
Dynamic User Resource Allocation for Downlink Multicarrier NOMA with an Actor–Critic Method

Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- Solving the combinatorial optimization problem in the case of two users in a subchannel of multicarrier NOMA, and we obtain a closed-form solution to represent the optimal resource allocation for users on each subchannel in the corresponding system scenario.
- In the AC framework, we use temporal difference estimation with the addition of baseline as the advantage function in the update gradient to improve the convergence efficiency of the algorithm. Then, we build a NOMA downlink communication scene and embed the DRL algorithm in this scene.
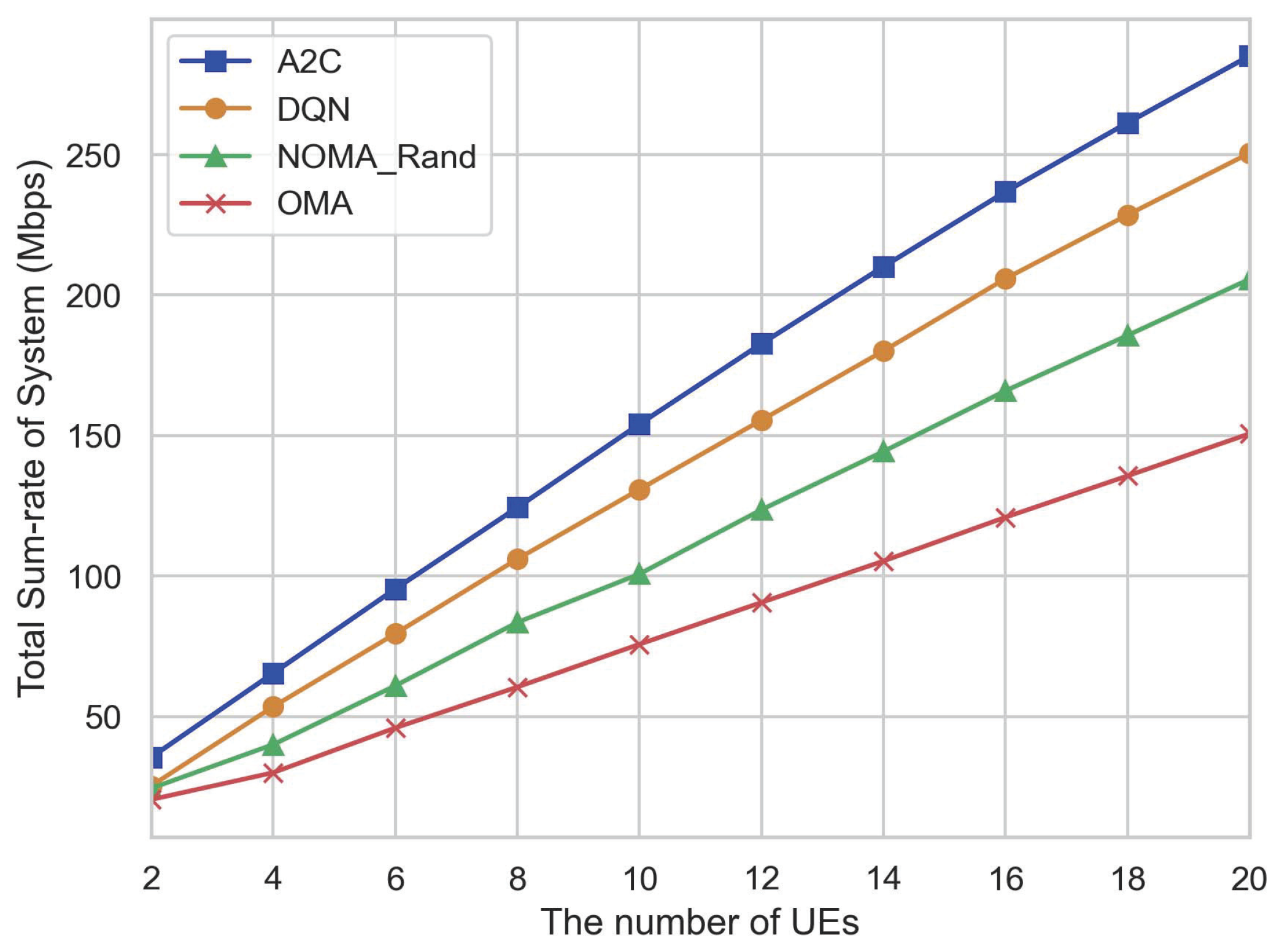
- For the dynamic user-pairing problem, we use the AC algorithm to obtain the optimal pairing scheme that maximizes the total communication rate of all user equipment (UEs). The DRL method provides a new scheme to solve the traditional user-pairing optimization problem. Simulation results have shown that our proposed scheme acquires better performance gains and lower complexity.
