

Assessing the Performance of Small Wind Energy Systems Using Regional Weather Data


Abstract
:1. Introduction
1.1. Turbine Performance Modelling
1.2. Aims and Objectives
2. Materials and Methods
- 1.
- Creation of a training data set and a validation data set (Section 2.1)
- (a)
- Splitting the full data set into one full year of data for training and retaining the remainder of the period for validation
- (b)
- Carefully screening of the training data set for known times of turbine or grid faults and remove those
- (c)
- Checking the remaining training data for potential bias arising from data gaps
- 2.
- Method 1, based on the performance curve (Section 2.2)
- (a)
- Creation of an empirical performance curve from the training data (Section 2.2.1)
- (b)
- Definition of a performance score function with reference to the empirical performance curve (Section 2.2.2)
- (c)
- Application of that performance score function to the validation data to calculate a score for each validation sample (Section 3.1)
- 3.
- Method 1a, incorporating wind direction (Section 2.2.3)
- (a)
- Identification of a partition of the data using wind direction from training data
- (b)
- Subdivision of all data into the appropriate directional data partition
- (c)
- Creation of empirical performance curves for each directional partition from the training data
- (d)
- Definition of a performance score function for the empirical performance curve in each directional partition
- (e)
- Application of the partition-appropriate performance score function to the validation data to calculate a score for each validation sample (Section 3.1)
- 4.
- Method 2, using PCA (Section 2.3)
- (a)
- Creation of the reference performance in PCA space from the training data (Section 2.3.1)
