


Unsupervised Machine Learning Techniques for Improving Reservoir Interpretation Using Walkaway VSP and Sonic Log Data



Abstract
:1. Introduction
2. Region Characterization
3. Unsupervised Machine Learning Methods
3.1. BIRCH Clustering
- Step 1 First scan. In this step, the whole dataset examination is performed to create the initial CFT.
- Step 2 Reorganization of the initial CFT if it is too long.
- Step 3 Adapted agglomerative global hierarchical clustering is performed to create sub-clusters.
- Step 4 This is an optional step that allows for other scans to improve and redefine the current structure.
3.2. Gaussian Mixture Model Clustering
- Step 1 Initialization for and evaluation of the initial likelihood.
- Step 2 This is the expectation step where the responsibilities are evaluated using the parameters’ values from the previous step.
- Step 3 This is the maximization step where the processes of parameter re-estimation are performed with the use of responsibilities from the expectation step.
- Step 4 Likelihood evaluation—if the convergence measure is satisfied, the algorithm ends; if not, another loop starting from step 2 is performed until the criterion is satisfied.
3.3. K-Means Clustering
- Step 1 Random M centroid initialization.
- Step 2 This is the expectation step where the distance computation between each data point and each centroid is calculated. Points are assigned to the closest cluster.
- Step 3 This is the maximization step where the mean for each cluster is calculated and then the centroids are updated.
- Step 4 The number of iterations is checked to see if it is reached or if there is no difference in cluster assignment. If it is reached, it is the end of the algorithm; if not, step 2 is carried out.
3.4. Spectral Clustering
- Step 1 Calculation of the similarity matrix S. An undirected, weighted graph is used as the whole dataset representation. Each vertex represents data point K and the weighted value M at the edge connection is used for the similarity measurement. The undirected weighted graph is created according to the similarity measurement between points (it is a graph partitioning problem). The adjacency matrix is used as graph information representation.
- Step 2 Calculation of the diagonal matrix D. The similarity between each point and all other points is represented by
- Step 3 Calculation of the non-normalized Laplace matrix . Each row of the matrix L contains information about both similarities between points and the sum of all similarities. This allows for preserving information in the graph.
- Step 4 Eigenvalues calculation. In this step, the p-smallest eigenvectors of the Laplace matrix are found and then the corresponding eigenvalues are calculated.
- Step 5 Creation of orthogonal matrix O, using vectors obtained in previous step.
- Step 6 Performance of clustering over normalized row vectors obtained in the previous step using k-means.
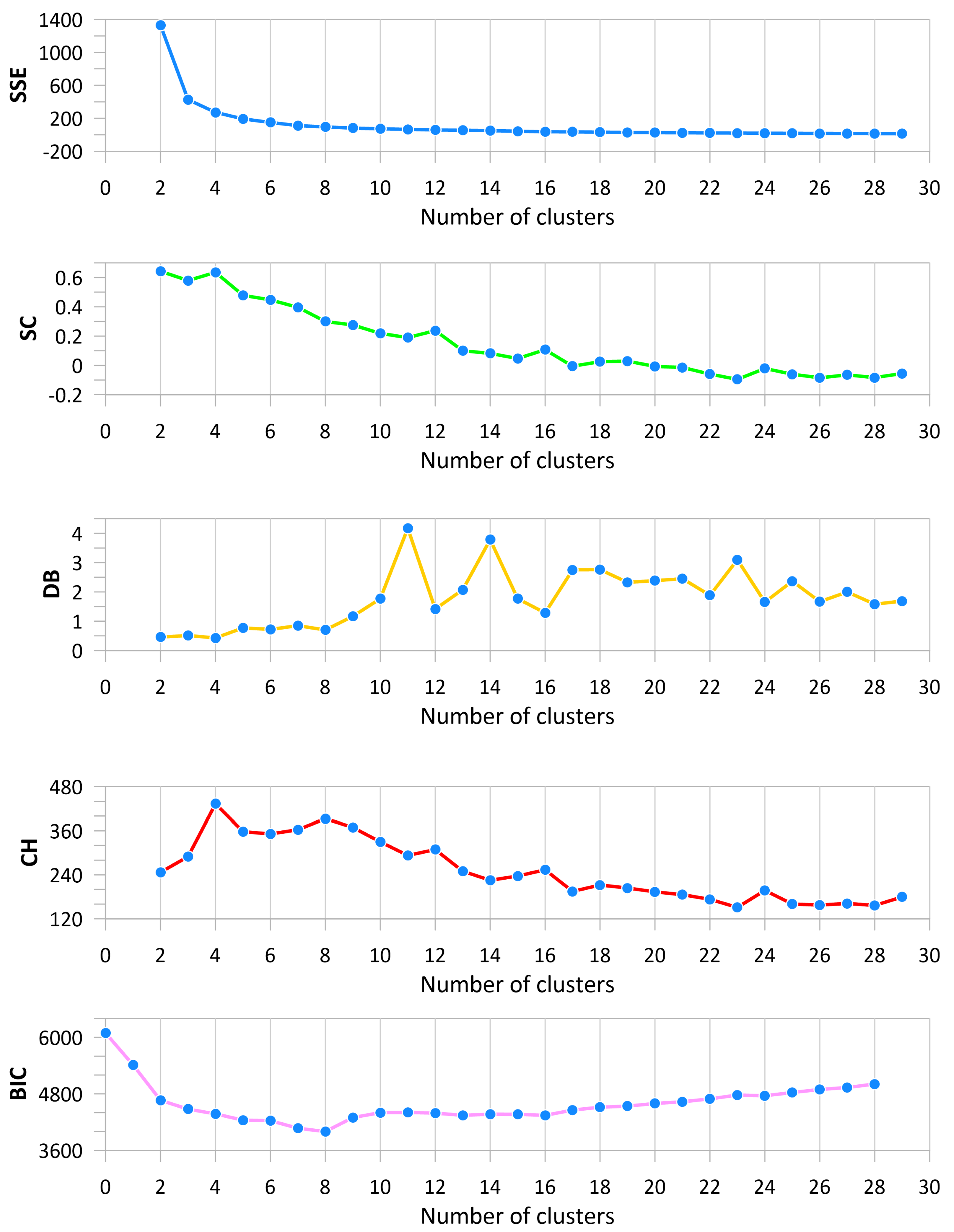
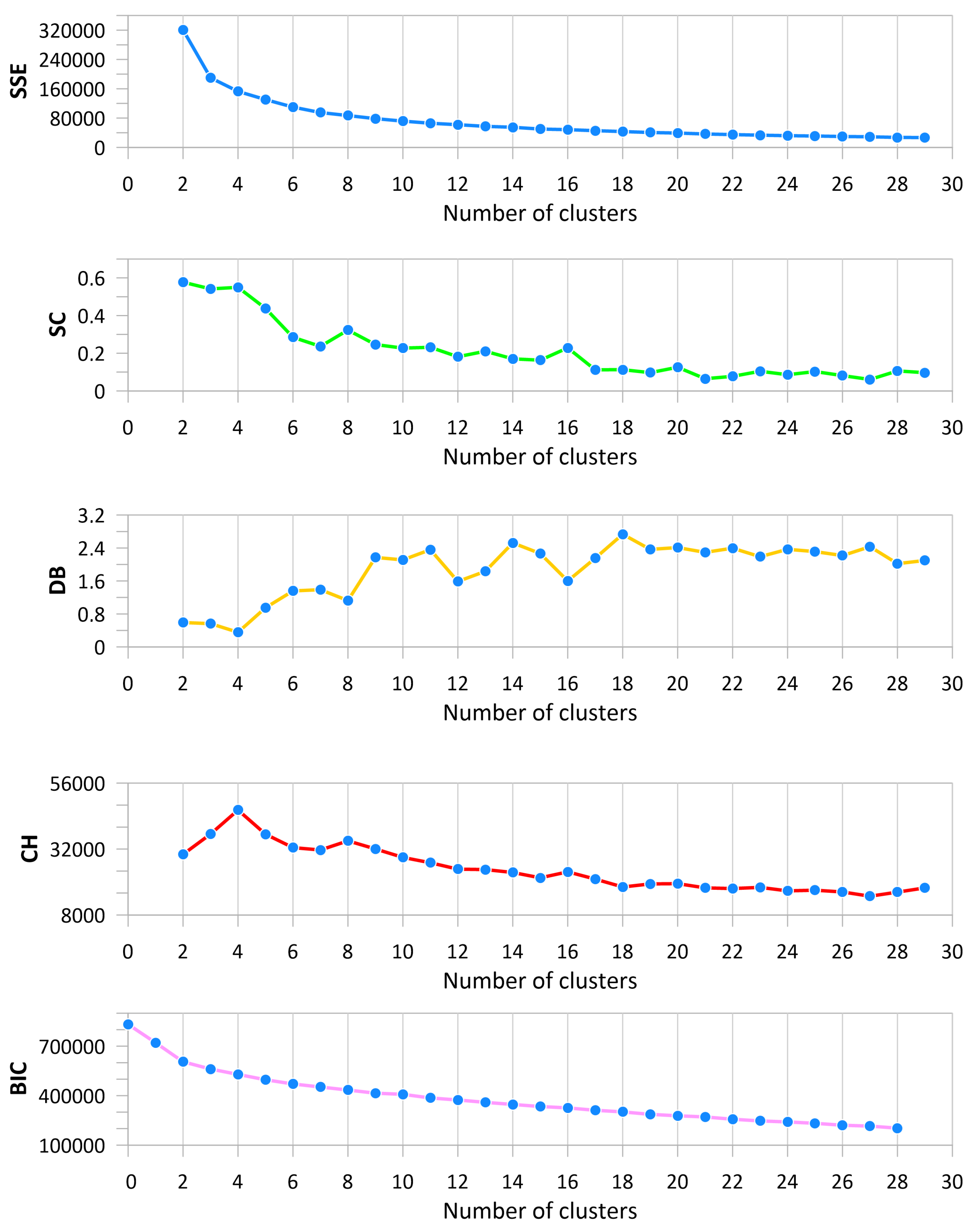
3.5. Validation of the Number of Clusters
3.5.1. Silhouette Coefficient
- —Silhouette coefficient;
- a—The mean distance between the point and other points inside the cluster;
- b—The distance between a point and the nearest cluster (to which this point does not belong).