2. NOMA System and Optimization Problems
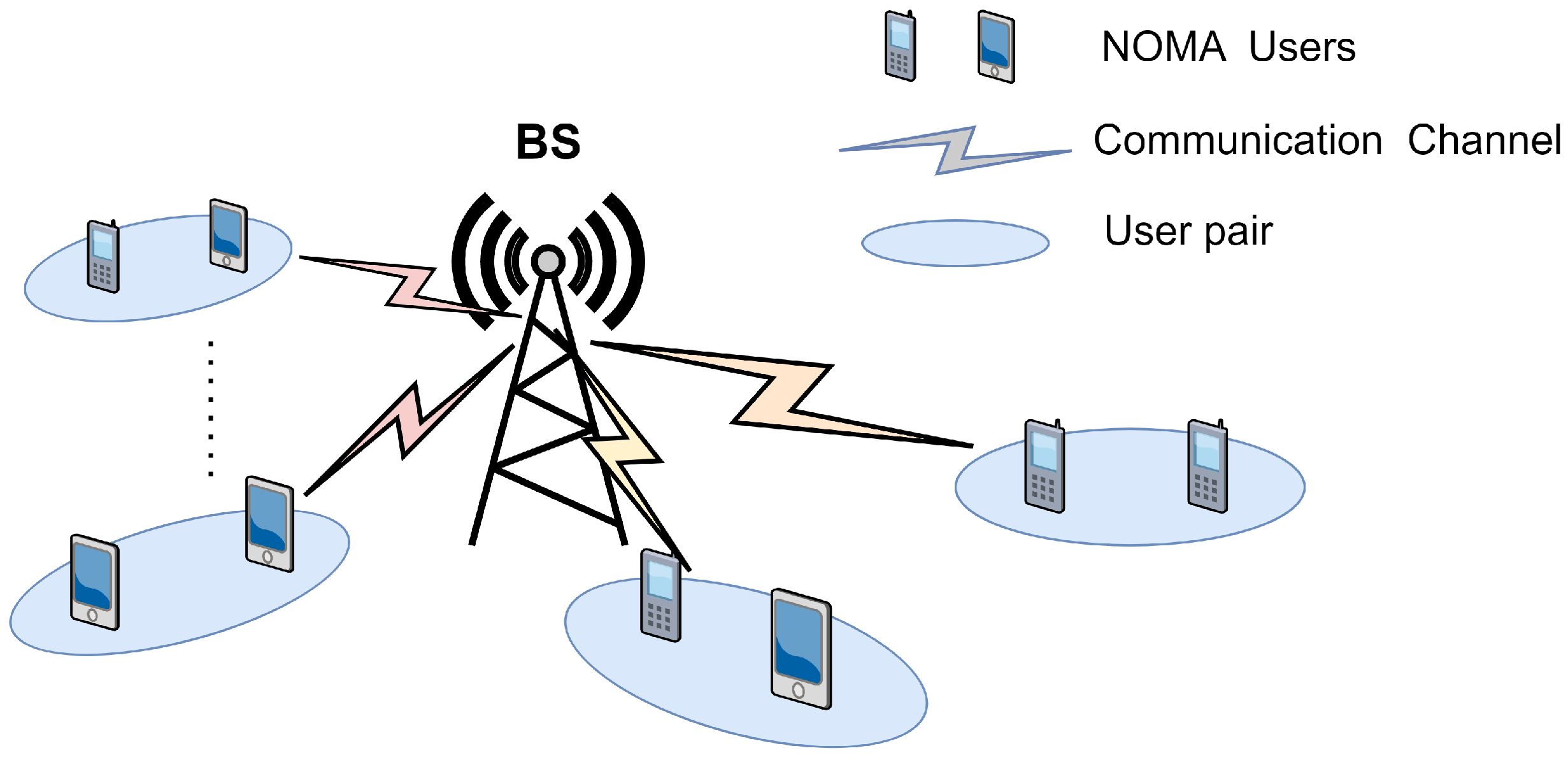
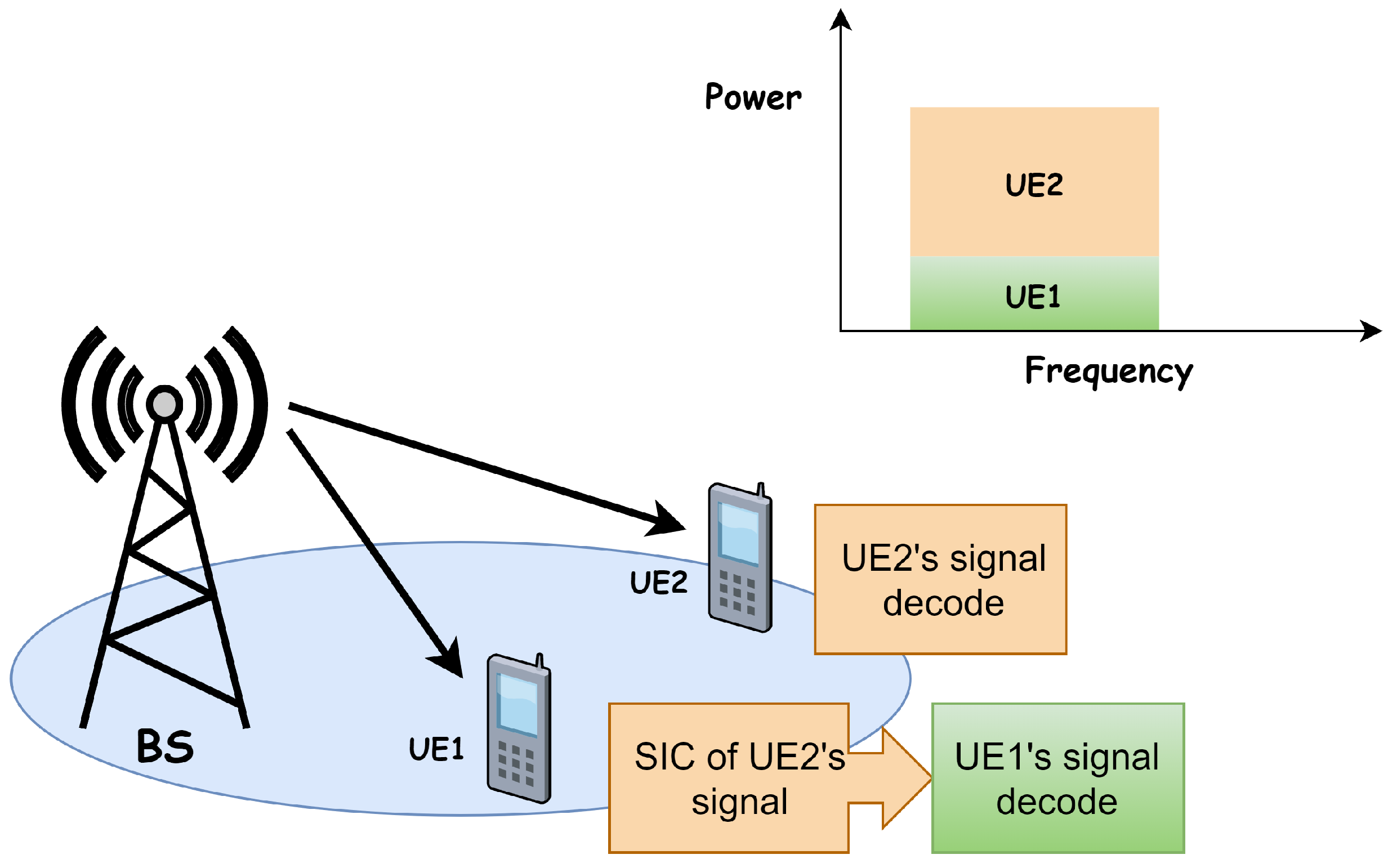
2.1. System Model
2.2. Optimization Problems
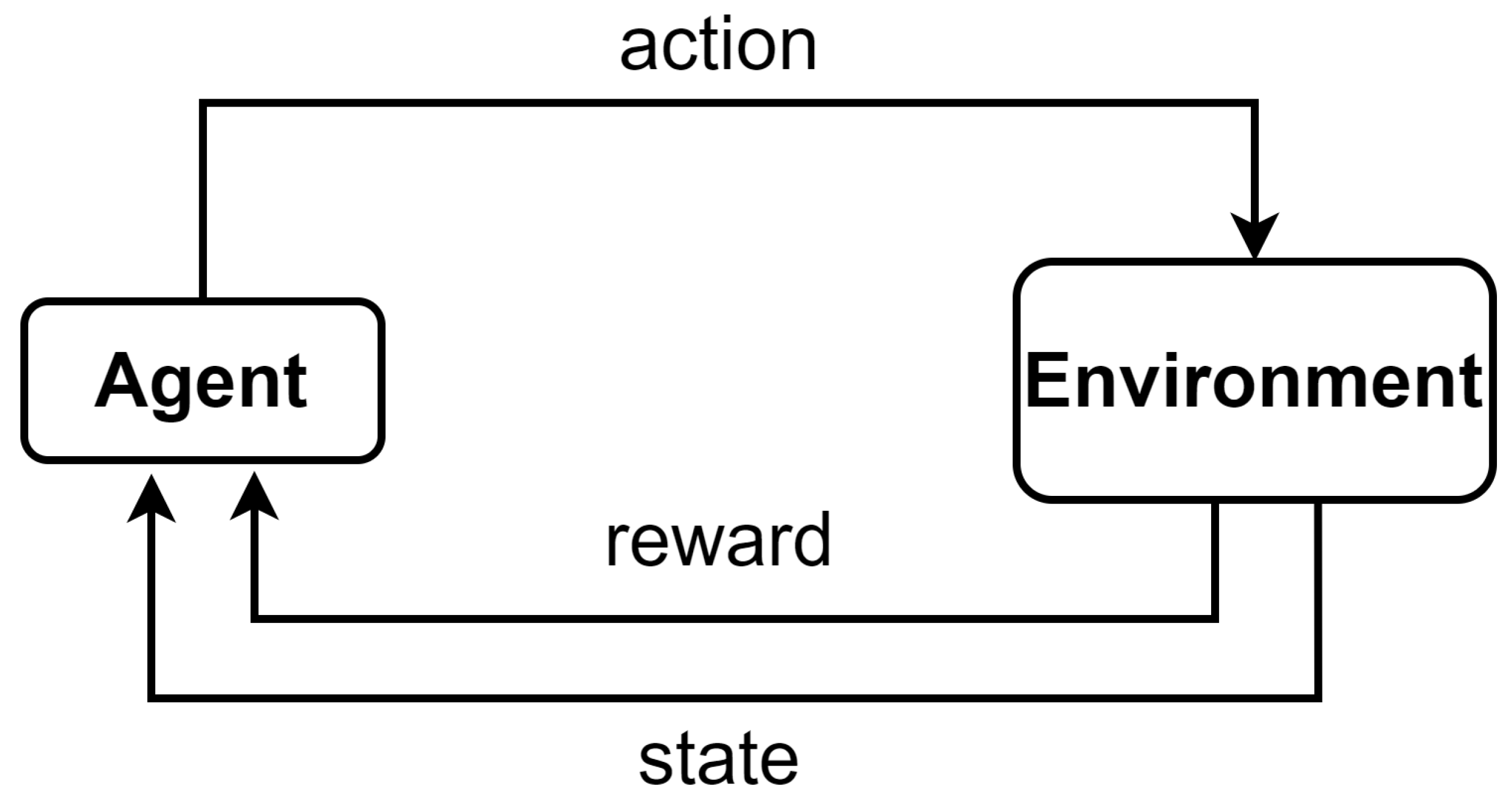
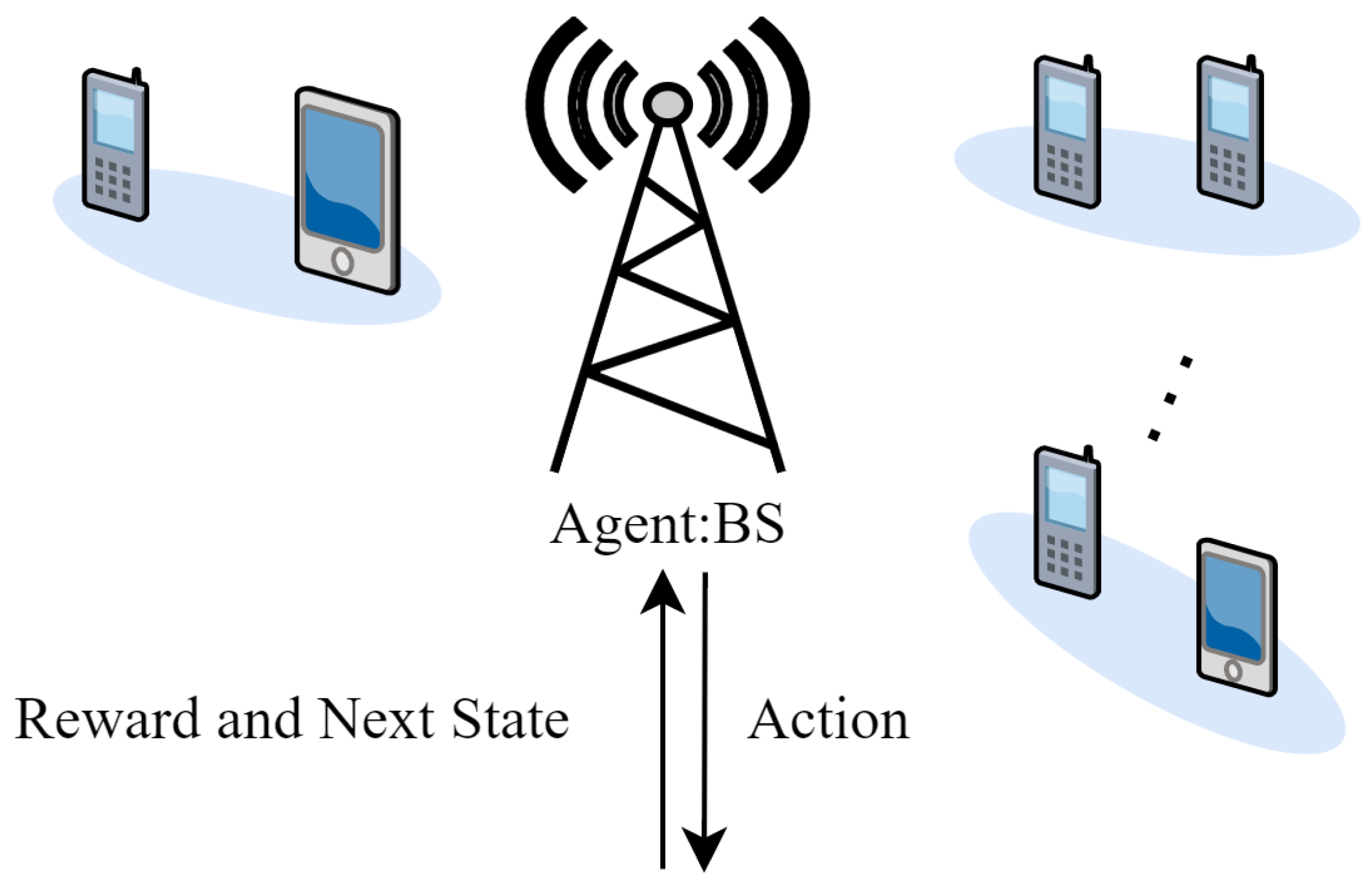
3. Deep-Reinforcement Learning Method for User Pairing
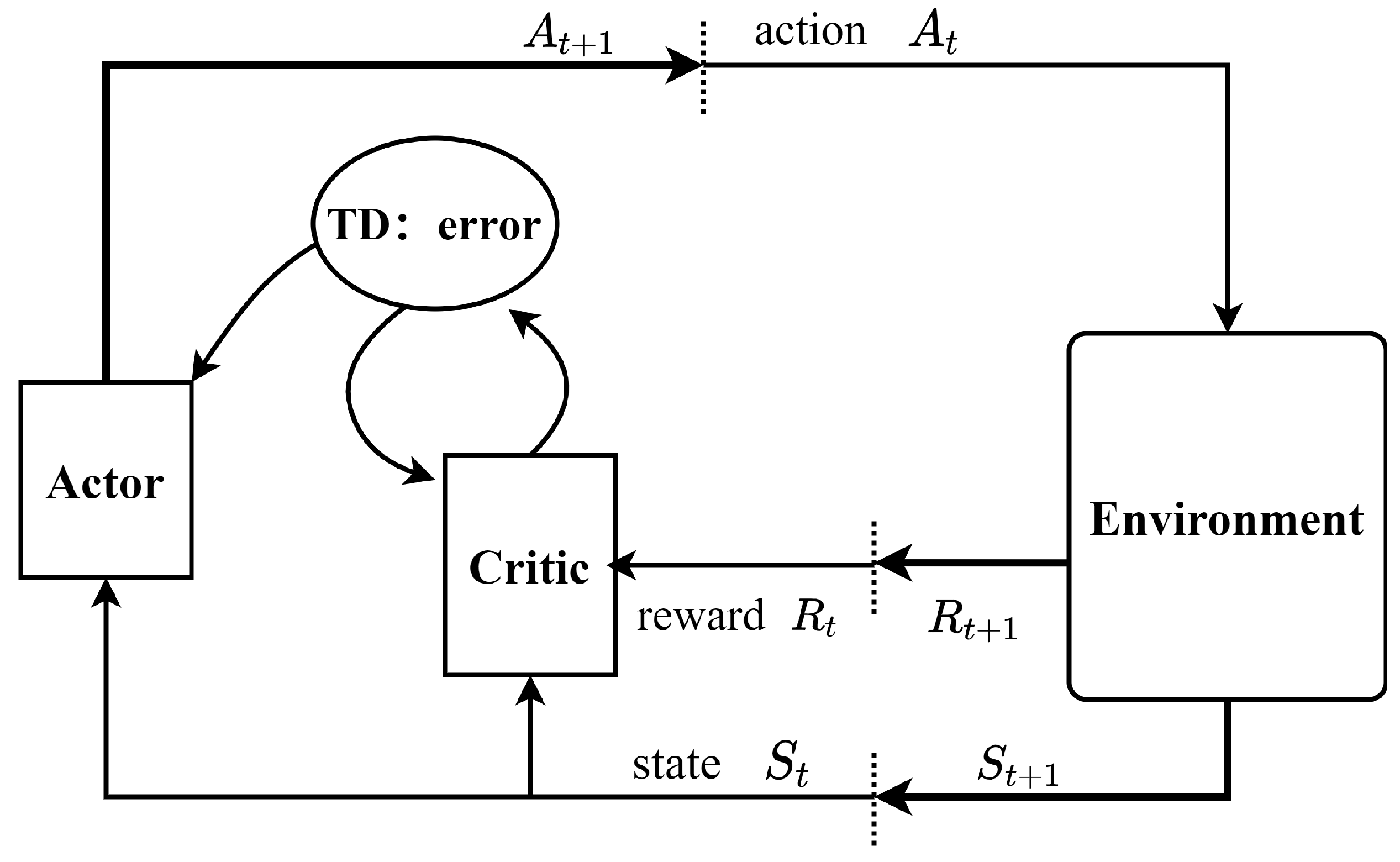
3.1. Actor–Critic Framework and Advantage Function
3.2. Scene-Building
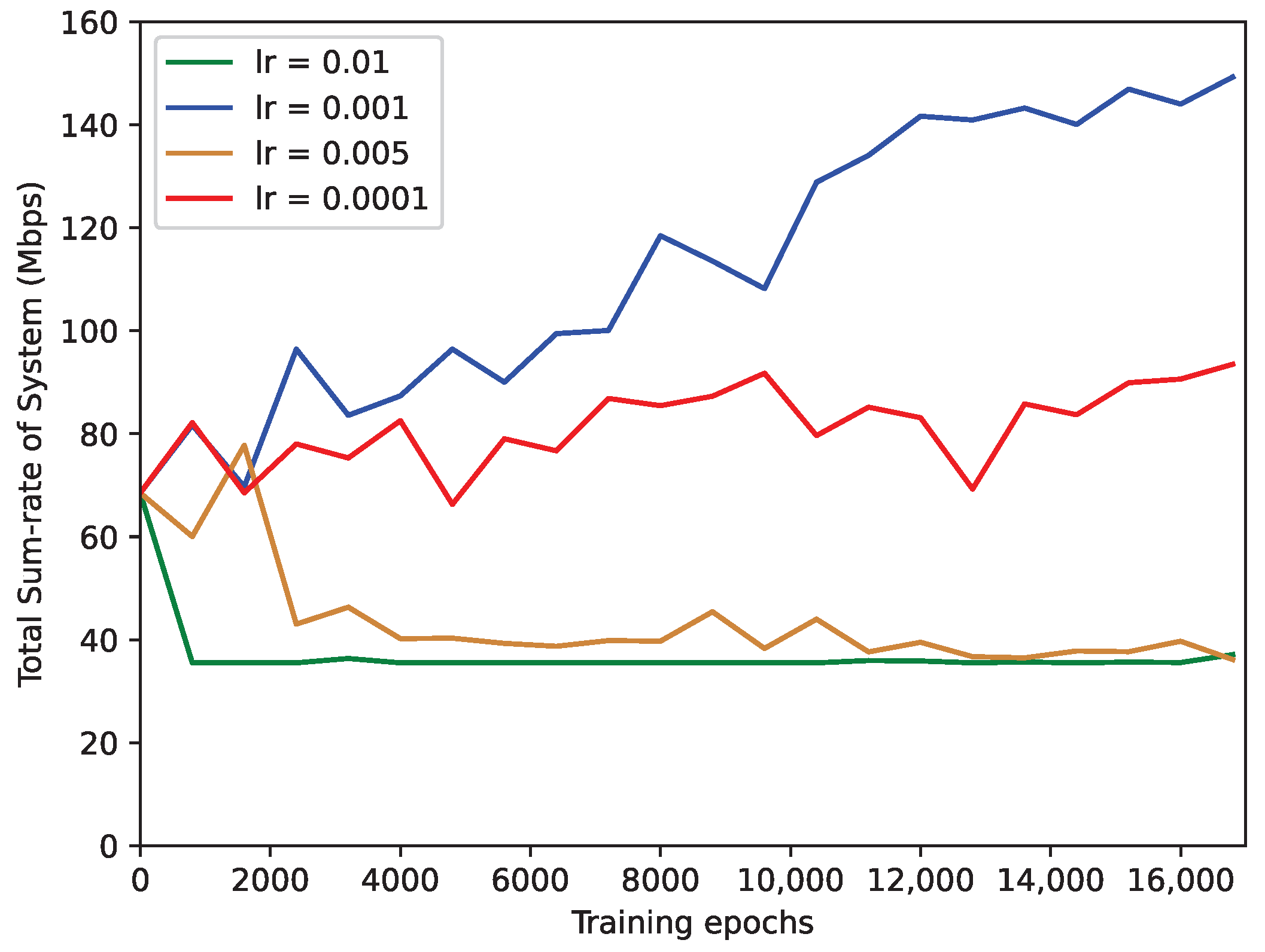
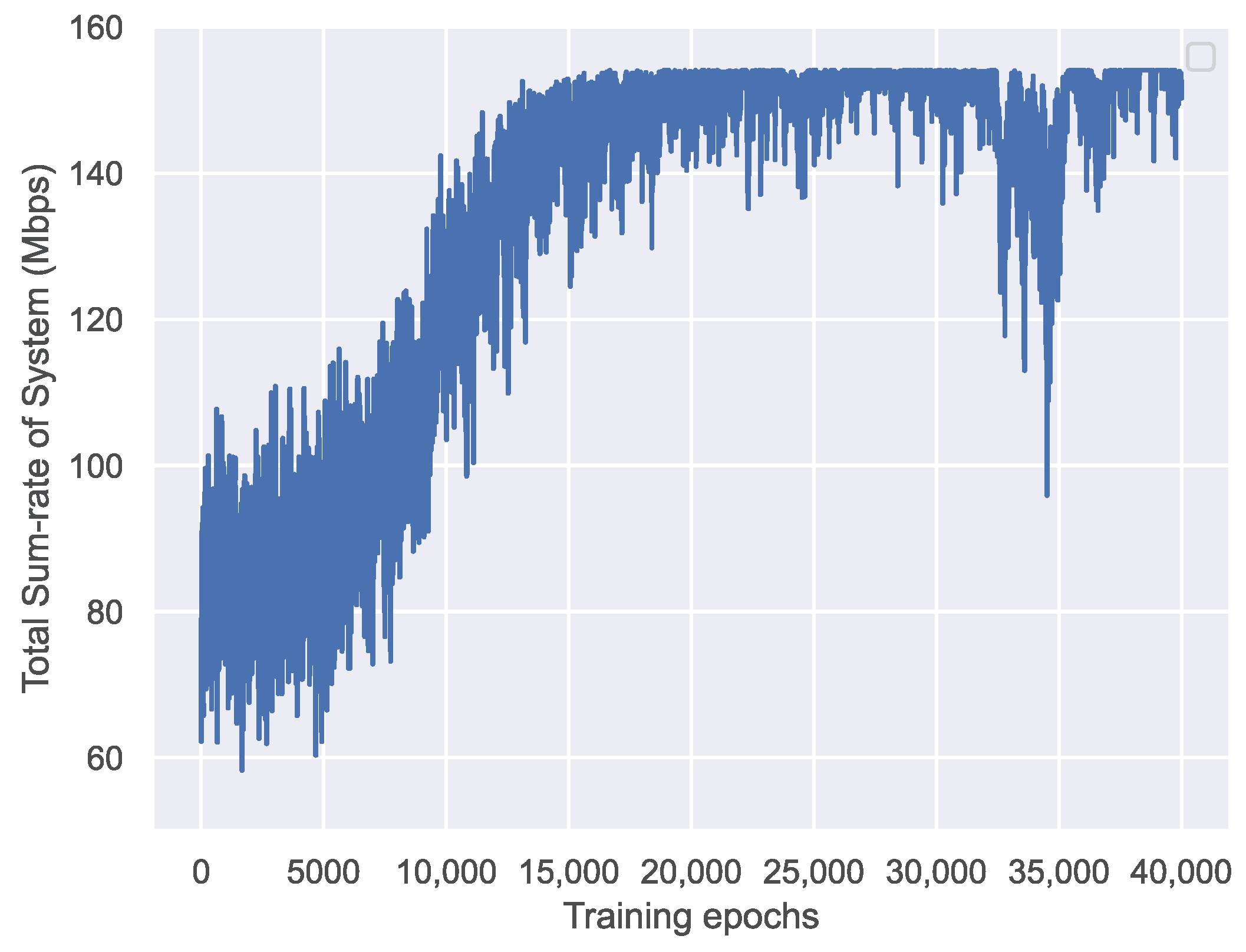
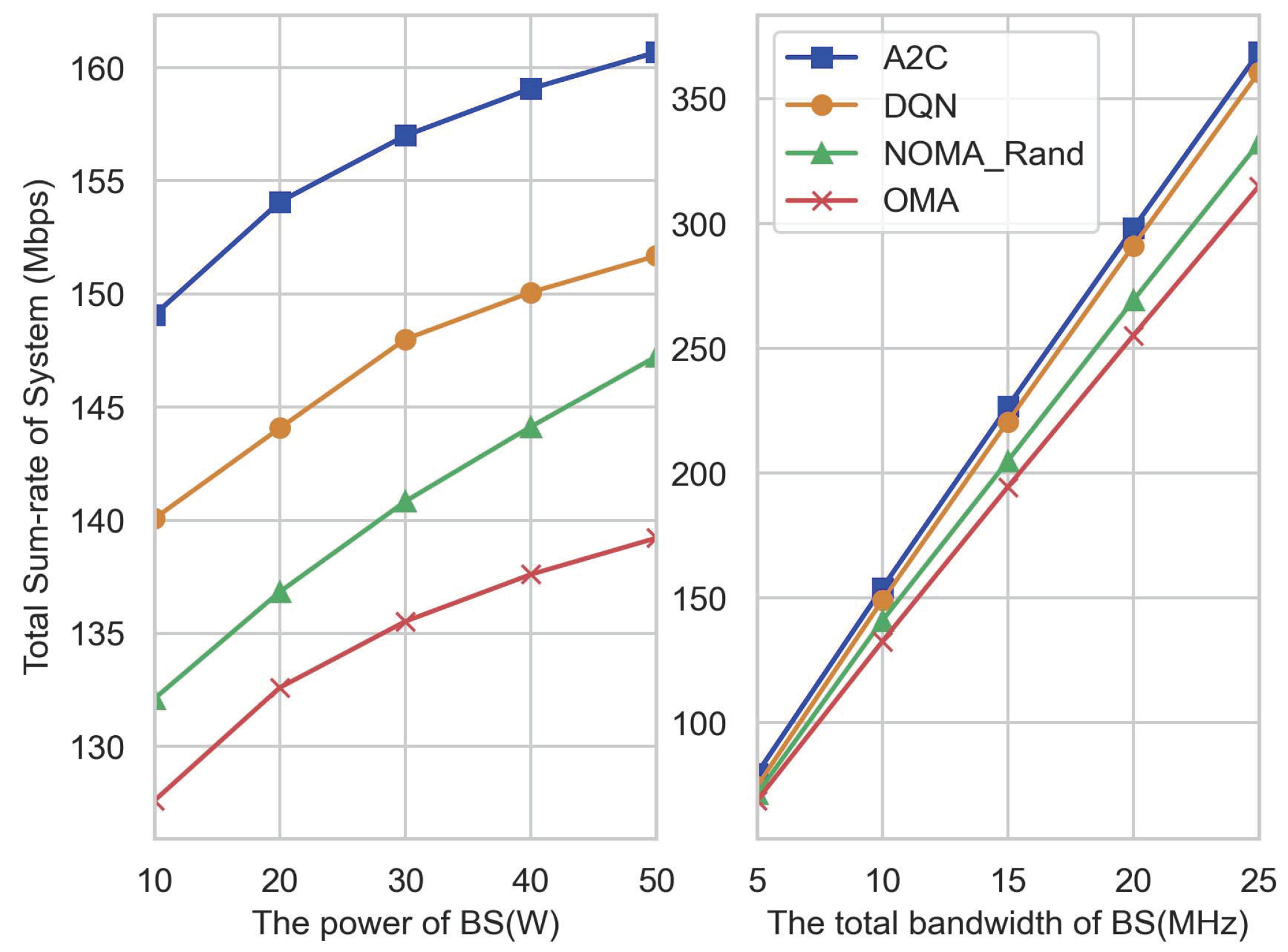
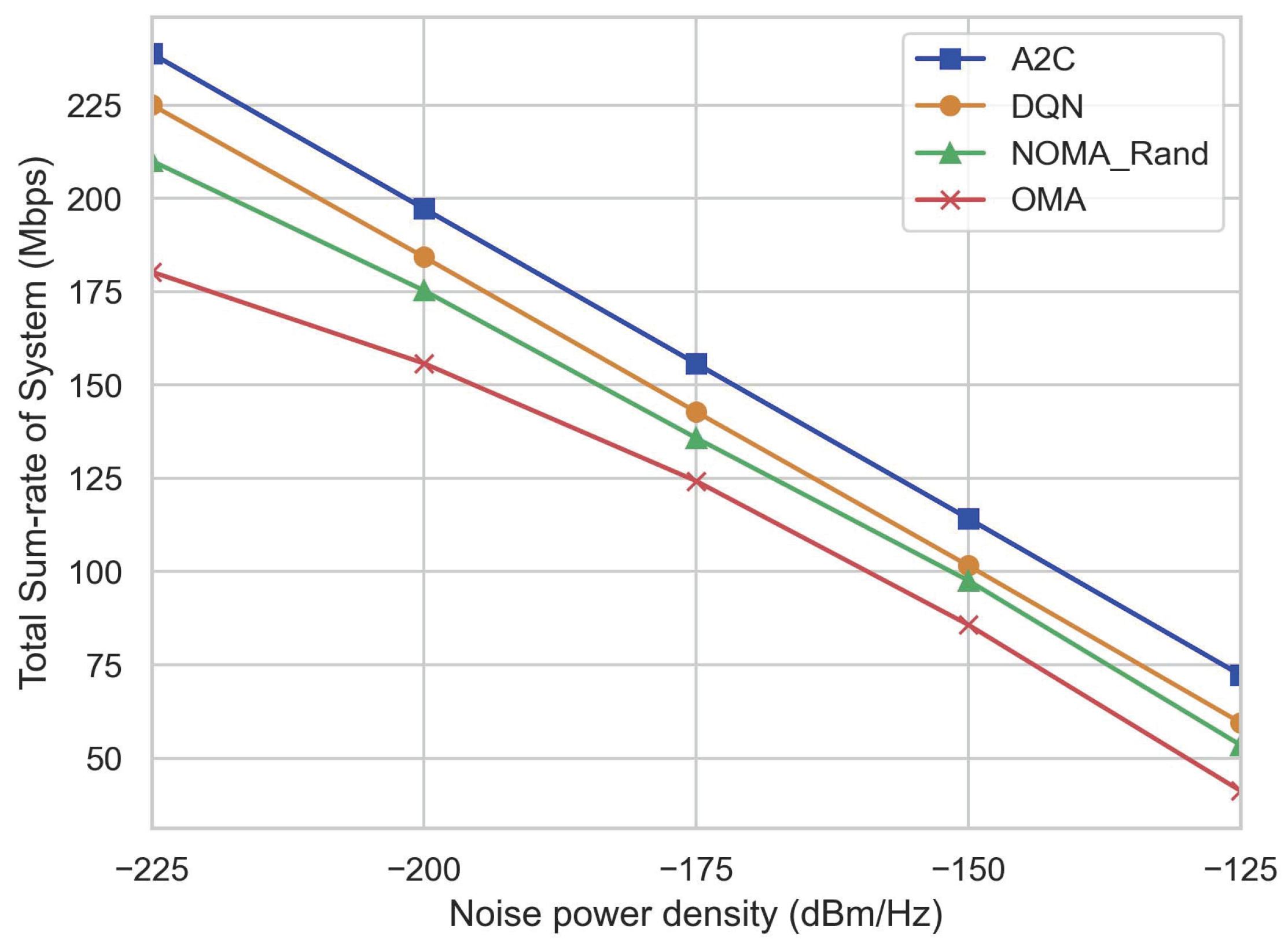
4. Simulation
| Algorithm 1 User Pairing A2C Algorithm |
 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. The Derivation for the Power of the k-th Channel
Appendix B. The Derivation for the Gradient of Policy Gradient
References
- David, K.; Berndt, H. 6g vision and requirements: Is there any need for beyond 5g? IEEE Veh. Technol. Mag. 2018, 13, 72–80. [Google Scholar] [CrossRef]
- Saad, W.; Bennis, M.; Chen, M. A vision of 6g wireless systems: Applications, trends, technologies, and open research problems. IEEE Netw. 2020, 34, 134–142. [Google Scholar] [CrossRef] [Green Version]
