
The Bi-Directional Prediction of Carbon Fiber Production Using a Combination of Improved Particle Swarm Optimization and Support Vector Machine

Abstract
:1. Introduction
2. Carbon Fiber Production and Its Bi-Directional Optimization
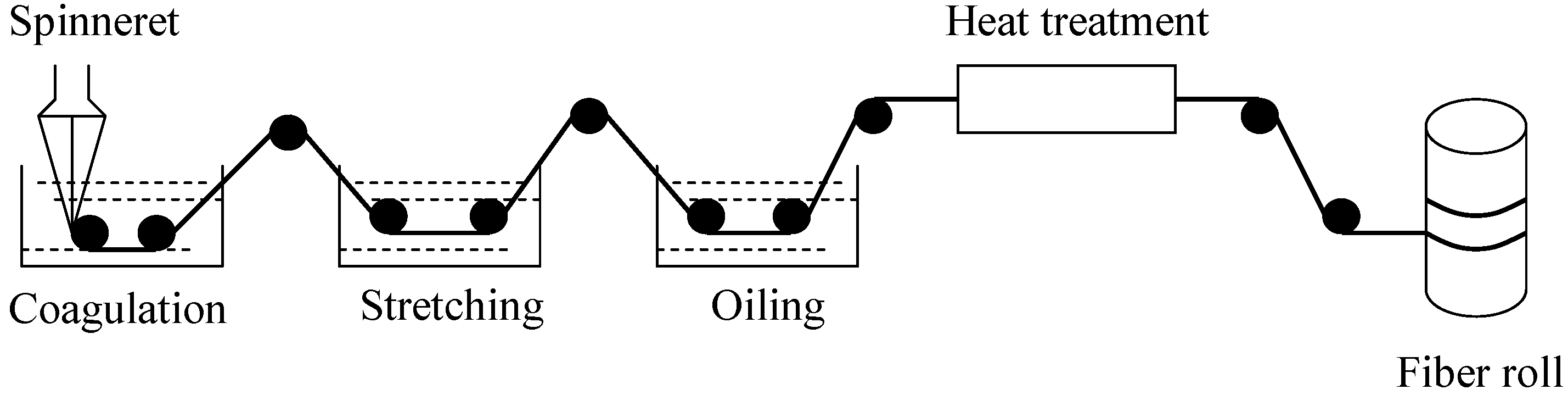
2.1. The Process of Carbon Fiber Production

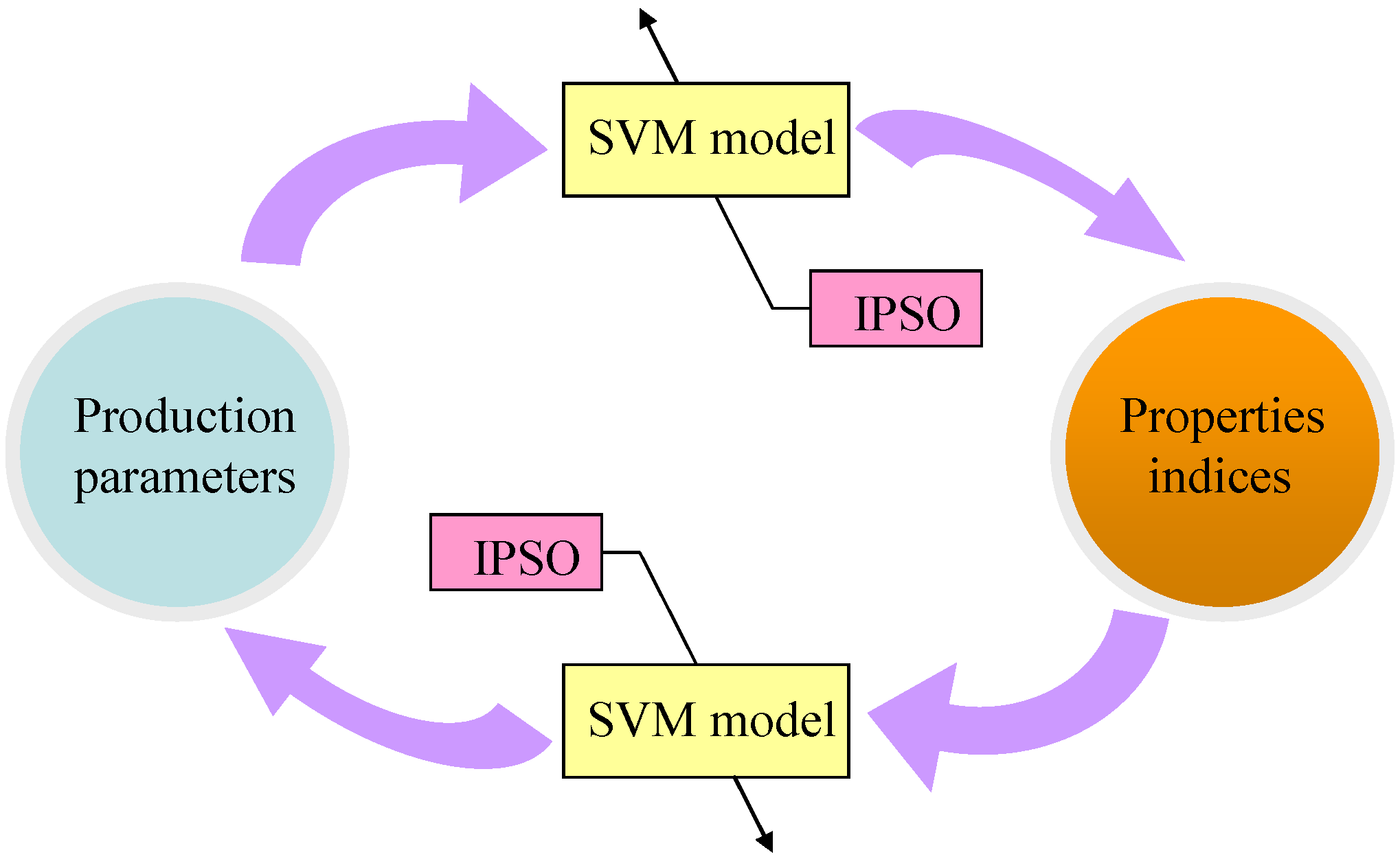
2.2. The Bi-Directional Prediction Methods for Carbon Fiber Production

3. Methodology of the SVM-IPSO Model
3.1. The SVM Model
3.2. Overview of Particle Swarm Optimization
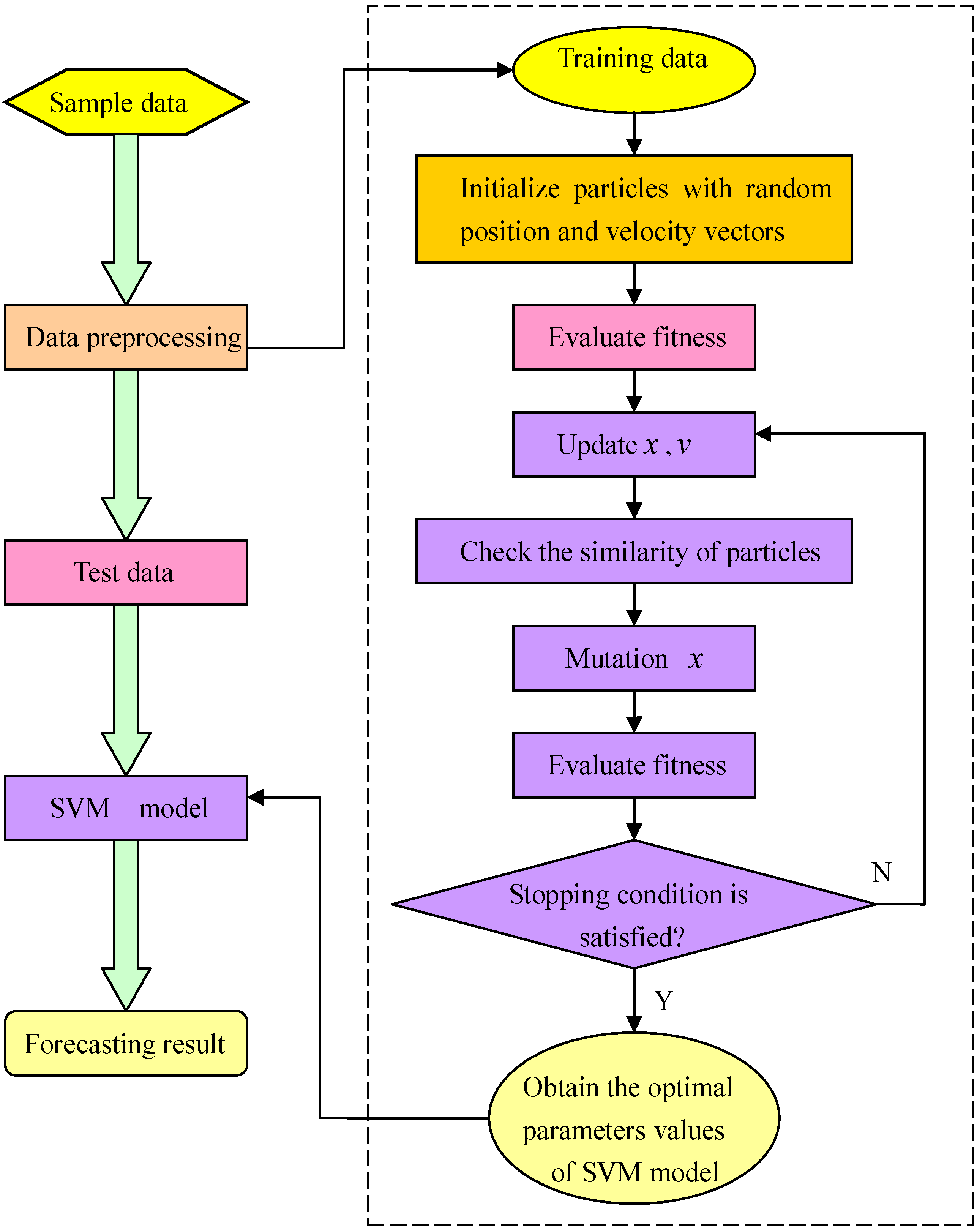
3.3. Improved Particle Swarm Optimization
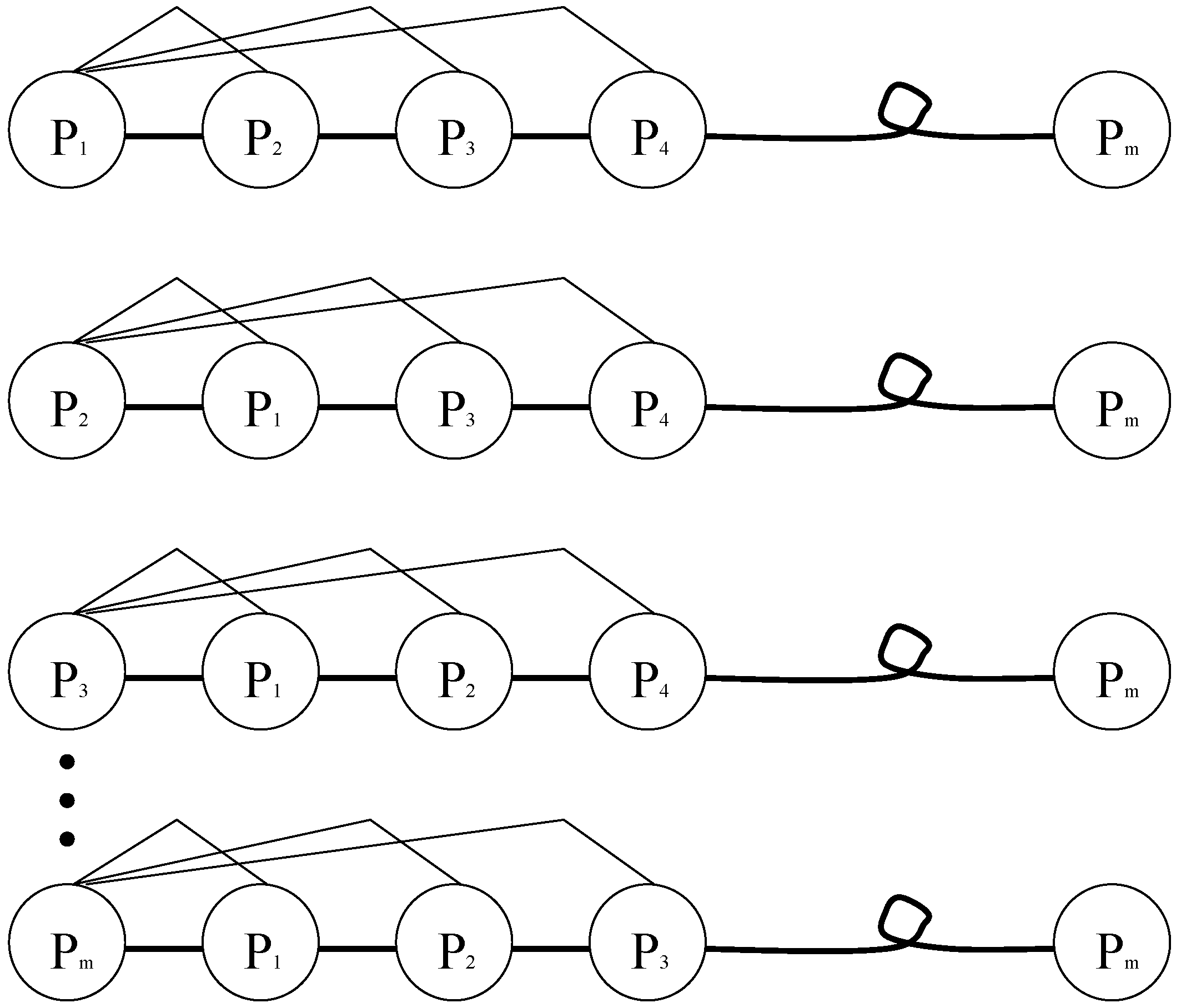
3.3.1. The Basic Concept of the Cell Communication
3.3.2. IPSO Based on the Communication Mechanism of Cells

3.4. SVM Based on the IPSO

4. Simulation and Discussion
4.1. The Preprocessing of Sample Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
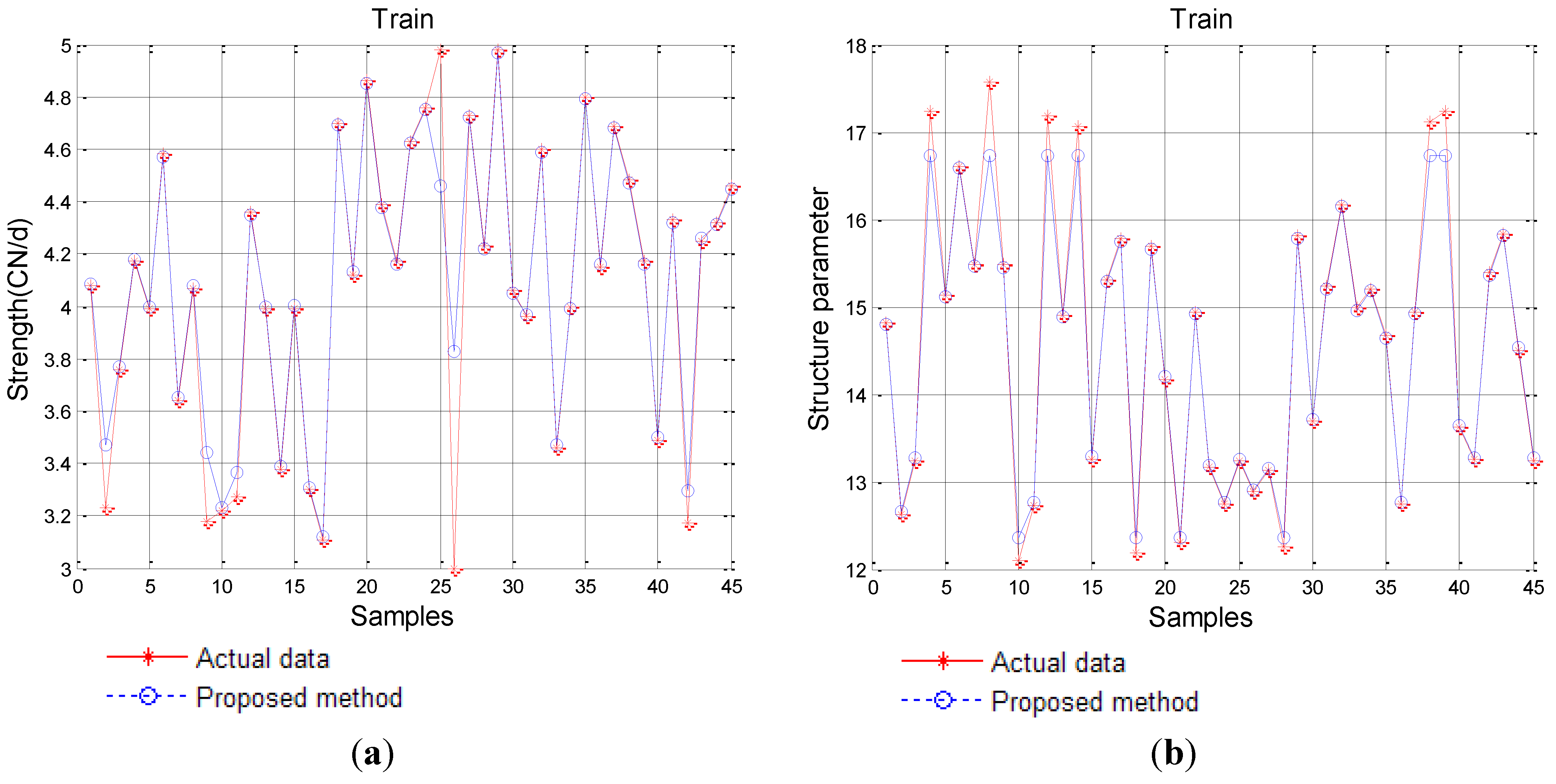{kind=link}
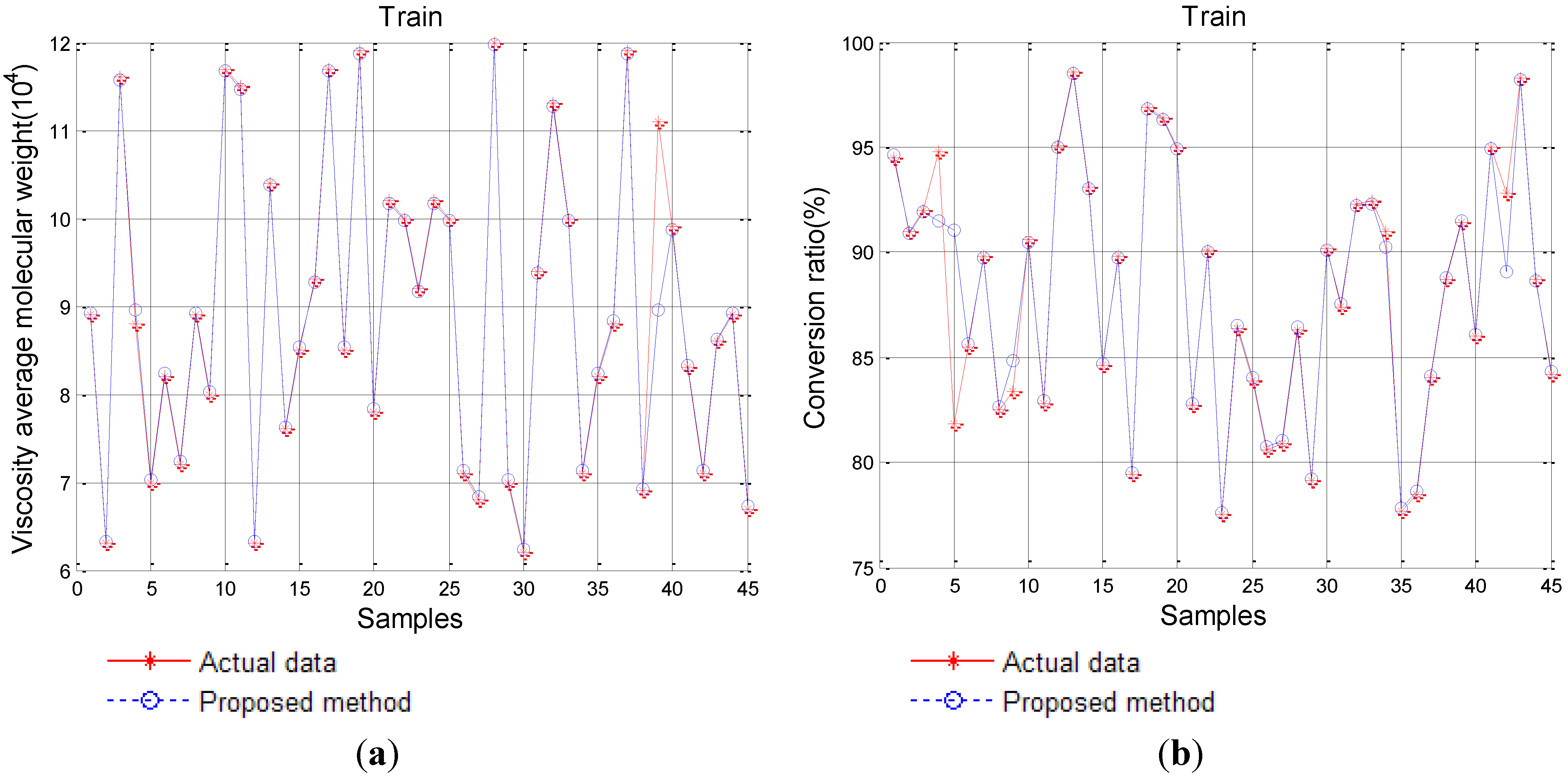{kind=link}
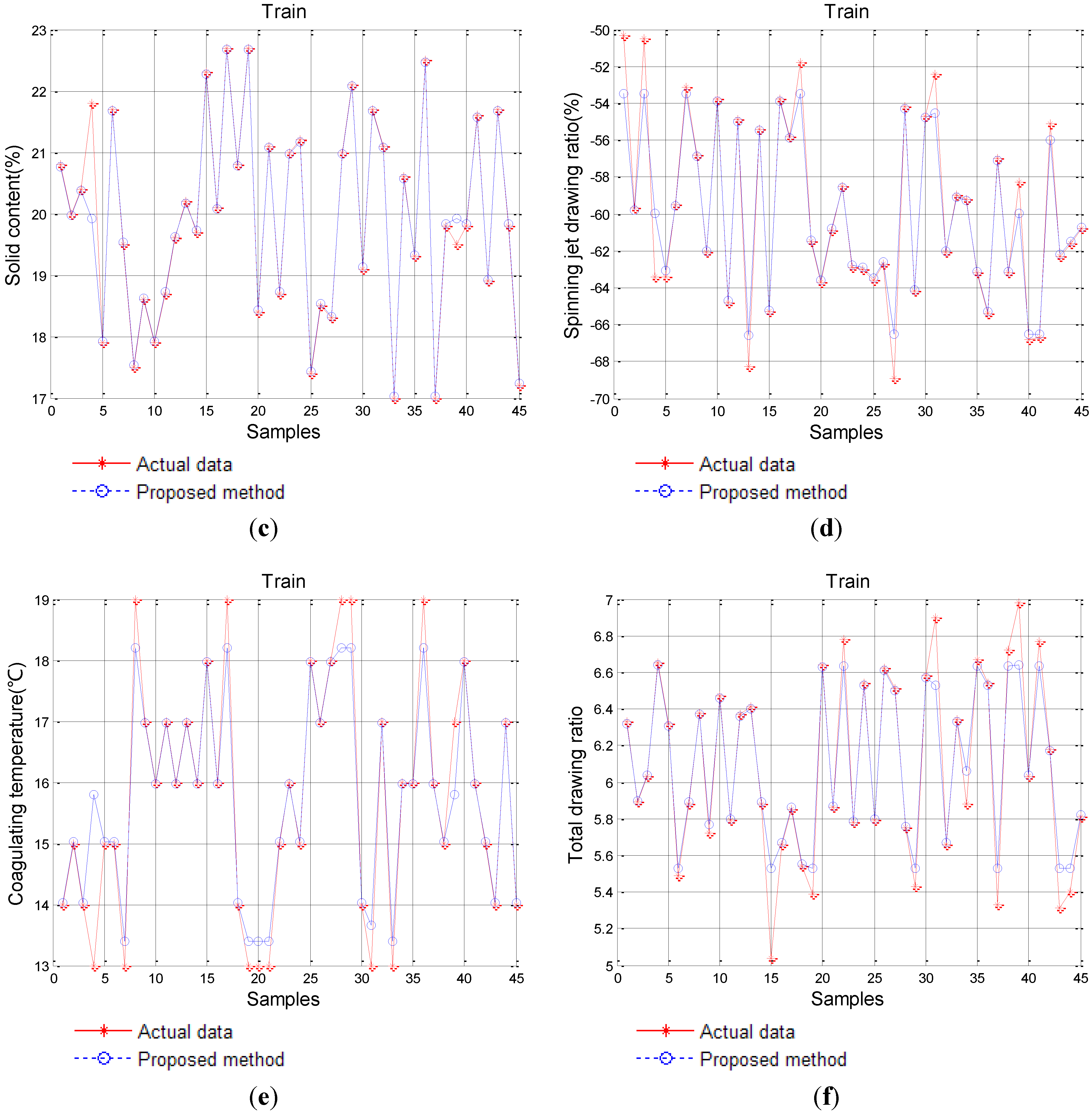{kind=link}
| No. | Viscosity Average Molecular Weight (104) | Conversion Ratio (%) | Solid Content (%) | Spinning Jet Drawing Ratio (%) | Coagulating Bath Temperature (°C) | Total Drawing Ratio | Strength (CN/d) | Structure Parameter |
|---|---|---|---|---|---|---|---|---|
| 1 | 8.9 | 94.5 | 20.8 | −50.3 | 14 | 6.33 | 4.08 | 14.82 |
| 2 | 6.3 | 91.0 | 20.0 | −59.7 | 15 | 5.89 | 3.23 | 12.63 |
| 3 | 11.6 | 92.0 | 20.4 | −50.5 | 14 | 6.03 | 3.76 | 13.24 |
| 4 | 8.8 | 94.8 | 21.8 | −63.4 | 13 | 6.65 | 4.17 | 17.24 |
| 5 | 7.0 | 81.8 | 17.9 | −63.4 | 15 | 6.32 | 3.99 | 15.14 |
| 6 | 8.2 | 85.5 | 21.7 | −59.5 | 15 | 5.49 | 4.58 | 16.61 |
| 7 | 7.2 | 89.8 | 19.5 | −53.1 | 13 | 5.88 | 3.64 | 15.49 |
