

Multivariate Data-Driven Models for Wind Turbine Power Curves including Sub-Component Temperatures




Abstract
:1. Introduction
- the model type;
- the input variables selection.
- The additional covariates can give something more to the data-driven model. In particular, since wind turbine faults are often associated with overheating and diminished extracted power [27,28], a model for the power which employs the temperatures as input variables has high potentiality for condition monitoring.
- data-driven approaches to wind turbine power curves are investigated with a focus on the effect of including internal temperatures in the set of possible covariates;
- differently with respect to most studies in the literature which are based on user’s discretion, in this work an automatic feature selection algorithm is employed for individuating the most appropriate input variables;
- two regression types are analyzed (support vector regression with Gaussian kernel and Gaussian process regression) and the input variables selection is shown to depend on the regression type, supporting the usefulness of an automatic features selection algorithm;
- a comparison against a benchmark multivariate model employing blade pitch and rotational speed (in addition to the wind speed) is pursued and the effect of including internal temperatures on the error metrics is discussed.
2. The Test Case and the Data Set
- nacelle wind speed v (m/s);
- output power P (kW);
- rotor speed (rpm);
- generator speed (rpm);
- blade pitch angle ;
- ambient temperature (K);
- generator bearing temperature 1 (K);
- generator bearing temperature 2 (K);
- maximum generator bearing temperature 1 (K);
- maximum generator bearing temperature 2 (K);
- generator phase 1 temperature (K);
- generator phase 2 temperature (K);
- generator phase 3 temperature (K);
- maximum generator phase 1 temperature (K);
- maximum generator phase 2 temperature (K);
- maximum generator phase 3 temperature (K);
- generator slip ring temperature (K);
- hydraulic oil temperature (K);
- gear oil temperature (K).
- In order to take into account the effect of environmental conditions as much as possible, it is recommended to renormalize the nacelle wind speed v by considering the effect of air density as indicated in Equation (2) and (3):where is the corrected wind speed, v is the estimate of undisturbed wind speed provided by the wind turbine nacelle anemometer, is the air density measured on site, is the air density in standard conditions, is the absolute temperature in standard conditions (288.15 K), and is the absolute ambient temperature measured on site. It should be noted that the above procedure does not solve all the issues related to the measurement of the wind speed for wind turbine performance monitoring. Actually, the wind speed to which we refer in this work is (as typical) measured through a cup anemometer placed behind the rotor span and the undisturbed wind speed is reconstructed through a nacelle transfer function. A mature approach to wind turbine performance monitoring should take into account that the nacelle wind speed measurement (and, therefore, the power curve) is site-dependent [29,30] and depends on the interaction with the rotor as well, which might be affected by systematic errors [31,32]. In order to overcome this point as much as possible, more complex renormalization methods might be applied, as for example in [33,34].
- Data are filtered on the condition that the wind turbine is producing power output by using the appropriate run-time counter, which is requested to be 600 s out of 600.
- Data are filtered below rated power, because the performance monitoring problem becomes trivial at rated power.
- Wind turbines operating in industrial wind farms not rarely are curtailed with respect to the design specifications: this can happen for grid requirements or for noise control issues. For the objectives of performance monitoring through power curve analysis, the above kind of measurements must be filtered out by appropriately clustering them [35]. This can be achieved by observing that a wind turbine is de-rated by forcing it to pitch anomalously. Therefore, a simple and effective method for filtering outliers is using the average wind speed–blade pitch curve [36], which can be retrieved from design specifications or from historical data. In this study, data characterized by an absolute deviation higher than with respect to the reference wind speed–blade pitch curve are excluded.
3. Method
3.1. Support Vector Regression
3.2. Gaussian Process Regression
3.3. Features Selection
- the matrix x, containing all the possible regressors organized in columns, and the vector y of power output are passed to a sequence of support vector regressions (respectively, Gaussian process regressions);
- the algorithm starts with an empty input variables matrix and adds each possible covariate of x one at a time performs the regression, and estimates the loss function through 10-fold cross-validation;
- the selected covariate is the one that provides the lowest value of the loss function;
- sequentially, each other possible covariate is added once at a time, the cross-validation is performed, the loss function is estimated;
- if there are no regressors which, if added, provide a decrease of the loss function, the algorithm stops;
- else, the algorithm adds to the input variables selection the regressor that diminishes the loss function the most, and the sequence proceeds.
- a random 50% selection is used for training the model and is noted as D1;
- the remaining 50% (hence named D2) is used for evaluating the goodness of the regression, by evaluating the out-of-sample error metrics.
