Hierarchical-Matching-Based Online and Real-Time Multi-Object Tracking with Deep Appearance Features


Abstract
:1. Introduction
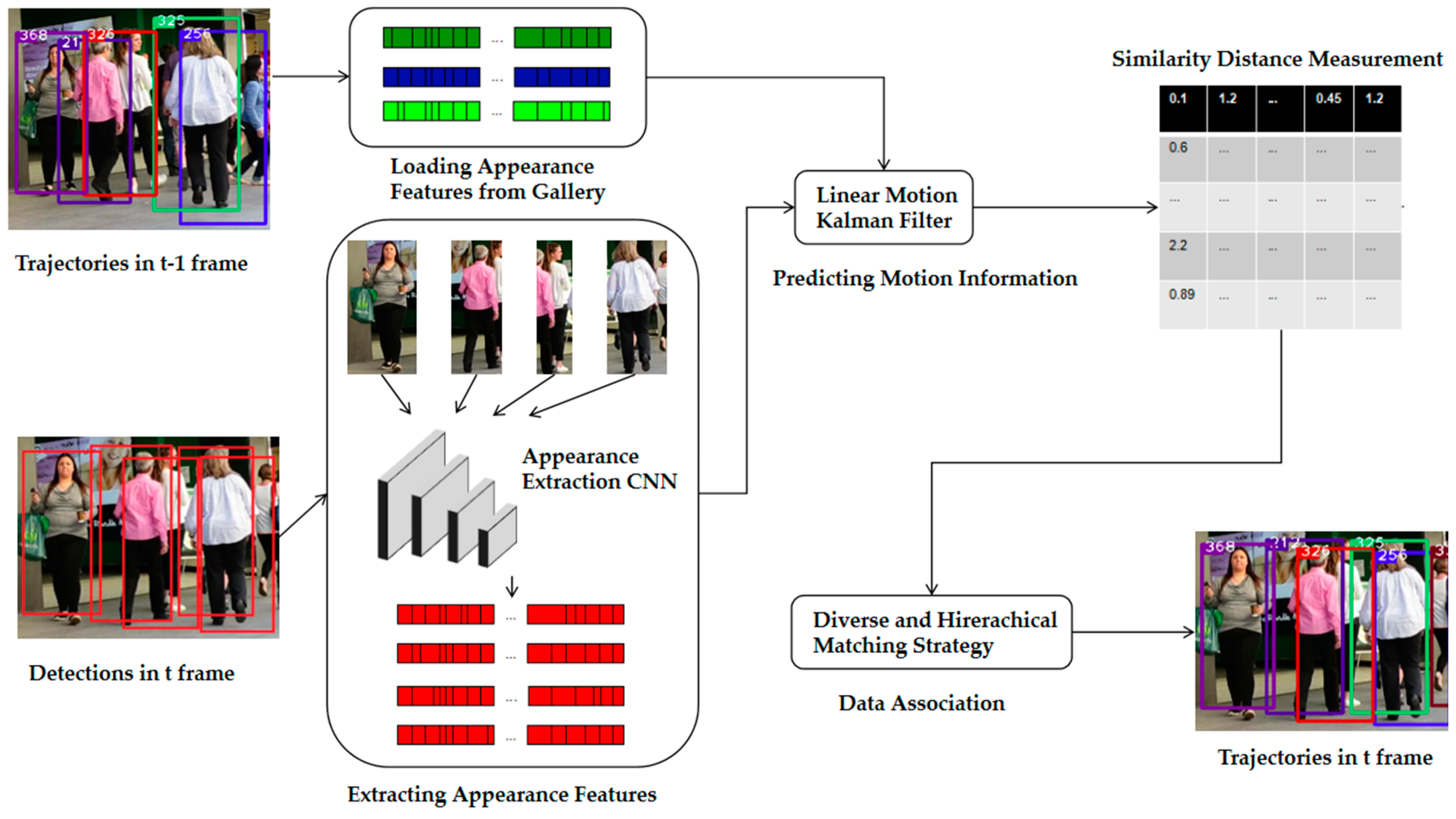
- In order to obtain discriminative appearance features, we exploited an extraction CNN which divided the input image into several different regions. Moreover, we trained the network on a large-scale pedestrian re-identification dataset, and evaluated it on the test set.
