An Enhanced Lightning Attachment Procedure Optimization Algorithm

Abstract
:1. Introduction
2. The Lightning Attachment Procedure Optimization Algorithm
2.1. Initialize the Population
2.2. Downward Leader Movement
2.3. Upward Leader Movement
2.4. Branch Fading
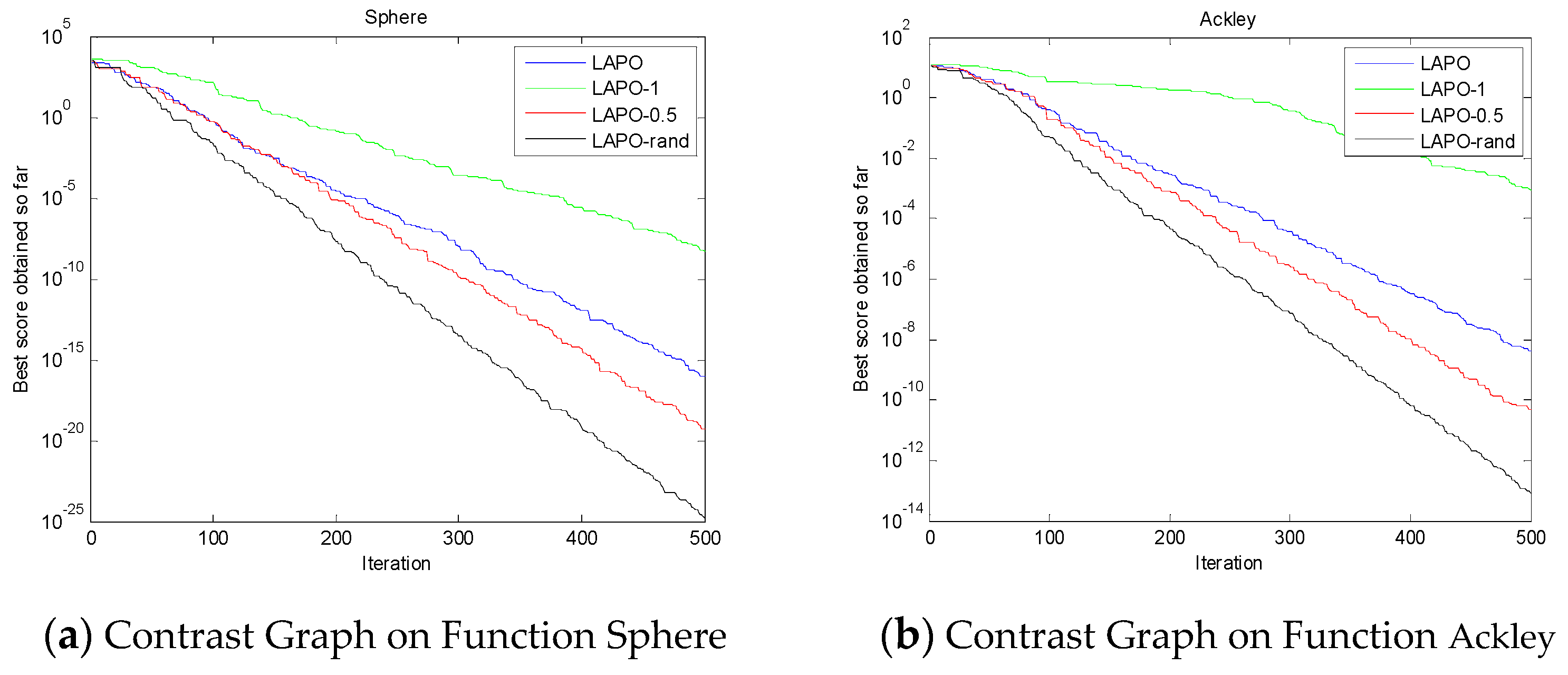
2.5. Enhancement of the Performance
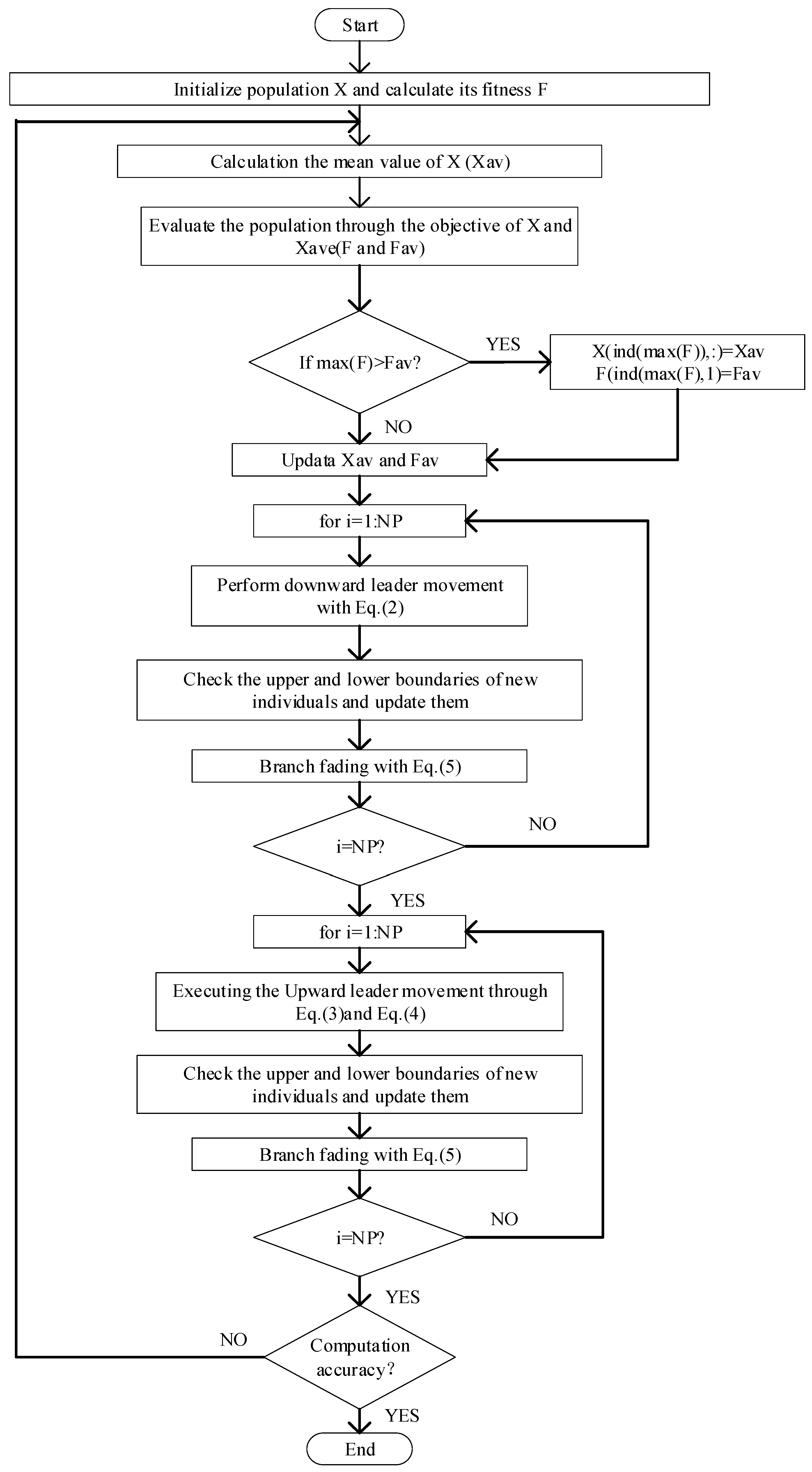
3. The Enhanced Lightning Attachment Procedure Optimization Algorithm
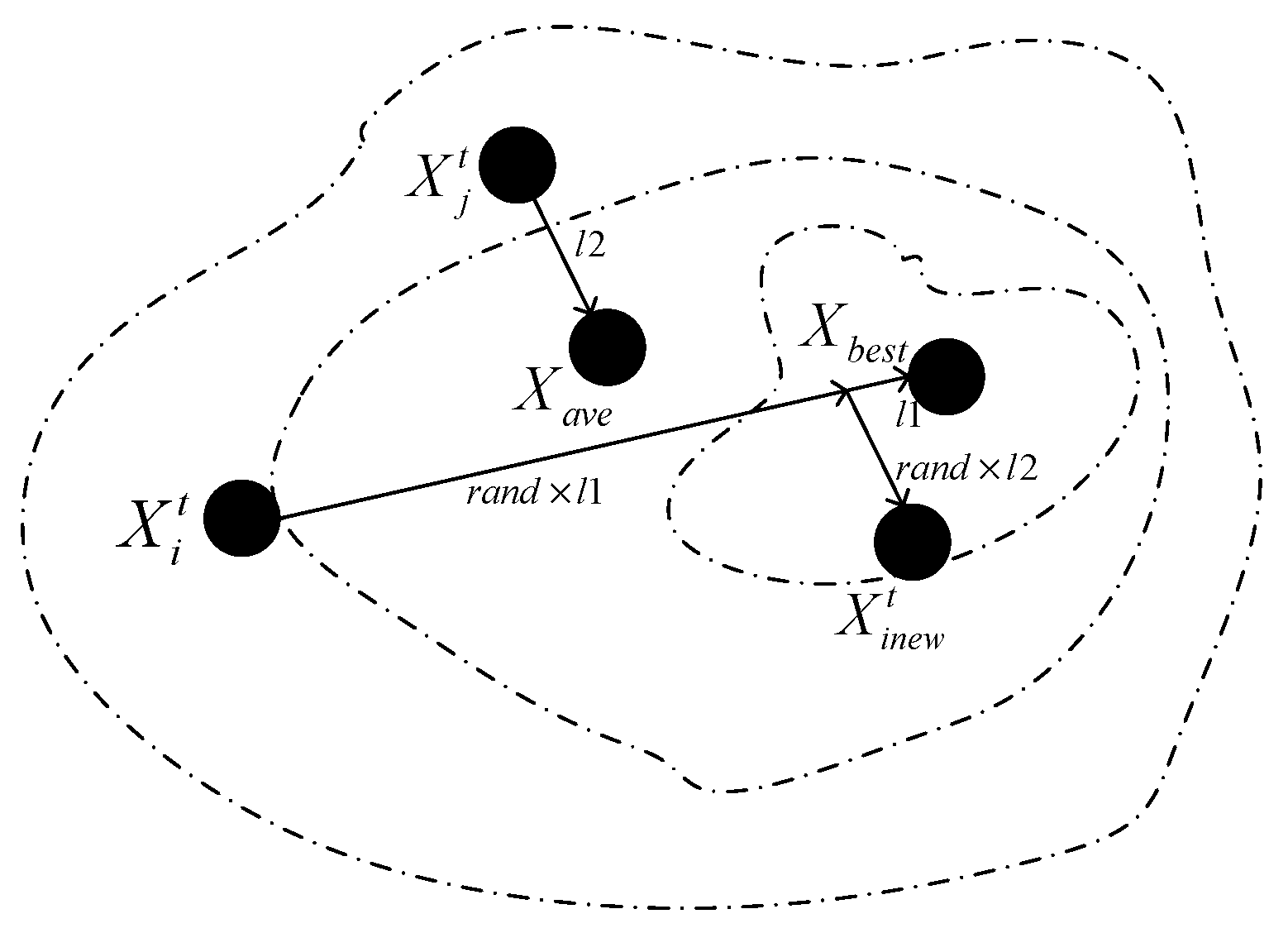
3.1. Improved Downward Leader Movement
3.2. Improvement of Upward Leader Movement
3.3. The Improved Enhancement Performance
3.4. The Pseudo Code of the ELAPO Algorithm
| Initialize the first population of test points randomly in the specific range |
| Calculate the fitness of test points |
| while the end criterion is not achieved |
| Set the test point with the worst fitness as Xw |
| for j = 1:D |
| end |
| if the fitness of is better than the fitness of Xw |
| end |
| Obtain Xave which is the mean value of all the test points |
| Calculate the fitness of Xave as Fave |
| for i = 1:NP (each test point) |
| Select randomly which is not equal to |
| Set the test point with the best fitness as |
| for j = 1:D (number of variables) |
| Update the variables of based on Equation (6), as |
| Check the boundary. If the particle exceeds the boundary value, it is generated randomly within the boundary. |