4. Results
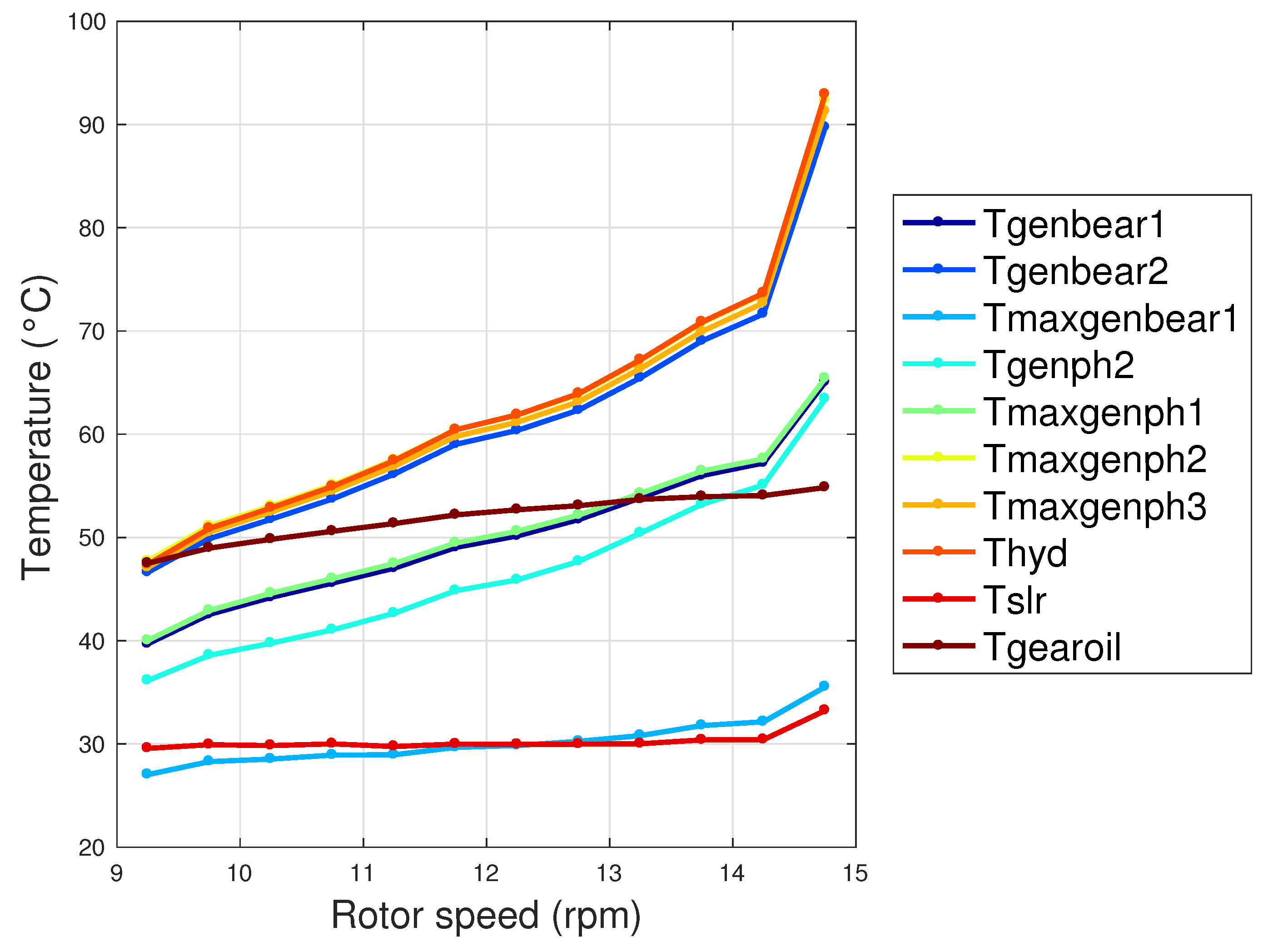
4.1. Input Variables Selection
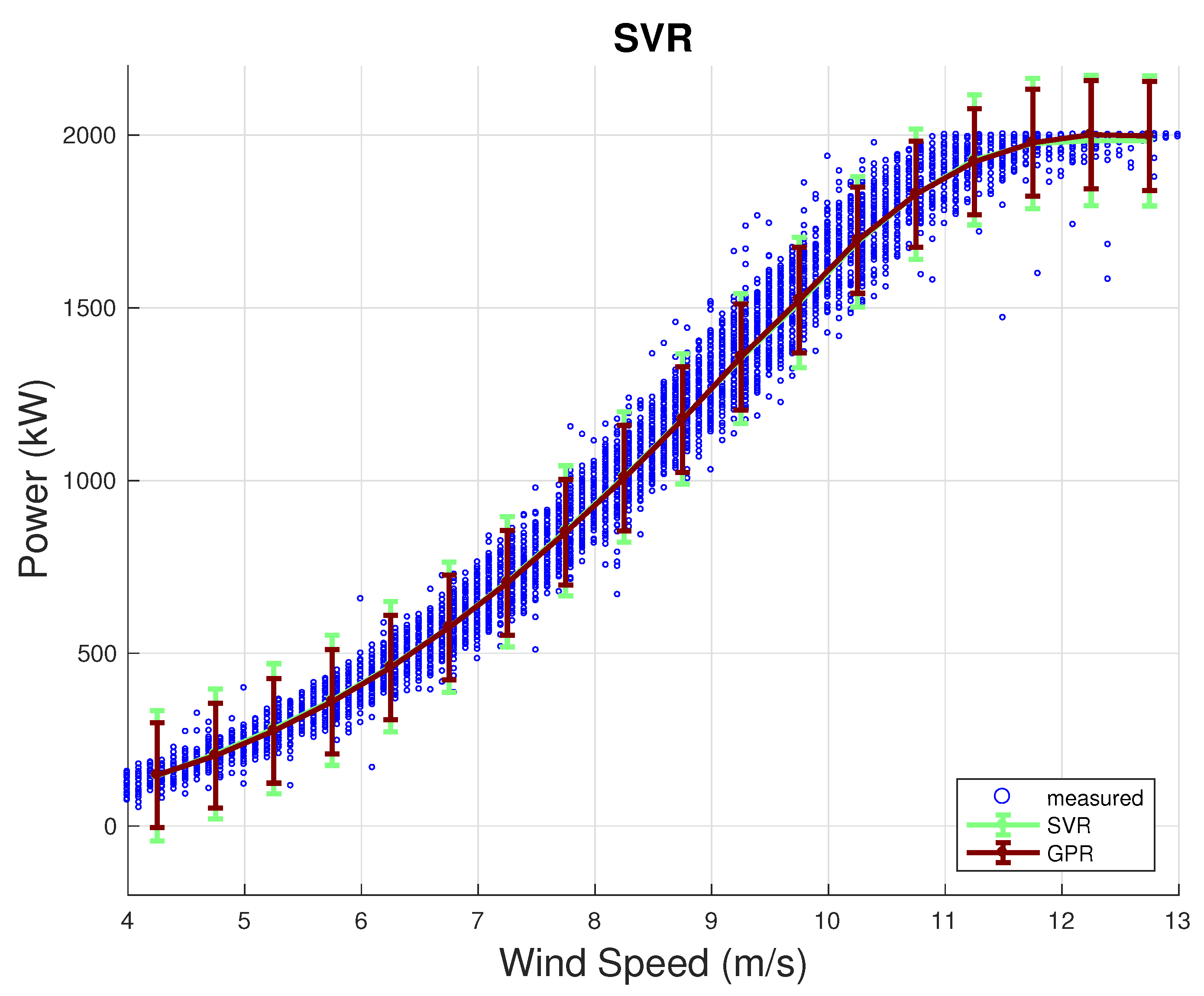
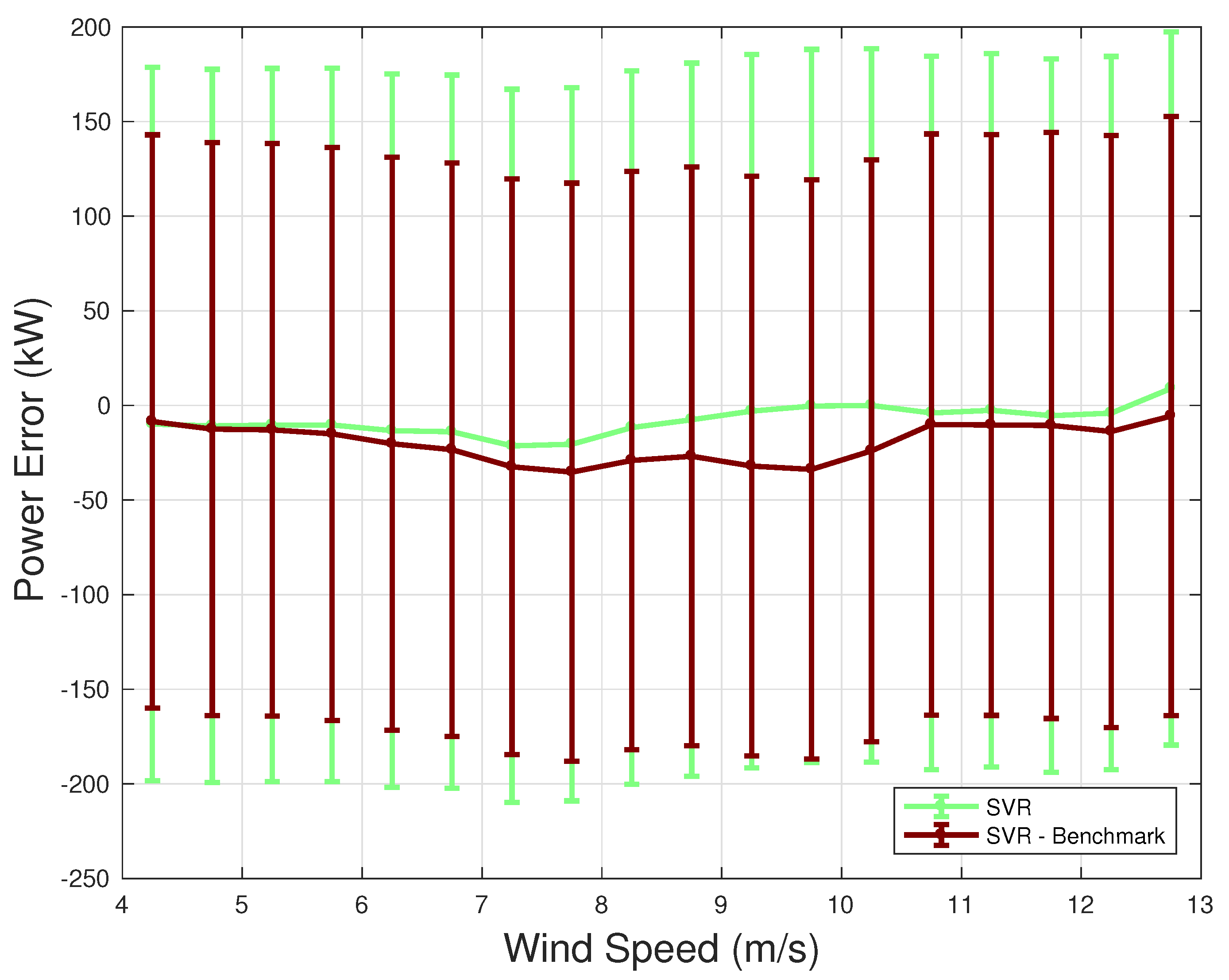
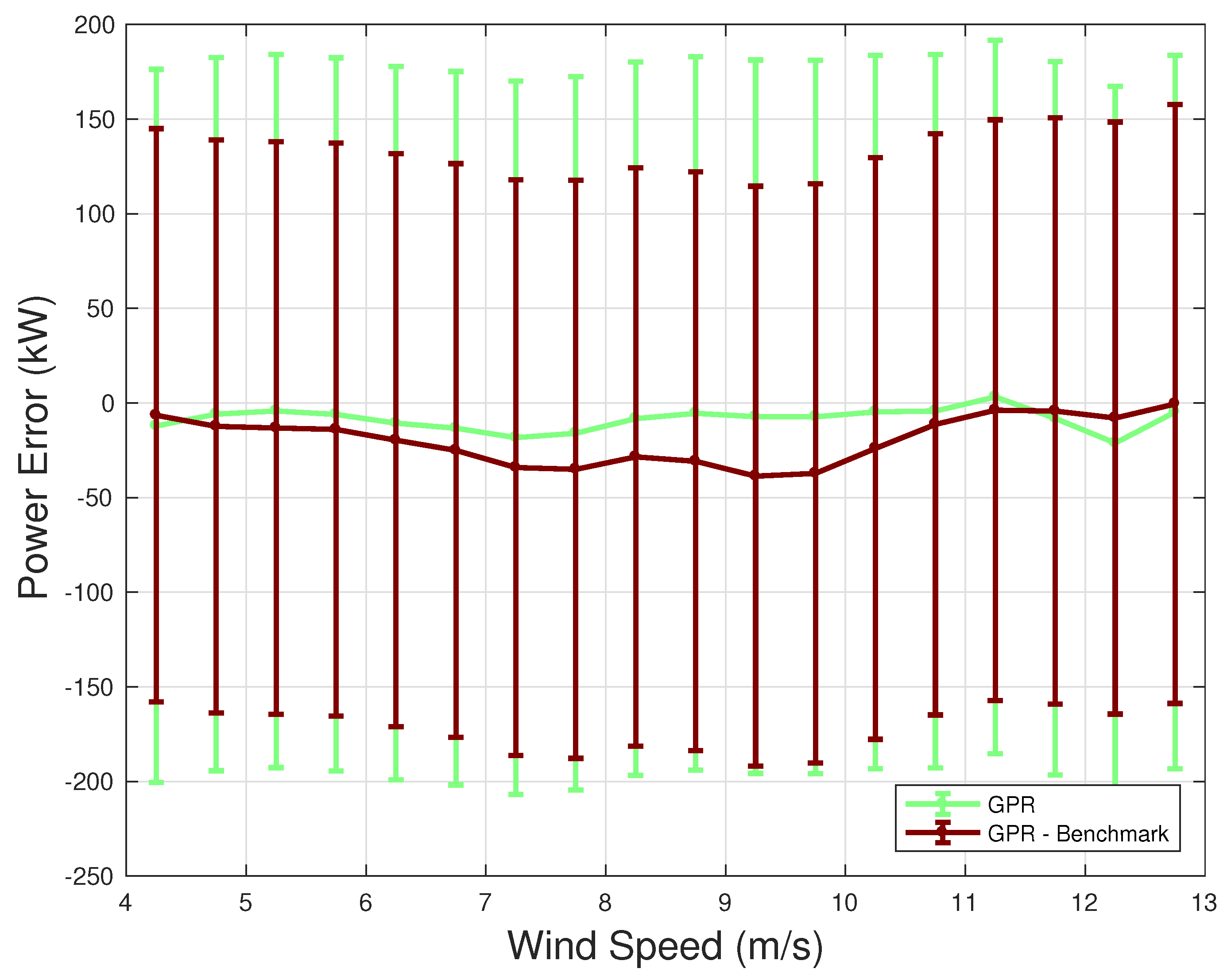
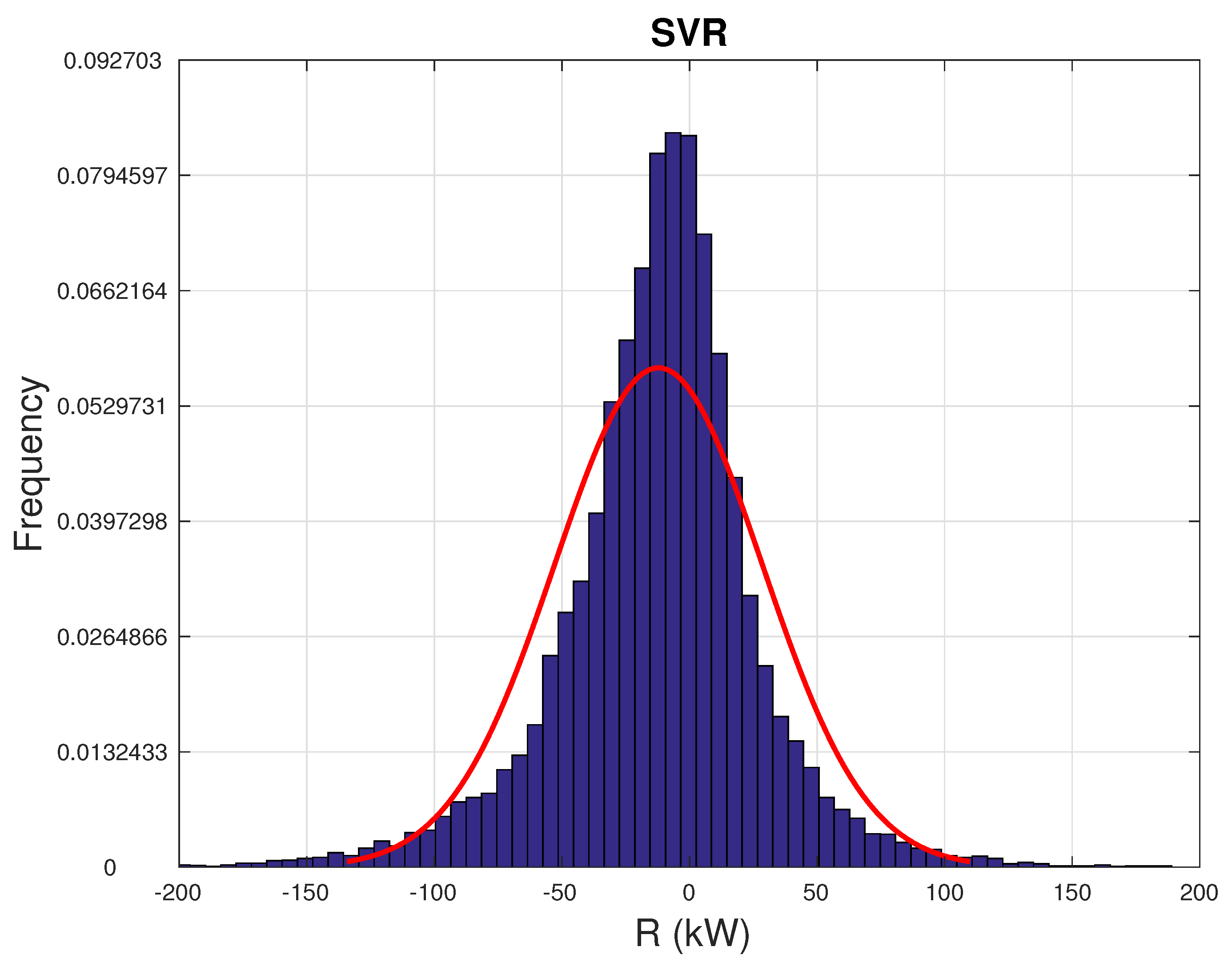
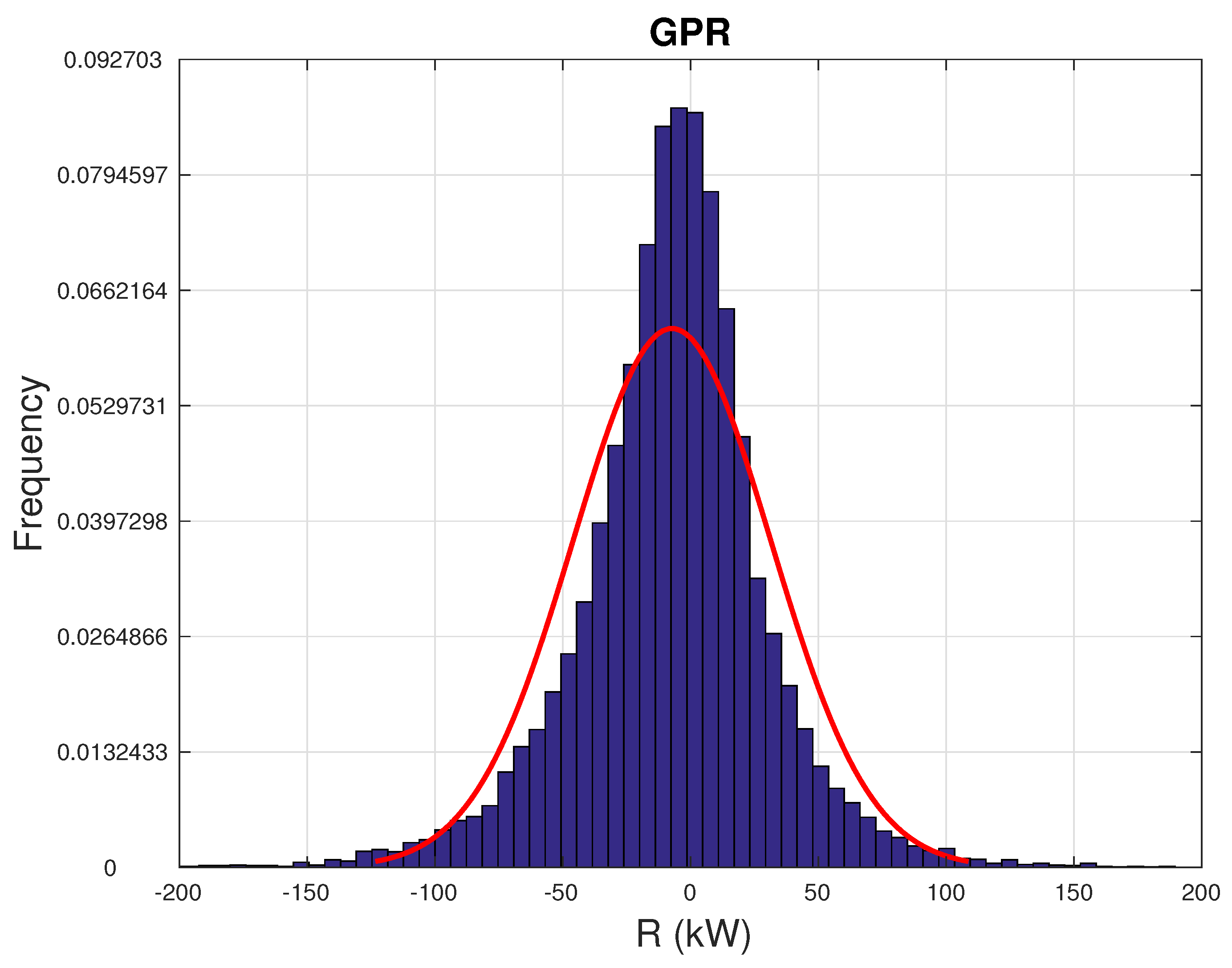
4.2. Error Metrics
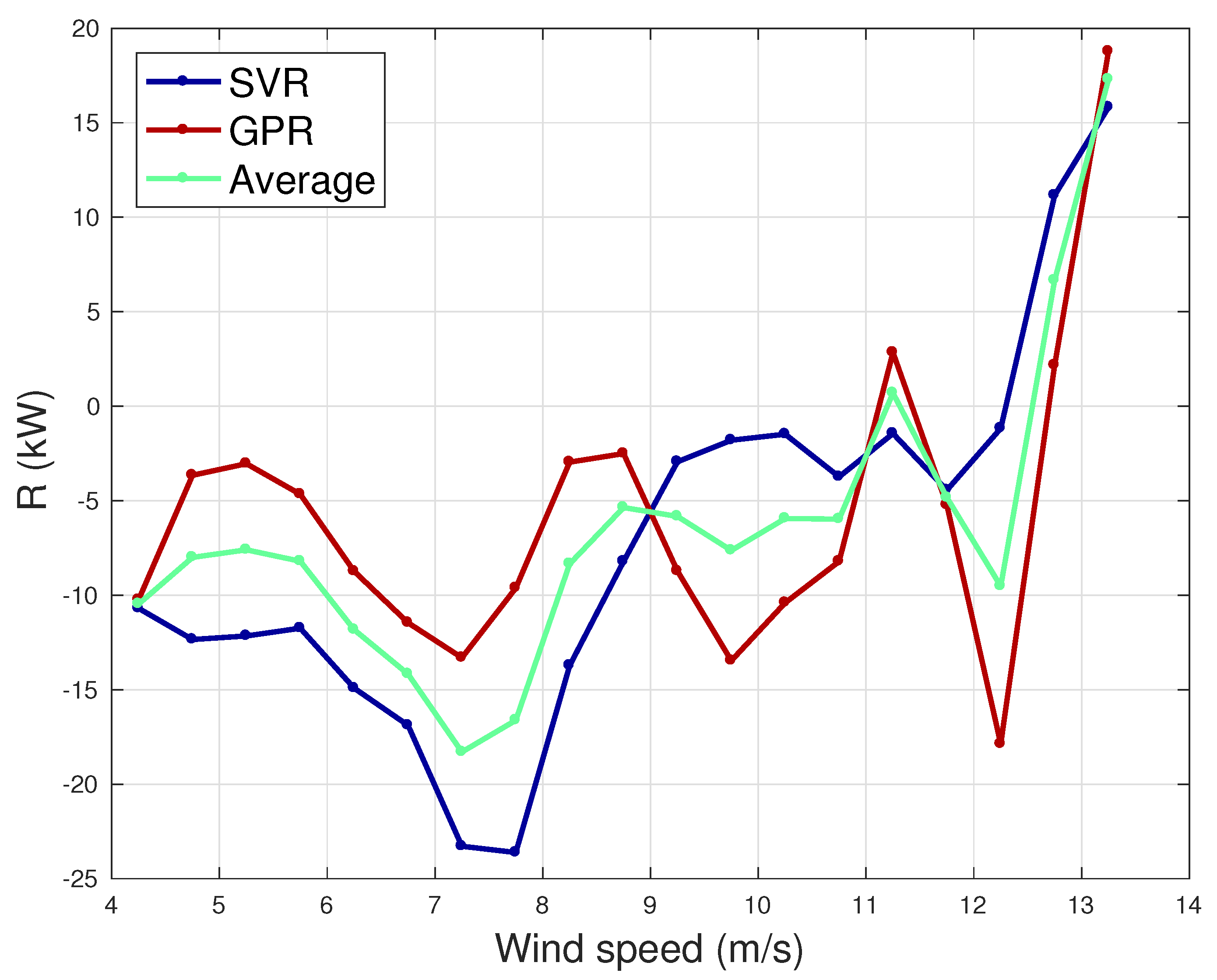
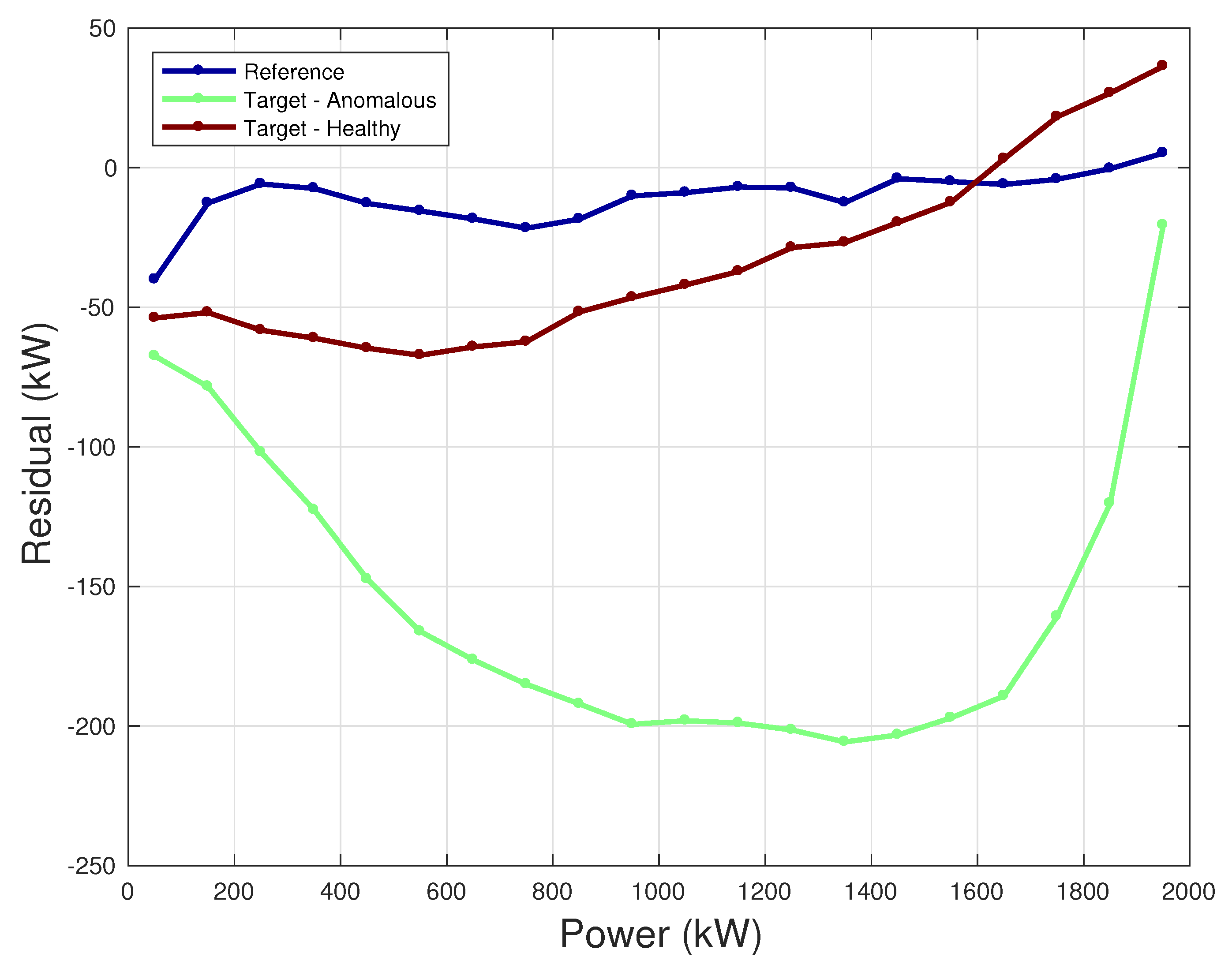
4.3. Application for Anomaly Detection
5. Conclusions and Further Directions
Author Contributions
Funding
Conflicts of Interest
References
- Ackermann, T. Wind Power in Power Systems; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Astolfi, D.; Pandit, R.; Terzi, L.; Lombardi, A. Discussion of wind turbine performance based on SCADA data and multiple test case analysis. Energies 2022, 15, 5343. [Google Scholar] [CrossRef]
- Honrubia, A.; Vigueras-Rodríguez, A.; Gómez-Lázaro, E. The influence of turbulence and vertical wind profile in wind turbine power curve. In Progress in Turbulence and Wind Energy IV; Springer: Berlin, Germany, 2012; pp. 251–254. [Google Scholar]
- Hedevang, E. Wind turbine power curves incorporating turbulence intensity. Wind Energy 2014, 17, 173–195. [Google Scholar] [CrossRef]
- Pandit, R.K.; Infield, D.; Carroll, J. Incorporating air density into a Gaussian process wind turbine power curve model for improving fitting accuracy. Wind Energy 2019, 22, 302–315. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Hu, Q.; Li, L.; Foley, A.M.; Srinivasan, D. Approaches to wind power curve modeling: A review and discussion. Renew. Sustain. Energy Rev. 2019, 116, 109422. [Google Scholar] [CrossRef]
- Ciulla, G.; D’Amico, A.; Di Dio, V.; Brano, V.L. Modelling and analysis of real-world wind turbine power curves: Assessing deviations from nominal curve by neural networks. Renew. Energy 2019, 140, 477–492. [Google Scholar] [CrossRef]
