A Robust Visual Tracking Algorithm Based on Spatial-Temporal Context Hierarchical Response Fusion

Abstract
:1. Introduction
- (1)
- The hierarchical features of CNNs are used as feature representation to handle large appearance variations, and we learn a spatial-temporal context correlation filter on each CNN layer as a discriminative classifier. We use multi-level correlation response maps for fusion to infer the target location. For scale estimation, we train DCF based on scale pyramid representation and estimate the desired object scale from the best score frame.
- (2)
- We employ the EdgeBox to redetect when tracking failure occurred and proposed a novel re-detection activation method. For model updating, we propose a novel model update method to solve the model noisy problems.
- (3)
- We extensively validate our method on benchmark datasets with large-scale sequences and extensive experimental results demonstrated that the proposed tracking algorithm is superior to the state-of-the-art methods in terms of accuracy and robustness.
2. Related Works
3. Robust Spatial-temporal Context Hierarchical Response Fusion
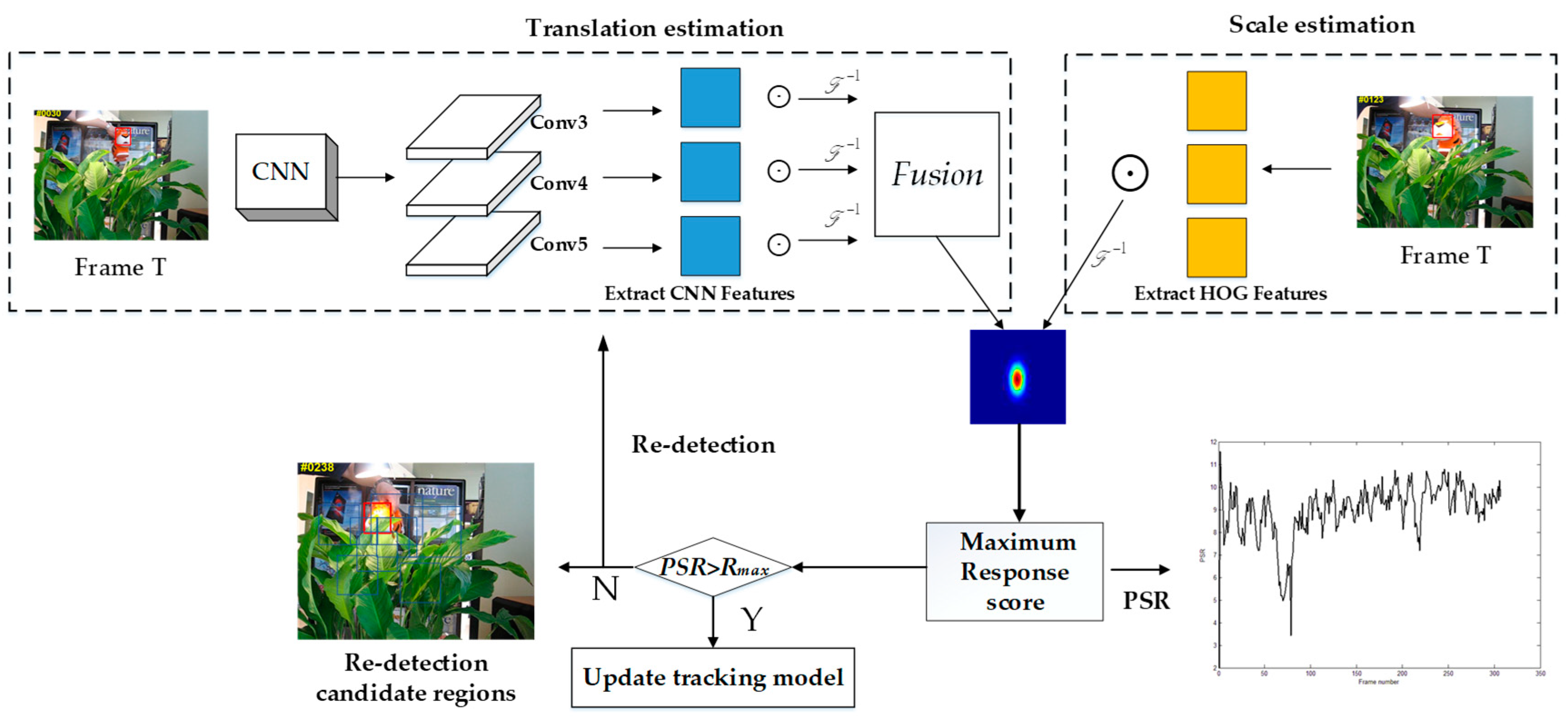
3.1. The Overall Flowchart of The Proposed Algorithm
3.1.1. Hierarchical Feature of Convolution Layer
3.1.2. Spatial-Temporal Context Correlation Filter
3.1.3. Multi-Response Maps Fusion
3.2. The Scale Discriminative Correlation Filter
3.3. Target Recovery
3.3.1. Detector Activation
3.4. Model Update
3.5. Algorithm Flowchart
| Algorithm 1. Proposed tracking algorithm | |
| Input: Initial target location P0 (x0, y0), initial scale S0 (w0, v0), initial PSR score PSR0, hierarchical correlation filters {|l = 3, 4, 5}. | |
| Output: Estimated object location Pt (xt, yt), estimated scale St (wt, vt). | |
| 1. | Repeat: |
| 2. | Crop out the image samples centered at P (xt, yt) and extract convolutional features and HOG features; |
| 3. | For each layer l computes the response map via Equation (2); |
| 4. | Estimate the location of the target by computing the maximum response map after fusion via Equation (6); |
| 5. | Construct a target scale pyramid around P (xt, yt) and estimate the optimal scale of the target as in Equation (10); |
| 6. | Calculate the PSR score of the response map peak; |
| 7. | If < , then |
| 8. | Activate re-detecting component D and find the possible candidate states C; |
