
A Hierarchical Approach Using Machine Learning Methods in Solar Photovoltaic Energy Production Forecasting

Abstract
:1. Introduction
2. Methodology
2.1. Artificial Neural Networks

2.2. Support Vector Regression
2.3. Hierarchical Forecasting

3. Performance Matrixes
- Mean bias error (MBE)
- Mean absolute error (MAE)
- Root mean square error (RMSE)
- Relative MBE (rMBE)
- Mean percentage error (MPE)
- Relative root mean squared error (rRMSE)
4. Data
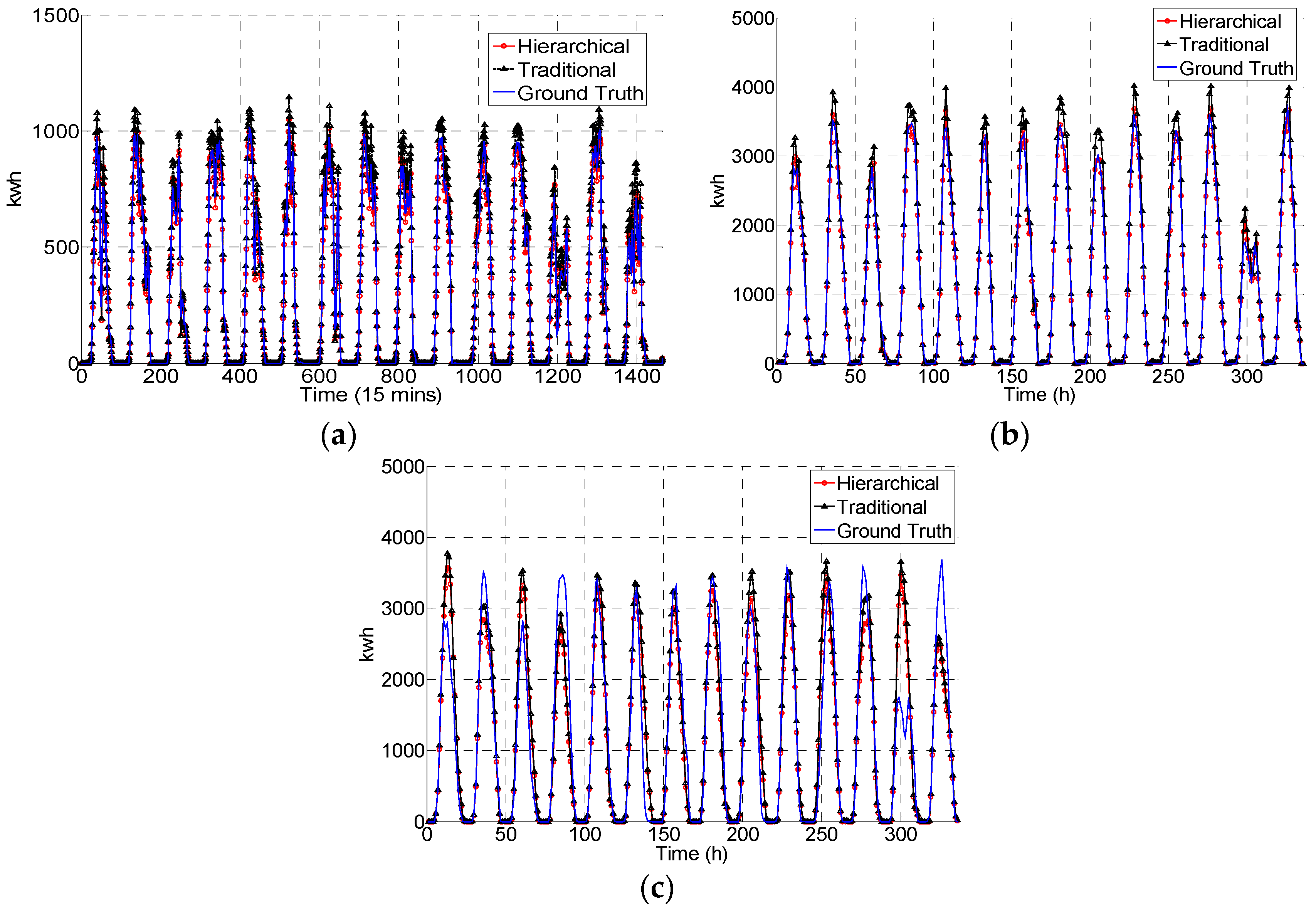
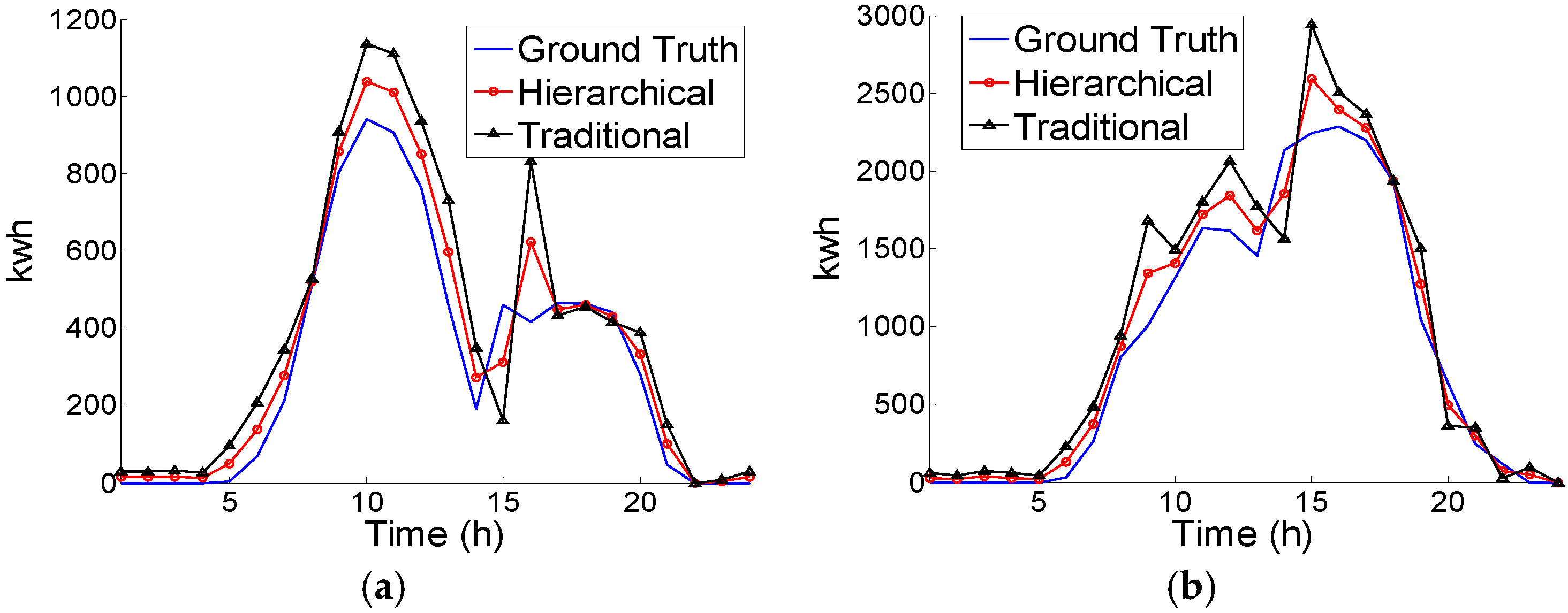
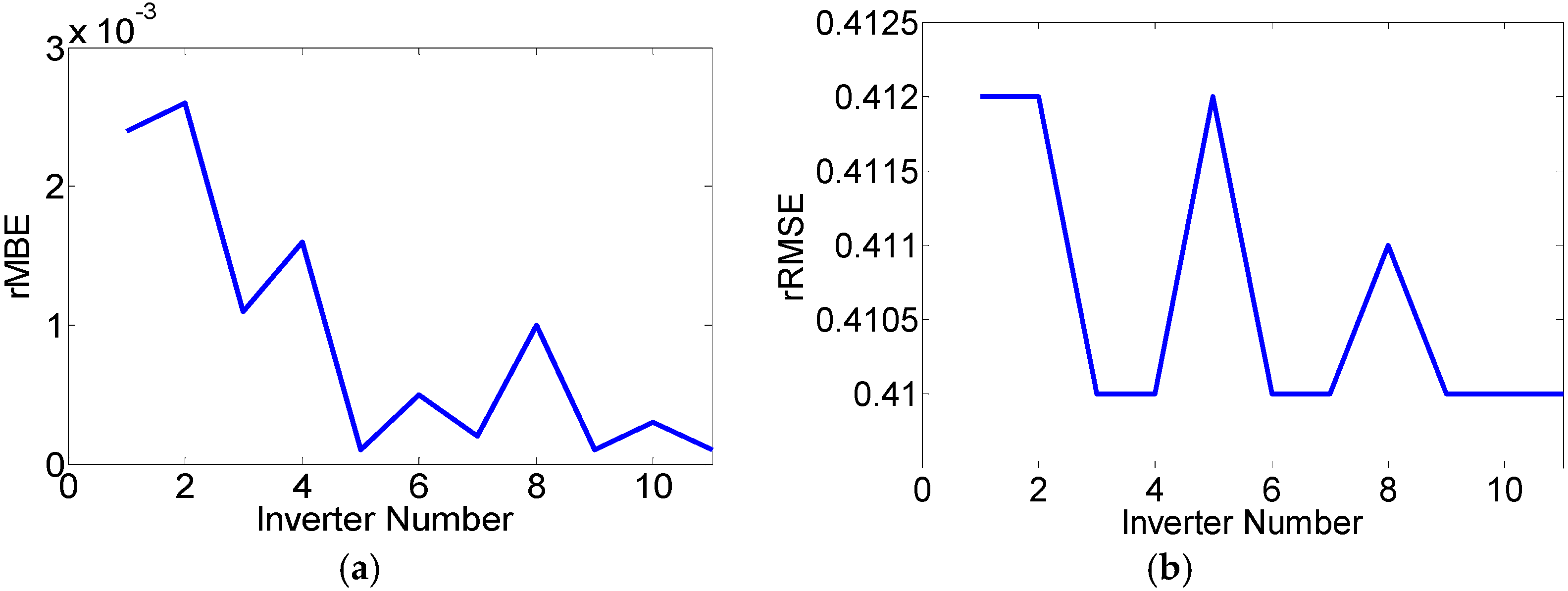
5. Results and Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Endogenous input | Model | MBE (kWh) | MAE (kWh) | RMSE (kWh) | rMBE | rRMSE | MPE |
|---|---|---|---|---|---|---|---|
| Inverters | ANN | 0.49 | 34.57 | 42.15 | 0.0131 | 0.131 | 4.32 |
| SVR | 0.58 | 35.73 | 43.52 | 0.0132 | 0.133 | 4.34 | |
| Whole plant | ANN | 0.54 | 35.85 | 43.67 | 0.0135 | 0.132 | 4.31 |
| SVR | 0.51 | 36.21 | 45.70 | 0.0132 | 0.135 | 4.31 |
| Endogenous input | Model | MBE (kWh) | MAE (kWh) | RMSE (kWh) | rMBE | rRMSE | MPE |
|---|---|---|---|---|---|---|---|
| Inverters | ANN | 0.50 | 51.56 | 63.62 | 0.0128 | 0.134 | 4.32 |
| SVR | 0.55 | 50.77 | 66.87 | 0.0131 | 0.136 | 4.34 | |
