1. Introduction
As a result of the clean transformation of the global energy structure, the high-carbon emission power system led by traditional fossil energy will gradually disappear and be replaced by a clean power system led by renewable energy [
1]. Wind power generation, as a typical form of renewable energy generation, has developed rapidly in recent years. However, due to the randomness and uncertainty of wind speed, large-scale wind power grid integration endangers the smooth operation of power systems [
2]. Wind power forecasting can provide data support for the power grid, help the dispatching department to formulate power generation strategies, and eliminate the fluctuations caused by wind power grid-connection to the maximum extent. Therefore, accurate wind power forecasting is very important [
3].
Many scholars at home and abroad have carried out related research on wind power forecasting. Wind power forecasting methods are mainly divided into physical methods and statistical methods [
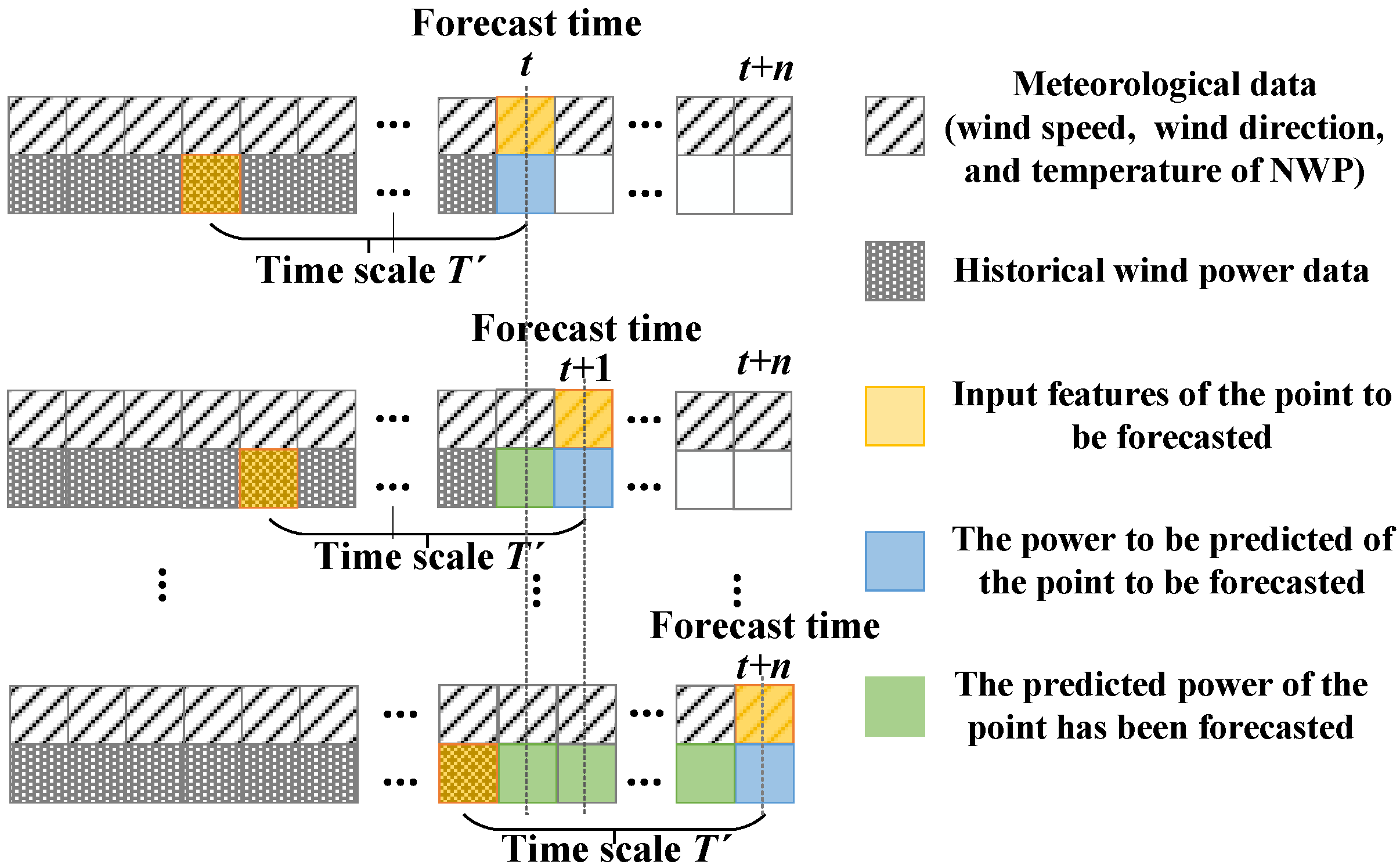
4]. The physical method establishes a flow field model through meteorological and topographical data and creates a forecast in combination with numerical weather prediction (NWP), which is suitable for medium- and long-term wind power forecasting. The calculation process is complicated, and the data real-time requirement is high, so it is not applicable for short-term wind power forecasting [
5]. The statistical method is based on historical data and NWP data, and it forms a forecasting model by establishing the mapping relationship between input features and power to carry out wind power forecasting, which is more suitable for short-term wind power forecasting [
