
A Multinomial DGA Classifier for Incipient Fault Detection in Oil-Impregnated Power Transformers


Abstract
:1. Introduction
2. Related Works
3. Methods and Modeling
3.1. Materials and Methods
3.2. Main Notations
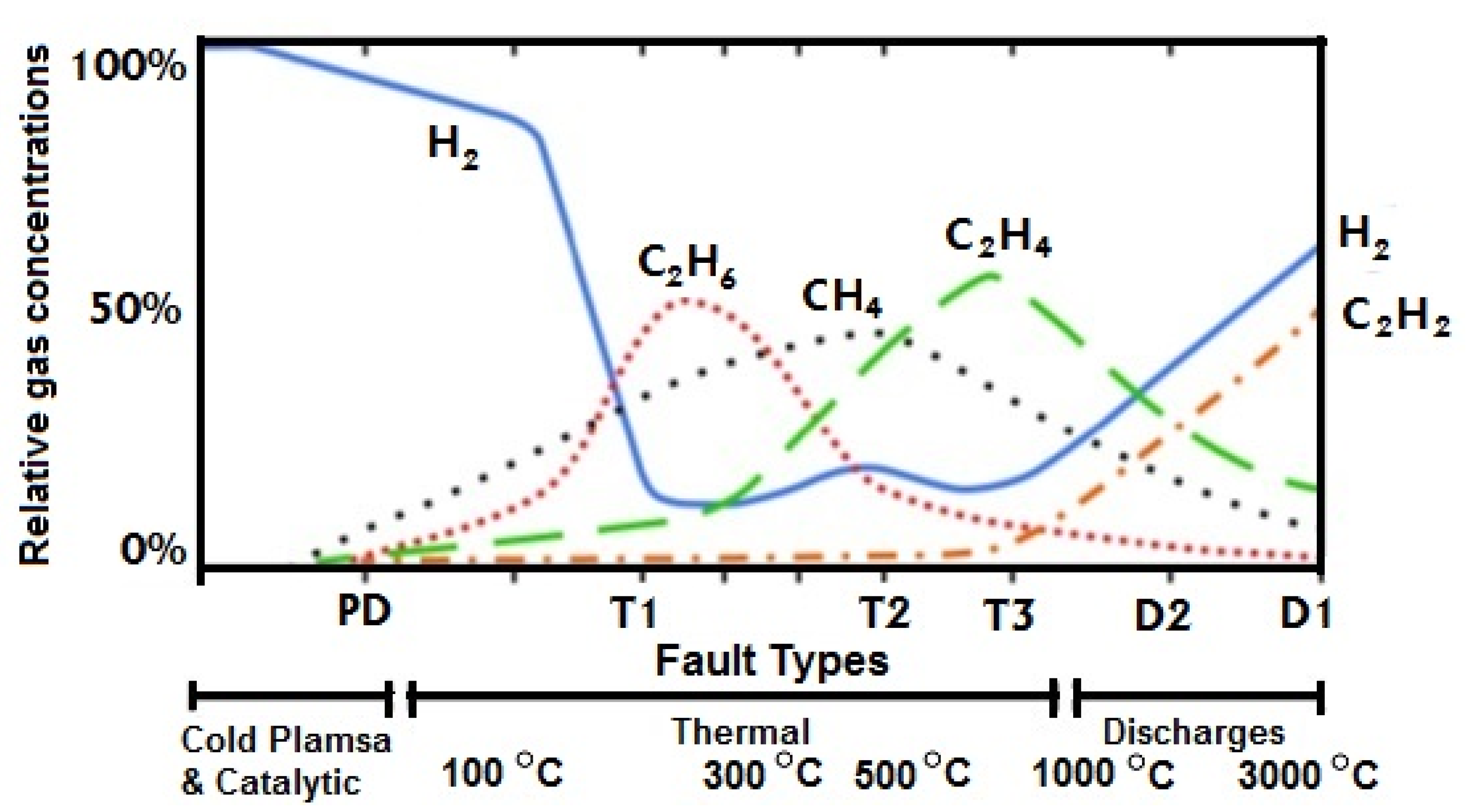
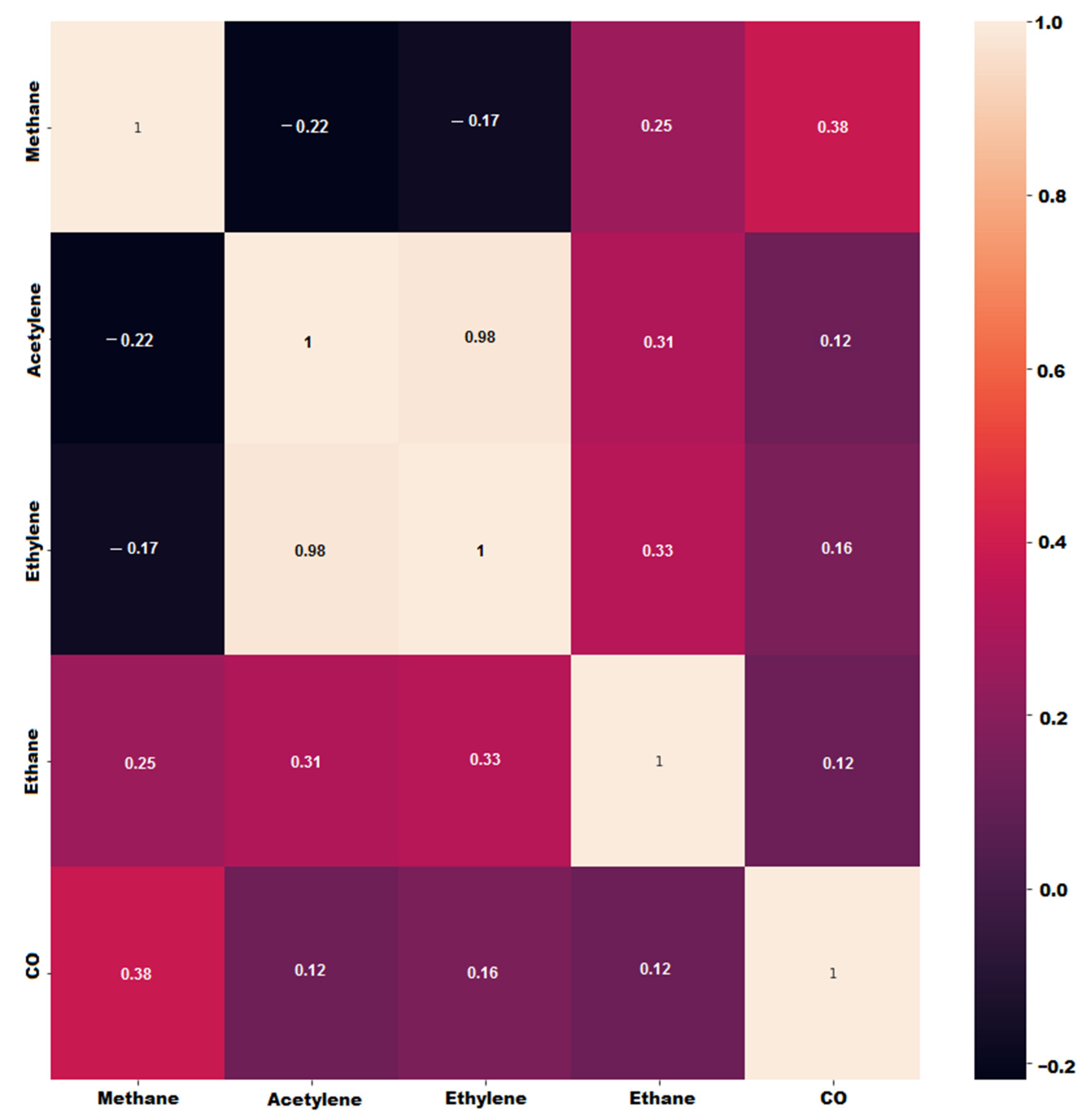
3.3. Analysis of Dissolved Gases
- Hydrogen gas and hydrocarbons: H2, CH4, C2H2, C2H4
- Carbon oxides: CO2 and CO
- Non-fault gases: N2 and O2
- Partial Discharge (PD)—A partial discharge occurs when a confined section of a solid or fluid insulation material under high voltage stress experiences a partial collapse but does not entirely seal the space in between two conducting materials. In our context, the term PD refers only to corona PDs occurring in gas bubbles or voids as explained in [40].
