
Self-Configuring (1 + 1)-Evolutionary Algorithm for the Continuous p-Median Problem with Agglomerative Mutation †


Abstract
:1. Introduction
1.1. Problem Statement
1.2. State-of-the-Art
1.3. Research Gap and Our Contribution
- The efficiency of the greedy agglomerative procedure applied to successive improvement of the p-median problem solution embedded into a more complex algorithm, such as evolutionary algorithm, highly depends on its parameter r (a number of excessive centers to be eliminated), and this dependence is hardly predictable.
- The principle of adjusting the numerical parameter of the mutation operator by changing the probability distribution of its values, which is used in (1 + 1)-evolutionary algorithms with 0–1 coding of solutions for pseudo-Boolean optimization problems, can also be effectively applied to adjust the numerical parameter of the agglomerative mutation operator based on the use of agglomerative procedures in an evolutionary algorithm with real coding of solutions when solving the p-median problems.
2. Methods
2.1. The Basic Algorithmic Approaches
| Algorithm 1 ALA (): Alternate Location-Allocation (Lloyd’s procedure) |
| Require: Set S of initial centers S = {. |
| 1. For each center , , define its cluster as a subset of demand points having the same closest center . |
| 2. For each cluster , , recalculate its center , i.e., solve the Weber problem: |
| 3. Repeat from Step 1 if Steps 1, 2 made any changes. |
2.2. Greedy Agglomerative Procedures
| Algorithm 2 BasicAggl (S) |
| Require: Set of initial centroids S = {X1, …, XK}, |S| = K > k, required final number of centroids k. |
| Improve S with the two-step local search algorithm if possible; |
| while |S| > k do |
| for do |
| end for; |
| Select a subset S’⊂S of to remove centroids with the minimum values of the corresponding variables Fi; // By default, rtoremove = 1; |
| Improve this new solution with the two-step local search algorithm; |
| end while. |
| Algorithm 3 AGGLr (S, S2) |
| Require: Two sets of centers S, S2, |S|=|S2|= p, the number of centers r of the solution S2 which are used to obtain the resulting solution, . |
| for do |
| 1. Select a subset ; |
| 2. |
| 3. if F(S’) < F(S) then |
| end if; |
| end for; |
| return S. |
2.3. CUDA Implementation of Greedy Agglomerative Procedures
| Algorithm 4 CUDA implementation of Step 1 in the ALA algorithm, part 1 (initialization) |
| // Here, are vectors used for recalculation of centers. |
| // Counters of objects assigned to each of centers. |
| // are used to calculate . |
| // -dimensional vectors to calculate . |
| Algorithm 5 CUDA implementation of Step 1 in the ALA algorithm |
| ifthen |
| return |
| end if |
| // number of a center for the th data point |
| ; // Assign to center . |
| ; ; ; ; |
| Synchronize threads. |
| Algorithm 6 CUDA implementation of Step 2 in the ALA algorithm |
| ifthen |
| return; |
| end if; |
| ; |
| ifthen |
| ; |
| end if; |
| ; |
| Synchronize threads. |
| Algorithm 7 CUDA implementation of Step 3 in Algorithm 2 |
| ; |
| ifthen |
| return; |
| end if; |
| Calculate in accordance with (2.8); |
| ifthen |
| ; |
| end if; |
| Synchronize threads. |
2.4. New Algorithm
| Algorithm 8 Aggl-EA () |
| Randomly select a subset S {A1, …, AN}; ; assign ; |
| repeat |
| randomly select a subset S2 {A1, …, AN}; ; |
| in proportion to the values of the probabilities Pi, , choose the value of r ; |
| if then |
| ; // we used k1 = 1.1 and k2 = 1.5. |
| // probability normalization |
| S |
| end if; |
| until time limitation is reached. |
| returnS. |
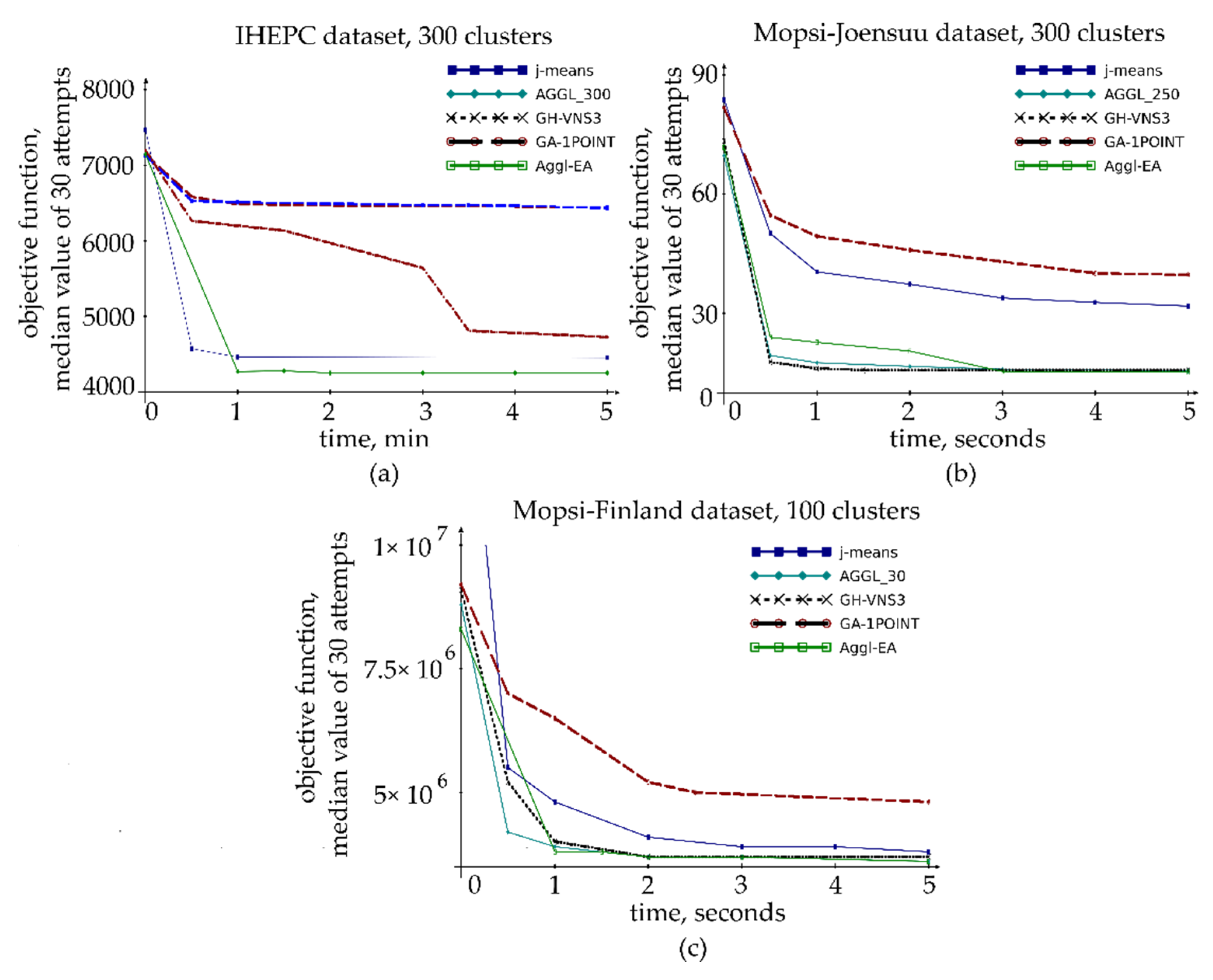
3. Results of Computational Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
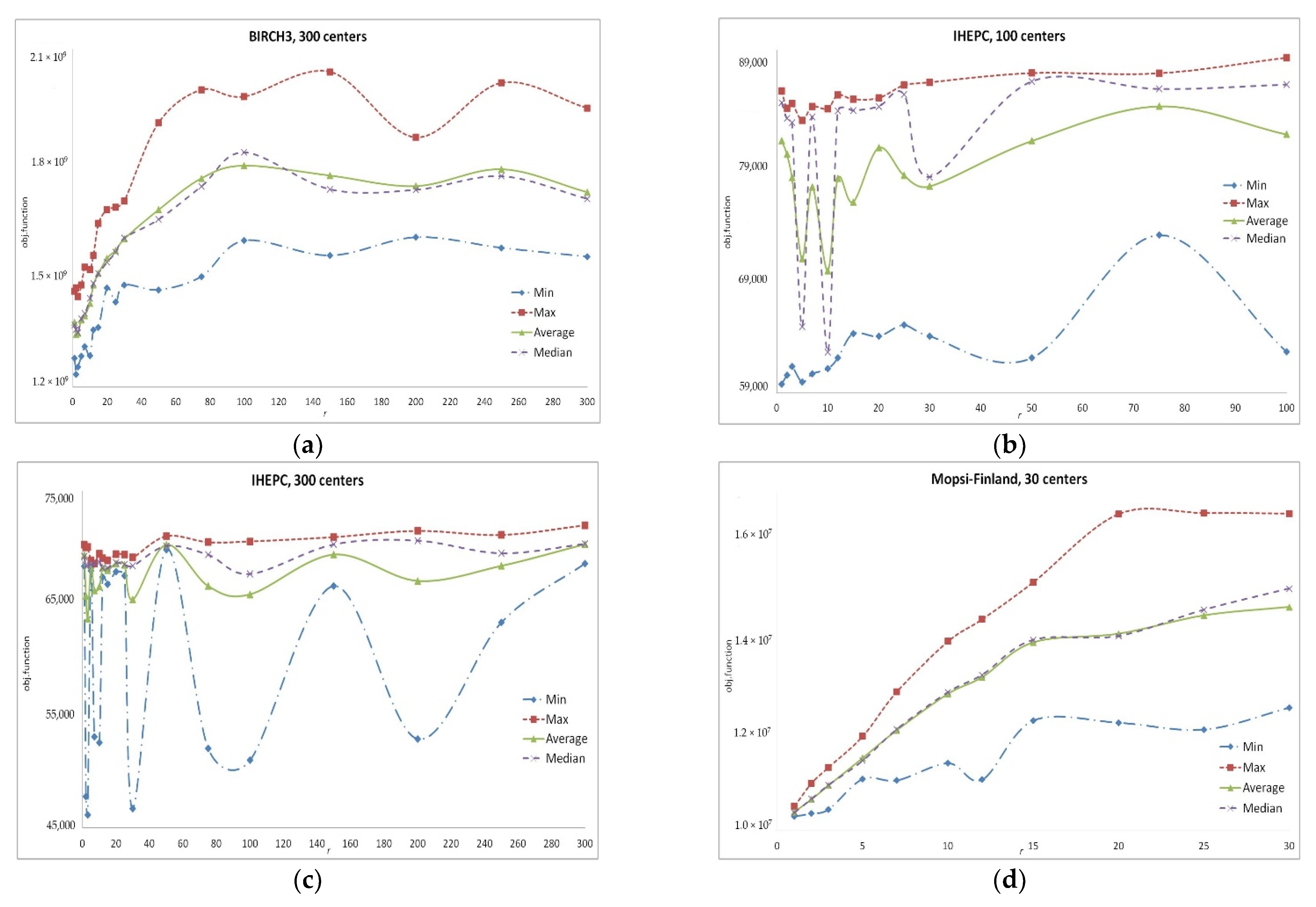
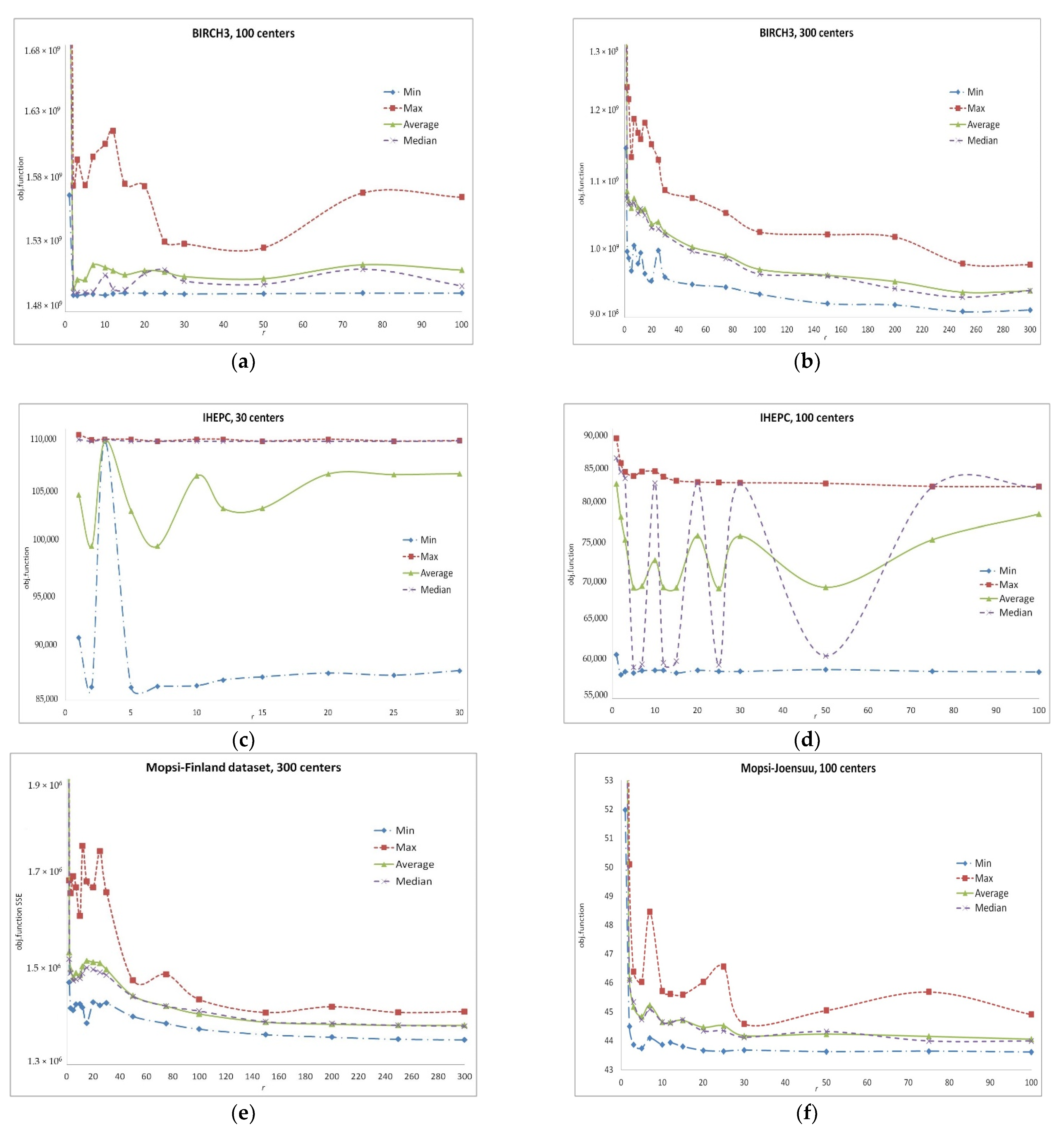
Appendix A. Detailed Results of Computational Experiments

{kind=link}
{kind=link}
{kind=link}
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 4.38183 × 109 | 4.67540 × 109 | 4.52387 × 109 | 4.51929 × 109 | 7.82433 × 107 |
| j-means (SWAP1 + Lloyd) | 3.56107 × 109 | 5.25877 × 109 | 3.92248 × 109 | 3.88872 × 109 | 3.09203 × 108 |
| AGGL1 | 3.45692 × 109 | 3.56599 × 109 | 3.46697 × 109 | 3.45692 × 109 | 2.40890 × 107 |
| AGGL2 | 3.45057 × 109 | 3.45692 × 109 | 3.45650 × 109 | 3.45692 × 109 | 1.61204 × 106 |
| AGGL3 | 3.45057 × 109 | 3.45692 × 109 | 3.45650 × 109 | 3.45692 × 109 | 1.61204 × 106 |
| AGGL5–20 (equal results) | 3.45692 × 109 | 3.45692 × 109 | 3.45692 × 109 | 3.45692 × 109 | 0.00000 |
| AGGL25 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 46.7390 |
| AGGL30 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 127.558 |
| GH-VNS1-3 (equal results) | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 0.00000 |
| SWAP1 (the best of SWAP) | 3.70386 × 109 | 4.43612 × 109 | 3.89665 × 109 | 3.89201 × 109 | 1.24246 × 108 |
| GA-1POINT | 3.51505 × 109 | 3.63646 × 109 | 3.56546 × 109 | 3.56848 × 109 | 3.24395 × 107 |
| GA-UNIFORM | 3.45057 × 109 | 3.59155 × 109 | 3.49515 × 109 | 3.49778 × 109 | 3.07081 × 107 |
| Aggl-EA | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 0.00000 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 2.27163 × 109 | 2.54224 × 109 | 2.44280 × 109 | 2.46163 × 109 | 7.42330 × 107 |
| j-means (SWAP1 + Lloyd) | 1.52130 × 109 | 1.88212 × 109 | 1.69226 × 109 | 1.67712 × 109 | 8.03684 × 107 |
| AGGL1 | 1.56737 × 109 | 2.14554 × 109 | 1.81181 × 109 | 1.80137 × 109 | 1.60897 × 108 |
| AGGL2 | 1.49271 × 109 | 1.57474 × 109 | 1.49822 × 109 | 1.49445 × 109 | 1.51721 × 107 |
| AGGL3 | 1.49232 × 109 | 1.59406 × 109 | 1.50429 × 109 | 1.49447 × 109 | 2.64626 × 107 |
| AGGL5 | 1.49341 × 109 | 1.57503 × 109 | 1.50433 × 109 | 1.49439 × 109 | 2.44200 × 107 |
| AGGL7 | 1.49341 × 109 | 1.59630 × 109 | 1.51531 × 109 | 1.49515 × 109 | 3.58332 × 107 |
| AGGL10 | 1.49261 × 109 | 1.60585 × 109 | 1.51345 × 109 | 1.50733 × 109 | 2.79785 × 107 |
| AGGL12 | 1.49358 × 109 | 1.61554 × 109 | 1.51105 × 109 | 1.49754 × 109 | 3.16092 × 107 |
| AGGL15 | 1.49414 × 109 | 1.57599 × 109 | 1.50791 × 109 | 1.49667 × 109 | 2.39108 × 107 |
| AGGL20 | 1.49406 × 109 | 1.57432 × 109 | 1.51096 × 109 | 1.50880 × 109 | 1.83795 × 107 |
