1. Introduction
The Traveling Salesman Problem (TSP), in all likelihood the most famous combinatorial optimization problem, calls for finding the shortest Hamiltonian cycle in a complete graph of n nodes, weighted on the arcs. In this paper we consider the symmetric TSP, i.e., the graph is undirected and the distance between two nodes is the same irrespective of the direction in which we traverse an edge. Let us denote by the distance between any two nodes i and j. We call each solution of the problem a tour. A tour is identified by a permutation of vertices . We call , for , and the edges of the tour. The length of a tour T, denoted by is the sum of the lengths of the edges of the tour. More generally, for any set F of edges, we denote by the value .
A large number of applications over the years have shown that local search is often a very effective way to tackle hard combinatorial optimization problems, including the TSP. The local search paradigm applies to a generic optimization problem in which we seek to minimize an objective function over a set X. Given a map which associates to every solution a set called its neighborhood, the basic idea is the following: start at any solution , set , and look for a solution better than s. If we find one, we replace s with and iterate the same search. We continue this way until we get to a solution s such that . In this case, we say that s is a local optimum. Replacing with is called performing a move of the search, and is the set of all solutions reachable with a move from s. The total number of moves performed to get from to the final local optimum is called the length of the convergence. If x is a solution reachable with a move from s and we say that the move is an improving move and x is an improving solution. When searching in the neighborhood of we can adopt two main strategies, namely first-improvement and best-improvement (also called steepest-descent). In the first-improvement strategy, we set to be the first solution that we find in such that . In best-improvement, we set to be such that . For small-size neighborhoods such as the one considered in this paper, most local search procedures choose to adopt the best-improvement strategy, since it causes the largest decrease in the objective function value at any given iteration of the search. In this paper we will focus precisely on the objective of finding the best possible move for a popular TSP neighborhood, i.e., the 3-OPT.
The idea of basic local search has been around for a very long time and it is difficult to attribute it to any particular author. Examples of its use are reported in standard textbooks on combinatorial optimization, such as [
1], or devoted surveys, such as [
2]. In time, many variants have been proposed to make local search more effective by avoiding it to get stuck in local optima. Namely, sometimes a non-improving move must be performed to keep the search going. Examples of these techniques are tabu search [
3] and simulated annealing [
4]. Our results apply to basic local search but can be readily adapted to use in more sophisticated procedures such as tabu search. This, however, is beyond the scope of this paper.
1.1. The K-OPT Neighborhood
Let be a constant. A K-OPT move on a tour T consists of first removing a set R of K edges and then inserting a set I of K edges so as is still a tour (we include, possibly, . This implies that the -OPT moves are a subset of the K-OPT moves). A K-OPT move is improving if i.e., . An improving move is best improving if is the maximum over all possible choices of .
The standard local search approach for the TSP based on the
K-OPT neighborhood starts from any tour
(usually a random permutation of the vertices) and then proceeds along a sequence of tours
where each tour
is obtained by applying an improving
K-OPT move to
. The final tour
is such that there are no improving
K-OPT moves for it. The hope is that
is a good tour (optimistically, a global optimum) but its quality depends on many factors. One of them is the size of the neighborhood, the rationale being that with a larger-size neighborhood we sample a larger number of potential solutions, and hence increase the probability of ending up at a really good one. Clearly, there is a trade-off between the size of a neighborhood and the time required to explore it, so that most times people resort to the use of small neighborhoods since they are very fast to explore (for a discussion on how to deal with some very large size, i.e., exponential, neighborhoods for various combinatorial optimization problems, see [
5]).
The exploration of the K-OPT neighborhood, for a fixed K, might be considered “fast” from a theoretical point of view, since there is an obvious polynomial algorithm (complete enumeration). However, in practice, complete enumeration makes the use of K-OPT impossible already for (if n is large enough, like 3000 or more). There are choices of K edges to remove which implies that 3-OPT can be explored in time by listing all possibilities. For a given tour nodes, the time required to try all 3-OPT moves, on a reasonably fast desktop computer, is more than one hour, let alone converging to a local optimum. For this reason, 3-OPT has never been really adopted for the heuristic solution of the TSP.
The first use of
K-OPT dates back to 1958 with the introduction of 2-OPT for the solution of the TSP in [
6]. In 1965 Lin [
7] described the 3-OPT neighborhood, and experimented with the
algorithm, on which he also introduced a heuristic step fixing some edges of the solution (at risk of being wrong) with the goal of decreasing the size of the instance. Still, the instances which could be tackled at the time were fairly small (
). Later in 1968, Steiglitz and Weiner [
8] described an improvement over Lin’s method which made it 2 or 3 times faster, but still cubic in nature.
It was soon realized that the case
was impractical, and later local search heuristics deviated from the paradigm of complete exploration of the neighborhood, replacing it with some clever ways to heuristically move from tour to tour. The best such heuristic is probably Lin and Kernighan’s procedure [
9] which applies a sequence of
K-OPT moves for different values of
K. Notice that our objective, and our approach, is fundamentally different from Lin and Kernighan’s in that we always look for the best
K-OPT move, and we keep
K constantly equal to 3. On the other hand, Lin and Kernighan, besides varying
K, apply a heuristic search for the best
K-OPT move, which is fast but cannot guarantee to find the best move, and, indeed, is not guaranteed to find an improving move even if some exist. For a very good chapter comparing various heuristics for the TSP, including the 3-OPT neighborhood, see Johnson and Mc Geich [
10].