- Butler, S.; Ringwood, J.; O’Connor, F. Exploiting SCADA system data for wind turbine performance monitoring. In Proceedings of the 2013 Conference on Control and Fault-Tolerant Systems (SysTol), Nice, France, 9–11 October 2013; pp. 389–394. [Google Scholar]
- Long, H.; Wang, L.; Zhang, Z.; Song, Z.; Xu, J. Data-driven wind turbine power generation performance monitoring. IEEE Trans. Ind. Electron. 2015, 62, 6627–6635. [Google Scholar] [CrossRef]
- Gonzalez, E.; Stephen, B.; Infield, D.; Melero, J.J. Using high-frequency SCADA data for wind turbine performance monitoring: A sensitivity study. Renew. Energy 2019, 131, 841–853. [Google Scholar] [CrossRef] [Green Version]
- Astolfi, D.; Castellani, F.; Terzi, L. Mathematical methods for SCADA data mining of onshore wind farms: Performance evaluation and wake analysis. Wind Eng. 2016, 40, 69–85. [Google Scholar] [CrossRef] [Green Version]
- Theodorakatos, N.P.; Lytras, M.; Babu, R. Towards smart energy grids: A box-constrained nonlinear underdetermined model for power system observability using recursive quadratic programming. Energies 2020, 13, 1724. [Google Scholar] [CrossRef] [Green Version]
- Theodorakatos, N.P.; Lytras, M.; Babu, R. A generalized pattern search algorithm methodology for solving an under-determined system of equality constraints to achieve power system observability using synchrophasors. J. Phys. Conf. Ser. 2021, 2090, 012125. [Google Scholar] [CrossRef]
- Vide, P.S.C.; Barbosa, F.M.; Ferreira, I.M. Combined use of SCADA and PMU measurements for power system state estimator performance enhancement. In Proceedings of the 2011 3rd International Youth Conference on Energetics (IYCE), Leiria, Portugal, 7–9 July 2011; pp. 1–6. [Google Scholar]
