A General Probabilistic Forecasting Framework for Offshore Wind Power Fluctuations

Abstract
:1. Introduction
- the modeling of a nonlinear and non-stationary stochastic process for which we propose a model that allows to capture up to three different time series effects: autocorrelation, heteroscedasticity and regime switching (the generic name of our model is MS-AR-GARCH),
- the numerous issues linked to the practical implementation of such model as it requires an advanced estimation method based on a Markov Chain Monte Carlo (MCMC) algorithm,
- the gap between applying such model to synthetic data and real world observations.
2. Motivations Based on the State-of-the-Art
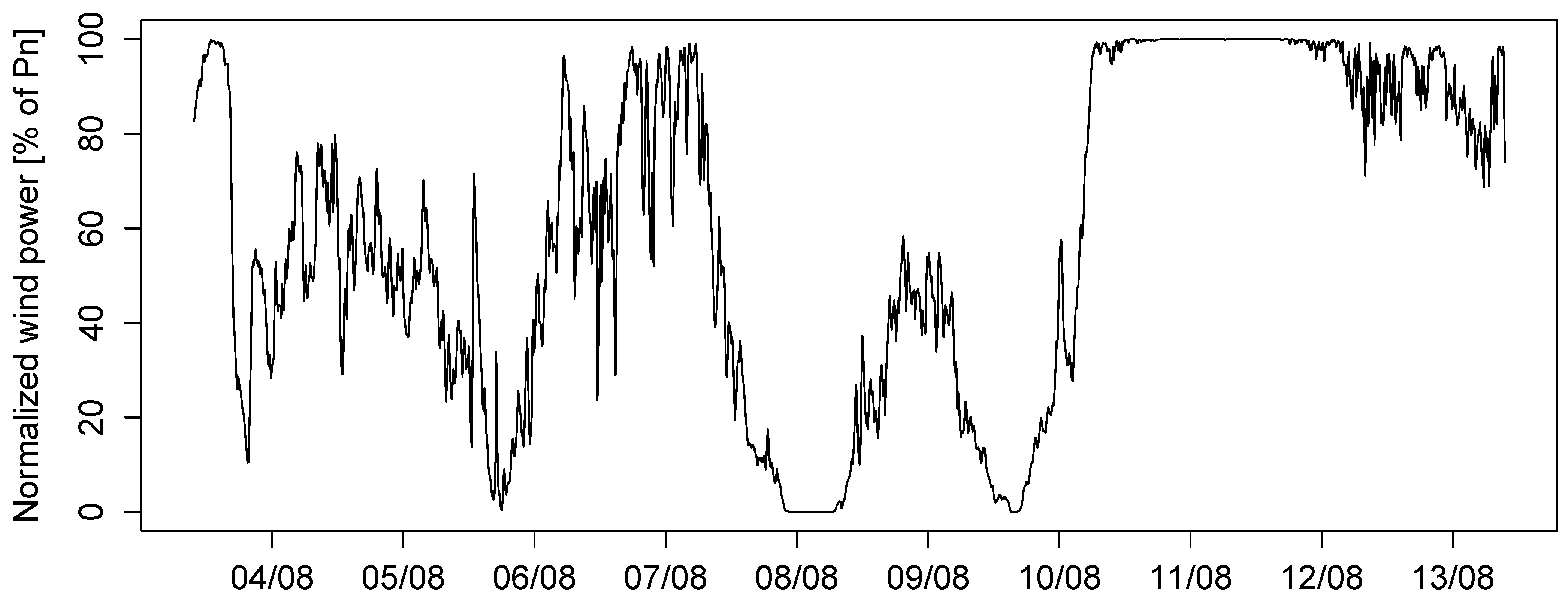
3. Data from Large Offshore Wind Farms



4. Model Specifications
4.1. Wind Power Predictive Density
4.2. GARCH Models in Meteorology
4.3. Existing Markov Switching Models with GARCH Errors
- the robustness of MCMC samplers to starting values can be evaluated by running several Markov chains with different starting values and tested for differences in their outputs,
