1. Introduction
The global population expansion, the reduction of natural resources and cropland area, and unpredictable weather patterns have resulted in a significant challenge to ensuring food accessibility [
1]. Considering these challenges, the agricultural industry has begun to adopt technology as a means of increasing efficiency and productivity. The use of the IoT (Internet of Things) and big data has become prevalent in this context. WSNs are a fundamental aspect of those systems, as they provide farmers with vital information about soil conditions, crop growth, and animal behavior, thus enabling them to make more informed decisions [
2]. In addition to food availability, the problem of water pollution caused by agriculture can lead to negative impacts on the environment and on human health, and the use of a WSN can help to solve this issue [
3]. The IoT ecosystem comprises various components, including sensors, actuators, smartphones, automobiles, personal computers, and cameras. It is anticipated that the IoT will continue to benefit a wide range of industries, including transportation, manufacturing, and healthcare, for the foreseeable future [
4].
Limited-power Wide Area Network (LPWAN) is a type of WSN technology that enables the connection of battery-powered devices with low bandwidth and low bit rate over extended distances. The most well-known LPWAN protocols include Narrowband IoT (NB-IoT), Sigfox, and LoRaWAN [
5]. This study focused on LoRaWAN, a protocol specifically designed to meet the critical requirements of the IoT, such as bidirectional communication, end-to-end security, mobility, and location services. LoRaWAN was developed to wirelessly connect devices in regional, national, and global networks to the internet, in order to provide coverage over a vast area, while consuming minimal energy [
6].
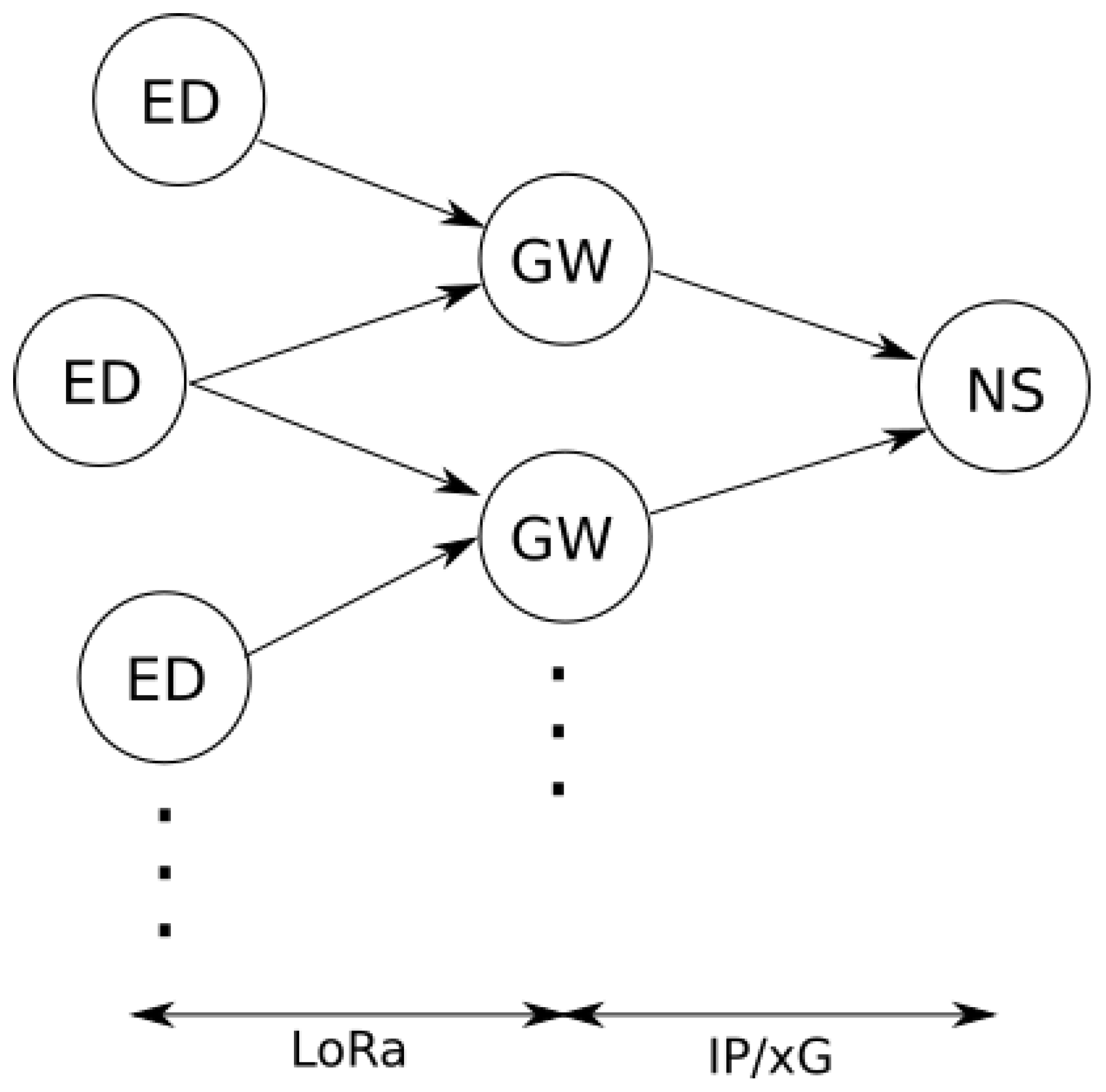
In LoRaWAN, GWs act as the intermediary between LoRaWAN end-devices (EDs) and the network server (NS), utilizing communication technologies such as WiFi, Ethernet, and cellular. Meanwhile, EDs connect to the GWs using the LoRa (Long Range) protocol [
7]. The coverage, collision probability, and power consumption of the network are contingent on the number and positioning of the GWs, as the transmission power of the EDs is relatively high. A network with inadequate or poorly positioned GWs will likely experience increased collisions, communication failures, and energy consumption. Furthermore, the power consumption of sensors, actuators, and radios can be significant, making the design of algorithms for energy-saving and power circuitry—including the selection of batteries and solar panels—a topic of ongoing research and debate in the scientific community [
8,
9].