- (b)
- Definition of a performance score function with reference to the PCA reference (Section 2.3.2)
- (c)
- Projection of the validation data onto the PCA space (Section 3.2)
- (d)
- Application of the performance score function to projected validation data to calculate a score for each validation sample (Section 3.2)
- 5.
- Method evaluation
- (a)
- Cross-method comparison by comparing the performance scores from each method as an initial validation of the methods (Section 4.1)
- (b)
- External validation (Section 4.2)
- (c)
- Demonstration of how the methods could be used to identify potential performance improvement (Section 4.3)
2.1. Data Availability and Quality
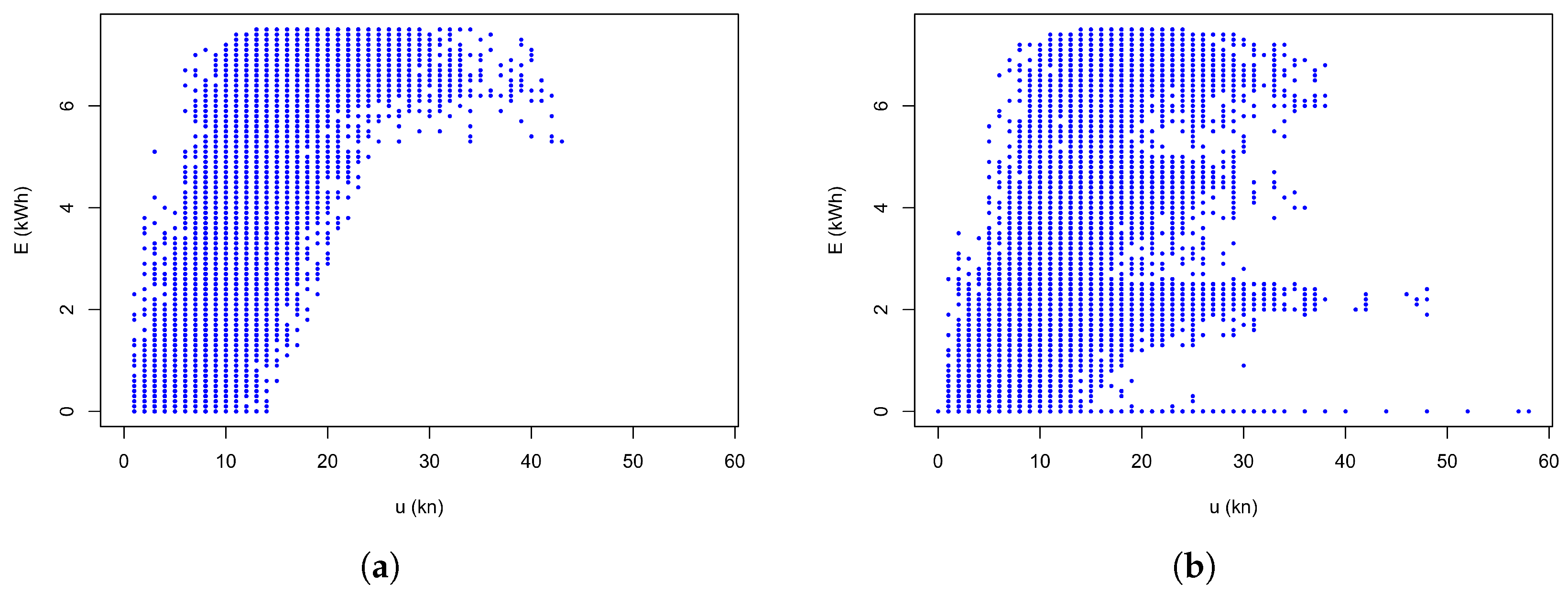
2.1.1. Electricity Production Data
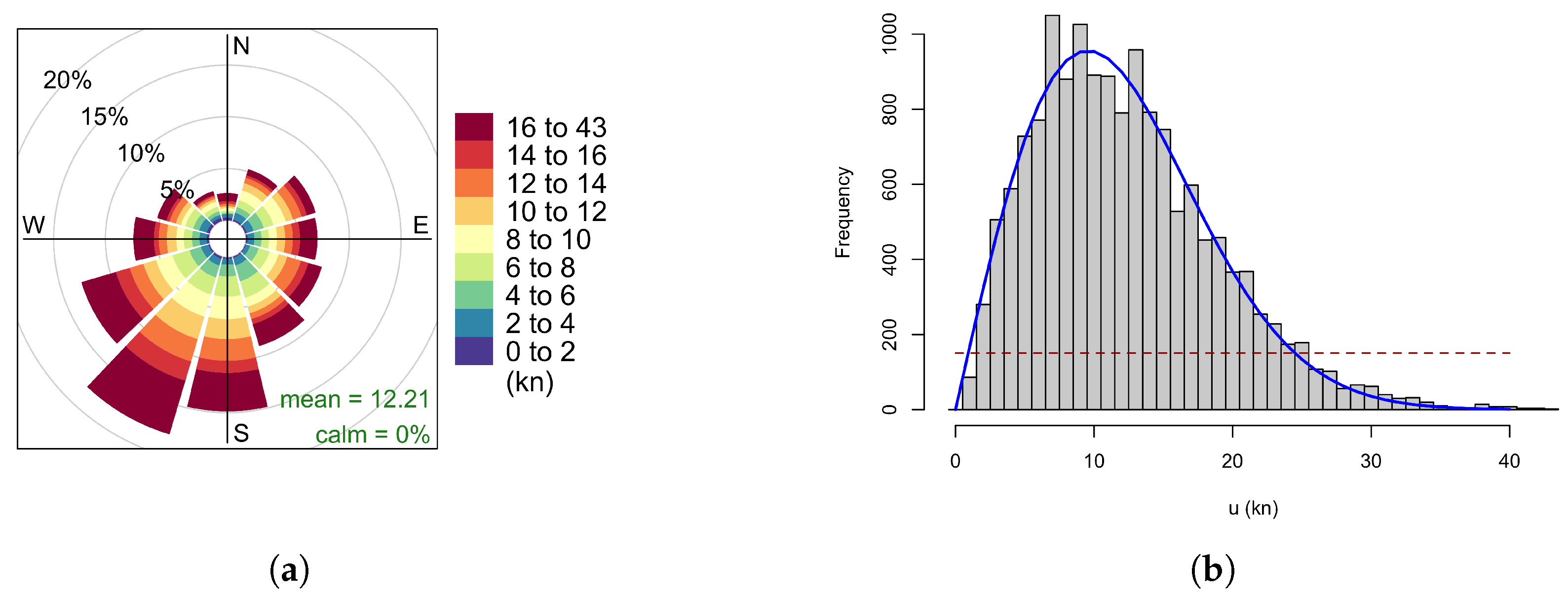
2.1.2. Weather Data
2.1.3. Data Alignment
2.2. Method 1, Based on the Performance Curve
2.2.1. Creation of a Reference Performance Curve Using Data Partitioning
2.2.2. Definition of a Performance Score
2.2.3. Method 1a Incorporating Wind Direction
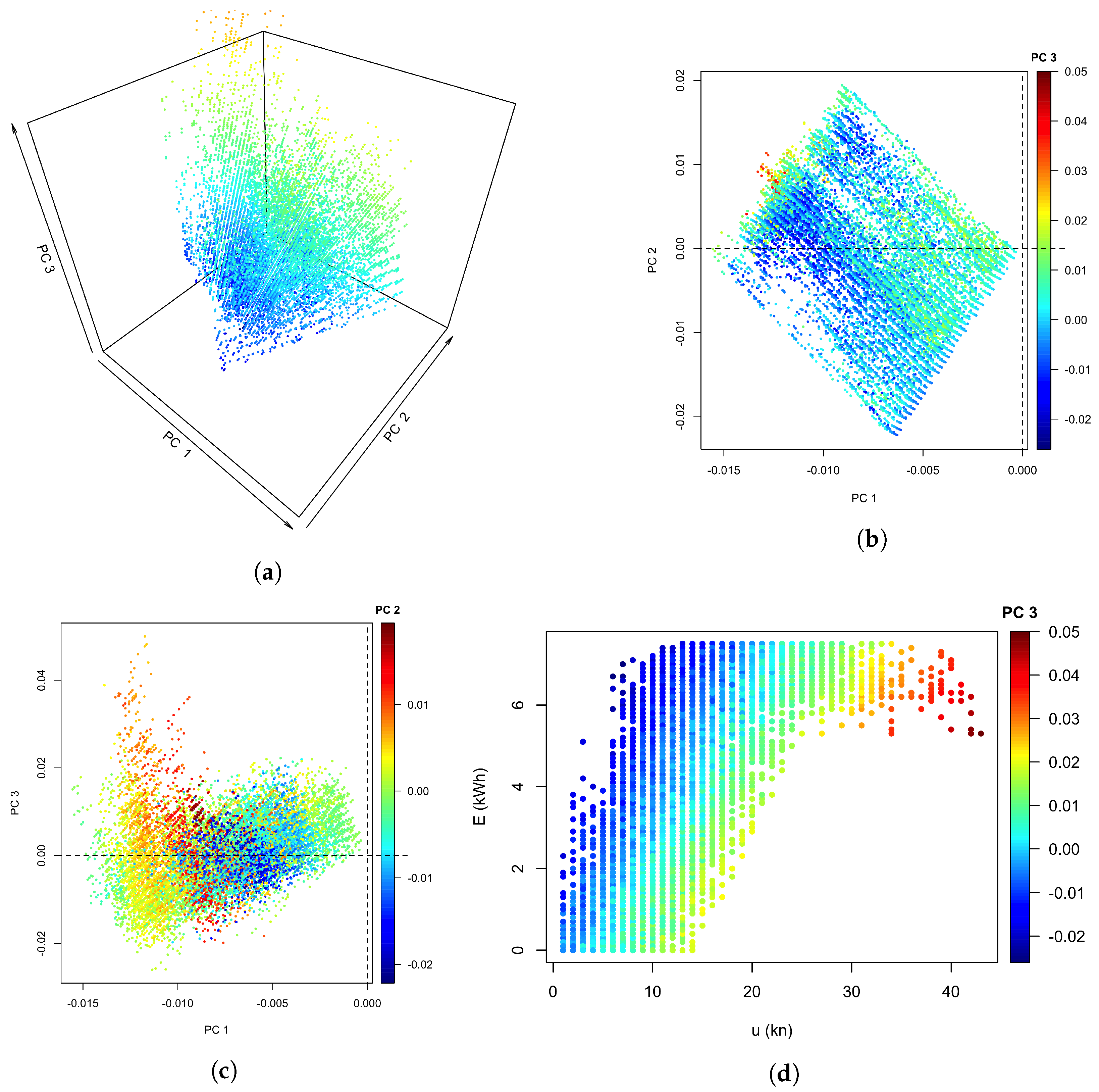
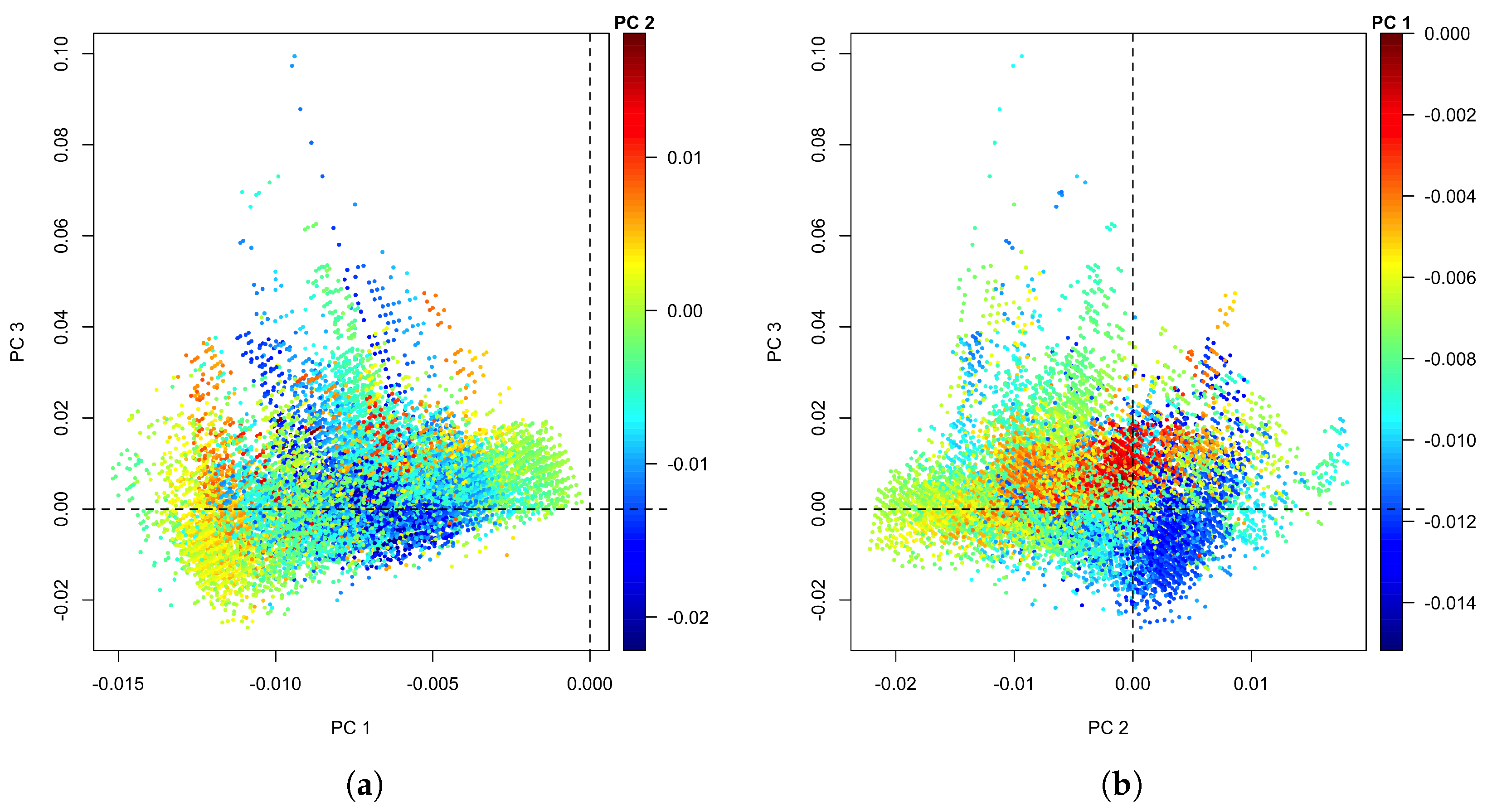
2.3. Method 2: PCA-Based Score
2.3.1. Creation of the Reference in PCA Space
- a matrix containing the column vectors of the principal components, also known as the ’loadings’ or components in a row to reconstruct the input sample in the same row in ;
- a diagonal matrix of the singular values, each measuring the contribution to the total variance of its corresponding singular vector;