6]. At present, short-term wind farm wind power forecasting models mainly include single models and hybrid models. The traditional single short-term wind power forecasting method mainly includes the following: the time series method [
7], the gray model method [
8], and the Kalman filter method [
9], etc. However, these methods are based on linear modeling and do not consider the uncertainty of wind power, resulting in large errors [
10]. With the continuous innovation and development of artificial intelligence, a variety of machine learning algorithms are used for wind power forecasting. Traditional machine learning algorithms such as a support vector machine (SVM) [
11], the least squares support vector machines (LSSVM) [
12], and other methods avoid falling into local optimal solutions, and the prediction accuracy is further improved. However, they are sensitive to parameter and kernel function selection, so the accuracy depends too much on the value of the parameter. Decision tree algorithms such as the Gradient Boosting Decision Tree (GBDT) [
13], eXtreme Gradient Boosting (XGBoost) [
14], and Light Gradient Boosting Machine (LightGBM) [
15] have good performance for wind power forecasting, but the space complexity is too high, and it is easy to overfit. Moreover, they do not perform well in processing data with strong feature correlation, so they are more suitable for processing data with low correlation. As an important part of machine learning, artificial neural networks are also used for wind power forecasting, which are used to extract the strong relationship between input features and future wind power. Shallow neural networks such as Back Propagation (BP) [
