1. Introduction
Emotion plays an important role in the daily interpersonal interactions and is considered an essential skill for human communication [
1]. It helps humans to understand the opinions of others by conveying feelings and giving feedback to people. Emotion has many useful benefits of affective computing and cognitive activities such as rational decision making, perception and learning [
2]. It has opened up an exhilarating research agenda because constructing an intelligent robotic dialogue system that can recognize emotions and precisely respond in the manner of human conversation is presently arduous. The requirement of emotion recognition is steadily increasing with the pervasiveness of intelligent systems [
3]. Huawei intelligent video surveillance systems, for instance, can support real-time tracking of a person in a distressed phase through emotion recognition. The capability to recognize human emotions is considered an essential future requirement of intelligent systems that are inherently supposed to interact with people to a certain degree of emotional intelligence [
4]. The necessity to develop emotionally intelligent systems is exceptionally important for the modern society of the internet of things (IoT) because such systems have great impact on decision making, social communication and smart connectivity [
5].
Practical applications of emotion recognition systems can be found in many domains such as audio/video surveillance [
6], web-based learning, commercial applications [
7], clinical studies, entertainment [
8], banking [
9], call centers [
10], computer games [
11] and psychiatric diagnosis [
12]. In addition, other real applications include remote tracking of persons in a distressed phase, communication between human and robots, mining sentiments of sport fans and customer care services [
13], where emotion is perpetually expressed. These numerous applications have led to the development of emotion recognition systems that use facial images, video files or speech signals [
14]. In particular, speech signals carry emotional messages during their production [
15] and have led to the development of intelligent systems habitually called speech emotion recognition systems [
16]. There is an avalanche of intrinsic socioeconomic advantages that make speech signals a good source for affective computing. They are economically easier to acquire than other biological signals like electroencephalogram, electrooculography and electrocardiograms [
17], which makes speech emotion recognition research attractive [
18]. Machine learning algorithms extract a set of speech features with a variety of transformations to appositely classify emotions into different classes. However, the set of features that one chooses to train the selected learning algorithm is one of the most important tools for developing effective speech emotion recognition systems [
3,
19]. Research has suggested that features extracted from the speech signal have a great effect on the reliability of speech emotion recognition systems [
3,
20], but selecting an optimal set of features is challenging [
21].
Speech emotion recognition is a difficult task because of several reasons such as an ambiguous definition of emotion [
22] and the blurring of separation between different emotions [
23]. Researchers are investigating different heterogeneous sources of features to improve the performance of speech emotion recognition systems. In [
24], performances of Mel-frequency cepstral coefficient (MFCC), linear predictive cepstral coefficient (LPCC) and perceptual linear prediction (PLP) features were examined for recognizing speech emotion that achieved a maximum accuracy of 91.75% on an acted corpus with PLP features. This accuracy is relatively low when compared to the recognition accuracy of 95.20% obtained for a fusion of audio features based on a combination of MFCC and pitch for recognizing speech emotion [
25]. Other researchers have tried to agglutinate different acoustic features with the optimism of boosting accuracy and precision rates of speech emotion recognition [
25,
26]. This technique has shown some improvement, nevertheless it has yielded low accuracy rates for the fear emotion in comparison with other emotions [
25,
26]. Semwal et al. [
26] fused some acoustic features such as MFCC, energy, zero crossing rate (ZCR) and fundamental frequency that gave an accuracy of 77.00% for the fear emotion. Similarly, Sun et al. [
27] used a deep neural network (DNN) to extract bottleneck features that achieved an accuracy of 62.50% for recognizing the fear emotion. The overarching objective of this study was to construct a set of hybrid acoustic features (HAFs) to improve the recognition of the fear emotion and other emotions from speech signal with high precision. This study has contributed to the understanding of the topical theme of speech emotion recognition in the following unique ways.