Clustering is a promising method for determining the number and placement of GWs: it has been used in WSNs to improve network scalability, reduce energy consumption, and increase data reliability [
10]. There are many types of clustering techniques that are classified as hierarchical, centroid-based, density-based, and distribution based. Hierarchical clustering is suitable for grouping similar items together, as it generates cluster trees. This type of clustering can be divided into two main methods: agglomerative and divisive. Agglomerative clustering combines clusters, to form hierarchical groups, using a bottom-up approach. Divisive clustering breaks down clusters into smaller groups, using a top-down approach. Centroid-based clustering employs center vectors to identify each cluster, and assigns items to the closest cluster center, to minimize squared distances. Density-based clustering forms clusters from areas with a high concentration of occurrences. Distribution-based clustering uses the distance from the probability distribution center, to determine the likelihood of an item belonging to a particular cluster. K-Means, a centroid-based method, is commonly used to solve cluster formation in WSNs [
11]. In addition to K-Means, there are three variations of it: Minibatch K-Means; Bisecting K-Means; and FCM.
End-users primarily value a communication system on the basis of its reliability and cost [
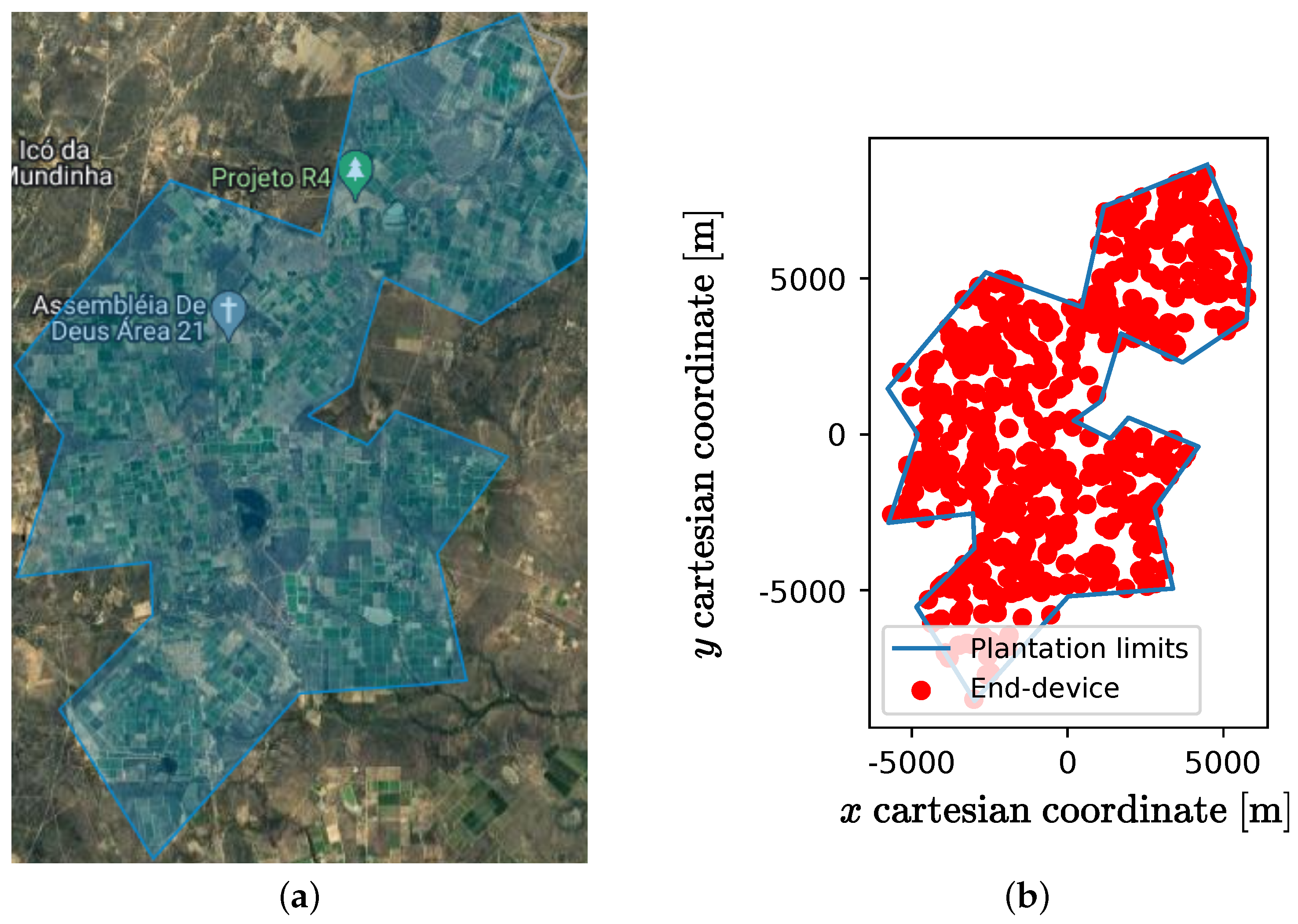
12]: with this in mind, this research presents new and promising results for planning LoRaWAN in smart agriculture IoT applications. Various scenarios were established in a large agricultural area located in Petrolina, one of the most productive fruit-growing cities in Brazil. By using the proposed method, designers can plan and evaluate the performance and behavior of WSNs, and make informed decisions on the parameters during the design process.