| end |
| Calculate the fitness of |
| if the fitness of is better than |
| end |
| end |
| for i = 1:NP (each test point) |
| for j = 1:D (number of variables) |
| Update the variables of based on Equation (8) as |
| Check the boundary. If the particle exceeds the boundary value, it is generated randomly within the boundary. |
| end |
| Calculation the fitness of |
| if the fitness of is better than |
| end |
| end |
| XBEST = the test point with the best fitness |
| FBEST = the best fitness |
| end |
| return XBEST, FBEST |
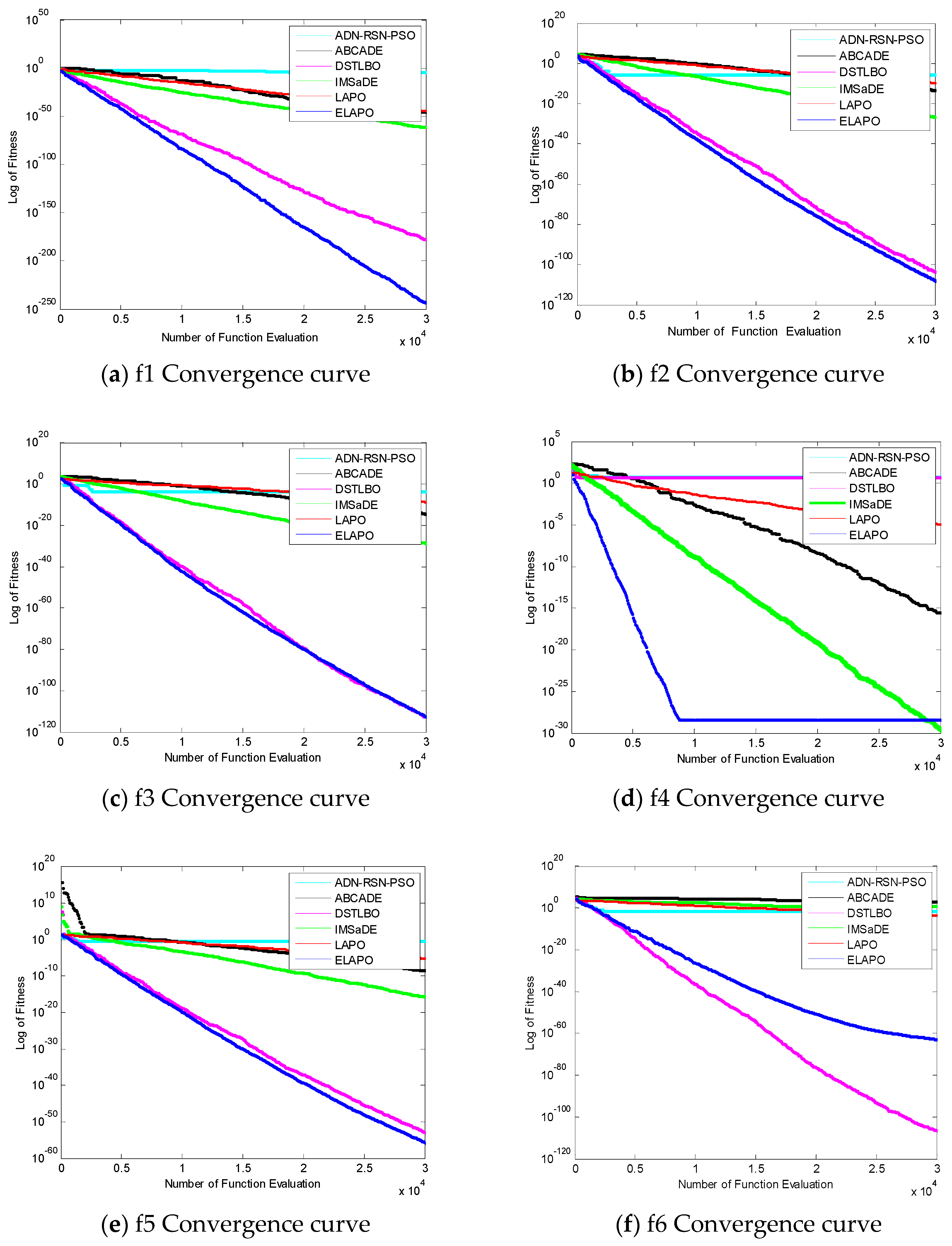
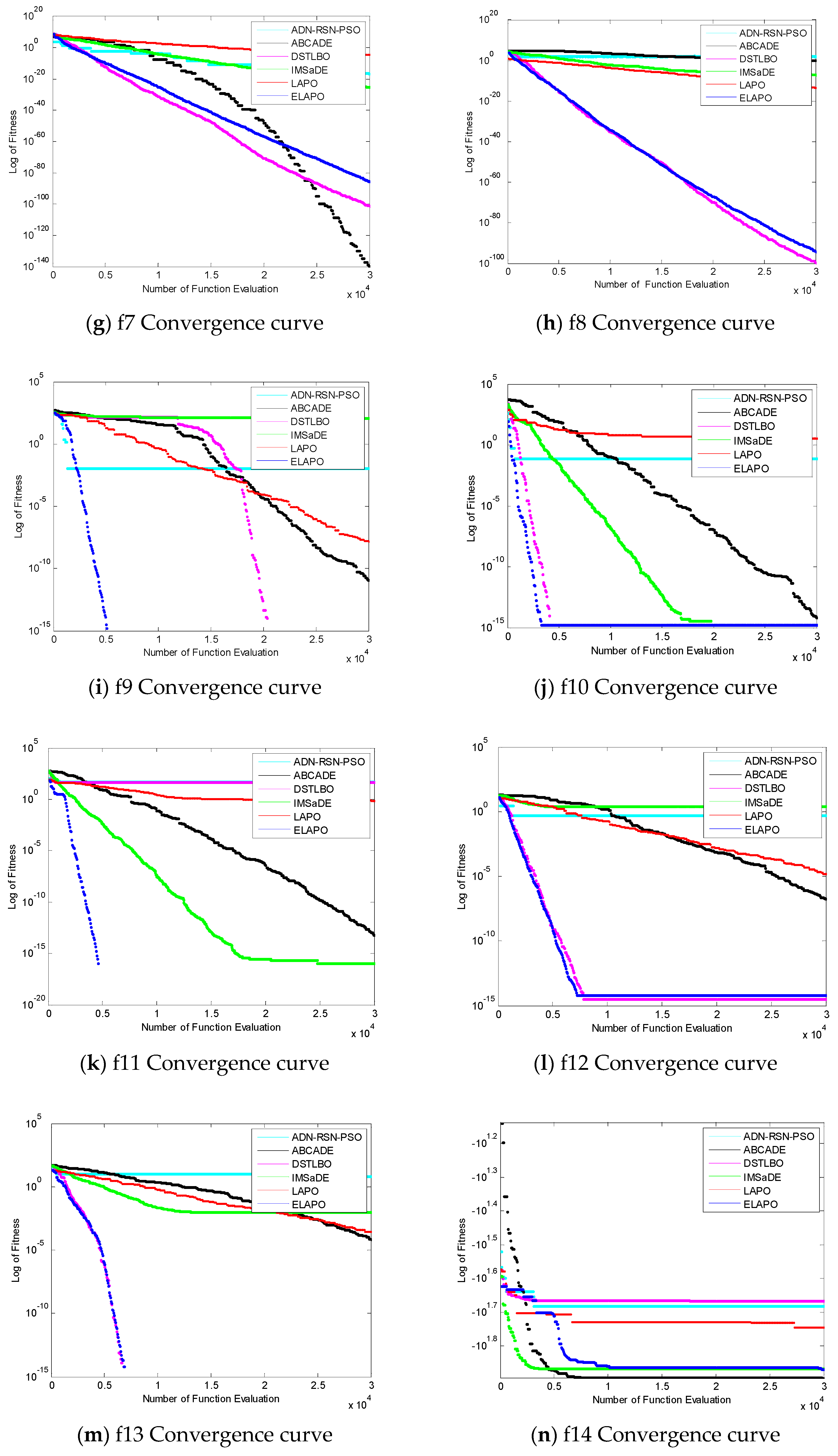
4. Analysis of the Simulation Results
5. Conclusions and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Boussaid, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Gogna, A.; Tayal, A. Metaheuristics: Review and application. J. Exp. Theor. Artif. Intell. 2013, 25, 503–526. [Google Scholar] [CrossRef]
- Mahdavi, S.; Shiri, M.E.; Rahnamayan, S. Metaheuristics in large-scale global continues optimization: A survey. Inf. Sci. 2015, 295, 407–428. [Google Scholar] [CrossRef]
- Liu, Y.K.; Li, M.K.; Xie, C.L.; Peng, M.J.; Xie, F. Path-planning research in radioactive environment based on particle swarm algorithm. Prog. Nucl. Energy 2014, 74, 184–192. [Google Scholar] [CrossRef]
