1. Introduction
Renewable energy, such as wind energy, is becoming more and more popular because it is cleaner and more efficient than traditional energy [
1,
2,
3]. Wind turbines are the core equipment that captures wind energy and converts it into electricity. For a long time, the design and optimization of wind turbines have been the focus of the wind power industry [
4,
5]. Many new methods and advanced tools have been used in the design and analysis of wind turbines, such as the CFD method, which is also widely used in various blade designs [
6,
7,
8]. To meet the need for more wind farms, Tang, X. et al. carried out theoretical and experimental research on low wind speed wind turbines and the power output is significantly improved through blade optimization [
9]. At present, the single-unit capacity of wind turbines is becoming larger and larger, and many wind turbines with a diameter of more than 100 m now exist. Even wind turbines more than 200 m in diameter have been designed. Because large wind turbines are assembled and debugged on-site, the actual performance can only be accurately obtained after operation. Due to the harsh working environment of wind turbines, the safety and operating costs of wind turbines have always been sensitive issues. Understanding the actual performance of wind turbines is of great help to improve their design and maintenance capabilities [
10,
11,
12]. In this scenario, the use of SCADA (supervisory control and data acquisition) data is widely carried out [
13,
14,
15]. With the extension of service time, the data stored in the SCADA system is accumulated year-by-year, which not only reflects the current operation status of wind turbines but also stores their historical service status. Therefore, making full use of SCADA data information during service is an important way to deepen our understanding and optimize the control strategy.
In recent years, much research on the operation mechanism and maintenance of wind turbines has been carried out based on SCADA data [
16,
17,
18]. Moreover, the research based on SCADA data is continuing with a more vigorous trend. For example, Singh, U. et al. developed a prediction tool based on time series data to estimate wind power using SCADA data [
19]. Morshedizadeh, M. et al. carried out a case study on rotor overspeed fault diagnosis of wind turbines based on SCADA data, vibration analysis, and field detection [
20]. Astolfi, D. et al. used SCADA data to discuss the long-term performance evaluation of wind turbines [
21]. Based on SCADA data, Dong, X. et al. built the blade icing identification model of wind turbines [
22]. However, because of random factors in the external environment, the equipment itself, and the connected power grid, SCADA data contains random interference information, which leads to its inability to be directly used for performance evaluation and analysis. Researchers have proposed a variety of SCADA data pre-processing methods, including data filtering, averaging, single-valued processing based on kernel density, etc. [
23,
24]. Yang, W. et al. used the averaging method to pre-process the data after filtering the outliers of the original SCADA data and evaluated the operation status of wind turbines [
25]. According to the type of abnormal data of wind turbines, Yao, Q. et al. proposed a new combination method to clean up the anomalous SCADA data. In the proposed combination method, a pre-processing method for removing outliers of the power curve based on the operation mechanism is first proposed, and a new data cleaning method, TTLOF, is presented, which quantifies specific data points and eliminates outliers by setting parameter thresholds [
24]. Marti-Puig, P. et al. evaluated the impact of using several widely used technologies (such as Quantile, Hampel, and ESD) to remove extreme values with recommended cut-off values [
26]. Long, H. et al. transformed the problem of wind turbine data cleaning into the problem of image processing, and a three-dimensional (3D) WPC image was constructed [
27]. Wang, Y. et al. designed a combined wind speed prediction system based on two-stage data pre-processing and multi-objective optimization. The main function of two-stage data pre-processing is to decompose and reshape the raw data to reduce noise and chaos disturbance [
28]. To use SCADA data for power curve cleaning, Morrison, R. et al. compared three data pre-processing algorithms [
29].
It has become a consensus that data pre-processing is very important in the process of using wind turbine SCADA data [
26,
30]. Despite the previous studies, there are still some issues to be further studied on how to effectively and reliably conduct SCADA data pre-processing. For example, there are several data pre-processing algorithms, but what are the differences between them? This problem lacks comprehensive and systematic research. In addition, the fundamental purpose of data pre-processing for SCADA data is to provide the reliability of data analysis, but how can the reliability of the data pre-processing itself be ensured? In our previous study, three evaluation indexes for the pre-processing algorithm are presented, including (1) the consistency of physical characteristics; (2) the robustness of the sampling time; (3) the robustness of the sampling frequency [
31]. In this paper, a novel evaluation method based on the energy characteristic consistency (ECC) of wind turbines is proposed to evaluate the reliability of various data pre-processing algorithms. A three-stage data processing mode is proposed, namely, preliminary data filtering and compensation (Stage Ⅰ), secondary data filtering (Stage Ⅱ), and single-valued processing (Stage Ⅲ). Its main purpose is to improve the reliability of data pre-processing. Different data processing algorithms are selected at different stages and finally merged into nine data processing algorithms. Moreover, the nine data processing algorithms are compared and analyzed from different perspectives. The main contribution of this paper is to make a comprehensive comparison of the SCADA data of wind turbines, to gain a deeper understanding and provide a basis for practical application.