- a matrix containing the column vectors of the singular vectors, which form an orthonormal set of basis vectors rotated with respect to the original basis vectors to maximise variance in the leading basis vector (Note that some software packages have implemented Singular Value Decomposition such that they return the singular vectors as row vectors, such that the singular vector matrix is the transpose of that described here).
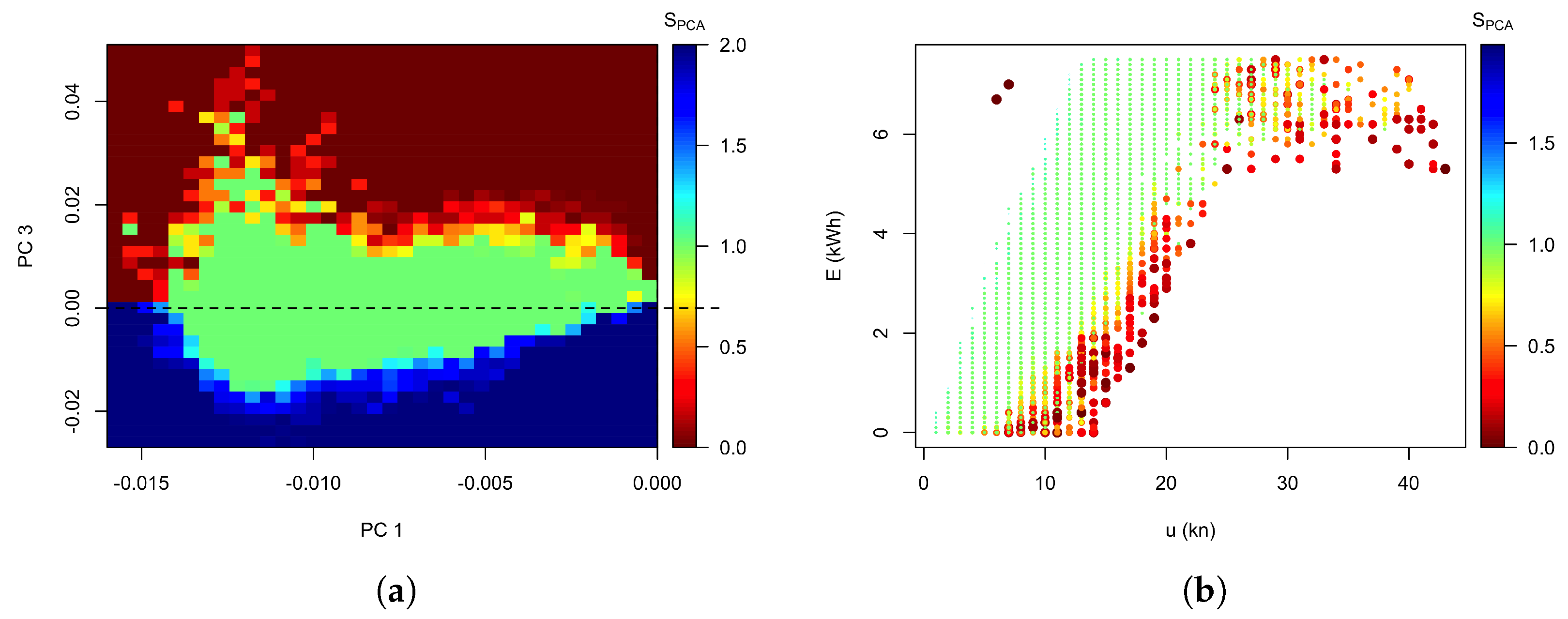
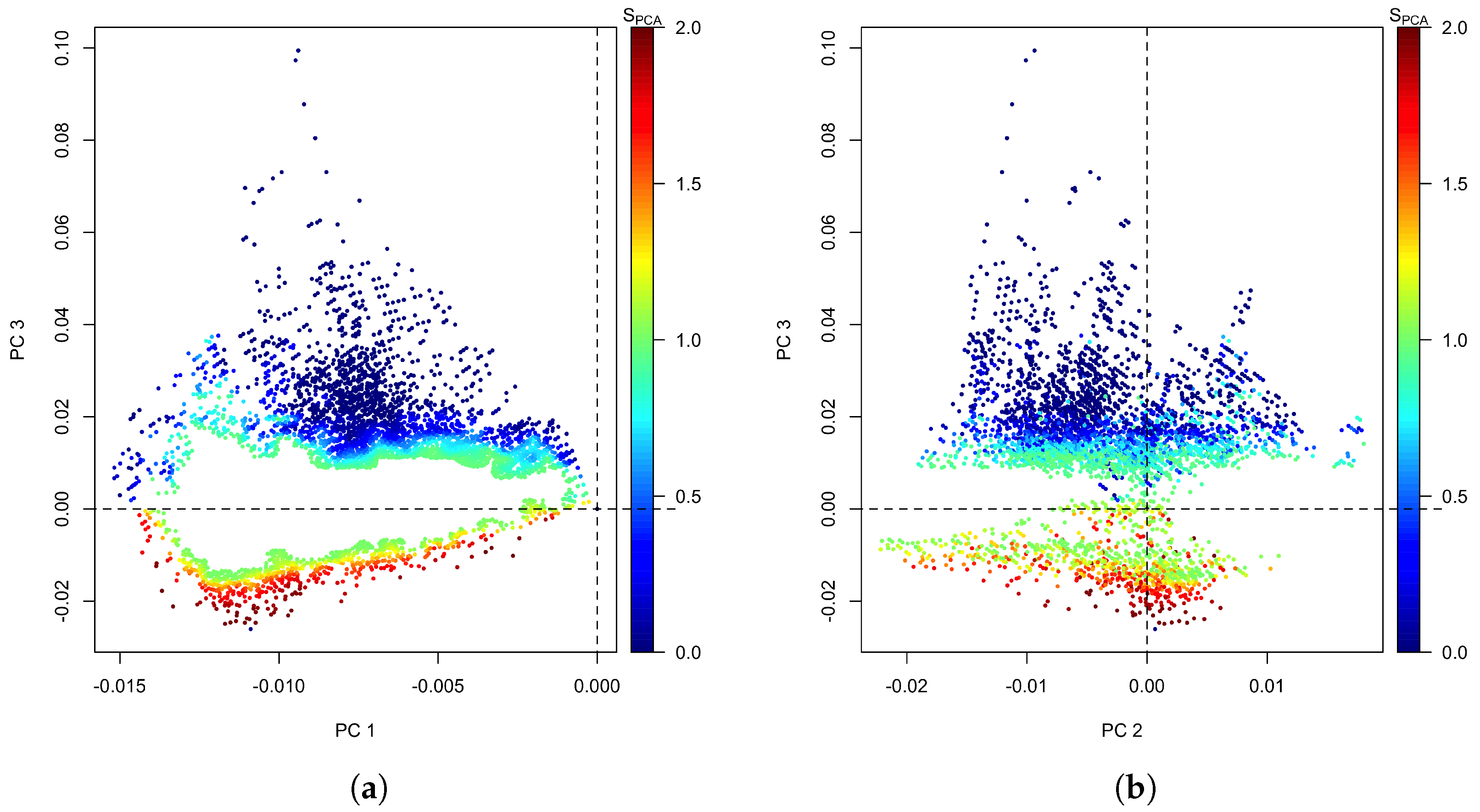
2.3.2. PCA Performance Score
3. Results
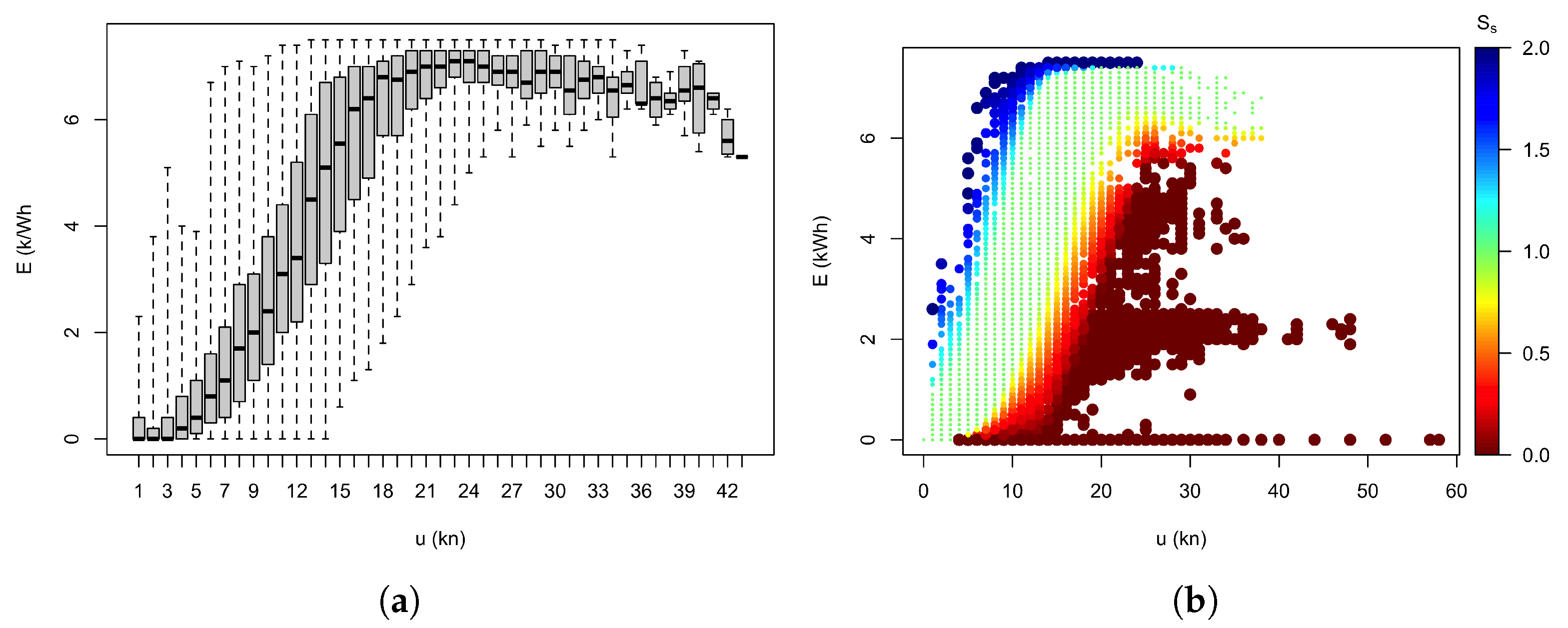
3.1. Method 1: Quartile-Based Performance Index
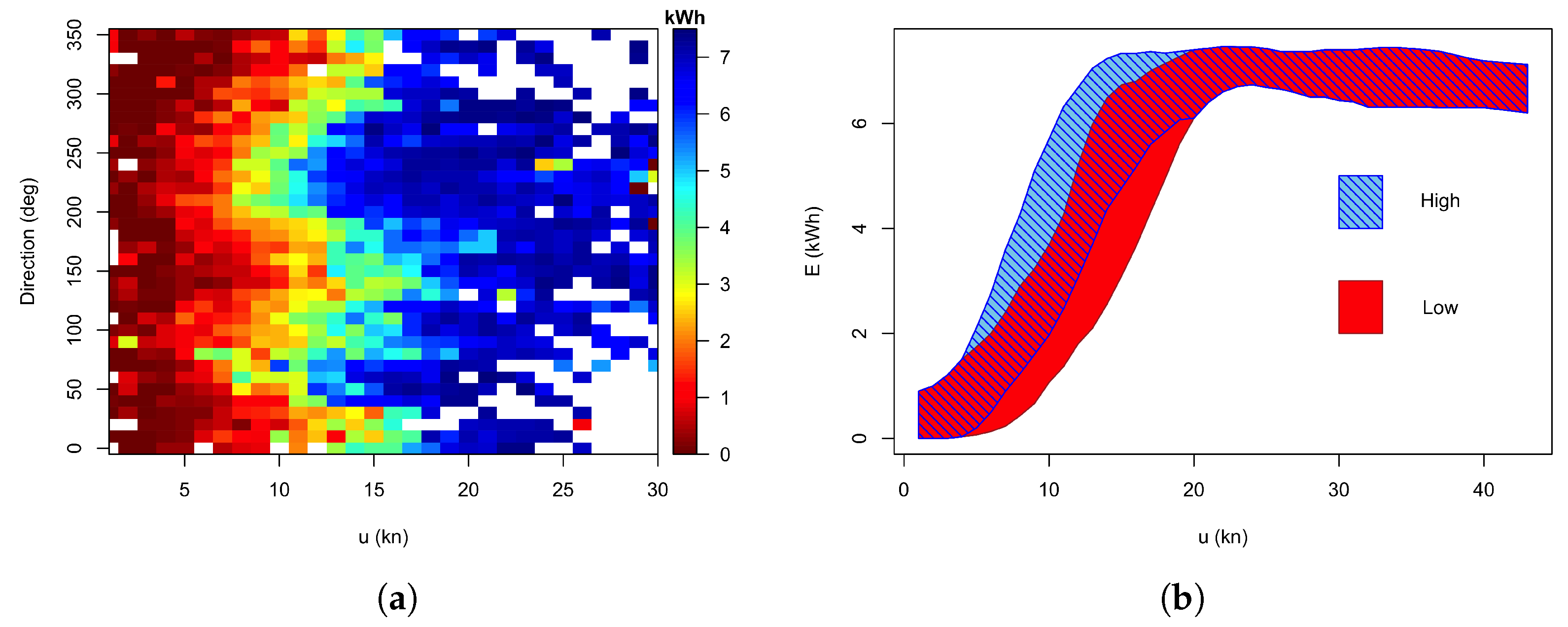
Method 1a: Effect of Wind Direction
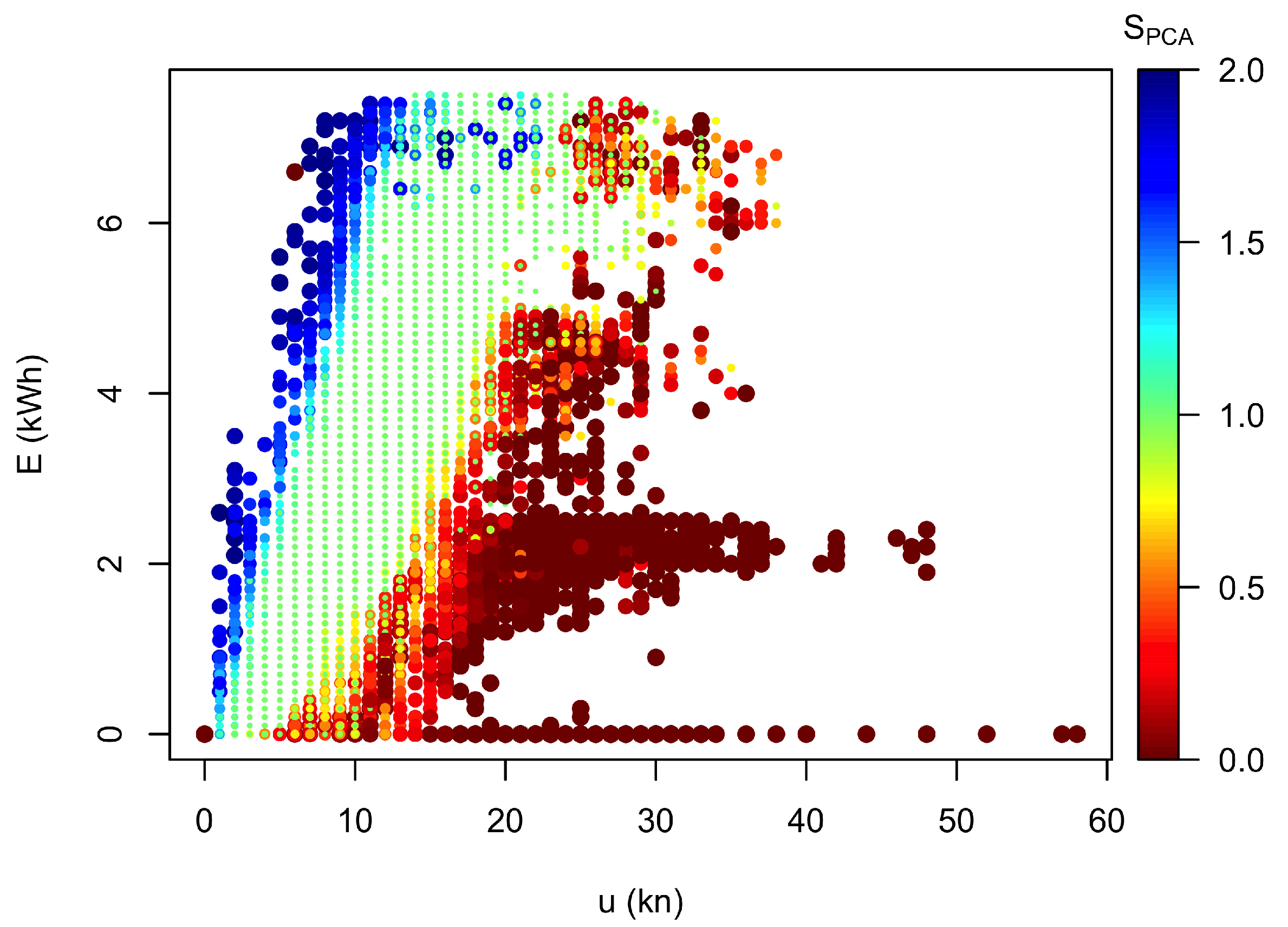
3.2. Method 2: PCA
3.2.1. PCA Training
3.2.2. Application to the Validation Data Set
4. Discussion
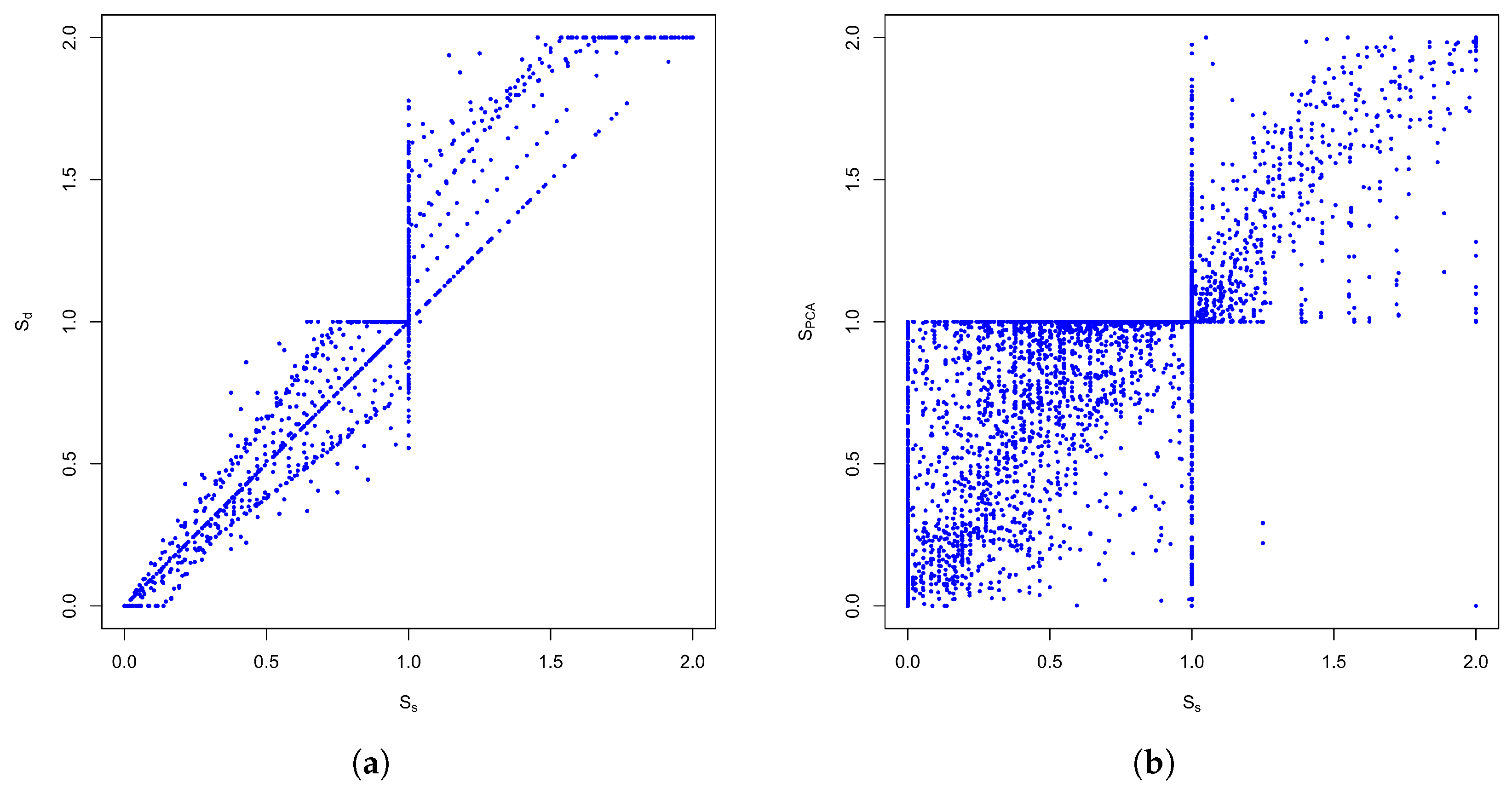
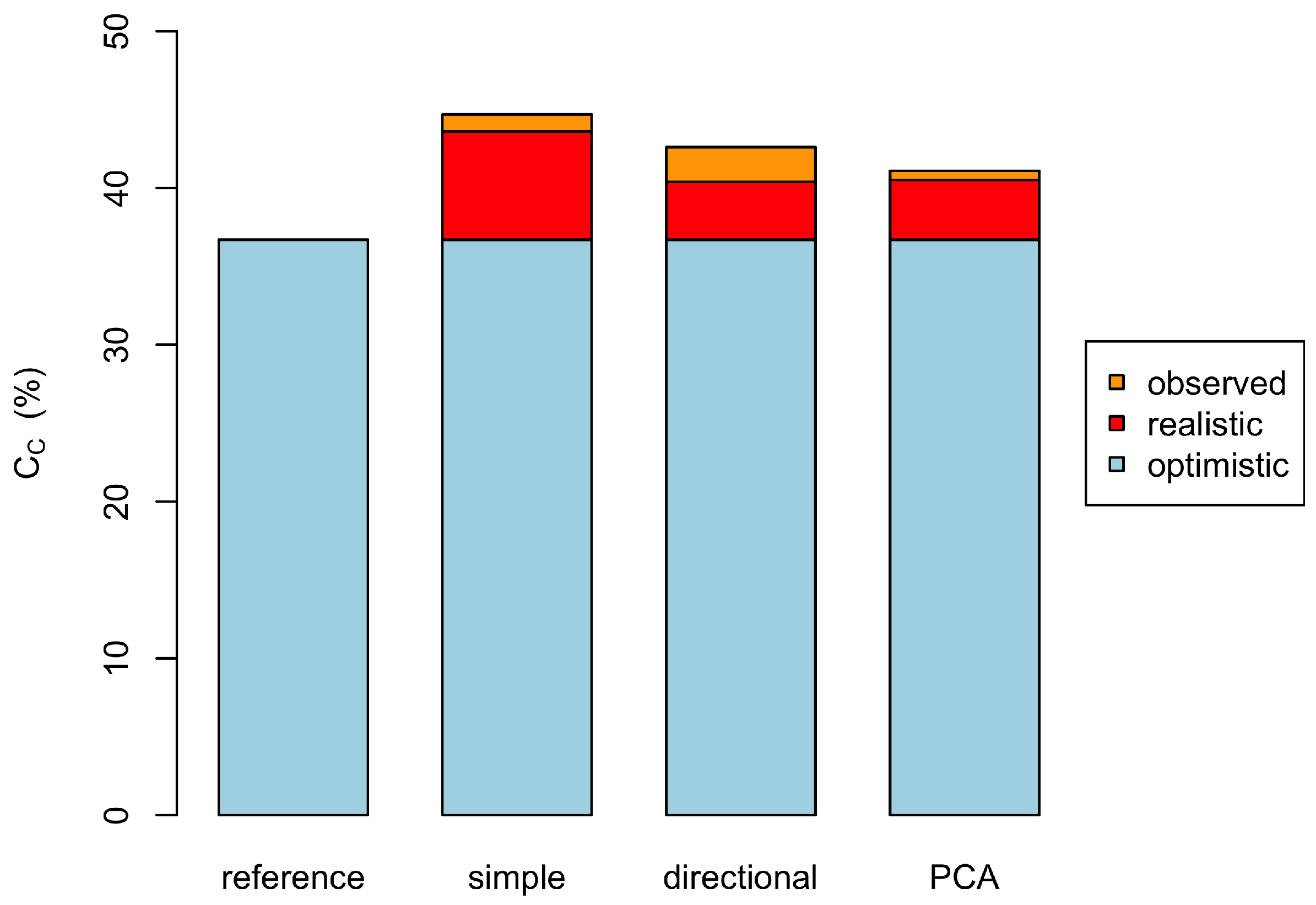
4.1. Inter-Model Comparison
4.2. External Validation
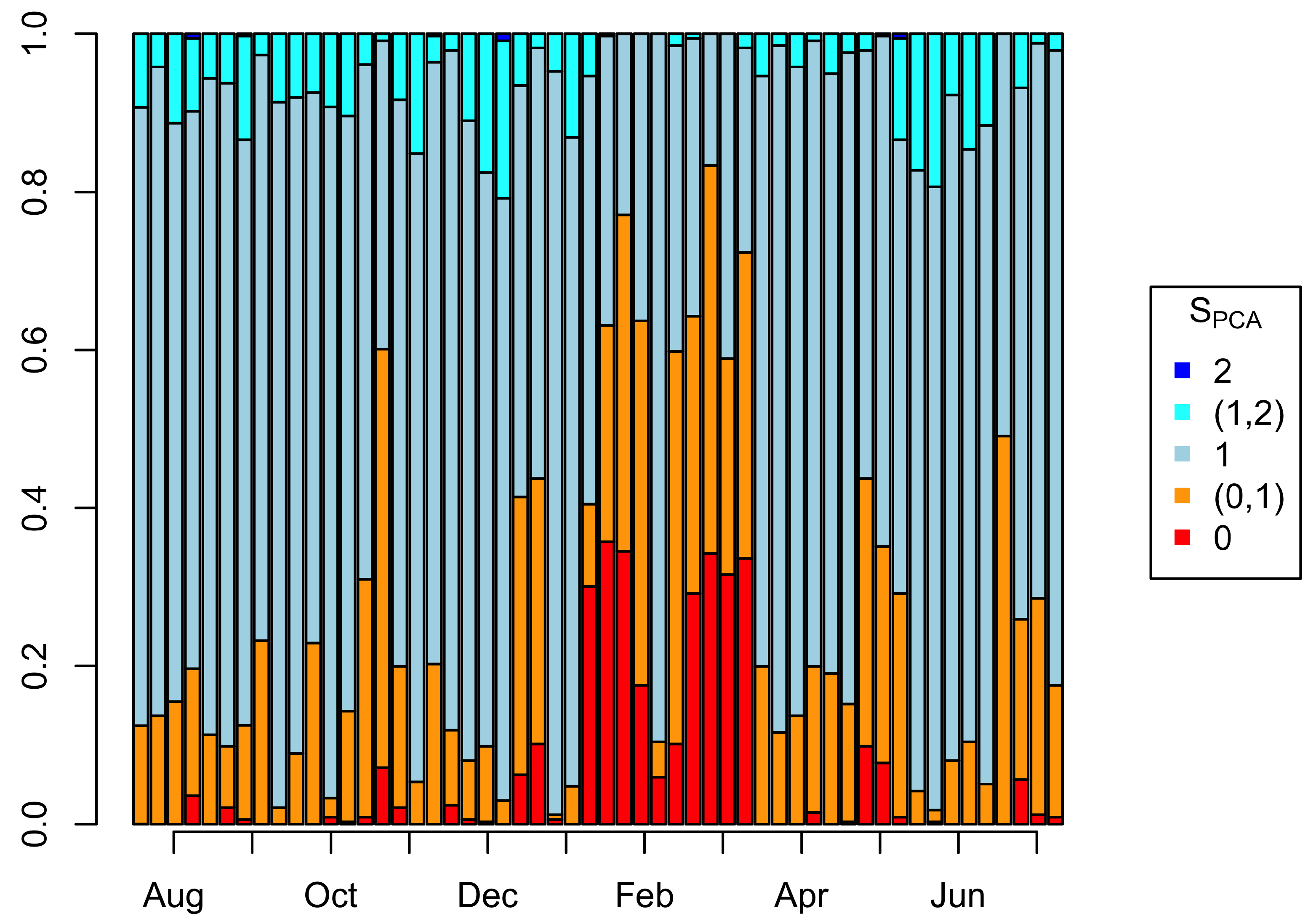
4.3. Potential Performance Improvement
4.4. Validation and Sensitivity to Training Data
4.5. Development Needs
5. Conclusions
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviations | |
| LCoE | Levelised Cost of Electricity |
| MCP | Measure-Correlate-Predict |
| PCA | Principal Component Analysis |
| SCADA | Supervisory Control and Data Acquisition Software |
| Variables | |
| E | Electricity production in a half-hour period |
| u | Wind speed (in knots) |
| Wind direction (in ) | |
| non-dimensionalised electricity production in a half-hour period | |
| non-dimensionalised wind speed | |
| non-dimensionalised wind direction (in ) | |
| Q | Quartile, with minimum, median, |
| maximum, and the interquartile range between and . | |
| Principal component matrix | |
| Singular value diagonal matrix | |
| Singular vector matrix | |