- Wari, E.; Zhu, W. A survey on metaheuristics for optimization in food manufacturing industry. Appl. Soft Comput. 2016, 46, 328–343. [Google Scholar] [CrossRef]
- Pyrz, M.; Krzywoblocki, M. Crashworthiness Optimization of Thin-Walled Tubes Using Macro Element Method and Evolutionary Algorithm. Thin Walled Struct. 2017, 112, 12–19. [Google Scholar] [CrossRef]
- Kadin, Y.; Gamba, M.; Faid, M. Identification of the Hydrogen Diffusion Parameters in Bearing Steel by Evolutionary Algorithm. J. Alloys Compd. 2017, 705, 475–485. [Google Scholar] [CrossRef]
- Shieh, M.D.; Li, Y.; Yang, C.C. Comparison of multi-objective evolutionary algorithms in hybrid Kansei engineering system for product form design. Adv. Eng. Inf. 2018, 36, 31–42. [Google Scholar] [CrossRef]
- Yang, J.H.; Honavar, V. Feature Subset Selection Using a Genetic Algorithm. In Feature Extraction, Construction and Selection; Springer: Boston, MA, USA, 1998; pp. 117–136. [Google Scholar] [Green Version]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Knowles, J.; Corne, D. The Pareto Archived Evolution Strategy: A New Baseline Algorithm for Pareto Multiobjective Optimisation. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99, Washington, DC, USA, 6–9 July 1999. [Google Scholar]
- Banzhaf, W.; Koza, J.R.; Ryan, C.; Spector, L.; Jacob, C. Genetic programming. IEEE Intell. Syst. 2000, 15, 74–84. [Google Scholar] [CrossRef]