- Gong, Y.; Zhang, L.; Liu, R.; Yu, K.; Srivastava, G. Nonlinear mimo for industrial internet of things in cyber–physical systems. IEEE Trans. Ind. Informatics 2021, 17, 5533–5541. [Google Scholar] [CrossRef]
- Jiang, T.; Cheng, H.V.; Yu, W. Learning to reflect and to beamform for intelligent reflecting surface with implicit channel estimation. IEEE J. Sel. Areas Commun. 2021, 39, 1931–1945. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R.; Lim, T.J. Wireless communications with unmanned aerial vehicles: Opportunities and challenges. IEEE Commun. 2016, 54, 36–42. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Yang, K.; Tan, Z.; Song, H.; Al-Dubai, A.; Zomaya, A.Y.; Li, X. Vehicular computation offloading for industrial mobile edge computing. IEEE Trans. Ind. Informatics 2021, 17, 7871–7881. [Google Scholar] [CrossRef]
- Zhao, L.; Yang, K.; Tan, Z.; Li, X.; Sharma, S.; Liu, Z. A novel cost optimization strategy for sdn-enabled uav-assisted vehicular computation offloading. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3664–3674. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Ding, Z.; Wang, Z.; Chen, S.; Hanzo, L. A survey of non-orthogonal multiple access for 5g. IEEE Commun. Surv. Tutorials 2018, 20, 2294–2323. [Google Scholar] [CrossRef] [Green Version]
- Ding, Z.; Lei, X.; Karagiannidis, G.K.; Schober, R.; Yuan, J.; Bhargava, V.K. A survey on non-orthogonal multiple access for 5g networks: Research challenges and future trends. IEEE J. Sel. Areas Commun. 2017, 35, 2181–2195. [Google Scholar] [CrossRef] [Green Version]
- Benjebbour, A.; Saito, Y.; Kishiyama, Y.; Li, A.; Harada, A.; Nakamura, T. Concept and practical considerations of non-orthogonal multiple access (noma) for future radio access. In Proceedings of the 2013 International Symposium on Intelligent Signal Processing and Communication Systems, Naha, Japan, 12–15 November 2013; pp. 770–774. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Zhou, F.; Lu, G.; Wen, M.; Liang, Y.C.; Chu, Z.; Wang, Y. Dynamic spectrum management via machine learning: State of the art, taxonomy, challenges, and open research issues. IEEE Netw. 2019, 33, 54–62. [Google Scholar] [CrossRef]
