
Optimal Dimensioning of Retaining Walls Using Explainable Ensemble Learning Algorithms




Abstract
:1. Introduction
2. Methods of Optimization and Predictive Model Development
2.1. Harmony Search Algorithm
2.2. Machine Learning Methodologies
2.2.1. Extreme Gradient Boosting (XGBoost)
2.2.2. Random Forest
2.2.3. Light Gradient Boosting Machine (LightGBM)
2.2.4. Categorical Gradient Boosting (CatBoost)
2.2.5. SHapley Additive exPlanations (SHAP)
3. Results
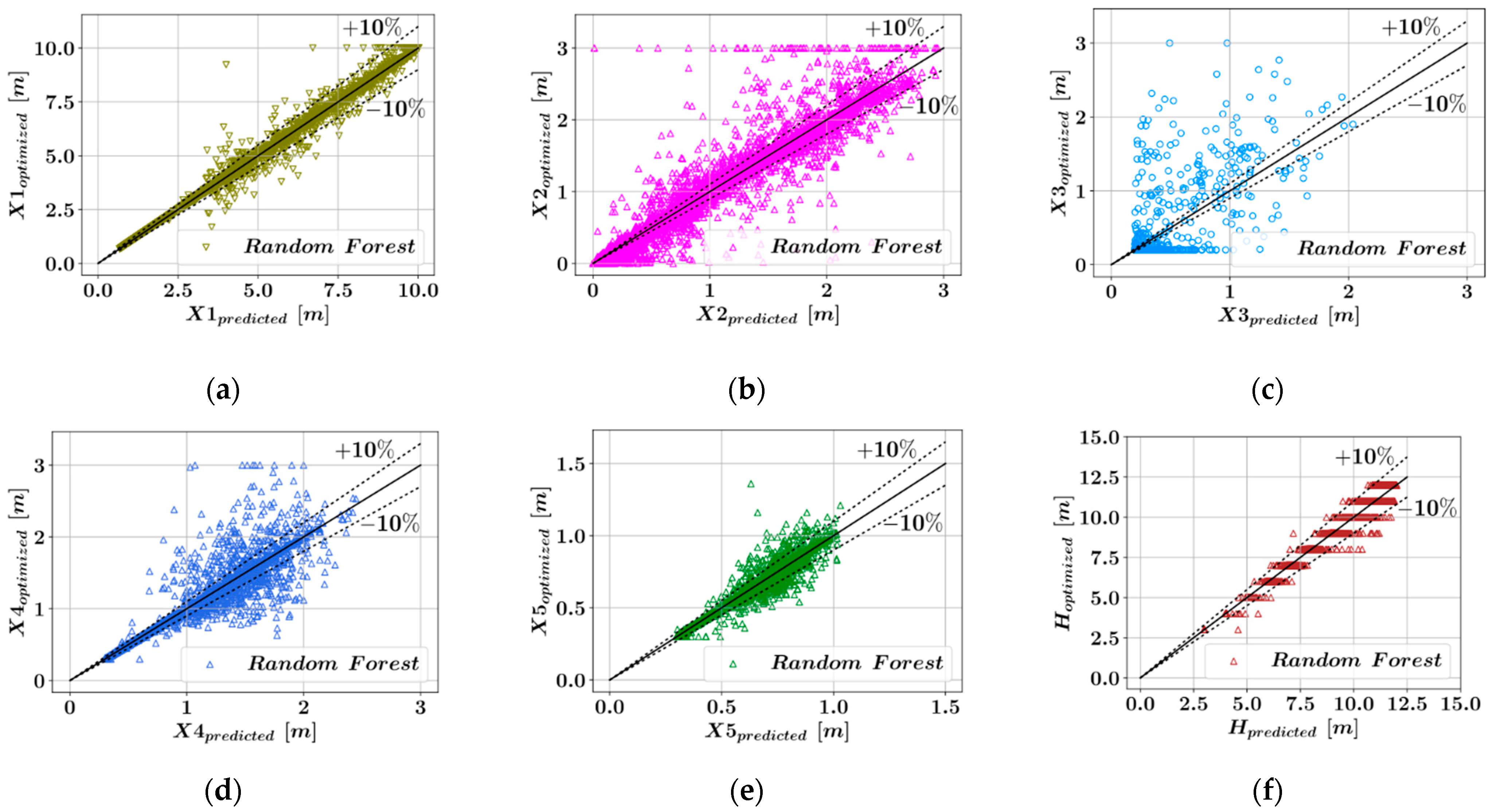