| 8 | 8.9 | 82.5 | 17.5 | −56.8 | 19 | 6.38 | 4.07 | 17.57 |
| 9 | 8.0 | 83.4 | 18.6 | −62.1 | 17 | 5.72 | 3.18 | 15.48 |
| 10 | 11.7 | 90.6 | 17.9 | −53.8 | 16 | 6.47 | 3.22 | 12.10 |
| 11 | 11.5 | 82.8 | 18.7 | −64.8 | 17 | 5.79 | 3.27 | 12.73 |
| 12 | 6.3 | 95.1 | 19.6 | −54.9 | 16 | 6.37 | 4.36 | 17.18 |
| 13 | 10.4 | 98.6 | 20.2 | −68.3 | 17 | 6.41 | 3.99 | 14.91 |
| 14 | 7.6 | 93.1 | 19.7 | −55.4 | 16 | 5.88 | 3.38 | 17.07 |
| 15 | 8.5 | 84.6 | 22.3 | −65.3 | 18 | 5.04 | 3.99 | 13.26 |
| 16 | 9.3 | 89.8 | 20.1 | −53.8 | 16 | 5.66 | 3.30 | 15.31 |
| 17 | 11.7 | 79.4 | 22.7 | −55.8 | 19 | 5.85 | 3.11 | 15.78 |
| 18 | 8.5 | 96.9 | 20.8 | −51.8 | 14 | 5.54 | 4.70 | 12.19 |
| 19 | 11.9 | 96.4 | 22.7 | −61.5 | 13 | 5.39 | 4.12 | 15.69 |
| 20 | 7.8 | 95.0 | 18.4 | −63.7 | 13 | 6.64 | 4.86 | 14.17 |
| 21 | 10.2 | 82.7 | 21.1 | −60.9 | 13 | 5.86 | 4.39 | 12.30 |
| 22 | 10.0 | 90.1 | 18.7 | −58.5 | 15 | 6.78 | 4.17 | 14.94 |
| 23 | 9.2 | 77.5 | 21.0 | −62.9 | 16 | 5.78 | 4.63 | 13.16 |
| 24 | 10.2 | 86.4 | 21.2 | −63.0 | 15 | 6.54 | 4.76 | 12.74 |
| 25 | 10.0 | 83.9 | 17.4 | −63.6 | 18 | 5.79 | 4.98 | 13.23 |
| 26 | 7.1 | 80.6 | 18.5 | −62.7 | 17 | 6.62 | 3.00 | 12.88 |
| 27 | 6.8 | 80.9 | 18.3 | −68.9 | 18 | 6.51 | 4.73 | 13.13 |
| 28 | 12.0 | 86.3 | 21.0 | −54.2 | 19 | 5.75 | 4.23 | 12.26 |
| 29 | 7.0 | 79.1 | 22.1 | −64.2 | 19 | 5.43 | 4.98 | 15.81 |
| 30 | 6.2 | 90.2 | 19.1 | −54.7 | 14 | 6.58 | 4.06 | 13.69 |
| 31 | 9.4 | 87.4 | 21.7 | −52.4 | 13 | 6.90 | 3.96 | 15.23 |
| 32 | 11.3 | 92.3 | 21.1 | −62.1 | 17 | 5.66 | 4.60 | 16.17 |
| 33 | 10.0 | 92.4 | 17.0 | −59.0 | 13 | 6.34 | 3.46 | 14.99 |
| 34 | 7.1 | 91.0 | 20.6 | −59.2 | 16 | 5.88 | 4.00 | 15.21 |
| 35 | 8.2 | 77.7 | 19.3 | −63.2 | 16 | 6.67 | 4.80 | 14.67 |
