
Machine Learning Requirements for Energy-Efficient Virtual Network Embedding


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
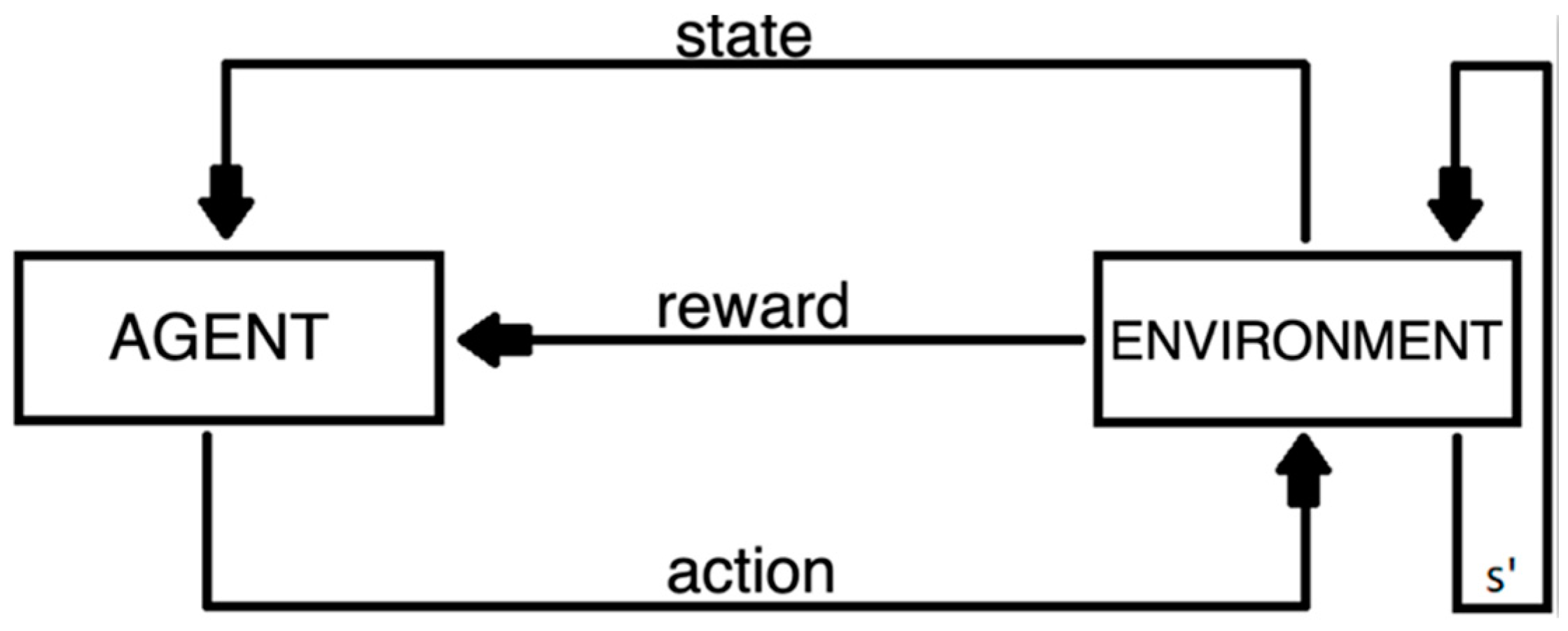
:1. Introduction
2. Materials and Methods
2.1. Development Tool
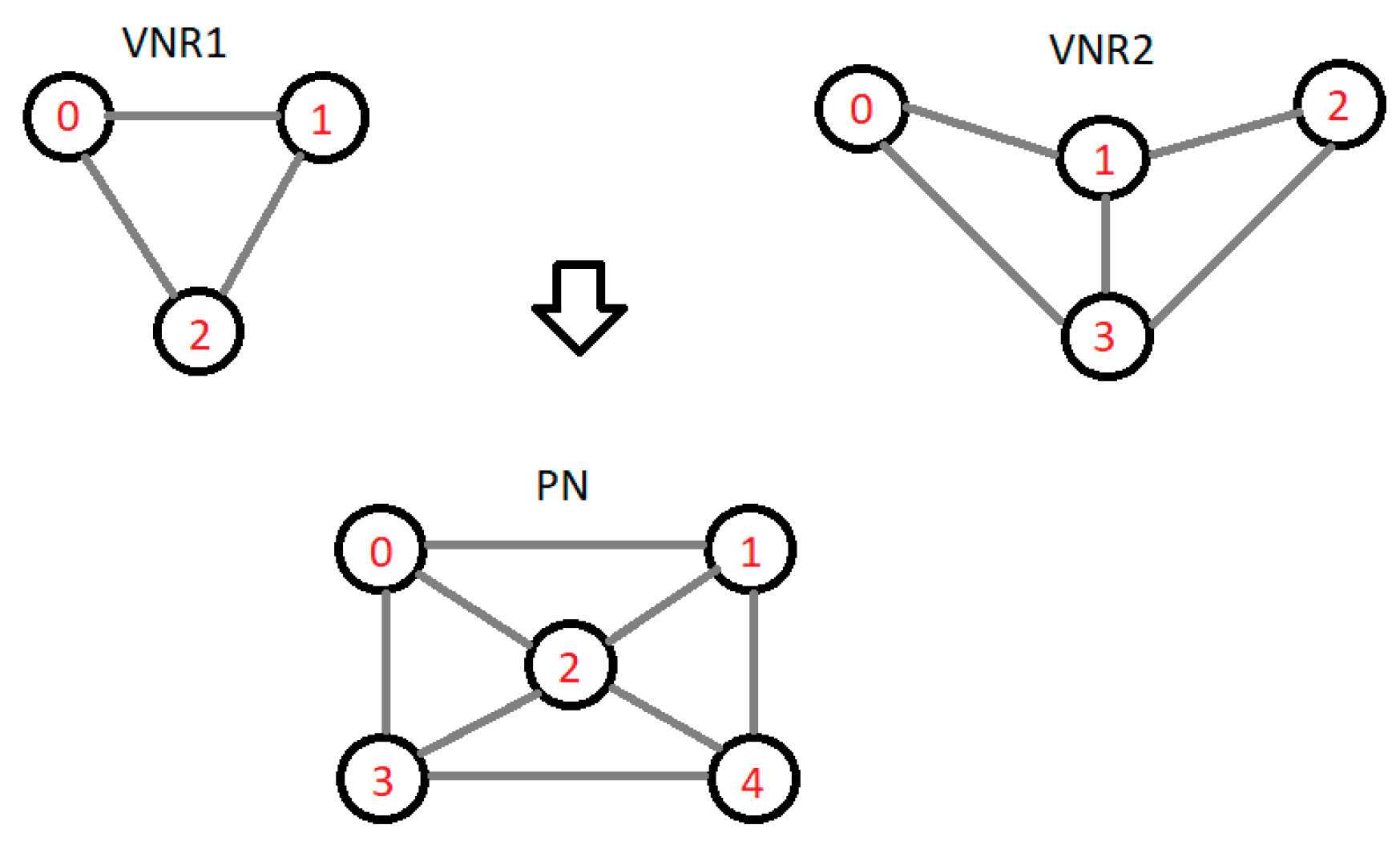
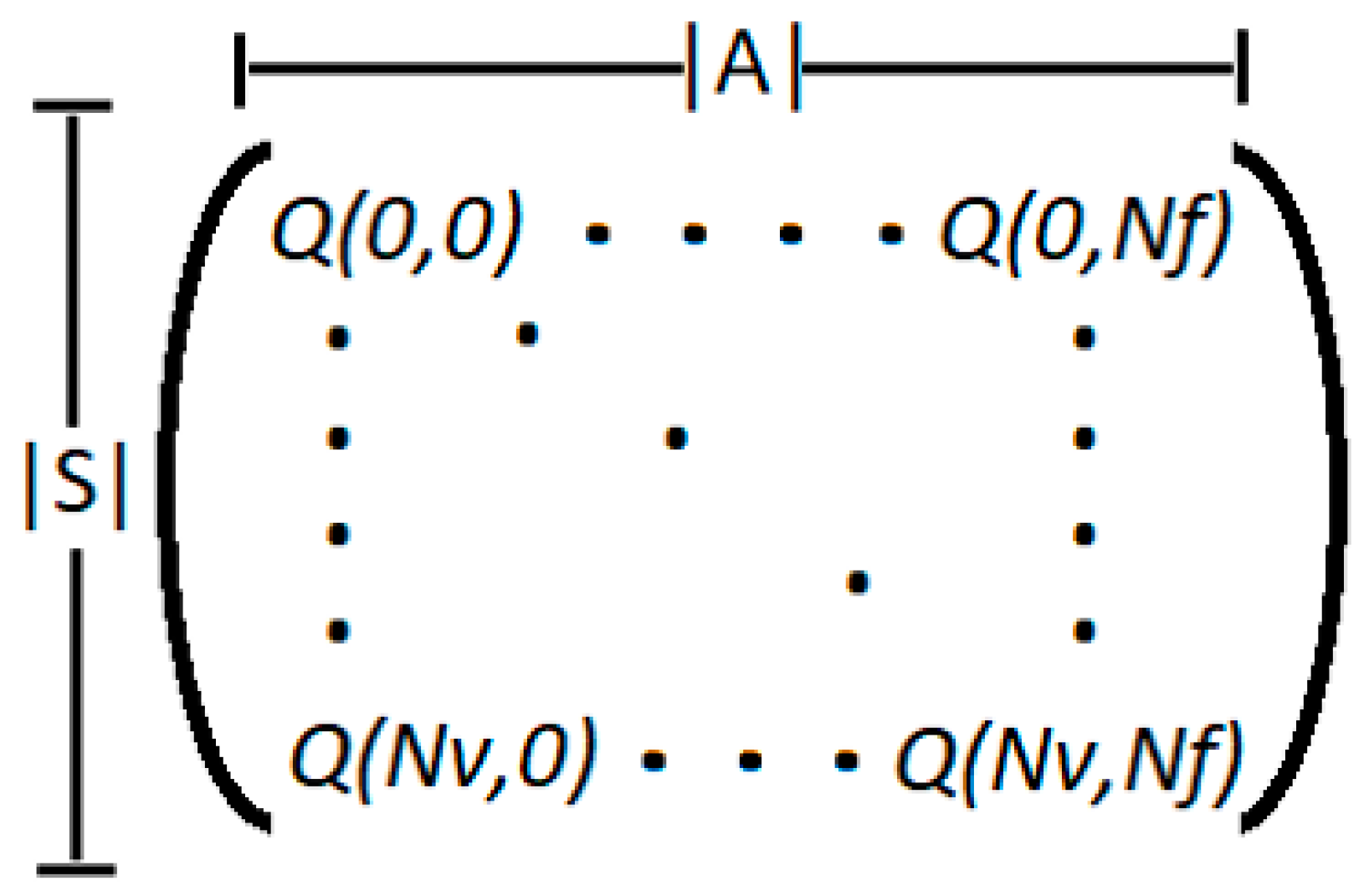
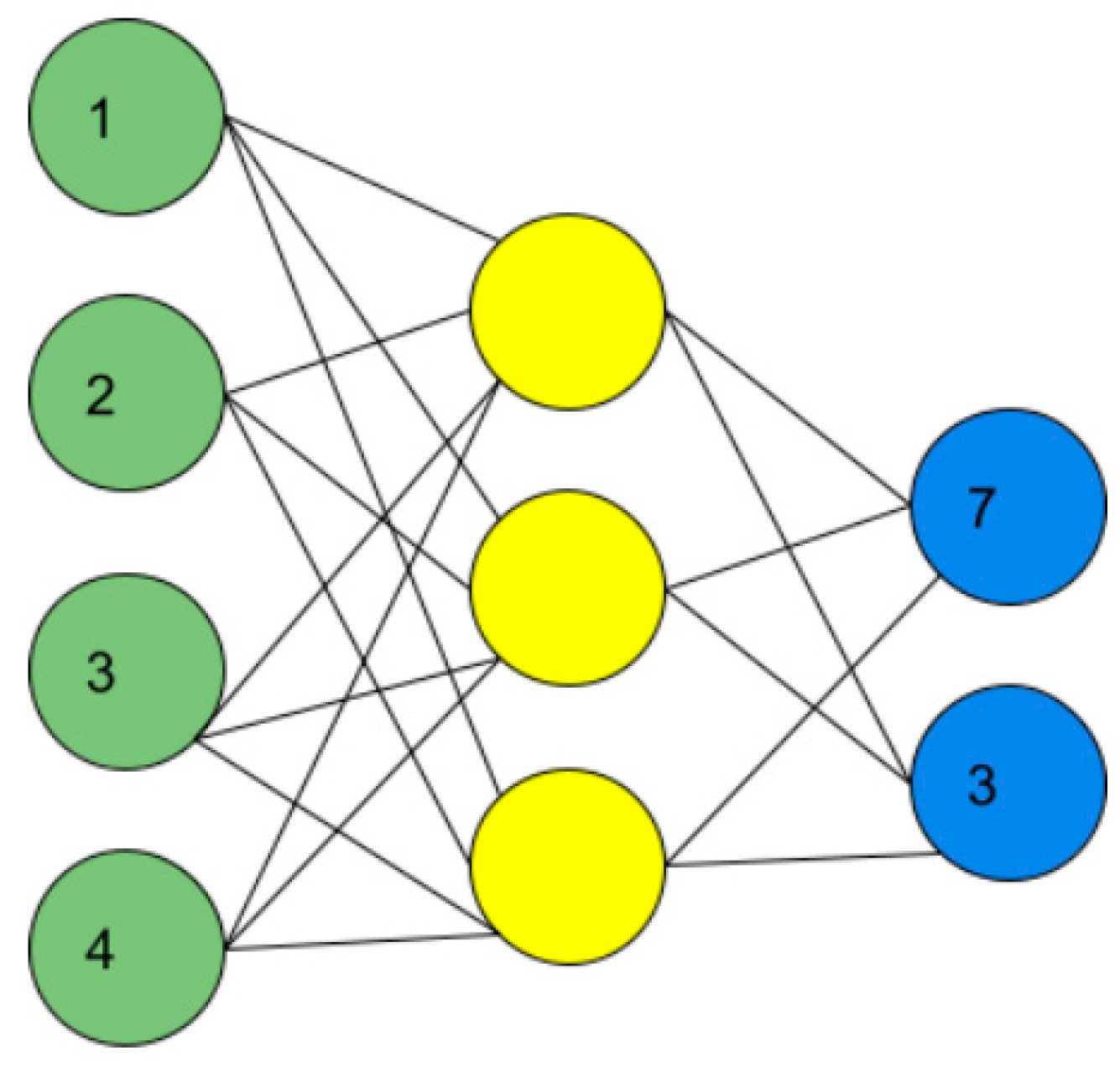
2.2. Construction of the Algorithm

