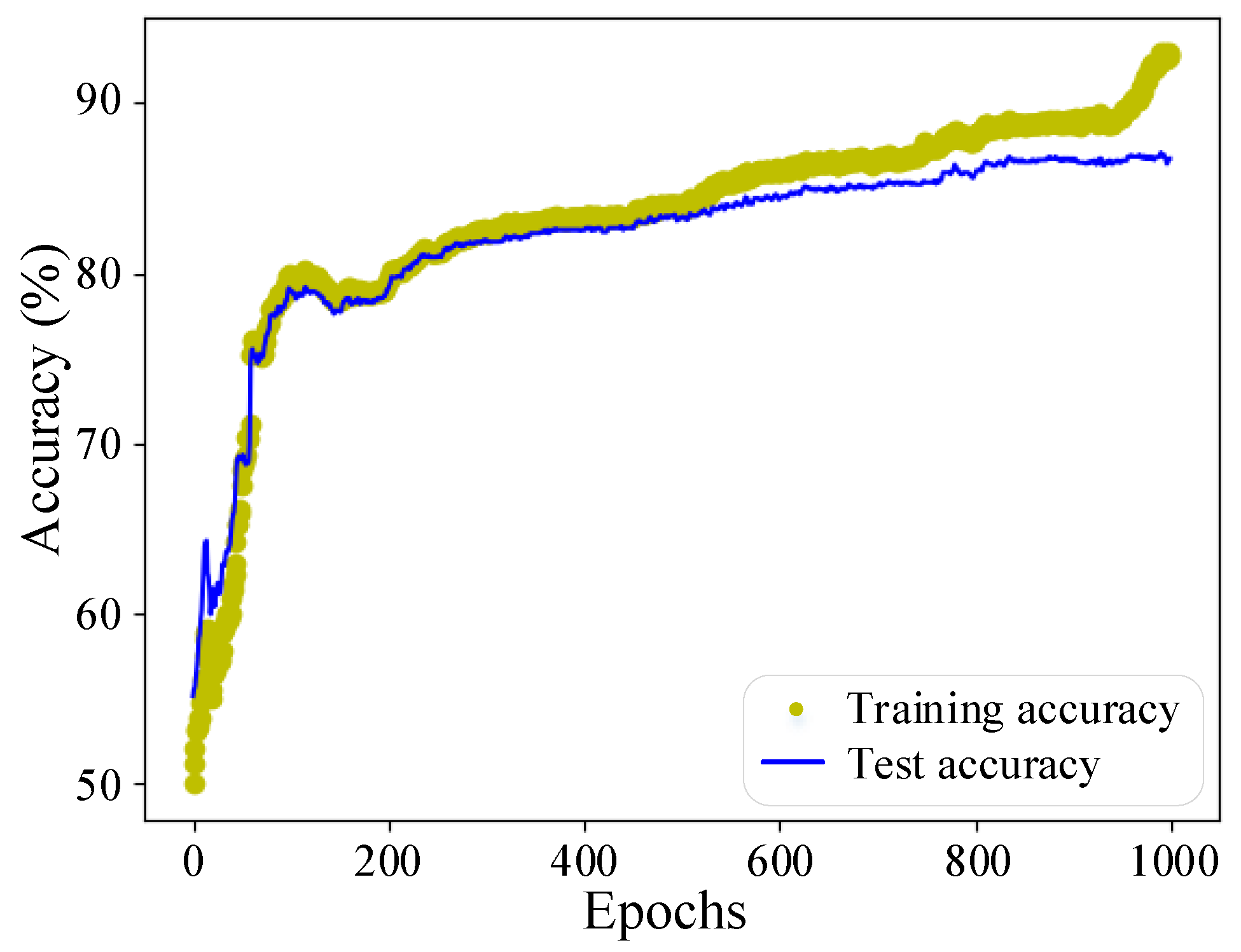
3.1.1. FLS Model Using One-Step Training Strategy
3.1.2. FLS Model Using Two-Step Training Strategy
3.2. The Effect of Proposed Model on Different Target SCGSs
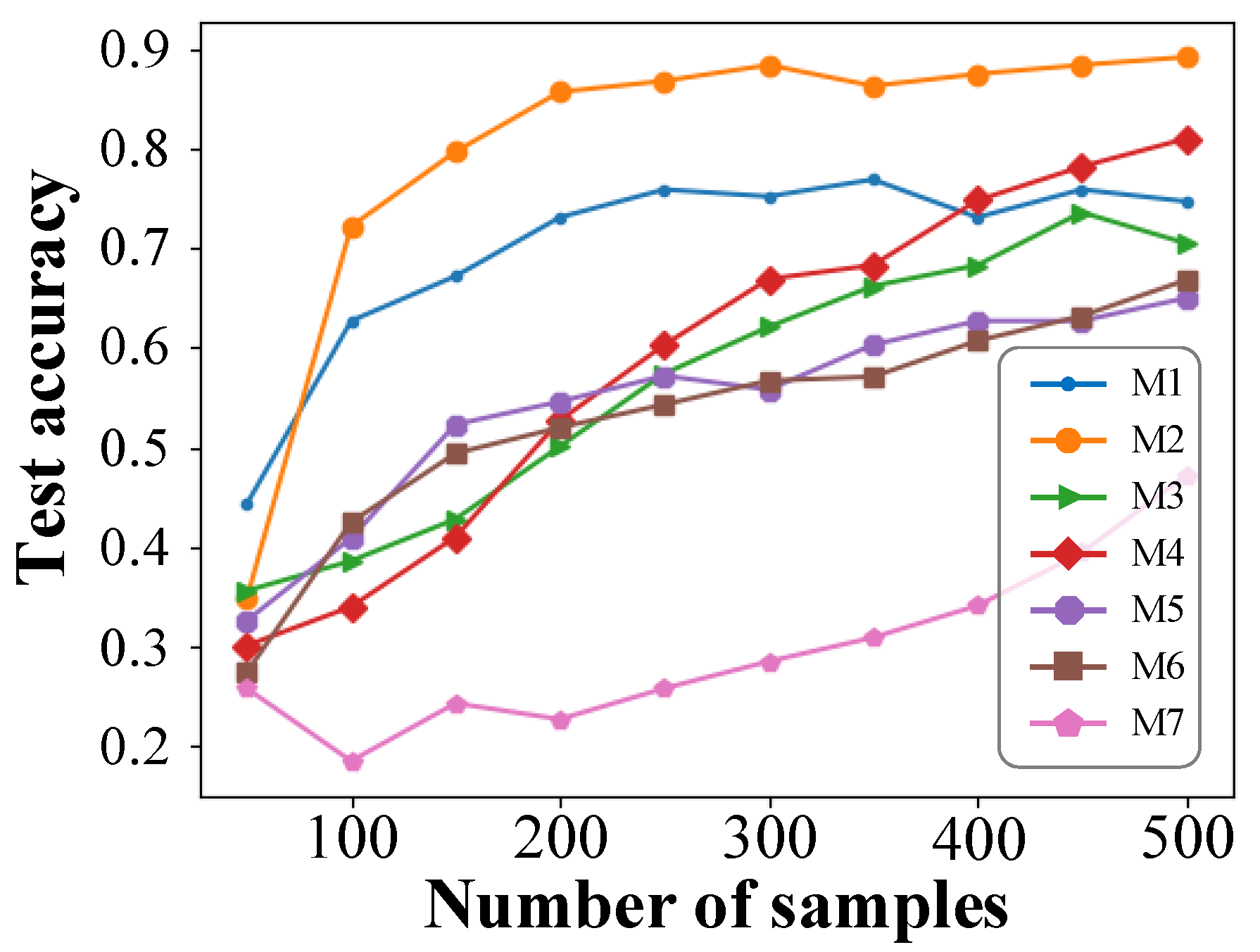
3.3. Model Comparison
- (1)
- When the number of samples is more than 100, the accuracy of M2 is much higher than in other models. Its accuracy can reach about 85% when the sample size is 200, and when the sample size is further increased, the accuracy can even exceed 90%.