- As for the data association, we proposed the calculation equations of trajectory confidence and the hierarchical matching strategy. By adopting the equations, we divided the trajectory set into different confidence sets, representing different reliability levels. Furthermore, we designed a hierarchical matching strategy, associating the trajectory set and detection set after measuring the similarity distance between each of them from the aspect of appearance and motion.
2. Proposed MOT Method
2.1. Trajectory States
2.2. Trajectory Confidence
2.3. Appearance Feature Extracting Network
2.4. Similarity Distance Measurement
2.5. Diverse and Hierarchical Matching Strategy
| Algorithm 1. Trajectories Association |
| Input: Trajectories set K, Detections set D |
| Output: Set of unmatched trajectories , set of unmatched detections , set of matches |
| 1: Initialize set of confirmed and tentative trajectories and set of vanished trajectories , set of high-confidence trajectories and set of low-confidence trajectories , set of high-confidence detections and set of low-confidence detections |
| 2: Initialize , and to |
| 3: Compute affinity matrix and appearance affinity matrix using Equation: (3) (4) (5) |
| 4: Associate and , and , and , and according to |
| 5: Associate remaining trajectories and remaining and according to IoU |
| 6: Associate and remaining and according to |
| 7: Update to remaining trajectories |
| 8: Update to remaining detections |
| 9: Update to successful matches |
| 10: return , , |
3. Experiments
3.1. Dataset
3.2. Evaluation Metrics
3.3. Implementation Details
3.4. Ablation Studies
3.5. Evaluations on MOT15
3.6. Evaluations on MOT17
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Candamo, J.; Shreve, M.; Goldgof, D.B.; Sapper, D.B.; Kasturi, R. Understanding transit scenes: A survey on human behavior-recognition algorithms. IEEE Trans. Intell. Transp. Syst. 2010, 11, 206–224. [Google Scholar] [CrossRef]
- Uchiyama, H.; Marchand, E. Object Detection and Pose Tracking for Augmented Reality: Recent Approaches. Available online: https://hal.inria.fr/hal-00751704/document (accessed on 29 March 2020).
- Meijering, E.; Dzyubachyk, O.; Smal, I.; van Cappellen, W.A. Tracking in cell and developmental biology. Semin. Cell Dev. Biol. 2009, 20, 894–902. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Jitendra, M.; Berkeley, U.C.; ICSI. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 24–27 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Ali, F. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Christian, S.; Scott, R.; Fu, C.-Y.; Alexander, C.B. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking The Untrackable: Learning To Track Multiple Cues with Long-Term Dependencies. In Proceedings of the ICCV, Venice, Italy, 22–29 October; 2017. [Google Scholar]
- Wu, H.; Hu, Y.; Wang, K.; Li, H.; Nie, L.; Cheng, H. Instance-Aware Representation Learning and Association for Online Multi-Person Tracking. Pattern Recognit. 2019, 94, 25–34. [Google Scholar] [CrossRef] [Green Version]
- Yoon, K.; Gwak, J.; Song, Y.M.; Yoon, Y.C.; Jeon, M.G. OneShotDA: Online Multi-Object Tracker with One-Shot-Learning-Based Data Association. IEEE Access 2020, 8, 38060–38072. [Google Scholar] [CrossRef]
- Baisa, N.L. Online multi-object visual tracking using a GM-PHD filter with deep appearance learning. In Proceedings of the 2019 22nd International Conference on Information Fusion (FUSION), Shaw Center, OT, Canada, 2–5 July 2019. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Rita, C.; Carlo, T. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision Springer, Amsterdam, The Netherlands, 8–16 October 2016; pp. 17–35. [Google Scholar] [CrossRef] [Green Version]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a Benchmark for Multi-object Tracking. ArXiv 2015, arXiv:1504.01942. Available online: https://arxiv.org/abs/1504.01942 (accessed on 29 March 2020).