- Hansen, N.; Ostermeier, A. Completely Derandomized Self-Adaptation in Evolution Strategies. Evol. Comput. 2001, 9, 159–195. [Google Scholar] [CrossRef]
- Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 2008, 12, 702–713. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Basturk, B.; Karaboga, D. An artificial bee colony (ABC) algorithm for numeric function optimization. In Proceedings of the IEEE Swarm Intelligence Symposium, Indianapolis, IN, USA, 12–14 May 2006; pp. 687–697. [Google Scholar]
- Mucherino, A.; Seref, O. Monkey search: A novel metaheuristic search for global optimization. AIP Conf. Proc. 2007, 953, 162–173. [Google Scholar]
- Yang, X.S. Firefly Algorithms for Multimodal Optimization. In Proceedings of the 5th International Symposium on Stochastic Algorithms, Foundations and Applications, Sapporo, Japan, 26–28 October 2009; pp. 169–178. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Shah-Hosseini, H. Principal components analysis by the galaxy-based search algorithm: A novel metaheuristic for continuous optimisation. Int. J. Comput. Sci. Eng. 2011, 6, 132–140. [Google Scholar]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Kaveh, A.; Khayatazad, M. A new meta-heuristic method: Ray Optimization. Comput. Struct. 2012, 112, 283–294. [Google Scholar] [CrossRef]