16], Radial Basis Function (RBF) [
17], Elman [
18], extreme learning machine (ELM) [
19], etc., have achieved good results. However, they do not consider the time-dependent information in the sample information, cannot automatically extract deep features, and cannot handle large changes in the wind power time series, which affects the learning efficiency of the algorithm [
20]. Due to their strong ability of data feature extraction and fitting, deep learning methods have developed rapidly in recent years. Convolutional neural network (CNN) [
21], traditional gated recurrent unit (GRU) [
22], deep belief network (DBN) [
23], short-term memory neural network (LSTM) [
24,
25], etc., have all been used for wind power forecasting. Among them, LSTM is a recurrent version of deep learning, which applies many temporal latent layers to effectively learn the strong temporal feature of wind power data [
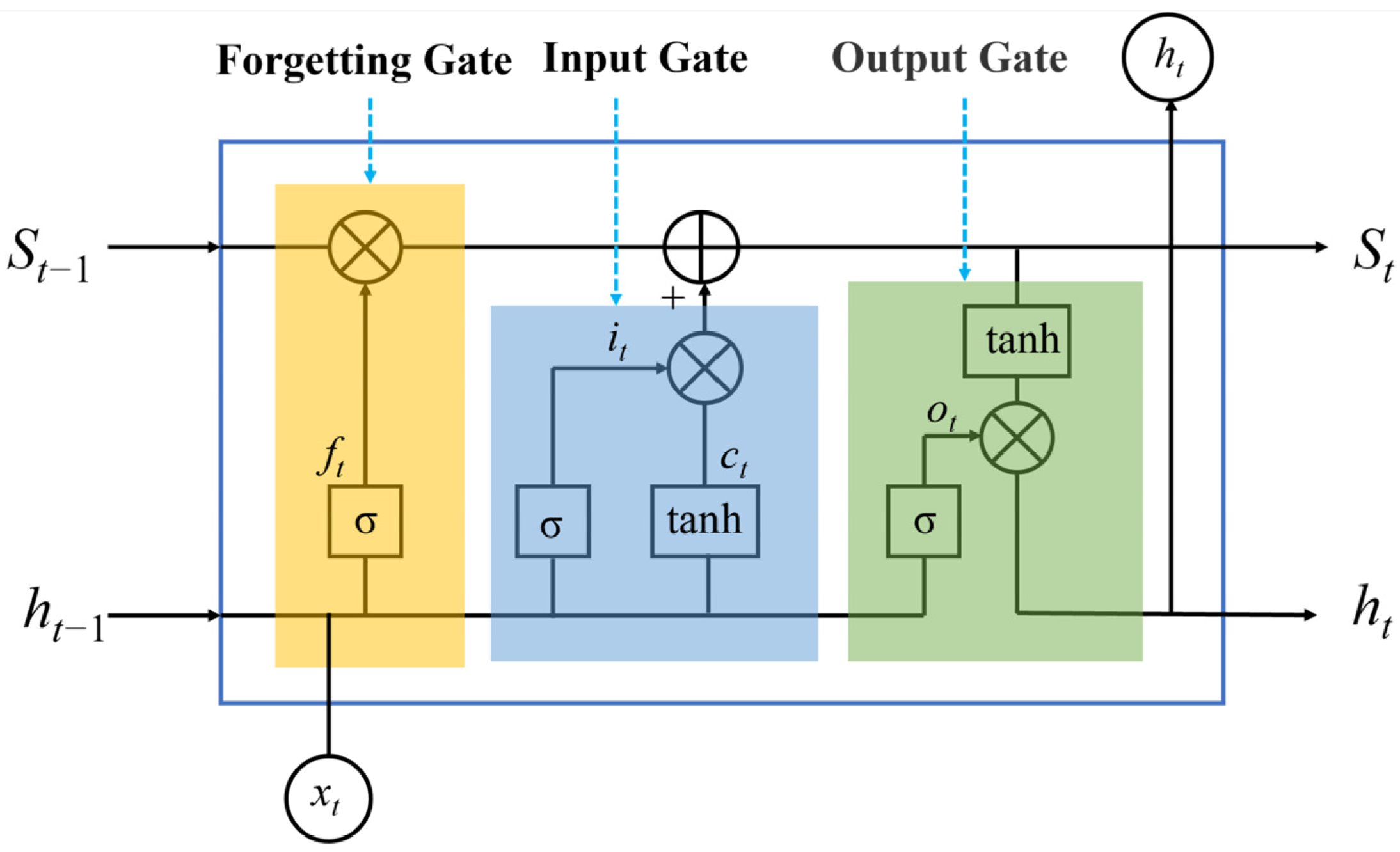
26], realizing the full utilization of long-distance time series information. However, LSTM only contains one-way information and the time correlation between data is not considered comprehensively. Therefore, the bidirectional long short-term memory neural network (BiLSTM), combining two groups of LSTMs with opposite directions, has emerged, which contains both historical and future information, and this network has been shown to improve the prediction accuracy [
5]. Therefore, this paper conducts power forecasting based on BiLSTM.