3.1. Comparison of the Model Predictions
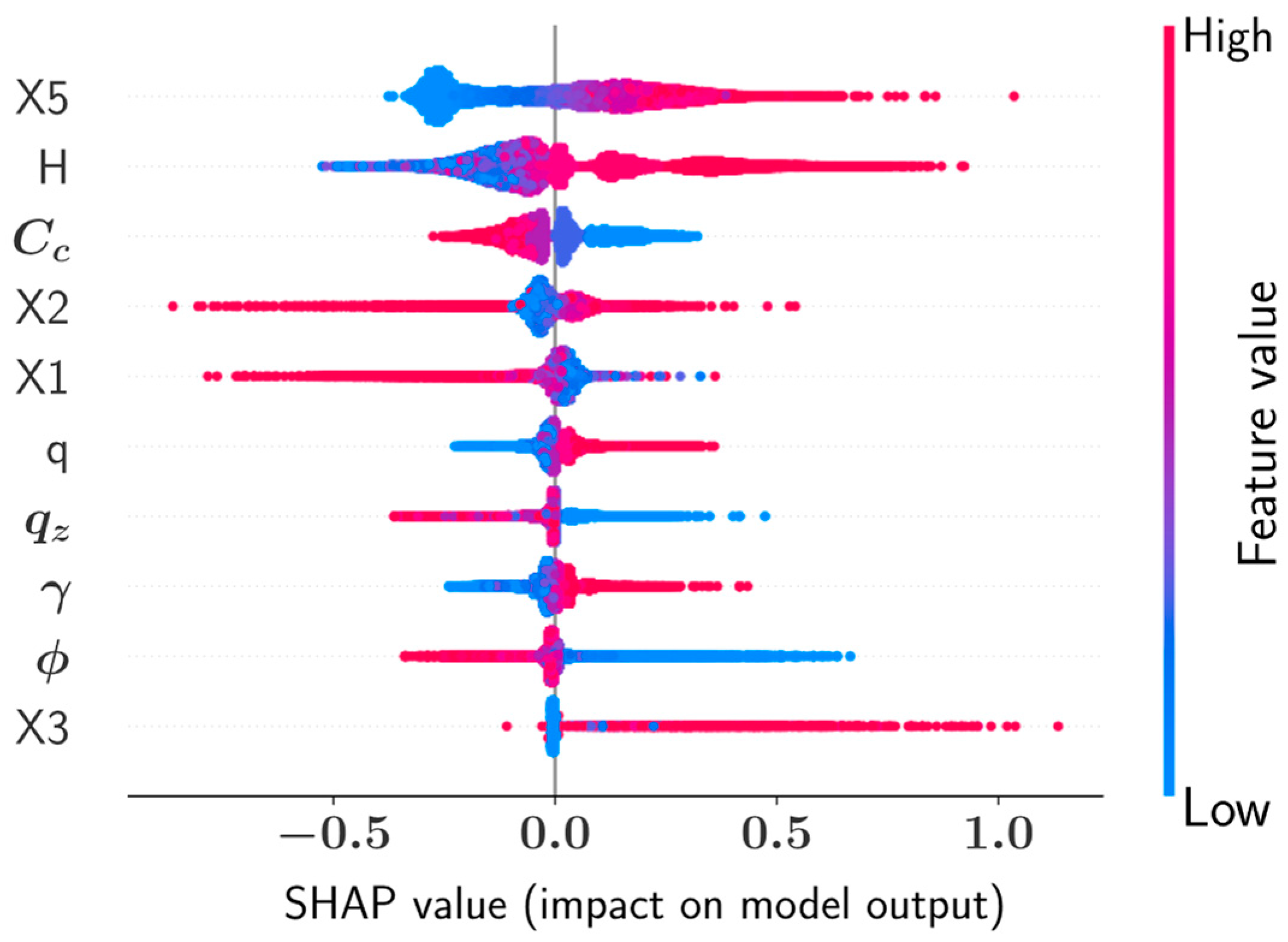
3.2. SHAP Analysis
4. Discussion
5. Conclusions
- Among the four ensemble learning models developed in this paper, the highest overall prediction accuracy could be achieved by the CatBoost model, with a maximum coefficient of determination score of 0.999 for the prediction of the optimum stem height and an average score of 0.927, while the XGBoost models demonstrated, on average, the lowest prediction accuracy.