- Vanfretti, L.; Baudette, M.; Domínguez-García, J.L.; Almas, M.S.; White, A.; Gjerde, J.O. A phasor measurement unit based fast real-time oscillation detection application for monitoring wind-farm-to-grid sub–synchronous dynamics. Electr. Power Compon. Syst. 2016, 44, 123–134. [Google Scholar] [CrossRef] [Green Version]
- Astolfi, D.; Castellani, F.; Lombardi, A.; Terzi, L. Multivariate SCADA data analysis methods for real-world wind turbine power curve monitoring. Energies 2021, 14, 1105. [Google Scholar] [CrossRef]
- Astolfi, D. Perspectives on SCADA Data Analysis Methods for Multivariate Wind Turbine Power Curve Modeling. Machines 2021, 9, 100. [Google Scholar] [CrossRef]
- Janssens, O.; Noppe, N.; Devriendt, C.; Van de Walle, R.; Van Hoecke, S. Data-driven multivariate power curve modeling of offshore wind turbines. Eng. Appl. Artif. Intell. 2016, 55, 331–338. [Google Scholar] [CrossRef]
- Pandit, R.K.; Infield, D.; Kolios, A. Gaussian process power curve models incorporating wind turbine operational variables. Energy Rep. 2020, 6, 1658–1669. [Google Scholar] [CrossRef]
- Shetty, R.P.; Sathyabhama, A.; Pai, P.S. Comparison of modeling methods for wind power prediction: A critical study. Front. Energy 2020, 14, 347–358. [Google Scholar] [CrossRef]
- Karamichailidou, D.; Kaloutsa, V.; Alexandridis, A. Wind turbine power curve modeling using radial basis function neural networks and tabu search. Renew. Energy 2021, 163, 2137–2152. [Google Scholar] [CrossRef]
- Astolfi, D.; Castellani, F.; Natili, F. Wind Turbine Multivariate Power Modeling Techniques for Control and Monitoring Purposes. J. Dyn. Syst. Meas. Control 2021, 143, 034501. [Google Scholar] [CrossRef]
- Niu, W.; Huang, J.; Yang, H.; Wang, X. Wind turbine power prediction based on wind energy utilization coefficient and multivariate polynomial regression. J. Renew. Sustain. Energy 2022, 14, 013306. [Google Scholar] [CrossRef]
- Jing, H.; Zhao, C. Adjustable piecewise regression strategy based wind turbine power forecasting for probabilistic condition monitoring. Sustain. Energy Technol. Assess. 2022, 52, 102013. [Google Scholar] [CrossRef]