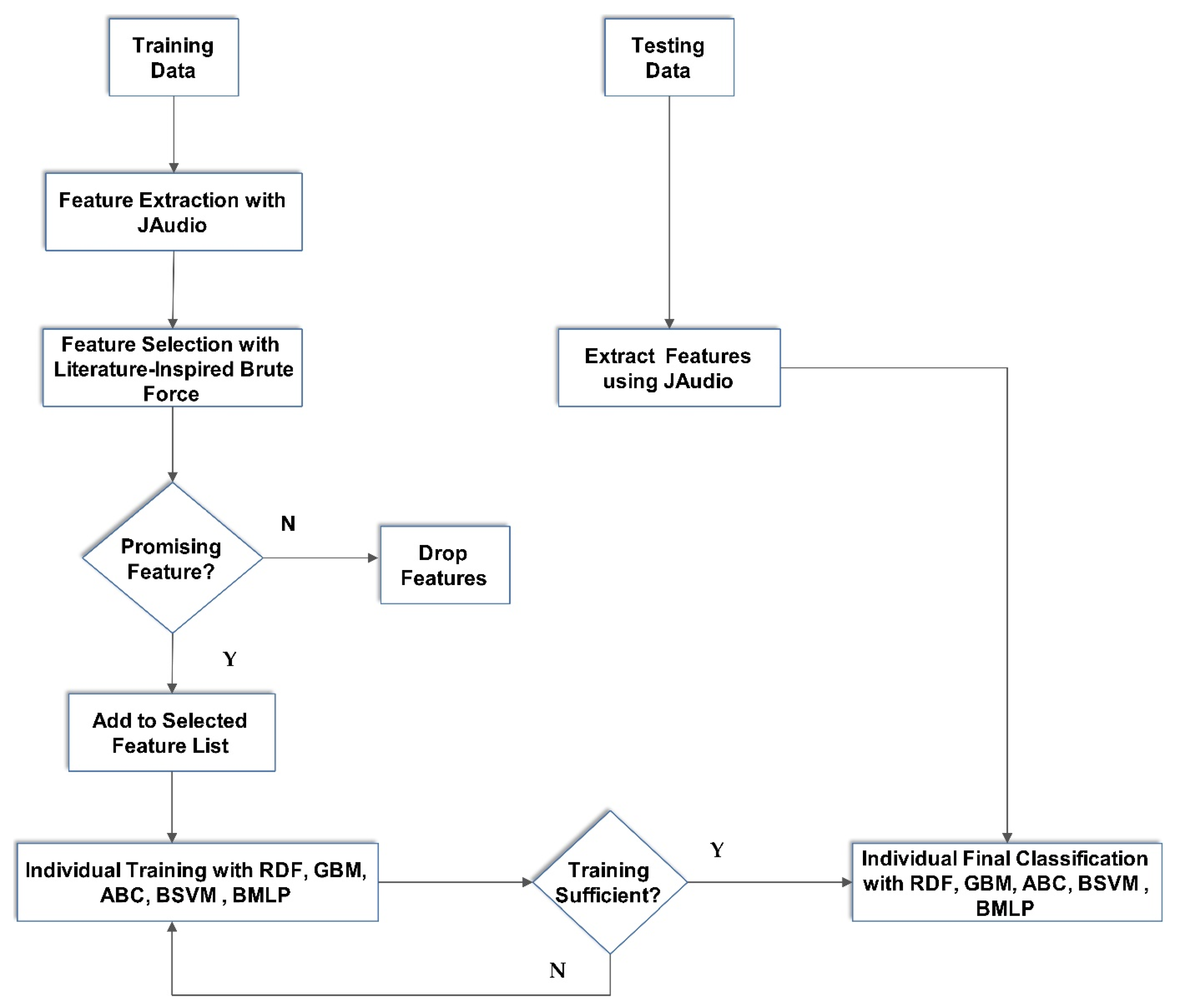
The application of a specialized software to extract highly discriminating speech emotion feature representations from multiple sources such as prosodic and spectral to achieve an improved precision in emotion recognition.
The agglutination of the extracted features using the specialized software to form a set of hybrid acoustic features that can recognize the fear emotion and other emotions from speech signal better than the state-of-the-art unified features.
The comparison of the proposed set of hybrid acoustic features with other prominent features of the literature using popular machine learning algorithms to demonstrate through experiments, the effectiveness of our proposal over the others.
The content of this paper is succinctly organized as follows.
Section 1 provides the introductory message, including the objective and contributions of the study.
Section 2 discusses the related studies in chronological order.
Section 3 designates the experimental databases and the study methods. The details of the results and concluding statements are given in
Section 4 and
Section 5 respectively.
2. Related Studies
Speech emotion recognition research has been exhilarating for a long time and several papers have presented different ways of developing systems for recognizing human emotions. The authors in [
3] presented a majority voting technique (MVT) for detecting speech emotion using fast correlation based feature (FCBF) and Fisher score algorithms for feature selection. They extracted 16 low-level features and tested their methods over several machine learning algorithms, including artificial neural network (ANN), classification and regression tree (CART), support vector machine (SVM) and K-nearest neighbor (KNN) on berlin emotion speech database (Emo-DB). Kerkeni et al. [
11] proposed a speech emotion recognition method that extracted MFCC with modulation spectral (MS) features and used recurrent neural network (RNN) learning algorithm to classify seven emotions from Emo-DB and Spanish database. The authors in [
15] proposed a speech emotion recognition model where glottis was used for compensation of glottal features. They extracted features of glottal compensation to zero crossings with maximal teager (GCZCMT) energy operator using Taiyuan University of technology (TYUT) speech database and Emo-DB.