- inequality constraints can be handled through the definition of prior distributions (Gibbs sampler) or through a rejection step when the constraint is violated (Metropolis–Hastings sampler),
- theoretically, local minima pitfalls are avoided by simulating the Markov chain over a sufficiently large number of iterations (law of large numbers),
- misspecification of the number of states of the Markov chain can be assessed by a visual inspection of the parameter posterior distributions (check for multiple modes).
4.4. The Model Definition
5. MCMC Implementation
- sample the regime sequence by data augmentation,
- sample the transition probabilities from a Dirichlet distribution,
- sample the AR and GARCH coefficients with the Griddy-Gibbs sampler.
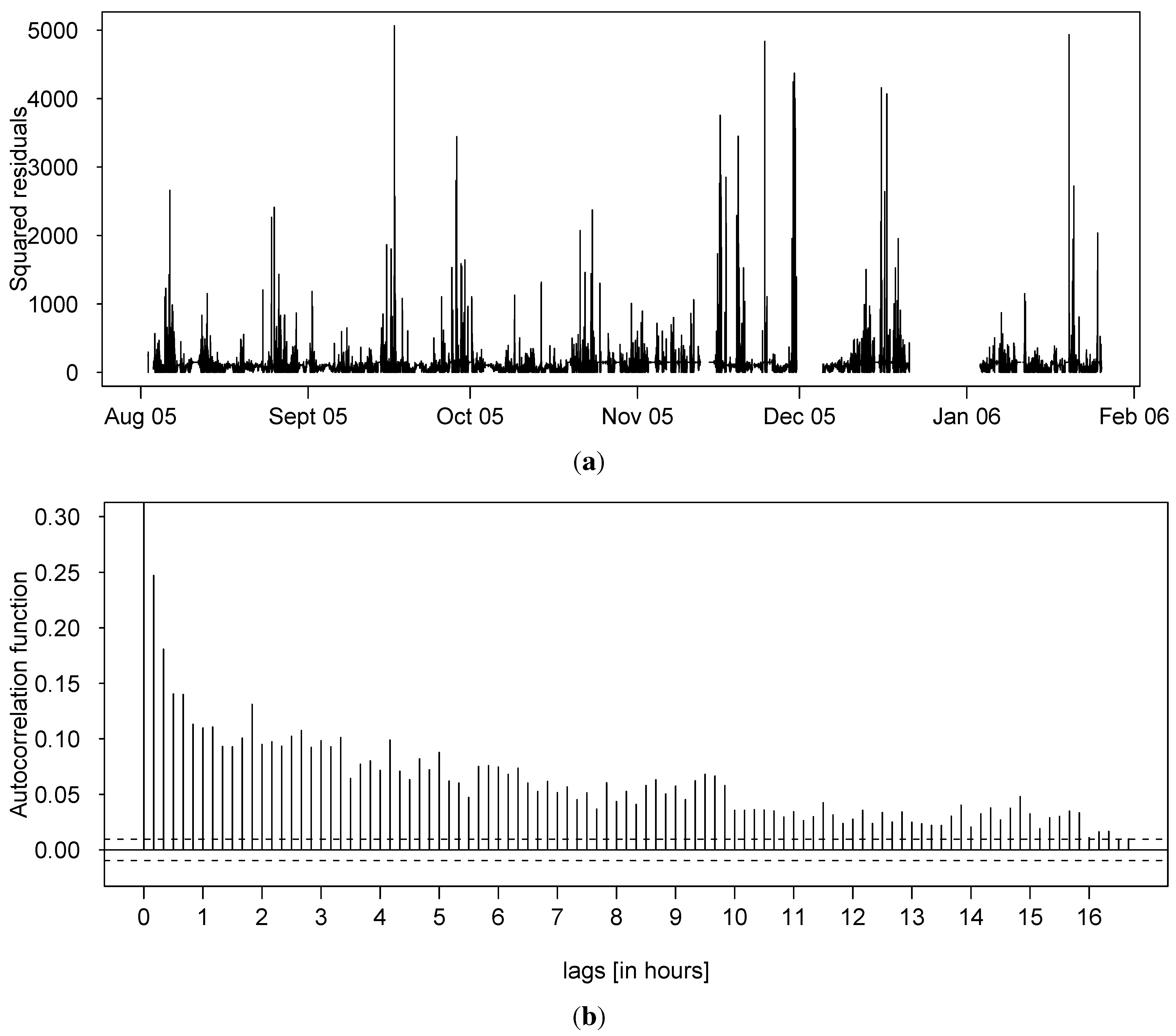
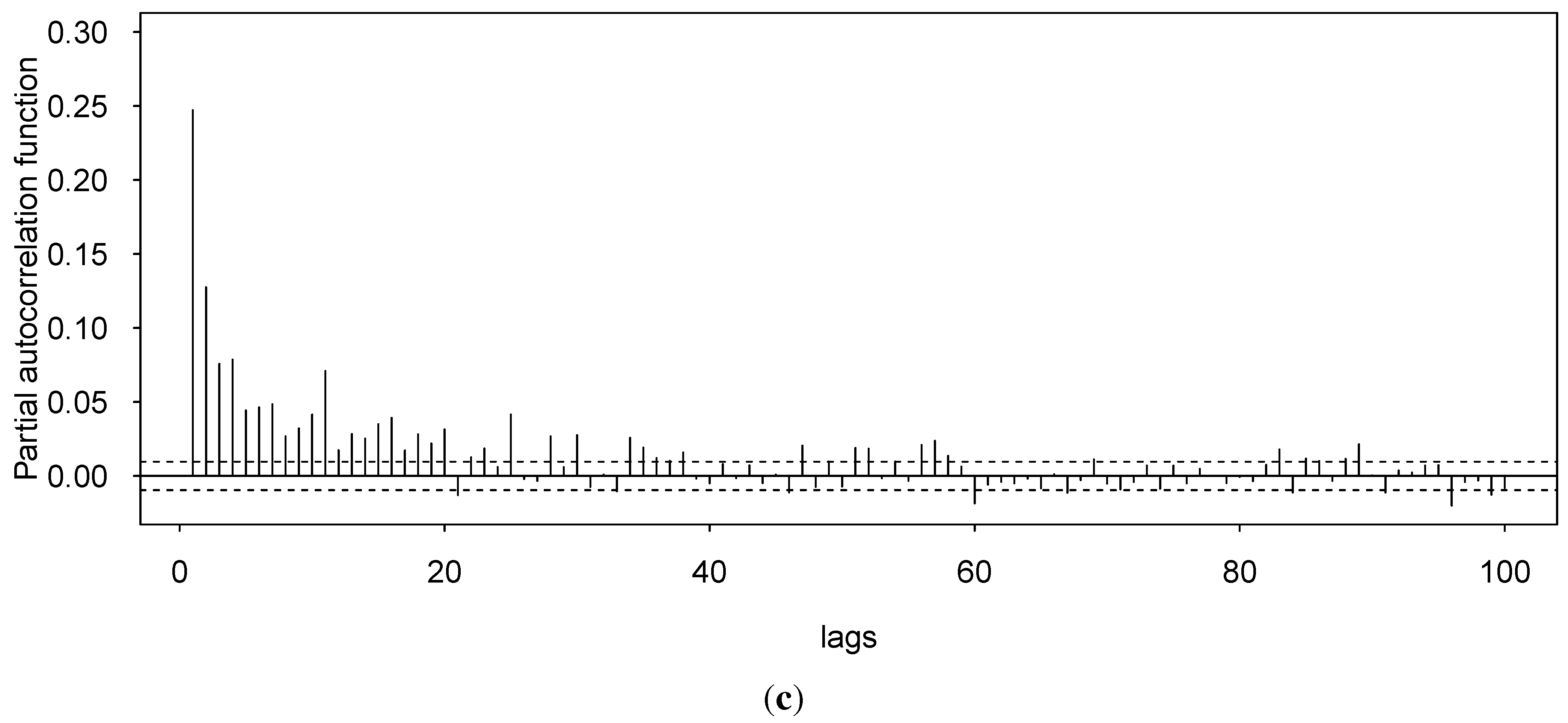
5.1. Sampling the Regime Sequence
- the filtered probabilities which infer the state variable conditioning upon the vector of parameters and all past and present information ,
- the smoothed probabilities which are the outputs of the inference of using the past, present and future information ,
- the predicted probabilities which correspond to the one-step ahead inference at time t and only use past information .