- Marčiukaitis, M.; Žutautaitė, I.; Martišauskas, L.; Jokšas, B.; Gecevičius, G.; Sfetsos, A. Non-linear regression model for wind turbine power curve. Renew. Energy 2017, 113, 732–741. [Google Scholar] [CrossRef]
- Rabanal, A.; Ulazia, A.; Ibarra-Berastegi, G.; Sáenz, J.; Elosegui, U. MIDAS: A benchmarking multi-criteria method for the identification of defective anemometers in wind farms. Energies 2019, 12, 28. [Google Scholar] [CrossRef] [Green Version]
- Zaher, A.; McArthur, S.; Infield, D.; Patel, Y. Online wind turbine fault detection through automated SCADA data analysis. Wind Energy Int. J. Prog. Appl. Wind Power Convers. Technol. 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Corley, B.; Koukoura, S.; Carroll, J.; McDonald, A. Combination of thermal modelling and machine learning approaches for fault detection in wind turbine gearboxes. Energies 2021, 14, 1375. [Google Scholar] [CrossRef]
- Barber, S.; Nordborg, H. Improving site-dependent power curve prediction accuracy using regression trees. J. Phys. Conf. Ser. 2020, 1618, 062003. [Google Scholar] [CrossRef]
- Barber, S.; Hammer, F.; Tica, A. Improving Site-Dependent Wind Turbine Performance Prediction Accuracy Using Machine Learning. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part B Mech. Eng. 2022, 8, 021102. [Google Scholar] [CrossRef]
- Astolfi, D.; Castellani, F.; Becchetti, M.; Lombardi, A.; Terzi, L. Wind Turbine Systematic Yaw Error: Operation Data Analysis Techniques for Detecting It and Assessing Its Performance Impact. Energies 2020, 13, 2351. [Google Scholar] [CrossRef]
- Astolfi, D.; Pandit, R.; Gao, L.; Hong, J. Individuation of Wind Turbine Systematic Yaw Error through SCADA Data. Energies 2022, 15, 8165. [Google Scholar] [CrossRef]