3.5.2. Davies–Bouldin Index
- —Davies-Bouldin index;
- —Cluster diameter—the average distance between the i-cluster centroid and points in this cluster;
- —Cluster diameter—the average distance between the j-cluster centroid and points in this cluster;
- —The distance between i and j cluster centroids.
3.5.3. Calinski–Harabasz Index
- —The trace of the covariance matrix (between groups);
- —The trace of the covariance matrix (within the cluster).
3.6. Inertia Analysis
- —The center of mass defined as ;
- —The i-point;
- —The weight of the i-point.
3.6.1. Bayesian Information Criterion
3.6.2. Domain-Based Interpretation
4. Geophysical Methods Characterization
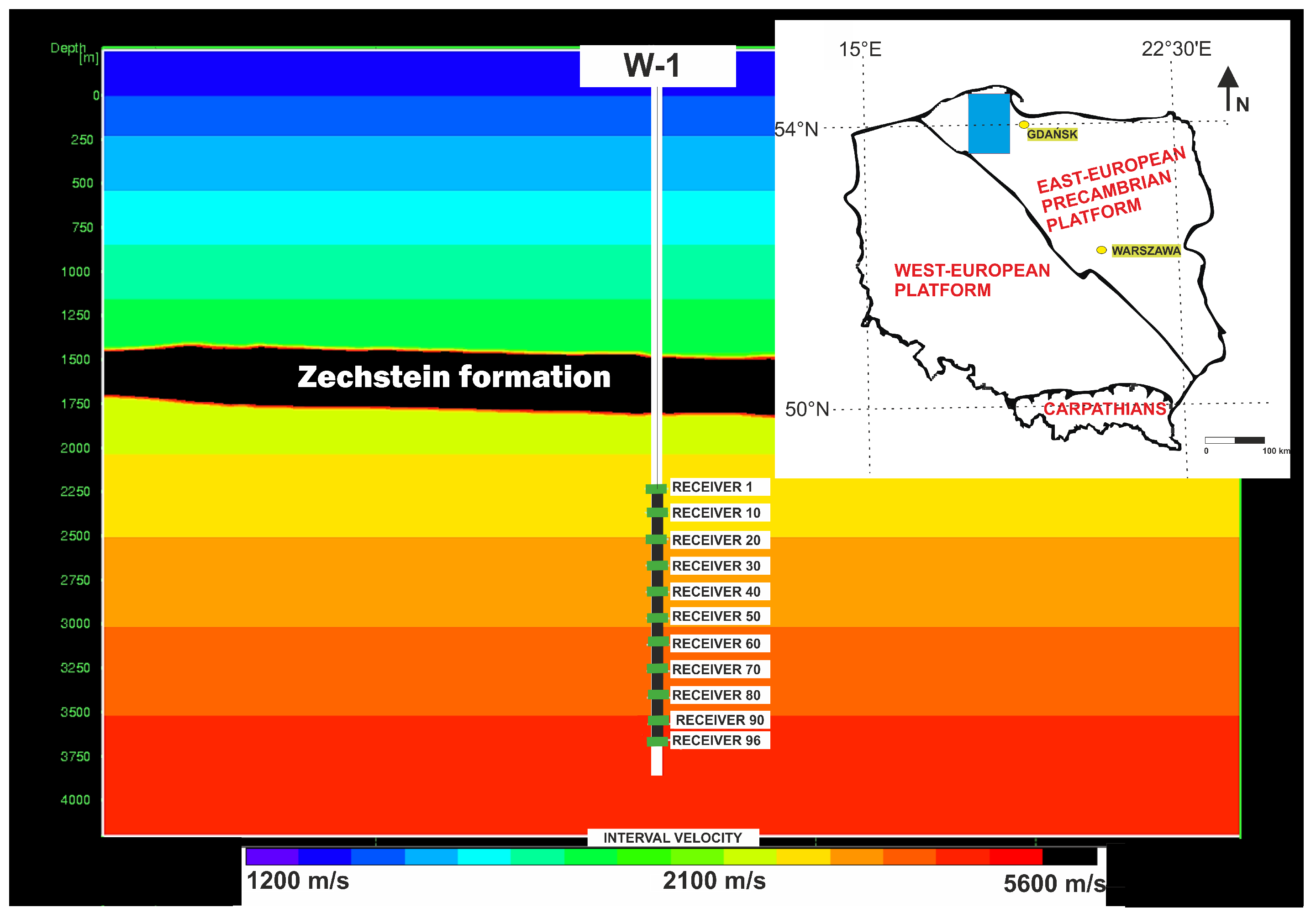
4.1. W-1 Well Dataset
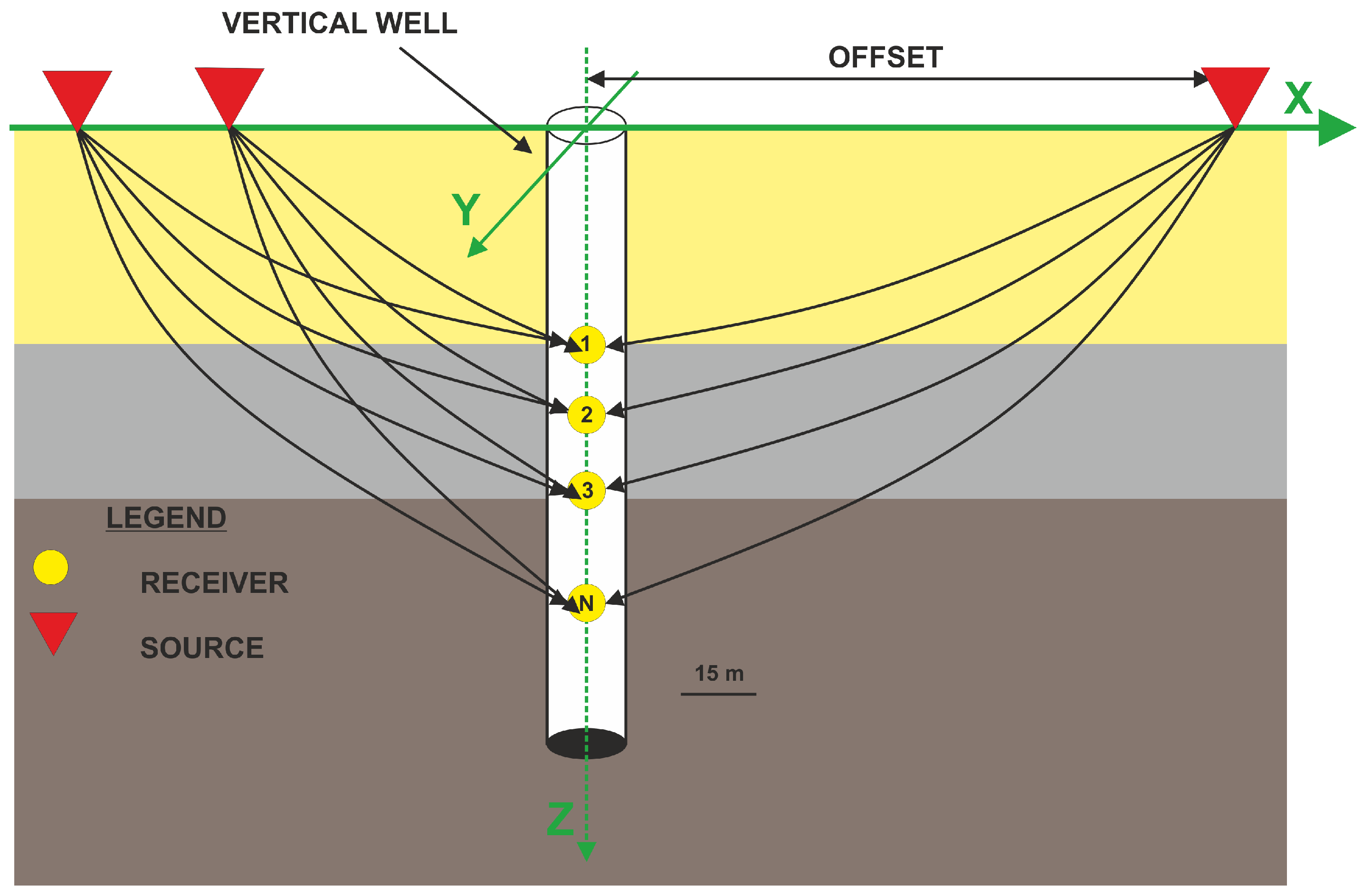
4.1.1. Walkaway VSP Measurment
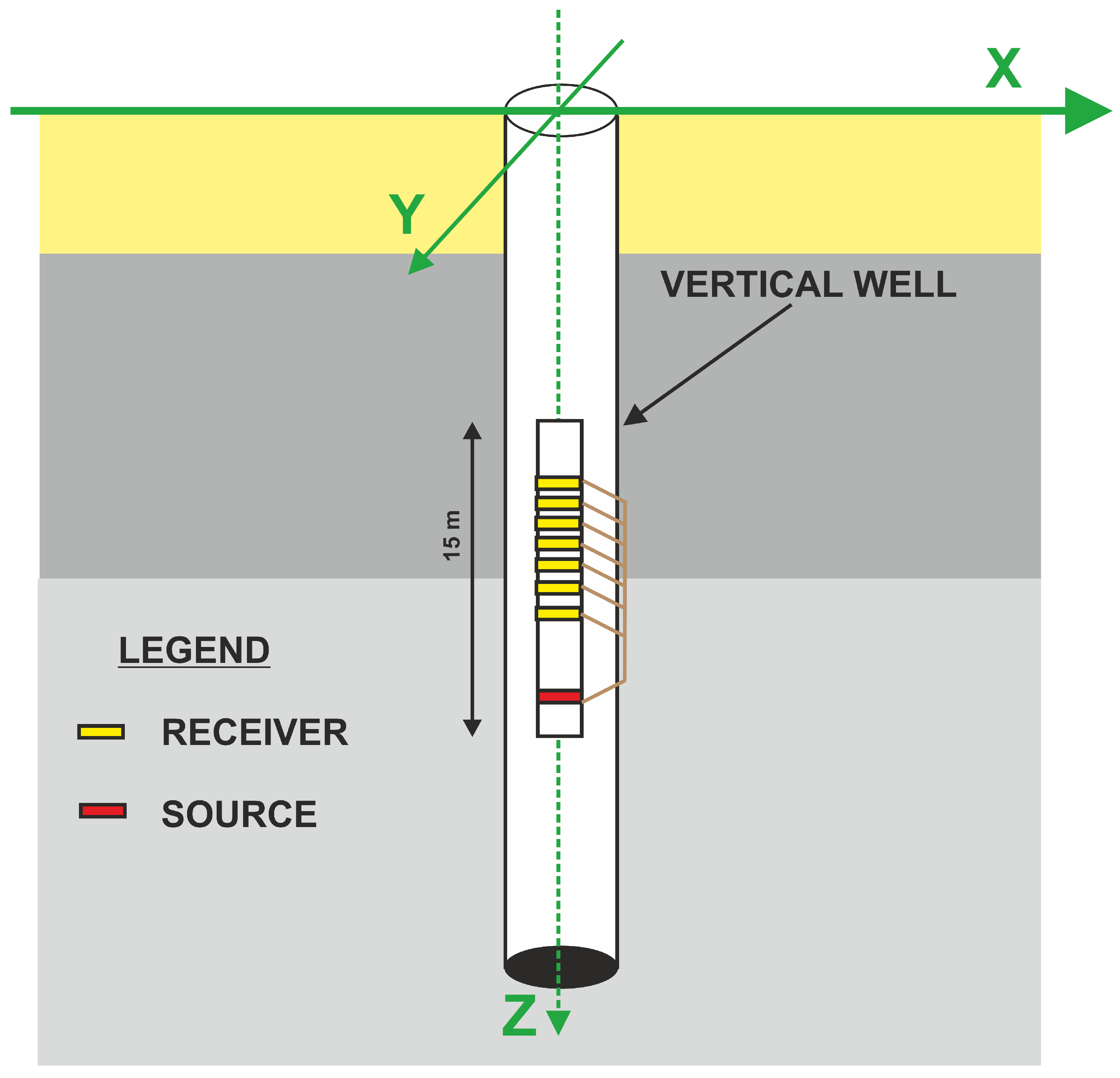
4.1.2. Borhole Sonic Measurment
- —The delay time of the slow shear wave;
- —The delay time of the fast shear wave;
- —The average delay time of the shear wave.
- —The lithology identifier;
- —The sonic wave velocity from the horizontal X-component;
- —The sonic P-wave velocity.
- —The Poisson ratio from the sonic tool;
- —The lithology identifier.
4.1.3. Resolution for Clustering
- Experiment 1—All parameters were adjusted to the resolution of the walkaway VSP measurements in W-1. This allowed for a significant data reduction and, consequently, for an acceleration of the computational time. On the other hand, fewer points can sometimes have a negative impact on clustering results. The upscaling of well-logs is not a trivial task, and is an interpretation procedure. This will filter out minor variations and leave only the main lithological changes. For this purpose, smoothing filters, Backus averaging, or blocking in the intervals can be used. In this case, the sonic log parameters’ values on the walkaway VSP receiver depth point were calculated as a simple average calculated in the window with a length equal to the P-wavelength centralized on this depth point. A total of 92 observations were obtained for 45 different parameters, which gave a dataset consisting of 4140 data points.
- Experiment 2—All parameters were adjusted to the resolution of the sonic log measurements in W-1. In this case, the number of observations was significantly improved, but, on the other hand, the computation time was also significantly increased. The cubic interpolation method was used for upscaling the walkaway VSP measurements. This procedure is much easier to perform than downscaling the well-log measurements. In experiment 2, sonic log measurements were smoothed using a Savitzky–Golay polynomial filter with a window length equal to 650 samples and a polynomial order of 3. We chose this filter because of its ability to cope with noise, which is undoubtedly present in the profiling of borehole geophysics. This is also a well-established method cited more than 3800× [52]. In this case, a total of 12,751 observations were obtained for 45 different parameters, which gave a dataset consisting of 599,291 data points.