5.2. Transition Probability Matrix Sampling
5.3. AR and GARCH Coefficient Sampling

5.4. Implementation Details
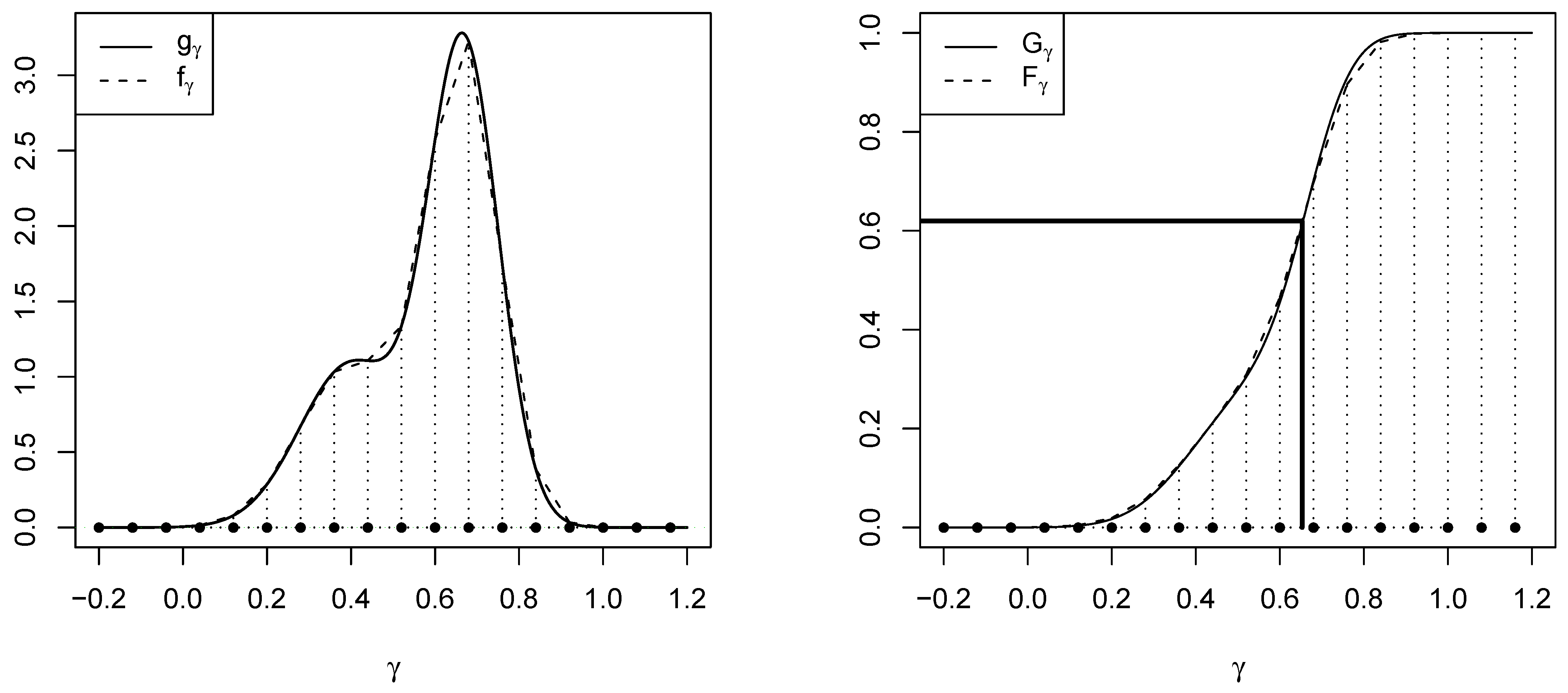
5.4.1. Prior Distributions
- a burn-in phase whose draws are discarded until the Markov chain reaches its stationary distribution,
- a second phase at the end of which posterior density estimates are computed and prior bounds are refined (the draws generated during this second phase are also discarded),
- a last phase with adjusted prior bounds at the end of which the final posterior densities are computed.
5.4.2. Label Switching
5.4.3. Grid Shape
5.4.4. Mixing of the MCMC Chain
5.4.5. Implementation Summary
| Algorithm 1 MCMC procedure for the estimation of MS-AR-GARCH models |
|
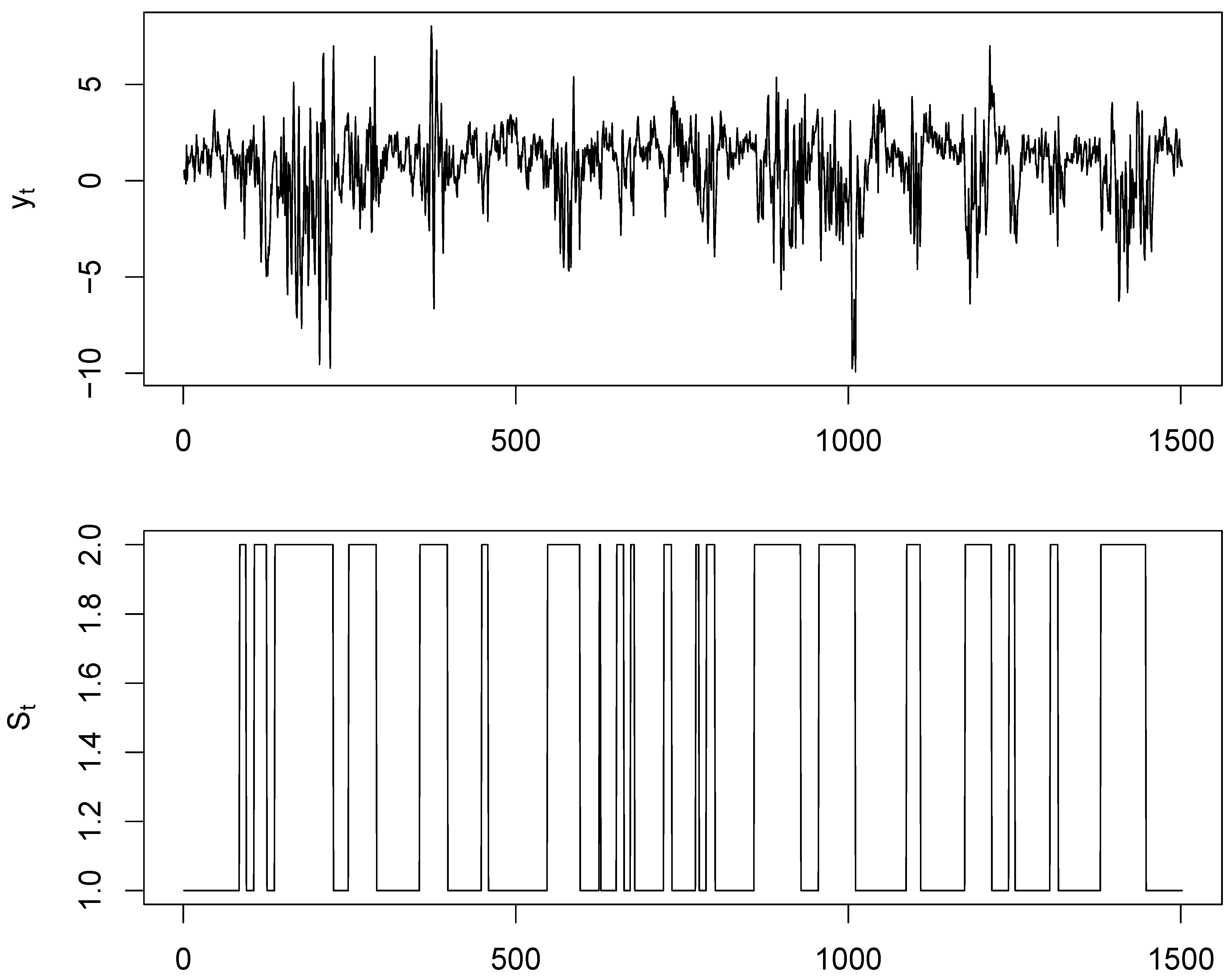
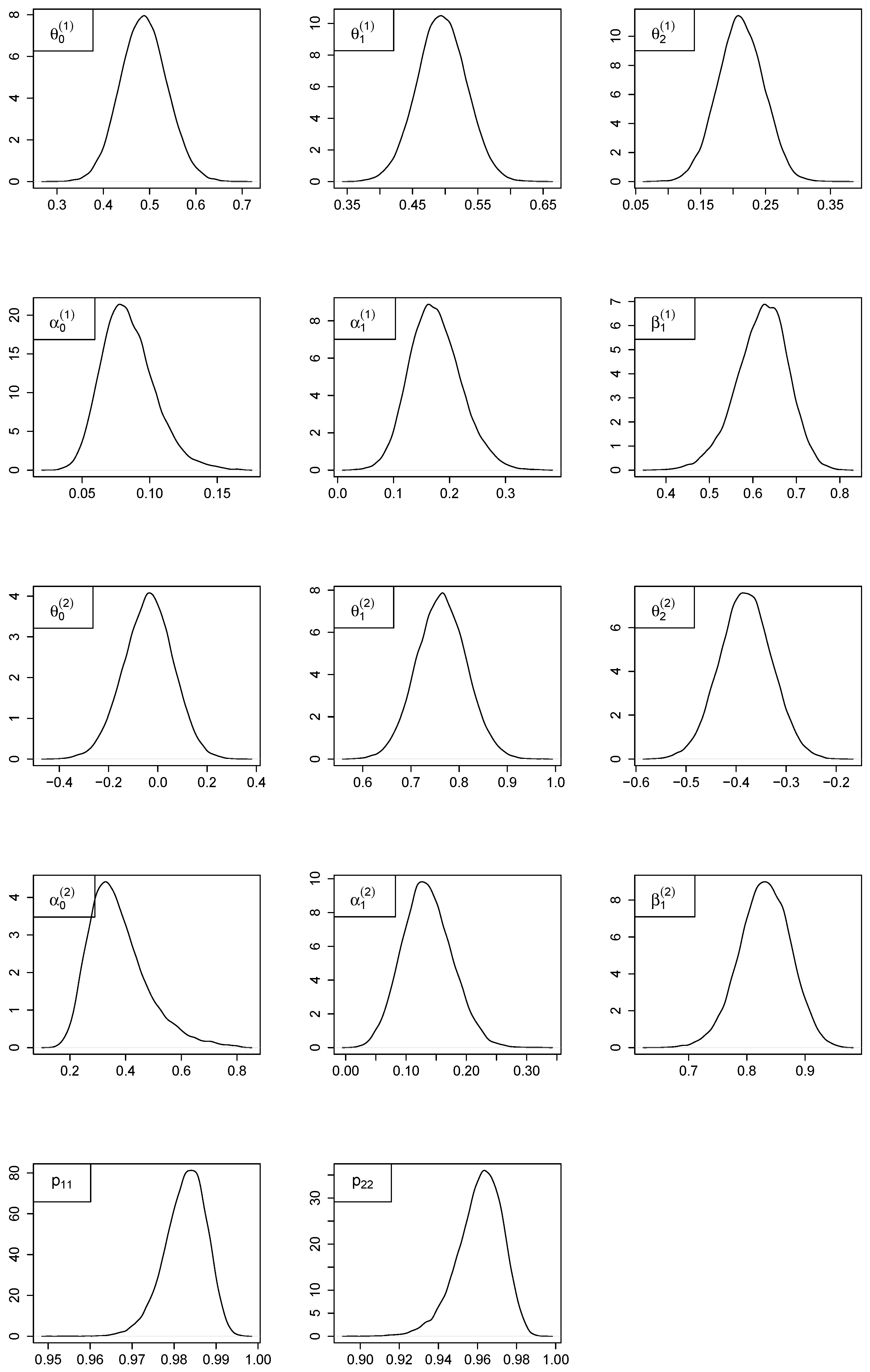
5.5. Simulation on Synthetic Time Series


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Param. | True Value | Intial prior | 50 sample | 1 sample | ||||
|---|---|---|---|---|---|---|---|---|
| Posterior mean | Posterior std. dev. | CP | Refined prior support | Posterior mean | Posterior std. dev. | |||
| 0.5 | [−0.2 ; 1.2] | 0.500 | 0.072 | 96% | [0.20 ; 0.78] | 0.488 | 0.050 | |
| 0.5 | [−0.2 ; 1.2] | 0.502 | 0.054 | 98% | [0.26 ; 0.72] | 0.495 | 0.037 | |
| 0.2 | [−0.2 ; 1.2] | 0.197 | 0.051 | 98% | [−0.01 ; 0.43] | 0.212 | 0.035 | |
| 0.1 | [0 ; 0.5] | 0.109 | 0.041 | 94% | [0 ; 0.17] | 0.084 | 0.020 | |
| 0.2 | [0 ; 0.5] | 0.195 | 0.068 | 94% | [0 ; 0.38] | 0.175 | 0.046 | |
| 0.6 | [0 ; 1] | 0.593 | 0.101 | 94% | [0.36 ; 0.88] | 0.621 | 0.059 | |
| 0 | [−0.7 ; 0.7] | -0.015 | 0.041 | 94% | [−0.44 ; 0.36] | −0.038 | 0.100 | |
| 0.7 | [0 ; 1.4] | 0.689 | 0.081 | 98% | [0.55 ; 0.99] | 0.764 | 0.051 | |
| −0.3 | [−1 ; 0.2] | −0.308 | 0.081 | 98% | [−0.59 ; −0.17] | −0.381 | 0.052 | |
| 0.4 | [0.1 ; 0.8] | 0.512 | 0.189 | 98% | [0 ; 0.82] | 0.373 | 0.105 | |
| 0.1 | [0 ; 0.5] | 0.114 | 0.073 | 92% | [0 ; 0.33] | 0.135 | 0.041 | |
| 0.85 | [0 ; 1] | 0.813 | 0.087 | 96% | [0.62 ; 1] | 0.831 | 0.044 | |
| 0.98 | [0 ; 1] | 0.977 | 0.009 | 90% | [0 ; 1] | 0.983 | 0.005 | |
| 0.96 | [0 ; 1] | 0.950 | 0.023 | 92% | [0 ; 1] | 0.961 | 0.012 | |

| Rate of successful | Probability of | |
|---|---|---|
| regime inference | regime retrieval | |
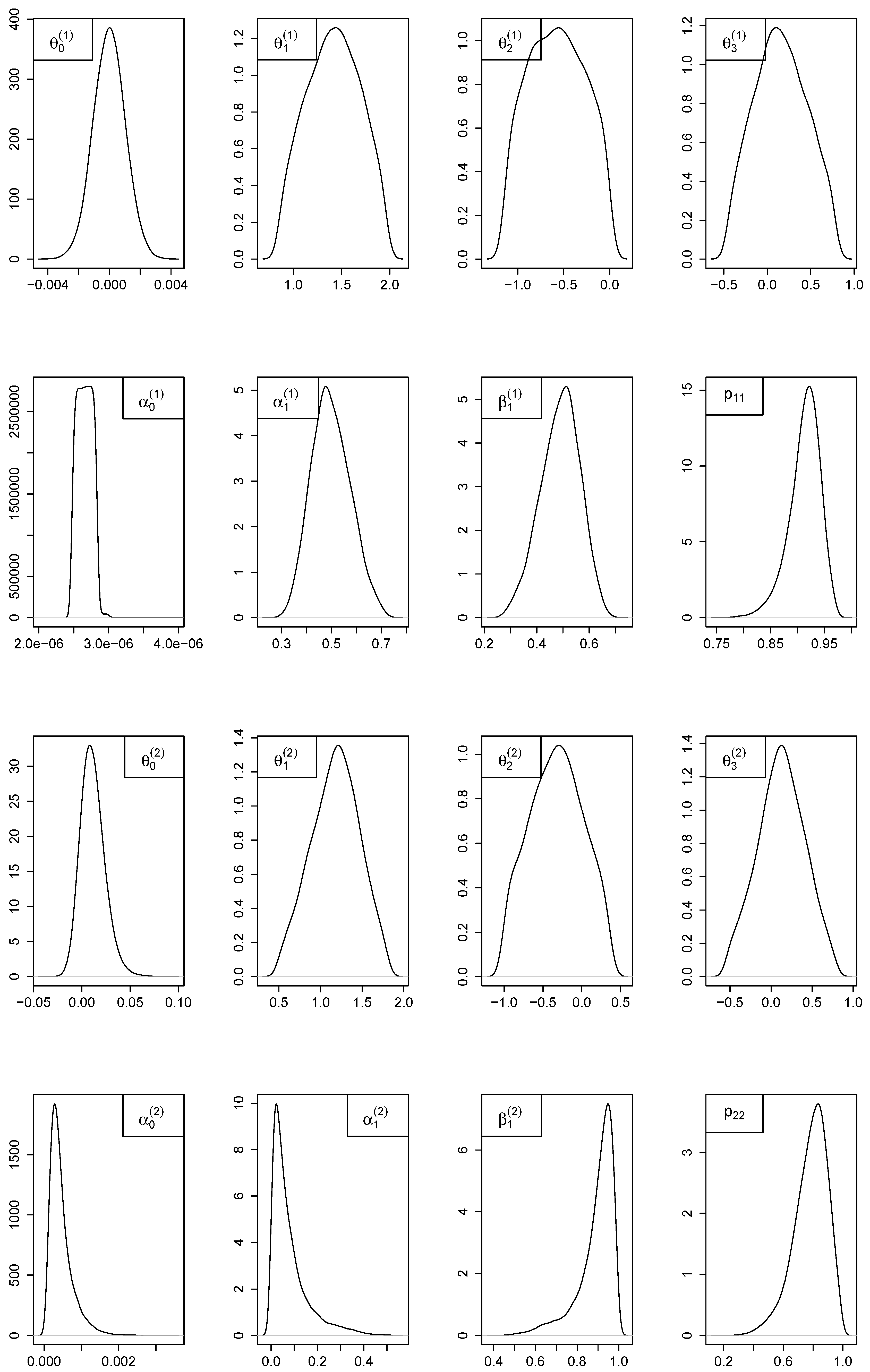
5.6. Study on an Empirical Time Series of Wind Power
| 1 Regime: AR(3)-GARCH(1,1) | 2 Regimes: MS(2)-AR(3)-GARCH(1,1) | |||||||
|---|---|---|---|---|---|---|---|---|
| Initial prior support | Refined prior support | Posterior mean | Posterior std. dev. | Initial prior support | Refined prior support | Posterior mean | Posterior std. dev. | |