| Whole plant | ANN | 0.53 | 52.23 | 65.45 | 0.0134 | 0.135 | 4.31 |
| SVR | 0.57 | 54.69 | 65.43 | 0.0131 | 0.135 | 4.31 |
| Endogenous input | Model | MBE (kWh) | MAE (kWh) | RMSE (kWh) | rMBE | rRMSE | MPE |
|---|---|---|---|---|---|---|---|
| Inverters | ANN | 0.03 | 126.32 | 182.64 | 0.0001 | 0.410 | 10.54 |
| SVR | 0.05 | 134.48 | 185.44 | 0.0002 | 0.410 | 10.53 | |
| Whole plant | ANN | −0.07 | 128.77 | 183.49 | 0.0012 | 0.412 | 10.51 |
| SVR | 0.01 | 126.89 | 185.67 | 0.0002 | 0.411 | 10.52 |


| Inverter | MBE (kWh) | MAE (kWh) | RMSE (kWh) | rMBE | rRMSE | MPE | Max energy (kWh) |
|---|---|---|---|---|---|---|---|
| A1 | −0.57 | 4.95 | 6.15 | 0.0124 | 0.134 | 4.36 | 113.4 |
| A2 | −0.55 | 5.06 | 6.27 | 0.0118 | 0.134 | 4.39 | 113.15 |
| B1 | −0.52 | 4.93 | 6.13 | 0.0112 | 0.131 | 4.39 | 110.45 |
| B2 | −0.39 | 5.03 | 6.24 | 0.0083 | 0.133 | 4.45 | 111.16 |
| C1 | 0.42 | 4.91 | 6.11 | 0.0119 | 0.133 | 4.42 | 110.45 |
| C2 | 0.51 | 4.97 | 6.19 | 0.0126 | 0.133 | 4.37 | 109.75 |
| D1 | 0.45 | 5.09 | 6.21 | 0.0133 | 0.134 | 4.46 | 110.5 |
| D2 | 0.56 | 5.14 | 6.15 | 0.0148 | 0.132 | 4.41 | 110.25 |
| E1 | −0.57 | 4.96 | 6.18 | 0.0134 | 0.131 | 4.36 | 112.89 |
| E2 | 0.43 | 5.07 | 6.22 | 0.0127 | 0.131 | 4.43 | 112.5 |