An important recent result in [
11] proves that, under a widely believed hypothesis similar to the
conjecture, it is impossible to find the best 3-OPT move with a worst-case algorithm of time
for any
so that complete enumeration is, in a sense, optimal. However, this gives us little consolation when we are faced with the problem of applying 3-OPT to a large TSP instance. In fact, for complete enumeration the average case and the worst case coincide, and one might wonder if there exists a better practical algorithm, much faster than complete enumeration on the majority of instances but still
in the worst case. The algorithm described in this paper (of which a preliminary version appeared in [
12]) is such an example. A similar goal, but for problems other than the TSP, is pursued in [
13], which focuses on the alternatives to brute force exploration of polynomial-size neighborhoods from the point of view of parameterized complexity.
1.2. The Goal of This Paper
The TSP is today very effectively solved, even to optimality, by using sophisticated mathematical programming-based approaches, such as Concorde [
14]. No matter how ingenious, heuristics can hardly be competitive with these approaches when the latter are given enough running time. It is clear that simple heuristics, such as local search, are even less effective.
However, simple heuristics have a great quality which lies in their very name: since they are simple (in all respects, to understand, to implement and to maintain), they are appealing, especially to the world of practical, real-life application solvers, i.e., in the industrial world where the very vast majority of in-house built procedures are of heuristic nature. Besides its simplicity, local search has usually another great appeal: it is in general very fast, so that it can overcome its simplemindedness by the fact that it is able to sample a huge amount of good solutions (the local optima) in a relatively small time. Of course, if its speed is too slow, one loses all the interest in using a local search approach despite its simplicity.
This is exactly the situation for the 3-OPT local search. It is simple, and might be effective, but we cannot use it in practice for mid-to-large sized instances because it is too slow. The goal of our work has been to show that, with a clever implementation of the search for improving moves, it can be actually used since it becomes much faster (even on the instances we tried) with respect to its standard implementation.
We remark that our intention in this paper is not that of proving that steepest-descent 3-OPT is indeed an effective heuristics for the TSP (this would require a separate work with a lot of experiments and can be the subject of future research). Our goal is to show anyone who is interested in using such a neighborhood how to implement its exploration so as to achieve a huge reductions in the running times. While a full discussion of the computational results can be found in
Section 5, here is an example of the type of results that we will achieve with our approach: on a graph of 1000 nodes, we can sample about 100 local optima in the same time that the enumerative approach would take to reach only one local optimum.
2. Selections, Schemes and Moves
Let
be a complete graph on
n nodes, and
be a cost function for the edges. Without loss of generality, we assume
, where
. In this paper, we will describe an effective strategy for finding either the best improving or any improving move for a given current tour
. Without loss of generality, we will always assume that the current tour
T is the tour
We will be using modular arithmetic frequently. For convenience, for each
and
we define
When moving from x to etc. we say that we are moving clockwise, or forward. In going from x to we say that we are moving counter-clockwise, or backward.
We define the forward distance
from node
x to node
y as the
such that
. Similarly, we define the
backward distance from
x to
y as the
such that
. Finally, the distance between any two nodes
x and
y is defined by
A 3-OPT move is fully specified by two sets, i.e., the set of removed and of inserted edges. We call a removal set any set of three tour edges, i.e., three edges of type . A removal set is identified by a triple with , where the edges removed are . We call any such triple S a selection. A selection is complete if for each , otherwise we say that S is a partial selection. We denote the set of all complete selections by .
Complete selections should be treated differently than partial selections, since it is clear that the number of choices to make to determine a partial selection is lower than 3. For instance, the number of selections in which
is not cubic but quadratic, since it is enough to pick
and
in all possible ways such that
and then set
. We will address the computation of the number of complete selections for a given
K in
Section 2.2. Clearly, if we do not impose any special requirements on the selection then there are
selections.
Let S be a selection and with . If is still a tour then I is called a reinsertion set. Given a selection S, a reinsertion set I is pure if , and degenerate otherwise. Finding the best 3-OPT move when the reinsertions are constrained to be degenerate is (in fact, 3-OPT degenerates to 2-OPT in this case). Therefore, the most computationally expensive task is to determine the best move when the selection is complete and the reinsertion is pure. We refer to these kind of moves as true 3-OPT. Thus, in the remainder of the paper, we will focus on true 3-OPT moves.
2.1. Reinsertion Schemes and Moves
Let
be a complete selection. When the edges
are removed from a tour, the tour gets broken into three consecutive segments which we can label by
(segment
j ends at node
). Since the selection is pure, each segment is indeed a path of at least one edge. A reinsertion set patches back the segments into a new tour. If we adopt the convention to start always a tour with segment 1 traversed clockwise, the reinsertion set: (i) determines a new ordering in which the segments are visited along the tour and (ii) may cause some segments to be traversed counterclockwise. In order to represent this fact, we use a notation called a reinsertion scheme. A reinsertion scheme is a signed permutation of
. The permutation specifies the order in which the segments
are visited after the move. The signing
tells that segment
s is traversed counterclockwise, while
tells that it is traversed clockwise. For example, the third reinsertion set depicted in
Figure 1 is represented by the reinsertion scheme
since, from the end of segment 1, we jump to the beginning of segment 3 and traverse it forward. We then move to the last element of segment 2 and proceed backward to its first element. Finally, we close the tour by going back to the first element of segment 1.