- Carullo, A.; Ciocia, A.; Di Leo, P.; Giordano, F.; Malgaroli, G.; Peraga, L.; Spertino, F.; Vallan, A. Comparison of correction methods of wind speed for performance evaluation of wind turbines. In Proceedings of the 24th IMEKO-TC4 International Symposium, Palermo, Italy, 14–16 September 2020; pp. 291–296. [Google Scholar]
- Carullo, A.; Ciocia, A.; Malgaroli, G.; Spertino, F. An Innovative Correction Method of Wind Speed for Efficiency Evaluation of Wind Turbines. Acta IMEKO 2021, 10, 46–53. [Google Scholar] [CrossRef]
- De Caro, F.; Vaccaro, A.; Villacci, D. Adaptive wind generation modeling by fuzzy clustering of experimental data. Electronics 2018, 7, 47. [Google Scholar] [CrossRef]
- Pandit, R.K.; Infield, D. Comparative assessments of binned and support vector regression-based blade pitch curve of a wind turbine for the purpose of condition monitoring. Int. J. Energy Environ. Eng. 2019, 10, 181–188. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E. Gaussian processes in machine learning. In Proceedings of the Summer School on Machine Learning, Canberra, Australia, 2–14 February 2003; pp. 63–71. [Google Scholar]
- Pang, C.; Yu, J.; Liu, Y. Correlation analysis of factors affecting wind power based on machine learning and Shapley value. IET Energy Syst. Integr. 2021, 3, 227–237. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, D.; Li, Z.; Han, X.; Liu, H.; Dong, C.; Wang, J.; Liu, C.; Xia, Y. Power prediction of a wind farm cluster based on spatiotemporal correlations. Appl. Energy 2021, 302, 117568. [Google Scholar] [CrossRef]
- Pandit, R.; Kolios, A. SCADA data-based support vector machine wind turbine power curve uncertainty estimation and its comparative studies. Appl. Sci. 2020, 10, 8685. [Google Scholar] [CrossRef]
- Ding, Y.; Kumar, N.; Prakash, A.; Kio, A.E.; Liu, X.; Liu, L.; Li, Q. A case study of space-time performance comparison of wind turbines on a wind farm. Renew. Energy 2021, 171, 735–746. [Google Scholar] [CrossRef]