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. ArXiv 2016, arXiv:1603.00831. Available online: https://arxiv.org/pdf/1603.00831.pdf (accessed on 29 March 2020).
- Kalman, R. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Varior, R.R.; Shuai, B.; Lu, J.; Xu, D.; Wang, G. A Siamese Long Short-Term Memory Architecture for Human Re-Identification. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016. [Google Scholar]
- He, L.; Liang, J.; Li, H.; Sun, Z. Deep Spatial Feature Reconstruction for Partial Person Re-Identification: Alignment-Free Approach. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; 2018. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, H.W. The hungarian method for the assignment problem. Nav. Res. Logist. Q. 1995, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Choi, W.; Lin, Y. Exploit All the Layers: Fast and Accurate CNN Object Detector with Scale Dependent Pooling and Cascaded Rejection Classifiers. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2129–2137. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained partbased models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. Image Video Process. 2008, 1, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, C.; Nevatia, R. Learning to associate: Hybrid Boosted multi-object tracker for crowded scene. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. In Proceedings of the BMVC, York, UK, 19–22 September 2016; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. Arxiv 2016, arXiv:1603.04467v2. Available online: https://arxiv.org/abs/1603.04467 (accessed on 29 March 2020).
- Wojke, N.; Bewley, A. Deep Cosine Metric Learning for Person Re-identification. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 748–756. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Future. ArXiv 2016, arXiv:1610.02984, Available online: https://arxiv.org/abs/1610.02984 (accessed on 29 March 2020).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection[C]. International Conference on computer vision & Pattern Recognition (CVPR’05). IEEE Comput. Soc. 2005, 1, 886–893. [Google Scholar]
- Song, Y.; Jeon, M. Online multiple object tracking with the hierarchically adopted gm-phd filter using motion and appearance. In Proceedings of the Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 26–28 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Ju, J.; Kim, D.; Ku, B.; David, K.H.; Hanseok, K. Online multi-person tracking with two-stage data association and online appearance model learning. Iet Comput. Vis. 2017, 11, 87–95. [Google Scholar] [CrossRef]
- Anh, N.T.L.; Khan, F.M.; Negin, F.; Francois, B. Multi-Object tracking using multi-channel part appearance representation, Advanced Video and Signal Based Surveillance (AVSS). In Proceedings of the 2017 14th IEEE International Conference on San Francisco, San Francisco, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Matilla, R.; Poiesi, F.; Cavallaro, A. Online multi-target tracking with strong and weak detections. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 84–99. [Google Scholar] [CrossRef]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to Track: Online Multi-Object Tracking by Decision Making. In Proceedings of the International Conference on Computer Vision (ICCV), Araucano Park, Chile, 11–18 December 2015. [Google Scholar]