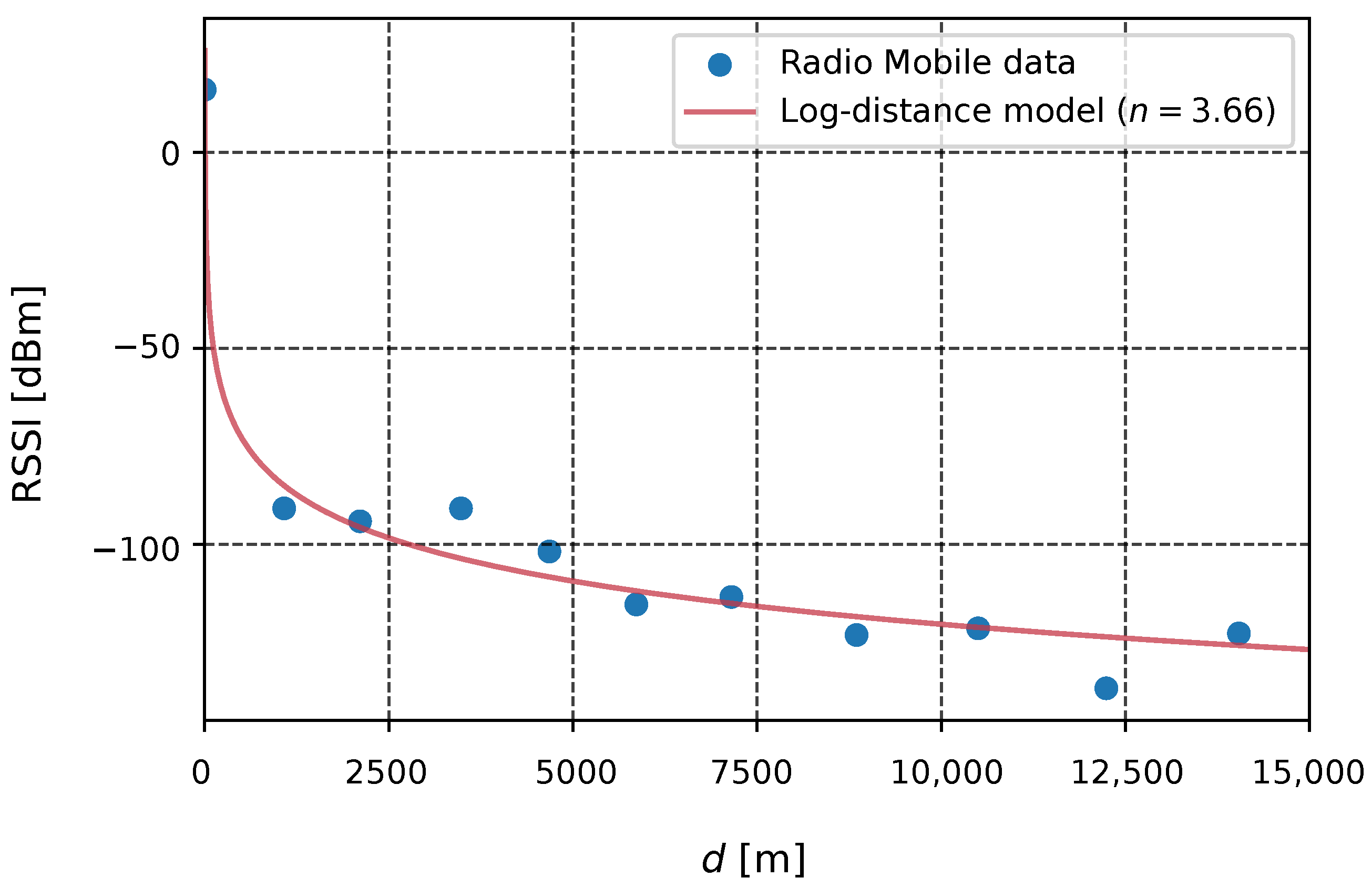
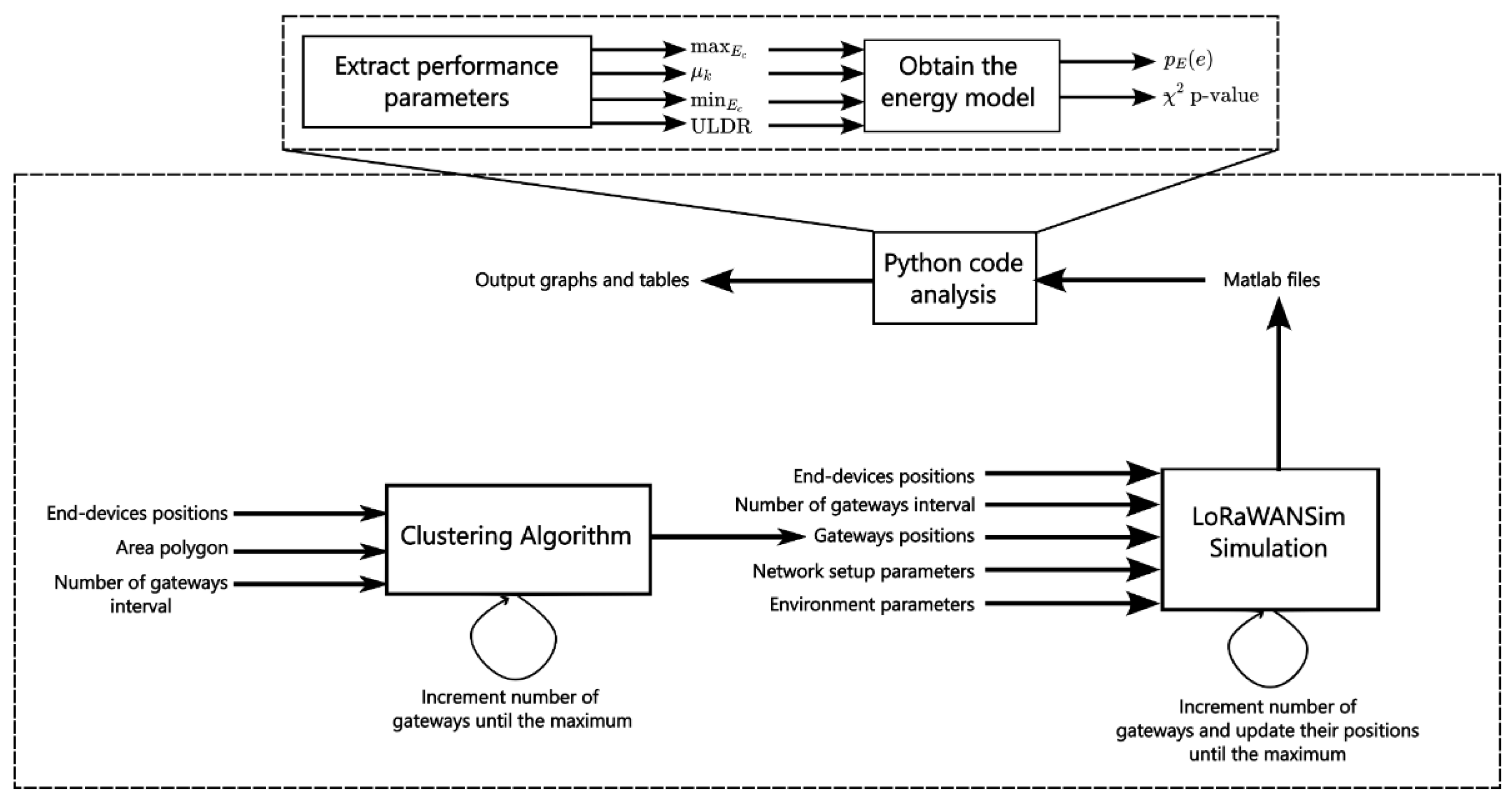
In this article, a method for placing LoRaWAN GWs in smart agriculture applications, using K-Means and its three variations, is proposed. The method is comprised of five phases: (1) characterization of the environment, including delimiting the plantation area, and modeling and parameterizing RF (Radio Frequency) signal propagation; (2) calculation of LoRaWAN GW location, using K-Means and its three variants, taking into account the positions of the EDs; (3) simulation of network performance, using LoRaWANSim (a free and open-source simulator [
13]) for various GW setups, up to the maximum number of GWs; (4) statistical analysis of the performance of all simulations; (5) selection of the best GW setup, based on performance results. Additionally, we propose the use of a stochastic energy model, to evaluate the power consumption performance of the WSN. The ULDR, mean, maximum, and minimum ED energy consumption levels were also used, to support the final deployment decision.