| Principal component i and column i of | |
| Singular value for | |
| S | Performance Score |
| N | Number of observations in a wind speed bin |
| minimum of for rescaling probability estimate | |
| p | likelihood |
| proxy for likelihood estimator | |
| Subscripts and superscripts | |
| simple performance curve | |
| directionally sub-divided performance curve | |
| PCA based method | |
| indicates interim variables |
References
- Tzen, E. Small wind turbines for on grid and off grid applications. IOP Conf. Ser. Earth Environ. Sci. 2020, 410, 012047. [Google Scholar] [CrossRef]
- Moreira Chagas, C.C.; Pereira, M.G.; Rosa, L.P.; da Silva, N.F.; Vasconcelos Freitas, M.A.; Hunt, J.D. From megawatts to kilowatts: A review of small wind turbine applications, lessons from the US to Brazil. Sustainability 2020, 12, 2760. [Google Scholar] [CrossRef]
- Simic, Z.; Havelka, J.G.; Bozicevic Vrhovcak, M. Small wind turbines—A unique segment of the wind power market. Renew. Energy 2013, 50, 1027–1036. [Google Scholar] [CrossRef]
- Drew, D.R.; Barlow, J.F.; Cockerill, T.T.; Vahdati, M.M. The importance of accurate wind resource assessment for evaluating the economic viability of small wind turbines. Renew. Energy 2015, 77, 493–500. [Google Scholar] [CrossRef]
- Peacock, A.D.; Jenkins, D.; Ahadzi, M.; Berry, A.; Turan, S. Micro wind turbines in the UK domestic sector. Energy Build. 2008, 40, 1324–1333. [Google Scholar] [CrossRef]
- Sunderland, K.M.; Narayana, M.; Putrus, G.; Conlon, M.F.; McDonald, S. The cost of energy associated with micro wind generation: International case studies of rural and urban installations. Energy 2016, 109, 818–829. [Google Scholar] [CrossRef]