| Algorithm 1 Q-learning-based VNE algorithm | |
| 1. | while (num_iter < max_iter){ |
| 2. | for (i = 0; i< Nv; i++){ |
| 3. | if (num_random > ){ |
| 4. | Choose action Ai with a better Q value for this state |
| 5. | This Q value has to satisfy the restrictions imposed on the nodes |
| 6. | }else{ |
| 7. | Chooses random action for this state |
| 8. | } |
| 9. | Calculate the reward R with the Equation (3) |
| 10. | Calculate the Q value with the Equation (2) |
| 11. | Update the Q table with the new Q value |
| 12. | If (i == Nv){ |
| 13. | Update all the Q values chosen in the actual embedding with a new reward depending on whether embedding has been completed or not} |
| 14. | } |
| 15. | num_iter++; |
| 16. | |
| 17. | Return an embedding based on the Q table |
| 18. | } |
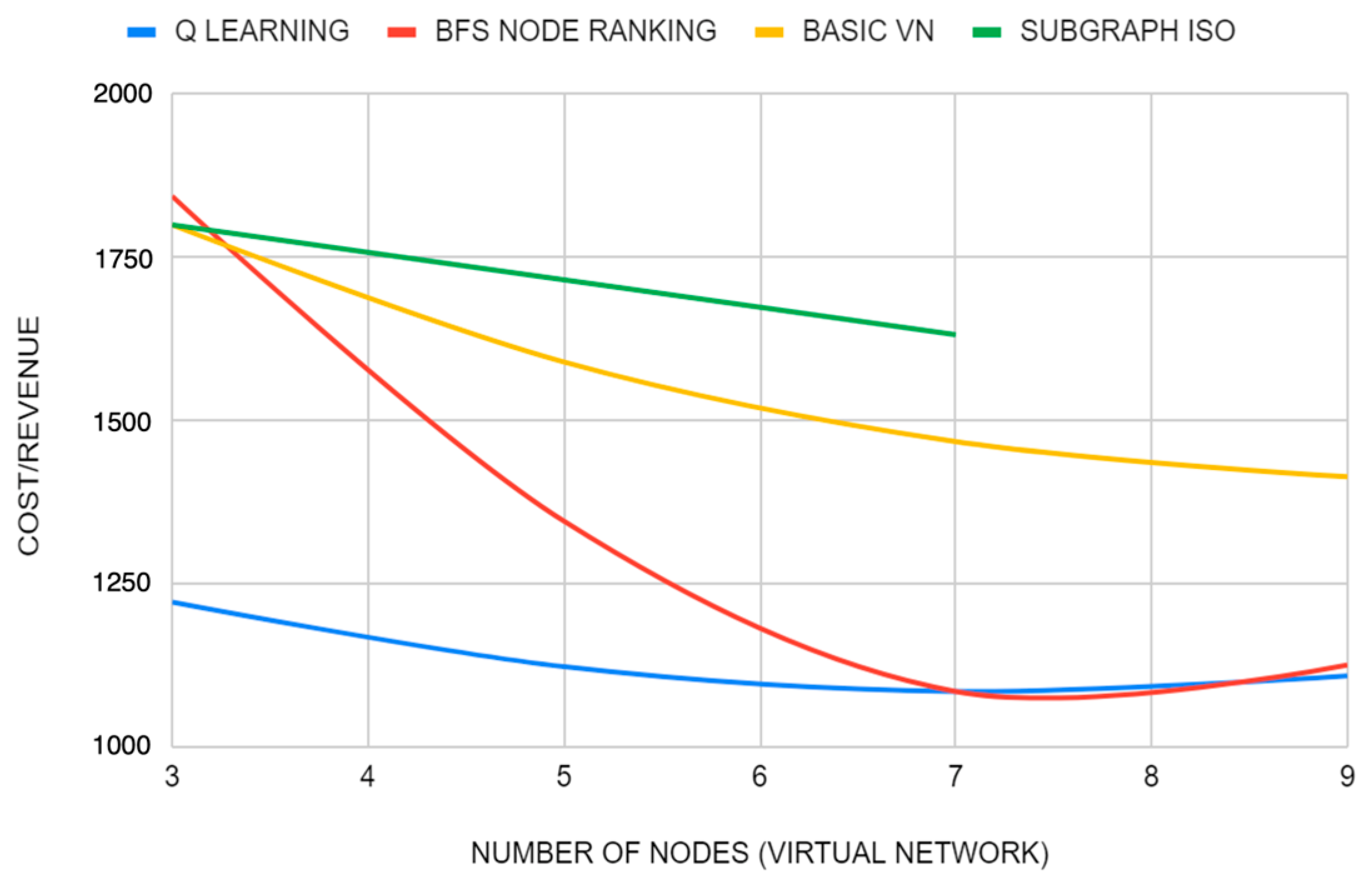
3. Results
3.1. Algorithms Used to Compare
3.2. Metrics Used for the Evaluation of the Algorithm
- Cost: Refers to the total physical resources required to map virtual networks. It is determined by taking into account all the resources of the physical network that have been used by the VNRs.
- Revenue: Refers to the sum of the virtual resources requested by the virtual networks that have been successfully mapped.
- Cost/Revenue: This metric will be used to evaluate how the algorithm optimizes the resources of the physical network to find embeddings. A high value of this metric means that a lot of resources are needed to embed virtual networks. Optimally, Cost/Revenue = 1.