| E3 | 0.44 | 5.03 | 6.26 | 0.0131 | 0.134 | 4.37 | 114.2 |
| Inverter | MBE (kWh) | MAE (kWh) | RMSE (kWh) | rMBE | rRMSE | MPE | Max energy (kWh) |
|---|---|---|---|---|---|---|---|
| A1 | 0.59 | 4.55 | 5.58 | 0.0146 | 0.139 | 4.08 | 446 |
| A2 | 0.48 | 4.69 | 5.74 | 0.0118 | 0.140 | 4.14 | 452.6 |
| B1 | 0.44 | 4.62 | 5.63 | 0.0107 | 0.137 | 4.18 | 441.8 |
| B2 | 0.47 | 4.71 | 5.74 | 0.0114 | 0.140 | 4.24 | 444.64 |
| C1 | 0.49 | 4.75 | 5.55 | 0.0127 | 0.135 | 4.19 | 441.8 |
| C2 | 0.55 | 4.63 | 5.62 | 0.0119 | 0.140 | 4.26 | 439 |
| D1 | 0.43 | 4.62 | 5.72 | 0.0125 | 0.139 | 4.19 | 442 |
| D2 | 0.52 | 4.59 | 5.67 | 0.0141 | 0.138 | 4.20 | 441 |
| E1 | 0.58 | 4.58 | 5.56 | 0.0135 | 0.137 | 4.16 | 451.56 |
| E2 | 0.50 | 4.68 | 5.63 | 0.0133 | 0.138 | 4.22 | 450 |
| E3 | 0.55 | 4.70 | 5.66 | 0.0129 | 0.136 | 4.21 | 456.8 |
| Inverter | MBE (kWh) | MAE (kWh) | RMSE (kWh) | rMBE | rRMSE | MPE | Max energy (kWh) |
|---|---|---|---|---|---|---|---|
| 1 | −0.10 | 11.46 | 16.37 | 0.0024 | 0.412 | 10.28 | 446 |
| 2 | −0.21 | 23.39 | 33.13 | 0.0026 | 0.412 | 10.41 | 898.6 |
| 3 | −0.14 | 35.27 | 49.73 | 0.0011 | 0.410 | 10.52 | 1340.4 |
| 4 | −0.25 | 47.19 | 66.40 | 0.0016 | 0.410 | 10.57 | 1785.04 |
| 5 | 0.01 | 58.95 | 83.09 | 0.0001 | 0.412 | 10.59 | 2226.84 |