| AGGL25 | 1.49386 × 109 | 1.53280 × 109 | 1.51017 × 109 | 1.51159 × 109 | 1.23389 × 107 |
| AGGL30 | 1.49355 × 109 | 1.53113 × 109 | 1.50656 × 109 | 1.50311 × 109 | 1.12716 × 107 |
| AGGL50 | 1.49380 × 109 | 1.52818 × 109 | 1.50495 × 109 | 1.50073 × 109 | 1.11666 × 107 |
| AGGL75 | 1.49415 × 109 | 1.56935 × 109 | 1.51541 × 109 | 1.51203 × 109 | 1.95288 × 107 |
| AGGL100 | 1.49413 × 109 | 1.56603 × 109 | 1.51133 × 109 | 1.49943 × 109 | 2.01570 × 107 |
| GH-VNS1 | 1.49362 × 109 | 1.66273 × 109 | 1.54540 × 109 | 1.51469 × 109 | 5.07461 × 107 |
| GH-VNS2 | 1.49413 × 109 | 1.59073 × 109 | 1.50692 × 109 | 1.50235 × 109 | 1.87495 × 107 |
| GH-VNS3 | 1.49247 × 109 | 1.55423 × 109 | 1.50561 × 109 | 1.49497 × 109 | 1.84421 × 107 |
| SWAP1 (the best of SWAP) | 1.70412 × 109 | 2.00689 × 109 | 1.83218 × 109 | 1.83832 × 109 | 6.04418 × 107 |
| GA-1POINT | 1.61068 × 109 | 1.85786 × 109 | 1.69042 × 109 | 1.65346 × 109 | 7.23930 × 107 |
| GA-UNIFORM | 1.67990 × 109 | 1.92521 × 109 | 1.77471 × 109 | 1.76783 × 109 | 6.95451 × 107 |
| Aggl-EA | 1.49199 × 109 | 1.57449 × 109 | 1.50670 × 109 | 1.49495 × 109 | 2.46374 × 107 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 1.54171 × 109 | 1.64834 × 109 | 1.59859 × 109 | 1.60045 × 109 | 2.62443 × 107 |
| j-means (SWAP1 + Lloyd) | 9.95926 × 108 | 1.15171 × 109 | 1.05927 × 109 | 1.04561 × 109 | 4.63788 × 107 |
| AGGL1 | 1.14784 × 109 | 1.88404 × 109 | 1.47311 × 109 | 1.42352 × 109 | 1.94210 × 108 |
| AGGL2 | 9.96893 × 108 | 1.23746 × 109 | 1.08456 × 109 | 1.07354 × 109 | 5.76487 × 107 |
| AGGL3 | 9.87064 × 108 | 1.21980 × 109 | 1.07148 × 109 | 1.06503 × 109 | 4.84664 × 107 |
| AGGL5 | 9.68357 × 108 | 1.13508 × 109 | 1.06002 × 109 | 1.06617 × 109 | 4.50726 × 107 |
| AGGL7 | 1.00537 × 109 | 1.19050 × 109 | 1.07440 × 109 | 1.06799 × 109 | 4.73520 × 107 |
| AGGL10 | 9.78925 × 108 | 1.17041 × 109 | 1.06123 × 109 | 1.05264 × 109 | 5.10834 × 107 |
| AGGL12 | 9.94720 × 108 | 1.16133 × 109 | 1.05659 × 109 | 1.05930 × 109 | 3.59604 × 107 |
| AGGL15 | 9.64129 × 108 | 1.18512 × 109 | 1.05884 × 109 | 1.04935 × 109 | 5.54774 × 107 |
| AGGL20 | 9.53544 × 108 | 1.15383 × 109 | 1.03729 × 109 | 1.03124 × 109 | 4.58983 × 107 |
| AGGL25 | 9.98103 × 108 | 1.13062 × 109 | 1.03990 × 109 | 1.02958 × 109 | 3.39141 × 107 |
| AGGL30 | 9.59132 × 108 | 1.08646 × 109 | 1.02528 × 109 | 1.02102 × 109 | 3.48713 × 107 |
| AGGL50 | 9.48152 × 108 | 1.07480 × 109 | 1.00313 × 109 | 9.97259 × 108 | 2.65919 × 107 |
| AGGL75 | 9.44390 × 108 | 1.05320 × 109 | 9.90754 × 108 | 9.86511 × 108 | 3.04626 × 107 |
| AGGL100 | 9.33977 × 108 | 1.02524 × 109 | 9.70365 × 108 | 9.63525 × 108 | 2.48207 × 107 |
| AGGL150 | 9.20206 × 108 | 1.02162 × 109 | 9.61877 × 108 | 9.60465 × 108 | 2.42984 × 107 |
| AGGL200 | 9.18310 × 108 | 1.01805 × 109 | 9.52666 × 108 | 9.42071 × 108 | 2.73422 × 107 |
| AGGL250 | 9.08532 × 108 | 9.78792 × 108 | 9.36947 × 108 | 9.29497 × 108 | 1.97893 × 107 |
| AGGL300 | 9.10975 × 108 | 9.77193 × 108 | 9.39030 × 108 | 9.39434 × 108 | 1.27907 × 107 |
| GH-VNS1 | 1.00289 × 109 | 1.08471 × 109 | 1.03856 × 109 | 1.03485 × 109 | 2.20294 × 107 |
| GH-VNS2 | 9.68045 × 108 | 1.11832 × 109 | 1.01461 × 109 | 1.00404 × 109 | 3.80607 × 107 |
| GH-VNS3 | 9.12455 × 108 | 9.44414 × 108 | 9.31225 × 108 | 9.32001 × 108 | 8.25653 × 106 |
| SWAP2 (the best of SWAP by avg.) | 1.23379 × 109 | 1.46395 × 109 | 1.33987 × 109 | 1.35305 × 109 | 5.64094 × 107 |
| SWAP3 (the best of SWAP by median) | 1.25432 × 109 | 1.44136 × 109 | 1.34388 × 109 | 1.34424 × 109 | 5.01104 × 107 |
| GA-1POINT | 1.11630 × 109 | 1.38598 × 109 | 1.23404 × 109 | 1.22828 × 109 | 7.05936 × 107 |
| GA-UNIFORM | 1.17534 × 109 | 1.37190 × 109 | 1.26758 × 109 | 1.25424 × 109 | 5.20153 × 107 |
| Aggl-EA | 9.14179 × 108 | 9.71905 × 108 | 9.34535 × 108 | 9.33403 × 108 | 1.51920 × 107 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 1.69034 × 108 | 2.02847 × 108 | 1.79099 × 108 | 1.69034 × 108 | 1.56374 × 107 |
| j-means (SWAP1 + Lloyd) | 1.69034 × 108 | 2.18797 × 108 | 1.74375 × 108 | 1.69034 × 108 | 1.40223 × 107 |
| AGGL1 | 1.69034 × 108 | 2.02619 × 108 | 1.71265 × 108 | 1.69034 × 108 | 8.49108 × 106 |
| AGGL2-15 (equal results) | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 0.00000 |
| SWAP1 (the best of SWAP) | 1.69034 × 108 | 2.08453 × 108 | 1.70348 × 108 | 1.69034 × 108 | 7.19690 × 106 |
| GA-1POINT | 1.69034 × 108 | 2.02783 × 108 | 1.76877 × 108 | 1.69034 × 108 | 1.44603 × 107 |
| GA-UNIFORM | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 2.92119 |
| Aggl-EA | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 0.00000 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 1.14205 × 108 | 1.16737 × 108 | 1.15594 × 108 | 1.15666 × 108 | 6.33573 × 105 |
| j-means (SWAP1 + Lloyd) | 1.13500 × 108 | 1.17631 × 108 | 1.15035 × 108 | 1.14954 × 108 | 9.38353 × 105 |
| AGGL1 | 1.13121 × 108 | 1.15265 × 108 | 1.14219 × 108 | 1.14035 × 108 | 6.23645 × 105 |
| AGGL2 | 1.12430 × 108 | 1.12572 × 108 | 1.12475 × 108 | 1.12464 × 108 | 3.76180 × 104 |
| AGGL3 | 1.12426 × 108 | 1.12548 × 108 | 1.12465 × 108 | 1.12457 × 108 | 2.92460 × 104 |
| AGGL5 | 1.12446E × 108 | 1.12552 × 108 | 1.12487 × 108 | 1.12483 × 108 | 3.00588 × 104 |
| AGGL7 | 1.12437 × 108 | 1.12591 × 108 | 1.12481 × 108 | 1.12478 × 108 | 3.26658 × 104 |
| AGGL10 | 1.12462 × 108 | 1.12558 × 108 | 1.12500 × 108 | 1.12500 × 108 | 2.68212 × 104 |
| AGGL15 | 1.12462 × 108 | 1.12579 × 108 | 1.12526 × 108 | 1.12528 × 108 | 2.83854 × 104 |
| AGGL20 | 1.12461 × 108 | 1.12590 × 108 | 1.12535 × 108 | 1.12538 × 108 | 3.27419 × 104 |
| AGGL25 | 1.12472 × 108 | 1.12632 × 108 | 1.12541 × 108 | 1.12543 × 108 | 4.34545 × 104 |
| AGGL30 | 1.12523 × 108 | 1.12662 × 108 | 1.12572 × 108 | 1.12566 × 108 | 3.55121 × 104 |
| AGGL50 | 1.12541 × 108 | 1.12848 × 108 | 1.12666 × 108 | 1.12651 × 108 | 7.48936 × 104 |
| GH-VNS1 | 1.12419 × 108 | 1.12796 × 108 | 1.12467 × 108 | 1.12446 × 108 | 7.47785 × 104 |
| GH-VNS2 | 1.12472 × 108 | 1.12601 × 108 | 1.12525 × 108 | 1.12519 × 108 | 3.37221 × 104 |
| GH-VNS3 | 1.12531 × 108 | 1.12969 × 108 | 1.12712 × 108 | 1.12708 × 108 | 9.60927 × 104 |