- (2)
- Comparing M1 and M2, it can be seen that the two-step training strategy can make the FLS model obtain about 85% accuracy when there are only 200 samples, and its transfer learning effect is significantly better than that of the one-step training strategy.
- (3)
- Comparing M2, M3, M4, and M5, it can be seen that the application of fine-turning and historical averaging techniques can significantly improve the accuracy of the FLS model in small-sample cases. When only one of the two techniques was used, fine-tuning performed slightly better than the historical averaging technique, but they were both significantly better than when neither technique was used.
- (4)
- Comparing M5 and M6 shows that when fine-turning and historical averaging techniques are not used in the two-step training strategy, it is equivalent to a supervised deep neural network model trained only with target domain data. In the two-step training strategy, the model extracts the source domain features in the first step, but if no measures are taken to preserve these features, they may be gradually forgotten by the model with training in the second step.
- (5)
- The effect obtained by M7 is far worse than other models, which indicates that it is difficult for the traditional shallow learning to extract fault features in high-dimensional data.
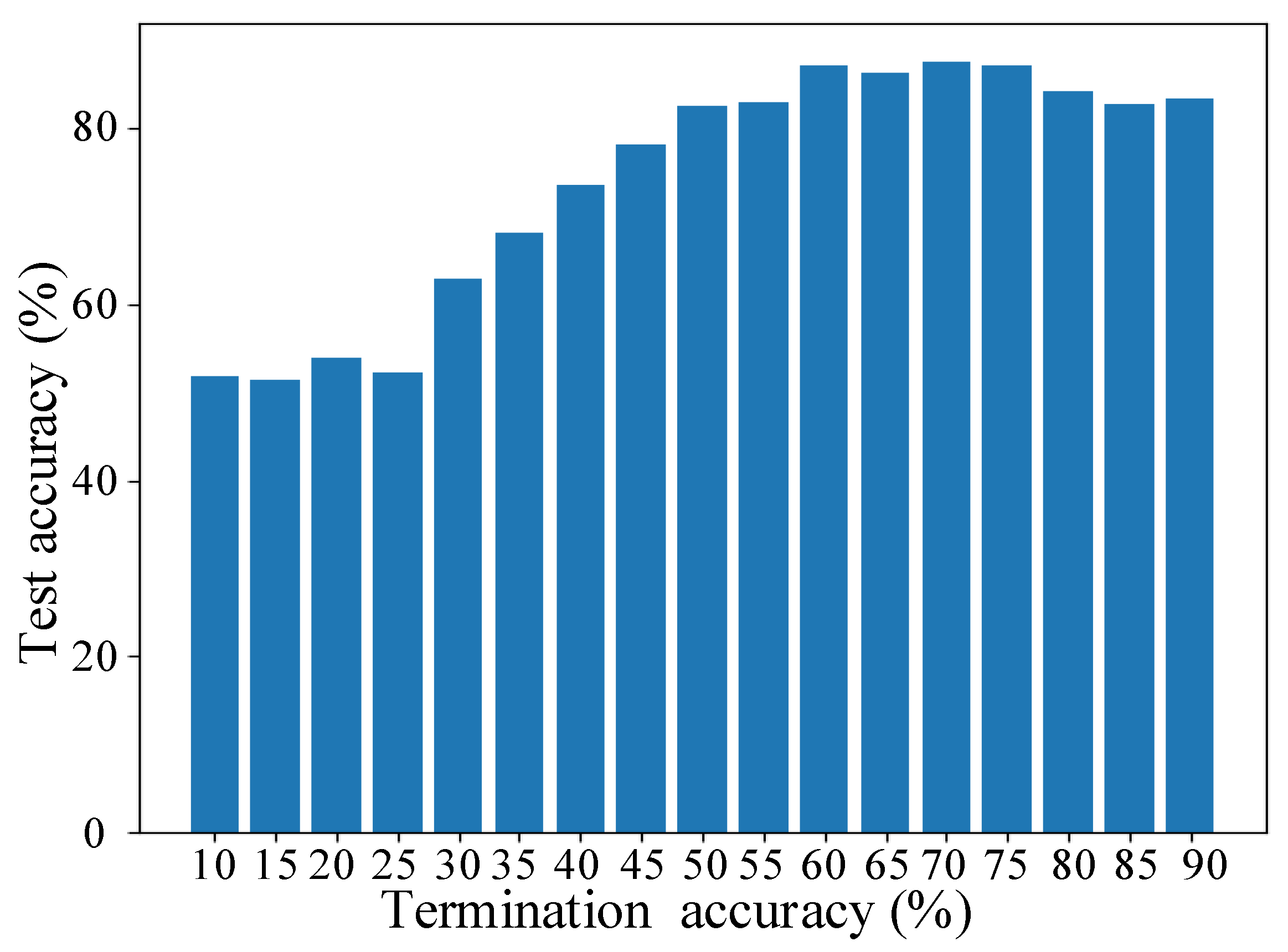
3.4. Effect of Termination Accuracy on FLS Models
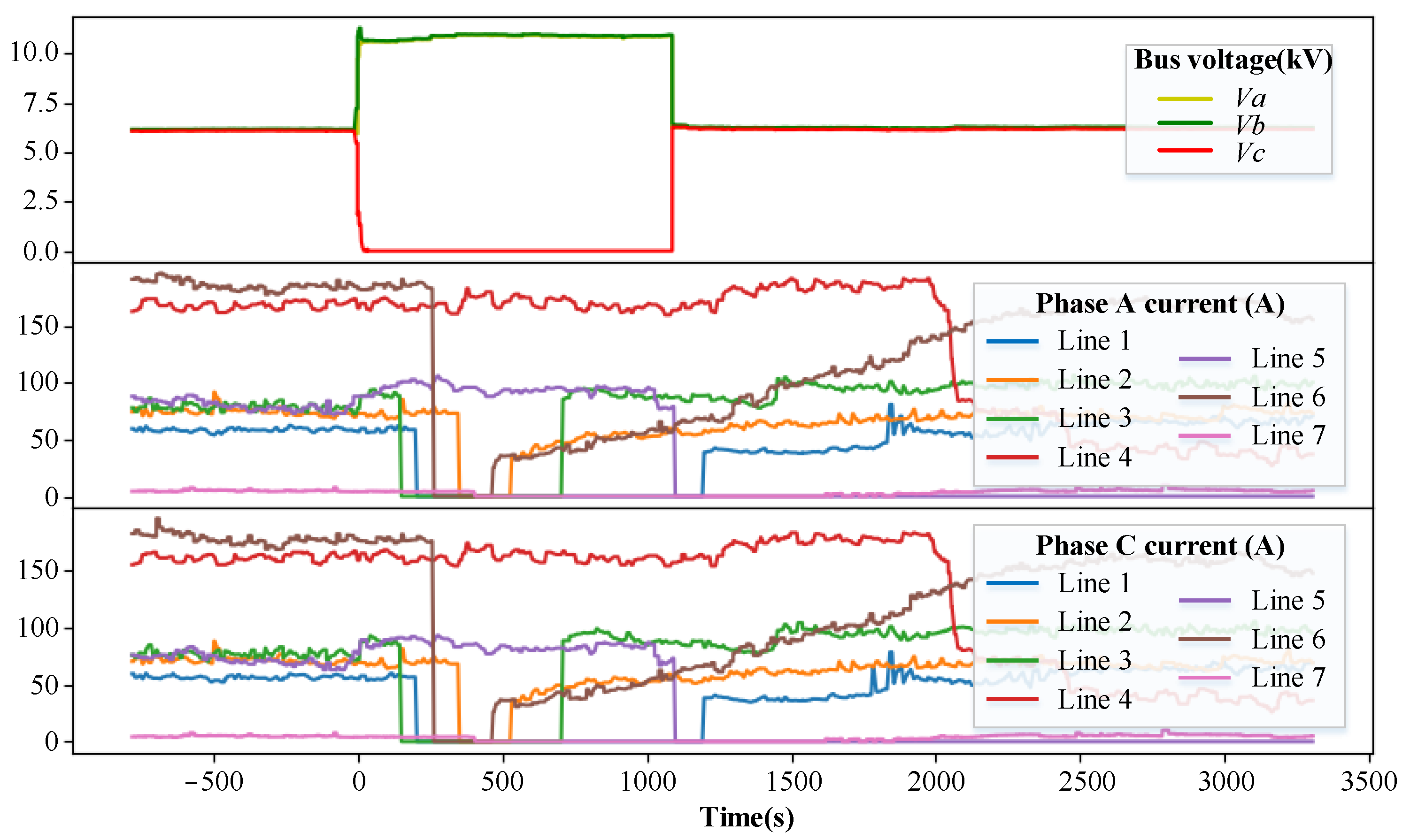
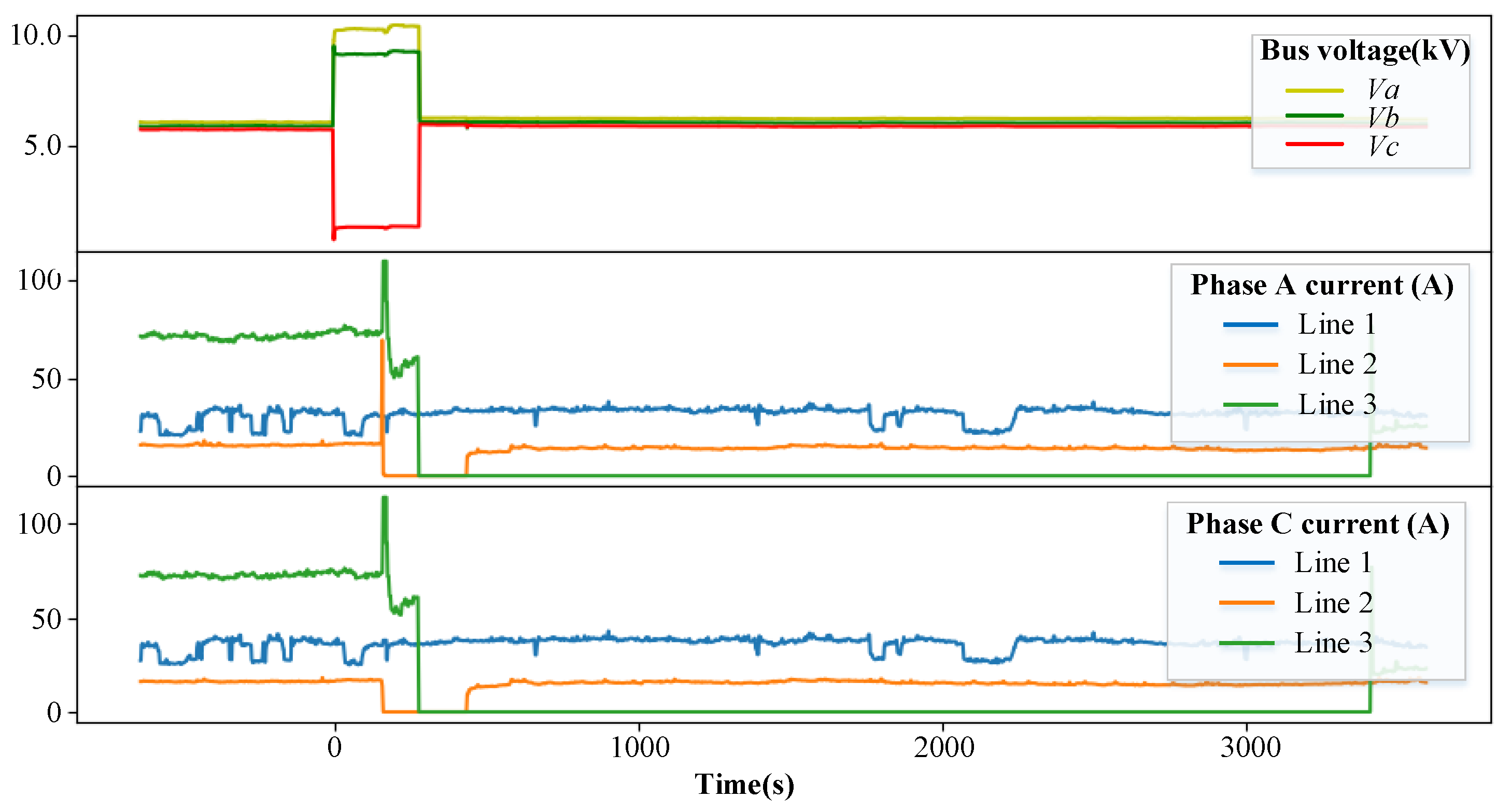
3.5. Operation of FLS Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- C62.92.4-1991—IEEE Guide for the Application of Neutral Grounding in Electrical Utility Systems, Part IV-Distributio. 1992. Available online: https://ieeexplore.ieee.org/servlet/opac?punumber=2900 (accessed on 21 April 2022).
- Jamali, S.; Bahmanyar, A. A new fault location method for distribution networks using sparse measurements. Int. J. Electr. Power Energy Syst. 2016, 81, 459–468. [Google Scholar] [CrossRef]
- Zhixia, Z.; Xiao, L.; Zailin, P. Fault line detection in neutral point ineffectively grounding power system based on phase-locked loop. IET Gener. Transm. Distrib. 2014, 8, 273–280. [Google Scholar] [CrossRef]