- Zamani, M.R.; Eslami, M.; Khorramizadeh, M. Optimal sum-rate maximization in a noma system with channel estimation error. In Proceedings of the Electrical Engineering (ICEE), Iranian Conference, Mashhad, Iran, 8–10 May 2018; pp. 720–724. [Google Scholar]
- Zhu, L.; Zhang, J.; Xiao, Z.; Cao, X.; Wu, D.O. Optimal user pairing for downlink non-orthogonal multiple access (noma). IEEE Wireless Commun. Lett. 2019, 8, 328–331. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, L.; Xiao, Z.; Cao, X.; Wu, D.O.; Xia, X. Optimal and sub-optimal uplink noma: Joint user grouping, decoding order, and power control. IEEE Wirel. Commun. Lett. 2020, 9, 254–257. [Google Scholar] [CrossRef]
- Mouni, N.S.; Kumar, A.; Upadhyay, P.K. Adaptive user pairing for noma systems with imperfect sic. IEEE Wirel. Commun. Lett. 2021, 10, 1547–1551. [Google Scholar] [CrossRef]
- Liang, G.; Zhu, Q.; Xin, J.; Feng, Y.; Zhang, T. Joint user-channel assignment and power allocation for non-orthogonal multiple access relaying networks. IEEE Access 2019, 7, 361–372. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, J.; Huang, Y.; He, S.; You, X.; Yang, L. On optimal power allocation for downlink non-orthogonal multiple access systems. IEEE J. Sel. Areas Commun. 