- Energy Discharges—Energy discharge is the creation of a local conducting path or short circuit between capacitive stress grading foils that creates sparking around loose connections.
- Thermal Faults—refers to the circulation of electric current in insulating paper that result from excessive dielectric losses. These losses are themselves associated with moisture or an improperly selected insulating material that result in excessive dielectric temperatures.
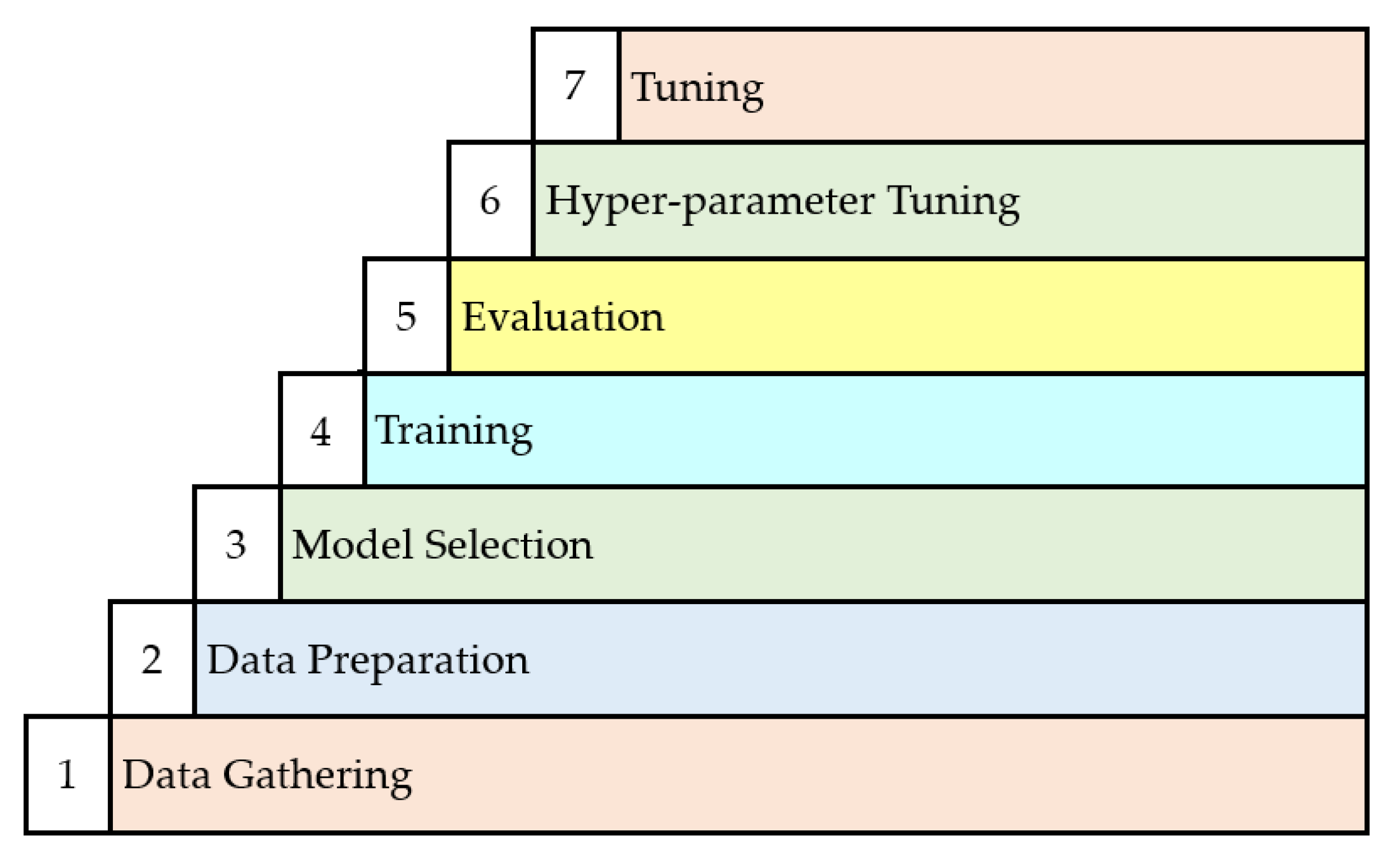
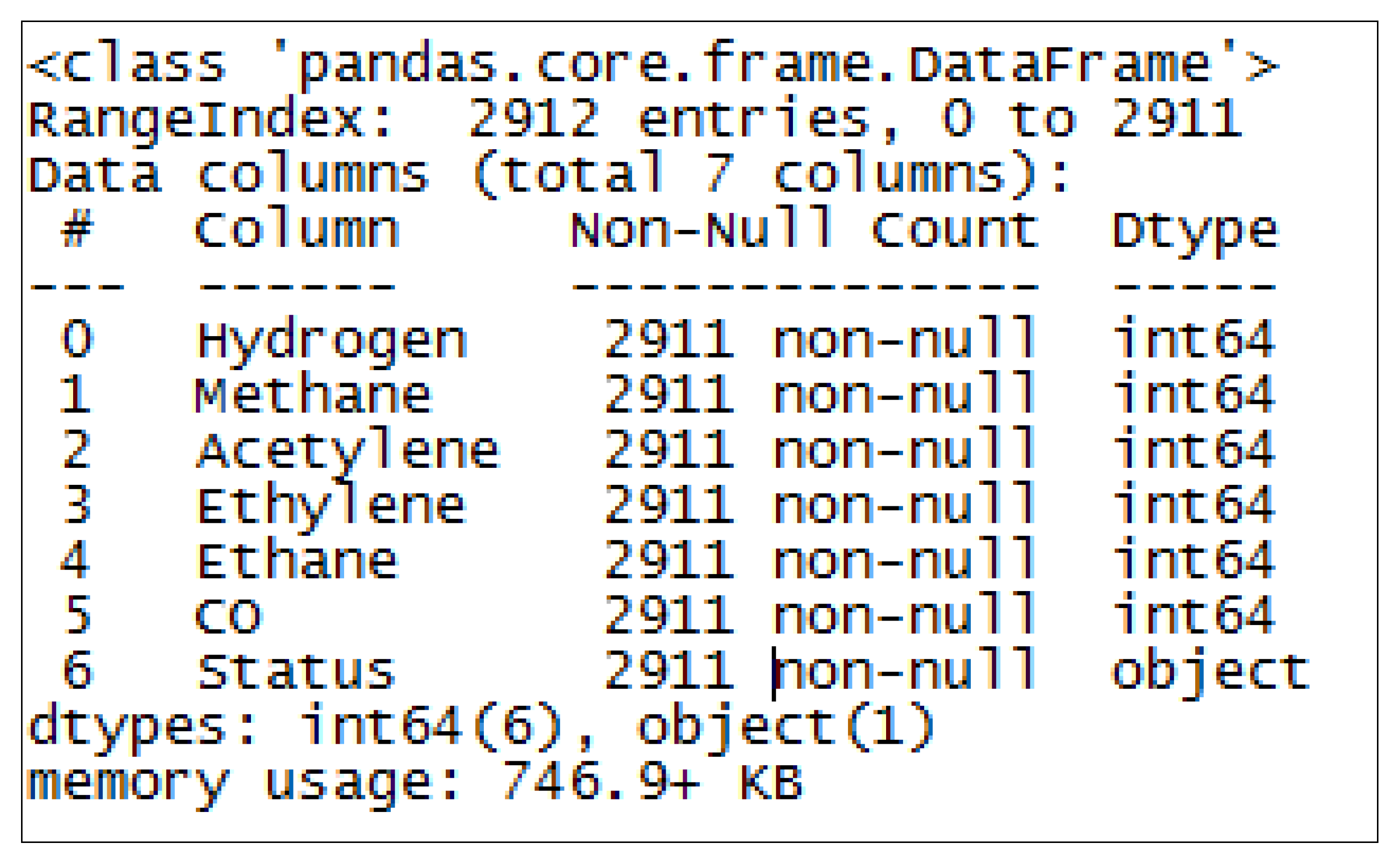
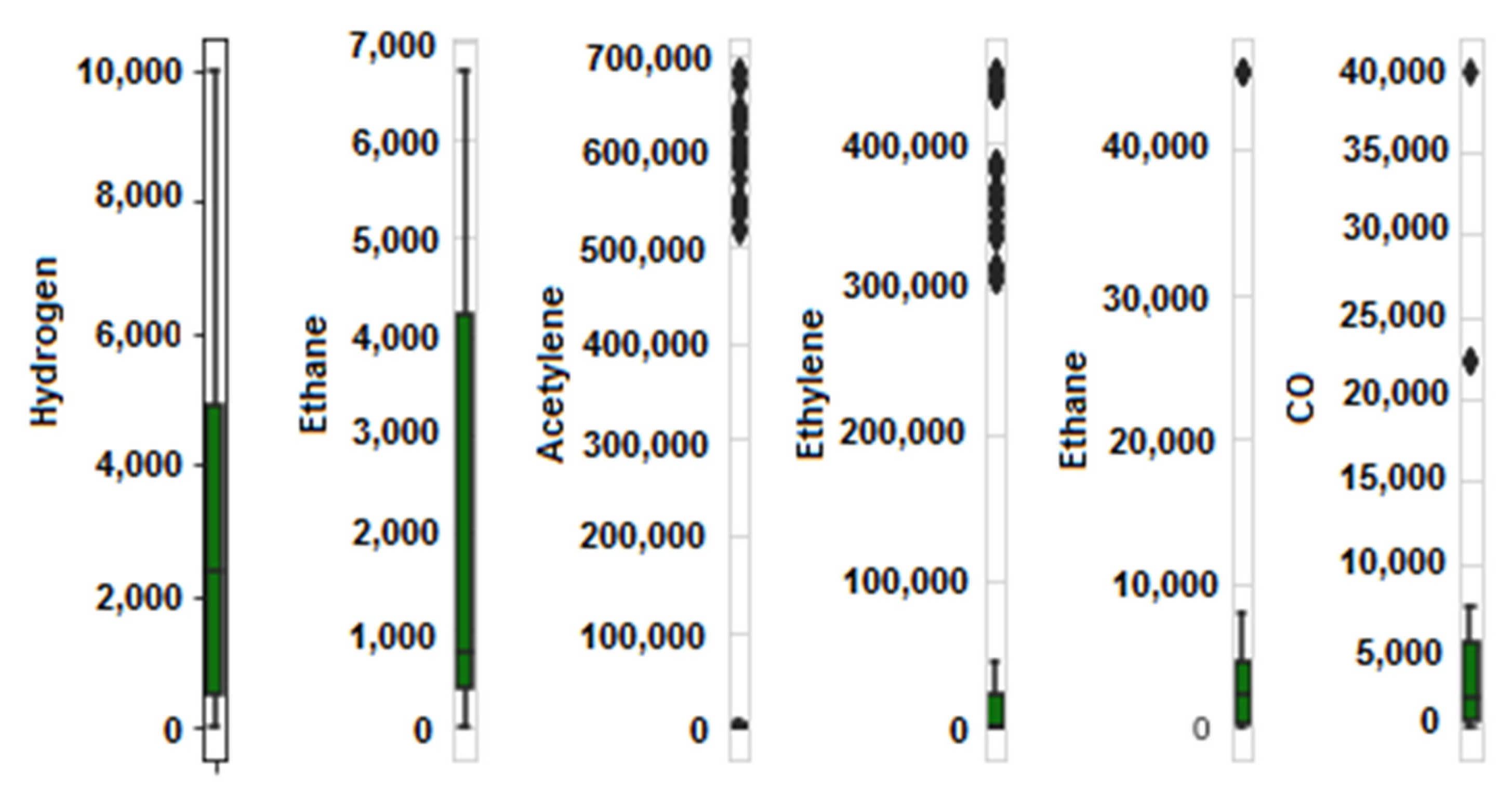