| 36 | 8.8 | 78.5 | 22.5 | −65.4 | 19 | 6.54 | 4.15 | 12.74 |
| 37 | 11.9 | 84.0 | 17.0 | −57.0 | 16 | 5.33 | 4.69 | 14.94 |
| 38 | 6.9 | 88.7 | 19.8 | −63.2 | 15 | 6.72 | 4.48 | 17.12 |
| 39 | 11.1 | 91.4 | 19.5 | −58.3 | 17 | 6.98 | 4.17 | 17.24 |
| 40 | 9.9 | 86.0 | 19.8 | −66.8 | 18 | 6.03 | 3.49 | 13.62 |
| 41 | 8.3 | 95.0 | 21.6 | −66.7 | 16 | 6.77 | 4.33 | 13.25 |
| 42 | 7.1 | 92.8 | 18.9 | −55.1 | 15 | 6.18 | 3.17 | 15.39 |
| 43 | 8.6 | 98.3 | 21.7 | −62.3 | 14 | 5.31 | 4.25 | 15.84 |
| 44 | 8.9 | 88.7 | 19.8 | −61.6 | 17 | 5.40 | 4.32 | 14.50 |
| 45 | 6.7 | 84.2 | 17.2 | −60.8 | 14 | 5.81 | 4.46 | 13.24 |
| 46 | 11.0 | 98.0 | 22.7 | −74.6 | 12 | 6.89 | 3.90 | 12.82 |
| 47 | 9.5 | 92.2 | 20.3 | −50.5 | 17 | 5.92 | 3.91 | 13.20 |
| 48 | 7.7 | 78.2 | 17.2 | −63.4 | 19 | 6.17 | 3.99 | 15.19 |
| 49 | 9.5 | 79.3 | 18.1 | −67.4 | 13 | 6.50 | 4.78 | 17.69 |
| 50 | 7.4 | 90.4 | 21.3 | −55.3 | 18 | 6.65 | 4.96 | 12.49 |
| Algorithms | Conventional RNN | Basic PSO-RNN | GA-IPSO-RNN | Proposed method | |
|---|---|---|---|---|---|
| MAE | 1 | 1.1950 | 0.4818 | 0.4258 | 0.3839 |
| 2 | 3.6827 | 2.0262 | 1.9833 | 1.7821 | |
| Mean | 2.4389 | 1.2540 | 1.2045 | 1.0830 | |
| MRE(%) | 1 | 28.63 | 10.65 | 9.39 | 8.71 |
| 2 | 27.96 | 14.61 | 14.01 | 12.41 | |
| Mean | 28.30 | 12.63 | 11.70 | 10.56 | |
| RMSE | 1 | 1.4843 | 0.5841 | 0.5157 | 0.4076 |
| 2 | 4.5364 | 2.2637 | 2.1177 | 1.9649 | |
| Mean | 3.0104 | 1.4239 | 1.3167 | 1.1863 | |
| TIC | 1 | 0.1675 | 0.0690 | 0.0609 | 0.0481 |
| 2 | 0.1452 | 0.0766 | 0.0727 | 0.0679 | |
| Mean | 0.1563 | 0.0728 | 0.0668 | 0.0580 | |
4.2. The Selection of Comparative Models
4.3. Forward Prediction

4.4. Backward Prediction


| Algorithms | MAE | MRE (%) | RMSE | TIC |
|---|---|---|---|---|