In general, the innovative contributions of the paper can be summarized as follows.
A three-stage data processing mode for power curve modeling of wind turbines is proposed.
A novel evaluation method based on the energy characteristic consistency (ECC) of wind turbines is proposed.
The advantages and disadvantages of the nine data processing methods are verified by four wind turbines.
The remainder of the paper is organized as follows. In
Section 2, energy characteristic consistency (ECC) is introduced and defined. Three performance curves of wind turbines are projected into three planes in a three-dimensional coordinate system, respectively. In
Section 3, the data relationship for power curve modeling is established. The reason why the wind speed measured by the nacelle anemometer needs to be compensated is theoretically proved. A three-stage data processing mode for the power curve modeling of wind turbines is presented in
Section 4. This section also explains why preliminary data filtering and compensation, secondary data filtering based on Binning, and single-valued processing based on Binnig are needed. In
Section 5, the influence of sliding mode and benchmark of Binning on data processing has been fully investigated through four quantitative indicators. Four wind turbines are selected to verify the advantages and disadvantages of data processing methods. Finally,
Section 6 ends the paper by summarizing the main achievements.
2. Energy Characteristic Consistency (ECC)
Wind turbines are complex devices that convert air kinetic energy into mechanical energy and then into electrical energy. With the increasing diameter of wind turbines, the cost is growing higher and higher. Performance is also expected to be better and more stable. In the design and operation of wind turbines, the behavior characteristics of capturing aerodynamic energy are of great concern. There are three curves commonly used to describe this energy feature: the curve of wind speed–power, the curve of wind speed–rotational speed, and the curve of rotational speed–power. The relationship between wind speed and power is generally expressed as
where,
P (W) is power,
is power coefficient,
(
) is air density,
S (
) is the area swept by the wind rotor, and
v (m/s) is wind speed.
In Equation (1), wind speed and power coefficient are variables. Wind speed is the description of airflow velocity in nature, which has the characteristics of time-variation and randomness. The power coefficient is the key parameter to reflect the wind energy capture ability, and it is related to the aerodynamic structure of wind turbines, as well as the controlling mode. In another scenario, if the wind turbine structure and control mode is determined, the power coefficient is essentially affected by wind speed. If the tip speed ratio is introduced, one has
where,
(rad/s) is the rotational speed of the wind rotor,
R (m) is the radius of the wind rotor,
is the tip speed ratio.
Substituting Equation (2) into Equation (1), it can be rewritten as [
15]
From Equation (1), a wind speed–power curve can be obtained, from Equation (2), a wind speed–rotational speed curve can be obtained, from Equation (3), a rotational speed–power curve can be obtained. From any two of these curves, the third curve can be obtained. In
Figure 1, three performance curves are projected into three planes in the xyz three-dimensional coordinate system, respectively. The wind speed–power curve is projected into the xoz plane, the wind speed-rotational speed curve is projected into the xoy plane, and the rotational speed–power curve is projected into the yoz plane. Given the corresponding points on any two of the three performance curves in
Figure 1, the corresponding points on the third curve can be obtained by spatial mapping. For example, if point
in the yoz plane and point
in the xoz plane are determined, the horizontal coordinates of the two points can be extracted and reconstructed to form point
in the xoy plane.
Here, the special relationship between the three performance curves of wind turbines is called energy characteristic consistency (ECC), because they describe the same energy characteristic of wind turbines from different angles and can be converted to each other. In other words, the characteristic of reconstructing the third curve from any two other curves is called ECC. The energy characteristic consistency of wind turbines can also be illustrated using
Figure 2.
3. Data Relationship for Power Curve Modeling
Wind turbines are generally equipped with supervisory control and data acquisition (SCADA) system, and a large number of wind turbine operating parameters are stored in real-time, for example, wind speed, rotational speed, power, and so on. However, whether these parameters can be used directly needs to be specifically discussed for different purposes. It is very important to extract the wind speed for establishing the wind speed-power curve. In the SCADA system, the wind speed stored is usually measured by the anemometer on the nacelle. In many works of literature, this wind speed is used to establish the wind speed–power curve after some data pre-processing. If the wind speed measured by the anemometer on the nacelle is used, Equation (1) can be rewritten as
where,
,
(m/s) is the wind speed at the front of the wind rotor,
(m/s) is the wind speed measured by the nacelle anemometer.