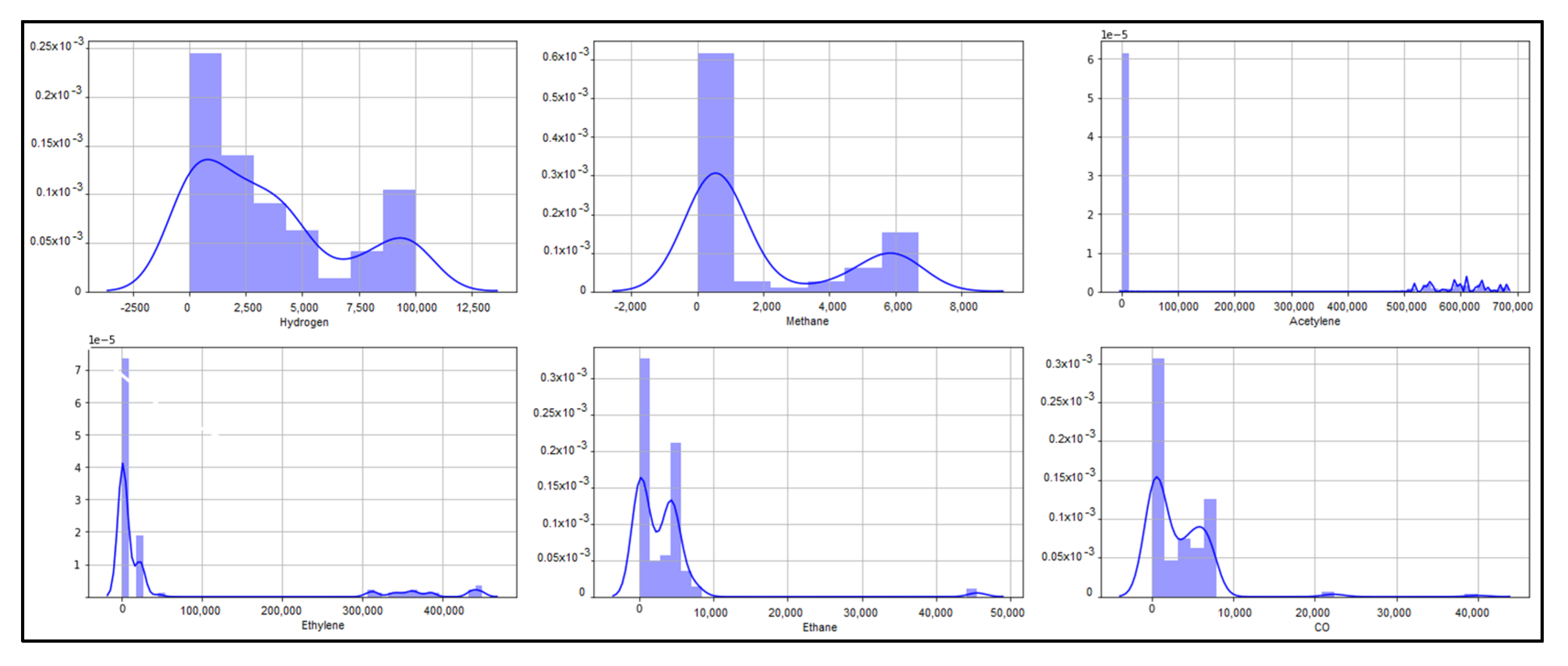
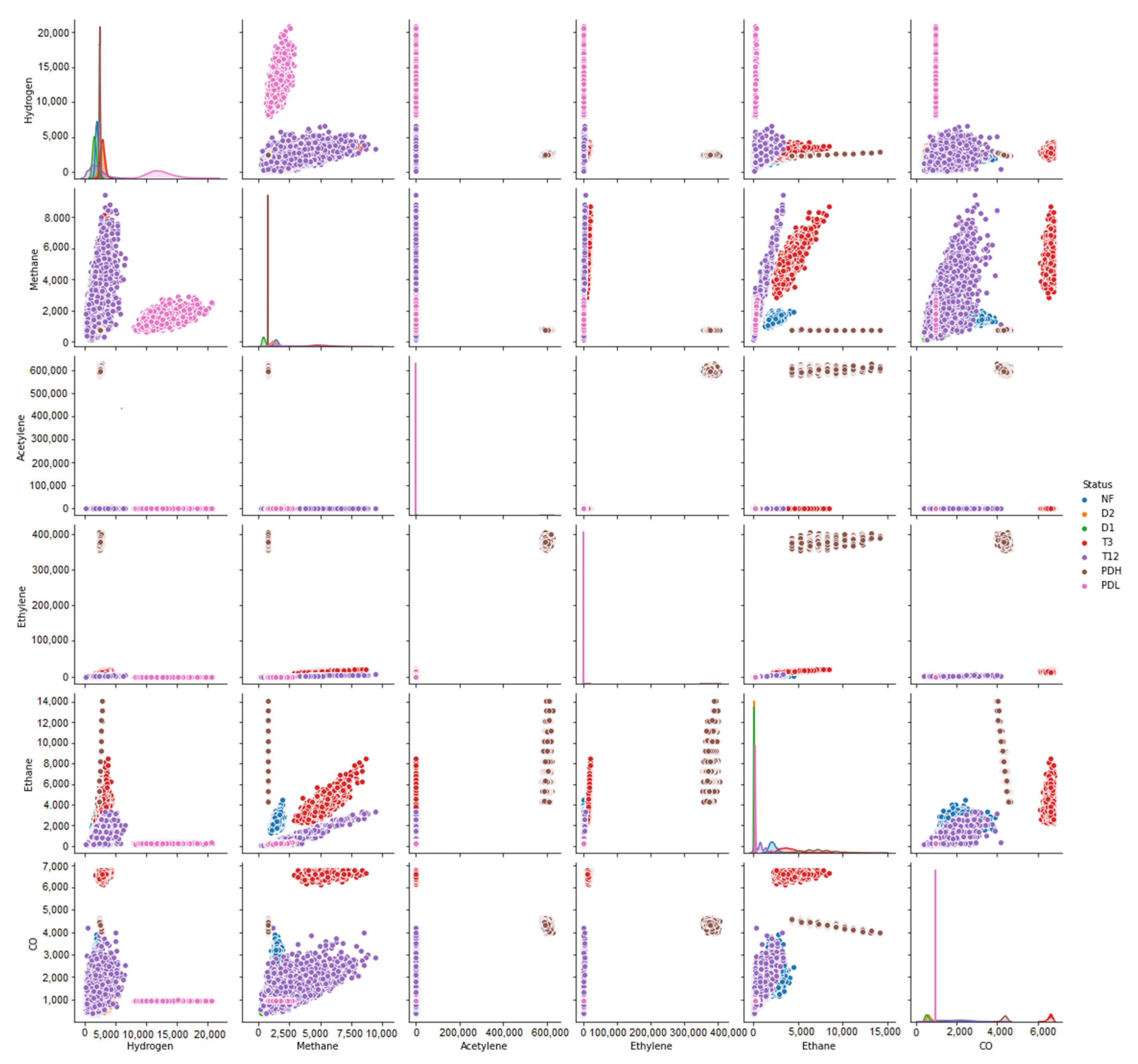
3.4. The Data Set
3.5. Decision Trees (DT)
3.6. Naïve Bayes
3.7. Gradient Boosting
3.8. The k–Near Neighbors (k-NN)
- First look for the most related occurrences (say XNN) to xtest that are in Xtrain.
- Obtain the labels yNN for all the occurrences in XNN.
- Predict the label for xtest by relating the labels yNN.
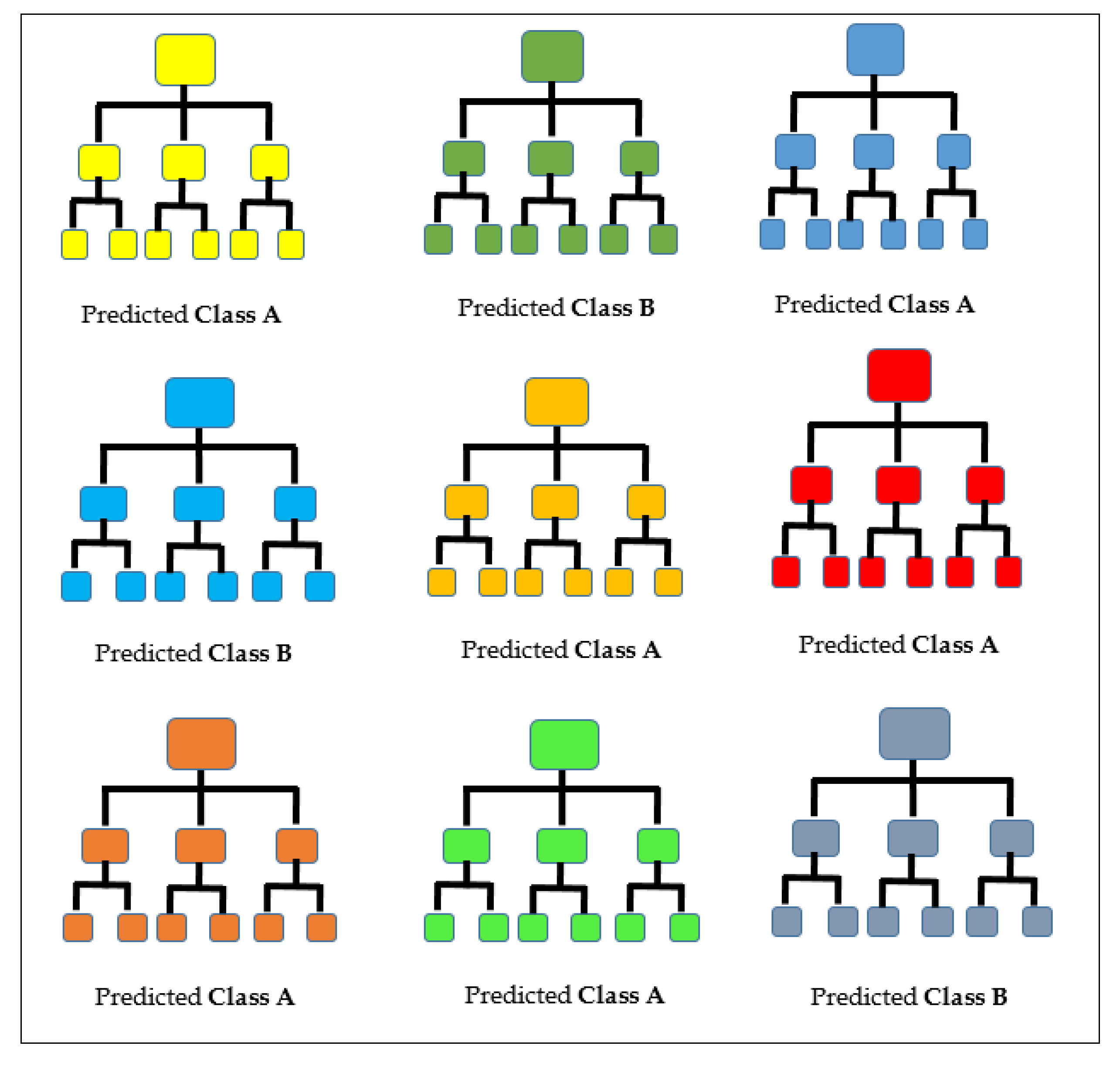
3.9. Random Forests
- Selection of the set used for training. Using an indiscriminate sampling technique, several training sets are selected from the first dataset such that the magnitude of each is equal to that of the original.
- Construction a Random Forest model. For each of the bootstrap training set, a forest of classification trees is created to produce a similar number of decision trees.
- Form a simple voting. The training of the Random Forest can proceed simultaneously because the process of training its members is independent of each other, thus considerably enhancing its efficiency. To decide on some sample input, every decision tree submits a vote. The Random Forest algorithm decides the ultimate category of the submitted sample in accordance to the voting pattern.