| SWAP1 (the best of SWAP) | 1.13142 × 108 | 1.16627 × 108 | 1.14430 × 108 | 1.14412 × 108 | 8.48529 × 105 |
| GA-1POINT | 1.14271 × 108 | 1.16790 × 108 | 1.15443 × 108 | 1.15343 × 108 | 7.16204 × 105 |
| GA-UNIFORM | 1.13119 × 108 | 1.15805 × 108 | 1.14384 × 108 | 1.14405 × 108 | 6.75227 × 105 |
| Aggl-EA | 1.12476 × 108 | 1.15978 × 108 | 1.14049 × 108 | 1.13985 × 108 | 1.05017 × 106 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 25.4490 |
| j-means (SWAP1 + Lloyd) | 2.27694 × 108 | 2.60475 × 108 | 2.30812 × 108 | 2.27694 × 108 | 7.33507 × 106 |
| AGGL1 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 26.4692 |
| AGGL2 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 6.88293 |
| AGGL3 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 7.84212 |
| AGGL5 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 14.9936 |
| AGGL7 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 26.1335 |
| AGGL10 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 112.307 |
| AGGL12 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 41.2754 |
| AGGL15 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 81.9819 |
| GH-VNS1 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 0.00000 |
| GH-VNS2 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 35.8018 |
| GH-VNS3 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 81.1213 |
| SWAP1 (the best of SWAP) | 2.27694 × 108 | 2.38720 × 108 | 2.28342 × 108 | 2.27694 × 108 | 2.48983 × 106 |
| GA-1POINT | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 17.3669 |
| GA-UNIFORM | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 8.55973 |
| Aggl-EA | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 78.6011 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 1.35718 × 108 | 1.38141 × 108 | 1.37187 × 108 | 1.37299 × 108 | 4.98608 × 105 |
| j-means (SWAP1 + Lloyd) | 1.35353 × 108 | 1.38227 × 108 | 1.36673 × 108 | 1.36589 × 108 | 7.55140 × 105 |
| AGGL1 | 1.35378 × 108 | 1.37459 × 108 | 1.36291 × 108 | 1.36286 × 108 | 5.78265 × 105 |
| AGGL2 | 1.35237 × 108 | 1.35416 × 108 | 1.35353 × 108 | 1.35378 × 108 | 5.39798 × 104 |
| AGGL3 | 1.35237 × 108 | 1.35450 × 108 | 1.35372 × 108 | 1.35384 × 108 | 5.64379 × 104 |
| AGGL5 | 1.35229 × 108 | 1.35675 × 108 | 1.35388 × 108 | 1.35388 × 108 | 6.46057 × 104 |
| AGGL7 | 1.35232 × 108 | 1.35449 × 108 | 1.35306 × 108 | 1.35294 × 108 | 5.64815 × 104 |
| AGGL10 | 1.35248 × 108 | 1.35438 × 108 | 1.35325 × 108 | 1.35314 × 108 | 5.64928 × 104 |
| AGGL12 | 1.35259 × 108 | 1.35422 × 108 | 1.35321 × 108 | 1.35312 × 108 | 4.98093 × 104 |
| AGGL15 | 1.35267 × 108 | 1.35424 × 108 | 1.35323 × 108 | 1.35312 × 108 | 4.16267 × 104 |
| AGGL20 | 1.35294 × 108 | 1.35448 × 108 | 1.35347 × 108 | 1.35331 × 108 | 4.45414 × 104 |
| AGGL25 | 1.35264 × 108 | 1.35470 × 108 | 1.35348 × 108 | 1.35342 × 108 | 5.03965 × 104 |
| AGGL30 | 1.35260 × 108 | 1.35453 × 108 | 1.35345 × 108 | 1.35336 × 108 | 4.55230 × 104 |
| AGGL50 | 1.35254 × 108 | 1.35467 × 108 | 1.35354 × 108 | 1.35336 × 108 | 5.50925 × 104 |
| GH-VNS1 | 1.35219 × 108 | 1.35758 × 108 | 1.35408 × 108 | 1.35383 × 108 | 1.27073 × 105 |
| GH-VNS2 | 1.35239 × 108 | 1.35433 × 108 | 1.35327 × 108 | 1.35324 × 108 | 4.90352 × 104 |
| GH-VNS3 | 1.35299 × 108 | 1.35469 × 108 | 1.35374 × 108 | 1.35382 × 108 | 5.29113 × 104 |
| SWAP1 (the best of SWAP) | 1.35930 × 108 | 1.39391 × 108 | 1.37402 × 108 | 1.37351 × 108 | 8.40302 × 105 |
| GA-1POINT | 1.35943 × 108 | 1.38086 × 108 | 1.36776 × 108 | 1.36723 × 108 | 4.96830 × 105 |
| GA-UNIFORM | 1.35260 × 108 | 1.36698 × 108 | 1.35917 × 108 | 1.35937 × 108 | 3.50731 × 105 |
| Aggl-EA | 1.35241 × 108 | 1.35438 × 108 | 1.35313 × 108 | 1.35304 × 108 | 5.26194 × 104 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 99.7279 | 123.1325 | 110.4963 | 109.9706 | 5.6551 |
| j-means (SWAP1 + Lloyd) | 48.3311 | 57.1689 | 51.6673 | 51.1146 | 2.0749 |
| AGGL1 | 51.9696 | 81.9848 | 64.2454 | 62.4350 | 8.3403 |
| AGGL2 | 44.4866 | 50.0924 | 46.1544 | 46.0973 | 1.0708 |
| AGGL3 | 43.8615 | 46.3881 | 45.1735 | 45.3303 | 0.7306 |
| AGGL5 | 43.7373 | 46.0294 | 44.8369 | 44.7245 | 0.6888 |
| AGGL7 | 44.0820 | 48.4483 | 45.2256 | 45.0851 | 0.9135 |
| AGGL10 | 43.8603 | 45.7149 | 44.6455 | 44.6387 | 0.5400 |
| AGGL15 | 43.7995 | 45.5927 | 44.7005 | 44.7173 | 0.5203 |
| AGGL20 | 43.6629 | 46.0316 | 44.4626 | 44.3353 | 0.5953 |
| AGGL25 | 43.6357 | 46.5550 | 44.5179 | 44.3408 | 0.6543 |
| AGGL30 | 43.6728 | 44.5830 | 44.1677 | 44.1137 | 0.2945 |
| AGGL50 | 43.6202 | 45.0433 | 44.2257 | 44.3137 | 0.3590 |
| AGGL75 | 43.6375 | 45.6856 | 44.1450 | 43.9860 | 0.4683 |
| AGGL100 | 43.6054 | 44.9035 | 44.0472 | 43.9875 | 0.3061 |
| GH-VNS1 | 47.7171 | 59.6970 | 53.4896 | 53.1948 | 3.4123 |
| GH-VNS2 | 43.7781 | 46.0085 | 44.8602 | 44.9149 | 0.5772 |
| GH-VNS3 | 43.8585 | 46.4490 | 44.7263 | 44.6593 | 0.6018 |
| SWAP1 (the best of SWAP) | 47.8800 | 52.4030 | 49.8287 | 49.5523 | 1.1239 |
| GA-1POINT | 61.2677 | 76.9114 | 67.2297 | 66.9182 | 3.8341 |
| GA-UNIFORM | 68.6276 | 102.0867 | 84.8705 | 83.8152 | 7.4129 |
| Aggl-EA | 43.5826 | 44.4452 | 43.7486 | 43.7560 | 0.1624 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 190.1025 | 229.0199 | 218.3214 | 219.6611 | 8.1825 |
| j-means (SWAP1 + Lloyd) | 146.3243 | 158.0798 | 151.0530 | 150.6979 | 2.7908 |
| AGGL1 | 145.7872 | 163.1270 | 152.6856 | 153.2432 | 5.6803 |
| AGGL2 | 145.7738 | 146.2262 | 145.8728 | 145.7798 | 0.1532 |
| AGGL3 | 145.7745 | 146.2161 | 145.9185 | 145.7841 | 0.1744 |
| AGGL5 | 145.7742 | 146.1392 | 145.8211 | 145.7830 | 0.1088 |
| AGGL7 | 145.7738 | 146.1416 | 145.8188 | 145.7829 | 0.1084 |
| AGGL10 | 145.7770 | 146.1370 | 145.8295 | 145.7831 | 0.1209 |
| AGGL15 | 145.7742 | 146.1392 | 145.8211 | 145.7830 | 0.1088 |
| AGGL20 | 145.7784 | 145.8113 | 145.7869 | 145.7847 | 0.0084 |
| AGGL25 | 145.7753 | 146.1479 | 145.8043 | 145.7893 | 0.0680 |
| AGGL30 | 145.7791 | 146.1466 | 145.8022 | 145.7877 | 0.0670 |
| GH-VNS1 | 145.7738 | 146.2193 | 145.8769 | 145.7789 | 0.1537 |
| GH-VNS2 | 145.7729 | 146.1506 | 145.8323 | 145.7780 | 0.1243 |
| GH-VNS3 | 145.7721 | 146.1273 | 145.7932 | 145.7761 | 0.0664 |