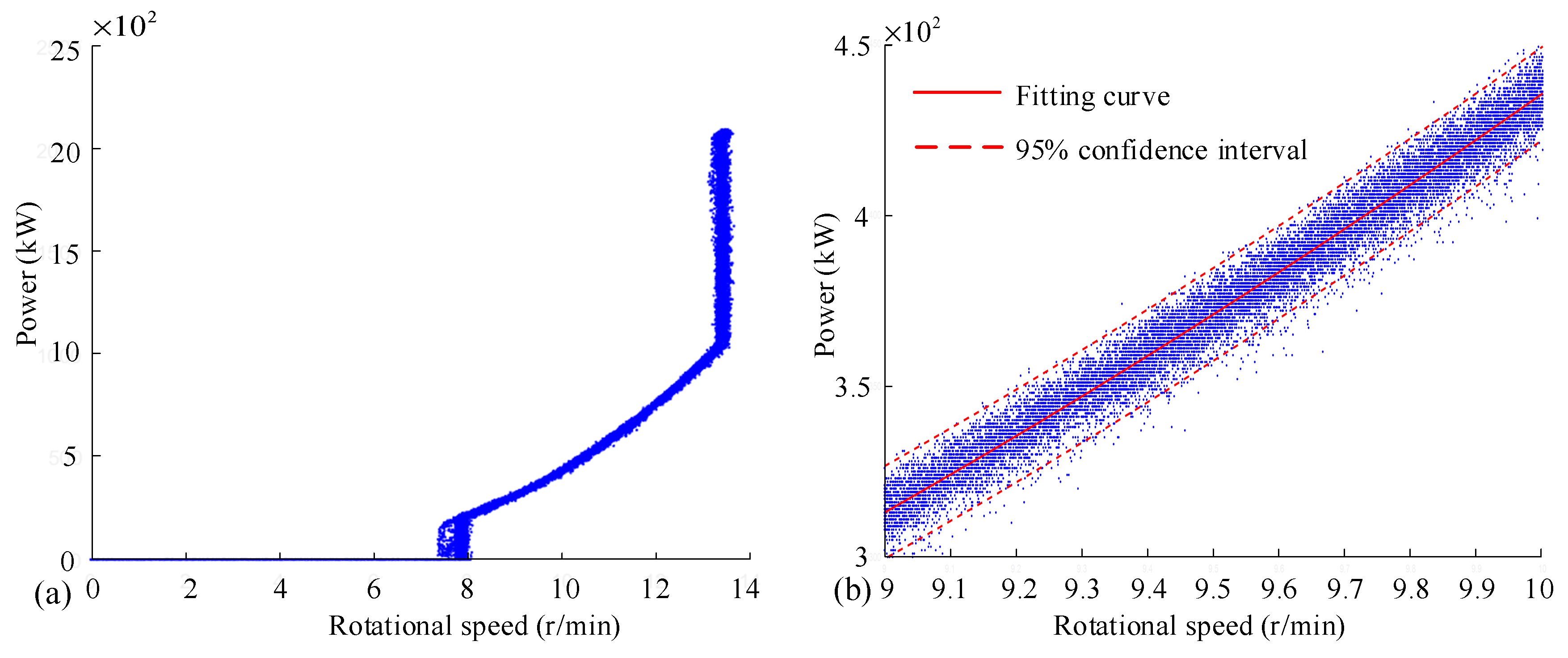
In
Figure 3, wind speed
is recorded in the SCADA system, while wind speed
is not measured and recorded. The relationship between
,
and
can also be expressed as
By combining Equations (4) and (5), there is
The following expression can be obtained by solving Equation (6)
Equation (7) does not give a clear relationship between power and power coefficient, which can be further simplified. The simplification strategy adopted is mainly reducing order and parameter substitution. From Equation (7), one has
where,
is a calculation factor (
). It should be noted that the derivation process from Equation (7) to Equation (8) is complex, and the derivation result is directly given.
Here, the analytical expression between the power and the wind speed measured by the nacelle anemometer is presented for the first time. From Equation (8), the relation between power and the wind speed measured by the nacelle anemometer is also cubic in theory, but it is complicated to calculate the power coefficient by using this relation. From the point of view of design and operation, it is preferred to establish the relation curve between real wind speed (wind speed at the front of the wind rotor) and power. Therefore, the strategy of wind speed correction is concerned [
15]. A method of wind speed correction may rely on Equation (5).