This paper presents five contributions to the field of LoRaWAN technology: (1) the use of a stochastic energy model to determine the optimal interval of GW numbers (as developed in previously published work), in order to minimize the energy consumption of LoRaWAN radios in all operation modes; (2) the testing of four different clustering algorithms, to determine the optimal GW locations and numbers, using the energy model and ULDR as a parameter; (3) a comprehensive characterization of the environment, focusing on a real polygonal plantation area in one of Brazil’s most fruit-productive regions; (4) a comparison of the proposed method under different levels of medium-access concurrence; (5) presentation of novel simulation results that provide insight into the performance of LoRaWAN and the impact of various configurations.
The organization of this paper is as follows:
Section 2 provides background information on LoRa and LoRaWAN technologies, delves into the basics of clustering, and highlights the current state of the art;
Section 3 details the performance measurements and methodology used in this study;
Section 4 presents the results obtained by the simulator, and compares them to the energy model and metrics;
Section 5 concludes with a summary of the findings, and suggestions for future research.
4. Simulation Results and Discussion
This section presents the simulation results regarding the number of GWs suggested by the proposed method, the ULDR, and the energy performance.
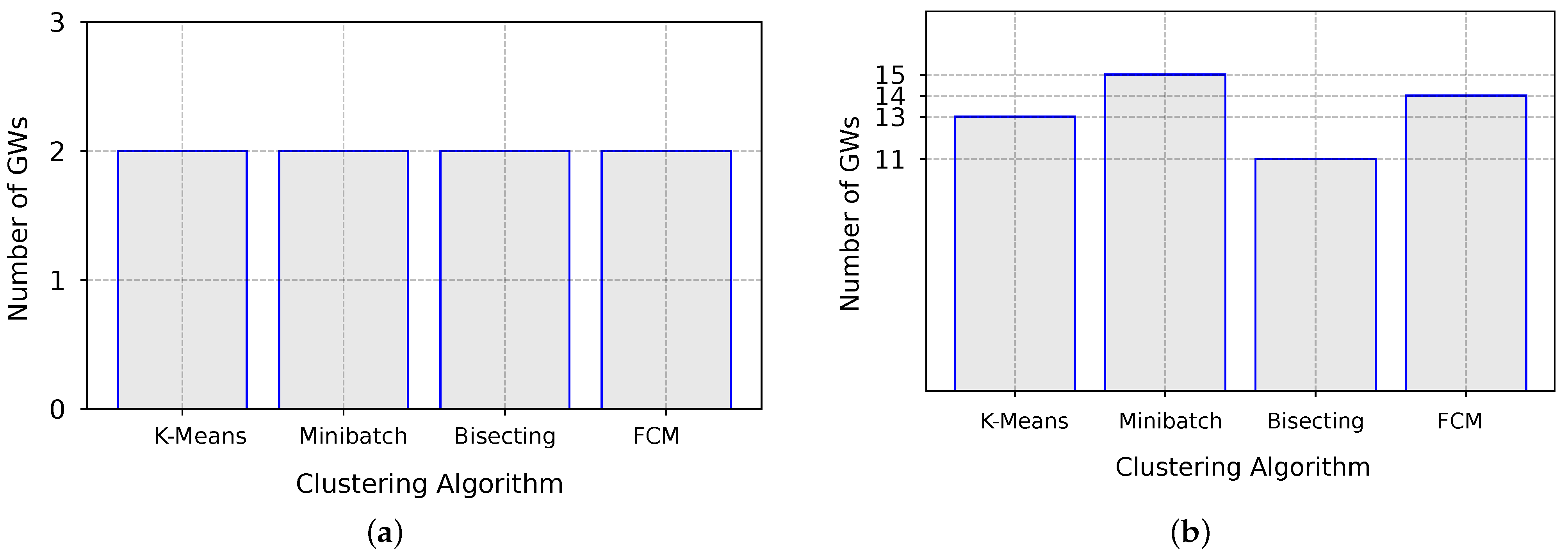
The proposed method used four clustering algorithms (K-Means, Bisecting K-Means, Minibatch K-Means, and FCM) to determine the number of GWs for two different scenarios.