- Hatamlou, A. Black hole: A new heuristic optimization approach for data clustering. Inf. Sci. 2013, 222, 175–184. [Google Scholar] [CrossRef]
- Kaveh, A.; Bakhshpoori, T. Water Evaporation Optimization: A Novel Physically Inspired Optimization Algorithm. Comput. Struct. 2016, 167, 69–85. [Google Scholar] [CrossRef]
- Nematollahi, A.F.; Rahiminejad, A.; Vahidi, B. A Novel Physical Based Meta-Heuristic Optimization Method Known as Lightning Attachment Procedure Optimization. Appl. Soft Comput. 2017, 59, 596–621. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Z.; Liu, Y.; Wang, J.; Jiang, D.; Chen, L. Space transformation search: A new evolutionary technique. In Proceedings of the First ACM/SIGEVO Summit on Genetic and Evolutionary Computation, Shanghai, China, 12–14 June 2009; pp. 537–544. [Google Scholar]
- Suganthan, P.N.; Hansen, N.; Liang, J.J.; Deb, K.; Chen, Y.P.; Auger, A.; Tiwari, S. Problem Definitions and Evaluation Criteria for the CEC 2005 Special Session on Real-Parameter Optimization. Available online: https://www.researchgate.net/profile/Ponnuthurai_Suganthan/publication/235710019_Problem_Definitions_and_Evaluation_Criteria_for_the_CEC_2005_Special_Session_on_Real-Parameter_Optimization/links/0c960525d3990de15c000000/Problem-Definitions-and-Evaluation-Criteria-for-the-CEC-2005-Special-Session-on-Real-Parameter-Optimization.pdf (accessed on 29 June 2019).