| SWAP1 (the best of SWAP) | 145.9265 | 155.8482 | 148.4986 | 148.0995 | 1.8866 |
| GA-1POINT | 148.2359 | 164.0893 | 154.9963 | 154.6930 | 3.4858 |
| GA-UNIFORM | 153.8591 | 201.7184 | 175.8969 | 174.2682 | 10.9540 |
| Aggl-EA | 145.7721 | 145.7752 | 145.7738 | 145.7739 | 0.0008 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 47.8874 | 54.4850 | 51.6395 | 51.1162 | 1.6453 |
| j-means (SWAP1 + Lloyd) | 23.6798 | 35.3805 | 31.2554 | 31.8670 | 2.7425 |
| AGGL1 | 34.3990 | 54.5291 | 42.5890 | 41.8879 | 5.0023 |
| AGGL2 | 18.6255 | 22.8995 | 20.4858 | 20.3853 | 1.0785 |
| AGGL3 | 16.7389 | 19.8415 | 18.5376 | 18.6063 | 0.7018 |
| AGGL5 | 16.5944 | 19.4305 | 17.7512 | 17.5557 | 0.7611 |
| AGGL7 | 16.1609 | 20.0563 | 17.8918 | 17.8397 | 0.8182 |
| AGGL10 | 16.4099 | 19.0087 | 17.3922 | 17.2220 | 0.6228 |
| AGGL15 | 16.0706 | 17.4835 | 16.7584 | 16.7537 | 0.4276 |
| AGGL20 | 15.7783 | 17.6122 | 16.6852 | 16.7338 | 0.4712 |
| AGGL25 | 15.6854 | 18.3011 | 16.7847 | 16.6473 | 0.5885 |
| AGGL50 | 15.7963 | 17.7948 | 16.2860 | 16.2920 | 0.4237 |
| AGGL100 | 15.1942 | 16.3370 | 15.6951 | 15.6738 | 0.3081 |
| AGGL150 | 15.2025 | 16.4996 | 15.7898 | 15.7990 | 0.2939 |
| AGGL200 | 15.1805 | 16.2245 | 15.7252 | 15.7801 | 0.2843 |
| AGGL250 | 15.0975 | 16.8500 | 15.7103 | 15.6757 | 0.3640 |
| AGGL300 | 15.2509 | 16.2803 | 15.7108 | 15.7224 | 0.2694 |
| GH-VNS1 | 21.5583 | 31.4467 | 27.7853 | 27.9011 | 2.5876 |
| GH-VNS2 | 15.5928 | 17.6197 | 16.6424 | 16.6345 | 0.5166 |
| GH-VNS3 | 15.3488 | 16.8864 | 15.9644 | 15.8850 | 0.4229 |
| SWAP5 (the best of SWAP by avg.) | 22.3193 | 30.7398 | 27.5174 | 27.9711 | 1.9760 |
| SWAP7 (the best of SWAP by median) | 24.0243 | 30.9356 | 27.6329 | 27.8934 | 1.9714 |
| GA-1POINT | 34.4429 | 45.0868 | 40.1539 | 39.6896 | 2.3970 |
| GA-UNIFORM | 37.4806 | 53.3750 | 43.8100 | 43.7275 | 3.7585 |
| Aggl-EA | 14.8354 | 19.4531 | 15.4576 | 15.3310 | 0.8131 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 88,145.6484 | 93,677.3281 | 90,681.1663 | 89,967.9297 | 1818.1249 |
| j-means (SWAP1 + Lloyd) | 87,907.7813 | 95,055.2422 | 89,657.8895 | 88,702.9297 | 2442.1302 |
| AGGL1 | 91,021.6016 | 110,467.5625 | 104,694.9900 | 109,976.7266 | 9278.2649 |
| AGGL2 | 86,291.1406 | 109,972.0781 | 99,788.2522 | 109,817.8125 | 12,557.4381 |
| AGGL3 | 109,817.8125 | 109,999.1328 | 109,913.6953 | 109,972.0781 | 90.3626 |
| AGGL5 | 86,240.7344 | 109,999.1328 | 103,145.4487 | 109,817.8281 | 11,519.4208 |
| AGGL7 | 86,345.9297 | 109,817.8359 | 99,781.6283 | 109,817.8203 | 12,517.3778 |
| AGGL10 | 86,414.0938 | 109,999.1563 | 106,500.3449 | 109,817.8281 | 8857.4620 |
| AGGL15 | 87,253.8281 | 109,817.8438 | 103,391.2009 | 109,817.8359 | 10,975.6502 |
| AGGL20 | 87,616.3984 | 109,999.1563 | 106,677.1384 | 109,817.8438 | 8405.2571 |
| AGGL25 | 87,409.8203 | 109,817.8438 | 106,616.6953 | 109,817.8438 | 8469.4358 |
| AGGL30 | 87,852.5938 | 109,878.0156 | 106,707.1674 | 109,853.0547 | 8314.1220 |
| GH-VNS1 | 86,228.4844 | 109,999.1250 | 99,811.1853 | 109,817.7734 | 12,593.8724 |
| GH-VNS2 | 86,368.7891 | 109,817.8281 | 99,807.6674 | 109,817.8125 | 12,485.0346 |
| GH-VNS3 | 86,304.9141 | 109,817.8281 | 96,518.5525 | 86,865.2813 | 12,441.4202 |
| SWAP1 (the best of SWAP) | 86,672.6250 | 112,683.0469 | 100,566.9531 | 109,979.8594 | 12,666.0305 |
| GA-1POINT | 88,170.4141 | 100,368.3438 | 92,664.3739 | 92,332.9922 | 4102.0677 |
| GA-UNIFORM | 87,650.1016 | 110,271.6172 | 96,631.6763 | 92,752.2813 | 9762.9279 |
| Aggl-EA | 86,147.6953 | 109,817.7969 | 91,515.1658 | 86,393.3750 | 10,377.0956 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 49,901.8086 | 58,872.1094 | 53,113.4275 | 52,599.0273 | 2781.6693 |
| j-means (SWAP1 + Lloyd) | 44,074.6445 | 47,562.4922 | 45,375.1657 | 44,608.1953 | 1505.4071 |
| AGGL1 | 67,508.2344 | 69,943.5000 | 69,070.9118 | 69,328.3750 | 845.3473 |
| AGGL2 | 43,966.8594 | 67,854.2500 | 60,923.9386 | 67,576.6875 | 11,525.2718 |
| AGGL3 | 43,867.1211 | 68,638.1953 | 58,670.0921 | 67,070.9375 | 11,658.5487 |
| AGGL5 | 44,337.6641 | 68,679.3125 | 61,875.6590 | 67,577.0625 | 10,517.0718 |
| AGGL7 | 43,688.3750 | 68,976.5469 | 64,480.6272 | 67,636.7188 | 9192.1896 |
| AGGL10 | 66,566.2969 | 68,004.2500 | 67,175.4855 | 67,188.0938 | 510.9257 |
| AGGL15 | 43,160.3125 | 67,295.1797 | 57,406.8198 | 66,625.8047 | 12,069.9982 |
| AGGL20 | 43,819.1289 | 67,265.2188 | 60,462.2919 | 66,883.5938 | 11,234.3160 |
| AGGL25 | 43,324.3203 | 67,231.0859 | 60,237.4286 | 66,842.1719 | 11,452.1535 |
| AGGL50 | 42,628.9141 | 66,279.0781 | 62,340.2411 | 65,467.8828 | 8700.5474 |
| AGGL100 | 64,635.6055 | 65,408.7891 | 65,055.4102 | 65,155.6328 | 284.9207 |
| AGGL150 | 64,458.3047 | 65,008.1641 | 64,682.8622 | 64,706.7969 | 188.7753 |
| AGGL200 | 41,754.1680 | 64,694.6328 | 58,240.8147 | 64,582.5625 | 10,883.6398 |
| AGGL250 | 64,385.2461 | 64,646.9141 | 64,538.0787 | 64,547.0820 | 82.7326 |
| AGGL300 | 41,373.4453 | 65,051.3594 | 61,283.1027 | 64,492.8828 | 8781.8445 |
| GH-VNS1 | 67,290.1406 | 68,655.8125 | 67,645.6563 | 67,467.4375 | 478.1909 |
| GH-VNS2 | 43,395.0273 | 67,046.0234 | 63,081.6233 | 66,222.0313 | 8689.9374 |
| GH-VNS3 | 42,124.9375 | 64,425.2734 | 61,204.4487 | 64,358.4844 | 8413.3478 |
| SWAP3 (the best of SWAP by avg.) | 46,137.9570 | 70,000.2813 | 63,618.6362 | 68,361.8672 | 9467.2699 |
| SWAP100 (the best of SWAP by median) | 51,026.5859 | 70,514.3359 | 65,787.6618 | 67,617.5781 | 6667.2423 |
| GA-1POINT | 45,618.3828 | 52,858.6875 | 49,198.6964 | 47,304.4453 | 3129.2994 |
| GA-UNIFORM | 46,171.7148 | 62,034.5273 | 52,218.1077 | 50,642.4961 | 5712.0544 |
| Aggl-EA | 41,795.5078 | 65,057.9375 | 51,888.0642 | 42,525.5000 | 12,122.2332 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 61,803.3047 | 65,997.1406 | 64,612.3371 | 65,037.8281 | 1431.8760 |
| j-means (SWAP1 + Lloyd) | 61,374.5742 | 70,854.6953 | 63,433.8962 | 62,227.1172 | 3308.9649 |
| AGGL1 | 60,709.2500 | 88,798.9453 | 82,890.4255 | 86,253.2539 | 9221.4664 |
| AGGL2 | 58,098.7578 | 85,587.0938 | 78,612.5859 | 84,406.7891 | 11,517.2424 |
| AGGL3 | 58,508.1367 | 84,416.4219 | 75,654.4905 | 83,573.3906 | 11,916.7366 |