There are potentially
reinsertion schemes, but for some of these the corresponding reinsertion sets are degenerate. A scheme for a pure reinsertion must not start with “
”, nor end with “
”, nor be
. This leaves only 4 possible schemes, let them be
, depicted in
Figure 1.
Given a selection
S, the application of a reinsertion scheme
r univocally determines reinsertion set
and clearly for every reinsertion set
I there is an
r such that
. Therefore, a 3-OPT move if fully specified by a pair
where
S is a complete selection and
r is a reinsertion scheme. Let us denote the set of all true 3-OPT moves by
The enumeration of all moves can be done as follows: (i) we consider, in turn, each reinsertion scheme ; (ii) given r, we consider all complete selections , obtaining the moves . Since step (ii) is done by complete enumeration, the cost of this procedure is . In the remainder of the paper we will focus on a method for lowering significantly its complexity.
2.2. The Number of True 3-OPT Moves
For generality, we state here a result which applies to K-OPT for any .
Theorem 1. For each the number of complete K-OPT selections is Proof. Assume the indices of a selection are
. Consider the tour and let:
be the number of nodes between node 0 (included) and node
(excluded);
, for
, be the number of nodes between node
(excluded) and node
(excluded);
be the number of nodes between node
(excluded) and node
(included). Then, there are as many complete selections in a
K-OPT move as the nonnegative integer solutions of the equation
subject to the constraints that
, and
for
. If we ignore the first constraint and replace
by
for
we get the equation
in nonnegative integer variables, which, by basic combinatorics, has
solutions. We then have to remove all solutions in which
, i.e., the solutions of the equation
, of which there are
. □
Corollary 1. The number of true 3-OPT moves isi.e., it is, asymptotically, . Proof. We know from Theorem 1 that there are
complete selections, and from
Section 2.1 that there are 4 reinsertion schemes. By multiplying the two values we get the claim. □
In
Table 1 we report the number of true moves for various values of
n, giving a striking example of why the exploration of the 3-OPT neighborhood would be impractical unless some effective strategies were adopted.
3. Speeding-Up the Search: The Basic Idea
The goal of our work is to provide an alternative, much faster, way for finding the best move to the classical “nested-for” approach over all reinsertion schemes and indices, which is something like
for ( )
for ( = 0; ; ++ )
for (; ; ++ )
for (; ; ++ )
evaluateMove; [* check if move is improving. possibly update best *]
and takes time . (The expression , given a predicate A returns 1 if A is true and 0 otherwise). As opposed to the brute force approach, we will call our algorithm the smart force procedure.
Our idea for speeding-up the search is based on this consideration. Suppose there is a magic box that knows all the best moves. We can inquire the box, which answers in time by giving us a partial move. A partial move is the best move, but one of the selection indices has been deleted (and the partial move specifies which one). For example, we might get the answer , and then we would know that there is some x such that the selection , with reinsertion scheme , is an optimal move. How many times should we inquire about the box to quickly retrieve an optimal move?
Suppose there are many optimal moves (e.g., the arc costs 1000 and all other arcs cost 1, so that the move is optimal for every and r). Then we could call the box times and get the reply for all possible without ever getting the value of the first index of an optimal selection. However, it is clear that with just one call to the box, it is possible to compute an optimal 3-OPT move in time . In fact, after the box has told us the reinsertion scheme to use and the values of two indices out of three, we can enumerate the values for the missing index (i.e., expand the two indices into a triple) to determine the best completion possible.
The bulk of our work has then been to simulate, heuristically, a similar magic box, i.e., a data structure that can be queried and should return a partial move much in a similar way as described above. In our heuristic version, the box, rather than returning a partial which could certainly be completed into a best move, returns a partial move which could likely be completed into a best move. As we will see, this can already greatly reduce the number of possible candidates to be best moves. In order to assess the likelihood with which a partial move could be completed into a best solution, we will use suitable functions described in the next sections.
Since there is no guarantee that a partial move suggested by our box can be indeed completed into an optimal move, we will have to iterate over many suggestions, looking for the best one. If there are iterations, given that each iteration costs us we end up with an algorithm. Some expansions will be winning, in that they produce a selection better than any one seen so far, while others will be losing, i.e., we enumerate completions for the partial move but none of them beats the best move seen so far. Clearly, to have an effective algorithm we must keep the number of losing iterations small. To achieve this goal, we provide an strong necessary condition that a partial move must satisfy for being a candidate to a winning iteration. When no partial move satisfies this condition, the search can be stopped since the best move found is in fact the optimal move.
The Fundamental Quantities and
In this section, we define two functions of into fundamental for our work. Loosely speaking, these functions will be used to determine, for each pair of indices of a selection, the contribution of that pair to the value of a move. The rationale is that, the higher the contribution, the higher the probability that a particular pair is in a best selection.
The two functions are called
and
. For each
, we define
to be the difference between the cost from
a to its successor and to the successor of
b, and
to be the difference between the cost from
a to its predecessor and to the predecessor of
b:
Clearly, each of these quantities can be computed in time , and computing their values for a subset of possible pairs can never exceed time .