- In terms of computational speed, the LightGBM models demonstrated the best performance, with an average duration of 6.17 s for the training and testing, whereas the CatBoost models were an order of magnitude slower than the LightGBM models.
- The results of the SHAP analysis showed that the thickness of the retaining wall foundation (X5), the unit cost of concrete (Cc), and the stem height of the wall have the greatest impact on the optimal design.
- The foundation thickness and concrete unit cost were found to be highly dependent on each other and a linear proportionality could be observed between the foundation thickness and the impact of this parameter on the optimal design configuration.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Root mean square error (RMSE): | |
| Coefficient of determination (R2): | |
| Mean absolute error (MAE): | |
| Pearson correlation coefficient: | |
References
- Gomes, H.M. Truss optimization with dynamic constraints using a particle swarm algorithm. Expert Syst. Appl. 2011, 38, 957–968. [Google Scholar] [CrossRef]
- Dede, T. Application of teaching-learning-based-optimization algorithm for the discrete optimization of truss structures. Ksce J. Civ. Eng. 2014, 18, 1759–1767. [Google Scholar] [CrossRef]
- Bekdaş, G.; Kayabekir, A.E.; Nigdeli, S.M.; Toklu, Y.C. Advanced energy-based analyses of trusses employing hybrid metaheuristics. Struct. Des. Tall Spec. Build. 2019, 28, e1609. [Google Scholar] [CrossRef]
- Bekdaş, G. New improved metaheuristic approaches for optimum design of posttensioned axially symmetric cylindrical reinforced concrete walls. Struct. Des. Tall Spec. Build. 2018, 27, e1461. [Google Scholar] [CrossRef]
- Ocak, A.; Nigdeli, S.M.; Bekdaş, G.; Kim, S.; Geem, Z.W. Adaptive Harmony Search for Tuned Liquid Damper Optimization under Seismic Excitation. Appl. Sci. 2022, 12, 2645. [Google Scholar] [CrossRef]
- Ocak, A.; Bekdaş, G.; Nigdeli, S.M.; Kim, S.; Geem, Z.W. Optimization of Tuned Liquid Damper Including Different Liquids for Lateral Displacement Control of Single and Multi-Story Structures. Buildings 2022, 12, 377. [Google Scholar] [CrossRef]
- Ulusoy, S. Optimum design of timber structures under fire using metaheuristic algorithm. Građevinar 2022, 74, 115–124. [Google Scholar] [CrossRef]
- Cakiroglu, C.; Islam, K.; Bekdaş, G.; Billah, M. CO2 emission and cost optimization of concrete-filled steel tubular (CFST) columns using metaheuristic algorithms. Sustainability 2021, 13, 8092. [Google Scholar] [CrossRef]
- Cakiroglu, C.; Islam, K.; Bekdaş, G.; Kim, S.; Geem, Z.W. CO2 Emission Optimization of Concrete-Filled Steel Tubular Rectangular Stub Columns Using Metaheuristic Algorithms. Sustainability 2021, 13, 10981. [Google Scholar] [CrossRef]
- Kaveh, A.; Kalateh-Ahani, M.; Fahimi-Farzam, M. Constructability optimal design of reinforced concrete retaining walls using a multi-objective genetic algorithm. Struct. Eng. Mech. 2013, 47, 227–245. [Google Scholar] [CrossRef]