- Stehly, T.; Heimiller, D.; Scott, G. Cost of Wind Energy Review; Technical Report; National Renewable Energy Laboratory, US Department of Energy: Golden, CO, USA, 2017. [Google Scholar]
- Bianchini, A.; Bangga, G.; Baring-Gould, I.; Croce, A.; Cruz, J.I.; Damiani, R.; Erfort, G.; Simao Ferreira, C.; Infield, D.; Nayeri, C.N.; et al. Current status and grand challenges for small wind turbine technology. Wind Energy Sci. 2022, 7, 2003–2037. [Google Scholar] [CrossRef]
- Battisti, L.; Benini, E.; Brighenti, A.; Dell’Anna, S.; Raciti Castelli, M. Small wind turbine effectiveness in the urban environment. Renew. Energy 2018, 129, 102–113. [Google Scholar] [CrossRef]
- KC, A.; Whale, J.; Urmee, T. Urban wind conditions and small wind turbines in the built environment: A review. Renew. Energy 2019, 131, 268–283. [Google Scholar] [CrossRef]
- Sunderland, K.; Woolmington, T.; Blackledge, J.; Conlon, M. Small wind turbines in turbulent (urban) environments: A consideration of normal and Weibull distributions for power prediction. J. Wind Eng. Ind. Aerodyn. 2013, 121, 70–81. [Google Scholar] [CrossRef]
- Emejeamara, F.C.; Tomlin, A.S.; Millward-Hopkins, J.T. Urban wind: Characterisation of useful gust and energy capture. Renew. Energy 2015, 81, 162–172. [Google Scholar] [CrossRef]
- Emejeamara, F.C.; Tomlin, A.S. A method for estimating the potential power available to building mounted wind turbines within turbulent urban air flows. Renew. Energy 2020, 153, 787–800. [Google Scholar] [CrossRef]
- Heath, M.; Walshe, J.; Watson, S. Estimating the potential yield of small building-mounted wind turbines. Wind Energy 2007, 10, 271–287. [Google Scholar] [CrossRef]
- Ledo, L.; Kosasih, P.B.; Cooper, P. Roof mounting site analysis for micro-wind turbines. Renew. Energy 2011, 36, 1379–1391. [Google Scholar] [CrossRef]