| 9. | For each state in C, do computing response score via Equation (2); |
| 10. | End if |
| 11. | If > , then |
| 12. | Update the tracking model via Equations (3a) and (3b); |
| 13. | Update the scale estimation model via Equations (9a) and (9b); |
| 14. | Update detector D; |
| 15. | End if |
| 16. | Until end of video sequence. |
4. Experimental Results
4.1. Implementation Details
4.2. The Overall Tracking Performance on OTB Benchmark Datasets
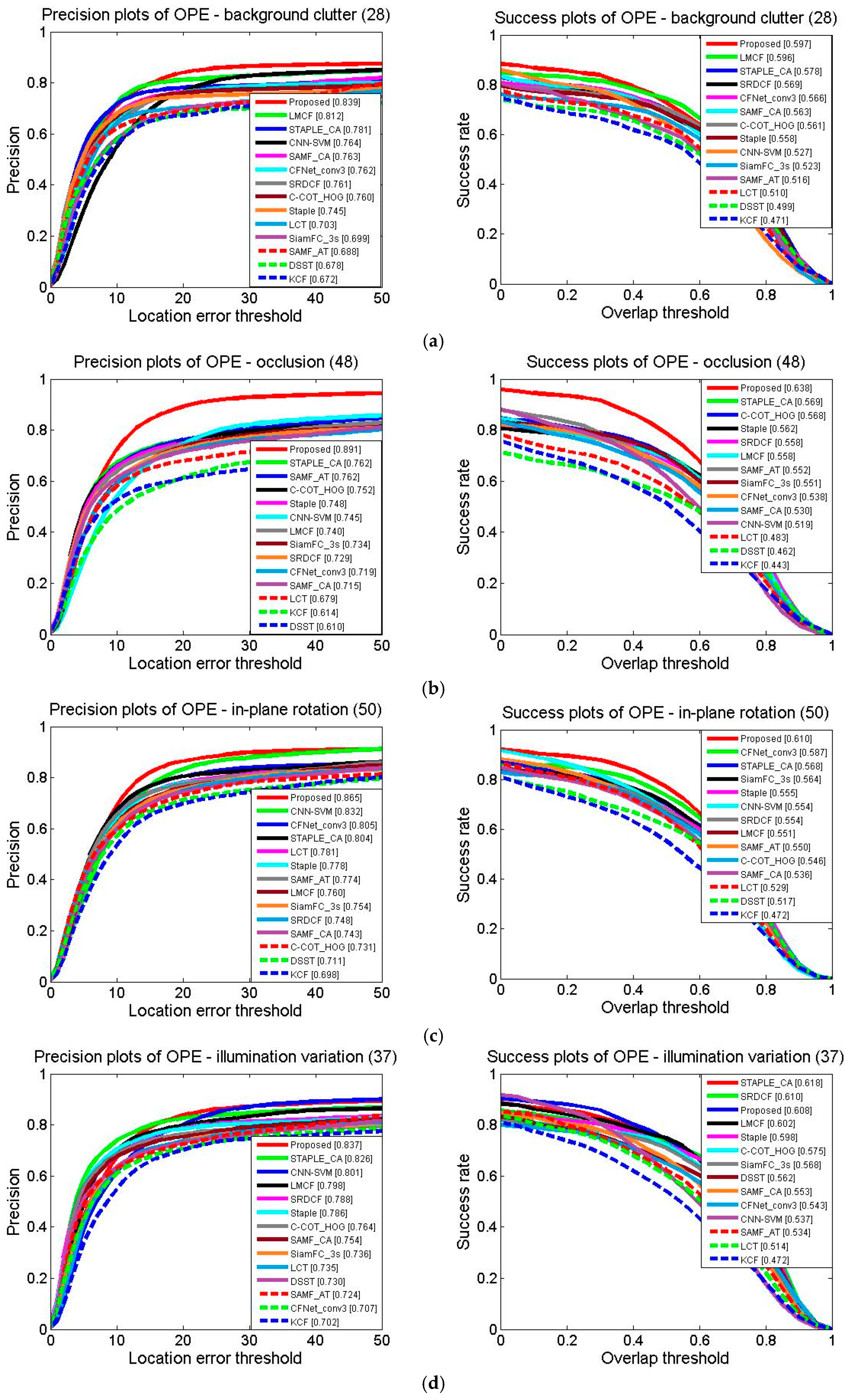
4.3. The Attribute-Based Tracking Evaluation
4.4. Qualitative Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual Tracking: An Experimental Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed] [Green Version]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38, 13. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–5 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representation. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H.; Zhang, D. Fast tracking via spatio-temporal context learning. arXiv, 2013; arXiv:1311.1939. [Google Scholar]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.H. Long-term correlation tracking. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-Aware Correlation Filter Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge Boxes: Locating Object Proposals from Edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; pp. 65.1–65.11. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary Learners for Real-Time Tracking. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Ning, J.; Yang, J.; Jiang, S.; Zhang, L.; Yang, M.H. Object Tracking via Dual Linear Structured SVM and Explicit Feature Map. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4266–4274. [Google Scholar]
- Rui, C.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast Visual Tracking via Dense Spatio-temporal Context Learning. In ECCV 2014 Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 127–141. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Wang, M.; Liu, Y.; Huang, Z. Large Margin Object Tracking with Circulant Feature Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4800–4808. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 472–488. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Alam, M.S.; Ochilov, S. Spectral fringe-adjusted joint transform correlation. Appl. Opt. 2010, 49, B18–B25. [Google Scholar] [CrossRef] [PubMed]