- Sun, W.; Lin, A.; Yu, H.; Liang, Q.; Wu, G. All-dimension neighborhood based particle swarm optimization with randomly selected neighbors. Inf. Sci. 2017, 405, 141–156. [Google Scholar] [CrossRef]
- Liang, Z.; Hu, K.; Zhu, Q.; Zhu, Z. An Enhanced Artificial Bee Colony Algorithm with Adaptive Differential Operators. Appl. Soft Comput. 2017, 58, 480–494. [Google Scholar] [CrossRef]
- Bi, X.-J.; Wang, J.-H. Teaching-learning-based optimization algorithm with hybrid learning strategy. J. Zhejiang Univ. Eng. Sci. 2017, 51, 1024–1031. [Google Scholar]
- Wang, S.; Li, Y.; Yang, H.; Liu, H. Self-adaptive differential evolution algorithm with improved mutation strategy. Soft Comput. 2018, 22, 3433–3447. [Google Scholar] [CrossRef]
- Demišar, J.; Schuurmans, D. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Guo, F.; Zhang, H.; Ji, H.; Li, X.; Leung, V.C. An Efficient Computation Offloading Management Scheme in the Densely Deployed Small Cell Networks with Mobile Edge Computing. IEEE/ACM Trans. Netw. 2018, 26, 2651–2664. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Function | Range | Optimal |
|---|---|---|---|
| f1 sumPower | [−1, 1] | 0 | |
| f2 Sphere | [−100, 100] | 0 | |
| f3 SumSquares | [−10, 10] | 0 | |
| f4 Step | [−1.28, 1.28] | 0 | |
| f5 Schwefel 2.22 | [−10, 10] | 0 | |
| f6 Schwefel 1.2 | [−100, 100] | 0 | |
| f7 Schwefel2.21 | [−100, 100] | 0 | |
| f8 Schwefel1.2 with Noise | [−100, 100] | 0 | |
| f9 Rastrigin | [−5.12, 5.12] | 0 | |
| f10 Shifted Rotated Rastrigin’s | [−5.12, 5.12] | 0 | |
| f11 Griewank | [−600, 600] | 0 | |
| f12 Ackley | [−32, 32] | 0 | |
| f13 Weierstrass | [−0.5, 0.5] | 0 | |
| f14 Himmelblau | [−5, 5] | −78.3323 | |
| f15 Cross-in-tray | [−10, 10] | −2.0626 | |
| f16 Six-hump Camel | [−5.12, 5.12] | −1.0316 |
| Algorithms | Parameter |
|---|---|
| ADN-RSN-PSO | W = 0.7298, c1 = c2 = 2.05 |
| ABCADE | SN = 50, limit = 200, m = 5, n = 10, c 1 = 0.9, c 2 = 0.999 |
| IMSaDE | NEP = 7([0.1,0.3]*NP), ST = 3, CRl = 0.3, Cru = 1, Fl = 0.1, Fu = 0.9 |
| Function | Statistic | ADN-RSN-PSO | ABCADE | DSTLBO | IMSaDE | LAPO | ELAPO |
|---|---|---|---|---|---|---|---|
| f1 | Min | 1.9433 × 105 | 1.0604 × 10−122 | 0 | 9.1175 × 10−190 | 1.2787 × 10−140 | 0 |
| Mean | 7.0621 × 10−3 | 5.0305 × 10−96 | 0 | 8.4357 × 10−171 | 1.4429 × 10−131 | 0 | |
| Max | 6.0864 × 10−2 | 1.5085 × 10−94 | 0 | 8.5523 × 10−170 | 3.7225 × 10−130 | 0 | |
| Std | 1.3886 × 10−2 | 2.7540 × 10−95 | 0 | 0 | 6.7837 × 10−131 | 0 | |
| Robustness | 0 | 100 | 100 | 100 | 100 | 100 | |
| Rank | 6 | 5 | 1.5 | 3 | 4 | 1.5 | |
| f2 | Min | 2.7340 × 10−9 | 6.1134 × 10−49 | 0 | 5.6607 × 10−95 | 1.3390 × 10−36 | 0 |
| Mean | 4.5246 × 10−1 | 4.3991 × 10−42 | 2.4682 × 10−318 | 4.4691 × 10−88 | 1.2060 × 10−33 | 0 | |
| Max | 8.1548 | 6.9662 × 10−41 | 7.2645 × 10−317 | 4.8224 × 10−87 | 1.3582 × 10−32 | 0 | |
| Std | 1.5287 | 1.3292 × 10−41 | 0 | 1.2051 × 10−87 | 3.0653 × 10−33 | 0 | |
| Robustness | 0 | 100 | 100 | 100 | 100 | 100 | |
| Rank | 6 | 4 | 2 | 3 | 5 | 1 | |
| f3 | Min | 2.0553× 10−13 | 2.9427× 10−51 | 0 | 2.0072 × 10−95 | 1.1679 × 10−38 | 0 |
| Mean | 2.5192 | 1.1781× 10−41 | 1.1660 × 10−321 | 1.1548 × 10−88 | 1.4772 × 10−33 | 0 | |
| Max | 4.9549 × 101 | 2.7244× 10−40 | 3.4760 × 10−320 | 3.4405 × 10−87 | 2.4542 × 10−32 | 0 | |
| Std | 9.134 | 5.0461× 10−41 | 0 | 6.2801 × 10−88 | 4.8781 × 10−33 | 0 | |
| Robustness | 10 | 100 | 100 | 100 | 100 | 100 | |
| Rank | 6 | 4 | 2 | 3 | 5 | 1 | |
