

Explainable AI for Material Property Prediction Based on Energy Cloud: A Shapley-Driven Approach


Abstract
:1. Introduction
1.1. Motivation
- Firstly, the utilization of this technology expedites the process of materials discovery by facilitating the swift screening and optimization of PZT compositions.
- Consequently, this approach substantially diminishes the temporal and financial resources often expended on experimental trials.
- Furthermore, it enables engineers and researchers to customize PZT materials for particular applications, such as sensors and actuators, by precisely adjusting the dielectric characteristics. This, in turn, promotes innovation in several technical domains.
- In general, the utilization of artificial intelligence (AI) for predicting the features of lead zirconate titanate (PZT) has the capacity to bring about a significant transformation in the field of materials science. This is achieved by optimizing research processes, enhancing productivity, and facilitating the creation of customized materials that exhibit enhanced performance characteristics.
1.2. Contribution
- Development of a novel deep learning (DL) framework based on TabNet specifically tailored to predict PZT ceramics’ properties, demonstrating its effectiveness in accurate predictions.
- Investigation into the intricate relationships between the model and predictor variables, particularly under various input parameters, through a comprehensive analysis of individual forecasts using Shapley outputs. This analysis not only enhances model interpretability but also provides insights into the underlying factors affecting ceramic property predictions.
- By developing a specialized deep learning framework based on TabNet, our research enables highly accurate predictions of ceramic properties crucial for advanced materials engineering, providing valuable insights into the predictive relationships and enhancing the precision of model evaluations in the field of piezoelectric material property prediction.
- The proposed study has the potential to provide valuable assistance to materials scientists and engineers in the optimization of production processes for piezoelectric materials. By accurately anticipating important features, this research can contribute to enhanced product performance and efficiency.
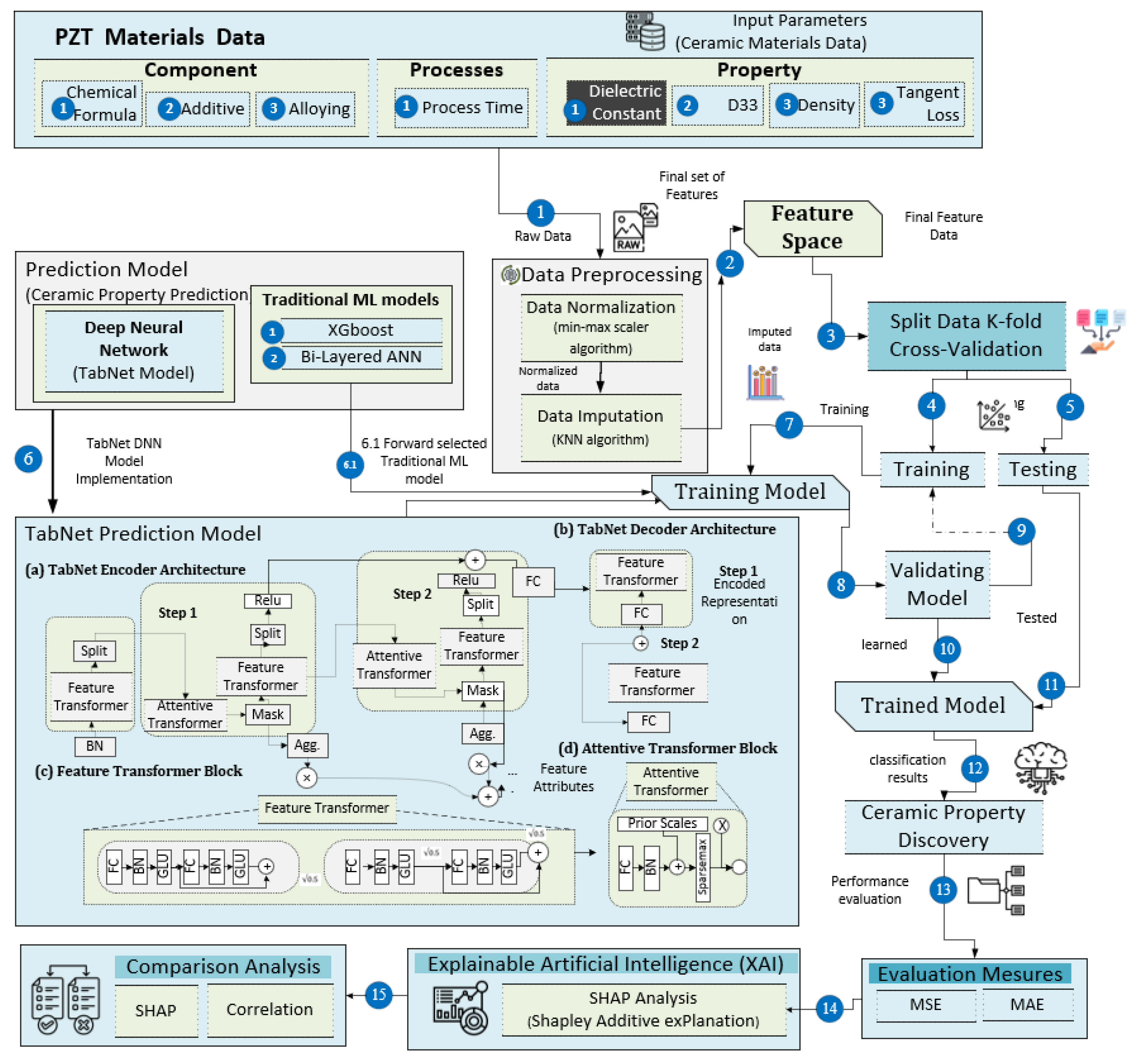
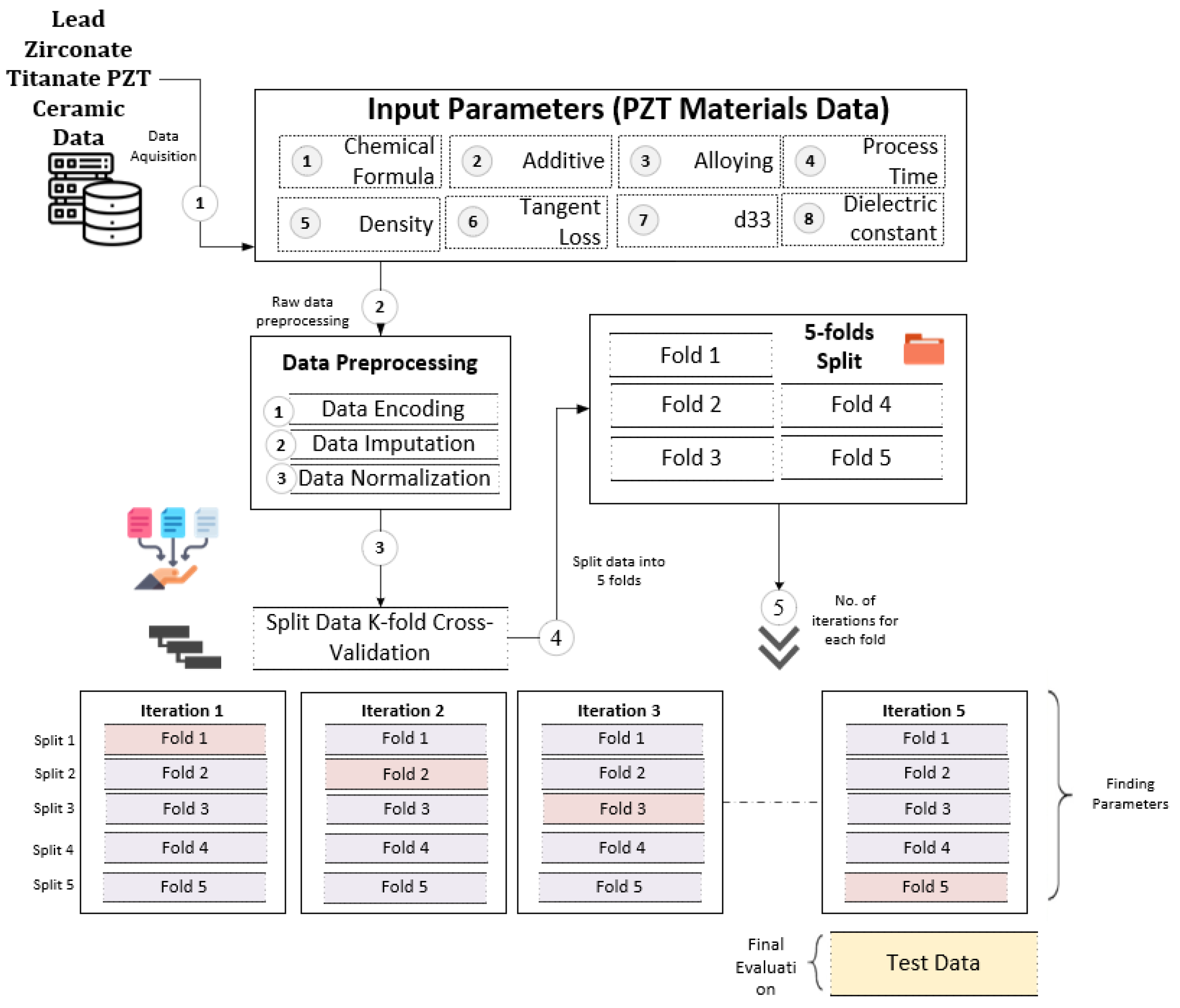
2. Materials and Methods
- This study utilized the TabNet-based deep learning (DL) [46] approach to construct a model. The inputs for the model included ceramic components and processes, covering host, additive, alloying, and process value. The model underwent training and testing using data related to PZT material processes and components.
- The XAI framework was applied to interpret the results of the TabNet model predictions. This approach facilitated the assessment of the individual impact of each input component on the prediction, ensuring the transparency and comprehensibility of the analysis.
- To bolster the robustness and reliability of the findings, a five-fold cross-validation technique was utilized.