| AGGL5 | 58,326.4648 | 83,891.5781 | 69,386.2210 | 59,046.0703 | 13,415.1144 |
| AGGL7 | 58,623.8203 | 84,465.2500 | 69,618.7757 | 59,477.0938 | 13,118.7602 |
| AGGL10 | 58,665.4414 | 84,494.0938 | 72,985.3951 | 82,966.5156 | 13,078.1135 |
| AGGL15 | 58,306.4961 | 83,287.7891 | 69,407.9023 | 59,881.0156 | 12,347.6134 |
| AGGL20 | 58,666.2383 | 83,110.8438 | 76,161.1618 | 82,986.7578 | 11,757.2349 |
| AGGL25 | 58,533.1406 | 83,046.0703 | 69,305.3025 | 59,392.3672 | 12,821.3261 |
| AGGL50 | 58,768.5430 | 82,938.1797 | 69,450.1853 | 60,540.5391 | 12,428.4255 |
| AGGL75 | 58,538.9922 | 82,544.6875 | 75,635.4358 | 82,477.6172 | 11,673.3413 |
| AGGL100 | 58,460.1914 | 82,531.0000 | 78,951.6490 | 82,422.8125 | 9036.9781 |
| GH-VNS1 | 59,228.6055 | 85,246.7969 | 73,899.8482 | 83,708.7031 | 13,239.8092 |
| GH-VNS2 | 82,966.8750 | 83,334.9688 | 83,061.5056 | 83,033.9844 | 128.9717 |
| GH-VNS3 | 59,417.9375 | 82,291.0391 | 78,905.5815 | 82,124.6094 | 8593.7433 |
| SWAP10 (the best of SWAP) | 61,196.4414 | 84,698.2109 | 70,051.5938 | 62,676.3125 | 10,652.0083 |
| GA-1POINT | 62,192.1719 | 64,413.2578 | 63,051.7500 | 63,028.9922 | 733.3966 |
| GA-UNIFORM | 60,873.5859 | 66,829.2969 | 63,656.8555 | 64,155.6875 | 2084.6202 |
| Aggl-EA | 57,594.0703 | 72,909.5000 | 65,782.6094 | 58,506.6484 | 3208.6879 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 6.28454 × 106 | 7.25139 × 106 | 6.92349 × 106 | 6.95864 × 106 | 198,384 |
| j-means (SWAP1 + Lloyd) | 3.76240 × 106 | 4.00651 × 106 | 3.85266 × 106 | 3.84859 × 106 | 59,481.8 |
| AGGL1 | 4.17611 × 106 | 5.71925 × 106 | 4.87105 × 106 | 4.79499 × 106 | 417,612 |
| AGGL2 | 3.64502 × 106 | 3.67299 × 106 | 3.65556 × 106 | 3.65350 × 106 | 7644.61 |
| AGGL3 | 3.64508 × 106 | 3.77758 × 106 | 3.66037 × 106 | 3.65225 × 106 | 28,242.8 |
| AGGL5 | 3.64502 × 106 | 3.77520 × 106 | 3.65956 × 106 | 3.65221 × 106 | 31,464.1 |
| AGGL7 | 3.64352 × 106 | 3.77238 × 106 | 3.66457 × 106 | 3.65259 × 106 | 36,374.3 |
| AGGL10 | 3.64503 × 106 | 3.74222 × 106 | 3.65639 × 106 | 3.65191 × 106 | 18,087.8 |
| AGGL12 | 3.64508 × 106 | 3.77121 × 106 | 3.65745 × 106 | 3.65299 × 106 | 22,688.4 |
| AGGL15 | 3.64351 × 106 | 3.78305 × 106 | 3.66115 × 106 | 3.65050 × 106 | 32,121.2 |
| AGGL20 | 3.64289 × 106 | 3.74971 × 106 | 3.65333 × 106 | 3.64965 × 106 | 19,010.0 |
| AGGL25 | 3.64354 × 106 | 3.66605 × 106 | 3.64913 × 106 | 3.64784 × 106 | 5184.35 |
| AGGL30 | 3.64290 × 106 | 3.67201 × 106 | 3.65106 × 106 | 3.64702 × 106 | 7780.79 |
| AGGL50 | 3.64511 × 106 | 3.67594 × 106 | 3.65120 × 106 | 3.64940 × 106 | 6920.69 |
| AGGL75 | 3.64510 × 106 | 3.68136 × 106 | 3.65552 × 106 | 3.65355 × 106 | 7722.98 |
| AGGL100 | 3.64508 × 106 | 3.67524 × 106 | 3.65651 × 106 | 3.65395 × 106 | 9106.84 |
| GH-VNS1 | 3.69265 × 106 | 5.20291 × 106 | 4.05038 × 106 | 3.93463 × 106 | 336,130 |
| GH-VNS2 | 3.64503 × 106 | 3.66884 × 106 | 3.65123 × 106 | 3.65015 × 106 | 6284.54 |
| GH-VNS3 | 3.64503 × 106 | 3.67655 × 106 | 3.65735 × 106 | 3.65370 × 106 | 9247.64 |
| SWAP1 (the best of SWAP) | 3.68260 × 106 | 3.79031 × 106 | 3.74321 × 106 | 3.74447 × 106 | 25,846.1 |
| GA-1POINT | 4.38348 × 106 | 5.29721 × 106 | 4.83383 × 106 | 4.82569 × 106 | 198,278 |
| GA-UNIFORM | 5.00518 × 106 | 6.29115 × 106 | 5.62017 × 106 | 5.60439 × 106 | 347,120 |
| Aggl-EA | 3.64285 × 106 | 3.65052 × 106 | 3.64473 × 106 | 3.64502 × 106 | 1467.87 |
| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| Lloyd (multistart) | 3.28826 × 106 | 3.58614 × 106 | 3.46203 × 106 | 3.47443 × 106 | 80,996.0 |
| j-means (SWAP1 + Lloyd) | 1.59039 × 106 | 2.13796 × 106 | 1.74473 × 106 | 1.71790 × 106 | 120,717 |
| AGGL1 | 2.34524 × 106 | 3.59085 × 106 | 3.03226 × 106 | 2.97788 × 106 | 300,773 |
| AGGL2 | 1.47203 × 106 | 1.68652 × 106 | 1.53552 × 106 | 1.52156 × 106 | 55,909.7 |
| AGGL3 | 1.41824 × 106 | 1.65971 × 106 | 1.49980 × 106 | 1.49186 × 106 | 50,351.7 |
| AGGL5 | 1.41376 × 106 | 1.69573 × 106 | 1.48142 × 106 | 1.47572 × 106 | 53,828.0 |
| AGGL7 | 1.42594 × 106 | 1.67197 × 106 | 1.49188 × 106 | 1.47882 × 106 | 50,893.8 |
| AGGL10 | 1.42666 × 106 | 1.61224 × 106 | 1.48780 × 106 | 1.48111 × 106 | 37,416.1 |
| AGGL15 | 1.38648 × 106 | 1.68429 × 106 | 1.51728 × 106 | 1.50331 × 106 | 61,906.0 |
| AGGL20 | 1.43027 × 106 | 1.67186 × 106 | 1.51494 × 106 | 1.49912 × 106 | 63,635.8 |
| AGGL25 | 1.42352 × 106 | 1.74796 × 106 | 1.51280 × 106 | 1.49324 × 106 | 75,237.2 |
| AGGL30 | 1.42871 × 106 | 1.66177 × 106 | 1.49960 × 106 | 1.48752 × 106 | 51,468.1 |
| AGGL50 | 1.40068 × 106 | 1.47648 × 106 | 1.44410 × 106 | 1.44245 × 106 | 17,875.2 |
| AGGL75 | 1.38586 × 106 | 1.48921 × 106 | 1.42238 × 106 | 1.42229 × 106 | 23,714.1 |
| AGGL100 | 1.37383 × 106 | 1.43596 × 106 | 1.40575 × 106 | 1.41181 × 106 | 17,442.5 |
| AGGL150 | 1.36240 × 106 | 1.40877 × 106 | 1.38853 × 106 | 1.38929 × 106 | 11,719.5 |
| AGGL200 | 1.35686 × 106 | 1.42109 × 106 | 1.38415 × 106 | 1.38600 × 106 | 17,504.0 |
| AGGL250 | 1.35268 × 106 | 1.40887 × 106 | 1.38198 × 106 | 1.38182 × 106 | 13,577.4 |
| AGGL300 | 1.35163 × 106 | 1.41077 × 106 | 1.38198 × 106 | 1.37998 × 106 | 15,384.2 |
| GH-VNS1 | 1.70022 × 106 | 2.04728 × 106 | 1.87817 × 106 | 1.88773 × 106 | 101,777 |
| GH-VNS2 | 1.43218 × 106 | 1.78314 × 106 | 1.51093 × 106 | 1.49528 × 106 | 70,431.8 |
| GH-VNS3 | 1.36493 × 106 | 1.43665 × 106 | 1.38037 × 106 | 1.37633 × 106 | 14,603.0 |
| SWAP1 (the best of SWAP) | 1.49832 × 106 | 1.72366 × 106 | 1.57134 × 106 | 1.56292 × 106 | 47,997.3 |
| GA-1POINT | 2.69754 × 106 | 3.29563 × 106 | 2.91834 × 106 | 2.88716 × 106 | 144,687 |
| GA-UNIFORM | 2.55194 × 106 | 3.53833 × 106 | 2.91604 × 106 | 2.89257 × 106 | 205,946 |
| Aggl-EA | 1.36496 × 106 | 1.40537 × 106 | 1.38311 × 106 | 1.38149 × 106 | 12,302.2 |
References
- Drezner, Z.; Hamacher, H. Facility Location: Applications and Theory; Springer: Berlin, Germany, 2004. [Google Scholar]
- Khachumov, M.V. Distances, metrics and data clustering. Sci. Tech. Inf. Proc. 2012, 39, 310–316. [Google Scholar] [CrossRef]
- Çolakoglu, H.B. A Generalization of the Minkowski Distance and a New Definition of the Ellipse. Available online: https://arxiv.org/abs/1903.09657v1 (accessed on 12 March 2021).