| Conventional RNN | ||||
| 1 | 173.1400 | 1876.58 | 341.7052 | 0.9612 |
| 2 | 1062.8000 | 1310.66 | 2004.3000 | 0.9391 |
| 3 | 151.6600 | 816.09 | 285.3062 | 0.9051 |
| 4 | 171.6800 | 264.56 | 285.1956 | 0.7416 |
| 5 | 62.6800 | 443.07 | 103.5493 | 0.8054 |
| 6 | 34.8800 | 533.97 | 63.3625 | 0.9510 |
| Mean | 276.1367 | 874.16 | 513.9031 | 0.8839 |
| Basic PSO-RNN | ||||
| 1 | 1.9652 | 22.73 | 2.2049 | 0.1138 |
| 2 | 9.7604 | 11.30 | 10.3417 | 0.0590 |
| 3 | 2.5932 | 13.19 | 2.7487 | 0.0690 |
| 4 | 8.9433 | 15.27 | 10.2110 | 0.0806 |
| 5 | 3.2098 | 20.66 | 3.2757 | 0.1054 |
| 6 | 0.4920 | 7.38 | 0.6731 | 0.0544 |
| Mean | 4.4940 | 15.09 | 4.9092 | 0.0804 |
| GA-IPSO-RNN | ||||
| 1 | 1.3996 | 14.37 | 1.7597 | 0.1026 |
| 2 | 8.2660 | 9.61 | 9.1148 | 0.0518 |
| 3 | 2.2693 | 11.04 | 2.5107 | 0.0647 |
| 4 | 8.0976 | 13.47 | 9.1473 | 0.0733 |
| 5 | 2.9085 | 19.20 | 2.9776 | 0.0944 |
| 6 | 0.3260 | 4.94 | 0.4054 | 0.0317 |
| Mean | 3.8778 | 12.11 | 4.3192 | 0.0697 |
| Proposed method | ||||
| 1 | 1.0585 | 11.80 | 1.2290 | 0.0693 |
| 2 | 7.7362 | 9.03 | 8.4285 | 0.0479 |
| 3 | 1.7943 | 9.17 | 1.9964 | 0.0500 |
| 4 | 7.9765 | 12.74 | 8.8876 | 0.0724 |
| 5 | 2.7471 | 18.42 | 2.9189 | 0.0920 |
| 6 | 0.3994 | 6.02 | 0.4855 | 0.0387 |
| Mean | 3.6187 | 11.20 | 3.9910 | 0.0617 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yusof, N.; Ismail, A.F. Post spinning and pyrolysis processes of polyacrylonitrile (PAN)-based carbon fiber and activated carbon fiber: A review. J. Anal. Appl. Pyrolysis 2012, 93, 1–13. [Google Scholar] [CrossRef]
- Chand, S. Review carbon fibers for composites. J. Mater. Sci. 2000, 35, 1303–1313. [Google Scholar] [CrossRef]