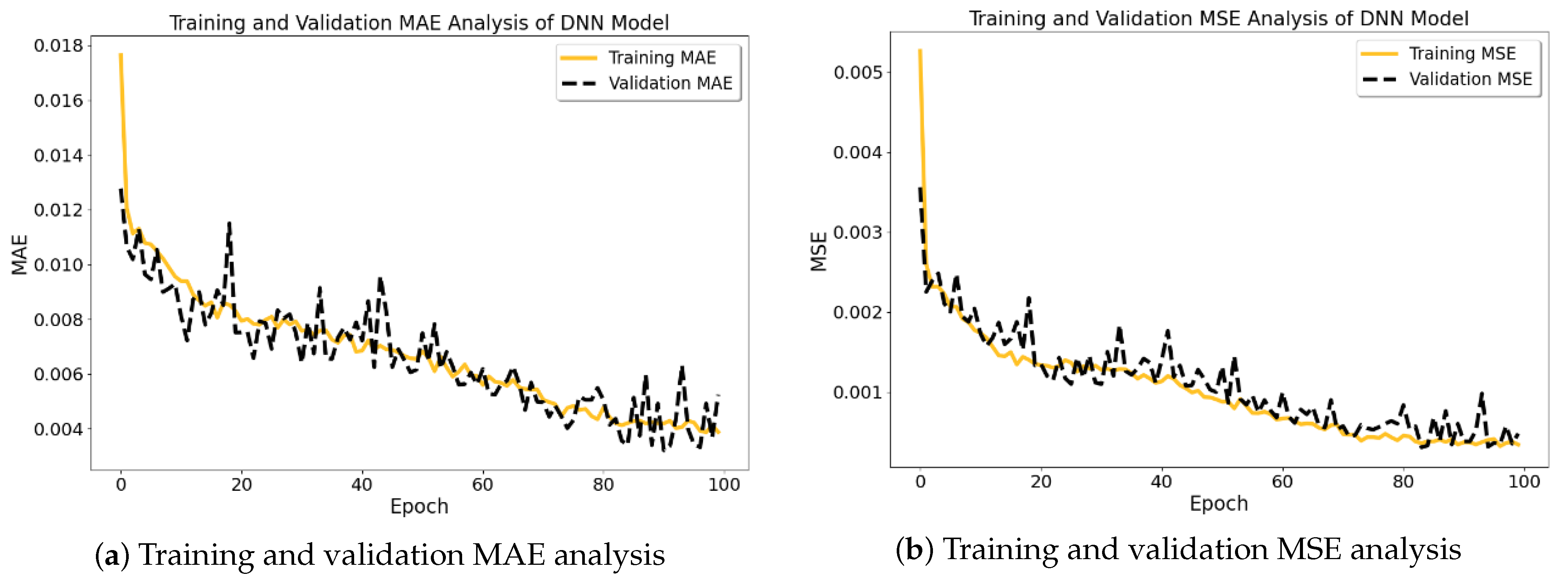
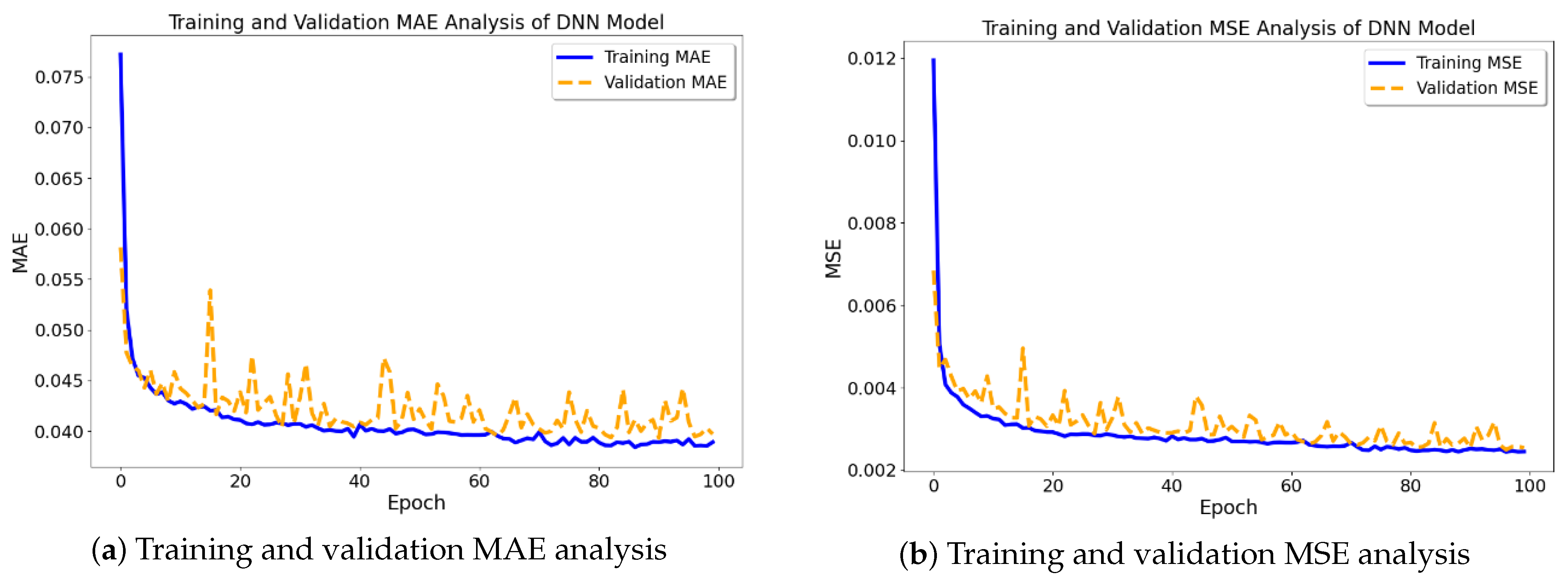
- To assess the effectiveness of the ML model, a performance evaluation was conducted using metrics such as mean squared error (MSE) and mean absolute error (MAE) for visualization of the outcomes.

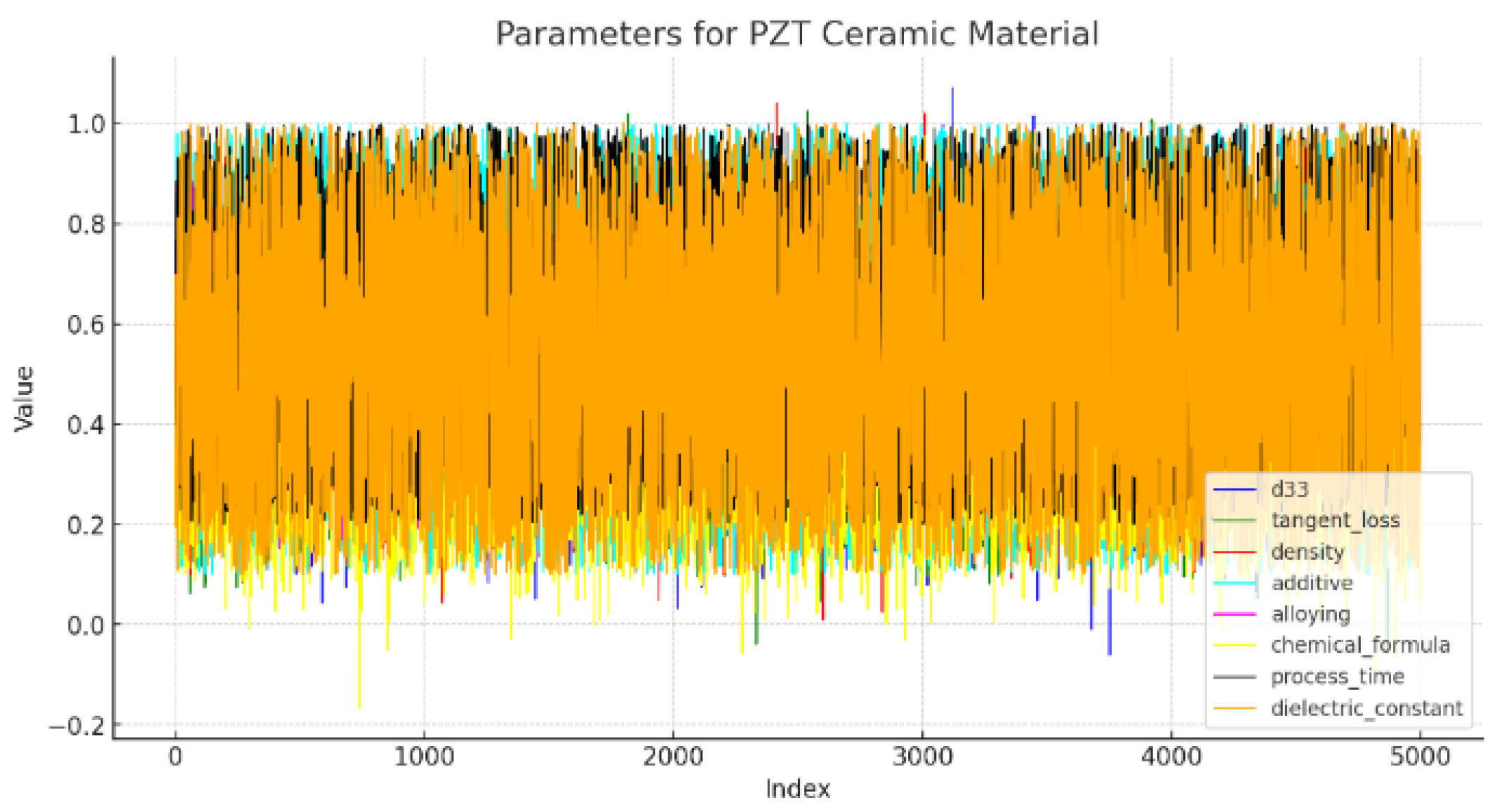
2.1. Dataset
| Algorithm 1 Shapley-based explainable algorithm for PZT property prediction |
 Comparison Analysis: CompareSHAPandCorrelation(SHAPValues, CorrelationResults) |
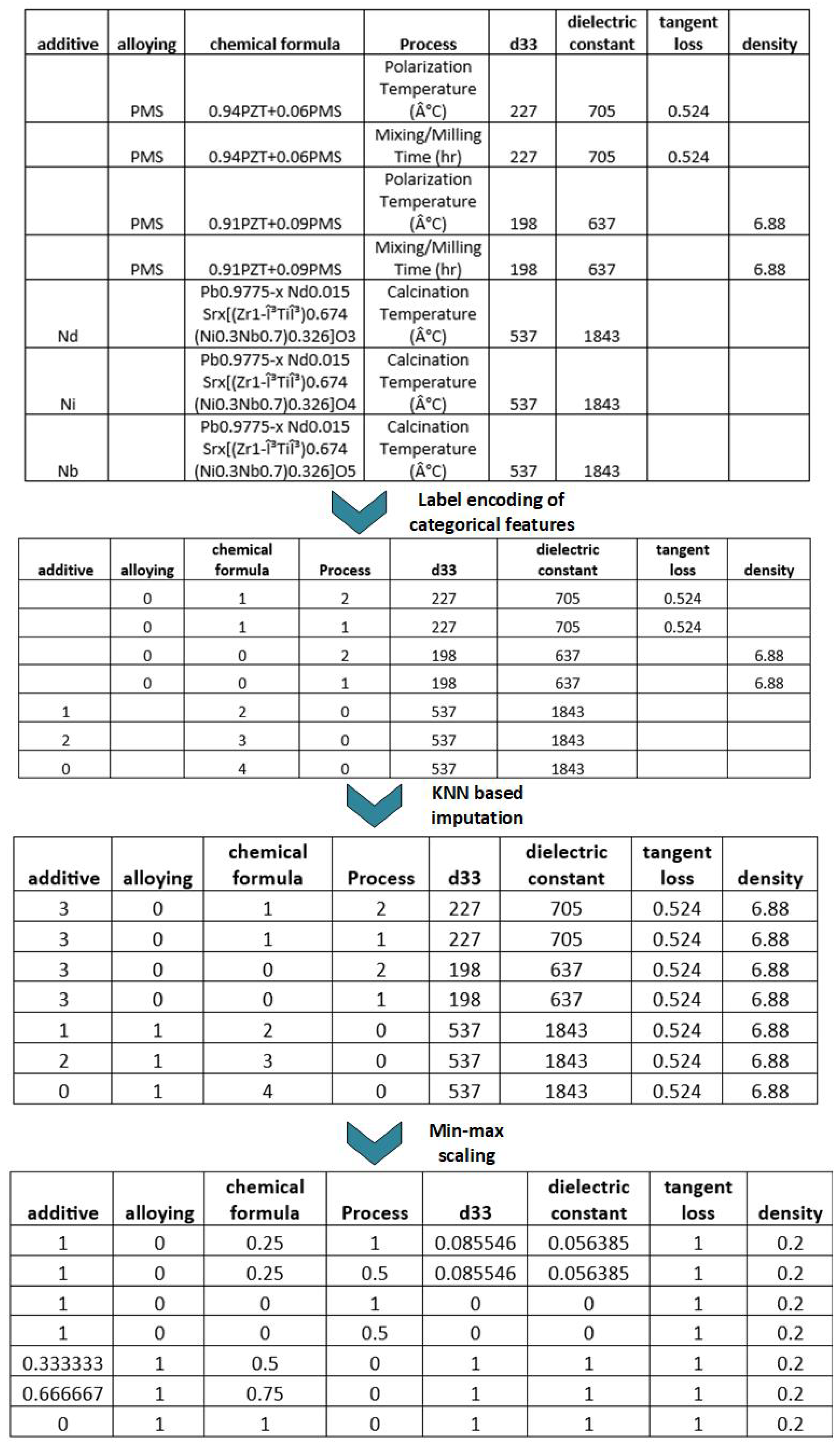
2.2. Data Preprocessing
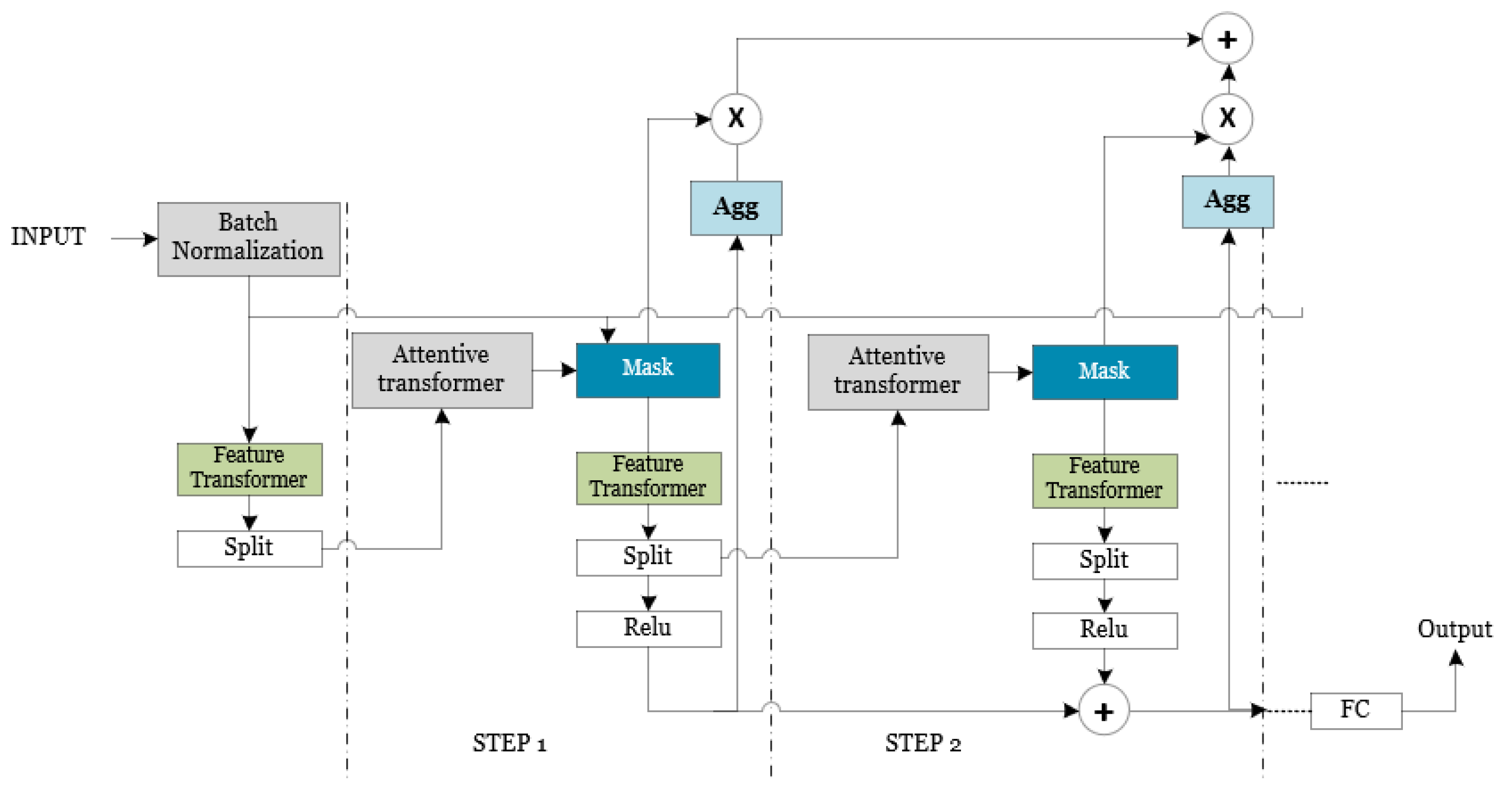
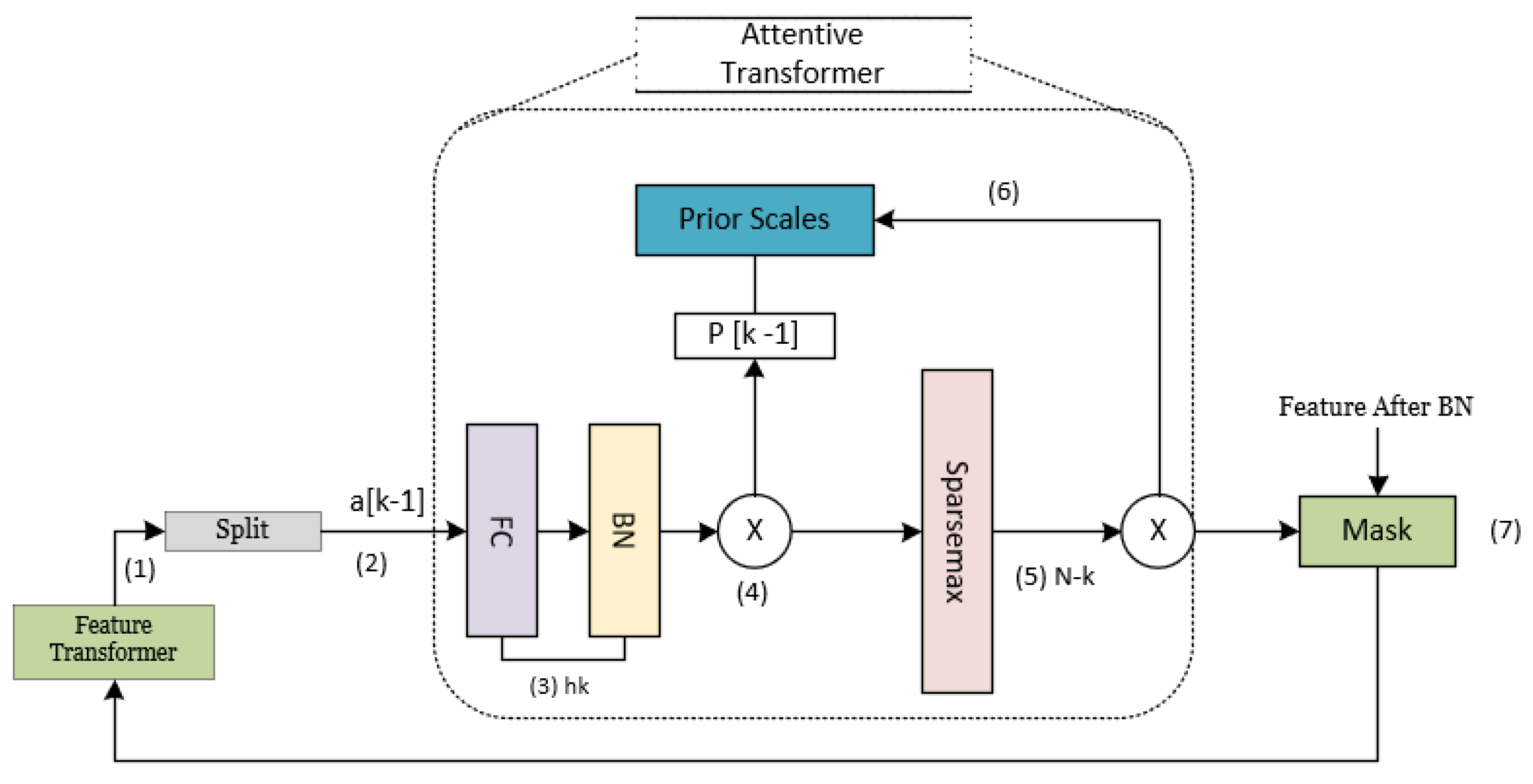
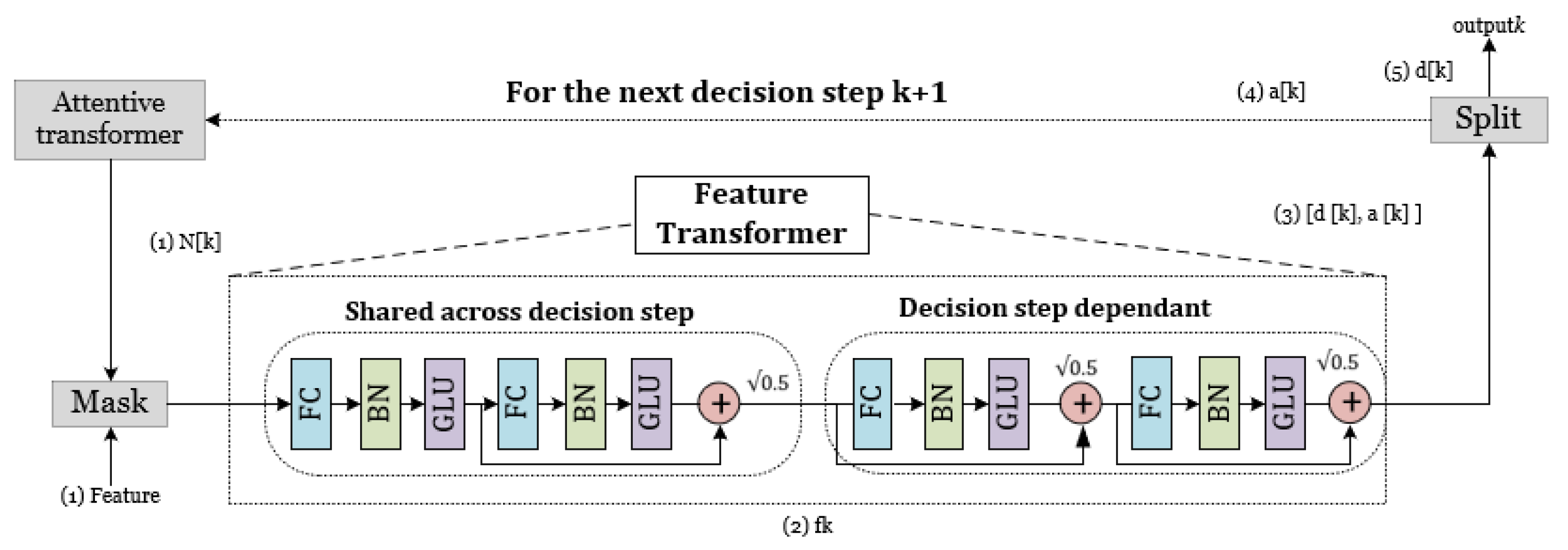
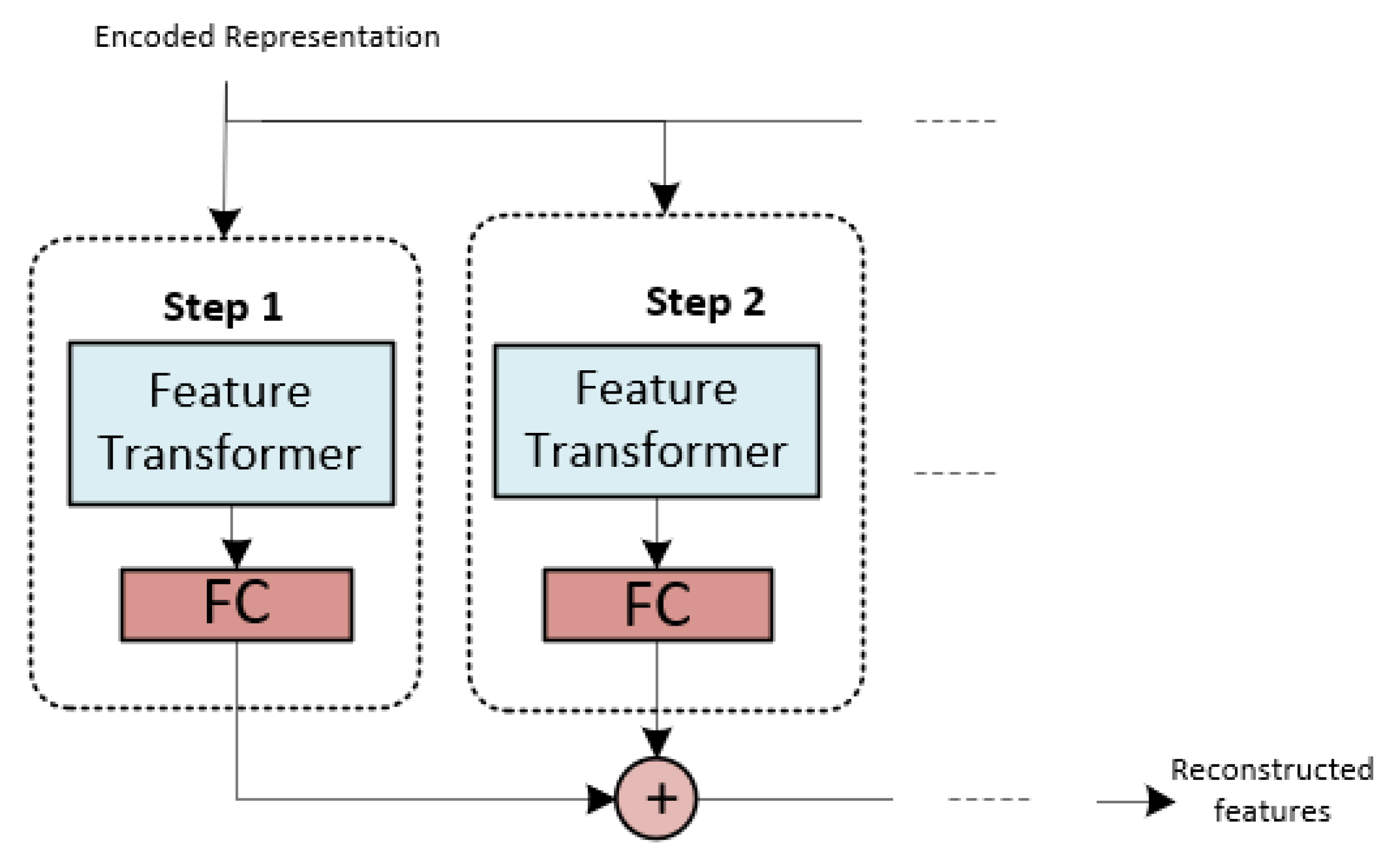
2.3. Detailed Architecture of TabNet Architecture
2.3.1. TabNet Decoder Architecture
2.3.2. Feature Selection
2.3.3. Feature Processing
2.3.4. Decoder Architecture
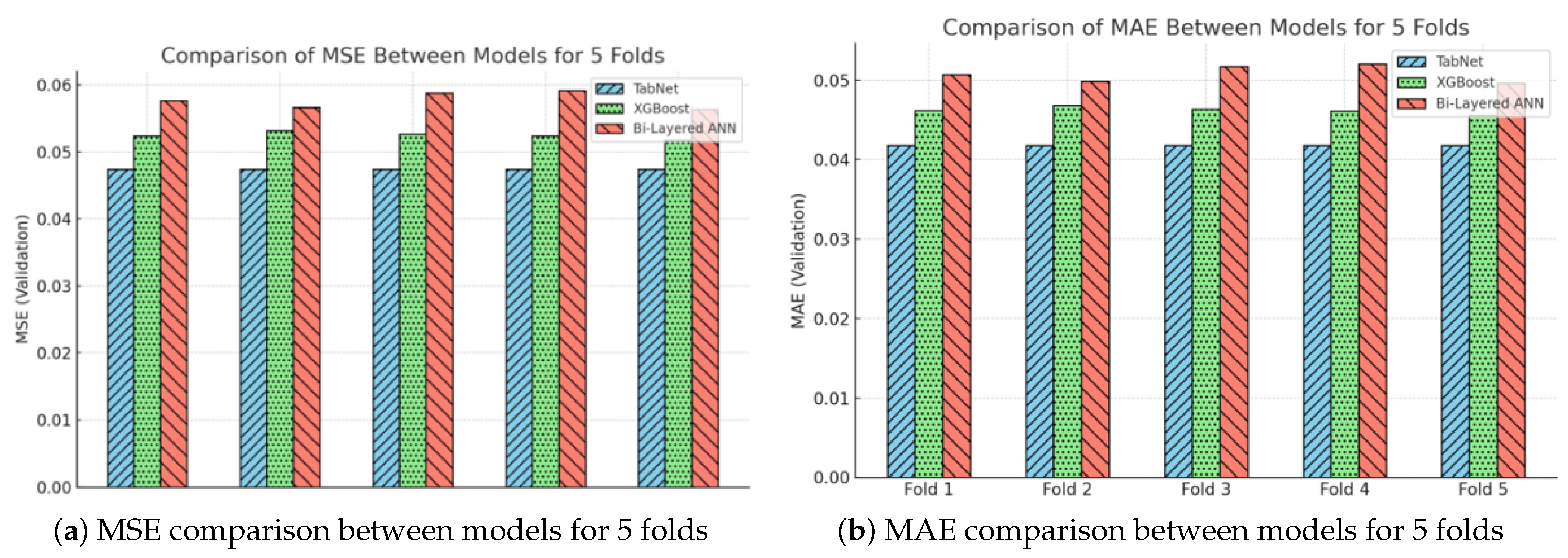
2.4. Conventional Machine Learning Algorithms
- Bi-layered ANN: Bi-Layered Artificial Neural Network (Bi-Layered ANN) is a specific architecture of an artificial neural network consisting of two distinct layers: an input layer and an output layer. The proposed approach utilizes a network of interconnected nodes, where the connections among nodes are assigned weights. This network is employed to acquire knowledge and establish mappings of intricate relationships in the input data, with the ultimate goal of predicting the material properties of PZT.