- France, S.; Carroll, J.D.; Xiong, H. Distance metrics for high dimensional nearest neighborhood recovery: Compression and normalization. Inform. Sci. 2012, 184, 92–110. [Google Scholar] [CrossRef]
- Weiszfeld, E.; Plastria, F. On the point for which the sum of the distances to n given points is minimum. Ann. Oper. Res. 2009, 167, 7–41. [Google Scholar] [CrossRef]
- Kuhn, H.W. A note on Fermat’s problem. Math. Program. 1973, 4, 98–107. [Google Scholar] [CrossRef]
- Weiszfeld, E. Sur le point sur lequel la somme des distances de n points donnes est minimum. Tohoku Math. J. 1937, 43, 335–386. [Google Scholar]
- Sturm, R. Ueber den Punkt kleinster Entfernungssumme von gegebenen Punkten. J. Rein. Angew. Math. 1884, 97, 49–61. [Google Scholar]
- Beck, A. Weiszfeld’s Method: Old and New Results. J. Optim. Theory Appl. 2015, 164, 1–40. [Google Scholar] [CrossRef]
- Garey, M.; Johnson, D.; Witsenhausen, H. The complexity of the generalized Lloyd—Max problem (Corresp.). IEEE Trans. Inf. Theory 1982, 28, 255–256. [Google Scholar] [CrossRef]
- Farahani, R.Z.; Hekmatfar, M. Facility Location Concepts, Models, Algorithms and Case Studies; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum locations of switching centers and the absolute centers and medians of a graph. Oper. Res. 1964, 12, 450–459. [Google Scholar] [CrossRef]
- Masuyama, S.; Ibaraki, T.; Hasegawa, T. The computational complexity of the m center problems on the plane. Trans. Inst. Electron. Commun. Eng. Jpn. 1981, 64E, 57–64. [Google Scholar]
- Kariv, O.; Hakimi, S.L. An algorithmic approach to network location problems. The p-medians. SIAM J. Appl. Math 1979, 37, 539–560. [Google Scholar] [CrossRef]
- Cooper, L. The weber problem revisited. Comput. Math. Appl. 1981, 7, 225–234. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, M. Ostresh. On the convergence of a class of iterative methods for solving the weber location problem. Oper. Res. 1978, 26, 597–609. [Google Scholar]
- Plastria, F.; Elosmani, M. On the convergence of the Weiszfeld algorithm for continuous single facility location allocation problems. TOP 2008, 16, 388–406. [Google Scholar] [CrossRef]
- Vardi, Y. The multivariate L1-median and associated data depth. Proc. Natl. Acad. Sci. USA 2000, 97, 1423–1426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Badoiu, M. Approximate clustering via core-sets. In Proceedings of the 34th Annual ACM Symposium on Theory of Computing, Montréal, QC, Canada, 19–21 May 2002; pp. 250–257. [Google Scholar]
- Kuhn, H.W. An efficient algorithm for the numerical solution of the generalized Weber problem in spatial economics. J. Reg. Sci. 1962, 4, 21–34. [Google Scholar]
- Mladenovic, N.; Brimberg, J.; Hansen, P.; Moreno-Perez, J.A. The p-median problem: A survey of metaheuristic approaches. Eur. J. Oper. Res. 2007, 179, 927–939. [Google Scholar] [CrossRef] [Green Version]
- Reese, J. Solution methods for the p-median problem: An annotated bibliography. Networks 2006, 48, 125–142. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum distribution of switching centers in a communication network and some related graph theoretic problems. Oper. Res. 1965, 13, 462–475. [Google Scholar] [CrossRef]
- Kuenne, R.E.; Soland, R.M. Exact and approximate solutions to the multisource Weber problem. Math. Program. 1972, 3, 193–209. [Google Scholar] [CrossRef]
- Ostresh, L.M.J. The stepwise location-allocation problem: Exact solutions in continuous and discrete spaces. Geogr. Anal. 1978, 10, 174–185. [Google Scholar] [CrossRef]
- Rosing, K.E. An optimal method for solving the (generalized) multi-weber problem. Eur. J. Oper. Res. 1992, 58, 414–426. [Google Scholar] [CrossRef]
- Rabbani, M. A novel approach for solving a constrained location allocation problem. Int. J. Ind. Eng. Comput. 2013, 4, 203–214. [Google Scholar] [CrossRef]
- Fathali, J.; Rad, N.J.; Sherbaf, S.R. The p-median and p-center problems on bipartite graphs. Iran. J. Math. Sci. Inf. 2014, 9, 37–43. [Google Scholar] [CrossRef]
- Avella, P.; Sassano, A.; Vasil’ev, I. Computational study of large-scale p-median problems. Math. Program. 2007, 109, 89–114. [Google Scholar] [CrossRef]
- Avella, P.; Boccia, M.; Salerno, S.; Vasilyev, I. An aggregation heuristic for large-scale p-median problem. Comput. Oper. Res. 2012, 39, 1625–1632. [Google Scholar] [CrossRef]
- Resende, M.G.C. Metaheuristic hybridization with greedy randomized adaptive search procedures. Inf. TutORials Oper. Res. 2008, 295–319. [Google Scholar] [CrossRef] [Green Version]
- Resende, M.G.C.; Ribeiro, C.C.; Glover, F.; Marti, R. Scatter search and path relinking: Fundamentals, advances, and applications. In Handbook of Metaheuristics; Gendreau, M., Potvin, J.-Y., Eds.; Springer: Boston, MA, USA, 2010; pp. 87–107. [Google Scholar] [CrossRef]
- Brimberg, J.; Drezner, Z.; Mladenovic, N.; Salhi, S. A New Local Search for Continuous Location Problems. Eur. J. Oper. Res. 2014, 232, 256–265. [Google Scholar] [CrossRef] [Green Version]
- Drezner, Z.; Brimberg, J.; Mladenovic, N.; Salhi, S. New heuristic algorithms for solving the planar p-median problem. Comput. Oper. Res. 2015, 62, 296–304. [Google Scholar] [CrossRef]
- Drezner, Z.; Brimberg, J.; Mladenovic, N.; Salhi, S. Solving the planar p-median problem by variable neighborhood and concentric searches. J. Glob. Optim. 2015, 63, 501–514. [Google Scholar] [CrossRef] [Green Version]
- Mladenovic, N.; Alkandari, A.; Pei, J.; Todosijevic, R.; Pardalos, P.M. Less is more approach: Basic variable neighborhood search for the obnoxious p -median problem. Int. Trans. Oper. Res. 2019, 27, 480–493. [Google Scholar] [CrossRef] [Green Version]
- Bernábe-Loranca, M.; González-Velázquez, R.; Granillo-Martinez, E.; Romero-Montoya, M.; Barrera-Cámara, R. P-median problem: A real case application. In Intelligent Systems Design and Applications. ISDA 2019. Advances in Intelligent Systems and Computing; Springer: Cham, Switherlands, 2021; Volume 1181. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-Means++: The Advantages of Careful Seeding. In Proceedings of the SODA’07, SIAM, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Hromkovic, J. Algorithmics for Hard Problems: Introduction to Combinatorial Optimization, Randomization, Approximation, and Heuristics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ng, T. Expanding Neighborhood Tabu Search for facility location problems in water infrastructure planning. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014; pp. 3851–3854. [Google Scholar] [CrossRef]
- Kochetov, Y.; Mladenovic, N.; Hansen, P. Local search with alternating neighborhoods. Discret. Anal. Oper. Res. 2003, 10, 11–43. (In Russian) [Google Scholar]
- Hansen, P. Variable neighborhood search: Principles and applications. Eur. J. Oper. Res 2001, 130, 449–467. [Google Scholar] [CrossRef]
- Hansen, P.; Mladenovic, N. Development of Variable Neighborhood Search. In Essays and Surveys in Metaheuristics; Ribeiro, C.C., Hansen, P., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; pp. 415–440. [Google Scholar]
- Mladenovic, N. Variable neighborhood search. Comput. Oper. Res. 1997, 24, 1097–1100. [Google Scholar] [CrossRef]
- Kochetov, Y.A. Local Search Methods for Discrete Location Problems. Ph.D. Thesis, Sobolev Institute of Mathematics SB RAS, Novosibirsk, Russia, 19 January 2010. (In Russian). [Google Scholar]
- Hansen, P. Variable Neighborhood Search. In Search Methodology; Bruke, E.K., Kendall, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 211–238. [Google Scholar] [CrossRef]
- Brimberg, J.; Mladenovic, N. A variable neighborhood algorithm for solving the continuous location-allocation problem. Stud. Locat. Anal. 1996, 10, 1–12. [Google Scholar]
- Hansen, P.; Mladenovic, N.; Perez-Brito, D. Variable neighborhood decomposition search. J. Heuristics 2001, 7, 335–350. [Google Scholar] [CrossRef]
- Brimberg, J.; Hansen, P.; Mladenovic, N.; Taillard, E. Improvements and comparison of heuristics for solving the uncapacitated multisource Weber problem. Oper. Res. 2000, 48, 444–460. [Google Scholar] [CrossRef]
- Kochetov, Y.; Alekseeva, E.; Levanova, T.; Loresh, M. Large neighborhood local search for the p-median problem. Yugosl. J. Oper. Res. 2005, 15, 53–63. [Google Scholar] [CrossRef]
- Lopez, F.G.; Batista, B.M.; Moreno-Perez, J.; Moreno-Vega, M. The parallel variable neighborhood search for the p-median problem. J. Heuristics 2002, 8, 375–388. [Google Scholar] [CrossRef]