4. Data Pre-Processing Methods and Process
4.1. Data Pre-Processing Methods
To establish the wind turbine power curve, the data processing can be divided into three levels, namely preliminary data filtering and compensation, secondary data filtering based on Binning partition, and single-valued processing of data based on Binning partition, as shown in
Table 1. Preliminary data filtering is mainly used to eliminate some obvious abnormal data. For example, data sets with zero or negative power will be deleted, data sets with negative rotational speed will be deleted, data sets with less than cut-in wind speed will be deleted, and data sets with more than cut-in wind speed will be deleted. It should be noted that the wind speed of the nacelle anemometer is lower than the actual inflow wind speed, so it should be compensated before eliminating the data set which is lower than the cut-in wind speed. The specific operation for the preliminary data filtering can be written as
where,
.
In
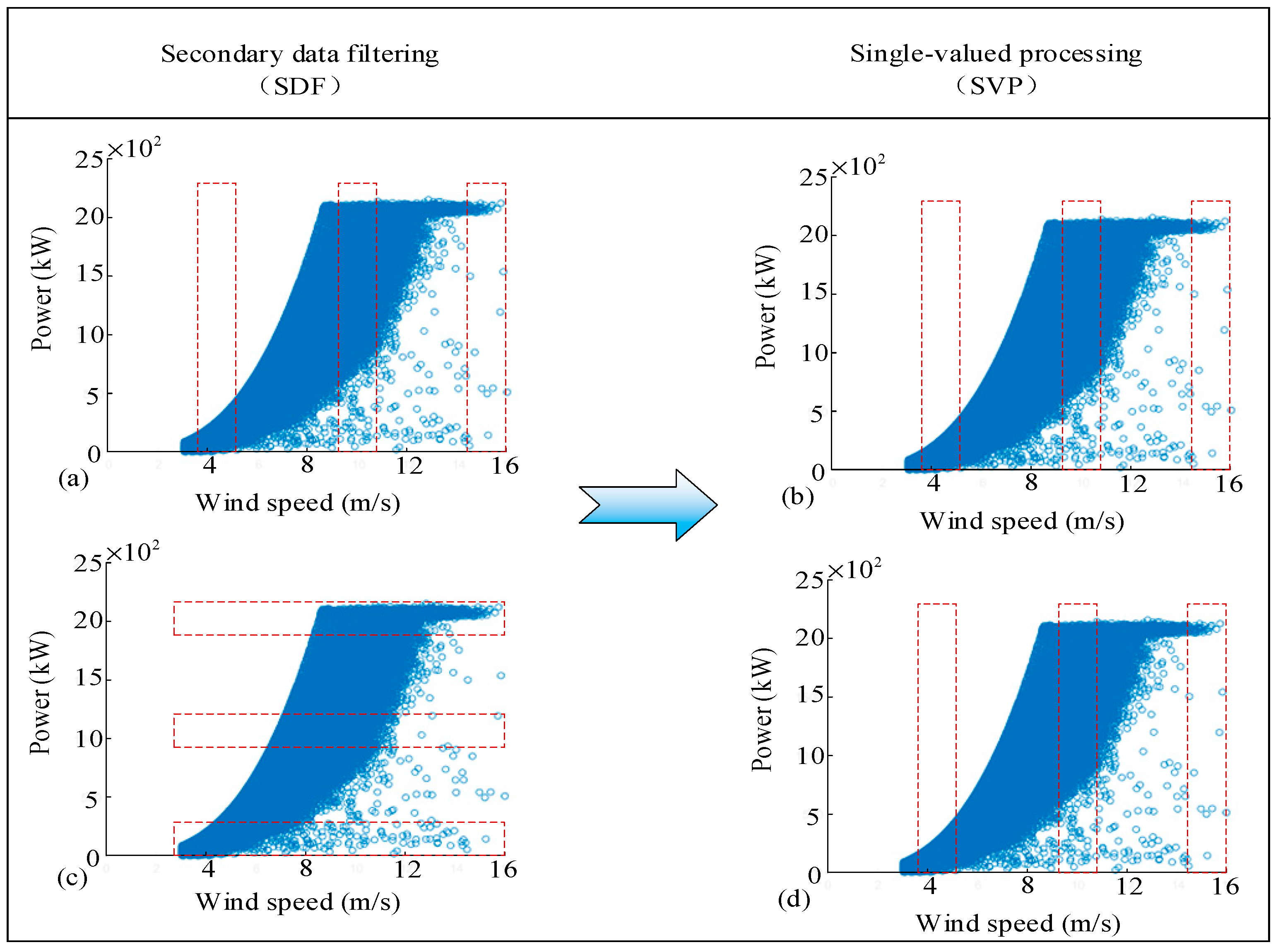
Table 1, three methods are listed for secondary data filtering based on Binning, namely the quartile method, PauTa criterion, and kernel density estimation (KDE) method. The quartile method is a statistical analysis method. The basic idea is to arrange all the data from small to large. The number just arranged in the first 1/4 position is called the first quartile, the number arranged in the last 1/4 position is called the third quartile, and the number arranged in the middle is called the second quartile, that is, the median value. PauTa criterion is also called 3σ method. It determines an interval according to a certain probability and believes that the error exceeding this interval is not random error but gross error, and the data containing this error should be eliminated. Kernel density estimation is used to estimate unknown density functions in probability theory. It is one of the non-parametric test methods. Furthermore, three methods are listed for single-valued processing based on Binning, namely the average method (AVE), least square method (LSM), and maximum likelihood estimation method (MLE).