- XGboost: In contrast, XGBoost, a type of ensemble learning algorithm, is founded upon decision trees and utilizes a boosting methodology. The proposed methodology involves the iterative and adaptive training process of constructing a series of decision trees. Each subsequent decision tree is designed to rectify the errors made by its predecessor. This sequential approach ultimately leads to the development of a robust predictive model for PZT material properties.
2.5. SHAP Interpretable Model
- The alignment between the explanation technique and the primary model’s findings is crucial for achieving local accuracy.
- The explanation method should effectively address the issue of missing features by discarding any characteristics that are not present in the primary input.
- The maintenance of consistency is of utmost importance in order to ensure that the significance of a variable remains constant, even when the model’s reliance on said variable is modified, irrespective of the relevance of other variables.
2.6. Data Split
2.7. Evaluation
2.7.1. Mean Absolute Error
2.7.2. Mean Squared Error
3. Performance Analysis
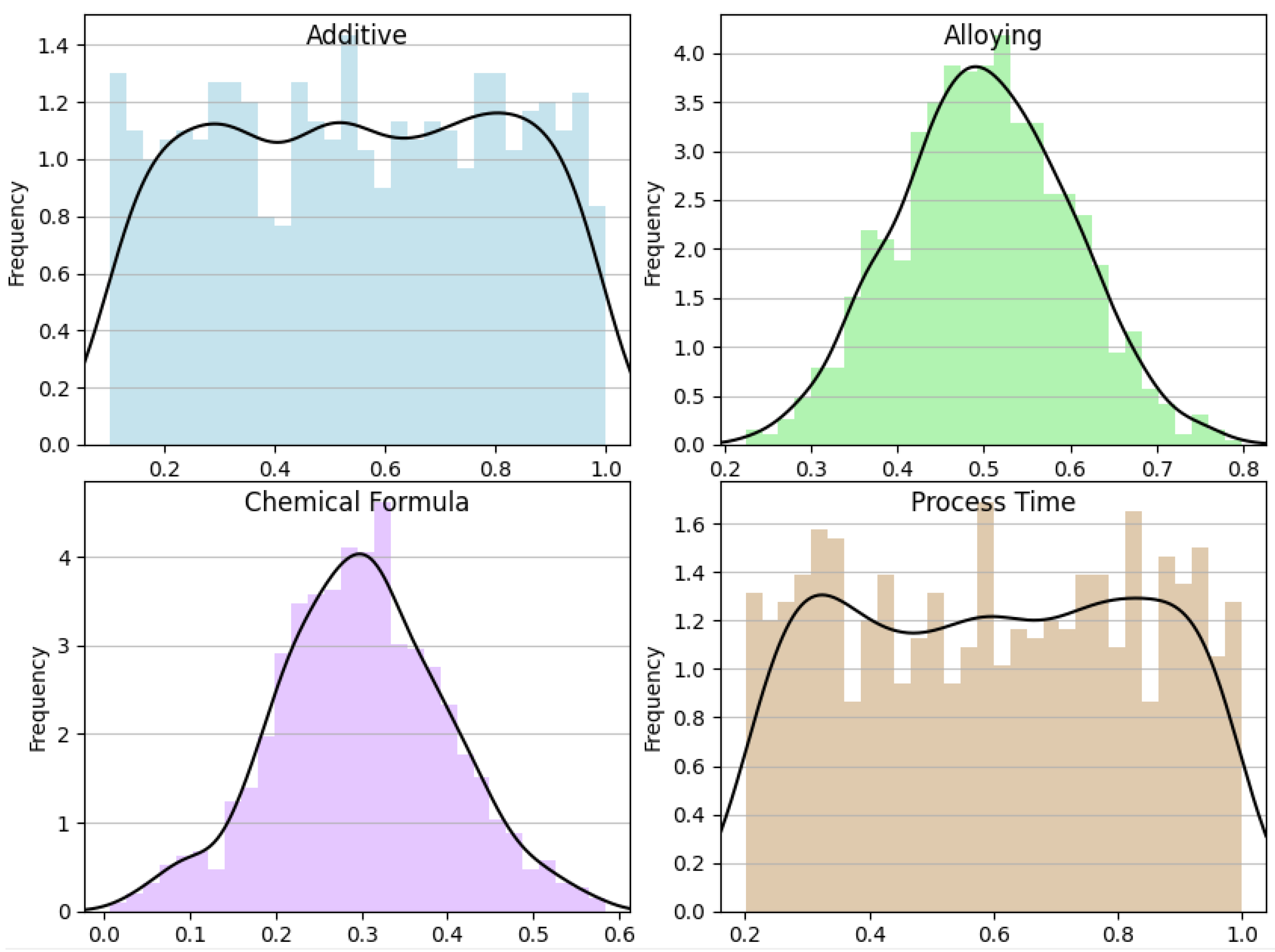
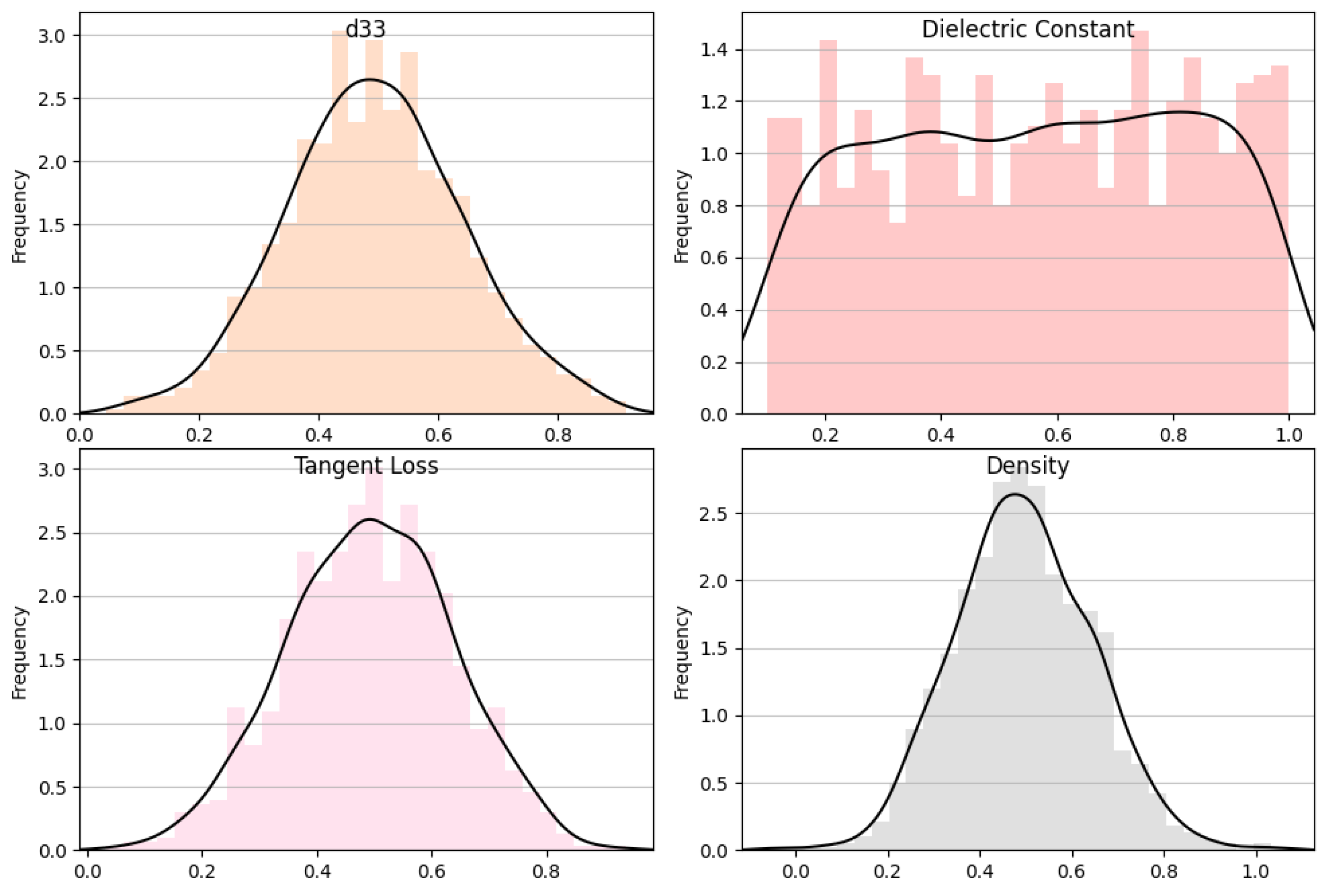
3.1. Data Distribution
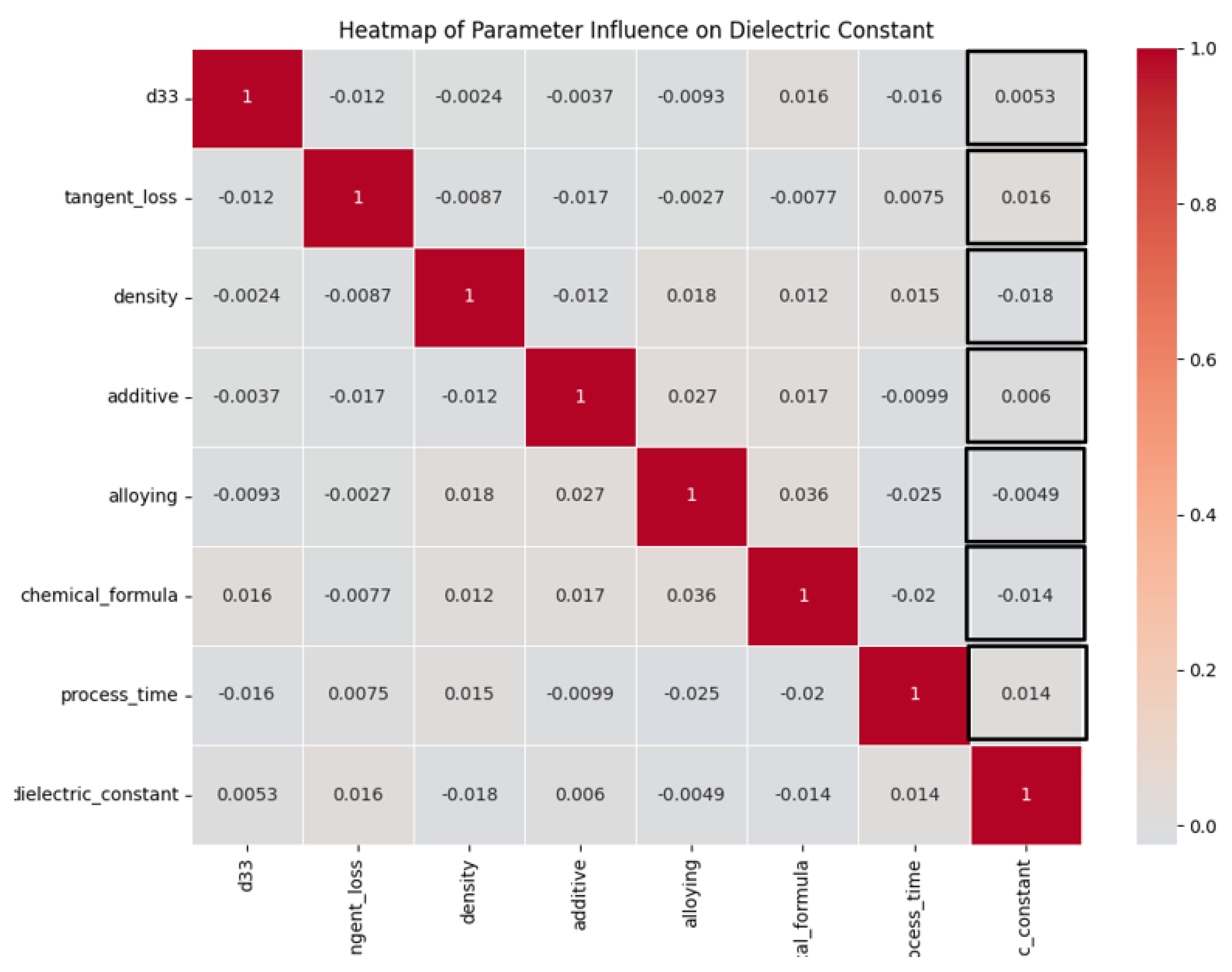
3.2. Correlation Analysis
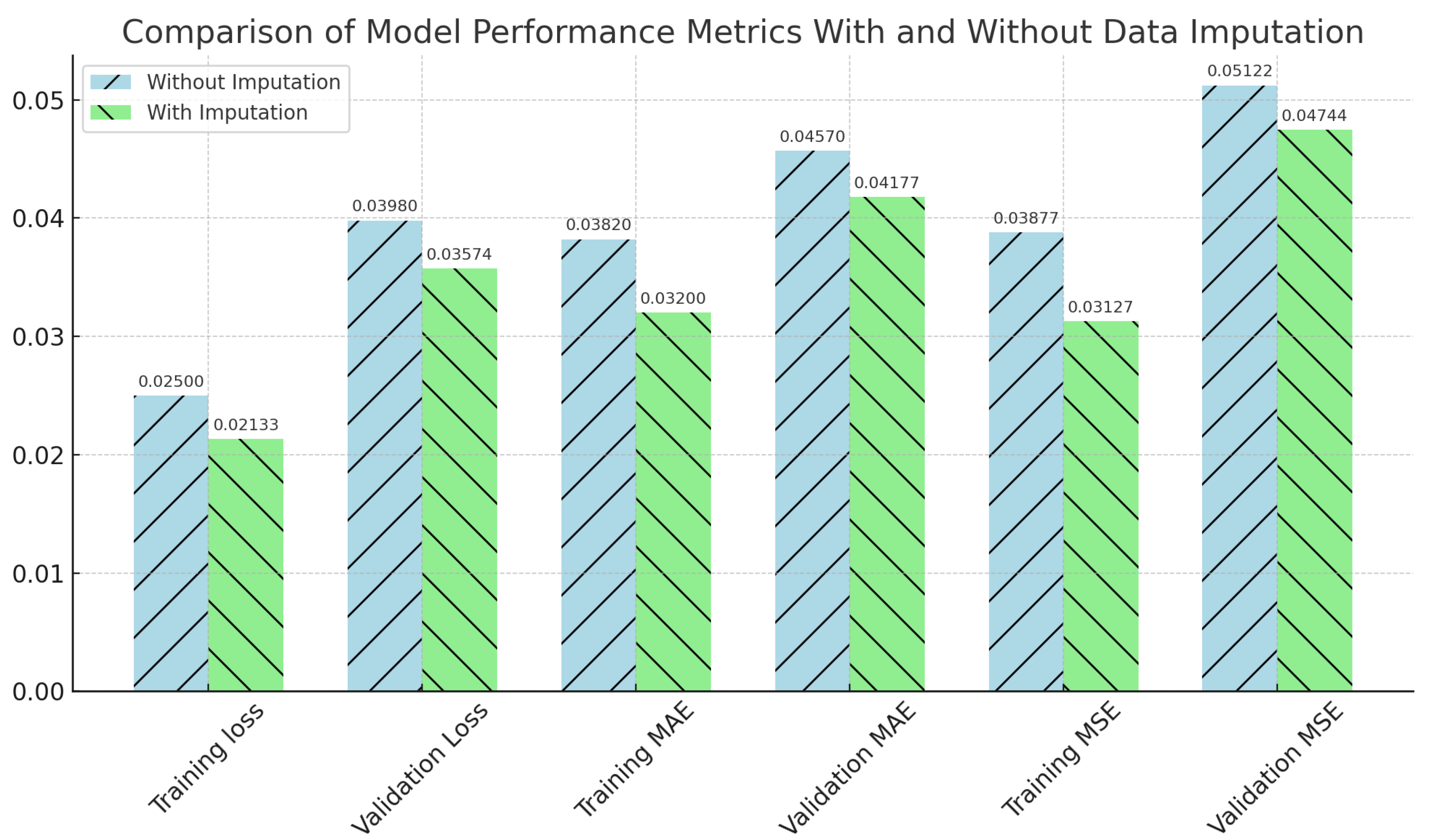
3.3. Comparative Impact Assessment of Imputation on Analysis Outcomes
3.4. Comparative Evaluation of TabNet and Conventional Machine Learning Models