- Cui, T.; Dong, X.; Bo, Z.; Juszczyk, A. Hilbert-Transform-Based Transient/Intermittent Earth Fault Detection in Noneffectively Grounded Distribution Systems. IEEE Trans. Power Deliv. 2010, 25, 143–151. [Google Scholar] [CrossRef]
- Michalik, M.; Okraszewski, T.M. Application of the wavelet transform to backup protection of MV networks-wavelet phase comparison method. In Proceedings of the 2003 IEEE Bologna Power Tech Conference Proceedings, Bologna, Italy, 23–26 June 2003; Volume 2, p. 6. [Google Scholar]
- Zhu, K.; Zhang, P.; Wang, W.; Xu, W. Controlled Closing of PT Delta Winding for Identifying Faulted Lines. IEEE Trans. Power Deliv. 2011, 26, 79–86. [Google Scholar] [CrossRef]
- Fan, S.; Xu, B. Comprehensive application of signal injection method in protection and control of MV distribution system. In Proceedings of the CICED 2010 Proceedings, Nanjing, China, 13–16 September 2010; pp. 1–7. [Google Scholar]
- Niu, L.; Wu, G.; Xu, Z. Single-phase fault line selection in distribution network based on signal injection method. IEEE Access 2021, 99, 21567–21578. [Google Scholar] [CrossRef]