- Liu, J.; Tian, Y.; Chen, Y.; Liang, J.; Zhang, L.; Fong, H. A surface treatment technique of electrochemical oxidation to simultaneously improve the interfacial bonding strength and the tensile strength of PAN-based carbon fibers. Mater. Chem. Phys. 2010, 122, 548–555. [Google Scholar] [CrossRef]
- Wang, Y.; Yin, W. Chemical modification for PAN fibers during heat-treatment process. Phys. Procedia 2011, 18, 202–205. [Google Scholar] [CrossRef]
- Rahman, M.A.; Ismail, A.F.; Mustafa, A. The effect of residence time on the physical characteristics of PAN-based fibers produced using a solvent-free coagulation process. Mater. Sci. Eng. 2007, 448, 275–280. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Ding, Y.S.; Ren, L.H.; Hao, K.R.; Wang, H.P.; Chen, J.J. A bio-inspired multi-layered intelligent cooperative controller for stretching process of fiber production. IEEE Trans. Syst. Man Cybern. C 2012, 42, 367–377. [Google Scholar]
- Rennhofer, H.; Loidl, D.; Puchegger, S.; Peterlik, H. Structural development of PAN-based carbon fibers studied by in situ X-ray scattering at high temperatures under load. Carbon 2010, 48, 964–971. [Google Scholar] [CrossRef]
- Belyaev, S.S.; Arkhangelsky, I.V.; Makarenko, I.V. Nonisothermal kinetic analysis of oxidative stabilization processes in PAN fibers. Thermochim. Acta 2010, 507–508, 9–14. [Google Scholar] [CrossRef]
- Chen, J.J.; Ding, Y.S.; Hao, K.R. The bidirectional optimization of carbon fiber production by neural network with a GA-IPSO hybrid algorithm. Math. Probl. Eng. 2013, 2013, 1–16. [Google Scholar]
- Sugimoto, Y.; Shioya, M.; Yamamoto, K.; Sakurai, S. Relationship between axial compression strength and longitudinal microvoid size for PAN-based carbon fibers. Carbon 2012, 50, 2860–2869. [Google Scholar] [CrossRef]