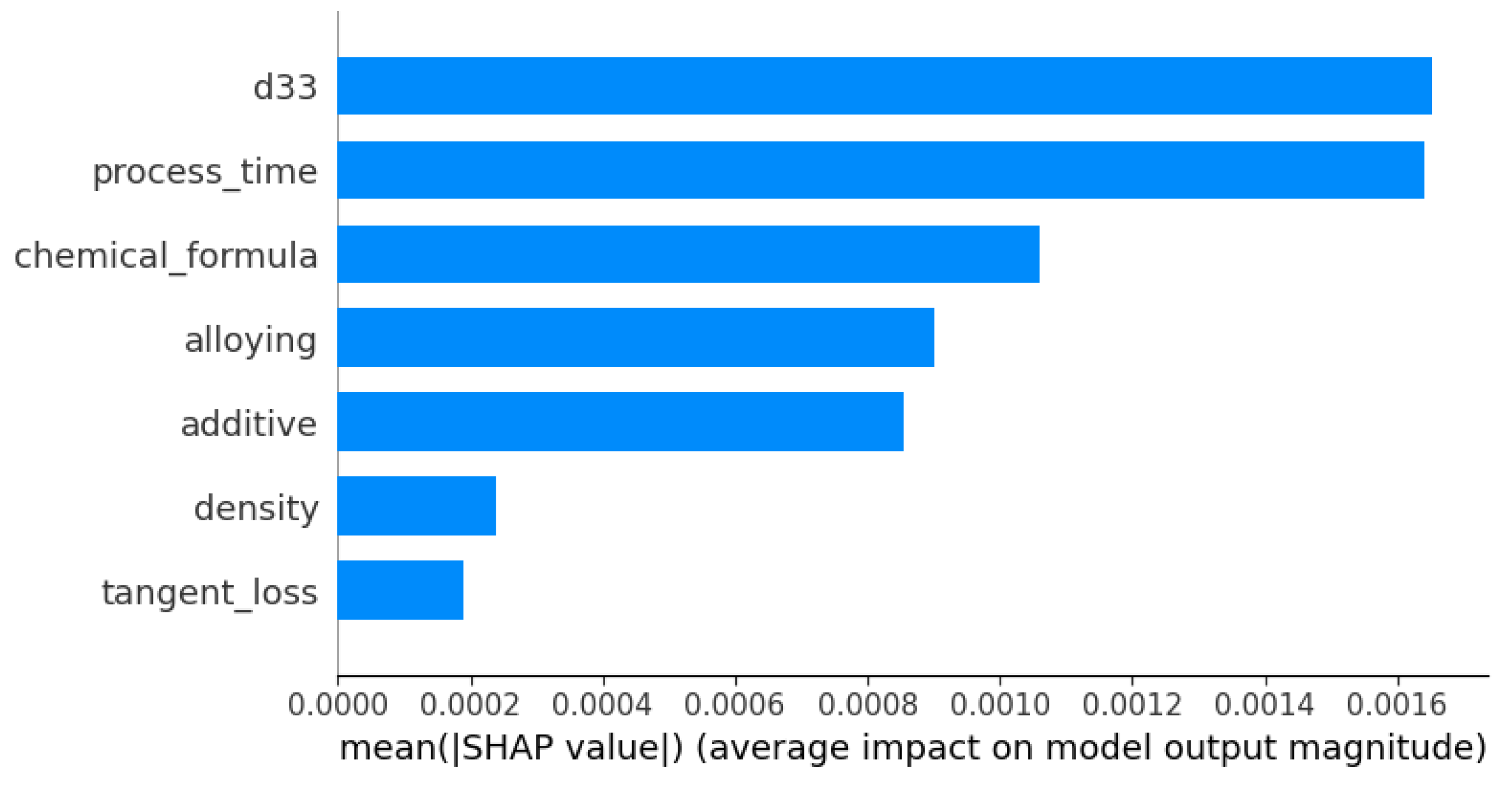
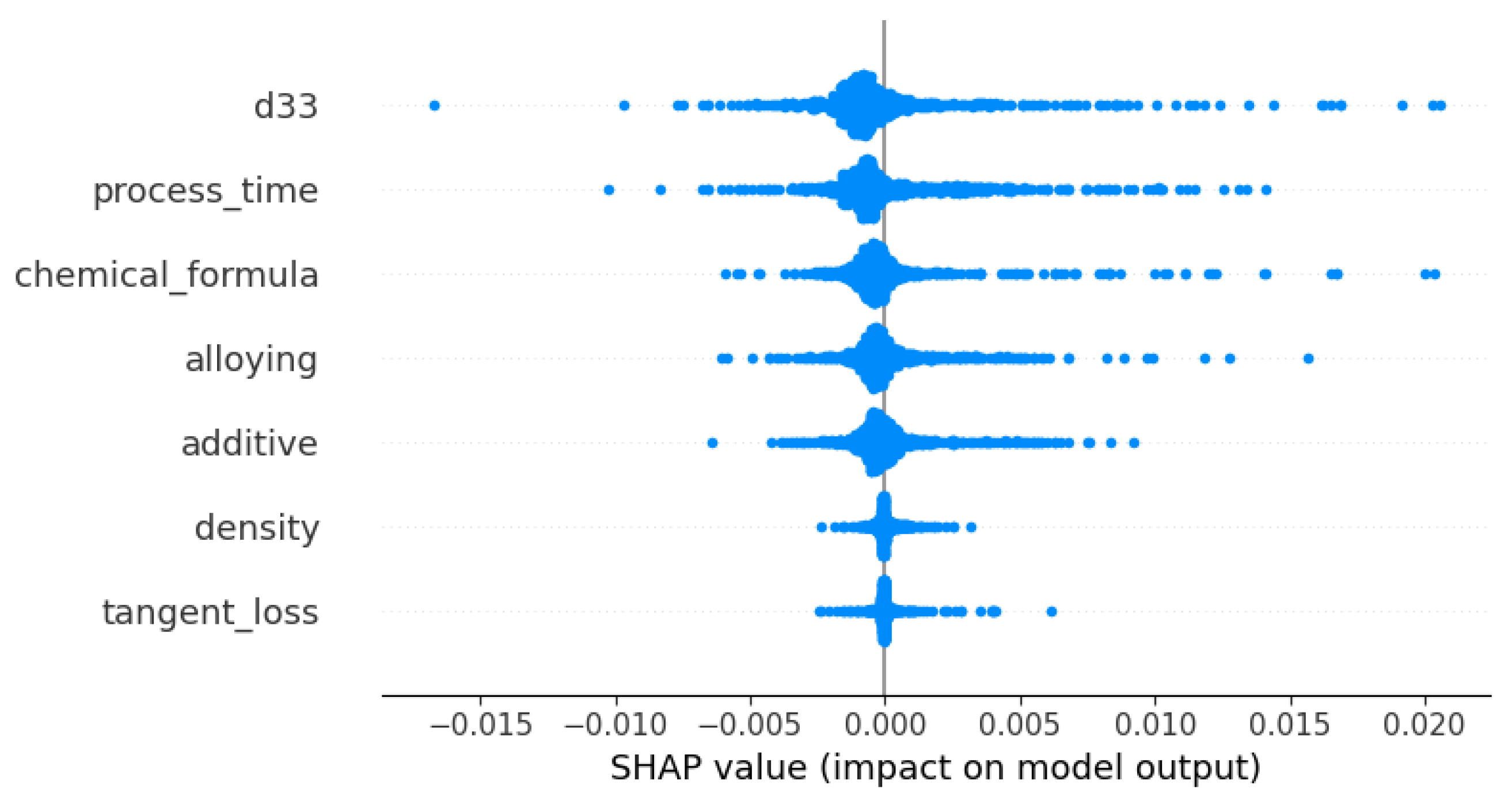
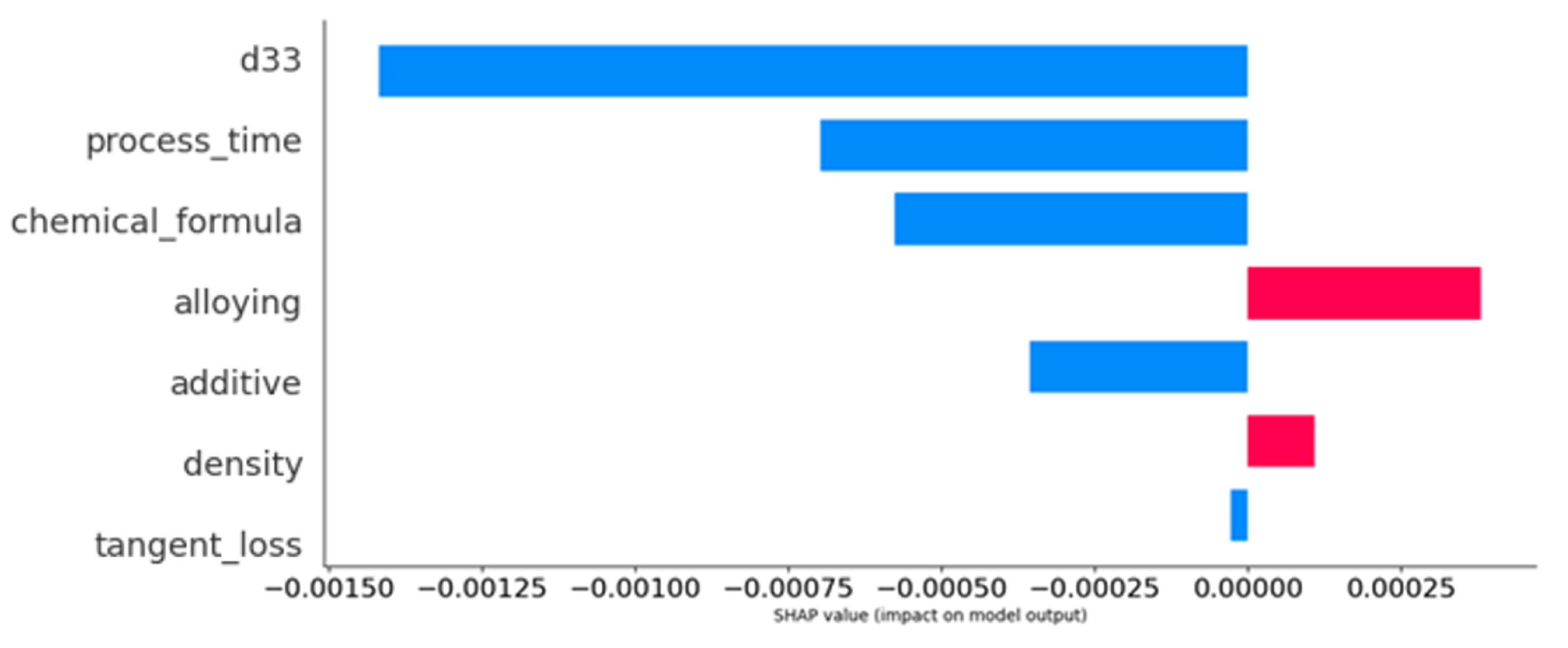
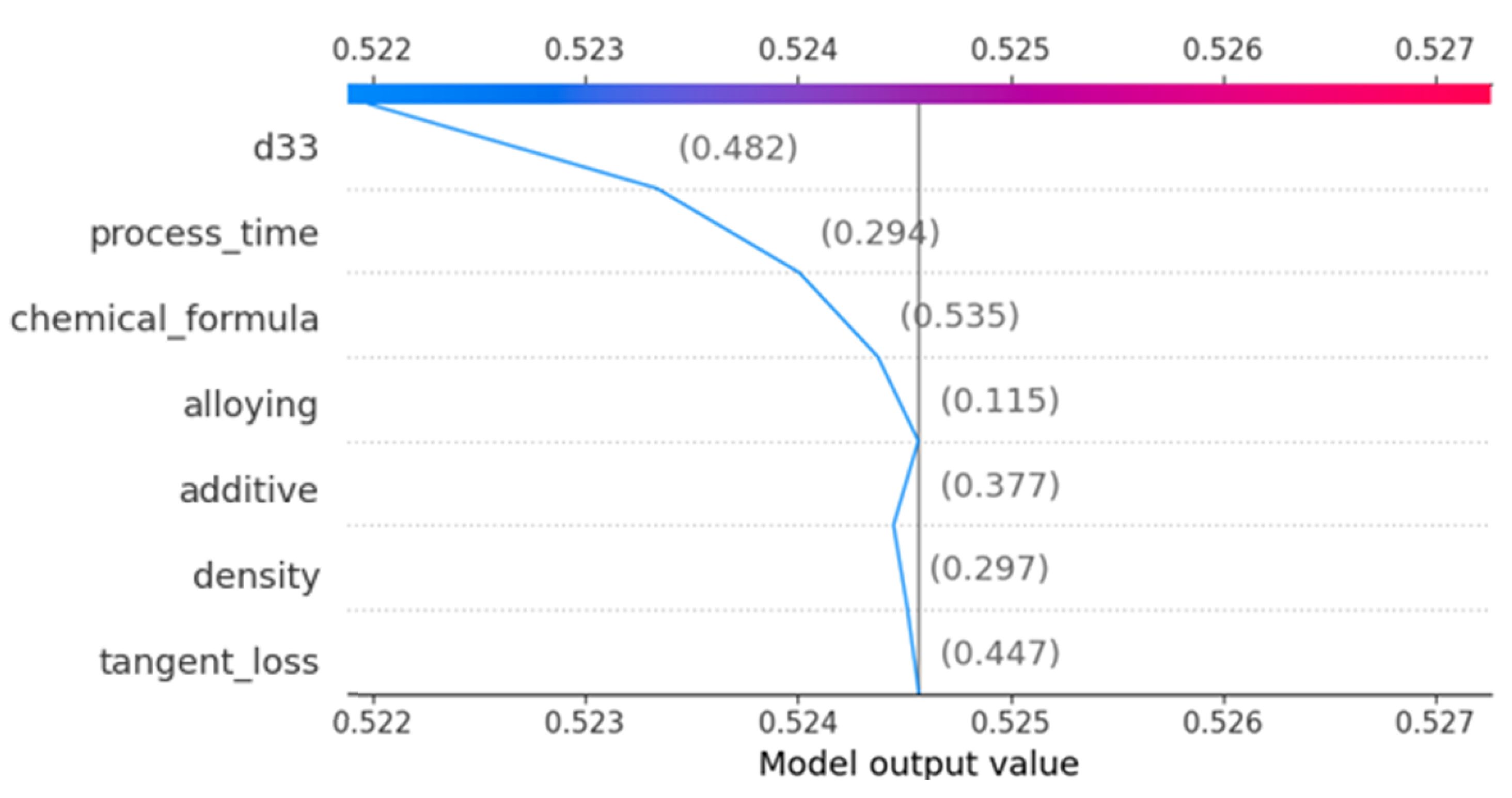
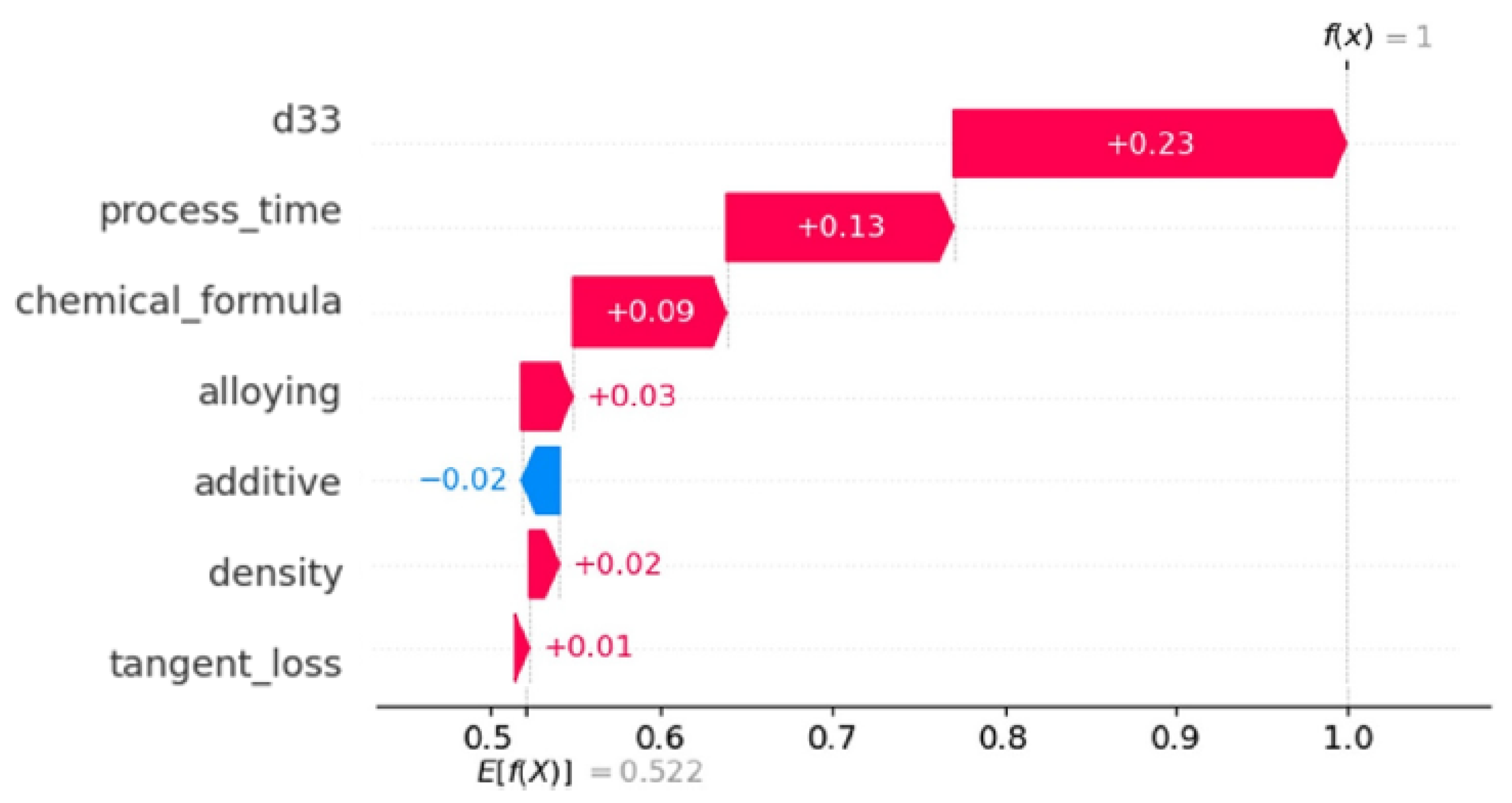
3.5. Shapely Analysis of Dielectric Constant Property Prediction Model
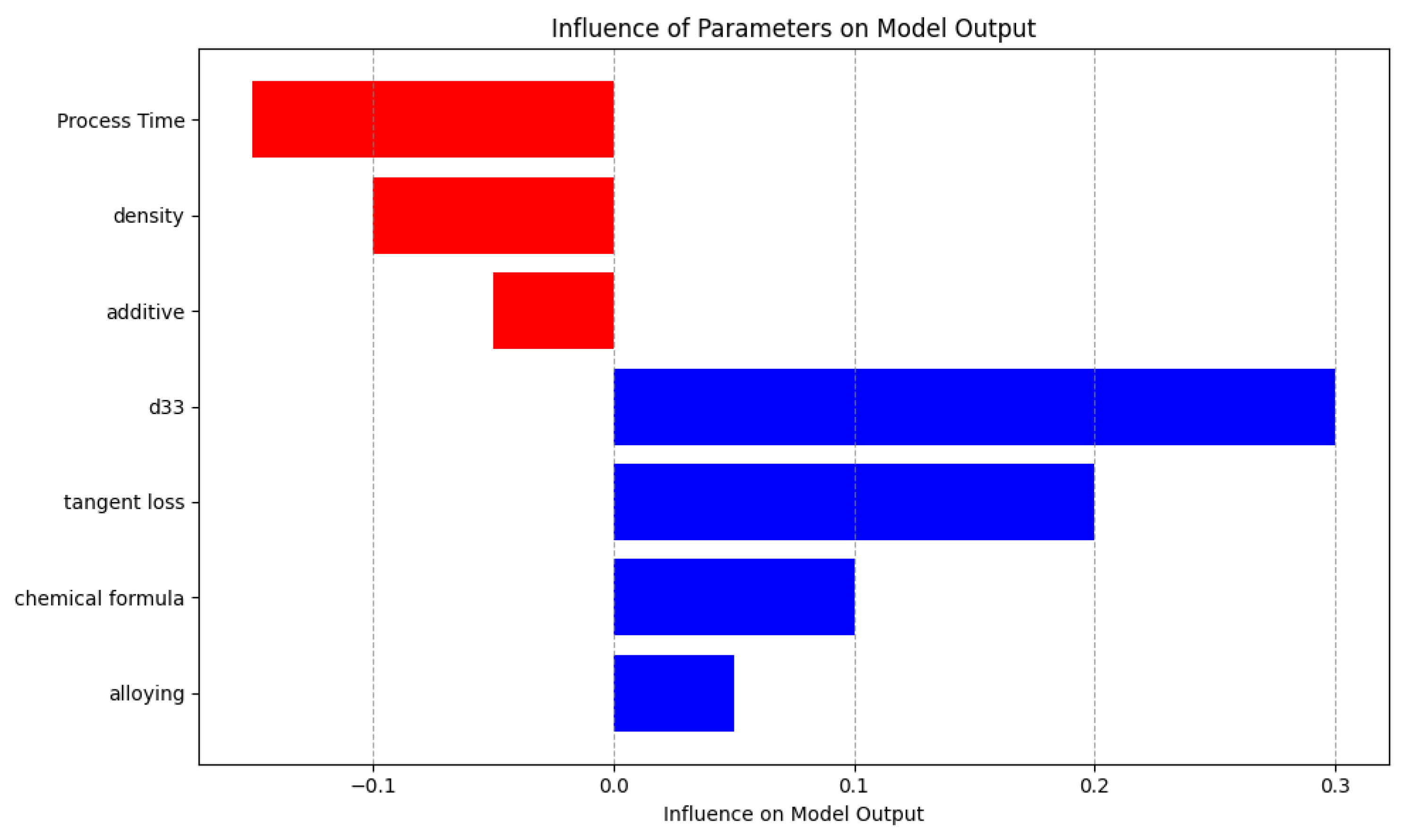
3.6. Factors Affecting the Dielectric Constant
- D33: The d33 coefficient emerges as the most influential parameter impacting the dielectric constant, as seen by the highest positive SHAP values. The metric that quantifies piezoelectric strain is strongly correlated with the dielectric behavior, highlighting its substantial advantageous influence.
- Process time: In contrast to the findings of d33, it was discovered that process time exerts a significant negative influence on the dielectric constant. Extended processing durations have a notable influence, albeit adverse in this particular case, on the dielectric characteristics, potentially leading to improved crystallinity or phase purity.
- Chemical formula: The SHAP study demonstrates that the chemical formula has a significant positive influence. The inherent qualities of a substance, such as permittivity, are determined by the precise composition and quantity of its components, thus highlighting the vital role they play.