3.10. KosaNet
4. Experiments and Model Evaluation
4.1. Implementation Environment, Cost, and Complexity
4.2. Classification Evaluation Metrics
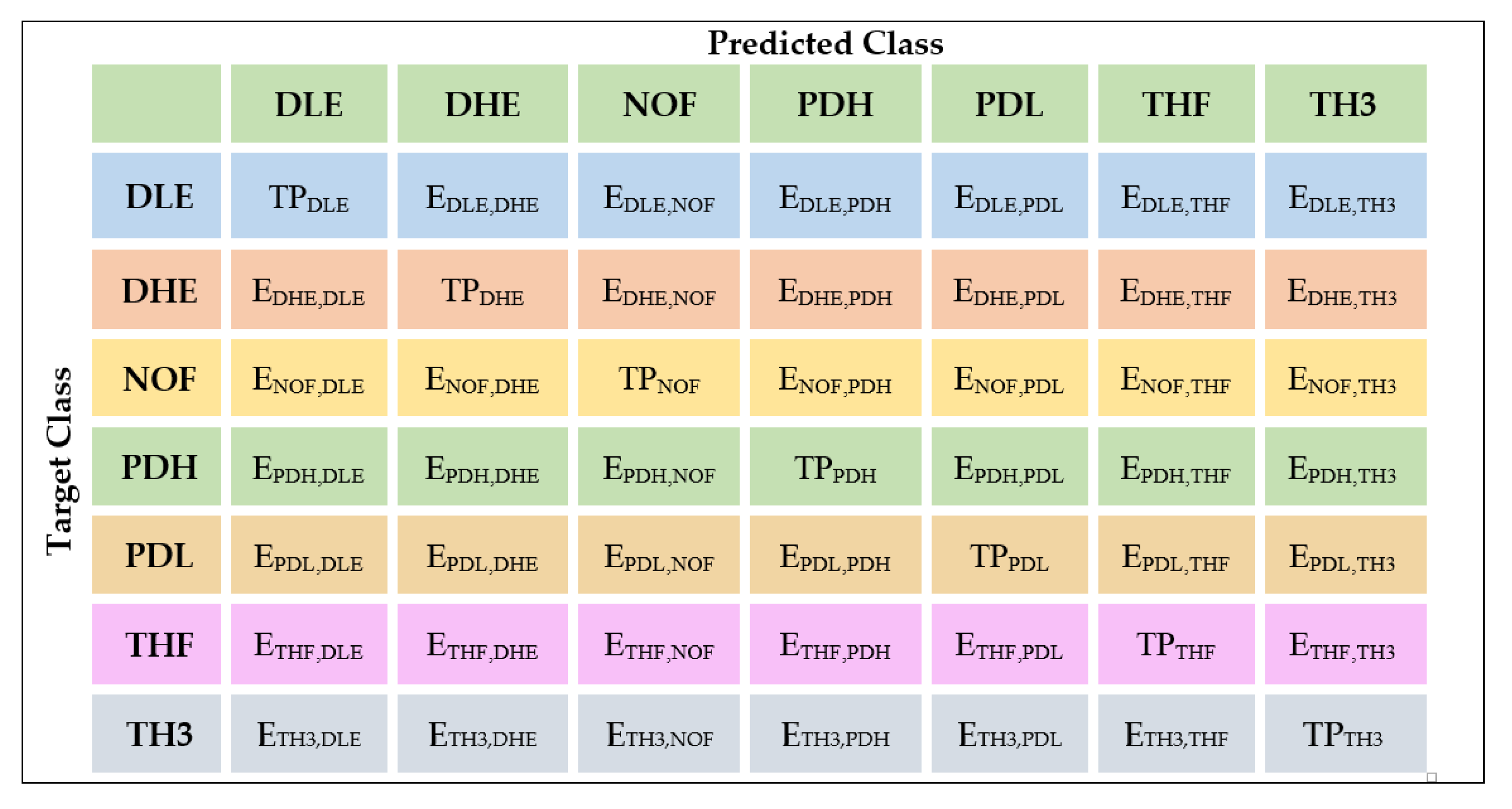
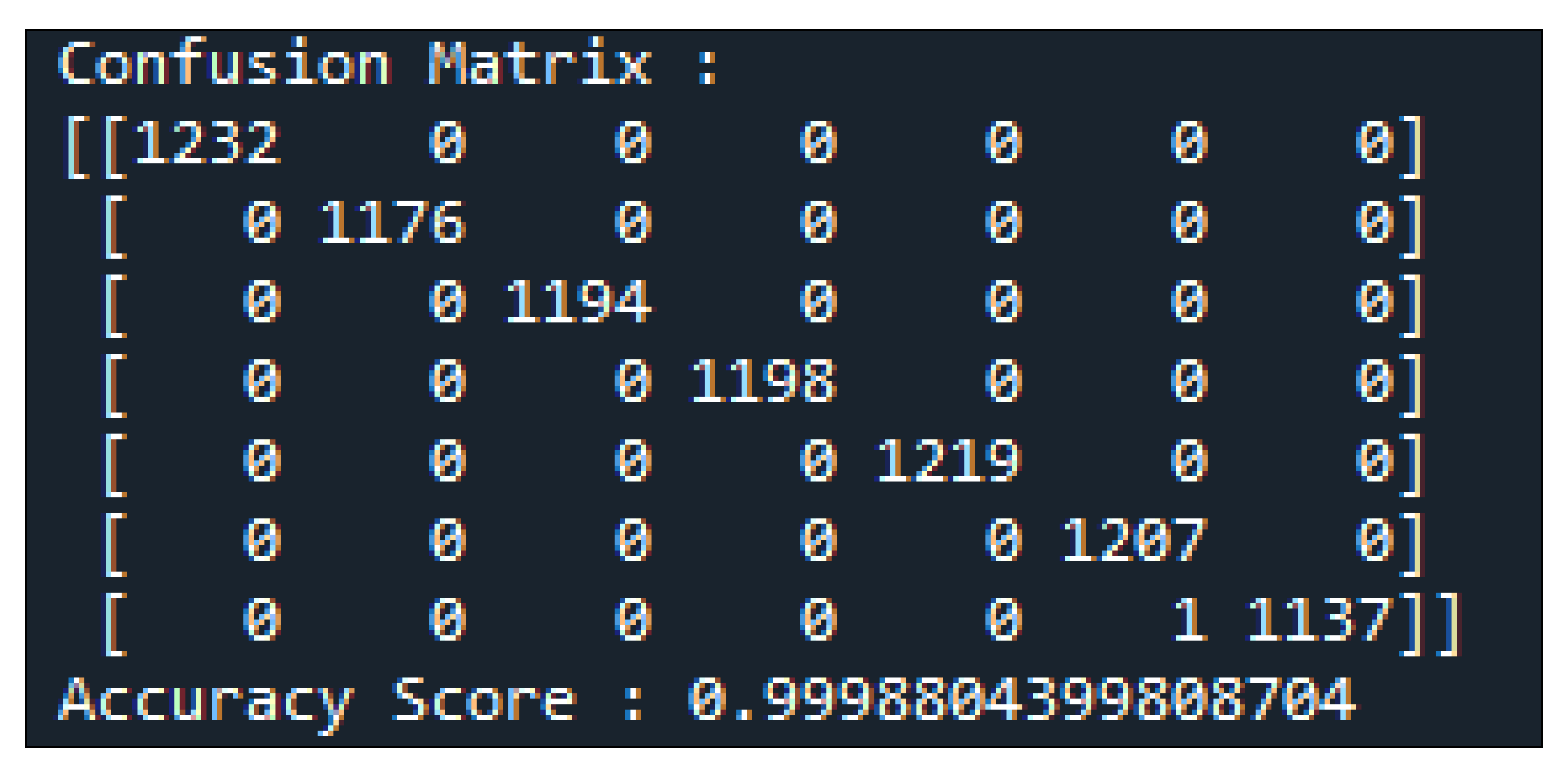
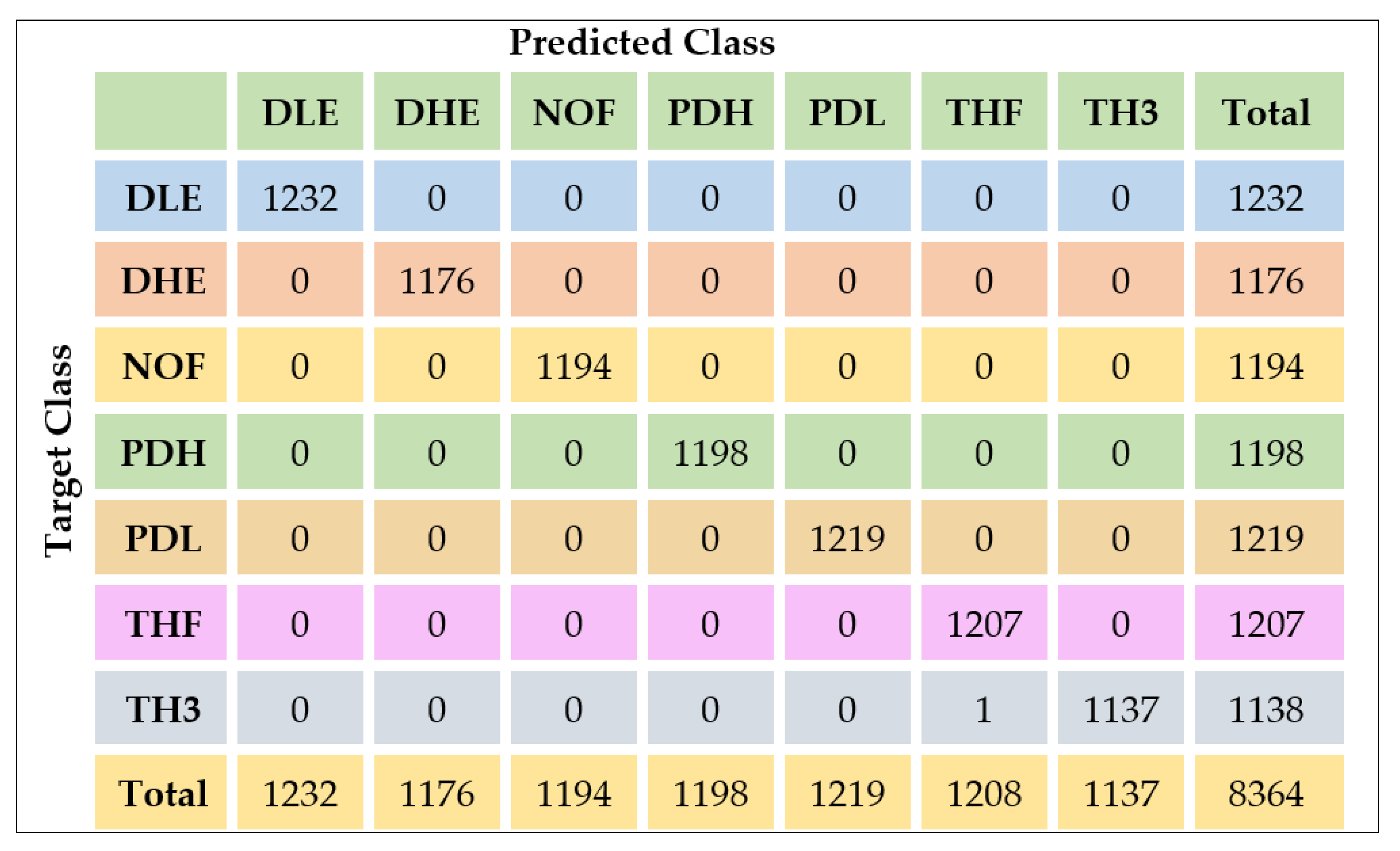
4.2.1. Confusion Matrix (CM)
4.2.2. Classification Accuracy
4.2.3. Classification Error
4.2.4. Averaged Instance Sensitivity
4.2.5. Averaged Precision
4.2.6. Averaged F1 Score
5. Evaluation and Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CIGRÉ | Conseil International des Grands Réseaux Électriques |
| CD | Cellulose Decomposition |
| DLE/D1 | Low Energy Discharge (Sparking) |
| DHE/D2 | High Energy Discharge (Arcing) |
| DGA | Dissolved gas analysis |
| DPM | Duval Pentagon Method |
| DSO | Distributed System Operator |
| EDA | Exploratory Data Analysis |
| emf | electromotive force |
| FN | False Negatives |
| FP | False Positives |
| H2 | Hydrogen |
| IEC | International Electrotechnical Commission |
| IEEE | The Institute of Electrical and Electronics Engineers |
| kNN | k-Nearest Neighbor |
| MLP | multilayer perceptron |
| N2 | Nitrogen |
| O2 | Oxygen |
| PD | Partial Discharge |
| ppm | Parts Per Million |
| PSO | Particle Swarm Optimization |
| PTD | Partial Discharge |
| RF | Random Forests |
| ROC | Region of Certainty |
| SVM | Support Vector Machine |
References
- Grigsby, L.L. Electric Power Generation, Transmission, and Distribution, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Ndungu, C.; Nderu, J.; Ngoo, L.; Hinga, P. A Study of the Root Causes of High Failure Rate of Distribution Transformer—A Case Study. Int. J. Eng. Sci. 2017, 6, 14–18. [Google Scholar] [CrossRef]
- Wang, L. The Fault Causes of Overhead Lines in Distribution Network. Int. Semin. Appl. Phys. Optoelectron. Photonics 2017, 61, 02017. [Google Scholar] [CrossRef] [Green Version]