| [−0.01 ; 0.01] | [−0.007 ; 0.006] | −2 × 10 | 0.002 | [−0.04 ; 0.04] | [−0.004 ; 0.004] | −3 × 10 | 6 × 10 | |
| [1 ; 1.7] | [0.68 ; 2.11] | 1.358 | 0.232 | [1 ; 1.8] | [0.64 ; 2.18] | 1.417 | 0.273 | |
| [−085 ; −0.05] | [−1.33 ; 0.34] | −0.460 | 0.284 | [−0.95 ; −0.15] | [−1.36 ; 0.21] | −0.574 | 0.304 | |
| [−0.15 ; 0.35] | [−0.52 ; 0.72] | 0.107 | 0.206 | [−0.35 ; 0.55] | [−0.67 ; 0.99] | 0.156 | 0.300 | |
| [0 ; 3 × 10] | [0 ; 3 × 10] | 7 × 10 | 6 × 10 | [5 × 10 ; 10] | [2 × 10 ; 10] | 3 × 10 | 2 × 10 | |
| [0.2 ; 1] | [0.03 ; 1] | 0.513 | 0.161 | [0 ; 1] | [0.23 ; 0.74] | 0.499 | 0.077 | |
| [0 ; 0.7] | [0 ; 0.95] | 0.467 | 0.161 | [0 ; 1] | [0.25 ; 0.74] | 0.489 | 0.074 | |
| - | - | - | - | [-0.06 ; 0.10] | [−0.04 ; 0.09] | 0.011 | 0.013 | |
| - | - | - | - | [0.7 ; 1.7] | [0.27 ; 2.02] | 1.178 | 0.285 | |
| - | - | - | - | [−0.7 ; 0.3] | [−1.22 ; 0.58] | −0.323 | 0.341 | |
| - | - | - | - | [−0.4 ; 0.6] | [−0.76 ; 1.01] | 0.126 | 0.284 | |
| - | - | - | - | [1 × 10 ; 8 × 10] | [0 ; 4 × 10] | 5 × 10 | 3 × 10 | |
| - | - | - | - | [0 ; 1] | [0 ; 0.54] | 0.079 | 0.080 | |
| - | - | - | - | [0 ; 1] | [0 ; 1] | 0.892 | 0.088 | |
| - | - | - | - | [0 ; 1] | [0 ; 1] | 0.913 | 0.029 | |
| - | - | - | - | [0 ; 1] | [0 ; 1] | 0.783 | 0.114 | |


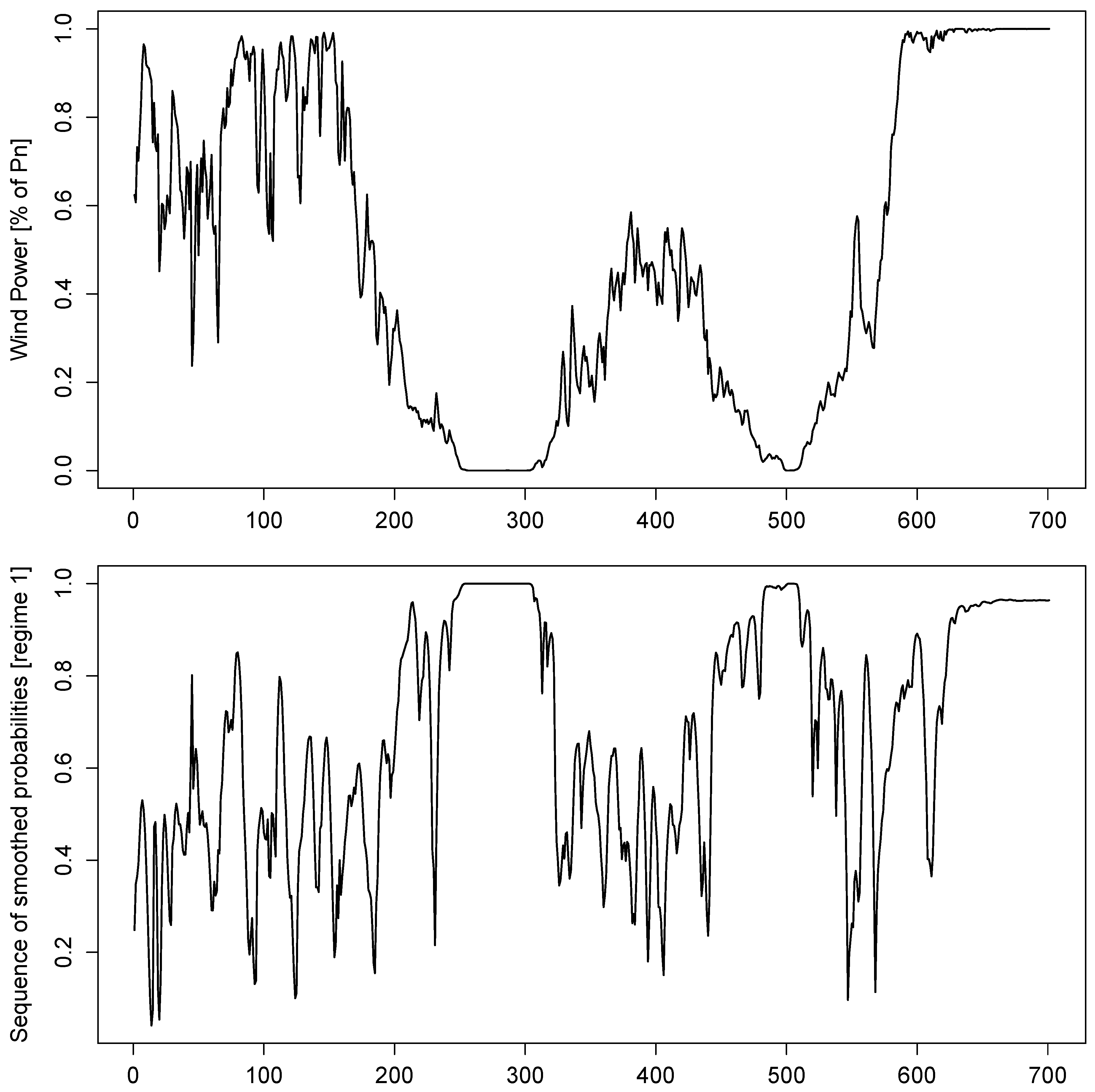
6. Wind Power Forecast Evaluation
6.1. Approximating the Conditional Variance for Prediction Applications
6.2. Evaluation of Point Forecasts
| Model | Oct. | Nov. | Dec. | Jan. | Total |
|---|---|---|---|---|---|
| Persistence | 2.41 | 2.58 | 3.01 | 2.47 | 2.55 |
| AR(3) | 2.36 | 2.64 | 2.98 | 2.46 | 2.53 |
| AR(3)-GARCH(1,1) | 2.29 | 2.60 | 2.95 | 2.41 | 2.49 |
| MS(2)-AR(3)-GARCH(1,1) | 2.27 | 2.50 | 2.89 | 2.38 | 2.44 |
| MSAR(2,3) | 2.28 | 2.49 | 2.89 | 2.37 | 2.44 |
| MSAR(3,3) | 2.26 | 2.49 | 2.89 | 2.36 | 2.42 |
| Model | Oct. | Nov. | Dec. | Jan. | Total |
|---|---|---|---|---|---|
| Persistence | 4.17 | 6.22 | 5.76 | 4.28 | 5.02 |
| AR(3)-GARCH(1,1) | 4.00 | 6.18 | 5.72 | 4.24 | 4.93 |
| AR(3) | 3.98 | 5.99 | 5.56 | 4.17 | 4.83 |
| MS(2)-AR(3)-GARCH(1,1) | 3.96 | 6.00 | 5.55 | 4.15 | 4.82 |
| MSAR(2,3) | 3.98 | 5.95 | 5.55 | 4.17 | 4.81 |
| MSAR(3,3) | 3.96 | 5.95 | 5.55 | 4.17 | 4.80 |
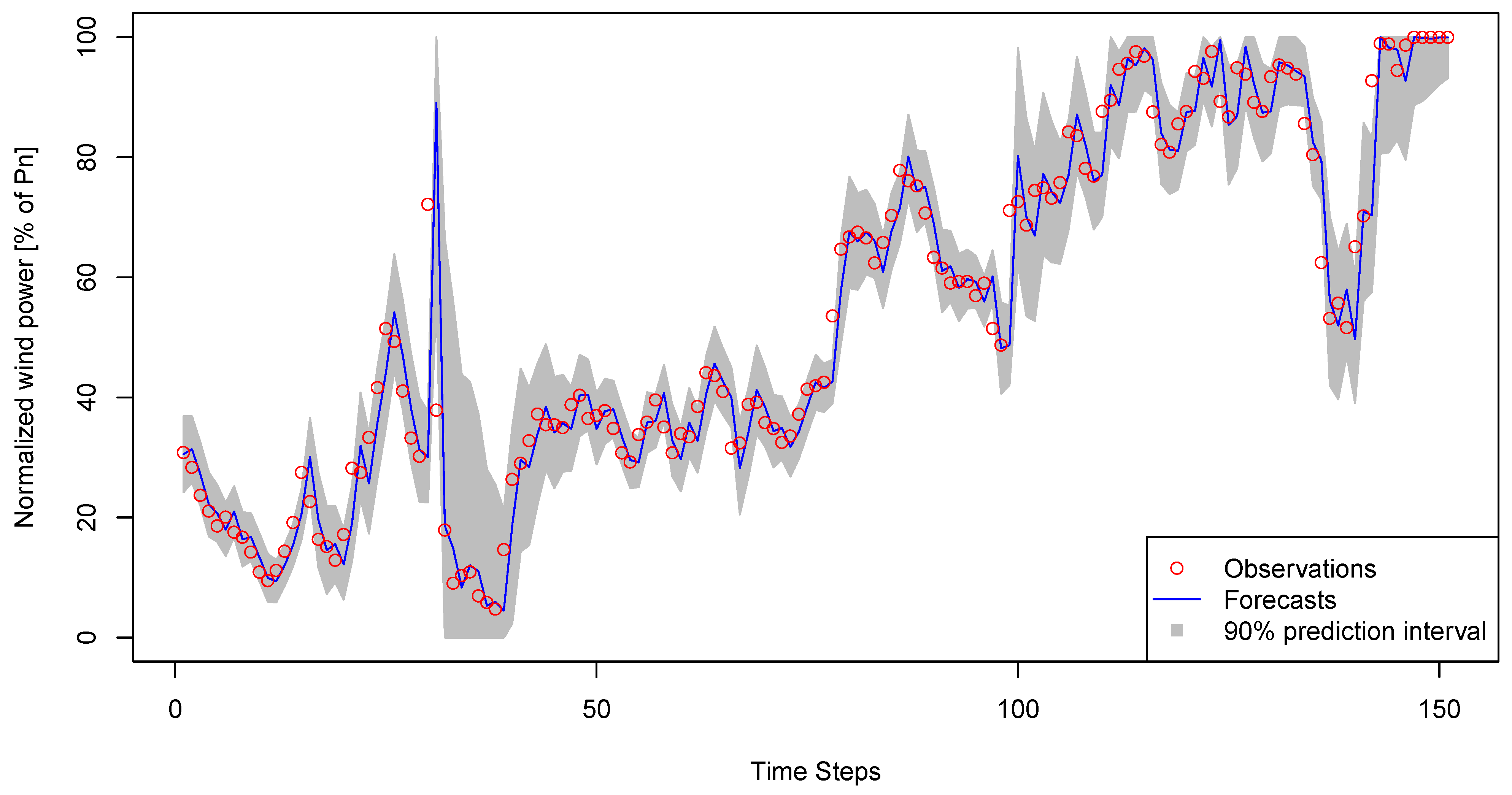
6.3. Evaluation of Interval and Density Forecasts
| Model | Oct. | Nov. | Dec. | Jan. | Total |
|---|---|---|---|---|---|
| AR(3) | 1.99 | 2.33 | 2.48 | 2.02 | 2.15 |
| MSAR(2,3) | 1.81 | 2.01 | 2.26 | 1.88 | 1.94 |
| MSAR(3,3) | 1.78 | 1.98 | 2.24 | 1.85 | 1.91 |
| AR(3)-GARCH(1,1) | 1.76 | 1.99 | 2.24 | 1.85 | 1.91 |
| MS(2)-AR(3)-GARCH(1,1) | 1.76 | 1.95 | 2.20 | 1.83 | 1.88 |
| Nom. cov. | Emp. cov. | Emp. cov. | Emp. cov. |
|---|---|---|---|
| AR(3) | MSAR(3,3) | MS(2)-AR(3)-GARCH(1,1) | |