Evaluation of feature selection algorithms on a combination of linear predictive coefficient (LPC), MFCC and prosodic features with three different multiclass learning algorithms to detect speech emotion was discussed in [
19]. Luengo et al. [
20] used 324 spectral and 54 prosody features combined with five voice quality features to test their proposed speech emotion recognition method on the Surrey audio-visual expressed emotion (SAVEE) database after applying the minimal redundancy maximal relevance (mRMR) to reduce less discriminating features. In [
28], a method for recognizing emotions in an audio conversation based on speech and text was proposed and tested on the SemEval-2007 database using SVM. Liu et al. [
29] used the extreme learning machine (ELM) method for feature selection that was applied to 938 features based on a combination of spectral and prosodic features from Emo-DB for speech emotion recognition. The authors in [
30] extracted 988 spectral and prosodic features from three different databases using the OpenSmile toolkit with SVM for speech emotion recognition. Stuhlsatz et al. [
31] introduced the generalized discriminant analysis (GerDA) based on DNN to recognize emotions from speech using the OpenEar specialized software to extract 6552 acoustic features based on 39 functional of 56 acoustic low-level descriptor (LLD) from Emo-DB and speech under simulated and actual stress (SUSAS) database. Zhang et al. [
32] applied the cooperative learning method to recognize speech emotion from FAU Aibo and SUSAS databases using GCZCMT based acoustic features.
In [
33], Hu moments based weighted spectral features (HuWSF) were extracted from Emo-DB, SAVEE and Chinese academy of sciences - institute of automation (CASIA) databases to classify emotions from speech using SVM. The authors used HuWSF and multicluster feature selection (MCFS) algorithm to reduce feature dimensionality. In [
34], extended Geneva minimalistic acoustic parameter set (eGeMAPS) features were used to classify speech emotion, gender and age from the Ryerson audio-visual database of emotional speech and song (RAVDESS) using the multiple layer perceptron (MLP) neural network. Pérez-Espinosa et al. [
35] analyzed 6920 acoustic features from the interactive emotion dyadic motion capture (IEMOCAP) database to discover that features based on groups of MFCC, LPC and cochleagrams are important for estimating valence, activation and dominance emotions in speech respectively. The authors in [
36] proposed a DNN architecture for extracting informative feature representatives from heterogeneous acoustic feature groups that may contain redundant and unrelated information. The architecture was tested by training the fusion network to jointly learn highly discriminating acoustic feature representations from the IEMOCAP database for speech emotion recognition using SVM to obtain an overall accuracy of 64.0%. In [
37], speech features based on MFCC and facial on maximally stable extremal region (MSER) were combined to recognize human emotions through a systematic study on Indian face database (IFD) and Emo-DB.
Narendra and Alku [
38] proposed a new dysarthric speech classification method from a coded telephone speech using glottal features with a DNN based glottal inverse filtering method. They considered two sets of glottal features based on time and frequency domain parameters plus parameters based on principal component analysis (PCA). Their results showed that a combination of glottal and acoustic features resulted in an improved classification after applying PCA. In [
39], four pitch and spectral energy features were combined with two prosodic features to distinguish two high activation states of angry and happy plus low activation states of sadness and boredom for speech emotion recognition using SVM with Emo-DB. Alshamsi et al. [
40] proposed a smart phone method for automated facial expression and speech emotion recognition using SVM with MFCC features extracted from SAVEE database.
Li and Akagi [
41] presented a method for recognizing emotions expressed in a multilingual speech using the Fujitsu, Emo-DB, CASIA and SAVEE databases. The highest weighted average precision was obtained after performing speaker normalization and feature selection. The authors in [
42] used MFCC related features for recognizing speech emotion based on an improved brain emotional learning (BEL) model inspired by the emotional processing mechanism of the limbic system in human brain. They tested their method on CASIA, SAVEE and FAU Aibo databases using linear discriminant analysis (LDA) and PCA for dimensionality reduction to obtain the highest average accuracy of 90.28% on CASIA database. Mao et al. [
43] proposed the emotion-discriminative and domain-invariant feature learning method (EDFLM) for recognizing speech emotion. In their method, both domain divergence and emotion discrimination were considered to learn emotion-discriminative and domain-invariant features using emotion label and domain label constraints. Wang et al. [
44] extracted MFCC, Fourier parameters, fundamental frequency, energy and ZCR from three different databases of Emo-DB, Chinese elderly emotion database (EESDB) and CASIA for recognizing speech emotion. Muthusamy et al. [
45] extracted a total of 120 wavelet packet energy and entropy features from speech signals and glottal waveforms from Emo-DB, SAVEE and Sahand emotional speech (SES) databases for speech emotion recognition. The extracted features were enhanced using the Gaussian mixture model (GMM) with ELM as the learning algorithm.