- Kadi, H.E. Modeling the mechanical behavior of fiber-reinforced polymeric composite materials using artificial neural networks—A review. Compos. Struct. 2006, 73, 1–23. [Google Scholar] [CrossRef]
- Yu, Y.; Hui, C.L.; Choi, T.M.; Au, R. Intelligent fabric hand prediction system with fuzzy neural network. IEEE Trans. Syst. Man Cybern. C 2010, 40, 619–629. [Google Scholar] [CrossRef]
- Du, D.; Li, K.; Fei, M. A fast multi-output RBF neural network construction method. Neurocomputing 2010, 73, 2196–2202. [Google Scholar] [CrossRef]
- Roy, A.; Govil, S.; Miranda, R. A neural-network learning theory and a polynomial time RBF algorithm. IEEE Trans. Neural Netw. 1997, 8, 1301–1313. [Google Scholar] [CrossRef]
- Hong, X.; Chen, S. A new RBF neural network with boundary value constraints. IEEE Trans. Syst. Man Cybern. B 2009, 39, 298–303. [Google Scholar] [CrossRef]
- Huang, G.B.; Saratchandran, P.; Sundararajan, N. A generalized growing and pruning RBF (GGAP-RBF) neural network for function approximation. IEEE Trans. Neural Netw. 2005, 16, 57–67. [Google Scholar] [CrossRef]
- Qiao, J.-F.; Han, H.-G. Identification and modeling of nonlinear dynamical systems using a novel self-organizing RBF-based approach. Automatica 2012, 48, 1729–1734. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, G. A forecasting method based on online self-correcting single model RBF neural network. Procedia Eng. 2012, 29, 2516–2520. [Google Scholar] [CrossRef]
- Hong, W.C.; Dong, Y.; Zhang, W.Y.; Chen, L.Y.; Panigrahi, B.K. Cyclic electric load forecasting by seasonal SVR with chaotic genetic algorithm. Int. J. Electr. Power Energy Syst. 2013, 44, 604–614. [Google Scholar] [CrossRef]
- Goh, A.T.C.; Goh, S.H. Support vector machines: Their use in geotechnical engineering as illustrated using seismic liquefaction data. Comput. Geotech. 2007, 34, 410–421. [Google Scholar] [CrossRef]