| f4 | Min | 3.3295 | 0 | 4.2081 | 3.0815 × 10−33 | 2.0431 × 10−17 | 0 |
| Mean | 5.6636 | 5.9986 × 10−32 | 5.476 | 1.1884 × 10−31 | 2.8720 × 10−16 | 1.0812 × 10−29 | |
| Max | 7.5679 | 8.0735 × 10−31 | 7.0288 | 1.5068 × 10−30 | 1.4498 × 10−15 | 4.2786 × 10−29 | |
| Std | 1.1575 | 1.4892 × 10−31 | 8.6427 × 10−1 | 2.7273 × 10−31 | 3.6114 × 10−16 | 1.7057 × 10−29 | |
| Robustness | 0 | 100 | 0 | 100 | 100 | 100 | |
| Rank | 6 | 1 | 5 | 2 | 4 | 3 | |
| f5 | Min | 5.2882 × 10−5 | 4.7392 × 10−32 | 5.7955 × 10−169 | 6.2444 × 10−53 | 5.1613 × 10−21 | 2.2875 × 10−175 |
| Mean | 2.1283 | 2.9518 × 10−25 | 1.8017 × 10−162 | 2.9148 × 10−49 | 1.8239 × 10−19 | 7.2628 × 10−171 | |
| Max | 1.4320 × 101 | 5.0681 × 10−24 | 2.3000 × 10−161 | 3.1393 × 10−48 | 1.0955 × 10−18 | 1.5612 × 10−169 | |
| Std | 3.6429 | 9.9107 × 10−25 | 5.8809 × 10−162 | 8.1886 × 10−49 | 2.5217 × 10−19 | 0 | |
| Robustness | 0 | 100 | 100 | 100 | 100 | 100 | |
| Rank | 6 | 4 | 2 | 3 | 5 | 1 | |
| f6 | Min | 7.9614 × 10−11 | 4.9825 × 10−1 | 0 | 1.7910 × 10−13 | 3.6024 × 10−5 | 2.0577 × 10−204 |
| Mean | 3.6063 × 101 | 2.1321 × 101 | 1.4778 × 10−317 | 2.2465 × 10−9 | 2.7988 × 10−4 | 3.8434 × 10−188 | |
| Max | 9.1658 × 102 | 1.0491 × 102 | 4.4236 × 10−316 | 6.6102 × 10−8 | 8.6964 × 10−4 | 1.1172 × 10−186 | |
| Std | 1.6698 × 102 | 2.3468 × 101 | 0 | 1.2061 × 10−8 | 2.1707 × 10−4 | 0 | |
| Robustness | 3.33 | 0 | 100 | 83.33 | 0 | 100 | |
| Rank | 6 | 5 | 1 | 3 | 4 | 2 | |
| f7 | Min | 1.4991 × 10−5 | 5.4163 | 5.0526 × 10−162 | 1.9698 × 10−2 | 1.1755 × 10−21 | 1.4981 × 10−122 |
| Mean | 2.2665 × 10−1 | 1.2694 × 101 | 9.8249 × 10−155 | 1.7505 × 10−1 | 1.5051 × 10−19 | 2.1015 × 10−116 | |
| Max | 2.6331 | 2.1428 × 101 | 1.5939 × 10−153 | 5.8210 × 10−1 | 1.4967 × 10−18 | 3.4242 × 10−115 | |
| Std | 5.3499 × 10−1 | 3.9118 | 3.6036 × 10−154 | 1.4560 × 10−1 | 2.8717 × 10−19 | 6.6285 × 10−116 | |
| Robustness | 0 | 0 | 100 | 0 | 100 | 100 | |
| Rank | 6 | 5 | 1 | 4 | 3 | 2 | |
| f8 | Min | 9.1385 × 10−7 | 3.7190 × 10−13 | 1.9123 × 10−315 | 4.2590 × 10−51 | 7.2925 × 10−18 | 1.5064 × 10−298 |
| Mean | 4.2904 × 102 | 6.4605 × 10−6 | 4.1842 × 10−298 | 6.1752 × 10−30 | 7.6451 × 10−17 | 1.7716 × 10−288 | |
| Max | 4.1982 × 103 | 7.5741 × 10−5 | 7.4227 × 10−297 | 1.8141 × 10−28 | 3.1112 × 10−16 | 3.2124 × 10−287 | |
| Std | 1.0583 × 103 | 1.8898 × 10−5 | 0 | 3.3101 × 10−29 | 6.9792 × 10−17 | 0 | |
| Robustness | 0 | 26.67 | 100 | 100 | 100 | 100 | |
| Rank | 6 | 5 | 1 | 3 | 4 | 2 | |
| f9 | Min | 8.0008 × 10−7 | 0 | 0 | 6.9647 | 0 | 0 |
| Mean | 1.3883 × 101 | 1.9899 × 10−1 | 0 | 1.9655 × 101 | 4.9931 | 1.368 | |
| Max | 1.4700 × 102 | 9.9496 × 10−1 | 0 | 7.1757 × 101 | 9.8831 × 101 | 1.5045 × 101 | |
| Std | 3.7141 × 101 | 4.0479 × 10−1 | 0 | 1.4266 × 101 | 2.0014 × 101 | 4.1857 | |
| Robustness | 0 | 80 | 100 | 0 | 93.33 | 90 | |
| Rank | 5 | 2 | 1 | 6 | 4 | 3 | |
| f10 | Min | 3.8725 × 10−13 | 1.7764 × 10−15 | 0 | 0 | 5.7384 × 10−2 | 0 |
| Mean | 4.2506 × 10−2 | 2.8422 × 10−15 | 0 | 1.5395 × 10−15 | 1.1063 | 0 | |
| Max | 4.4505 × 10−1 | 1.7764 × 10−14 | 0 | 1.7764 × 10−15 | 4.6539 | 0 | |
| Std | 1.0456 × 10−1 | 3.0447 × 10−15 | 0 | 6.1417 × 10−16 | 1.0863 | 0 | |
| Robustness | 6.67 | 100 | 100 | 100 | 0 | 100 | |
| Rank | 5 | 4 | 1.5 | 3 | 6 | 1.5 | |
| f11 | Min | 2.8111 × 101 | 0 | 3.1916 × 101 | 0 | 6.2061 × 10−14 | 0 |
| Mean | 5.2552 × 101 | 1.1102 × 10−16 | 5.4567 × 101 | 1.3323 × 10−16 | 2.7950 × 10−3 | 0 | |