4. Searching the 3-OPT Neighborhood
As discussed in
Section 2.1, the pure 3-OPT reinsertion schemes are four (see
Figure 1), namely:
Notice that and are symmetric to . Therefore, we can just consider and since all we say about can be applied, mutatis mutandis (i.e., with a suitable renaming of the indices), to and as well.
Given a move
, where
, its value is the difference between the cost of the set
of removed edges and the cost of the reinsertion set
. We will denote the value of the move
μ by
A key observation is that we can break-up the function
, that has
possible arguments, into a sum of functions of two parameters each (each has
arguments). That is, we will have
for suitable functions
, each representing the contribution of a particular pair of indices to the value of the move. The domains of these functions are subsets of
which limit the valid input pairs to values obtained from two specific elements of a selection. For
, with
, let us define
Then the domain of is , the domain of is and the domain of is .
The functions can be obtained through the functions and as follows:
- [r1: ]
We have
(see
Figure 1) so that
The three functions are
;
;
.
- [r2: ]
We have
(see
Figure 1) so that
The three functions are
;
;
.
(For convenience, these functions, as well as the functions of some other moves described later on, are also reported in
Table 2 of
Section 6). The functions
are used in our procedure in two important ways. First, we use them to decide which are the most likely pairs of indices to belong in an optimal selection for
r (the rationale being that, the higher a value
, the more likely it is that
belongs in a good selection).
Secondly, we use them to discard from consideration some moves which cannot be optimal. These are the moves such that no two of the indices give a sufficiently large contribution to the total. Better said, we keep in consideration only moves for which at least one contribution of two indices is large enough. With respect to the strategy outlined in
Section 3, this corresponds to a criterion for deciding if a partial move suggested by our heuristic box is worth expanding into all its completions.
Assume we want to find the best move overall and the best move we have seen so far (the current “champion”) is
. We make the key observation that for a move
to beat
it must be
These three conditions are not exclusive but possibly overlapping, and in our algorithm, we will enumerate only moves that satisfy at least one of them. Furthermore, we will not enumerate these moves with a complete enumeration, but rather from the most promising to the least promising, stopping as soon as we realize that no move has still the possibility of being the best overall.
The most appropriate data structure for performing this kind of search (which hence be used for our heuristic implementation of the magic box described in
Section 3) is the Max-Heap. A heap is perfect for taking the highest-valued elements from a set, in decreasing order. It can be built in linear time with respect to the number of its elements and has the property that the largest element can be extracted in logarithmic time, while still leaving a heap.
We then build a max-heap
H whose elements are records of type
where
,
,
, and
. The heap elements correspond to partial moves. The heap is organized according to the values of
f, and the field
is a label identifying which selection indices are associated to a given heap entry. We initialize
H by putting in it an element for each
,
r and
such that
. We then start to extract the elements from the heap. Let us denote by
the
j-th element extracted. Heuristically, we might say that
and
are the most likely values that a given pair of indices (specified by
) can take in the selection of a best-improving move, since these values give the largest possible contribution to the move value (
2). We will keep extracting the maximum
from the heap as long as
. This does not mean that we will extract all the elements of
H, since
could change (namely, increase) during the search and hence the extractions might terminate before the heap is empty.
Each time we extract the heap maximum, we have that and are two possible indices out of three for a candidate move to beat . With a linear-time scan, we then enumerate the third missing index (identified by ) and see if we get indeed a better move than . For example, if then the missing index is and we run a for-loop over , with , checking each time if the move is a better move than . Whenever this is the case, we update . Note that, since increases, the number of elements still in the heap for which after updating the champion may be considerably smaller than it was before the update.
Lemma 1. When the procedure outlined above terminates, is an optimal move.