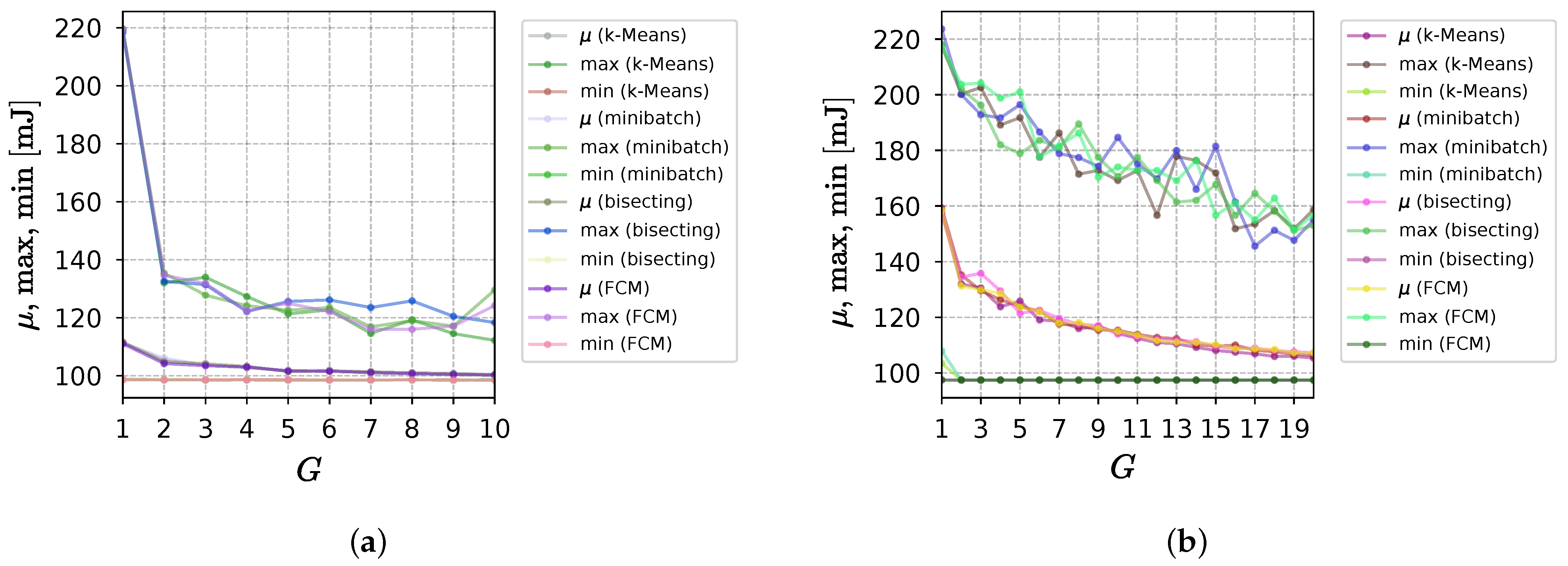
Figure 7a illustrates that the suggested method recommended 2 GWs for Scenario 1, based on the results from the four clustering algorithms. For Scenario 2 (
Figure 7b), the proposed method suggested a range for the number of GWs that needed to be analyzed in greater detail. The number of GWs at which the minimum
p-value occurred was 11, 13, 14, and 15 for K-Means, Bisecting K-Means, Minibatch K-Means, and FCM, respectively. While the energy model may have adhered better with a smaller number of GWs for one algorithm, this did not necessarily mean that its performance, in terms of packet delivery rate and energy usage, was superior to other algorithms that recommend more GWs; therefore, it was essential to compare the metrics for the GW number interval, rather than just evaluating one single metric.
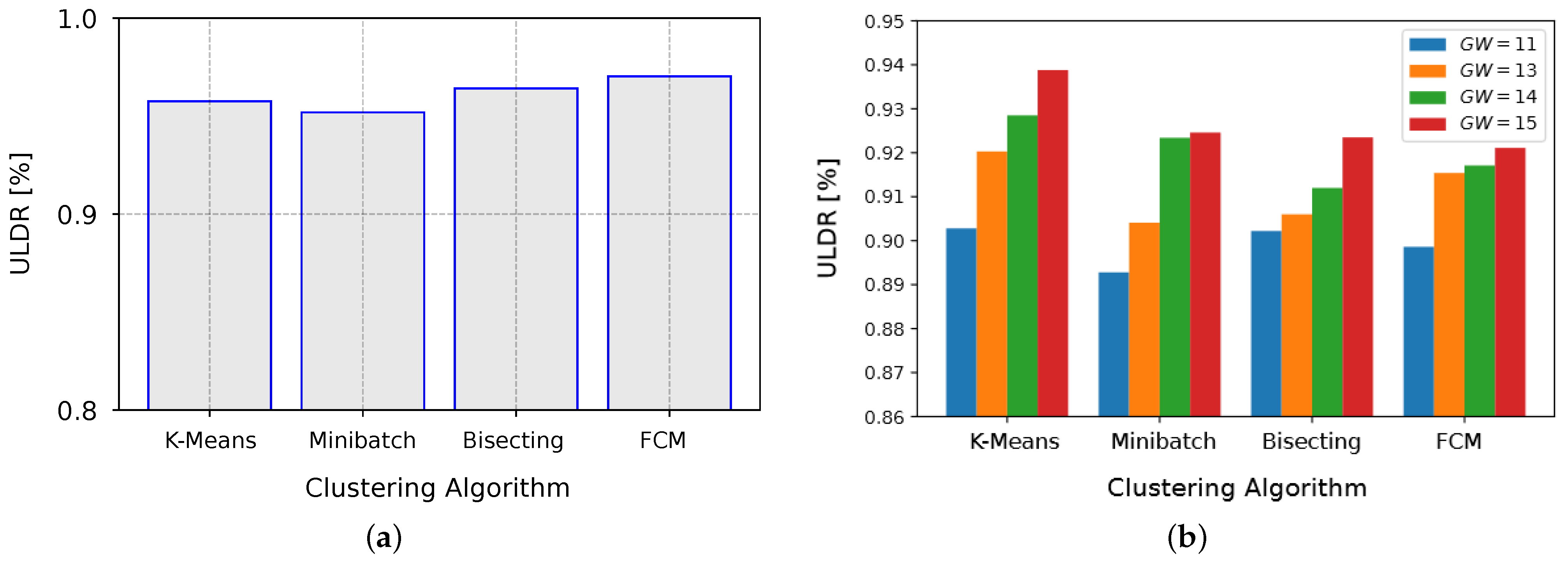
Different cluster models are available in the literature, and distinct algorithms can be provided for each of these cluster models. Clusters discovered by one clustering method will probably differ from clusters discovered by another technique; this explains why the ULDR differed from one algorithm to another in Scenario 2, in which more random factors took place (
Figure 8). The performance of the clustering algorithms, regarding the ULDR for Scenario 1, showed no considerable difference among the clustering techniques, according to the graph shown in
Figure 8a; the FCM algorithm gave the best performance, by a small margin; on the other hand, considering Scenario 2,
Figure 8b shows that the K-Means algorithm performed better for all the suggested GW quantities.
