2.1. Electrical Characterization and Device Modeling
The devices employed in this study are TiN/Ti-HfO
2-W metal–insulator–metal (MIM) structures. They were fabricated on silicon wafers either with an oxide isolation scheme or as a single crossbar on a thermally grown 200 nm-thick silicon dioxide. The 10 nm-thick HfO
2 layer was deposited by atomic layer deposition at 225 °C using TDMAH and H
2O as precursors, and N
2 as carrier and purge gas. The top and bottom metal electrodes were deposited by magnetron sputtering and patterned by photolithography. The bottom electrode (BE) consists of a W layer and the top electrode (TE) of TiN on a 10 nm-Ti layer acting as oxygen getter material. The fabricated devices are square cells with an area of 5 × 5 μm
2.
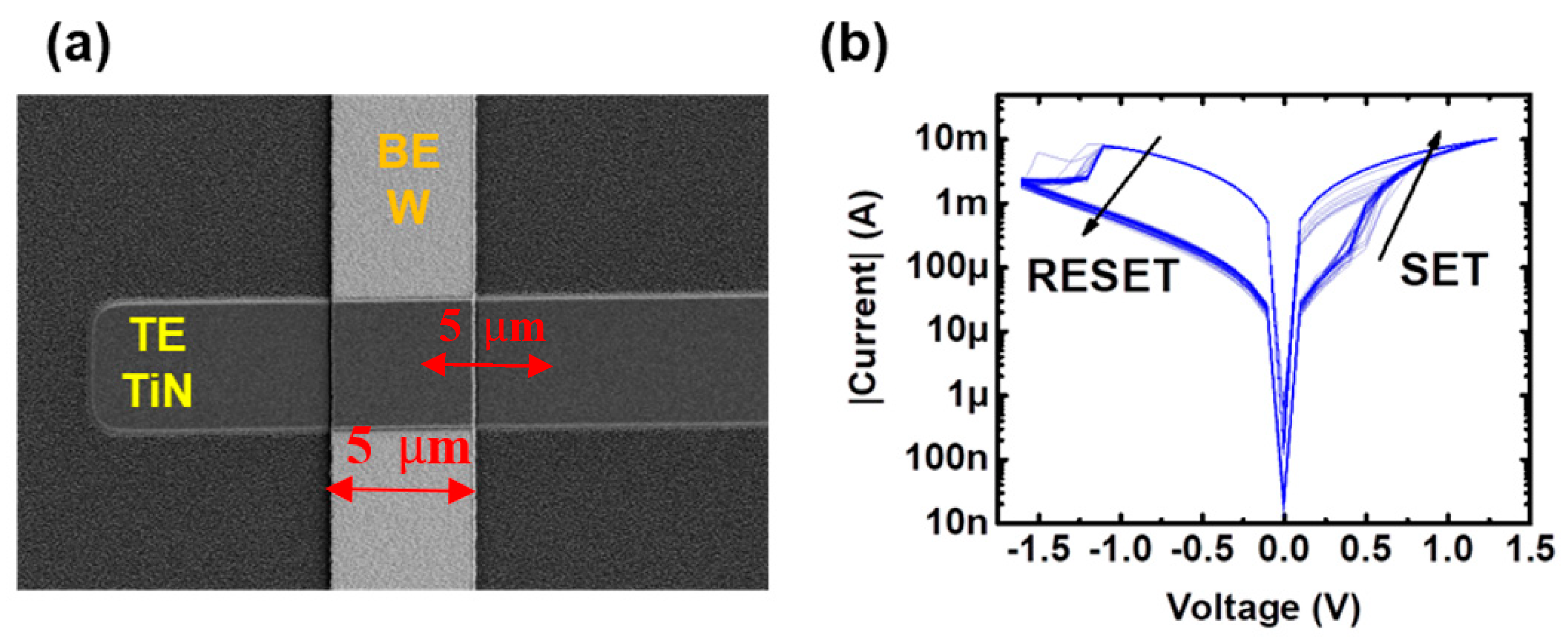
Figure 4a shows a scanning electron microscope (SEM) (IMB-CNM (CSIC), Barcelona, Spain) image of the tested structures, where the TE and BE are indicated. More details on the electrical behavior and fabrication process of these samples can be found in [
30,
31].