- Alloying: The process of alloying demonstrates a discernible beneficial influence on the piezoelectric properties, hence changing the dielectric constant in a significant manner. The incorporation of supplementary elements has been recognized as a substantial catalyst in improving the performance of a material.
- Additive: Additives, although they possess a certain degree of influence, exhibit comparatively reduced magnitude of impact when juxtaposed with the underlying composition of the material. The SHAP values indicate a slight negative impact, indicating that additives may be involved in modifying microstructural properties such as grain size.
- Density: The relationship between density and the dielectric constant is less straightforward compared with its influence on mechanical qualities.
3.7. Comparison Analysis between Correlation and Shapely
4. Practical Implementation and Use Cases
- The incorporation of Computer-Aided Design (CAD) systems enables the enhancement of material selection for the purpose of optimizing the design of piezoelectric devices.
- Real-time quality control is a crucial aspect of manufacturing lines, as it involves the continuous adjustment of process parameters to guarantee that the material qualities align with the specified design specifications.
- This study aims to provide guidance for experimental design in the research and development (R&D) of novel piezoelectric materials by utilizing predictive models to estimate attributes based on compositional data.
- The practice of strategically stocking materials in supply chains is informed by the use of predictive analytics to forecast market demands and assess product performance requirements.
- The objective is to identify materials that effectively balance performance attributes while also minimizing their environmental impact, thus aligning with the principles of eco-friendly design.
- This study aims to provide training tools specifically designed for engineers and materials scientists, with the purpose of facilitating the application of artificial intelligence (AI) in the prediction and selection of material properties.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cole, J.M. A design-to-device pipeline for data-driven materials discovery. Accounts Chem. Res. 2020, 53, 599–610. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, T.; Ju, W.; Shi, S. Materials discovery and design using machine learning. J. Mater. 2017, 3, 159–177. [Google Scholar] [CrossRef]
- Ryu, B.; Wang, L.; Pu, H.; Chan, M.K.Y.; Chen, J. Understanding, discovery, and synthesis of 2D materials enabled by machine learning. Chem. Soc. Rev. 2022, 51, 1899–1925. [Google Scholar] [CrossRef] [PubMed]
- Nazir, A.; Gokcekaya, O.; Billah, K.M.M.; Ertugrul, O.; Jiang, J.; Sun, J.; Hussain, S. Multi-material additive manufacturing: A systematic review of design, properties, applications, challenges, and 3D printing of materials and cellular metamaterials. Mater. Des. 2023, 226, 111661. [Google Scholar] [CrossRef]