- Stathopoulos, T.; Alrawashdeh, H.; Al-Quraan, A.; Blocken, B.; Dilimulati, A.; Paraschivoiu, M.; Pilay, P. Urban wind energy: Some views on potential and challenges. J. Wind Eng. Ind. Aerodyn. 2018, 179, 146–157. [Google Scholar] [CrossRef]
- Energy Saving Trust. Location, Location, Location: Domestic Small-Scale Wind Field Trial Report; Technical Report; Energy Saving Trust: London, UK, 2007. [Google Scholar]
- García Márquez, F.P.; Tobias, A.M.; Pinar Pérez, J.M.; Papaelias, M. Condition monitoring of wind turbines: Techniques and methods. Renew. Energy 2012, 46, 169–178. [Google Scholar] [CrossRef]
- Gonzalez, E.; Stephen, B.; Infield, D.; Melero, J.J. Using high-frequency SCADA data for wind turbine performance monitoring: A sensitivity study. Renew. Energy 2019, 131, 841–853. [Google Scholar] [CrossRef]
- Kong, K.; Dyer, K.; Payne, C.; Hamerton, I.; Weaver, P.M. Progress and Trends in Damage Detection Methods, Maintenance, and Data-driven Monitoring of Wind Turbine Blades—A Review. Renew. Energy Focus 2022, 44, 390–412. [Google Scholar] [CrossRef]
- Sissons, M.F.; James, P.A.; Bradford, J.; Myers, L.E.; Bahaj, A.S.; Anwar, A.; Green, S. Pole-mounted horizontal axis micro-wind turbines: UK field trial findings and market size assessment. Energy Policy 2011, 39, 3822–3831. [Google Scholar] [CrossRef]
- Damanik, N.; Robiansyah, M.R.; Apriliana, A.; Purba, S. Design of Energy Monitoring System for Small Scale Wind Turbine Applications. IOP Conf. Ser. Earth Environ. Sci. 2019, 345, 012003. [Google Scholar] [CrossRef]
- Lydia, M.; Kumar, S.S.; Selvakumar, A.I.; Prem Kumar, G.E. A comprehensive review on wind turbine power curve modeling techniques. Renew. Sustain. Energy Rev. 2014, 30, 452–460. [Google Scholar] [CrossRef]