Proof. Suppose, by contradiction, that there exists a move better than . Since , there exists at least one pair such that . Then the partial move would have eventually been popped from the heap and evaluated, producing a move better than . Therefore the procedure could not have ended with the move . □
Assume
L denotes the initial size of the heap and
M denotes the number of elements that are extracted from the heap overall. Then the cost of the procedure is
since: (i)
is the cost for computing the
values; (ii)
is the cost for building the heap; (iii) for each of the
M elements extracted from the heap we must pay
for re-adjusting the heap, and then we complete the move in
ways. Worst-case, the procedure has complexity
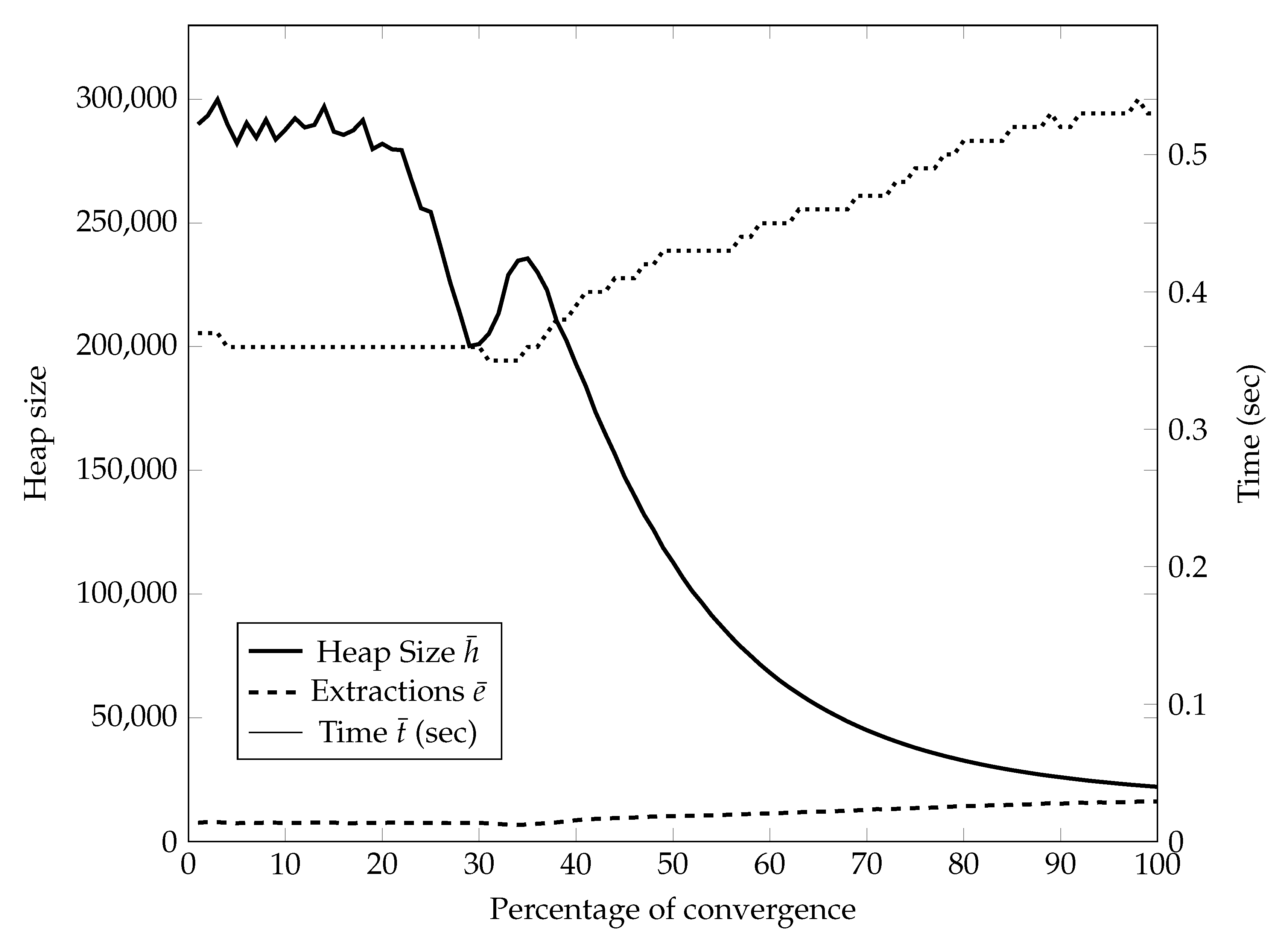
like complete enumeration but, as we will show in our computational experiments, it is much smaller in practice. In fact, on our tests the complexity was growing slightly faster than a quadratic function of
n (see
Section 5). This is because the
selections which are indeed evaluated for possibly becoming the best move have a much bigger probability of being good than a generic selection, since two of the three indices are guaranteed to help the value of the move considerably.
4.1. Worst-Case Analysis
A theoretical result stated in [
11] shows that no algorithm with a less than cubic worst-case complexity is possible for 3-OPT (under the widely believed ALL-PAIRS SHORTEST PAIR conjecture). In light of this result, we expected that there should exist some instances which force our algorithm to require cubic time. In particular, we have found the following example.
Theorem 2. The Smart Force algorithm has a worst-case complexity .
Proof. Clearly, the complexity is since there are partial moves and the evaluation of each of them takes time. To show the lower bound consider the following instance.
Fix any
and, for each
, define
to be
(Notice that if this instance is in fact metric). For these costs, the current tour is a local optimum. In fact, for each selection, at least two of the nodes have the same parity and hence at least one edge of value would be introduced by a move. Therefore the inserted edges would have cost at least , while the removed edges have cost .
Therefore, for each of the
pairs
such that
i and
j have the same parity, it is
. Since
each such pair would be put in the heap and evaluated, fruitlessly, for a total running time of
. □
4.2. Implementing the Search Procedure
We now describe more formally the procedure that finds the best improving 3-OPT move. To simplify the description of the code, we will make use of a global variable representing the current champion move. Initially is NULL, and we extend the function by defining .