- Kordjazi, A.; Nejad, F.P.; Jaksa, M.B. Prediction of ultimate axial load-carrying capacity of piles using a support vector machine based on CPT data. Comput. Geotech. 2014, 55, 91–102. [Google Scholar] [CrossRef]
- Lin, J.Y.; Cheng, C.T.; Chau, K.W. Using support vector machines for long-term discharge prediction. Hydrol. Sci. J. 2006, 51, 599–612. [Google Scholar] [CrossRef]
- Niu, D.; Wang, Y.; Wu, D.D. Power load forecasting using support vector machine and ant colony optimization. Expert Syst. Appl. 2010, 37, 2531–2539. [Google Scholar] [CrossRef]
- Wang, J.J.; Li, L.; Niu, D.; Tan, Z.F. An annual load forecasting model based on support vector regression with differential evolution algorithm. Appl. Energy 2012, 94, 65–70. [Google Scholar] [CrossRef]
- Gilan, S.; Jovein, H.B.; Ali, A.R. Hybrid support vector regression-Particle swarm optimization for prediction of compressive strength and RCPT of concretes containing metakaolin. Constr. Build. Mater. 2012, 34, 321–329. [Google Scholar] [CrossRef]
- Hong, W.C. Chaotic particle swarm optimization algorithm in a support vector regression electric load forecasting model. Energy Convers. Manag. 2009, 50, 105–117. [Google Scholar] [CrossRef]
- Kang, Q.; Zhou, M.; An, J.; Wu, Q. Swarm intelligence approaches to optimal power flow problem with distributed generator failures in power networks. IEEE Trans. Autom. Sci. Eng. 2013, 10, 343–353. [Google Scholar] [CrossRef]
- Liang, X.; Li, W.; Zhang, Y.; Zhou, M. An adaptive particle swarm optimization method based on clustering. Soft Comput. 2014. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Li, X.; Zhang, A.; Li, C.C.; Zhang, L. Rolling element bearing fault detection using support vector machine with improved ant colony optimization. Measurement 2013, 46, 2726–2734. [Google Scholar] [CrossRef]