Zhu et al. [
46] used a combination of acoustic features based on MFCC, pitch, formant, short-term ZCR and short-term energy to recognize speech emotion. They extracted the most discriminating features and performed classification using the deep belief network (DBN) with SVM. Their results showed an average accuracy of 95.8% on the CASIA database across six emotions, which is an improvement when compared to other related studies. Álvarez et al. [
47] proposed a classifier subset selection (CSS) for the stacked generalization to recognize speech emotion. They used the estimation of distribution algorithm (EDA) to select optimal features from a collection of features that included eGeMAPS and SVM for classification that achieved an average accuracy of 82.45% on Emo-Db. Bhavan et al. [
48] used a combination of MFCCs, spectral centroids and MFCC derivatives of spectral features with a bagged ensemble algorithm based on Gaussian kernel SVM for recognizing speech emotion that achieved an accuracy of 92.45% on Emo-DB. Shegokar et al. [
49] proposed the use of continuous wavelet transform (CWT) with prosodic features to recognize speech emotion. They used PCA for feature transformation with quadratic kernel SVM as a classification algorithm that achieved an average accuracy of 60.1% on the RAVDESS database. Kerkeni et al. [
50] proposed a model for recognizing speech emotion using empirical mode decomposition (EMD) based on optimal features that included the reconstructed signal based on Mel frequency cepstral coefficient (SMFCC), energy cepstral coefficient (ECC), modulation frequency feature (MFF), modulation spectral (MS) and frequency weighted energy cepstral coefficient (FECC). They achieved an average accuracy of 91.16% on the Spanish database using the RNN algorithm for classification.
Emotion recognition is still a great challenge because of several reasons as previously alluded in the introductory message. Further reasons include the existence of a gap between acoustic features and human emotions [
31,
36] and the non-existence of a solid theoretical foundation relating the characteristics of voice to the emotions of a speaker [
20]. These intrinsic challenges have led to the disagreement in the literature on which features are best for speech emotion recognition [
20,