The main procedure is
Find3-OPTmove (Procedures 1 and 2). The procedure starts by setting
to a solution for which, possibly,
. This is not strictly necessary, and setting
to
NULL would work too, but a little effort in finding a “good” starting champion can yield a smaller heap and thus a faster, overall, procedure. In our case, we have chosen to just sample
random solutions and keep the best.
| Procedure 1 Find3-OPTmove |
| 1. |
| 2. |
| 3. while |
| 4. |
| 5. for |
| 6. |
| 7. if then /* update global optimum */ |
| 8. ((i, j, k), r) |
| 9. /* if = NULL there are no improving moves */ |
| Procedure 2StartingSolution () |
| Output: move (such that ) |
| 1. |
| 2. for |
| 3. for to n |
| 4. |
| 5. if then |
| 6. |
| 7. return |
The procedure then builds a max-heap (see Procedure 3
BuildHeap) containing an entry for each
,
and
such that
. The specific functions
, for each
and
r, are detailed in
Table 2 of
Section 6. The heap is implemented by an array
H of records with five fields:
and
, which represent two indices of a selection;
which is a label identifying the two type of indices;
which is the numerical value used as the key to sort the heap; and
which is a label identifying a reinsertion scheme. By using the standard implementation of a heap (see, e.g., [
15]), the array corresponds to a complete binary tree whose nodes are stored in consecutive entries from 1 to
. The left son of node
is
, while the right son is
. The father of node
is
. The heap is such that the key of each node
is the largest among all the keys of the subtree rooted at
.
In the procedure BuildHeap we use a function which returns the set of all values that a pair of indices of type can assume. More specifically,
- -
/* x is and y is */
- -
/* x is and y is */
- -
/* x is and y is */
| Procedure 3BuildHeap () |
| Output: heap H |
| 1. new H |
| 2. |
| 3. for |
| 4. for |
| 5. for |
| 6. if then |
| 7. |
| 8. |
| 9. |
| 10. |
| 11. |
| 12. |
| 13. |
| 14. for |
| 15. /* turns the array into a heap */ |
| 16. return H |
BuildHeap terminates with a set of calls to the procedure
Heapify (a standard procedure for implementing heaps), described in Procedure 4. To simplify the code, we assume
to be defined also for
, with value
. The procedure
Heapify requires that the subtree rooted at
t respects the heap structure at all nodes, except, perhaps, at the root. The procedure then adjusts the keys so that the subtree rooted at
t becomes indeed a heap. The cost of
heapify is linear in the height of the subtree. The loop of line 14 in procedure
BuildHeap turns the unsorted array
H into a heap, working its way bottom-up, in time
.
| Procedure 4Heapify |
| Input: array H, integer |
| 1. /* left son */ |
| 2. /* right son */ |
| 3. if () then large ← ls else large ← t |
| 4. if () then large ← rs |
| 5. if (large ≠ t) then |
| 6. /* swaps with the largest of its sons */ |
| 7. |
Coming back to Find3-OPTMove, once the heap has been built, a loop (lines 3–8) extracts the partial moves from the heap, from the most to the least promising, according to their value (field val). For each partial move popped from the heap we use a function to obtain the set of all values for the missing index with respect to a pair of type . More specifically.
- -
/* missing index is */
- -
/* missing index is */
- -
/* missing index is */.
We then complete the partial move in all possible ways, and each way is compared to the champion to see if there has been an improvement (line 7). Whenever the champion changes, the condition for loop termination becomes easier to satisfy than before.
In line 6 we use a function that, given three indices x, y, z and a pair type , rearranges the indices so as to return a correct selection. In particular, , , and .
The procedure
ExtractMax (in the Procedure 5) returns the element of a maximum value of the heap (which must be in the root node, i.e.,
). It then replaces the root with the leaf
and, by calling
, it moves it down along the tree until the heap property is again fulfilled. The cost of this procedure is
.
| Procedure 5ExtractMax |
| Input: heap H |
| Output: the partial move of maximum value in H |
| 1. /* gets the max element */ |
| 2. /* overwrites it */ |
| 3. |
| 4. /* restores the heap */ |
| 5. return |
6. Other Types of Cubic Moves
The ideas outlined for the 3-OPT neighborhood and the corresponding successful computational results have prompted us to investigate the possibility of speeding up in a similar way some other type of cubic moves. In this section, we just give a few examples to show that indeed this can be done.
Consider, for instance, some special types of
K-OPT moves (where
edges are taken out from the tour and replaced by
K new edges) in which the removed edges are identified by three indexes
. For instance, let
and the removed edges be
The tour is then reconnected in any way that excludes the removed edges (clearly there are many possibilities, we’ll just look at a few). To describe the way in which the tour is reconnected we can still use the concept of the reinsertion scheme. Let us describe the tour before the move (by default, clockwise) as
where
,
and
. In the new tour, each segment
can be traversed clockwise (denoted by
) or counter-clockwise (denoted by
). A reinsertion scheme is then a permutation of
, starting with
(we adopt the convention that
A is always the first segment and is always traversed clockwise) and with
B and
C signed either ’+’ or ’-’. Let us first consider two simple examples of reinsertion schemes, i.e., those in which the move maintains the pattern “segment, node, segment, node, segment, node” and the segments keep the clockwise orientation and the original order (i.e.,
,
,
). This leaves only two possible reinsertion schemes for the true moves (as many as the derangements of
), namely (see
Figure 4)
The value of a move
is
So we have
if we define the three functions
to be
Similarly, a move
has value
where we have defined the three functions
as
Let us now consider the case of the above move when we keep the order
A,
B,
C, but we also allow for reversing either
B or
C. It turns out that, over all the signings of
B and
C and permutations of
, there is only one possible reinsertion scheme, namely (see
Figure 4)
The value of a move
is
where we have defined the three functions
as
Finally, let us consider one last example of these special 6-OPT moves, in which we rearrange the permutation of segments and nodes, namely (see
Figure 4)
The value of a move
is
where we have defined the three functions
as
To finish this section let us consider another type of cubic move, for example, a special 5-OPT move. In particular, let the removed edges be
The tour is then reconnected in any way that excludes the removed edges (clearly there are many possibilities, we will just look at one of them). By using the previous notation for the reinsertion schemes, let us consider the scheme (see
Figure 4)
The value of a move
is
where we have defined the three functions
as
It should be clear that, to find the best move of the special types described in this section, we can put the partial moves in a heap and use the same strategy we have developed in
Section 4. The algorithm is the same as before, with the difference that in line 2 of procedure
BuildHeap we iterate over the schemes
instead of
.