- Mergos, P.E.; Mantoglou, F. Optimum design of reinforced concrete retaining walls with the flower pollination algorithm. Struct. Multidisc. Optim. 2020, 61, 575–585. [Google Scholar] [CrossRef]
- Khajehzadeh, M.; Taha, M.R.; Eslami, M. Efficient gravitational search algorithm for optimum design of retaining walls. Struct. Eng. Mech. 2013, 45, 111–127. [Google Scholar] [CrossRef]
- Kayabekir, A.E.; Yücel, M.; Bekdaş, G.; Nigdeli, S.M. Comparative study of optimum cost design of reinforced concrete retaining wall via metaheuristics. Chall. J. Concr. Res. Lett. 2020, 11, 75–81. [Google Scholar] [CrossRef]
- Kayabekir, A.E.; Arama, Z.A.; Bekdaş, G.; Nigdeli, S.M.; Geem, Z.W. Eco-friendly design of reinforced concrete retaining walls: Multi-objective optimization with harmony search applications. Sustainability 2020, 12, 6087. [Google Scholar] [CrossRef]
- Arama, Z.A.; Kayabekir, A.E.; Bekdaş, G.; Kim, S.; Geem, Z.W. The usage of the harmony search algorithm for the optimal design problem of reinforced concrete retaining walls. Appl. Sci. 2021, 11, 1343. [Google Scholar] [CrossRef]
- Feng, D.C.; Wang, W.J.; Mangalathu, S.; Taciroglu, E. Interpretable XGBoost-SHAP machine-learning model for shear strength prediction of squat RC walls. J. Struct. Eng. 2021, 147, 04021173. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.S.; DesRoches, R. Critical uncertainty parameters influencing seismic performance of bridges using Lasso regression. Earthq. Eng. Struct. Dyn. 2018, 47, 784–801. [Google Scholar] [CrossRef]
- Somala, S.N.; Karthikeyan, K.; Mangalathu, S. Time period estimation of masonry infilled RC frames using machine learning techniques. Structures 2021, 34, 1560–1566. [Google Scholar] [CrossRef]
- Ahmed, B.; Mangalathu, S.; Jeon, J.S. Seismic damage state predictions of reinforced concrete structures using stacked long short-term memory neural networks. J. Build. Eng. 2022, 46, 103737. [Google Scholar] [CrossRef]
- Ni, P.; Mangalathu, S.; Liu, K. Enhanced fragility analysis of buried pipelines through Lasso regression. Acta Geotech. 2020, 15, 471–487. [Google Scholar] [CrossRef]
- Bekdaş, G.; Cakiroglu, C.; Islam, K.; Kim, S.; Geem, Z.W. Optimum Design of Cylindrical Walls Using Ensemble Learning Methods. Appl. Sci. 2022, 12, 2165. [Google Scholar] [CrossRef]
- Cakiroglu, C.; Islam, K.; Bekdaş, G.; Kim, S.; Geem, Z.W. Interpretable Machine Learning Algorithms to Predict the Axial Capacity of FRP-Reinforced Concrete Columns. Materials 2022, 15, 2742. [Google Scholar] [CrossRef] [PubMed]
- Hasançebi, O.; Erdal, F.; Saka, M.P. Adaptive harmony search method for structural optimization. J. Struct. Eng. 2010, 136, 419–431. [Google Scholar] [CrossRef]
- Geem, Z.W.; Cho, Y.H. Optimal design of water distribution networks using parameter-setting-free harmony search for two major parameters. J. Water Resour. Plan. Manag. 2011, 137, 377–380. [Google Scholar] [CrossRef]
- Geem, Z.W. Parameter estimation of the nonlinear Muskingum model using parameter-setting-free harmony search. J. Hydrol. Eng. 2011, 16, 684–688. [Google Scholar] [CrossRef]