5. W-1 Case Study
5.1. Features Description
5.2. Number of Clusters
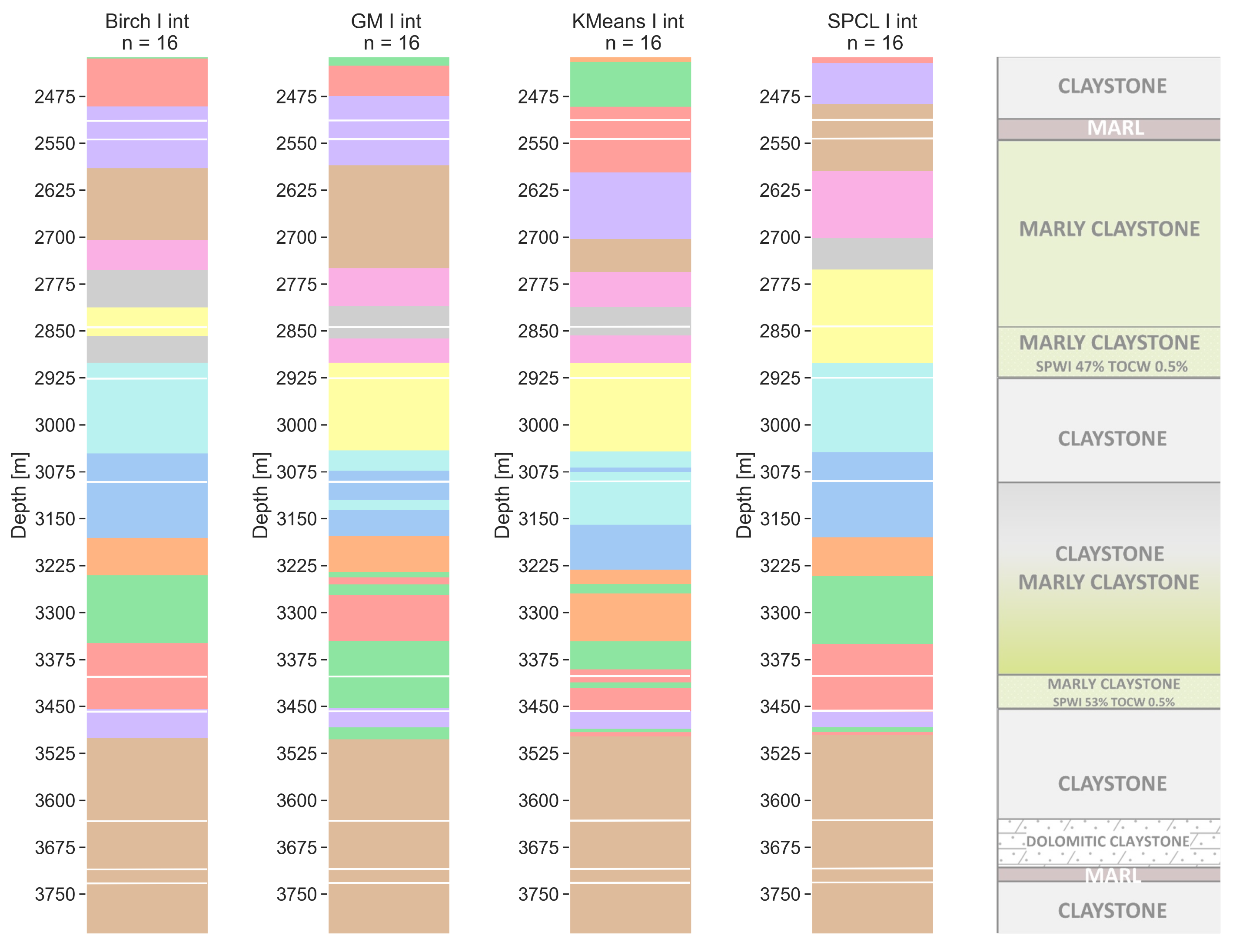
6. Clustering Results
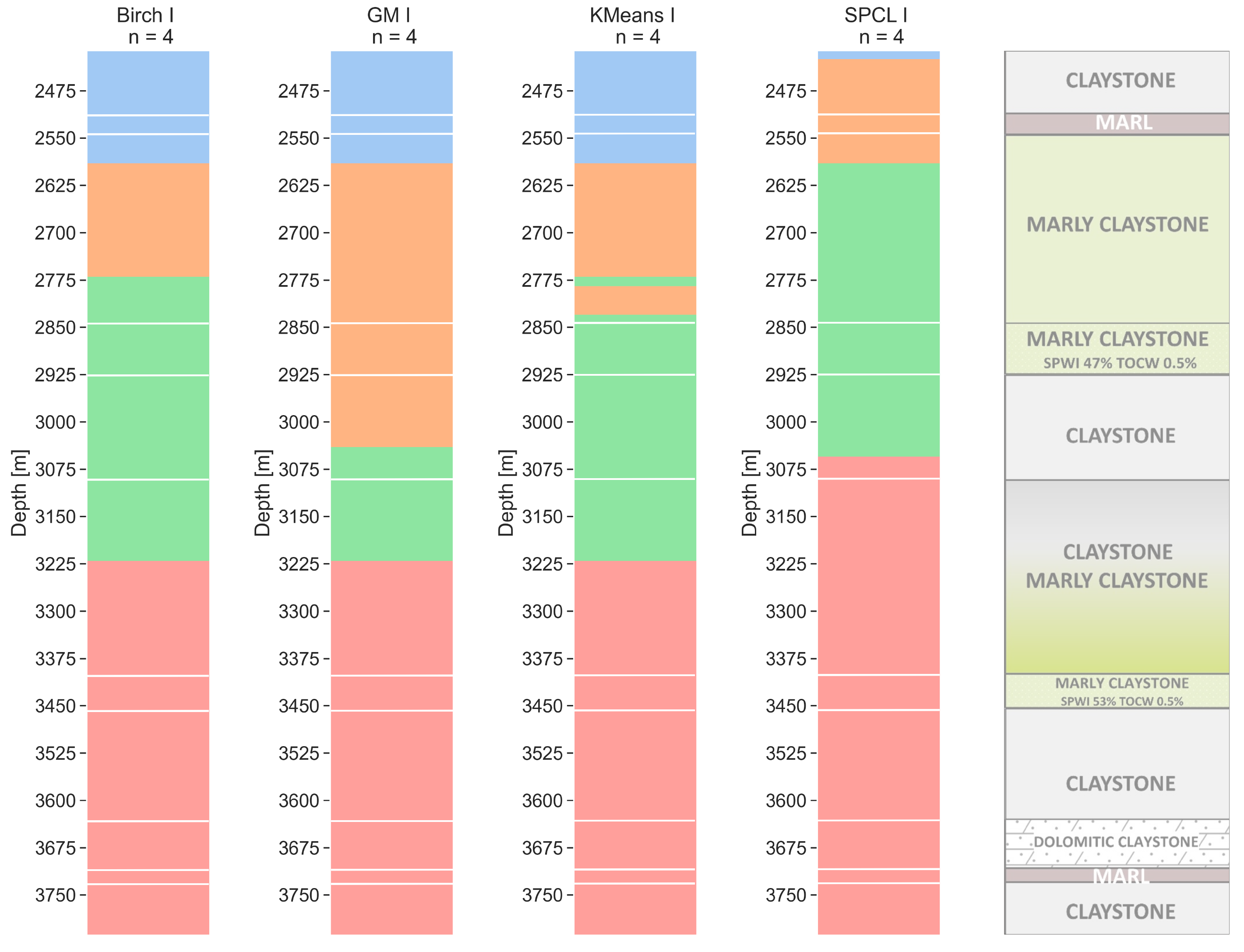
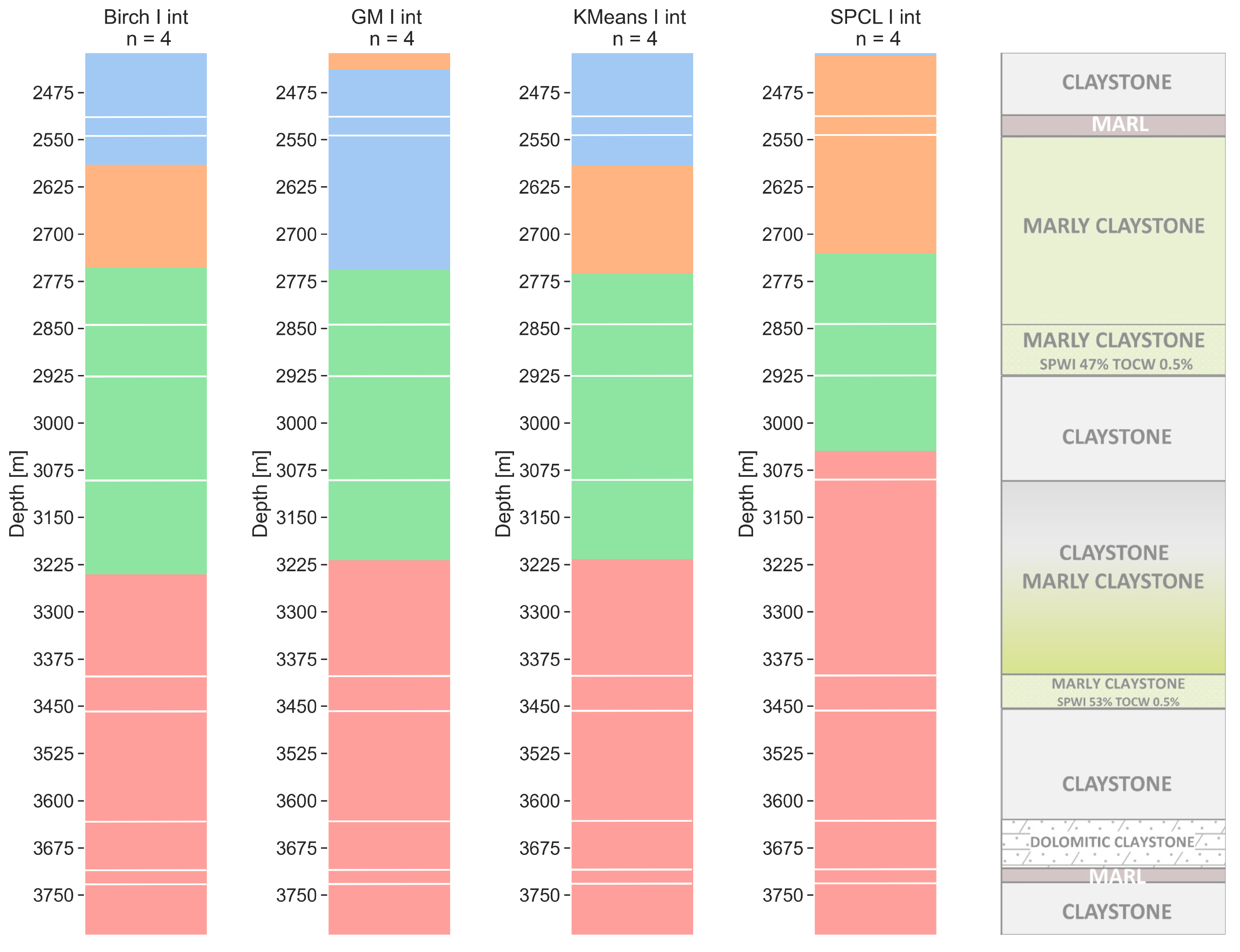
6.1. Four Clusters
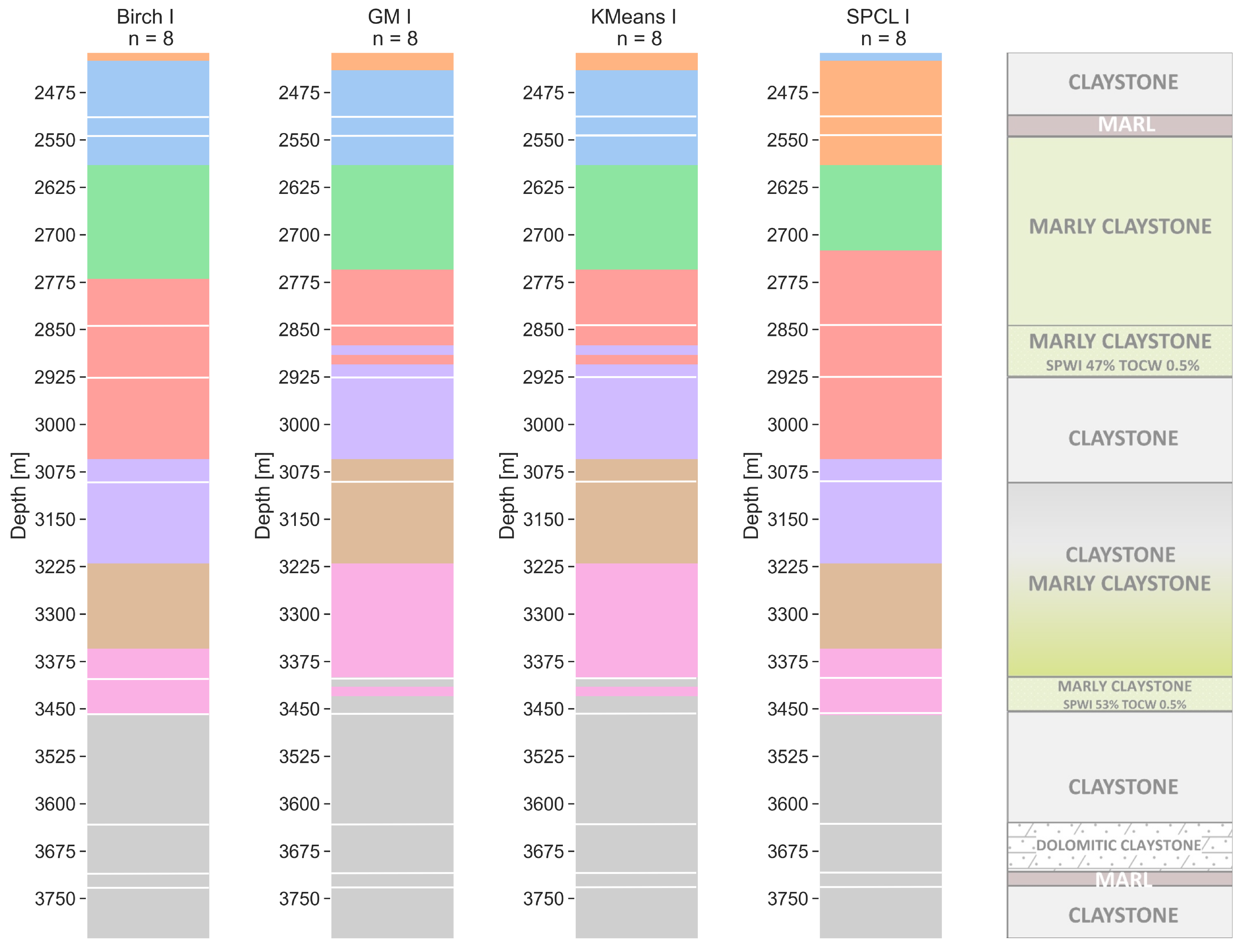
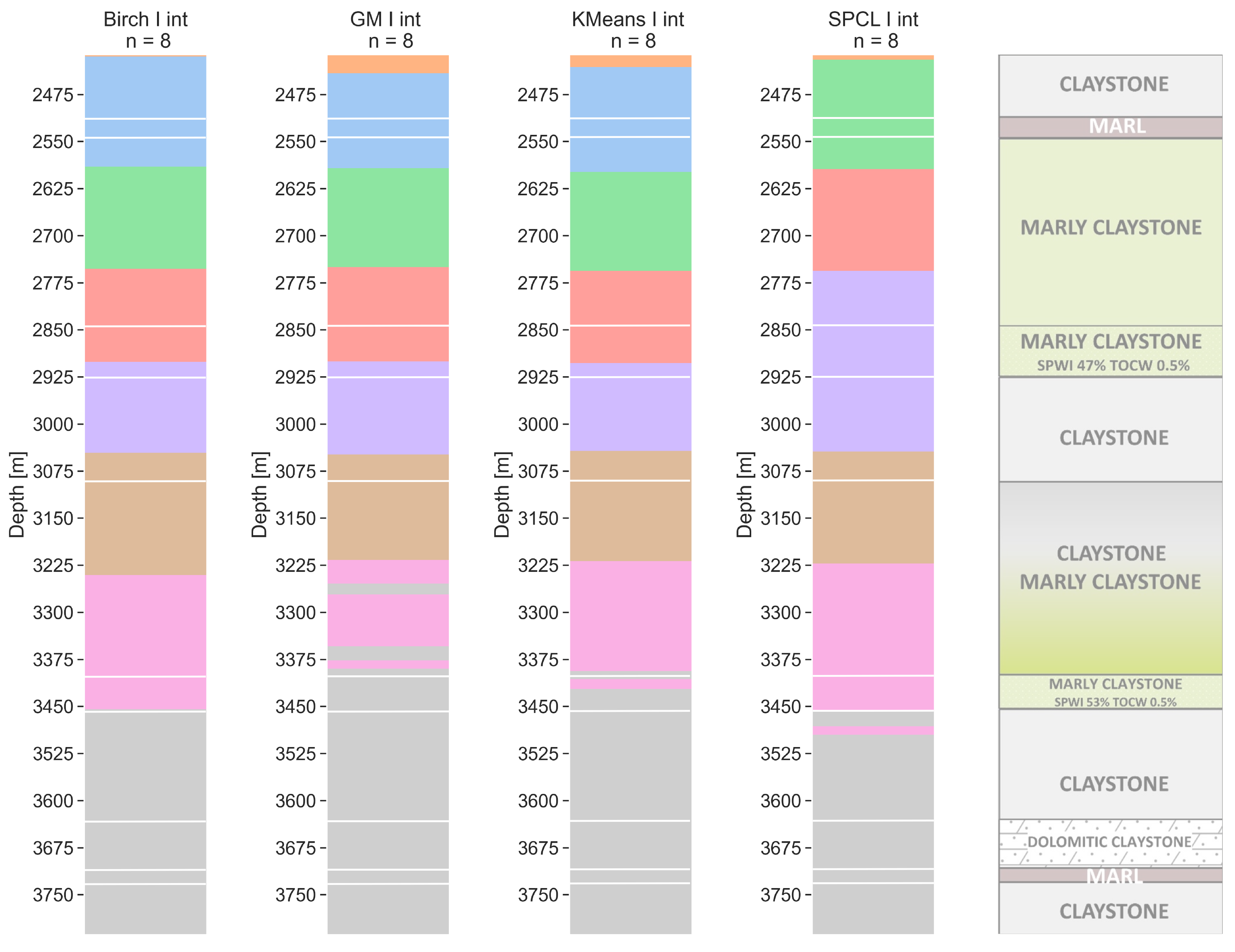
6.2. Eight Clusters
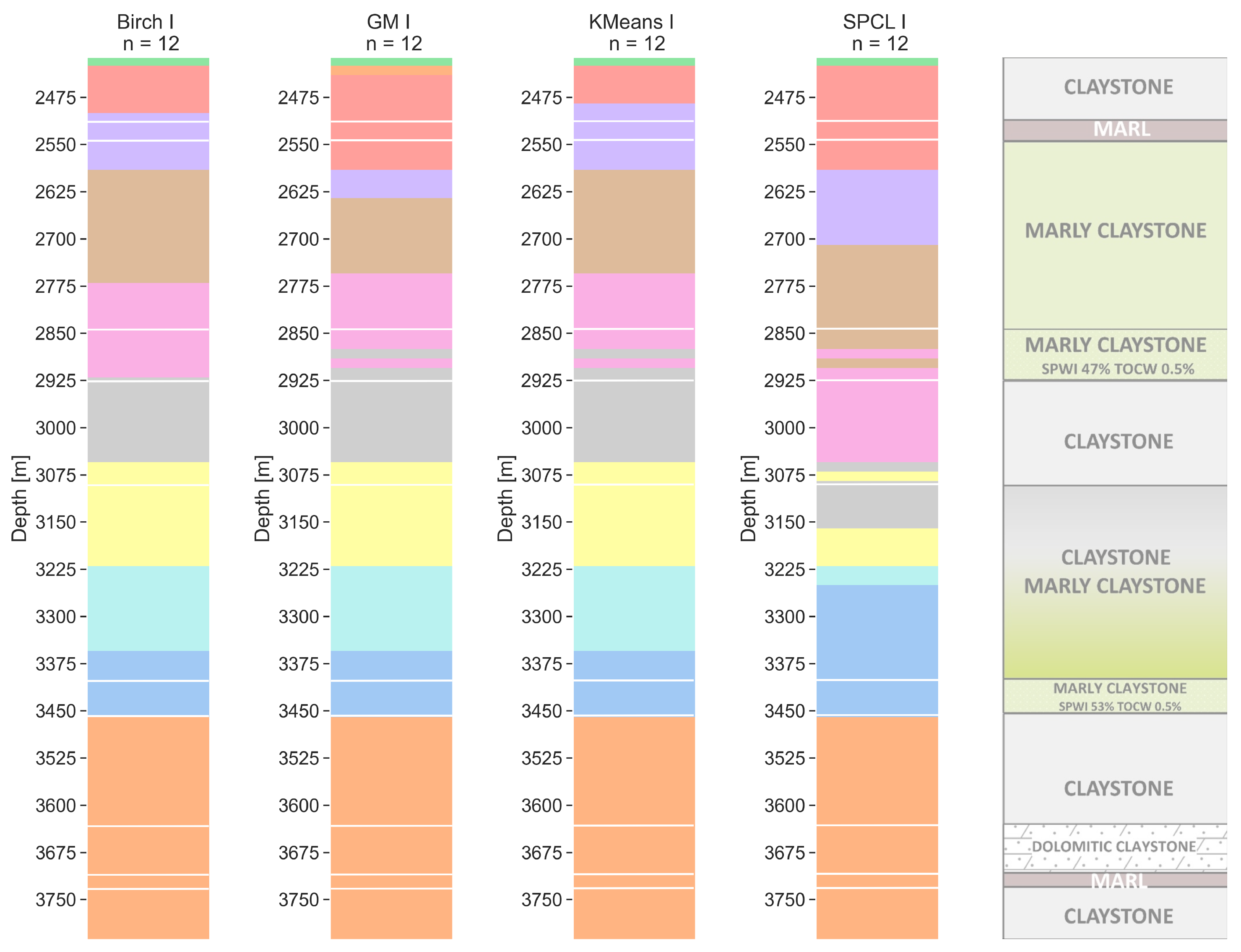
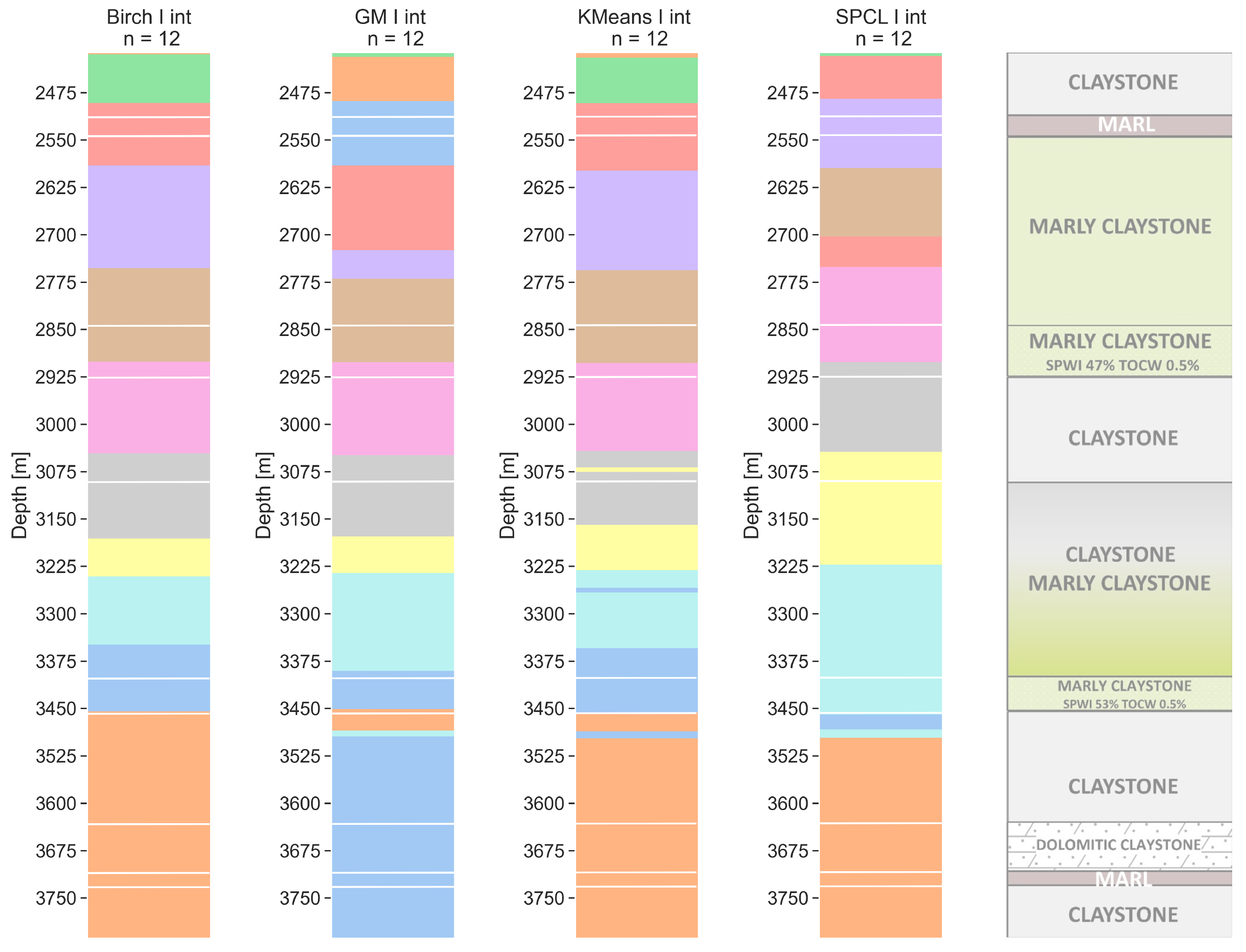
6.3. Twelve Clusters
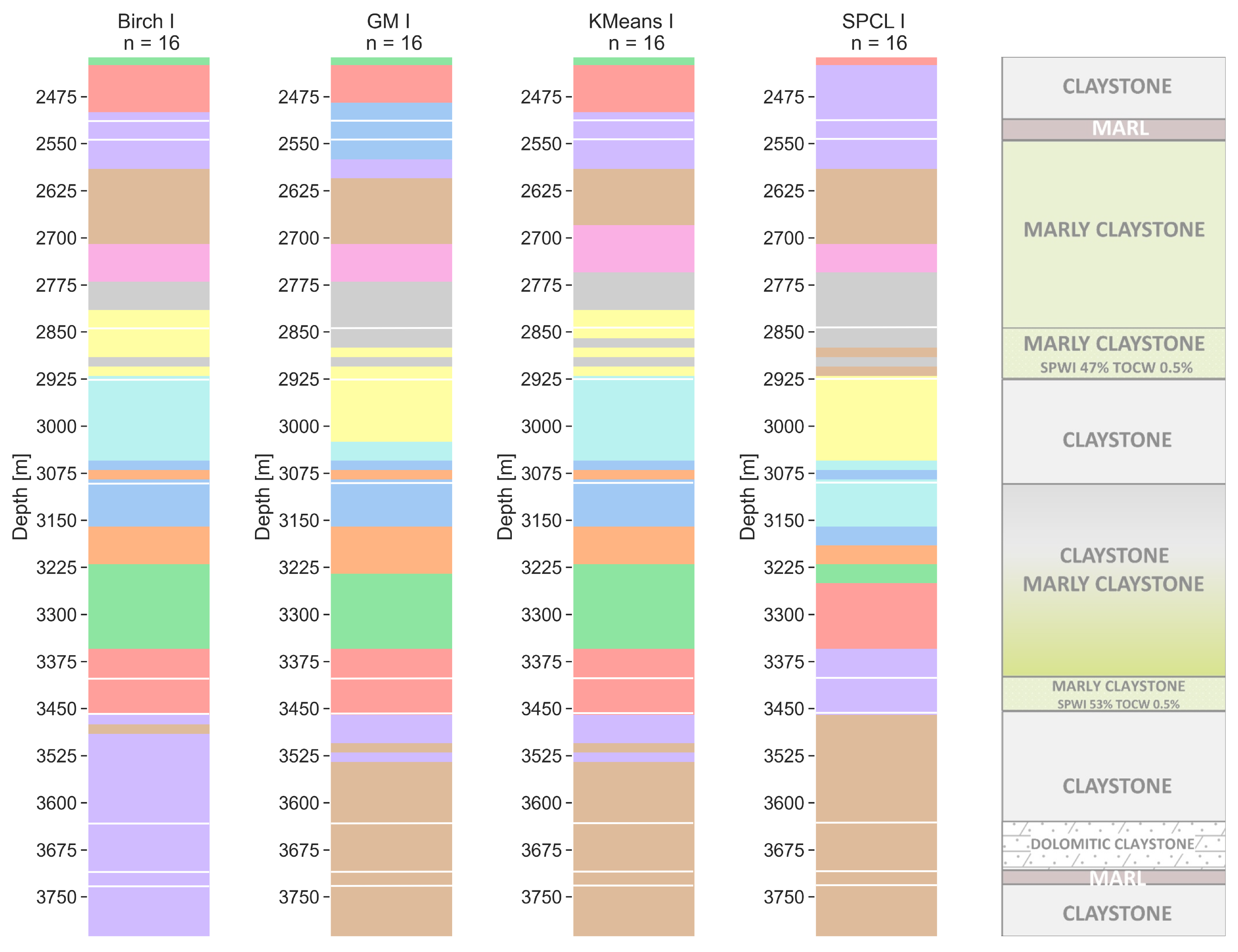
6.4. Sixteen Clusters
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tsvankin, I.; Gaiser, G.; Grechka, V.; Baan, M.V.D.; Thomsen, L. Seismic anisotropy in exploration and reservoir characterization: An overview. Geophysics 2010, 75, 75A15. [Google Scholar] [CrossRef] [Green Version]
- Zareba, M.; Danek, T. Nonlinear anisotropic diffusion techniques for seismic signal enhancing—Carpathian Foredeep study. E3S Web Conf. 2018, 66, 1–10. [Google Scholar] [CrossRef]
- Zareba, M.; Danek, T. VSP polarization angles determination: Wysin-1 processing case study. Acta Geophys. 2018, 66, 1047–1062, Erratum in Acta Geophys. 2019, 67, 737. [Google Scholar] [CrossRef]
- Bashir, Y.; Ghosh, D.; Sum, C. Influence of seismic diffraction for high-resolution imaging: Applications in offshore Malaysia. Acta Geophys. 2018, 66, 305–316. [Google Scholar] [CrossRef]
- Zareba, M.; Danek, T.; Zajac, J. On Including Near-surface Zone Anisotropy for Static Corrections Computation-Polish Carpathians 3D Seismic Processing Case Study. Geosciences 2020, 10, 66. [Google Scholar] [CrossRef] [Green Version]
- Zareba, M.; Laskownicka, A.; Zajac, J. The use of S-guided CREP methodology for advanced seismic structure enhancing processing. Acta Geophys. 2019, 67, 1711–1719. [Google Scholar] [CrossRef] [Green Version]
- Michie, D.; Spiegelhalter, D. Machine Learning, Neural and Statistical Classification Ellis Horwood Series in Artificial Intelligence; Prentice Hall: Hoboken, NJ, USA, 1994. [Google Scholar]
- Ayodele, T.O. Introduction to Machine Learning. In New Advances in Machine Learning; Zhang, Y., Ed.; IntechOpen: London, UK, 2010; Chapter 1. [Google Scholar] [CrossRef] [Green Version]
- Zareba, M.; Danek, T.; Stefaniuk, M. P-Wave-Only Inversion of Challenging Walkaway VSP Data for Detailed Estimation of Local Anisotropy and Reservoir Parameters: A Case Study of Seismic Processing in Northern Poland. Energies 2021, 14, 2061. [Google Scholar] [CrossRef]