7. Conclusions
In this work, we have described an algorithmic strategy for optimizing the 3-OPT neighborhood in an effective way. Our strategy relies on a particular order of enumeration of the triples which allows us to find the best 3-OPT move without having to consider all the possibilities. This is achieved by a pruning rule and by the use of the max-heap as a suitable data structure for finding in a quick way good candidates for the best move.
Extensive computational experiments prove that this strategy largely outperforms the classical “nested-for” approach on average. In particular, our approach exhibits a time complexity bounded by on various types of random graphs.
The goal of our work was to show how the use of the 3-OPT neighborhood can be extended to graphs of much larger size than before. We did not try to assess the effectiveness of this neighborhood in finding good-quality tours, nor possible refinements to 3-OPT local search (such as restarts, perturbations, the effectiveness of the other type of 3-OPT moves we introduced, etc.). These types of investigations would have required a large set of experiments and further coding, and can be the matter of future research. We also leave to further investigation the possibility of using our type of enumeration strategy for other polynomial-size neighborhoods, including some for different problems than the TSP. In this respect, we have obtained some promising preliminary results for the application of our approach to the 4-OPT neighborhood [
17].
Perhaps the main open question deriving from our work is to prove that the expected time complexity of our algorithm is subcubic on, for instance, uniform random graphs. Note that the problem of finding the best 3-OPT move is the same as that of finding the largest triangle in a complete graph with suitable edge lengths
. For instance, for the reinsertion scheme
in (
4), the length of an edge
is
. For a random TSP instance, each random variable
is therefore the difference of two uniform random variables, and this definitely complicates a probabilistic analysis of the algorithm. If one makes the simplifying assumption that the lengths
are independent uniform random variables drawn in
, then it can be shown that finding the largest triangle in a graph takes quadratic time on average, and this already requires a quite complex proof [
18]. However, since in our case the variables
are not independent, nor uniformly distributed, we were not able to prove that the expected running time is subcubic, and such a proof appears very difficult to obtain.








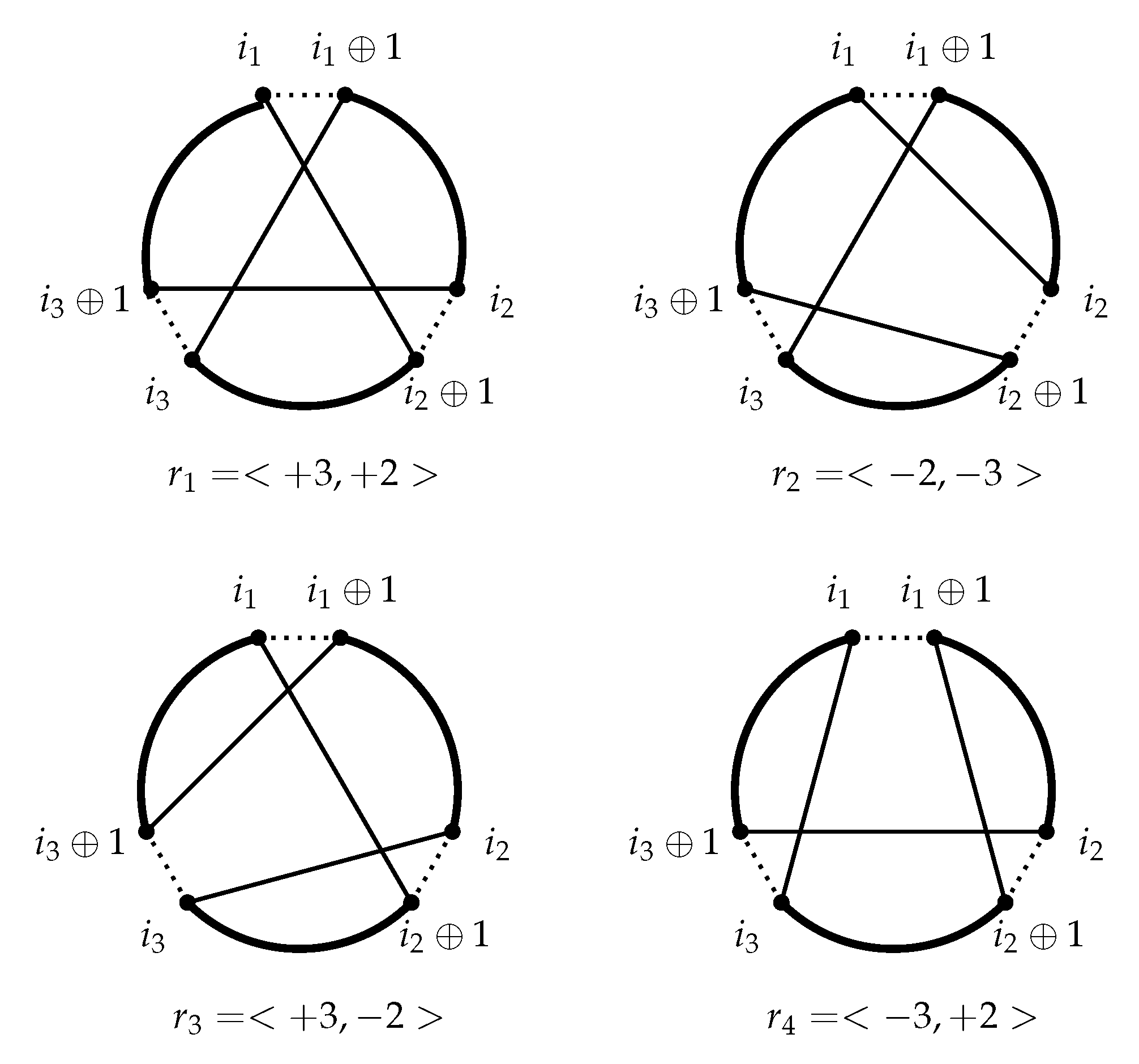{kind=link}
{kind=link}
{kind=link}
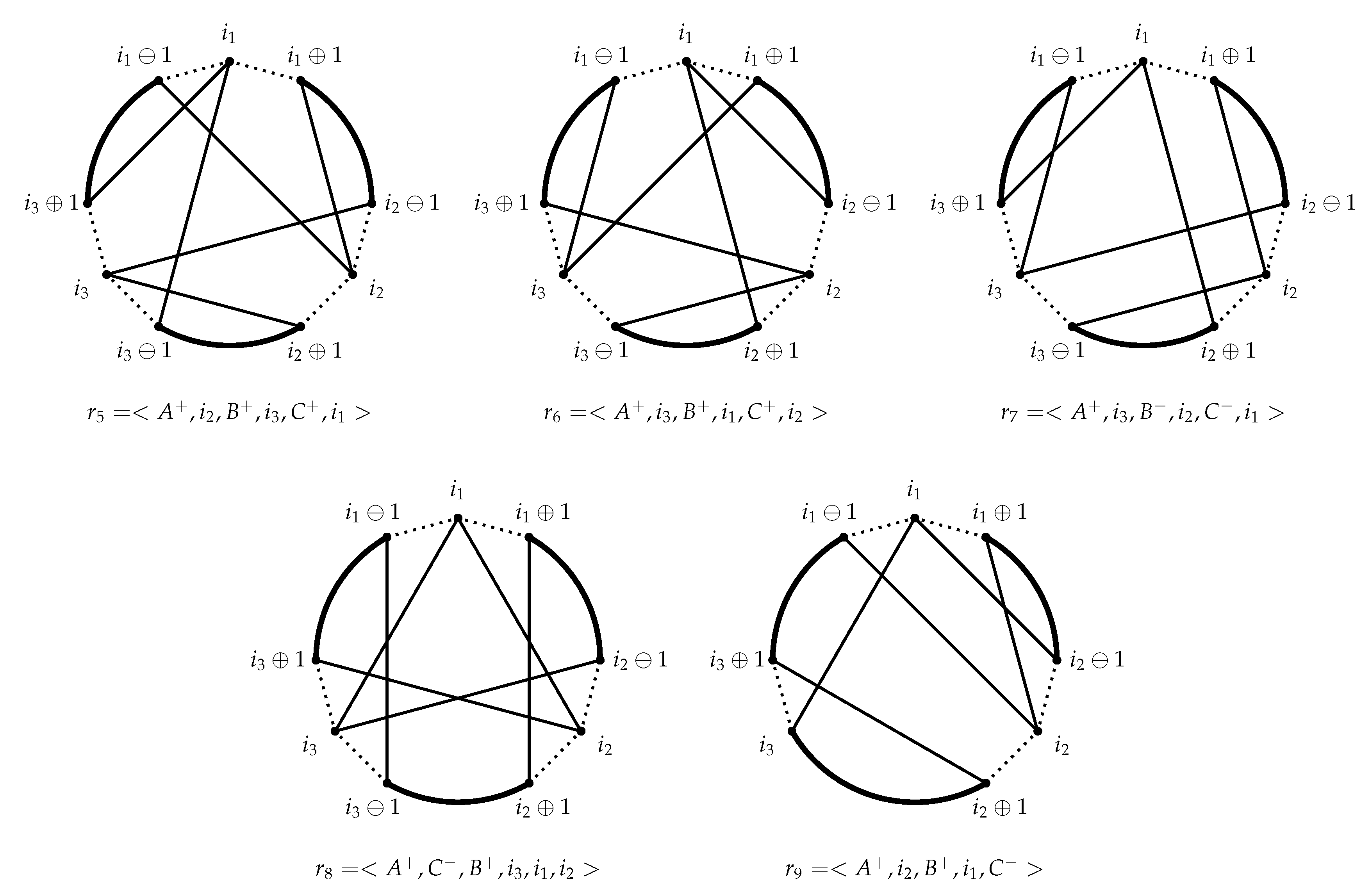{kind=link}