| 10 | 13.2 | 7.1 | 9.4 |
| 20 | 42.6 | 25.8 | 20.7 |
| 30 | 55.5 | 35.2 | 31.3 |
| 40 | 64.3 | 42.9 | 42.3 |
| 50 | 71.4 | 52.4 | 63.2 |
| 60 | 77.2 | 60.3 | 71.2 |
| 70 | 81.6 | 68.8 | 78.1 |
| 80 | 89.9 | 77.7 | 84.4 |
| 90 | 90.0 | 86.9 | 90.0 |

7. Discussion and Concluding Remarks
Acknowledgements
References
- The Danish Energy Agency. Energy Statistics 2010. 2011. Available online: http://www.ens.dk (accessed on 28 February 2012).
- Pryor, S.; Barthelmie, R. Comparison of potential power production at on-and offshore sites. Wind Energy 2002, 4, 173–181. [Google Scholar] [CrossRef]
- Jones, L.; Clark, C. Wind Integration—A Survey of Global Views of Grid Operators. In Proceedings of the 10th International Workshop on Large-Scale Integration of Wind Power into Power Systems, Aarhus, Denmark, 25–26 October 2011.
- Akhmatov, V. Influence of wind direction on intense power fluctuations in large offshore wind farms in the North Sea. Wind Eng. 2007, 31, 59–64. [Google Scholar] [CrossRef]
- Focken, U.; Lange, M.; Mönnich, K.; Wald, H.P.; Beyer, G.; Luig, A. Short term prediction of the aggregated power output of wind farms—A statistical analysis of the reduction of the prediction error by spatial smoothing effects. J. Wind Eng. Ind. Aerodyn. 2002, 90, 231–246. [Google Scholar] [CrossRef]
- Giebel, G.; Brownsword, R.; Kariniotakis, G.; Denhard, M.; Draxl, C. The State-of-the-Art in Short-Term Prediction of Wind Power: A Literature Overview; The ANEMOS.plus project: Paris, France, 2011. [Google Scholar]
- Akhmatov, V.; Rasmussen, C.; Eriksen, P.B.; Pedersen, J. Technical aspects of status and expected future trends for wind power in Denmark. Wind Energy 2007, 10, 31–49. [Google Scholar] [CrossRef]
- Sørensen, P.; Cutululis, A.; Vigueras-Rodriguez, A.; Madsen, H.; Pinson, P.; Jensen, L.; Hjerrild, J.; Donovan, M. Modelling of power fluctuations from large offshore wind farms. Wind Energy 2008, 11, 29–43. [Google Scholar] [CrossRef]
- Vincent, C.; Giebel, G.; Pinson, P.; Madsen, H. Resolving nonstationary spectral information in wind speed time series using the Hilbert-Huang transform. J. Appl. Meteorol. Climatol. 2010, 49, 253–269. [Google Scholar] [CrossRef]
- Kristoffersen, J.; Christiansen, P. Horns Rev offshore wind farm: Its main controller and remote control system. Wind Eng. 2003, 27, 351–359. [Google Scholar] [CrossRef]
- Gneiting, T. Editorial: Probabilistic forecasting. J. R. Stat. Soc. 2008, 171, 319–321. [Google Scholar] [CrossRef]
- Hamilton, J. A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica 1989, 57, 357–384. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B. Fundamentals of Speech Recognition; Prentics-Hall, Int.: Englewoods Cliffs, NJ, USA, 2005. [Google Scholar]