- Creech, A.; Früh, W.G.; Maguire, A.E. Simulations of an Offshore Wind Farm Using Large-Eddy Simulation and a Torque-Controlled Actuator Disc Model. Surv. Geophys. 2015, 36, 1–55. [Google Scholar] [CrossRef]
- Bulaevskaya, V.; Wharton, S.; Clifton, A.; Qualley, G.; Miller, W.O. Wind power curve modeling in complex terrain using statistical models. J. Renew. Sustain. Energy 2015, 7, 013103. [Google Scholar] [CrossRef]
- Ouyang, T.; Kusiak, A.; He, Y. Modeling wind-turbine power curve: A data partitioning and mining approach. Renew. Energy 2017, 102, 1–8. [Google Scholar] [CrossRef]
- Marvuglia, A.; Messineo, A. Monitoring of wind farms’ power curves using machine learning techniques. Appl. Energy 2012, 98, 574–583. [Google Scholar] [CrossRef]
- Stephen, B.; Galloway, S.J.; McMillan, D.; Hill, D.C.; Infield, D.G. A copula model of wind turbine performance. IEEE Trans. Power Syst. 2011, 26, 965–966. [Google Scholar] [CrossRef]
- Jollife, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar] [CrossRef]
- Skittides, C.; Früh, W.G. Wind forecasting using Principal Component Analysis. Renew. Energy 2014, 69, 365–374. [Google Scholar] [CrossRef]
- Zakaria, A.; Früh, W.G.; Ismail, F.B. Wind resource forecasting using enhanced measure correlate predict (MCP). AIP Conf. Proc. 2018, 2035, 040005. [Google Scholar] [CrossRef]
- Broomhead, D.S.; Jones, R.; King, G.P.; Pike, E.R. Singular systems. In Chaos, Noise and Fractals, 1st ed.; Pike, E.R., Lugiato, L.A., Eds.; Adam Hilger: Bristol, UK, 1987; pp. 15–27. [Google Scholar]