- Szczypiorska, A. Program Blue Gas—Polski Gaz Łupkowy. 2014. Available online: https://infolupki.pgi.gov.pl/pl/technologie/program-blue-gas-polski-gaz-lupkowy (accessed on 1 June 2022). (In Polish)
- Alkhalifah, T.; Tsvankin, I. Velocity analysis for transversely isotropic media. Geophysics 1995, 60, 1550–1556. [Google Scholar] [CrossRef]
- Thomsen, L. Weak elastic anisotropy. Geophysics 1986, 51, 1954–1966. [Google Scholar] [CrossRef]
- Grechka, V.; Mateeva, A. Inversion of P-wave VSP data for local anisotropy: Theory and case study. Geophysics 2007, 72, 69–79. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kondracki, J. Regional Geography of Poland; WN PWN: Warszawa, Poland, 2011. [Google Scholar]
- Kasperska, M.; Marzec, P.; Pietsch, P.; Golonka, K. Seismo-geological model of the Baltic Basin (Poland). Ann. Soc. Geol. Pol. 2019, 89, 195–213. [Google Scholar] [CrossRef] [Green Version]
- Domagala, K.; Mackowski, T.; Stefaniuk, M.; Reicher, B. Prediction of Reservoir Parameters of Cambrian Sandstones Using Petrophysical Modelling—Geothermal Potential Study of Polish Mainland Part of the Baltic Basin. Energies 2021, 14, 3942. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Alternatives to the k-means algorithm that find better clusterings. In Proceedings of the 2002 ACM CIKM International Conference on Information and Knowledge Management, McLean, VA, USA, 4–9 November 2002; pp. 600–607. [Google Scholar] [CrossRef]
- Hamerly, G. Learning Structure and Concepts in Data through Data Clustering. Ph.D. Thesis, University of California, San Diego, CA, USA, 2003. [Google Scholar]
- Judd, D.; McKinley, P.; Jain, A. Large-scale parallel data clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 871–876. [Google Scholar] [CrossRef] [Green Version]
- Abbas, H.M.; Fahmy, M.M. Classified vector quantization using variance classifier and maximum likelihood clustering. Pattern Recognit. Lett. 1994, 15, 49–55. [Google Scholar] [CrossRef]