To speed up the processing speed and improve the reliability of data processing, the data are processed using the Binning method. In the case of the wind speed–power curve, there are two modes for Binning. One is to deal with the wind speed using Binning and then eliminate the corresponding unreliable power data. The other is to process the power using Binning and then eliminate the corresponding unreliable wind speed data. From another scenario, Binning can be divided into shoulder-to-shoulder Binning (SSB) and discrete sliding Binning (DSB). After secondary data filtering, more unreliable data are eliminated as shown in
Table 2.
In
Table 2, after preliminary data filtering, some abnormal data or non-working data are eliminated. After the wind speed data compensation, whether the wind speed–power scatter distribution or the wind speed–rotational speed scatter distribution, their upper contour is more regular. There are several power values corresponding to a certain wind speed in the power curve scatters of wind turbines. Conversely, there are several wind speed values corresponding to a given power. This is because the wind speed has a random character, changing from time to time. Therefore, not every scatter is the real performance. From the perspective of probability statistics, when the sample is large enough, it is possible to find its true performance from a number of scatterers. In the process of data processing, it is necessary to use some methods to further eliminate some unreliable data. Here, it is called secondary data filtering based on Binning partition.
4.2. Secondary Data Filtering Principle
In this section, taking the wind speed–power curve as an example, the principles of the three data filtering methods will be introduced.
The quartiles rank all values from small to large and divide them into four parts. Each part contains 25% of the data. The greater the interquartile range, the more discrete the data are. Conversely, the less discrete the data are. The quartile method is suitable for data sets with a small number of outliers and has a certain ability to resist interference.
Using Binning method, the wind speed can be divided into several intervals. In the nth interval, the wind speed data set is marked with
. Then, the power set corresponding to
is marked as
=
, as shown in
Figure 4 and
Figure 5a.
According to the data size in the power set, the set
is rearranged in ascending order. For ease of understanding, set
=
is re-expressed as
=
. Then, the three quartiles can be expressed as [
32]
where,
(W),
(W), and
(W) are the first quartile, the second quartile, and the third quartile, respectively.
After calculating
and
, the quartile range
(W) can be obtained, and the data range
can be obtained according to
as shown in Equation (13). Values outside the interval
are considered outliers.
where,
.
After data processing, a new set
is obtained, which can be expressed as
The PauTa criterion method is to calculate the standard deviation and mean value of a group of data, determine an interval according to a certain probability, and determine the data beyond the interval as abnormal values. This method is easy to implement and has a good effect in removing outliers, but the data distribution is required to obey normal distribution or approximate normal distribution. When the wind speed–power curve is processed by using the PauTa criterion method, the standard deviation and the mean value of the data in the set
are calculated and marked as
(W) and
(W), respectively [
33].
Then, the outliers are eliminated according to Equation (15).
where,
k is the parameter determined in the statistical analysis of small probability events,
is the normal value, and the rest are marked as abnormal values for elimination as shown in
Figure 5b.
After data processing, a new set
is obtained, which can be expressed as
KDE (kernel density estimation) method is a nonparametric estimation method. KDE does not require any prior knowledge of the data and does not attach any assumptions to the data distribution. It only needs to start from the data itself [
23,
34]. The calculation expression of KDE can be written as
where,
h is the window width, and its value will affect the smoothness of
;
is the kernel function,
;
is the sample point of independent distribution,
. Here, Gaussian kernel is used.