- Encalada-Dávila, Á.; Moyón, L.; Tutivén, C.; Puruncajas, B.; Vidal, Y. Early fault detection in the main bearing of wind turbines based on Gated Recurrent Unit (GRU) neural networks and SCADA data. IEEE/ASME Trans. Mechatron. 2022, 27, 5583–5593. [Google Scholar] [CrossRef]
- Xiang, L.; Wang, P.; Yang, X.; Hu, A.; Su, H. Fault detection of wind turbine based on SCADA data analysis using CNN and LSTM with attention mechanism. Measurement 2021, 175, 109094. [Google Scholar] [CrossRef]
- Jin, X.; Xu, Z.; Qiao, W. Condition monitoring of wind turbine generators using SCADA data analysis. IEEE Trans. Sustain. Energy 2020, 12, 202–210. [Google Scholar] [CrossRef]
- Peter, R.; Zappalá, D.; Schamboeck, V.; Watson, S.J. Wind turbine generator prognostics using field SCADA data. J. Phys. Conf. Ser. 2022, 2265, 032111. [Google Scholar] [CrossRef]
- Liu, X.; Teng, W.; Liu, Y. A Model-Agnostic Meta-Baseline Method for Few-Shot Fault Diagnosis of Wind Turbines. Sensors 2022, 22, 3288. [Google Scholar] [CrossRef]
- Castellani, F.; Astolfi, D.; Natili, F. SCADA data analysis methods for diagnosis of electrical faults to wind turbine generators. Appl. Sci. 2021, 11, 3307. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, D.; Dong, A.; Kang, D.; Lv, Q.; Shang, L. Fault prediction and diagnosis of wind turbine generators using SCADA data. Energies 2017, 10, 1210. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Qian, Z.; Zareipour, H.; Zhang, F. Comprehensive aging assessment of pitch systems combining SCADA and failure data. IET Renew. Power Gener. 2022, 16, 198–210. [Google Scholar] [CrossRef]