- Geem, Z.W. Economic dispatch using parameter-setting-free harmony search. J. Appl. Math. 2013, 2013, 427936. [Google Scholar] [CrossRef]
- Lee, J.H.; Yoon, Y.S. Modified harmony search algorithm and neural networks for concrete mix proportion design. J. Comput. Civ. Eng. 2009, 23, 57–61. [Google Scholar] [CrossRef]
- dos Santos Coelho, L.; de Andrade Bernert, D.L. An improved harmony search algorithm for synchronization of discrete-time chaotic systems. Chaos Solitons Fractals 2009, 41, 2526–2532. [Google Scholar] [CrossRef]
- Al-Betar, M.A.; Khader, A.T. A harmony search algorithm for university course timetabling. Ann. Oper. Res. 2012, 194, 3–31. [Google Scholar] [CrossRef]
- Chang, Y.Z.; Li, Z.W.; Kou, Y.X.; Sun, Q.P.; Yang, H.Y.; Zhao, Z.Y. A new approach to weapon-target assignment in cooperative air combat. Math. Probl. Eng. 2017, 2017, 2936279. [Google Scholar] [CrossRef] [Green Version]
- Aghakhani, K.; Karimi, A. A new approach to predict stock big data by combination of neural networks and harmony search algorithm. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 36. [Google Scholar]
- Fahad, A.M.; Muniyandi, R.C. Harmony search algorithm to prevent malicious nodes in mobile ad hoc networks (MANETs). Inf. Technol. J. 2016, 15, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Basu, A.; Sheikh, K.H.; Cuevas, E.; Sarkar, R. COVID-19 detection from CT scans using a two-stage framework. Expert Syst. Appl. 2022, 193, 116377. [Google Scholar] [CrossRef] [PubMed]
- Loy-Benitez, J.; Li, Q.; Nam, K.; Nguyen, H.T.; Kim, M.; Park, D.; Yoo, C. Multi-objective optimization of a time-delay compensated ventilation control system in a subway facility—A harmony search strategy. Build. Environ. 2021, 190, 107543. [Google Scholar] [CrossRef]
- Kayabekir, A.E.; Bekdaş, G.; Yücel, M.; Nigdeli, S.M.; Geem, Z.W. Harmony Search Algorithm for Structural Engineering Problems. In Nature-Inspired Metaheuristic Algorithms for Engineering Optimization Applications; Springer Tracts in Nature-Inspired Computing; Carbas, S., Toktas, A., Ustun, D., Eds.; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- National Bureau of Statistics of China, Market Prices of Important Means of Production in Circulation, 1–10 June 2022. Available online: http://www.stats.gov.cn/english/PressRelease/202206/t20220614_1858099.html (accessed on 7 July 2022).
- Zhang, H. (Ed.) Building Materials in Civil Engineering; Woodhead Publishing: Sawston, UK, 2011; ISBN 978-1-84569-955-0. [Google Scholar]
- Carter, H.; Bentley, S.P. Correlations of Soil Properties; Pentech: London, UK, 1990. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Mangalathu, S.; Jeon, J.-S. Machine Learning–Based Failure Mode Recognition of Circular Reinforced Concrete Bridge Columns: Comparative Study. J. Struct. Eng. 2019, 145, 04019104. [Google Scholar] [CrossRef]
- Scikit-Learn Documentation. Available online: https://scikit-learn.org/stable/modules/ensemble.html#forest (accessed on 26 June 2022).