The single model has limitations [
27], so the hybrid model emerges as the times require, giving full play to the advantages of each model to achieve the goal of complementarity. It mainly includes two combination methods. One is an overall combination based on model performance. By assigning different weights, the prediction results of multiple single models are linearly combined to further improve the prediction accuracy. For example, [
28] combines four neural networks: BP, Elman, ELM, and generalized regression neural network (GRNN); [
29] combines three deep neural networks: LSTM, DBN, and echo state network (ESN). However, there are too many selection methods for the basic single models and their corresponding weights, and it is difficult to determine whether the performance of multiple single models is complementary, resulting in excessive randomness of the results. The other is component forecasting based on data features, extracting similar data through feature engineering, to enhance the representativeness and adaptability of the model to specific situations through the refinement of data selection [
30]. The following methods are currently popular: the original data is denoised by wavelet decomposition [
31], empirical mode decomposition (EMD) [
32], ensemble empirical mode decomposition (EEMD) [
33], variational modal decomposition (VMD) [
34], etc., to be decomposed into components of different frequency bands, and appropriate models are used to predict each subsequence separately. Based on different features (such as weather conditions, wind conditions, output mode, power change trend, etc.), cluster analysis is carried out on the original data [
35,
36], and power forecasting is made for different types of data, respectively; a similarity calculation method is defined in units of days, and the similar day data are extracted for model training and forecasting [
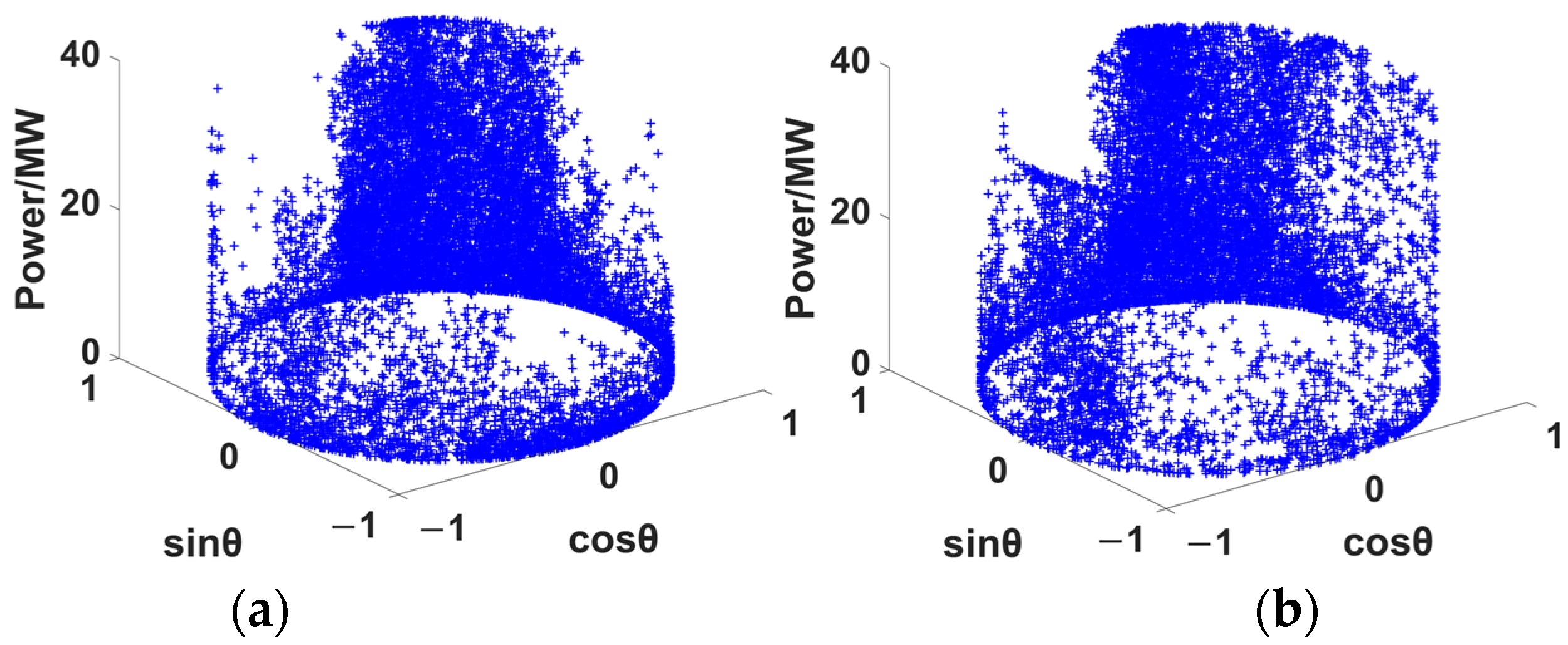
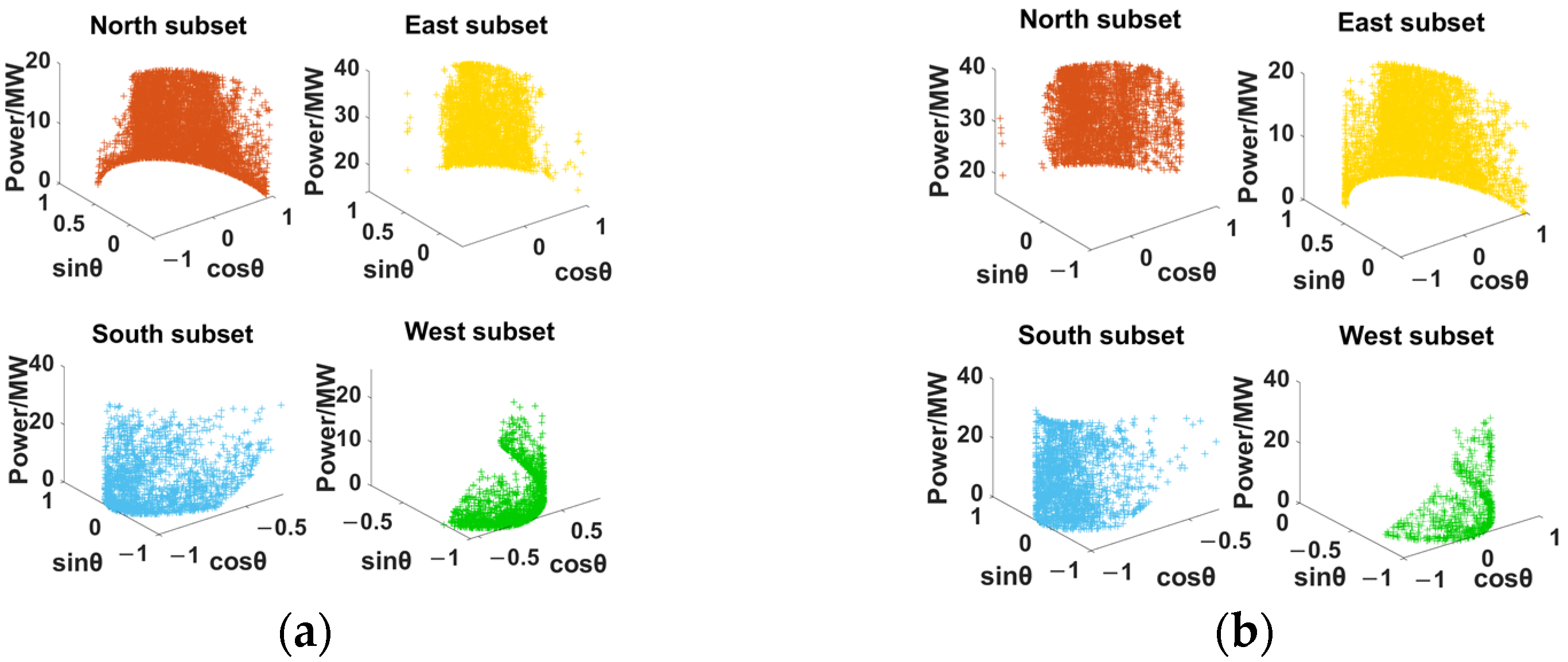
37]. However, the above methods mostly extract feature similarity from the perspective of power output—ignoring the wind speed and wind direction, which are the two meteorological factors that have the greatest impact on future power—and have not excavated the strong correlation between the above two factors and power. Therefore, based on emphasizing the inseparable relationship between the above two factors and power, this paper focuses on extracting similar data from these two perspectives for component forecasting.