- Rozhnov, I.P.; Orlov, V.I.; Kazakovtsev, L.A. VNS-Based algorithms for the centroid-based clustering problem. FACTA Univ. Ser. Math. Inform. 2019, 34, 957–972. [Google Scholar]
- Still, S.; Bialek, W.; Bottou, L. Geometric clustering using the information bottleneck method, Advances. In Neural Information Processing Systems. 16; MIT Press: Cambridge, UK, 2004. [Google Scholar]
- Sun, Z.; Fox, G.; Gu, W.; Li, Z. A parallel clustering method combined information bottleneck theory and centroid-based clustering. J. Supercomput. 2014, 69, 452–467. [Google Scholar] [CrossRef]
- Houck, C.R.; Joines, J.A.; Kay, M.G. Comparison of genetic algorithms, random restart and two-opt switching for solving large location-allocation problems. Comput. Oper. Res. 1996, 23, 587–596. [Google Scholar] [CrossRef]
- Maulik, U.; Bandyopadhyay, S. Genetic algorithm-based clustering technique. Pattern Recognit. 2000, 33, 1455–1465. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M.M. Genetic k-means algorithm. IEEE Trans. Syst. Man Cybernetics. Part B 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neema, M.N.; Maniruzzaman, K.M.; Ohgai, A. New genetic algorithms based approaches to continuous p-median problem. Netw. Spat. Econ. 2011, 11, 83–99. [Google Scholar] [CrossRef]
- Tuba, E.; Strumberger, I.; Tuba, I.; Bacanin, N.; Tuba, M. Water cycle algorithm for solving continuous p-median problem. In Proceedings of the SACI 2018 IEEE 12th International Symposium on Applied Computational Intelligence and Informatics, Timiuoara, Romania, 17–19 May 2018; pp. 351–354. [Google Scholar] [CrossRef]
- Levanova, T.V.; Gnusarev, A.Y. Simulated annealing for competitive p–median facility location problem. J. Phys. Conf. Ser. 2018, 1050, 012044. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Zhang, C. An online-learning-based evolutionary many-objective algorithm. Inf. Sci. 2020, 509, 1–21. [Google Scholar] [CrossRef]
- Dulebenets, M.A. An adaptive island evolutionary algorithm for the berth scheduling problem. Memetic Comp. 2020, 12, 51–72. [Google Scholar] [CrossRef]
- Liu, Z.Z.; Wang, Y.; Huang, P.Q. AnD: A many-objective evolutionary algorithm with angle-based selection and shift-based density estimation. Inf. Sci. 2020, 509, 400–419. [Google Scholar] [CrossRef] [Green Version]
- Ruiz, E.; Soto-Mendoza, V.; Barbosa, A.E.R.; Reyes, R. Solving the open vehicle routing problem with capacity and distance constraints with a biased random key genetic algorithm. Comput. Ind. Eng. 2019, 133, 207–219. [Google Scholar] [CrossRef]
- Bae, H.; Moon, I. Multi-depot vehicle routing problem with time windows considering delivery and installation vehicles. Appl. Math. Model. 2016, 40, 6536–6549. [Google Scholar] [CrossRef]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Wang, H.; Guo, W. An optimization model and solution algorithms for the vehicle routing problem with a “factory-in-a-box”. IEEE Access 2020, 8, 134743–134763. [Google Scholar] [CrossRef]
- D’Angelo, G.; Pilla, R.; Tascini, C.; Rampone, S. A proposal for distinguishing between bacterial and viral meningitis using genetic programming and decision trees. Soft Comput. 2019, 23, 11775–11791. [Google Scholar] [CrossRef]
- Panda, N.; Majhi, S.K. How Effective is the Salp Swarm Algorithm in Data Classification. In Computational Intelligence in Pattern Recognition. Advances in Intelligent Systems and Computing; Das, A., Nayak, J., Naik, B., Pati, S., Pelusi, D., Eds.; Springer: Singapore, 2020; Volume 999. [Google Scholar] [CrossRef]
- Falkenauer, E. Genetic Algorithms and Grouping Problems; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Alp, O.; Erkut, E.; Drezner, Z. An efficient genetic algorithm for the p-median problem. Ann. Oper. Res. 2003, 122, 21–42. [Google Scholar] [CrossRef]
- Kazakovtsev, L.A.; Antamoshkin, A.N. Genetic algorithm with fast greedy heuristic for clustering and location problems. Informatica 2014, 38, 229–240. [Google Scholar]
- Hosage, C.M.; Goodchild, M.F. Discrete space location-allocation solutions from genetic algorithms. Ann. Oper. Res. 1986, 6, 35–46. [Google Scholar] [CrossRef]
- Blum, C.; Roli, A. Metaheuristics in combinatorial optimization: Overview and conceptual comparison. Acm Comput. Surv. 2001, 35, 268–308. [Google Scholar] [CrossRef]
- Kazakovtsev, L.; Rozhnov, I.; Popov, A.; Tovbis, E.M. Self-adjusting variable neighborhood search algorithm for near-optimal k-means clustering. Computation 2020, 8, 90. [Google Scholar] [CrossRef]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some methods of classification and analysis of multivariate observations. In Proceedings of the 5th Berkley Symposium on Mathematical Statistics and Probability, California, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Kazakovtsev, L.A.; Rozhnov, I.P. Comparative study of local search in SWAP and agglomerative neighbourhoods for the continuous p-median problem. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Volume 1047, III International Conference MIST: Aerospace 2020: Advanced Technologies in Aerospace, Mechanical and Automation Engineering (Aerospace 2020), Krasnoyarsk, Russia, 20–21 November 2020; Volume 1047. [Google Scholar] [CrossRef]
- Droste, S.; Jansen, T.; Wegener, I. On the analysis of the (1+1) evolutionary algorithm. Theor. Comput. Sci. 2002, 276, 51–81. [Google Scholar] [CrossRef] [Green Version]
- Borisovsky, P.A.; Eremeev, A.V. A study on performance of the (1+1)-Evolutionary Algorithm. In Foundations of Genetic Algorithms; De Jong, K., Poli, R., Rowe, J., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 2003; pp. 271–287. [Google Scholar]
- Eremeev, A.V.; Borisovsky, P.A. Comparing evolutionary algorithms to the (1+1)–EA. Theor. Comput. Sci. 2008, 403, 33–41. [Google Scholar] [CrossRef] [Green Version]
- Sung, C.W.; Yuen, S.Y. Analysis of (1+1) evolutionary algorithm and randomized local search with memory. Evol. Comput. 2011, 19, 287–323. [Google Scholar] [CrossRef]
- Doerr, B.; Johannsen, D.; Schmidt, M. Runtime analysis of the (1+1) evolutionary algorithm on strings over finite alphabets. In Proceedings of the 11th Workshop on Foundations of Genetic Algorithms (FOGA’11), Schwarzenberg, Austria, 5–9 January 2011; pp. 119–126. [Google Scholar] [CrossRef]
- Peng, X. Performance analysis of (1+1)EA on the maximum independent set problem. In Lecture Notes in Computer Science; Springer: Cham, Switherlands, 2015; Volume 9483. [Google Scholar] [CrossRef]
- Xia, X.; Zhou, Y. Approximation performance of the (1+1) evolutionary algorithm for the minimum degree spanning tree problem. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 562. [Google Scholar] [CrossRef]
- Bian, C.; Qian, C.; Tang, K.; Yu, Y. Running time analysis of the (1+1)-EA for robust linear optimization. Theor. Comput. Sci. 2020, 843, 57–72. [Google Scholar] [CrossRef]
- Doerr, B.; Le, H.P.; Makhmara, R.; Nguyen, T.D. Fast genetic algorithms. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO 2017; Bosman, P.A.N., Ed.; Spriger: Berlin, Germany, 2017; pp. 777–784. [Google Scholar] [CrossRef]
- Cooper, L. Heuristic methods for location-allocation problems. SIAM Rev. 1964, 6, 37–53. [Google Scholar] [CrossRef]
- Jiang, J.L.; Yuan, X.M. A heuristic algorithm for constrained multi-source Weber problem. The variational inequality approach. Eur. J. Oper. Res. 2007, 187, 357–370. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar] [CrossRef]
- O’Callaghan, L.; Mishra, N.; Meyerson, A.; Guha, S.; Motwani, R. Streaming-data algorithms for high-quality clustering. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 685–694. [Google Scholar] [CrossRef]
- Ackermann, M.R.; Martens, M.; Raupach, C.; Swierkot, K.; Lammersen, C.; Sohler, C. Streamkm: A clustering algorithm for data streams. J. Exp. Algorithms 2010, 17, art.2.4. [Google Scholar] [CrossRef]
- Kazakovtsev, L.; Stashkov, D.; Gudyma, M.; Kazakovtsev, V. Algorithms with Greedy Heuristic Procedures for Mixture Probability Distribution Separation. Yugosl. J. Oper. Res. 2018, 29, 51–67. [Google Scholar] [CrossRef]
- Nikolaev, A.; Mladenovic, N.; Todosijevic, R. J-means and I-means for minimum sum-of-squares clustering on networks. Optim. Lett. 2017, 11, 359–376. [Google Scholar] [CrossRef]
- Clustering Basic Benchmark. Available online: http://cs.joensuu.fi/sipu/datasets/ (accessed on 25 September 2020).