In
Figure 4b, a few examples of experimental I–V curves are shown, where it can be noted that the tested devices display a bipolar resistive switching behavior, consisting in transitions from high (HRS) to low (LRS) resistance states and vice versa. These transitions are identified as the SET and RESET processes, respectively. The main results of a previous work [
30] show that small changes in the conductivity at the low resistance state (LRS) can be induced by means of controlling the maximum current driving the devices during the SET process, proving their plasticity property, and thus indicating that the tested devices are suitable to play the synaptic role in a neuromorphic crossbar-array. In [
29], a pulse-programming setup was proposed, with the aim of analyzing in which ways fine changes in the conductivity of the device can be induced by the application of single pulses. The proposed setup allowed obtaining the experimental G–V characteristics of the tested devices, by means of the application of increasing and decreasing amplitude single pulses with a fixed pulse-width over time. Results from [
29] are shown in
Figure 5, where the pulse amplitude and the conductivity measured after every single applied pulse (in G
o units, being G
o = 77.5 µS the quantum of conductance unit) are plotted against the number of applied pulses. The conductivity state G was measured after the application of every pulse (
Figure 5a, red pulses), by means of applying 50mV (
Figure 5b, gray pulses) and reading the current flowing through the device. In the analyzed voltage range, conductivity can take values between ~10 Go and 30 Go.
By means of representing the obtained experimental conductivity as a function of the applied voltage, the experimental the G–V characteristics can be fitted according to the compact model of [
32]. In here, the so-called hysteron function is used to describe a time-independent conductivity window as a function of the applied voltage in non-linear memristive devices. An example of an ideal hysteron function of a non-linear memristive device is depicted in
Figure 6a. The normalized internal state λ is represented as a function of voltage drop at the memristor. The top and bottom boundaries are identified as the maximum (g
max) and minimum (g
min) conductivity states. In order to increase (decrease) the conductivity state of the device, a positive (negative) voltage has to be applied so that λ shifts towards g
max (g
min), describing the Γ
+ (Γ
−) trajectories. The pair of logistic ridge functions Γ
+ and Γ
− can be modeled with two cumulative distribution functions (cdf) [
29], related to the pulse amplitudes applied to the non-linear memristive device, being V
+, σ
+ and V
−, σ
− the average and standard deviation values of the cdf related to Γ
+ (for dV/dt > 0) and Γ
− (dV/dt < 0) curves, respectively. Both of them define the boundaries of the possible conductivities of the device within a range limited by the minimum and maximum conductivity states, g
min and g
max, respectively.
In
Figure 6b, examples of the experimental G–V characteristics of the tested device are shown, alongside an example of a fitted curve (continuous lines). In here, a conductivity state sub-space is identified as a sub-hysteron (gray area). The main parameters which allow confining the conductivity of a device within the g
SHmax and g
SHmin conductivity boundaries as the top and bottom limits of the identified sub-hysteron are V
±max and V
±min. Asymmetry of the obtained G–V characteristics can be noted by comparing the mean value on the two cdf, V
+ and V
−, which were used to fit the experimental data to the logistic ridge functions Γ
+ and Γ
−. The obtained time-independent empirical model allows computing the conductivity change of the employed devices when single pulses with varying amplitude are applied, such as the ones required for studying the STDP property of electronic synapses.
2.2. STDP as a Learning Rule
For this application, the experimental STDP windows obtained in [
33] were fitted using the above described model. The experimental STDP measurements were obtained by means of applying identical pre and post-synaptic waveforms with a spike width of 1 ms and a maximum voltage of |0.7V
peak| (
Figure 7a), which corresponds to the voltage required to set the conductivity state of the device at g
SHmin ~15G
o (
Figure 6b). Two examples of the experimental and modeled STDP functions are shown in
Figure 7b. In here, a bias towards synaptic depression is observed. This biasing is related to the asymmetry observed in the G–V characteristics shown in
Figure 6b. Also, saturation of the synaptic weight update is observed for small and negative Δt. This occurs mainly because the voltage drop applied to the device is so large in magnitude, that the reached conductivity state after its application is its lowest value g
min, so the dependence of Δg with Δt is lost for −0.5 ms < Δt < 0 ms.