Table 1 shows the comparison of the above models. In addition to the above models, data pre-processing and post-processing are also effective ways to improve the accuracy of wind power forecasting. The pre-processing of the data mainly uses a maximum information coefficient (MIC) [
26], principal component analysis (PCA) [
17], conditional mutual information [
38], etc., to perform correlation sorting, and to reduce the dimension of high-dimensional input features. By introducing as many features as possible, the forecasting model can reflect the impact of complex external conditions on wind power to some extent. However, the features with lower correlation have limited improvement on prediction performance. Traditional methods do not consider the different influence of the input features on the change of wind power in different wind farms, that is, different wind farms are applicable to different model input features. At the same time, when multiple original features are used as the input features of the prediction model, the complexity of the model will be increased, and the running speed of the model will be seriously reduced. In order to improve the above situations, it is necessary to have the corresponding algorithm to select several appropriate features from multiple original features as the input variables of the model. The relevant feature selection algorithm can not only screen out the features that have a greater impact on wind power and eliminate the coupling relationship between variables, but also help to improve the running speed of the model, which makes the prediction model achieve higher prediction accuracy and efficiency with less input. The post-processing of data is mainly to correct the error of the predicted wind power [
39] by describing the distribution of the prediction error, ref. [
40] by predicting the error, and to correct the preliminary prediction power value. Compared with the load forecast, due to the uncertainty of wind speed, the wind power forecasting result is more volatile and there is still a large error in the preliminary forecasting. The preliminary prediction result is substituted into the error model, and the error value obtained is correspondingly superimposed with the preliminary forecasting value as the prediction correction result, which plays the role of checking the leakage and filling it. At the same time, different types of models are selected for the preliminary forecasting and error correction, which can avoid the limitations of a single model to a certain extent and give full play to the advantages of different models to further improve the prediction accuracy. The error correction has strong generality and is not limited to the specific forecasting process. Therefore, the multi-link forecasting method of “ input screening + model combination + error correction” has become a research hotspot and strives to maximize the prediction accuracy from the perspective of each link optimization.
In summary, this paper proposes a short-term wind power forecasting method based on feature analysis and error correction. First, the MIC is introduced to analyze the correlation of multiple factors affecting wind power, and then feature selection is performed based on this. Second, the data are divided based on wind speed, and cluster analysis is conducted on the data from the aspect of wind direction. Then, each component builds a prediction model based on the BiLSTM to complete the preliminary forecasting of wind power. Finally, lightGBM is used to perform error forecasting and correct the preliminary prediction results. The results of practical examples show that the method proposed in this paper effectively improves the forecasting accuracy and establishes a hybrid forecasting framework including feature selection, similar data component extraction, model forecasting, and error correction. Our contributions are summarized as follows:
MIC is used for feature selection. Several factors with the strongest correlation with wind power are selected from multiple features, which avoids the interference of irrelevant features on the wind power prediction results, reduces the input features dimension, reduces the workload of neural network, and thus greatly improves the operation speed. In addition, the features most closely related to power can also be observed, thus laying a foundation for the extraction of similarity components.
A hybrid model based on component forecasting is used for wind power forecasting. The strong correlations between wind speed and power, wind direction and power are separately mined. The prediction components are extracted from the above two features for the first time, which makes the similarity between components stronger. The relationship between wind turbine output and wind speed is fully utilized, and the influence of wind blowing from different wind directions on wind energy absorbed by wind turbines is considered. This provides a new idea for improving the accuracy of wind power forecasting, which has not been studied in the previous literature.
Based on the forecasting model, an error correction method is proposed. Since the correlation between prediction error and input features such as wind speed and wind direction are smaller than the correlation between predicted power and the above factors, the data post-processing method uses the lightGBM algorithm to predict the error for the first time, which is more suitable for processing data with low correlation. At the same time, it can make up for the shortcomings caused by only using the BiLSTM model. The two algorithms with completely different principles complement each other, making the prediction results more accurate.
The rest of this paper is organized as follows: The basic principles and methods of MIC feature selection and the extraction of similar data components based on wind speed and wind direction are introduced in
Section 2. The forecasting model and error correction model are established in
Section 3. The example analysis is in
Section 4. Finally, conclusions are drawn in
Section 5.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}