2017, 35, 2744–2757. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Li, Y.; Dai, C.; Dai, H.; Poor, H.V. Reinforcement learning-based noma power allocation in the presence of smart jamming. IEEE Trans. Veh. Technol. 2018, 67, 3377–3389. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutorials 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Kibria, M.G.; Nguyen, K.; Villardi, G.P.; Zhao, O.; Ishizu, K.; Kojima, F. Big data analytics, machine learning, and artificial intelligence in next-generation wireless networks. IEEE Access 2018, 6, 328–338. [Google Scholar] [CrossRef]
- Lin, T.; Zhu, Y. Beamforming design for large-scale antenna arrays using deep learning. IEEE Wirel. Commun. Lett. 2020, 9, 103–107. [Google Scholar] [CrossRef] [Green Version]
- Al-Eryani, Y.; Hossain, E. Self-organizing mmwave mimo cell-free networks with hybrid beamforming: A hierarchical drl-based design. IEEE Trans. Commun. 2022, 70, 3169–3185. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Shen, R.; Xu, Y.; Zheng, F. Drl-based energy-efficient resource allocation frameworks for uplink noma systems. IEEE Internet Things J. 2020, 7, 7279–7294. [Google Scholar] [CrossRef]
- Jiang, F.; Gu, Z.; Sun, C.; Ma, R. Dynamic user pairing and power allocation for noma with deep reinforcement learning. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021. [Google Scholar]
- Zhang, X.; Yu, P.; Feng, L.; Zhou, F.; Li, W. A drl-based resource allocation framework for multimedia multicast in 5g cellular networks. In Proceedings of the 2019 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Jeju, Republic of Korea, 5–7 June 2019. [Google Scholar]
- Ciftler, B.S.; Alwarafy, A.; Abdallah, M. Distributed drl-based downlink power allocation for hybrid rf/vlc networks. IEEE Photon. J. 2022, 14, 8632510. [Google Scholar] [CrossRef]
- Lu, K.; Liu, X.; Ai, Z.; Liu, Z.; Tao, D.; Lou, S. A drl based real-time computing load scheduling method. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Penghu, Taiwan, 15–17 September 2021. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Distance between user and BS | 20–300 m |
| Distance between each user | <=10 m |