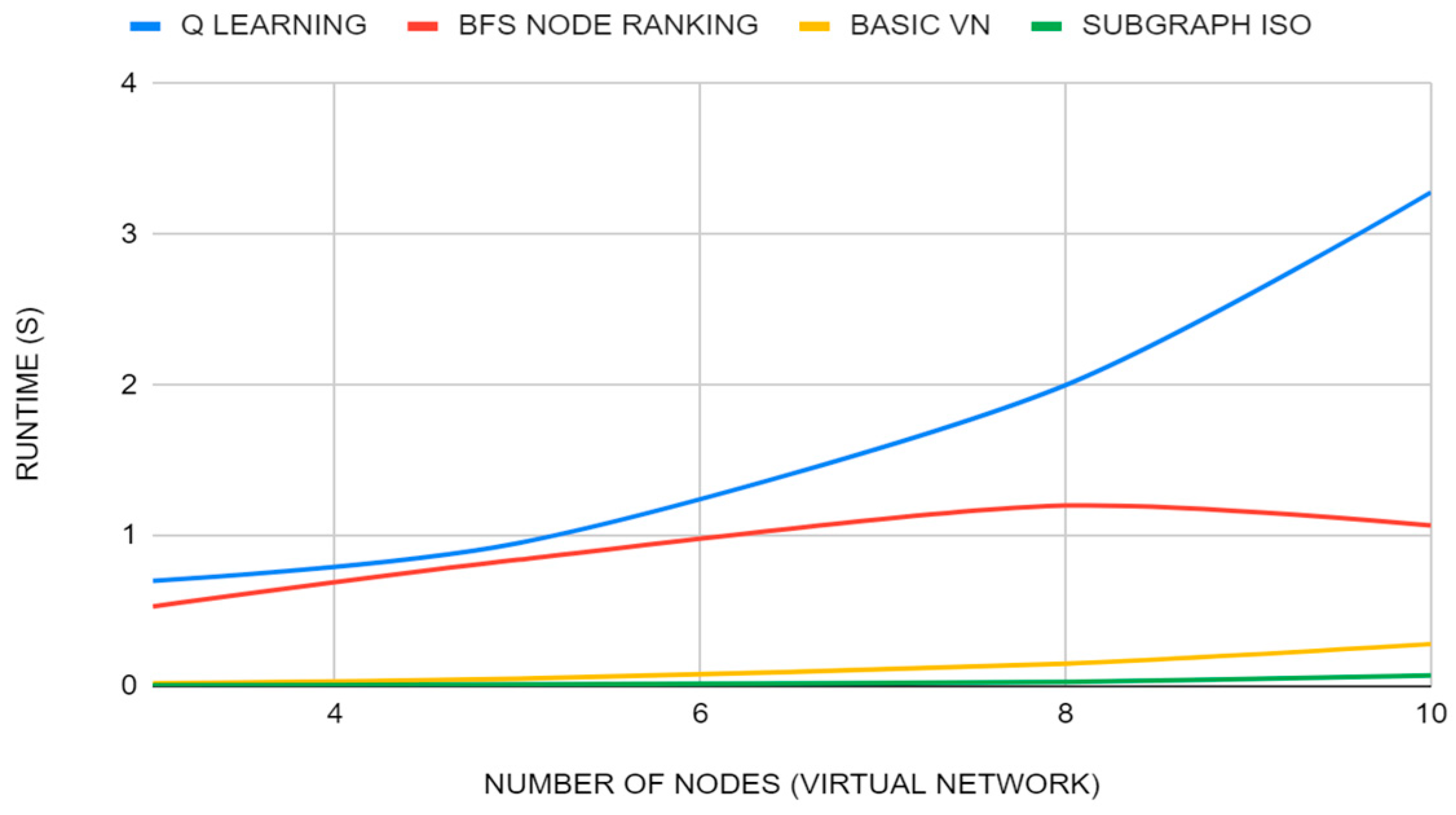
- Runtime: This metric measures the time it takes the algorithm to complete the embeddings. This is relevant in terms of the mathematical complexity of the problem and the heuristics that are taken into consideration.