- Yin, H.; Miao, S.; Guo, S.; Han, J.; Wang, Z. Novel method for single-phase grounding fault line selection in distribution network based on S-transform correlation and deep learning. Electr. Power Autom. Equip. 2021, 41, 88–96. [Google Scholar]
- Hao, S.; Zhang, X.; Ma, R.; Wen, H.; An, B.; Li, J. Fault Line Selection Method for Small Current Grounding System Based on Improved GoogLeNet. Power Syst. Technol. 2022, 46, 361–368. [Google Scholar]
- Zhang, L.; Wei, H.; Lyu, Z.; Wei, H.; Li, P. A small-sample faulty line detection method based on generative adversarial networks. Expert Syst. Appl. 2020, 169, 114378. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Liu, X.; Liu, Z.; Wang, G.; Cai, Z.; Zhang, H. Ensemble transfer learning algorithm. IEEE Access 2017, 6, 2389–2396. [Google Scholar] [CrossRef]
- Gretton, A.; Sejdinovic, D.; Strathmann, H.; Balakrishnan, S.; Pontil, M.; Fukumizu, K.; Sriperumbudur, B.K. Optimal kernel choice for large-scale two-sample tests. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper/2012/hash/dbe272bab69f8e13f14b405e038deb64-Abstract.html (accessed on 21 April 2022).