- Yao, Z.; Lum, Y.; Johnston, A.; Mejia-Mendoza, L.M.; Zhou, X.; Wen, Y.; Aspuru-Guzik, A.; Sargent, E.H.; Seh, Z.W. Machine learning for a sustainable energy future. Nat. Rev. Mater. 2022, 8, 202–215. [Google Scholar] [CrossRef] [PubMed]
- Lv, C.; Zhou, X.; Zhong, L.; Yan, C.; Srinivasan, M.; Seh, Z.W.; Liu, C.; Pan, H.; Li, S.; Wen, Y.; et al. Machine learning: An advanced platform for materials development and state prediction in lithium-ion batteries. Adv. Mater. 2021, 34, 2101474. [Google Scholar] [CrossRef]
- Qayyum, F.; Kim, D.H.; Bong, S.J.; Chi, S.Y.; Choi, Y.H. A Survey of Datasets, Preprocessing, Modeling Mechanisms, and Simulation Tools Based on AI for Material Analysis and Discovery. Materials 2022, 15, 1428. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 2nd ed.; Pearson Education: London, UK, 2003; Volume 263, pp. 2829–2833. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Vahed, A.; Omlin, C.W. Rule extraction from recurrent neural networks using a symbolic machine learning algorithm. In Proceedings of the 6th International Conference on Neural Information Processing (Cat. No.99EX378), Perth, WA, Australia, 16–20 November 1999; pp. 712–717. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- De’ath, G.; Fabricius, K.E. Classification and regression trees: A powerful yet simple technique for ecological data analysis. Ecology 2000, 81, 3178–3192. [Google Scholar] [CrossRef]
- SAS Institute Inc. Available online: http://www.sas.com/en_us/home.html (accessed on 15 November 2023).