36]. The trend in the literature shows that a combination of heterogeneous acoustic features is promising for speech emotion recognition [
20,
29,
30,
36,
39], but how to effectively unify the different features is highly challenging [
21,
36]. The importance of selecting relevant features to improve the reliability of speech emotion recognition systems is strongly emphasized in the literature [
3,
20,
29]. Researchers frequently apply specialized software such as OpenEar [
31,
32,
35], OpenSmile [
30,
32,
34,
36] and Praat [
35] for extraction, selection and unification of speech features from heterogeneous sources to ease the intricacy inherent in the processes. Moreover, the review of numerous literature has revealed that different learning algorithms are trained and validated with the specific features extracted from public databases for speech emotion recognition.
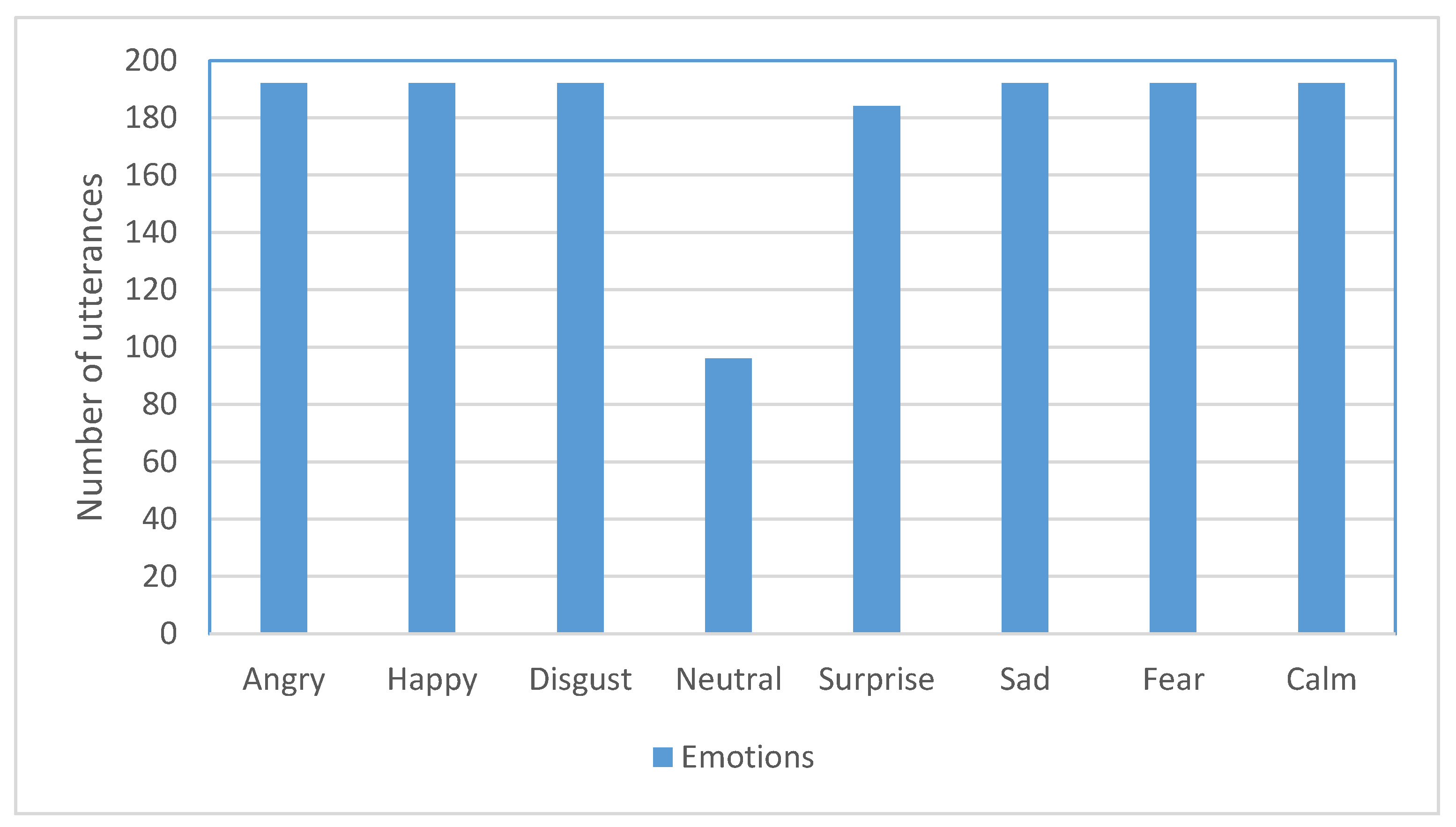
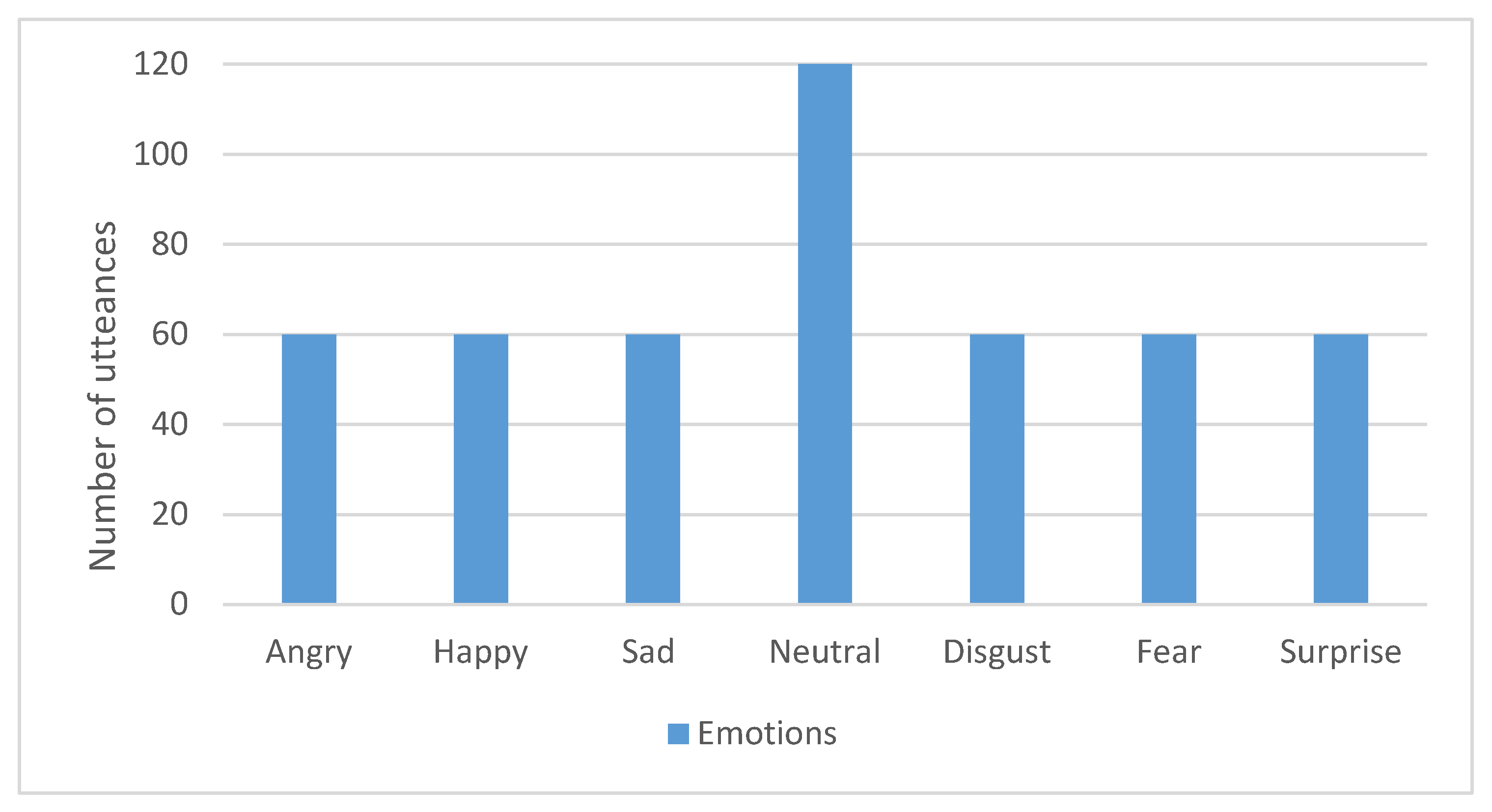
Table 1 shows the result of the comparative analysis of our method with the related methods in terms of the experimental database, type of recording, number of emotions, feature set, classification method and maximum percentage accuracy results obtained. It is conspicuous from the comparative analysis that our emotion recognition method is highly promising because it has achieved the highest average accuracy of 99.55% across two dissimilar public experimental databases.
4. Results and Discussion
The present authors have extracted the set of 404 HAFs from RAVDESS and SAVEE experimental databases. The features were used to train five famous ensemble learning algorithms in order to determine their effectiveness using four standard performance metrics. The performance metrics were selected because the experimental databases were not equally distributed. Data were subjected to 10 fold cross-validation and divided into training and testing groups as the norm permits. Gaussian noise was added to the training data to provide a regularizing effect, reduce overfitting, increase resilience and improve generalization performance of the ensemble learning algorithms.