| Max | 7.8919 × 101 | 2.2204 × 10−16 | 7.1519 × 101 | 4.4409 × 10−16 | 4.9323 × 10−3 | 0 | |
| Std | 1.1032 × 101 | 4.1233 × 10−17 | 7.837 | 7.9313 × 10−17 | 2.4859 × 10−3 | 0 | |
| Robustness | 0 | 100 | 0 | 100 | 43.33 | 100 | |
| Rank | 5 | 2 | 6 | 3 | 4 | 1 | |
| f12 | Min | 2.8188 × 10−5 | 7.1054 × 10−15 | 0 | 3.5527 × 10−15 | 6.2061 × 10−14 | 3.5527 × 10−15 |
| Mean | 7.2291 × 10−1 | 1.4211 × 10−14 | 2.7237 × 10−15 | 1.0725 | 2.7950 × 10−3 | 3.9080 × 10−15 | |
| Max | 6.5883 | 3.1974 × 10−14 | 3.5527 × 10−15 | 5.3162 | 4.9323 × 10−3 | 7.1054 × 10−15 | |
| Std | 1.6003 | 7.6368 × 10−15 | 1.5283 × 10−15 | 1.1266 | 2.4859 × 10−3 | 1.0840 × 10−15 | |
| Robustness | 0 | 100 | 100 | 36.67 | 43.33 | 100 | |
| Rank | 5 | 3 | 1 | 6 | 4 | 2 | |
| f13 | Min | 7.2301 × 10−1 | 0 | 0 | 4.3238 × 10−2 | 0 | 0 |
| Mean | 3.9722 | 1.0394 × 10−3 | 0 | 9.1739 × 10−1 | 0 | 0 | |
| Max | 6.0091 | 3.1181 × 10−2 | 0 | 3.4394 | 0 | 0 | |
| Std | 2.4463 | 5.6928 × 10−3 | 0 | 9.1925 × 10−1 | 0 | 0 | |
| Robustness | 0 | 96.67 | 100 | 0 | 100 | 100 | |
| Rank | 6 | 4 | 2 | 5 | 2 | 2 | |
| f14 | Min | −5.3861 × 101 | −7.8332 × 101 | −5.3644 × 101 | −7.7390 × 101 | −6.1359 × 101 | −7.8332 × 101 |
| Mean | −4.6574 × 101 | −7.8332 × 101 | −4.7669 × 101 | −7.4720 × 101 | −5.8293 × 101 | −6.8451 × 101 | |
| Max | −3.8905 × 101 | −7.8332 × 101 | −4.2338 × 101 | −7.2678 × 101 | −5.6084 × 101 | −5.3228 × 101 | |
| Std | 3.1993 | 1.3964 × 10−14 | 2.4718 | 1.5473 | 1.6251 | 4.6141 | |
| Robustness | 0 | 100 | 0 | 0 | 0 | 6.67 | |
| Rank | 6 | 1 | 5 | 2 | 4 | 3 | |
| f15 | Min | −2.0626 | −2.0626 | −2.0626 | −2.0626 | −2.0626 | −2.0626 |
| Mean | −2.0626 | −2.0626 | −2.0626 | −2.0626 | −2.0626 | −2.0626 | |
| Max | −2.0626 | −2.0626 | −2.0626 | −2.0626 | −2.0626 | −2.0626 | |
| Std | 1.0856 × 10−12 | 4.2561 × 10−4 | 2.8300 × 10−6 | 4.0365 × 10−6 | 6.0550 × 10−8 | 9.0336 × 10−16 | |
| Robustness | 100 | 100 | 100 | 100 | 100 | 100 | |
| Rank | 2 | 6 | 4 | 5 | 3 | 1 | |
| f16 | Min | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0316 |
| Mean | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0316 | |
| Max | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0316 | −1.0316 | |
| Std | 1.3596 × 10−5 | 1.3074 × 10−4 | 2.5463 × 10−12 | 4.5168 × 10−16 | 1.4600 × 10−7 | 4.5168 × 10−16 | |
| Robustness | 100 | 100 | 100 | 100 | 100 | 100 | |
| Rank | 5 | 6 | 3 | 2 | 4 | 2 |
| Fridman | Holm | ||||
|---|---|---|---|---|---|
| i | Algorithm | Rank mean (Ri) | pi | ||
| 1 | ADN-RSN-PSO | 5.4375 | 5.4808 | 0.0000 | 0.01 |
| 2 | LAPO | 4.0625 | 3.4019 | 0.0009 | 0.0125 |
| 3 | ABCADE | 3.8125 | 3.0238 | 0.0035 | 0.0166 |
| 4 | IMSaDE | 3.5 | 2.5514 | 0.011 | 0.025 |
| 5 | DSTLBO | 2.4375 | 0.9450 | 0.3221 | 0.05 |
| 6 | ELAPO | 1.8125 | / | / | / |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jiang, X. An Enhanced Lightning Attachment Procedure Optimization Algorithm. Algorithms 2019, 12, 134. https://doi.org/10.3390/a12070134
Wang Y, Jiang X. An Enhanced Lightning Attachment Procedure Optimization Algorithm. Algorithms. 2019; 12(7):134. https://doi.org/10.3390/a12070134
Chicago/Turabian StyleWang, Yanjiao, and Xintian Jiang. 2019. "An Enhanced Lightning Attachment Procedure Optimization Algorithm" Algorithms 12, no. 7: 134. https://doi.org/10.3390/a12070134
APA StyleWang, Y., & Jiang, X. (2019). An Enhanced Lightning Attachment Procedure Optimization Algorithm. Algorithms, 12(7), 134. https://doi.org/10.3390/a12070134