- Dua, D.; Graff, C. UCI Machine Learning Repository 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 30 September 2020).
- Kazakovtsev, L.; Rozhnov, I.; Shkaberina, G.; Orlov, V. K-Means genetic algorithms with greedy genetic operators. Math. Probl. Eng. 2020, 2020, 8839763. [Google Scholar] [CrossRef]
- Kazakovtsev, L.; Rozhnov, I. Application of algorithms with variable greedy heuristics for k-medoids problems. Informatica 2020, 44, 55–61. [Google Scholar] [CrossRef] [Green Version]
- Luebke, D.; Humphreys, G. How GPUs work. Computer 2007, 40, 96–100. [Google Scholar] [CrossRef]
- Lim, G.; Ma, L. GPU-based parallel vertex substitution algorithm for the p-median problem. Comput. Ind. Eng. 2013, 64, 381–388. [Google Scholar] [CrossRef]
- AlBdaiwi, B.F.; AboElFotoh, H.M.F. A GPU-based genetic algorithm for the p-median problem. J. Supercomput. 2017, 73, 4221–4244. [Google Scholar] [CrossRef] [Green Version]
- Herda, M. Parallel genetic algorithm for capacitated p-median problem. Procedia Eng. 2017, 192, 313–317. [Google Scholar] [CrossRef]
- Zechner, M.; Granitzer, M. Accelerating K-Means on the Graphics Processor via CUDA. In Proceedings of the International Conference on Intensive Applications and Services, Valencia, Spain, 20–25 April 2009; pp. 7–15. [Google Scholar] [CrossRef] [Green Version]
- Charikar, M.; Guha, S.; Tardos, E.; Shmoys, D.B. A constant-factor approximation algorithm for the k-median problem. In Proceedings of the 31st Annual ACM Symposium on Theory of Computing, Atlanta, GA, USA, 1–4 May 1999; pp. 1–10. [Google Scholar]
- Jain, K.; Vazirani, V. Approximation algorithms for metric facility location and k-median problems using the primal-dual schema and lagrangian relaxation. J. ACM 2001, 48, 274–296. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Smucker, M.D.; Allan, J.; Carterette, B.A. Comparison of Statistical Significance Tests for Information Retrieval. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management (CIKM’07), Lisbon, Portugal, 6−10 November 2007; pp. 623–632. [Google Scholar]
- Park, H.M. Comparing Group Means: The t-Test and One-Way ANOVA Using STATA, SAS, and SPSS; Indiana University: Bloomington, IN, USA, 2009. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Fay, M.P.; Proschan, M.A. Wilcoxon-Mann-Whitney or t-Test? On Assumptions for Hypothesis Tests and Multiple Interpretations of Decision Rules. Stat. Surv. 2010, 4, 1–39. [Google Scholar] [CrossRef]



| Algorithm or Neighborhood | Achieved Objective Function Values (1) Summarized after 30 Runs | ||||
|---|---|---|---|---|---|
| Min (Record) | Max (Worst) | Average | Median | Std. Dev | |
| BIRCH3 dataset. 100,000 data vectors in , k = 30 clusters, time limitation 10 s | |||||
| GH-VNS1 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 0.00000 |
| Aggl-EA↔⇔ | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 3.45057 × 109 | 0.00000 |
| BIRCH3 dataset. 100.000 data vectors in , k = 100 clusters, time limitation 10 s | |||||
| AGGL2 | 1.49271 × 109 | 1.57474 × 109 | 1.49822 × 109 | 1.49445 × 109 | 1.51721 × 107 |
| AGGL5 | 1.49341 × 109 | 1.57503 × 109 | 1.50433 × 109 | 1.49439 × 109 | 2.44200 × 107 |
| Aggl-EA↔⇔ | 1.49199 × 109 | 1.57449 × 109 | 1.50670 × 109 | 1.49495 × 109 | 2.46374 × 107 |
| BIRCH3 dataset. 100.000 data vectors in , k = 300 clusters, time limitation 10 s | |||||
| AGGL250 | 9.08532 × 108 | 9.78792 × 108 | 9.36947 × 108 | 9.29497 × 108 | 1.97893 × 107 |
| GH-VNS3 | 9.12455 × 108 | 9.44414 × 108 | 9.31225 × 108 | 9.32001 × 108 | 8.25653 × 106 |
| Aggl-EA↔⇔ | 9.14179 × 108 | 9.71905 × 108 | 9.34535 × 108 | 9.33403 × 108 | 1.51920 × 107 |
| Mopsi-Joensuu dataset. 6014 data vectors in , k = 30 clusters, time limitation 5 s | |||||
| AGGL20 | 145.7784 | 145.8113 | 145.7869 | 145.7847 | 0.0084 |
| GH-VNS3 | 145.7721 | 146.1273 | 145.7932 | 145.7761 | 0.0664 |
| Aggl-EA↑⇑ | 145.7721 | 145.7752 | 145.7738 | 145.7739 | 0.0008 |
| Mopsi-Joensuu dataset. 6014 data vectors in , k = 100 clusters, time limitation 5 s | |||||
| AGGL75 | 43.6375 | 45.6856 | 44.1450 | 43.9860 | 0.4683 |
| AGGL100 | 43.6054 | 44.9035 | 44.0472 | 43.9875 | 0.3061 |
| Aggl-EA↑⇑ | 43.5826 | 44.4452 | 43.7486 | 43.7560 | 0.1624 |
| Mopsi-Joensuu dataset. 6014 data vectors in , k = 300 clusters, time limitation 5 s | |||||
| AGGL250 | 15.0975 | 16.8500 | 15.7103 | 15.6757 | 0.3640 |
| Aggl-EA↔⇔ | 14.8354 | 19.4531 | 15.4576 | 15.3310 | 0.8131 |
| IHEPC dataset. 2,075,259 data vectors in , k = 30 clusters, time limitation 5 min | |||||
| j-means | 87907.7813 | 95,055.2422 | 89,657.8895 | 88,702.9297 | 2442.1302 |
| Aggl-EA↔⇔ | 86147.6953 | 10,9817.7969 | 91,515.1658 | 86,393.3750 | 10,377.0956 |
| IHEPC dataset. 2,075,259 data vectors in , k = 100 clusters, time limitation 5 min s | |||||
| GA-1POINT | 62,192.1719 | 64,413.2578 | 63,051.7500 | 63,028.9922 | 733.3966 |
| Aggl-EA↔⇑ | 57,594.0703 | 72,909.5000 | 65,782.6094 | 58,506.6484 | 3208.6879 |
| IHEPC dataset. 2,075,259 data vectors in , k = 300 clusters, time limitation 5 min s | |||||
| j-means | 44,074.6445 | 47,562.4922 | 45,375.1657 | 44,608.1953 | 1505.4071 |
| Aggl-EA↔⇔ | 41,795.5078 | 65,057.9375 | 51,888.0642 | 42,525.5000 | 12,122.2332 |
| Mopsi- Finland dataset.13,467 data vectors in , k = 30 clusters, time limitation 5 s | |||||
| AGGL7 | 1.03013 × 107 | 1.03013 × 107 | 1.03013 × 107 | 1.03013 × 107 | 3.35641 |
| Aggl-EA↔⇔ | 1.03013 × 107 | 1.03013 × 107 | 1.03013 × 107 | 1.03013 × 107 | 2.42022 |
| Mopsi-Finland dataset. 13,467 data vectors in , k = 100 clusters, time limitation 5 s | |||||
| AGGL25 | 3.64354 × 106 | 3.66605 × 106 | 3.64913 × 106 | 3.64784 × 106 | 5184.35 |
| AGGL30 | 3.64290 × 106 | 3.67201 × 106 | 3.65106 × 106 | 3.64702 × 106 | 7780.79 |
| Aggl-EA↔⇔ | 3.64285 × 106 | 3.65052 × 106 | 3.64473 × 106 | 3.64502 × 106 | 1467.87 |
| Mopsi-Finland dataset. 13,467 data vectors in , k = 300 clusters, time limitation 5 s | |||||
| GH-VNS3 | 1.36493 × 106 | 1.43665 × 106 | 1.38037 × 106 | 1.37633 × 106 | 14603.0 |
| Aggl-EA↔⇔ | 1.36496 × 106 | 1.40537 × 106 | 1.38311 × 106 | 1.38149 × 106 | 12302.2 |
| S1 dataset. 5000 data vectors in , k = 15 clusters, time limitation 1 s | |||||
| GH-VNS1 | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 0.00000 |
| Aggl-EA↔⇔ | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 1.69034 × 108 | 0.00000 |
| S1 dataset. 5000 data vectors in , k = 50 clusters, time limitation 1 s | |||||
| AGGL3 | 1.12426 × 108 | 1.12548 × 108 | 1.12465 × 108 | 1.12457 × 108 | 2.92460 × 104 |
| GH-VNS1 | 1.12419 × 108 | 1.12796 × 108 | 1.12467 × 108 | 1.12446 × 108 | 7.47785 × 104 |
| Aggl-EA↔⇔ | 1.12476 × 108 | 1.15978 × 108 | 1.14049 × 108 | 1.13985 × 108 | 1.05017 × 106 |
| S4 dataset. 5000 data vectors in , k = 15 clusters, time limitation 1 s | |||||
| GH-VNS1 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 0.00000 |
| Aggl-EA↔⇔ | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 2.27694 × 108 | 78.6011 |
| S4 dataset. 5000 data vectors in , k = 50 clusters, time limitation 1 s | |||||
| AGGL7 | 1.35232 × 108 | 1.35449 × 108 | 1.35306 × 108 | 1.35294 × 108 | 5.64815 × 104 |
| Aggl-EA↔⇔ | 1.35241 × 108 | 1.35438 × 108 | 1.35313 × 108 | 1.35304 × 108 | 5.26194 × 104 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kazakovtsev, L.; Rozhnov, I.; Shkaberina, G. Self-Configuring (1 + 1)-Evolutionary Algorithm for the Continuous p-Median Problem with Agglomerative Mutation. Algorithms 2021, 14, 130. https://doi.org/10.3390/a14050130
Kazakovtsev L, Rozhnov I, Shkaberina G. Self-Configuring (1 + 1)-Evolutionary Algorithm for the Continuous p-Median Problem with Agglomerative Mutation. Algorithms. 2021; 14(5):130. https://doi.org/10.3390/a14050130
Chicago/Turabian StyleKazakovtsev, Lev, Ivan Rozhnov, and Guzel Shkaberina. 2021. "Self-Configuring (1 + 1)-Evolutionary Algorithm for the Continuous p-Median Problem with Agglomerative Mutation" Algorithms 14, no. 5: 130. https://doi.org/10.3390/a14050130
APA StyleKazakovtsev, L., Rozhnov, I., & Shkaberina, G. (2021). Self-Configuring (1 + 1)-Evolutionary Algorithm for the Continuous p-Median Problem with Agglomerative Mutation. Algorithms, 14(5), 130. https://doi.org/10.3390/a14050130