- Sidike, P.; Asari, V.K.; Alam, M.S. Multiclass Object Detection with Single Query in Hyperspectral Imagery Using Class-Associative Spectral Fringe-Adjusted Joint Transform Correlation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1196–1208. [Google Scholar] [CrossRef]
- Krieger, E.; Aspiras, T.; Asari, V.K.; Krucki, K.; Wauligman, B.; Diskin, Y.; Salva, K. Vehicle tracking in full motion video using the progressively expanded neural network (PENNet) tracker. Proc. SPIE 2018, 10649. [Google Scholar] [CrossRef]
- Krieger, E.W.; Sidike, P.; Aspiras, T.; Asari, V.K. Deterministic object tracking using Gaussian ringlet and directional edge features. Opt. Laser Technol. 2017, 95, 133–146. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, Q.; Xing, J.; Gao, J.; Peng, P.; Hu, W.; Maybank, S. Visual Tracking via Spatially Aligned Correlation Filters Network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 469–485. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.H.; Yang, M.H. VITAL: VIsual Tracking via Adversarial Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Santiago, Chile, 7–13 December 2015; pp. 621–629. [Google Scholar]
- Fan, J.; Xu, W.; Wu, Y.; Gong, Y. Human tracking using convolutional neural networks. IEEE Trans. Neural Netw. 2010, 21, 1610–1623. [Google Scholar] [PubMed]
- Li, H.; Li, Y.; Porikli, F. DeepTrack: Learning Discriminative Feature Representations by Convolutional Neural Networks for Visual Tracking. IEEE Trans. Image Process. 2014, 25, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.H. Robust Visual Tracking via Convolutional Networks Without Training. IEEE Trans. Image Process. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Ma, C.; Gong, L.; Zhang, J.; Lau, R.W.; Yang, M.H. CREST: Convolutional Residual Learning for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2574–2583. [Google Scholar]
- Zhu, Z.; Huang, G.; Zou, W.; Du, D.; Huang, C. UCT: Learning Unified Convolutional Networks for Real-Time Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 22–29 October 2017; pp. 1973–1982. [Google Scholar]
- Yao, Y.; Wu, X.; Zhang, L.; Shan, S.; Zuo, W. Joint Representation and Truncated Inference Learning for Correlation Filter based Tracking. arXiv, 2018; arXiv:1807.11071. [Google Scholar]
- Zhang, T.; Xu, C.; Yang, M.H. Multi-task Correlation Particle Filter for Robust Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4819–4827. [Google Scholar]