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Chang, H.; Han, J.; Zhong, C.; Snijders, A.M.; Mao, J.H. Unsupervised transfer learning via multi-scale convolutional sparse coding for biomedical applications. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1182–1194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, J.T.; Li, J.; Yu, D.; Deng, L.; Gong, Y. Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html (accessed on 21 April 2022). [CrossRef]
- Simonyan, K.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv Prepr. 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Naushad, R.; Kaur, T.; Ghaderpour, E. Deep Transfer Learning for Land Use and Land Cover Classification: A Comparative Study. Sensors 2021, 21, 8083. [Google Scholar] [CrossRef] [PubMed]
- Elhenawy, M.; Ashqar, H.I.; Masoud, M.; Almannaa, M.H.; Rakotonirainy, A.; Rakha, H.A. Deep Transfer Learning for Vulnerable Road Users Detection using Smartphone Sensors Data. Remote Sens. 2020, 12, 3508. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Su, X.; Wei, H.; Zhang, X.; Gao, W. A Fault-Line Detection Method in Non-Effective Grounding System based on Bidirectional Long-Short Term Memory Network. In Proceedings of the 2021 Power System and Green Energy Conference (PSGEC), Shanghai, China, 20–22 August 2021; pp. 624–628. [Google Scholar] [CrossRef]
- Prechelt, L. Early Stopping—But When? Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Domain | Target Domain | Methods | Accuracy (%) | Time (s) | ||
|---|---|---|---|---|---|---|
| Training | Test | Training | Test | |||
| System A | System B | M1 | 95.6 | 73.1 | 75.8 | 0.285 |
| M2 | 94.1 | 87.6 | 136.3 | 0.279 | ||
| System B | System A | M1 | 97.3 | 74.8 | 74.2 | 0.141 |
| M2 | 96.9 | 90.3 | 117.3 | 0.152 | ||
| Methods | Accuracy (%) | Time (s) | ||
|---|---|---|---|---|
| Training | Test | Training | Test | |
| M1 | 94.7 | 72.8 | 74.9 | 0.281 |
| M2 | 93.5 | 86.3 | 139.2 | 0.276 |
| M3 | 89.2 | 49.7 | 114.8 | 0.281 |
| M4 | 90.3 | 52.1 | 93.5 | 0.279 |
| M5 | 98.9 | 53.7 | 107.0 | 0.285 |
| M6 | 98.7 | 51.1 | 99.2 | 0.284 |
| M7 | 87.6 | 24.9 | 33.8 | 0.130 |
| Line | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| Output | 0.030 | 0.233 | 0.239 | 0.145 | 0.863 | 0.471 | 0.322 |
| Line | 1 | 2 | 3 |
|---|---|---|---|
| Output | 0.001 | 0.327 | 0.946 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, X.; Wei, H. A Fault-Line Selection Method for Small-Current Grounded System Based on Deep Transfer Learning. Energies 2022, 15, 3467. https://doi.org/10.3390/en15093467
Su X, Wei H. A Fault-Line Selection Method for Small-Current Grounded System Based on Deep Transfer Learning. Energies. 2022; 15(9):3467. https://doi.org/10.3390/en15093467
Chicago/Turabian StyleSu, Xianxin, and Hua Wei. 2022. "A Fault-Line Selection Method for Small-Current Grounded System Based on Deep Transfer Learning" Energies 15, no. 9: 3467. https://doi.org/10.3390/en15093467
APA StyleSu, X., & Wei, H. (2022). A Fault-Line Selection Method for Small-Current Grounded System Based on Deep Transfer Learning. Energies, 15(9), 3467. https://doi.org/10.3390/en15093467