In order to get symmetrical STDP functions, instead of using identical pre and post-synaptic waveforms, we propose using the pair of synaptic pulse shapes shown in
Figure 8a (pre) and
Figure 8b (post), so the STDP function can be easily tuned in terms of biasing, according to the desired working regime of the employed devices. The resulting equivalent voltage drop applied to the simulated device is depicted in
Figure 8c. The maximum and minimum voltage drops at the synaptic device are defined as the V
±max and V
±min parameters, respectively (see
Figure 6b). By using the proper V
±max and V
±min values, a linear operation regime can be achieved (gray area identified as a sub-hysteron in
Figure 6b), where the conductivity state can be finely updated according to the STDP rule, and the saturation of ΔG is withdrawn. Moreover, the stochasticity related to the RESET process is avoided. In our case, the following parameters were employed: V
pre+ = 0.7 V, V
pre− = −0.225 V, V
post+ = 0.875 V and V
post− = −0.25 V. With these voltages, the conductivity is kept within a sub-hysteron region, in this case ranging from g
SHmin = 0.33 (13 G
o) to g
SHmax = 0.8 (22 G
o).
This procedure allows implementing the balanced STDP functions shown in
Figure 8e (simulation), where multiple cases involving different initial conductivity values (g
init) within the sub-hysteron region are shown. Since there is a dependence on the STDP function shape and g
init, the symmetry in the induced conductivity changes has to be checked at the normalized conductivity state of g
init ~0.5 within the sub-hysteron region, corresponding to g
init ~17.5 G
o in our case. These results support that symmetrical conductivity changes can be induced by using the proposed pre and post-synaptic waveforms, this symmetry being a key factor for increasing the neural network performance [
6].
2.3. Self-Organizing Neural Networks Based on OxRAM with Fully-Unsupervised Learning Training
The obtained symmetric STDP function in
Figure 8e is used as a local learning rule in a proposed electronic implementation of a unidimensional self-organizing map (SOM). The simulated system consists in a single memristive synaptic layer, which is implemented by an OxRAM-based crossbar array. Input and output neurons share the same structure and functionality, so that the neuron layer roles can be interchanged, and multiple synaptic layers can be concatenated without adding extra circuitry.
The neurons are considered to be integrate-and-fire neurons: the received charge is accumulated, which causes the neuron to depolarize along its membrane (membrane potential), until a certain threshold potential is reached. This process is analogous to a capacitor being charged. Finally, due to this depolarization, the neuron is able to transmit an electrochemical signal towards its synapses, thus communicating with post-synaptic (output) neurons. A schematic of the proposed electronic neuron is shown in
Figure 9a. It has six input/output terminals: terminals In1 and In4 receive current signals from the previous and following synaptic arrays, respectively. These signals polarize the neuron and update its accumulated charge, related to the membrane potential. The depolarization is monitored by means of comparing the accumulated charge to a charge threshold, Q
thr. In the case of an output neuron, when this threshold is reached, the neuron is discharged (its accumulated charge is reset to 0). Then, it triggers a voltage pulse backwards through Out1 and forwards via terminal Out4, towards its synapses. Lastly, I/O2 and I/O3 are communication ports related to the neuron neighbor’s activity signaling, providing communication with the neuron immediate neighbors. For instance, if a neuron fires a pulse, its terminal I/O2 and I/O3 flags will be activated, so its neighbors are warned and will consequently trigger a pulse, which is independent of its actual accumulated charge. When this event occurs, the accumulated charge of the neighbors is also reset. The system depicted in
Figure 9b is a simple example of a 2 × 2 crossbar array, showing all of the above mentioned connections. The system consists in two neural layers behaving as the input and output layers. The input and output layers are connected through the 2 × 2 memristive crossbar array, where every intersection corresponds to a weighted connection between an input and an output neuron, provided by a memristor. Adjacent neurons within the neuron layers are connected (black wide line) in order to provide lateral interaction, which is one of the key aspects of the proposed hardware-adapted learning algorithm.
For simplicity, a system with a single synaptic layer is considered in this work. The neuron behavior was included mathematically. Implementations of the designs of electronic neurons based in CMOS technology can be found in [
34,
35]. In the case of a single synaptic layer system, such as the one depicted in
Figure 9b, the input neurons of the system are in charge of triggering voltage pulses through terminal Out4 according to the input dataset (signaled via In1), sourcing or draining current from/to the synaptic layer, and have the integrate function disabled, as well as the neighbor interaction. Output neurons integrate the received current through terminal In1, which corresponds to the summation of each of the input neurons voltage pulse, weighted by its connection weight or device conductivity. These output neurons fire a post-synaptic pulse backwards, as a response to the input neurons activity if their accumulated charge reaches the charge threshold, and also communicate with their immediate neuronal neighbors within the output layer via terminals I/O2 and I/O3. Its activity is measured through Out4. Finally, its terminal In4 is left unconnected.