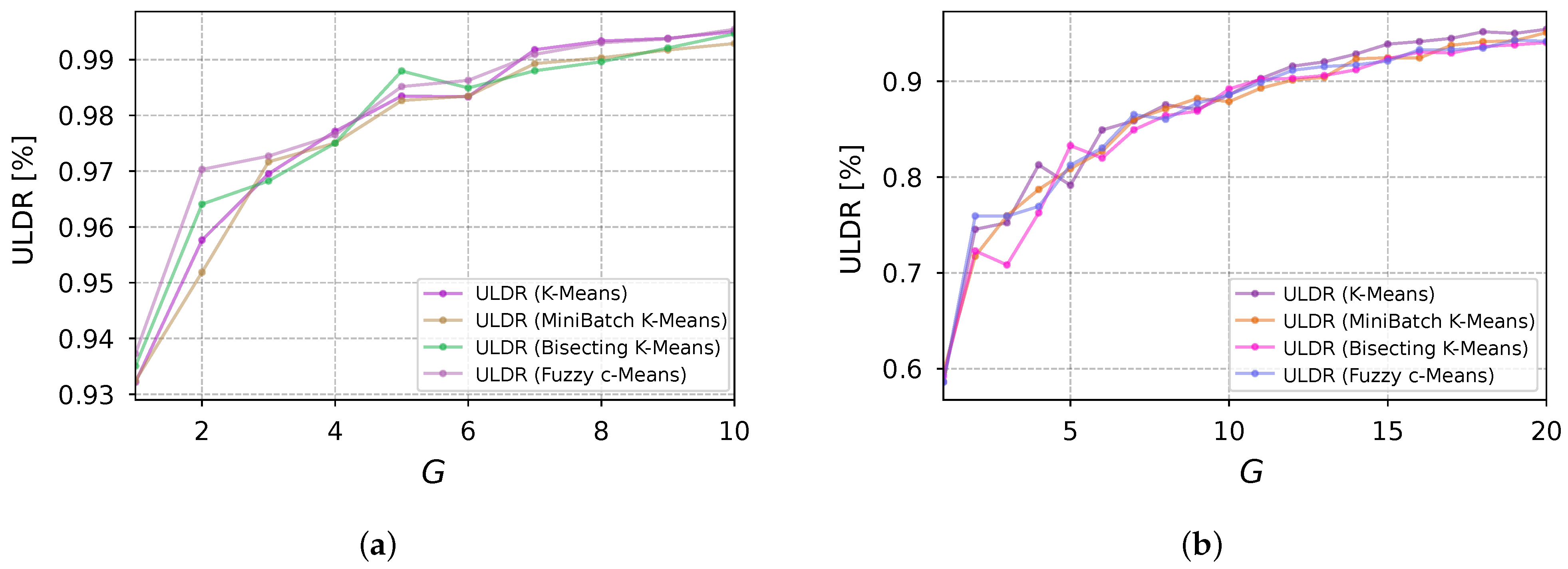
By analyzing the ULDR values in
Figure 9, it can be seen that they improved as the number of GWs increased, for both Scenario 1 and 2; this behavior was expected, as less energy was needed for the EDs to transmit their messages, increasing the SIR (signal-to-interference ratio) and, consequently, reducing packet loss. The Scenario 1 impairment was dominated only by noise, while Scenario 2 impairments were also dominated by collisions and interference. Comparing both scenarios, it can be seen that the ULDR performance improved faster in Scenario 1—that is, with fewer GWs—than in Scenario 2, because of the amount of deterioration signals.
Table 3 displays the ULDR values for the lower-medium concurrence case (Scenario 1) when using the clustering techniques. The maximum
difference was 1.8% for every number of GWs. It can also be seen that the least
p-value equaled 0.12 for all clustering algorithms. The average ULDR improvement was 2.67%, when adding the second GW considering all the clustering schemes. From this point forward (
), adding more GWs resulted in an average gain of 0.41% per GW added.
The ULDR values for the higher-medium concurrence case (Scenario 2) are shown in
Table 4. Differences in the performance are apparent, unlike Scenario 1. For every given total number of GWs, the largest
difference was 5.13% when
GW = 3. The minimum
p-value was different for every clustering algorithm. The average ULDR improvement brought about by the addition of 14 GWs (maximum number of GWs) was 33.66%, which gave 2.40% of ULDR gain per added GW, on average. When 5 more GWs were installed, the average gain per added GW was 0.04%.