Then, in the set
, power points larger than
are retained, and the rest are eliminated as shown in
Figure 5c. Here,
is a judgment coefficient. After data processing, a new set
is obtained, which can be expressed as
4.3. Single-Valued Processing Principle
The purpose of single-valued processing is to obtain the data relationship that can reflect the one-to-one correspondence between wind speed and power. As mentioned in the previous section, before single-valued processing, some outliers can be removed from the data. The main purpose is to further improve the reliability of the results. There are many methods available for single-valued processing. The basic principles of the three methods used in this paper will be briefly introduced below.
The arithmetic mean method is the most widely used method, and its greatest advantage is simple and easy to calculate. For the set
, based on the arithmetic mean method, one has
where,
is the power estimation value corresponding to the nth interval wind speed.
During the performance analysis of wind turbines, this power estimate can be used as the true power value of this interval.
The method of least square is a curve fitting method, which obtains the best-fit curve based on the minimal sum of the deviations squared from a given set of data. Here, the least square method is used to find a data point to replace the data of the entire interval. To estimate the power value of this interval
for the set
, the expression can be written as
The maximum likelihood estimation method is a parameter estimation method used when the distribution type is known. Likelihood and probability can also express the probability of an event, but they are very different. Probability is the probability of observation results when parameters are known. The likelihood is to calculate the possibility of a parameter being a certain value from the observation results. For the set
in the nth interval, the estimated power value can be written as
where,
is the likelihood function of the parameter
;
is the maximum likelihood estimate of the parameter
;
is the value of the density function of power at
.
4.4. Data Pre-Processing Procedure
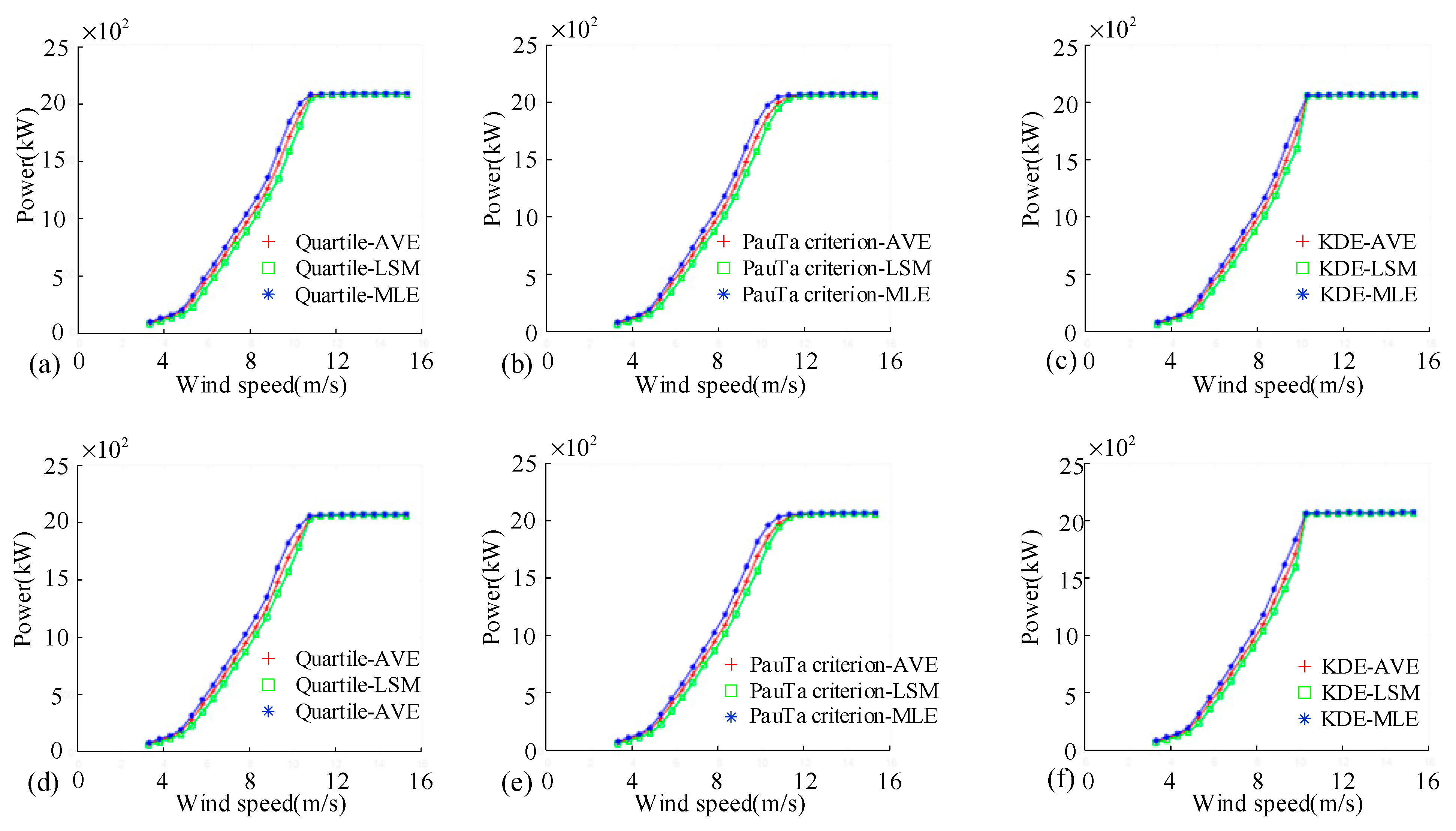
As shown in