- Durbin, R.; Eddy, S.; Krogh, A.; Mitchison, G. Biological Sequence Analysis; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Pinson, P.; Christensen, L.; Madsen, H.; Sørensen, P.; Donovan, M.; Jensen, L. Regime-switching modelling of the fluctuations of offshore wind generation. J. Wind Eng. Ind. Aerodyn. 2008, 96, 2327–2347. [Google Scholar] [CrossRef]
- Pinson, P.; Madsen, H. Adaptative modelling and forecasting of offshore wind power fluctuations with Markov-Switching autoregressive models. J. Forecast. 2010. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized Autoregressive Conditional Heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Madsen, H.; Pinson, P.; Nielsen, T.; Nielsen, H.; Kariniotakis, G. Standardizing the performance evaluation of short-term wind power prediction models. Wind Eng. 2005, 29, 475–489. [Google Scholar] [CrossRef] [Green Version]
- Sánchez, I. Short-term prediction of wind energy production. Int. J. Forecast. 2006, 22, 43–56. [Google Scholar] [CrossRef]
- Vincent, C. Mesoscale Wind Fluctuations Over Danish Waters. PhD Thesis, Technical University of Denmark, Copenhagen, Denmark, 2010. Available online: http://www.dtu.dk/English/Service/Phonebook.aspx?lg=showcommon&id=276913 (accessed on 2 March 2012). [Google Scholar]
- Lau, A.; McSharry, P. Approaches for multi-step density forecasts with application to aggregated wind power. Ann. Appl. Stat. 2010, 4, 1311–1341. [Google Scholar] [CrossRef]
- Gneiting, T.; Larson, K.; Westrick, K.; Genton, M.; Aldrich, E. Calibrated probabilistic forecasting at the Stateline wind energy center: The regime-switching space-time method. J. Am. Stat. Assoc. 2006, 101, 968–979. [Google Scholar] [CrossRef]
- Thorarinsdottir, T.; Gneiting, T. Probabilistic forecasts of wind speed: Ensemble model output statistics using heteroskedastic censored regression. J. R. Stat. Soc. 2010, 173, 371–388. [Google Scholar] [CrossRef]
- Pinson, P. Very short-term probabilistic forecasting of wind power with generalized logit-Normal distributions. J. R. Stat. Soc., Series C 2012. Available online. [Google Scholar] [CrossRef]
- Klaasen, F. Improving GARCH volatility forecasts with regime-switching GARCH. Empir. Econ. 2002, 27, 363–394. [Google Scholar] [CrossRef]
- Gray, S. Modeling the conditional distribution of interest rates as a regime-switching process. J. Financ. Econ. 1996, 42, 27–62. [Google Scholar] [CrossRef]
- Tol, R. Autoregressive conditional heteroscedasticity in daily wind speed measurements. Theor. Appl. Climatol. 1997, 56, 113–122. [Google Scholar] [CrossRef]
- Cripps, E.; Dunsmuir, W. Modeling the variability of Sydney Harbor wind measurments. J. Appl. Meteorol. 2003, 42, 1131–1138. [Google Scholar] [CrossRef]