- Ding, Y. Data Science for Wind Energy; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Turnbull, A.; Carroll, J.; McDonald, A. A comparative analysis on the variability of temperature thresholds through time for wind turbine generators using normal behaviour modelling. Energies 2022, 15, 5298. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Selected Input Variables | |
|---|---|---|
| SVR | v, , , , , , , , , , , | (0.98, 0.48, 0.76, 0.87, 0.44, 0.76, 0.76, 0.88, 0.88, 0.88, 0.26, 0.55) |
| GPR | v, , , , , , , | (0.98, 0.85, 0.48, 0.76, 0.44, 0.76, 0.76, 0.88, 0.26) |
| Model | Selected Temperatures | |
|---|---|---|
| SVR | , , , , , , , , , | (0.75, 0.77, 0.48, 0.75, 0.75 0.78, 0.78, 0.78, 0.25, 0.69) |
| Model | (kW) | (kW) | (%) | (%) |
|---|---|---|---|---|
| SVR | 29.6 | 40.7 | 1.48 | 2.03 |
| GPR | 27.7 | 38.7 | 1.35 | 1.94 |
| Model | (kW) | (kW) | (%) | (%) |
|---|---|---|---|---|
| SVR—Benchmark | 35.7 | 48.3 | 1.79 | 2.41 |
| GPR—Benchmark | 36.5 | 48.5 | 1.82 | 2.43 |
| Model | Mean (kW) | Skewness | Kurtosis |
|---|---|---|---|
| SVR | −7.2 | −0.41 | 9.36 |
| GPR | −5.4 | −0.36 | 9.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Astolfi, D.; Pandit, R.; Lombardi, A.; Terzi, L. Multivariate Data-Driven Models for Wind Turbine Power Curves including Sub-Component Temperatures. Energies 2023, 16, 165. https://doi.org/10.3390/en16010165
Astolfi D, Pandit R, Lombardi A, Terzi L. Multivariate Data-Driven Models for Wind Turbine Power Curves including Sub-Component Temperatures. Energies. 2023; 16(1):165. https://doi.org/10.3390/en16010165
Chicago/Turabian StyleAstolfi, Davide, Ravi Pandit, Andrea Lombardi, and Ludovico Terzi. 2023. "Multivariate Data-Driven Models for Wind Turbine Power Curves including Sub-Component Temperatures" Energies 16, no. 1: 165. https://doi.org/10.3390/en16010165
APA StyleAstolfi, D., Pandit, R., Lombardi, A., & Terzi, L. (2023). Multivariate Data-Driven Models for Wind Turbine Power Curves including Sub-Component Temperatures. Energies, 16(1), 165. https://doi.org/10.3390/en16010165