- Abotsi, A.K. Power Outages and Production Efficiency of Firms in Africa. Int. J. Energy Econ. Policy 2016, 6, 98–104. [Google Scholar] [CrossRef] [Green Version]
- Sarma, J.J.; Sarma, R. Fault analysis of High Voltage Power. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2017, 6, 2411–2419. [Google Scholar]
- Sun, H.C.; Huang, Y.C.; Huang, C.M. A review of dissolved gas analysis in power transformers. Energy Procedia 2012, 14, 1220–1225. [Google Scholar] [CrossRef] [Green Version]
- Chakravorti, S.; Dey, D.; Chatterjee, B. Recent Trends in the Condition Monitoring of Transformers; Springer: London, UK, 2013. [Google Scholar]
- Ranjan, S.; Narayana, P.L.; Kirar, M. Dissolved Gas Analysis based Incipient Fault Diagnosis of Transformer: A Review. Impending Power Demand Innov. Energy Paths 2015, 1, 325–332. [Google Scholar]
- Theraja, B.L.; Theraja, A.K. A Textbook of Electrical Technology; S Chand & Co Ltd.: Uttar Pradesh, India, 1999; Volume 1. [Google Scholar]
- Turkar, R.; Shahare, R.; Sidam, P.; Giradkar, V.; Patil, A.; Sarode, P. Design and fabrication of a Single-phase 1KVA Transformer with automatic cooling system. Int. Res. J. Eng. Technol. 2018, 5, 679–682. [Google Scholar]
- Nickelson, L. Electromagnetic Theory and Plasmonics for Engineers; Springer: Singapore, 2019. [Google Scholar]
- IEEE-C57.104. IEEE Guide for the Interpretation of Gases Generated in Mineral Oil-Immersed Transformers; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Hartnack, M. Rising Power Outage Cost and Frequency Is Driving Grid Modernization Investment. Navig. Res. 2018. Available online: https://www.navigantresearch.com/news-and-views/rising-power-outage-cost-and-frequency-is-driving-grid-modernization-investment (accessed on 27 December 2020).
- Africa Energy Series: Kenya Special Report; Invest in the Energy Sector of Kenya: Nairobi, Kenya, 2020.