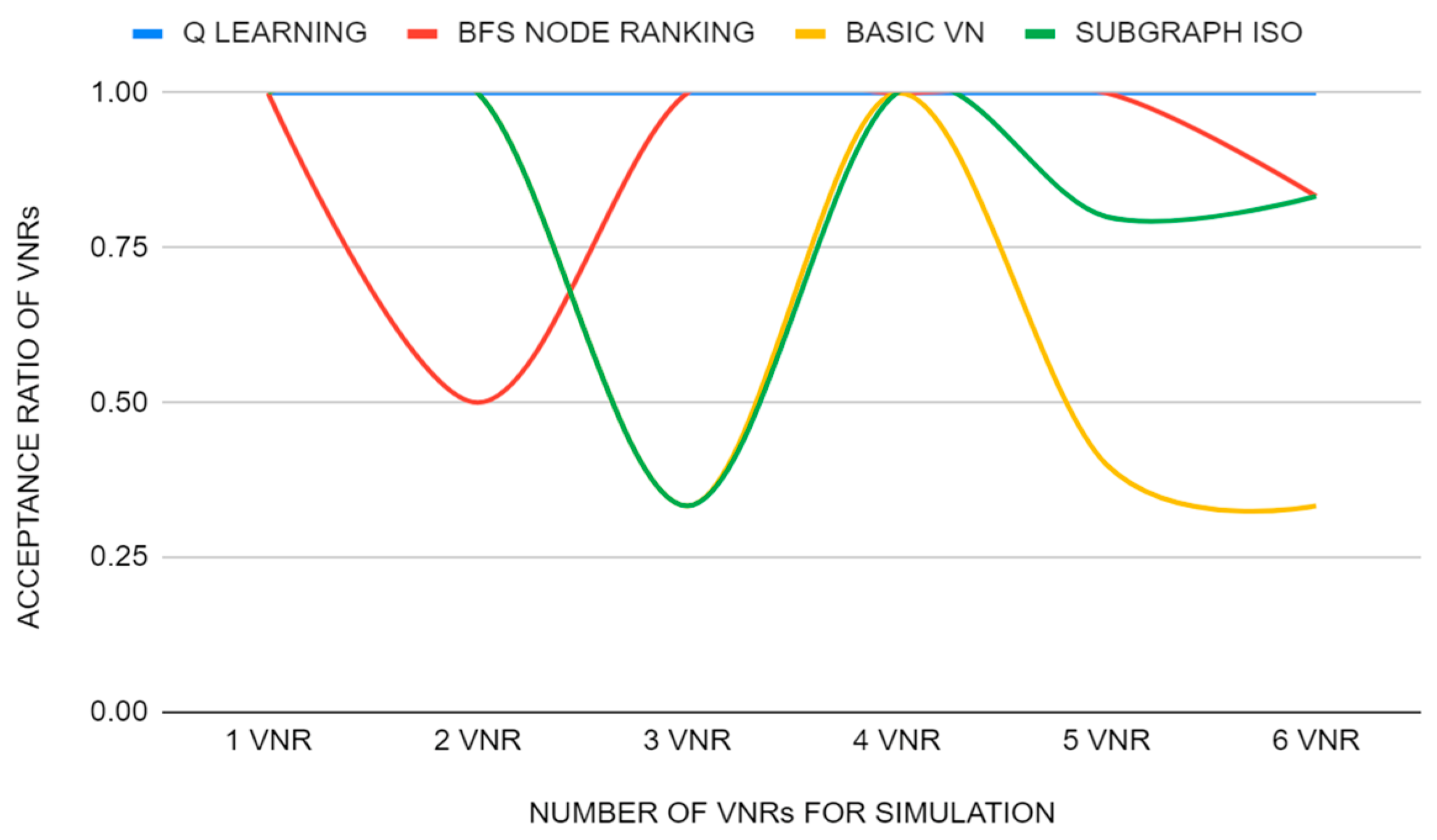
- Acceptance of VNRs: This metric will be used to assess the ability of the algorithm to host different VNs on the same physical network, taking into account the use of network resources.
3.3. Simulation Scenario 1
3.4. Simulation Scenario 2
3.5. Simulation Scenario 3
4. Discussion
- Try a new AI algorithm that solves the VNE problem, which means that all the progress made in terms of cost/revenue and acceptance of VNRs may change.
- Improve the algorithm with new tools to be able to obtain better results in terms of execution time, with good results in the other metrics.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fischer, A.; Botero, J.F.; Beck, M.T.; De Meer, H.; Hesselbach, X. Virtual Network Embedding: A Survey. IEEE Commun. Surv. Tutor. 2013, 15, 1888–1906. [Google Scholar] [CrossRef]
- Cao, H.; Wu, S.; Hu, Y.; Liu, Y.; Yang, L. A survey of embedding algorithm for virtual network embedding. China Commun. 2019, 16, 1–33. [Google Scholar] [CrossRef]
- Fan, W.; Xiao, F.; Lv, M.; Han, L.; Wang, J.; He, X. Node Essentiality Assessment and Distributed Collaborative Virtual Network Embedding in Datacenters. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 1265–1280. [Google Scholar] [CrossRef]
- Andersen, D.G. Theorical Approaches to Node Assignment. 2002. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.119.1332 (accessed on 29 September 2021).