| 6 | 0.11 | 70.11 | 99.08 | 0.0005 | 0.410 | 10.52 | 2665.84 |
| 7 | 0.06 | 81.96 | 115.80 | 0.0002 | 0.410 | 10.55 | 3107.84 |
| 8 | −0.31 | 93.43 | 132.07 | 0.0010 | 0.411 | 10.53 | 3548.84 |
| 9 | 0.03 | 105.58 | 149.10 | 0.0001 | 0.410 | 10.56 | 4000.4 |
| 10 | 0.11 | 117.27 | 165.70 | 0.0003 | 0.410 | 10.54 | 4450.4 |
| 11 | 0.03 | 126.32 | 182.64 | 0.0001 | 0.410 | 10.54 | - |
| Whole plant | −0.07 | 128.77 | 183.49 | 0.0002 | 0.412 | 10.51 | - |

6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mellit, A. Artificial intelligence technique for modelling and forecasting of solar radiation data: A review. Int. J. Artif. Intell. Soft Comput. 2008, 1, 52–76. [Google Scholar] [CrossRef]
- Paoli, C.; Voyant, C.; Muselli, M.; Nivet, M. Forecasting of preprocessed daily solar radiation time series using neural networks. Sol. Energy 2010, 84, 2146–2160. [Google Scholar] [CrossRef]
- Marquez, R.; Coimbra, C.F.M. Forecasting of global and direct solar irradiance using stochastic learning methods, ground experiments and the NWS database. Sol. Energy 2011, 85, 746–756. [Google Scholar] [CrossRef]
- Bacher, P.; Madsen, H.; Nielson, H.A. Online short-term solar power forecasting. Sol. Energy 2009, 83, 1772–1783. [Google Scholar] [CrossRef]