- Ewing, B.; Kruse, J.; Schreoder, J. Time series analysis of wind speed with time-varying turbulence. Environmetrics 2006, 17, 119–127. [Google Scholar] [CrossRef]
- Taylor, J.; Buizza, R. A comparison of temperature density forecasts from GARCH and atmospheric models. J. Forecast. 2004, 23, 337–355. [Google Scholar] [CrossRef]
- Taylor, J.; Buizza, R. Density forecasting for weather derivative pricing. Int. J. Forecast. 2006, 22, 29–42. [Google Scholar] [CrossRef]
- Taylor, J.; McSharry, P.; Buizza, R. Wind power density forecasting using ensemble predictions and time series models. IEEE Trans. Energy Convers. 2009, 24, 775–782. [Google Scholar] [CrossRef]
- Cai, J. A Markov model of switching-regime ARCH. J. Bus. Econ. Stat. 1994, 12, 309–316. [Google Scholar]
- Hamilton, J.; Susmel, R. Autoregressive conditional heteroskedasticity and changes in regime. J. Econom. 1994, 64, 307–333. [Google Scholar] [CrossRef]
- Haas, M.; Mittnik, S.; Paolella, M. A new approach to Markov-Switching GARCH models. J. Financ. Econom. 2004, 2, 493–530. [Google Scholar] [CrossRef]
- Fruhwirth-Schnatter, S. Finite Mixture and Markov Switching Models; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Henneke, J.; Rachev, S.; Fabozzi, F.; Nikolov, M. MCMC-based estimation of Markov-Switching ARMA-GARCH models. Appl. Econ. 2011, 43, 259–271. [Google Scholar] [CrossRef]
- Chen, C.; So, M.; Lin, E. Volatility forecasting with Double Markov switching GARCH models. J. Forecast. 2009, 28, 681–697. [Google Scholar] [CrossRef]
- Bauwens, L.; Preminger, A.; Rombouts, V. Theory and inference for a Markov switching GARCH model. Econom. J. 2010, 13, 218–244. [Google Scholar] [CrossRef]
- Rydén, T. EM versus Markov chain Monte Carlo for Estimation of Hidden Markov models: A computational perspective. Bayesian Anal. 2008, 3, 659–688. [Google Scholar] [CrossRef]
- Gilks, W.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman & Hall: London, UK, 1996. [Google Scholar]
- Tanner, M.; Wong, W. The calculation of the posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987, 82, 528–540. [Google Scholar] [CrossRef]
- Robert, C.; Celeux, G.; Diebolt, J. Bayesian estimation of hidden Markov chains: A stochastic implementation. Stat. Probab. Lett. 1993, 16, 77–83. [Google Scholar] [CrossRef]
- Scott, S. Bayesian methods for Hidden Markov Models: Recursive computing in the 21st century. J. Am. Stat. Assoc. 2002, 97, 337–351. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distribution and bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Chib, S. Calculating posterior distributions and modal estimates in Markov mixture models. J. Econom. 1996, 75, 79–97. [Google Scholar] [CrossRef]