- NP (Complexitat)—Viquipèdia, L’enciclopèdia Lliure. Available online: https://ca.wikipedia.org/wiki/NP_(Complexitat) (accessed on 29 September 2021).
- Hesselbach, X.; Amazonas, J.R.; Villanueva, S.; Botero, J.F. Coordinated node and link mapping VNE using a new paths algebra strategy. J. Netw. Comput. Appl. 2016, 69, 14–26. [Google Scholar] [CrossRef]
- Sermakani, A.M.; Paulraj, D. Effective Data Storage and Dynamic Data Auditing Scheme for Providing Distributed Services in Federated Cloud. J. Circuits Syst. Comput. 2020, 29, 2050259. [Google Scholar] [CrossRef]
- Andriy Burkov, B. The Hundred-Page Machine Learning. 2019. Available online: http://themlbook.com/ (accessed on 23 September 2021).
- Qiang, W.; Zhongli, Z. Reinforcement Learning Model, Algorithms and Its Application. In Proceedings of the IEEE 2011 International Conference on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, 19–22 August 2011; pp. 1143–1146. [Google Scholar] [CrossRef]
- Fischer, A.; Botero, J.F.; Duelli, M.; Schlosser, D.; Hesselbach, X.; De Meer, H. ALEVIN—A Framework to Develop, Compare, and Analyze Virtual Network Embedding Algorithms. Electron. Commun. Eur. Assoc. Softw. Sci. Technol. 2011, 37. [Google Scholar] [CrossRef]
- Duelli, M.; Schlosser, D.; Botero, J.F.; Hesselbach, X.; Fischer, A.; de Meer, H. VNREAL: Virtual Network Resource Embedding Algorithms in the Framework ALEVIN. In Proceedings of the 7th EURO-NGI Conference on Next Generation Internet Networks, Kaiserslautern, Germany, 27–29 June 2011. [Google Scholar] [CrossRef]
- Duelli, M.; Fischer, A.; Botero, J.F.; Diaz, L.; Till, M.; Schlosser, D.; Singeorzan, V.; Hesselbach, X. Alevin2/Wiki/Home. Available online: https://sourceforge.net/p/alevin/wiki/home/ (accessed on 26 September 2021).
- JUNG—Java Universal Network/Graph Framework. Available online: http://jung.sourceforge.net/ (accessed on 27 September 2021).
- Messmer, B.T.; Bunkem, H. Efficient subgraph isomorphism detection: A decomposition approach. IEEE Trans. Knowl. Data Eng. 2000, 12, 307–323. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Ammar, M. Algorithms for Assigning Substrate Network Resources to Virtual Network Components. In Proceedings of the 25TH IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006. [Google Scholar] [CrossRef]
- Cheng, X.; Su, S.; Zhang, Z.; Wang, H.; Yang, F.; Luo, Y.; Wang, J. Virtual network embedding through topology-aware node ranking. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 38–47. [Google Scholar] [CrossRef]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A Theoretical Analysis of Deep Q-Learning. Available online: http://arxiv.org/abs/1901.00137 (accessed on 10 January 2019).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hesselbach, X.; Escobar-Perez, D. Machine Learning Requirements for Energy-Efficient Virtual Network Embedding. Energies 2023, 16, 4439. https://doi.org/10.3390/en16114439
Hesselbach X, Escobar-Perez D. Machine Learning Requirements for Energy-Efficient Virtual Network Embedding. Energies. 2023; 16(11):4439. https://doi.org/10.3390/en16114439
Chicago/Turabian StyleHesselbach, Xavier, and David Escobar-Perez. 2023. "Machine Learning Requirements for Energy-Efficient Virtual Network Embedding" Energies 16, no. 11: 4439. https://doi.org/10.3390/en16114439
APA StyleHesselbach, X., & Escobar-Perez, D. (2023). Machine Learning Requirements for Energy-Efficient Virtual Network Embedding. Energies, 16(11), 4439. https://doi.org/10.3390/en16114439