| Total bandwidth of BS | 10 MHz |
| Total power of the BS | 20 W |
| Path loss | 2 |
| Power spectral density | −174 dBm/Hz |
| QoS | 2 bps/Hz |
| Number of hidden layers | 2 |
| Number of neurons in hidden layers | 128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Meng, K.; Wang, X.; Liu, Z.; Ma, Y. Dynamic User Resource Allocation for Downlink Multicarrier NOMA with an Actor–Critic Method. Energies 2023, 16, 2984. https://doi.org/10.3390/en16072984
Wang X, Meng K, Wang X, Liu Z, Ma Y. Dynamic User Resource Allocation for Downlink Multicarrier NOMA with an Actor–Critic Method. Energies. 2023; 16(7):2984. https://doi.org/10.3390/en16072984
Chicago/Turabian StyleWang, Xinshui, Ke Meng, Xu Wang, Zhibin Liu, and Yuefeng Ma. 2023. "Dynamic User Resource Allocation for Downlink Multicarrier NOMA with an Actor–Critic Method" Energies 16, no. 7: 2984. https://doi.org/10.3390/en16072984
APA StyleWang, X., Meng, K., Wang, X., Liu, Z., & Ma, Y. (2023). Dynamic User Resource Allocation for Downlink Multicarrier NOMA with an Actor–Critic Method. Energies, 16(7), 2984. https://doi.org/10.3390/en16072984