Figure 6, there are multiple composite results after the combination of secondary data filtering and data single-valued processing. They are the Quartile–AVE method, Quartile–LSM method, Quartile–MLE method, PauTa–AVE method, PauTa–LSM method, PauTa–MLE method, KDE–AVE method, KDE–LSM method, and KDE–MLE method. In the data processing process, there will be a method selected from these methods. The key is how to choose the most appropriate method, or what are the advantages and disadvantages of each method. For a long time, in the process of wind turbine SCADA data processing, there is a lack of systematic research on this problem. Among these data processing methods, Quartile–AVE, Quartile–LSM, and Quartile–MLE have the advantage that they do not need to know the data distribution characteristics in stage II (secondary data filtering). The disadvantage is that the quartile method only focuses on the middle 50% of the data without considering the entire dataset. The advantage of PauTa–AVE, PauTa–LSM, and PauTa–MLE is that if the data obey the approximate positive distribution, the outliers can be effectively eliminated at stage II. The disadvantage of the PauTa criterion is that when the data distribution is skewed, it may mistakenly identify normal data points as outliers or fail to detect true outliers. The advantage of KDE–AVE, KDE–LSM, and KDE–MLE is that when processing data in stage II, it can obtain its data distribution without prior knowledge. The disadvantage of the KDE method is that it depends on the selection of kernel function and bandwidth parameter, and inappropriate choices may lead to inaccurate estimation results.
Figure 7 shows the data processing methods and the whole process. In addition to data filtering and single value processing, an important link is to evaluate the processing effect. One of the main contributions of this paper is to propose an evaluation method based on the energy characteristic consistency (ECC) of wind turbines. The specific evaluation method is described below.
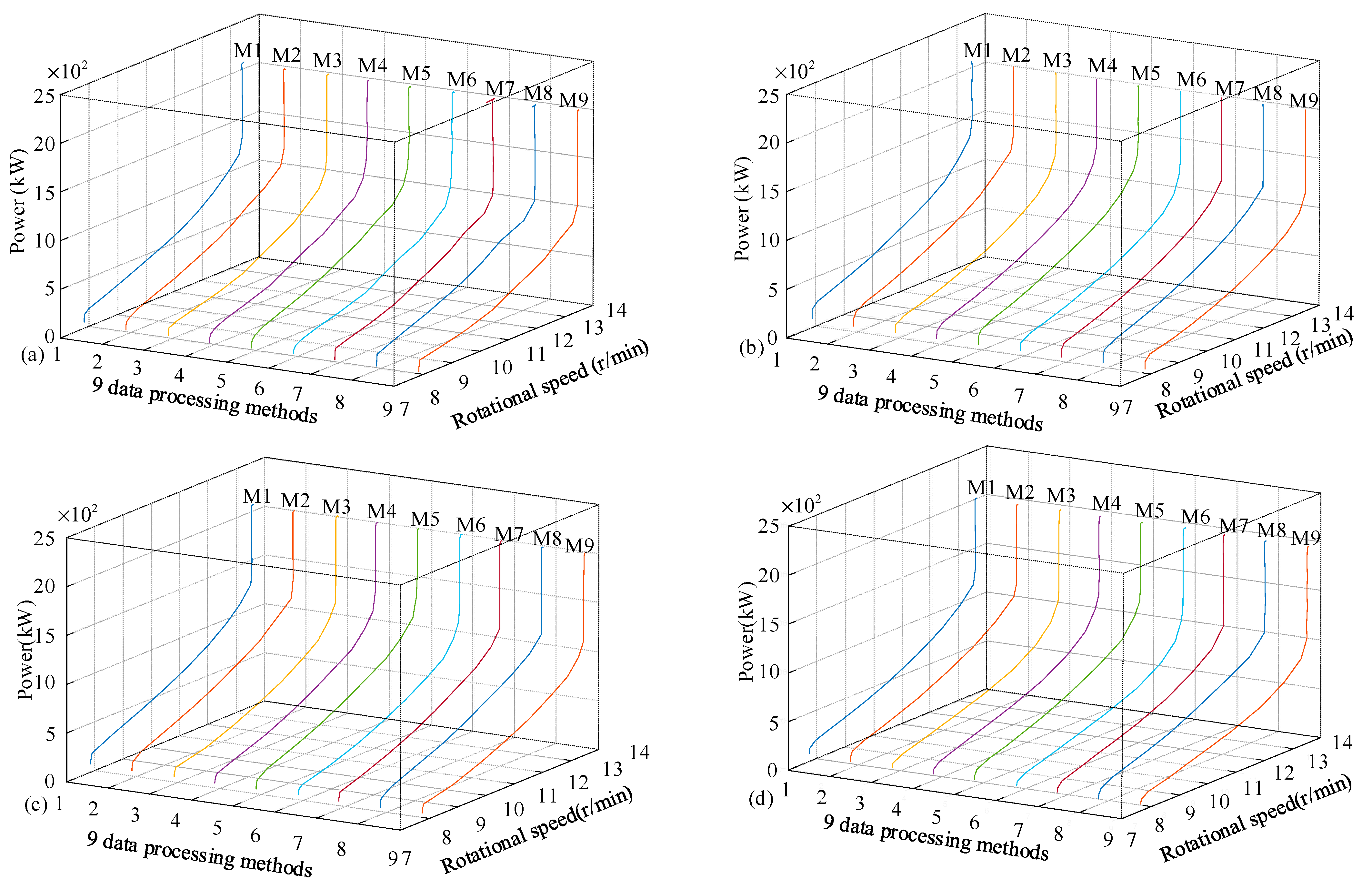
Step 1: Obtaining the single-valued curves of wind speed–power and wind speed–rotational speed through single-valued processing.
Step 2: Selecting several discrete wind speed values , extracting the corresponding power value from the single-valued wind speed–power curve, and extracting the corresponding speed value from the single-valued wind speed–rotational speed curve.
Step 3: Using the extracted series of discrete power and rotational speed, the rotational speed–power curve is reconstructed, which is also a single-valued power curve.
Step 4: From SCADA data, the rotational speed and power data are extracted, and the actual rotational speed–power curve is obtained.
Step 5: Comparing the reconstructed rotational speed–power curve with the actual rotational speed–power curve. The designed evaluating index is
where,
(W)is the power value corresponding to the rotational speed