- Skittides, C.; Früh, W.G. A new Measure-Correlate-Predict Wind Resource Prediction method. In Proceedings of the International Conference on Renewable Energies and Power Quality (ICREPQ’15), La Coruña, Spain, 25–27 April 2015; Volume 13, pp. 612–615. [Google Scholar] [CrossRef]
- Früh, W.G. From local wind energy resource to national wind power production. AIMS Energy 2015, 3, 101–120. [Google Scholar] [CrossRef]
- UK Meteorological Office. Met Office Integrated Data Archive System (MIDAS) Land and Marine Surface Stations Data (1853–Current); NCAS British Atmospheric Data Centre: Oxford, UK, 2012; Available online: https://archive.ceda.ac.uk/ (accessed on 3 February 2023).
- Copernicus Climate Change Service, Climate Data Store. ERA5 Hourly Data on Single Levels from 1940 to Present. 2023. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels (accessed on 10 April 2023).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | |||||
|---|---|---|---|---|---|
| simple | 14.3 | 29.6 | 51.1 | 4.6 | 0.5 |
| directional | 15.3 | 20.9 | 52.7 | 10.0 | 1.1 |
| PCA | 5.9 | 27.1 | 58.7 | 8.2 | 0.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Früh, W.-G. Assessing the Performance of Small Wind Energy Systems Using Regional Weather Data. Energies 2023, 16, 3500. https://doi.org/10.3390/en16083500
Früh W-G. Assessing the Performance of Small Wind Energy Systems Using Regional Weather Data. Energies. 2023; 16(8):3500. https://doi.org/10.3390/en16083500
Chicago/Turabian StyleFrüh, Wolf-Gerrit. 2023. "Assessing the Performance of Small Wind Energy Systems Using Regional Weather Data" Energies 16, no. 8: 3500. https://doi.org/10.3390/en16083500
APA StyleFrüh, W. -G. (2023). Assessing the Performance of Small Wind Energy Systems Using Regional Weather Data. Energies, 16(8), 3500. https://doi.org/10.3390/en16083500