- Omran, M.; Engelbrecht, A.; Salman, A.A. An overview of clustering methods. Intell. Data Anal. 2007, 11, 583–605. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishna, R.; Livny, M. BIRCH: An Efficient Data Clustering Method for Very Large Databases. SIGMOD Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Lang, A.; Schubert, E. BETULA: Fast clustering of large data with improved BIRCH CF-Trees. Inf. Syst. 2021, 108, 101918. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Basford, K.E. Mixture Models: Inferenceand Applications to Clustering; Marcel Dekker: New York, NY, USA, 1988. [Google Scholar]
- McLachlan, G.J.; Peel, D. Robust cluster analysis via mixturesof multivariatet-distributions. In Lecture Notes in Computer Science; Amin, A., Dori, D., Pudil, P., Freeman, H., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1451, pp. 658–666. [Google Scholar]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; Wiley Series in Probability and Statistics; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization, 2nd ed.; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2000. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning. In Information Science and Statistics; Jordan, M., Kleinberg, J., Scholkopf, B., Eds.; Springer: Cham, Switzerland, 2006. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Mohiuddin, A.; Seraj, R.; Islam, S.M.S. The k-means Algorithm: A Comprehensive Survey and Performance Evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Jia, H.; Ding, S.; Xu, X.; Nie, R. The latest research progress on spectral clustering. Neural Comput. Appl. 2014, 24, 1477–1486. [Google Scholar] [CrossRef]
- Huang, Z. A fast clustering algorithm to cluster very large categorical data sets in data mining. In SIGMOD Workshop on Research Issues on Data Mining and Knowledge Discovery; DMKD: Tucson, AZ, USA, 1997; pp. 146–151. [Google Scholar]
- Ding, S.; Jia, H.; Zhang, L.; Jin, F. Research of semi-supervised spectral clustering algorithm based on pairwise constraints. Neural Comput. Appl. 2014, 24, 211–219. [Google Scholar] [CrossRef]
- Zhang, L.; Hou, L.; Lei, D. Spectral clustering algorithm based on Hadoop cloud platform research and implementation. In Proceedings of the 2016 5th International Conference on Advanced Materials and Computer Science, Qingdao, China, 26–27 March 2016; pp. 495–498. [Google Scholar] [CrossRef] [Green Version]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On Clustering Validation Techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Banthia, A.; Jayasumana, A.; Malaiya, Y. Data size reduction for clustering-based binning of ICs using principal component analysis (PCA). In Proceedings of the 2005 IEEE International Workshop on Current and Defect Based Testing, Palm Springs, CA, USA, 1 May 2005; pp. 24–30. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat 1974, 3, 1–27. [Google Scholar]