- Wang, L.; Liu, T.; Wang, G.; Chan, K.L.; Yang, Q. Video tracking using learned hierarchical features. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2015, 24, 1424–1435. [Google Scholar] [CrossRef] [PubMed]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Computer Vision—ECCV 2016 Workshops. ECCV 2016; Hua, G., Jégou, H., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9914. [Google Scholar]
- Bibi, A.; Mueller, M.; Ghanem, B. Target Response Adaptation for Correlation Filter Tracking. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 419–433. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Crossing | Crowds | Couple | Surfer | Girl | Motor Rolling | David3 |
|---|---|---|---|---|---|---|---|
| Fixed Threshold | 0.983 | 0.896 | 0.929 | 0.753 | 1 | 0.878 | 1 |
| Dynamic Threshold | 1 | 0.991 | 0.929 | 0.843 | 1 | 0.957 | 1 |
| Sequence | Scale-Step | Precision |
|---|---|---|
| Jogging-1 | 1.02 | 0.974 |
| 1.03 | 0.974 | |
| 1.04 | 0.974 | |
| 1.05 | 0.974 | |
| 1.2 | 0.915 | |
| 1.3 | 0.863 |
| KCF | DSST | LCT | CNN-SVM | SAMF_CA | SAMF_AT | LMCF | |
| DP | 0.686 | 0.690 | 0.758 | 0.823 | 0.769 | 0.795 | 0.789 |
| OP | 0.471 | 0.518 | 0.525 | 0.554 | 0.555 | 0.571 | 0.579 |
| Staple | SiamFC_3s | STAPLE_CA | SRDCF | CFNet_conv3 | C-COT_HOG | Proposed | |
| DP | 0.790 | 0.781 | 0.817 | 0.793 | 0.791 | 0.808 | 0.876 |
| OP | 0.583 | 0.590 | 0.599 | 0.599 | 0.601 | 0.604 | 0.627 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Luo, Y.; Chen, Z.; Du, Y.; Zhu, D.; Liu, P. A Robust Visual Tracking Algorithm Based on Spatial-Temporal Context Hierarchical Response Fusion. Algorithms 2019, 12, 8. https://doi.org/10.3390/a12010008
Zhang W, Luo Y, Chen Z, Du Y, Zhu D, Liu P. A Robust Visual Tracking Algorithm Based on Spatial-Temporal Context Hierarchical Response Fusion. Algorithms. 2019; 12(1):8. https://doi.org/10.3390/a12010008
Chicago/Turabian StyleZhang, Wancheng, Yanmin Luo, Zhi Chen, Yongzhao Du, Daxin Zhu, and Peizhong Liu. 2019. "A Robust Visual Tracking Algorithm Based on Spatial-Temporal Context Hierarchical Response Fusion" Algorithms 12, no. 1: 8. https://doi.org/10.3390/a12010008
APA StyleZhang, W., Luo, Y., Chen, Z., Du, Y., Zhu, D., & Liu, P. (2019). A Robust Visual Tracking Algorithm Based on Spatial-Temporal Context Hierarchical Response Fusion. Algorithms, 12(1), 8. https://doi.org/10.3390/a12010008