(rad/s) in the reconstructed rotational speed–power curve;
(W) is the power value corresponding to the rotational speed
in the actual rotational speed–power curve.
is the number of power values corresponding to
.
N is the number of discrete rotational speed
. For a
,
is unique, and
has multiple.
6. Conclusions
This paper has fully explored various data pre-processing algorithms for power curve online modeling of wind turbines. The purpose is to find the most suitable algorithm. To analyze the reliability of various data processing algorithms, the novel energy characteristic consistency (ECC) is proposed for the first time. The analytical expression between the power and the wind speed measured by the nacelle anemometer is presented. This theoretically proves why the wind speed measured by the nacelle anemometer should be compensated. Moreover, the SCADA data processing is divided into three stages, namely, preliminary data filtering and compensation, secondary data filtering based on Binning, and single-valued processing based on Binnig. Different data processing algorithms are selected at different stages and finally merged into 9 data processing algorithms. Among these data processing methods, Quartile–AVE, Quartile–LSM, and Quartile–MLE have the advantage that they do not need to know the data distribution characteristics in stage II (secondary data filtering). The advantage of PauTa–AVE, PauTa–LSM, and PauTa–MLE is that if the data obey the approximate positive distribution, the outliers can be effectively eliminated at stage II. The advantage of KDE–AVE, KDE–LSM, and KDE–MLE is that when processing data in stage II, it can obtain its data distribution without prior knowledge. An evaluation method based on the energy characteristic consistency (ECC) of wind turbines is proposed which is one of the main contributions of this paper. This evaluating index quantitatively compares the reconstructed rotational speed–power curve with the actual rotational speed–power curve. The influence of sliding mode and the benchmark of Binning on data processing has been fully analyzed through four quantitative indicators. Furthermore, four wind turbines are selected to verify the advantages and disadvantages of the nine data processing methods. The results show that KDE–LSM has good performance in general. The sum of four evaluating index values obtained by KDE–LSM from four wind turbines is the smallest. The evaluating index values of the four wind turbines are 6.51 kW, 5.53 kW, 9.23 kW, and 8.96 kW, respectively, and the sum is 30.23 kW.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