- Chul, Y.; Song, Y.-M.; Yoon, K.; Jeon, M. Online Multi-Object Tracking Using Selective Deep Appearance Matching; IEEE: Jeju, Korea, 2018; pp. 206–212. [Google Scholar] [CrossRef]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 941–951. [Google Scholar]
- Eiselein, V.; Arp, D.; Patzold, M.; Sikora, T. Real-Time Multi-human Tracking Using a Probability Hypothesis Density Filter and Multiple Detectors; IEEE Computer Society: NW Washington, DC, USA, 2012. [Google Scholar] [CrossRef]
- Kutschbach, T.; Bochinski, E.; Eiselein, V.; Sikora, T. Sequential Sensor Fusion Combining Probability Hypothesis Density and Kernelized Correlation Filters for Multi-Object Tracking in Video Data; IEEE: Lecce, Italy, 2017. [Google Scholar] [CrossRef] [Green Version]
- Baisa, N.L.; Wallace, A. Development of a N-type GM-PHD filter for multiple target, multiple type visual tracking. J. Vis. Commun. Image Represent. 2019, 59, 257–271. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.; Kim, E. Multiple Object Tracking via Feature Pyramid Siamese Networks. IEEE Access 2019, 7, 8181–8194. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Patch Size, Channel, Stride | ||
|---|---|---|---|---|
| Global | Local Cross | Local Horizontal | ||
| Conv1 | 128 × 64 | [3 × 3, 32] × 2 | ||
| Conv2 | G: 64 × 32 LC: 64 × 32 LH: 32 × 64 | 3 × 3 MP, S-2 | SL-4, 2x2 MP, S-1 | SL-4, 2x2 MP, S-1 |
| [3 × 3, 32] × 2 | [3 × 3, 32] × 2 | [3 × 3, 32] × 2 | ||
| Conv3 | G: 64 × 32 LC: 32 × 16 LH: 16 × 32 | [3 × 3, 32] × 2 | [3 × 3, 64], S-2 [3 × 3, 64] | [3 × 3, 64], S-2 [3 × 3, 64] |
| Conv4 | G: 32 × 16 LC: 16 × 8 LH: 8 × 16 | [3 × 3, 64], S-2 [3 × 3, 64] | [3 × 3, 64] × 2 3 × 3 MP, S-2 | [3 × 3, 64] × 2 3 × 3 MP, S-2 |
| Conv5 | G: 32 × 16 | [3 × 3, 64] × 2 | ||
| Conv6 | G: 16 × 8 | [3 × 3, 128], S-2 [3 × 3, 128] | ||
| Conv7 | G: 16 × 8 | [3 × 3, 128] × 2 | ||
| Fc | 1 × 1 | 16 × 8 MP | CA-4, 16x8 MP | CA-4, 8x16 MP |
| CA-3, [1 × 1, 640] | ||||
| Batch and L2 normalization | 1 × 1 | [1 × 1, 640] | ||
| Method | MOTA(↑) | MT(↑) | ML(↓) | FP(↓) | FN(↓) | IDS(↓) | Frag(↓) |
|---|---|---|---|---|---|---|---|
| Proposed Algorithm | 30.0 | 59 | 269 | 4101 | 23,580 | 269 | 845 |
| B1 | 26.3 | 60 | 245 | 5088 | 23,028 | 1284 | 1518 |
| B2 | 26.8 | 40 | 297 | 2559 | 25,891 | 742 | 889 |
| B3 | 25.8 | 40 | 306 | 4018 | 24,126 | 933 | 968 |
| B4 | 27.3 | 40 | 300 | 2488 | 26,133 | 404 | 690 |
| MOTA(↑) | MT(↑) | ML(↓) | FP(↓) | FN(↓) | IDS(↓) | Frag(↓) | |
|---|---|---|---|---|---|---|---|
| 1 | 29.2% | 67 | 250 | 5036 | 22,875 | 360 | 985 |
| 2 | 30.0% | 59 | 269 | 4101 | 23,580 | 269 | 845 |