- Hastings, W. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Ritter, C.; Tanner, M. Facilitating the Gibbs Sampler: The Gibbs stopper and the Griddy Gibbs sampler. J. Am. Stat. Assoc. 1992, 87, 861–868. [Google Scholar] [CrossRef]
- Bauwens, L.; Lubrano, M. Bayesian inference on GARCH models using the Gibbs sampler. Econom. J. 1998, 1, 23–46. [Google Scholar] [CrossRef]
- Asai, M. Comparison of MCMC methods for estimating GARCH models. J. Jpn. Stat. Soc. 2006, 36, 199–212. [Google Scholar] [CrossRef]
- Liu, J.; Wong, W.; Kong, A. Covariance structure and Convergence rate of the Gibbs sampler with various scans. J. R. Stat. Soc. Ser. B 1995, 57, 157–169. [Google Scholar]
- Gelman, A.; Rubin, D. Inference from Iterative Simulation Using Multiple Sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Forney Jr, G. The viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Psaradakis, Z.; Spagnolo, N. Joint determination of the state dimension and autoregressive order for Markov regime switching. J. Time Ser. Anal. 2006, 27, 753–766. [Google Scholar] [CrossRef]
- Cheung, C.; Miu, P. Currency instability: Regime switching versus volatility clustering. Q. J. Financ. Acc. 2009, 48, 67–81. [Google Scholar]
- Gallego, C.; Pinson, P.; Madsen, H.; Costa, A.; Cuerva, A. Influence of local wind speed and direction on wind power dynamics—Application to offshore very short-term forecasting. Appl. Energy 2011, 88, 4087–4096. [Google Scholar] [CrossRef] [Green Version]
- Pinson, P.; Chevallier, C.; Kariniotakis, G. Trading wind generation with short-term probabilistic forecasts of wind power. IEEE Trans. Power Syst. 2007, 22, 1148–1156. [Google Scholar] [CrossRef]
- Gneiting, T.; Balabdaoui, F.; A.E., R. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. B 2007, 69, 243–268. [Google Scholar] [CrossRef]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trombe, P.-J.; Pinson, P.; Madsen, H. A General Probabilistic Forecasting Framework for Offshore Wind Power Fluctuations. Energies 2012, 5, 621-657. https://doi.org/10.3390/en5030621
Trombe P-J, Pinson P, Madsen H. A General Probabilistic Forecasting Framework for Offshore Wind Power Fluctuations. Energies. 2012; 5(3):621-657. https://doi.org/10.3390/en5030621
Chicago/Turabian StyleTrombe, Pierre-Julien, Pierre Pinson, and Henrik Madsen. 2012. "A General Probabilistic Forecasting Framework for Offshore Wind Power Fluctuations" Energies 5, no. 3: 621-657. https://doi.org/10.3390/en5030621
APA StyleTrombe, P.-J., Pinson, P., & Madsen, H. (2012). A General Probabilistic Forecasting Framework for Offshore Wind Power Fluctuations. Energies, 5(3), 621-657. https://doi.org/10.3390/en5030621