Table 3 shows the result of the CPU computational time of training an individual ensemble learning algorithm with three different sets of features across two experimental databases. The training time analysis shows that RDF spent the least amount of training time when compared to other ensemble learning algorithms. The least training time was recorded with respect to MFCC1 and MFCC2 irrespective of databases. However, the training time of RDF (0.43) was slightly higher than that of BSVM (0.39) with respect to SAVEE HAF, but it claimed superiority with respect to the RAVDESS HAF. The reason for this inconsistent result might be because of the smaller data size (480) of SAVEE when compared to the size (1432) of RAVDESS. The experimental results of a study that was aimed at fully assessing the predictive performances of SVM and SVM ensembles over small and large scale datasets of breast cancer show that SVM ensemble based on BSVM method can be the better choice for a small scale dataset [
78]. Moreover, it can be observed that GBM and BMLP were generally time consuming when compared to the other ensemble learning algorithms because they took 1172.3 milliseconds to fit MFCC2 RAVDESS and 1319.39 milliseconds to fit MFCC2 SAVEE features respectively.
The experimental results of the overall recognition performance obtained are given in
Table 4. The percentage average recognition performance rates differ depending on critical factors such as the type of database, the accent of the speakers, the way data were collected, the type of features and the learning algorithm used. In particular, RDF consistently recorded the highest average accuracy, while BMLP consistently recorded the lowest average accuracy across the sets of features, irrespective of databases. These results indicate that RDF gave the highest performance because the computed values of the precision, recall, F1-score and accuracy of the ensemble learning algorithm are generally impressive when compared to other ensemble learning algorithms. However, average recognition accuracies of 61.5% and 66.7% obtained by RDF for the SAVEE MFCC1 and MFCC2 were respectively low, but the values were better than that of BMLP (55.4% and 60.7%) for SAVEE MFCC1 and MFCC2 respectively. In general, an improvement can be observed when a combination of features (MFCC2) was used in an experiment drawing inspiration from the work done in [
46], where MFCC features were combined with pitch and ZCR features. In addition, we borrowed the same line of thought from Sarker and Alam [
3] and Bhaskar et al. [
28] where some of the above mentioned features were combined to form hybrid features.