- Apte, S.; Somalwar, R.; Wajirabadkar, A. Incipient Fault Diagnosis of Transformer by DGA Using Fuzzy Logic. In Proceedings of the 2018 IEEE International Conference on Power Electronics, Drives and Energy Systems (PEDES), Chennai, India, 18–21 December 2018; pp. 1–5. [Google Scholar]
- Soni, R.; Joshi, S.; Lakhiani, V.; Jhala, A. Condition Monitoring of Power Transformer Using Dissolved Gas Analysis of Mineral Oil: A Review. Int. J. Adv. Eng. Res. Dev. 2015, 3, 2348–4470. [Google Scholar]
- Faiz, J.; Heydarabadi, R. Diagnosing power transformers faults. Russ. Electr. Eng. 2014, 85, 785–793. [Google Scholar] [CrossRef]
- Bage, M.; Bisht, P.S.; Khanna, A. Transformer Fault Diagnosis Based on DGA using Classical Methods. Int. J. Eng. Res. Technol. 2016, 4, 1–7. [Google Scholar]
- Abu-Siada, A. Improved consistent interpretation approach of fault type within power transformers using dissolved gas analysis and gene expression programming. Energies 2019, 12, 730. [Google Scholar] [CrossRef] [Green Version]
- Prasojo, R.A.; Gumilang, H.; Suwarno; Maulidevi, N.U.; Soedjarno, B.A. A fuzzy logic model for power transformer faults’ severity determination based on gas level, gas rate, and dissolved gas analysis interpretation. Energies 2020, 13, 1009. [Google Scholar] [CrossRef] [Green Version]
- Malik, H.; Sharma, R.; Mishra, S. Fuzzy reinforcement learning based intelligent classifier for power transformer faults. ISA Trans. 2020, 101, 390–398. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, K.; Dawn, S.; Jadoun, V.K.; Jarial, R.K. Novel prediction-reliability based graphical DGA technique using multi-layer perceptron network & gas ratio combination algorithm. IET Sci. Meas. Technol. 2019, 13, 836–842. [Google Scholar]
- Bustamante, S.; Manana, M.; Arroyo, A.; Castro, P.; Laso, A.; Martinez, R. Dissolved Gas Analysis Equipment for online monitoring of transformer oil: A review. Sensors 2019, 19, 4057. [Google Scholar] [CrossRef] [Green Version]
- Benmahamed, Y.; Kemari, Y.; Teguar, M.; Boubakeur, A. Diagnosis of Power Transformer Oil Using KNN and Naïve Bayes Classifiers. In Proceedings of the 2018 IEEE 2nd International Conference on Dielectrics ICD, Budapest, Hungary, 1–5 July 2018; pp. 1–4. [Google Scholar]
- Tanfilyeva, D.V.; Tanfyev, O.V.; Kazantsev, Y.V. K-nearest neighbor method for power transformers condition assessment. IOP Conf. Ser. Mater. Sci. Eng. 2019, 643, 012016. [Google Scholar] [CrossRef]
- Parejo, A.; Personal, E.; Larios, D.F.; Guerrero, J.I.; García, A.; León, C. Monitoring and Fault Location Sensor Network for Underground Distribution Lines. Sensors 2019, 19, 576. [Google Scholar] [CrossRef] [Green Version]
- Illias, H.A.; Chai, X.R.; Bakar, A.H.A.; Mokhlis, H. Transformer incipient fault prediction using combined artificial neural network and various particle swarm optimisation techniques. PLoS ONE 2015, 10, e0129363. [Google Scholar] [CrossRef]
- Illias, H.A.; Liang, W.Z. Identification of transformer fault based on dissolved gas analysis using hybrid support vector machine-modified evolutionary particle swarm optimisation. PLoS ONE 2018, 13, e0191366. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Song, B.; Wang, L.; Gao, J.; Xu, R. Power transformer fault diagnosis based on dissolved gas analysis by correlation coefficient-DBSCAN. Appl. Sci. 2020, 10, 4440. [Google Scholar] [CrossRef]
- Pattanadech, N.; Sasomponsawatline, K.; Siriworachanyadee, J.; Angsusatra, W. The conformity of DGA interpretation techniques: Experience from transformer 132 units. In Proceedings of the 2019 IEEE 20th International Conference on Dielectric Liquids (ICDL), Roma, Italy, 23–27 June 2019; pp. 1–4. [Google Scholar]
- Borcard, D.; Gillet, F.; Legendre, P. Numerical Ecology with R; Springer International Publishing AG: Manhattan, NY, USA, 2018. [Google Scholar]
- Bin, N.; Bakar, A. A New Technique to Detect Loss of Insulation Life in Power Transformers. Ph.D. Thesis, Curtin University, Perth, Australia, 2016. [Google Scholar]
- Bakar, N.A.; Abu-Siada, A.; Islam, S. A Review of Dissolved Gas. Deis Featur. Artic. 2014, 30, 39–49. [Google Scholar]
- Sisic, E. Chromatographic analysis of gases from the transformer. Transform. Mag. 2015, 2, 36–41. [Google Scholar]
- Ravichandran, N.; Jayalakshmi, V. Investigations on power transformer faults based on dissolved gas analysis. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 296–299. [Google Scholar]
- Duval, M. A review of faults detectable by gas-in-oil analysis in transformers. In IEEE Electrical Insulation Magazine; IEEE: New York, NY, USA, 2002; Volume 18, pp. 8–17. [Google Scholar]
- Akbari, A.; Setayeshmehr, A.; Borsi, H.; Gockenbach, E.; Fofana, I. Intelligent agent-based system using dissolved gas analysis to detect incipient faults in power transformers. In IEEE Electrical Insulation Magazine; IEEE: New York, NY, USA, 2010; Volume 26, pp. 27–40. [Google Scholar]
- Golkhah, M.; Shamshirgar, S.S.; Vahidi, M.A. Artificial neural networks applied to DGA for fault diagnosis in oil-filled power transformers. J. Electr. Electron. Eng. Res. 2011, 3, 1–10. [Google Scholar]
- Huang, Y.C.; Huang, C.M.; Sun, H.C. Data mining for oil-insulated power transformers: An advanced literature survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 138–148. [Google Scholar] [CrossRef]
- CIGRE-SC.15. Recent Developments on the Interpretation of Dissolved Gas Analysis in Transformers; Commission Electrotechnique Internationale: Geneva, Switzerland, 2006; Volume 296. [Google Scholar]
- IEC-60599. Mineral Oil-Filled Electrical Equipment in Service–Guidance on the Interpretation of Dissolved and Free Gases Analysis; IEC: Geneva, Switzerland, 2015. [Google Scholar]
- ASTM-D923-15. Standard Practices for Sampling Electrical Insulating Liquids; ASTM International: West Conshohocken, PA, USA, 2015. [Google Scholar]
- ASTM-D3612-02. Standard Test Method for Analysis of Gases Dissolved in Electrical Insulating Oil by Gas Chromatography; Conseil International des Grands Réseaux Électriques: Paris, France, 2017; Volume 5. [Google Scholar]
- Kumar, A. Master Data Science and Data Analysis With Pandas; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Garg, H. Mastering Exploratory Analysis with Pandas; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Larose, D.T.; Larose, C.D. Discovering Knowledge in Data: An Introduction to Data Mining; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2014. [Google Scholar]
- Mostafa, S.M. Imputing missing values using cumulative linear regression. CAAI Trans. Intell. Technol. 2019, 4, 182–200. [Google Scholar] [CrossRef]
- Niederhut, D. Safe handling instructions for missing data. In Proceedings of the Python in Science Conferences, Trento, Italy, 28 August–1 September 2018; pp. 56–60. [Google Scholar]
- Bertsimas, D.; Pawlowski, C.; Zhuo, Y.D. From predictive methods to missing data imputation: An optimization approach. J. Mach. Learn. Res. 2018, 18, 1–39. [Google Scholar]
- Devroop, K. Correlation versus Causation: Another Look at a Common Misinterpretation. Alberta J. Educ. Res. 2000, 41, 271–284. [Google Scholar]
- Basuki, A.; Suwarno. Online dissolved gas analysis of power transformers based on decision tree model. In Proceedings of the 2018 Conference on Power Engineering and Renewable Energy (ICPERE), Solo, Indonesia, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Galitskaya, E.G.; Galitskkiy, E.B. Classification trees. Sotsiologicheskie Issled. 2013, 3, 84–88. [Google Scholar]
- Chiu, S.; Tavella, D. Introduction to Data Mining; Routledge: Oxfordshire, UK, 2008; pp. 137–192. [Google Scholar]
- Luo, X.; Yu, J.X.; Li, Z. Advanced Data Mining and Applications. In Proceedings of the 10th International Conference, ADMA, Guilin, China, 19–21 December 2014; Volume 8933. [Google Scholar]