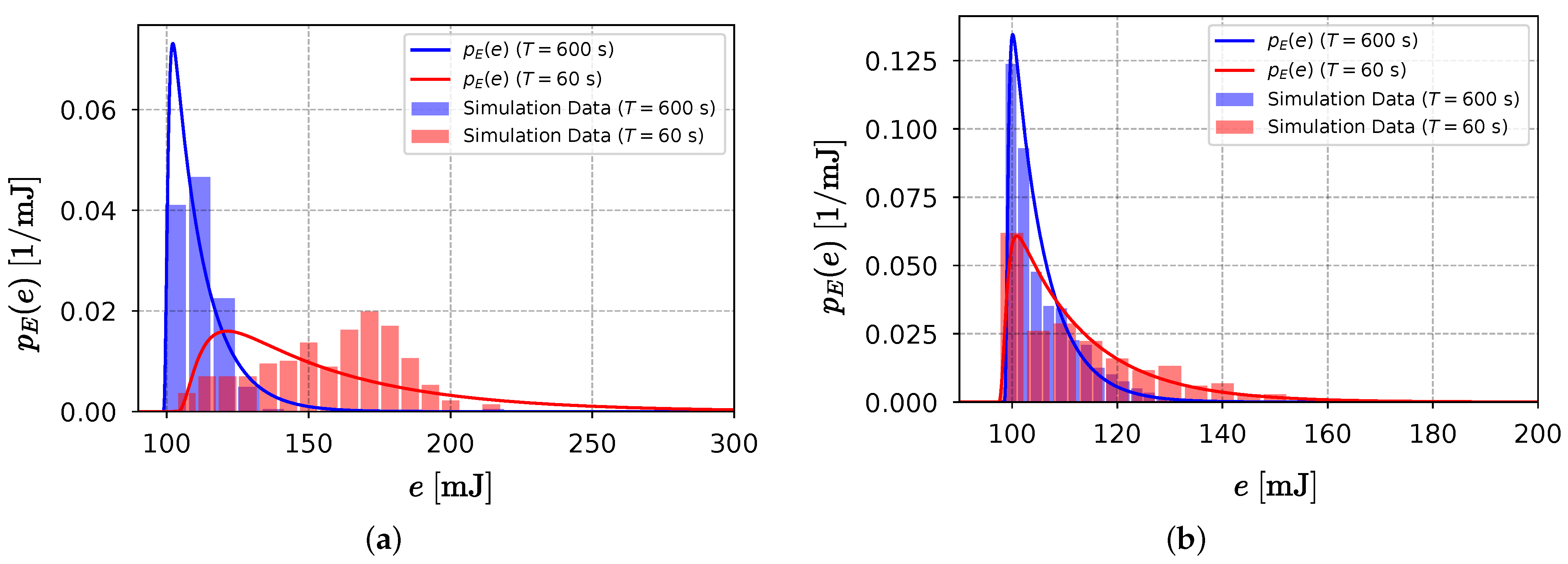
The theoretical model and energy consumption histograms (shown in
Figure 10) for the two scenarios are presented before and after the application of the method. Regarding the one GW case (before the method), increasing the time between transmissions decreased power consumption, as expected. For the one GW scenario case, the theoretical PDF was more accurately matched by the simulation findings for
T = 600 s. Energy consumption observations for the
T = 60 s scenario were outside the expected range for the exponential convolution PDF; this was because of higher interference and collisions, which affected SNR and made the ADR algorithm push the energy values further from the minimum. After the method application, the energy dispersion of both Scenario 1 and 2 closely matched the theoretical energy model. When the number of GWs continued increasing, the energy values became closer to the minimum; however, the ULDR gain and the energy reduction occurred at a much slower rate.
Figure 11 depicts the evolution of maximum, mean, and minimum energy usage over GW amount for Scenarios 1 and 2. Considering the highest energy consumption in Scenario 1, it can be seen that it decreased considerably after the initial increase in the number of GWs. The consumption in Scenario 2, on the other hand, decreased more slowly, and fluctuated more, due to the larger number of factors that disturbed the operation of the network. The application of the method in Scenario 2 saved considerably more energy than Scenario 1, despite the absolute values of power consumption in Scenario 2 remaining higher. The effectiveness of the different clustering techniques was equivalent in both cases. Almost no variation in minimum consumption was observed.
Table 5 displays the energy values for the lower-medium concurrence case. As the number of GWs increased, the GWs became closer to EDs; this led to SNR increasing, which made the ADR algorithm recommend smaller values of
and the SF to the EDs. As a consequence, the mean power consumption decreased. The maximum
difference was 1.90 mJ for every number of GWs and clustering algorithms. The average improvement was 6.18 mJ, when adding the second GW, considering all the clustering schemes. From this point forward (
), adding more GWs resulted in an average gain of 0.60 mJ per GW added, regarding the mean consumption. As noted above, the minimum consumption hardly ever changed. Great improvement was attained in the maximum consumption. The average saving reduction was 85.58 mJ when adding the second GW. The average improvement for the extra GWs was 1.57 mJ per GW added.
The energy values in the case of a higher-medium concurrence are listed in
Table 6. More GWs were required, to provide an acceptable decrease in power usage due to the 10-times increase in medium concurrence. The installation of 14 GWs resulted in an average improvement of 48.71 mJ in the mean energy, and 49.67 mJ in the maximum, or an average of 3.48 mJ and 3.55 mJ reduction in energy consumption per GW for the mean and maximum consumption, respectively. After accounting for the least
p-value, the average reduction per additional GW was 2.84 mJ when 5 more GWs were implemented.
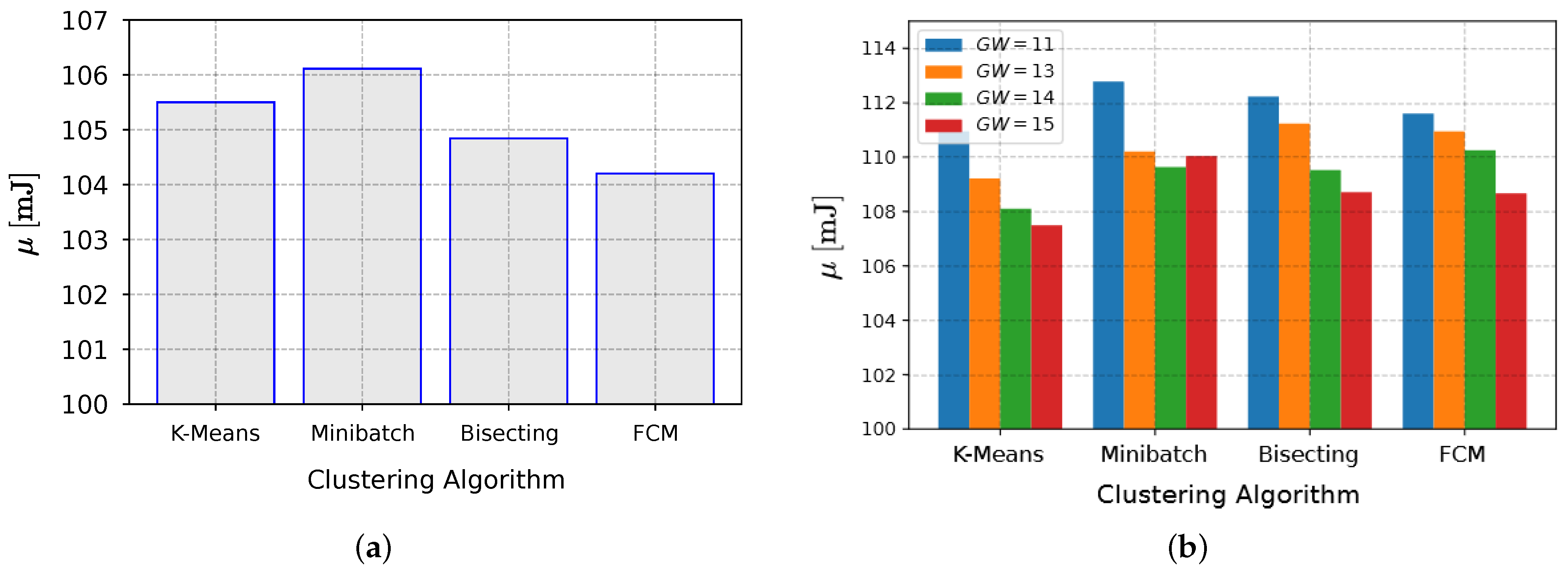
Regarding the lowest
p-value results, the mean network energy consumption numbers were relatively close, within a small margin of error, for the setups in Scenario 1; this was in contrast to Scenario 2, in which there was a larger fluctuation in the average consumption of one algorithm compared to the other, as the delivery rate increased. In Scenario 1, the performance of the FCM algorithm was superior, as evidenced by the smallest mean consumption values presented in
Figure 12a.