A few aspects concerning the learning algorithm are worth to be highlighted: lateral neural neighbor interaction and vertical inhibition within a synaptic column. Lateral neighborhood interaction is one of keys regarding the self-organizing property of the network. According to T. Kohonen in [
22], “it is crucial to the formation of ordered maps that the cells doing the learning are not affected independently of each other but as topologically related subsets, on each of which a similar kind of correction is imposed”. This means that when one output neuron receives a signal from a neighbor, which has recently fired a voltage pulse, it is also meant to trigger an identical pulse, both to its own connections with the input layer, and also to its other output neuron neighbor. In other words, the output activity of a particular output neuron propagates through the output neuron layer, leading to the activation of its neighbors. The number of affected neighbors can be defined externally, as well as the shape of the neighborhood interaction function.
The implementation of a neighborhood interaction function whose amplitude decays laterally is often used in the software versions of the self-organizing networks (
Figure 10). This is motivated by both anatomical and physiological evidence of the way neurons in nervous system interact laterally. The most popular choices for this function include a rectangular (abrupt) interaction function, Gaussian (a soft transition) or the so-called Mexican hat function, which consists in a soft transition involving the inhibition of the outermost neurons within the neighborhood. In our case, the decaying amplitude of the neighborhood interaction function is inherent to our system, because of the implementation of the above described STDP function as a local learning rule. Despite the neighbors of the maximally responding output neuron are intended to fire an identical pulse, this pulse will be delayed in comparison with the response of the main responding neuron (center of the neighborhood). With increasing Δt, the induced ΔG/G will also decay with increasing lateral distance, as shown in
Figure 10. The radius or number of affected neighbors can be set externally by controlling the time delay: the whole neighborhood activity can be delayed (all delayed, AD), and the propagation delay (PD) between immediate neighbors.
In
Figure 10, different neighbor interaction functions are depicted as examples considering different types of delay, where ND states for “not delayed”. The ND curve corresponds to a function where minimum delays are considered: the main firing output neuron B is firing with an accumulative delay AD of one time unit with respect to the last pre-synaptic pulse sent by neuron A, and the PD is also of one time unit. Therefore, the time delay in which a neuron C within the neighborhood fires a pulse after the main responding neuron A has triggered one, as an answer to an input neuron, corresponds to AD + PD·(N+1), being N the number of neurons which separate neurons B and C. In
Figure 10, the distance between neurons B and C is none, thus N = 0. The AD/NPD and AD/PD curves present a delay of AD = 5 time units, so that all the conductivity changes in the neighborhood are diminished equally. The difference between these two functions relies on the propagation delay: AD/NPD has the minimum PD, whereas AD/PD has a PD of two time units. As seen in
Figure 10, increasing PD results in a narrower function, reducing the number of affected neurons.
Another important aspect is the inhibition of the synapses within the synaptic column of an active neuron. The synaptic column comprises all of its synapses, some of them connecting the neurons with inactive input neurons. For our system, both potentiation of the synapse, relating the firing neuron with the active inputs, and the depression of its synaptic weights which connect it with the inactive inputs, are mandatory to efficiently group or cluster the output neurons, so that a complete correction of the synaptic weights (and thus, of its neighborhood) is performed. This means that if a particular OxRAM conductivity is increased as a result of applying the STDP rule, the other OxRAMs in that synaptic column, connecting the same output neuron with the inactive input neurons, shall be depressed (i.e., their conductivity is decreased). We refer to this process as synaptic inhibition, which leads to an increase of the sensitization of an output neuron to a single input neuron, facilitating clusters specialization to a specific input property. In order to implement this feature electronically, the silent input neurons at a particular time are not actually silent, but rather applying a small and negative voltage through terminal Out4 to their synapses, in analogy with the biological neurons’ resting potential. When an output neuron is firing a pulse backwards, the induced voltage drop at the synapses connecting to a silent input neuron will cause a decrease in their conductivity states. In this case, there is no direct relationship with the STDP rule, since the induced voltage drop at the synapses is not related to any time correlation between the pre and post-synaptic activities.
A sketch of the operation of the 2 × 2 crossbar array with active and silent neurons, where all of these signals are indicated, is shown in
Figure 11. In here, the arrows indicate the current flow in the system. The accumulated charge of the output neurons is also depicted. The input neuron layer consists on neurons A and X, whereas the output neuron layer consists on neurons B and C. In
Figure 11a, input neuron X fires a pulse through Out4, and input neuron A remains silent. These signals update the accumulated charge of the output neurons B and C. In
Figure 11b, input neuron A fires a pulse, and output neuron B accumulated charge reaches the charge threshold, Q
thr. In
Figure 11c, the accumulated charge of B is reset, and B fires a pulse delayed by a certain delay AD with respect to the firing time of input neuron A. The voltage drop at the synapses within the B column causes a change in their synaptic weights. Then, neuron B communicates with its neighbors (only neuron C is depicted). Finally, in
Figure 11d, neuron C triggers a pulse with increased time delay with respect to the firing time of A, AD + PD, and its accumulated charge is reset. Because its pulse presents a larger time delay, the magnitude of the change of its synapses will be smaller, according to the induced STDP function.