- Zhang, Z. Introduction to machine learning: K-nearest neighbors. Ann. Transl. Med. 2016, 4, 218–226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Imandoust, S.B.; Bolandraftar, M. Application of K-Nearest Neighbor (KNN) Approach for Predicting Economic Events: Theoretical Background. Int. J. Eng. Res. Appl. 2013, 3, 605–610. [Google Scholar]
- Gao, X.; Wen, J.; Zhang, C. An Improved Random Forest Algorithm for Predicting Employee Turnover. Math. Probl. Eng. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Sug, H. Applying randomness effectively based on random forests for classification task of datasets of insufficient information. J. Appl. Math. 2012, 2012, 1–13. [Google Scholar] [CrossRef]
- Kaur, M.; Kalra, S. A Review on IOT Based Smart Grid. Int. J. Energy Inf. Commun. 2016, 7, 11–22. [Google Scholar] [CrossRef]
- Bakhtouchi, A. A Tree Decision Based Approach for Selecting Software Development Methodology. In Proceedings of the 2018 International Conference on Smart Communications in Network Technologies (SaCoNeT), Nice, France, 20–24 May 2018; pp. 211–216. [Google Scholar]
- Williams, E. Python for Data Science; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Shaw, Z.A. Learn Python 3 the Hard Way; Addison-Wesley: Boston, MA, USA, 2017. [Google Scholar]
- Morgan, P. Data Analysis From Scratch with Python; AI Sciences LLC.: Conshohocken, PA, USA, 2019. [Google Scholar]
- Géron, A. Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019; Volume 53. [Google Scholar]
- Buczak, A.L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection. IEEE Commun. Surv. Tutor. 2016, 18, 1153–1176. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, Y.; Miao, D. Three-way confusion matrix for classification: A measure driven view. Inf. Sci. 2020, 507, 772–794. [Google Scholar] [CrossRef]
- Beauxis-Aussalet, E.; Hardman, L. Simplifying the visualization of confusion matrix. In Proceedings of the Belgian/Netherlands Artificial Intelligence Conference, Belgian, The Netherlands, 6–7 November 2014; pp. 133–134. [Google Scholar]
- Visa, S.; Ramsay, B.; Ralescu, A.; van der Knaap, E. Confusion Matrix-based Feature Selection. In Proceedings of the 22nd Midwest Artificial Intelligence and Cognitive Science, Cincinnati, OH, USA, 16–17 April 2011; Volume 710, p. 8. [Google Scholar]
- Gopinath, J.; Manirathnam, A.V.; Kumar, K.M.; Murugan, C. High Impedance Fault Detection and Location in a Power Transmission Line Using ZIGBEE. Int. J. Innov. Res. Sci. Eng. Technol. 2016, 5, 2586–2591. [Google Scholar]
- Oprea, S.; Tudorica, B.G.; Belciu, A.; Botha, I. Internet of Things, Challenges for Demand Side Management. Inform. Econ. 2017, 21, 59–72. [Google Scholar] [CrossRef]
- Bikmetov, R.; Raja, M.Y.A.; Sane, T.U. Infrastructure and applications of Internet of Things in smart grids: A survey. In Proceedings of the 2017 North American Power Symposium (NAPS), Morgantown, West Virginia, 17–19 September 2017; pp. 1–6. [Google Scholar]
- Gu, Q.; Zhu, L.; Cai, Z.; Science, C. Evaluation Measures of the Classification Performance of Imbalanced Data Sets. Commun. Comput. Inf. Sci. 2009, 51, 461–471. [Google Scholar]
- Hossin, M.; Sulaiman, M.N.A. Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process. 2015, 5, 1–11. [Google Scholar]
- Cichosz, P. Assessing the quality of classification models: Performance measures and evaluation procedures. Cent. Eur. J. Eng. 2011, 1, 132–158. [Google Scholar] [CrossRef]
- Staeheli, L.A.; Mitchell, D. The Relationship between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 546–559. [Google Scholar]
- Flach, P. Performance Evaluation in Machine Learning: The Good, the Bad, the Ugly, and the Way Forward. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9808–9814. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| C2H2 | Acetylene |
| C2H4 | Ethylene |
| C2H6 | Ethane |
| CD | Cellulose Decomposition |
| CH4 | Methane |
| D1/DLE | Discharge of Low Energy |
| D2/ DHE | Discharge of High Energy |
| DPM | Duval Pentagon Method |
| DT | Mix of Thermal and Electrical Faults |
| H2 | Hydrogen |
| N2 | Nitrogen |
| O2 | Oxygen |
| PD | Partial Discharge |
| T1/ TF1 | Thermal Fault 1 (temp < 300 °C) |
| T2/ TF2 | Thermal Fault 2 (300 °C < temp < 700 °C) |
| T3/ TF3 | Thermal Fault 3 (temp > 700) |
| Type | Fault |
|---|---|
| PTD | Partial Discharge |
| DLE | Discharge of Low Energy |
| DHE | Discharge of High Energy |
| TF1 | Thermal Fault 1 (for t < 300 °C) |
| TF2 | Thermal Fault 2 (for 300 °C < t < 700 °C) |
| TF3 | Thermal Fault 3 (t > 700) |
| Gases Concentration (ppm) | |||||||
|---|---|---|---|---|---|---|---|
| SN | Hydrogen | Methane | Acetylene | Ethylene | Ethane | CO | CO2 |
| 0 | 112 | 29 | 62 | 27 | 20 | 672 | 1441 |
| 1 | 1 | 23 | 1 | 141 | 90 | 255 | 3864 |
| 2 | 59 | 609 | 0.3 | 1649 | 731 | 99 | 1315 |
| 3 | 7 | 147 | 0.2 | 15 | 240 | 557 | 1648 |
| 4 | 131 | 77 | 50 | 21 | 32 | 881 | 3523 |
| 5 | 243 | 39 | 222 | 61 | 21 | 839 | 5164 |
| 6 | 374 | 900 | 55 | 5759 | 932 | 327 | 2689 |
| 7 | 59 | 29 | 1.6 | 9 | 18 | 867 | 3124 |
| 8 | 653 | 47 | 333 | 50 | 0.6 | 211 | 3009 |
| 9 | 2 | 605 | 59 | 1593 | 439 | 156 | 3221 |
| 10 | 1446 | 3902 | 111 | 599 | 1111 | 939 | 15,653 |
| 11 | 2 | 7 | 3 | 24 | 15 | 243 | 3543 |
| 12 | 1073 | 2813 | 1 | 319 | 673 | 679 | 7798 |
| 13 | 75 | 281 | 0.8 | 631 | 291 | 55 | 59 |
| 14 | 109 | 27 | 66 | 30 | 9 | 297 | 2208 |
| 15 | 0.3 | 113 | 0.9 | 15 | 149 | 472 | 3473 |
| 16 | 19 | 17 | 33 | 80 | 20 | 297 | 7056 |
| 17 | 9 | 11 | 0.4 | 10 | 4 | 23 | 289 |
| 18 | 2 | 114 | 0.1 | 6 | 233 | 357 | 1978 |
| 19 | 12 | 103 | 0.9 | 0.7 | 113 | 600 | 1964 |
| SN | Key Gases | Duval | Nomography | KosaNet | Actual Fault |
|---|---|---|---|---|---|
| 0 | ARC | D1 | TH and PD | DLE | ARC |
| 1 | TH | T3 | TH | TH3 | TH > 700 °C + CD |
| 2 | TH | T3 | TH | TH3 | TH > 700 °C |
| 3 | TH | T1 | TH and PD | THF | TH < 300 °C |
| 4 | ARC | D1 | ARC | DHE | ARC + CD |
| 5 | ARC | D1 | ARC | DHE | ARC + CD |
| 6 | TH | T3 | TH and PD | TH3 | TH > 700 °C |
| 7 | NR | DT | TH | NOF | NR |
| 8 | TH | D1 | ARC | DLE | ARC |
| 9 | TH | T2 | TH | TH3 | TH > 700 °C |
| 10 | TH | T1 | TH and PD | TH3 | TH > 700 °C + CD |
| 11 | NR | T3 | TH | NR | NR |
| 12 | TH + ARC | T3 | TH | THF | TH |
| 13 | TH | T3 | TH | THF | TH |
| 14 | ARC | D2 | TH | NOF | DP |
| 15 | TH | T1 | TH | TH3 | TH < 300 °C |
| 16 | ARC | DT | DP et TH | DHE | ARC + CD |
| 17 | ARC | T3 | ARC | THF | TH |
| 18 | TH | T1 | TH | TH3 | TH < 300 °C |
| 19 | ARC | T1 | ARC | TH3 | TH > 700 °C + CD |
| Decision Tree | Naïve Bayes | Gradient Boosting | k-NN | Random Forest | KosaNet | |
|---|---|---|---|---|---|---|
| Accuracy | 0.685 | 0.70 | 0.83 | 0.8967 | 0.9241 | 0.9998 |
| Precision | 0.685 | 0.67 | 0.83 | 0.8967 | 0.9241 | 0.9998 |
| Recall | 0.685 | 0.80 | 0.83 | 0.8967 | 0.9241 | 0.9998 |
| F1 Score | 0.685 | 0.73 | 0.82 | 0.8851 | 0.9241 | 0.9998 |
| Error | 0.315 | 0.30 | 0.17 | 0.1033 | 0.0759 | 0.0002 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Odongo, G.; Musabe, R.; Hanyurwimfura, D. A Multinomial DGA Classifier for Incipient Fault Detection in Oil-Impregnated Power Transformers. Algorithms 2021, 14, 128. https://doi.org/10.3390/a14040128
Odongo G, Musabe R, Hanyurwimfura D. A Multinomial DGA Classifier for Incipient Fault Detection in Oil-Impregnated Power Transformers. Algorithms. 2021; 14(4):128. https://doi.org/10.3390/a14040128
Chicago/Turabian StyleOdongo, George, Richard Musabe, and Damien Hanyurwimfura. 2021. "A Multinomial DGA Classifier for Incipient Fault Detection in Oil-Impregnated Power Transformers" Algorithms 14, no. 4: 128. https://doi.org/10.3390/a14040128
APA StyleOdongo, G., Musabe, R., & Hanyurwimfura, D. (2021). A Multinomial DGA Classifier for Incipient Fault Detection in Oil-Impregnated Power Transformers. Algorithms, 14(4), 128. https://doi.org/10.3390/a14040128