Figure 12b presents the findings of Scenario 2, which show that the K-Means technique was superior to the alternatives for all of the GW values.
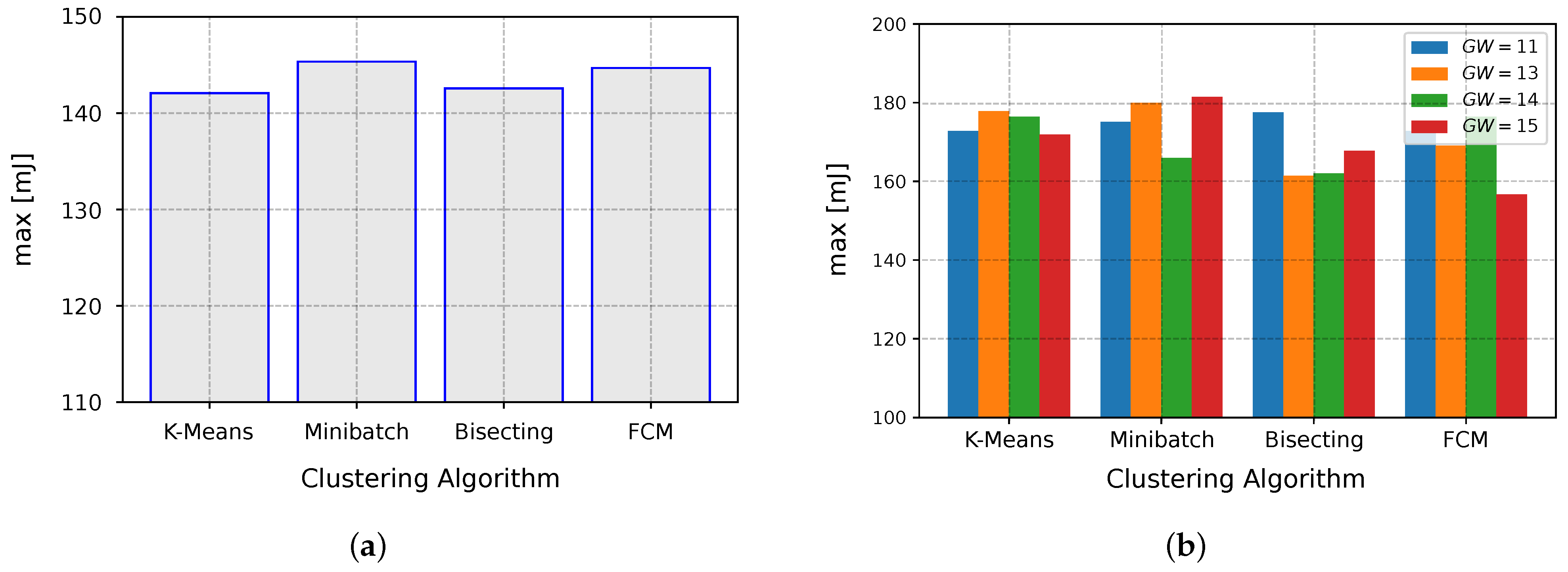
The time at which the network nodes began to run out of power is influenced by the maximum amount of power that they use. For the Scenario 1 settings, the maximum network energy consumption estimates were also very similar, in contrast to Scenario 2, in which the average consumption of one algorithm compared to the other fluctuated more. The K-Means method was more efficient in Scenario 1.
Figure 13b illustrates the findings of Scenario 2, which demonstrated that the FCM technique was superior to the alternatives, with 15 GWs.
5. Conclusions
This study presents novel and promising outcomes for implementing LoRaWAN in smart agriculture IoT applications in a large agricultural area in one of the most important fruit-producing regions in Brazil. This research offers a comprehensive characterization of the environment, focusing on a real polygonal plantation area. A method for placing LoRaWAN GWs in smart agriculture applications, using K-Means and its variations, is proposed. The use of a stochastic energy model to evaluate power consumption and various performance metrics to support the final deployment decision is also proposed. The authors consider that the main original contribution of this work is the utilization of the stochastic energy model, in conjunction with the clustering algorithms, to solve the GW placement problem for agricultural IoT applications, although the method could be adapted to other technologies and contexts.
Simulations were performed, considering two scenarios that provided insight into the performance of LoRaWAN, showing that the method suggested 2 GWs for Scenario 1 and a range for the number of GWs for Scenario 2. The performance of the clustering algorithms, in terms of the ULDR, was improved after the method application, and varied between the two scenarios and among the different algorithms. The study also found that increasing the time between transmissions decreased power consumption, and that the energy efficiency of the system was improved, reducing the mean and maximum energy consumption. The study concluded that the FCM and K-Means techniques were superior in the different scenarios, with different numbers of GWs for the specific studied parameters.
Future Work
Whether utilizing a particular cluster model or algorithm, the clusters discovered will always be distinct and varied; therefore, the authors intend to study more clustering algorithms, and different network technologies (such as SigFox and NB-IoT) and configurations in the future. It is planned to perform experimental tests in the presented agriculture area.





 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}