- Martín, L.; Zarzalejo, L.F.; Polo, J.; Navarro, A.; Marchante, R.; Cony, M. Prediction of global solar irradiance based on time series analysis: Application to solar thermal power plants energy production planning. Sol. Energy 2010, 84, 1772–1781. [Google Scholar] [CrossRef]
- Picault, D.; Raison, B.; Bacha, S.; De La Casa, J.; Aguilera, J. Forecasting photovoltaic array power production subject to mismatch losses. Sol. Energy 2010, 84, 1301–1309. [Google Scholar] [CrossRef]
- Chow, C.W.; Urquhart, B.; Lave, M.; Dominguez, A.; Kleissl, J.; Shields, J.; Washom, B. Intra-hour forecasting with a total sky imager at the UC San Diego solar energy testbed. Sol. Energy 2011, 85, 2881–2893. [Google Scholar] [CrossRef]
- Chen, C.; Duan, S.; Cai, T.; Liu, B. Online 24-h solar power forecasting based on weather type classification using artificial neural network. Sol. Energy 2011, 85, 2856–2870. [Google Scholar] [CrossRef]
- Tao, C.; Duan, S.; Chen, C. Forecasting Power Output for Grid-connected Photovoltaic Power System without using Solar Radiation Measurement. In Proceedings of the 2nd IEEE International Symposium on Power Electrics for Distributed Generation Systems, Heifei, China, 16–18 June 2010.