Lastly, the methodology suggested for the unsupervised self-organization process to arise is discussed. The synaptic layer is randomly initialized, that is, the conductivity state of each RRAM device is set randomly between the g
SHmin and g
SHmax values defined previously in
Figure 6b. In order to amplify the initial differences between each output neuron synaptic weight values, the threshold potential has to be set large enough, so that the first post-synaptic firing occurs after the presentation of at least 100 pre-synaptic pulses in the case of our electronic synapses. This value takes into account the initial conductivity state values of the employed synaptic devices, and the voltages required to induce the conductivity change according to the STDP function (
Figure 8e).
The active input neurons provide current (red arrows) to the output neuron layer, whereas silent input neurons drain current (blue arrows) from the system because of the polarity of its resting potential. In this way, active inputs depolarize the neurons increasing their membrane potential, whereas silent inputs decrease it (
Figure 11a,b). The identification of the best matching unit by means of calculating the Euclidean distance of the whole set of synaptic columns is avoided, which simplifies the electronic implementation of the learning algorithm compared to the original Kohonen’s self-organizing learning algorithm, despite a larger number of iterations being required in order to execute this step. On the other hand, if a neuron has recently fired a spike, it will present a refractory period, meaning that it will not be able to fire again after some time, because its accumulated charge has been reset. By doing this, the output neurons which have not fired recently are encouraged to do it. We do not explore the effects of dynamically changing the threshold potential of the output layer. However, a dynamic threshold could improve the performance in terms of convergence time of learning algorithms [
36].
The whole training stage is summarized in the flow diagram depicted in
Figure 12. Initially, all of the devices are assumed to have a random conductivity around 15–18G
o in our case. The output neurons membrane potentials are also initialized to zero. The input dataset is then fed to the system through the input neurons, which are triggering the pre-synaptic voltage waveform depicted in
Figure 8a if active, or applying their resting potential (small negative voltage) to the synaptic array, if silent (as shown in the sketches of
Figure 11a,b). The output neurons potentials increase as the output neurons integrate the pulses of the input neurons that they receive, which are weighted by the conductivity of the synaptic devices. That is, the output neurons are receiving a charge whose magnitude is related to the input activity and the weight of the connections between each of them and the input layer. Eventually, one of the output neurons potential will reach the defined charge threshold Q
thr. At this point, the weight updating process occurs: the output neuron resets its accumulated potential to zero, and triggers the post-synaptic voltage waveform from
Figure 8b backwards, affecting its synapses (
Figure 11c). The maximum voltage drop given by this post-synaptic voltage pulse and the active input neuron corresponds to the sum of V
+pre and V
−post (positive Δt), so this particular synapse is strengthened. On the other hand, the synapses with silent input neurons are depressed, being their voltage drop equal to the sum of V
+pre and the input neurons resting potential, which is a DC voltage of 0.2·V
+pre V. Therefore, the induced conductivity change in these synapses has a smaller magnitude in comparison with the one induced to the synapse that connects the winning output neuron with the active input neurons. After the weight updating of the main neuron has been executed, its activity is propagated through the output layer, affecting its immediate neighbors. These other output neurons trigger a voltage pulse with the same amplitude, but with a certain accumulated delay (
Figure 11d). That is, the magnitude of the change in the strengthened synapses will be decreasing as the output signal propagates through the output layer, until reaching a non-significant synaptic change, following the neighbor interaction function of
Figure 10. The affected neighbors will also reset their output potential to zero.
In order to reach a convergence state of the map, the maximum synaptic change is diminished by increasing the firing neuron time delay over the iterations. Also, the size of the neighborhood is naturally decreasing over time, since the neighbor firings are consequently delayed. At the end of this training stage, the crossbar weights are organized in clusters, which present overlapped areas. In this way, nearby output neurons will be prompt to react to the same input, whereas distant output neurons will be sensitized to other inputs, as occurs in the software version of the Kohonen map.

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