- Nielsen, F. Partition-Based Clustering with k-Means. In Introduction to HPC with MPI for Data Science; Springer: Cham, Switzerland, 2016; pp. 163–193. [Google Scholar] [CrossRef]
- Keribin, C. Consistent Estimation of the Order of Mixture Models. Sankhyā Indian J. Stat. Ser. A 2000, 62, 49–66. [Google Scholar]
- Celeux, G.; Fruhwirth-Schnatter, S.; Robert, C. Model Selection for Mixture Models-Perspectives and Strategies. In Handbook of Mixture Analysis; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Quinto, B. Unsupervised Learning. In Next-Generation Machine Learning with Spark: Covers XGBoost, LightGBM, Spark NLP, Distributed Deep Learning with Keras, and More; Apress: Berkeley, CA, USA, 2020; pp. 189–244. [Google Scholar] [CrossRef]
- Huang, P.; Yao, P.; Hao, Z.; Peng, H.; Guo, L. Improved Constrained k-Means Algorithm for Clustering with Domain Knowledge. Mathematics 2021, 9, 2390. [Google Scholar] [CrossRef]
- Keribin, C. Characterization of well logs using K-mean cluster analysis. J. Pet. Explor. Prod. Technol. 2020, 10, 2245–2256. [Google Scholar] [CrossRef]
- Churochkin, I.I.; Kharitontseva, P.A.; Roslin, P. Well log clustering as a tool for rock typing of carbonate reservoir. Data Sci. Oil Gas 2020, 2020, 1–5. [Google Scholar] [CrossRef]
- Schlanser, K.; Grana, D.; Campbell-Stone, E. Lithofacies classification in the Marcellus Shale by applying a statistical clustering algorithm to petrophysical and elastic well logs. Interpretation 2016, 4, SE31–SE49. [Google Scholar] [CrossRef]
- Zareba, M.; Danek, T.; Stefaniuk, M. Some statistical consideration of azimuth and inclination angles determination based on walk-away VSP data in Python. E3S Web Conf. 2019, 133, 01006. [Google Scholar] [CrossRef]
- Brie, A.; Endo, T.; Hoyle, D.; Codazzi, D.; Esmersoy, C.; Hsu, K.; Denoo, S. New Directions in Sonic Logging. Oilfield Rev. 1998, 10, 40–55. [Google Scholar]
- Luo, J.; Ying, K.; Bai, J. Savitzky–Golay smoothing and differentiation filter for even number data. Signal Process. 2005, 85, 1429–1434. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SP Number | abs offset [m] | avg incl [deg] |