- Feng, D.C.; Wang, W.J.; Mangalathu, S.; Hu, G.; Wu, T. Implementing ensemble learning methods to predict the shear strength of RC deep beams with/without web reinforcements. Eng. Struct. 2021, 235, 111979. [Google Scholar] [CrossRef]
- Degtyarev, V.V.; Naser, M.Z. Boosting machines for predicting shear strength of CFS channels with staggered web perforations. Structures 2021, 34, 3391–3403. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jang, H.; Hwang, S.H.; Jeon, J.S. Data-driven machine-learning-based seismic failure mode identification of reinforced concrete shear walls. Eng. Struct. 2020, 208, 110331. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. Catboost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Lee, S.; Vo, T.P.; Thai, H.T.; Lee, J.; Patel, V. Strength prediction of concrete-filled steel tubular columns using Categorical Gradient Boosting algorithm. Eng. Struct. 2021, 238, 112109. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.H.; Jeon, J.S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]










| Algorithm | Variable | R2 | MAE | RMSE | Duration [s] |
|---|---|---|---|---|---|
| XGBoost | X1 | 0.977 | 0.0697 | 0.2988 | 16.49 |
| X2 | 0.958 | 0.0573 | 0.1319 | 19.12 | |
| X3 | 0.562 | 0.0092 | 0.0759 | 16.89 | |
| X4 | 0.967 | 0.0197 | 0.0708 | 17.88 | |
| X5 | 0.988 | 0.0075 | 0.0192 | 17.62 | |
| H | 0.998 | 0.0907 | 0.1351 | 14.98 | |
| Random Forest | X1 | 0.997 | 0.0279 | 0.1091 | 65.02 |
| X2 | 0.958 | 0.0378 | 0.1220 | 62.47 | |
| X3 | 0.559 | 0.0083 | 0.0762 | 94.74 | |
| X4 | 0.960 | 0.0162 | 0.0776 | 66.19 | |
| X5 | 0.989 | 0.0052 | 0.0188 | 61.61 | |
| H | 0.997 | 0.0702 | 0.1525 | 51.24 | |
| LightGBM | X1 | 0.998 | 0.0463 | 0.0989 | 5.86 |
| X2 | 0.947 | 0.0719 | 0.1383 | 5.68 | |
| X3 | 0.566 | 0.0100 | 0.0756 | 6.27 | |
| X4 | 0.966 | 0.0208 | 0.0725 | 5.59 | |
| X5 | 0.989 | 0.0075 | 0.0186 | 7.36 | |
| H | 0.997 | 0.1051 | 0.1517 | 6.28 | |
| CatBoost | X1 | 0.998 | 0.0281 | 0.0860 | 85.31 |
| X2 | 0.960 | 0.0505 | 0.1189 | 73.05 | |
| X3 | 0.642 | 0.0093 | 0.0687 | 74.85 | |
| X4 | 0.971 | 0.0167 | 0.0660 | 85.76 | |
| X5 | 0.991 | 0.0056 | 0.0170 | 90.40 | |
| H | 0.999 | 0.0524 | 0.0890 | 75.43 |
| Algorithm | R2 | MAE | RMSE | Duration [s] |
|---|---|---|---|---|
| XGBoost | 0.9083 | 0.04235 | 0.12195 | 17.16 |
| Random Forest | 0.91 | 0.0276 | 0.0927 | 66.88 |
| LightGBM | 0.9105 | 0.0436 | 0.0926 | 6.17 |
| CatBoost | 0.92683 | 0.0271 | 0.07427 | 80.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bekdaş, G.; Cakiroglu, C.; Kim, S.; Geem, Z.W. Optimal Dimensioning of Retaining Walls Using Explainable Ensemble Learning Algorithms. Materials 2022, 15, 4993. https://doi.org/10.3390/ma15144993
Bekdaş G, Cakiroglu C, Kim S, Geem ZW. Optimal Dimensioning of Retaining Walls Using Explainable Ensemble Learning Algorithms. Materials. 2022; 15(14):4993. https://doi.org/10.3390/ma15144993
Chicago/Turabian StyleBekdaş, Gebrail, Celal Cakiroglu, Sanghun Kim, and Zong Woo Geem. 2022. "Optimal Dimensioning of Retaining Walls Using Explainable Ensemble Learning Algorithms" Materials 15, no. 14: 4993. https://doi.org/10.3390/ma15144993
APA StyleBekdaş, G., Cakiroglu, C., Kim, S., & Geem, Z. W. (2022). Optimal Dimensioning of Retaining Walls Using Explainable Ensemble Learning Algorithms. Materials, 15(14), 4993. https://doi.org/10.3390/ma15144993