- Keerthi, S.S.; Lin, C.J. Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. IEEE Proc. Int. Conf. Neural Netw. 1995, 4, 1942–1948. [Google Scholar]
- Zhu, H.; Wang, Y.; Wang, K.; Chen, Y. Particle Swarm Optimization (PSO) for the constrained portfolio optimization problem. Expert Syst. Appl. 2011, 38, 10161–10169. [Google Scholar] [CrossRef]
- Ahmed, K.A.; Xiang, J. Mechanisms of cellular communication through intercellular protein transfer. J. Cell. Mol. Med. 2011, 15, 1458–1473. [Google Scholar] [CrossRef] [PubMed]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, C.; Hao, K.; Ding, Y. The Bi-Directional Prediction of Carbon Fiber Production Using a Combination of Improved Particle Swarm Optimization and Support Vector Machine. Materials 2015, 8, 117-136. https://doi.org/10.3390/ma8010117
Xiao C, Hao K, Ding Y. The Bi-Directional Prediction of Carbon Fiber Production Using a Combination of Improved Particle Swarm Optimization and Support Vector Machine. Materials. 2015; 8(1):117-136. https://doi.org/10.3390/ma8010117
Chicago/Turabian StyleXiao, Chuncai, Kuangrong Hao, and Yongsheng Ding. 2015. "The Bi-Directional Prediction of Carbon Fiber Production Using a Combination of Improved Particle Swarm Optimization and Support Vector Machine" Materials 8, no. 1: 117-136. https://doi.org/10.3390/ma8010117
APA StyleXiao, C., Hao, K., & Ding, Y. (2015). The Bi-Directional Prediction of Carbon Fiber Production Using a Combination of Improved Particle Swarm Optimization and Support Vector Machine. Materials, 8(1), 117-136. https://doi.org/10.3390/ma8010117