The results in
Table 4 can be used to demonstrate the effectiveness of the proposed HAF. The values of the precision, recall, F1-score and accuracy performance measures can be seen to be generally high for the five ensemble learning algorithms using the HAF irrespective of databases. Specifically, RDF and GBM concomitantly recorded the highest accuracy of 99.3% for the SAVEE HAF, but RDF claims superiority with 99.8% accuracy when compared to the 92.6% accuracy for the HAF RAVDESS. Consequently, the results of RDF learning of the proposed HAF were exceptionally inspiring with an average accuracy of 99.55% across the two databases. The ranking of the investigated ensemble learning algorithms in terms of percentage average accuracy computed for HAF across the databases is RDF (99.55%), GBM (95.95%), ABC (95.00%), BSVM (93.90%) and BMLP (92.95%). It can be inferred that application of ensemble learning of HAF is highly promising for recognizing emotions in human speech. In general, high accuracy values computed by all learning algorithms across databases indicate the effectiveness of the proposed HAF for speech emotion recognition. Moreover, the confidence factors show that the true classification accuracies of all the ensemble learning algorithms investigated lie in the range between 0.002% and 0.045% across all the corpora. The results in
Table 4 show that HAF significantly improved the performance of emotion recognition when compared to the methods of the SAVEE MFCC related features [
42] and RAVDESS wavelet transform features [
49] that recorded the highest recognition accuracies of 76.40% and 60.10% respectively.
In particular, the results of precision, recall, F1-score and accuracy per each emotion, learning algorithm and database were subsequently discussed.
Table 5 shows that angry, calm and disgust emotions were easier to recognize using RDF and GBM ensemble learning of RAVDESS MFCC1 features. The results were particularly impressive with RDF ensemble learning with perfect precision, recall and F1-score computed by the algorithm, which also recorded highest accuracy values across all emotions. However, BMLP generally gave the least performing result across all emotions. RAVDESS MFCC1 features achieved a precision rate of 92.0% for the fear emotion using RDF ensemble learning, which is relatively high when compared to the results in [
27].
Table 6 shows the results of percentage precision, recall, F1-score and accuracy performance analysis of RAVDESS MFCC2 features. The performance values were generally higher for recognizing angry, calm and disgust emotions using RDF. However, the performance values were relatively low for happy and neutral emotions showing that the hybridization of MFCC, ZCR, energy and fundamental frequency features yielded a relatively poor result in recognizing happy and neutral emotions using ensemble learning. The MFCC2 combination of acoustic features achieved an improved recognition performance of the fear (90.0%) emotion using RDF in comparison with the report in [
44], where 81.0% recognition was achieved for the fear emotion using the CASIA database.
Emotion recognition results shown in
Table 7 with respect to the RAVDESS HAF were generally impressive across emotions, irrespective of the ensemble learning algorithms utilized. RDF was highly effective in recognizing all the eight emotions because it had achieved perfect accuracy value by 100.0% on almost all the emotions, except fear (98.0%). Moreover, perfect precision and accuracy values were achieved in recognizing the neutral emotion, which was really difficult to identify using other sets of features. In addition, 98.0% accuracy and perfect values obtained for precision, recall and F1-score for the fear emotion is impressive because of the difficulty of recognizing the fear emotion as reported in the literature [
25,
26,
27]. All the other learning algorithms performed relatively well, considering the fact that noise was added to the training data. These results attest to the effectiveness of the proposed HAF for recognizing emotions in human speech. In addition, the results point to the significance of sourcing highly discriminating features for recognizing human emotions. They further show that the fear emotion could be recognized efficiently when compared to other techniques used in [
44]. It can be seen that the recognition of fear emotion was successfully improved using the proposed HAF. In addition, HAF gave better performance than the bottleneck features used for six emotions from CASIA database [
27] that achieved a recognition rate of 60.5% for the fear emotion.
Table 8 shows the results of percentage precision, recall, F1-score and accuracy analysis of SAVEE MFCC1 features. In the results, the maximum percentage precision F1-score of the neutral emotion had achieved 94.0% using the RDF ensemble algorithm. This F1-score was quite high when compared to the F1-score obtained from RAVDESS database using the same features. The percentage increase in overall precision of neutral emotion was observed to be 133.33%, 77.36%, 18.57%, 12.66% and 10.39% using GBM, RDF, BMLP, ABC and BSVM respectively. Moreover, RDF and GBM algorithms achieved perfect prediction (100.0%) for recognizing the surprise emotion. The results show that MFCC features still achieved low recognition rates for the fear emotion as reported by other authors [
25]. However, RDF (94.0%) and GBM (91.0%) show higher precision rates for the neutral emotion, which is higher than what was reported in [
11].