- Joze, H.R.V.; Drew, M.S. Improved machine learning for image category recognition by local color constancy. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3881–3884. [Google Scholar]
- Larrañaga, P.; Calvo, B.; Santana, R.; Bielza, C.; Galdiano, J.; Inza, I.; Lozano, J.A.; Armañanzas, R.; Santafé, G.; Pérez, A.; et al. Machine learning in bioinformatics. Briefings Bioinform. 2005, 7, 86–112. [Google Scholar] [CrossRef]
- Eminagaoglu, M.; Eren, S. Implementation and comparison of machine learning classifiers for information security risk analysis of a human resources department. In Proceedings of the 2010 International Conference on Computer Information Systems and Industrial Management Applications, Krakow, Poland, 8–10 October 2011; Volume 3, pp. 391–398. [Google Scholar]
- Olsson, F. A Literature Survey of Active Machine Learning in the Context of Natural Language Processing; Swedish Institute of Computer Science: Kista, Sweden, 2009. [Google Scholar]
- Rao, H.S.; Mukherjee, A. Artificial neural networks for predicting the macro mechanical behavior of ceramic-matrix composites. Comput. Mater. Sci. 1996, 5, 307–322. [Google Scholar] [CrossRef]
- Reich, Y.; Travitzky, N. Machine learning of material behavior knowledge from empirical data. Mater. Des. 1996, 16, 251–259. [Google Scholar] [CrossRef]
- Li, C.H.; Guo, J.; Qin, P.; Chen, R.L.; Chen, N.Y. Some regularities of melting points of AB-type intermetallic compounds. J. Phys. Chem. Solids 1996, 57, 1797–1802. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2007. [Google Scholar]
- Pei, J.F.; Cai, C.Z.; Zhu, Y.M.; Yan, B. Modeling and predicting the glass transition temperature of polymethacrylates based on quantum chemical descriptors by using hybrid PSO-SVR. Macromol. Theory Simulations 2013, 22, 52–60. [Google Scholar] [CrossRef]
- Fang, S.F.; Wang, M.P.; Qi, W.H.; Zheng, F. Hybrid genetic algorithms and support vector regression in forecasting atmospheric corrosion of metallic materials. Comput. Mater. Sci. 2008, 44, 647–655. [Google Scholar] [CrossRef]
- Isayev, O.; Oses, C.; Toher, C.; Gossett, E.; Curtarolo, S.; Tropsha, A. Universal fragment descriptors for predicting properties of inorganic crystals. Nat. Commun. 2017, 8, 15679. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Xie, T.; Grossman, J.C. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Phys. Rev. Lett. 2018, 120, 145301. [Google Scholar] [CrossRef]
- Schmidt, M.; Lipson, H. Distilling free-form natural laws from experimental data. Science 2009, 324, 81–85. [Google Scholar] [CrossRef]
- Ward, L.; Agrawal, A.; Choudhary, A.; Wolverton, C. A general-purpose machine learning framework for predicting properties of inorganic materials. npj Comput. Mater. 2016, 2, 16028. [Google Scholar] [CrossRef]
- Pilania, G.; Wang, C.; Jiang, X.; Rajasekaran, S.; Ramprasad, R. Accelerating materials property predictions using machine learning. Sci. Rep. 2013, 3, 2810. [Google Scholar] [CrossRef]
- Meftahi, N.; Klymenko, M.; Christofferson, A.J.; Bach, U.; Winkler, D.A.; Russo, S.P. Machine learning property prediction for organic photovoltaic devices. npj Comput. Mater. 2020, 6, 166. [Google Scholar] [CrossRef]
- Wang, Z.L.; Adachi, Y. Property prediction and properties-to-microstructure inverse analysis of steels by a machine-learning approach. Mater. Sci. Eng. A 2019, 744, 661–670. [Google Scholar] [CrossRef]
- Kondo, R.; Yamakawa, S.; Masuoka, Y.; Tajima, S.; Asahi, R. Microstructure recognition using convolutional neural networks for prediction of ionic conductivity in ceramics. Acta Mater. 2017, 141, 29–38. [Google Scholar] [CrossRef]
- Yang, C.; Ren, C.; Jia, Y.; Wang, G.; Li, M.; Lu, W. A machine learning-based alloy design system to facilitate the rational design of high entropy alloys with enhanced hardness. Acta Mater. 2022, 222, 117431. [Google Scholar] [CrossRef]
- Iquebal, A.S.; Pandagare, S.; Bukkapatnam, S. Learning acoustic emission signatures from a nanoindentation-based lithography process: Towards rapid microstructure characterization. Tribol. Int. 2020, 143, 106074. [Google Scholar] [CrossRef]
- Giles, S.A.; Sengupta, D.; Broderick, S.R.; Rajan, K. Machine-learning-based intelligent framework for discovering refractory high-entropy alloys with improved high-temperature yield strength. npj Comput. Mater 2022, 8, 235. [Google Scholar] [CrossRef]
- Zhong, X.; Gallagher, B.; Liu, S.; Kailkhura, B.; Hiszpanski, A.; Han, T.Y.J. Explainable machine learning in materials science. npj Comput. Mater. 2022, 8, 204. [Google Scholar] [CrossRef]
- Yang, J.; Jiang, P.; Suhail, S.A.; Sufian, M.; Deifalla, A.F. Experimental investigation and AI prediction modelling of ceramic waste powder concrete—An approach towards sustainable construction. J. Mater. Res. Technol. 2023, 23, 3676–3696. [Google Scholar] [CrossRef]
- Tian, X.L.; Song, S.W.; Chen, F.; Qi, X.J.; Wang, Y.; Zhang, Q.H. Machine learning-guided property prediction of energetic materials: Recent advances, challenges, and perspectives. Energetic Mater. Front. 2022, 3, 177–186. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B. Explainable artificial intelligence (XAI) for interpreting the contributing factors feed into the wildfire susceptibility prediction model. Sci. Total Environ. 2023, 879, 163004. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Wang, J.; Li, H.; Zhang, Y.; Wu, L.; Liu, Y. A method to evaluate task-specific importance of spatio-temporal units based on explainable artificial intelligence. Int. J. Geogr. Inf. Sci. 2020, 35, 2002–2025. [Google Scholar] [CrossRef]
- Qayyum, F.; Jamil, H.; Jamil, F.; Kim, D.H. Towards potential content-based features evaluation to tackle meaningful citations. Symmetry 2021, 13, 1973. [Google Scholar] [CrossRef]
- Qayyum, F.; Afzal, M.T. Identification of important citations by exploiting research articles’ metadata and cue-terms from content. Scientometrics 2019, 118, 21–43. [Google Scholar] [CrossRef]
- Qayyum, F.; Jamil, H.; Iqbal, N.; Kim, D.; Afzal, M.T. Toward potential hybrid features evaluation using MLP-ANN binary classification model to tackle meaningful citations. Scientometrics 2022, 127, 6471–6499. [Google Scholar] [CrossRef]
- Qayyum, F.; Jamil, H.; Jamil, F.; Kim, D. Predictive Optimization Based Energy Cost Minimization and Energy Sharing Mechanism for Peer-to-Peer Nanogrid Network. IEEE Access 2022, 10, 23593–23604. [Google Scholar] [CrossRef]
- Arik, S.Ö.; Pfister, T. Tabnet: Attentive interpretable tabular learning. Proc. Aaai Conf. Artif. Intell. 2021, 35, 6679–6687. [Google Scholar] [CrossRef]
- Malarvizhi, R.; Thanamani, A.S. K-nearest neighbor in missing data imputation. Int. J. Eng. Res. Dev. 2012, 5, 5–7. [Google Scholar]
- Kappal, S. Data normalization using median median absolute deviation MMAD based Z-score for robust predictions vs. min–max normalization. Lond. J. Res. Sci. Nat. Form. 2019, 19, 39–44. [Google Scholar]
- Wang, S.C.; Wang, S.C. Artificial neural network. In Interdisciplinary Computing in Java Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Chen, Z.; Jiang, F.; Cheng, Y.; Gu, X.; Liu, W.; Peng, J. XGBoost classifier for DDoS attack detection and analysis in SDN-based cloud. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing (BigComp), Shanghai, China, 15–17 January 2018; pp. 251–256. [Google Scholar]
- Zaki, M.; Venugopal, V.; Bhattoo, R.; Bishnoi, S.; Singh, S.K.; Allu, A.R.; Jayadeva; Krishnan, N.M.A. Interpreting the optical properties of oxide glasses with machine learning and Shapely additive explanations. J. Am. Ceram. Soc. 2022, 105, 4046–4057. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr # | Feature Name | Category | Description |
|---|---|---|---|
| 1 | Additive | Component | Additives incorporated into PZT (lead zirconate titanate) materials serve as supplementary components that are introduced to alter or augment the material’s properties, hence rendering it acceptable for particular applications. |
| 2 | Alloying | Component | The process of alloying in PZT materials involves incorporating additional elements or metals to modify and improve the material’s characteristics, such as electrical conductivity or mechanical strength, to cater to certain applications. |
| 3 | Chemical formula | Component | The chemical formula utilized in PZT materials denotes the precise amalgamation of components and their respective proportions, commonly denoted as Pb(ZrxTi1−x)O3. The variable x inside the formula specifies the ratio of Zr to Ti, influencing the material’s qualities. |
| 4 | Process value | Process | Within the context of PZT materials, the term “process” pertains to the stages involved in their manufacturing, encompassing activities such as mixing and sintering. Conversely, “process time” denotes the time required to complete these stages. The duration of the processing period has a significant influence on the quality and characteristics of the material. The process value represents the amalgamation of both factors. |
| 5 | D33 | Property | The feature denoted by “d33” refers to a piezoelectric characteristic that quantifies the response of a material to mechanical stress exerted in a direction perpendicular to its electric field. The term “d33” denotes the 3-3 mode, which specifically refers to measuring a material’s piezoelectric response when subjected to stress perpendicular to its electric field. |
| 6 | Dielectric constant | Property | The dielectric constant, commonly represented as “” or “k”, quantifies the ability of a substance to store electrical energy within an electric field. PZT materials are important in various applications, such as capacitors, sensors, and transducers. |
| 7 | Tangent loss | Property | The tangent loss, also known as “tan ” is a measure of the amount of energy dissipated in a dielectric material during the oscillation of an electric field. Using PZT materials with low tangent loss is highly advantageous in various applications such as sensors and actuators, since it enables effective energy utilization. |
| 8 | Density | Property | The concept of density in PZT materials refers to measuring mass per unit volume. Mechanical strength and performance are crucial factors in certain applications, such as sensors and actuators, where a preference is generally given to increased density. |
| Category | Description |
|---|---|
| Method and version | TabNet 3.1 in Python |
| Programming environment | Python 3.8, key libraries: TensorFlow 2.4, Keras 2.4, PyTorch 1.7, scikit-learn 0.24, pandas 1.2, NumPy 1.19 |
| Hardware specifications | CPU: Intel Core i7-10700K, GPU: NVIDIA GeForce RTX 3080, RAM: 32 GB DDR4 |
| Sr # | Parameter | Missing Records | Sr # | Parameter | Missing Records |
|---|---|---|---|---|---|
| 1 | Additive | 205 | 5 | Density | 200 |
| 2 | Alloying | 79 | 6 | d33 | 35 |
| 3 | Chemical formula | 321 | 7 | Tangent loss | 24 |
| 4 | Process Time | 185 | 8 | Dielectric constant | 101 |
| Metric | Without Imputation | With Imputation |
|---|---|---|
| Training MAE | 0.03820 | 0.03200 |
| Validation MAE | 0.04570 | 0.04177 |
| Training MSE | 0.03877 | 0.03127 |
| Validation MSE | 0.05122 | 0.04744 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qayyum, F.; Khan, M.A.; Kim, D.-H.; Ko , H.; Ryu, G.-A. Explainable AI for Material Property Prediction Based on Energy Cloud: A Shapley-Driven Approach. Materials 2023, 16, 7322. https://doi.org/10.3390/ma16237322
Qayyum F, Khan MA, Kim D-H, Ko H, Ryu G-A. Explainable AI for Material Property Prediction Based on Energy Cloud: A Shapley-Driven Approach. Materials. 2023; 16(23):7322. https://doi.org/10.3390/ma16237322
Chicago/Turabian StyleQayyum, Faiza, Murad Ali Khan, Do-Hyeun Kim, Hyunseok Ko , and Ga-Ae Ryu. 2023. "Explainable AI for Material Property Prediction Based on Energy Cloud: A Shapley-Driven Approach" Materials 16, no. 23: 7322. https://doi.org/10.3390/ma16237322
APA StyleQayyum, F., Khan, M. A., Kim, D. -H., Ko , H., & Ryu, G. -A. (2023). Explainable AI for Material Property Prediction Based on Energy Cloud: A Shapley-Driven Approach. Materials, 16(23), 7322. https://doi.org/10.3390/ma16237322