|---|---|---|
| SP 1010 | 177 | 3.98 |
| SP 1020 | 262 | 5.34 |
| SP 1030 | 347 | 6.27 |
| SP 1040 | 440 | 7.82 |
| SP 1050 | 533 | 8.97 |
| SP 1060 | 630 | 12.09 |
| SP 1070 | 730 | 14.22 |
| SP 1080 | 830 | 15.19 |
| SP 1090 | 930 | 16.67 |
| SP 1100 | 1030 | 16.89 |
| SP 1110 | 1130 | 16.79 |
| SP 1120 | 1231 | 20.04 |
| SP 1130 | 1332 | 22.78 |
| SP 1140 | 1430 | 23.17 |
| SP 1150 | 1530 | 23.19 |
| SP 1160 | 1630 | 24.99 |
| SP 1170 | 1730 | 26.14 |
| SP 1180 | 1835 | 30.92 |
| SP 1190 | 1927 | 34.51 |
| SP 1200 | 2077 | 36.87 |
| SP 1210 | 2280 | 38.11 |
| SP 1220 | 2377 | 40.67 |
| SP 1230 | 2479 | 42.29 |
| SP 1240 | 2479 | 42.29 |
| SP 1250 | 2732 | 43.89 |
| SP 1260 | 3034 | 46.77 |
| SP 1270 | 3232 | 47.76 |
| SP 1280 | 3430 | 49.73 |
| SP 1290 | 3630 | 54.05 |
| SP 1300 | 3830 | 54.02 |
| SP 1310 | 4032 | 58.87 |
| Walkaway VSP Data | Well-Log Data | ||
|---|---|---|---|
| Parameter | Range | Parameter | Range |
| Inclinations—31 different offsets [DEG] | [1.75, 70] | DTSX [us/ft] | [110, 173] |
| [−0.002, 0.0005] | DTSY [us/ft] | [110, 170] | |
| [−0.007, 0.02] | DTP [us/ft] | [63, 86] | |
| from inversion [m/s] | [3600, 4600] | [m/s] | [1743, 2700] |
| from zero-offset [m/s] | [3550, 4580] | [m/s] | [1775, 2800] |
| [m/s] | [3500, 4800] | ||
| [1.5, 2.2] | |||
| [1.7, 2.1] | |||
| PR | [0.25, 0.35] | ||
| [0.01, 0.03] | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zareba, M.; Danek, T.; Stefaniuk, M. Unsupervised Machine Learning Techniques for Improving Reservoir Interpretation Using Walkaway VSP and Sonic Log Data. Energies 2023, 16, 493. https://doi.org/10.3390/en16010493
Zareba M, Danek T, Stefaniuk M. Unsupervised Machine Learning Techniques for Improving Reservoir Interpretation Using Walkaway VSP and Sonic Log Data. Energies. 2023; 16(1):493. https://doi.org/10.3390/en16010493
Chicago/Turabian StyleZareba, Mateusz, Tomasz Danek, and Michal Stefaniuk. 2023. "Unsupervised Machine Learning Techniques for Improving Reservoir Interpretation Using Walkaway VSP and Sonic Log Data" Energies 16, no. 1: 493. https://doi.org/10.3390/en16010493
APA StyleZareba, M., Danek, T., & Stefaniuk, M. (2023). Unsupervised Machine Learning Techniques for Improving Reservoir Interpretation Using Walkaway VSP and Sonic Log Data. Energies, 16(1), 493. https://doi.org/10.3390/en16010493