- Yona, A.; Senjyu, T.; Yousuf, A.; Funabashi, T.; Sekine, H.; Kim, C.H. Application of Neural Network to One-Day-Ahead 24 hours Generating Power Forecasting for Photovoltaic System. In Proceedings of the 2007 International Conference on Intelligent Systems Applications to Power Systems, Niigata, Japan, 5–8 November 2007.
- Ciabattoni, L.; Grisostomi, M.; Longhi, S.; Mainardi, E. Online Tuned Neural Networks for PV Plant Production Forecasting. In Proceedings of the 38th IEEE Photovoltaic Specialists Conference, Austin, TX, USA, 3–8 June 2012.
- Benghanem, M.; Mellit, A. Radial Basis Function Network-based prediction of global solar radiation data: Application for sizing of a stand-alone photovoltaic system at Al-Madinah, Saudi Arabia. Energy 2010, 35, 3751–3762. [Google Scholar] [CrossRef]
- Benghanem, M.; Mellit, A.; Alamri, S.N. ANN-based modeling and estimation of daily global solar radiation data: A case study. Energy Consersion Manag. 2009, 50, 1644–1655. [Google Scholar] [CrossRef]
- Dorvlo, A.S.S.; Jervase, J.A.; Al-Lawati, A. Solar radiation estimation using artificial neural networks. Appl. Energy 2002, 71, 307–319. [Google Scholar] [CrossRef]
- Yadav, A.K.; Chandel, S.S. Solar radiation prediction using Artificial Neural Network techniques: A review. Renew. Sustain. Energy Rev. 2014, 33, 772–781. [Google Scholar] [CrossRef]
- Mellit, A.; Menghanem, M.; Bendekhis, M. Artificial Neural Network Model for Prediction Solar Radiation Data: Application for Sizing Stand-Alone Photovoltaic Power System. In Proceedings of the 2005 Power Engineering Society General Meeting, San Francisco, CA, USA, 12–16 June 2005.
- Behrang, M.A.; Assareh, E.; Ghanbarzadeh, A.; Noghrehabadi, A.R. The potential of different artificial neural network (ANN) techniques in daily global solar radiation modeling based on meteorological data. Sol. Energy 2010, 84, 1468–1480. [Google Scholar] [CrossRef]
- Zeng, J.; Qiao, W. Short-Term Solar Power Prediction Using an RBF Neural Network. In Proceedings of the 2011 Power and Energy Society General Meeting, San Diego, CA, USA, 24–29 July 2011.
- Ciabattoni, L.; Grisostomi, M.; Ippoliti, G.; Longhi, S.; Mainardi, E. On Line Solar Irradiation Forecasting by Minimal Resource Allocating Networks. In Proceedings of the 20th Mediterranean Conference on Control & Automation (MED), Barcelona, Spain, 3–6 July 2012; pp. 1506–1511.
- Cao, J.; Lin, X. Application of the diagonal recurrent wavelet neural network to solar irradiation forecast assisted with fuzzy technique. Eng. Appl. Artif. Intell. 2008, 21, 1255–1263. [Google Scholar] [CrossRef]
- Ciabattoni, L.; Grisostomi, M.; Ippoliti, G.; Pagnotta, D.P.; Foresi, G.; Longhi, S. Residential Energy Monitoring and Management Based on Fuzzy Logic. In Proceedings of the IEEE International Conference on Consumer Electronics, Berlin, Germany, 9–12 January 2015.
- Deng, F.; Su, G.; Liu, C.; Wang, Z. Prediction of Solar Radiation Resources in China Using the LS-SVM Algorithms. In Proceedings of the 2nd International Conference on Computer and Automation Engineering, Singapore, 26–28 February 2010.