| 3 | 29.9% | 57 | 280 | 3550 | 24,205 | 207 | 726 |
| 4 | 29.5% | 55 | 287 | 3185 | 24,785 | 177 | 665 |
| 5 | 29.2% | 46 | 302 | 2833 | 25,270 | 153 | 609 |
| 8 | 27.8% | 42 | 326 | 2147 | 26,552 | 112 | 509 |
| 10 | 26.8% | 33 | 346 | 1837 | 27,282 | 104 | 464 |
| Method | MOTA(↑) | MT(↑) | ML(↓) | FP(↓) | FN(↓) | IDS(↓) | Frag(↓) | FPS(↑) | |
|---|---|---|---|---|---|---|---|---|---|
| A | GMPHD [32] | 18.5% | 3.9% | 55.3% | 7864 | 41,766 | 459 | 1266 | 19.8 |
| TSDA_OAL [33] | 18.6% | 9.4% | 42.3% | 16,350 | 32,853 | 806 | 1544 | 19.7 | |
| MTSTracker [34] | 20.6% | 9.0% | 36.9% | 15,161 | 32,212 | 1387 | 2357 | 19.3 | |
| EAMTTpub [35] | 22.3% | 5.4% | 52.7% | 7924 | 38,982 | 833 | 1485 | 12.2 | |
| MDP [36] | 30.3% | 13.0% | 38.4% | 9717 | 32,422 | 680 | 1500 | 1.1 | |
| B | TC_SIAMESE [37] | 20.2% | 2.6% | 67.5% | 6127 | 42,596 | 294 | 825 | 13.0 |
| INARLA [10] | 34.7% | 12.5% | 30.0% | 9855 | 29,158 | 1112 | 2848 | 2.6 | |
| AMIR15 [9] | 37.6% | 15.8% | 26.8% | 7933 | 29,397 | 1026 | 2024 | 1.0 | |
| Tracktor++ [38] | 44.1% | 18.0% | 26.2% | 6477 | 26,577 | 1318 | 1790 | 0.9 | |
| HMB_DAF (Ours) | 22.4% | 3.3% | 57.4% | 5603 | 41,410 | 634 | 1686 | 37.6 |
| Method | MOTA(↑) | MT(↑) | ML(↓) | FP(↓) | FN(↓) | IDS(↓) | Frag(↓) | FPS(↑) | |
|---|---|---|---|---|---|---|---|---|---|
| A | GM_PHD [39] | 36.4% | 4.1% | 57.3% | 23,723 | 330,767 | 4607 | 11,317 | 38.4 |
| GMPHD_KCF [40] | 39.6% | 8.8% | 43.3% | 50,903 | 284,228 | 5811 | 7414 | 3.3 | |
| GMPHD_N1Tr [41] | 42.1% | 11.9% | 42.7% | 18,214 | 287,646 | 10,698 | 10,864 | 9.9 | |
| EAMTT [35] | 42.6% | 12.7% | 42.7% | 30,711 | 288,474 | 4488 | 5720 | 12.0 | |
| GMPHD_HDA [32] | 43.7% | 11.7% | 43.0% | 25,935 | 287,758 | 3838 | 4046 | 9.2 | |
| B | GMPHD_DAL [12] | 44.4% | 14.9% | 39.4% | 19,170 | 283,380 | 11,137 | 13,900 | 3.4 |
| FPSN [42] | 44.9% | 16.5% | 35.8% | 33,757 | 269,952 | 7136 | 14,491 | 10.1 | |
| YOONKJ17 [11] | 51.4% | 21.2% | 37.3% | 29,051 | 243,202 | 2118 | 3072 | 3.4 | |
| Tracktor++ [38] | 53.5% | 19.5% | 36.6% | 12,201 | 248,047 | 2072 | 4611 | 1.5 | |
| HMB_DAF (Ours) | 45.5% | 14.6% | 40.4% | 21,161 | 282,901 | 3592 | 7696 | 35.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Q.; Yu, H.; Wu, X. Hierarchical-Matching-Based Online and Real-Time Multi-Object Tracking with Deep Appearance Features. Algorithms 2020, 13, 80. https://doi.org/10.3390/a13040080
Ji Q, Yu H, Wu X. Hierarchical-Matching-Based Online and Real-Time Multi-Object Tracking with Deep Appearance Features. Algorithms. 2020; 13(4):80. https://doi.org/10.3390/a13040080
Chicago/Turabian StyleJi, Qingge, Haoqiang Yu, and Xiao Wu. 2020. "Hierarchical-Matching-Based Online and Real-Time Multi-Object Tracking with Deep Appearance Features" Algorithms 13, no. 4: 80. https://doi.org/10.3390/a13040080
APA StyleJi, Q., Yu, H., & Wu, X. (2020). Hierarchical-Matching-Based Online and Real-Time Multi-Object Tracking with Deep Appearance Features. Algorithms, 13(4), 80. https://doi.org/10.3390/a13040080