Table 9 shows the analysis results of the percentage precision, recall, F1-score and accuracy obtained after performing the classification with SAVEE MFCC2 features. It can be observed from the table that all the learning algorithms performed well for recognizing the surprise emotion, but performed poorly in recognizing other emotions. In general, all learning algorithms achieved a low prediction of emotions with the exception of surprise emotion in which the perfect F1-score was obtained using the RDF algorithm. The lowest precision value of 93.0% was achieved for the surprise emotion using MFCC2 features with BMLP. These results indicate the unsuitability of MFCC, ZCR, energy and fundamental frequency features for recognizing human emotions. However, RDF and GBM gave higher recognition results for happy and sad emotions, RDF gave a higher recognition result for fear emotion while ABC and BSVM gave higher recognition results for the sad emotion that the traditional and bottleneck features [
27].
Table 10 shows the analysis results of the percentage precision, recall, F1-score and accuracy obtained after performing classification with SAVEE HAF. Accordingly, all the emotions were much easier to recognize using the HAF that had tremendously improved the recognition of the fear emotion reported in the literature to be difficult with lower performance results recorded with traditional and bottleneck features for fear emotion [
27]. Moreover, Kerkeni et al. [
11] obtained a recognition accuracy rate of 76.16% for the fear emotion using MFCC and MS features based on the Spanish database of seven emotions. These results show that using HAF with ensemble learning is highly promising for recognizing emotions in human speech. The study findings were consistent with the literature that ensemble learning gives a better predictive performance through the fusion of information knowledge of predictions of multiple inducers [
75,
85]. The ability of ensemble learning algorithms to mimic the nature of human by seeking opinions from several inducers for informed decision distinguish them from inducers [
73]. Moreover, it can be seen across
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 that the set of HAF presented the most effective acoustic features for speech emotion recognition, while the set MFCC1 presented the worst features. In addition, the study results supported the hypothesis that a combination of acoustic features based on prosodic and spectral reflects the important characteristics of speech [
42,
53,
54].
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 show that HAF features had a higher discriminating power because higher performance results were achieved across all emotion classes in the SAVEE and RAVDESS corpora. The performance of each ensemble learning algorithm was generally low when MFCC1 and MFCC2 were applied because the sets of the features had a much lower discriminating power compared to HAF. The recognition results across the experimental databases were different because RAVDESS had more instances than SAVEE. Moreover, SAVEE constitutes male speakers only while RAVDESS is comprised of both male and female speakers. According to the literature, this diversity has an impact on the performance of emotion recognition [
35]. The literature review revealed that most emotion recognition models have not been able to recognize the fear emotion with a higher classification accuracy of 98%, but the results in
Table 4 show that HAF significantly improved the recognition performance of emotion beyond expectation.
5. Conclusions
The automatic recognition of emotion is still an open research because human emotions are highly influenced by quite a number of external factors. The primary contribution of this study is the construction and validation of a set of hybrid acoustic features based on prosodic and spectral features for improving speech emotion recognition. The constructed acoustic features have made it easy to effectively recognize eight classes of human emotions as seen in this paper. The agglutination of prosodic and spectral features has been demonstrated in this study to yield excellent classification results. The proposed set of acoustic features is highly effective in recognizing all the eight emotions investigated in this study, including the fear emotion that has been reported in the literature to be difficult to classify. The proposed methodology seems to work well because combining certain prosodic and spectral features increases the overall discriminating power of the features hence increasing classification accuracy. This superiority is further underlined by the fact that the same ensemble learning algorithms were used on different feature sets, exposing the performance of each group of features regarding their discriminating power. In addition, we saw that ensemble learning algorithms generally performed well. They are widely judged to improve recognition performance better than a single inducer by decreasing variability and reducing bias. Experimental results show that it was quite difficult to achieve high precisions and accuracies when recognizing the neutral emotion with either pure MFCC features or a combination of MFCC, ZCR, energy and fundamental frequency features that were seen to be effective in recognizing the surprise emotion. However, we provided evidence through intensive experimentation that random decision forest ensemble learning of the proposed hybrid acoustic features was highly effective for speech emotion recognition.
The results of this study were generally fantastic, even though the Gaussian noise was added to the training data. The gradient boosting machine algorithm yielded good results, but the main challenge with the algorithm is that its training time is long. In terms of effectiveness, the random decision forest algorithm is superior to the gradient boosting machine algorithm for speech emotion recognition with the proposed acoustic features. The results obtained in this study were quite stimulating, nevertheless, the main limitation of this study was that the experiments were done on acted speech databases in consonance with the research culture. There can be major differences between working with acted and real data. Moreover, there are new features such as breath and spectrogram not investigated in this study for recognizing speech emotion. In the future, we would like to pursue this direction to determine how the new features will compare with the proposed hybrid acoustic features. In addition, future research will harvest real emotion data for emotion recognition using the Huawei OceanConnect cloud based IoT platform and Narrow Band IoT resources in South Africa Luban workshop at the institution of the authors, which is a partnership project with the Tianjin Vocational Institute in China.







{kind=link}
{kind=link}
{kind=link}