- Ogliari, E.; Grimaccia, F.; Leva, S.; Mussetta, M. Hybrid predictive models for accurate forecasting in PV systems. Energies 2013, 6, 1918–1929. [Google Scholar] [CrossRef] [Green Version]
- Bouzerdoum, M.; Mellit, A.; Pavan, A.M. A hybrid model (SARIMA-SVM) for short-term power forecast of a small-scale grid-connected photovoltaic plant. Sol. Energy 2013, 98, 226–235. [Google Scholar] [CrossRef]
- Izgi, E.; Oztopal, A.; Yerli, B.; Kaymak, M.K.; Sahin, A.D. Short-mid-term solar power prediction by using artificial neural networks. Sol. Energy 2012, 86, 725–733. [Google Scholar] [CrossRef]
- Leva, S.; Dolara, A.; Grimaccia, F.; Mussetta, M.; Sahin, E. Analysis and validation of 24 hours ahead neural network forecasting for photovoltaic output power. Math. Comput. Simul. 2015. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Lee, W.J.; Liu, Y.; Yang, Y.; Wang, P. Forecasting Power Output of Photovoltaic Systems Based on Weather Classification and Support Vector Machines. IEEE Trans. Ind. Appl. 2012, 48, 1064–1069. [Google Scholar] [CrossRef]
- Grimaccia, F.; Mussetta, M.; Zich, R. Neuro-Fuzzy Predictive Model for PV Energy Production based on Weather Forecast. In Proceedings of the 2011 IEEE International Conference on Fuzzy Systems, Taipei, Taiwan, 27–30 June 2011.
- Caputo, D.; Grimaccia, F.; Mussetta, M.; Zich, R.E. Photovoltaic Plants Predictive Model by means of ANN trained by a Hybrid Evolutionary Algorithm. In Proceedings of the 2010 International Joint Conference on Neural Network, Barcelona, Spain, 18–23 July 2010.
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995; pp. 116–121. [Google Scholar]
- Rahman, S.M.M.; Dong, B.; Vega, R. Machine Learning Approach Applied in Electricity Load Forecasting: Within Residential Houses Context. In Proceedings of the ASHRAE 2015 Annual Conference, Atlanta, GA, USA, 21 June–1 July 2015.
- Dong, B.; Li, Z.; Rahman, S.M.M.; Vega, R. A Hybrid Model Approach for Forecasting Future Residential Electricity Consumption. J. Energy Build. 2015. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer-Verlag: New York, NY, USA, 1995. [Google Scholar]
- Smits, G.F.; Jordaan, E.M. Improved SVM Regression Using Mixtures of Kernels. In Proceedings of the 2002 International Joint Conference on Neural Networks, IJCNN'02, Honolulu, HI, USA, 12–17 May 2002; pp. 2785–2790.
- Ahmad, A.S.; Hassan, M.Y.; Abdullah, M.P.; Rahman, H.A.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Rahman, S.M.; Vega, R.; Dong, B. A Hierarchical Approach Using Machine Learning Methods in Solar Photovoltaic Energy Production Forecasting. Energies 2016, 9, 55. https://doi.org/10.3390/en9010055
Li Z, Rahman SM, Vega R, Dong B. A Hierarchical Approach Using Machine Learning Methods in Solar Photovoltaic Energy Production Forecasting. Energies. 2016; 9(1):55. https://doi.org/10.3390/en9010055
Chicago/Turabian StyleLi, Zhaoxuan, SM Mahbobur Rahman, Rolando Vega, and Bing Dong. 2016. "A Hierarchical Approach Using Machine Learning Methods in Solar Photovoltaic Energy Production Forecasting" Energies 9, no. 1: 55. https://doi.org/10.3390/en9010055
APA StyleLi, Z., Rahman, S. M., Vega, R., & Dong, B. (2016). A Hierarchical Approach Using Machine Learning Methods in Solar Photovoltaic Energy Production Forecasting. Energies, 9(1), 55. https://doi.org/10.3390/en9010055